specialized models and ranking for coreference resolution pascal denis alpage project team inria...
TRANSCRIPT

Specialized models and ranking for coreference resolution
Pascal DenisALPAGE Project TeamINRIA Rocquencourt
F-78153 Le Chesnay, France
Jason BaldridgeDepartment of Linguistics
University of Texas at Austin
In Proceedings of EMNLP-2008
1
Yi-Ting Huang2010/12/24

Outline
1. Introduction2. Anaphoric filter3. Ranking4. Specialized models5. Experiment6. Conclusion7. Comments
2

1. Introduction
• Coreference resolution is the task of partitioning a set of entity mentions in a text, where each partition corresponds to some entity in an underlying discourse model.
pair-wise classification(c1, m)=Y (c2, m)=N(c3, m)=N (c4, m)=Y(c5, m)=Y (c6, m)=N
Combineentity1(c1, c4, c5, m)entity2(c2, c3)entity3(c6)
3
c1….c2…….…c3……c4..……c5……..c6………m..

Research problem 1. Numerous approaches to anaphora and coreference
resolution reduce these tasks to a binary classification task, whereby pairs of mentions are classified as coreferential or not.– these approaches make very strong independence
assumptions.2. Only one pair-wise classification to identify any type of noun
phrases.
4
pair-wise classification(c1, m)=Y (c2, m)=N(c3, m)=N (c4, m)=Y(c5, m)=Y (c6, m)=N
Combineentity1(c1, c4, c5, m)entity2(c2, c3)entity3(c6)
c1….c2…….…c3……c4..……c5……..c6………m..

However… (1/2)• For many authors, the relation takes the form of a
continuum and is often represented in the form of a referential hierarchy, such as:
• The higher up, the more accessible (or salient) the entity is.
• This type of hierarchy is validated by corpus studies of the distribution of different types of expressions.
5M. Ariel. 1988. Referring and accessibility. Journal of Linguistics, pages 65–87.

However… (2/2)
• At the extremes are pronouns (these forms typically require a previous mention in the local context) and proper names (these forms are often used without previous mentions of the entity).
• For instance, pronouns find their antecedents very locally (in a window of 1-2 sentences), while proper names predominantly find theirs at longer distances (Ariel, 1988).
6

Research purpose
• The use of rankers instead of classifiers• The use of linguistically motivated, specialized
models for different types of mentions.– third-person pronouns, – speech pronouns (i.e., first and second person
pronouns), – proper names, – definite descriptions – other types of nominals (e.g., anaphoric uses of
indefinite, quantified, and bare noun phrases).7

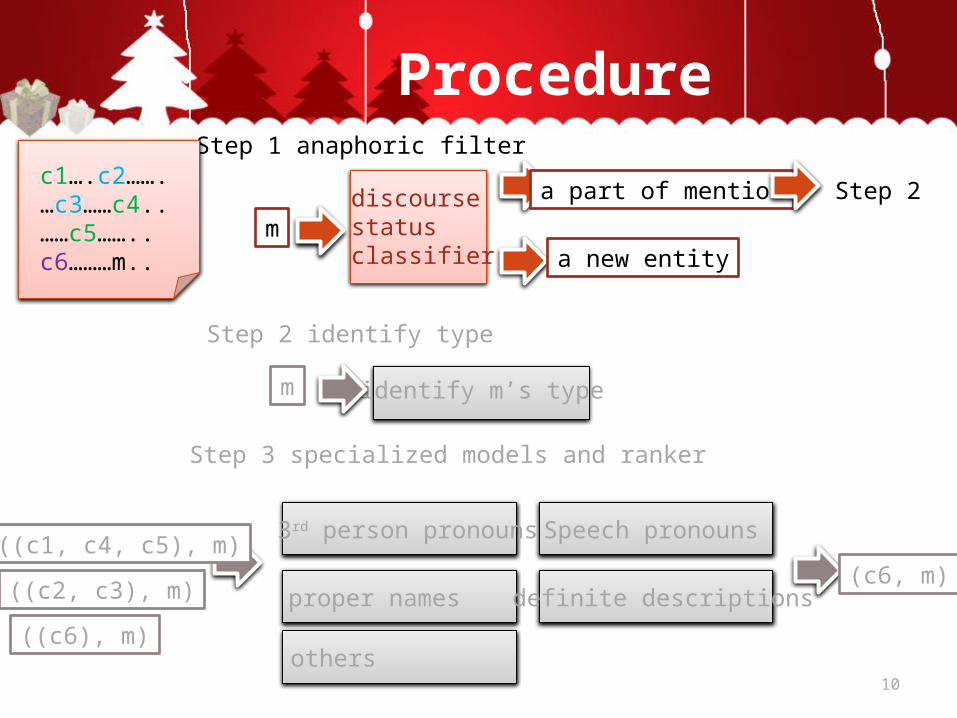
Procedure
discourse status classifier
Step 1 anaphoric filter
m
a part of mention
a new entity
Step 2
3rd person pronouns
Step 3 specialized models and ranker
((c1, c4, c5), m)
c1….c2…….…c3……c4..……c5……..c6………m..
((c2, c3), m)
((c6), m)
m
proper names
others
Speech pronouns
definite descriptions
identify m’s type
Step 2 identify type
8
(c6, m)

Term definition
• referential expressions mention• a discourse entity entity
9
c1….c2…….…c3……c4..……c5……..c6………m..
Combineentity1(c1, c4, c5, m)entity2(c2, c3)entity3(c6)
Procedure
discourse status classifier
Step 1 anaphoric filter
m
a part of mention
a new entity
Step 2
3rd person pronouns
Step 3 specialized models and ranker
((c1, c4, c5), m)
c1….c2…….…c3……c4..……c5……..c6………m..
((c2, c3), m)
((c6), m)
m
proper names
others
Speech pronouns
definite descriptions
identify m’s type
Step 2 identify type
10
(c6, m)

2. anaphoric filter (1/2)• Not all referential expressions in a given document are
anaphors: some expressions introduce a discourse entity, rather than accessing an existing one.
• It is more troublesome for rankers, which always pick an antecedent from the candidate set.
• A natural solution is to use a model that specifically predicts the discourse status (discourse-new vs. discourse-old) of each expression: only expressions that are classified as “discourse-old” by this model are considered by rankers.
11

2. anaphoric filter (2/2)• We use a similar discourse status classifier to Ng and Cardie’s
(Ng and Cardie, 2002a) as a filter on mentions for our rankers.• We rely on three main types of information sources:
– the form of mention (e.g., type of linguistic expression, number of tokens),
– positional features in the text, – comparisons of the given mention to the mentions that
precede it in the text.• Evaluated on the ACE datasets, the model achieves an overall
accuracy score of 80.8%, compared to a baseline of 59.7% when predicting the majority class (“discourse-old”).
12V. Ng and C. Cardie. 2002a. Identifying anaphoric and non-anaphoric noun phrases to improve coreference resolution. In Proceedings of COLING 2002.

Procedure
discourse status classifier
Step 1 anaphoric filter
m
a part of mention
a new entity
Step 2c1….c2…….…c3……c4..……c5……..c6………m..
3rd person pronouns
Step 3 specialized models and ranker
((c1, c4, c5), m)
((c2, c3), m)
((c6), m)
m
proper names
others
Speech pronouns
definite descriptions
identify m’s type
Step 2 identify type
13
(c6, m)

3. Ranking (1/3)
14
c1….c2…….…c3……c4..……c5……..c6………m..

3. Ranking (2/3)
• For the training of the different ranking models, we use the following procedure.
• For each model, instances are created by pairing each anaphor with a set of candidates which contains:– true antecedent– a set of non-antecedents
15

3. Ranking (3/3)• True antecedent:
The selection of the true antecedent varies depending on the model we are training: – for pronominal forms, the antecedent is selected as the
closest preceding mention in the chain; – for non-pronominal forms, we used the closest preceding
non-pronominal mention in the chain as the antecedent.
• Non-antecedent set:we collect all the non-antecedents that appear in a window of two sentences around the antecedent.
16

3. Specialized models (1/2)• Our second strategy is to use different, specialized
models for different referential expressions.• We use separate models for the following types:
1. third person pronouns, 2. speech pronouns, 3. proper names, 4. definite descriptions, and 5. others.
17

3. Specialized models (2/2)
• Note that our split of referential types only partially cover the referential hierarchies of Ariel (1988).
• Thus, there is no separate model for demonstrative noun phrases and pronouns: these are very rare in the corpus we used (i.e., the ACE corpus).
18

3.1 features (1/6)
• The total number of anaphors (i.e., of mentions that are not chain heads) in the data is 19322 and 4599 for training and testing, respectively.
22-24%
11-13%
33-40%
16-17%
19

3.1 features (2/6)
• Our feature extraction relies on limited linguistic processing: we only made use of a sentence detector, a tokenizer, a POS tagger (as provided by the OpenNLP Toolkit) and the WordNet database.
• Since we did not use parser, lexical heads for the NP mentions were computed using simple heuristics relying solely on POS sequences.
20

3.1 features (3/6)
21

3.1 features (4/6)• Linguistic form:
• Distance:
• Morph syntactic Agreement
• Semantic compatibility
22
we collected the synonymset (or synset) as well as the synset of their direct hypernyms associated with each mention. we used the synset associated with the first sense associated with the mention’shead word.

3.1 features (5/6)
• Context: – these features can be seen as approximations of
the grammatical roles, as indicators of the salience of the potential candidate.
• the part of speech tags surrounding the candidate, • indicates whether the potential antecedent is the first
mention in a sentence (approximating subject-hood), • indicating whether the candidate is embedded inside
another mention.
23

3.1 features (6/6)• String similarity: for PN, Def-NP, Other
• Acronym: for PN, Def-NP
• Apposition: for PN
24

5.1 Experiment 1
• Purpose: their ability to select a correct antecedent for each anaphor.
• Accuracy: the ratio of correctly resolved anaphors.
25

5.2 Experiment 2
• Metric: MUC, B3, CEAF• DataSet: ACE02
26
Ng and Cardie (2002b)
V. Ng and C. Cardie. 2002b. Improving machine learning approaches to coreference resolution. In Proceedings of ACL 2002, pages 104–111.

5.2 error analysis
• missed anaphors– i.e., an anaphoric mention that fails to be linked to
a previous mention• spurious anaphors
– i.e., an non-anaphoric mention that is linked to a previous mention
• invalid resolutions– a true anaphor that is linked to a incorrect
antecedent
27

5.3 Experiment 3
• RANK+DS-ORACLE+SP– uses the specialized rankers in combination with a
perfect discourse status classifier.• LINK-ORACLE
– uses the discourse status classifier with a perfect coreference resolver.
28

6. Conclusion
• We present and evaluate two straight-forward tactics for improving coreference resolution: – ranking models, and – separate, specialized models for different types of
referring expressions.• This simple pipeline architecture produces
significant improvements over various implementations of the standard, classifier-based coreference system.
29

7. Comments
• Advantage:– The proposed method by ranker and specialized
model, and the result of 3rd pronouns, proper names and link-oracle shows good performance.
30

Thank you for your attention&
Merry Christmas!
31