statistical relational learning: a tutorial learning - university of
TRANSCRIPT

Statistical Relational Learning: A TutorialLearning: A Tutorial
Li G tLise GetoorUniversity of Maryland, College Park

AcknowledgementsThis tutorial is a synthesis of ideas of many individuals who have participated in various SRL events, workshops and classes (SRL00, SRL03, SRL04, SRL06, Dagstuhl05, Dagstuhl07, others)SRL04, SRL06, Dagstuhl05, Dagstuhl07, others)
Dagstuhl April 2007
Hendrik Blockeel, Mark Craven, James Cussens, Bruce D’Ambrosio, Luc De Raedt, Tom Dietterich, Pedro Domingos, Saso Dzeroski, Peter Flach, Rob Holte, Manfred Jaeger, David Jensen, Kristian Kersting, Heikki Mannila, Andrew McCallum, Tom
Dagstuhl April 2007
Mitchell, Ray Mooney, Stephen Muggleton, Kevin Murphy, Jen Neville, David Page, Avi Pfeffer, Claudia Perlich, David Poole, Foster Provost, Dan Roth, Stuart Russell, Taisuke Sato, Jude Shavlik, Ben Taskar, Lyle Ungar and many others

RoadmapSRL: What is it?SRL Tasks & ChallengesSRL Tasks & Challenges4 SRL ApproachesApplications and Future directionspp cat o s a d utu e d ect o s

Why SRL?Traditional statistical machine learning approaches assume:
A random sample of homogeneous objects from single relation
Traditional ILP/relational learning approaches assume:No noise or uncertainty in data
Real world data sets:Real world data sets:Multi-relational, heterogeneous and semi-structuredNoisy and uncertain
Statistical Relational Learning:newly emerging research area at the intersection of research in social network and link analysis, hypertext and web mining, graph mining, relational learning and inductive logic programmingg g g p g g
Sample Domains:web data, bibliographic data, epidemiological data, communication data customer networks collaborative filtering trust networksdata, customer networks, collaborative filtering, trust networks, biological data, natural language, vision
What is SRL?Three views…

View 1: Alphabet Soup

View 2: Representation Soup
Hierarchical Bayesian Model + Relational R t tiRepresentation
Logic Add probabilities StatisticalLogic Add probabilities
Add relationsProbabilities
Relational
Learning

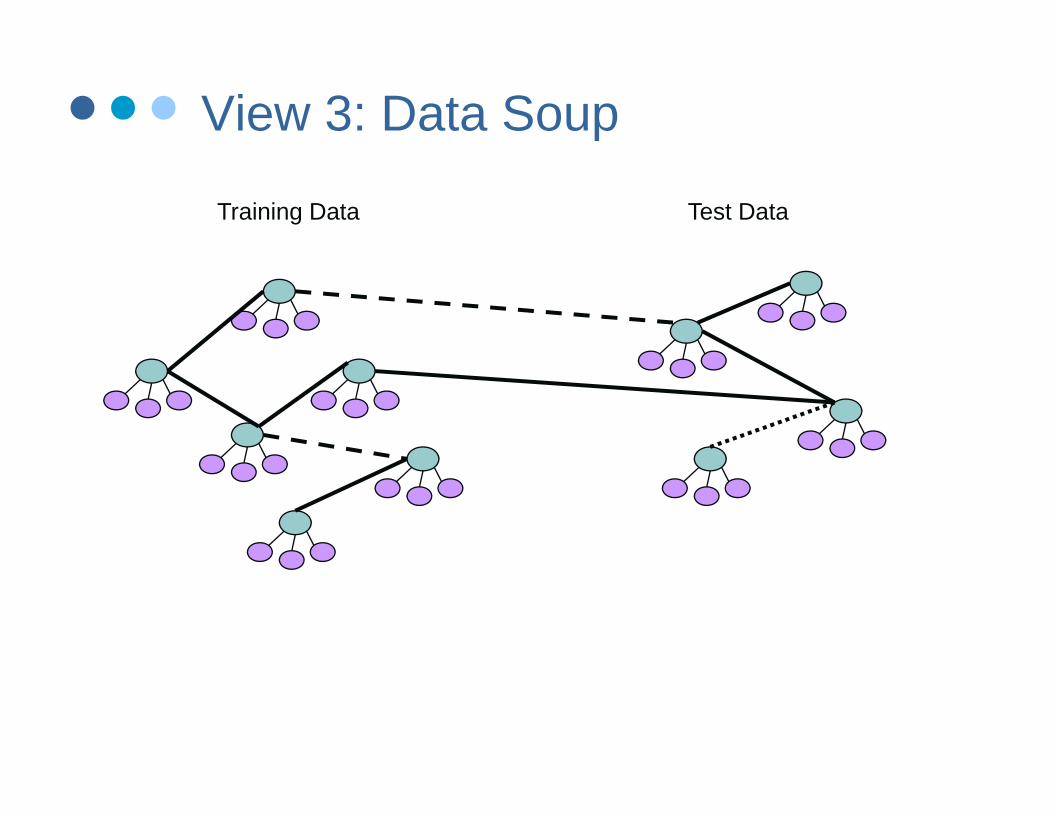
View 3: Data Soup
Training Data Test Data

View 3: Data Soup
Training Data Test Data

View 3: Data Soup
Training Data Test Data
View 3: Data Soup
Training Data Test Data

View 3: Data Soup
Training Data Test Data

View 3: Data Soup
Training Data Test Data

GoalsBy the end of this tutorial, hopefully, you will be:
1. able to distinguish among different SRL tasksg g2. able to represent a problem in one of several SRL
representations3. excited about SRL research problems and practical
applications

RoadmapSRL: What is it?SRL Tasks & ChallengesSRL Tasks & Challenges4 SRL ApproachesApplications and Future directionspp cat o s a d utu e d ect o s

SRL TasksTasks
Object ClassificationjObject Type PredictionLink Type PredictionPredicting Link ExistencePredicting Link ExistenceLink Cardinality EstimationEntity ResolutionGroup Detection Subgraph DiscoveryMetadata Miningg

Object Prediction
Object ClassificationPredicting the category of an object based on itsPredicting the category of an object based on its attributes and its links and attributes of linked objectse.g., predicting the topic of a paper based on the words used in the paper the topics of papers it cites theused in the paper, the topics of papers it cites, the research interests of the author
Object Type PredictionObject Type PredictionPredicting the type of an object based on its attributes andits links and attributes of linked objectse g predict the venue type of a publication (conferencee.g., predict the venue type of a publication (conference, journal, workshop) based on properties of the paper

Link PredictionLink Classification
Predicting type or purpose of link based on properties of the participating objectsparticipating objects e.g., predict whether a citation is to foundational work, background material, gratuitous PC reference
Predicting Link ExistencePredicting whether a link exists between two objectse.g. predicting whether a paper will cite another paper
Link Cardinality EstimationyPredicting the number of links to an object or predicting the number of objects reached along a path from an objecte.g., predict the number of citations of a paperg , p p p

More complex prediction tasksGroup Detection
Predicting when a set of entities belong to the same group based on clustering both object attribute values and link structureon clustering both object attribute values and link structuree.g., identifying research communities
Entity ResolutionEntity ResolutionPredicting when a collection of objects are the same, based on their attributes and their links (aka: record linkage, identity uncertainty)
di ti h t it ti f i t the.g., predicting when two citations are referring to the same paper.
Predicate InventionPredicate InventionInduce a new general relation/link from existing links and pathse.g., propose concept of advisor from co-author and financial supportpp
Subgraph Identification, Metadata Mapping

SRL ChallengesCollective ClassificationCollective Consolidation Logical vs. Statistical dependenciesFeature Construction – aggregation, selectionFlexible and Decomposable Combining RulesFlexible and Decomposable Combining RulesInstances vs. ClassesEffective Use of Labeled & Unlabeled DataEffective Use of Labeled & Unlabeled DataLink PredictionClosed vs. Open Worldp
Challenges common to any SRL approachl!Bayesian Logic Programs Markov Logic Networks Probabilistic Relational Models Bayesian Logic Programs, Markov Logic Networks, Probabilistic Relational Models,
Relational Markov Networks, Relational Probability Trees, Stochastic Logic Programming to name a few

RoadmapSRL: What is it?SRL Tasks & ChallengesSRL Tasks & Challenges4 SRL ApproachesApplications and Future directionspp cat o s a d utu e d ect o s

Four SRL ApproachesDirected Approaches
Rule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesFrame-based Undirected ModelsRule-based Undirected Models
P i L A h ( fi !)Programming Language Approaches (oops, five!)

Emphasis in Different ApproachesRule-based approaches focus on facts
what is true in the world?h t f t d th f t d d ?what facts do other facts depend on?
Frame-based approaches focus on objects and relationshipswhat types of objects are there, and how are they related to each th ?other?
how does a property of an object depend on other properties (of the same or other objects)?
Directed approaches focus on causal interactionsDirected approaches focus on causal interactionsUndirected approaches focus on symmetric, non-causal interactionsP i l h fProgramming language approaches focus on processes
how is the world generated?how does one event influence another event?

Four SRL ApproachesDirected Approaches
BN TutorialRule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesMarkov Network TutorialRule-based Undirected ModelsF b d U di t d M d lFrame-based Undirected Models

Bayesian Networks
Good Writer Smart SW P(Q| W S)
conditional probability table (CPT)
Good Writer0.6 0.4
w 0 3 0 7
sw
s
SW P(Q| W, S)
QualityReviewer
Mood
w
s
w
0.3 0.7
0 1 0 90.4 0.6
s
s
w
nodes = domain variables
s 0.1 0.9w
AcceptedReview Length
edges = direct causal influence
Network structure encodes conditional independencies:I(Review-Length , Good-Writer | Reviewer-Mood)

BN Semantics
conditional f ll j i tW S
conditionalindependenciesin BN structure
+ localCPTs
full jointdistribution
over domain=M Q
AL AL
),,,,,( alqmswP =
),()|(),|()|()()(),,,,,(
qmaPmlPswqPwmPsPwPalqmswP
|Compact & natural representation:
nodes ≤ k parents ⇒ O(2k n) vs. O(2n) paramsnatural parameters

Reasoning in BNsFull joint distribution answers any query
P(event | evidence)(e e t | e de ce)
Allows combination of different types of reasoning:yp gCausal: P(Reviewer-Mood | Good-Writer)Evidential: P(Reviewer-Mood | not Accepted)Intercausal: P(Reviewer-Mood | not Accepted, Quality)
W SW
M
S
Q
AL

Variable Elimination
To compute ∑= alqmswPaP )()(o co pute ∑lqmsw
alqmswPaP,,,,
),,,,,()(
factors
∑ qmaPmlPswqPwmPsPwP )|()|()|()|()()(
factors
∑lqmsw
qmaPmlPswqPwmPsPwP,,,,
),|()|(),|()|()()(
mood good writerpissypissy true
false01 A factor is a function from
values of variables togoodgood
falsetrue
0.70.3
values of variables to positive real numbers

Variable Elimination
To compute ∑= alqmswPaP )()(To compute ∑lqmsw
alqmswPaP,,,,
),,,,,()(
∑ ∑ qmaPmlPswqPwmPsPwP )|()|()|()|()()(∑ ∑qmsw l
qmaPmlPswqPwmPsPwP,,,
),|()|(),|()|()()(

Variable Elimination
To compute ∑= alqmswPaP )()(To compute ∑=lqmsw
alqmswPaP,,,,
),,,,,()(
∑∑ lPPPPPP )|()|()|()|()()( ∑∑lqmsw
mlPqmaPswqPwmPsPwP )|(),|(),|()|()()(,,,
sum out l

Variable Elimination
To compute ∑= alqmswPaP )()(To compute ∑lqmsw
alqmswPaP,,,,
),,,,,()(
)()|()|()|()()( mfqmaPswqPwmPsPwP∑ )(),|(),|()|()()(,,,
mfqmaPswqPwmPsPwPqmsw
∑ 1
new factornew factor

Variable Elimination
To compute ∑= alqmswPaP )()(To compute ∑=lqmsw
alqmswPaP,,,,
),,,,,()(
)|()|()()()|()( sqPmPPmfqmaPsP ∑∑ ),|()|()()(),|()(,,
swqPwmPwPmfqmaPsPwqms∑∑ 1
multiply factors togethery gthen sum out w

Variable Elimination
To compute ∑= alqmswPaP )()(To compute ∑lqmsw
alqmswPaP,,,,
),,,,,()(
)()()|()( sqmfmfqmaPsP∑ ),,()(),|()(,,
sqmfmfqmaPsPqms
21∑new factornew factor

Variable Elimination
To compute ∑= alqmswPaP )()(To compute ∑lqmsw
alqmswPaP,,,,
),,,,,()(
)(aP )(aP

Other Inference AlgorithmsExact
Junction Tree [Lauritzen & Spiegelhalter 88][ & p g ]Cutset Conditioning [Pearl 87]
ApproximateLoopy Belief Propagation [McEliece et al 98]Likelihood Weighting [Shwe & Cooper 91]Markov Chain Monte Carlo [eg MacKay 98]
• Gibbs Sampling [Geman & Geman 84]• Metropolis-Hastings [Metropolis et al 53 Hastings 70]Metropolis Hastings [Metropolis et al 53, Hastings 70]
Variational Methods [Jordan et al 98]

Learning BNs
Parameters only Structure andParameters onlyParameters
Complete Data Easy: counting Structure search
EM [Dempster et al 77]Incomplete Data
EM [Dempster et al 77]or gradient descent
[Russell et al 95]
Structural EM [Friedman 97]
[ ]
See [Heckerman 98] for a general introduction

BN Parameter EstimationAssume known dependency structure GGoal: estimate BN parameters θp
entries in local probability models,
)][Pa|( uXxXP ===θ
θ is good if it’s likely to generate observed data.
)][Pa|(, uXxXPuxθ
),|(log),:( GDPGDl θθ =
MLE Principle: Choose θ∗ so as to maximize lAlt ti i t iAlternative: incorporate a prior

Learning With Complete DataFully observed data: data consists of set of instances, each with a value for all BN variables
With fully observed data, we can compute swqN ,,= number of instances with , and
and similarly for other counts
q ,,q w s
We then estimateN
sw
swqswq N
NswqP
,
,,,, ),|( ==θ

Dealing w/ missing valuesCan’t computeBut can use Expectation Maximization (EM)
swqN ,,
But can use Expectation Maximization (EM) 1. Given parameter values, can compute expected
counts: ∑= iiiiswq swqPNE ,, )evidence|,,(][
2. Given expected counts, estimate parameters:
∑i
q instances
,,
][NE
this requires BN inference
Begin with arbitrary parameter values][][
),|(,
,,,,
sw
swqswq NE
NEswqP ==θ
Begin with arbitrary parameter valuesIterate these two stepsConverges to local maximum of likelihoodConverges to local maximum of likelihood

Structure searchBegin with an empty networkConsider all neighbors reached by a search operator g y pthat are acyclic
add an edgeremove an edgeremove an edgereverse an edge
For each neighborcompute ML parameter values
*
*sθ
compute score(s) =
Choose the neighbor with the highest score
)(log),|(log * sPsDP s +θ
Choose the neighbor with the highest scoreContinue until reach a local maximum

Mini-BN Tutorial SummaryRepresentation – probability distribution factored according to the BN DAGgInference – exact + approximateLearning – parameters + structure

Four SRL ApproachesDirected Approaches
BN TutorialRule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsR l b d U di t d M d lRule-based Undirected Models

Directed Rule-based FlavorsGoldman & Charniak [93]Breese [92][ ]Probabilistic Horn Abduction [Poole 93]Probabilistic Logic Programming [Ngo & Haddawy 96]Relational Bayesian Networks [Jaeger 97]Bayesian Logic Programs [Kersting & de Raedt 00]Stochastic Logic Programs [Muggleton 96]Stochastic Logic Programs [Muggleton 96]PRISM [Sato & Kameya 97]CLP(BN) [Costa et al. 03]Logical Bayesian Networks [Fierens et al 04, 05]etc.

Intuitive ApproachIn logic programming,
accepted(P) :- author(P,A), famous(A).
meansFor all P,A if A is the author of P and A is famous, then P
is acceptedThis is a categorical inferenceB t thi t b t i llBut this may not be true in all cases

Fudge FactorsUse
accepted(P) :- author(P,A), famous(A). (0.6)This means
For all P,A if A is the author of P and A is famous, then Pis accepted with probability 0 6is accepted with probability 0.6
But what does this mean when there are otherBut what does this mean when there are other possible causes of a paper being accepted?e.g. accepted(P) :- high_quality(P). (0.8)

Intuitive Meaningaccepted(P) :- author(P,A), famous(A). (0.6)
meansFor all P,A if A is the author of P and A is famous, then P
is accepted with probability 0.6, provided no other possible cause of the paper being accepted holdspossible cause of the paper being accepted holds
If more than one possible cause holds a combiningIf more than one possible cause holds, a combining rule is needed to combine the probabilities

Meaning of DisjunctionIn logic programming
accepted(P) :- author(P,A), famous(A). accepted(P) :- high_quality(P).
means For all P,A if A is the author of P and A is famous, or if P
is high quality, then P is accepted

Probabilistic DisjunctionNow
accepted(P) :- author(P,A), famous(A). (0.6)accepted(P) : high quality(P) (0 8)accepted(P) :- high_quality(P). (0.8)
meansFor all P,A, if (A is the author of P and A is famous , , (
successfully cause P to be accepted) or (P is high quality successfully causes P to be accepted), then Pis accepted.p
If A is the author of P and A is famous, they successfully cause P to be accepted with probability 0.6.
If P is high quality it successfully causes P to beIf P is high quality, it successfully causes P to be accepted with probability 0.8.
All causes act independently to produce effect (causal independence)p y p ( p )Leak probability: effect may happen with no cause
e.g. accepted(P). (0.1)

Computing ProbabilitiesWhat is P(accepted(p1)) given that Alice is an author and Alice is famous, and that the paper is p phigh quality, but no other possible cause is true?
1 fail) causes possible true all(succeeds) causetrueoneleast P(at
−==
PP
92801018016011 .).)(.)(.(
))(-(1-1 successcauses possible true
=−−−−=
= ∏ ip i
))()((
leak

Combination Rules
Other combination rules are possiblee.g., max
)(maxeffect)( successibltipP
i=
In our case,P(accepted(p1)) = max {0 6 0 8 0 1} = 0 8
causespossibletrue i
P(accepted(p1)) = max {0.6,0.8,0.1} = 0.8Harder to interpret in terms of logic program

KBMCKnowledge-Based Model Construction (KBMC) [Wellman et al. 92, Ngo & Haddawy 95]M th d f ti l b bilitiMethod for computing more complex probabilitiesConstruct a Bayesian network, given a query Qand evidence Eand evidence E
query and evidence are sets of ground atoms, i.e., predicates with no variable symbols
th ( 1 li )• e.g. author(p1,alice)
Construct network by searching for possible proofs of the query and the variablesp q yUse standard BN inference techniques on constructed network

KBMC Example
smart(alice). (0.8)smart(bob). (0.9)author(p1,alice). (0.7)author(p1,bob). (0.3)(p , ) ( )high_quality(P) :- author(P,A), smart(A). (0.5)high_quality(P). (0.1)accepted(P) : high quality(P) (0 9)accepted(P) :- high_quality(P). (0.9)
Query is accepted(p1)Query is accepted(p1).Evidence is smart(bob).

Backward ChainingStart with evidence variable smart(bob)
smart(bob)

Backward ChainingRule for smart(bob) has no antecedents – stop
backward chainingg
smart(bob)

Backward ChainingBegin with query variable accepted(p1)
smart(bob)
accepted(p1)

Backward Chaining
Rule for accepted(p1) has antecedent high_quality(p1)dd hi h lit ( 1) t t k d k t fadd high_quality(p1) to network, and make parent of accepted(p1)
smart(bob)
high_quality(p1)
accepted(p1)

Backward ChainingAll of accepted(p1)’s parents have been found –
create its conditional probability table (CPT)p y ( )
smart(bob)
high_quality(p1)high_quality(p1) accepted(p1)
accepted(p1) hq
hq 0.9 0.1
0 1

Backward Chaininghigh_quality(p1) :- author(p1,A), smart(A) has two
groundings: A=alice and A=bobg g
smart(bob)
high_quality(p1)
accepted(p1)

Backward ChainingFor grounding A=alice, add author(p1,alice) and
smart(alice) to network, and make parents ofsmart(alice) to network, and make parents of high_quality(p1)
smart(bob)smart(alice)
author(p1,alice)
high_quality(p1)
accepted(p1)
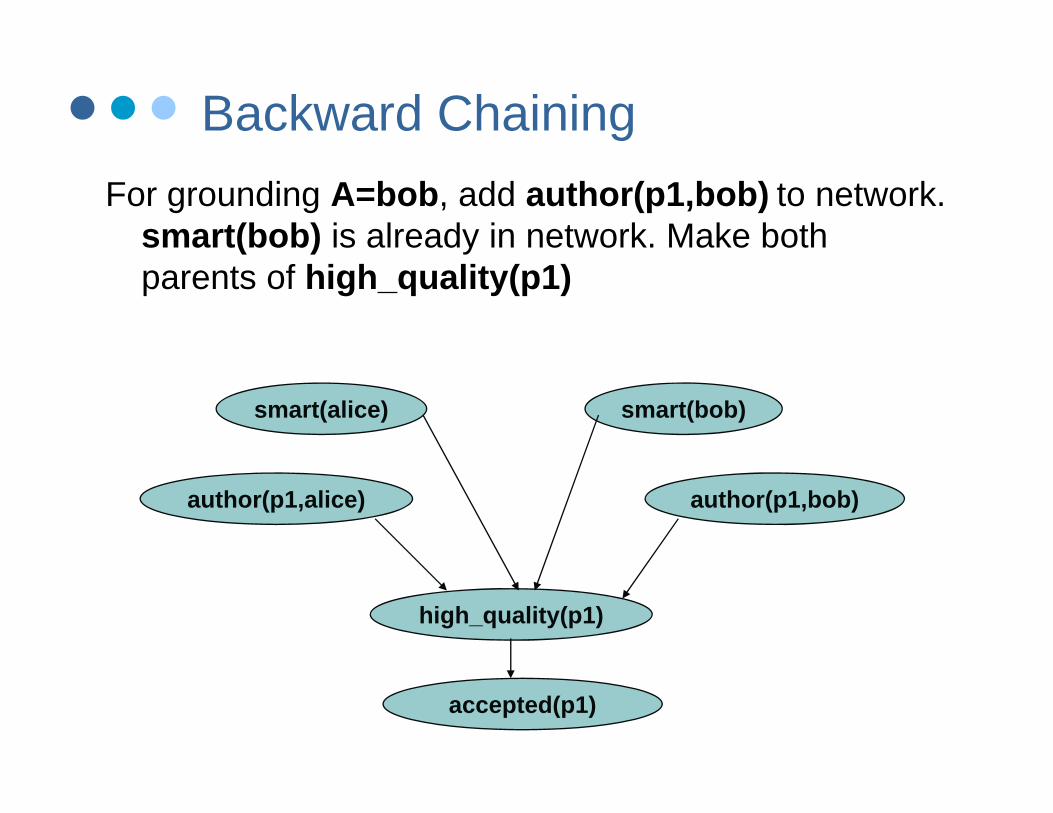
Backward ChainingFor grounding A=bob, add author(p1,bob) to network.
smart(bob) is already in network. Make both ( ) yparents of high_quality(p1)
smart(bob)smart(alice)
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)

Backward ChainingCreate CPT for high_quality(p1) – make noisy-or
smart(bob)smart(alice)
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)
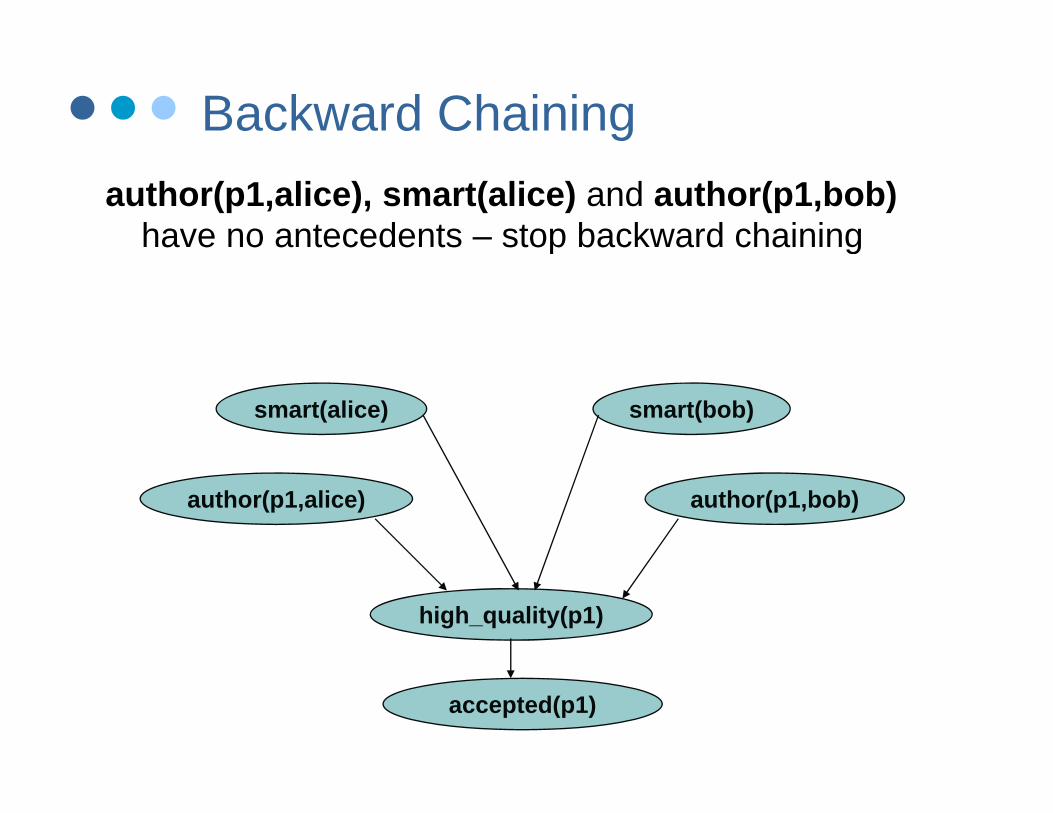
Backward Chainingauthor(p1,alice), smart(alice) and author(p1,bob)
have no antecedents – stop backward chainingp g
smart(bob)smart(alice)
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)

Backward Chainingassert evidence smart(bob) = true, and compute P(accepted(p1) | smart(bob) = true)(accepted(p ) | s a t(bob) t ue)
tsmart(bob)smart(alice)
true
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)

Backward Chaining on Both Query and EvidenceQuery and Evidence
Necessary, if query and evidence have common ancestor
Ancestor
S ffi i t P(Q | E id ) b t d
Query Evidence
Sufficient. P(Query | Evidence) can be computed using only ancestors of query and evidence nodesnodes
unobserved descendants are irrelevant

The Role of ContextContext is deterministic knowledge known prior to the network being constructedg
May be defined by its own logic programIs not a random variable in the BN
Used to determine structure of the constructed BNIf a context predicate P appears in the body of a rule R only backward chain on R if P is trueR, only backward chain on R if P is true

Context exampleSuppose author(P,A) is a context predicate,
author(p1,bob) is true, and author(p1,alice) cannot (p , ) (p , )be proven from deterministic KB (and is therefore false by assumption)
Network is
N th ( 1 b b) dsmart(bob) No author(p1,bob) nodebecause it is a context predicate
high_quality(p1) No smart(alice) nodebecause author(p1,alice) is false
accepted(p1)

SemanticsAssumption: no cycles in resulting BN
If there are cycles, cannot interpret BN as definition y , pof joint probability distribution
Assuming BN construction process terminates, conditional probability of any query given any evidence is defined by the BN.Somewhat unsatisfying becauseSomewhat unsatisfying because
1. meaning of program is query dependent (depends on constructed BN))
2. meaning is not stated declaratively in terms of program but in terms of constructed network i t dinstead

Disadvantages of Approach
Up until now, ground logical atoms have been d i bl irandom variables ranging over T,Fcumbersome to have a different random variable for lead author(p1,alice), lead author(p1,bob)for lead_author(p1,alice), lead_author(p1,bob)and all possible values of lead_author(p1,A)
worse, since lead_author(p1,alice) and lead_author(p1,bob) are different random variables, it is possible for both to be true at thevariables, it is possible for both to be true at the same time

Bayesian Logic Programs [Kersting and de Raedt][Kersting and de Raedt]
Now, ground atoms are random variables with gany range (not necessarily Boolean)
now quality is a random variable, with values high medi m lohigh, medium, low
Any probabilistic relationship is allowedAny probabilistic relationship is allowedexpressed in CPT
Semantics of program given once and for allnot query dependentnot query dependent

Meaning of Rules in BLPsaccepted(P) :- quality(P).
meansmeans“For all P, if quality(P) is a random variable, then accepted(P) is a random variable”
Associated with this rule is a conditional probability table (CPT) that specifies the probability distribution over accepted(P) for any possible value ofquality(P)quality(P)

Combining Rules for BLPs
accepted(P) :- quality(P).accepted(P) : quality(P).accepted(P) :- author(P,A), fame(A).
Before, combining rules combined individual probabilities with each otherp
noisy-or and max rules easy to interpretNow, combining rules combine entire CPTs

Semantics of BLPsRandom variables are all ground atoms that have finite proofs in logic programsp g p g
assumes acyclicityassumes no function symbols
Can construct BN over all random variablesparents derived from rulesCPTs derived using combining rules
Semantics of BLP: joint probability distribution over all random variablesall random variables
does not depend on queryInference in BLP by KBMCInference in BLP by KBMC

An IssueHow to specify uncertainty over single-valued relations?Approach 1: make lead_author(P) a random variable taking values bob alice etcvalues bob, alice etc.
we can’t say accepted(P) :- lead_author(P), famous(A)because A does not appear in the rule head or in a previous term in the bodyprevious term in the body
Approach 2: make lead_author(P,A) a random variable with values true, false
i t th bl ith th i t itiwe run into the same problems as with the intuitive approach (may have zero or many lead authors)
Approach 3: make lead_author a functionsay accepted(P) :- famous(lead_author(P))need to specify how to deal with function symbols and uncertainty over themy

First-Order Variable Elimination[Poole 03, Braz et al 05] Generalization of variable elimination to firstGeneralization of variable elimination to first order domainsReasons directly about first-order variables, y ,instead of at the ground levelAssumes that the size of the population for each type of entity is known

Learning Rule Parameters
[Koller & Pfeffer 97, Sato & Kameya 01] P bl d fi itiProblem definition:
Given a skeleton rule base consisting of rules without uncertainty parameterswithout uncertainty parametersand a set of instances, each with
• a set of context predicates• observations about some random variables
Goal: learn parameter values for the rules that maximize the likelihood of the datamaximize the likelihood of the data

Basic Approach1. Construct a network BNi for each instance i using
KBMC, backward chaining on all the observed gvariables
2. Expectation Maximization (EM)• exploit parameter sharing

Parameter SharingIn BNs, all random variables have distinct CPTs
only share parameters between different instances, not different random variables
In logical approaches, an instance may contain many objects of the same kindmany objects of the same kind
multiple papers, multiple authors, multiple citationsParameters are shared within instances
same parameters used across different papers, authors, citations
Parameter sharing allows faster learning andParameter sharing allows faster learning, and learning from a single instance

Rule Parameters & CPT EntriesIn principle, combining rules produce complicated relationship between model parameters and CPT p pentriesWith a decomposable combining rule, each node
fis derived from a single ruleMost natural combining rules are decomposable
• e g noisy or decomposes into set of ands followed by or• e.g. noisy-or decomposes into set of ands followed by or

Parameters and CountsEach time a node is derived from a rule r, it provides one experiment to learn about the parameters
i t d ithassociated with r
Each such node should therefore make a separateEach such node should therefore make a separate contribution to the count for those parameters
: the parameter associated with P(X=x|Parents[X]=u) when rule r applies
rux ,θ
: the number of times a node has value x and its parents have value u when rule r applies
ruxN ,p pp

EM With Parameter SharingGiven parameter values, compute expected counts:
)|],(][ ,i
i X
rux uXxXPNE evidenceParents[
instances === ∑ ∑
where the inner sum is over all nodes derived from rule r in BNi
Given expected counts, estimate:
][][ ,
, ru
ruxr
ux NENE
=θ
Iterate these two steps
][ u

Learning Rule Structure
[Kersting and De Raedt 02] P bl d fi itiProblem definition:
Given a set of instances, each with • context predicatescontext predicates• observations about some random variables
Goal: learn • a skeleton rule base consisting of rules and parameter
values for the rules
Generalizes BN structure learningGe e a es s uc u e ea gdefine legal modelsscoring function same as for BNdefine search operators

Legal ModelsHypothesis space consists of all rule sets using given predicates, together with parameter valuesg p g pA legal hypothesis:
is logically valid: rule set does not draw false conclusions for any data casesthe constructed BN is acyclic for every instance

Search operatorsAdd a constant-free atom to the body of a single clauseRemove a constant-free atom from the body of a single clause
accepted(P) :- author(P,A).accepted(P) :- quality(P).
accepted(P).t d(P) lit (P)
delete add
accepted(P) :- quality(P).
accepted(P) :- author(P,A), famous(A).accepted(P) :- quality(P)accepted(P) :- quality(P).

Summary: Directed Rule-based ApproachesApproaches
Provide an intuitive way to describe how one fact d d th f tdepends on other factsIncorporate relationships between entitiesGeneralizes to many different situationsGeneralizes to many different situations
Constructed BN for a domain depends on which objects exist and what the known relationships are j pbetween them (context)
Inference at the ground level via KBMCor lifted inference via FOVE
Both parameters and structure are learnable

Four SRL ApproachesDirected Approaches
BN TutorialRule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsR l b d U di t d M d lRule-based Undirected Models

Frame-based ApproachesProbabilistic Relational Models (PRMs)
Representation & Inference [Koller & Pfeffer 98, p & [ & ,Pfeffer, Koller, Milch &Takusagawa 99, Pfeffer 00] Learning [Friedman et al. 99, Getoor, Friedman, K ll & T k 01 & 02 G t 01]Koller & Taskar 01 & 02, Getoor 01]
Probabilistic Entity Relation Models (PERs)Probabilistic Entity Relation Models (PERs)Representation [Heckerman, Meek & Koller 04]

Four SRL ApproachesDirected Approaches
BN TutorialR l b d Di t d M d lRule-based Directed ModelsFrame-based Directed Models
• PRMs w/ Attribute UncertaintyInference in PRMs• Inference in PRMs
• Learning in PRMs• PRMs w/ Structural Uncertainty
• PRMs w/ Class Hierarchies
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

Relational Schema
AuthorG d W it
ReviewGood Writer Mood
LengthSmart
PaperQuality
Author ofHas ReviewAccepted
Describes the types of objects and relations in the database

Probabilistic Relational Model
Author ReviewSmart
Length
Mood
Good Writer
Smart
g
PaperPaper
Quality
Accepted

Probabilistic Relational Model
Author ReviewSmart
Length
Mood
Good Writer
Smart
g
PaperPaper
Quality⎟⎞⎜
⎛ Paper.Accepted |
Accepted⎟⎟⎟
⎠⎜⎜⎜
⎝ Paper.Review.MoodPaper.Quality,P

Probabilistic Relational Model
Author ReviewSmart
Length
Mood
Good Writer
Smart
g
PaperPaper
Quality
80209.01.0,
,
tfff
P(A | Q, M)MQ
Accepted
30704.06.08.02.0
,,
ttfttf
3.07.0, tt

Relational Skeleton
P i KAuthor A1
Paper P1Author: A1Review: R1
Review R1
Paper P2
Primary Keys
Review R2Author A2
Paper P2Author: A1Review: R2
P P3 Review R2Paper P3Author: A2Review: R2 Foreign Keys
Review R2
Fixed relational skeleton σ:set of objects in each classrelations between them

PRM w/ Attribute UncertaintyAuthor A1
Paper P1Author: A1Review: R1 Review R1
SmartMoodQuality
Paper P2
Good Writer Length
Mood
Accepted
Review R2Author A2 Author: A1
Review: R2
Length
MoodQuality
AcceptedGood Writer
Smart
Paper P3Author: A2Review: R2
Review R3
Accepted
Review: R2Quality
AcceptedLength
Mood
PRM defines distribution over instantiations of attributes

A Portion of the BN
P2.Quality r2.Mood
9010,
ffP(A | Q, M)MQPissyLow
9010,
ffP(A | Q, M)MQ
P2.Accepted
4.06.08.02.09.01.0
,,,
fttfff
4.06.08.02.09.01.0
,,,
fttfff
P3 Accepted
P3.Quality3.07.04.06.0
,,ttft
3.07.04.06.0
,,ttft
r3.Mood
P3.Accepted

A Portion of the BN
P2.Quality r2.MoodPissyLow
9.01.0,,
ffP(A | Q, M)MQ
P2.Accepted
4.06.08.02.09.01.0
,,,
fttfff
P3 Accepted
P3.Quality r3.MoodHigh 3.07.0, ttPissy
P3.Accepted

PRM: Aggregate Dependencies
Mood
Paper
Quality
Review
Length
Quality
Accepted
Review R1
Length
Mood
Review R2
MoodPaper P1
LengthReview R3
MoodAccepted
Quality
Length

PRM: Aggregate Dependencies
Mood
Paper
Quality
Review
Length
Quality
Accepted
Review R19.01.0,
,ff
P(A | Q, M)MQ
Length
Mood
Review R2
MoodPaper P1 30704.06.08.02.0
,,,
ttfttf
LengthReview R3
MoodAccepted
Quality
mode
3.07.0, tt
sum, min, max, avg, mode, count
Length

PRM with AU SemanticsAuthor
Paper AuthorA1 Paper
R i
ReviewR1
Review PaperP2
P1
ReviewR3
ReviewR2Author
A2
Paper
PRM relational skeleton σ+ =
PaperP3
probability distribution over completions I:
)).(|.(),,|( ,.
AxparentsAxPP Sx Ax
σσ
σ ∏ ∏∈
=ΘSI
AttributesObjects

Four SRL ApproachesDirected Approaches
BN TutorialR l b d Di t d M d lRule-based Directed ModelsFrame-based Directed Models
• PRMs w/ Attribute UncertaintyInference in PRMs• Inference in PRMs
• Learning in PRMs• PRMs w/ Structural Uncertainty
• PRMs w/ Class Hierarchies
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

PRM InferenceSimple idea: enumerate all attributes of all objectsConstruct a Bayesian network over all the attributesConstruct a Bayesian network over all the attributes

Inference Example
Review
Review
R1Paper
P1
Skeleton
R2Author
A1Review
R3
ReviewR4
R3Paper
P2
R4
Query is P(A1 good writer)Query is P(A1.good-writer)Evidence is P1.accepted = T, P2.accepted = T

PRM Inference: Constructed BN
A1.Smart
P1.Quality
A1.Good WriterQ y
R1.Mood R2.Mood
P1 AcceptedR1.Length R2.Length P2.Quality
P1.AcceptedR3.Mood R4.Mood
P2.AcceptedR3.Length R4.Length

PRM InferenceProblems with this approach:
constructed BN may be very largey y gdoesn’t exploit object structure
Better approach:reason about objects themselvesreason about whole classes of objects
In particular, exploit:reuse of inference
l ti f bj tencapsulation of objects

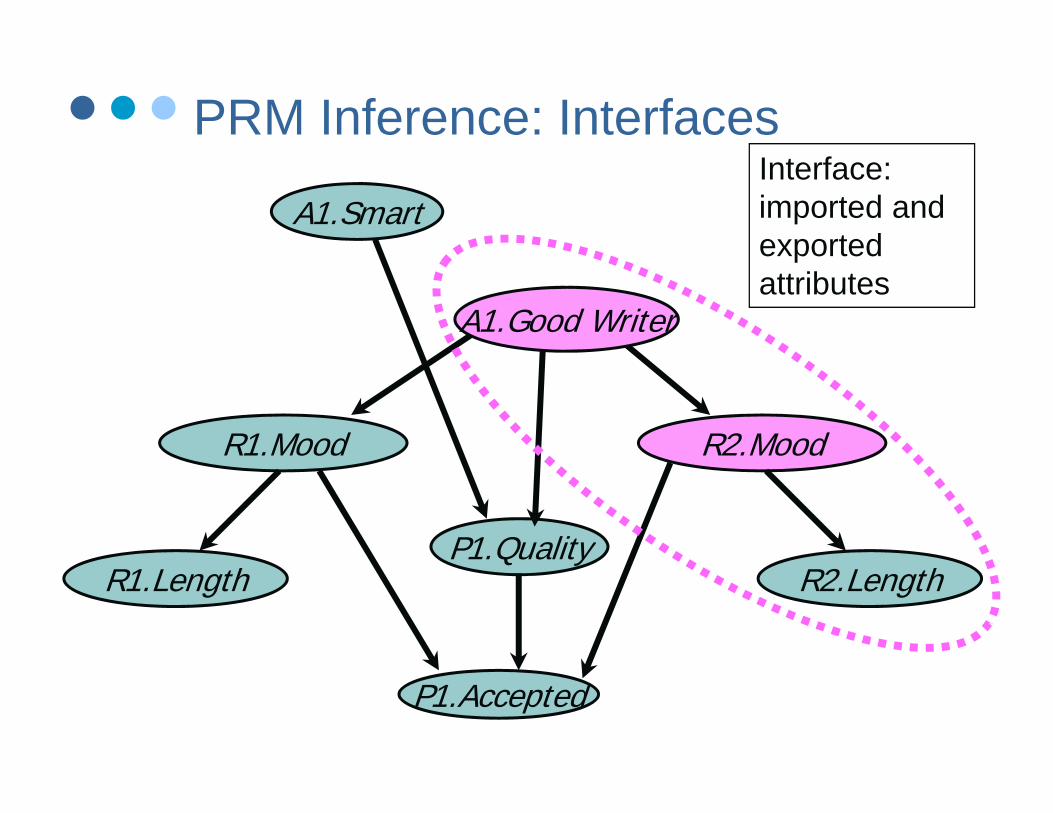
PRM Inference: Interfaces
A1.SmartVariables pertainingto R2: inputs and i t l tt ib t
A1.Good Writer
internal attributes
R2.MoodR1.Mood
P1.QualityQ yR2.LengthR1.Length
P1.Accepted
PRM Inference: Interfaces
A1.SmartInterface: imported and exported
A1.Good Writer
exportedattributes
R2.MoodR1.Mood
P1.QualityQ yR2.LengthR1.Length
P1.Accepted

PRM Inference: Encapsulation
A1.Smart R1 and R2 areencapsulated
P1.QualityA1.Good Writer inside P1
Q y
R1.Mood R2.Mood
P1 AcceptedR1.Length R2.Length P2.Quality
P1.AcceptedR3.Mood R4.Mood
P2.AcceptedR3.Length R4.Length

PRM Inference: Reuse
A1.Smart
P1.QualityA1.Good Writer
Q y
R1.Mood R2.Mood
P1 AcceptedR1.Length R2.Length P2.Quality
P1.AcceptedR3.Mood R4.Mood
P2.AcceptedR3.Length R4.Length

Structured Variable Elimination
Author 1
A1.Smart
A1 Good WriterA1.Good Writer
Paper-1
Paper-2

Structured Variable Elimination
Author 1
A1.Smart
A1 Good WriterA1.Good Writer
Paper-1
Paper-2

P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer
P1 Quality
Review-2Review-1
P1.Quality
P1.Accepted
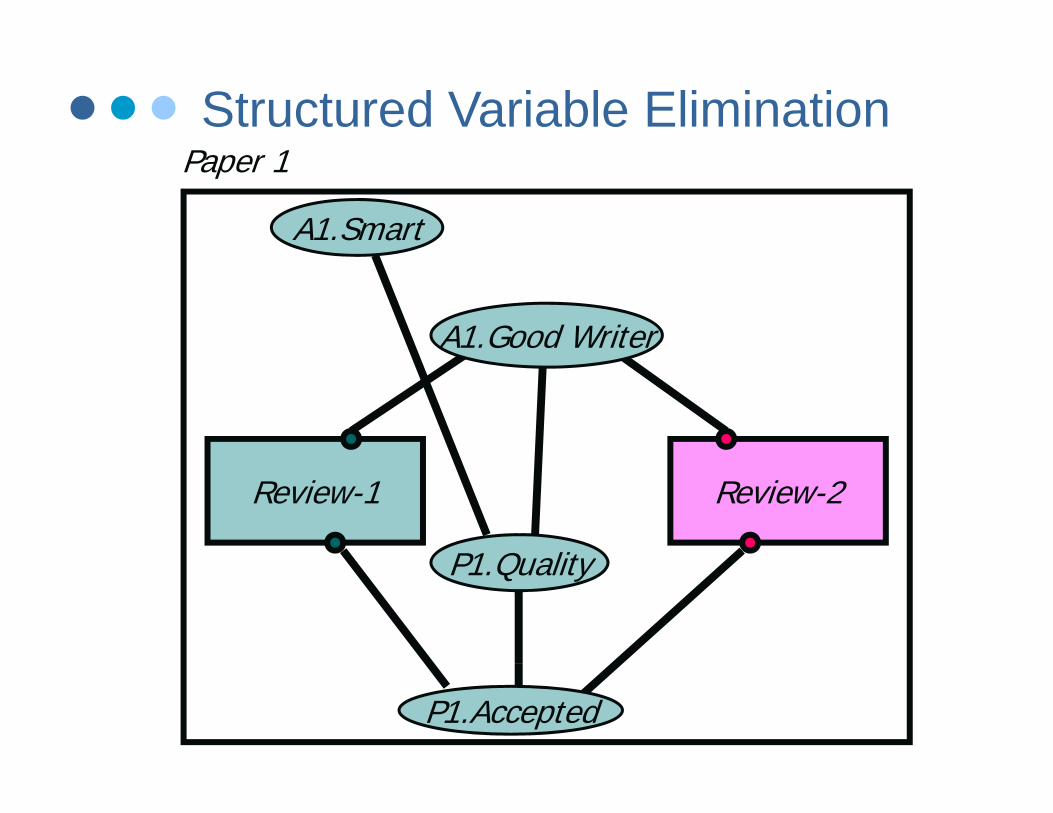
P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer
Review-2Review-1
P1 QualityP1.Quality
P1.Accepted

Structured Variable Elimination
Review 2
A1.Good Writer
R2 MoodR2.Mood
R2 L hR2.Length

Structured Variable Elimination
Review 2
A1.Good Writer
R2 MoodR2.Mood

P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer
Review-2Review-1
P1 QualityP1.Quality
P1.Accepted

P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer
Review-1 R2.Mood
P1 QualityP1.Quality
P1.Accepted

Structured Variable EliminationP 1
A1.Smart
Paper 1
A1.Good Writer
Review-1 R2.Mood
P1 QualityP1.Quality
P1.Accepted

P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer
R2.MoodR1.Mood
P1 QualityP1.Quality
P1.Accepted

P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer
R2.MoodR1.Mood
P1 QualityP1.Quality
P1.Accepted True

P 1Structured Variable Elimination
A1.Smart
Paper 1
A1.Good Writer

Structured Variable Elimination
Author 1
A1.Smart
A1 Good WriterA1.Good Writer
Paper-1
Paper-2
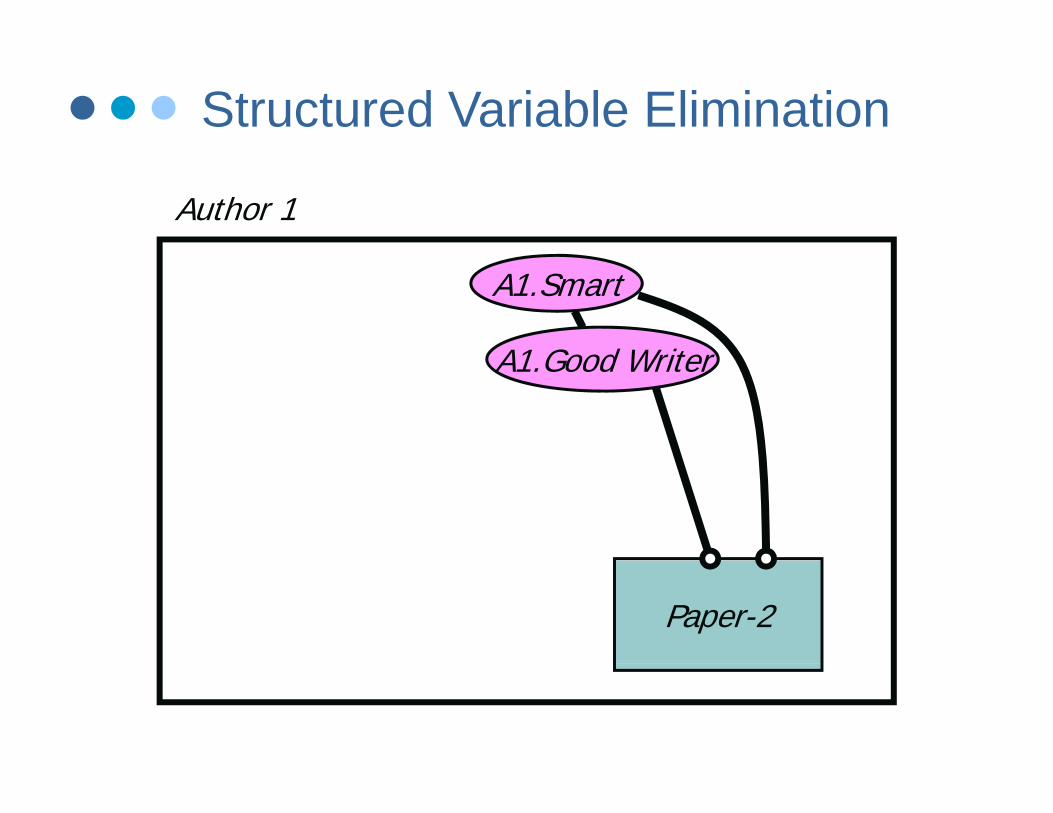
Structured Variable Elimination
Author 1
A1.Smart
A1 Good WriterA1.Good Writer
Paper-2

Structured Variable Elimination
Author 1
A1.Smart
A1 Good WriterA1.Good Writer
Paper-2

Structured Variable Elimination
Author 1
A1.Smart
A1 Good WriterA1.Good Writer

Structured Variable Elimination
Author 1
A1 Good WriterA1.Good Writer

Benefits of SVEStructured inference leads to good elimination orderings for VEg
interfaces are separators• finding good separators for large BNs is very hard
therefore cheaper BN inferenceReuses computation wherever possible

Limitations of SVEDoes not work when encapsulation breaks down
ReviewerP R2
AuthorA1
PaperP1
ReviewerR3Paper
P2
R3 is notencapsulatedinside P2
But when we don’t have specific information about the
ReviewerR4
P2
connections between objects, we can assume that encapsulation holds
i.e., if we know P1 has two reviewers R1 and R2 but they are not ynamed instances, we assume R1 and R2 are encapsulated
Cannot reuse computation when different objects have different evidenceevidence

Four SRL ApproachesDirected Approaches
BN TutorialR l b d Di t d M d lRule-based Directed ModelsFrame-based Directed Models
• PRMs w/ Attribute UncertaintyInference in PRMs• Inference in PRMs
• Learning in PRMs• PRMs w/ Structural Uncertainty
• PRMs w/ Class Hierarchies
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

Learning PRMs w/ AUDatabase
Paper
Author
p
Review
A th
Paper
Author
Review
• Parameter estimation• Structure selection
RelationalSchema

ML Parameter Estimation
PaperQ lit
ReviewMoodLength
, P(A | Q, M)MQQuality
Accepted
Length
,,tfff ?
???
APMRQPN .,.,.θ∗
,,ttft ?
???
MRQP
Q
N .,.
,,θ∗ =
APMRQPN .,.,.where is the number of accepted, l litlow quality papers whose reviewer was in a poor mood

ML Parameter Estimation
PaperQ lit
ReviewMoodLength
, P(A | Q, M)MQQuality
Accepted
Length
,,tfff ?
???
APMRQPN .,.,.θ∗
,,ttft ?
???
MRQP
Q
N .,.
,,θ∗ =
Q f
Count
Query for counts:
Review PaperπCount table table
AcceptedPMoodR
QualityP
..
.π

Structure Selection
Idea:d fi i f tidefine scoring function do local search over legal structures
Key Components:legal models scoring modelssearching model space

Structure Selection
Idea:d fi i f tidefine scoring function do local search over legal structures
Key Components:» legal models
scoring modelssearching model space

Legal Models
PRM defines a coherent probability model over a skeleton σ if the dependencies between object
th f
skeleton σ if the dependencies between object attributes is acyclic
Paperauthor-of
ResearcherProf. Gump
Reputation
P1Accepted
yes PaperP2p
highP2
Accepted yes
sum
How do we guarantee that a PRM is acyclic for every skeleton?for every skeleton?

Attribute StratificationPRM
dependency dependencygraphstructure S graph
Paper AcceptedPaper.Acceptedif Researcher.Reputationdepends directly on Paper.Accepted
Researcher.Reputation
Attribute stratification:dependency graph acyclic ⇒ acyclic for any σ
Attribute stratification:
Algorithm more flexible; allows certainAlgorithm more flexible; allows certain cycles along guaranteed acyclic relations

Structure Selection
Idea: d fi i f tidefine scoring function do local search over legal structures
Key Components:legal models
» scoring models – same as BNsearching model space

Structure Selection
Idea: d fi i f tidefine scoring function do local search over legal structures
Key Components:legal models scoring models
» searching model space

Searching Model SpacePhase 0: consider only dependencies within a class
Author ReviewPaper
ReviewAuthor Paper
U)( BRARParentsPotential U)(.
.).(RattributesedescriptivBR
BRARParentsPotential−∈
=−
ReviewAuthor Paper

Phased Structure SearchPhase 1: consider dependencies from “neighboring”
classes, via schema relations
ReviewPaperAuthor
ReviewAuthor Paper
U)( CSARParentsPotential U<> )(.
.).(SRattributesedescriptivCS
CSARParentsPotential−∈
=−
ReviewAuthor Paper

Phased Structure SearchPhase 2: consider dependencies from “further”
classes, via relation chains
ReviewAuthor Paper
ReviewAuthor Paper
U)( DTARParentsPotential U<><> )(.
.).(TSRattributesedescriptivDT
DTARParentsPotential−∈
=−
ReviewAuthor Paper

Four SRL ApproachesDirected Approaches
BN TutorialR l b d Di t d M d lRule-based Directed ModelsFrame-based Directed Models
• PRMs w/ Attribute UncertaintyInference in PRMs• Inference in PRMs
• Learning in PRMs• PRMs w/ Structural Uncertainty
• PRMs w/ Class Hierarchies
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

Reminder: PRM w/ AU SemanticsAuthor
Paper AuthorA1 Paper
R i
ReviewR1
Review PaperP2
P1
ReviewR3
ReviewR2Author
A2
Paper
PRM relational skeleton σ+ =
PaperP3
probability distribution over completions I:
)).(|.(),,|( ,.
AxparentsAxPP Sx Ax
σσ
σ ∏ ∏∈
=ΘSI
AttributesObjects

Kinds of structural uncertaintyHow many objects does an object relate to?
how many Authors does Paper1 have?Which object is an object related to?
does Paper1 cite Paper2 or Paper3?Which class does an object belong to?
is Paper1 a JournalArticle or a ConferencePaper?D bj t t ll i t?Does an object actually exist?Are two objects identical?

Structural UncertaintyMotivation: PRM with AU only well-defined when the skeleton structure is knownMay be uncertain about relational structure itselfConstruct probabilistic models of relational structure that capture structural uncertaintythat capture structural uncertaintyMechanisms:
Reference uncertaintyReference uncertaintyExistence uncertainty Number uncertaintyNumber uncertaintyType uncertaintyIdentity uncertaintyy y

Citation Relational Schema
AuthorInstitutionInstitutionResearch Area
Wrote
PaperPaperTopicp
TopicWord1Word2
pWord1
…Word2Cites
Citi
WordN… WordNCiting
PaperCited Paper

Attribute Uncertainty
AuthorInstitution P( Institution |
Research Area
P( Institution | Research Area)
Wrote P( Topic | Paper Author Research Area
PaperTopic
Paper.Author.Research Area
Word1 WordN...
P( WordN | Topic)

Reference Uncertainty
Bibliography
`1. -----2. -----
??
Scientific Paper
2. 3. -----?
Scientific Paper
Document CollectionDocument Collection

PRM w/ Reference Uncertainty
Paper Paper
CitesCiting
pTopicWords
PaperTopicWordsCiting
Cited
Dependency model for foreign keys
N ï A h lti i l i kNaïve Approach: multinomial over primary key• noncompact• limits ability to generalize• limits ability to generalize

Reference Uncertainty ExamplePaper
P5Topic
PaperP4
T i
PaperP3
PaperM2Paper
PaperP5
PaperC1Topic AI
Topic AI
Topic AI
M2Topic
AI
PaperP1
Topic Theory
P5Topic
AIPaper
P3
P4Topic Theory
PaperP2
Topic Theory
PaperP1
C1
P3Topic
AITopic Theory
Paper.Topic = AI Paper.Topic = TheoryC2
p p y
CitesCitingCited
C1 C23.0 7.0
Cited

Reference Uncertainty ExamplePaper
P5Topic
PaperP4
T i
PaperP3
PaperM2Paper
PaperP5
PaperC1Topic AI
Topic AI
Topic AI
M2Topic
AI
PaperP1
Topic Theory
P5Topic
AIPaper
P3
P4Topic Theory
PaperP2
Topic Theory
PaperP6
C1
P3Topic
AITopic Theory
Paper.Topic = AI Paper.Topic = TheoryC2
p p y
PaperTopic C1 C2TopicCites
CitingCited
TopicWords
C1 C21.0 9.0
Topic
99.0 01.0Theory
AICited 99.0 01.0

Introduce Selector RVs
Cites1.Selector P2.Topic
Cites1.Cited P3.Topic
P1.Topic P4.Topic
Cites2 SelectorP5.Topic
Cites2 Cited
Cites2.Selector
P6.TopicCites2.Cited
Introduce Selector RV whose domain is {C1 C2}Introduce Selector RV, whose domain is {C1,C2}The distribution over Cited depends on all of the topics, and the selector

PRMs w/ RU Semantics
Paper Paper PaperP5
PaperP2 PaperPaper
P2
CitesCitedCiti
TopicWords
TopicWords
P5Topic
AI
PaperP4Topic Theory
P2Topic TheoryPaperP3Topic AI
PaperP1
Topic ???
P5Topic
AI
PaperP4Topic Theory
P2Topic TheoryPaperP3Topic AI
PaperP1
Topic
RegReg
RegRegCitesCiting
PRM RU
??? ???gRegCites
entity skeleton σ
PRM RU + entity skeleton σ
entity skeleton σ
PRM-RU + entity skeleton σ⇒ probability distribution over full instantiations I

Learning PRMs w/ RUIdea:
define scoring function do phased local search over legal structures
Key Components:Key Components:legal models
model new dependenciesscoring models
unchangedsearching model space
new operators

Legal Models
Review
Mood
Paper
Important
Paper
Important
Cites
Citing
Important
Accepted Accepted
CitingCited

Legal Models
Cites1.Selector
Cites1.CitedP2 Important
R1.Mood
P2.Important
P3 Important
P1.Accepted
P3.Important
P4.Importantp
When a node’s parent is defined using an uncertain
p
p grelation, the reference RV must be a parent of the node as well.

Structure Search
CitesCiting
PaperTopicW d
PaperTopicWords
PaperPaper
PaperPaperPaper
PaperPaper AuthorCiting
CitedWordsWordsp
PaperPaperPaper
PaperPaper
Institution
CitedPapers
1 01.0

Structure Search: New Operators
CitesCiting
PaperTopicW d
PaperTopicWords
PaperPaper
PaperPaperPaper
PaperP AuthorCiting
CitedWordsWords
Cited
PaperPaper
PaperPaper
PaperPaper
Institution
Cited
Topic PaperPaper
PaperPaper
PaperPaper
PaperPaperPaper
PaperPaper
Paper

Structure Search: New Operators
CitesCiting
PaperTopicW d
PaperTopicWords
PaperPaper
PaperPaperPaper
PaperPaper AuthorCiting
CitedWordsWords
Cited
pPaper
PaperPaper
PaperPaper
Institution
Cited
Topic Paper
PaperPaper
Paper
PaperPaper
PaperP Paper
PaperpPaper
Paper Institution
PaperPaper
PaperP PaperPaper
PaperPaperPaper
Paper

PRMs w/ RU SummaryDefine semantics for uncertainty over which entities are related to each otherSearch now includes operators Refine and Abstract for constructing foreign-key dependency modelProvides one simple mechanism for link uncertainty
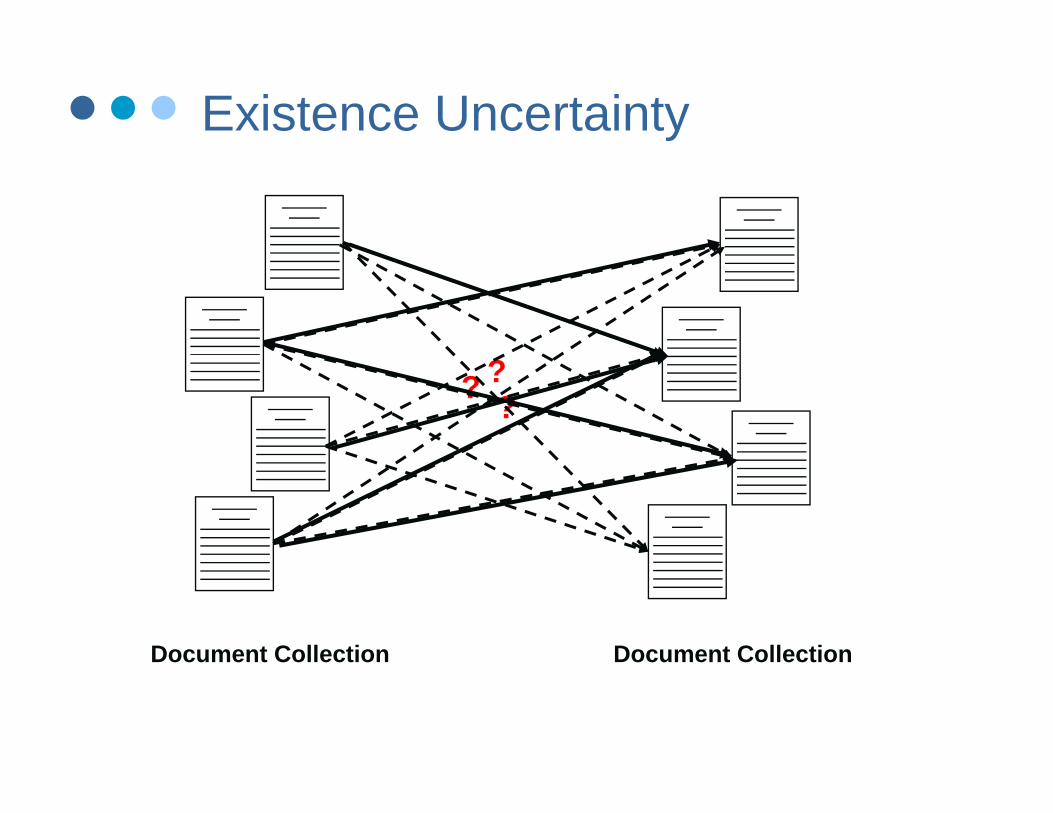
Existence Uncertainty
? ??
Document CollectionDocument Collection

PRM w/ Exists Uncertainty
Paper
Cites
PaperTopicWords
PaperTopicW dWords Words
Exists
Dependency model for existence of relationship

Exists Uncertainty Example
Cites
PaperTopic
PaperTopicCitesWords Words
Exists
Citer.Topic Cited.Topic
0 995 0005Theory Theory
False True
0.995 0005Theory TheoryAITheory 0.999 0001
AIAI 0 993 0008
AI Theory 0.997 0003AIAI 0.993 0008

Introduce Exists RVs
Author #1 Author #2Author #1Area Inst Area Inst
Paper#2 Topic Paper#3Topic
WordN
Paper#1
Word1
Topic...
WordNWord1
... ... ...
Word1WordN
#1-#2Exists
#2-#3Exists
#2-#1Exists
#3-#1Exists
#1-#3Exists Exists
#3-#2

Introduce Exists RVs
Author #1 Author #2Author #1Area Inst Area Inst
Paper#2 Topic Paper#3Topic
WordN
Paper#1
Word1
Topic...
WordNWord1 WordNWord1
WordNWord1
... ... ...
Word1WordN Word1WordN
#1-#2Exists
#2-#3Exists
#2-#1Exists
#3-#1Exists
#1-#3Exists Exists ExistsExists Exists ExistsExists Exists
#3-#2

PRMs w/ EU Semantics
PaperP5
PaperP2 PaperPaper
P2Paper Paper P5Topic
AI
PaperP4Topic Theory
P2Topic TheoryPaperP3Topic AI
PaperP1
Topic ???
P5Topic
AI
PaperP4Topic Theory
P2Topic TheoryPaperP3Topic AI
PaperP1
Topic
???CitesExists
Paper
TopicWords
Paper
TopicWords
??? ???
object skeleton σPRM EU
Exists
PRM EU + object skeleton σ
j
PRM-EU + object skeleton σ⇒ probability distribution over full instantiations I

PRMs w/ EULearningIdea:
define scoring function do phased local search over legal structures
Key Components:Key Components:legal models
model new dependenciesscoring models
unchangedsearching model space
unchanged

Four SRL ApproachesDirected Approaches
BN TutorialR l b d Di t d M d lRule-based Directed ModelsFrame-based Directed Models
• PRMs w/ Attribute UncertaintyInference in PRMs• Inference in PRMs
• Learning in PRMs• PRMs w/ Structural Uncertainty
• PRMs w/ Class Hierarchies
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

PRMs with classesRelations organized in a class hierarchy
Venue
Subclasses inherit their probability model from superclasses
Journal Conference
Subclasses inherit their probability model from superclassesInstances are a special case of subclasses of size 1As you descend through the class hierarchy, you can have y g y yricher dependency models
e.g. cannot say Accepted(P1) <- Accepted(P2) (cyclic)but can say Accepted(JournalP1) <- Accepted(ConfP2)but can say Accepted(JournalP1) <- Accepted(ConfP2)

Type UncertaintyIs 1st-Venue a Journal or Conference ?Create 1st-Journal and 1st-Conference objectsCreate 1 Journal and 1 Conference objectsIntroduce Type(1st-Venue) variable with possible values Journal and ConferenceMake 1st-Venue equal to 1st-Journal or 1st-Conference according to value of Type(1st-Venue)

Learning PRM-CHs
Vote
TVProgramDatabase: PersonTVProgram
Instance I
Vote
R l ti l
TVProgram Person • Class hierarchy providedL l hi hRelational
Schema• Learn class hierarchy

Learning PRMs w/ CHIdea:
define scoring function do phased local search over legal structures
Key Components:Key Components:legal models
model new dependencies
scoring modelsunchanged
searching model spacenew operators

Guaranteeing Acyclicity w/ Subclasses
JournalJournalTopicQuality
C f P
PaperTopic
Accepted Conf-PaperTopicQuality
QualityAccepted
Accepted
Journal AcceptedJournal.AcceptedPaper.AcceptedPaper.Class
Conf-Paper.Accepted

Learning PRM-CHScenario 1: Class hierarchy is provided
New OperatorsS i li /I h itSpecialize/Inherit
AcceptedPaper
AcceptedJournal AcceptedConference AcceptedWorkshopAcceptedWorkshop

Learning Class HierarchyIssue: partially observable data setConstruct decision tree for class defined over attributes observed in training setNew operator
S lit l tt ib tSplit on class attributeRelated class attribute
Paper.Venue
conferenceworkshop
class1 class3
journal
class1 class2
high
Paper.Author.Fame
medium low
class4 class5 class6

PRMs w/ Class HierarchiesAllow us to:
Refine a “heterogenous” class into moreRefine a heterogenous class into more coherent subclassesRefine probabilistic model along classRefine probabilistic model along class hierarchy
Can specialize/inherit CPDsCan specialize/inherit CPDsConstruct new dependencies that were originally “acyclic”originally acyclic
Provides bridge from class-based model to instance based modelto instance-based model

Summary: Directed Frame-based ApproachesApproaches
Focus on objects and relationshipswhat types of objects are there and how are theywhat types of objects are there, and how are they related to each other?how does a property of an object depend on other properties (of the same or other objects)?
Representation supportRepresentation supportAttribute uncertainty Structural uncertaintyyClass Hierarchies
ff fEfficient Inference and Learning Algorithms

Four SRL ApproachesDirected Approaches
BN TutorialRule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

Markov Networks
A th 1 A th 2 F4F2 (F2 F4)
clique potential
Author1Fame
Author2Fame 0.6
f2 0 3
f4f2
f
F4F2 φ(F2,F4)
Author3Fame
Author4Fame
f2
f2
0.3
0.3
f4
f4
nodes = domain variablesedges = mutual influence
f4 1.5f2
parameters measuregcompatibility of values
Network structure encodes conditional independencies:I(A1 Fame, A4 Fame | A2 Fame, A3 Fame)

Markov Network Semantics
conditional l l f ll j i tF1 F2
conditionalindependenciesin MN structure
+localclique
potentials
full jointdistribution
over domain=F3 F4
)43()42()31()21(14321 ffffffff)fffP(f φφφφ )4,3()4,2()3,1()2,1(4321 34241312 ffffffffZ
)f,,ff,P(f φφφφ=
where Z is a normalizing factor that ensures that thewhere Z is a normalizing factor that ensures that theprobabilities sum to 1
G d li it t i tGood news: no acyclicity constraintsBad news: global normalization (1/Z)

Four SRL ApproachesDirected Approaches
BN TutorialRule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

Advantages of Undirected Models
Symmetric, non-causal interactionsyWeb: categories of linked pages are correlatedSocial nets: individual correlated with peersCannot introduce direct edges because
of cycles
Patterns involving multiple entitiesWeb: “triangle” patternsWeb: triangle patternsSocial nets: transitive relations

Relational Markov NetworksLocality:
Local probabilistic dependencies given by relational linksU i lUniversals:
Same dependencies hold for all objects linked in a particular pattern
Paper1Topic
Author1Area T2T1 φ(T1,T2)
Template potential
Venue
Topic1.8
AI 0.3
AIAI
TH
T2T1 φ(T1,T2)
Author2 Paper2
SubAreaAI
TH
TH
0.3
1.50.2
TH
AI
THAuthor2 Paper2TopicArea
TH 1.5TH

RMNso Semantics
• Instantiated RMN MNvariables: attributes of all objectsvariables: attributes of all objectsdependencies: determined by links & RMN
LearningDiscriminative trainingMax-margin Markov networksAssociative Markov networksAssociative Markov networks
Collective classification:Classifies multiple entities and links simultaneouslyExploits links & correlations between related entitiesentities

Collective Classification OverviewRelational
MarkovV Author
Training Data
NetworkVenue Author
Paper
LearningApprox.
Model Structure
g
New DataInference
ConclusionsApprox.
Inference
Example:
Train on one labeled conference/venuePredict labels on a new conference given papers and links

Maximum Likelihood
D
o1.x, o1.y*…
D
Estimation Classification…om.x, om.y*
maximizew
log P (D y* D x)
Estimation Classification
argmaxyP (D’ y | D’ x)f(x,y) log Pw(D.y*, D.x) Pw(D’.y | D’.x)
We don’t care about the jointdistribution P(D.X=x, D.Y=y*)

Maximum Conditional Likelihood
D
o1.x, o1.y*…
D
Estimation Classification…om.x, om.y*
maximizew
log P (D y* | D x)
Estimation Classification
argmaxyP (D’ y | D’ x)f(x,y) log Pw(D.y* | D.x) Pw(D’.y | D’.x)
[Lafferty et al ’01]

Learning RMNs
RegGrade
StudentIntelligence CC
Template potential φ
CourseDifficulty BA
BBBCCACB
Student2 Reg2GradeIntelligence
Difficulty
AAABAC
)},(...),(exp{),( 212121 yyfwyyfwyy CCCCAAAA ⋅++⋅=φ
)()f(ww D.XZD.Y,D.XD.XD.YP log)|(log −⋅=
)f()f( )|(ww wXDYDEXDYDXDYDP XDYDP .,..,.).|.(log ..−=∇

Learning RMNs
φMaximize L = log P(D.Grade,D.Intelligence|D.Difficulty)
φ(Reg1.Grade,Reg2.Grade)
CACBCC
CACBCC
CACBCC
Difficulty Intelligence
Gradelow / higheasy / hard ABC
Intelligence
Grade
Intelligence
Grade
AAABACBABBBCCA
AAABACBABBBCCA
AAABACBABBBCCADifficulty
I t lli
Intelligence
Grade
I t lli
Intelligence
Grade
I t lli
Intelligence
Grade
0 0.5 1 1.5 20 0.5 1 1.5 20 0.5 1 1.5 2Intelligence
Grade
Intelligence
Grade
Intelligence
Grade
Difficulty Intelligence
Grade ),( 21 ggfwL
DggAA
AA∑
∈
−=∂∂
Intelligence
Grade
Intelligence
Grade
).|,(),( 21,
21
,
21
21
DifficultyDggPggf
w
DggAA
Dgg
∑∈
∈∂

Four SRL ApproachesDirected Approaches
BN TutorialRule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesMarkov Network TutorialFrame-based Undirected ModelsRule-based Undirected Models

Markov Logic Networks[Richardson and Domingos 03,Singla & Domingos 05, Kok & Domingos 05]
A Markov Logic Network (MLN) is a set of pairs (F, w) whereF is a formula in first-order logicw is a real number
Together with a finite set of constants,it defines a Markov network with
One node for each grounding of each predicate in the MLNOne feature for each grounding of each formula F in the MLN, with the corresponding weight w

Example of an MLN
( ))()(),(,)()(_
)(_)(),(
ysmartxsmartyxauthorcoyxpacceptedpqualityhighx
pqualityhighxsmartpxauthorx
⇔⇒∀⇒∀
⇒∧∀
2.11.15.1
( )),(_),(),(,
)()(),(_,yxauthorcopyauthorpxauthorpyx
yyy⇒∧∃∀∞

Example of an MLN
( ))()(),(,)()(_
)(_)(),(
ysmartxsmartyxauthorcoyxpacceptedpqualityhighx
pqualityhighxsmartpxauthorx
⇔⇒∀⇒∀
⇒∧∀
2.11.15.1
( )),(_),(),(,
)()(),(_,yxauthorcopyauthorpxauthorpyx
yyy⇒∧∃∀∞
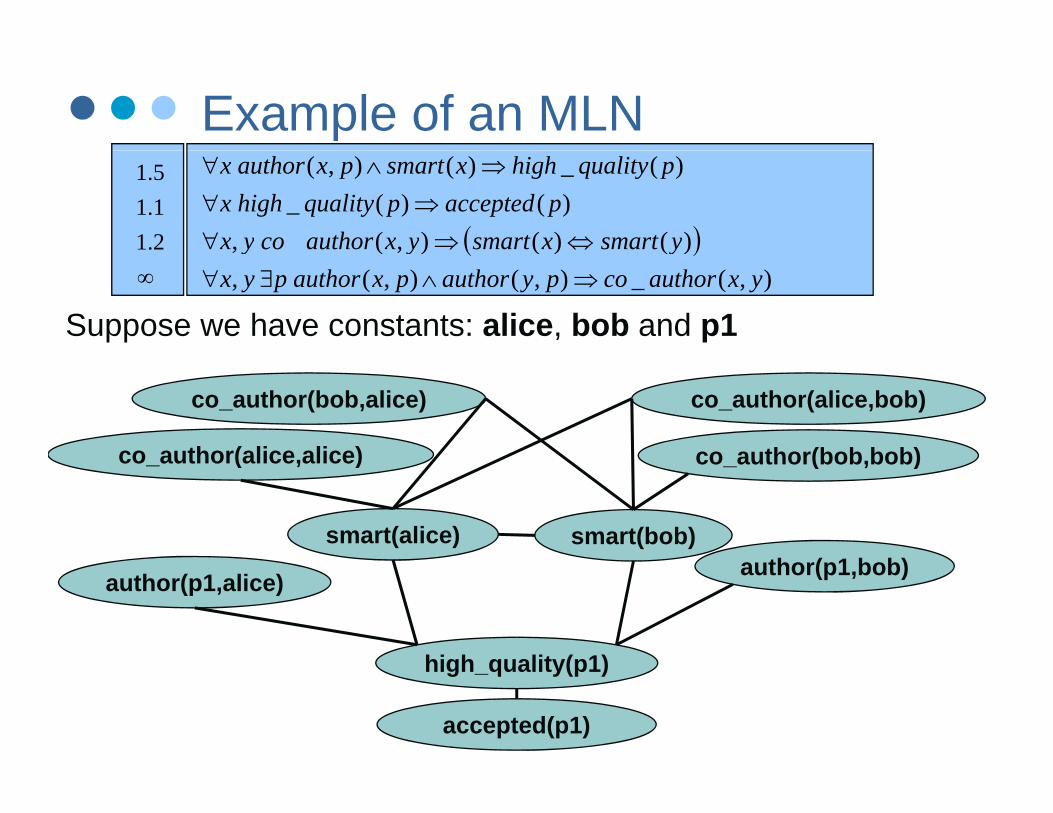
Suppose we have constants: alice, bob and p1

Example of an MLN
( ))()(),(,)()(_
)(_)(),(
ysmartxsmartyxauthorcoyxpacceptedpqualityhighx
pqualityhighxsmartpxauthorx
⇔⇒∀⇒∀
⇒∧∀
2.11.15.1
( )),(_),(),(,
)()(),(_,yxauthorcopyauthorpxauthorpyx
yyy⇒∧∃∀∞
Suppose we have constants: alice, bob and p1
co_author(bob,alice) co_author(alice,bob)
co author(alice alice) co author(bob bob)
smart(bob)smart(alice)th ( 1 b b)
co_author(alice,alice) co_author(bob,bob)
high quality(p1)
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)

Example of an MLN
( ))()(),(,)()(_
)(_)(),(
ysmartxsmartyxauthorcoyxpacceptedpqualityhighx
pqualityhighxsmartpxauthorx
⇔⇒∀⇒∀
⇒∧∀
2.11.15.1
( )),(_),(),(,
)()(),(_,yxauthorcopyauthorpxauthorpyx
yyy⇒∧∃∀∞
Suppose we have constants: alice, bob and p1
co_author(bob,alice) co_author(alice,bob)
co author(alice alice) co author(bob bob)
smart(bob)smart(alice)th ( 1 b b)
co_author(alice,alice) co_author(bob,bob)
high quality(p1)
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)
Example of an MLN
( ))()(),(,)()(_
)(_)(),(
ysmartxsmartyxauthorcoyxpacceptedpqualityhighx
pqualityhighxsmartpxauthorx
⇔⇒∀⇒∀
⇒∧∀
2.11.15.1
( )),(_),(),(,
)()(),(_,yxauthorcopyauthorpxauthorpyx
yyy⇒∧∃∀∞
Suppose we have constants: alice, bob and p1
co_author(bob,alice) co_author(alice,bob)
co author(alice alice) co author(bob bob)
smart(bob)smart(alice)th ( 1 b b)
co_author(alice,alice) co_author(bob,bob)
high quality(p1)
author(p1,alice) author(p1,bob)
high_quality(p1)
accepted(p1)

Markov Logic Networks
Combine first-order logic and Markov networksSyntax: First-order logic + WeightsSemantics: Templates for Markov networks
I f KBMC M W lkS t MCMCInference: KBMC + MaxWalkSat + MCMCLearning: ILP + Pseudo-likelihood / discriminitive trainingtraining

Summary: Undirected Approaches
Focus on symmetric, non-causal relationshipsLike directed approaches, support collective classification

Four SRL ApproachesDirected Approaches
Rule-based Directed ModelsFrame-based Directed Models
Undirected ApproachesFrame-based Undirected ModelsRule-based Undirected Models

Themes: RepresentationBasic representational elements and focus
rules: factsframes: objectsprograms: processes
R ti d i t tRepresenting domain structurecontextrelational skeletonrelational skeletonnon-probabilistic language constructs
Representing local probabilitiesnoise factorsconditional probability tablesclique potentialsclique potentials

Themes: Representational IssuesStructural uncertainty
reference, exists, type, number, identityCombining probabilities from multiple sources
combining rulestiaggregation
Cyclicityruling out (stratification)ruling out (stratification)introducing timeguaranteed acyclic relationsundirected models
Functions and infinite chainsiterative approximationiterative approximation

Themes: InferenceInference on ground random variables
knowledge based model constructionInference at the first-order object level
first-order variable eliminationunification• unification
• quantification over populationsstructured variable eliminationmemoization
Utilizing entity-relations structureQuery directed inferenceQuery-directed inference
backward chaining on query and evidencelazy evaluationy

Themes: LearningLearning parameters
Parameter sharingg• rules apply many times• same type of object appears many times
same function is called many times• same function is called many times
Expectation-MaximizationLearning structureLearning structure
structure search legal modelsgscoring functionsearch operators

GoalsBy the end of this tutorial, hopefully, you will be:
1. able to distinguish among different SRL tasksg g2. able to represent a problem in one of several SRL
representations3. excited about SRL research problems and practical
applications
Many other interesting topics that I didn’t have timeMany other interesting topics that I didn t have time to cover…

ConclusionStatistical Relational Learning
Supports multi-relational, heterogeneous domainsSupports noisy, uncertain, non-IID datapp y, ,aka, real-world data!
Differences in approaches:rule-based vs frame-basedrule based vs. frame baseddirected vs. undirected
Many common issues:Need for collective classification and consolidationNeed for collective classification and consolidationNeed for aggregation and combining rulesNeed to handle labeled and unlabeled dataN d t h dl t t l t i tNeed to handle structural uncertaintyetc.
Great opportunity for combining rich logical representation d i f d l i ith hi hi l t ti ti land inference and learning with hierarchical statistical
models!!