structure data 2014: big data analytics re-invented, ryan waite
DESCRIPTION
Presentation from Ryan Waite, General Manager, Data Services, Amazon Web Services #gigaomlive More at http://events.gigaom.com/structuredata-2014/TRANSCRIPT



© 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc.
Data Services at AWS or Why We Built Amazon Kinesis
Ryan Waite, General Manager, AWS Data Services

• Metering service • 10s of millions records per second • Terabytes per hour • Hundreds of thousands of sources • Auditors guarantee 100% accuracy at month end
• Data Warehouse • 100s extract-transform-load (ETL) jobs every day • Hundreds of thousands of files per load cycle • Hundreds of daily users • Hundreds of queries per hour
• Fraud • 95% of new customers able to use AWS in minutes • Random forest model to detect fraudulent behavior
• Tagging Service • Hundreds of millions of tags on 10s of millions of resources • 99.9% of read/write operations handled in < 250ms
Some statistics about what AWS Data Services does

Metering service

Workload • 10s of millions records/sec • Multiple TB per hour • 100,000s of sources
Pain points • Doesn’t scale elastically • Customers want real-time
alerts • Expensive to operate • Relies on eventually
consistent storage
Internal AWS Metering Service
S3
ProcessSubmissions
StoreBatches
ProcessHourly w/Hadoop
ClientsSubmitting
Data
DataWarehouse

Data Warehouse
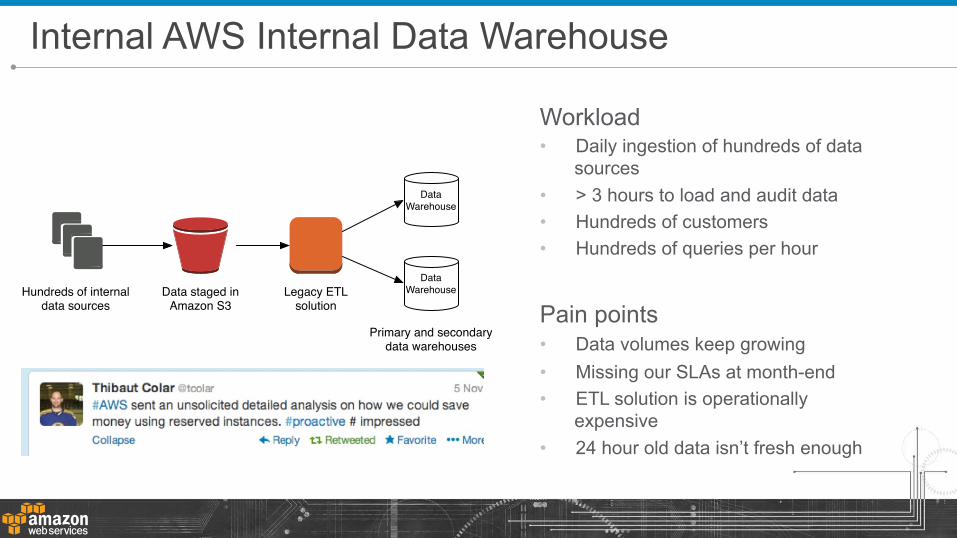
Workload • Daily ingestion of hundreds of data
sources • > 3 hours to load and audit data • Hundreds of customers • Hundreds of queries per hour
Pain points • Data volumes keep growing • Missing our SLAs at month-end • ETL solution is operationally
expensive • 24 hour old data isn’t fresh enough
Internal AWS Internal Data Warehouse
Hundreds of internal data sources
Legacy ETLsolution
Data staged inAmazon S3
Primary and secondarydata warehouses
DataWarehouse
DataWarehouse

Old requirements • Capture huge amounts of data and process it in hourly
or daily batches
New requirements • Make decisions faster, sometimes in real-time • Make it easy to “keep everything” • Multiple applications can process data in parallel
Our big data transition
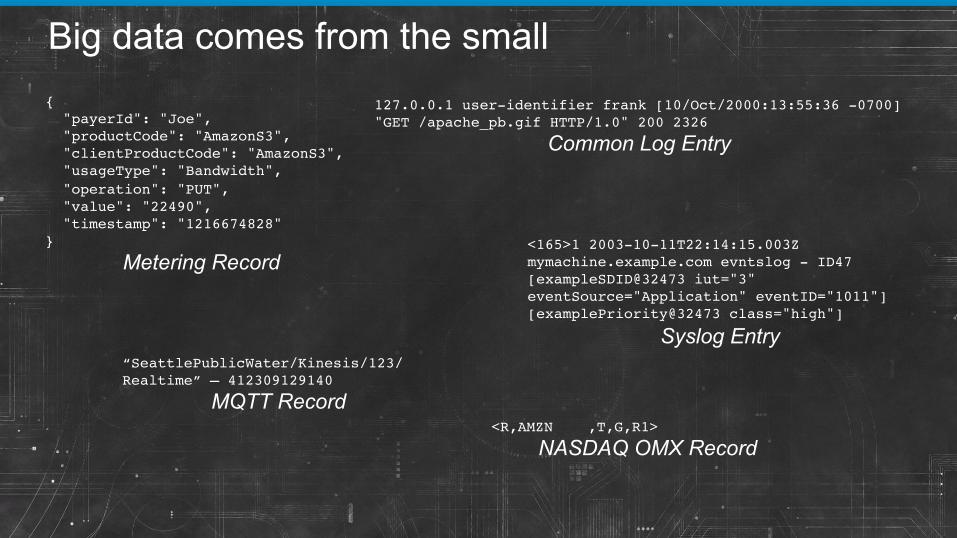
Big data comes from the small {! "payerId": "Joe",! "productCode": "AmazonS3",! "clientProductCode": "AmazonS3",! "usageType": "Bandwidth",! "operation": "PUT",! "value": "22490",! "timestamp": "1216674828"!}!
Metering Record
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326!
Common Log Entry
<165>1 2003-10-11T22:14:15.003Z mymachine.example.com evntslog - ID47 [exampleSDID@32473 iut="3" eventSource="Application" eventID="1011"][examplePriority@32473 class="high"]!
Syslog Entry “SeattlePublicWater/Kinesis/123/Realtime” – 412309129140!
MQTT Record <R,AMZN ,T,G,R1>!
NASDAQ OMX Record

Kinesis
Movement or activity in response to a stimulus.
A fully managed service for real-time processing of high-volume, streaming data. Kinesis can store and process terabytes of data an hour from hundreds of thousands of sources. Data is replicated across multiple Availability Zones to ensure high durability and availability.

Kinesis architecture
Amazon Web Services
AZ AZ AZ
Durable, highly consistent storage replicates dataacross three data centers (availability zones)
Aggregate andarchive to S3
Millions ofsources producing100s of terabytes
per hour
FrontEnd
AuthenticationAuthorization
Ordered streamof events supportsmultiple readers
Real-timedashboardsand alarms
Machine learningalgorithms or
sliding windowanalytics
Aggregate analysisin Hadoop or a
data warehouse
Inexpensive: $0.028 per million puts

• Simple Put interface to store data in Kinesis • Producers use a put call to store data in a Stream
• A Partition Key is used to distribute the puts across Shards
• A unique Sequence # is returned to the Producer upon a successful put call
• Streams are made of Shards • A Kinesis Stream is composed of multiple Shards • Each Shard ingests up to 1MB/sec of data and up to 1000 TPS
• All data is stored for 24 hours
• Scale Kinesis streams by adding or removing Shards
Producer
Shard 1
Shard 2
Shard 3
Shard n
Shard 4
Producer
Producer
Producer
Producer
Producer
Producer
Producer
Producer
Kinesis
Make it easy to “capture everything”

Shard 1
Shard 2
Shard 3
Shard n
Shard 4
KCL Worker 1
KCL Worker 2
EC2 Instance
KCL Worker 3
KCL Worker 4
EC2 Instance
KCL Worker n
EC2 Instance
Kinesis
Making it easier to process data in parallel
• In order to keep up with the stream, an application must: • Be distributed, to handle multiple shards and scaling up/down • Be fault tolerant, to handle failures in hardware or software
• Scale up and down as the number of shards increase or decrease
• Kinesis Client Library (KCL) helps with distributed processing: • Abstracts code from knowing about individual shards • Automatically starts a Worker for each shard • Increases and decreases Workers as number of shards changes
• Uses checkpoints to keep track of a Worker’s position in the stream • Restarts Workers if they fail
• Also works with EC2 Auto Scaling

Sending & Reading data from Kinesis Streams
HTTP Post
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client Library + Connector Library
Apache Storm
Amazon Elastic MapReduce
Sending Reading

New Internal Metering Service
CaptureSubmissions
Process in Realtime
Store inRedshift
ClientsSubmitting
Data
Workload • Tens of millions records/sec • Multiple TB per hour • 100,000s of sources
New features • Scale with the business • Provide real-time alerting • Inexpensive • Improved auditing

Workload • Daily load of billions records from millions of files
from hundreds of sources • 3 hour SLA to load and audit data • Hundreds of customers • Hundreds of queries per hour New features • Our data is fresh, we ingest every 6 hours • Ingesting new data sets for the business • “Hammerstone” ETL solution
• Built on AWS Data Pipeline • Build business specific marts • Build workload specific clusters
• Now processing triple the volume in less than 25% of the time
• Supports a variety of analytics tools: Tableau, R, Toad, SQL Developer, etc.
New Internal AWS Data Warehouse
Over 200 internal data sources
Data staged inAmazon S3
"Hammerstone:" Custom ETLusing AWS
Data Pipeline
Data processingRedshift cluster
Batch reportingRedshift cluster
Ad hoc queryRedshift cluster

• “Our services and applications emit more than 1.5 million events per second during peak hours, or around 80 billion events per day. The events could be log messages, user activity records, system operational data, or any arbitrary data that our systems need to collect for business, product, and operational analysis.”
• “As the number of clients that utilize targeted advertising grows, access to on-demand compute and storage resources becomes a requirement.”
• Customers use Market Replay on the trade support desk to validate client questions; compliance officers use it to validate execution requirements and rate National Market System (NMS) compliance; and traders and brokers use it to look at certain points in time to view missed opportunities or, potentially, unforeseen events
Common use cases

Bizo: Digital Ad. Tech Metering with Amazon Kinesis
Continuous Ad Metrics Extraction
Incremental Ad. Statistics Computation
Metering Record Archive
Ad Analytics Dashboard

Supercell: Gaming Analytics with Amazon Kinesis
Real-time Clickstream Processing App
Aggregate Statistics
Clickstream Archive
In-Game Engagement Trends Dashboard

Thank You
