strephit ieg kick-off seminar
TRANSCRIPT
STREPHITA WIKIMEDIA FOUNDATION IEG PROJECT
MARCO FOSSATI - HJFOCS - [email protected]
TRENTO, 15TH JANUARY 2016

HAPPY BIRTHDAY, WIKIPEDIA!
Preamble
PREAMBLE 2

INDIVIDUAL ENGAGEMENT GRANTS
Preamble
PREAMBLE 3

THE FREE KNOWLEDGE BASE
THAT ANYONE CAN EDIT
Preamble
PREAMBLE 4

5
MARCO FOSSATI EMILIO DORIGATTI
WHO?

WHO?
‣ ADVISOR: CLAUDIO GIULIANO ‣ VOLUNTEERS: ‣ AUVA87, BOLIOLIANDREA, DANROK,
NISPRATEEK, PROJEKT ANA, VLADIMIR ALEXIEV
6

WHAT?
‣ IS A NLP PIPELINE ‣ HARVESTS STRUCTURED DATA FROM
RAW TEXT ‣ PRODUCES WIKIDATA CONTENT WITH
REFERENCES
7

WHY?
1. THE CRITICAL ISSUE 2. THE VISION 3. THE TECHNICAL PROBLEM
8

▸Reliability of content across Wikimedia projects
▸ Trust needed on the content addition process
▸Mature in Wikipedia, but what about Wikidata?
WHY
THE CRITICAL ISSUE
9

WHY
THE CRITICAL ISSUE
▸ StrepHit = novel, automatic process
▸Generates trust and reliability over Wikidata content
▸Alleviates the burden of manual curation
10
WHY
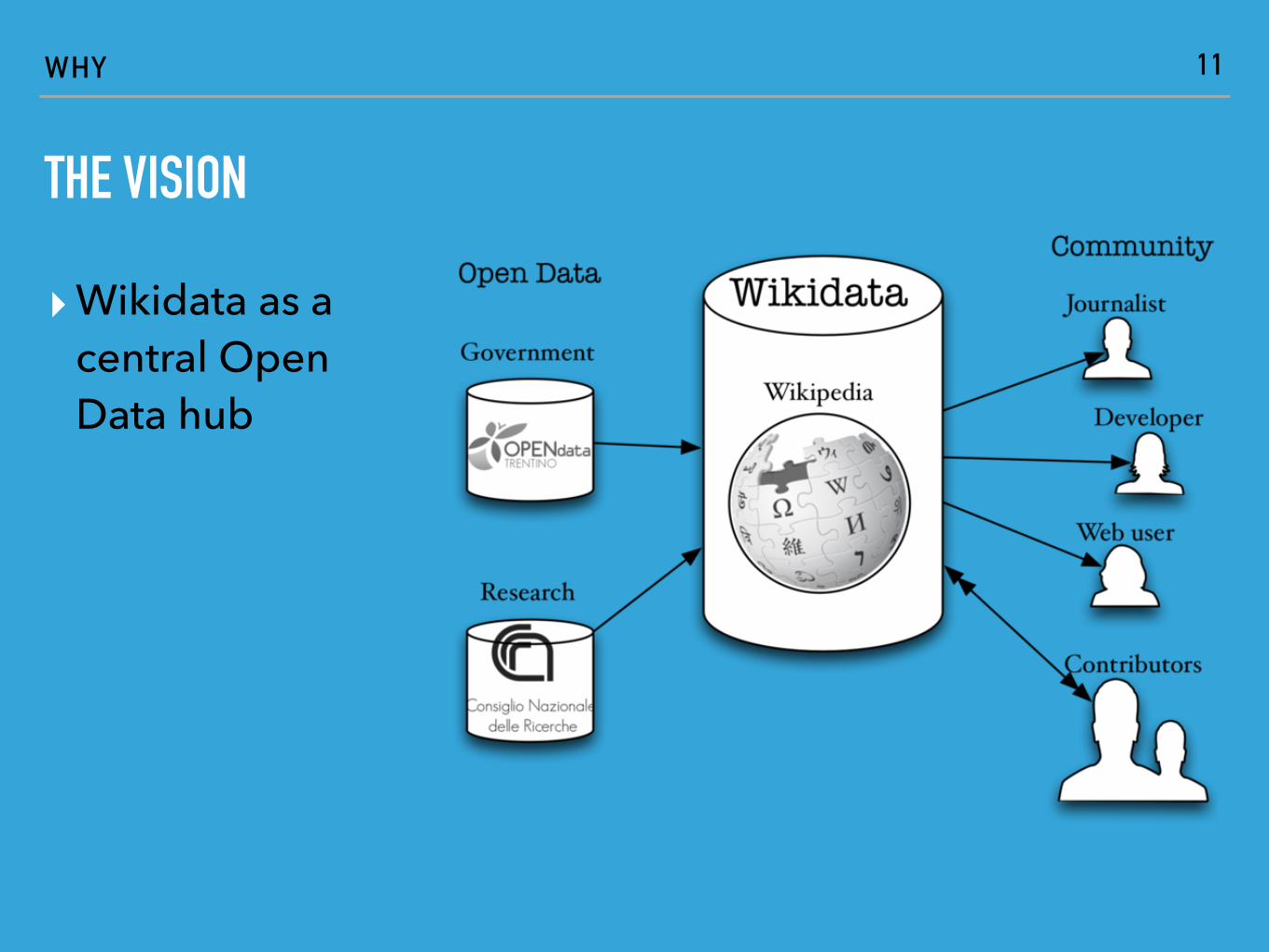
THE VISION
▸Wikidata as a central Open Data hub
11

WHY
THE TECHNICAL PROBLEM
▸Content should be validated against third-party resources
▸References to external authoritative sources
▸Ensure at least one reference for each piece of data
12

HOW?
‣ INPUT = PRIMARY SOURCES CORPUS ‣ OUTPUT = DATASET FOR WIKIDATA ‣ AUTHENTICATE EXISTING CONTENT ‣ PROPOSE NOVEL CONTENT ‣ VIA REFERENCES TO SUCH SOURCES
13

HOW?
‣ LEXICOGRAPHICAL ANALYSIS ‣ RELATION EXTRACTION ‣ FRAME SEMANTICS ‣ MACHINE LEARNING
14

HOW
MAIN TASKS
1. Sources selection
2. Corpus harvesting
3. Corpus analysis
4. Frame repository selection
5. Training set construction
6. Frame extraction
7. Dataset production
15
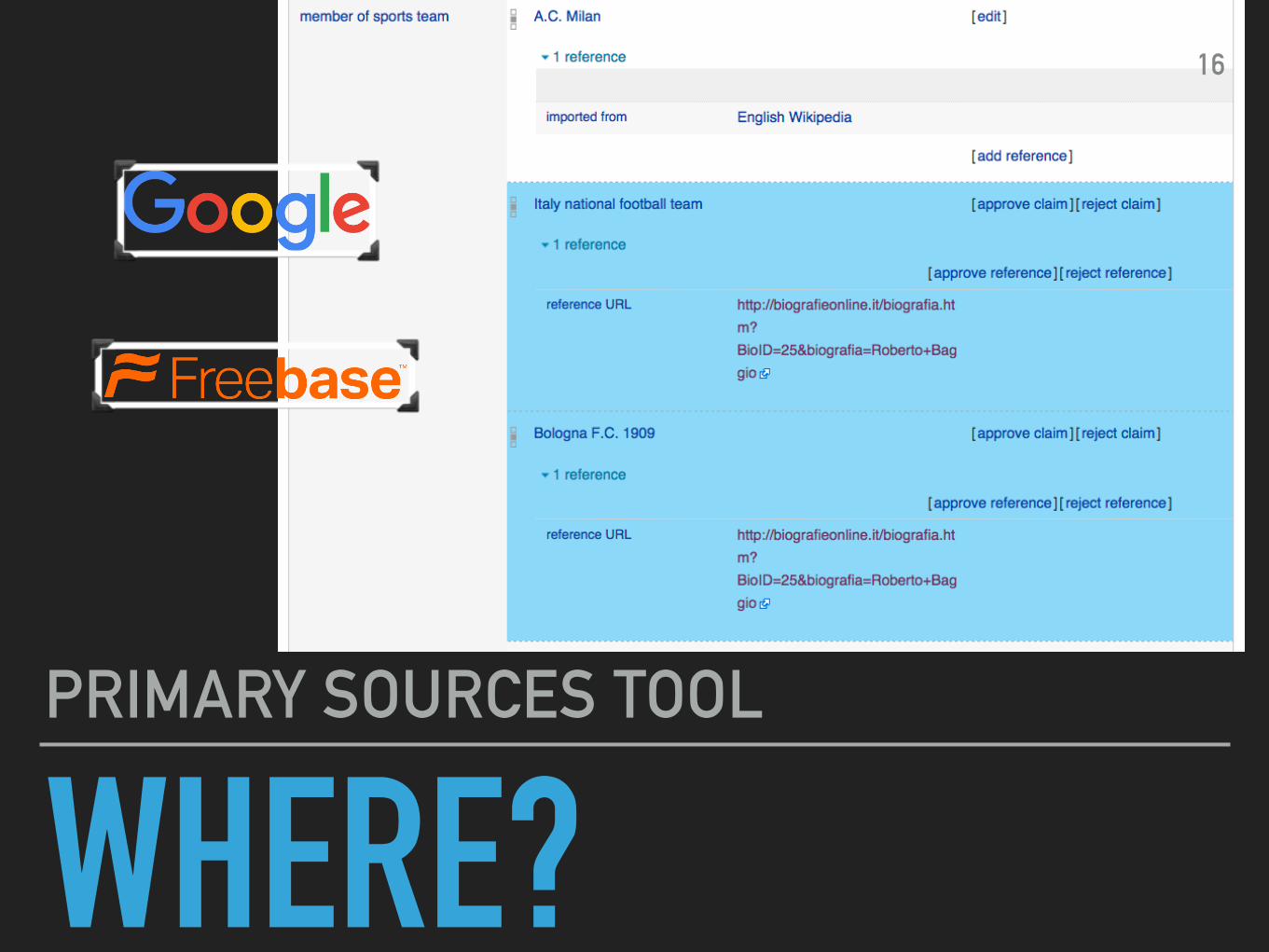
WHERE?PRIMARY SOURCES TOOL
16

A. BIOGRAPHIES B. COMPANIES C. BIOMEDICAL
which domain?
FIRST STEP 17
THANKS NEMO FOR OUR PRECIOUS CONVERSATION

FIRST STEP
BIOGRAPHIES
▸ plenty of existing data
▸ broad coverage
▸ potentially easy to find valuable primary sources
18
LIBRARIANS, WHAT DO YOU THINK?

FIRST STEP
COMPANIES
▸ relatively biased domain
▸ ad-prone content
▸ the company edits the page on the company itself
▸ low-quality data
19

FIRST STEP
BIOMEDICAL
▸ great primary source
▸ PubMed: scientific papers
▸ proof of usage for an Open Access corpus
20

OPEN DISCUSSION DOMAIN + SOURCES SELECTION
MARCO FOSSATI - HJFOCS - [email protected]
TRENTO, 15TH JANUARY 2016
THIS WORK IS LICENSED UNDER A CC BY SA 4.0 LICENSE
https://pad.okfn.org/p/strephit