statistical automatic identification of microchiroptera from echolocation calls lessons learned from...
TRANSCRIPT

Statistical automatic identification of microchiroptera from echolocation calls
Lessons learned from human automatic speech recognition
Mark D. Skowronski and John G. Harris
Computational Neuro-Engineering Lab
Electrical and Computer Engineering
University of Florida
Gainesville, FL, USA
November 19, 2004

Overview• Motivations for bat acoustic research
• Review bat call classification methods
• Contrast with 1970s human ASR
• Experiments
• Conclusions

Bat research motivations• Bats are among:
– the most diverse,– the most endangered,– and the least studied mammals.
• Close relationship with insects– agricultural impact– disease vectors
• Acoustical research non-invasive, significant domain (echolocation)
• Simplified biological acoustic communication system (compared to human speech)

Echolocation calls• Features (holistic)
– Frequency extrema– Duration– Shape– # harmonics– Call interval
Mexican free-tailed calls, concatenated

Current classification methods
• Expert spectrogram readers– Manual or automatic feature extraction– Comparison with exemplar spectrograms
• Automatic classification– Decision trees– Discriminant function analysis
Parallels the knowledge-based approach to human ASR from the 1970s (acoustic phonetics, expert systems, cognitive approach).
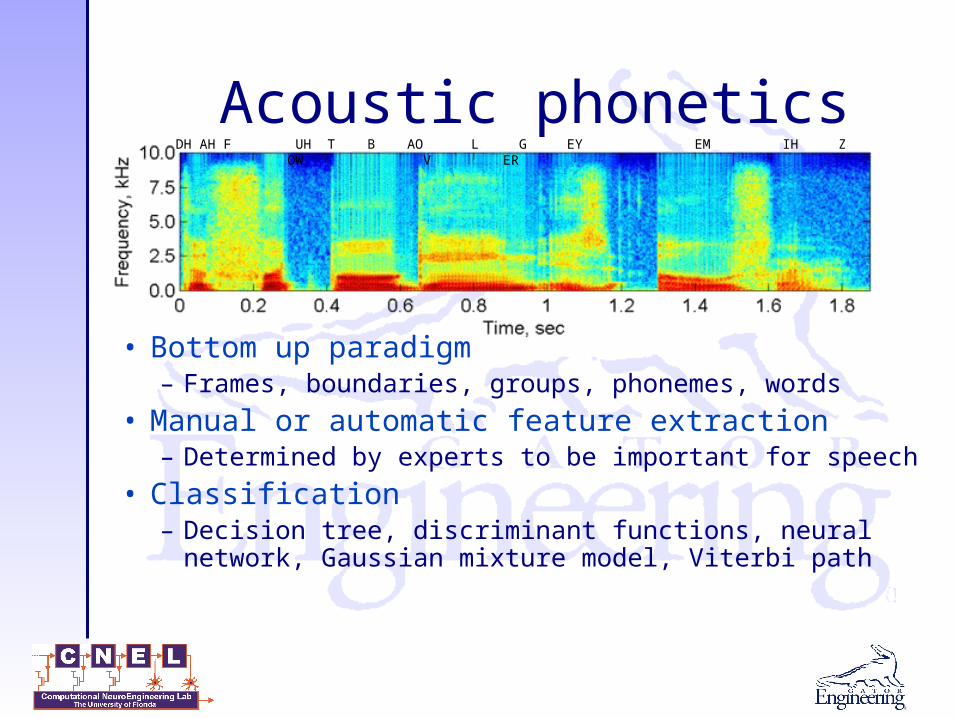
Acoustic phonetics
• Bottom up paradigm– Frames, boundaries, groups, phonemes, words
• Manual or automatic feature extraction– Determined by experts to be important for speech
• Classification– Decision tree, discriminant functions, neural network,
Gaussian mixture model, Viterbi path
DH AH F UH T B AO L G EY EM IH Z OW V ER

Acoustic phonetics limitations
• Variability of conversational speech– Complex rules, difficult to implement
• Feature estimates brittle– Variable noise robustness
• Hard decisions, errors accumulate
Shifted to information theoretic (machine learning) paradigm of human ASR, better able to account for variability of speech, noise.

Information theoretic ASR• Data-driven models from computer
science– Non-parametric: dynamic time warp (DTW)– Parametric: hidden Markov model (HMM)
• Frame-based– Expert information in feature extraction– Models account for feature, temporal
variability

Data collection• UF Bat House, home to 60,000 bats
– Mexican free-tailed bat (vast majority)– Evening bat– Southeastern myotis
• Continuous recording– 90 minutes around sunset– ~20,000 calls
• Equipment:– B&K mic (4939), 100 kHz– B&K preamp (2670)– Custom amp/AA filter– NI 6036E 200kS/s A/D card– Laptop, Matlab

Experiment design• Hand labels
– 436 calls (2% of data)– Four classes, a priori: 34, 40, 20, 6%– All experiments on hand-labeled data only– No hand-labeled calls excluded from experiments
1 2 3 4

Experiments• Baseline
– Features• Zero crossing• MUSIC super resolution frequency estimator
– Classifier• Discriminant function analysis, quadratic boundaries
• DTW and HMM– Features
• Frequency (MUSIC), log energy, first derivatives (HMM only)
– HMM• 5 states/model• 4 Gaussian mixtures/state• diagonal covariances

Results• Baseline, zero crossing
– Leave one out: 72.5% correct– Repeated trials: 72.5 ± 4% (mean ± std)
• Baseline, MUSIC– Leave one out: 79.1%– Repeated trials: 77.5 ± 4%
• DTW, MUSIC– Leave one out: 74.5 %– Repeated trials: 74.1 ± 4%
• HMM, MUSIC– Test on train: 85.3 %

Confusion matrices1 2 3 4
1 107 38 1 2 72.3%
2 21 134 16 4 76.6%
3 2 29 57 0 64.8%
4 4 3 0 18 72.0%
72.5%
Baseline, zero crossing Baseline, MUSIC
DTW, MUSIC HMM, MUSIC
1 2 3 4
1 110 36 1 1 74.3%
2 12 149 12 2 85.1%
3 4 18 66 0 75.0%
4 3 2 0 20 80.0%
79.1%
1 2 3 4
1 115 29 0 4 77.7%
2 32 131 11 1 74.9%
3 5 20 63 0 71.6%
4 5 4 0 16 64.0%
74.5%
1 2 3 4
1 118 25 0 5 79.7%
2 10 154 5 6 88.0%
3 1 12 75 0 85.2%
4 0 0 0 25 100%
85.3%

Conclusions• Human ASR algorithms applicable to bat
echolocation calls• Experiments
– Weakness: accuracy of class labels– HMM most accurate, undertrained– MUSIC frequency estimate robust, slow
• Machine learning– DTW: fast training, slow classification– HMM: slow training, fast classification

Further information• http://www.cnel.ufl.edu/~markskow• [email protected]• DTW reference:
– L. Rabiner and B. Juang, Fundamentals of Speech Recognition, Prentice Hall, Englewood Cliffs, NJ, 1993
• HMM reference:– L. Rabiner, “A tutorial on hidden Markov models and
selected applications in speech recognition,” in Readings in Speech Recognition, A. Waibel and K.-F. Lee, Eds., pp. 267–296. Kaufmann, San Mateo, CA, 1990.