technologies and challenges
TRANSCRIPT

Technologies and Challenges Multilingual Sentiment Analysis

Lei Zhang (张镭) Computer Scien.st in Text Analy.cs team at Adobe, Ph.D. in Computer Science
Machine Learning 80%
Natural Language Processing 100%
Data Mining 90%

Sentiment Analysis
Computa.onal study of people’s opinions, appraisals, a?tudes from subjec.ve informa.on (i.e., text, audio and video etc. ) Basic task of sen.ment analysis is to classify the polari.es of a given informa.on (posi:ve, nega:ve, or neutral)
“The digital media cloud so0ware is hard to install .”
“The new Adobe digital media cloud is great !”

Traditional Approaches for Sentiment Analysis
• Individuals Get opinions from family, friends or colleagues. • Organiza.ons Get opinions from polls and surveys.

Current Technologies
With the booming of Web, especially Social Media, a huge amount of subjec.ve data generated by people in forums, blogs, TwiPer, etc. Now, it is impossible for human-‐being to analyze them all. We want computer to automa.cally mine sen.ments from the big data. It is a challenging task but very useful. It would provide insight for people and organiza.ons to make decisions.

Social Media Analytics
Listen Understand
Retrieve, store and analyze people’s conversa.ons
Explore topics driving people’ conversa.ons and understand internal dynamics
Evaluate impact of marke.ng campaigns in social media channels
Iden.fy issues, themes and paPerns. Deliver appropriate content to target audience
01 03
02 04 Act Measure

Sen:ments Reasons Ac:ons
Sentiment Analysis in Social Media Analytics
For example, “The new digital media cloud so0ware is hard to install”

An Example Review
“ I bought an iPhone a few days ago. It was such a nice phone. The touch screen was really cool. The voice quality was clear too. Although the baAery life was not long, that is ok for me. However, my mother was mad with me as I did not tell her before I bought the phone. She also thought the phone was too expensive, and wanted me to return it to the shop. …”
What we see here?
Sen.ments, targets of sen.ments and opinion holders

What is a Sentiment
• A sen.ment is a quintuple (ej, fjk, soijkl, hi, tl), where – ej is a target en.ty. – fjk is a feature(aspect) of the en.ty ej. – soijkl is the sen.ment value of the sen.ment of the opinion holder hi on
feature(aspect) fjk of en.ty ej at .me tl. soijkl is +ve, -‐ve, or neu, or a more granular ra.ng.
– hi is an opinion holder. – tl is the .me when the sen.ment is expressed.

Sentiment Analysis Objective
• Objec.ve: given an opinionated document, – Discover all quintuples (ej, fjk, soijkl, hi, tl),
• i.e., mine the five corresponding pieces of informa.on in each quintuple, and
– Or, solve some simpler problems.
• With the quintuples, – Unstructured text → Structured data
• Tradi.onal data and visualiza.on tools can be used to slice, dice and visualize the results in all kinds of ways
• Enable qualita.ve and quan.ta.ve analysis.

Sentiment Classification: Document Level
• Classify a document (e.g., a review) based on the overall sen.ment expressed by opinion holder – Classes: posi.ve, or nega.ve (and neutral)
• It assumes
Each document focuses on a single en.ty and contains opinions from a single opinion holder

Subjectivity Analysis : Sentence Level
• Sentence-‐level sen.ment analysis has two tasks: – Subjec.vity classifica.on: Subjec.ve or objec.ve.
• Objec.ve: e.g., “I bought an iPhone a few days ago.” • Subjec.ve: e.g., “It is such a nice phone.”
– Sen.ment classifica.on: For subjec.ve sentences or clauses, classify posi.ve or nega.ve. • Posi.ve: e.g., “It is such a nice phone.” • Nega.ve: e.g., “The screen is bad.”

Aspect-based Sentiment Analysis
• Sen.ment classifica.on at both document and sentence (or clause) levels are NOT sufficient, – They do not tell what people like and/or dislike – A posi.ve sen.ment on an en.ty does not mean that the opinion
holder likes everything. – An nega.ve sen.ment on an en.ty does not mean that the opinion
holder dislikes everything.

Aspect-based Sentiment Summary “I bought an iPhone a few days ago. It was such a nice phone. The touch screen was really cool. The voice quality was clear too. Although the baAery life was not long, that is ok for me. However, my mother was mad with me as I did not tell her before I bought the phone. She also thought the phone was too expensive, and wanted me to return it to the shop. …”
….
Aspect based summary: Aspect1: Touch screen Posi.ve: 212 ¢ The touch screen was really cool. ¢ The touch screen was so easy to use and
can do amazing things. … Nega.ve: 6 ¢ The screen is easily scratched. ¢ I have a lot of difficulty in removing finger
marks from the touch screen. … Aspect2: baHery life …
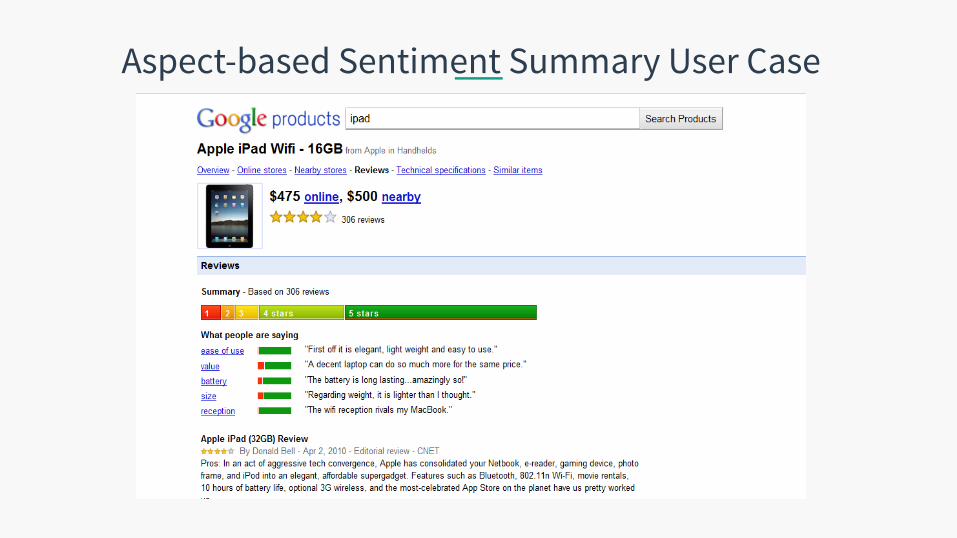
Aspect-based Sentiment Summary User Case

Sentiment Analysis is a Multifaceted Problem
• (ej, fjk, soijkl, hi, tl),
– ej -‐ an en.ty: Named en.ty extrac.on (more) – fjk – an feature(aspect) of ej: Informa.on extrac.on – soijkl is sen.ment: Sen.ment determina.on – hi is an opinion holder: Informa.on/Data Extrac.on – tl is the .me: Data Extrac.on
• Rela.on extrac.on • Synonym match (voice = sound quality) …

Methods for Sentiment Analysis
Machine Learning Method Lexicon-‐based Method
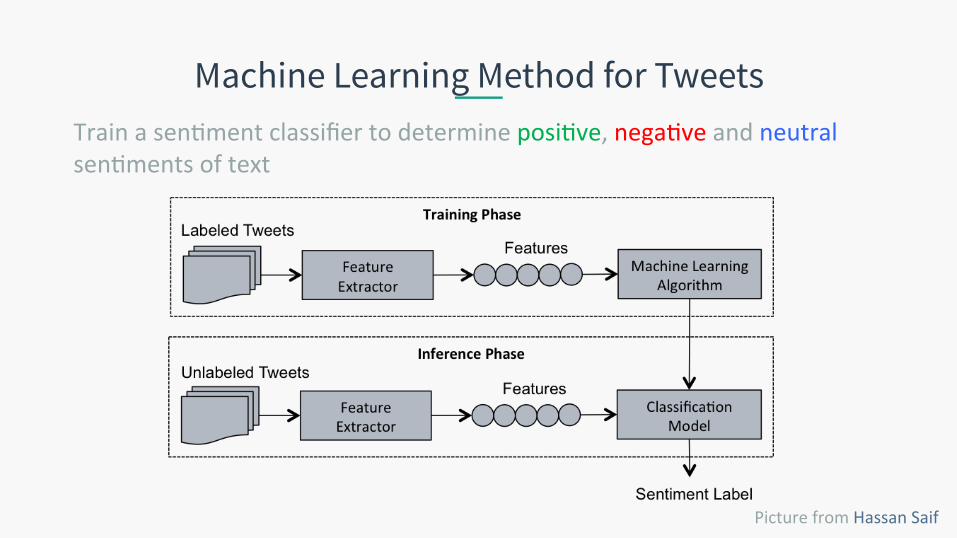
Machine Learning Method for Tweets
Picture from Hassan Saif
Train a sen.ment classifier to determine posi.ve, nega.ve and neutral sen.ments of text

Machine Learning Method
Pros: 1. Tradi.onal and dominant sen.ment analysis method for long
documents (e.g. reviews, blogs)
Cons: 1. Domain-‐transfer problem. A sen.ment classifier may perform well in
one domain but ofen performs bad in another domain.
2. Manually labeling a large set of texts is labor-‐intensive and .me-‐consuming.
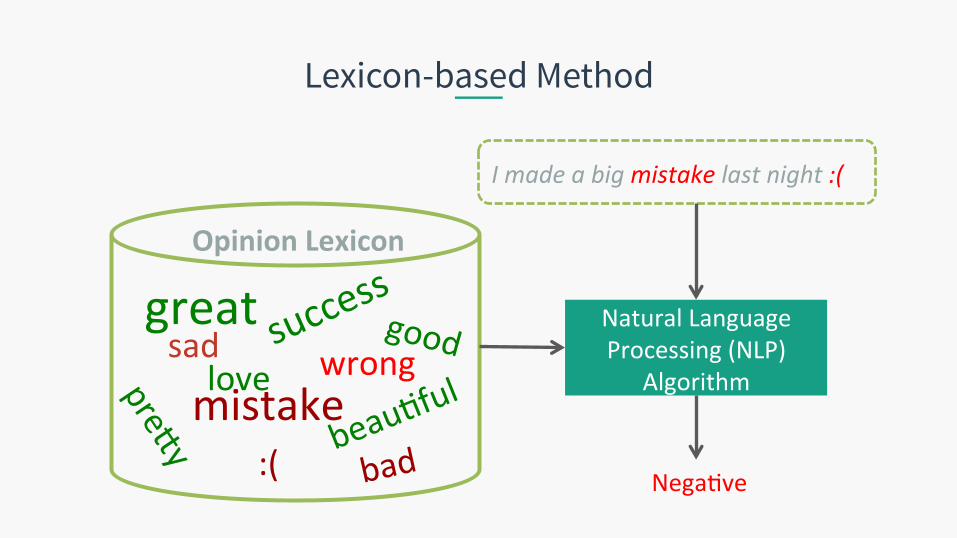
Lexicon-based Method
I made a big mistake last night :(
Nega.ve
Opinion Lexicon
Natural Language Processing (NLP)
Algorithm
great sad
:(
wrong mistake
bad
love good
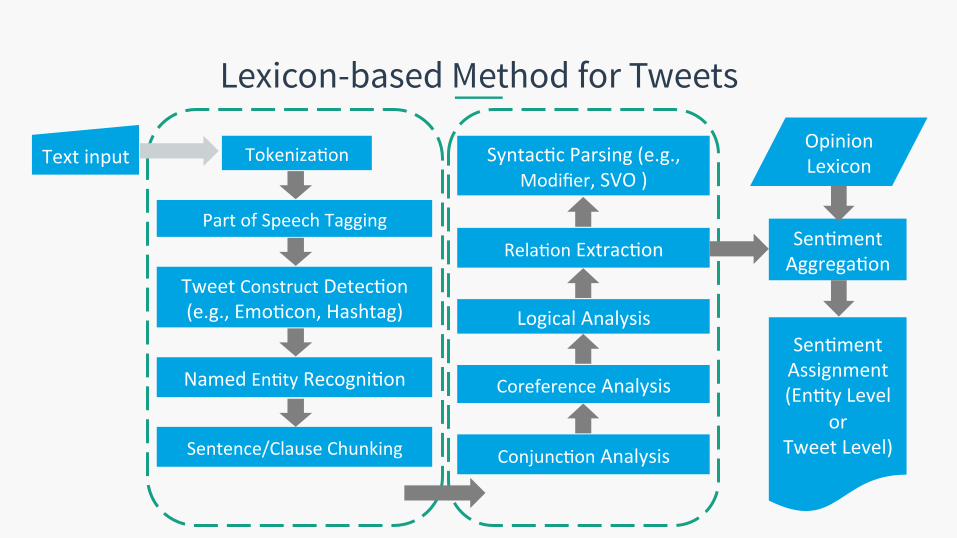
Lexicon-based Method for Tweets
Text input Tokeniza.on
Part of Speech Tagging
Tweet Construct Detec.on (e.g., Emo.con, Hashtag)
Named En.ty Recogni.on
Sentence/Clause Chunking Conjunc.on Analysis
Coreference Analysis
Logical Analysis
Syntac.c Parsing (e.g., Modifier, SVO )
Rela.on Extrac.on
Sen.ment Assignment (En.ty Level
or Tweet Level)
Sen.ment Aggrega.on
Opinion Lexicon

Lexicon-based Method
Pros: 1. Only need opinion lexicon; do not need to label training examples. 2. Generally domain-‐independent.
Cons: 1. Some linguis:c knowledge is required.
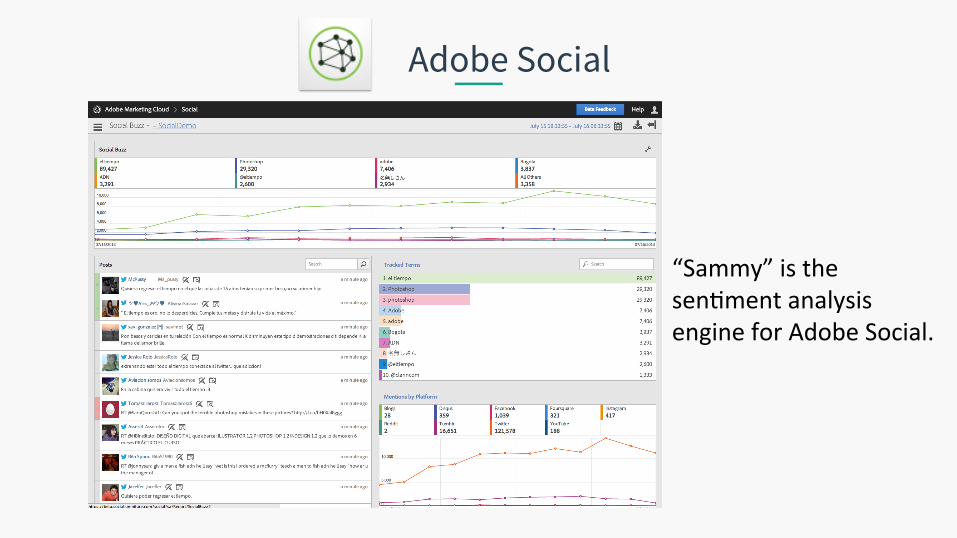
Adobe Social
“Sammy” is the sen.ment analysis engine for Adobe Social.
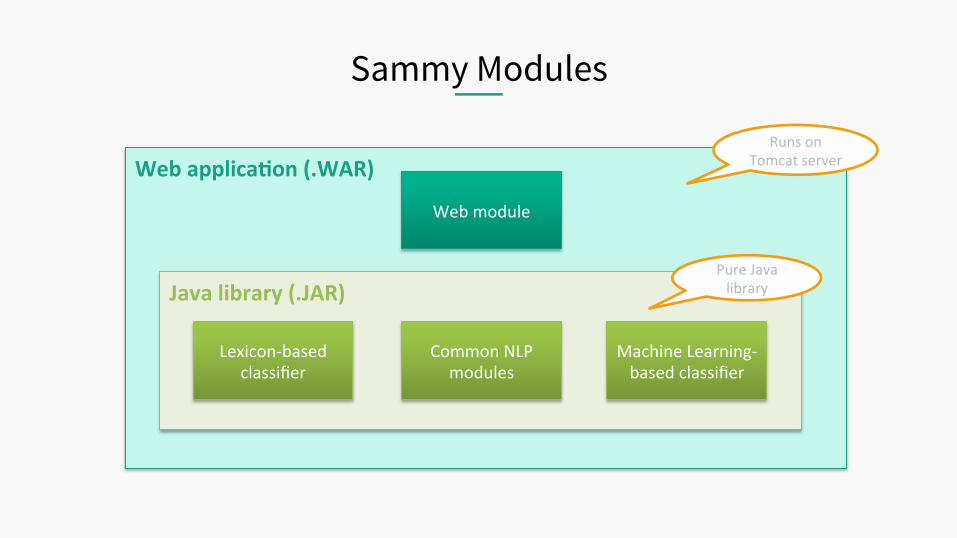
Sammy Modules
Web applica:on (.WAR)
Java library (.JAR)
Lexicon-‐based classifier
Machine Learning-‐based classifier
Common NLP modules
Web module
Runs on Tomcat server
Pure Java library

Multilingual Sentiment Analysis
As the use of Social Media has spread globally, there is an increasing importance to analyze mul.lingual social media data. Sammy need to consider the following (challenges) for mul.lingual analysis: -‐ Language encoding -‐ Language-‐specific natural language processing (NLP) tools -‐ Language-‐specific dic.onaries and resources -‐ Cross-‐language sen.ment analysis approaches

Language Encoding
There are many different encodings used worldwide, some of them designed for a par.cular language, others covering the en.re range of characters defined by Unicode. We uses the facili.es provided by Java and so it has access to over 100 different encodings including the most popular locales ones, such as ISO 8859-‐1 in Western countries or ISO-‐8859-‐9 in Eastern Europe.

Language Identification
Language iden.fica.on is to determine natural language by inspec.on of given data. It is an important preprocess step for sen.ment analysis. There are three main approaches as follows. (1) Common words approach (2) Sta.s.cal approach (3) N-‐gram approach

Common Words Approach
The basic idea: (1) Sample text in different languages (2) Store highly frequent words for each language in a database. (3) The text to be classified is compared to all the word lists in database. (4) Via a scoring system, the word list with most occurrences indicates the language of the text.

Statistical Approach
The basic idea (machine learning): (1) Sample texts in different languages (2) Segment strings, compute probabili.es of the occurrence of all string sequences, and get a language model (a probability distribu.on over sequences of words) for each language. (3) For the text to be iden.fied, compute ( Markov model) the probability p (text | language model) for all modes. (4) Pick the highest probability of the model that produced the text.

N-gram Approach
N-‐gram is a con.guous sequence of sequence of n items from a give sequence of text. The n-‐gram of size 1 is referred as a “unigram”; size 2 is a “bigram”; size 3 is a “trigram” … e.g., the word “garden”, bi-‐grams: ga, ar, rd, de, en tri-‐grams: gar, ard, rde, den

N-gram Approach (continue)
The basic idea:
(1) Sample texts in different languages (2) Generate N-‐gram profile for each language (3) For the text to be iden.fied, calculates the N-‐gram profile and compares it to the language specific N-‐gram profiles. (4) The language profile which has the smallest distance to our text N-‐gram profile indicates the language.

Language Identification Challenges
For social media data, we have some new challenges. (1) Handing very short texts (2) Handling texts of unknown language and texts comprised of mul.ple languages. e.g., “ @LEGOJurassic \n@AudiJapan \nアウディA5\nアウディ―A5\n#アウディA5\n #アウディ―A5\nA1 A3 A3 A4 Q1 TT “

Language-specific Part of Speech Part of Speech (POS) is a category of words which have similar gramma.cal proper.es. Commonly listed English parts of speech are noun, verb, adjec.ve, adverb, pronoun etc. Input: “My dog also likes ea^ng Sausage” Output: “My/PRP$ dog/NN also/RB likes/VBZ ea^ng/VBG Sausage/NN” Other languages have their own POS. e.g., Japanese has language specific POS such as “助詞” (auxiliary word). We need to incorporate language-‐specific POS informa.on for analysis.

Language-specific Opinion Lexicon Opinion Lexicon is a list of opinion (bearing) word (e.g., “good” “bad”). It plays a cri.cal role in sen.ment analysis. We have several well-‐regarded sen.ment lexicons in English. The same is not true for most of the world’s languages. Two main approaches to get opinion lexicons from other languages (1) Machine transla.on (2) Graph propaga.on (given seed words, try to expand words by external knowledge bases, such as Wik.onary and WordNet).

Multilingual Sentiment Analysis Approaches
For sen.ment analysis at document level and sentence level, its basic idea is as follows. Focused on using extensive resources and tools available in English and automated transla.ons to help build sen.ment analysis systems in other languages which have few resources or tools

Multilingual Sentiment Analysis Approaches (Continue)
Current research proposed two main strategies: (1) Translate test sentences in the target language into the source language and classify them using a source language classifier. (2) Translate a source language training corpus into the target language and build a corpus-‐based classifier in the target language.

Multilingual Sentiment Analysis Approaches (Continue)
For sen.ment analysis at aspect level, the basic idea is as follows: Apply language-‐specific tools (POS tagger, Parser) to extract useful informa.on between aspect and sen.ment, and then apply language –agonis.c aggrega.on methods to determine sen.ments.

Reference
• Bing Liu, Sen.ment Analysis and Opinion Mining, Morgan & Claypool, 2012 • Simon Kranig, Evalua.on of Language Iden.fica.on Methods, Thesis

Thank You Q & A