synthesis of customized loop caches for core-based embedded systems susan cotterell and frank vahid*...
Post on 22-Dec-2015
216 views
TRANSCRIPT

Synthesis of Customized Loop Caches for Core-Based
Embedded Systems
Susan Cotterell and Frank Vahid*Department of Computer Science and Engineering
University of California, Riverside*Also with the Center for Embedded Computer Systems at UC
IrvineThis work was supported in part by the U.S. National Science Foundation and a
U.S. Department of Education GAANN Fellowship
2
Introduction
Opportunity to tune the microprocessor architecture to the program
Traditional
Core Basedmicroprocessor
architecture

3
Introduction
I$
JPEG
Processor
USB
D$
Bridge
CCDP P4
Mem
• I-cache– Size– Associativity– Replacement
policy
I$I$
JPEG
• JPEG– Compression
• Buses– Width– Bus invert/gray
code
JPEG

4
Introduction
• Memory access can consume 50% of an embedded microprocessor’s system power– Caches tend to be power
hungry
• M*CORE: unified cache consumes half of total power (Lee/Moyer/Arends 99)
• ARM920T: caches consume half of total power (Segars 01)
arm925%
SysCtl3%
CP 152%
BIU8%
PATag RAM1%
Clocks4%
Other4%
D MMU5%
D Cache19%
I Cache25%
I MMU4%

5
Introduction
Advantageous to focus on the instruction fetching subsystem
Processor
USB
I$
D$
Bridge
JPEG CCDP P4
Mem

6
Introduction
• Techniques to reduce instruction fetch power– Program Compression
• Compress only a subset of frequently used instructions (Benini 1999)
• Compress procedures in a small cache (Kirvoski 1997)
• Lookup table based (Lekatsas 2000)
– Bus Encoding• Increment (Benini 1997)
• Bus-invert (Stan 1995)
• Binary/gray code (Mehta 1996)

7
Introduction
• Techniques to reduce instruction fetch power (cont.)– Efficient Cache Design
• Small buffers: victim, non-temporal, speculative, and penalty to reduce miss rate (Bahar 1998)
• Memory array partitioning and variation in cache sizes (Ko 1995)
– Tiny Caches• Filter cache (Kin/Gupta/Magione-Smith 1997)• Dynamically loaded tagless loop cache (Lee/Moyer/Arends 1999)• Preloaded tagless loop cache (Gordon-Ross/Cotterell/Vahid 2002)

8
Cache Architectures – Filter Cache
• Small L0 direct mapped cache
• Utilizes standard tag comparison and miss logic
• Has low dynamic power– Short internal bitlines
– Close to the microprocessor
• Performance penalty of 21% due to high miss rate (Kin 1997)
Processor
Filter cache (L0)
L1 memory

9
Cache Architectures – Dynamically Loaded Loop Cache
• Small tagless loop cache
• Alternative location to fetch instructions
• Dynamically fills the loop cache– Triggered by any short
backwards branch (sbb) instruction
• Flexible variation– Allows loops larger than the
loop cache to be partially stored
...add r1,2...sbb -5
Processor
Dynamic loop cache
L1 memory
Mux
Iteration 3 :fetch from loop cache
Dynamic loop cache
Iteration 1 :detect sbb instruction
L1 memory
Iteration 2 :fill loop cache
Dynamic loop cache
L1 memory

10
Cache Architectures – Dynamically Loaded Loop Cache (cont.)
• Limitations– Does not support loops with
control of flow changes (cofs)
– cofs terminate loop cache filling and fetching
– cofs include commonly found if-then-else statements
...add r1,2bne r1, r2, 3...sbb -5
Processor
Dynamic loop cache
L1 memory
Mux
Iteration 1 :detect sbb instruction
L1 memory
Iteration 3 :fill loop cache, terminate at cof
Dynamic loop cache
L1 memory
Iteration 2 :fill loop cache, terminate at cof
Dynamic loop cache
L1 memory

11
Processor
Preloaded loop cache
L1 memory
Mux
Cache Architectures – Preloaded Loop Cache
• Small tagless loop cache• Alternative location to fetch
instructions• Loop cache filled at
compile time and remains fixed– Supports loops with cof
• Fetch triggered by any short backwards branch
• Start address variation– Fetch begins on first
loop iteration
...add r1,2bne r1, r2, 3...sbb -5
Iteration 1 :detect sbb instruction
L1 memory
Iteration 2 :check to see if loop preloaded, if so fetch from cache
Preloaded loop cache
L1 memory

12
Traditional Design
• Traditional Pre-fabricated IC– Typically optimized for best average
case
– Intended to run well across a variety of programs
– Benchmark suite is used to determine which configuration Processor
L1 memory
Mux
?

13
Core Based Design
• Core Based Design– Know application
– Opportunity to tune the architecture • Is it worth tuning the architecture to the application or is
the average case good enough?
microprocessor architecture

14
Evaluation Framework – Candidate Cache Configurations
Type Size Number of loops/ line size
Configuration
Original dynamically loaded loop cache
8-1024 entries n/a 1-8
Flexible dynamically loaded loop cache
8-1024 entries n/a 9-16
Preloaded loop cache (sa)
8-1024 entries 2 - 3loop address registers
17-32
Preloaded loop cache (sbb)
8-1024 entries 2 - 6 loop address registers
33-72

15
Evaluation Framework – Motorola's Powerstone Benchmarks
Benchmark # Instr Executed
Description
adpcm 63891 Voice Encoding
bcnt 1938 Bit Manipulation
binary 816 Binary Insertion
blit 22845 Graphics Application
brev 2377 Bit Reversal
compress 138573 Data Compression Program
crc 37650 Cyclic Redundancy Check
des 122214 Data Encryption Standard
Benchmark # Instr Executed
Description
engine 410607 Engine Controller
fir 16211 FIR Filtering
g3fax 1128023 Group Three Fax Decode
insert 1942 Insertion Sort
jpeg 4594721 JPEG Compression
summin 1909787 Handwriting Recognition
ucbqsort 219978 U.C.B Quick Sort
v42 2442551 Modem Encoding/Decoding

16
Tool Chain - Simulation
LOOAN lcsimlc
power calc
loop stats
packed loops &
explr script
loop cache stats
loop cache power
program instr trace
many configs. tech info

17
Results - Averages
• Configuration 11 (flexible/32entry/dynamically loaded loop cache)– On average does well – 25% Instruction Fetch Energy Savings
• Loop cache selection on a per application basis– Saves additional 70% Instruction Fetch Energy Savings
0
20
40
60
80
100
Benchmark
% E
ner
gy
Sav
ing
s
Config 11
ProgramOptimal

18
Tool Chain - Simulation
LOOANlc
power calc
loop stats
packed loops &
explr script
loop cache stats
loop cache power
many configs. tech info
program instr trace
lcsimlcsim
program instr trace
...lcsim
19
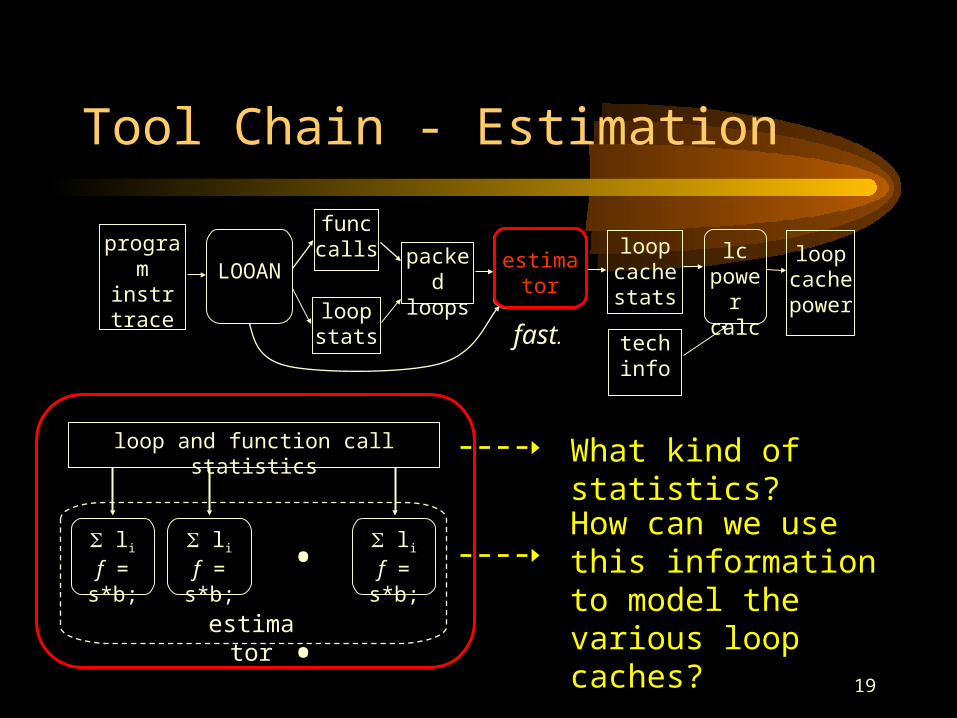
Tool Chain - Estimation
loop and function call statistics
...estimator
li
f = s*b; li
f = s*b; li
f = s*b;
funccalls
LOOANlc
power calcloop
stats
packed loops
loop cache stats
loop cache power
program instr trace
fast. tech info
estimatorestimator
What kind of statistics?
How can we use this information to model the various loop caches?

20
LOOAN
Loop Start EndStatic Size
Num Exec
Total Instrs Exec
avg min max avg min max. 2 1491 1490 4594721 4594721 4594721 1 1 1 1 4594721..main 1379 1491 113 4594611 4594611 4594611 1 1 1 1 476963..main.1 1395 1410 16 121557 121557 121557 600 600 600 1 9600..main.1.FCall:huff_dc_dec 901 962 62 187 101 325 1 1 1 600 0..main.2 1412 1419 8 1407106 1407106 1407106 600 600 600 1 4800..main.2.FCall:huff_ac_dec 963 1114 152 2337 1544 4658 1 1 1 600 0..main.3 1422 1429 8 430800 430800 430800 600 600 600 1 4800..main.3.FCall:dquantz_lum 1362 1378 17 710 710 710 1 1 1 600 0..main.4 1432 1439 8 2181600 2181600 2181600 600 600 600 1 4800..main.4.FCall:j_rev_dct 1332 1361 30 3628 3628 3628 1 1 1 600 0..main.5 1445 1473 29 452922 452922 452922 21 21 21 1 452922..main.5.1 1446 1468 23 22640 22640 22640 8 8 8 20 452800..main.5.1.1 1448 1464 17 2824 2824 2824 31 31 31 160 451840..main.5.1.1.1 1449 1459 11 88 88 88 8 8 8 4800 422400
Dynamic Instructions per Execution
Iterations per Execution
How big are the loops?Loop hierarchy, function callsOnce the loop is called, how many times does it iterate?How many times is the loop called?

21
if( loop size <= lc size && loop iteration >= 2)fills = # times loop called * loop size
Estimation – Original Dynamically Loaded Loop Cache
• How many times do we fill the loop cache?mov r5,r4...add r1,2sub r1, r2, 3...sbb -5
mov r5, r4...add r1,2sub r1, r2, 3bne r1, r2, 3...sbb -5
if( loop size <= lc size && loop iteration >= 2)if( cof != sbb)
fills = # loop called * (iter per exec–1) * offset to 1st cofelse
fills = # loop called * loop size
iter 1: detect sbb
iter 2: fill
xx
xx
iter 1: detect sbb
iter 2: fill, abort at cof iter 3: fill, abort at cof
Loop Start EndStatic Size
Num Exec
Total Instrs Exec
avg min max avg min max. 2 1491 1490 4594721 4594721 4594721 1 1 1 1 4594721..main 1379 1491 113 4594611 4594611 4594611 1 1 1 1 476963..main.5 1445 1473 29 452922 452922 452922 21 21 21 1 452922..main.5.1 1446 1468 23 22640 22640 22640 8 8 8 20 452800..main.5.1.1 1448 1464 17 2824 2824 2824 31 31 31 160 451840..main.5.1.1.1 1449 1459 11 88 88 88 8 8 8 4800 422400
Dynamic Instructions per Execution
Iterations per Execution

22
Estimation - Original Dynamically Loaded Loop Cache
• How many times do we fetch from the loop cache?
if( loop size <= lc size && loop iteration >= 3)fetch = # times loop called * (loop iter – 2) * loop size
if( loop size <= lc size && loop iteration >= 3)if( cof == sbb)
fetch = # times loop called * (loop iter – 2) * loop size
mov r5, r4...add r1,2sub r1, r2, 3bne r1, r2, 3...sbb -5
mov r5,r4...add r1,2sub r1, r2, 3...sbb -5
iter 1: detect sbb
iter 2: fill
iter 3: fetch from loop cache
xx
xx
iter 1: detect sbb
iter 2: fill, abort at cof iter 3: fill, abort at cof

23
Estimation
• Loop Cache Equations– Each loop cache type is characterized by
approximately 5 unique equations– 20 different equations in all

24
Estimation Results - Accuracy
Average across all benchmarks
0
20
40
60
80
100
Cache Configuration
Avg
% E
ner
gy
Sav
ing
s Simulation
Estimation
• Ranges from 0-16% difference• Average 2% difference

25
Estimation Results - Fidelity
• Does the estimation method preserve the fidelity?– summin shows the worst case – 10%– On average <1% difference in savings between loop
cache chosen via simulation vs. loop cache chosen via estimation
0
20
40
60
80
100
Benchmark
% E
ne
rgy
Sa
vin
gs
Simulation
Estimation

26
Time Comparison
Simulation Tool Chain Estimation Tool Chain
Benchmark Num Instr Exec.
LOOAN Script Gen
lcsim lc power calc
total sim time
(sec.)
LOOAN Est. lc power calc
total est time
(sec.)
speedup
adpcm 63891 0.31 0.01 32.15 0.01 32.48 0.31 0.16 0.01 0.48 68
compress 138573 0.85 0.01 82.50 0.01 83.37 0.85 0.14 0.01 1.00 83
engine 410607 2.12 0.02 214.99 0.01 217.14 2.12 0.08 0.01 2.21 98
g3fax 1128023 3.54 0.02 385.44 0.01 389.01 3.54 0.09 0.01 3.64 107
jpeg 4594721 17.57 0.01 1837.28 0.01 1854.87 17.57 0.12 0.01 17.7 105
summin 1909787 11.42 0.01 903.73 0.01 915.17 8.25 0.09 0.01 8.35 110
v42 2442551 12.07 0.01 1252.48 0.01 1264.57 12.27 0.12 0.01 12.40 102
more benchmarks in paper ...
AVERAGE : 67
Required for both methodssimulation was bottleneckBiggest example only 30 minutes – small programStarted looking at MediaBench – simulation takes hours

27
Conclusion and Future Work
• Important to tune the architecture to the program
• Simulation methods are slow– Presented a equation based methodology which is faster than the
simulation based methodology previously used
– Accuracy/fidelity preserved
• Future Work– Expand types of tiny caches
– Look at more benchmarks• MediaBench - several hours (up to 48 hours) for our simulations
– Expand hierarchy search

28
Thank you for your attention.
Questions?