t-110.5111 computer networks ii - tkk
TRANSCRIPT

23.9.2010
T-110.5111 Computer Networks II Advanced Transport Protocols – part 1 16.9.2012 Matti Siekkinen
1

Outline
• Transport Layer Overview – Congestion Control
• TCP congestion control evolution • Issues with basic TCP and solutions
– More recent developments with TCP
2

Transport Layer Overview
• Transmission Control Protocol – Reliable, connection oriented – RFC 793
• User Datagram Protocol (UDP) – Best effort, connectionless – RFC 768
• TCP and UDP form the core of transport layer in today’s Internet
3

What does TCP need to do?
Application Application
TCP TCP Network
Sender Receiver
buffers
2. Error control § Deal with the best effort unreliable network
3. Flow control § Do not overload the receiving application
4. Congestion control § Do not overload the network itself
1. Connection management § Establish, close, reset
4

Congestion Control
• Goal: prevent and recover from network overload situations
• Implemented at the transport layer (TCP) in Internet • Why not another layer?
– Application: • Would need to be handled separately for each application • Would not have common way of handling congestion • Unfair applications would not implement it -> try to get more bw
– IP: • In overload situation, traffic should be reduced
à end hosts sending packets need to slow down à not sufficient to implement at IP level
5

Congestion Control
• Unknown concept when TCP/IP was conceived – First TCP versions did not include congestion control – No congestion ctrl in the Internet’s ancestor
• UDP does not have congestion control – Used instead of TCP by applications that prefer timeliness over
reliability – A problem with long-lived flows and traffic intensive flows
(streaming video, audio, internet telephony)
• Lack of congestion control -> risk of congestion collapse
6

What happens upon congestion: scenario 1
• two senders, two receivers
• one router, infinite buffers
• no retransmission
• large delays when congested
• maximum achievable throughput
unlimited shared output link buffers
Host A λin : original data
Host B
λout
7

• four senders • multihop paths • timeout/retransmit
λ in
Q: what happens as and increase ? λ
in
finite shared output link buffers
Host A λin : original data
Host B
λout
λ'in : original data, plus retransmitted data
What happens upon congestion: scenario 2
8
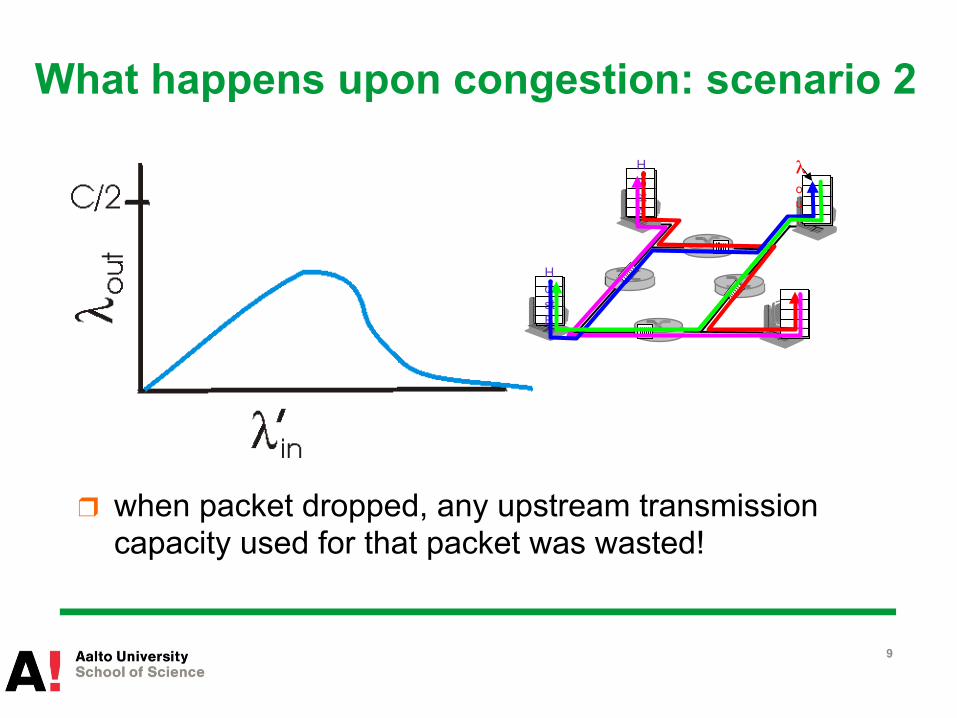
❒ when packet dropped, any upstream transmission capacity used for that packet was wasted!
Host A
Host B
λout
What happens upon congestion: scenario 2
9

Approaches towards congestion control
end-to-end congestion control:
• no explicit feedback from network
• congestion inferred from end-system observed loss, delay
• approach taken by TCP
network-assisted congestion control:
• routers provide feedback to end systems – single bit indicating
congestion (e.g. TCP/IP’s ECN)
– explicit rate sender should send at
Which devices implement congestion control?
10

Closed loop end-to-end congestion control • Principle:
– Senders continuously throttle their transmission rate – Probe the network by increasing the rate when all is fine – Decrease rate when signs of congestion
• Packet loss or increased delay • Objectives
– Preventing congestion collapse – Fairness
11

Explicit Congestion Notification (ECN)
• Routers flag packets upon congestion – Must use active queue management (e.g. RED)
• Do something before the queue overflows – Put ECN marking in packet that arrives to almost full queue
• Receiver must cooperate – Tell sender about ECN markings in received packets – ECN-Echo
• Sender adjusts sending rate – Reduce cwnd size upon receiving indication of congestion
12

ECN: robustness
• Misbehaving receiver: ECN cheating – Receiver lies about received packets to get its data faster
• Solution: ECN nonce – Sender fills part of ECN header field with random one-bit value – Receiver must report sum of ECN Nonces it has received thus
far – ECN marking destroys the nonce
• Malicious receiver has 50% chance of guessing right for a single packet
• Unlikely to always guess right in a series of nonces
13

ECN: deployment
• Standard already 2001 • Deployment lags
– Initial deployment problems with middleboxes and firewalls • ECN capable packets dropped or connections reset
– Supported by routers but apparently not widely used • Default configurations often disable it • Mistrust due to initial problems • Fear of software bugs
14

ECN: deployment (cont.)
• Measurement studies suggest rapid growth in ECN support in recent couple of years – Roughly 30% of top 100K web servers support it (August 2012)
• Was well below 5% in 2008 – Over 90% of paths towards these servers were also ECN-
capable • Still some old problems persist
• BUT ECN usage is still very low – Well below 1% of traffic sources
15

TCP congestion control
• TCP is self-clocking – Sliding window limits number of
segments sent – Need to receive ACKs before sending
more packets • TCP uses congestion window
(cwnd): #outstanding bytes = min(cwnd, rwnd)
• Control transmission rate by adjusting cwnd size flow
control
Host A Host B
time
seq1 seq2 seq3 seq4 ACK2
ACK3 ACK4 ACK5 seq5
seq6 seq7 seq8 ACK2
ACK3 ACK4 ACK5
sliding window
16

TCP congestion control
• How is cwnd resized? – When no congestion -> increase continuously – Signs of congestion -> decrease
• Differences between TCP versions – Congestion detection
• Loss-based vs. delay-based – Congestion window sizing strategy
• Aggressive vs. timid
17

Outline
• Transport Layer Overview – Congestion Control
• TCP congestion control evolution • Issues with basic TCP and solutions
– More recent developments with TCP
• Other transport protocols – LEDBAT
18

Evolution of TCP
ARPAnet TCP (Cerf et Kahn) RFC 793
1981 1974 1969 1983
TCP/IP
Only flow control (receiver advertised window)
- Link LBL to UC Berkeley - throughput dropped from 32 Kbps
to 40 bps (factor of ~1000!)
1986
1st congestion collapse
Main differences lie in congestion control mechanisms
CTCP
1988
TCP Tahoe
Congestion control included
1990
TCP Reno
1994 1999
- TCP Vegas - ECN
TCP New Reno
1996
SACK
-04 -05
CUBIC
- FAST TCP - BIC
-06
19

TCP Tahoe
• 1988 Van Jacobson • The basis for TCP congestion control • Lost packets are sign of congestion
– Detected with timeouts: no ACK received in time • Two modes:
– Slow Start – Congestion Avoidance
• New retransmission timeout (RTO) calculation – Incorporates variance in RTT samples – Timeout really means a lost packet (=congestion)
• Fast Retransmit
20
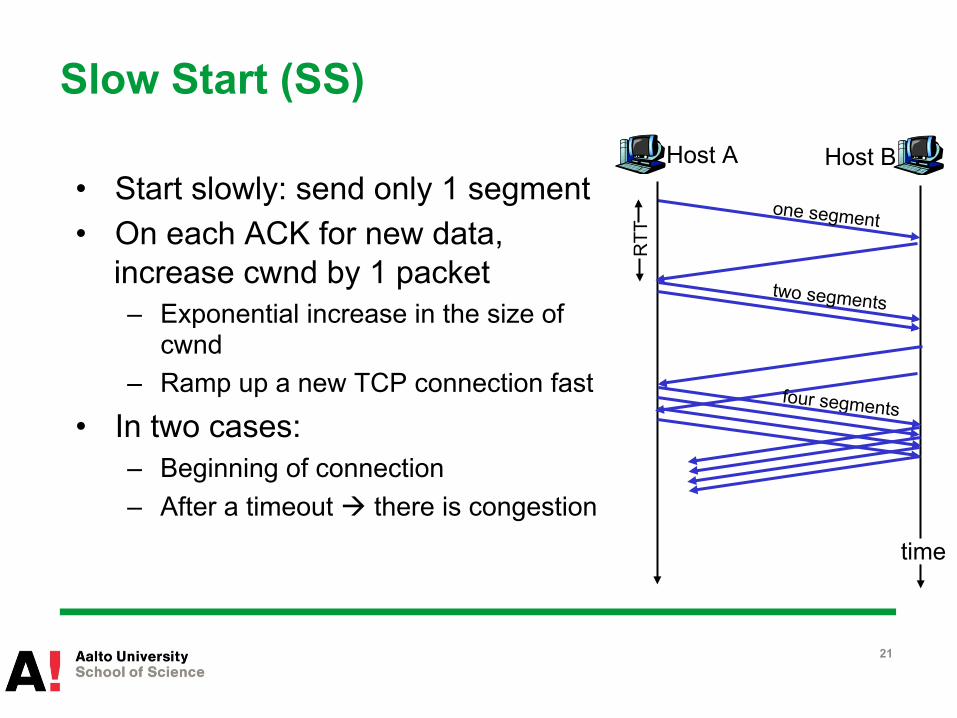
Slow Start (SS)
• Start slowly: send only 1 segment • On each ACK for new data,
increase cwnd by 1 packet – Exponential increase in the size of
cwnd – Ramp up a new TCP connection fast
• In two cases: – Beginning of connection – After a timeout à there is congestion
Host A
one segment
RTT
Host B
time
two segments
four segments
21
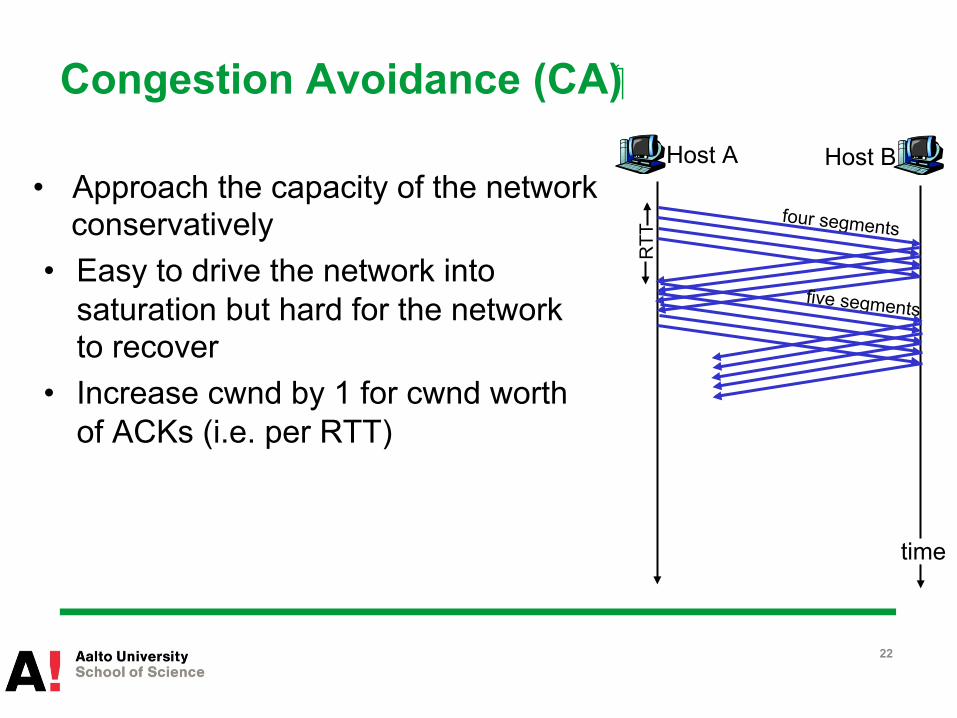
Congestion Avoidance (CA)
• Approach the capacity of the network conservatively
• Easy to drive the network into saturation but hard for the network to recover
• Increase cwnd by 1 for cwnd worth of ACKs (i.e. per RTT)
Host A
RTT
Host B
time
four segments
five segments
22

Combining SS and CA
• Introduce Slow start threshold (ssthresh)
• On timeout: – ssthresh = 0.5 x cwnd – cwnd = 1 packet
• On new ACK: – If cwnd < ssthresh: do Slow Start – Else: do Congestion Avoidance
❒ ACKs: increase cwnd by 1 MSS per RTT: additive increase
❒ loss: cut cwnd in half (non-timeout-detected loss ): multiplicative decrease
AIMD
AIMD: Additive Increase Multiplicative Decrease
23

TCP Tahoe: adjusting cwnd
Timeouts
Slow Start
t
cwnd
Congestion avoidance after cwnd reaches half of previous cwnd
Set ssthresh to half of cwnd
24

TCP Reno
• Van Jacobson 1990 • Fast retransmit with Fast recovery
– Duplicate ACKs tell sender that packets still go through – Do less aggressive back-off:
• ssthresh = 0.5 x cwnd • cwnd = ssthresh + 3 packets • Increment cwnd by one for each additional duplicate ACK • When the next new ACK arrives: cwnd = ssthresh
Nb of packets that were delivered
Fast recovery
25

TCP Reno: adjusting cwnd
cwnd
Slow Start Congestion Avoidance Time
“inflating” cwnd with dupACKs
“deflating” cwnd with a new ACK
(ini$al) ssthresh
new ACK
fast-‐retransmit fast-‐retransmit
new ACK
$meout
26

ssthresh
ssthresh
TCP Tahoe
TCP Reno
Transmission round
cwnd
win
dow
siz
e (in
se
gmen
ts)
Tahoe vs. Reno
27
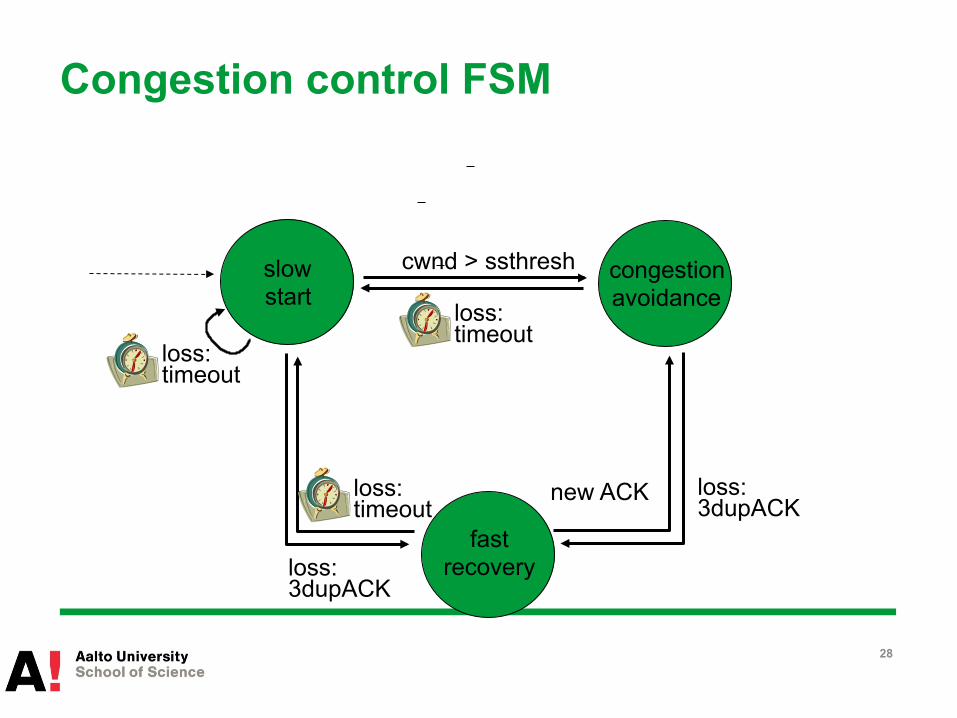
slow start
congestion avoidance
fast recovery
cwnd > ssthresh
loss: timeout
loss: timeout
new ACK loss: 3dupACK
loss: 3dupACK
loss: timeout
Congestion control FSM
28

slow start
congestion avoidance
fast recovery
timeout ssthresh = cwnd/2
cwnd = 1 MSS dupACKcount = 0
retransmit missing segment timeout ssthresh = cwnd/2
cwnd = 1 MSS dupACKcount = 0
retransmit missing segment
Λ cwnd > ssthresh
cwnd = cwnd+MSS dupACKcount = 0 transmit new segment(s),as allowed
new ACK cwnd = cwnd + MSS (MSS/cwnd)
dupACKcount = 0 transmit new segment(s),as allowed
new ACK .
dupACKcount++
duplicate ACK
ssthresh= cwnd/2 cwnd = ssthresh + 3 retransmit missing segment
dupACKcount == 3
dupACKcount++
duplicate ACK
ssthresh= cwnd/2 cwnd = ssthresh + 3
retransmit missing segment
dupACKcount == 3
timeout ssthresh = cwnd/2 cwnd = 1 dupACKcount = 0 retransmit missing segment
cwnd = cwnd + MSS transmit new segment(s), as allowed
duplicate ACK
cwnd = ssthresh dupACKcount = 0
New ACK
Λ cwnd = 1 MSS
ssthresh = 64 KB dupACKcount = 0
Congestion control FSM: details
29

TCP New Reno
• 1999 by Sally Floyd • Modification to Reno’s Fast Recovery phase • Problem with Reno:
– Multiple packets lost in a window – Sender out of Fast Recovery after retransmission of only one
packet è cwnd closed up
è no room in cwnd to generate duplicate ACKs for additional Fast Retransmits
è eventual timeout • New Reno continues Fast Recovery until all lost packets from
that window are recovered
30

Outline
• Transport Layer Overview – Congestion Control
• TCP congestion control evolution • Issues with basic TCP and solutions
– More recent developments with TCP
• Other transport protocols – LEDBAT
31

Some issues with basic TCP (Reno)
• Deep buffers – Poor congestion responsiveness – Solution: e.g. TCP Vegas
• Differentiating losses: congestion vs. random packet loss – Wireless access (“connectivity drops”)
• Signal fading, handoffs, interference – Solutions: e.g. ECN, TCP Veno, TCP Westwood
• Paths with high bandwidth*delay – These “long fat pipes” require large cwnd to be saturated – Reno grows window too slowly – Solutions: TCP CUBIC, Compound TCP (CTCP)
• Fairness
32

Is TCP fair?
• Take moment to discuss these with the person(s) sitting next to you – What is fairness? – Is TCP fair? – How and in which situations is TCP fair/unfair?
33

TCP Fairness
fairness goal: if K TCP sessions share same bottleneck link of bandwidth R, each should have average rate of R/K
TCP connection 1
bottleneck router
capacity R
TCP connection 2
34
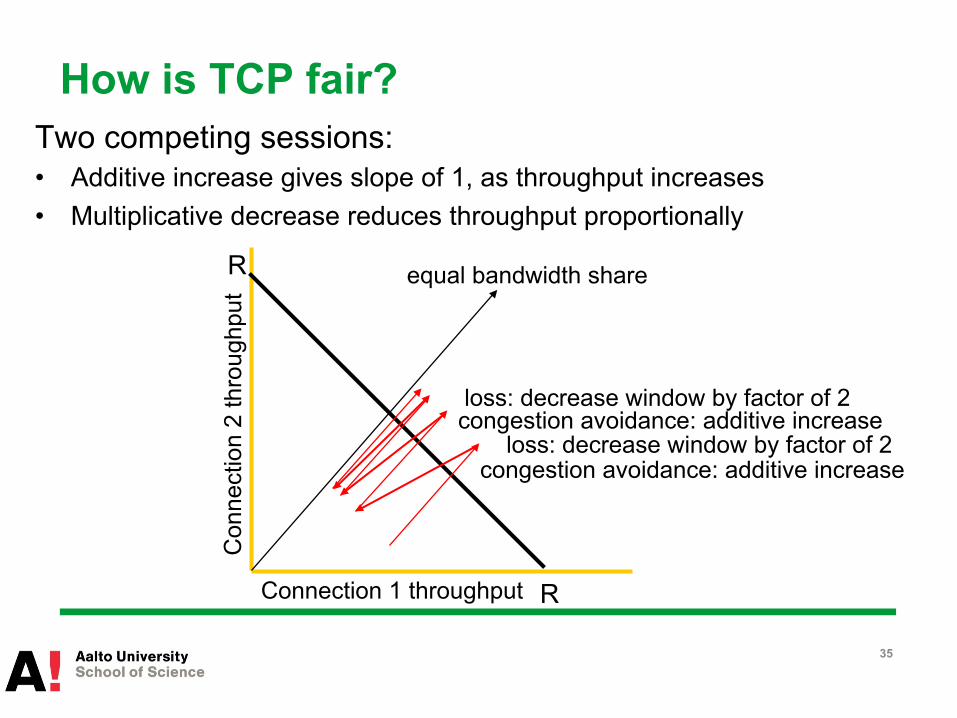
How is TCP fair? Two competing sessions: • Additive increase gives slope of 1, as throughput increases • Multiplicative decrease reduces throughput proportionally
R
R
equal bandwidth share
Connection 1 throughput
Con
nect
ion
2 th
roug
hput
congestion avoidance: additive increase
loss: decrease window by factor of 2
congestion avoidance: additive increase
loss: decrease window by factor of 2
35

TCP Fairness Issues
RTT Fairness • What if two connections
have different RTTs? – “Faster” connection grabs
larger share • Reno’s (AIMD) fairness is
RTT biased • More RTT-fair TCP
versions exist – E.g. TCP Libra (2006)
Fairness and parallel TCP connections
• nothing prevents app from opening parallel connections between 2 hosts.
• web browsers do this • example: link of rate R
supporting 9 connections; – new app asks for 1 TCP, gets
rate R/10 – new app asks for 11 TCPs, gets
R/2 !
36

Fairness and UDP
• Multimedia apps sometimes use UDP – Do not want rate throttled by congestion control – Pump audio/video at constant rate, tolerate packet loss – UDP is not congestion responsive at all
• But vast majority of e.g. streaming traffic is HTTP over TCP – NATs and firewalls among the primary reasons
37

Some issues with basic TCP (Reno)
• Deep buffers – Poor congestion responsiveness – Solution: e.g. TCP Vegas
• Wireless paths – Differentiating losses: congestion vs. random packet loss – Signal fading, handoffs, interference may cause packet drops – Solutions: e.g. ECN, TCP Veno, TCP Westwood
• Paths with high bandwidth*delay – These “long fat pipes” require large cwnd to be saturated – Reno grows window too slowly – Solutions: TCP CUBIC, Compound TCP (CTCP)
• Fairness
38

Deep buffers: What’s the problem?
• Deep (i.e. large) buffers in routers can hold a lot of packets
• Absorb larger bursts and tolerate instantaneously higher peak rates à reduce packet loss – This is good, or..?
• Problem: TCP reacts late – Packet loss is the main congestion indicator for TCP – Upon packet loss, congestion may already be quite severe
• Timeouts happen – Potentially large fluctuations in throughput
39

TCP Vegas
• 1994 by Brakmo et Peterson • Delay-based congestion detection • Increasing delay is a sign of congestion
– Packets start to fill up queues
• Adjust rate before packets are lost – React faster than TCP Reno
40

TCP Vegas: the rationale
• When congestion builds up – Delay grows first – Then packets get lost
• But throughput does not grow – Cannot increase beyond
capacity • TCP Reno continues to
increase cwnd – More packets into the network – But as many still go through à Absorbed by the buffers
unlimited shared output link buffers
Host A λin : original data
Host B
λout
41

TCP Vegas: how it works • Measure some metrics
– Expected throughput exp = cwnd / BaseRTT – rttLen – number of bytes transmitted during the last RTT. – rtt – average RTT of the segments acknowledged during the
last RTT. – Actual throughput act = rttLen / rtt – diff = exp – act
• Congestion avoidance – Define two thresholds: α < β – diff < α è increase the congestion window linearly during the
next RTT. – diff > β è decrease the congestion window linearly during the
next RTT. – α < diff < β è do nothing
minimum of measured round trip times
42

TCP Vegas: performance and issues
• Potentially up to 70% better throughput than Reno
• Issues – Fairness with Reno
• Reno grabs larger share due to late congestion detection
– Rerouting • Propagation delay increases -> Vegas may falsely
conclude congestion – “Persistent congestion”
• Initiate connection when path already congested • Overestimate BaseRTT -> underestimate
congestion backlog -> add to congestion
43

Some issues with basic TCP (Reno)
• Deep buffers – Poor congestion responsiveness – Solution: e.g. TCP Vegas
• Wireless paths – Differentiating losses: congestion vs. random packet loss – Signal fading, handoffs, interference may cause packet drops – Solutions: e.g. ECN, TCP Veno, TCP Westwood
• Paths with high bandwidth*delay – These “long fat pipes” require large cwnd to be saturated – Reno grows window too slowly – Solutions: TCP CUBIC, Compound TCP (CTCP)
• Fairness
44

Wireless paths: What’s the problem?
• Loss is the sole congestion indicator for TCP Reno – Packets dropped by routers due to filled up queues
• Wireless links may cause also packet loss – Signal fading, handoffs, interference – So called random packet loss
• Reno reduces cwnd also upon random packet loss – Thinks that it is congestion – Result is under-utilized path
45

TCP Veno
• Fu and Liew, 2003 • Wireless environments (random packet loss) • Veno = Vegas + Reno • Estimate the backlog N accumulated along the path
due to congestion (queues fill up) – N = act x (rtt - BaseRTT) – If N < threshold => no congestion
• inferred segment loss as a random loss
46

TCP Veno: How it works
• Two refinements to Reno’s AIMD – In congestion avoidance, if N > threshold :
• cwnd increased by 1 segment every 2 RTTs instead of each RTT – Random loss inferred (N < threshold)
• fast retransmit: ssthresh set to 0.8 cwnd instead of 0.5 cwnd
• Same issues than in Vegas
47

Some issues with basic TCP (Reno)
• Deep buffers – Poor congestion responsiveness – Solution: e.g. TCP Vegas
• Wireless paths – Differentiating losses: congestion vs. random packet loss – Signal fading, handoffs, interference may cause packet drops – Solutions: e.g. ECN, TCP Veno, TCP Westwood
• Paths with high bandwidth*delay – These “long fat pipes” require large cwnd to be saturated – Reno grows window too slowly – Solutions: TCP CUBIC, Compound TCP (CTCP)
• Fairness
48

“Fat Pipes”: What’s the problem?
• High bandwidth x delay – Can send a lot of packets before receiving any ACKs – Note: Such paths did not exist when TCP was designed
• Want to saturate the path quickly – Optimal utilization of the capacity
• TCP Reno is too slow – Example path: 10Gbps & 100ms à Takes 1 hour of error free transmission to saturate with TCP Reno!
• Need to increase cwnd faster – New cwnd growing strategies in Cubic and Compound TCP
49

BIC-TCP: Binary Increase Congestion Control • 2004 by Xu and Rhee • Change window adjustment strategy
– No longer pure AIMD – Grow CWND using binary search and linear increase
• Goals: – Saturate also large bw x delay paths – RTT fair
• Intra-protocol fairness when competing with flows that have different RTTs
– TCP fair • Limited impact to regular TCP flows sharing the same bottleneck
50

Response function shows tradeoffs
1,0E+01
1,0E+02
1,0E+03
1,0E+04
1,0E+05
1,0E+06
1,0E-07 1,0E-06 1,0E-05 1,0E-04 1,0E-03 1,0E-02
Packet Loss Probability
Thro
ughp
ut (M
bps)
TCPAIMDHSTCPSTCPBIC
TCP Friendly
Scalability, RTT Fairness
More scalable
Higher slope -> less RTT fair
More TCP friendly
other “high speed” TCPs
like Reno but with larger AI, and smaller
MD
51

BIC window sizing
• Binary search increase – Iteratively
• set cwnd size to middle point between upper and lower limits – upper limit is assumed to saturate the path
• No packet loss à we are below target à update lower limit to current cwnd
• until upper and lower limit differ by less than a predefined threshold – Initially more aggressive window increase – The closer to target, the less aggressive increase
• Additive increase – Bound the max window increment – Avoid too aggressive initial window increase
52

BIC window sizing: illustration
0
32
64
96
128
160
192
224
256
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20Time (RTT)
cwnd
Linear Search
Binary Search with Smax and Smin
Smin
Smax
Wmax
Wmin
Available Bandwidth (assumption)
maximum allowed increment
minimum increment
53

BIC window sizing (cont.)
• Q: What to do when cwnd grows beyond current upper limit? • A: Slow start
– Upper limit becomes unknown à set upper limit to default max (a large constant)
– Start probing slowly to be on the safe side – Slow start until increment reaches Smax, then back to normal
operation (binary search+AI) • Q: What to do upon packet loss? • A: Multiplicative decrease (MD) and update upper limit to
current cwnd – Packet loss with cwnd smaller than previous upper limit indicates
we are above target à set upper limit to smaller value than current cwnd (called fast convergence in BIC)
54

BIC in action

CUBIC TCP
56
• 2005 by Xu and Rhee • Enhanced version of BIC • Simplifies BIC window control using a cubic function • Use real-time, rather than ACK-clocked, updates to
window – Improves fairness

BIC vs. CUBIC
accelerate
accelerate
slow down
[3]
BIC
CUBIC

Compound TCP (CTCP)
• Microsoft research, 2006 • Competitor for BIC and CUBIC
– Efficient use of high speed and long distance networks – RTT fairness, TCP friendliness
• Loss-based vs. delay-based approaches – Loss-based (e.g. HSTCP, BIC...) too aggressive – Delay-based (e.g. Vegas) too timid
• Compound approach – Loss-based component: cwnd (standard TCP Reno) – Scalable delay-based component: dwnd – TCP sending window is Win = cwnd + dwnd
58

CTCP congestion control
• Vegas-like early congestion detector – Estimate the backlogged packets (diff) and compare it to a
threshold, γ
• Binomial increase when no congestion
• Multiplicative decrease when loss
• On detecting incipient congestion – Decrease dwnd and yield to competing flows
ktwintwintwin )()()1( ⋅+=+ α
( )β−⋅=+ 1)()1( twintwin

CTCP congestion control
• cwnd is updated as TCP Reno • dwnd control law
• Control law kicks in only when – in congestion avoidance and – cwnd >= 40 packets
• Slow start phase unchanged • γ value set empirically
€
dwnd(t +1) =
dwnd(t) + (α⋅ win(t)k −1)+, if diff < γ
dwnd(t) −ζ⋅ diff( )+, if diff ≥ γ
win(t)⋅ (1− β) − cwnd /2( )+, if loss is detected
⎧
⎨ ⎪ ⎪
⎩ ⎪ ⎪

CTCP window evolution
B
γ
D E F G Loss Free Period
W(1-‐b)
Ws = cwnd + dwnd
Wm
dwnd = 0

CTCP window evolution (cont.)

BIC/CUBIC vs. CTCP
• Unfairness: BIC/CUBIC are over aggressive and steal bandwidth
– Contrary opinions exist too…
• Windows uses CTCP – New servers use it by default – Vista and 7 support it but seems to be disabled by default – CTCP can be enabled in older servers and 64-bit XP
• Linux – TCP BIC default in kernels 2.6.8 through 2.6.18 – TCP CUBIC since 2.6.19
63

Wrapping up
• Transport protocols – Congestion control one of the most crucial features in packet
switched networks – Two main trends:
• New TCP versions • New protocols
• TCP – Many different versions – Modern versions take into account wireless access and long fat
paths – Also very recently focus on data center networks (later lecture)
64

Next lecture
• Other protocols – SCTP, DCCP – LEDBAT
• Congestion control for background (BitTorrent) traffic
• Bufferbloat
65