tecniche di simulazione real-time per convertitori ... · corso di laurea in ingegneria informatica...
TRANSCRIPT

UNIVERSITÀ DEGLI STUDI DEL SANNIO
Facoltà di Ingegneria Corso di Laurea in Ingegneria Informatica
Tesi di Laurea in
MODELLISTICA E SIMULAZIONE
Tecniche di simulazione real-time per convertitori elettronici di alta potenza
Relatore Candidato Prof. Luigi Iannelli Giuseppe Giordano Matr. 195/1050
Correlatore Ing. Roberto Frasca
Anno accademico 2007/2008

2
INDICE
Introduzione ...................................................................................................................4
Capitolo 1. Componenti del sistema di simulazione
1.1 Introduzione …………………………………………………………………......6
1.2 Motore Sincrono …………………………………………………………….......7
1.2.1 Introduzione ..............................................................................................7
1.2.2 Trasformata di Park …………………………………………………….11
1.2.3 Modello motore sincrono …..…………………………………………..14
1.2.4 Modello saturazione ……………………………………………………18
1.2.5 Simulazioni ed effetti saturazione ………………………………...........22
1.2.6 Reti R-L e motore sincrono …………………………………………….25
1.3 Inverter e banco condensatori …………………………………………………31
1.4 Modulatore ……………………………………………………………………..34
Capitolo 2. Sistema di simulazione real-time hardware in the loop
2.1 Introduzione ……………………………………………………………………36
2.2 La fase di testing ……………………………………………………………….37
2.3 Testing Hardware in the loop …………………………………………………..39
2.4 La piattaforma RT-Lab ………………………………………………………...43
2.4.1 Caratteristiche principali ……………………………………………….45
2.4.2 La modalità XHP ………………………………………………………47
2.4.3 Principi di funzionamento ……………………………………………...49
2.5 Xilinx System Generator (XSG) ……………………………………………….51
2.6 HILBox di RT-Lab……………………………………………………………..53
2.6.1 Caratteristiche principali ……………………………………………….54

3
2.7 dSpace ACE-kit DS1103 PPC Controller Board ………………………………57
Capitolo 3. Implementazione modello real-time
3.1 Introduzione ……………………………………………………………………59
3.2 Setup Sperimentale …………………………………………………………….60
3.3 Implementazione real-time……………………………………………………..62
Capitolo 4. Risultati delle simulazioni
4.1 Introduzione ……………………………………………………………………73
4.2 Risultati ………………………………………………………………………...74
4.2.1 Condizioni nominali
4.2.2 Variazione coppia di carico del +30% ....................................................74
4.2.3 Variazione tensione di linea del +30% ...................................................76
4.2.4 Variazione tensione di linea del -20% …………………………………80
4.2.5 Variazione tensione di eccitazione del -75% …………………………..94
4.2.6 Perdita di passo ………………………………………………………...87
4.2.7 Diversi valori di induttanza per i singoli rami della rete R-L ………….92
4.2.8 Modulazione PD e POD ………………………………………………..94
Conclusioni ……………………………………………………………………………97
Appendice A – Calcolo equazioni elettro-magnetiche motore …………………….99
Appendice B – Implementazione modello inverter in FPGA …………………….103
Appendice C – Interfaccia utente di RT-Lab ……………………………………...110
Appendice D – Specifiche tecniche …………………………………………………120
Appendice E – Lista dei simboli ……………………………………………………124
Bibliografia .................................................................................................................126

4
INTRODUZIONE
Il presente lavoro di tesi si pone come obiettivo lo sviluppo di tecniche di
simulazione in tempo reale e la loro implementazione su piattaforme real-time ad
elevate prestazioni per applicazioni relative a convertitori elettronici di alta potenza.
Costituisce parte integrante di questo lavoro la realizzazione di un “banco di
prova” in laboratorio per il testing delle centraline di controllo di tali convertitori, un
banco che consenta di limitare i costi di sviluppo, i rischi legati ad una validazione non
efficace e i tempi che normalmente caratterizzano tali test.
La simulazione real-time del tipo Hardware-in-the-loop realizza questo compito in
quanto combina componenti reali e virtuali in una configurazione operativa tale da
permettere la simulazione della dinamica di sistemi complessi sotto diverse condizioni
di funzionamento e, soprattutto, nei tempi reali di funzionamento dell’hardware inserito.
Il sistema di simulazione in questione ha una complessa struttura nella quale si
interfacciano componenti meccanici, sistemi di controllo elettronici, strumenti
informatici e, naturalmente, l’uomo; è pertanto un sistema che per raggiungere gli
obiettivi preposti richiede una coordinazione totale tra le diverse parti.
Si ricorre all’approccio hardware-in-the-loop in quanto consente di simulare in
maniera efficace il comportamento di questi componenti: si tratta di un avanzato
strumento di diagnostica che adduce come valore aggiunto la possibilità di comparare
esaustivamente i software e, soprattutto, l’elettronica di controllo senza che questi
debbano essere necessariamente collegati al sistema reale.

5
Tenendo presente questo quadro d’insieme è stato realizzato un simulatore real-
time, sfruttando le potenzialità di un innovativo sistema hardware della Opal RT,
denominato HILBox .
Il primo passo intrapreso ha riguardato la modellistica del sistema reale da
simulare; è stato ricavato un modello matematico del funzionamento dell’impianto di
interesse e tale modello è stato implementato in Matlab/Simulink/Stateflow[1] e quindi
integrato in un modello real-time.
In questa fase si colloca un lavoro di sviluppo di tecniche che favoriscono il
miglioramento delle prestazioni della simulazione, in termini di passo di integrazione e
di affidabilità dei risultati numerici.
L’ultima fase del lavoro ha riguardato il testing vero e proprio. E’ stato testato
tutto il modello dell’applicazione in esame in condizioni di funzionamento nominali o
variando alcuni parametri rappresentativi di qualche azione particolare, ad esempio
legata a malfunzionamenti. Gli andamenti delle grandezze in esame sono stati
visualizzati sia su di un oscilloscopio, sia salvati nella memoria del simulatore per una
successiva visualizzazione ed analisi.

6
CAPITOLO 1
COMPONENTI DEL SISTEMA DI SIMULAZIONE
1.1 Introduzione
Il sistema di simulazione proposto, mostrato in figura 1.1, prevede un motore
sincrono, una rete di controllo motore composta da 4 inverter connessa ad una banco
condensatori, un modulatore e una rete R-L che collega gli inverter al motore.
Figura 1.1: Schema a blocchi del sistema di simulazione.

7
I 4 inverter ricevono in ingresso la tensione di linea, Vdc, e i segnali di controllo,
SWi, provenienti dal modulatore, e forniscono in uscita le tensioni di controllo al
motore sincrono.
1.2 Motore sincrono
1.2.1 Introduzione
Il motore sincrono è una macchina magneto-elettrica costituita da due elementi
fondamentali: lo statore ed il rotore (fig.1.2). Lo statore della macchina sincrona trifase
è cilindrico. Su di esso sono presenti tre avvolgimenti costruttivamente uguali disposti
simmetricamente lungo il traferro (lo spazio che divide lo statore dal rotore) in modo
che gli assi magnetici (a, b, c) sono disposti a 120° elettrici tra di loro. Questi
costituiscono gli avvolgimenti principali, collegati all'esterno, che generano un campo
magnetico rotante.
Il rotore si trova all’interno dello statore; è la parte rotante ed è solidale all’albero.
Per non perdere di generalità si considererà un rotore anisotropo, ossia costituito da un
certo numero di espansioni polari. I poli magnetici di rotore sono generati da un circuito
di eccitazione in cui scorre una corrente iF impressa dall’esterno e che agisce nella
direzione dell'asse diretto (o asse polare, asse d). Esistono altri tipi di macchine
sincrone, dette isotrope, in cui sul rotore sono disposti degli avvolgimenti simili a quelli
di statore e che, percorsi dalla corrente iF generano un campo magnetico per il quale è
possibile riconoscere formalmente una certa successione di poli.
Si lavorerà sotto le seguenti ipotesi:

8
• si considererà una macchina anisotropa a 2p poli salienti;
• si supporrà la permeabilità magnetica dei tratti in ferro infinita;
• si considererà la macchina come sistema simmetrico ed equilibrato;
• si supporrà che la forza magnetomotrice di eccitazione, determinata
dall’alternarsi dei poli di rotore al traferro della macchina, sia perfettamente
sinusoidale;
• si supporrà di poter pensare gli avvolgimenti di statore come concentrati sui
propri assi magnetici.
In Fig.1.2 è rappresentata la struttura della macchina sincrona che ci si propone di
analizzare. In particolare si nota come sullo statore sia presente l’avvolgimento trifase
simmetrico rappresentato da tre avvolgimenti monofase, uguali e posti a 120° l’uno
rispetto all’altro; sul rotore è presente l’avvolgimento di eccitazione, percorso dalla
corrente iF, e la gabbia smorzatrice, studiata pensandola scomposta in due avvolgimenti
equivalenti e mutuamente disaccoppiati, l’uno agente sull’asse diretto d e l’altro
sull’asse in quadratura q.

9
Figura 1.2: Struttura della macchina sincrona anisotropa.
Le gabbie smorzatrici rappresentano a volte il comportamento di prima
approssimazione delle correnti indotte nel rotore massiccio di grosse macchine.
Esistono modelli più accurati che rappresentano tali fenomeni con più avvolgimenti
smorzatori equivalenti su ogni asse (il numero non è necessariamente lo stesso: l’asse q,
di maggiore importanza per la dinamica, presenta spesso un numero maggiore di
smorzatori).
In molte macchine, soprattutto se piccole o progettate come motori a frequenza
variabile, gli smorzatori sono assenti (o le correnti indotte nel rotore massiccio sono
irrilevanti).
La macchina sincrona è pertanto costituita da sei avvolgimenti induttivi con mutui
accoppiamenti tra di loro.
Tenuto conto di tutte le resistenze, le autoinduttanze e le mutue induttanze, la
teoria mostra che le equazioni magnetoelettriche descrittive della macchina nel dominio
delle fasi a, b, c risultano essere:
Ω⋅=
−=
−=
=
nϑ
πϑϑ
πϑϑ
ϑϑ
&
3
43
2
3
2
1

10
+
=
c
b
a
c
b
a
s
s
s
c
b
a
dt
d
i
i
i
R
R
R
V
V
V
ψψψ
00
00
00
Equazioni di statore
+
=
F
Q
D
F
Q
D
F
Q
D
F
Q
D
dt
d
i
i
i
R
R
R
V
V
V
ψψψ
00
00
00
Equazioni di rotore
=
F
Q
D
c
b
a
rrt
sr
srss
F
Q
D
c
b
a
i
i
i
i
i
i
LM
ML
)()(
)()(
ϑϑϑϑ
ψψψψψψ
Relazioni tra flussi concatenati e correnti (1.1)
dove:
Il pedice F si riferisce all’avvolgimento di eccitazione ( o campo- field).
Il pedice D si riferisce all’avvolgimento smorzatore sull’asse diretto.
Il pedice Q si riferisce all’avvolgimento smorzatore sull’asse in quadratura.
VD e VQ sono considerati nulli essendo le tensioni ai capi di avvolgimenti cortocircuitati.
A queste equazioni vanno aggiunte le equazioni meccaniche:
- -Ω = Ωm
em L m
dJ T T B
dt (1.2)
dove J è il momento d’inerzia delle masse rotanti, Tem la coppia elettromagnetica, TL la
coppia di carico, B il coefficiente di attrito viscoso mΩ è la velocità meccanica
esprimibile in funzione della velocità elettrica di rotore ( eω ) attraverso la seguente
relazione:
Ω = em PP
ω

11
dove PP rappresenta il numero delle coppie di poli.
Esprimendo la (1.2) in funzione della ωe si ottiene:
- - =
e eem L
d PPT T B
dt J PP
ω ω
Inoltre:
=e
d
dt
θω
Quindi si tratta di un sistema differenziale dell’ottavo ordine, composto da 8 equazioni
nelle otto incognite rappresentate dai sei flussi magnetici, dall’anomalia ϑ e dalla
velocità ωe ([2], [3])
Per semplificare il modello viene impiegata la Trasformata di Park per ottenere
una macchina equivalente a collettore della macchina sincrona originaria.
ϑ
vd
iq
id
q
vq
a
d
ϑ
vd
iq
id
q
vq
a
d
vd
iq
id
q
vq
a
d
Figura 1.3: Macchina equivalente a collettore della macchina sincrona, ottenuta mediante la Trasformata di Park
1.2.2 Trasformata di Park

12
La Trasformata di Park costituisce un potente strumento analitico di analisi delle
macchine elettriche rotanti; grazie infatti alla sua origine fisica, legata proprio al campo
rotante che viene generato all’interno delle macchine elettriche, sia sincrone che
asincrone, con essa è possibile semplificare il modello della macchina e vedere
quest’ultima come una macchina equivalente a collettore.
Indicando con yabc(t) una generica terna di grandezze tempo-varianti nel dominio
“originario” delle fasi a, b, c è possibile trasformare tale terna in una terna equivalente
sugli assi α, β
, o oppure in una terna equivalente sugli assi d, q, o. Gli assi α, β
, o,
disposti in modo che l’asse α coincida sempre con l’asse a e l’asse β
sia in anticipo
rispetto ad esso di π/2, sono detti assi fissi di Park; la trasformazione che permette il
passaggio dalla terna originaria alla terna su assi fissi è la seguente:
αβ0 0 abcy (t)=T y (t)
dove la matrice T0, detta “di Park su assi
fissi” o “di Clarke”, ha espressione:
1 11 - -
2 2
2 3 3= 0 -
3 2 21 1 1
2 2 2
0T
La trasformazione su assi d, q, o, detti assi rotanti di Park, avviene invece nel
seguente modo:
Figura 1.4: Disposizione degli assi di Park
ϑ
β
a≡α
b
d
c
q

13
0 2( ) ( ) ( )= ⋅ϑϑϑϑdq abcy t T y t
dove ( )tϑ ϑ= indica l’angolo fra gli assi fissi di Park e gli assi rotanti di Park, mentre
la matrice coinvolta è ottenuta applicando, in successione, la matrice di Park su assi fissi
e la matrice di rotazione:
θθθθ1T ( ) cos( ) sin( ) 0
= -sin( ) cos( ) 0
0 0 1
θ θ θ θ
Se ne conclude che risulta:
θ θθ θθ θθ θ2 1 0T ( )=T ( )T
2 2cos( ) cos - π cos + π
3 3
2 2 2= -sin( ) -sin - π -sin + π
3 3 3
1 1 1
2 2 2
θ θ θ
θ θ θ
detta, semplicemente, matrice di Park; ovviamente la matrice di Park su assi fissi è
ricavabile come caso particolare della matrice di Park, ponendo t 0)t( ∀=ϑ . La matrice
di Park è ortogonale senza eccezioni, dunque conserva i prodotti interni e la sua inversa
coincide con la trasposta; siccome tale proprietà vale anche per la matrice di Park su
assi fissi, ciò significa, in primo luogo, che:
Tabc 0 αβoy (t)=T y (t) , θθθθT
abc 2 dqoy (t)=T ( )y (t)
I vettori di Park consentono, in sistemi simmetrici ed equilibrati, di ricavare una
rete monofase equivalente del sistema originario in cui, a parte alcune particolarità , le

14
grandezze sugli assi a, b, c sono sostituite equivalentemente dai relativi vettori di Park
essendo le componenti omopolari identicamente nulle. I vettori di Park rappresentano
sostanzialmente un’estensione allo spazio del ben noto concetto temporale di fasore, e
per tale ragione vengono anche denominati fasori spaziali.
1.2.3 Modello motore sincrono
Applicando allo statore la trasformazione di Park su assi rotanti solidali con il
rotore (assi rotorici) si ottengono i seguenti circuiti equivalenti:
Figura 1.5: Circuito equivalente sull’asse d
Figura 1.6: Circuito equivalente sull’asse q
RSD qeψω
-
XLD
XAD
XRD
RRD
XLF
RF
+
-
+
+
-
-
Vd
VD
VF
iF
iD
id
RSQ deψω
-
XLQ
XAQ
+
-
Vq
iq
+
-
VQ
XRQ RRQ
iQ

15
A seguito della trasformazione le equazioni elettromagnetiche assumono la seguente
forma:
-= + dd SD d e q
dV R i
dt
ψω ψ (1.3)
= + + qq SQ q e d
dV R i
dt
ψω ψ (1.4)
= + DD RD D
dV R i
dt
ψ (1.5)
= + QQ RQ Q
dV R i
dt
ψ (1.6)
dt
diRV FFFF
ψ+= (1.7)
)( FDdADdLDd iiiXiX +++=ψ (1.8)
( )= + +q LQ q AQ q QX i X i iψ (1.9)
)( FDdADDRDD iiiXiX +++=ψ (1.10)
( )= + +Q RQ D AQ q QX i X i iψ (1.11)
)( FDdADFLFF iiiXiX +++=ψ (1.12)
Definiamo:
)( FDdADmd iiiX ++=ψ (1.13)
( )= +mq AQ q QX i iψ (1.14)
Per la nomenclatura dei simboli utilizzati fare riferimento all’Appendice E.
Utilizziamo ora queste equazioni per ricavare un modello dinamico del motore
con variabili di stato miste ( FQDqd ii ψψψ ,,,, ). Attraverso una serie di passaggi
(Appendice A) otteniamo che il modello dinamico del settimo ordine del motore

16
sincrono in forma mista ( TeeFQDqd iix ],,,,,,[ θωψψψ= ) è descritto dalle seguente
equazioni differenziali:
( ) ( ) ( )
( )mdFFLF
dF
LF
d
mdDRDRD
dLDddmqqLQedSDd
RX
XV
X
X
RX
XXXiiXiRV
ψψ
ψψψω
−−+
+−−+++⋅−⋅=
22
2&&
( ) ( ) ( )mqQRQ
RQ
qmddLDeqSQLQqqq R
X
XIXiRXXiV ψψψω −−+⋅+⋅++=
2&
)( mdDRD
RDD
X
R
dt
d ψψψ−−=
)( mqQRQ
RQQ
X
R
dt
dψψ
ψ−−=
)( mdFLF
FF
F
X
RV
dt
d ψψψ−−=
)(PP
BTTJ
PP
dt
d eLem
e ωω−−=
ee
dt
d ωθ=
dove:
( )dqqdemn
RQAQq
LFRDADd
RQ
Qqqmq
LF
F
RD
Dddmd
iiPPT
XXX
XXXX
XiX
XXiX
⋅−⋅=
+=
++=
+=
++=
−
−
ψψ
ψψ
ψψψ
1
1
11
111
Note le variabili FQDqd ii ψψψ ,,,, è possibile valutare le grandezze FQDqd iii ,,,,ψψ
attraverso la relazione:

17
=
F
Q
D
q
d
f
Q
D
q
d
i
i
LLLLLL
LLLL
LLLLLL
LLLL
LLLLLL
i
i
i
ψψψ
ψψ
13012011
010090
80706
05040
30201
dove:
RDADADLFRDLF
RDLFLDADLFRDRDADLDADLFLD
XXXXXX
XXXXXXXXXXXXLL
+++++=1
RDADADLFRDLF
LFAD
XXXXXX
XXLL
++=2
RDADADLFRDLF
ADRD
XXXXXX
XXLL
++=3
AQRQ
RQAQAQLQRQLQ
XX
XXXXXXLL
+++
=4
AQRQ
AQ
XX
XLL
+=5
LFRDLFADADRD
LFAD
XXXXXX
XXLL
++=6
LFRDLFADADRD
LFAD
XXXXXX
XXLL
+++=7
LFRDLFADADRD
AD
XXXXXX
XLL
++−=8
AQRQ
AQ
XX
XLL
+−
=9
AQRQ XXLL
+= 1
10
LFADADRDLFRD
ADRD
XXXXXX
XXLL
++−=11

18
LFADADRDLFRD
AD
XXXXXX
XLL
++−=12
LFADADRDLFRD
ADRD
XXXXXX
XXLL
+++=13
1.2.4 Modello saturazione
Gli effetti della saturazione sulle prestazioni di una macchina sincrona sono
usualmente trattati nel frame d-q, assumendo che:
• non ci sia accoppiamento tra gli avvolgimenti dell’asse d-q
• la saturazione interessa solo i flussi mutui degli assi d-q e perciò interessa solo le
reattanze mutue sugli assi e non le reattanze di leakage
• non ci siano effetti di accoppiamento mutuo tra gli assi d-q (cross saturation)
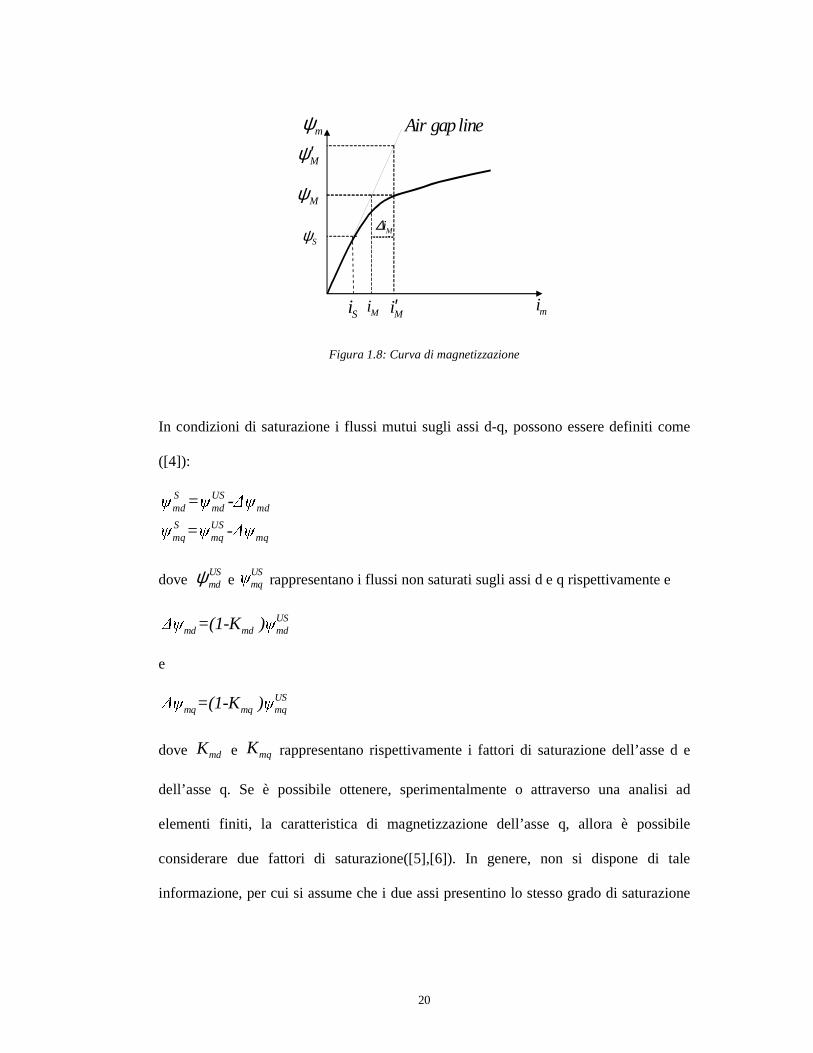
La curva di magnetizzazione, riportata in Figura 1.8, lega il flusso e la corrente di
magnetizzazione totale, ovvero:
2 2m md mqψ = ψ +ψ
2 2m md mqi i i= +
In realtà, la curva di magnetizzazione, ottenuta da prove sperimentali a regime in
assenza di carico e con la macchina sincrona operante come generatore ad una
pulsazione fissata Sω
, lega la tensione tV (tensione di linea in rms) ai morsetti (aperti)
della macchina e la corrente di eccitazione fi . Per passare da tale curva a quella che

19
lega flusso di magnetizzazione-corrente di eccitazione si attua la seguente
trasformazione:
tm
S
Vψ = ω×p
dove pè il numero di coppie polari e Sω
è la velocità elettrica di rotore. In assenza di
carico, si assume che la corrente di eccitazione rappresenti la corrente di
magnetizzazione della macchina, per cui mf ii ≅ .
Le grandezze, riportate in Figura 1.8, sono così definite:
• S Sψ ,i : massimo flusso e massima corrente di magnetizzazione in assenza di
saturazione;
• Mi : valore di corrente che produce un flusso di magnetizzazione Mψ in assenza di
saturazione;
• Mi′ : valore di corrente che produce un flusso di magnetizzazione Mψ in presenza di
saturazione;
• Mψ ′ : flusso di magnetizzazione corrispondente alla corrente Mi′ in assenza di
saturazione.
Definiamo ora L come il valore dell’induttanza che corrispondenza alla “air gap line”.
20
Sψ
Mψ
Mψ ′
Si Mi Mi′
Mi∆
mi
mψ Air gapline
Sψ
Mψ
Mψ ′
Si Mi Mi′
Mi∆
mi
mψ Air gapline
Figura 1.8: Curva di magnetizzazione
In condizioni di saturazione i flussi mutui sugli assi d-q, possono essere definiti come
([4]):
S USmd md md
S USmq mq mq
ψ =ψ -ψψ =ψ -ψ
dove USmdψ e
USmqψ
rappresentano i flussi non saturati sugli assi d e q rispettivamente e
USmd md md
ψ=(1-K )
ψ
e
USmq mq mq
ψ=(1-K )
ψ
dove mdK e mqK rappresentano rispettivamente i fattori di saturazione dell’asse d e
dell’asse q. Se è possibile ottenere, sperimentalmente o attraverso una analisi ad
elementi finiti, la caratteristica di magnetizzazione dell’asse q, allora è possibile
considerare due fattori di saturazione([5],[6]). In genere, non si dispone di tale
informazione, per cui si assume che i due assi presentino lo stesso grado di saturazione

21
([7],[8]). Ciò implica che i due fattori di saturazione siano uguali ( mqmd KK = ). Il
fattore di saturazione, si può quindi scrivere ([2]):
M M Mmd mq
M M M M M
i i ψK =K = = =
i i +i ψ +L×f(ψ )′
dove
Lif M
MM
ψψ −′=)(
con Mi ′ ed L ottenibili dalla curva di saturazione data in Figura 1.8. Indicando:
MM
M M
ψg(ψ )=1-ψ +L×f(ψ )
allora i flussi mutui possono essere espressi come:
S US USmd md m mdψ =ψ -g(ψ )ψ
e
S US USmq mq m mq
ψ =ψ -g(ψ )ψ
La funzione mg(ψ ) può essere ottenuta attraverso una approssimazione polinomiale, a
partire dai punti presenti nella curva di magnetizzazione data in Figura 8.
Quindi il modello del motore sincrono, in precedenza implementato senza l’effetto della
saturazione, si modifica nel calcolo dei flussi mutui mdψ e mqψ .
In definitiva si perviene alla seguente espressione dei flussi mutui:
S US USadmd md m md
md
Lψ =ψ - g(ψ )ψL
e

22
aqS US USmq mq m mq
mq
Lψ =ψ - g(ψ )ψL
1.2.5 Simulazioni ed effetti saturazione
In questo paragrafo sono riportati i grafici che mostrano l’andamento in funzione
del tempo di alcune variabili caratterizzanti il comportamento del motore sincrono. In
particolare, è effettuato un confronto fra le variabili di un motore sincrono in cui è
assente l’effetto della saturazione e un motore in cui invece è presente.
Le simulazioni sono state effettuate imponendo al motore di lavorare in
condizioni nominali, ovvero:
• Vn ( tensione di alimentazione nominale) = 400 Vrms
• In (corrente di motore nominale) = 144 Arms
• V fn (tensione di eccitazione nominale) = 18 V
• I fn (corrente di eccitazione nominale) = 10.2 A
• Temn ( coppia elettromagnetica nominale) = 318 Nm
• mnω ( velocità meccanica di rotazione nominale) = 3000 rpm
Inoltre si è supposto di aumentare progressivamente il valore della coppia di carico TL.

23
Figura 1.9: Componente Ir della corrente assorbita dal motore
Dalla figura 1.9 si evince, che a causa della limitazione del flusso di magnetizzazione, le
correnti statoriche devono aumentare per compensare la riduzione di coppia erogata.
3 3.02 3.04 3.06 3.08 3.1 3.12-400
-200
0
200
400Corrente (Ir)
t [s]
[A]
unsat
sat
0 0.5 1 1.5 2 2.5 3 3.5 4-3000
-2000
-1000
0
1000
2000
3000Corrente (Ir)
t [s]
[A]
unsat
sat
24
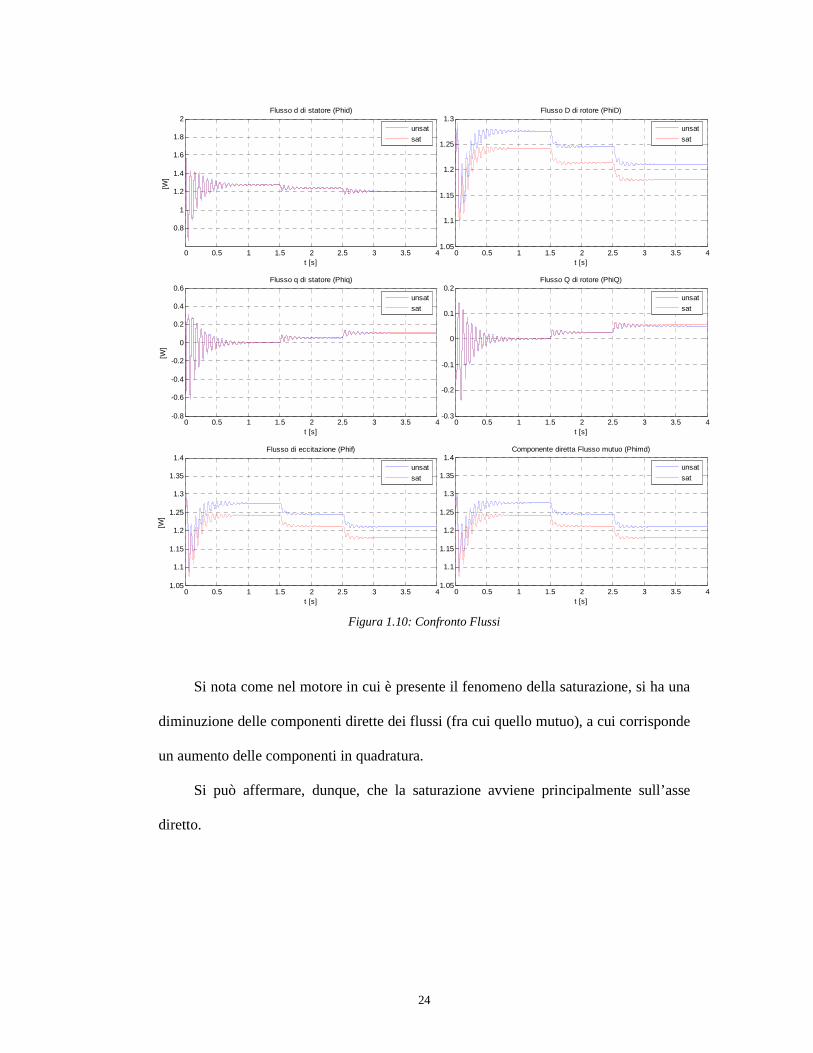
Figura 1.10: Confronto Flussi
Si nota come nel motore in cui è presente il fenomeno della saturazione, si ha una
diminuzione delle componenti dirette dei flussi (fra cui quello mutuo), a cui corrisponde
un aumento delle componenti in quadratura.
Si può affermare, dunque, che la saturazione avviene principalmente sull’asse
diretto.
0 0.5 1 1.5 2 2.5 3 3.5 41.05
1.1
1.15
1.2
1.25
1.3
1.35
1.4Componente diretta Flusso mutuo (Phimd)
t [s]
[W]
unsat
sat
0 0.5 1 1.5 2 2.5 3 3.5 41.05
1.1
1.15
1.2
1.25
1.3
1.35
1.4Flusso di eccitazione (Phif)
t [s]
[W]
unsat
sat
0 0.5 1 1.5 2 2.5 3 3.5 4-0.3
-0.2
-0.1
0
0.1
0.2Flusso Q di rotore (PhiQ)
t [s][W
]
unsat
sat
0 0.5 1 1.5 2 2.5 3 3.5 4-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6Flusso q di statore (Phiq)
t [s]
[W]
unsat
sat
0 0.5 1 1.5 2 2.5 3 3.5 41.05
1.1
1.15
1.2
1.25
1.3Flusso D di rotore (PhiD)
t [s]
[W]
unsat
sat
0 0.5 1 1.5 2 2.5 3 3.5 4
0.8
1
1.2
1.4
1.6
1.8
2Flusso d di statore (Phid)
t [s]
[W]
unsat
sat

25
1.2.6 Reti R-L e motore sincrono
Nei precedenti paragrafi sono state derivate le equazioni matematiche che
governano la dinamica del motore sincrono. In questo paragrafo si procederà alla
modellistica delle reti RL che si trovano tra motore sincrono e inverter. Per evitare
problemi di convergenza numerica, si deriverà il modello complessivo del sistema
motore sincrono - reti RL. Consideriamo il circuito in figura 1.7, in cui sono modellate
le tre fasi del motore sincrono e le quattro reti RL a monte dello stesso. Senza perdere di
generalità, in questa fase, sostituiamo ogni singolo inverter con tre generatori di
tensione ( gav , gbv , gcv ), non necessariamente bilanciati, e il cui centro stella rappresenta
il neutral point dell’inverter stesso.
Figura 1.7: Rete R-L e motore.
vga1
vgb1
vgc1
vc1
R1
R1
R1
L1
L1
L1
vgb2
vgc2
vc2
R2
R2
R2
L2
L2
L2
vgb3
vgc3
vc3
R3
R3
R3
L3
L3
L3
vgb4
vgc4
vc4
R4
R4
R4
L4
L4
L4
vga2
vga3
vga4
a b c
ia
ib
ic
A
va vb
vc

26
Si noti che sia il centro stella (O) del motore sincrono che i quattro neutral point
( )4321 ,,, CCCC VVVV dell’inverter, tutti riferiti rispetto ad O, sono considerati flottanti.
Supponendo che per ogni ramo trifase le resistenze e le induttanze siano uguali tra loro,
è possibile calcolare lo squilibrio di tensione tra il neutral point dell’inverter e il centro
stella del motore. Per far ciò si consideri il circuito equivalente riportato in Figura 1.8
rappresentativo di un inverter , dove ( )cba VVV ,, rappresentano le tensioni di fase del
motore sincrono e ( )gcgbga VVV ,, le tensioni dei tre generatori di tensione equivalenti
all’inverter.
Figura 1.8: Singolo ramo RL-motore .
Applicando la legge di Kirchoff alle tensioni si ottiene:
=−−−+
=−−−+
=−−−+
0
0
0
'
'
'
cccgcoo
bbbgboo
aaagaoo
vRiiLvV
vRiiLvV
vRiiLvV
&
&
&
A partire dalle equazioni del motore presentate nella (1.1), si può dimostrare che se il
centro stella del motore è flottante, allora 0=++ cba vvv . Inoltre dalla prima legge di
Kirchoff applicata al nodo O’ si ha che 0=++ cba iii . Da questo ne consegue che,
sommando membro a membro le equazioni:
( )gcgbgaoo vvvV ++−=3
1'
vga
vgb
vgc
R
R
R L
L
L
O
O’ Voo’ va
vb vc

27
Essendo le tensioni ( )4321 ,,, CCCC VVVV riferite ad O, si ha che:
( ) 4,3,2,13
1 =++−= ivvvV gcigbigaici (1.15)
Noto lo sbilanciamento tra il centro stella del motore e il neutral point, è possibile
passare alla risoluzione delle reti R-L. Dalla figura 1.7, si ricava che:
=−−−+
=−−−+
=−−−+
0
0
0
111111
111111
111111
cacgcc
babgbc
aaagac
viLiRvV
viLiRvV
viLiRvV
&
&
&
>=
−−
−−
−−
+
−−
−+
−−
−=
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
32
31
31
31
32
31
31
31
32
00
00
00
00
00
00
gc
gb
ga
c
b
a
c
b
a
c
b
a
v
v
v
i
i
i
R
R
R
i
i
i
L
L
L
v
v
v
&
&
&
dove si tenuto conto della relazione (1.15). In generale, l’equazione precedente può
essere riscritta nella forma:
gabcabcabcabc vBiRiLv ⋅+⋅+⋅= & (1.16)
dove
[ ]Tcbaabc vvvv = , [ ]Tcbaabc iiii = , [ ]Tgcgbgagabc vvvv = ,
−−
−=
1
1
1
00
00
00
L
L
L
L ,
−−
−=
1
1
1
00
00
00
R
R
R
R ,
−−
−−
−−
=
32
31
31
31
32
31
31
31
32
B .
Trasformiamo la relazione (1.16) nel frame dq, applicando la trasformata di Park.
Ricordando che la matrice di trasformazione T è ortogonale ( TTT =−1 ), si ha che:
( ) abcdq vTv ⋅= ϑ0 ⇒ 0dqT
abc vTv ⋅=
( ) abcdq iTi ⋅= ϑ0 ⇒ 0dqT
abc iTi ⋅=

28
Sostituendo le precedenti espressioni nella (1.16) si ha che:
00000 gdqT
dqT
dqT
dqT
dqT vBTiTLiTLiTRvT ⋅⋅+⋅⋅+⋅⋅+⋅⋅=⋅ && ⇒
00000 gdqT
dqT
dqT
dqT
dq vTBTiTLTiTLTiTRTv ⋅⋅⋅+⋅⋅⋅+⋅⋅⋅+⋅⋅⋅= && ⇒
0000 gdqtdqtdqtdq vBiRiLv ⋅+⋅+⋅= &
che, sotto forma matriciale, diventa:
+
−−−
−+
−−
−=
01
1
1
01
1
1
1
11
11
01
1
1
1
1
1
0000
010
001
00
0
0
00
00
00
g
gq
gd
q
d
q
d
q
d
v
v
v
i
i
i
R
RL
LR
i
i
i
L
L
L
v
v
v
ωω
&
&
&
Poiché il centro stella è flottante, si ha che la terza equazione non contribuisce alla
dinamica, per cui:
+
+
=
1
1
1
11
1
11
gq
gd
q
d
tq
d
tq
d
v
vI
i
iR
i
iL
v
v
&
&
(1.17)
dove
−−
=1
11 0
0
L
LLt ,
−−−
=11
111 RL
LRRt ω
ω,
=
10
01I .
Ripetendo lo stesso ragionamento, si perviene per le altri rete RL ad equazioni del tipo
della (1.17). Quindi, considerando anche le altre tre reti R-L e le equazioni statoriche
del motore, otteniamo:
+
+
=
1
1
1
11
1
11
gq
gd
q
d
tq
d
tq
d
v
vI
i
iR
i
iL
v
v
&
&
(1.18)
+
+
=
2
2
2
22
2
22
gq
gd
q
d
tq
d
tq
d
v
vI
i
iR
i
iL
v
v
&
&
(1.19)
+
+
=
3
3
3
33
3
33
gq
gd
q
d
tq
d
tq
d
v
vI
i
iR
i
iL
v
v
&
&
(1.20)

29
+
+
=
4
4
4
44
4
44
gq
gd
q
d
tq
d
tq
d
v
vI
i
iR
i
iL
v
v
&
&
(1.21)
),,( ψiqidgi
iL
v
v
q
d
q
d +
=
&
&
(1.22)
dove
−−
=1
11 0
0
L
LLt ,
−−−
=11
111 RL
LRRt ω
ω,
−−
=2
22 0
0
L
LLt ,
−−−
=22
222 RL
LRRt ω
ω,
−−
=3
33 0
0
L
LLt ,
−−−
=33
333 RL
LRRt ω
ω,
−−
=4
44 0
0
L
LLt ,
−−−
=44
444 RL
LRRt ω
ω,
=
10
01I ,
++
=LQq
LDd
XX
XXL
0
0 e
g è la funzione che lega le tensioni dv , qv alle correnti e ai cinque flussi, ovvero:
( ) ( ) ( )
( ) ( )
−−+⋅+⋅
−−+−−+⋅−⋅=
=
=
−
−−−
mqQRQ
RQ
mddLDeqSQ
mdFF
LF
F
LF
mdDRD
RD
mqqLQedSD
RX
XiXiR
RX
XV
X
XR
X
XiXiR
g
giqidg
ψψψω
ψψψψψω
ψ
2
12
2
11
2
11
2
11
2
1),,(
(1.23)
Combinando le equazioni (1.18)-(1.22), o in modo equivalente applicando la legge di
Kirchoff alle tensioni nel circuito di Figura 1.7, si ottengono le equazioni che
descrivono la dinamica del sistema. Definito lo stato del sistema
[ ]Tqdqdqdqdqd iiiiiiiiiix 44332211= , le equazioni del sistema possono
essere riscritte nella forma ),( uxfxE =& con la matriceE non invertibile. Ciò è dovuto
alla presenza di nodi in cui insistono solo induttori (cut-sets di soli induttori). Tali nodi
sono formati dalle induttanze delle reti RL e da quelle dello statore del motore. In altre

30
parole, non è possibile individuare maglie indipendenti nel circuito. Una soluzione
potrebbe essere quella di introdurre i vincoli 4321 ddddd iiiii +++= ,
4321 qqqqq iiiii +++= e chiudere maglie indipendenti tra loro,ottenendo:
=
−−
−−
−−−−
10
9
8
7
6
5
4
3
2
1
4
4
3
3
2
2
1
1
41
31
21
3321
000
000
000
4444
F
F
F
F
F
F
F
F
F
F
i
ii
ii
ii
ii
i
LL
LL
LL
IIIII
LLLLL
q
d
q
d
q
d
q
d
q
d
tt
tt
tt
tttt
&
&
&
&
&
&
&
&
&
&
(1.24)
dove le componenti del vettore a secondo membro dell’equazione (1.24) verranno di
seguito esplicitate. Si noti che la matrice a blocchi definita nella (1.24) è invertibile, per
cui la dinamica del sistema in esame può essere espressa nella forma ),( uxfx =& . Le
equazioni della (1.23) sono così ottenute:
• Il primo blocco di equazioni si ottiene sommando membro a membro le (1.18)-
(1.21), ricavando le tensioni qd vv , e sostituendole nella (1.22). Quindi:
( ) 14321
44443333222211111
41
4
1
4
1
4
1
4
1
4
1
4
1
4
1
4
1
gvvvv
iLiRiLiRiLiRiLiRF
gdgdgdgd
qdqdqdqd
−++++
+⋅+−⋅+−⋅+−⋅+−= ωωωω
( ) 24321
44443333222211112
4
14
1
4
1
4
1
4
1
4
1
4
1
4
1
4
1
gvvvv
iLiRiLiRiLiRiLiRF
gqgqgqgq
dqdqdqdq
−++++
+⋅−−⋅−−⋅−−⋅−−= ωωωω

31
dove 1g e 2g sono date dall’equazione del motore riportate nella (1.23)
• Il secondo blocco rappresenta i vincoli 4321 ddddd iiiii +++= e
4321 qqqqq iiiii +++= espresso nella forma di derivata, per cui 43, FF sono nulle.
• Il terzo blocco si ottiene sostituendo la (1.19) nella (1.18); quindi 65,FF sono
date da:
21222211115 gdgdqdqd vviLiRiLiRF +−+−⋅−= ω
21222211116 gqgqdqdq vviLiRiLiRF +−−−⋅+= ω
• Il quarto blocco si ottiene sostituendo la (1.20) nella (1.18); quindi 87 , FF sono
date da:
31333311117 gdgdqdqd vviLiRiLiRF +−+−⋅−= ω
31333311118 gqgqdqdq vviLiRiLiRF +−−−⋅+= ω
• Il quinto blocco si ottiene sostituendo la (1.21) nella (1.18); quindi 109,FF sono
date da:
31333311119 gdgdqdqd vviLiRiLiRF +−+−⋅−= ω
414444111110 gqgqdqdq vviLiRiLiRF +−−−⋅+= ω
1.3 Inverter e banco condensatori
L’inverter è l’elemento del sistema che ha il compito di convertire la tensione
continua, proveniente dal banco condensatori, in tensione alternata trifase, da fornire al

32
motore sincrono. L’inverter assolve questo compito attraverso un rete di interruttori
comandati da opportuni segnali, provenienti dal modulatore [13-16].
Il progressivo sviluppo dei convertitori elettronici verso applicazioni di sempre
maggiore potenza ha recentemente portato alla diffusione degli inverter multilivello.
Grazie all’utilizzo di tali convertitori è infatti possibile aumentare il range di
potenza in uscita utilizzando una opportuna combinazione di componenti che
singolarmente gestirebbero potenze relativamente modeste. In particolare, con
riferimento ad inverter a tensione impressa, la tensione di uscita può assumere valori in
proporzione al numero di “stadi” con i quali viene realizzato il convertitore. Si ha infatti
una suddivisione della tensione sui singoli componenti senza un vero e proprio
collegamento in serie, evitando le complicazioni di sincronizzazione e ripartizione che
ne conseguirebbero.
Inoltre, la forma d’onda della tensione di uscita assume il tipico andamento a
gradini, che consente di ottenere un basso contenuto armonico anche con frequenze di
commutazione relativamente modeste, rendendo quindi possibile l’impiego di
componenti di grossa taglia.
Anche i disturbi elettromagnetici condotti ed irradiati risultano mitigati in quanto
le commutazioni avvengono non sull’intera escursione della tensione di uscita ma solo
sui singoli gradini, riducendo sensibilmente i dv/dt a pari tempo di commutazione.
Tra le possibili configurazioni base di inverter multilivello la nostra attenzione è
incentrata su quella denominata NPC (Neutral Point Clamped) e in particolare su una
configurazione a tre livelli (Fig.1.11) [14-15].

33
Figura 1.11: Inverter multilivello – banco condensatori
In figura è mostrato l’inverter a tre livelli connesso al banco condensatori e alla linea di
bus. Da questa rappresentazione del circuito possiamo giungere alle seguenti relazioni:
−=⋅
−=⋅
IDBUCD
IUBUCU
iidt
dvC
iidt
dvC
(1.25)
−−=⋅
−−=⋅
CDBDCddBD
CUIBuCduBU
vRivdt
diL
vRivdt
diL
0CdCddCdu VVV =−=
Come abbiamo già accennato precedentemente, l’inverter è comandato da un
modulatore che genera i segnali di fase SW1 e SW2 che corrispondono a: ( cbai ,,= )
+ -
- +
L R
L R
vCdu
vCdd
vCD
vCU
NP NP NP NP
iBD
iBU
iCU
iCD
i IU
i ID
ia ib ic
S1
S2
S3
S4
C
C

34
da cui si ricava che:
iddidui SWvSWvv 21 ⋅+⋅= con cbai ,,=
⋅+⋅+⋅=⋅+⋅+⋅=
ccbbaaID
ccbbaaIU
SWiSWiSWii
SWiSWiSWii
222
111
dove cba iii ,, provengono dall’integrazione delle reti RL tra inverter e motore. Le
relazioni appena trovate per iv e ii possono essere sostituite all’interno della (1.25),
ottenendo così la dinamica completa del banco condensatori e dell’inverter.
1.4 Modulatore
Il modulatore rappresenta la parte di controllo del nostro sistema. Esso, infatti,
fornisce gli opportuni segnali (SWi) all’inverter, per l’apertura e la chiusura degli
interruttori. Questi segnali vengono generati utilizzando una modulazione di larghezza
di impulso (PWM), in cui il segnale desiderato, nel nostro caso la tensione in uscita
all’inverter e da fornire al motore, è codificato tramite impulsi di ampiezza unitaria ma
di durata variabile.
Input Switching Device
SW1 SW2 S1i S2i S3i S4i
Logic State
1 0 0 0 0 1
1 1 0 0 0 1 1 0 0 0 1 1

35
Questo tipo di modulazione è ottenuta confrontando il segnale di ingresso con due
segnali a dente di sega di frequenza maggiore (almeno dieci volte) dell'ampiezza di
banda del segnale (fig.1.12). I segnali a dente di sega hanno ampiezza unitaria, sono
situati uno nel semipiano negativo e l’altro in quello positivo e sono in fase tra loro
(PD) [17].
Gli impulsi otteuti saranno di larghezza proporzionale a quella del segnale.
Figura 1.12: Modulazione PWM

36
CAPITOLO 2
SISTEMA DI SIMULAZIONE REAL-TIME HARDWARE IN THE LO OP
2.1 Introduzione
Una fase critica nella progettazione di un nuovo sistema, di qualunque tipo, è la
fase di testing, indispensabile per la rilevazione di malfunzionamenti e difetti.
Questa fase, però, rappresenta solo uno dei passi da compiere per giungere alla
realizzazione completa di un nuovo sistema di controllo; essa si colloca, infatti, in una
procedura iterativa concepita all’interno di un processo globale di sviluppo software:
l’approccio “V-Cycle”, applicato con strumenti evoluti attualmente disponibili in
commercio [9].
Figura 2.1: Schema del processo “V-Cycle”.

37
L’intero processo è diviso in 5 fasi:
1. control strategy design: in questa fase vengono definite le specifiche che il
sistema di controllo dovrà rispettare e viene effettuata un prima modellazione della
strategia di controllo;
2. rapid control prototyping: in questa fase la strategia di controllo viene
validata preliminarmente sul sistema reale utilizzando tecniche di prototipazione rapida;
3. target code generation: a partire dai modelli sviluppati nelle prime due fasi,
vengono generati i codici di controllo destinati al target reale (es.: la centralina);
4. hardware in the loop: il controllo, implementato adesso sul dispositivo
hardware reale, viene testato in un ambiente real-time in cui il processo da controllare è
simulato via software;
5. calibration definition: sulla base delle verifiche effettuate, si imposta il set di
parametri che ottimizzano le prestazioni.
Il presente lavoro è incentrato, dunque, sulla quarta fase del V-Cycle, la fase di
testing appunto, in cui si suppone di essere già in possesso della strategia di controllo e
la si vuole validare attraverso tecniche opportune. L’hardware in the loop è proprio una
di queste tecniche.
2.2 La fase di testing
Generalmente testare un sistema vuol dire inserirlo nel suo ambiente di lavoro e
vedere se le funzionalità e le prestazioni sono conformi alle specifiche. Ciò comporta
che per poter effettuare un test è necessario attendere che la progettazione e la

38
realizzazione di ogni sua parte sia stata portata a termine; inoltre bisogna assicurarsi di
poter effettuare prove senza il rischio di danneggiare cose o persone.
Se si pensa ai sistemi di controllo bisogna tener presente che la loro complessità
sta subendo un incremento notevole. Si parla di complessità relativamente ai dispostivi
elettronici che compongono i sistemi di controllo e alle strategie di controllo da
realizzare, sempre più avanzate. È sufficiente pensare alle strategie di controllo digitale
che possono essere implementate in ben oltre centomila linee di codice per progetto e
richiedere diverse piattaforme di controllori, ognuna con processori multipli che devono
comunicare tra loro in tempo reale, necessitando quindi di diversi bus di
comunicazione.
Il testing dei sistemi di controllo presenta inoltre aspetti peculiari quando si
considera la necessità di validare e verificare tali sistemi quando questi sono impiegati
all’interno di un sistema più generale e complesso. Molto spesso tali problematiche
sono vincolate alla necessità di testare modelli e strategie di controllo usando
simulazioni, poiché non si ha a disposizione l’effettivo sistema oggetto del controllo.
Una strategia di controllo è corretta quando essa si comporta in modo conforme
alle sue specifiche. La certezza sulla validità di una legge di controllo si ottiene
dimostrandola con tecniche di prova che costituiscono la fase di test. Purtroppo la
complessità di queste prove è tale che, se realizzate sull'impianto reale, risultano molto
onerose in termini di:
− Rischi, perdita di vite umane o di capitale;
− Costi, il test nel sistema finito può essere, proibitivamente, dispendioso;
− Disponibilità, il sistema o l’ambiente di lavoro non sono disponibili;

39
− Sicurezza, non tutti gli stati del test possono essere raggiunti durante
operazioni regolari.
Le precedenti considerazioni portano a capire perché al giorno d’oggi occorre dare
sempre più importanza all’integrazione, alla verifica e al testing del sistema [10].
2.3 Testing Hardware in the loop
La metodologia di testing hardware in the loop (HIL), come già accennato nel
paragrafo introduttivo, indica le tecniche di verifica (testing) di unità di controllo
elettronico collegate ad appositi banchi che riproducono in modo più o meno completo
il sistema elettrico ed elettronico del sistema a cui sono destinate. Questi banchi sono
apparati complessi che riproducono in tutto o in parte, fisicamente e/o in software, il
prodotto a cui sono destinate le unità da verificare.
Essi sono costituiti dai seguenti componenti :
− sensori, cioè i dispositivi di input (la manetta per la velocità del motore, i sensori
di pick-up per la velocità del motore,...);
− attuatori, cioè i dispositivi che eseguono un'azione su comando della centralina
(la pompa che controlla la pinza dei freni,...);
− cablaggi elettrici ed elettronici e relative connessioni (cioè l'impianto elettrico e
la rete che interconnette tra loro le centraline con le relative terminazioni dove
collegare fisicamente sensori, attuatori e centraline);

40
− modelli, cioè programmi informatici che emulano tutto ciò che fisicamente non
è implementato nel banco, ”ingannando” i dispositivi effettivamente collegati
(ad es. il motore con tutti i suoi sensori ed attuatori).
Scopo delle prove hardware in the loop è di utilizzare i banchi per anticipare le
verifiche su componenti, sottosistemi e sistemi già nella fase di progettazione e
prototipazione, senza attendere la disponibilità del prodotto finale a cui sono destinate.
Infatti, i componenti reali installati rispondono ai segnali simulati come se
stessero operando in un ambiente reale, poiché non sono in grado di distinguere segnali
provenienti da un ambiente fisico da quelli prodotti da modelli software. In questo
modo il metodo HIL permette di riprodurre le condizioni operative più diverse ed
osservare il comportamento del sistema e dei singoli elementi.
Un frequente campo di applicazione dell'HIL è costituito dai test di fault-tolerance
(robustezza rispetto ai malfunzionamenti), di affidabilità e di durata dei nuovi
componenti (ad es. verifiche per il corretto comportamento di dispositivi di sicurezza
come l'ABS nelle condizioni più estreme).
L’ approccio HIL permette un passaggio graduale dalla simulazione
all’applicazione reale in quanto consente di partire da una simulazione pura e di
integrare gradualmente sottosistemi elettrici e meccanici reali nel ciclo, appena essi
diventano disponibili [10].
Il cuore di un sistema hardware in the loop è rappresentato dalla componente di
modellistica, ovvero rappresentazione matematica di tutti i sistemi dinamici relativi
all’impianto. Per esempio, nel nostro caso, una piattaforma di simulazione hardware in
the loop si compone di tutti i modelli di cui le rappresentazioni matematiche sono state
trattate nel primo capitolo: motore sincrono, inverter trifase, banco condensatori e rete

41
R-L, modulatore; includendo, inoltre, anche includere l'emulazione elettrica dei sensori
e degli attuatori. La simulazione di queste parti elettriche funge da interfaccia fra
l’impianto di simulazione ed il sistema di controllo da testare.
Ma perché utilizzare tecniche di simulazioni hardware in the loop? Ovvero perché
non collegare il sistema di controllo all’impianto reale che il sistema deve essere in
grado di gestire?
Questo quesito è determinante per capire la tecnologia real-time. In molti casi, il
modo più efficace di sviluppare un sistema embedded è quello di collegare il sistema
stesso all’impianto reale. In altri casi è più efficiente, la simulazione HIL. Il metro
giudizio sta nella formula: Costo-Durata-Sicurezza.
Se solo si vuol pensare a tutti i settori dell’ingegneria coinvolti nello sviluppo,
nella realizzazione e nell’implementazione di tali sistemi, dall’ingegneria gestionale a
quelle di elettronica ed informatica, ci si rende conto che un errore nelle specifiche di
progetto e quindi il non raggiungimento degli obiettivi preposti comporta perdite di
denaro e di tempo in termini di attrezzature e ore-uomo, oltre a mettere a rischio
l’impianto e l’incolumità delle persone.
Adottando il metodo HIL si rende, quindi possibile superare le problematiche
relative a: - Programmi di sviluppo; - Complessità dell’impianto; - Sviluppo iniziale delle risorse umane.
Per programmi di sviluppo s’intende la maggior parte dei programmi per i quali
non conviene attendere che il prototipo reale sia disponibile, per testare il sistema
embedded con un modello reale. Infatti, la maggior parte di nuovi programmi di

42
sviluppo presuppone che la simulazione HIL avverrà in parallelo allo sviluppo
dell’impianto. Ciò vuol dire che, nel momento in cui un nuovo prototipo di motore sarà
reso disponibile per il sistema di controllo da esaminare, il 95% della prova sarà già
stato completato usando la simulazione HIL.
In molti casi, l’impianto è molto più costoso di un simulatore real-time altamente
affidabile, e quindi ha un livello di complessità più alto. Ovvero, risulta più economico
effettuare le fasi di sviluppo e testing collegati ad un simulatore HIL piuttosto che ad un
impianto reale. Per i fornitori di motori, ad esempio, la simulazione HIL è una parte
fondamentale dello sviluppo del motore. Lo sviluppo di ogni motore può costare milioni
di Euro, mentre un simulatore HIL per testare l’intera linea di produzione può richiedere
soltanto un decimo del costo di sviluppo del singolo motore.
La simulazione HIL è un punto chiave, quindi, nel processo di sviluppo delle
risorse umane, un metodo per accertare il possibile impiego e la consistenza del sistema
usando software ergonomici, risorse umane di ricerca, nonché di sviluppo, riferendosi in
quest’ultimo caso all’ operazione di raccolta dei dati utilizzati dal man in the loop per il
testing di componenti che avranno un'interfaccia umana.
Quindi, l'esigenza di stabilire una prima validazione del software di controllo
senza ricorrere all'esecuzione di numerose e costose prove nell’ambiente di lavoro, ha
portato allo sviluppo ed alla diffusione di sistemi di simulazione hardware in the loop,
attraverso i quali è possibile testare componenti hardware, simulando il sistema da
controllare con un modello capace di fornire in uscita dati plausibili e verosimili in
sostituzione di quelli inviati dal sistema reale.

43
2.4 La Piattaforma RT-Lab
RT-LAB è una piattaforma real-time distribuita [11] che facilita il processo di
progettazione dei sistemi e consente di portare le attività dalla fase di simulazione di
modelli dinamici, in Simulink oppure SystemBuild, alla fase di realizzazione real-time
con la metodologia hardware in the loop in tempi estremamente brevi e costi contenuti
(figura 2.2). Infatti, i modelli destinati alla simulazione real-time possono essere scritti
direttamente utilizzando le librerie tradizionali di Simulink e integrandole con i blocchi
delle librerie di RT-Lab che consentono di effettuare azioni particolari (gestione I/O con
l’esterno, comunicazione e sincronizzazione hardware con il simulatore, ecc.).
La sua scalabilità permette allo sviluppatore di aggiungere potenza
computazionale dove e ogni qual volta sia necessario. È abbastanza flessibile da essere
applicato a problemi di controllo e problemi di simulazione complessi, sia per
applicazioni real-time HIL che per l'esecuzione veloce, il controllo e il testing di
modelli.
Fornisce gli strumenti per l'esecuzione di simulazioni di modelli altamente
complessi su una rete distribuita di target, che comunicano tra loro mediante tecnologie
a latenza ultra bassa per garantire le prestazioni richieste. In più, la modularità di RT-
LAB permette la realizzazione di sistemi scalabili mediante la fornitura dei soli moduli
necessari alle applicazioni, in modo da minimizzare i requisiti computazionali e
soddisfare le esigenze applicative specifiche. L’aggiunta successiva di moduli permette
di far fronte a cambiamenti nei requisiti dell’applicazione. Tutto questo è fondamentale
le per applicazioni embedded high-volume.

44
Figura 2.2: Piattaforma RT-Lab.
RT-LAB permette all'utente di convertire prontamente modelli SystemBuild o
Simulink in sistemi per simulazioni real-time, attraverso Real Time Workshop (RTW) o
Autocode e ed eseguirli su uno o più processori. Ciò viene fatto specialmente per le
applicazioni hardware in the loop e applicazioni di controllo veloce. RT-LAB maneggia
in modo trasparente la sincronizzazione, l'interazione con l'utente, e l'interfacciamento
con l'ambiente esterno usando per l'esecuzione distribuita schede ingresso/uscita e
scambi di dati.
La configurazione Single Target (figura 2.3) viene usata tipicamente per prototipi
a controllo veloce. Un singolo calcolatore esegue la simulazione o il controllo logico
dell’impianto; uno o più host sono connessi al target via Ethernet. Il target può lavorare
sotto ambiente QNX o RedHawk Linux per applicazioni real-time o per le simulazioni
veloci utilizzando PC con processori single e multi-CPU.

45
Figura 2.3: Configurazione single-target.
Il vantaggio di una configurazione distribuita consiste nel poter eseguire modelli
complessi su cluster di pc funzionanti in parallelo, ripartendo il carico computazionale. I
nodi target nel cluster comunicano fra loro con i protocolli a bassa latenza come ad
esempio FireWire, SignalWire o InfiniBand, i quali sono abbastanza veloci per fornire
una comunicazione certa (scambio di dati consistenti) per l’applicazioni real-time.
2.4.1 Caratteristiche principali
− È perfettamente integrato con Matlab/Simulink: tutta la preparazione dei modelli
per RT-LAB avviene in ambienti dinamici per lo sviluppo dei sistemi il che
permette all’utente di far leva sulla sua esperienza nell’utilizzo di questi tools.
− È dotato di blocchi specializzati per l'elaborazione distribuita, per la
comunicazioni tra i nodi e la segnalazione dell'Input/Output fornendo strumenti
per una facile separazione del modello in sottosistemi che possono essere
eseguiti su processori paralleli (PC con sistema operativo real-time QNX oppure
Linux Red Hawk) in modo da suddividere il carico su diversi processori.

46
− È pienamente integrato con gli ambienti di sviluppo di terze parti e le librerie
utente. Supporta modelli StateFlow, SateMate, CarSim RT, GT-Power , così
come supporta codice legacy in C, C++ e FORTRAN.
− È dotato di un’ interfaccia API per lo sviluppo di applicazioni on-line:
utilizzando ambienti come LabView, C, C++, Visual Basic, TestStand, è
possibile creare e testare automaticamente interfacce utente personalizzate.
− RT- Lab è un pacchetto per il controllo e la simulazione perfettamente scalabile
che permette di dividere i modelli per una loro esecuzione in parallelo su una
rete di PC, PC/104, oppure su server SMP (multiprocessori simmetrici). RT-
LAB utilizza comunicazioni standard quali Ethernet e FireWire (IEEE1936) e
schede I/O analogiche e digitali.
− A tempo di esecuzione, RT-Lab fornisce il supporto senza giunte per la
comunicazione inter-processor, usando combinazione di UDP/IP, e memoria
condivisa con bassa latenza dei dati fra i processori target. E’ possibile anche
interagire con la simulazione in tempo reale mediante le stazioni host utilizzando
il protocollo UDP/IP.
− Ha un’interfaccia integrata per la visualizzazione ed il controllo di segnali e
parametri: attraverso il pannello di controllo di RT-LAB è possibile selezionare
dinamicamente i segnali da seguire, modificare in tempo reale qualche segnale o
parametro del modello.

47
− RT-LAB si integra con i dispositivi hardware d'interfaccia OP5000 del Opal-RT
per la sincronizzazione di precisione al nanosecondo e per le prestazioni in tempo
reale. Un grande vantaggio è il supporto a differenti schede di altri fornitori quali
National Instruments, Acromag, Softing e SBS.
− Un sistema di simulazione, durante un passo d'integrazione oltre alle fasi
computazionali del modello dinamico si occupa di altri task amministrativi, come
operazioni di lettura e scrittura dell'I/O, aggiornamento del clock di sistema,
sheduling, aggiornamento dei dati e gestione delle comunicazioni. Questo
restringe l’ammontare di tempo disponibile all’interno di un frame per calcolare i
valori del modello limitando così la dimensione del modello che può essere
calcolato su un singolo processore. RTLAB ha ridotto questo overhead senza
perdere funzionalità, quindi aumentando la capacità computazionale per modelli
più complessi.
2.4.2 La modalità XHP
Un’ altra importante caratteristica di RT-Lab utilizzata per la simulazione è la
modalità XHP (eXtra High Performance) che permette al sistema operativo real-time di
disabilitare gli interrupt evitando così le commutazioni di processi e rimuovendo i
tempi di latenza dovuti a questi calcoli aggiuntivi.
La modalità XHP è indicata sopratutto per quelle applicazioni real-time con bassi
periodi di campionamento che eseguiti in modalità standard causerebbero overrun.

48
In questa modalità il counter di CPU viene utilizzato come riferimento e poiché
questo counter opera alla frequenza di CPU, esso offre un’alta risoluzione anche per
passi d’integrazione dell’ordine di microsecondi. Inoltre poiché si trova nella CPU, il
suo valore viene letto all’interno di un ciclo di CPU e questa operazione non introduce
alcun tempo di latenza aggiuntivo.
Se il numero di sottosistemi eseguiti in modalità XHP su un target è minore del
numero di CPU, il sistema operativo non verrà disabilitato e tutte le funzionalità da esso
fornite saranno ancora disponibili. Se invece il numero di sottosistemi XHP è pari al
numero di CPU allora verranno applicate delle limitazioni. Innanzi tutto il driver della
scheda di rete non è disponibile, per cui le comunicazioni tra il nodo computazionale e
la console non sono possibili; solo le comunicazioni tra i nodi computazionali tramite
FireWire o shared memory sono ancora disponibili. Questo vuol dire che per acquisire
dei segnali, durante l’esecuzione in XHP mode, è necessario instradarli su un nodo
computazionale non-XHP, che li invierà poi alla console. In assenza di altri nodi è
sufficiente mettere in pausa la simulazione, infatti quando il modello è in pausa il suo
stato commuta in modalità normale ed è quindi possibile inviare i dati acquisiti alla
console. Questo però è possibile solo per quei modelli che possono regolarmente essere
interrotti ed è per questo motivo che è sempre una soluzione ottimale [11].
In altre parole possiamo dire che:
− La modalità XHP permette un più veloce calcolo del modello in tempo reale sul
sistema target.
− Permette di simulare complessi sistemi su processori distribuiti, con ingressi e
uscite analogiche e digitale, in tempi di ciclo inferiore a 10µs.

49
Permette di ridurre l'overhead di programmazione, permettendo di sfruttare tuta la
potenza di calcolo del sistema real-time per modelli altamente dinamici. Anche quando
si tratta di un semplice aggiornamento di segnali in un sistema hardware in the loop che
avviene con un passo d'integrazione di 100µs, il modello può avere bisogno di diversi
passi computazionali per mantenere l'accuratezza dei dati.
2.4.3 Principi di funzionamento
Il software RT-Lab funziona su una configurazione hardware che consiste dei
seguenti componenti:
− Stazione di comando (Command station);
− Nodo di compilazione (Compilation node);
− Nodi target;
− Schede di ingresso/uscita.
La Command station è una stazione di lavoro rappresentata dal PC che funziona sotto
il Windows 2000 /XP e serve da interfaccia utente. La Command Station permette di:
− Editare e modifica i modelli;
− Visualizzare i dati di modello;
− Eseguire il modello originale sotto il relativo software di simulazione (Simulink,
SystemBuild, ecc.);
− distribuire il codice;
− controllare le sequenze di simulazione.

50
Le simulazioni possono essere eseguite interamente sul calcolatore della
Command station, ma tipicamente sono eseguite su uno o più nodi target. Per
simulazione real-time, è preferibile che per i nodi target lavorare in ambiente QNX o
Redhawk Linux. Quando ci sono nodi target multipli, uno di loro è indicato come nodo
di compilazione o Compilation node. Esso viene usato per compilare il codice C
generato. Qualsiasi nodo target potrebbe essere usato come nodo di compilazione. I
nodi target sono calcolatori che usano processori commerciali e, come detto, possono
includere un'interfaccia per la trasmissione dei dati in tempo reale come FireWire,
SignalWire, Infiniband o cLan (a seconda del sistema operativo), così come schede
ingresso/uscita per l'accesso a dispositivi esterni.
I nodi target real-time effettuano:
− Esecuzione in tempo reale della simulazione del modello;
− Comunicazione in tempo reale fra i nodi e i dispositivi di I/O;
− Inizializzazione dei dispositivi ingresso/uscita;
− Acquisizione delle variabili interne del modello e delle uscite esterne tramite
moduli di I/O;
− Modifica on line dei parametri del modello;
− Registrazione dei dati su hard disk locale;
− Controllo dell'esecuzione della simulazione del modello e comunicazione con
altri nodi.
La Command station e i nodi target comunicano tra loro usando link di comunicazione
e per simulazioni HIL i nodi target possono anche comunicare con altri dispositivi
attraverso le schede ingresso/uscita.

51
2.5 Xilinx System Generator (XSG)
XSG, acronimo di Xilinx System Generator, è un tool fornito da Xilinx che, una
volta installato in Matlab, genera due librerie di simulazione Simulink. Usando i blocchi
di queste librerie e quelli della libreria di RT-LAB FPGA, l’utente può costruire
modelli, effettuare simulazioni e gestire segnali di I/O analogici e digitali su FPGA
(figura 2.4).
RT-LAB XSG fornisce blocchi specifici FPGA che includono le funzionalità
standard delle schede FPGA Opal-RT :
• Piena integrazione con Simulink e RTW;
• Input ed Output digitali statici;
• Interfacciamento rapido ai moduli DAC e ADC OP5000.
XSG permette di distribuire il calcolo di un complesso impianto o di un complesso
modello di controllore su differenti nodi computazionali permettendo l'uso dei
processori FPGA dedicati, con cicli di calcolo al di sotto del microsecondo.
Figura 2.4:Scheda FPGA.

52
Mentre i convenzionali processori funzionano in maniera sequenziale su un
insieme di istruzioni, i processori FPGA realizzano operazioni in parallelo. Ciò li rende
adatti per simulazioni molto veloci di modelli loosely-coupled [12].
XSG permette al codice FPGA del target di essere incluso come componente di
un più grande modello di simulazione real-time (figura 2.5). Il modello include tutte le
parti della simulazione mentre il codice C ed il codice HDL FPGA vengono
automaticamente generati da RT-Lab XSG. Questo permette la creazione di codice
HDL senza la necessaria conoscenza del linguaggio.
Il blocco XSG Manager si occupa di settare tutti i parametri necessari al
blocchetto Xilinx System Generator, in base alla scheda I/O utilizzata, per la
generazione del bitstream. Il bitstream generato viene poi caricato sull'hardware durante
la fase di caricamento del modello real-time.
Figura 2.5:Sistema di simulazione real-time.

53
2.6 HILBox di RT-Lab
Il sistema hardware adottato per la simulazione real-time prende il nome di
HILBox (figura 2.6). È una piattaforma compatta e robusta per la prototipizzazione
veloce di controllori elettronici di potenza e per simulazione real-time hardware in the
loop di azionamenti usati in veicoli ibridi elettrici e nelle applicazioni industriali.
È completamente integrata con Simulink, Real Time Workshop e con
SimPowerSystem. É basata su tecnologie di processo parallelo che permettono di
distribuire modelli complessi su differenti target di calcolo, da eseguire su sistemi
operativi QNX o RedHawk Linux RT, trattando in maniera trasparente sincronizzazioni,
comunicazioni di dati tra processori e segnali ingresso/uscita.
È dotata di un processore Intel Xeon QuadCore, 2.33 GHz e di una scheda FPGA
Opal-RT OP5110 XILINX VIRTEX II Pro per poter gestire segnali di ingresso e uscita,
e schede FPGA supplementari OP5130 XILINX con moduli ingresso/uscita aggiuntivi
per l’uso in applicazioni complesse. I componenti I/O possono essere aggiunti,
individualmente o in numero, agli ambienti esistenti di RT-LAB attraverso interfacce
FireWire (400MS/s) o SignalWire (1.25 Gbits/s). Inoltre, i componenti ingresso/uscita
possono essere collegati in maniera remota ai PC target attraverso fibra ottica
minimizzando la lunghezza del cavo, il rumore di trasmissione ed i costi. Ciò permette
di connettere tra loro i modelli ed effettuare test su larga scala.

54
Figura 2.6: Sistema HILBox.
2.6.1 Caratteristiche principali
In base agli scopi cui è destinata, la HILbox può assumere diverse configurazioni
operative [11], ma in ognuna di queste possono essere individuati dei componenti
fondamentali, come mostra la figura 2.7.
Figura 2.7: Componenti principali sistema HILBox.
55
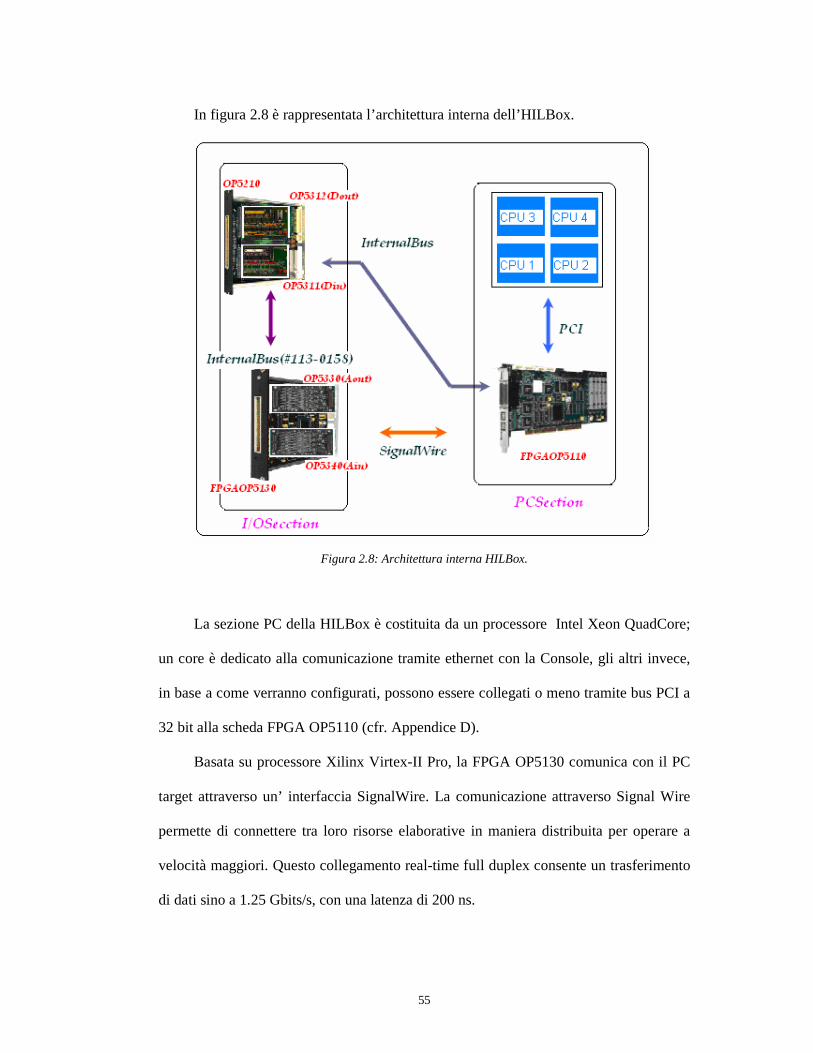
In figura 2.8 è rappresentata l’architettura interna dell’HILBox.
Figura 2.8: Architettura interna HILBox.
La sezione PC della HILBox è costituita da un processore Intel Xeon QuadCore;
un core è dedicato alla comunicazione tramite ethernet con la Console, gli altri invece,
in base a come verranno configurati, possono essere collegati o meno tramite bus PCI a
32 bit alla scheda FPGA OP5110 (cfr. Appendice D).
Basata su processore Xilinx Virtex-II Pro, la FPGA OP5130 comunica con il PC
target attraverso un’ interfaccia SignalWire. La comunicazione attraverso Signal Wire
permette di connettere tra loro risorse elaborative in maniera distribuita per operare a
velocità maggiori. Questo collegamento real-time full duplex consente un trasferimento
di dati sino a 1.25 Gbits/s, con una latenza di 200 ns.

56
La scheda OP5130 può essere collegata a diversi carrier passivi OP5200 ed è
possibile connettere tra loro diverse schede OP5130, con il solo limite dovuto ad un
fattore di spazio e di larghezza di banda richiesta per l’intera simulazione.
La mezzanina OP5330 per le uscite analogiche è uno dei moduli che alloggia sulla
OP5130 e permette di produrre fino a 16 segnali analogici a 16 bit e assicura la
generazione simultanea del segnale da canali multipli, eliminando così gli skew error
connessi ai canali multiplexed. Ogni DAC può aggiornare fino a 1 MS/s per un
throughput totale di 16 MS/s.
L’altro modulo locato sulla scheda FPGA OP5130 è la mezzanina OP5340 per la
gestione degli ingressi analogici. Caratterizza 16 canali a 16 bit e assicura l’
acquisizione simultanea del segnale da canali multipli. Ogni ADC può campionare fino
a 500 kS/s, per un throughput totale di 8MS/s.
La OP5210 è un carrier passivo collegato tramite bus interno proprietario
all’interfaccia OP5110 e tramite bus interno (#113-0158) alla FPGA OP5130. Il carrier
OP5210 può accomodare fino a due moduli mezzanine, permettendo di gestire fino a 32
segnali per carrier. I due moduli che sono ospitati sono il modulo OP5312 e il modulo
OP5311, adibiti alla gestione ed al condizionamento dei segnali digitali rispettivamente
in uscita e in ingresso
Ciascuna mezzanina permette di acquisire e generare fino a 16 segnali digitali e di
convertire i livelli di tensione esterna ai livelli di tensione della circuiteria TTL e
viceversa.

57
2.7 D-Space ACE-kit DS1103 PPC Controller Board
Come il sistema HILBox, descritto nel precedente paragrafo, anche l’ACE-Kit è
un tipo di simulatore real-time che permette l’esecuzione di modelli complessi, inseriti
in configurazioni hardware in the loop tramite opportune schede di acquisizione dati.
In particolare, l’ACE-kit DS1103 della dSpace è un tipo di hardware single-board
che supporta una grande varietà di applicazioni per il rapid control prototyping e che è
dotato di un processore real-time per il calcolo veloce dei modelli. Inoltre tutti i segnali
di I/O possono essere gestiti attraverso un connector panel di 19”.
A differenza dell’HILBox, l’ACE-Kit è meno performante in quanto l’hardware a
disposizione non permette l’esecuzione real-time di modelli molto complessi con un
buon passo di integrazione. D’altra parte, però, esso permette un’elevata scalabilità, in
termini di riprogrammazione, e la possibilità di essere riconfigurato velocemente e con
facilità per essere adattato a diversi setup. Per queste motivazioni, l’ACE-Kit può essere
utilizzato non tanto per simulare processi fisici, ma per implementare le strategie di
controllo, come farebbe un componente hardware reale (es.: una centralina).
L’implementazione del modello real-time da scaricare sull’ACE-kit avviene in
ambiente Simulink, integrando le librerie standard con quelle RTI (Real-Time Interface)
della dSpace, così come avviene per il simulatore RT-Lab.
La figura 2.8 mostra l’architettura interna dell’ACE-Kit.

58
Figura 2.8: Architettura interna ACE-Kit.
Le caratteristiche principali del DS1103 sono le seguenti:
• Processore: PowerPC PPC604e;
• Memoria: 256Kx64-bit logical memory SRAM (2 MB), 16Mx64-bit
SDRAM (128 MB);
• ADCs: 4x16bit muxADC, 4x12bit ADC;
• DACs: 8x14bit DAC;
• Digital I/O: 32 bit parallel I/O (ogni gruppo di 8 bit può essere settato
come input o output).

59
CAPITOLO 3
IMPLEMENTAZIONE MODELLO REAL-TIME
3.1 Introduzione
In questo terzo capitolo verrà presentato il modo in cui i modelli matematici,
analizzati nel primo capitolo e descrittivi delle dinamiche del sistema reale da testare,
sono stati integrati in un sistema di simulazione real-time, attraverso gli strumenti
hardware e software presentati, invece, nel secondo capitolo.
Il nostro sistema si compone di tre parti fondamentali: il modulatore (che modella
la strategia di controllo del sistema, simulando il comportamento della centralina), la
rete di inverter, connessa al banco condensatori e alla linea di bus, e il motore sincrono,
connesso alla rete R-L.
Si tratta, dunque, di un sistema hardware in the loop in cui l’hardware reale (la
centralina) non è presente, ma la sua azione può essere implementata utilizzando un
dispositivo hardware esterno che permette la stessa configurazione operativa di una
centralina reale (cfr. §3.2). Infatti una volta che sarà disponibile la centralina reale,
basterà sostituirla al suo simulatore, senza modificare il setup sperimentale.
Inoltre si tratta di un sistema senza retroazione, in quanto il modulatore compie la
sua azione di controllo a ciclo aperto; i vari test effettuati in questo lavoro, dunque, sono
orientati alla validazione del modello finora descritto, per assicurare che la sua risposta
a ciclo aperto sia conforme al funzionamento reale.
Solo una volta che si avrà la certezza che il sistema risponde correttamente, infatti,
si potrà passare al testing degli algoritmi di controllo implementati sulle centraline.

60
Anche quest’ultimo passo potrà essere facilmente implementato all’interno del
setup corrente, grazie all’alta scalabilità e riconfigurabilità dell’hardware in uso, come
descritto nel capitolo precendente.
3.2 Setup sperimentale
I simulatori a disposizione possono essere individuati nei seguenti componenti:
- l’ACE-Kit, con passo d’integrazione dell’ordine dei microsecondi;
- l’HILBox, con passo d’integrazione dell’ordine delle decine di microsecondi;
- L’FPGA, interna all’HILBox, con passo d’integrazione dell’ordine delle
decine di nanosecondi.
Sono state analizzate le singole parti del sistema per capire quali potessero
rappresentare un collo di bottiglia per quanto riguarda la necessità di impiegare un passo
di integrazione quanto più piccolo possibile.
La scelta del passo di integrazione è, infatti, un aspetto fondamentale ai fini delle
simulazioni real-time: un periodo di campionamento troppo piccolo potrebbe portare
all’esecuzione di molti calcoli che renderebbero impossibile il real-time; d’altra parte
c’è bisogno di un passo non eccessivamente grande per evitare che i segnali diventino
inconsistenti nei confronti delle dinamiche reali del processo in simulazione. Per questo
motivo vengono impiegati sia strumenti hardware (processori multi-core, fpga) che
tecniche software (ottimizzatori di codice, riformulazione dei modelli matematici) che
permettano l’utilizzo di passi di integrazione adatti.

61
Si può concludere che l’FPGA può essere destinata all’esecuzione delle parti più
veloci del modello, che individueremo in seguito, nonché alla gestione di tutto l’I/O tra
l’HILBox e l’esterno.
Sull’ACE-Kit sarà caricato, invece, il solo modello del modulatore. Questa scelta
ha due motivazioni:
1. la possibilità di simulare un dispositivo che fornisce dall’esterno i segnali di
controllo, come farebbe una centralina reale;
2. la possibilità essere riconfigurato velocemente, in modo da permettere, ad
esempio, una modifica dell’algoritmo di controllo, senza intervenire anche sulle altre
parti del setup.
Inoltre è da considerare il fatto che il modulatore genera i segnali di controllo con
una frequenza dell’ordine delle centinaia di Herz: la presenza di altri modelli in
esecuzione insieme al modulatore, sullo stesso simulatore, potrebbe portare all’impiego
di un passo di integrazione troppo elevato, provocando la perdita di alcuni campioni dei
segnali di controllo.
Sull’HILBox, infine, possono essere caricate le restanti parti del modello (rete di
inverter, banco condensatori, rete R-L, motore sincrono).
In figura 3.1 è rappresentato uno schema del sistema di simulazione real-time. Il
modulatore invia 7 segnali verso l’HILBox: i primi sei rappresentano i segnali di
modulazione che comandano l’inverter a tre livelli (due per ogni livello), mentre il
settimo segnale rappresenta l’impulso di sincronizzazione tra il modulatore e la restante
parte del modello in esecuzione sull’HILBox, sincronizzazione necessaria in quanto il
sistema è a ciclo aperto.

62
Figura 3.1:Setup sperimentale
3.3 Implementazione modello real-time
A questo punto occorre effettuare alcune considerazioni al fine di ottenere un
modello di simulazione real-time quanto più performante possibile.
L’elaborazione dei segnali, provenienti dal modulatore, avviene direttamente in
FPGA (è questo componente, infatti, che gestisce l’I/O tra HILBox e l’esterno); ciò
permette un’acquisizione con una risoluzione pari a 10 ns, sufficientemente piccola per
evitare la perdita di campioni. Ma si deve tener presente che la restante parte del
modello, e quindi anche l’inverter, sarà eseguito nella CPU dell’HILBox con un passo
di campionamento dell’ordine delle decine di microsecondi, il che vanificherebbe la
corretta acquisizione in FPGA qualora questi segnali fossero inviati direttamente in
CPU, senza essere adattati in qualche modo al cambiamento di rate.
Per questo motivo, definito con Ts il passo di integrazione della CPU e con period
quello dell’FPGA, una prima versione del modello real-time (figura 3.2) prevede sia
l’acquisizione che una prima elaborazione di questi segnali in FPGA (sottosistema
FPGA_IO), in modo da fornire alla CPU (su cui è in esecuzione il sottosistema

63
INVERTER_MOTORE_RETE RL) un valore medio rappresentativo di quante volte
all’interno di un Ts questi segnali hanno assunto valore alto o basso (figura 3.3).
Figura 3.2: Prima versione modello real-time
In figura 3.3 è descritto, graficamente, il calcolo della media di un segnale di
controllo, proveniente dal modulatore. Il segnale a punti rappresenta il clock (Ts) a cui
sta operando la CPU; il segnale in verde, invece, rappresenta uno dei segnali di fase
provenienti dalla modulatore; Ton sarà il periodo di tempo in cui il segnale in verde
permane nello stato alto all’interno di un Ts. Il valore medio (segnale in rosso), quindi,
calcolato come S
ON
T
T è il segnale che viene fornito alla CPU nel passo di integrazione
successivo, descrittivo di tutti i cambiamenti alto-basso che il segnale di fase ha
compiuto in un Ts. Prendendo come esempio il secondo intervallo di Ts in figura, si può
notare che il segnale in verde non permane nello stato alto per tutta la durata di Ts;, per
questo motivo il segnale in rosso, fornito al passo successivo, avrà un’ampiezza
proporzionale alla durata di Ton.
In questo modo, all’inverter in esecuzione in CPU, giungerà il corretto valore del
segnale modulante, evitando la perdita di commutazioni.

64
Figura 3.3:Media dei segnali di fase
Questa prima versione del modello ha portato al raggiungimento di un passo
minimo di integrazione Ts pari a 35 µs.
A questo punto, per riuscire a scendere ulteriormente con il passo di integrazione,
si è deciso di alleggerire il carico computazionale destinato alla CPU. Tenendo anche
presente che la parte più veloce del modello è costituita dai quattro inverter, si è giunti
ad una seconda versione del modello real-time che prevede l’esecuzione dei modelli
degli inverter in FPGA (figura 3.4).
Figura 3.4:Seconda versione modello real-time.
S
ONm T
TSW =
Valore medio disponibile al successivo Ts

65
Il modello dell’inverter, oltre a descrivere il comportamento della rete di
interruttori, contiene al suo interno anche la linea di bus ed il banco condensatori;
quest’ultimo elemento è da tenere in considerazione per quanto riguarda la sua
implementazione in FPGA.
La scrittura del codice destinato all’esecuzione sulla scheda FPGA avviene in
ambiente Matlab/Simulink, con librerie dedicate della Xilinx (cfr. §2.4). Queste
librerie, naturalmente, offrono solo un’astrazione di più alto livello di quello che
potrebbe essere un linguaggio di programmazione destinato a questo tipo di logica
programmabile (es.: VHDL, VeriLog); per questo motivo il set di elementi messo a
disposizione ha come target principale quello delle operazioni su stringhe di bit.
Il modello dell’inverter, destinato all’FPGA, è stato quindi riscritto secondo le
considerazione appena fatte (figura 3.5).
Figura 3.5:ModelloSimulink inverter in FPGA.

66
In figura 3.6 è mostrato il sottosistema BANCO_CONDENSATORI di figura 3.5;
si può notare come tutte le operazioni di questo nuovo modello siano orientate alle
singole stringhe di bit. Per questo motivo bisogna scegliere opportunamente il tipo di
rappresentazione binaria per la codifica dei segnali da elaborare. Occorre quindi
conoscere, almeno in linea generale, il range di variazione di tutte le grandezza da
trattare, ai fini di minimizzare l’impiego di risorse.
Figura 3.6:Sottosistema BANCO_CONDENSATORI.
Ad esempio, l’integratore descrittivo della dinamica sul condensatore
(sottosistema Integratore di figura 3.6) è stato implementato utilizzando l’algoritmo di
Forward Eulero (figura 3.7) e, in particolare, la moltiplicazione per il passo di
integrazione è stata effettuata utilizzando un shift; questo a causa della limitatezza di
risorse disponibili in FPGA, in quanto la moltiplicazione per un numero molto piccolo
(dell’ordine delle decine di nanosecondi) impiegherebbe un numero eccessivo di
moltiplicatori, fisicamente non disponibili. Per una più ampia analisi del modello
dell’inverter destinato all’esecuzione in FPGA, fare riferimento all’Appendice B.

67
Figura 3.7:Sottosistema Integratore.
Se questa soluzione ha, da una parte, permesso di alleggerire il carico
computazionale destinato alla CPU, da un’altra, ha ridotto la precisione dei calcoli,
questo a causa delle approssimazioni introdotte dalle operazioni in FPGA.
Inoltre il carico computazionale è stato alleggerito solo relativamente in quanto la
presenza di quattro inverter in FPGA ha implicato un notevole aumento del numero di
segnali che devono essere scambiati tra CPU e FPGA.
Nella prima versione del modello real-time, infatti, l’FPGA inviava alla CPU
esclusivamente i 6 segnali di fase mediati più il segnale di sincronizzazione proveniente
dal modulatore. Adesso gli inverter in FPGA devono ricevere in ingresso le correnti
trifase dei 4 rami R-L e fornire in uscite le 4 tensioni trifase destinate al motore, per un
totale di 12 ingressi e 12 uscite.
Questo, da come si è potuto osservare anche sperimentalmente, ha introdotto un
onere computazionale non trascurabile.
In definitiva questa soluzione ha portato ad un peggioramento in termini di passo
di integrazione, in quanto, dai precedenti 35 µs, si è passati a 40 µs, al di sotto dei quali
la CPU presentava overruns. Questo accade quando il processore non riesce, all’interno
di un singolo passo di integrazione, a campionare gli ingressi, integrare le equazioni del

68
modello e calcolare il corretto valore delle uscite da fornire al passo di integrazione
successivo.
Bisogna sottolineare, però, che nel caso del simulatore in questione (HILBox),
quando si verifica un overrun, il processore continua a simulare il modello, senza
fornire, almeno a runtime, alcuna segnalazione di quanto è accaduto. Solo al termine
dell’esecuzione occorre analizzare quanti overruns si sono verificati e decidere se, in
rapporto al numero totali di cicli di esecuzione effettuati dalla CPU, questo numero è
tale da inficiare l’attendibilità dei segnali generati. Infatti, una percentuale di overruns,
che si aggira intorno al 7-8% dei cicli totali di esecuzione, potrebbe già portare a
scartare i risultati ottenuti in quanto non c’è la sicurezza che i segnali siano consistenti
con il comportamento reale del processo.
A questo punto si è giunti ad una terza versione del modello real-time, tale da
ridurre l’onere computazionale dovuto alla gestione di molti segnali da scambiare tra
CPU e FPGA.
Questa nuova versione sfrutta i mezzi hardware messi a disposizione dal sistema
HILBox: la suddivisione e la possibilità di esecuzione del modello su più core del
processore del simulatore real-time.
Si ricorda, infatti, che l’HILBox è dotata di un processore QuadCore, in grado di
permettere l’esecuzione di parti del modello in modalità XHP (cfr. §2.3.2) su tre dei
quattro core a disposizione (il quarto core è destinato alla comunicazione via Ethernet
tra il simulatore e il computer host).
Fino a questo momento l’intero modello veniva caricato su uno solo dei quattro
core a disposizione.
In figura 3.8 è rappresentato il nuovo modello di simulazione real-time.

69
Figura 3.8: Terza versione modello real-time.
Figura 3.9: Schema Simulink modello real-time destinato all’HILBox.
Per capire meglio la struttura di questa nuova soluzione, in figura 3.9 è stato
riportato lo schema Simulink del modello che sarà caricato sull’HILBox.

70
I sottosistemi indicati con i nomi SM_Master e SS_Slave (cfr. appendice C) di
figura 3.8 rappresentano le due parti del modello che saranno eseguite su due core
separati.
In particolare, il sottosistema SS_Slave contiene al suo interno il modello del
motore sincrono e della rete R-L (si ricorda che i 4 inverter sono stati implementati in
FPGA), mentre SS_Master contiene il modello che definisce la comunicazione ed il
trasferimento dei dati tra CPU e FPGA. Il sottosistema SC_Console, invece, verrà
eseguito sulla macchina host e rappresenta la console attraverso la quale sarà possibile
visualizzare le grandezze da analizzare ed inviare comandi al modello in esecuzione in
tempo reale.
Questa suddivisione ha permesso l’esecuzione della simulazione real-time con un
passo di integrazione Ts pari a 24 s, ovvero un miglioramento di circa il 30% il rispetto
alla situazione precedente (35 s).
Questo ultimo risultato ha dato conferma del fatto che il collo di bottiglia
rilevante, in termini di passo di integrazione, è rappresentato dalla gestione dei segnali
che dalla CPU vengono inviati all’FPGA e viceversa. Per questo motivo si è giunti ad
una quarta, ed ultima, versione del modello di simulazione real-time (figura 3.10), che
prevede la presenza della rete dei quattro inverter di nuovo in CPU, ma questa volta su
un core separato (sottosistema SS_Master), e il solo calcolo delle medie dei segnali di
fase affidato all’FPGA, come prevedeva la prima versione. Questa scelta è, inoltre,
supportata dalla considerazione riguardante la diminuzione di precisione all’interno
dell’FPGA, fatta precendetemente: da un punto di vista economico, infatti, una FPGA
più performante, in termini di risorse per il calcolo, è più costosa rispetto ad un

71
simulatore che permette l’esecuzione di parti del modello su più core, o, addirittura, su
più CPU.
Figura 3.10: Quarta versione modello real-time.
Quest’ultima soluzione ha permesso il raggiungimento di un passo di integrazione
minimo Ts pari a 20 s, un miglioramento di quasi il 45% rispetto ai 35 s iniziali.
In tabella 3.1 è riportato un schema riassuntivo dei risultati ottenuti.
L’analisi condotta finora ha portato alla determinazione del modello real-time da
utilizzare per validare i modelli. A questo punto si può procedere con la fase di testing
vero e proprio. Il quarto capitolo fornirà tutta una serie di risultati su prove condotte per
analizzare il comportamento del sistema sottoposto a diverse condizioni di
funzionamento.
72
Setup Sperimentale HILBox
Versione modello
real-time
Ace-kit
FPGA CORE1 CORE2
Passo integrazione
minimo
1
- Modulatore
- Acquisizione e calcolo media segnali di fase
- 4 inverter, banco condensatori - Rete R-L, motore sincrono - Gestione I/O con FPGA
/
35 s
2
- Modulatore
- Acquisizione segnali di fase - 4 inverter, banco condensatori
- Rete R-L, motore sincrono - Gestione I/O con FPGA
/
40 s
3
- Modulatore
- Acquisizione segnali di fase - 4 inverter, banco condensatori
- Rete R-L, motore sincrono
- Gestione I/O
con FPGA
24 s
4
- Modulatore
- Acquisizione e calcolo media segnali di fase
- Rete R-L, motore sincrono
- 4 inverter, banco condensatori
- Gestione I/O
con FPGA
20 s
Tabella 3.1: Schema riassuntivo risultati implementazione real-time

73
CAPITOLO 4
RISULTATI DELLE SIMULAZIONI
4.1 Introduzione
In questo capitolo saranno presentati i risultati delle simulazioni effettuate
utilizzando l’ultima versione del modello real-time ottenuto, come già anticipato alla
fine del terzo capitolo.
Lo scopo di una simulazione real-time hardware in the loop è quello di analizzare
la risposta del sistema alla strategia di controllo sia in condizioni nominali di
funzionamento ma, soprattutto, in scenari diversi da quello nominale.
Nel caso in esame le prove sono state effettuate sia modificando in real-time il
valore nominale di alcuni parametri, che modificando la strategia stessa di controllo.
I diversi scenari di testing sono stati i seguenti:
- condizioni nominali;
- variazione coppia di carico del +30%;
- variazione tensione di linea (Vdc0) del +30%;
- variazione tensione di linea del -20%;
- variazione tensione di eccitazione del -75%;
- perdita di passo;
- diversi valori di induttanza per i singoli rami della rete R-L;
- modulazione PD e POD.

74
Per ottenere un’analisi completa della risposta del sistema sono state prese in
considerazione le grandezze maggiormente rappresentative delle dinamiche in esame,
quali: le correnti del motore, le correnti dei singoli rami R-L, i flussi all’interno dello
statore, la velocità del rotore, la coppia elettromagnetica, la tensione sul DC-Link.
Alcune delle acquisizioni sono state salvate direttamente in tempo reale tramite
l’oscilliscopio: per queste acquisizione il fattore di conversione è G = 65, per ottenere il
corrispettivo valore della grandezza raffigurata.
4.2 Risultati
4.2.1 Condizioni nominali
Per prima cosa è stata analizzata la risposta del sistema alle condizioni nominali di
funzionamento. È stato simulato l’avvio del motore, per controllare se, effettivamente,
la modulazione fornisse i segnali corretti.
L’avviamento è stato effettuato fornendo inizialmente una coppia di carico pari ad
un quarto di quella nominale e, successivamente, una volta controllato che la velocità
del rotore avesse raggiunto il valore stabilito (circa 3000 rpm), è stata fornita la coppia
nominale.
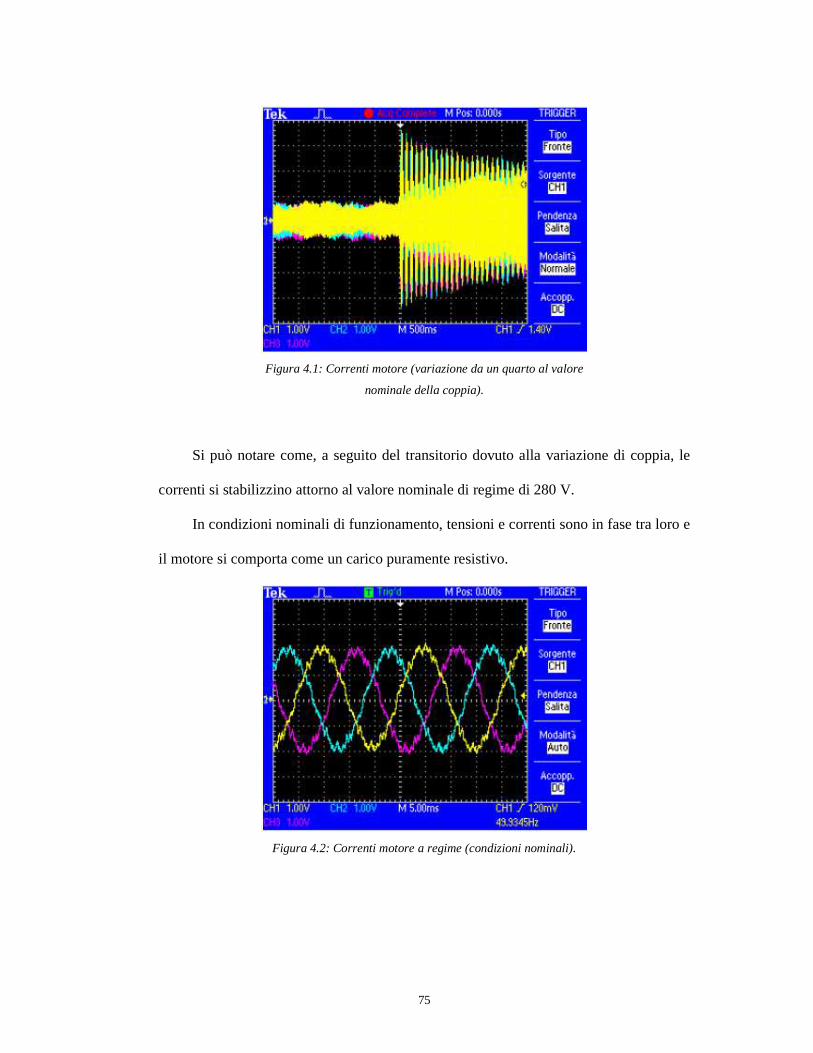
75
Figura 4.1: Correnti motore (variazione da un quarto al valore
nominale della coppia).
Si può notare come, a seguito del transitorio dovuto alla variazione di coppia, le
correnti si stabilizzino attorno al valore nominale di regime di 280 V.
In condizioni nominali di funzionamento, tensioni e correnti sono in fase tra loro e
il motore si comporta come un carico puramente resistivo.
Figura 4.2: Correnti motore a regime (condizioni nominali).
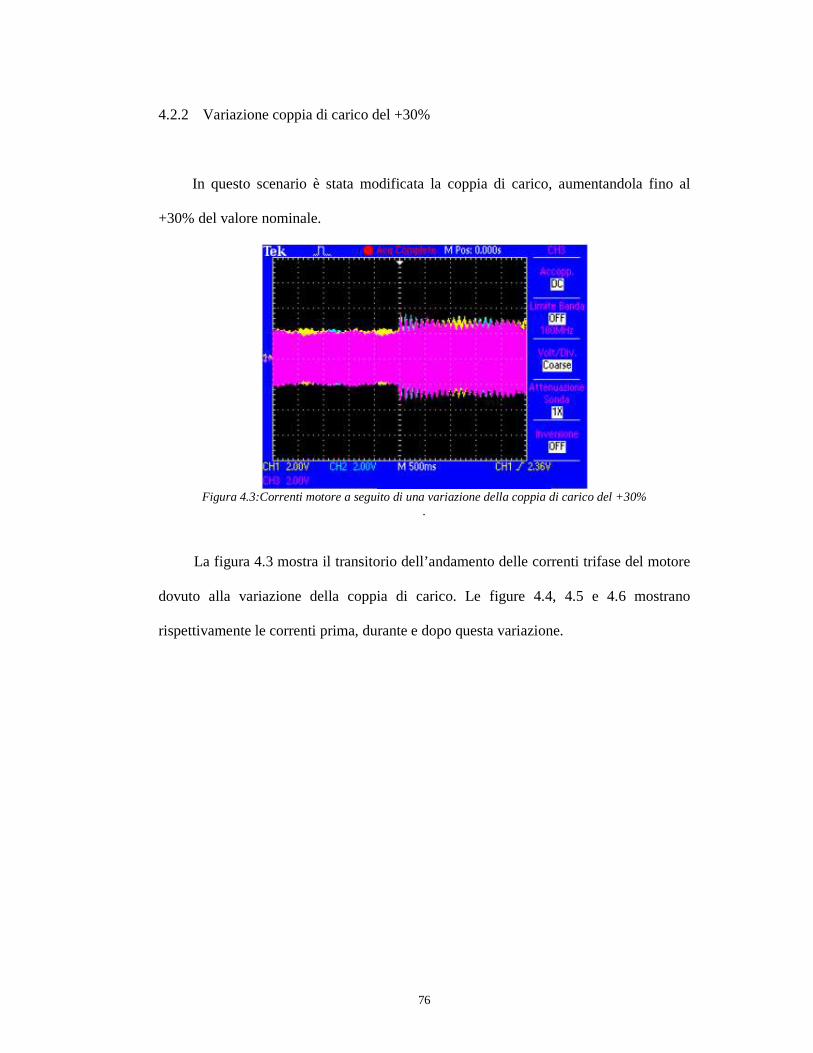
76
4.2.2 Variazione coppia di carico del +30%
In questo scenario è stata modificata la coppia di carico, aumentandola fino al
+30% del valore nominale.
Figura 4.3:Correnti motore a seguito di una variazione della coppia di carico del +30%
.
La figura 4.3 mostra il transitorio dell’andamento delle correnti trifase del motore
dovuto alla variazione della coppia di carico. Le figure 4.4, 4.5 e 4.6 mostrano
rispettivamente le correnti prima, durante e dopo questa variazione.

77
Fig 4.4: Correnti motore prima della variazione della coppia di carico
L’aumento della coppia di carico comporta un conseguente aumento della coppia
elettromagnetica che il motore deve generare per inseguire la velocità di sincronismo.
Per aumentare la coppia, e quindi potenza erogata, occorre aumentare la potenza
assorbita e, dunque, a parità di tensione di alimentazione, ciò che deve aumentare è la
corrente.
Fig 4.5: Transitorio delle correnti motore durante la variazione coppia di carico

78
La figura 4.6 mostra come le correnti si stabilizzino ad un valore di regime pari a
360 A, ovvero un aumento del 30% rispetto al valore nominale di regime (280 A).
Fig 4.6: Correnti motore dopo la variazione della coppia di carico
Le figure 4.7, 4.8 e 4.9 mostrano rispettivamente gli andamenti della velocità del
rotore, della coppia elettromagnetica e dei flussi di statore, in risposta alla variazione
della coppia di carico.
Figura 4.7: Velocità rotore (variazione coppia +30%).

79
Figura 4.8: Coppia elettromagnetica (variazione coppia +30%).
La velocità del rotore (figura 4.7), nell’istante in cui la coppia aumenta, subisce
prima una leggera diminuzione e poi incomincia ad oscillare, per riassestarsi infine
attorno al valore di regime di 314 rad/s.
Analogo discorso per la coppia elettromagnetica ma, naturalmente, essa si
stabilizza attorno ad un valore più alto, circa 420 Nm, ovvero un aumento del 30%
rispetto al valore nominale di regime (318 Nm).

80
Figura 4.9: Flussi statore d e q (variazione coppia +30%).
La figura 4.9 mostra l’andamento dei flussi. In particolare si nota che il flusso
sull’asse diretto, più significativo per la dinamica del motore, subisce un diminuzione
dovuta al corrispettivo aumento di corrente.
4.2.3 Variazione tensione di linea del +30%
Le figure 4.10-4.11 mostrano l’andamento delle correnti del motore al variare
della tensione di linea Vdc0 di +30%.
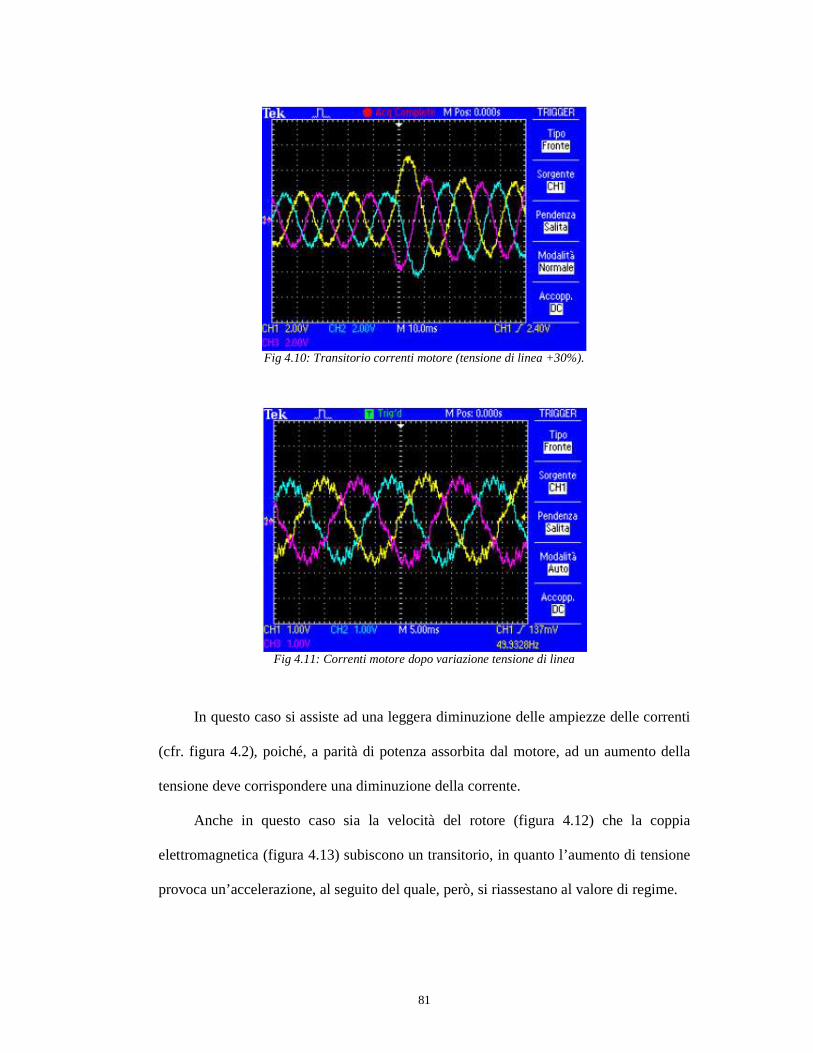
81
Fig 4.10: Transitorio correnti motore (tensione di linea +30%).
Fig 4.11: Correnti motore dopo variazione tensione di linea
In questo caso si assiste ad una leggera diminuzione delle ampiezze delle correnti
(cfr. figura 4.2), poiché, a parità di potenza assorbita dal motore, ad un aumento della
tensione deve corrispondere una diminuzione della corrente.
Anche in questo caso sia la velocità del rotore (figura 4.12) che la coppia
elettromagnetica (figura 4.13) subiscono un transitorio, in quanto l’aumento di tensione
provoca un’accelerazione, al seguito del quale, però, si riassestano al valore di regime.

82
Figura 4.12: Velocità rotore (variazione Vdc0 +30%).
Figura 4.13: Coppia elettromagnetica (variazione Vdc0 +30%).
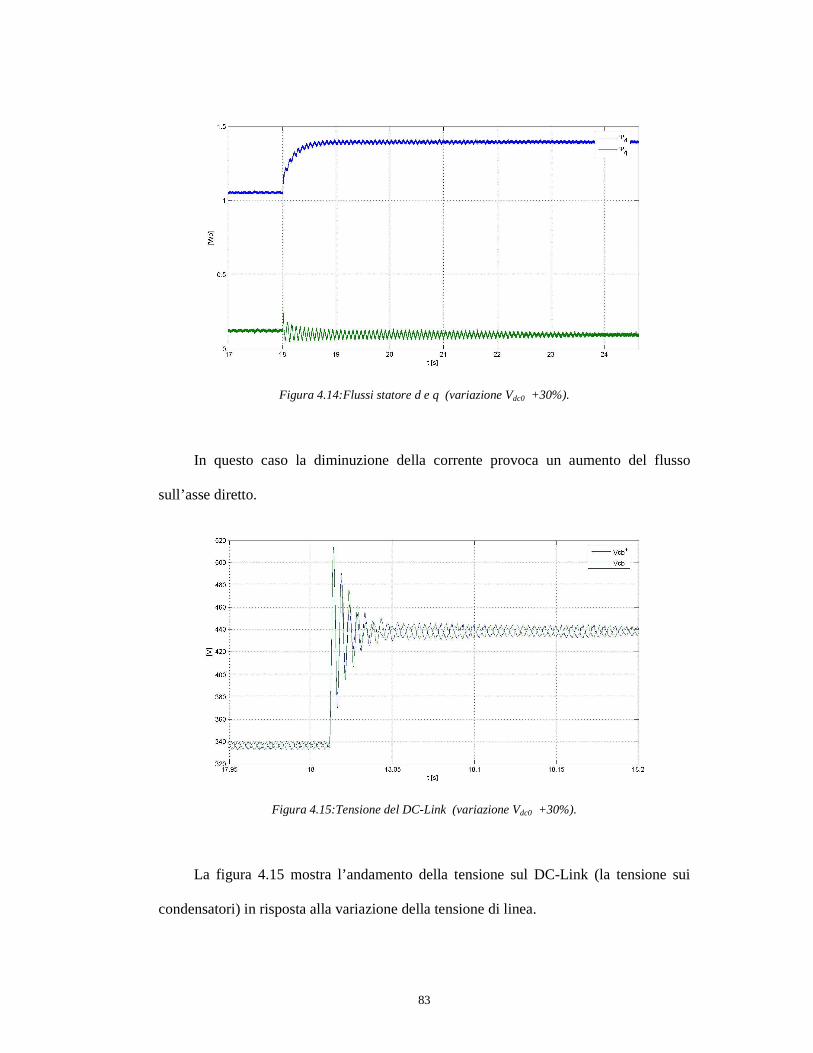
83
Figura 4.14:Flussi statore d e q (variazione Vdc0 +30%).
In questo caso la diminuzione della corrente provoca un aumento del flusso
sull’asse diretto.
Figura 4.15:Tensione del DC-Link (variazione Vdc0 +30%).
La figura 4.15 mostra l’andamento della tensione sul DC-Link (la tensione sui
condensatori) in risposta alla variazione della tensione di linea.

84
A seguito dell’aumento della tensione di linea si assiste ad un corrispettivo
aumento della tensione sul DC-Link. Si può notare, infatti, come questa tensione passi
dal valore nominale di circa 338 V ad un valore di regime pari a 440 V, a seguito di un
breve transitorio determinato dalla presenza di un’induttanza sul bus.
4.2.4 Variazione tensione di linea del -20%
Al contrario, diminuendo di un 20% il valore nominale della tensione di linea si
verifica un aumento delle ampiezze delle correnti (figure 4.16 e 4.17), in quanto, come
nel caso precedente, la potenza assorbita deve essere sempre la stessa.
Fig 4.16: correnti motore tensione di linea -20%

85
Fig 4.17: correnti motore dopo variazione tensione di linea -
20%
Dalla figura 4.17 si può notare come la risposta delle correnti alla diminuzione
della tensione di linea sia simile a quella relativa all’aumento della coppia di carico,
mostrata precedentemente.
Figura 4.18:Velocità rotore (variazione Vdc0 -20%).

86
Figura 4.19:Coppia elettromagnetica (variazione Vdc0 -20%).
Analogo discorso del paragrafo precedente vale per la velocità di rotore e per
coppia elettromagnetica. Il flusso sull’asse diretto, in questo caso, subisce una
diminuzione in seguito all’aumento della corrente.
Figura 4.20:Flussi statore d e q (variazione Vdc0 -20%).

87
Figura 4.21:Tensione DC-Link (variazione Vdc0 -20%).
Anche la tensione sul DC-Link diminuisce, passando dai 338 V nominali a circa
270 V.
4.2.5 Variazione tensione di eccitazione del -75%
In figura 4.22 sono rappresentante le correnti del motore dopo un diminuzione del
75% della tensione di eccitazione.

88
Fig 4.22: correnti motore dopo variazione tensione di eccitazione -75%
Come per il caso precedente, le ampiezze delle correnti aumentano in quanto
devono sopperire alla diminuzione della tensione di eccitazione.
Figura 4.23:Velocità motore (variazione tensione di eccitazione -75%).

89
Figura 4.24: Coppia elettromagnetica (variazione tensione di eccitazione -75%).
Dalle figure 4.23 e 4.24 si può notare come, in questo caso, sia la velocità del
rotore che la coppia elettromagnetica incomincino ad oscillare maggiormente attorno al
valore nominale di regime, in quanto, in questo scenario, il motore è sottoeccitato e si
comporta come un carico induttivo, producendo maggiori oscillazioni.
Figura 4.25: Flussi statore d e q (variazione tensione di eccitazione -75%).
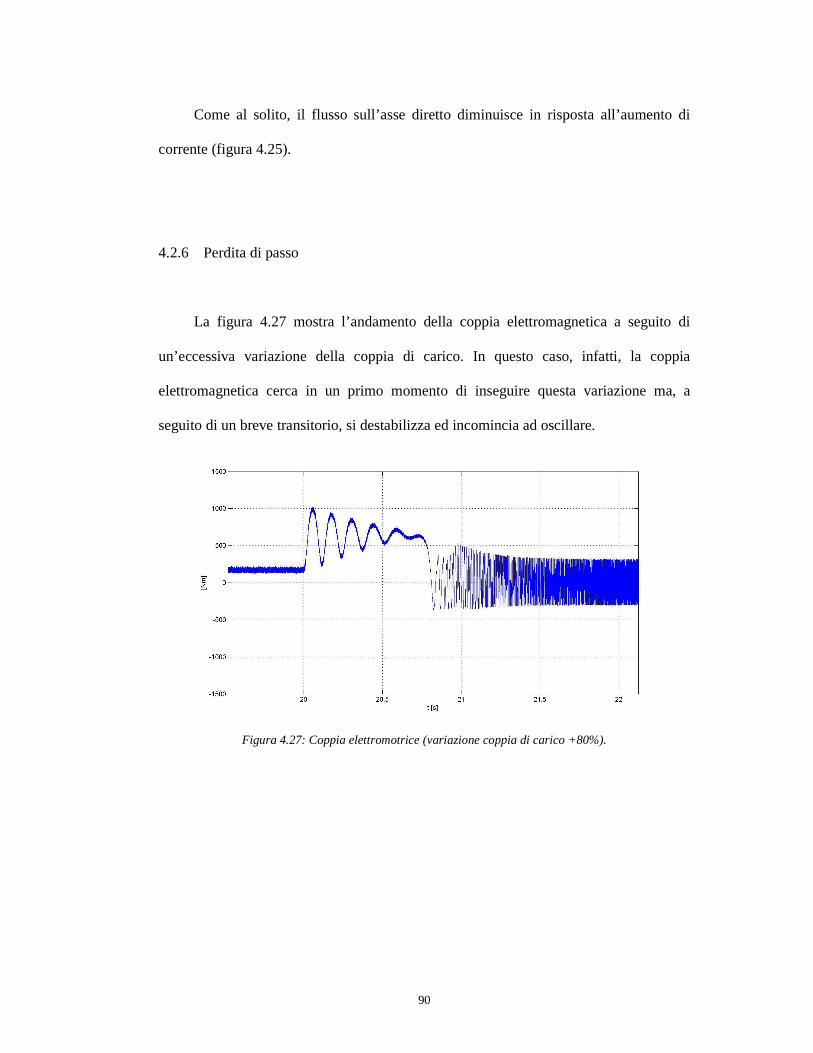
90
Come al solito, il flusso sull’asse diretto diminuisce in risposta all’aumento di
corrente (figura 4.25).
4.2.6 Perdita di passo
La figura 4.27 mostra l’andamento della coppia elettromagnetica a seguito di
un’eccessiva variazione della coppia di carico. In questo caso, infatti, la coppia
elettromagnetica cerca in un primo momento di inseguire questa variazione ma, a
seguito di un breve transitorio, si destabilizza ed incomincia ad oscillare.
Figura 4.27: Coppia elettromotrice (variazione coppia di carico +80%).
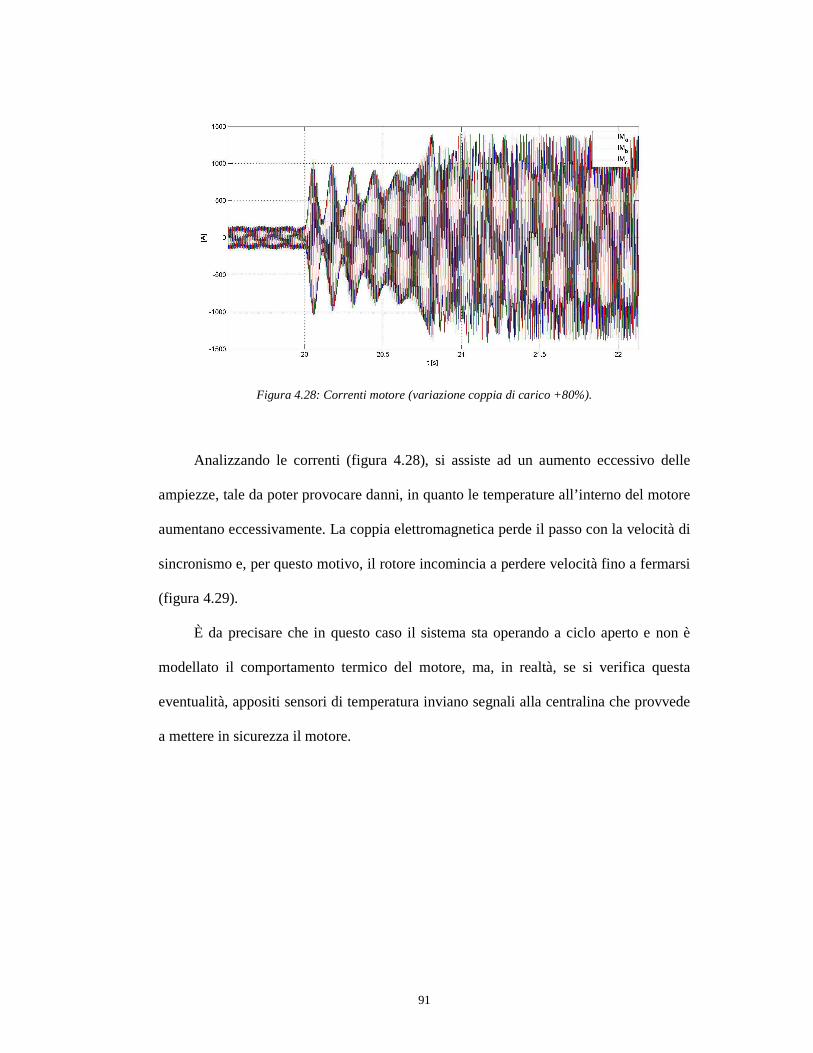
91
Figura 4.28: Correnti motore (variazione coppia di carico +80%).
Analizzando le correnti (figura 4.28), si assiste ad un aumento eccessivo delle
ampiezze, tale da poter provocare danni, in quanto le temperature all’interno del motore
aumentano eccessivamente. La coppia elettromagnetica perde il passo con la velocità di
sincronismo e, per questo motivo, il rotore incomincia a perdere velocità fino a fermarsi
(figura 4.29).
È da precisare che in questo caso il sistema sta operando a ciclo aperto e non è
modellato il comportamento termico del motore, ma, in realtà, se si verifica questa
eventualità, appositi sensori di temperatura inviano segnali alla centralina che provvede
a mettere in sicurezza il motore.

92
Figura 4.29:Velocità motore (variazione coppia di carico +80%).
Questo risultato evidenzia l’importanza delle simulazioni real-time hardware in
the loop, in quanto un variazione di questa portata della coppia di carico è praticamente
irrealizzabile a meno di non compromettere il corretto funzionamento dell’intero
sistema.
4.2.7 Diversi valori di induttanza per i singoli rami della rete R-L
Le simulazioni effettuate finora sono state compiute su un modello della rete R-L
caratterizzato dallo stesso valore di induttanza per tutti e quattro i rami, ma la
complessità del modello permette di simulare anche il caso in cui ogni ramo della rete
abbia un diverso valore di L.

93
È possibile anche analizzare il caso in cui vari il valore di L sul singolo ramo, ma
questo caso non ha una grossa rilevanza in quanto, sul singolo ramo, si verifica
un’automatica compensazione di questa variazione ad opera del controllo.
Mentre il caso di valori di L diversi per ogni ramo è più interessante da analizzare,
in quanto non esiste un controllo congiunto di tutti e quattro i rami della rete, ma è il
sistema stesso che deve adeguarsi per fornire al motore il valore corretto di tensione e
corrente.
In figura 4.30 sono rappresentati gli andamenti delle 4 correnti dei singoli rami R-
L, su ognuno dei quali è presente un valore di induttanza diverso. In particolare per il
primo ramo (segnale in blu) il valore di L è pari a 2.3 mH, per il secondo ramo (segnale
in verde) L = 2.5 mH, per il terzo ramo (segnale in rosso) L = 2.1 mH e per il quarto
ramo (segnale in celeste) L = 2 mH.
Figura 4.30: Fase a delle correnti dei singoli rami R-L

94
Si può notare come le diverse ampiezza delle correnti rispecchiano il corrispettivo
valore di L per quel ramo. Inoltre, anche se non è riportato in figura, si è verificato che
la somma delle correnti è uguale a quella assorbita dal motore, come ci si aspettava.
4.2.8 Modulazione PD e POD
I seguenti risultati riguardano, invece, delle simulazioni effettuate modificando la
strategia di controllo. Infatti, i segnali di fase sono generati confrontando la sinusoide
che si vuole riprodurre in uscita agli inverter con due segnali modulanti a dente di sega
in fase tra loro (PD), uno situato nel semipiano positivo delle ordinate e l’altro in quello
negativo (cfr. §1.4).
La nuova modulazione, al contrario, è stata effettuata ponendo in opposizione di
fase questi due segnali (POD), ottenendo i risultati in figura 4.31, in cui si nota che il
contributo armonico a particolari frequenze è aumentato.

95
Fig 4.31: Correnti motore con modulazione POD
Questo effetto risulta più evidente analizzando le trasformate di Fourier dei segnali
in esame (figure 4.32, 4.33).
Figura 4.32:Trasformata di Fourier della fase a della corrente del motore (modulazione PD)
Come ampiamente discusso in letteratura [17], si può notare come l’effetto della
modulazione POD produca un aumento del contenuto armonico del segnale in uscita
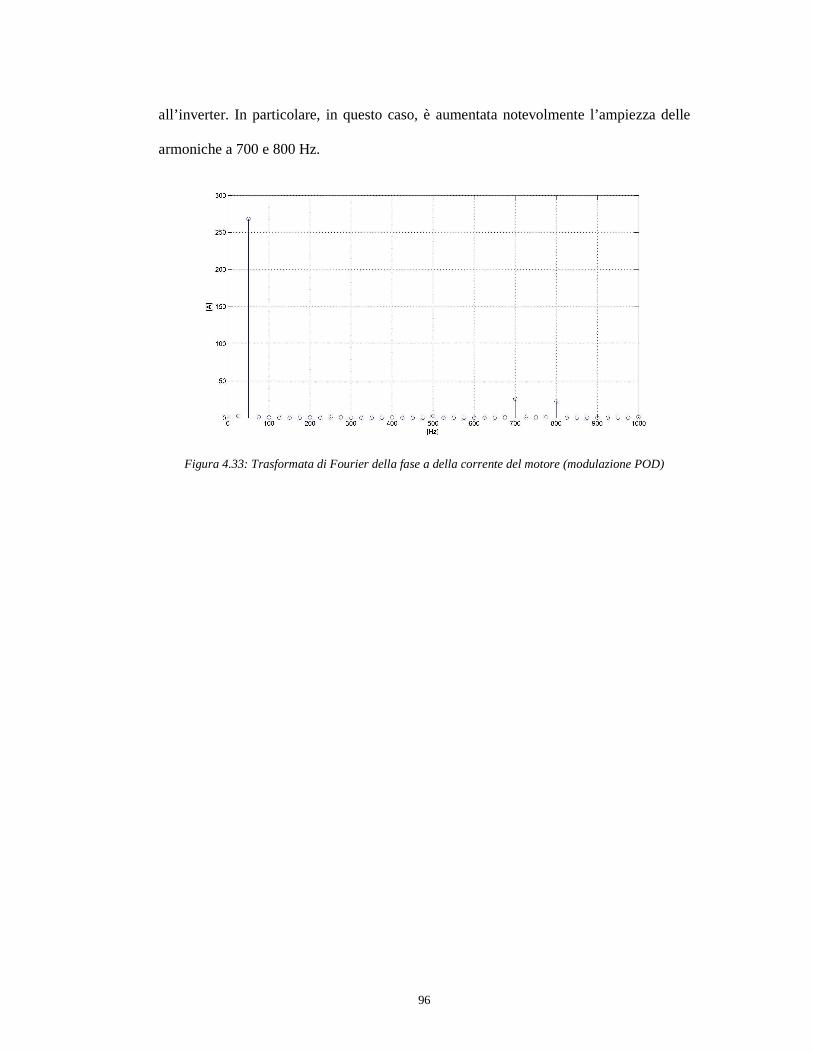
96
all’inverter. In particolare, in questo caso, è aumentata notevolmente l’ampiezza delle
armoniche a 700 e 800 Hz.
Figura 4.33: Trasformata di Fourier della fase a della corrente del motore (modulazione POD)

97
CONCLUSIONI
Il presente lavoro di tesi ha proposto una soluzione innovativa per il testing dei
sistemi di controllo nel campo dei convertitori elettronici di alta potenza. È stato
realizzato un ambiente di simulazione real-time del tipo Hardware in the loop attraverso
l’utilizzo di tecniche software e componenti hardware ad alte prestazioni.
Le varie fasi che hanno portato al raggiungimento di tale obiettivo sono state
molteplici e tutte di rilevante importanza.
In primo luogo si è arrivati ad una descrizione completa del sistema in esame,
riuscendo a raggiungere un grado di complessità adatto per una corretta analisi del suo
funzionamento. Si è passati, poi, alla fase di sviluppo di tecniche che permettessero
l’integrazione di questo modello all’interno di un sistema di simulazione real-time.
Questo è stato possibile anche grazie all’utilizzo di appositi strumenti hardware,
come l’HILBox, che hanno permesso di mantenere la complessità del modello ad un
livello tale da non perdere in accuratezza e precisione dei risultati. È stato verificato,
infatti, che l’HILBox mette a disposizione risorse di calcolo sufficienti alla simulazione
real-time del sistema in esame, permettendo il raggiungimento di un passo di
integrazione sufficientemente piccolo da per garantire l’affidabilità e la correttezza dei
test.
Il sistema real-time così ottenuto è stato utilizzato per testare e validare
l’integrazione numerica in tempo reale del modello matematico dell’impianto. Questo
ha permesso di ottenere risultati significativi del comportamento del sistema in esame,
che, dimostrandosi conforme al comportamento reale, ha fornito una base importante
per uno sviluppo futuro del sistema di simulazione.

98
Infatti, il lavoro fatto finora, benché di una certa importanza, è solo un primo
passo verso la creazione di un sistema di simulazione real-time completo, comprensivo
della reale componentistica hardware di controllo e chiuso in retroazione con essa.
In questo modo, una volta assodato che il sistema risponde correttamente a ciclo
aperto, si può passare al testing degli algoritmi di controllo implementati sulle
centraline.
Altro importante sviluppo futuro riguarda il completamento della descrizione del
modello, con la modellazione dell’Active Front End e del trasformatore che collega la
parte motore con l’alimentazione e, inoltre, la modellazione della rete stessa di
generazione di potenza elettrica, implementata attraverso una turbina ed un generatore
sincrono.
In ogni caso i risultati ottenuti hanno mostrato la validità dell’approccio utilizzato
e l’efficacia degli strumenti real-time Hardware-in-the-loop quando vengono utilizzati
nella fase di validazione e testing di centraline di controllo sofisticate e dedicate ad
impianti complessi.

99
APPENDICE A
Calcolo equazioni magneto-elettriche motore
A partire dal gruppo di equazioni (1.3)-(1.14), scegliamo come variabili di stato le
correnti statoriche qd ii , e i flussi rotorici FQD ψψψ ,, e ricaviamo il modello nello
spazio di stato.
Dalle equazioni (1.10), (1.11) e (1.12), utilizzando le (1.13) e (1.14) si ricava:
RD
mdDD X
iψψ −
= (A.1)
RQ
mqQQ X
iψψ −
= (A.2)
LF
mdFF X
iψψ −
= (A.3)
Utilizzando le equazioni (A.2) e (A.3), dall’equazione (1.13) si ricava che:
⇒−+−+=++= )()(LF
md
LF
F
RD
md
RD
DdADFDdADmd XXXX
iXiiiXψψψψψ
++=
LF
F
RD
Dddmd XX
iXψψψ (A.4)
dove 1
111−
++=
LFRDADd XXX
X
Quindi dall’equazione (1.8) si ricava la derivata del flusso dψ in funzioni delle variabili
di stato scelte:
→
+++=+=
dt
d
Xdt
d
Xdt
diX
dt
diX
dt
d
dt
diX
dt
d F
LF
D
RD
dd
dLD
mddLD
d ψψψψ 11

100
−−+
−−+= )(
1)(
1mdF
LF
FF
LFmdD
RD
RD
RDd
dLD
d
X
RV
XX
R
XX
dt
diX
dt
d ψψψψψ (A.5)
avendo osservato che dalla (1.5) e (1.7) si ricava, attraverso le (A.1) e (A.3),
)( mdDRD
RDD
X
R
dt
d ψψψ−−= (A.6)
)( mdFLF
FF
F
X
RV
dt
d ψψψ−−= , (A.7)
rispettivamente.
Utilizzando la (A.5) e (1.9), la (1.3) si riscrive:
( ) ( ) ( )
( )mdFFLF
dF
LF
d
mdDRDRD
dLDddmqqLQedSDd
RX
XV
X
X
RX
XXXiiXiRV
ψψ
ψψψω
−−+
+−−+++⋅−⋅=
22
2&&
(A.8) (A.8)
Analogamente si procede per l’asse q. Utilizzando l’ equazione (A.2), dall’equazione
(1.14) si ricava che:
+=
RQ
Qdqmq X
iXψ
ψ (A.9)
dove
1
11−
+=
RQAQq XX
X .
Quindi dall’equazione (1.9) si ricava la derivata del flusso qψ in funzioni delle variabili
di stato scelte:
−−+= )(
1mqQ
RQ
RQ
RQq
qLQ
q
X
R
XX
dt
diX
dt
dψψ
ψ (A.10)
avendo osservato che dalla (1.6), attraverso la (A.2), si ricava che

101
)( mqQRQ
RQQ
X
R
dt
dψψ
ψ−−= (A.11)
Utilizzando la (A.10) e (1.8), la (1.4) si riscrive:
( ) ( ) ( )mqQRQ
RQ
qmddLDeqSQLQqqq R
X
XIXiRXXiV ψψψω −−+⋅+⋅++=
2& (A.12)
Il modello del motore può quindi essere espresso attraverso le equazioni (A.6), (A.7),
(A.8), (A.11) e (A.12) per la parte elettromagnetica e dalle equazioni dalle equazioni
(1.1) e (1.2) per la parte meccanica.
Riepilogando, il modello dinamico del settimo ordine del motore sincrono in forma
mista ( TeeFQDqd iix ],,,,,,[ θωψψψ= ) è descritto dalle seguente equazioni differenziali:
( ) ( ) ( )
( )mdFFLF
dF
LF
d
mdDRDRD
dLDddmqqLQedSDd
RX
XV
X
X
RX
XXXiiXiRV
ψψ
ψψψω
−−+
+−−+++⋅−⋅=
22
2&&
( ) ( ) ( )mqQRQ
RQ
qmddLDeqSQLQqqq R
X
XIXiRXXiV ψψψω −−+⋅+⋅++=
2&
)( mdDRD
RDD
X
R
dt
d ψψψ−−=
)( mqQRQ
RQQ
X
R
dt
dψψ
ψ−−=
)( mdFLF
FF
F
X
RV
dt
d ψψψ−−=
)(PP
BTTJ
PP
dt
d eLem
e ωω−−=
ee
dt
d ωθ=
dove:

102
( )dqqdemn
RQAQq
LFRDADd
RQ
Qqqmq
LF
F
RD
Dddmd
iiPPT
XXX
XXXX
XiX
XXiX
⋅−⋅=
+=
++=
+=
++=
−
−
ψψ
ψψ
ψψψ
1
1
11
111

103
APPENDICE B
Implementazione modello inverter in FPGA
In questa appendice verrà mostrato come è stato implementato il modello
dell’inverter NPC in modo da poter essere eseguito sulla scheda FPGA.
Come già accennato nel paragrafo 3.3, la scrittura del codice destinato
all’esecuzione sulla scheda FPGA avviene in ambiente Matlab/Simulink, con librerie
dedicate della Xilinx (cfr. §2.4). Queste librerie, naturalmente, offrono solo
un’astrazione di più alto livello di quello che potrebbe essere un linguaggio di
programmazione destinato a questo tipo di logica programmabile (es.: VHDL,
VeriLog); per questo motivo il set di elementi messo a disposizione ha come target
principale quello delle operazioni su stringhe di bit.
Il modello, quindi, deve essere riscritto secondo le considerazioni appena fatte.
In figura B.1 è mostrato il modello dell’inverter scritto nell’ambiente
Matlab/Simulink tradizionale.
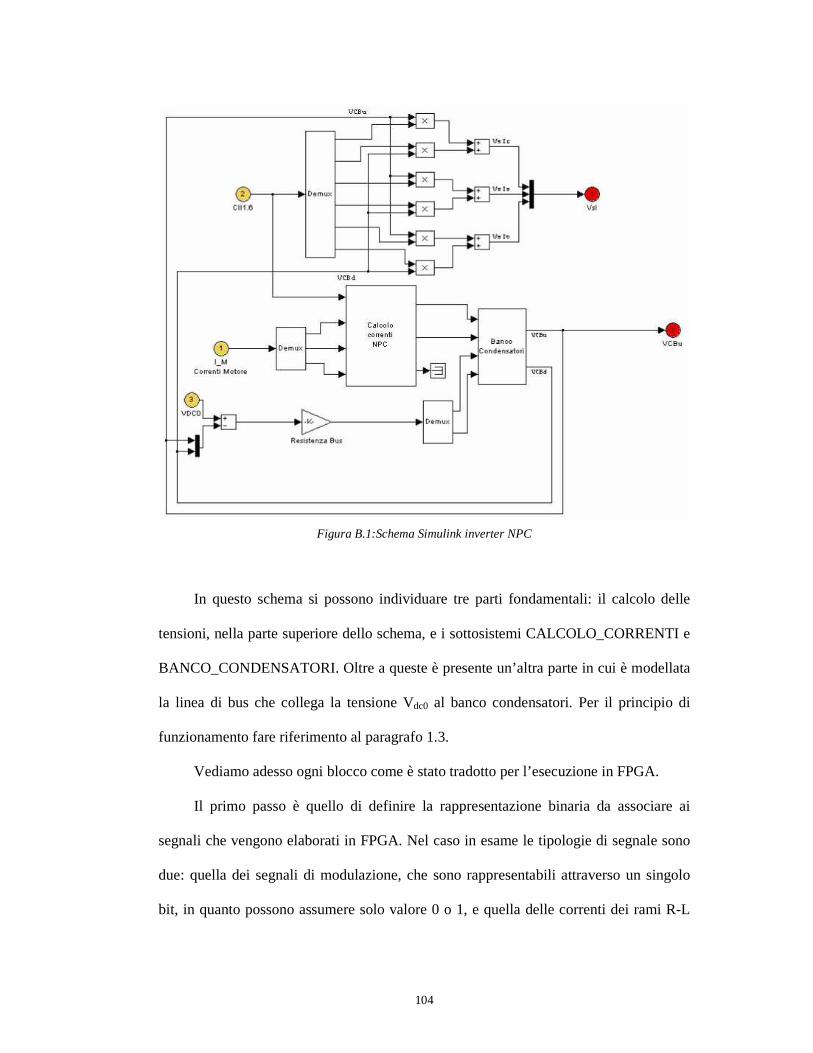
104
Figura B.1:Schema Simulink inverter NPC
In questo schema si possono individuare tre parti fondamentali: il calcolo delle
tensioni, nella parte superiore dello schema, e i sottosistemi CALCOLO_CORRENTI e
BANCO_CONDENSATORI. Oltre a queste è presente un’altra parte in cui è modellata
la linea di bus che collega la tensione Vdc0 al banco condensatori. Per il principio di
funzionamento fare riferimento al paragrafo 1.3.
Vediamo adesso ogni blocco come è stato tradotto per l’esecuzione in FPGA.
Il primo passo è quello di definire la rappresentazione binaria da associare ai
segnali che vengono elaborati in FPGA. Nel caso in esame le tipologie di segnale sono
due: quella dei segnali di modulazione, che sono rappresentabili attraverso un singolo
bit, in quanto possono assumere solo valore 0 o 1, e quella delle correnti dei rami R-L

105
che vengono portate in ingresso all’inverter. Per queste ultime grandezze, si è scelta una
rappresentazione binaria in virgola fissa (l’unica possibile in FPGA), con segno, del tipo
16_6 (Fix16_6), ovvero sui 16 bit totali, 10 bit sono destinati alla rappresentazione della
parte intera e 6 bit alla parte decimale.
In figura B.2 è mostrato lo schema interno del blocco CALCOLO_CORRENTI,
analogo a quello per il calcolo delle tensioni, che effettua la moltiplicazione dei 6
segnali di fase con le opportune correnti; queste grandezze vengono poi sommate per
ottenere il corretto valore di corrente da fornire al banco condensatori.
Figura B.2:Schema Simulink CALCOLO_CORRENTI

106
Tenendo presente che i segnali di modulazione possono assumere solo i valori 0 e
1, la moltiplicazione per questi segnali si traduce in un AND bit a bit, mentre la somma
viene effettuata attraverso gli addizionatori binari messi a disposizione dalle librerie
della Xilinx. Ne consegue che il corrispettivo schema FPGA è il seguente:
Figura B.3:Implementazione in FPGA blocco CALCOLO_CORRENTI.
Le uscite di questo blocco sono segnali rappresentati nel formato Fix18_6, in
quanto i due livelli di addizionatori hanno aggiunto due ulteriori bit per eventuali
overflow. Queste grandezze rappresentano le correnti di inverter che vanno in ingresso
al banco condensatori, assieme alle due correnti di bus.
Analogo discorso vale per il calcolo delle tensioni di inverter (la parte superiore
dello schema in figura B.1).
Le figure B.4 e B.5 mostrano un confronto tra il blocco
BANCO_CONDENSATORI e la corrispettiva implementazione in FPGA.

107
Figura B.4:Schema Simulink BANCO CONDENSATORI
Figura B.5:Implementazione in FPGA blocco BANCO_CONDENSATORI .
Da questo confronto risulta evidente la differenza tra i due livelli di astrazione
utilizzati per descrivere i due schemi.
La prima operazione è una sottrazione, il risultato è fornito nella rappresentazione
Fix35_4: è necessario un cast per riportare la rappresentazione ad un numero di bit
minore o uguale di 18 in quanto la successiva operazione è la moltiplicazione per
l’inverso della capacità, effettuata in FPGA attraverso moltiplicatori embedded a 18bit.

108
Questo non esclude la possibilità di effettuare moltiplicazioni tra valori codificati
con un numero di bit maggiore a 18, ma questa eventualità è da evitare se, come nel
caso in esame, è necessario utilizzare il minor numero di risorse possibile.
Questo problema risulta più evidente analizzando il blocco Integratore (figura
B.6). In questo caso, infatti, l’operazione più onerosa è la moltiplicazione dell’ingresso
u per il periodo di integrazione, necessaria per implementare l’algoritmo di Forward
Eulero descrittivo della dinamica sul condensatore.
Il passo di integrazione, nel caso in esame, vale 10ns esprimibile quindi con non
meno di 33 bit. Questo significa che verranno utilizzati più moltiplicatori embedded a
18bit per effettuare questa operazione. Considerando che in ognuno dei quattro inverter
è presente un banco condensatori e per ogni banco condensatori ci sono due integratori e
considerando anche le altre operazioni all’interno dell’inverter che utlizzano i
moltiplicatori, si arriva all’impiego di un numero di risorse eccessivo (la FPGA in
esame ha a disposizione solo 44 moltiplicatori embedded a 18 bit).
Figura B.6:Implementazione in FPGA blocco Integratore .
Occorre, dunque, trovare un’altra soluzione per far fronte a questo problema. In
figura B.6, è rappresentato il modello dell’integratore in cui la moltiplicazione per il
passo di integrazione viene effettuata attraverso uno shift più una moltiplicazione per un

109
numero più piccolo. Infatti esprimendo 10ns in potenze di 2 si giunge alla seguente
relazione: 279 23422.11010 −− ∗=⋅ .
Dalla figura si nota infatti la prima moltiplicazione per 1.3422, numero
esprimibile con 13 bit, e il successivo shift di 27 bit a destra. In questo modo si è riusciti
a diminuire il numero di risorse utilizzate, ma allo stesso tempo sono stati introdotti
degli errori dovuti alle approssimazioni effettuate.
L’insieme delle operazioni descritte fino ad ora hanno portato alla determinazione
del termine Ts*u dell’algoritmo di Forward Eulero: xk+1 = xk + Ts*u.
Le restanti operazioni sono, dunque, la somma del valore appena trovato con il
campione all’istante corrente, per ottenere quello successivo, e la somma della
condizione iniziale (indicata con Initial_condition in figura B.6).
Infine, il valore così calcolato viene di nuovo convertito nella rappresentazione
Fix16_6 per essere consistente con le altre grandezze del blocco InverterNPC.
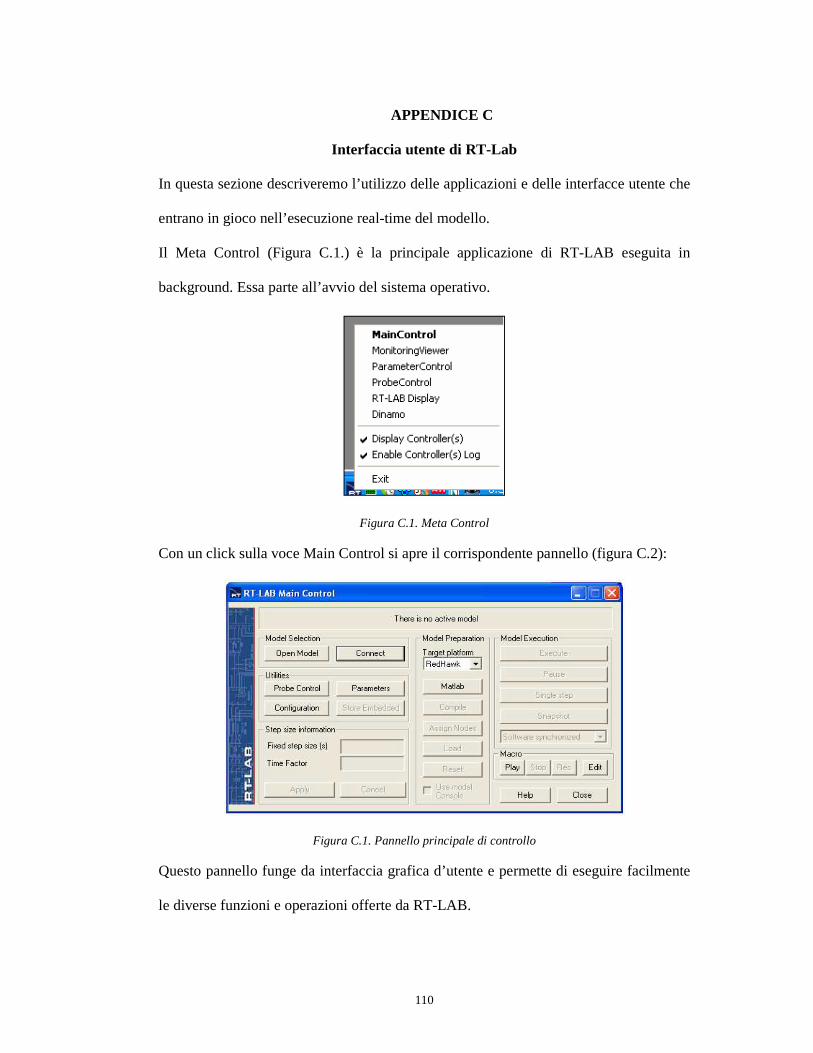
110
APPENDICE C
Interfaccia utente di RT-Lab
In questa sezione descriveremo l’utilizzo delle applicazioni e delle interfacce utente che
entrano in gioco nell’esecuzione real-time del modello.
Il Meta Control (Figura C.1.) è la principale applicazione di RT-LAB eseguita in
background. Essa parte all’avvio del sistema operativo.
Figura C.1. Meta Control
Con un click sulla voce Main Control si apre il corrispondente pannello (figura C.2):
Figura C.1. Pannello principale di controllo
Questo pannello funge da interfaccia grafica d’utente e permette di eseguire facilmente
le diverse funzioni e operazioni offerte da RT-LAB.

111
Ciccando su Open Model è possibile selezionare il modello da processare ed eseguire
(figura C.3).
Figura C.3. Finestra di apertura modelli
È necessario che il modello originale sia raggruppato in sottosistemi e che ciascuno di
essi sia identificato attraverso specifici prefissi SC_ , SM_, SS_.
− SC_: indicativo per il sottosistema Console; è un sottosistema che opera sulla
stazione di comando e permette l’interazione da parte dell’utente con il
sistema. Contiene i blocchetti Simulik relativi all’acquisizione e alla
visualizzazione dei dati (scope, manual switch, To workspace block etc.). Si
può avere una sola Console per modello.
− SM_: indicativo per il sottosistema Master, e contiene gli elementi
computazionali del modello. Ci può essere uno ed un solo sottosistema Master
all’interno di un modello.
− SS_: indicativo per il sottosistema Slave; contiene gli elementi computazionali
del modello quando il processo viene distribuito su più nodi target. Ci possono
essere diversi sottosistemi Slave all’interno di un modello.

112
Il selettore Target Platform permette di selezionare la piattaforma target su cui far
eseguire il modello (QNX6, RedHawk, Window NT/2000/XP) (figura C.4).
Figura C.2. Selezione della piattaforma Target
Con il tasto Edit è possibile visualizzare il modello Matlab/Simulink selezionato, per
eventuali modifiche; Il comando Compile invece avvia la compilazione del modello, in
particolare esegue la separazione del modello, genera il codice e compila i vari
sottosistemi del modello distribuito.
È possibile selezionare le appropriate opzioni di compilazione ciccando col tasto destro
su Compile. Compare la seguente finestra:
Figura C.5. Opzioni di compilazione
che include:

113
− Separazione del modello; il modello viene suddiviso in sottosistemi come
specificato nel modello. Questa opzione viene sempre applicata a tutti i
sottosistemi;
− Generazione del codice; abilitando questa opzione viene generato il codice C
per il sottosistema selezionato;
− Trasferimento dei files; il codice generato per i sottosistemi selezionati e i
files supplementari specificati, se ve ne sono, vengono trasferiti tramite FTP
al nodo di compilazione;
− Compilazione del codice generato; con questa opzione il codice generato per
il sottosistema selezionato viene compilato sul relativo nodo di compilazione;
− Richiamare i files dal target; con questa opzione il codice binario per il
sottosistema selezionato e i files supplementari vengono trasferiti tramite FTP
dal nodo di compilazione alla Command Station.
La fase di compilazione può essere seguita dall’utente sul pannello RT-LAB Display
che compare all’avvio della compilazione:
Figura C.3. Finestra di compilazione

114
Compilato il modello, Simulink sul tasto Assign Node assegniamo a ciascun
sottosistema un nodo target. Nel relativo pannello compare il nome del sottosistema ed
il nodo target su cui deve essere eseguito, accanto compare la lista dei nodi target ancora
disponibili (figura C.7).
Figura 4. Assegnazione del nodo target
La modalità XHP può essere selezionata al fine di ridurre i tempi di integrazione del
modello riservando tutte le risorse al task, disabilitando gli interrupt di sistema.
CPU indica il numero della CPU sulla quale il sottosistema sarà eseguito; mentre il tasto
Ping controlla che il nodo selezionato sia connesso alla rete.
NOTA: É necessario configurare i nodi target sui quali deve avvenire la compilazione.
Essi sono definiti da un nome e da un indirizzo IP; tutto deve essere fatto prima
dell’assegnazione dei nodi ai sottosistemi.
Una volta effettuata la compilazione è possibile caricare il modello; cliccando sul
comando Load viene caricato il codice eseguibile sui diversi nodi. Al caricamento
compare nuovamente il pannello RT-LAB Display, che consente all’utente di seguire la
procedura (figura C.8).

115
Figura 5. Finestra di caricamento
Prima di eseguire il modello è possibile scegliere la modalità di esecuzione con
l’opzione Execution mode (figura C.9) che ti permette di scegliere tra:
− Simulation: il modello non è sincronizzato; avvia un nuovo passo
computazionale non appena il primo sia completato. Nelle simulazioni
distribuite i nodi target sono sincronizzati tra loro attraverso link di
comunicazione.
− Simulation with low Simulink: è come la modalità Simulation ma i
sottosistemi computazionali vengono eseguiti con bassa priorità. È utile
quando la simulazione avviene sulla Command Station in modo da lasciare
libere le risorse di CPU per alte applicazioni (è una modalità disponibile solo
per target Window).
− Software Synchronized: la sincronizzazione real-time dell’ intera simulazione
è realizzata dal sistema operativo usando, come riferimento, il clock della
CPU. Nelle simulazione distribuite su più nodi, soltanto un nodo

116
computazionale è sincronizzato, tutti gli altri si sincronizzano a questo
tramite link di comunicazione.
− Hardware Synchronized: la sincronizzazione dell’intera simulazione viene
realizzata utilizzando il clock delle schede di I/O. È necessario inserire uno
blocco OpSync che serve ad individuare e configurare il clock esterno. Se si
esegue un modello distribuito su più target, solo un nodo computazionale si
sincronizza con il clock esterno, tutti gli altri si sincronizzano attraverso link
di comunicazione.
Figura C.6. Selezione della modalità di esecuzione
Il tasto Execute avvia il sistema e l’esecuzione del modello distribuito in rete; se si
seleziona la modalità Use Console Model, la Console del modello si avvia
automaticamente la prima volta che si esegue il modello.
Il tasto di Pause mette il sistema in uno stato di attesa, arrestando le procedure di calcolo
senza ripristinare i nodi. Per continuare l’esecuzione, è sufficiente premere nuovamente
Execute. Il comando Reset invece inizializza i nodi del sistema e causa un arresto
completo e un unloading del sistema.
È possibile che sia necessario modificare alcuni valori, questo può essere fatto con il
comando Parameters.

117
Ciccando su Parameters si apre il pannello di controllo mostrato in figura64; questo
pannello si occupa delle modifiche on line dei parametri del modello una volta che
questo è caricato sul target. Permette di modificare i parametri contenuti nei blocchi
Simulino e le variabili definite nel Workspace di Matlab. Tutti i parametri possono
essere modificati senza dover ricompilare il modello.
Figura C.7. Pannello di controllo dei parametri
Con il comando Configuration si apre una interfaccia grafica che permette di settare i
parametri locali e globali presenti in RT-LAB (figura C.11):
Figura C.8. Finestra di configurazione generale
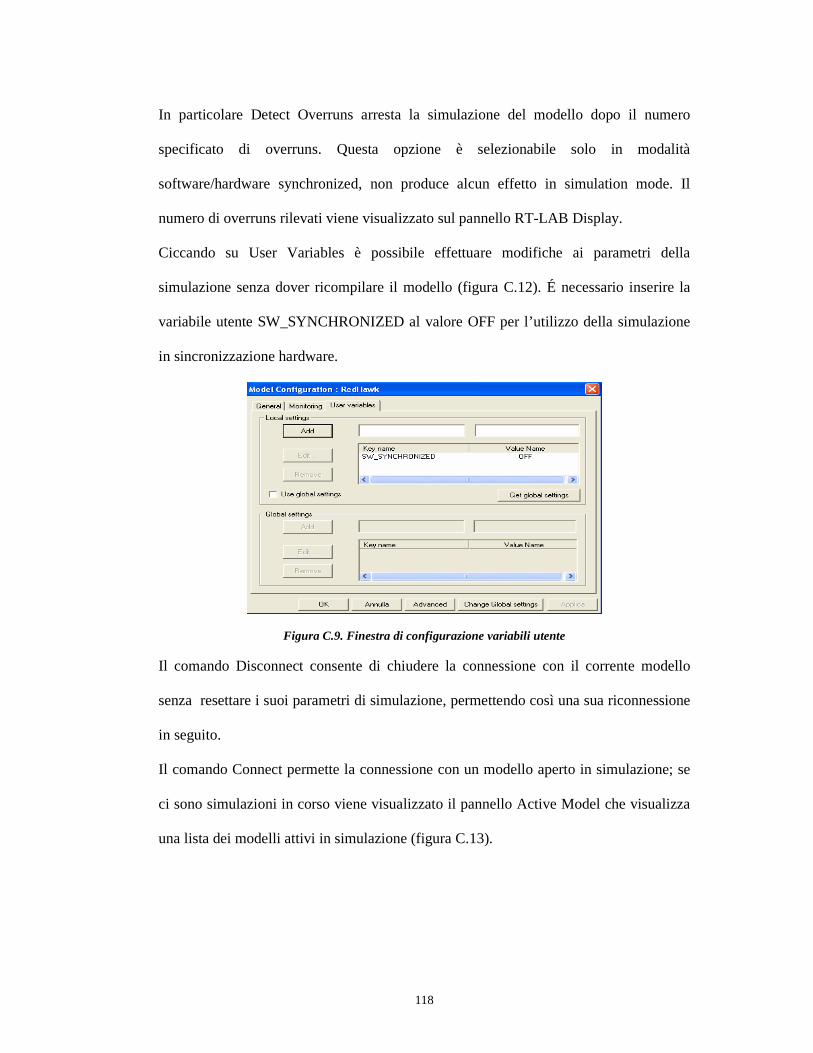
118
In particolare Detect Overruns arresta la simulazione del modello dopo il numero
specificato di overruns. Questa opzione è selezionabile solo in modalità
software/hardware synchronized, non produce alcun effetto in simulation mode. Il
numero di overruns rilevati viene visualizzato sul pannello RT-LAB Display.
Ciccando su User Variables è possibile effettuare modifiche ai parametri della
simulazione senza dover ricompilare il modello (figura C.12). É necessario inserire la
variabile utente SW_SYNCHRONIZED al valore OFF per l’utilizzo della simulazione
in sincronizzazione hardware.
Figura C.9. Finestra di configurazione variabili utente
Il comando Disconnect consente di chiudere la connessione con il corrente modello
senza resettare i suoi parametri di simulazione, permettendo così una sua riconnessione
in seguito.
Il comando Connect permette la connessione con un modello aperto in simulazione; se
ci sono simulazioni in corso viene visualizzato il pannello Active Model che visualizza
una lista dei modelli attivi in simulazione (figura C.13).
119
Figura C.10. Finestra dei modelli attivi

120
APPENDICE D
Specifiche tecniche
OP5110-Reconfigurable FPGA Platform and I/O Interface
Figura D.1. Scheda FPGAOP5110
Basata su FPGA XilinxVirtexII Pro, l’OP5110 può essere installata permettendo di
trarre il massimo vantaggio dall’ampiezza di banda del Bus, e offre fino a 144 pin di I/O
user-configurable.
I canali digitali di I/O lavorano ad una frequenza di ciclo di 100 MHz per una
risoluzione inferiore ai 10 ns. La OP5110 include l’interfaccia SignalWire real-time ad
alta velocità che permette di connettere tra loro processori RT-Lab distribuiti per
operare ad una frequenza maggiore. Questo collegamento sfrutta la potenza FPGA per
trasferire fino a 1,2 Gbits/s full-duplex, quasi il doppio del rate della Fire Wire (IEEE
1394) e circa il 10% della latenza, permettendo di eseguire simulazioni distribuite a cicli
di tempo inferiori a 10 µs e senza generare overruns.
Le principali caratteristiche sono:
− Processore Xilinx VirtexII Pro per installazione su PC;
− Fino a 144 linee I/O software-configurable;

121
− Trasferimento rapido DMA burst tra memoria FPGA e memoria modello
(30ns per evento);
− Fino a 4 porte Signal Wire per la comunicazione di dati a latenze ultra-basse;
− Libreria drag-and-drop di blocchi RTLAB per Simulink.
OP5130-Reconfigurable FPGA Platform and I/O Interface e
OP5330 Analog Output-OP5340 Analog Input Module
Figura D.2. Scheda FPGA OP5130 e moduli mezzanine
Basata su FPGA Xilinx Virtex-II Pro, la OP5130 può essere installata in uno slot 4U di
un HILbox RT-LAB o su uno chassis esterno di condizionamento di segnale per I/O
remoti, comunicante con il PC Target attraverso un’interfaccia SignalWire. La scheda
OP5130 include due interfacce per due moduli mezzanine. La porta Signal Wire
sull’OP5130 permette di connettere tra loro processori distribuiti per operare a velocità
maggiori. Questo collegamento real-time trasporta fino a 1.25 Gbits/s full duplex, con
una latenza di 200 ns.
Le principali caratteristiche sono:
− Processore Xilinx VirtexII Pro per installazione esterna;

122
− Fino a 64 linee di I/O digitale software-configurable per event
capture/generator, PWM I/O, e funzioni utente;
− Locazione per due moduli mezzanine per la l’acquisizione e la conversione
dei segnali;
− Fino a 32 canali di I/O Analogici a 16 bit, che campionano simultaneamente a
1MS/s per canale;
− Libreria drag-and-drop di blocchi RT-Lab per Simulink.
− Fino a 16 canali analogici di ingresso/uscita;
− DAC/ADC a 16bit per canale;
− Uscita simultanea di tutti i canali : si eliminano gli skew error;
− La OP5330 ha un tasso di aggiornamento massimo per canale di 1 MS/s per
un throughput totale di 16 MS/s per 16 canali;
− La OP5340 ha un tasso di aggiornamento di 500 kS/s per canale per un
throughput totale di 8MS/s;
− Libreria drag-and-drop di blocchi per Simulink.
OP5210 Type A I/O Module Carrier - OP5312 Digital Output Signal Conditioning
Module - OP5311 Digital Input Signal Conditionig Module
FiguraD.3.Carrier passivo OP5210 e moduli mezzanine

123
La OP5210 è un carrier passivo dalle seguenti caratteristiche:
− OPXI Form-factor per HILbox 4U;
− Robusto case in alluminio;
− Connettore esterno a 96 vie;
− Collegamento diretto alle OP5100 e alle interfacce I/O di terze parti;
− Locazione per due moduli mezzanine OP5310 e/o OP5320
o Signal conditioning I/O Analogico;
o Signal conditioning I/O Digitale;
− Può essere connessa ad una OP5130 per connessione tramite Signal Wire ad
un PC Target.
Le OP5311/5312 sono due moduli che alloggiano sul carrier, consentono di avere fino
a 16 segnali digitali in ingresso/uscita per singolo modulo. Poiché il carrier OP5210 può
accomodare fino a due moduli mezzanine, esse permette di fornire fino a 32 segnali per
carrier.

124
APPENDICE E
Lista dei simboli
Convenzioni generali:
a) I pedici R o S si riferiscono, rispettivamente, al lato rotore o statore
b) Il pedice F si riferisce all’avvolgimento di eccitazione (o campo-field)
c) Il pedice D si riferisce all’avvolgimento smorzatore sull’asse diretto d
d) Il pedice Q si riferisce all’avvolgimento smorzatore sull’asse in quadratura q
e) Le lettere maiuscole contraddistinte dallo stile grassetto rappresentano matrici
f) Le lettere minuscole contraddistinte dallo stile grassetto rappresentano vettori
d q,ψ ψ Flussi di statore degli assi d e q [Wb]
D Q,ψ ψ Flussi degli avvolgimenti smorzatori degli assi d e q [Wb]
Fψ Flusso dell’avvolgimento di eccitazione F [Wb]
md mq,ψ ψ Flussi di mutua induttanza degli assi d e q [Wb]
d qi , i Correnti di statore degli assi d e q [A]
D Qi , i Correnti circolanti nei avvolgimenti smorzatori ( assi d e q) [A]
Fi Corrente di eccitazione [A]
d qV , V Tensioni di statore negli assi d e q [V]
D QV , V Tensioni ai capi degli avvolgimenti negli assi d e q [V]
FV Tensione d’ eccitazione [V]
RSD Resistenza di statore nell’asse diretto d. [Ohm]

125
RSQ Resistenza di statore nell’asse in quadratura q [Ohm]
RRD Resistenza dell’avvolgimento smorzatore nell’asse d (riferita allo statore)
[Ohm]
RRQ Resistenza dell’avvolgimento smorzatore nell’asse q (riferita allo statore)
[Ohm]
XAD Induttanza lineare magnetizzante nell’asse diretto d [H]
XAQ Induttanza lineare magnetizzante nell’asse in quadratura q [H]
XLD Induttanza di leakage lato statore nell’asse diretto d [H]
XLQ Induttanza di leakage lato statore nell’asse in quadratura q [H]
XRD Induttanza di leakage dell’avvolgimento smorzatore nell’asse diretto d
[H]
XRQ Induttanza di leakage dell’avvolgimento smorzatore nell’asse in
quadratura q [H ]
RF Resistenza dell’avvolgimento d’eccitazione ( field) ( riferita allo statore)
XLF Induttanza di leakage dell’avvolgimento d’eccitazione ( riferita allo
statore) [H]
e m,ω Ω Velocità elettrica e meccanica di rotore [rad/sec]
θ Angolo di carico [rad]
PP Numero di coppie polari
em LT ,T Coppia elettromagnetica e coppia di carico [Nm]
J Costante di inerzia [kg*m2]
B Coefficiente di attrito viscoso

126
BIBLIOGRAFIA
[1] Cavallo, Setola, Vasca, “La nuova guida a Matlab Simulink e Control Toolbox”,
Liguori Editore, Napoli, 2002.
[2] IEEE Power Engineering Society, IEEE Guide for Synchronous Generator Modeling
Practices and Applications in Power System Stability Analyses, IEEE Std. 1110-2002
[3] S.A. Nasar, I. Boldea, Electric machines dynamics and control, CRC Press.
[4] Ojo, J.O. and Lipo, T.A., “An improved model for saturated salient pole
synchronous motors”, IEEE Transactions on Energy Conversion, Vol. 4, No. 1, pp. 135-
142, March 1989.
[5] Xie, G. and Ramshaw, R.S., “Nonlinear model of synchronous machines with
saliency”, IEEE Transactions on Energy Conversion, Vol. 1, No. 3, pp. 198-204, 1986.
[6] Tahan, S.A. and Kamwa, I., “A two-factor saturation model for synchronous
machines with multiple rotor circuits”, IEEE Transactions on Energy Conversion, Vol.
10, No. 4, pp. 609-616, December 1995.
[7] I. Iglesis, L. Garcia-Tabares and J. Tamarit. “A d-q model for the self commutated
synchronous machine considering the effects of magnetic saturation”, IEEE
Transactions on Energy Conversion, Vol. 7, No. 4, pp. 768-776, December 1992.

127
[8] E. Levi, “Saturation modelling in d-q- axis models of salient pole synchronous
machines”, IEEE Transactions on Energy Conversion, Vol. 14, No. 1, pp. 44-50, March
1999.
[9] D. Brunel, L. Flambard, C. Lompre, A. Sarrazin, “Hardware in the loop (HIL) tools
development and use process for testing and validating car and trucks electronic control
units (ECU)“, Automotive Technologies Congress (OTEKON) 2006.
[10] P. Terwiesch, T. Keller, E. Scheiben, “Rail Vehicle Control System Integration
Testing Using Digital Hardware-in-the-Loop Simulation”, IEEE Transactions on
Control Systems Technology, vol. 7, no. 3, pp. 352–362, May 1999.
[11] www.opal-rt.com
[12] K.B. Bose, “Power Electronics and Ac Driver”, Prentice-Hall, Englewood Cliffs,
New Jersey.
[13] Mohan, Undeland, Robbins, “Power Electronics”, John Wiley & Sons, 1995.
[14] P. Chaturvedi, Shailendra Jain and Pramod Agrawal , “Modeling, simulation and
analysis of three-level neutral point clamped inverter using Matlab/Simulink/power
system blockset”, Proceedings of the Eighth International Conference on Electrical
Machines and Systems, Vol. 2, pp. 1223 – 1227, Sept. 2005.

128
[15] M. Giesselmann and B. Crittenden, “Design and construction of a neutral point
clamped inverter”, IEEE Twenty-Second International Power Modulator Symposium,
pp. 235-238, June 1996.
[16] A.I. Alolah, L.N. Hulley and W. Shepherd, ”A three-phase neutral point clamped
inverter for motor control”, IEEE Transactions on Power Electronics, Vol. 3, Issue 4,
pp. 399 – 405, Oct.1988
[17] B.P. McGrath and D.G. Holmes, “A comparison of multicarrier PWM strategies
for cascaded and neutral point clamped multilevel inverters”, IEEE 31st Power
Electronics Specialists Conference, Vol. 2, pp. 674-679, June 2000