statistical analysis of scorer interrater reliability
DESCRIPTION
Statistical Analysis of Scorer Interrater Reliability. JENNA PORTER DAVID JELINEK SACRAMENTO STATE UNIVERSITY. Background & Overview. Piloted since 2003-2004 Began with our own version of training & calibration Overarching question: Scorer interrater reliability - PowerPoint PPT PresentationTRANSCRIPT

JENNA PORTERDAVID JELINEK
SACRAMENTO STATE UNIVERSITY
Statistical Analysis of Scorer Interrater
Reliability

Background & Overview
Piloted since 2003-2004Began with our own version of training &
calibrationOverarching question: Scorer interrater reliability
i.e., Are we confident that the TE scores our candidates receive are consistent from one scorer to the next?
If not -- the reasons? What can we do out it?
Jenna: Analysis of data to get these questionsThen we’ll open it up to “Now what?” “Is there
anything we can/should do about it?” “Like what?”

Presentation Overview
• Is there interrater reliability among our PACT scorers?
• How do we know?• Two methods of analysis
• Results
• What do we do about it?• Implications

Data Collection
• 8 credential cohorts– 4 Multiple subject and 4 Single subject
• 181 Teaching Events Total – 11 rubrics (excludes pilot Feedback rubric)– 10% randomly selected for double score– 10% TEs were failing and double scored
• 38 Teaching Events were double scored (20%)

Scoring Procedures
Trained and calibrated scorers University Faculty Calibrate once per academic year
Followed PACT Calibration Standard-Scores must: Result in same pass/fail decision (overall) Have exact agreement with benchmark at least 6 times Be within 1 point of benchmark
All TEs scored independently once If failing, scored by second scorer and evidence
reviewed by chief trainer

Methods of Analysis
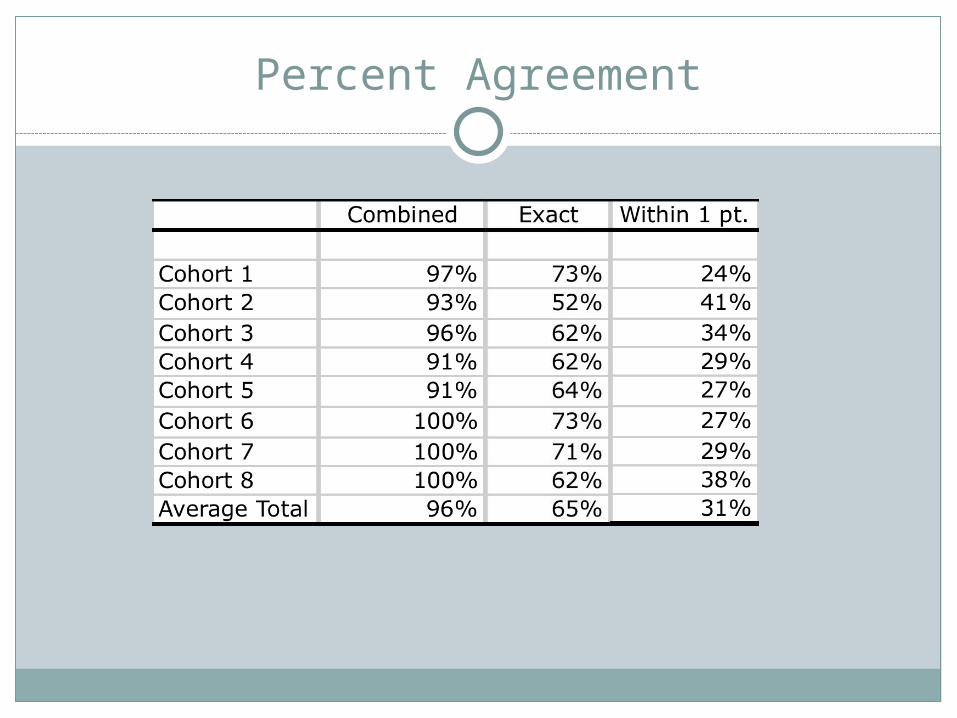
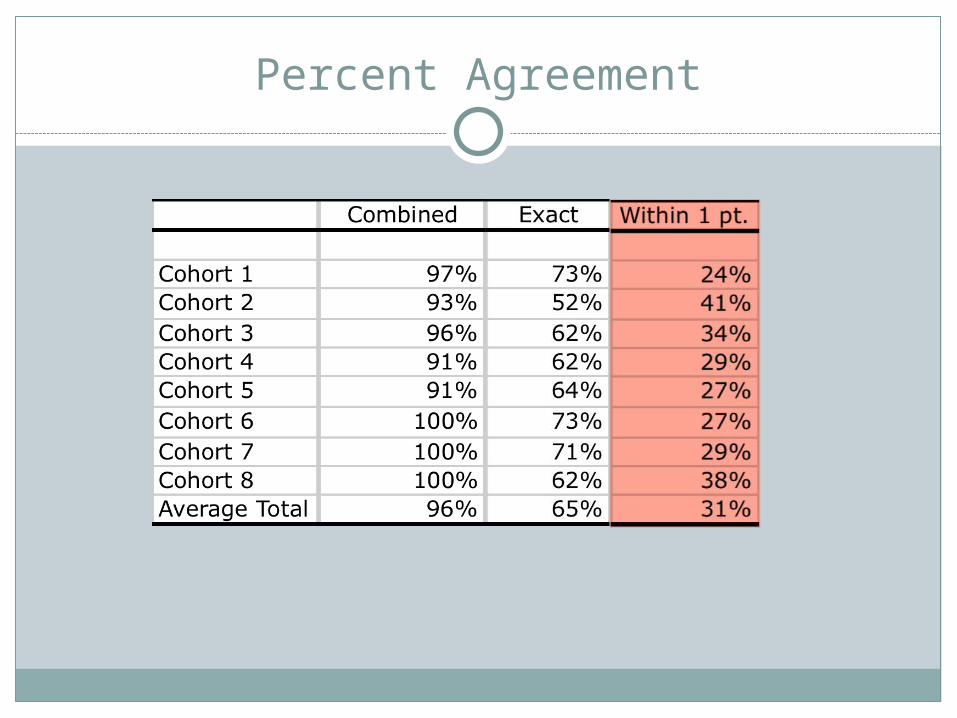
Percent Agreement Exact Agreement Agreement within 1 point Combined (Exact and within 1 point)
Cohen’s Kappa (Cohen, 1960) Indicates percentage of agreement accounted for
from raters above what is expected by chanceCohen (1960).
Cohen, J. (1960). A coefficient of agreement for nominal scales, Educational and Psychological Measurement, 20 (1), pp.37–46.

Percent Agreement
Benefits Easy to Understand
Limitations Does not account for chance agreement Tends to overestimate true agreement (Berk, 1979;
Grayson, 2001).
Berk, R. A. (1979). Generalizability of behavioral observations: A clarification of interobserver agreement and interobserver reliability. American Journal of Mental Deficiency, 83, 460-472.
Grayson, K. (2001). Interrater Reliability. Journal of Consumer Psychology, 10, 71-73.

Cohen’s Kappa
Benefits Accounts for chance agreement Can be used to compare across different conditions
(Ciminero, Calhoun, & Adams, 1986).
Limitations Kappa may decrease if low base rates, so need at least
10 occurances (Nelson and Cicchetti, 1995)
Ciminero, A. R., Calhoun, K. S., & Adams, H. E. (Eds.). (1986). Handbook of behavioral assessment (2nd ed.).
New York: Wiley. Nelson, L. D., & Cicchetti, D. V. (1995). Assessment of emotional functioning in brain impaired individuals.
Psychological Assessment, 7, 404–413.

Kappa coefficient
Kappa= Proportion of observed agreement – chance agreement
1- chance agreement
Coefficient ranges from -1.0 (disagreement) to 1.0 (perfect agreement)
Altman, D.G. (1991). Practical Statistics for Medical Research. London: Chapman and Hall.Fleiss, J. L. (1981). Statistical methods for rates and proportions. NY:Wiley.Landis, J. R., Koch, G. G. (1977). The measurement of observer agreement for categorical data. Biometrics 33:159-
174.
Percent Agreement
Percent Agreement
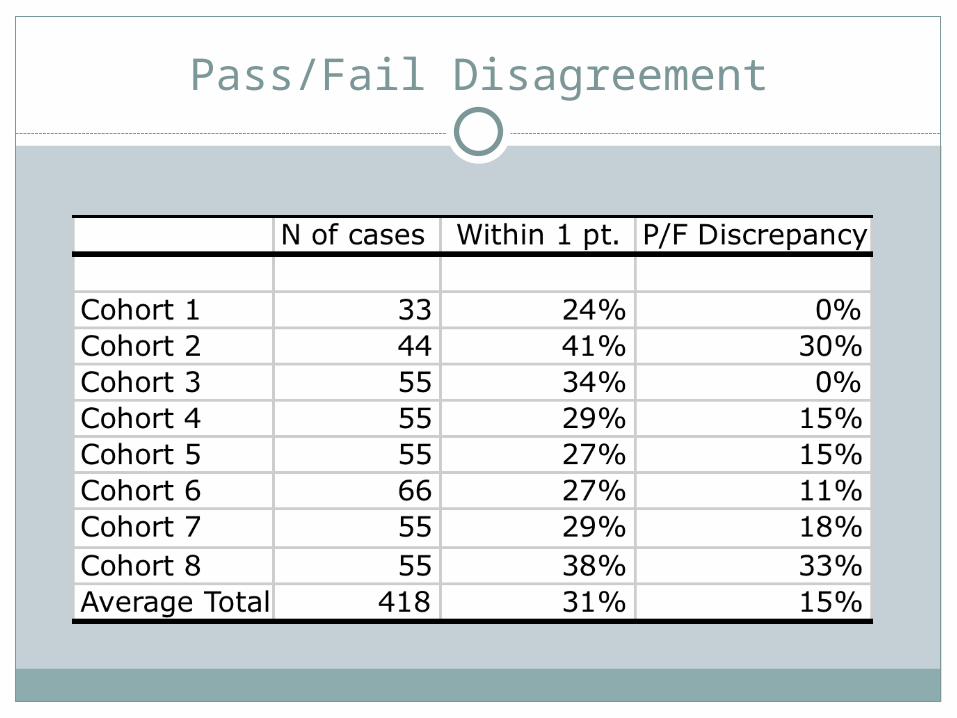
Pass/Fail Disagreement
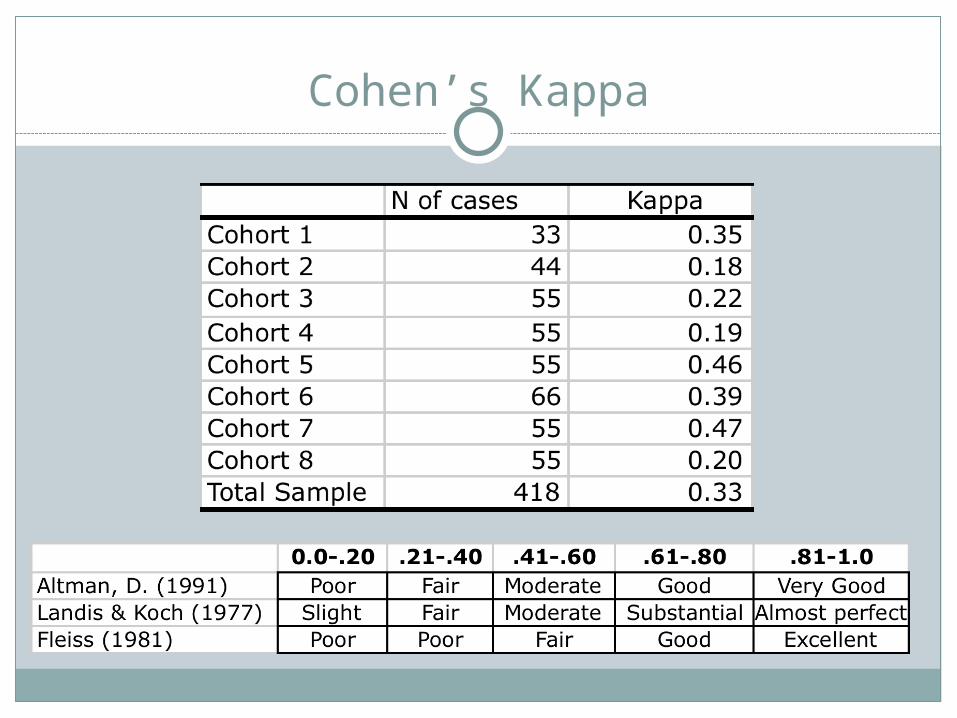
Cohen’s Kappa
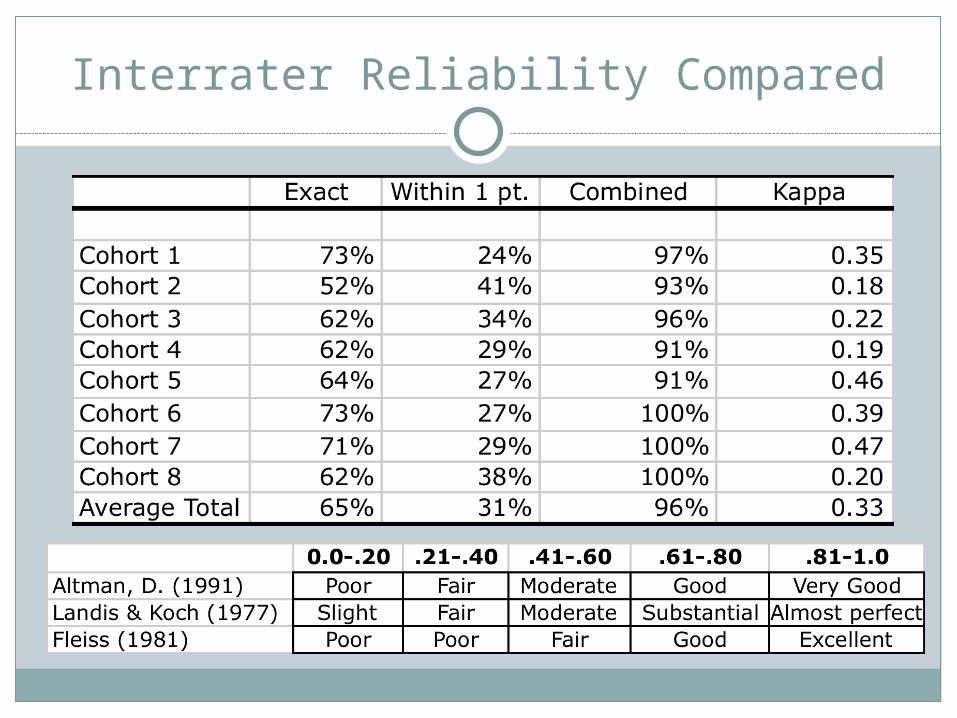
Interrater Reliability Compared

Implications
Overall interrater reliability poor to fair Consider/reevaluate protocol for calibration Calibration protocol may be interpreted differently Drifting scorers?
Use multiple methods to calculate interrater reliabilityOther?
How can we increase interrater reliability?
Your thoughts . . . Training protocol
Adding “Evidence Based” Training- Jeanne Stone, UCI More calibration