supporting efficient multimedia database exploration
TRANSCRIPT

The VLDB Journal (2001) 9: 312–326 / Digital Object Identifier (DOI) 10.1007/s007780100040
Supporting efficient multimedia database exploration
Wen-Syan Li, K. Selcuk Candan, Kyoji Hirata, Yoshinori Hara
C&C Research Laboratories, NEC USA, 110 Rio Robles, M/S SJ100, San Jose, CA 95134, USA;E-mail:{wen,candan,hirata,hara}@ccrl.sj.nec.com
Edited by S. Christodoulakis. Received: 9 June 1998/ Accepted: 21 July 2000Published online: 4 May 2001 –c© Springer-Verlag 2001
Abstract. Due to the fuzziness of query specification andme-dia matching, multimedia retrieval is conducted by way of ex-ploration. It is essential to provide feedback so that users canvisualize query reformulation alternatives and database con-tent distribution. Since media matching is an expensive task,another issue is how to efficiently support exploration so thatthe system is not overloadedbyperpetual query reformulation.In this paper, we present a uniform framework to represent sta-tistical information of both semantics and visual metadata forimages in the databases.Wepropose the concept ofquery veri-fication, which evaluates queries using statistics, and providesusers with feedback, including the strictness and reformula-tion alternatives of each query condition as well as estimatednumbers of matches. With query verification, the system in-creases the efficiency of the multimedia database explorationfor both users and the system. Such statistical informationis also utilized to support progressive query processing andquery relaxation.
Key words: Multimedia database – Exploration – Query re-laxation – Progressive processing – Selectivity statistics – Hu-man computer interaction
1 Introduction
Query processing in multimedia databases is different fromquery processing in traditional database systems. Contentsstored in traditional database systems are generally preciseand, as a result, query processing answers are deterministic.On the other hand, in both document retrieval and image re-trieval, results are based on similarity calculations. In docu-ment retrieval, documents are represented as keyword lists. Toretrieve a document, information systems compare keywordsspecified by users with the documents’ keyword lists. Images,
Correspondence to: K.S. Candan, Computer Science and Engineer-ing Department, College of Engineering and Applied Sciences, Ari-zona State University, Box 875406 Tempe, AZ 85287-5406, USA;E-mail: [email protected]
This work was performed when K.S. Candan visited NEC, CCRL.
in a similar manner, are usually represented asmedia features.However, image matching is carried out through comparingthese feature vectors.Comparisonof these three typesof queryprocessing are illustrated at the top of Fig. 1.We see that mul-timedia database query processing is truly an integration ofthese three types of query processing.
An image consists of three types of information repre-senting its contents: visual features, structural layout (spatialrelationships), and semantics of image objects, as shown at thebottom of Fig.1. A multimedia database query requires simi-larity measures in all these aspects. For example, a query maybe posed as “retrieve images in which there is a woman to theright of an object and the object is visually similar to the pro-vided image". This query results in a list of candidate imagesranked by their aggregated scores with degrees of uncertaintybased on all above three aspects. Thus, we view multime-dia database query processing as a combination of: (1) infor-mation retrieval notions described in [1] (exploratory query-ing, inexact match, query refinement); and (2) ORDBMS orOODBMS database notions (recognition of specific concepts,variety of data types).
In most multimedia applications, supporting partial matchcapability – in contrast to supportingonly exact match func-tionalities in relational DBMSs – is essential and desirable.There are two major reasons:
1. There may not be a reasonable number of images whichmatch with the user query. Figure 2 (Query) shows theconceptual representation of a query. Figures 2a–d showexamples of candidate images that may match this query.The numbers next to the objects in these candidate imagesdenote the similarity values for the object-level matching.The candidate image in Fig.2a satisfies object matchingconditions but its layout does notmatch user specification.Figure 2b and d satisfy image layout conditions but objectsdo not perfectly match the specification. Figure 2c hasstructural and object matching with low scores.Note that in Fig.2a, the spatial constraint, and in Fig.2c,the image similarity constraint for the lake completely fail(i.e., the match is0.0). Such candidate images in gen-eral would not be returned by SQL/DBMS-based imageretrieval systems. Query relaxation is needed to includesuch types of partially matched images.

W.-S. Li et al.: Supporting efficient multimedia database exploration 313
Fig. 1.Multimedia databases: integration of tradi-tional query processing, IR, and image matching
2. The users may not be able to specify queries preciselyor correctly due to the so-called “word mismatch prob-lem" described and studied in the field of informationretrieval[2]. Another reason for such misspecified imagequeries is that it is difficult for users to describe a color ora shape without ambiguity.
Due to the large volume of data, the unstructured or semi-structured nature of information, and the vagueness in the con-cept of amatch, queryingmultimedia databases should be con-ducted in an exploratory fashion guided by system feedback.In other words, image retrieval should be performed throughcomputer human interaction (CHI). We define a CHI explo-ration cycle as a user query followed by a sequence of queryreformulations guided by the system for honing target images.In the design of a multimedia database system, along with theoptimization of query processing, we concentrate on the im-provement of the speed of the image retrieval in a whole CHIexploration cycle.
We view media retrieval as transitions of correspondingquery result space. By reformulating a query, the result spacethat a user sees is shifted from one to another until the targetresult space is reached.Webelieve that themedia retrieval pro-cess can be improved through well-designed computer humaninteraction. Li et al.[4] introduced the concept ofsystem facil-itated exploration, in which users interact with themultimediadatabase system to reformulate queries. This approach is be-
yond browsing which is supported by most existing systems.However, some drawbacks observed are that the system canonly provide feedbackafterquery processing and feedback islimited tosemantics-basedquery criteria.
In this paper, we present a new approach tomedia retrievalby systematically facilitating users to reformulate queries inthe scope of the SEMCOG Multimedia Database System[3]developed at NEC C&C Research Laboratories in San Jose.SEMCOG providesquery verificationfunctionalities, whichpresents users with various types of feedback regarding thequery and the database content to assist users in exploringmultimedia databasesmore efficiently. The feedback includes:(1) query reformulation alternatives for both semantics- andvisual characteristics-based query criteria; (2) the estimatednumber of matched images; and (3) database content distribu-tion related to query conditions. With this information, usersare facilitated to “navigate" from the current result space to-ward the target result space, rather than ad hoc trial and erroron an image-by-image basis. The facilitation allows the usersto reformulate queries interactively based on system feedbackand query analysis.
To support such facilitation efficiently, the system utilizesmultimedia content statistics. Using content statistics for re-sult estimation and query optimization has been studied fordecades in the scope of traditional databases. However, to ex-tend it to multimedia contents is not an easy task.We develop

314 W.-S. Li et al.: Supporting efficient multimedia database exploration
Fig. 2.Query image and candi-dates of partial matches
Fig. 3.Using multimedia statistics for facilitat-ing query and exploration
a uniform framework for representing statistics for both tex-tual and media data. SEMCOG classifies media objects intoclusters based on semantics and visual characteristics. Thenumber of images in each cluster is viewed as the selectivityfor such criteria, which can be color, shape, or object position.In Fig.3, a user issues a query image and specifies one of theimage objects asProGolfer. Based on the selectivity values ofthemedia and semantics specified in thequery, SEMCOGesti-mates the number ofmatching images and provides alternativeconditions, such as related semantic terms or similar colors,for the user to reformulate the query. Based on the indexingscheme, SEMCOG also supports automated query relaxationand progressive processing to generate the top ranked resultsincrementally.
The rest of the paper is organized as follows: we firstpresent background information about our system. In Sects.3 and 4, we describe the schemes to compute the selectivityfor semantics and visual characteristics of multimedia con-tents. In Sect. 5, we present the usage of these indices andselectivity values for: (1) estimation of matching images; (2)automated query relaxation; and (3) progressive processing.We also present experimental results to estimate the efficiencyof image retrieval by clustering. In Sect.6, we review relatedwork. In Sect. 7 we offer our concluding remarks.
2 Object-based modeling and query language
In this section, we give a summary of the modeling and lan-guage design in SEMCOG.We only describe the material re-lated to the work presented in this paper. Additional informa-
tion about the system architecture, language syntax, and userinterface can be found in [3].
We view images as compound objects containing mul-tiple component objects and their spatial relationships. Thesemantic interpretation of an object is itsreal-world mean-ing. The visual interpretation of an object, on the other hand,is what it looks like based on the perception of humans orimage-matching engines. Our object extraction technique isbased on region-division. A region is defined as a homoge-neous (in terms of colors) and continuous segment identifiedin an image. SEMCOG stores and retrieves atomic and com-pound objects. This enables the query verifier to create finergranularity feedback: instead of returning feedback that en-compasses the whole image, the query verifier can now returnfeedback that describes alternatives for semantics, visual con-tents, and spatial relationships of the constituent objects. Inaddition, the hierarchical structure of the image content al-lows the system to choose the level of feedback granularitydepending on the needs and inputs of the user. Furthermore,since the data model captures alternative semantic and visualrepresentations and the correspondingconfidence(or match-ing) values, the system can manipulate the objects for queryreformulation very naturally.
When an image isregisteredin SEMCOG, content-inde-pendent metadata, such as size, format, etc., are automaticallyextracted,while somecontent-dependentmetadata, suchas se-mantics of images, cannot be extracted automatically. Figure 4illustrates media object extraction and semantics specificationin our system. On the left of the figure there is a set of images.Regions in these images are extracted based on color homo-

W.-S. Li et al.: Supporting efficient multimedia database exploration 315
Fig. 4.Region and semantics specification
geneities and segment continuities. The region extraction re-sults are shown to the user for verification. In this example, forthe second and third images, the user overrides the system’srecommendation and specifies proper region segmentations.After confirmation or modification of the segments, the userspecifies the semantics of each region using the tool shown inFig.5. The segmented regions and the corresponding seman-tics and visual characteristics are then stored in the database.Note that the number of the regions identified depends on theimagecontent and the level of detail the user requests. InSEM-COG, we set a constraint that the number of regions for onelevel of the hierarchy must be less than or equal to 8.
Like the data model used in SEMCOG, the Cognition andSemantics-based Query Language, CSQL, used for image re-trieval by SEMCOG, is inherently suitable for query refor-mulation. CSQL consists of predicates which correspond todifferent levels of query strictness:
– Semantics-based selection predicates.The following three predicates can be used to describe dif-ferent levels of semantic relationships:– is: The is predicate returns true if and only if both argu-ments have identical semantics (man versus man).
– is a: The is a predicate returns true if and only if thesecond argument is a generalization of the first one (caris a transportation).
– s like: Thes like (i.e., semantically like) predicate returnstrue if andonly if both arguments are semantically similar(man versus male).
– Cognition-based selection predicate : Thecognition-based predicate introduced in CSQL isi like (i.e.,image like). In fact,i like is a combination of a group offeature-specific predicates, such asi like hist andi like shape. If the user specifiesi like, then SEMCOG usesall possible features and returns a single, merged similarityvalue. The corresponding weights of the features are as-sumed to be set by the user earlier. Alternatively, users canspecify a conjunction of feature-specific predicates along
with the corresponding weights. SEMCOG uses only thespecified features along with the specified weights to iden-tify the final similarity value.
– Spatial relationship-based selectionpredicate : CSQL supports the following spatial predi-cates:above, andbelow, to theright of, andto theleft of.
By definition, thes likeandi likepredicates act as implicitquery relaxation tools: they let non-exactmatches in the result.Furthermore, the query verifier can explicitly relax the queryby changing the constant terms in a given query, as done bymany relaxation systems, as well as by changing semantic,visual, and spatial predicates. The complete syntax definitionsof the CSQL query language are described in [3].
3 Semantics indexing and selectivity construction
As is the case in most database systems, SEMCOG period-ically collects database statistics for query optimization pur-poses.SEMCOGalsouses thesestatistics to recommendqueryreformulation alternatives to users, to estimate the numbers ofmatches, and to automate query relaxation. In this section,we describe the indexing schemes for semantics selectivityvalues.
3.1 Semantics selectivity statistics
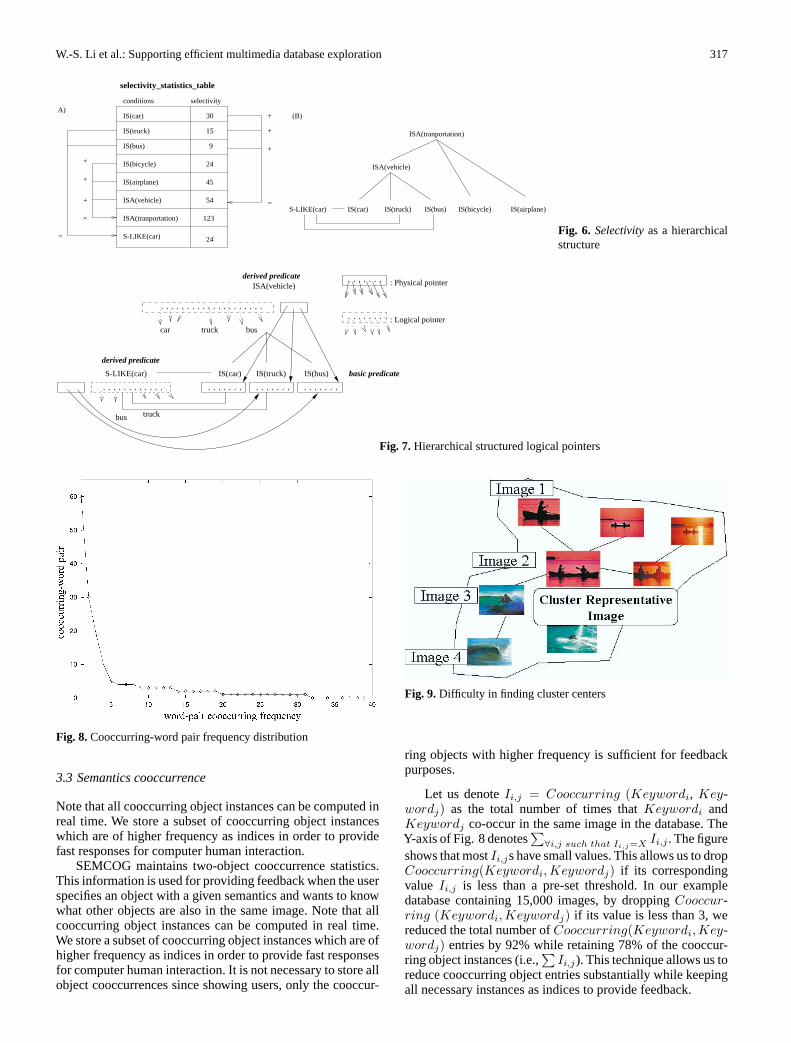
In SEMCOG, semantics are indexed within a hierarchicalstructure as shown in Fig.6. This structure benefits from therelationships between different predicates and their resultsin improving the utilization of database statistics. Figure 6shows a hierarchical structure for semantic selectivity for ob-jects related to transportation. This hierarchical structure isconstructed by consulting with an online dictionary,Word-Net[5]. Two important uses of the hierarchical structure areas follows: (1) some predicates can be translated into a dis-junction of other predicates. For example,ISA(vehicle,X)can

316 W.-S. Li et al.: Supporting efficient multimedia database exploration
Fig. 5. Image object semantics specification process
be translated into a disjunction ofIS(car,X), IS(truck,X), andIS(bus,X); and (2) clustered predicates can bereformulatedfrom/to eachother. For example,IS(car,X)canbe reformulatedhorizontally toS-LIKE(car,X)or vertically to ISA(vehicle,X)or ISA(transportation,X).
Hierarchically structured indexing takes advantage of thefirst property above. In order to provide quick response times,we build indices for each predicate. There are two types ofpredicates:basicandderivedpredicates. AllIS() predicatesarebasicpredicates, whileS-LIKE()andISA()predicates arederived. As shown in Fig. 7,ISA(vehicle,X)can be derivedfromadisjunctionofIS(car,X), IS(truck,X)andIS(bus,X).Sim-ilarly, ISA(transportation,X)can be derived froma disjunctionof ISA(vehicle,X), IS(bicycle,X), andIS(airplane,X).
The semantic index construction is done in two steps: wefirst build indices forbasicpredicates. We call these types ofindicesphysical(or direct) indices. For instance, in the aboveexample, indices forIS(car,X), IS(bus,X), andIS(truck,X)arephysical pointers pointing to corresponding objects. Then,we build indices for derived predicates. These indices, onthe other hand, are logical. As shown in Fig.7, the index forISA(vehicle,X)is a logical index for tupleswhosesemanticsarecar, truck, or bus. However, the physical index consists of onlythree pointers pointing to the physical indices ofIS(car,X),IS(car,X), andIS(truck,X). Similarly, S-LIKE(car,X)consistsof only two physical pointers while logically it consists ofpointers to all objects whose semantics are truck or bus.
3.2 Semantic relevance
Relevant semantics and their selectivities are used for dealingwith word mismatch problems (i.e., authors and users mayuse different vocabularies). We build the relevant semanticsdatabase by collecting all the relevant terms associated withthe semantic terms specified in the database. For a givenword,the system retrieves its hypernyms, synonyms, and holonymswhose “similarity" (word distance) iswithin a given threshold.
For example, for the word “person", by consulting Word-Net, we find a long list of termswhich are relevant to “person",includingman, woman, human,andchild. Suppose that thedatabase contains a set of objects whose semantics areman,woman,andhuman, but there is no object whose semantics isspecified aspersonorchild. Our system can provide feedbackshowing that the termpersondoes not exist in the databaseand provides the user with alternative terms which are rele-vant topersonand exist in the database. In this example, the
system can show the user alternative terms forIS(person,X)asIS(man,X), IS(woman,X),andISA(human,X). Note that SEM-COG does not need to show the user the termchildsince therewill not be a match for a query to retrieve images containinga child.
System feedback also includes term and predicate similar-ity values and selectivity values of each alternatives. The cal-culation of selectivity values is shown in Fig.6. WordNet[5],provides semantic distance[6],0.0 ≤ Distance(α, β) ≤ 1.0,for given two termsα andβ. Although the distance valuesare arguable, we leave this task to domain experts in the fieldof linguistics. We compute the similarities between differentpredicates, based on the term distance values returned by thedictionary, as follows:
– Similarity betweenIS(α,X) andIS(β,X’), 1 whereα andβare two terms, is1 − Distance(α, β). The similarity be-tweenIS(α,X) andIS(β,X’) is defined as the average simi-larity of pairs of terms,t1 andt2, wheret1 satisfiesIS(α,X)andt2 satisfiesIS(β,X’). Since the only termwhich satisfiesIS(α,X) isα and since the only termwhich satisfiesIS(β,X’)isβ, the similarity of the predicates is equal to the similarityof α andβ, which is, by definition,1−Distance(α, β).
– Similarity betweenIS(α,X)andS-LIKE(α,X’), whereα is a
term, is
∑ni=1(1−Distance(α, si))
n,wheren is the num-
ber of terms semantically similar to (or synonym of)αand eachsi (1 ≤ i ≤ n) is such a term. Such a sim-ilarity value can be used for query reformulation from,for instance,IS(car,X)to S-LIKE(car,X’). In this example,si ∈ {truck, bus, . . .}.
– Similarity betweenIS(α,X)andISA(β,X’) is∑mi=1(1−Distance(α, si))
m, whereα andβ are two terms,
β is a hyponym ofα, m is the number of hypernyms (ex-cludingα) of β, and eachsi (1 ≤ i ≤ m) is a hypernym(different fromα) ofX ′. Such a similarity value can be usedfor query reformulation from, for instance,IS(car,X)andIS-A(transportation,X’). In this example,β = transpor-tation andsi ∈ {truck, bus, airplane, . . .}.
1 X andX ′ are the same variables, but their corresponding tupleswhich satisfy the predicates are different due to query reformulationfrom IS(α,X) andIS(β,X’). We use the same notation in the rest ofthis section.
W.-S. Li et al.: Supporting efficient multimedia database exploration 317
IS(car) IS(truck) IS(bus) IS(bicycle)S-LIKE(car)
ISA(vehicle)
ISA(tranportation)
IS(airplane)
conditions
IS(truck)
IS(car)
selectivity
ISA(tranportation)
S-LIKE(car)
ISA(vehicle)
IS(airplane)
IS(bicycle)
IS(bus)
+
+
+
+
+
=
+
=
=
30
15
9
24
45
54
123
24
A)(B)
selectivity_statistics_table
Fig. 6. Selectivityas a hierarchicalstructure
: Physical pointer
: Logical pointer
IS(car) IS(bus)S-LIKE(car)
ISA(vehicle)
IS(truck)
car truck bus
truckbus
derived predicate
derived predicate
basic predicate
Fig. 7.Hierarchical structured logical pointers
Fig. 8.Cooccurring-word pair frequency distribution
3.3 Semantics cooccurrence
Note that all cooccurring object instances can be computed inreal time. We store a subset of cooccurring object instanceswhich are of higher frequency as indices in order to providefast responses for computer human interaction.
SEMCOG maintains two-object cooccurrence statistics.This information is used for providing feedback when the userspecifies an object with a given semantics and wants to knowwhat other objects are also in the same image. Note that allcooccurring object instances can be computed in real time.We store a subset of cooccurring object instances which are ofhigher frequency as indices in order to provide fast responsesfor computer human interaction. It is not necessary to store allobject cooccurrences since showing users, only the cooccur-
Fig. 9.Difficulty in finding cluster centers
ring objects with higher frequency is sufficient for feedbackpurposes.
Let us denoteIi,j = Cooccurring (Keywordi, Key-wordj) as the total number of times thatKeywordi andKeywordj co-occur in the same image in the database. TheY-axis of Fig. 8 denotes
∑∀i,j such that Ii,j=X Ii,j . The figure
shows that mostIi,js have small values. This allows us to dropCooccurring(Keywordi,Keywordj) if its correspondingvalue Ii,j is less than a pre-set threshold. In our exampledatabase containing 15,000 images, by droppingCooccur-ring (Keywordi,Keywordj) if its value is less than 3, wereduced the total number ofCooccurring(Keywordi,Key-wordj) entries by 92% while retaining 78% of the cooccur-ring object instances (i.e.,
∑Ii,j). This technique allows us to
reduce cooccurring object entries substantially while keepingall necessary instances as indices to provide feedback.

318 W.-S. Li et al.: Supporting efficient multimedia database exploration
Fig. 10. Region/color extraction,mapping, and image classification
4 Image indexing and selectivity construction
In the previous section, we described the indexing schemesand selectivity construction for the semantic information con-tained within images. In this section, we present the indexingschemes and selectivity construction mechanisms we use forvisual information, i.e., colors and shapes. During the imageregistration phase, the system extracts the visual characteris-tics of the images. Based on these visual characteristics, thesystem finds one or more clusters which matches the givenimage the best and places it in these clusters. The classifica-tion results, cluster centers (i.e., representative images) and thenumber of members in each cluster, are used as selectivity val-ues.With such an approach, we provide a uniform frameworkof selectivity for both semantics and visual characteristics forproviding feedback or query processing.
4.1 Challenges in image clustering
Ideally, image selectivity can be calculated using the follow-ing steps (as calculated in traditional text-only databases): (1)cluster images based on colors and shapes into categories, say,Cluster1 · · ·Clusterm; (2) select an imageIi with represen-tative colors and shapes for each clusterClusteri wherei isbetween1 andm. The number of images inClusteri, Si, canbe viewed as selectivity for colors and shapes represented byIi; and for a given imageI, we can estimate the number ofmatching images by comparing colors and shapes betweenIandIi. Si is the estimated number of matching images ifImatches withIi above a pre-determined threshold for colorand shape similarity.
In reality, however, it is difficult to select representativevisual characteristics, especially shape, for clustering images.
For example, Fig.9 shows a cluster of similar images. In thiscase, the images labeled1and2, and the images labeled3and4 are similar, based on colors, while the images labeled2 and3are similar, based on shapes. In this case, it is hard to choosethe representative image since similarity is not transitive ingeneral. We may select the image labeled2 as the represen-tative image, although it is not an ideal one. In many cases, areasonable representative image for a cluster of images maynot exist.
To overcome these difficulties, we take an alternative ap-proach as follows: (1) classify images based on colors andshapesseparatelywhileprovidingauniformviewpoint in clas-sification; and (2) synthesize, rather than select, representa-tive images (i.e., template colors and shapes) to form clusters.Next, we present the classification schemes based on colors,followed by the schemes based on shapes.
4.2 Color-based image classification
Our system first extracts major colors from each image. Inthe current implementation, up to 8 major colors are extractedfrom each image although the number of major colors canbe an arbitrary number. Our system maps each image colorto HLS (Hue, Lightness, and Saturation) space and uses thelocations of these points in the HLS space for classification.This is shownat the topof Fig.10. In this example, sevenmajorcolors are extracted from the imageman boat.gif and aremapped to the HLS space. In the bottom of Fig.10, we showthree clusters in whichman boat.gif is classified basedon color similarity. Note thatman boat.gif is highlightedin these clusters. There are a total of seven clusters whichman boat.gif is classified into. The number of members

W.-S. Li et al.: Supporting efficient multimedia database exploration 319
Fig. 11.Color-based cluster hierarchy
in a cluster for a given color is the selectivity value for such acolor.
For image retrieval, the user specifies colors and a thresh-old for color similarity. Based on the color clustering hier-archy, our system finds the cluster or clusters whose colorsmatch with the specified colors. Figure 10 shows an exam-ple output for image retrieval based on the color clustering.Currently, 128 colors and black are used as templates in ourimplementation for image classification by color. The numberof template colors required depends on the applications, colordistributions, and complexity in image collection. The systemadministrator can control the maximum cluster diameter byadjusting the color similarity threshold.
In Fig.11, the cluster diameter of the level 1 clusteringis smaller than the cluster diameter of level 2. As the clus-ter diameter gets larger, the precision of the classification de-creases. The clustering scheme brings together those colorsthat are closer to each other to form higher levels of the hierar-chy.This color classificationhierarchyassistsSEMCOG in thequery-relaxation task by providing alternative colors. It alsocontributes to query processing by providing color selectivi-ties. Note the similarity between the hierarchical structure forcolors in Fig.11 and the hierarchical structure for semanticsin Fig.6. In Fig.11, we can observe that there are sevenlevel1 color clusters with the “ISACOLOROF level 2 color clus-ter" relationship. Such a hierarchical color clustering structureis used for both query relaxation and progressive processingdescribed later in Sects.5.3 and 5.4.
4.3 Shape-based image classification
Shape similarity is rather hard and ambiguous to define. Ourapproach to shape-based image classification is to identify aset of template shapes and classify images into clusters basedon the similarity between the major shapes in images and thetemplate shapes provided. In the current implementation, 45template shapes are defined as shown in Fig.12. These tem-plate shapes are are given by the system designers based onapplications. Major shapes are extracted from images as fol-lows:
– For an imageI, we match it with 45 template shapes,
T = {template shapei|1 ≤ i ≤ 45}.The similarity between the imageI andtemplate shapei
is
shape similarity(I, template shapei).
– The major shapes,T ′, of the imageI is a subset ofT ,such that for everytemplate shapej ∈ T ′, the value of
Fig. 12.Shape templates for image clustering
shape similarity(I, template shapej) is greater than athreshold. Theprimary shapeis defined as
template shapepr ∈ T ′
such that
shape similarity(I, template shapepr)= max({shape similarity(I, template shapej)
|template shapej ∈ T ′}).Based on these template shapes, images are classified into
up to 45 clusters.As was the case in color-based classification,each imagemay be assigned to multiple clusters. Examples ofclustering results are shown in Fig.13.
4.4 Classification based on primary objects
The classification process based on primary objects involvestwo steps. In the first step, we calculate the similarity betweenthe primary objects and image metadata. The final step is tocategorize the images. Since the object in an imagemay be lo-cated in various places within the image, several sets of queryimages are created by shifting the location of the primary ob-jects. Our boundary comparison algorithms consider shiftingfactors in matching boundaries of nearby objects. This can beused to reduce imagematching time with a larger shifting stepfor boundary comparison globally. In our current implementa-tion, shifted images are created for every 15% of image space.When the system classifies images based on the compositionof theobject, the systemuses theprimaryobjectswithout shift-ing in the image. We have designed the matching algorithmsby considering the local correlation among the blocks of theimage. The procedure is illustrated in Fig.14.
In this process, the system divides a target metadataUt ={uij} and a primary objectV = {vij} into several blocks(rectangular partitions or grid). Each local block size isf × g.Each local block is shifted in 2-dimensional (2D) directionnear the same position of the metadata to find the best matchposition. Because of this 2D direction shifting, the systemmatches the object located in different positions. Even if theobject in the metadata includes some noise and additionallines, or the size of the object is different, these errors may notinfluence any other local blocks because of the small match-ing size.We calculate the correlation,abCδε between the localblocks,abU andabV , by shifting abV by δ vertically andδhorizontally.

320 W.-S. Li et al.: Supporting efficient multimedia database exploration
Fig. 13.Image classification based on shapes
Fig. 14.Matching images with primary objects
abCδε =f(a+1)−1∑
r=fa
g(b+1)−1∑s=gb
×(αUrs · Vr+δ,s+ε + βUrs · Vr+δ,s+ε
⊕γUrs + Vr+δs+ ε) (1)
Here, coefficientsα, β, γ are the control parameters usedto estimate matching and mismatching patterns. We calculatethe similarity valueCt between primary objects and metadataas follows:
Ct =∑ ∑
max(abCδε) (2)
If there is no boundary lines on the specific pixels in the queryimages, we can derive one of the two conclusions. Either no
boundary line exists, or none have been specified for that re-gion. For the classification based on the primary objects, weapply the second strategy. The system focuses on the basiclines of the primary object and ignores other parts. We nor-malize the similarity based on the pixel number,NLp, of thelines in the primary object. We define the similarity valueSt
between the metadata and the primary object as follows:
St =Ct
NLp. (3)
This algorithmevaluates the similarity using each line elementas a unit. It is possible to evaluate the similarity even when theboundary lines are detected partially.

W.-S. Li et al.: Supporting efficient multimedia database exploration 321
Fig. 15.Upper bound of estimated numberof matching images
Fig. 16.Lower bound of estimated numberof matching images
The next step in this process is to determine the category ofthe image. After the matching procedure, the maximum valueof the similarity between every image created by shifting pri-mary objects and the image is used to determine whether suchan imagecontains theprimary object.Thus, our technique sup-ports location-independent identification of primary object inan image. If the similarity between the primary object and theboundary image is greater than a certain threshold, the imageis determined to contain the primary object and is classifiedinto that primary object category. By adjusting the thresholdvalue, the system designer can control the number of imagesclassified under one primary object.
4.5 Creation of statistics using image classification
To store the statistics for estimating numbers of matching im-ages, SEMCOG uses one table for the upper bounds and an-other table for the lower bounds. In these tables, the rows andcolumnscorrespond to colors andshapes, respectively.At eachslot in the table, there is an integer which denotes the numberof images which contain the corresponding color and shape(Figs. 15 and 16). Since we employ 129 template colors and45 template shapes, these two tables are 129 by 45. Note thatin Fig.15, all major colors and shapes are used. On the otherhand, in Fig.16, only the primary color and shape are used.
Using these two tables, SEMCOG estimates the maximumand minimum number of matches for a given query image asfollows:
– Calculation of maximum number of matches: as illustratedin Fig.15, we identify all the major shapes and colors inimages. In the example of the Golden Gate Bridge image,color04 , color06 , color34 , shape03 , andshape06 are extracted. We sum the values in the slots
(color04, shape03), (color06, shape03),(color34, shape03), (color04, shape06),(color06, shape06), and (color34, shape06)
to find themaximumnumber of possiblematches (i.e., 168).Note that this estimation is based on the assumption thatthe images in the result will correspond to one and only oneshape-color pair in the image; otherwise, wewould be over-estimating the number of matches. However, this assump-tion is valid for the calculation of the maximum number ofmatches.
– Calculation of minimum number of matches: the systemidentifies the primary color and shape from the given imageand uses the corresponding color-shape slot for the mini-mum number of matches. As shown in Fig.16, the systemlocates the value in the slot(color06, shape03), 21 as the

322 W.-S. Li et al.: Supporting efficient multimedia database exploration
estimatedminimumnumber ofmatches for thegiven image.This approach is based on the assumption that the given im-age has only one major shape (i.e., its primary shape). Thisis the lower bound of number of matching images. Sincethere may be more than one equally likely color and shapecombination due to the fact that this is a similarity-basedcomputation, the system may locate multiple slots. We usethe minimum value among them as the minimum numberof matches.
5 Using statistics for facilitatingmultimedia database exploration
In Sects.3 and 4 we present the schemes for constructing se-lectivity statistics for semantics-based and media-based pred-icates. In this section, we describe how the two statistics areintegrated and used for multimedia database exploration andautomated query reformulation. We start with the function-alities of query verification followed by its underlying tech-niques.
5.1 Providing feedback for query reformulation
We first use an example query, shown in Fig.17, involvingboth semantics-based andmedia-based predicates to illustratethe feedback provided by our system. The specific tasks per-formed by the query verifier are as follows:
– Estimating the number of matching images and query pred-icate selectivity analysis:Query verifierprovides the maxi-mum, minimum, and estimated numbers of matches for thequery, in the small panel located in the middle of the queryinterface.With this feedback, theuser knowswhetherhe/sheshould relax or refine the query. Users can view the detailedanalysis of eachquery predicate by clicking theShowbuttonon the right side of the panel. The strictness of query criteriadepends on its selectivity. This is shown in Fig.17b. Theseselectivity values are pre-computed. Note that the statisticsof selectivity values are used for the matching image esti-mation purpose and they are used for image retrieval whenfast response is crucial.
– System feedback for semantics-based predicates: for eachsemantic condition, the user interface provides: (1) a set ofalternatives; (2) similarity between each alternative condi-tion and initial condition; and (3) selectivity of the alterna-tive condition. Figure 17c shows system feedback for theconditionsis(man) . The system also provides feedbackfor object co-occurrence relationship. Figure 17f showssys-tem feedback on objects which are in the same image asman. With this information, the user knows not only thefact that some imagesdocontainbothmanandtranspor -tation (i.e., car and bicycle), but also the distribution andselectivity of objects which are in the same images with aman, such ascar, bicycle, woman, andhouse.
– System feedback for media-based predicates: for eachvisual-based condition, the user is providedwith alternativecolors and shapes. Figure 17d and e shows the system feed-back for alternative colors and shapes.The feedback also in-cludes similarity between the alternative colors and shapes
and the colors and shapes ofcar.gifand their correspondingselectivity. This selectivity is pre-computed through imageclassification by color and shape as described in Sect.4.
5.2 Estimating the number of matchesfor feedback generation
In Fig.17, we illustrate the query verification functionalities.These functionalities are supported using multimedia contentselectivity statistics to avoid expensive query processing. Inthis section, we describe these schemes in detail.
Let us assume that a user specifies a query to retrieve im-ages containing at least two objects:manand an object whosevisual characteristics is similar tocar.gif . We assume thatthe multimedia content statistics are as follows:
– The total number of images is 50.– The images in the database contain at most two objects.Wesimplify this example for ease of illustration.
– The number of matches for the conditions
containing two objects, is(man,X), andi like(car.gif,Y)
are known to be66, 27, and18 respectively.– The total number of objects is83.
Since, the maximum number of objects in a given imageis two, there is no difference between the number of imageswhich contain at least two objects and the number of imageswhich contain exactly two objects. Note, on the other hand,that in our system, there is a difference between the number ofimages which contain two objects and the number of matchesfor the query “images containing two objects”. The numberof matches is twice the number of images since there are twomatches for each image. Therefore, there are33 (i.e., 66/2)images containing exactly two objects and17 (i.e.,50 − 33)images containing exactly one object.
Using the above information, we compute the expected,maximum, and minimum number of matches for the abovequery as follows next.
5.2.1 Expected number of matches
Assuming that the semantics of image objects are uniformly-distributed, the estimated number of matches, based on prob-abilities, is
P (there are two objects in the image)×P (one object is man and the other object
looks like car.gif
| there are two objects in the image).
Tosolve the aboveprobability, weneeda conditional prob-ability for the second term. However, we do not have thisinformation in the given set of selectivity values. We cal-culate its approximated value as2 × selectivity(man) ×selectivity(car.gif). Hence, the approximate probability, forour example, is3350 × 2 × 27
83 × 1883 = 0.093, or the expected
number of images satisfying the query is50× 0.093 = 4.65.

W.-S. Li et al.: Supporting efficient multimedia database exploration 323
Fig. 17.Multimedia database query specifi-cation with system feedback
��������man &car.gif
man
car.gif
27
18
37If
Min
8
(b)
�������� ������������
������������
���������������
���������������
������
33 + 17
27
18
18
man
car.gif
man & car.gif
Max
(a)
Min Min
(d) (e)33 + 17
18
27 man
car.gif
man &car.gif
Min
(c)
man &car.gif
man car.gif man car.gif
man &car.gif1 Fig. 18. Maximum and minimumnumbers of matches
5.2.2 Minimum and maximum numbers of matches
We denote the following selectivity functions: (1) the imageselectivity function for the conditioncontaining exact N ob-jectsasObjectContainmentImageSelectivity(N); (2) theobject selectivity function for the semantics-based conditionS asObject SemanticsSelectivity(S); and (3) the objectselectivity function for the cognition-based conditionC asObjectCognitionSelectivity(C). In this example,
– ObjectContainmentImageSelectivity(2),– ObjectContainmentImageSelectivity(1),– ObjectSemanticsSelectivity(is(man)), and– ObjectCognitionSelectivity(i− like(car.gif))
are required. The maximum number of matches is the mini-mum value of the object semantics selectivity;18 in this ex-ample. In Fig.18, three bars are used to represent selectivityfor is(man), i like(car.gif), and the estimated number ofmatching images for this query. The maximum number ofmatches is illustrated in Fig.18a, where the overlap area ofthe bars foris(man) andi like(car.gif) is maximized.
Assuming that the objects with a certain semantics are uni-formly distributed in images, the minimum number of match-ing images can be computed as follows:
•(∑
ObjectSemanticsSelectivity
+∑
ObjectCognitionSelectivity)
−2∑
N=1
(ObjectContainmentImageSelectivity(N))
if2∑
N=1
ObjectContainmentImageSelectivity(N)
<(∑
ObjectSemanticsSelectivity
+∑
ObjectCognitionSelectivity).
This is illustrated in Fig.18b as if the total number of im-ages was 37, instead of 50.

324 W.-S. Li et al.: Supporting efficient multimedia database exploration
• 0
if2∑
N=1
ObjectContainmentImageSelectivity(N)
≥(∑
ObjectSemanticsSelectivity
+∑
ObjectCognitionSelectivity).
This is illustrated in Fig. 18c.
The minimum number of matching images for this exam-ple is 0 because
ObjectContainmentImageSelectivity(2)+ObjectContainmentImageSelectivity(1)
= 33 + 17> ObjectSemanticsSelectivity(is(man))
+ObjectCognitionSelectivity(i− like(car.gif))= 27 + 18
Note thatwithout the assumption that the objectswith a certainsemantics are uniformly-distributed in images, the minimumnumberofmatching imageswouldbeeither 1or0,which isnotmeaningful for users.We illustrate this inFig.18dande.Basedon the above formula, the systemcalculates and provides userswith the feedback on the expected, maximum, and minimumnumbers of matching images as4.65, 18, and0 respectively.
To generalize the formula presented above, for a queryassociated withM objects andM conditions on databaseswith images containing at most two objects, the minimumnumber of matching images can be computed as follows:
•(∑
ObjectSemanticsSelectivity
+∑
ObjectCognitionSelectivity)
−M∑
N=1
(ObjectContainmentImageSelectivity(N))
ifM∑
N=1
ObjectContainmentImageSelectivity(N)
<(∑
ObjectSemanticsSelectivity
+∑
ObjectCognitionSelectivity).
• 0
ifM∑
N=1
ObjectContainmentImageSelectivity(N)
≥(∑
ObjectSemanticsSelectivity
+∑
ObjectCognitionSelectivity).
5.3 Usage in automated query relaxation
In Fig.17, we illustrate how the system uses statistics and in-dices of visual and semantic characteristics of image database
contents to assist users in reformulating queries in an inter-active mode fashion. Alternatively, if users prefer, the systemcan automatically and incrementally reformulate queries untilthere are sufficient results. The system chooses the most rele-vant alternative conditions in respect to the original condition.Such relevancy is calculated during the semantics indexing(Sect.3) and image clustering (Sect.4) phases. The relevanceof two semantics-based conditions is calculated using the for-mula presented in Sect.3.2. The relevance of twomedia-basedconditions is calculated based on a feature set (e.g., color his-togram, texture, shape, etc.) of two conditions.As summarizedin Sect.2, our model and language are object-based and thusour system can support query reformulation at a fine granular-ity. The query language used in SEMCOG can be viewed as alogic-based language consisting of a single rule of the form
Q(Y1, . . . , Yn)← D1 ∧D2 ∧ . . . ∧Dd.
whereY1, . . . , Yn are free variables andD1, .., Dd are dis-junctions that consist of predicates,P1, . . . , Pp, their nega-tions, ¬P1, . . . ,¬Pp, variables,X1, X2,. . ., Xn, and con-stants. There ared possible query reformulation options bychanging only one condition (i.e., predicate). We denote thequery whosemth predicate,Predicate from, is reformu-lated toPredicate to asQm(Y1, . . . , Yn). Note that a resultof Qm(Y1, . . . , Yn) ranked with a scoreS(Qm) should beranked as
similarity(Predicate from,Predicate to) ∗ S(Qm)for the original queryQ. Thus, the value of
similarity(Predicate from,Predicate to)can be viewed as apenaltyfor the ranking scores of resultsof reformulated queries. For query reformulation involvingkpredicates, thepenaltyfor the ranking scores is∏i=1...k
similarity(Predicate fromi, P redicate toi).
This value can be shown to the users for visualizing how dif-ferent the alternatives are from the original query criteria, orthey can be used for automatic query relaxation as discussednext.
Let usassume that auser submits aquery to retrieve imagescontaining aman and a car. If there are nomatches or very fewmatches, SEMCOG can automatically reformulate the initialquery. In the given example, the system may alter the queryto retrieve images which contain a man with a bus, a womanwith a car, or a woman with a bus.
Let us assume that the similarity values among relatedpredicates are as follows:
– Similarity betweenis(car)andis(bus)is 0.8– Similarity betweenis(man)andis(woman)is 0.7.
The matching value for the images containing a car and amanis1 (these imagesmatch theoriginal query criterion perfectly).On the other hand, the results for the relaxed queries are sub-ject to a “penalty”. The images generated by the reformulatedqueries and the relevance of the results are as follows:
– Images containing a man and a bus:0.8– Images containing a woman and a car:0.7– Images containing awoman and a bus:0.56 (i.e.,0.8×0.7).
Note thatwemultiply thedegreesof relevancebecause thesetwo conditions are associated by anANDoperator.

W.-S. Li et al.: Supporting efficient multimedia database exploration 325
Fig. 19.Progressive query process-ing
5.4 Progressive processing
In this section, we introduce multi-level classification and ap-ply it for progressive query processing, which can be viewedas a more intelligent approach to the automated query relax-ation presented in Sect.5.3. Figure 19 shows the multi-levelclassification based on similarities. In Fig.19, the system de-fines multiple levels of clustering based on a primary object:Class1is more relevant thanClass2andClass2is more rele-vant thanClass3. Using this hierarchy, the system can performa proximity search, which is suitable for navigation, by joinoperations on the image IDs of each clusters. In the givenexample, the user specifies a query image with the two pri-mary objects,Shape30andColor48. Images in the first classfor bothShape30andColor48clusters have the highest scores(i.e., first rankcandidates). Images in thefirst class forShape30and the second class forColor48and the image in the secondclassShape30and the first class forColor48 have the sec-ond highest scores (i.e., second rank candidates). With thisproperty, for a query to retrieve topK results, our system cangenerate candidates in the first classes, followed by generat-ing candidates in the second classes, progressively, until thetotal number of candidates reachesK. Similarly, if the userspecifies that the shape is more important than the color in im-agematching, the systemgenerates results in(class1, class2)before(class2, class1).
5.5 Evaluation of the image retrieval by clustering
We have presented many usages for statistics of multimediacontents. Many require user usability, which is in the field ofCHI. Here we present an experimental study to evaluate ourclassification technique regarding aspects of the reduction ofsearch space versus recall ratio. The ideal classification is thatthe search space can be reduced while recall is maintained ata satisfactory level.
In this experiment, 15,032 photographs are used. We firstclassify images using 45 shape primary objects and 129 colorprimaryobjects.Note that theseprimaryobjectsaredefined fora general-purpose image collection and are not specialized forthis particular image set. The size of clusters can be adjustedby the threshold values for the similarity between images andprimary objects.The larger the similarity threshold value used,the more the search space can be reduced. However, there is
a higher chance that the recall may drop. In this experiment,we set the threshold value as0.6.2 We issued 6,928 queries tosearch: (1) all 15,032 images; and (2) only the images clas-sified into the same categories as the query image. We thencompared the top 5 query results for two schemes. If these twoschemes generate the same query results, the scheme whichsearches only clusters gains substantial search space reduc-tion while maintaining the perfect recall. If the scheme whichsearches only clusters generates only 4 out of 5 images gen-erated by the scheme which matches with all 15,032 images,the recall is 80%.
In this experiment, our approach to image retrieval basedon clustering can reduce the search space by 76%while main-taining 73% of initial recall of performing image matchingon all 15,032 images. We do find 27% loss of recall in ourexperiments. However, our system performs image matchingbased on clustering mainly for the purpose of fast responsetime for navigation, in which fast response time is more im-portant than perfect recall. For image retrieval by query, thesystemcanperform imagematching onall 15,032 images.Ourapproach provides more flexible image database exploration.
6 Related work
One approach, such as [7,8], is to create feature vectors forrepresenting the visual characteristics. Similarity between twoimages is determined by calculating the distances betweenthe vectors of a query image and each of the images in thedatabase. The attribute values are assigned to the whole im-ages. Each attribute value has less semantic meanings and it isdifficult for users to understand the contribution of the values.It is very hard to integrate these visual characteristics with thesemantics tightly. This whole image-based image modeling isnot suitable to refine the parameters based on the retrieval.
Another approach is to extract regions or blocks from im-ages based on color continuities and shapes. [9–11] Imagesimilarity is calculated using the spatial information of theseregions. However, they mainly focus on the image matchingcapability and do not focus on the integration with the se-mantics. [12] extracts objects from images and stores them as
2 The similarity values are normalized scores between0 and1.The similarity calculation function and normalization procedure aredescribed in [3].

326 W.-S. Li et al.: Supporting efficient multimedia database exploration
Semcons. Users can navigate based on both semantic and vi-sual characteristics at the object level. However, this methodassumes that the object extraction and semantic assignmentare performed completely manually. On the other hand, SEM-COGcanperformobject extractionautomatically using regiondivision methods based on colors and shapes.
Research in [7–12] mainly addresses matching/retrievingcapabilities and does not address feedback from the queryand refinement of the query based on the system feedback.SCORE[13] focuses on the use of a refined ER model to rep-resent the contents of pictures. It calculates the similarity val-ues based on these ER representations. SCORE manages thesimilarity based on the semantics; however, it does not supportimage-matching capability.
Many techniques have been proposed for image cluster-ing. [14] focuses on the color information. They extract colorvalues from images and map them onto the HLS color spaces.Based on the resulting clusters, users can access image direc-tories or filter out the images for searching. [15] focuses on theclustering of shape similarity. Based on the multi-scale analy-sis, it extracts the hierarchical structure of shape.According tothis hierarchical structure, it attempts toprovidemoreeffectivesearch capabilities. Many of the methods described in “ImageRetrieval”, also propose the classification methods using theirmatching criteria. QBIC [16] clusters images using featurevectors. [11] extracts the objects from the images based on thecolor and texture. Using the combination of extracted objects(BLOB) and their attributes (top two colors and texture), theytry to categorize the images into several groups.
Most of existing work focuses on image clustering and re-trieval tasks. Our work aims at providingmore efficient multi-media database exploration in terms of usability, system load,and response time. To support such utility, we present a uni-form framework to represent the statistics for both textual data(i.e., semantics) and visual characteristics. Our work is uniqueand novel in this respect.
7 Conclusions
Retrieval in multimedia databases is different from traditionaldatabase query processing since it is based on similarity calcu-lation for media and semantics comparisons. In this paper wepresent a system SEMCOG which supports a new approachto media retrieval by systematically facilitating users to refor-mulate queries. Our approach is to use semantic and visualindices and selectivity values to provide various system feed-backs to assist users in reformulating queries. We describe auniform framework to represent statistics for both semanticsand visual characteristics of images. Based on such statis-tics, our system also performs automated query relaxation bychoosing the most relevant colors, shapes, or object seman-tics to reformulate users’ queries incrementally until there isa reasonable number of candidates in the answer set. We alsopresent experimental results of evaluating the efficiency of im-age retrieval based on clustering.Additional evaluation relatedto usability in the scope of CHI is left as future work.
The contributions and novelty of this work include: (1)a framework for multimedia database exploration through acomputer-human interaction-based query cycle; (2) tech-niques for generating and maintaining selectivity values for
both semantics- and visual-based predicates and using themfor estimating query results without expensive query process-ing; (3) schemes for interactive and automated incrementalquery reformulation; and (4) schemes supporting progressivequery processing for image retrieval.
References
1. Salton G (1989) Automatic text processing: the transformation,analysis, and retrieval of information by computer. Addison-Wesley, Reading, Mass.,
2. Sparck Jones K,Willett P (editors) (1997) Readings in Informa-tion Retrieval. Morgan Kaufmann, San Francisco
3. Li W-S, Selcuk Candan K (1998) SEMCOG: A hybrid object-based image database system and its modeling, language, andquery processing. In: Proc. 14th Int. Conf. on Data Engineering,Orlando, Fla., February 1998
4. Li W-S, Selcuk Candan K, Hirata K, HaraY (1997) Facilitatingmultimedia database exploration through visual interfaces andperpetual query reformulations. In: Proc. 23th Int. Conf. onVeryLarge Data Bases, Athens, Greece, August 1997, pp 538–547
5. Miller GA (1995) WordNet: a lexical databases for English.CommACM, November 1995, pp 39–41
6. Richardson R, Smeaton A, Murphy J (1994) Using Wordnet asa knowledge base for measuring conceptual similarity betweenwords. In: Proc. Artificial Intelligence and Cognitive ScienceConference, Trinity College, Dublin
7. Bach JR, Fuller C, Gupta A, Hampapur A, Horowitz B, Jain R,Shu CF (1996) TheVirage image search engine: an open frame-work for image management. In: Proc. SPIE - The InternationalSociety for Optical Engineering: Storage and Retrieval for StillImage and Video Databases IV, San Jose, Calif., February 1996
8. Flickner M, Sawhney H, Niblack W, Ashley J, Huang Q (1997)Query by image and video content: the QBIC system. In: MTMaybury (ed) Intelligent Multimedia Information Retrieval.MIT, Cambridge, Mass.
9. Smith JR, Chang S-F (1996) VisualSEEk: a fully automatedcontent-based image query system. In: Proc. 1996 ACM Multi-media Conference, Boston, Mass., pp 87–98
10. Ma W, Manjunath BS (1996) NeTra: a toolbox for navigatinglarge image databases. In: Proc. 1997 IEEE ICIP Conference,pp 568–571
11. Carson C, Belongie S, Greenspan H, Malik J (1997) Color- andtexture-based image segmentation using EM and its applicationto image querying and classification. IEEE Trans Pattern AnalMach Intell (submitted)
12. Grosky WI (1997) Managing multimedia information indatabase systems. CommACM, December 1997, pp 72–80
13. Prasad Sistla A,Yu C, Liu C, Liu K (1995) Similarity based re-trieval of pictures using indices on spatial relationships. In: Proc.1995VLDBConference, Zurich, Switzerland, 23–25September1995
14. Hirata K, HaraY (1994) The concept of media-based navigationand its implementation on hypermedia system ’miyabi’. NECRes Dev 35(4):410–420
15. Del BimboA, Pala P (1997) Shape indexing by structural prop-erties. In: Proc. 1997 IEEEMultimedia Computing and SystemsConference, Ottawa, Ontario, June 1997, pp 370–378
16. Flickner M, Sawhney H, NiblackW,Ashley Qian Huang J, DomB, Gorkani B, Hafner J, Lee D, Petkovic D, Steele D, Yanker P(1995) Query by image and video content: the QBIC system.IEEE Comput 28(9):23–32