speeding up information extraction programs: a holistic optimizer and a learning-based approach to...
TRANSCRIPT

Speeding up Information Extraction Programs
Helena Galhardas
INESC-ID and IST, Universidade de Lisboa

Who am I? • Assistant Professor at IST, University of Lisbon (http://
www.ist.utl.pt) • Researcher at INESC-ID (http://www.inesc-id.pt) • Former (2000) PhD student at INRIA Rocquencourt/Univ.
Versailles • Main research interests:
– Data Cleaning • Support for User Involvement in Data Cleaning, DaWaK 2011 • Automatic optimization of the match operation (similarity join)
– Medical Information Systems • A Machine Learning based Natural Language Interface for a
Database of Medicines, poster paper DILS 2014 • ProntApp: A Mobile Question Answering System for Medicines
– Information Extraction 4/3/15 2 2

Who am I? • Assistant Professor at IST, University of Lisbon (http://
www.ist.utl.pt) • Researcher at INESC-ID (http://www.inesc-id.pt) • Former (2000) PhD student at INRIA Rocquencourt/Univ.
Versailles • Main research interests:
– Data Cleaning • Support for User Involvement in Data Cleaning, DaWaK 2011 • Automatic optimization of the match operation (similarity join)
– Medical Information Systems • A Machine Learning based Natural Language Interface for a
Database of Medicines, poster paper DILS 2014 • ProntApp: A Mobile Question Answering System for Medicines
Ø Information Extraction 4/3/15 3 3

Agenda
• A Holistic Optimizer for Speeding up Information Extraction Programs – PVLDB’13 and presented at VLDB’14 – Joint work with Gonçalo Simões, INESC-ID and IST/Univ.
Lisboa and Luis Gravano, Columbia University • A Learning-based Approach to Rank Documents
(briefly) – EDBT’15 – Joint work with Pablo Barrio, Columbia University, Gonçalo
Simões and Luis Gravano
4

Information Extraction Discovers Structured Information In Text Documents
The erup+on of Grímsvötn during 22-‐25 May 2011 brought back the memories of the erup+ons of EyjaEallajökull in 2010.
Natural Disaster
erup+on of Grímsvötn
erup+ons of EyjaEallajökull
Temporal Expression
22-‐25 May 2011
2010
Temporal Expression
22-‐25 May 2011
Natural Disaster Temporal Expression
erup+on of Grímsvötn 22-‐25 May 2011
Extract Occurs-‐In
Extract Natural Disaster
Select Temporal Expressions
From 2011
Extract Temporal Expressions
Much richer querying and analysis
5

IE SpecificaCon
Naïve ExecuCon Plan
Information Extraction Specification and Execution Plans are Graphs of
Operators Type of Operator: EE: En+ty Extractor RE: Rela+on Extractor
Technique
Algorithm

Information Extraction is Challenging and Time-consuming
• Operates on a large set of features
• Relies on complex text analysis
• Often applied over large document collections
erupCon brought memories erupCons
erupCon bring memory erupCon
Grímsvötn 22-‐25 brought 2010
Cc+ N+.N+ c+ N+
Ccccccccc NN.NN ccccccc NNNN
The erupCon brought back the memories the erupCons 2010
det nsubj prt det
dobj prep_of
prep_of det
LemmaCzaCon Features Character CapitalizaCon Features
7

IE Implementation Choices to the Rescue
• These implementation choices have an impact on execution time and quality of results (recall and precision)
– Recall: fraction of correct tuples that the plan produces – Precision: fraction of produced tuples that are correct
D
A C
B
D1
A1
A2
A3
C1
B1
B2
Choosing an Algorithm for Each Operator Choosing Operator ExecuCon Order
A
DC
B
A
DC
B
A
DC
B
A2
D1 C1
B1
ExecuCon Plan
Query(210K docs)
EECRF
EECRF Viterbi
EECRF VBS-‐10
EECRF VBS-‐5
RESVM RESVM All SVM
Choosing Document Retrieval Strategy
Query for Relevant Docs
Scan whole CollecCon
1. Execute A 2. Find sentences that produced results for A. 3. Execute B with those sentences only
Query for: [“natural disaster”], [earthquake], [erup+on], [tornado], (…)
8

State-of-the-art IE Optimization Systems
D
A C
B
D1
A1
A2
A3
C1
B1
B2
Choosing an Algorithm for Each Operator Choosing Operator ExecuCon Order
A
DC
B
A
DC
B
A
DC
B
SystemT CIMPLE
¡ Both use a cost-based optimizer to choose the execution order of operators ¡ System T uses heuristics to choose among different algorithms for an operator ¡ Do not allow approximate results
Choosing Document Retrieval Strategy
Query for Relevant Docs
Scan whole CollecCon
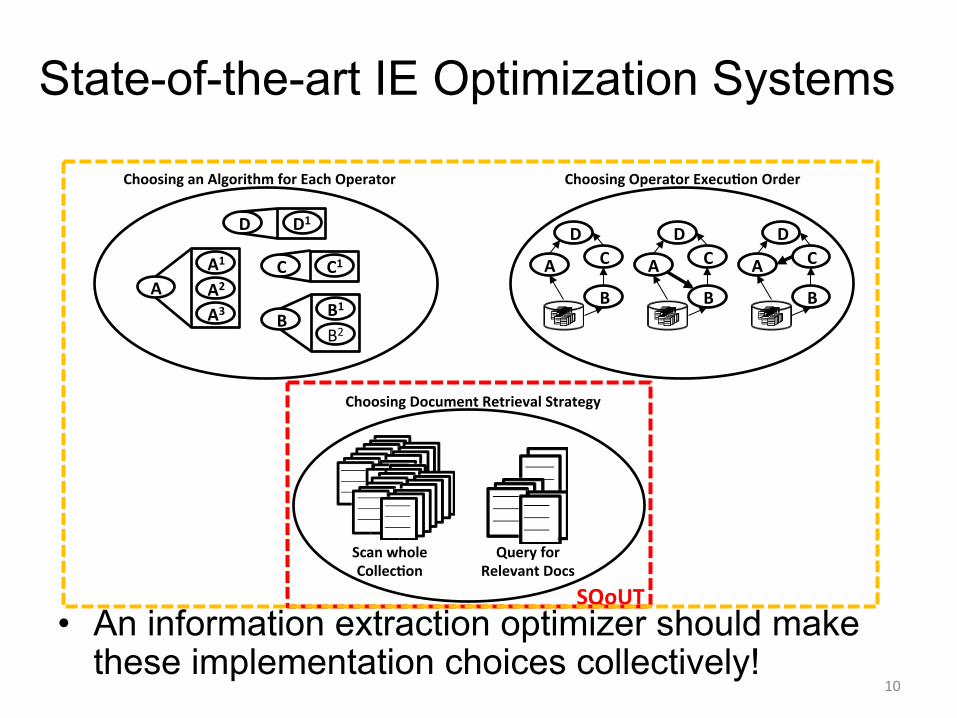
• An information extraction optimizer should make these implementation choices collectively!
D
A C
B
D1
A1
A2
A3
C1
B1
B2
Choosing an Algorithm for Each Operator Choosing Operator ExecuCon Order
A
DC
B
A
DC
B
A
DC
B
SQoUT
Choosing Document Retrieval Strategy
Query for Relevant Docs
Scan whole CollecCon
10
State-of-the-art IE Optimization Systems

Making implementation choices collectively leads to faster plans
A
DC
B
A1
D1 C1
B1
Scan(1M docs)
Time: 7h 30 m Recall: 93% Precision: 100%
A3
D1 C1
B2
Scan(1M docs)
Time: 9h 23 m Recall: 91% Precision: 95%
A1
D1 C1
B1
Scan(1M docs)
Time: 13h 16 m Recall: 100% Precision: 100%
Naive Plan
A1
D1 C1
B1
Query(153K docs)
Time: 2h 07 m Recall: 50% Precision: 100%
• By combining multiple choices we get a faster plan • We only control the quality results with collective
optimization
Algorithms OpCmizaCon
Operator Order OpCmizaCon
Document Retrieval OpCmizaCon
A3
D1 C1
B2
Query(210K docs)
Time: 1h 31 m Recall: 50% Precision: 96%
CollecCvely OpCmized Plan
A3
D1 C1
B2
Query(153K docs)
Time: 57 m Recall: 39% Precision: 98%
Direct CombinaCon Plan
Hard to control the expected recall and precision
Precision >= 90%
Recall >= 50%
Recall and Precision Constraints
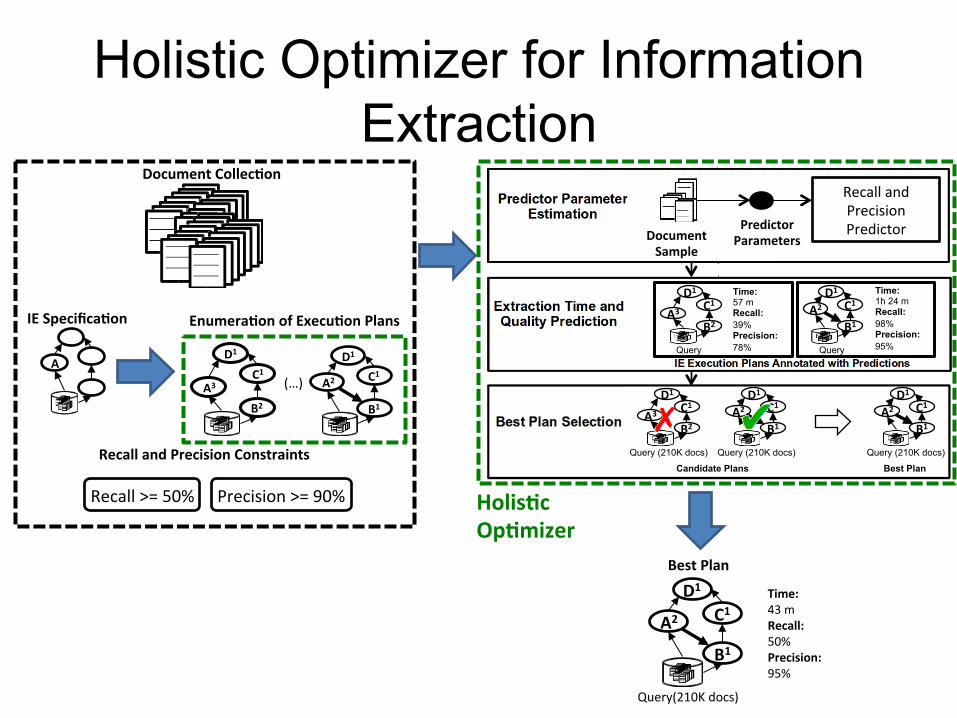
Holistic Optimizer for Information Extraction
A2
D1 C1
B1
Query(210K docs)
Time: 43 m Recall: 50% Precision: 95%
Best Plan
Document CollecCon
A
D C
B
IE SpecificaCon
Precision >= 90% Recall >= 50%
Recall and Precision Constraints
A3
D1 C1
B2 A2
D1 C1
B1 A2
D1 C1
B1
Query (210K docs) Query (210K docs) Query (210K docs)
Candidate Plans Best Plan
Document Sample
Predictor Parameters
Recall and Precision Predictor
Time: 57 m Recall: 39% Precision: 78%
A2 D1
C1
B1
Time: 1h 24 m Recall: 98% Precision: 95% Query
A3
D1 C1
B2
Query
HolisCc OpCmizer
(…)
EnumeraCon of ExecuCon Plans
A2
D1 C1
B1
A3
D1 C1
B2
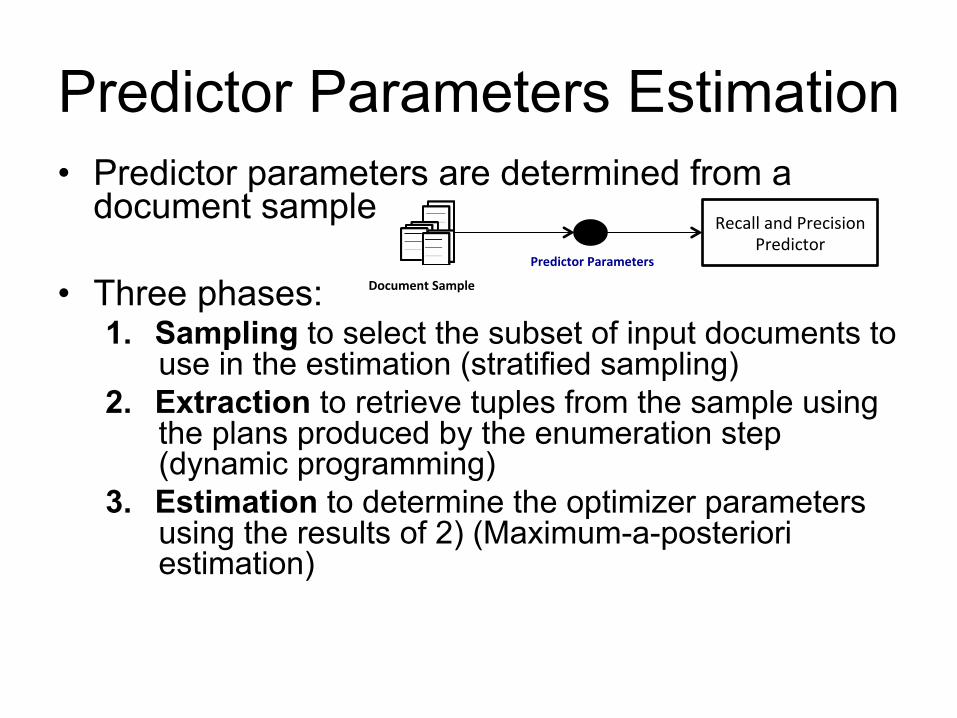
Predictor Parameters Estimation • Predictor parameters are determined from a
document sample
• Three phases: 1. Sampling to select the subset of input documents to
use in the estimation (stratified sampling) 2. Extraction to retrieve tuples from the sample using
the plans produced by the enumeration step (dynamic programming)
3. Estimation to determine the optimizer parameters using the results of 2) (Maximum-a-posteriori estimation)
Document Sample
Predictor Parameters
Recall and Precision Predictor

Extraction Quality Prediction
• Based on two predictions: – Number of input tuples of operator
– Number of output tuples of operator
A2
D1
C1
(…) (…) Path 1 Path 2
D1
t1 t2 t3 t4 (…)
• • • • • • • •
• •
A A2 A1 A3
t1 t2 t3 (…)
t1 t2 t1
t1 t3

Experimental Validation
• Impact of the Sample Size and Prediction Quality
• Impact of the Parameter Estimation Strategy
• Impact of Individual Implementation Choices
• Impact of Precision Constraints • Comparison With the State-of-the-Art
Techniques
15

Experimental Validation
• Impact of the Sample Size and Prediction Quality
• Impact of the Parameter Estimation Strategy
Ø Impact of Individual Implementation Choices
• Impact of Precision Constraints Ø Comparison With the State-of-the-Art
Techniques 16

Experimental Setup
• Datasets
• Information Extraction Programs
Researchers’ Homepages
Kedar Bellare’ Homepage
PhD student at University of Massachusegs, Amherst under supervision of Andrew McCallum. Publica+ons Generalized Expecta+on Criteria for Bootstrapping Extractors using Record-‐Text Alignment, EMNLP 2009, August 2009
Advisor Advisee
Andrew McCallum
Kedar Bellare
Conference Date
EMNLP 2009 August 2009
Advises
ConferencesDates
The Hai+ cholera outbreak between 2010 and 2013 was the worst epidemic of cholera in recent history
Google co-‐founders Larry Page and Sergey Brin recently sat down with billionaire venture capitalist Vinod Khosla for a lengthy interview.
Disease Time Period
Cholera Between 2010 and 2013
DiseaseOutbreaks
Person OrganizaCon
Larry Page Google
Sergey Brin Google
Organiza+onAffilia+on
Sparse RelaCons
Dense RelaCons 17

Experimental Setup (cont.) • IE Optimization Systems (baselines):
– Cimple – System T – SQoUT – SQoUt-Boosted: variation of SQoUT that uses the execution
plans produced by Cimple and System T • IE Optimization Techniques:
– Optimized-Ret: implementation choice of retrieval strategy – Optimized-Alg: implementation choice of the algorithms – Optimized-Order: implementation choice of the operator execution
order – Holistic-Map: uses maximum a posteriori for estimating the
parameters – Holistic-ML: uses maximum likelihood for estimating the parameters
18

Impact of Individual Implementation Choices
• Holistic-MAP obtains the fastest plan in every case • Optimized-Ret becomes too slow when desired recall
increases • Optimized-Order and Optimized-Alg consistently produce slow
plans • Holistic optimization outperforms individual optimization
ConferencesDates
19

Comparison with State-of-the-Art Techniques
• For dense relations, Holistic-MAP – Obtains faster plans – Closely matches recall constraints
OrganizaConAffiliaCon
20

Comparison with State-of-the-Art Techniques
• For sparse relations, Holistic-MAP – Obtains faster plans – Does not always matches recall constraints – Can correct the errors in recall constraints as the target recall
increases
DiseaseOutbreaks
21

Conclusions: Holistic Optimizer
• IE programs can be optimized along multiple interrelated dimensions, namely, the choice of: – Algorithms for each extraction operator – Operator execution order – Document retrieval strategy
• We presented the first holistic optimization approach for IE that collectively optimizes all dimensions simultaneously – It outperforms the state-of-the-art techniques and
selects efficient plans that meet target recall and precision values
22

What Comes Next?
• Ranking Models for IE (second part of the talk)
• Distributed Executions for IE (on-going work)
– by determining document placement in distributed file system
Random order
Ranked order

Agenda
• A Holistic Optimizer for Speed up Information Extraction Programs – PVLDB’13 and presented at VLDB’14 – Joint work with Gonçalo Simões and Luis
Gravano • A learning-based Approach to Rank
Documents – EDBT’15 – Joint work with Pablo Barrio, Gonçalo Simões
and Luis Gravano
24

Reducing IE Processing Time
• Small, topic-specific fraction of the entire collection is useful
Ex: Only 2% of documents in a New York Times archive, mostly environment-related, are useful for Natural Disaster-Location with a state-of-the-art IE system
• Useful documents share distinctive words and phrases Ex: “earthquake”, “storm,” “richter,” “volcano eruption” for Natural Disaster-Location
• Information extraction system labels documents as useful or not, for free
Should focus extraction over these documents
and ignore rest
Should learn to distinguish useful
documents for an IE task
Could use the result of an IE process to
generate an ever-expanding training set for learning and further
identifying useful documents
Documents are useful if they produce output for a given IE task

Existing Approaches: Qxtract and FactCrawl
• Qxtract and FactCrawl learn from a small document sample and so exhibit far-from-perfect recall
• FactCrawl re-ranks documents
using the quality of learned queries
• FactCrawl relies on queries derived from small set of documents and does not adapt to new processed documents

Our Approach • Focus on the potentially useful documents for the extraction
task at hand Ø Learning to rank approach for document ranking
• Results of extraction process form ever-expanding training set Ø Adaptive approach to update document ranking continuously
Features: Words and phrases, and agribute values
Document Collec+on
f(di) = si s1 ≥ s2 ≥ s3 ≥ ... si ≥ … sn
New words: lava, fissure
Learning Ranking and processing
New training instances

Ranking Documents Adaptively for IE
Learns that “tornado,” “earthquake,” are makers of useful documents
Learning
Document processing and update detec+on
Document Collec+on
Useful documents but on volcanoes, not yet observed prominently in IE process
<tornado, hawaii>
“… ‘Acermath’ narrates the story of a man that goes missing…”
“… S+ll recovering from an earthquake, Chile is threatened by the erupCon of
Copahue volcano…”
Online relearning
+
Performs online learning
New informaCon can poten+ally help improve ranking, so Update!
<volcano, chile>
Learns that “volcano” and “erup+on” are now makers of
useful documents
Ranking adaptaCon

Ranking Documents Adaptively for IE: Key Ideas
• To address efficiency, rely on online learning – Train the ranking model incrementally, one document at a time
• To handle large (and expanding) feature sets, rely on in-training feature selection – The learning-to-rank algorithm can efficiently identify the most
discriminative features during the training of the document ranking model
• We propose two learning-to-rank techniques for IE that integrate online learning and in-training feature selection: – BAgg-IE – RSVM-IE
• And two update detection techniques for document ranking adaptation: – Top-K – Mod-C

Experimental Validation
1. Impact of learning-to-rank approach 2. Impact of sampling strategies 3. Impact of adaptation 4. Impact of update detection 5. Scalability of our approach 6. Comparison with the state-of-the-art
ranking strategies
30

Experimental Validation
1. Impact of learning-to-rank approach 2. Impact of sampling strategies 3. Impact of adaptation 4. Impact of update detection 5. Scalability of our approach Ø Comparison with the state-of-the-art
ranking strategies
31

Complex extrac+on systems: CRFs, SVM kernels
Simple extrac+on systems: HMMs, text pagerns
• Dataset: • Information extraction systems
1.8 million ar+cles from 1987-‐2007
Experimental Setup
The Hai+ cholera outbreak between 2010 and 2013 was the worst epidemic of cholera in recent history
Google co-‐founders Larry Page and Sergey Brin recently sat down with billionaire venture capitalist Vinod Khosla for a lengthy interview.
"This is not a vic+mless crime," said Jim Kendall, president of the Washington Associa+on of Internet Service Providers.
A fire destroyed a Cargill Meat Solu+ons beef processing plant in Booneville.
Disease Time Period
cholera between 2010 and 2013
Disease-‐Outbreaks Person OrganizaCon
Larry Page Google
Sergey Brin Google
Person-‐Organiza+on
Person Career
Jim Kendall President
Person-‐Career Disaster LocaCon
fire Booneville
Man Made Disaster-‐Loca+on
Other rela+ons: Person-‐Charge, Elec+on-‐Winner, Natural Disaster-‐Loca+on
Dense rela+ons Sparse rela+ons

Recall Analysis
Update detec+on: Mod-‐C
Our adapCve implementa+on of the state of the art
Disease-‐Outbreak
• Our techniques bring significant improvement • RSVM-IE performs best, as it prioritizes useful documents better, favoring
adaptation

Extraction Time
Person-‐Organiza+on Affilia+on
• Our techniques improve efficiency of process even for inexpensive IE systems
Our adapCve implementa+on of the state of the art

Conclusion: Document Ranking for Scalable Information Extraction
• Running IE system over large text collections is computationally expensive
• Proposed lightweight, adaptive approach and learning-based alternatives
– Online learning algorithms with in-training feature selection: RSVM-IE, Bagg-IE
– Update detection based on feature changes: Mod-C, Top-K
– RSVM-IE + Mod-C performs best: Useful documents are better prioritized, enabling richer, more efficient ranking adaptation
Text Collec+on
IE system
<tornado, Florida>
<volcano, Chile> …

Future Work: Ranking at Different Granularities
• Few collections on the Web are relevant to an IE task
• Prioritize them based on number of useful documents
• Few sentences in a text
document output tuples for an IE task
• Prioritize them based on usefulness and diversity

Try REEL, our toolkit to easily develop and evaluate IE systems
– Open source and freely available at http://reel.cs.columbia.edu
Before We Leave…
Thank you!