supermarket shelf management – market-basket model: goal: identify items that are bought together...
TRANSCRIPT

Association Rules

J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 2
Association Rule Discovery
Supermarket shelf management – Market-basket model:
Goal: Identify items that are bought together by sufficiently many customers
Approach: Process the sales data collected with barcode scanners to find dependencies among items
A classic rule: If someone buys diaper and milk, then he/she is
likely to buy beer Don’t be surprised if you find six-packs next to diapers!

J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 3
The Market-Basket Model A large set of items
e.g., things sold in a supermarket
A large set of baskets Each basket is a
small subset of items e.g., the things one
customer buys on one day Want to discover
association rules People who bought {x,y,z} tend to buy {v,w}
Amazon!
Rules Discovered: {Milk} --> {Coke} {Diaper, Milk} --> {Beer}
Rules Discovered: {Milk} --> {Coke} {Diaper, Milk} --> {Beer}
TID Items
1 Bread, Coke, Milk
2 Beer, Bread
3 Beer, Coke, Diaper, Milk
4 Beer, Bread, Diaper, Milk
5 Coke, Diaper, Milk
Input:
Output:

4
Applications – (1)
Items = products; Baskets = sets of products someone bought in one trip to the store
Real market baskets: Chain stores keep TBs of data about what customers buy together Tells how typical customers navigate stores, lets
them position tempting items Suggests tie-in “tricks”, e.g., run sale on diapers
and raise the price of beer Need the rule to occur frequently, or no $$’s
Amazon’s people who bought X also bought Y
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org

5
Applications – (2)
Baskets = sentences; Items = documents containing those sentences Items that appear together too often could
represent plagiarism Notice items do not have to be “in” baskets
Baskets = patients; Items = drugs & side-effects Has been used to detect combinations
of drugs that result in particular side-effects But requires extension: Absence of an item
needs to be observed as well as presenceJ. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org

J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 6
More generally
A general many-to-many mapping (association) between two kinds of things But we ask about connections among “items”,
not “baskets”
For example: Finding communities in graphs (e.g., Twitter)

7
Example:
Finding communities in graphs (e.g., Twitter) Baskets = nodes; Items = outgoing neighbors
Searching for complete bipartite subgraphs Ks,t of a big graph
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
How? View each node i as a
basket Bi of nodes i it points to Ks,t = a set Y of size t that occurs
in s buckets Bi
Looking for Ks,t set of support s and look at layer t – all frequent sets of size t
…
…
…
A dense 2-layer graph
s no
des
t no
des

8
Frequent Itemsets
Simplest question: Find sets of items that appear together “frequently” in baskets
Support for itemset I: Number of baskets containing all items in I (Often expressed as a fraction
of the total number of baskets) Given a support threshold s,
then sets of items that appear in at least s baskets are called frequent itemsets
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
TID Items
1 Bread, Coke, Milk
2 Beer, Bread
3 Beer, Coke, Diaper, Milk
4 Beer, Bread, Diaper, Milk
5 Coke, Diaper, Milk
Support of {Beer, Bread} = 2

9
Example: Frequent Itemsets
Items = {milk, coke, pepsi, beer, juice} Support threshold = 3 baskets
B1 = {m, c, b} B2 = {m, p, j}
B3 = {m, b} B4 = {c, j}
B5 = {m, p, b} B6 = {m, c, b, j}
B7 = {c, b, j} B8 = {b, c}
Frequent itemsets: {m}, {c}, {b}, {j},
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
, {b,c}, {c,j}.
{m,b}

10
Association Rules
Association Rules:If-then rules about the contents of baskets
{i1, i2,…,ik} → j means: “if a basket contains all of i1,…,ik then it is likely to contain j”
In practice there are many rules, want to find significant/interesting ones!
Confidence of this association rule is the probability of j given I = {i1,…,ik}
)support(
)support()conf(
I
jIjI
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org

11
Interesting Association Rules Not all high-confidence rules are interesting
The rule X → milk may have high confidence for many itemsets X, because milk is just purchased very often (independent of X) and the confidence will be high
Interest of an association rule I → j: difference between its confidence and the fraction of baskets that contain j
Interesting rules are those with high positive or negative interest values (usually above 0.5)
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
]Pr[)conf()Interest( jjIjI

12
Example: Confidence and Interest
B1 = {m, c, b} B2 = {m, p, j}
B3 = {m, b} B4= {c, j}
B5 = {m, p, b} B6 = {m, c, b, j}
B7 = {c, b, j} B8 = {b, c}
Association rule: {m, b} →c Confidence = 2/4 = 0.5 Interest = |0.5 – 5/8| = 1/8
Item c appears in 5/8 of the baskets Rule is not very interesting!
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org

Definition: Association Rule
Example:Beer}Diaper,Milk{
4.052
|T|)BeerDiaper,,Milk(
s
67.032
)Diaper,Milk()BeerDiaper,Milk,(
c
Association Rule– An implication expression of the
form X Y, where X and Y are itemsets
– Example: {Milk, Diaper} {Beer}
Rule Evaluation Metrics– Support (s)
Fraction of transactions that contain both X and Y
– Confidence (c) Measures how often items in Y
appear in transactions thatcontain X
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
3 Milk, Diaper, Beer, Coke
4 Bread, Milk, Diaper, Beer
5 Bread, Milk, Diaper, Coke

14
Finding Association Rules Problem: Find all association rules with
support ≥s and confidence ≥c Note: Support of an association rule is the support
of the set of items on the left side Hard part: Finding the frequent itemsets!
If {i1, i2,…, ik} → j has high support and confidence, then both {i1, i2,…, ik} and{i1, i2,…,ik, j} will be “frequent”
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
)support(
)support()conf(
I
jIjI

J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 15
Mining Association Rules
Step 1: Find all frequent itemsets I (we will explain this next)
Step 2: Rule generation For every subset A of I, generate a rule A → I \ A
Since I is frequent, A is also frequent Variant 1: Single pass to compute the rule confidence
confidence(A,B→C,D) = support(A,B,C,D) / support(A,B)
Variant 2: Observation: If A,B,C→D is below confidence, so is A,B→C,D Can generate “bigger” rules from smaller ones!
Output the rules above the confidence threshold

J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 16
Example
B1 = {m, c, b} B2 = {m, p, j}
B3 = {m, c, b, n} B4= {c, j}
B5 = {m, p, b} B6 = {m, c, b, j}
B7 = {c, b, j} B8 = {b, c} Support threshold s = 3, confidence c = 0.75 1) Frequent itemsets:
{b,m} {b,c} {c,m} {c,j} {m,c,b} 2) Generate rules:
b→m: c=4/6 b→c: c=5/6 b,c→m: c=3/5 m→b: c=4/5 … b,m→c: c=3/4 b→c,m: c=3/6

Mining Association RulesExample of Rules:
{Milk,Diaper} {Beer} (s=0.4, c=0.67){Milk,Beer} {Diaper} (s=0.4, c=1.0){Diaper,Beer} {Milk} (s=0.4, c=0.67){Beer} {Milk,Diaper} (s=0.4, c=0.67) {Diaper} {Milk,Beer} (s=0.4, c=0.5) {Milk} {Diaper,Beer} (s=0.4, c=0.5)
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
3 Milk, Diaper, Beer, Coke
4 Bread, Milk, Diaper, Beer
5 Bread, Milk, Diaper, Coke
Observations:• All the above rules are binary partitions of the same itemset:
{Milk, Diaper, Beer}
• Rules originating from the same itemset have identical support but can have different confidence
• Thus, we may decouple the support and confidence requirements

Mining Association Rules
Two-step approach: 1. Frequent Itemset Generation
– Generate all itemsets whose support minsup
2. Rule Generation– Generate high confidence rules from each frequent
itemset, where each rule is a binary partitioning of a frequent itemset

Rule Generation
Given a frequent itemset L, find all non-empty subsets f L such that f L – f satisfies the minimum confidence requirement If {A,B,C,D} is a frequent itemset, candidate rules:
ABC D, ABD C, ACD B, BCD A, A BCD, B ACD, C ABD, D ABCAB CD, AC BD, AD BC, BC AD, BD AC, CD AB,
If |L| = k, then there are 2k – 2 candidate association rules (ignoring L and L)
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 20
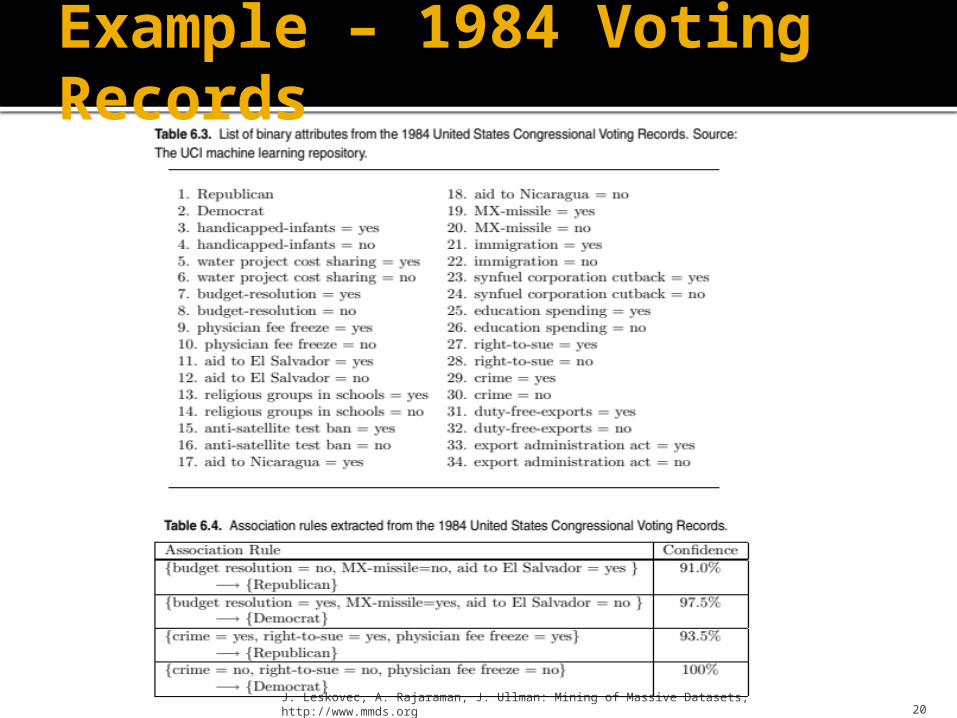
Example – 1984 Voting Records

Rule Generation
How to efficiently generate rules from frequent itemsets? In general, confidence does not have an anti-
monotone propertyc(ABC D) can be larger or smaller than c(AB D)
But confidence of rules generated from the same itemset has an anti-monotone property
e.g., L = {A,B,C,D}:
c(ABC D) c(AB CD) c(A BCD) Confidence is anti-monotone w.r.t. number of items on the
RHS of the rule

Rule Generation
ABCD=>{ }
BCD=>A ACD=>B ABD=>C ABC=>D
BC=>ADBD=>ACCD=>AB AD=>BC AC=>BD AB=>CD
D=>ABC C=>ABD B=>ACD A=>BCD
Lattice of rulesABCD=>{ }
BCD=>A ACD=>B ABD=>C ABC=>D
BC=>ADBD=>ACCD=>AB AD=>BC AC=>BD AB=>CD
D=>ABC C=>ABD B=>ACD A=>BCD
Pruned Rules
Low Confidence Rule

Pattern Evaluation
Association rule algorithms tend to produce too many rules many of them are uninteresting or redundant Redundant if {A,B,C} {D} and {A,B} {D}
have same support & confidence
Interestingness measures can be used to prune/rank the derived patterns
In the original formulation of association rules, support & confidence are the only measures used

Application of Interestingness
Feature
Pro
duct
Pro
duct
Pro
duct
Pro
duct
Pro
duct
Pro
duct
Pro
duct
Pro
duct
Pro
duct
Pro
duct
FeatureFeatureFeatureFeatureFeatureFeatureFeatureFeatureFeature
Selection
Preprocessing
Mining
Postprocessing
Data
SelectedData
PreprocessedData
Patterns
KnowledgeInterestingness Measures

Computing Interestingness
Given a rule X Y, information needed to compute rule interestingness can be obtained from a contingency table
Y Y
X f11 f10 f1+
X f01 f00 fo+
f+1 f+0 |T|
Contingency table for X Yf11: support of X and Yf10: support of X and Yf01: support of X and Yf00: support of X and Y
Used to define various measures
support, confidence, lift, Gini, J-measure, etc.

Drawback of Confidence
Coffee Coffee
Tea 15 5 20
Tea 75 5 80
90 10 100
Association Rule: Tea Coffee
Confidence= P(Coffee|Tea) = 0.75
but P(Coffee) = 0.9
Þ Although confidence is high, rule is misleading
Þ P(Coffee|Tea) = 0.9375
ÞKnowing a person is a Tea drinker actually lessons prob. that they are a coffee drinker
)support(
)support()conf(
I
jIjI

Statistical Independence
Population of 1000 students 600 students know how to swim (S) 700 students know how to bike (B) 420 students know how to swim and bike (S,B)
P(SB) = 420/1000 = 0.42 P(S) P(B) = 0.6 0.7 = 0.42
P(SB) = P(S) P(B) => Statistical independence P(SB) > P(S) P(B) => Positively correlated P(SB) < P(S) P(B) => Negatively correlated

Statistical-based Measures Measures that take into account statistical
dependence
)](1)[()](1)[(
)()(),(
)()(),(
)()(
),(
)(
)|(
YPYPXPXP
YPXPYXPtcoefficien
YPXPYXPPS
YPXP
YXPInterest
YP
XYPLift
Lift & Interest are equivalentin the case of binary variables

Example: Lift/Interest
Coffee Coffee
Tea 15 5 20
Tea 75 5 80
90 10 100
Association Rule: Tea Coffee
Confidence= P(Coffee|Tea) = 0.75
but P(Coffee) = 0.9
Þ Lift = 0.75/0.9= 0.8333 (< 1, therefore is negatively associated)
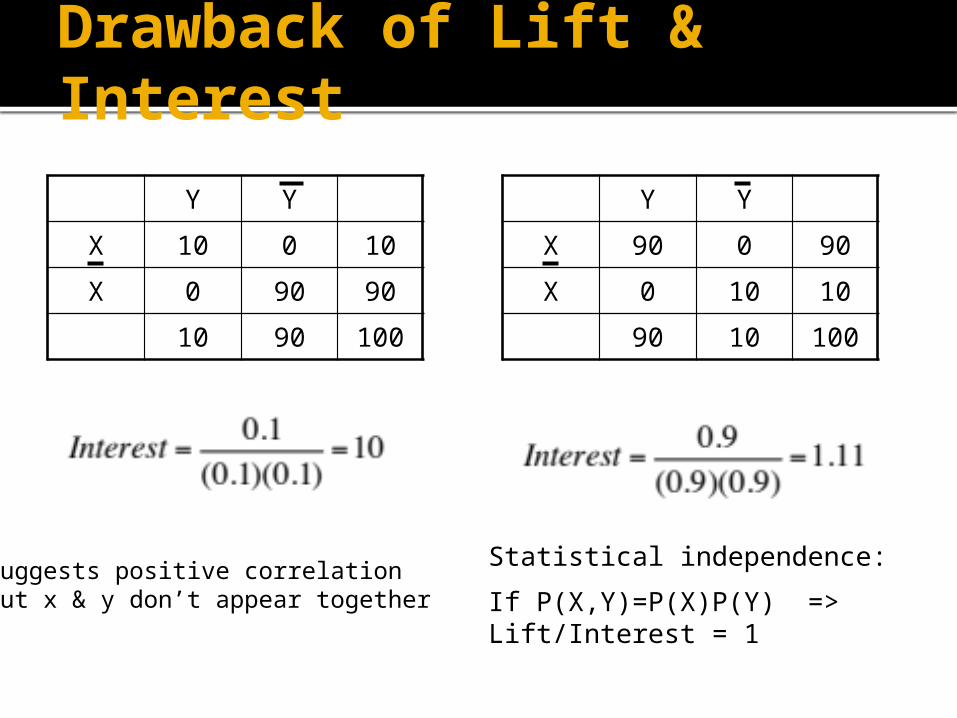
Drawback of Lift & Interest
Y Y
X 10 0 10
X 0 90 90
10 90 100
Y Y
X 90 0 90
X 0 10 10
90 10 100
Statistical independence:
If P(X,Y)=P(X)P(Y) => Lift/Interest = 1
Suggests positive correlationBut x & y don’t appear together

There are lots of measures proposed in the literature
Some measures are good for certain applications, but not for others
What criteria should we use to determine whether a measure is good or bad?
What about Apriori-style support based pruning? How does it affect these measures?