speaker recognition systems - icsi | icsi
TRANSCRIPT

The 2004 MIT Lincoln Laboratory Speaker Recognition System
D.A.Reynolds, W. Campbell, T. Gleason, C. Quillen, D. Sturim, P. Torres-Carrasquillo, A. Adami (ICASSP 2005)
CS298 Seminar
Shaunak Chatterjee
09-23-2011 1

Actually …
• Robust text-independent speaker identification using Gaussian mixture speaker models – Reynolds, Rose (1995)
• Speaker verification using adapted Gaussian mixture models – Reynolds, Quatieri, Bunn (2000)
• Speaker recognition based on idiolectal differences between speakers – Doddington (2001)
• Generalized linear discriminant sequence kernels for speaker recognition – Campbell (2002)
• Modeling prosodic dynamics for speaker recognition – Adami, Mihaescu, Reynolds, Godfrey (2003)
• Speaker adaptive cohort selection for Tnorm in text-independent speaker verification – Sturim, Reynolds (2005)
• The 2004 MIT Lincoln Laboratory Speaker Recognition System – Reynolds et al (2005)
• The MIT Lincoln Laboratory 2008 Speaker Recognition System – Sturim, Campbell, Karam, Reynolds, Richardson (2009)
2

Douglas A. Reynolds
• PhD (Georgia Tech, 1992)
• Currently Senior Member of Technical Staff at MIT Lincoln Lab
• Most cited author in speaker recognition (by far?)
• Contributed several key ideas currently used in robust speaker recognition systems
• MIT Lincoln Lab has won numerous awards at the NIST SRE over the years
3

What can we learn from speech?
Slide courtesy: Reynolds, Heck 4

Speaker Recognition
Identification
• No identity claim is made
• Classification
Verification
• Identity claim is made
• Binary decision
• Open-set vs closed-set • Text-dependent vs text-independent
5

Applications
• (Telephonic) Transaction Authentication
• Access Control
– Physical facilities
– Computer and data networks
• Parole Monitoring
• Information Retrieval
– Audio indexing in call centers
• Forensics
6

Components of a speaker recognition system
Slide courtesy: Reynolds, Heck 7
Universal Background Model
Background’s “Voiceprint”
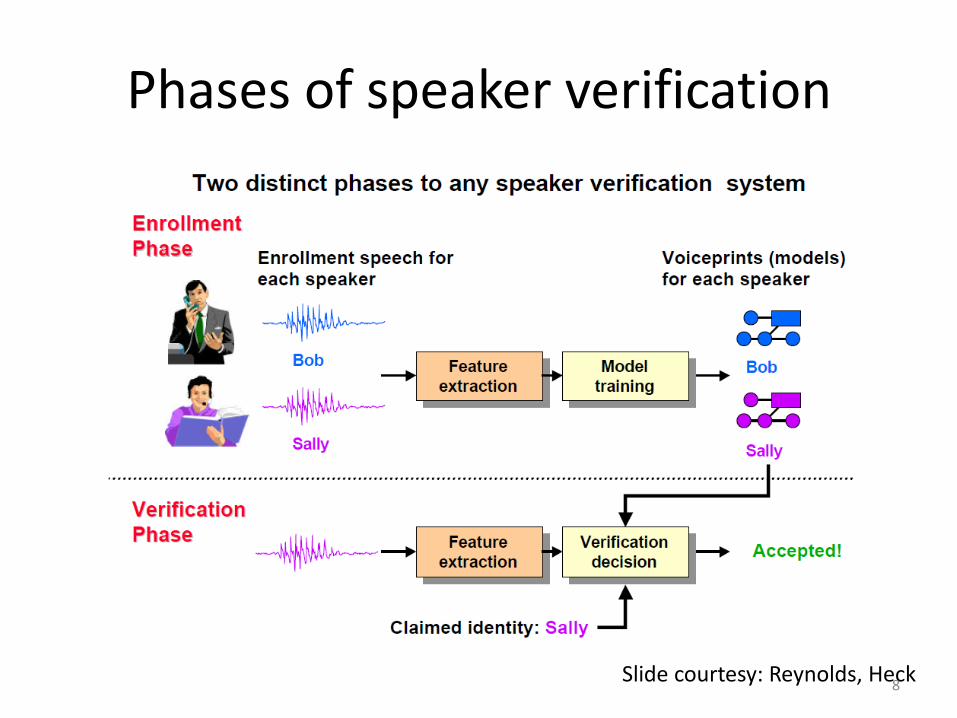
Phases of speaker verification
Slide courtesy: Reynolds, Heck 8

Feature Extraction
9
Universal Background Model
Background’s “Voiceprint”

Feature Extraction
• Pre-processing
– Bandlimiting
– Silence, noise removal
– Channel bias removal (RASTA et al)
• Feature computation
– MFCC computed every 10ms over a 20ms window
– F0 and energy features
– Phonetic features
10

Speaker models
Slide courtesy: Reynolds, Heck 11
Universal Background Model
Background’s “Voiceprint”

Gaussian mixture models (GMMs)
12
• Trained using EM • Often converges within 5 iterations • Wide range of choices to constrain
parameters

Why GMMs? - I Histogram of one cepstral coefficient for a 25-second speech sequence Unimodal distribution Gaussian mixture model Vector Quantization (VQ)
[Reynolds 95] 13

Why GMMs? - II
Each component of the GMM corresponds to a speaker-dependent vocal tract configuration
[Reynolds 95] Image: wikipedia 14
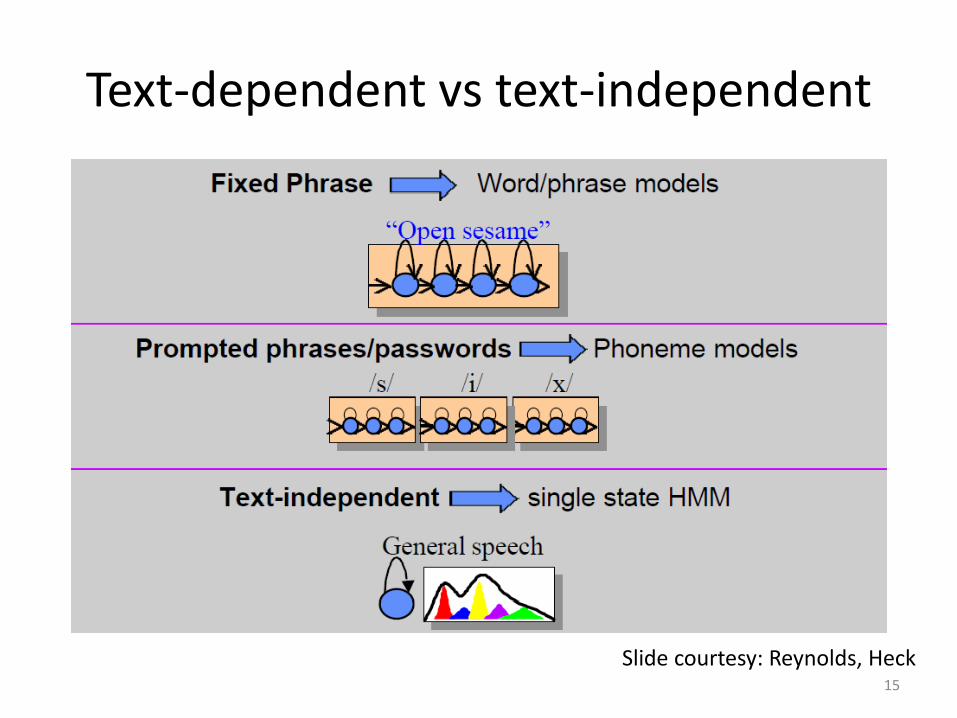
Text-dependent vs text-independent
15
Slide courtesy: Reynolds, Heck
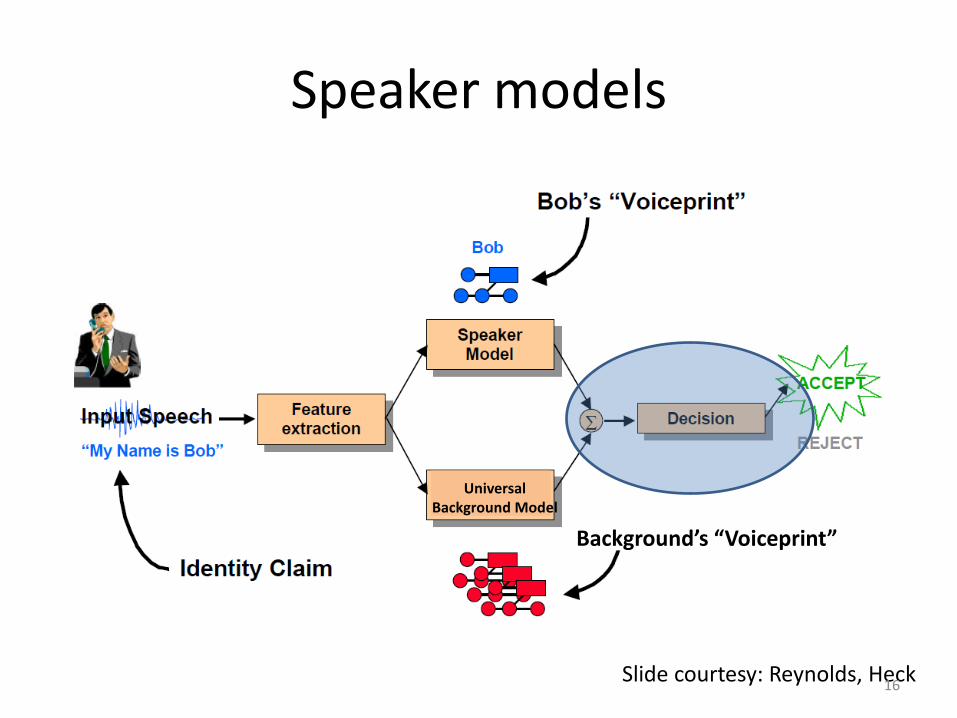
Speaker models
Slide courtesy: Reynolds, Heck 16
Universal Background Model
Background’s “Voiceprint”

Hypothesis testing
17

2004 MIT Lincoln Lab Speaker Recognition System (MITLL)
• Seven core systems – Spectral based
• GMM-UBM
• (Spectral) SVM
– Prosodic based • Pitch and Energy GMM
• Slope and duration GMM
– Phonetic based • Phone N-grams
• Phone SVM
– Idiolectal based
18

2004 MIT Lincoln Lab Speaker Recognition System (MITLL)
• Seven core systems – Spectral based
• GMM-UBM
• (Spectral) SVM
– Prosodic based • Pitch and Energy GMM
• Slope and duration GMM
– Phonetic based • Phone N-grams
• Phone SVM
– Idiolectal based
19

Feature Extraction – GMM-UBM
• 19-dimensional MFCC every 10ms using a 20ms window
• Bandlimiting: 300-3138Hz
• RASTA filtering
– To reduce channel bias effects
• Δ-cepstral coefficients computed for ±2 frames
• Silence removal, feature mapping, normalization
20

UBM training
• Gender-independent 2048 mixture UBM trained from Switchboard and OGI National Cellular Database Corpora – MIXER corpus (the test data) was not used
• Target models (for individual speakers) are derived by Bayesian adaptation of the UBM parameters and training data from MIXER – “compensating” for UBM
21

2004 MIT Lincoln Lab Speaker Recognition System (MITLL)
• Seven core systems – Spectral based
• GMM-UBM
• (Spectral) SVM
– Prosodic based • Pitch and Energy GMM
• Slope and duration GMM
– Phonetic based • Phone N-grams
• Phone SVM
– Idiolectal based
22
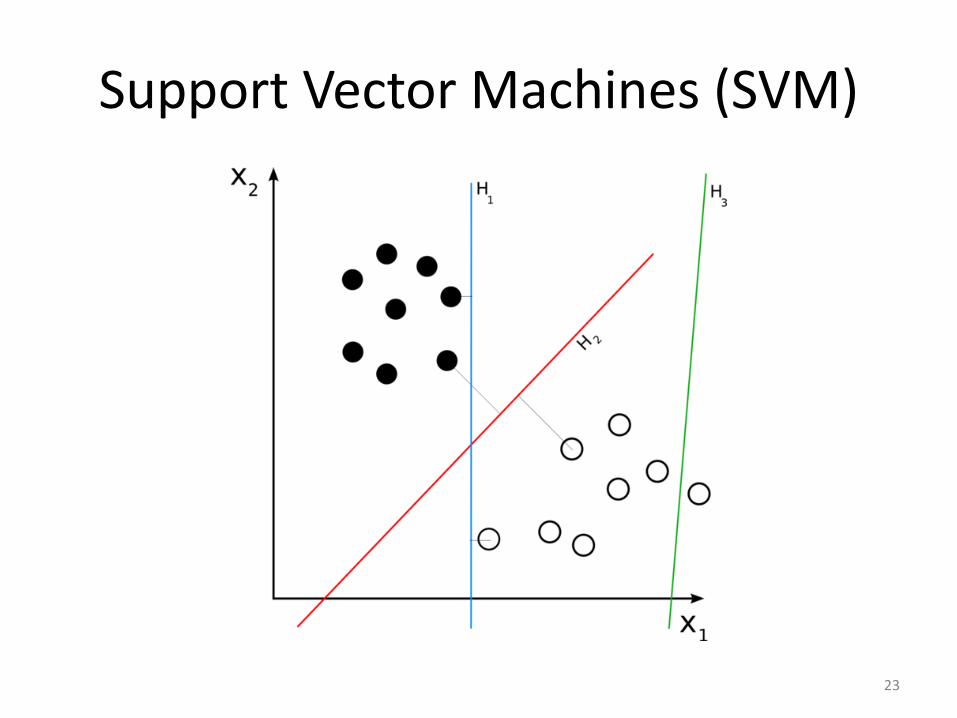
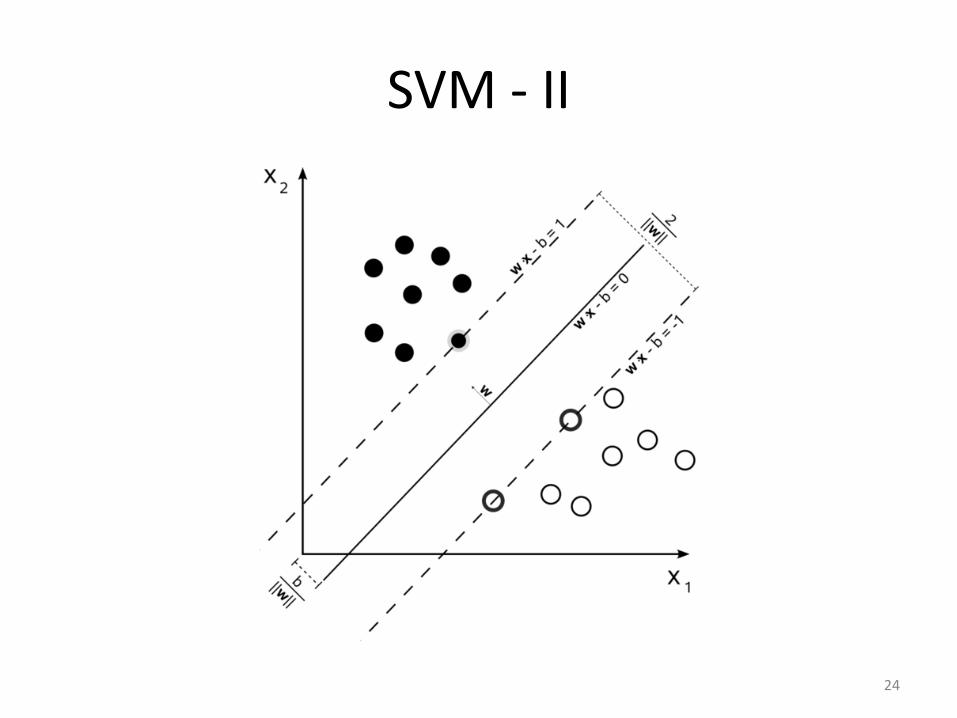
Support Vector Machines (SVM)
23
SVM - II
24

SVM - III
25

Spectral SVM (for speech)
• Campbell (2002) showed that good performance in speaker recognition tasks could be achieved using sequence kernels
• Sequence kernel: provides a numerical comparison of speech utterances as entire sequences
• Campbell introduced a novel sequence kernel derived from generalized linear discriminants
26

SVM setup in MITLL
• Same front-end processing as before
• Background (or the other class) for every speaker consisted of a set of speakers taken from Switchboard
– Current speaker under training had target of +1 and every other speaker had target of -1
• SVM training was performed using the GLDS kernel
27

2004 MIT Lincoln Lab Speaker Recognition System (MITLL)
• Seven core systems – Spectral based
• GMM-UBM
• (Spectral) SVM
– Prosodic based • Pitch and Energy GMM
• Slope and duration GMM
– Phonetic based • Phone N-grams
• Phone SVM
– Idiolectal based
28

Prosodic based systems
• Prosody: the rhythm, stress and intonation of speech
• Spectral approaches focus on capturing short-term information
• Prosodic systems can model long-term information
• Two systems in 2004 MITLL SRS – Distribution based pitch/energy classifier
– Pitch/energy sequence modeling system
29

Pitch and Energy GMM
• Very similar to GMM-UBM
– Main difference: feature set
• Log F0 and log energy estimated every 10ms using RAPT – Robust Algorithm for Pitch Tracking (Talkin 1995)
• Δ features (over 50ms window) appended
• Silence and noisy region removal
• UBM: 512 components (Switchboard)
30

What is F0?
• Fundamental frequency of a human voice
– Between 85-180 in males
– 165-255 in females
– Range is below most band
limits
– Higher harmonics are
transmitted
– F0 is not static
31

Slope and duration n-gram - I
• The dynamics of F0 and energy also convey information about speaker identity
• Dynamics of both trajectories jointly represent certain prosodic gestures characteristic of a speaker (Adami et al, 2003)
32

Slope and duration n-gram - II
• F0 and energy trajectories converted into a sequence of tokens
– Each token reflects a joint state of the trajectories (rising or falling)
33

2004 MIT Lincoln Lab Speaker Recognition System (MITLL)
• Seven core systems – Spectral based
• GMM-UBM
• (Spectral) SVM
– Prosodic based • Pitch and Energy GMM
• Slope and duration GMM
– Phonetic based • Phone N-grams
• Phone SVM
– Idiolectal based
34

Phonetic based system - I
• Gender independent phone recognition
• Phone recognizers trained on phonetically marked speech from OGI multi-language corpus
• Output token streams were processed to produce a sequence of token symbols
35

Phonetic based system – II
• Two systems
– Standard n-gram modeling
• Bi-gram model estimated for each speaker (for each phone/language)
• UBM from Switchboard
• 6 scores fused
– Phone SVM
• Very similar to Spectral SVM
36

2004 MIT Lincoln Lab Speaker Recognition System (MITLL)
• Seven core systems – Spectral based
• GMM-UBM
• (Spectral) SVM
– Prosodic based • Pitch and Energy GMM
• Slope and duration GMM
– Phonetic based • Phone N-grams
• Phone SVM
– Idiolectal based
37

Idiolectal differences
• Only look at content!
• It is possible to determine authorship of papers/literary works by looking at them
38

Idiolectal differences
• Speech content is conventionally less constrained and therefore more distinctive
• Unfortunately, a lot of data is needed for reasonable accuracy
39

MITLL idiolectal based system
• Only considered bigrams
– Trigrams and higher did not improve performance
• Switchboard data used to create UBM
• BBN Byblos 3.0 used for speech-to-text conversion
40

System fusion
• Perceptron classifier
41
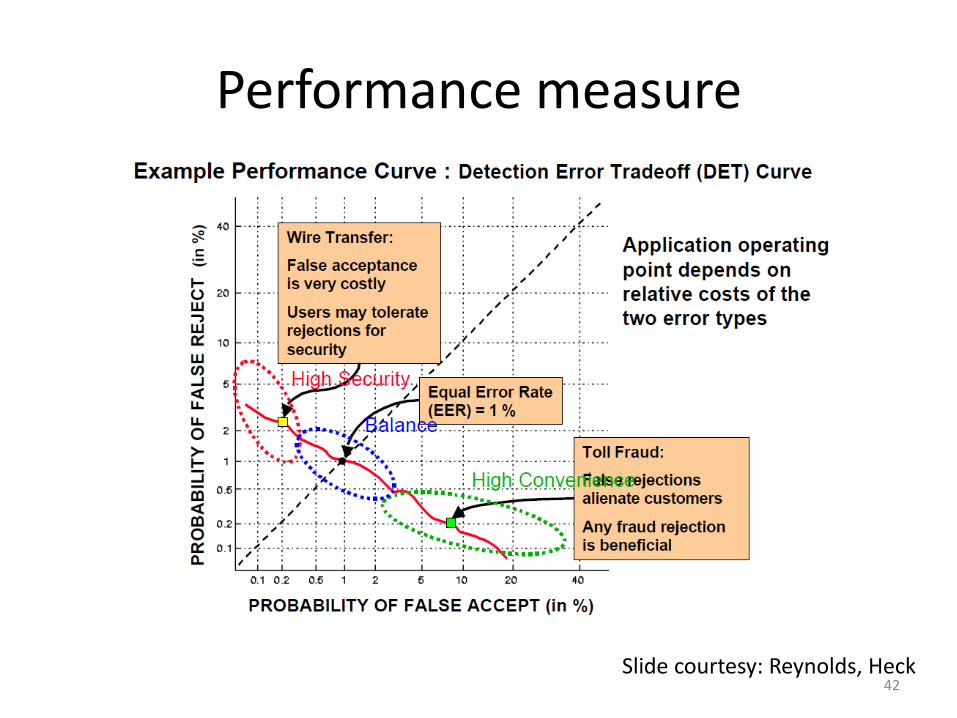
Performance measure
Slide courtesy: Reynolds, Heck 42

DET – different scenarios
43
Slide courtesy: Reynolds, Heck

Results - I
44
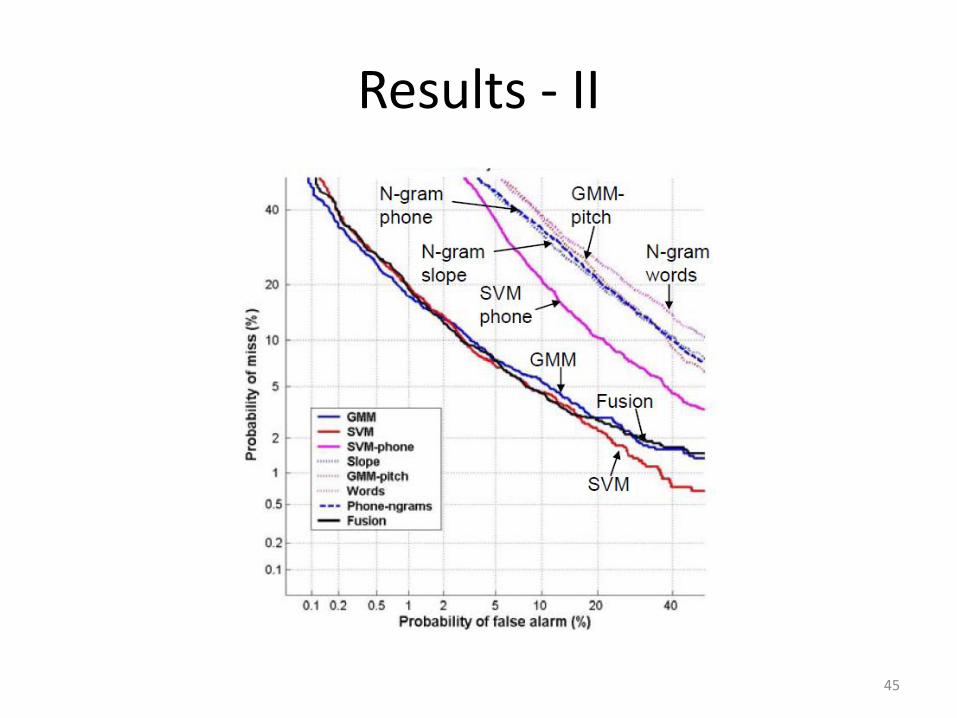
Results - II
45

No gain from higher-level information
• All development data from English – Could have led to a bias in the UBMs
• SRE04 dataset had tons of channel mismatch – More difficult task, potentially masks gains
• Both are essentially mismatches between training and test distributions/data
46

Results - III
• All Pool: all languages • Common pool: English
only
• Clear indication of cross-lingual degradation
• N-gram system reduces error significantly
47

Conclusions
• 2004 MITLL system attempted to exploit other levels of information (prosodic, phonetic, idiolectal) to better characterize and recognize a speaker
• 7 core systems • Generative, discriminative and discrete classifiers • Results on the “challenging” MIXER corpus
(SRE04) • Previous success in system fusion needs to be
tailored better for cross-lingual environments
48

2008 MITLL Speaker Recognition system (Interspeech 2009)
• Two main themes
– Variational nuisance modeling to allow for better compensation for channel variation
– Fuse systems targeting different linguistic tiers of information (high and low)
49

QUESTIONS?
Thanks for the attention!
50