testy základných štatistických hypotézfiles.bio-med-stat.webnode.sk/200000091-c6d96c7d33/testy...
TRANSCRIPT

Testy základných štatistických hypotéz
Peter Kvasnička KJFB FMFI UK
(Projekt KEGA 003UK-4/2012 )
Obsah 1. Štatistika na Webe, voľne dostupné materiály a software 2. Úvod do testovania štatistických hypotéz 3. Hypotézy o stredných hodnotách 4. Alternatívne náhodné premenné 5. Testy dobrej zhody a kontingenčné tabuľky 6. Analýza rozptylu a viacnásobné porovnania 7. Lineárna regresia

Testy základných štatistických hypotéz 2
1. Zdroje na Webe a voľne dostupné materiály Na Webe nájdete všetky potrebné nástroje pre základnú štatistiku - študijné materiály, štatistické kalkulátory i softvér na stiahnutie. V tomto prehľade som sa sústredil na veci, ktoré sú zadarmo a môžete ich využiť pri riešení úloh.
Materiály o štatistike, on-line učebnice, články a pod.
Statistics.com (http://www.statistics.com)
Veľké množstvo odkazov na štatistické stránky a softvér na Webe. Nájdete tu väčšinu nasledujúcich odkazov.
Statistics at Square One
(http://bmj.bmjjournals.com/collections/statsbk/index.shtml)
On-line štatistická príručka pre medikov, obsahuje prehľad základných štatistických testov s nenáročným, ale celkom dobrým výkladom. Nájdete tu všetky testy, o ktorých bude reč v tomto dokumente, aj s príkladmi a tabuľkami kritických hodnôt.
HyperStat Online Statistics Textbook
(http://davidmlane.com/hyperstat/)
On-line príručka, orientovaná na analýzu rozptylu, pokrýva ale základy štatistiky a základné testy. Nenechajte sa znechutiť trochu zmätenou úpravou; veľmi odporúčam odkazy na iné texty pri jednotlivých častiach; tak nájdete napríklad k t-testu celý zoznam rôznych textov. Stačí si vybrať. Ďalšie užitočné odkazy nájdete na úvodnej stránke.
VassarStats: Richard Lowry (http://faculty.vassar.edu/lowry/webtext.html)
On-line knižka, veľmi odporúčam. Staršie verzie textov sa dajú stiahnuť v pdf (časť Printing). Okrem toho tu on-line nájdete množstvo užitočných pomôcok, napríklad kalkulátory kvantilových funkcií pre štandardné normálne, t-, F- a χ2 rozdelenie.
Electronic Statistics Textbook (http://www.statsoft.com/textbook/stathome.html) To je on-line manuál k programu Statistica, ale stojí za to aj sám osebe.
NIST/Sematech Statistical Textbook (http://www.itl.nist.gov/div898/handbook/index.htm)
Inžiniersky orientovaná štatistika. Podrobná a dôkladná. Nenájdete tu biologicky a medicínsky orientované veci, ako štatistiku dôb prežitia. Ale to čo nájdete je naozaj dobré.
Practice of Business Statistics (http://bcs.whfreeman.com/pbs/pages/bcs-main.asp?s=00180&n=99000&i=99180.01&v=category&o=&ns=0&uid=0&rau=0)
Tu nájdete ukážkové kapitoly z knižky pre ekonómov. Veľmi odporúčam, aj keď z vecí, ktoré potrebujete pre tento kurz, je tam iba ANOVA a neparametrické testy.

Testy základných štatistických hypotéz 3
Dostupný štatistický softvér Väčšinu príkladov v tomto texte som počítal v Exceli a kontroloval v R. Z R pochádzajú aj krajšie grafy, tie škaredšie sú samozrejme z Excelu.
Microsoft Excel
Excel vám stačí na väčšinu počítania, ak si nájdete kritické hodnoty pre niektoré špeciálne testy (napríklad Tukeyho alebo neparametrické testy) na Webe. Excel je vybavený množstvom štatistických funkcií (Analytické nástroje), ktoré sú však 1. často nešikovné (histogramy), chybné (štandardné odchýlky, čiary trendu) alebo používajú netradičné konvencie, ktoré okrem Microsoftu nepoužíva nikto iný (poradia). Prehľad vecí, ktoré v Exceli nefungujú, spísal v peknom článku Hans Pottel (Statistical flaws in Excel, http://www.mis.coventry.ac.uk/~nhunt/pottel.pdf). Preto odporúčam počítať si radšej všetko ručne. (Ja som sa nevyhol použitiu funkie pre výberovú varianciu, pretože človeku sa nechce zakaždým zriaďovať stĺpec rozdielov). Na druhej strane, Excel ako programovateľný tabuľkový kalkulátor je ideálne prostredie pre prácu s dátami. Ak sa nebudete spoliehať na jeho štatistické funkcie, budete pracovať pohodlne a rýchlo. Ešte upozorním na desatinné čiarky: Ak budete prenášať dáta z anglicky hovoriaceho programu do česky alebo slovensky hovoriaceho Excelu, narazíte na problém s desatinnými čiarkami a bodkami. Použite ako medzistanicu textový editor alebo Word a nahraďte bodky čiarkami alebo naopak.
Komerčný štatistický softvér
Sem patria programy ako Statistica, SAS, SPSS a pod., ktoré sú poväčšine rozprávkovo drahé. Ak máte to šťastie, že k nim máte prístup, využite to.
Štatistický softvér zadarmo
R R je otvorený systém pre štatistické výpočty. Je podobný Matlabu, tvorí ho interaktívna konzola s možnosťou spúšťania skriptov. Prostredie je oproti veľkým komerčným programom trocha sparťanské, ale vďaka dobrej dokumentácii sa naučíte robiť základné veci rýchlo a efektívne. Vďaka programovateľnosti máte navyše k dispozícii možnosti, ktoré v komerčných programoch spravidla nemáte, to sa týka predovšetkým rozsiahlych možností simulácií a moderných výpočtovo náročných štatistických metód. Domovská stránka je www.r-project.org, program si môžete stiahnuť zadarmo aj s dokumentáciou a rozširujúcimi balíkmi z www.cran.r-project.org.
OpenStat4 a PAST (http://www.statpages.org/miller/openstat/) (http://folk.uio.no/ohammer/past/) Toto sú pomerne malé programíky, robia väčšinu vecí, ktoré budete potrebovať, len musíte prísť na to, ako - ale nebude to náročné.
Štatistický softvér, ktorý si môžete stiahnuť na vyskúšanie
xlStat a StatTools (http://www.xlstat.com/ a http://www.palisade.com/stattools/) Toto sú doplnky k Excelu, ktoré ho vybavujú rozsiahlymi štatistickými možnosťami. xlStat je overený a veľmi dobrý, ale aj veľmi drahý. StatTools je skromnejší produkt, ale tiež vám bude stačiť. Ak si stiahnete trial verzie, bude sa vám pracovať pohodlne a efektívne.

Testy základných štatistických hypotéz 4
Štatistické kalkulátory na Webe
StatPages.net (http://StatPages.org)
Tu nájdete odkazy na veľký počet rôznych kalkulátorov, vrátane kalkulátorov pre štatistické testy a lineárnu regresiu. Okrem toho tu nájdete veľa ďalších odkazov na materiály o štatistike a štatistický softvér.
WebStat (http://www.webstatsoftware.com)
Úplne základné štatistické texty, pohodlné načítanie dát, grafika.
VassarStats: Richard Lowry
(http://faculty.vassar.edu/lowry/webtext.html)
Množstvo užitočných pomôcok, napríklad kalkulátory kvantilových funkcií pre štandardné normálne, t-, F- a χ2 rozdelenie.
Tabuľky a kalkulátory kritických hodnôt Základné tabuľky kritických hodnôt si môžete stiahnuť napríklad zo stránok VassarStats v pdf formáte.

Testy základných štatistických hypotéz 5
2. Úvod do testovania štatistických hypotéz
Vzťah medzi štatistickými rozdeleniami a testmi hypotéz Pripomenieme si základné fakty o dôležitých štatistických rozdeleniach. Tieto vám často môžu poslúžiť pri výbere vhodného štatistického textu v danej situácii.
T-testy
Nech má náhodná premenná X normálne rozdelenie s nulovou strednou hodnotou a varianciou σ2. Nech je ďalej x pozorovaná hodnota náhodnej premennej a s2 štandardná odchýlka s ν stupňami voľnosti. Potom veličina
sxt =
má t- (Studentovo) rozdelenie s ν stupňami voľnosti. S pravdepodobnosťou 1-α bude pre t platiť:
αν
αν
αν
−
−
−
−><<
1,
1,
2/1,
tttttt
kde tν,1-α/2 a tν,1-α sú príslušné kritické hodnoty t-rozdelenia s daným počtom stupňov voľnosti.
t má zmysel podielu signál/šum. T-test použijeme tam, kde chceme zistiť, či je hodnota s rozdelením, nie veľmi odlišným od normálneho, významne odlišná od nuly: pre testovanie hypotéz o stredných hodnotách, koeficientoch lineárnej regresie a pod.
χ2 testy
Nech sú X1, X2, ... Xn nezávislé náhodné premenné s normálnym rozdelením (nie nevyhnutne rovnakým pre všetky veličiny). Nech ξi, i=1,2,... n sú odhady veličín Xi, <Xi>=ξi, <(Xi – ξi)2>=σi
2. Potom veličina
⌠=
���
�⌡⌡
−=n
i i
iix1
22
σξχ
má rozdelenie χ2 s n-p stupňami voľnosti, kde p je počet parametrov, vypočítaných z hodnôt xi. Takže s pravdepodobnosťou 1-α platí
21
2αχχ −<
χ2 je súčet štvorcov odchýlok od očakávaných hodnôt. Takéto testy teda použijeme tam, kde budeme chcieť merať odchýlky pozorovaných a očakávaných (súborov) hodnôt (napríklad testy dobrej zhody a kontingenčné tabuľky).
F testy Majme dva súbory nezávislých hodnôt s normálnym rozdelením s rovnakou varianciou:

Testy základných štatistických hypotéz 6
[ ][ ]
( ) ( )11
11
,,2,1 ,,~
,,2,1 ,,~
1
2
21
2
2
11
2
2
−
−=
−
−=
==
=
=
��
��
==
==
y
n
ii
yx
n
ii
x
n
ii
y
n
ii
x
yYi
xxi
n
yys
n
xxs
yn
yxn
x
niNYniNX
yx
yx
�
�
σµσµ
Potom pomer štandardných odchýlok
2
2
y
x
ssF =
má rozdelenie F s nx-1 a ny-1 stupňami voľnosti. Takáto štatistika sa používa v celom rade testov, pretože veľmi často vieme za predpokladov nulovej hypotézy získať dva nezávislé odhady štandardnej odchýlky (analýza rozptylu -ANOVA, testy adekvátnosti modelov).

Testy základných štatistických hypotéz 7
3. Hypotézy o stredných hodnotách
Jednovýberový test: µ = µ0
Nech Xi, i=1,2,...n, sú i.i.d. N[µ,σ2] (i.i.d.= nezávislé s rovnakým rozdelením, z angl. independent identically distributed). Predpokladajme, že máme dôvod očakávať, že stredná hodnota X má špecifickú hodnotu µ=µ0. Nech je výberová stredná hodnota a výberová variancia
�
�
=
=
−−
=
=
n
ii
n
ii
xXn
s
Xn
x
1
22
1
)(1
1
1
Pre test hypotézy H0: µ=µ0 proti (dvojstrannej) alternatíve H1: µ≠µ0 alebo jednostranným alternatívam H-: µ<µ0, resp. H+: µ>µ0 použijeme testovaciu štatistiku
nss
sxt
x
x2
2
0 ,
=
−= µ
ktorá má t- (Studentovo) rozdelenie s n-1 stupňami voľnosti, a kritické oblasti
{ }{ }{ }α
α
α
−−+
−−−
−−
<=−<=
<=
1,1
1,1
2/1,11
: : :
nH
nH
nH
tttWtttW
tttW
kde tν,1-α/2 a tν,1-α sú príslušné kritické hodnoty t-rozdelenia s n-1 stupňami voľnosti.
Poznámky k jednovýberovému t-testu
Uvedený test predpokladá normálne rozdelenie hodnôt v testovanom súbore dát. Našťastie, t-test je robustný vzhľadom k miernym odchýlkam od normality, čo znamená, že nestráca platnosť, ak sa rozdelenie dát mierne odlišuje od normálneho.
Vo všeobecnosti možno povedať, že robustnosť
– je nižšia pre testy proti jednostranným alternatívam
– klesá s hladinou významnosti α
– rastie s objemom súboru n.

Testy základných štatistických hypotéz 8
Príklad 1 Výrobca vyrobil zariadenie, ktoré má spustiť alarm, ak koncentrácia kysličníka uhoľnatého vo vzduchu presiahne 10 mg/m3. Chceme overiť, či zariadenie skutočne pracuje podľa špecifikácie. Pre overenie sa uskutočnil nasledujúci experiment: Do komory o známom objeme naplnenej zo začiatku vzduchom bez CO sa postupne vpúšťali známe množstvá CO a sledovalo sa, pri ktorej koncentrácii sa aktivuje alarm. Postup sa opakoval osemnásťkrát s nasledujúcimi výsledkami:
Meranie cC O, mg.m-3
1 10,252 10,373 10,664 10,475 10,566 10,227 10,448 10,389 10,6310 10,4011 10,3912 10,2613 10,3214 10,3515 10,5416 10,3317 10,4818 10,68
Koncentrácie CO potrebné pre spustenie alarmu Histogram cCO
cCO
frekv
enci
a
10.0 10.1 10.2 10.3 10.4 10.5 10.6 10.7
01
23
45
67
Pre uvedené hodnoty máme:
3
232
3
232
3
/ 0329,0
)/( 0010820,0/ 140,0
)/( 0194761,0/ 429,10
18
mmgsmmgs
mmgsmmgs
mmgxn
x
x
=
==
=
=
=
Testovacia štatistika je
07,130329,0
1043,100 =−=−=xs
xt µ
Pre zistenie kritických hodnôt 975,0,17t pre test H0 proti H1 a 95,0,17t pre test H0 proti H+ môžeme
použiť Microsoft Excel a funkciu TINV(2*p, počet st. voľnosti), alebo štatistické tabuľky, alebo kalkulátor na Webe. Nájdeme 975,0,17t =2,11 a 95,0,17t =1,74. Pretože sme našli t=13,07, zamietame
nulovú hypotézu pre dvoj- i jednostrannú alternatívu, pričom vidno, že naša hodnota t je veľmi vysoká.
Alternatívne môžeme vypočítať pravdepodobnosť získania rovnakej alebo vyššej hodnoty t za predpokladu nulovej hypotézy. Použijeme buď funkciu TDIST(t, počet st. voľnosti, počet strán) z Excelu, štatistické tabuľky alebo kalkulátor na Webe. Dozvieme sa, že pravdepodobnosť je rádu 10-10, teda zanedbateľná. Skutočne, 95%-ný interval spoľahlivosti pre µ je (alebo inak povedané, s pravdepodobnosťou 95% platí):
50,1036,10975,0;17975,0;17
≤≤−≤≤−
µµ xx stxstx
Záver: Testované zariadenie aktivuje alarm pri hodnote štatisticky významne vyššej než 10 mg/m3. Ako vidno z histogramu dát, takýto výsledok je celkom zrejmý. Pretože vaše oko je najlepší štatistik, používajte ho a kým začnete počítať, najskôr si dáta zobrazte.

Testy základných štatistických hypotéz 9
Príklad 2 Nasledujúce dáta sú telesné teploty krabov prílivového pásma po tom, ako sa dostali na vzduch pri okolitej teplote 24,3°C. Úloha je zistiť, či je telesná teplota krabov rovná teplote okolia alebo sa od nej líši.
Histogram telesných teplôt
Telesná teplota, °C
Poče
t
22 23 24 25 26 27 28 29
01
23
45
6
Pre uvedené hodnoty máme:
C 26836,0)( 072017,0
C 341802,1)( 800433,1
C 028,2525
22
22
°=°=
°=°=
°==
x
x
sCs
sCs
xn
Testovacia štatistika je
2,7126836,0
3,24028,250 =−=−=xs
xt µ
a kritická oblasť pre test proti dvojstrannej alternatíve je 975,0;24tt ≥ . Pre zistenie kritických
hodnôt 975,0,24t pre test H0 proti H1 môžeme použiť Microsoft Excel a funkciu TINV(2*p, počet st.
voľnosti), alebo štatistické tabuľky, alebo kalkulátor na Webe. Nájdeme 975,0,24t =2,06. Pretože
sme našli t=2,71, zamietame nulovú hypotézu.
Môžeme tiež vypočítať pravdepodobnosť získania rovnakej alebo vyššej hodnoty t za predpokladu nulovej hypotézy. Použijeme buď funkciu TDIST(t, počet st. voľnosti, počet strán) z Excelu, štatistické tabuľky alebo kalkulátor na Webe. Dozvieme sa, že pravdepodobnosť je 0,012. 95%-ný interval spoľahlivosti pre µ je:
58,2547,24975,0;24975,0;24
≤≤−≤≤−
µµ xx stxstx
Záver: Telesná teplota krabov je štatisticky významne vyššia ako teplota okolitého vzduchu. V tomto prípade sme netestovali jednostrannú alternatívu, pretože z okolností nijako nevyplývalo, ktorým smerom by sa mala telesná teplota krabov odchyľovať od teploty okolia.
Meranie Teplota, °C1 25,802 24,603 26,104 22,905 25,106 27,307 24,008 24,509 23,9010 26,2011 24,3012 24,6013 23,3014 25,5015 28,1016 24,8017 23,5018 26,3019 25,4020 25,5021 23,9022 27,0023 24,8024 22,9025 25,40
Telesné teploty krabov prílivového pásma pri vonkajšej tepolte 24,3°C

Testy základných štatistických hypotéz 10
Dvojvýberový test: µ1 = µ2
Nech Xi, i=1,2,...nx, sú i.i.d. N[µx,σx2], Yi, i=1,2,...ny, sú i.i.d. N[µy,σy
2]. Potrebujeme testovať hypotézu µx=µy proti dvojstrannej alternatíve µx≠µy alebo jednostranným alternatívam µx<µy, resp. µx<µy. Inak povedané, zaujíma nás, aký veľký musí byť rozdiel medzi výberovými strednými hodnotami (aritmetickými priemermi X a Y, aby sme mohli spochybniť predpoklad µx=µy. Nech sú výberové stredné hodnoty a výberové variancie
��
��
==
==
−−
==
−−
==
y
x
n
ii
yy
n
ii
y
n
ii
xx
n
ii
x
yYn
sXn
y
xXn
sXn
x
1
22
1
1
22
1
)(1
11
)(1
11
Pre test hypotézy H0: µx=µy proti dvojstrannej alternatíve H1: µx≠µy alebo jednostranným alternatívam H1-: µx<µy, resp. H1+: µx>µy použijeme testovaciu štatistiku
y
y
x
xyxyx
yx
ns
nssss
syxt
22222 +=+=
−=
−
−
Takto síce dokážeme vypočítať yxs − , nevieme ale určiť jeho počet stupňov voľnosti. Ďalší postup závisí od dodatočného predpokladu o varianciách hodnôt X a Y:
(i) Rovnaké variancie: 22yx σσ = .
Predpoklad o rovnosti variancií nám umožňuje vypočítať lepší odhad spoločnej výberovej variancie s0
2 (súčet štvorcov odchýlok od priemeru pre X a Y, delený počtom nezávislých štvorcov):
2)1()1( 22
20 −+
−+−=
yx
yyxx
nnsnsn
s
Tento odhad potom použijeme namiesto príslušných výberových variancií pri výpočte yxs − :
��
�
�
⌡⌡
+=+=−
yxyxyx nn
sns
nss 112
0
20
202
Príslušný počet stupňov voľnosti je 2−+= yx nnν .
(ii) Rôzne variancie: 22yx σσ ≠ .
V tomto prípade nevieme vylepšiť odhad yxs − , a zo štatistického hľadiska je to zložitá situácia. Táto úloha sa nazýva Behrensov-Fisherov problém a existuje k nej rozsiahla literatúra a viacero riešení. Dnes sa štandardne používa jednoduché a dostatočne spoľahlivé riešenie, ktoré sa nazýva „Welchovo približné t“. Počet stupňov voľnosti pre
yxs − , a teda pre testovaciu štatistiku t, sa počíta ako vážený harmonický priemer:

Testy základných štatistických hypotéz 11
11
2222222
−
��
�
�
��
�
�
+−
���
����
�
=��
�
�
��
�
�+
y
y
y
x
x
x
y
y
x
x
nns
nns
ns
ns
ν
V oboch prípadoch, (i) aj (ii), má testovacia štatistika t Studentovo rozdelenie s ν stupňami voľnosti (kde ν je odlišné podľa toho, či sú variancie rovnaké alebo nie), a kritické oblasti sú
{ }{ }{ }αν
αν
αν
−+
−−
−
<=−<=
<=
1,1
1,1
2/1,1
: :
:
tttWtttW
tttW
H
H
H
kde tν,1-α/2 a tν,1-α sú príslušné kritické hodnoty t-rozdelenia s n-1 stupňami voľnosti.
Rovnako možno testovať hypotézy o predpokladanom rozdiele medzi strednými hodnotami. Konkrétne, pre test hypotézy H0: µx-µy=µ0 proti dvojstrannej alternatíve H1: µx–µy≠µ0 alebo jednostranným alternatívam H1-: µx–µy<µ0, resp. H1+: µx–µy>µ0, kde µ0 je predpokladaný rozdiel, použijeme testovaciu štatistiku
yxsyxt
−
−−= 0µ
a postupujeme rovnako.
Poznámky k dvojvýberovému t-testu
Narušenie predpokladov o normálnom rozdelení dát Aj dvojvýberový t-test je robustný vzhľadom na značné odchýlky od normality, a to najmä:
– ak sú veľkosti súborov rovnaké alebo temer rovnaké,
– ak testujeme dvojstranné hypotézy,
– ak sú súbory veľké,
– ak nepoužívame príliš nízke hladiny významnosti (napr. α<0,01).
Ak 22yx σσ ≠ , bude test poskytovať správnu hladinu významnosti, ak sú veľkosti súborov
rovnaké, a bude mierne konzervatívny (teda skutočná hladina významnosti bude nižšia než predpokladaná), ak väčší súbor pochádza z rozdelenia s väčšou varianciou. Test bude dávať chybné výsledky, ak menší súbor pochádza z rozdelenia s väčšou varianciou.
Použitie testu pre 22yx σσ = a 22
yx σσ ≠
Tieto testy sú identické, ak yx nn = alebo 22yx ss = . Ak yx nn ≠ a variancie sú výrazne
odlišné (pomer väčší ako 3), je Welchov test lepší. Naopak, ak sú variancie rovnaké, je lepší test pre rovnaké variancie.
Niektorí autori odporúčajú rozhodnúť o použití varianty testu na základe štatistického testu hypotézy o rovnosti variancií (napr. F-testu alebo Bartlettovho testu). Tieto testy sú však omnoho citlivejšie na odchýlky dát od normality než samotný t-test, a teda ich výsledky v skutočnosti často nebudú relevantné. Existuje mnoho prác, ukazujúcich, že neexistuje prípad, kedy by rozhodnutie na základe testu na rovnosť variancií dávalo lepšie výsledky než jednoduché rozhodnutie o použití niektorého testu na základe hrubého porovnania štandardných odchýlok.
Testy základných štatistických hypotéz 12
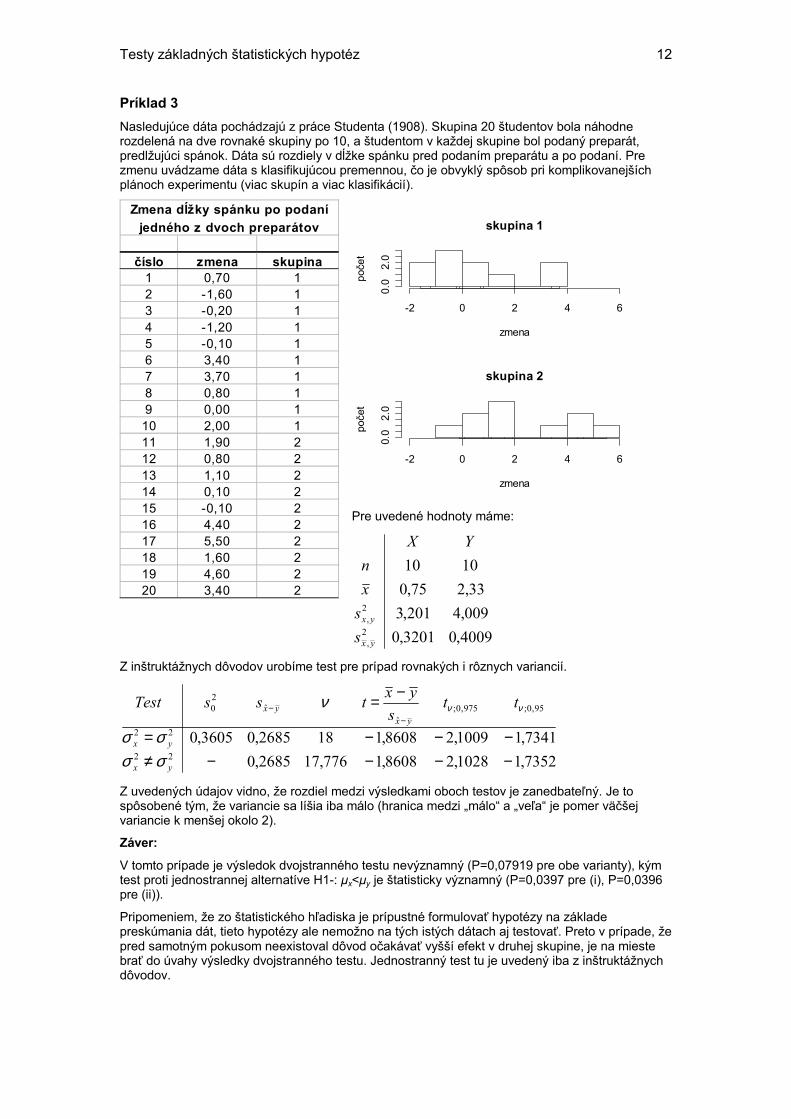
Príklad 3 Nasledujúce dáta pochádzajú z práce Studenta (1908). Skupina 20 študentov bola náhodne rozdelená na dve rovnaké skupiny po 10, a študentom v každej skupine bol podaný preparát, predlžujúci spánok. Dáta sú rozdiely v dĺžke spánku pred podaním preparátu a po podaní. Pre zmenu uvádzame dáta s klasifikujúcou premennou, čo je obvyklý spôsob pri komplikovanejších plánoch experimentu (viac skupín a viac klasifikácií).
skupina 1
zmena
poče
t
-2 0 2 4 6
0.0
2.0
skupina 2
zmena
poče
t
-2 0 2 4 6
0.0
2.0
Pre uvedené hodnoty máme:
4009,03201,0009,4201,333,275,0
1010
2,
2,
yx
yx
ssxn
YX
Z inštruktážnych dôvodov urobíme test pre prípad rovnakých i rôznych variancií.
7352,11028,28608,1776,172685,07341,11009,28608,1182685,03605,0
22
22
95,0;975,0;ˆ
ˆ20
−−−−≠−−−=
−=−
−
yx
yx
yxyx tt
syxtssTest
σσσσ
ν νν
Z uvedených údajov vidno, že rozdiel medzi výsledkami oboch testov je zanedbateľný. Je to spôsobené tým, že variancie sa líšia iba málo (hranica medzi „málo“ a „veľa“ je pomer väčšej variancie k menšej okolo 2).
Záver:
V tomto prípade je výsledok dvojstranného testu nevýznamný (P=0,07919 pre obe varianty), kým test proti jednostrannej alternatíve H1-: µx<µy je štatisticky významný (P=0,0397 pre (i), P=0,0396 pre (ii)).
Pripomeniem, že zo štatistického hľadiska je prípustné formulovať hypotézy na základe preskúmania dát, tieto hypotézy ale nemožno na tých istých dátach aj testovať. Preto v prípade, že pred samotným pokusom neexistoval dôvod očakávať vyšší efekt v druhej skupine, je na mieste brať do úvahy výsledky dvojstranného testu. Jednostranný test tu je uvedený iba z inštruktážnych dôvodov.
číslo zmena skupina1 0,70 12 -1,60 13 -0,20 14 -1,20 15 -0,10 16 3,40 17 3,70 18 0,80 19 0,00 110 2,00 111 1,90 212 0,80 213 1,10 214 0,10 215 -0,10 216 4,40 217 5,50 218 1,60 219 4,60 220 3,40 2
Zmena dĺžky spánku po podaní jedného z dvoch preparátov

Testy základných štatistických hypotéz 13
Test strednej hodnoty rozdielu: „párový t-test“ Test v tejto časti je tiež testom na rozdiel stredných hodnôt, vzťahuje sa však na iný plán experimentu: Predpokladajme, že pozorovania v súboroch X a Y sú korelované, napríklad že { }ii YX , sú hodnoty pre subjekt i za rozličných okolností, i=1,2,..n. V
takomto prípade je výhodné zohľadniť vzťah medzi pármi hodnôt { }ii YX , , preto použijeme iný postup: namiesto dvojvýberového testu hypotézy µx=µy budeme testovať hypotézu
0=≡− dyx µµµ
Za štandardných predpokladov o normálnom rozdelení rozdielov iii YXd −= (di sú i.i.d.
N[µd,σd2]) môžeme pre test hypotézy 0=dµ použiť jednovýberový t-test a postup,
uvedený vyššie.
Poznámky k párovému t-testu
Narušenie predpokladov o normálnom rozdelení dát Tento test predpokladá, že rozdiely di sú i.i.d. s normálnym rozdelením. Tento predpoklad môže byť narušený v dôsledku povahy dát, napríklad rozdiely môžu byť úmerné hodnotám (zmena dĺžky môže byť úmerná dĺžke a pod.). V takýchto prípadoch
možno namiesto rozdielu ii YX − použiť inú mieru odchýlky, napríklad podiel i
i
YX
,
relatívnu odchýlku i
ii
YYX −
a podobne. Cieľom je odstrániť závislosť di od X a Y a získať
podľa možnosti hodnoty so symetrickým a dobre lokalizovaným rozdelením. Tu veľmi pomôže dáta si nakresliť a vyskúšať rôzne varianty.
Na párový t-test sa vzťahujú aj všetky poznámky o robustnosti, uvedené u jednovýberového t-testu.
Kedy používať párový test Párový test je vhodný tam, kde existuje vzájomný vzťah medzi hodnotami X a Y. Pri nie veľmi malých objemoch súborov je párový test silnejší (=má menšiu pravdepodobnosť chyby 2. druhu) ako dvojvýberový t-test už pri malých koreláciách (malej miere lineárnej závislosti X a Y). Naopak, ak medzi hodnotami X a Y neexistuje žiadna korelácia, je dvojvýberový t-test silnejší ako párový test.

Testy základných štatistických hypotéz 14
Príklad 4 18 elastických pásov bolo rozdelených na dvojice tak, aby v každej dvojici boli páry s podobnou pružnosťou. Následne bol jeden pás z každého páru na 4 minúty ponorený do vody o teplote 65°C. Zostávajúce pásy boli ponechané pri izbovej teplote. Po 10 minútach bolo zistené roztiahnutie pásov pod váhou 1,34 kg. Má sa zistiť, či má horúci kúpeľ vplyv na elasticitu materiálu.
Izbová teplota
220 240 260 280 300
01
23
4
Zohriate
220 240 260 280 300
01
23
45
220 240 260 280 300
220
240
260
280
300
Roztiahnutie, izb. t., %
Roz
tiahn
utie
, zoh
r.,%
Histogram rozdielov
Rozdiel,%
Poče
t
-5 0 5 10 15 20
01
23
45
Použijeme jednovýberový t-test s H0: µd = 0 proti dvojstrannej alternatíve H1: µd ≠ 0:
Z uvedených dát máme:
( )
31,2
811,3
8
0344,21389,49
1033,625,3719
933,6
975,0,8
22
9
1
2
2
=
===
=
===
==−
−=
==
�=
tsdt
sss
sdd
s
nd
d
dd
d
di
i
d
ν
ν
Pár Vysoká Izbová Rozdiel1 244 225 19,002 255 247 8,003 253 249 4,004 254 253 1,005 251 245 6,006 269 259 10,007 248 242 6,008 252 255 -3,009 292 286 6,00
Vplyv zahriatia na roztiahnutie elastických pásov

Testy základných štatistických hypotéz 15
Záver: Na hladine významnosti α=0,05 zamietame nulovú hypotézu o nulovej strednej hodnote rozdielu medzi pármi hodnôt. Inak povedané, stredný rozdiel v rozťažnosti je Rozdiel v rozťažnosti dstredné=6,33 je štatisticky významný (P=0,014).
Pre ilustráciu ešte uvedieme výsledky dvojvýberového t-testu pre tieto dáta. Použijeme test pre rovnaké variancie (máme rovnaký počet dát), a dostaneme
)8572,0(181829,0 === Pt ν .
Pri takejto malej hodnote t ani netreba pozerať do tabuliek (kritické hodnoty pri α=0,05 budú niekde okolo t=2. Ako vidno, dvojvýberový t-test je v tejto situácii veľmi slabý, pretože štatistika t je ovplyvnená celkovou variabilitou medzi dvojicami, ktorá je veľmi veľká oproti rozdielom hodnôt v jednotlivých dvojiciach.
Neparametrické testy Neparametrické testy sú určené hlavne pre dve situácie:
1. Rozdelenie dát je veľmi vzdialené od normálneho
2. Dáta nemajú kvantitatívny charakter, ale sú to čísla z nejakej škály a možno ich porovnávať - typickými príkladmi sú školské známky (ordinálne dáta) alebo iné hodnotenia.
Neparametrické testy sa vyznačujú tým, že nepracujeme s pôvodnými hodnotami dát, ale s poradiami. Teda ak máme súbor dát X1, X2,... Xn, usporiadame ich podľa veľkosti, XInd(1) ≤ XInd(2) ≤...≤ XInd(n),, kde Ind(j) je index, prislúchajúci j-tej najmenšej hodnote spomedzi X1, X2,... Xn, j=1,2,...N. Hodnoty j(i)=rank(Xi) (angl. rank=poradie) sú teda poradia dát vo vzostupnom usporiadaní podľa veľkosti a použijeme ich namiesto pôvodných dát.
Príklad:
Xi 2,32 4,27 1,28 3,12 4,88 15,55
rank(i) 2 4 1 3 5 6
(koniec príkladu)
Technická komplikácia vzniká, keď sú niektoré hodnoty Xi rovnaké. Takáto situácia sa nazýva väzba a ako poradie sa u rovnakých hodnôt použije aritmetický priemer poradí takýchto rovnakých hodnôt.
Príklad:
Xi 15 15 12 13 13 13
poradia 5 6 1 2 3 4
rank(i) 5,5 5,5 1 3 3 3
(koniec príkladu)
Toto je veľmi bohatá téma, ktorá dosť komplikuje teóriu neparametrických testov. My sa jej v tomto texte vyhneme s poukazom na to, že ordinálne dáta nie sú pre naše potreby príliš zaujímavé a u číselných dát môžeme k rovnakým hodnotám pridať maličké náhodné číslo a stanú sa odlišnými.
Dva najdôležitejšie neparametrické testy, ktoré sú analógmi nepárového t-testu a párového t-testu, navrhli Wilcoxon a nezávisle na ňom Mann a Whitney. Preto sa označenie testov v literatúre líši, ale spravidla sa párový test označuje ako Wilcoxonov a nepárový Mann-Whitneyho U-test. V tomto texte sa obmedzíme na tieto dva testy, pretože sú najpoužívanejšie a navyše, čo je u neparametrických textov nie časté, sa silou vyrovnajú príslušným parametrickým testom.

Testy základných štatistických hypotéz 16
Mann-Whitneyho (U) test
Tento test môžete nájsť aj pod názvom Wilcoxonov-Mann-Whitneyho test (alebo v angličtine Wilcoxon rank sum test). Je to neparametrický analóg dvojvýberového t-testu a je temer rovnako silný: v prípadoch, keď sú použiteľné oba testy, je sila Mann-Whitneyho testu asi 95% v porovnaní s t-testom; v prípade silného narušenia normality ale môže byť Mann-Whitneyho test podstatne silnejší ako t-test. Alternatívou k použitiu Mann-Whitneyho testu je použitie t-testu na poradia dát. Takýto test má rovnakú silu ako Mann-Whitneyho test.
Majme dva súbory hodnôt Xi, i=1,2,..nx, a Yi, i=1,2,..ny. Namiesto vlastných údajov použijeme poradia príslušných hodnôt v súbore všetkých N=ny+ny hodnôt. Môžeme pritom použiť vzostupné i zostupné poradia. Z poradí vypočítame Mann-Whitneyho štatistiku
( )x
xxyx RnnnnU −++=
21
,
kde nx a ny sú počty dát v súboroch X, resp. Y, a Rx je súčet poradí v skupine X. U-štatistiku možno interpretovať aj ako úhrn súčtov poradí zo súboru Y, menších než daná hodnota zo súboru X, pre všetky hodnoty z X. Ekvivalentne môžeme použiť aj štatistiku U´, založenú na Ry:
( )y
yyxy R
nnnnU −
++=′
21
, pričom platí UnnU xy ′−= .
Pre test hypotézy
H0: Hodnoty X sú symetricky rozdelené okolo mediánu Y, alebo, inak povedané, P(X > med(Y))=P(X < med(Y)) = 0,5
proti alternatíve
H1: Hodnoty X sú symetricky rozdelené okolo odlišnej hodnoty (resp., okolo hodnoty väčšej alebo menšej ako medián), inak povedané, P(X > med(Y)) > 0,5, resp. P(X < med(Y)) > 0,5.
alebo analogických hypotéz o rozdelení hodnôt Y okolo mediánu X na hladine významnosti α použijeme kritickú hodnotu Uα(2);nx,ny z distribučnej funkcie štatistiky U. Kritické hodnoty nájdete v štatistických tabuľkách alebo na Webe, Excel tieto hodnoty nevie počítať. Pri dvojstrannej alternatíve zamietame nulovú hypotézu, ak je U alebo U´ väčšie ako kritická hodnota, pri jednostrannej alternatíve porovnávame s kritickou hodnotou iba jednu z hodnôt U, U´ takto:
H0: P(X < med(Y)) ≥ 0,5 H0: P(X > med(Y)) ≥ 0,5
H1: P(X > med(Y)) > 0,5 H1: P(X < med(Y)) > 0,5
Vzostupné poradia použiť U použiť U´
Zostupné poradia použiť U´ použiť U
Špeciálne vzťahy sa používajú v prípade väzieb (rovnakých hodnôt dát). Tieto vzťahy tu nebudeme uvádzať a nebudeme diskutovať ani iné technické otázky okolo normálnej aproximácie pre veľké N, opravy na spojitosť a podobne. Radšej odporučíme nesnažiť sa počítať tento test ručne a použiť štatistický program (napr. R) alebo kalkulátor na Webe, napríklad VassarStats. Toto odporúčanie platí tým skôr, že Excel síce má funkciu pre výpočet poradí (funkcia RANK), tá ale pracuje s väzbami v poradiach veľmi zvláštne a preto ani spočítanie základných štatistík nie je úplne bezproblémové, ako vidno z príkladov v Exceli.

Testy základných štatistických hypotéz 17
Príklad 5 Použijeme dáta z predchádzajúceho príkladu na dvojvýberový t-test (Studentove dáta o spánku)
Všimnite si znova výhodu usporiadania dát s klasifikujúcou premennou. Červeno označené hodnoty sú upravené ručne, pretože funkcia Rank v Exceli pracuje s väzbami v poradiach nevhodným spôsobom.
Štatistiky pre U-test sú nasledujúce:
skupina skupina1 2
Súčet R 80,50 129,50Počet 10,00 10,00U 74,50 25,50 Nasledujúce výsledky sú vypočítané v programe R (funkcia wilcox.test), môžete použiť aj applet z VassarStats:
Kritická oblasť
P Výsledok (α=0,05)
H1: P(x>med(y))<>0,5
U´ > Ukrit 0,06372 Prijímame H0
H1: P(x>med(y))<0,5
U´ > Ukrit 0,03186 Zamietame H0
Príklad 6 Ako sme uviedli, alternatívou k použitiu Mann-Whitneyho testu je použiť t-test na poradiach. Test ilustrujeme na dátach z predchádzajúceho príkladu.
skupina skupina1 2
Súčet 80,50 129,50Počet 10 10Priemer 8,050 12,950s2 33,5250 26,8583s2
priem 3,35250 2,68583
Test s rôznymi varianc iami (W elc h)s2
x p-y p 6,03833sx p-y p 2,4573ν 17,7832t -1,994tν ;0 ,975 2,110tν ;0 ,95 1,740
Výsledky testu:
Krit. oblasť Výsledok (α=0,05) P(t´>t|tkr it = t17,783;0,975 2,1098 abs(t) > tkr it Pr ijímame H0 0,06244tkr it = t17,783;0,95 1,7396 -t > tkr it Zamietame H0 0,03122H1- : µx<µy
Kritické hodnotyAlternatívaH1: µx <>µy
Všimnite si, že tak Wilcoxonov test ako aj t-test na poradiach dali o niečo silnejšie výsledky ako obyčajný t-test. Je to dané odchýlkou rozdelenia dát od normality. V prípadoch, kedy existuje pochybnosť o rozdelení dát a jeho vplyve na výsledky t-testu, je celkom dobrý nápad urobiť t-test na poradiach. Ak sa výsledky výrazne líšia, treba použiť radšej neparametrický test.
číslo zmena skupina poradie1 0,70 1 82 -1,60 1 13 -0,20 1 34 -1,20 1 25 -0,10 1 4,56 3,40 1 15,57 3,70 1 178 0,80 1 9,59 0,00 1 610 2,00 1 1411 1,90 2 1312 0,80 2 9,513 1,10 2 1114 0,10 2 715 -0,10 2 4,516 4,40 2 1817 5,50 2 2018 1,60 2 1219 4,60 2 1920 3,40 2 15,5
Zmena dĺžky spánku po podaní jedného z dvoch preparátov

Testy základných štatistických hypotéz 18
Wilcoxonov (párový) test
Wilcoxonov párový test (Wilcoxon signed rank test) možno použiť všade tam, kde sa dá použiť párový t-test. Jeho sila (=schopnosť zamietnuť nulovú hypotézu, ak neplatí) je 3/π (t.j. asi 95%) v porovnaní s párovým t-testom, teda je len o málo slabší. Sú ale situácie, kde párový t-test nemožno použiť, napríklad keď dáta evidentne nepochádzajú z normálneho rozdelenia alebo nemajú kvantitatívny charakter; Wilcoxonov test v takýchto prípadoch použiť možno. Test ale predpokladá symetriu rozdelenia X-Y za predpokladu nulovej hypotézy. V prípade silnej nesymetrie možno použiť jednoduchý znamienkový neparametrický test (sign test), ktorý je ale omnoho slabší.
Wilcoxonov test je test hypotézy
H0: Rozdelenie hodnôt X - Y je symetrické okolo µ=0 (alebo µ=µ0)
proti alternatíve
H1: skutočné µ je rôzne od (prípadne menšie či väčšie než) 0 (resp. µ0).
Tento test možno v princípe použiť aj ako jednovýberový, s nulovou hypotézou že rozdelenie X je symetrické okolo nuly alebo zadanej hodnoty.
Postup vidno na nasledujúcom príklade. Podobne ako u párového t-testu použijeme rozdiely dát v dvojiciach (alebo nejakú inú vhodnú mieru odlišnosti, napríklad podiel, relatívnu odchýlku a pod., tentoraz bez starosti, či sa tým nenaruší normálne rozdelenie).
Rozdielom priradíme poradia a ku každému poradiu doplníme znamienko príslušného rozdielu. Vytvoríme sumy kladných a záporných poradí T+ a T–. V prípade platnosti nulovej hypotézy by obe sumy mali byť približne rovnaké, s náhodnými odchýlkami smerom na jednu či druhú stranu. Nulovú hypotézu zamietame, ak T+ a T– prekročí kritickú hodnotu.
Príslušné hodnoty možno nájsť v tabuľkách, ale pre testovanie odporúčam použiť štatistický program alebo kalkulátor na webe VassarStats. V literatúre totiž nie je postup pri Wilcoxonovom teste ustálený, niektorí autori (a niektoré programy) napríklad od testovanej sumy poradí odpočítavajú príspevok od maximálneho rozdielu poradí a iné nie, niekde sa vynechávajú nulové rozdiely a inde nie, takisto sa rôzne používajú normálne aproximácie a opravy na spojitosť. Ak použijete štatistický program, máte dobrú záruku, že má potrebné detaily správne zosúladené, pri ručnom výpočte ste nútení sledovať pomerne veľa detailov. Toto je bohužiaľ tienistá stránka mnohých neparametrických testov: Zatiaľ čo ich princíp je dobre pochopiteľný, realizácia obsahuje množstvo technikalít. Výsledky v nasledujúcom príklade pochádzajú z programu R, kalkulátor na VassarStats dáva mierne odlišné výsledky.
Testy základných štatistických hypotéz 19
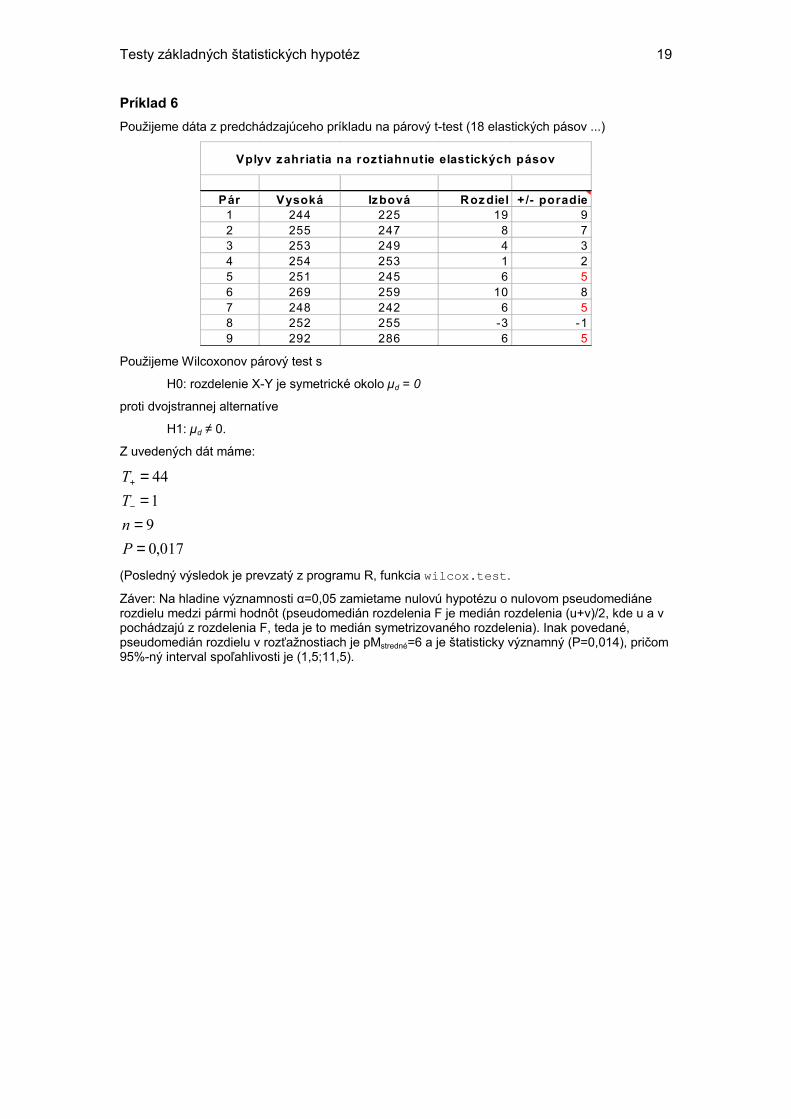
Príklad 6 Použijeme dáta z predchádzajúceho príkladu na párový t-test (18 elastických pásov ...)
Pár Vysoká Izbová Roz diel + /- poradie1 244 225 19 92 255 247 8 73 253 249 4 34 254 253 1 25 251 245 6 56 269 259 10 87 248 242 6 58 252 255 -3 -19 292 286 6 5
Vplyv zahriatia na roz tiahnutie elastických pásov
Použijeme Wilcoxonov párový test s
H0: rozdelenie X-Y je symetrické okolo µd = 0
proti dvojstrannej alternatíve
H1: µd ≠ 0.
Z uvedených dát máme:
017,09144
====
−
+
PnTT
(Posledný výsledok je prevzatý z programu R, funkcia wilcox.test.
Záver: Na hladine významnosti α=0,05 zamietame nulovú hypotézu o nulovom pseudomediáne rozdielu medzi pármi hodnôt (pseudomedián rozdelenia F je medián rozdelenia (u+v)/2, kde u a v pochádzajú z rozdelenia F, teda je to medián symetrizovaného rozdelenia). Inak povedané, pseudomedián rozdielu v rozťažnostiach je pMstredné=6 a je štatisticky významný (P=0,014), pričom 95%-ný interval spoľahlivosti je (1,5;11,5).

Testy základných štatistických hypotéz 20
4. Alternatívne náhodné premenné V tejto časti budeme pracovať s náhodnými premennými s alternatívnym rozdelením, teda
101 osťoupravdepodn s0 osťoupravdepodn s1
≤≤
=
p-pp
X i .
Naše súbory dát budú pozostávať z realizácií takýchto náhodných premenných, teda zo sérií núl a jednotiek. Takéto dáta nie je užitočné vypisovať, ako sme to robili v predchádzajúcich častiach, pretože nám úplne stačí uviesť počet jednotiek a celkový počet hodnôt. Preto budú dáta príkladov vyzerať inak, ale netreba sa tým nechať pomýliť, robíme vlastne stále to isté.
Vieme, že súčet n takýchto premenných,
�=
=n
iin XS
1
má binomické rozdelenie:
( )
10,...2,1,0
,)1(0
≤≤=
−���
����
�== �=
−
pnS
ppkn
pkSP
n
n
k
knkn
s parametrami p a n. P je rozdelením pravdepodobnosti počtu úspechov v n pokusoch, pričom pravdepodobnosti úspechu v jednotlivých pokusoch sú nezávislé a rovné p. Pripomenieme, že pre náhodnú premennú Sn platí
)1( ),1( , 2Sn
pnppnpnpSnSn −=−== σσ
Vďaka tomu vieme zistiť základné výberové štatistiky pre pozorovania náhodných premenných s alternatívnym rozdelením a ich rozdelenia pravdepodobnosti.
Všimnite si, že aj keď sú výsledné vzťahy iné, v podstate iba počítame priemer, štandardnú odchýlku a štandardnú odchýlku priemeru, rovnako ako v predchádzajúcich častiach.

Testy základných štatistických hypotéz 21
Veličina Vyjadrenie cez rozdelenie pravdepodobnosti
Odhad
Stredná hodnota X pppX =−+=≡ )1.(0.1µ pnkX
n
n
ii ˆ1ˆ
1≡== �
=
µ
Štandardná odchýlka X
)1()1.()0(.)1(
)(22
22
pppppp
pXx
−=−−+−
=−≡σ
[ ]
1)ˆ1(ˆ
1ˆ)ˆ1()ˆ1(ˆ
1ˆ)()ˆ1(
)ˆ(1
1ˆ
22
221
2
22
−−
=−
−+−
=−
−+−
=−−
=≡
�=
nppn
nppppn
npknpk
pXn
sn
ii
xxσ
Štandardná odchýlka strednej hodnoty
npp
np
nS
nSn
p
)1(
1)( 22
22ˆ
−=
==−≡ σσ1
)ˆ1(ˆ1ˆ 22ˆ
2ˆ −
−==≡n
ppsn
s pppσ
Náhodný výber z populácie Predstavte si, že nás zaujíma pomer pohlaví u pavúkov. Na rôznych miestach a v rôznych časoch odchytíme n=20 pavúkov a zistíme, že k=4 z nich sú samčekovia a n-k=16 je samičiek. Predpokladáme pritom, že populácia je veľmi veľká; ak by sme robili výber z obmedzenej populácie, museli by sme každého odchyteného pavúka vrátiť (v prípade výberu bez vracania by bola štatistika iná - spomínate si na hypergeometrické rozdelenie?) Aké závery môžeme z tohoto zistenia urobiť?
Predovšetkým,
%20ˆ ==nkp
je nestranný odhad zastúpenia samčekov v populácii. Odhad je ale náhodná premenná, a inokedy by sme mohli nájsť 5 samčekov a niekedy možno iba dvoch. Aká je teda presnosť tohoto odhadu? Zo vzťahu pre štandardnú odchýlku p vidíme, že to je
092,01
)ˆ1(ˆ=
−−=
nppsp .
Teda presnosť nášho odhadu je asi 10% (v absolútnom, nie relatívnom vyjadrení).
Vzniká tu ale komplikácia: pre p≠0,5 je rozdelenie odhadu p nesymetrické, pričom asymetria je zvlášť silná pre p blízke k 0 a k 1. Aby sme získali lepšiu predstavu o oblasti možných hodnôt p, bude výhodné vypočítať interval spoľahlivosti. Pre určenie jeho hraníc použijeme špeciálnu techniku, ktorá sa zakladá na podobnosti medzi F-rozdelením a rozdelením p. Hranice (1-α).100%-ného intervalu spoľahlivosti pre odhad p sú

Testy základných štatistických hypotéz 22
( )
( )knkFkkn
FkL
kknFknk
kL hornéédo
−=′+=′++−
+=
=+−=
+−+=
′′
′′
2)1(2
)1(1
2)1(2
)1(
21
,,2/
,,2/
21
,,2/ln
21
21
21
ννννννα
ννα
ννα
V špeciálnych prípadoch k=0, k=n–1 a k=n môžu mať niektoré programy alebo kalkulátory problémy s výpočtom príslušných kritických hodnôt. Ak sa to stane, možno použiť modifikované vzťahy:
pre k=0: n
L/1
2 21 �
�
���
�−= α
pre k=n–1: n
L/1
2 21 �
�
���
� −= α
pre k=n: 12 =L
Zo symetrie kombinačných čísel okrem toho vyplýva:
(L1 pre k) = (1–L2 pre n–k) a (L2 pre k) = (L1 pre n–k)
Tieto vzťahy možno vyzerajú zložito, a keď zalistujete v štatistických knižkách, nájdete množstvo približných vzťahov založených na normálnom priblížení. Žiaden z nich ale dobre nefunguje pre p blízke k 0 a k 1. Vyššie uvedené vzťahy dávajú presné hranice a na ich výpočet stačia dve kritické hodnoty F-rozdelenia.
Príklad 1 Náhodná vzorka 200 ľudí obsahuje 4 ľudí s prirodzenou odolnosťou proti hepatitíde B. Aké je zastúpenie takýchto ľudí v populácii?
Základné dáta: V tomto prípade máme n=200, k=4; odtiaľ 02,0ˆ =p so štandardnou odchýlkou
( ) 010,010.849,91ˆ1ˆ
ˆ52
ˆ ==−−= −
pp sn
pps .
95%-ný interval spoľahlivosti (α=0,05) určíme vyššie uvedeným postupom takto:
Dolná hranica Horná hranic aν1 394 ν´1 10ν2 8 ν´2 392Fα /2,ν1 ,ν2 3,687915751 Fα/2,ν1 ,ν2 2,08113Ldolné 0,005475556 Ldolné 0,050414 Záver: Frekvencia výskytu jedincov s prirodzenou odolnosťou proti vírusu leží s 95%-nou pravdepodobnosťou v intervale 0,0055 ≤ p ≤ 0,0504, pričom nestranný odhad tejto frekvencie na základe uvedených údajov je 0,020.
Všimnite si, že získaný interval spoľahlivosti je nesymetrický okolo odhadu strednej hodnoty.
Príklad 2 Čo by sme mohli povedať o frekvencii výskytu jedincov s prirodzenou odolnosťou proti vírusu, ak by sme medzi 200 osobami nenašli ani jedného?
Toto nie je žiadny chyták. Ak by bola frekvencia výskytu takýchto jednotlivcov nízka, môže sa naozaj stať, že medzi 200 ľuďmi takého nenájdeme.

Testy základných štatistických hypotéz 23
V tomto prípade máme n=200, k=0; odtiaľ 0ˆ =p so štandardnou odchýlkou
( ) 001ˆ1ˆ
ˆ2ˆ ==
−−= pp s
npps .
Odhad štandardnej odchýlky je tu neužitočný. Skúsme vypočítať hranice intervalu spoľahlivosti:
Dolná hranica Horná hranicaν1 402 ν´1 2ν2 0 ν´2 400Fα /2,ν1 ,ν2 netreba poč ítať Fα/2,ν1 ,ν2 3,723102Ldolné 0 Ldolné 0,018275 Teda negatívny výsledok nám poskytuje hornú hranicu hľadanej frekvencie výskytu, p≤0,0183 s 95%-nou pravdepodobnosťou.

Testy základných štatistických hypotéz 24
5. Testy dobrej zhody a kontingenčné tabuľky V tejto časti budeme pracovať s náhodnými premennými, nadobúdajúcimi hodnoty z konečnej množiny, teda s náhodnými premennými
{ }
⌠=
=
≥==∈
k
ii
iii
k
p
pAXPAAAX
1
21
1
0)(,...,
Ai pritom môžu byť číselné hodnoty, ale môžu tiež označovať nečíselné kategórie, napríklad farbu očí alebo diagnózu. Takéto premenné nazývame faktory, a príslušné hodnoty Ai úrovne faktorov.
Naše dáta budú súbormi pozorovaní náhodnej premennej X. Opäť, tak ako v predchádzajúcej časti, nie je praktické uvádzať všetky zistené hodnoty ako u premenných so spojitým rozdelením, ale stačí uviesť počty výskytov jednotlivých kategórií, napríklad vo forme tabuľky:
k
k
fffnAAA
...
...
21
21
S takýmito počtami výskytov budeme pracovať, a budeme sa snažiť niečo dozvedieť o pravdepodobnostiach pi. Preto nás bude zaujímať rozdelenie pravdepodobnosti pre počty výskytov fi. Tá je, v prípade výberu z nekonečnej populácie (čo v praxi znamená, že n je omnoho menšie ako objem populácie), daná multinomickým rozdelením:
��==
==
=���
����
�
���
����
�=
k
ii
k
ii
kk
fk
ff
kk
pnf
fffn
fffn
pppfff
nfffP k
11
2121
2121
21
1
!!...!!
...
......
),...,( 21
Metódy, založené na tomto rozdelení, sú výpočtovo náročné. Aj keď to dnes, prinajmenšom pre aplikácie, o ktorých budeme hovoriť v tomto texte, nepredstavuje zásadný problém, presné testy založené na multinomickom rozdelení sa používajú iba v zvláštnych prípadoch. Namiesto nich sa používajú omnoho jednoduchšie techniky, založené na normálnom priblížení, ktoré pre väčšinu praktických aplikácií úplne vyhovujú.
Tak ako v predchádzajúcej časti by sme sa mali najskôr venovať odhadom pravdepodobností pi a ich vlastnostiam. Predovšetkým, nestranné odhady pravdepodobností sú
nfp i
i =ˆ
Ťažkosť s hodnotami fi spočíva v tom, že nie sú vzájomne nezávislé: ich súčet musí byť za každých okolností n, a teda nám stačí poznať iba k-1 z nich. V technikách, ktoré budeme používať, nás budú zaujímať kolektívne vlastnosti hodnôt fi, a budeme používať asymptotický (t.j. platný tým lepšie, čím sú fi väčšie) vzťah pre rozdelenie fi:

Testy základných štatistických hypotéz 25
ii
ii
ii
ff
Nzf
ff
≡
=− ),1,0(~
kde sme použili tradičné označenie pre strednú hodnotu fi. Uvedený pomer teda má (asymptoticky) štandardné normálne rozdelenie, a štatistika
( )�
=
−=k
i i
ii
fff
1
22χ
bude mať rozdelenie χ2 s k-1 stupňami voľnosti. Ako vidno, táto štatistika je mierou vzdialenosti pozorovaného a očakávaného rozdelenia frekvencií výskytu, a teda pri jej známom rozdelení pravdepodobnosti dokážeme počítať pravdepodobnosti získania pozorovaného rozdelenia pri danom očakávaní, a teda testovať hypotézy.
Testy o rozdelení pravdepodobnosti Začneme príkladom:
Príklad 1 Podľa Mendelovských zákonov dedičnosti očakávame nasledujúce pomery v zastúpení charakteristík semien v populácií rastlín hrachu:
žlté hladké : žlté vráskavé : zelené hladké : zelené vráskavé
9 :3 :3 :1
V skutočnosti sme pozorovali nasledujúci výskyt:
žlté hladké
f1
žlté vráskavé
f2
zelené hladké
f3
zelené vráskavé
f4
spolu
n
152 35 53 6 250
Je pozorovaný výskyt v zhode s teoretickým očakávaním?
Takéto zadanie môžeme riešiť ako test hypotézy
H0: Uvedené znaky sa u rastlín vyskytujú v proporciách 9:3:3:1
proti alternatíve
H1: Uvedené znaky sa u rastlín vyskytujú v inej proporcii.
Vypočítajme najskôr očakávané zastúpenia jednotlivých znakov pri danom celkovom počte rastlín:
625,1401339
9.25011 =
+++==
⌠i
iqqnf atď., a odtiaľ určíme χ2:
Očakávaný výskyt za predpokladov nulovej hypotézy:
Znak Žltý hladký
Žltý vráskavý
Zelený hladký
Zelený vráskavý Spolu
Očakávaný výskyt 140,625 46,875 46,875 15,625 250
Rozdiel 11,375 -7,875 6,125 -9,625 0 Získanú hodnotu porovnáme s kritickou hodnotou pre α=0,05 a ν=4-1=3 (Excel má funkciu chiinv(alfa, stupne voľnosti), ktorá vráti požadovanú hodnotu): χ2
0,05;3=7,8147. Môžeme tiež vypočítať úroveň významnosti pre zistenú hodnotu χ2 (v Exceli je to funkcia chidist(hodnota, stupne voľnosti), dostaneme P=0,0297.

Testy základných štatistických hypotéz 26
Použiteľnosť priblíženia χ2 Technika, ktorú sme použili, je približná, a môžeme sa pýtať, kedy je použiteľná. V prípade, že sú pozorované počty v niektorej kategórii príliš malé, bude hodnota χ2 nadhodnotená a budeme nulovú hypotézu budeme zamietať častejšie než s pravdepodobnosťou α. To je nežiadúce, a preto je potrebné mať pre test dostatočný počet pozorovaní. „Dostatočný“ počet pozorovaní znamená:
1. Pre rozdelenia blízke k rovnomernému je prípustné 1 pozorovanie v niektorých kategóriách pre testovanie na hladine α=0,05, a najmenej 2 pozorovania pri testovaní na hladine α=0,01. Pre rozdelenia s veľkými rozdielmi očakávaných hodnôt je treba príslušné hodnoty zdvojnásobiť.
2. Test pracuje prijateľne dobre, ak súčasne platí k≥3, n≥10, a n2/k≥10.
3. Ak k=2 (a teda počet stupňov voľnosti je ν=1, je treba použiť buď opravu na spojitosť (Yatesovu korekciu, pozri nižšie), alebo binomický test.
V prípade, že máme malé počty dát (napríklad pri veľkom počte kategórií, treba použiť exaktné metódy, založené na multinomickom rozdelení, alebo použiť numerickú simuláciu.
Korekcia na spojitosť Kritické hodnoty štatistiky χ2 určujeme z tabuliek rozdelenia χ2, čo je spojité rozdelenie, Vzhľadom na to, že pracujeme s celočíselnými hodnotami, rozdelenie pravdepodobnosti štatistiky χ2 je v skutočnosti diskrétne a kritické hodnoty za určitých okolností nebudú správne. Tento efekt je dôležitý predovšetkým pre ν=1, pri vyšších počtoch stupňov voľnosti je zanedbateľný.
Pri ν=1 sa situácia rieši tzv. Yatesovou korekciou na spojitosť, ktorá spočíva v zmenšení rozdielov o 0,5:
( )�
=
−−=
k
i i
iiYC f
ff
1
2
25,0
χ
Táto úprava výrazne zlepšuje parametre testu. Pre špeciálne prípady existujú aj iné, ešte lepšie korekcie na spojitosť, používajú sa ale zriedka. Yatesovu korekciu je treba používať systematicky vždy pri jednom stupni voľnosti χ2 (2 kategórie pri testoch rozdelení, kontingenčné tabuľky 2x2, pozri nižšie).
Kontingenčné tabuľky Opäť začneme príkladom:
Príklad 2 Zaujíma nás, či je zastúpenie rôznych farieb vlasov rovnaké u oboch pohlaví. Toto sú zistenia na vzorke 300 ľudí:
Farba vlasov Č ierne Hnedé Blond Ryšavé SpoluMuži 32 43 16 9 100
očakávanie (29,00) (36,00) (26,67) (8,33)Ženy 55 65 64 16 200
očakávanie (58,00) (72,00) (53,33) (16,67)Spolu 87 108 80 25 300
Chceme testovať hypotézu
H0: Rôzne farby vlasov sa u mužov a žien vyskytujú v rovnakých proporciách
proti alternatíve
H1: Rôzne farby vlasov sa u mužov a žien vyskytujú v rôznych proporciách.

Testy základných štatistických hypotéz 27
Za predpokladu nulovej hypotézy môžeme vypočítať očakávané hodnoty pre jednotlivé polia tabuľky. Napríklad pre očakávanú hodnotu počtu mužov s hnedými vlasmi môžeme písať
Očakávaný počet mužov s hnedými
vlasmi = Pravdepodobnosť,
že človek je muž x Pravdepodobnosť,
že človek má hnedé vlasy)
x Celkový počet ľudí vo vzorke
Inak povedané,
Počet mužov vo vzorke
Počet ľudí s hnedými vlasmi Očakávaný počet
mužov s hnedými vlasmi
= Celkový počet ľudí
vo vzorke
x Celkový počet ľudí
vo vzorke
x Celkový počet ľudí vo vzorke
a vo všeobecnom vyjadrení
cjri
fCfRnCR
nn
CnRf
r
iijj
c
jiji
jijiij ,...,2,1
,...,2,1,,,
11 ==
===⋅���
�⌡⌡
⋅��
�⌡
= ⌠⌠==
kde Ri a Cj sú riadkové, resp. stĺpcové súčty. Potom už ľahko sformujeme štatistiku χ2:
( )��
= =
−=
r
i
c
j ij
ijij
fff
1 1
22χ ,
pričom počet stupňov voľnosti je
)1)(1( −−= crν .
Tým máme všetky potrebné vzťahy pohromade a mohli by sme testovať, ale ešte nám jedna vec chýba: zobrazenie dát. Tu je, a je to formát, umožňujúci rýchlo sa zorientovať v dátach tabuľky (Anglické popisy som v obrázku ponechal, pretože dlhšie slovenské sa nechceli zmestiť.).
Hair colours in men and women
sex
hair
male female
blac
kbr
own
blon
dere
d
Podobné obrázky dokáže vytvoriť aj Excel, s výnimkou proporcionálnych šírok pásov, čo ale poväčšine nie je dôležité - stačí použiť príslušný preddefinovaný typ stĺpcového grafu (a narýchlo odstrániť aspoň najzúfalejšie predvoľby dizajnérov Microsoftu).

Testy základných štatistických hypotéz 28
Rozdiely a pr íspevky k χ 2
Farba vlasov Č ierne Hnedé Blond Ryšavé SpoluMuži - rozdiely 3,00 7,00 -10,67 0,67 0,00
χ2 0,31 1,36 4,27 0,05 5,99Ženy - rozdiely -3,00 -7,00 10,67 -0,67 0,00
χ2 0,16 0,68 2,13 0,03 3,00Spolu -rozdiely 0 0 0 -1,8E-15 -5,3E-15
χ2 0,47 2,04 6,40 0,08 8,99χ 2 8,99Počet stupňov voľnosti: 3P 0,029462
α 0,05χ 2
0,05;3 7,814725 Pretože χ2 je väčšie ako kritická hodnota, zamietame nulovú hypotézu.
Zastúpenie rôznych farieb vlasov je teda u mužov a žien odlišné. Môžeme si však položiť otázku, či možno identifikovať farbu alebo farby vlasov, ktoré sú zodpovedné za disproporcie. Z tabuľky vidno, že najväčší príspevok k χ2 pochádza od stĺpca blond vlasov. Aby sme toto zistenie overili, použijeme nasledujúci postup:
1. Vyradíme z tabuľky osoby s blond vlasmi a χ2 testom na výslednej tabuľke 2x3 zistíme, či možno prijať hypotézu o rovnakých proporciách u mužov a žien.
2. V prípade kladného výsledku skombinujeme tri farby vlasov do jedného stĺpca tabuľky a vytvoríme tabuľku 2x2 (muži, ženy) x (čierne+hnedé+ryšavé x blond). Znova vykonáme χ2 test a overíme, či sa proporcie významne odlišujú.
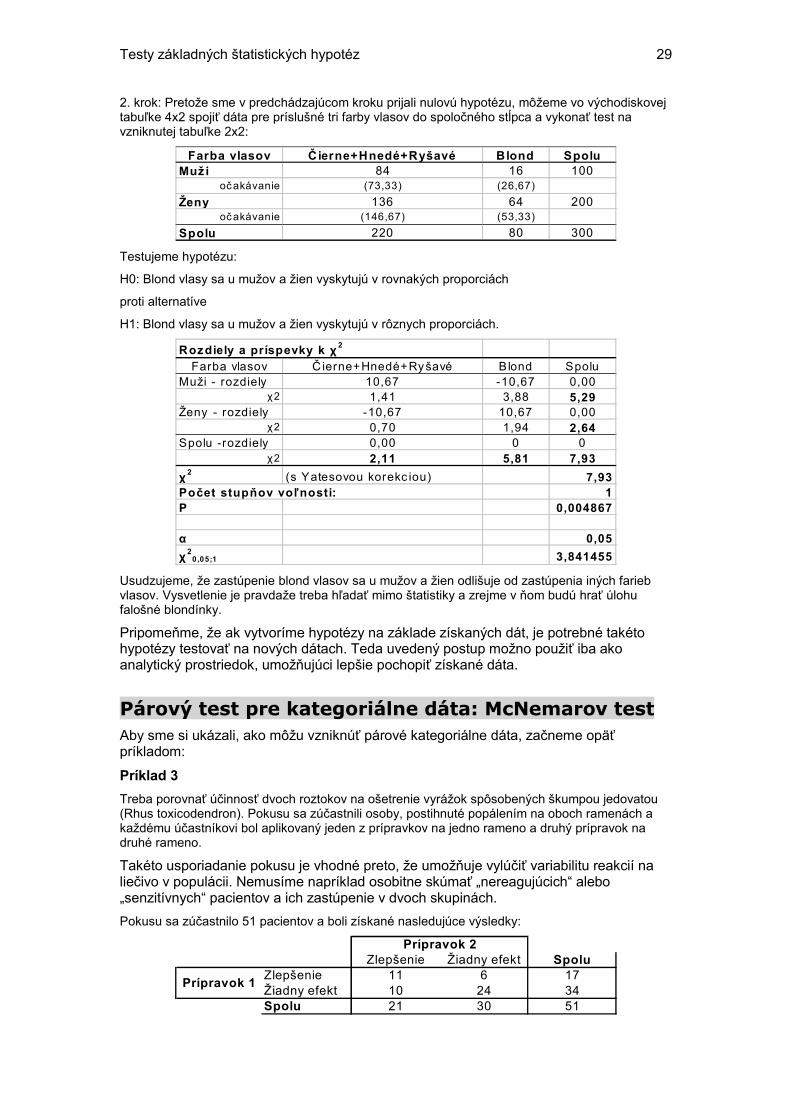
1. krok: Vytvoríme tabuľku 2x3:
Farba vlasov Č ierne Hnedé Blond Ryšavé SpoluMuži 32 43 16 9 84
očakávanie (33,22) (41,24) (9,55)Ženy 55 65 64 16 136
očakávanie (53,78) (66,76) (15,45)Spolu 87 108 80 25 220
Testujeme hypotézu
H0: Čierne, hnedé a ryšavé vlasy sa u mužov a žien vyskytujú v rovnakých proporciách
proti alternatíve
H1: Čierne, hnedé a ryšavé vlasy sa u mužov a žien vyskytujú v rôznych proporciách.
Rozdiely a pr íspevky k χ 2
Farba vlasov Č ierne Hnedé Blond Ryšavé SpoluMuži - rozdiely -1,22 1,76 -0,55 0,00
χ2 0,04 0,08 0,03 0,15Ženy - rozdiely 1,22 -1,76 0,55 0,00
χ2 0,03 0,05 0,02 0,09Spolu -rozdiely 0 0 0 0 0
χ2 0,07 0,12 0,00 0,05 0,24χ 2 0,24Počet stupňov voľnosti: 2P 0,884837
α 0,05χ 2
0,05;2 5,991476 Usudzujeme, že v zastúpení osôb s čiernymi, hnedými a ryšavými vlasmi nie je rozdiel medzi mužmi a ženami - prijímame nulovú hypotézu.
Testy základných štatistických hypotéz 29
2. krok: Pretože sme v predchádzajúcom kroku prijali nulovú hypotézu, môžeme vo východiskovej tabuľke 4x2 spojiť dáta pre príslušné tri farby vlasov do spoločného stĺpca a vykonať test na vzniknutej tabuľke 2x2:
Farba vlasov Č ierne+Hnedé+Ryšavé Blond SpoluMuži 84 16 100
očakávanie (73,33) (26,67)Ženy 136 64 200
očakávanie (146,67) (53,33)Spolu 220 80 300
Testujeme hypotézu:
H0: Blond vlasy sa u mužov a žien vyskytujú v rovnakých proporciách
proti alternatíve
H1: Blond vlasy sa u mužov a žien vyskytujú v rôznych proporciách.
Rozdiely a príspevky k χ 2
Farba vlasov Č ierne+Hnedé+Ryšavé Blond SpoluMuži - rozdiely 10,67 -10,67 0,00
χ2 1,41 3,88 5,29Ženy - rozdiely -10,67 10,67 0,00
χ2 0,70 1,94 2,64Spolu -rozdiely 0,00 0 0
χ2 2,11 5,81 7,93χ 2 (s Yatesovou korekc iou) 7,93Počet stupňov voľnosti: 1P 0,004867
α 0,05χ 2
0,05;1 3,841455 Usudzujeme, že zastúpenie blond vlasov sa u mužov a žien odlišuje od zastúpenia iných farieb vlasov. Vysvetlenie je pravdaže treba hľadať mimo štatistiky a zrejme v ňom budú hrať úlohu falošné blondínky.
Pripomeňme, že ak vytvoríme hypotézy na základe získaných dát, je potrebné takéto hypotézy testovať na nových dátach. Teda uvedený postup možno použiť iba ako analytický prostriedok, umožňujúci lepšie pochopiť získané dáta.
Párový test pre kategoriálne dáta: McNemarov test Aby sme si ukázali, ako môžu vzniknúť párové kategoriálne dáta, začneme opäť príkladom:
Príklad 3 Treba porovnať účinnosť dvoch roztokov na ošetrenie vyrážok spôsobených škumpou jedovatou (Rhus toxicodendron). Pokusu sa zúčastnili osoby, postihnuté popálením na oboch ramenách a každému účastníkovi bol aplikovaný jeden z prípravkov na jedno rameno a druhý prípravok na druhé rameno.
Takéto usporiadanie pokusu je vhodné preto, že umožňuje vylúčiť variabilitu reakcií na liečivo v populácii. Nemusíme napríklad osobitne skúmať „nereagujúcich“ alebo „senzitívnych“ pacientov a ich zastúpenie v dvoch skupinách. Pokusu sa zúčastnilo 51 pacientov a boli získané nasledujúce výsledky:
Zlepšenie Žiadny efekt SpoluZlepšenie 11 6 17Žiadny efekt 10 24 34Spolu 21 30 51
Prípravok 1
Prípravok 2

Testy základných štatistických hypotéz 30
Pre analýzu takýchto dát potrebujeme testovať hypotézu:
H0: Oba prípravky sú rovnako účinné
proti alternatíve
H1: Účinnosť prípravkov sa líši.
Ako obvykle, uvažujme, ako budú vyzerať dáta v prípade nulovej hypotézy. Predovšetkým, o rozdieloch v účinnosti nás informujú nediagonálne polia tabuľky, diagonálne polia nenesú žiadnu informáciu o rozdieloch. Ak sú prípravky rovnako účinné, budú nediagonálne polia približne rovnaké. Ako testovaciu štatistiku použijeme
( )2112
221122
ffff
+−=χ , resp., s opravou na spojitosť,
( )2112
221122 1
ffff+
−−=χ , pričom ν=1.
Pre dáta z nášho príkladu o účinnosti prípravkov máme
χ2 (s korekciou na spojitosť) 0,56ν 1P 0,453254709χ2
0,05;1 3,841455338 a teda usudzujeme, že účinnosť prípravkov sa nelíši.

Testy základných štatistických hypotéz 31
6. Analýza rozptylu a viacnásobné porovnania V tejto časti sa vrátime ku kvantitatívnym dátam a budeme sa zaoberať testovaním hypotéz v zložitejších situáciách - presne povedané, v najjednoduchších zo zložitejších situácií. Naučíme sa používať silnú techniku, ktorá sa v praktickej štatistike využíva v širokej škále situácií - (jednofaktorovú) analýzu rozptylu (ANOVA - ANalysis Of VAriance).
Jednofaktorová analýza rozptylu Na úvod príklad:
Príklad 1 19 svíň bolo náhodne rozdelených do 4 skupín. Každá zo skupín bola kŕmená iným krmivom. Posúďte, či majú jednotlivé druhy krmiva významný vplyv na váhu svíň.
Vplyv diéty na váhu svíň
Diéta 1 Diéta 2 Diéta 3 Diéta 460,8 68,7 102,6 87,957,0 67,7 102,1 84,265,0 74,0 100,2 83,158,6 66,3 96,5 85,760,7 69,8 90,3
60 70 80 90 100
Dié
ta1
Dié
ta2
Dié
ta3
Dié
ta4
Váhy svíň po jednotlivých diétach
Váha (kg)
Ako pristúpiť k takejto úlohe?
Predovšetkým zavrhneme myšlienku použiť t-testy. Dôvod je inflácia hladiny významnosti pri viacnásobnom testovaní. Presne povedané, pri testovaní na hladine αt-test=0,05 bude pravdepodobnosť, že pri K porovnaniach urobíme aspoň 1 chybu 1. druhu, teda že odmietneme hypotézu o rovnosti niektorých priemerov, hoci je v skutočnosti pravdivá, alebo ešte inak, pravdepodobnosť aspoň 1 nesprávneho zistenia bude:
Kcelkové
K)1(1
chporovnania vchyby žiadnej
bnosťpravdepodo1
druhu 2.chyby 1 aspoň
bnosťpravdepodoαα −−=
���
�
�
���
�
�
−==���
�
�
���
�
�
Pri testovaní významnosti rozdielov medzi k skupinami musíme vo všeobecnosti urobiť K=k(k+1)/2 porovnaní (výsledok takéhoto testovania je zaviesť čiastočné usporiadanie v množine k priemerov, a teda vo všeobecnosti by sme mali testovať každý pár priemerov; tento počet síce možno zmenšiť, ale nedá sa vopred povedať o koľko - viac v časti o viacnásobných porovnaniach). Celková hladina významnosti (ktorú v tomto kontexte často označujú ako FWE - Family-wise error, teda chyba pre rodinu porovnaní) rýchlo rastie s počtom skupín, ako ukazuje tabuľka na nasledujúcej strane.
Tento problém sa často rieši tak, že sa jednotlivé porovnania vykonávajú na K-krát nižšej hladine významnosti, čím sa zabezpečí FWE na hodnote pôvodnej hladiny významnosti. Takýto postup sa nazýva Bonferroniho korekcia a hoci sa používa dosť často, nemožno ho odporúčať, pretože je veľmi konzervatívny - pri väčšom počte skupín sa jednotlivé testy vykonávajú na veľmi malej hladine významnosti a rýchlo rastie pravdepodobnosť chýb 2. druhu, to jest pravdepodobnosť prijatia nulovej hypotézy napriek tomu, že neplatí

Testy základných štatistických hypotéz 32
- strácame teda schopnosť zisťovať skutočné rozdiely. Tento efekt je zvlášť dramatický v modernej molekulárnej biológii, kde je pri mapovaní génov často potrebné testovať tisíce hypotéz.
Počet skupín
Počet porovnaní
k K 0,05 0,012 1 0,05 0,013 3 0,14 0,034 6 0,26 0,065 10 0,40 0,106 15 0,54 0,14
Hladina významnosti pre 1 porovnanie
Pravdepodobnosť aspoň 1 chyby 1. druhu pri viacnásobných porovnaniach
Štatisticky korektný postup spočíva v dvoch krokoch. Prvým je analýza rozptylu, a v prípade, že táto zamietne nulovú hypotézu o rovnosti priemerov vo všetkých skupinách, použijeme v druhom kroku špeciálne párové testy (často z tohoto dôvodu označované ako post-hoc testy), ktoré udržiavajú FWE (hladinu významnosti α) na požadovanej hodnote pri vzájomných porovnaniach priemerov vo všetkých skupinách. Začneme analýzou rozptylu:
Definujme celkovú variabilitu dát ako súčet štvorcov odchýlok všetkých dát od ich spoločného priemeru:
( ) �����== =
••= =
•• ==−=k
ii
k
i
n
jij
k
i
n
jijcelk nnx
nxxxSS
ii
11 11 1
2 1
Zaradením dát do skupín vysvetlíme časť variability dát: hodnota xij je odlišná od priemeru preto, že patrí do i-tej skupiny, a hodnoty v tejto skupine sú v priemere iné než v ostatných skupinách. Ešte nám ale ostane variabilita vnútri skupín, pretože aj tam máme rozdielne hodnoty, ale nevieme vysvetliť, a takéto odchýlky budeme považovať za náhodné chyby. Teda náš model bude vyzerať takto:
j
k
iiijiij nj
kiX
,...2,1,...,2,1
,01 =
==∆+∆+= �
=
µεµµ
takúto variabilitu považujeme za chybu modelu. Elegancia analýzy rozptylu spočíva v tom, že ak vytvoríme súčet štvorcov odchýlok modelu („medzi skupinami“) ako mieru variácie dát, vysvetlenú modelom,
( ) ��=
•=
••• =−=in
jij
ii
k
iiimedzi x
nxxxnSS
11
2 1
a súčet štvorcov chýb ako mieru variácie, ktorú model nedokázal vysvetliť (variácia „vnútri skupín“, alebo reziduálna variácia),
( ) ���=
•= =
• =−=ii n
jij
ii
k
i
n
jiijvnútri x
nxxxSS
11 1
2 1
bude platiť
vnútrimedzicelk SSSSSS += .
Je zrejmé, že bodkované hodnoty sú odhadmi celkového priemeru µ a efektov skupín ∆µi:

Testy základných štatistických hypotéz 33
kixx iiii ,...,2,1ˆˆ =∆+≡≡≡ ••• µµµµµ
Chceme testovať hypotézu
H0: µ1=µ2=...=µk=µ
proti alternatíve
H1: Aspoň dve zo stredných hodnôt sa líšia.
Ak prijmeme dodatočný predpoklad o chybách, totiž že
[ ]2,0~i.i.d. sú σε Nij ,
potom za predpokladu nulovej hypotézy (teda v prípade, že náš model vôbec nič nevysvetľuje a hodnoty v skupinách sa líšia iba v dôsledku náhodných vplyvov) budú stredné štvorce
)1( spolu ,odchýlkach hnezávislýc 1 po skupín )(
odchýlok hnezávislýc 1 teda spoločný, spočítali sme priemerov z)1(
hnezávislýc je 1 len teda priemer, spoločný počítali smeodchýlok z)1(
2
2
2
⌠ −=−−
=
−=
−=
knn-nkkn
SSs
k-kk
SSs
n-nSSs
iivnútri
vnútri
medzimedzi
celkcelk
všetky odhadmi variancie chýb σ2, t.j. 2222ˆ vnútrimedzicelk sss ===σ
V prípade, že nulová hypotéza neplatí, bude 22vnútrimedzi ss > ,
pretože bude obsahovať aj systematické odchýlky. Preto využijeme fakt, že za uvedených predpokladov o chybách a za predpokladu platnosti nulovej hypotézy má štatistika
2
2
vnútri
medzi
ssF =
Fisherovo (F-) rozdelenie s k-1 a n-k stupňami voľnosti. Nulovú hypotézu o rovnosti všetkých priemerov zamietneme, ak bude hodnota F vyššia ako kritická hodnota F-rozdelenia pre požadovanú hladinu významnosti. Poznamenávame, že toto je vždy jednostranný test, zaujímajú nás iba veľké hodnoty F (ak dostanete F<1, potom už nie je čo testovať - nulová hypotéza určite platí.)
Výsledky analýzy rozptylu sa tradične zapisujú do tabuľky tvaru
Zdroj variácie Súčet štvorcov s.v. Stredný
štvorec F P
Model SSmedzi k-1 s2medzi
Chyby SSvnútri n-k s2vnútri 2
2
vnútri
medzi
ssF =
P(F>Fkrit)
Spolu SScelk n-1 —
Ako dodatočný údaj sa tradične uvádza koeficient determinácie

Testy základných štatistických hypotéz 34
celk
vnútri
celk
medzi
SSSS
SSSSR −== 12 ,
čo je vlastne podiel variácie, vysvetlenej modelom, alebo index determinácie
)1(111 22
22 R
knn
ssR
celk
vnútrid −
−−−=−= ,
ktorý na rozdiel od koeficientu determinácie možno využiť na porovnanie odlišných modelov (čo uvádzam skôr preto, že môžete niekde takúto veličinu uvidieť, než ako odporúčanie ju uvedeným spôsobom používať).
A takto vyzbrojení sa už môžeme vrátiť k nášmu príkladu. Začneme tým, že si preorganizujeme dáta:
Por. č. Váha Diéta1 60,8 12 57,0 13 65,0 14 58,6 15 60,7 16 68,7 27 67,7 28 74,0 29 66,3 2
10 69,8 211 102,6 312 102,1 313 100,2 314 96,5 315 87,9 416 84,2 417 83,1 418 85,7 419 90,3 4
Takéto usporiadanie si vyžaduje prevažná väčšina štatistických programov, a je výhodné aj v Exceli, kde môžete výhodne využiť databázové funkcie. Užitočnosť takéhoto usporiadania vynikne zvlášť pri zložitejších modeloch, keď máme viac faktorov - ďalší faktor prídáme jednoducho ako nový stĺpec.
Začneme tým, že spočítame dáta v skupinách, skupinové priemery a celkový priemer.
Ďalej spočítame štvorce odchýlok od priemeru v skupinách, súčet štvorcov odchýlok všetkých dát od celkového priemeru a súčet štvorcov odchýlok skupinových priemerov od celkového priemeru (násobený počtom dát v skupine). Tým máme všetky potrebné dáta a môžeme vytvoriť tabuľku analýzy rozptylu.
Diéta Diéta Diéta Diéta Súhrnne1 2 3 4
Počet hodnôt 5 5 4 5 19Priemer 60,420 69,300 100,350 86,240 77,958Štvorce modelu 1537,889 374,796 2005,626 342,966Štvorce chýb 36,208 34,260 22,970 33,552 4388,266
(Vysvetlivky:
Štvorce modelu: (počet dát v skupine) x (skupinový priemer - celkový priemer)^2
Štvorce chýb: (súčet štvorcov odchýlok dát v skupine od skupinového priemeru); pre súhrn: súčet štvorcov odchýlok všetkých dát od spoločného priemeru.
V Exceli používame na výpočet skupinových dát funkciu pre výberovú varianciu (DVAR.VÝBĚR) a ako kritériá používame záhlavie tabuľky. Túto funkciu je treba používať opatrne, ak pracujete s veľkými číslami, pretože môže dochádzať k zaokrúhľovacím chybám.
Zdroj variácie Súčet štvorcov s.v. Stredný
štvorec F P
Model 4261,276 3 1420,425 167,78 9,25206E-12Chy by 126,99 15 8,466 (3,29)Spolu 4388,266 18
Pretože zistená hodnota F je podstatne väčšia ako kritická hodnota F0,95;3;15 = 3,29 (uvedená v tabuľke v zátvorkách pod zistenou hodnotou F), alebo, inak povedané, pravdepodobnosť získania rovnakej alebo väčšej hodnoty F ako tej, ktorú sme našli, je P=9.10-11, zamietame nulovú hypotézu

Testy základných štatistických hypotéz 35
a usudzujeme, že niektoré zo skupinových priemerov sú rôzne. Ešte inak povedané, usudzujeme, že zaradením svíň do skupín sme vysvetlili podstatnú časť variácie (R2=97%) v ich váhach.
ANOVA s použitím priemerov a štandardných odchýlok Jednofaktorovú analýzu rozptylu možno uskutočniť aj keď nemáte k dispozícii kompletné dáta, ale iba počty dát, priemery a štandardné odchýlky (prípadne štandardné chyby = štandardné odchýlky priemerov) v jednotlivých skupinách. Zo štandardných odchýlok možno totiž zrekonštruovať reziduálny súčet štvorcov:
( )
( )
( ) vnútrimedzicelk
k
iiimedzi
k
i
k
iii
k
i
n
jiijvnútri
n
jiij
ii
SSSSSSxxnSS
xk
x
snxxSS
kixxn
s
i
i
+=−≡
=
−=−≡
=−−
=
�
�
���
�
=••
=••
== =•
=
1
2
1
1
2
1 1
2
1
22
1
)1(
,...,2,11
1
a máme všetky veličiny, potrebné pre výpočet F.
Predpoklady pre použitie analýzy rozptylu Pri analýze rozptylu sme o dátach v skupinách predpokladali, že pochádzajú z normálnych rozdelení s rovnakou varianciou. Splnenie týchto predpokladov sa testuje pomerne ťažko; presne povedané, nefunguje často používaný naivný prístup spočívajúci v použití testu normality (napríklad Shapiro-Wilksov test) na dáta v skupinách a porovnanie variancií v skupinách (napríklad Bartlettovým testom). Týmto testom sa tu nebudem venovať, ak ich budete potrebovať, použite štatistický program alebo kalkulátor na Webe. Sú to dobré testy, ale:
1. V skupinách sa väčšinou nachádza neveľký počet dát a testovanie malého počtu dát na rozdelenie je naivné. Navyše ANOVA (a napríklad aj t-test) funguje dobre aj v situáciách, keď je test normality negatívny.
2. Bartlettov test a iné testy na rovnosť variancií sú citlivejšie na narušenie normality dát ako samotná ANOVA alebo t-test, a nemožno sa na ne spoliehať; rozhodne neposkytujú kritérium, kedy ANOVu alebo t-test možno použiť a kedy nie.
Preto použitie týchto testov nie je užitočné. Namiesto toho uvediem jeden súbor faktov a dve odporúčania:
1. Ak sú počty dát v skupinách rovnaké, je ANOVA veľmi robustná k odchýlkam od normality. Upozorňujem, že toto sa týka predovšetkým jednofaktorovej analýzy rozptylu, ktorú sme popísali vyššie. Viacfaktorové analýzy a hlavne tzv. repeated-measures analýzy (čo sú viacskupinové analógie párových porovnaní) majú na dodržanie normality a rovnosti variancií vyššie požiadavky. Máme teda podobnú situáciu ako u t-testu a platia všetky poznámky, uvedené v príslušnej časti. Tak ako pre t-test existuje dokonca Welchova verzia analýzy rozptylu určená pre prípad rôznych variancií v skupinách.
2. Testujte zvyšky. Hoci použitie testu normality pre dáta v skupinách možno označiť za skôr naivný počin, pripomeňme si, že všetky chyby majú rovnaké rozdelenie N[0,σ2], a to je ekvivalentná požiadavka ako normálne rozdelenia dát s rovnakou varianciou v skupinách. Zvyškov ale máme toľko, koľko máme dát, takže tu má zmysel testovať rozdelenie. V štatistike je ale vždy rozumnejšie si veci nakresliť, a nižšie ukážeme postup, ktorý je tradičný a univerzálne použiteľný (nielen pre analýzu rozptylu): kvantilový graf (quantile-quantile plot).

Testy základných štatistických hypotéz 36
3. Zopakujte rovnaký test s poradiami. Ak dostanete veľmi odlišné výsledky, znamená to, že rozdelenie dát nie je v poriadku a treba použiť neparametrický test alebo transformovať dáta.
Kvantilový graf Vezmime si akékoľvek dáta yi, u ktorých predpokladáme, že majú normálne rozdelenie. Zoradíme dáta podľa veľkosti (vzostupne) a vytvoríme empirickú distribučnú funkciu týchto dát:
( ) ( )
=
<== ⌠=
neplatí 0platí 1
)(
)(1 než menších ,počet 11
AA
AI
yyIn
yyn
yFn
iiiemp
Máme teda stupňovitú funkciu so skokom 1/n v každej hodnote yi.
Ak naše dáta pochádzajú z normálneho rozdelenia N[µ,σ2], potom hodnoty
[ ]1,0~ Nyz ii σ
µ−=
a ich empirická distribučná funkcia by mala rovnaké hodnoty. Pretože my ale tieto hodnoty poznáme, môžeme vypočítať odhady veličín zi:
nin
izi ,...,2,1,ˆ 21
1 =��
���
� −Φ= −
Tu Φ-1 je kvantilová funkcia štandardného normálneho rozdelenia a odpočítali sme jednu polovinu, aby sme sa vyhli počítaniu kvantilov v nule a jednotke (čo je +∞, resp. -∞). Kvantilový graf dostaneme, ak vynesieme hodnoty yi proti zi. Ak majú yi normálne rozdelenie, budú body ležať na priamke yi =µ +σzi. Podľa odchýlok od lineárnej závislosti môžeme usudzovať na odchýlky dát od normality.
Príklad. Zostrojíme kvantilový graf zo zvyškov po analýze rozptylu (teda rozdielov váh od skupinových priemerov.
Zvyšok
-6,0
-4,0
-2,0
0,0
2,0
4,0
6,0
0 5 10 15 20
Vidíme, že zvyšky sú rozložené rovnomerne a s približne rovnakým rozptylom po oboch stranách osi.
Kvantilový graf zvyškov po analýze rozptylu
y = 2,6173x
-6
-4
-2
0
2
4
6
-3 -2 -1 0 1 2 3
Z kvantilového grafu vidno, že zvyšky dobre sledujú lineárnu závislosť.
Kvantilový graf - simulácia (pre nácvik oka)
y = 2,6017xy = 2,6017x
-6
-4
-2
0
2
4
6
-3 -2 -1 0 1 2 3
Kvantilový graf - simulácia (pre nácvik oka)
y = 2,506xy = 2,506x
-6
-4
-2
0
2
4
6
-3 -2 -1 0 1 2 3
Kvantilový graf - simulácia (pre nácvik oka)
y = 3,0321xy = 3,0321x
-10
-5
0
5
10
-3 -2 -1 0 1 2 3
Kvantilový graf - simulácia (pre nácvik oka)
y = 2,6082xy = 2,6082x
-6-4-202468
-3 -2 -1 0 1 2 3
Kvantilový graf - simulácia (pre nácvik oka)
y = 2,941xy = 2,941x
-10
-5
0
5
10
-3 -2 -1 0 1 2 3
Pre posúdenie, či sú odchýlky od lineárnosti v kvantilovom grafe závažné, je najľahšie pozrieť sa na niekoľko simulovaných grafov (tieto vznikli tak, že som vygeneroval 19 čísel s normálnym

Testy základných štatistických hypotéz 37
rozdelením a rovnakou varianciou ako majú zvyšky, a vytvoril som kvantilový graf. Pri každom prepočítaní v Exceli (F9) sa vytvorí graf z odlišných simulovaných dát.
Takýto graf je omnoho ilustratívnejší ako výsledky batérie testov.
A čo ak dáta naozaj nie sú normálne? Vtedy máte k dispozícii podobné možnosti ako pri t-teste:
1. Transformovať dáta.
2. Použiť neparametrický test. Neparametrický analóg jednofaktorovej analýzy rozptylu sa nazýva Kruskal-Wallisov test a pracuje podobne ako Mann-Whitneyho test. Tento test tu nebudem popisovať a odporúčam zveriť počítanie štatistickému programu.
Viacnásobné porovnania Vráťme sa k tomu, s čím sme začali: chceme porovnávať priemery vo viacerých skupinách. Naučili sme sa síce elegantnú techniku, ale zatiaľ iba vieme zistiť, že niektoré zo skupinových priemerov sú rôzne. Chceli by sme ale zistiť, ktoré priemery sa štatisticky významne líšia.
Testy, ktoré sa používajú pre tieto účely, sa nazývajú viacnásobné porovnania (multiple comparisons) alebo post-hoc testy. Pre naše účely sa typicky používajú štyri testy:
1. Tukeyho test, označovaný často ako Tukey HSD (=honest significant difference). Toto je štandardný test a odporúčam ho používať v bežných situáciách. Tento test je pre niektoré aplikácie príliš konzervatívny (napr. pri väčšom počte porovnaní).
2. Newman-Keulsov test, označovaný niekedy ako Student-Newman-Keulsov, je silnejší (a teda menej konzervatívny ako Tukeyho test. Tento test býva často zatracovaný, pretože negarantuje FWE na úrovni hladiny významnosti. Namiesto toho tento test garantuje na úrovni nastavenej hladiny významnosti percento porovnaní, ktoré nesprávne vyjdú ako významné (FDR - false discovery rate). To je vhodná vlastnosť pri veľkom počte porovnaní a toto je aj oblasť použitia pre tento test. Existuje kompromisná verzia Tukeyho testu, označovaná často ako Tukeyho LSD (=least significance difference), ktorá je založená na kombinácií kritických hodnôt Tukeyho HSD a Newman-Keulsovho testu.
3. Scheffého test je slabší než Tukeyho a Newman-Keulsov test, ale umožňuje viacnásobné testy významnosti kontrastov - teda lineárnych kombinácií skupinových priemerov. Prirodzene, aj porovnania dvojíc priemerov možno chápať ako kontrasty µi-µj; Scheffého test ale použijeme, ak chceme testovať významnosť viacerých výrazov typu 1/2µ1-µ2+1/2µ3,1/2µ1-µ2+1/2µ3.
4. Dunnettov test vychádza z iných teoretických princípov ako predchádzajúce testy a používa sa pre porovnanie skupinových priemerov s priemerom kontrolnej skupiny.
Viacnásobné porovnania odporúčam prenechať štatistickému softwaru, pretože si vyžadujú pomerne veľa počítania a špeciálne tabuľky.
Tukeyho test Popíšeme v stručnosti postup pri Tukeyho HSD teste; podobný postup sa používa aj pri Newman-Keulsovom teste.
Test použijeme, ak sme pri analýze rozptylu odmietli nulovú hypotézu o rovnosti k skupinových priemerov.

Testy základných štatistických hypotéz 38
(Inak žiadne významné rozdiely nezistíme. Párové porovnania sú slabšie ako analýza rozptylu, takže naopak nemusíme zistiť žiadne rozdiely medzi skupinovými priemermi aj keď analýza rozptylu ukázala, že nie sú rovnaké.)
Budeme testovať k(k-1)/2 nulových hypotéz typu H0: µi=µj proti obojstrannej alternatíve.
Postup si budeme ilustrovať na dátach o vplyve diéty na váhu svíň, ktoré sme používali v tejto kapitole.
1. Zoradíme skupinové priemery podľa veľkosti a vytvoríme tabuľku rozdielov.
Skupinové priemery
Skupina 3 4 2 1Priemer 100,350 86,240 69,300 60,420ni 4 5 5 5
Vytvoríme tabuľku rozdielov priemerov, ktoré chceme porovnávať, v našom prípade všetkých dvojíc. Poradie porovnávania volíme tak, aby sme v prípade potreby mohli vynechať porovnania, ktoré nemôžu byť významné (teda začneme najväčšími rozdielmi a pokračujeme k menším.). Pre každú dvojicu vypočítame štandardnú chybu
��
�
�
��
�
�+=
ji
vnútriij nn
ss 112
2
a testovaciu štatistiku
ij
jiij s
xxq •• −
=
Získané hodnoty porovnávame s kritickou hodnotou qα,n,k, ktorá je spoločná pre všetky porovnania. V prípade, že je hodnota testovacej štatistiky väčšia ako kritická hodnota, zamietame nulovú hypotézu. Pre dáta z nášho príkladu dostávame:
s2vn útr i
8,466
A B nA nB Rozdiel sij q q 0,025;19;4 H0:3 1 4 5 39,930 1,380 28,931 4,076 Zamiet.3 2 4 5 31,050 1,380 22,497 4,076 Zamiet.3 4 4 5 14,110 1,380 10,223 4,076 Zamiet.4 1 5 5 25,820 1,301 19,843 4,076 Zamiet.4 2 5 5 16,940 1,301 13,018 4,076 Zamiet.2 1 5 5 8,880 1,301 6,824 4,076 Zamiet.
Zistili sme teda, že všetky skupinové priemery sa významne odlišujú. To nie je veľmi typická situácia.
Pre rozdiely možno vypočítať aj intervaly spoľahlivosti; ich hranice sú
ijknji
ijknji
sqxxsqxx
,,
,,
:horná:dolná
α
α
+−−−
••
••

Testy základných štatistických hypotéz 39
Pre naše dáta:
A B SE q 0,025;19;4 Rozdiel Dolná hr. Horná hr.3 1 1,380 4,076 39,930 34,304 45,5563 2 1,380 4,076 31,050 25,424 36,6763 4 1,380 4,076 14,110 8,484 19,7364 1 1,301 4,076 25,820 20,516 31,1244 2 1,301 4,076 16,940 11,636 22,2442 1 1,301 4,076 8,880 3,576 14,184
Tieto intervaly spoľahlivosti prinášajú ekvivalentnú informáciu ako porovnanie s kritickou hodnotou: Ak interval neobsahuje nulu, je rozdiel významný.
Výsledky takéhoto testovania vedú často iba k čiastočnému usporiadaniu skupinových priemerov. Často sa stáva, že medzi dvoma významne odlišnými hodnotami sa nachádza tretia, od ktorej sa ani jedna z týchto dvoch významne neodlišuje. Spravidla sa používa grafické znázornenie, v ktorom sa skupiny (klastre) priemerov, ktoré nie sú významne odlišné, spájajú spoločnou čiarou.
Newman-Keulsov test sa používa podobne, s tým rozdielom, že kritické hodnoty závisia od vzdialenosti medzi porovnávanými priemermi v rade usporiadanom podľa veľkosti.

Testy základných štatistických hypotéz 40
7. Lineárna regresia V tejto časti sa budeme venovať lineárnej regresii. Použijeme pritom všeobecný maticový formalizmus, ktorý je spoločný pre množstvo situácií a je výhodný aj pri štatistickej analýze. Ak sa nezľaknete a osvojíte si ho, zistíte, že je veľmi praktický a dobre sa pamätá.
Základné pojmy a označenia
Dáta: Našimi dátami bude i dvojíc (xi, yi), kde i=1, 2,... n., a xi môžu byť čísla alebo n-tice čísel.
Model: ikikiii fffy εβββ ++++= �1100 ,
kde i=1,2,... n čísluje dáta, fji sú faktory, j=0,1,...k, βj sú parametre, εi sú chyby.
Toto je lineárny model, a myslí sa tým, že je lineárny v parametroch βj. Faktory môžu byť ľubovoľné funkcie xi; dobré ale je, aby sa nepodobali. Číslujeme ich od nuly, pričom index nula je vyhradený pre konštantný faktor.
O chybách predpokladáme (zatiaľ; ďalšie predpoklady budeme potrebovať, keď budeme chcieť niečo tvrdiť o vlastnostiach odhadov parametrov a robiť diagnostiku regresie), že sú nezávislé a majú nulové stredné hodnoty:
2iijji σδεε =
0=iε
Príklady: Jednoduchá lineárna regresia:
iiiiii xffxy ==++= 1010 ,1 teda ,εββ
Fit kvadratickou funkciou: 2
2102
110 , ,1 teda ,i
xfxffxxy iiiiiiii ===+++= εβββ
Fit Fourierovým radom:
),...2cos( ),cos( ,1 teda ,...)2cos()cos( 210110 iiiiiiiii xfxffxxy ωωεωβωββ ===++++= ANOVA, 1 faktor:
kjj-i
ffffy jiikikiii ,..2,1 prípade opačnom v0
skupiny tej z jehodnota ta 1 kde ,...2211 =
��� −
=+++++= εβββ
Maticový zápis
�����
�
�
�����
�
�
=
�����
�
�
�����
�
�
=
�����
�
�
�����
�
�
=
�����
�
�
�����
�
�
=
+=
nkknnn
k
k
n fff
ffffff
F
y
yy
Y
FY
ε
εε
ε
β
ββ
β
εβ
.........
..................
...2
1
1
0
10
21202
11101
2
1
Testy základných štatistických hypotéz 41
Metóda najmenších štvorcov: Poznáme Y a F, potrebujeme parametre β. Nevieme, aké sú chyby ε, takže hľadáme odhady parametrov b metódou najmenších štvorcov: hľadáme čísla b = (b0, b1, ...bk) tak, aby minimalizovali reziduálny súčet štvorcov:
� �= =
���
����
�−=
n
i
k
jkiki fbyS
1
2
0
2
alebo maticovo:
)()(2 FbYFbYS T −−= T označuje transpozíciu (preklopenie podľa uhlopriečky).
Riešenie je (v maticovej forme):
( ) YFFFb TT 1−=
Symetrická matica FTF sa nazýva informačná matica.
b sú odhady koeficientov β, sú to teda náhodné veličiny, pretože závisia od chýb ε. Majú teda svoje rozdelenia pravdepodobnosti, stredné hodnoty a chyby, ktoré používame pre diagnostiku regresie. Matíc sa netreba báť, vie s nimi pracovať aj Excel: vie matice násobiť, transponovať, a počítať inverzné matice. Nie zvlášť šikovne, ale ide to, hlavne ak nezabudnete stlačiť Ctrl-Shift pri zadávaní maticových vzorcov. To vám umožní počítať si veci sami.
Príklad: Anscombove dáta.
Toto je slávny súbor dát: ide o štyri súbory 11 dvojíc hodnôt x a y, ktoré majú identické základné charakteristiky súborov, ako aj parametre lineárnej regresie. My začneme so súborom číslo 1, ktorý je „klasický“, ostatné si vyskúšajte sami, je to cvičenie na tému KRESLITE SI DÁTA.
Dáta Anscombe 1x1 y1
1 10 8,042 8 6,953 13 7,584 9 8,815 11 8,336 14 9,967 6 7,248 4 4,269 12 10,84
10 7 4,8211 5 5,68
0
2
4
6
8
10
12
14
0 5 10 15
Na obrázku vidíte dáta (modré krúžky), a nižšie uvidíte, ako nakresliť zvyšné veci (regresnú priamku a hranice konfidenčného pásu), a vypočítať ďalšie užitočné veci (chyby a spoľahlivosť koeficientov a analýzu rozptylu).
Kým začneme počítať, pozrite si dobre dáta. Vidíme, že:
1. Existuje viditeľná lineárna závislosť y od x.
2. Hodnoty y sú rozložené pravidelne okolo regresnej priamky a žiadna hodnota nie je „uletená“.
3. Rozptyl hodnôt y sa nemení v závislosti od x.
Začneme s výpočtom koeficientov; v maticovom zápise vyzerajú naše dáta takto:

Testy základných štatistických hypotéz 42
Y F8,04 1 106,95 1 87,58 1 138,81 1 98,33 1 119,96 1 147,24 1 64,26 1 410,84 1 12
4,82 1 75,68 1 5
Potrebujeme kovariančnú maticu koeficientov C, to je (FTF)-1, teda
C=(FTF)-1
0,82727273 -0,081818-0,0818182 0,009091
a matica koeficientov b je CFTY, teda
b=CFTY3,000090910,50009091
Zídu sa nám hodnoty predpovedané modelom Y=Fb a zvyšky ε=Y-Fb:
Model=Fb Zvyšky=Y-8,001 0,04
7,000818 -0,059,501273 -1,927,500909 1,318,501091 -0,1710,00136 -0,046,000636 1,245,000455 -0,749,001182 1,846,500727 -1,685,500545 0,18
Vlastnosti odhadov b
1. Vlastnosti nezávislé od rozdelenia pravdepodobnosti chýb ε (a) β=b
teda b sú nevychýlené odhady skutočných koeficientov.
( )( ) 1
2cov−=
=
FFC
cbbT
ijji σ
a predpokladáme, že rozptyly chýb σ2 sú rovnaké pre všetky pozorovania.
Teda inverzná matica informačnej matice dáva kovariancie koeficientov b; špeciálne diagonálne koeficienty dávajú variancie (rozptyly, kvadráty štandardných odchýlok) koeficientov b.
Z toho vyplýva, že model, kde
(i) informačná matica je zle podmienená (má malý determinant ≡ nemá plnú hodnosť ≡ jej vlastné hodnoty sa líšia o mnoho rádov), alebo

Testy základných štatistických hypotéz 43
(ii) inverzná matica k informačnej matici má veľké nediagonálne elementy
bude zlý v tom zmysle, že odhady parametrov b budú mať veľké chyby a/alebo budú vzájomne silne závislé. Typický príklad je model v tvare polynómu vysokého stupňa. Nápravu možno dosiahnuť použitím iných faktorov (napríklad ortogonálnych polynómov namiesto mocnín x) alebo menšieho počtu faktorov.
(b) Odhady b sú efektívne, teda najlepšie zo všetkých lineárnych nevychýlených odhadov v zmysle odchýlky od skutočných hodnôt β.
(c) Odhady b sú konzistentné, teda s rastúcim počtom pozorovaní sa blížia k skutočným hodnotám.
(d) Chyby odhadov y:
( ) ( )
���
�
�
���
�
�
=
=
= −
)(...
)(,)(ˆ
,)(ˆvar
0
21
xf
xff
bfxyfFFfxy
k
x
Tx
xTT
x σ
(e) Nevychýlený odhad σ2 je
( )
kn
yys
n
iii
−
−=�
=1
2
20
ˆ
Pokračovanie príkladu: Pre naše dáta máme (zo zvyškov po regresii, ktoré sme už spočítali): s0
2=1,376 a var(Y(xi)) použijeme na výpočet konfidenčného pásu.
2. Vlastnosti, súvisiace s predpokladom o normálnom rozdelení chýb ε (f) Ak chyby ε sú nezávislé s normálnym rozdelením, strednou hodnotou 0 a varianciou σ2, potom koeficienty b majú normálne rozdelenie so strednou hodnotou β a kovariačnou maticou (FTF)-1σ2.
(g) Aj predpovede modelu )(ˆ xy budú mať normálne rozdelenie (lebo sú to lineárne kombinácie b) s varianciou, uvedenou vyššie (bod (d)).
(h) Podiel
( )2
1
2
2
2 ˆ
σσ
�=
−=
n
iii yyS
má rozdelenie χ2 s (n-k) stupňami voľnosti.
(h) Chyby koeficientov sú potom dané výrazmi
1
20
2
)(
)(−=
=
FFC
scbsT
jjj
( )
kn
yys
n
iii
−
−=�
=1
2
20
ˆ

Testy základných štatistických hypotéz 44
(i) Veličina
)( j
j
bsb
t =
bude mať rozdelenie t s n-k stupňami voľnosti.
Odtiaľ:
100α%-ný interval spoľahlivosti pre parameter bj je
���
����
�+−
−−−−2
1,2
1,)( ;)( αα knjjknjj tbsbtbsb
Test významnosti koeficientu bj: Test hypotézy βj=0 proti alternatíve βj≠0:
- Zamietame, ak interval spoľahlivosti neobsahuje 0
- Možno uviesť hladinu významnosti P z inverznej distribučnej funkcie t-rozdelenia s n-k stupňami voľnosti.
Toto dobre platí iba v prípade, že parametre nie sú korelované. V opačnom prípade by sme sa museli zaoberať spoločným rozdelením parametrov a kresliť namiesto konfidenčných intervalov konfidenčné elipsy a hľadať kombinácie parametrov, ktoré sa významne líšia od 0.
Pokračovanie príkladu: Pre naše dáta máme:
95% int. spoľahlivostiHodnota sb t P Dolná hr. Horná hr.
b0 3,000 1,067 2,812 0,018 0,190 5,810b1 0,500 0,112 4,471 0,001 0,205 0,795 Ako vidno, oba koeficienty sú významne odlišné od nuly, teda oba sú v modeli užitočné. Zároveň vidíte, aká je presnosť určenia koeficientov z daných dát.
(j) Chyby odhadov y z modelu:
( ) ( )
���
�
�
���
�
�
=
=
= −
)(...
)(,)(ˆ
,)(ˆ
0
20
12
xf
xff
bfxysfFFfxys
k
x
Tx
xTT
x
Veličina
( ))(ˆ)(ˆ)(
xysxyxyt −=
bude mať zase t-rozdelenie s n-k stupňami voľnosti a intervaly spoľahlivosti možno počítať podobne ako v predchádzajúcom prípade.

Testy základných štatistických hypotéz 45
Pokračovanie príkladu Môžeme vypočítať hranice konfidenčného pásu. Vypočítame ich ako 95% intervaly spoľahlivosti v hodnotách xi, aj keď by sme ich mohli počítať v ľubovoľnom inom súbore hodnôt x.
Konfidenčné pásys2(yi)= fTCf C.I. dolný C.I. horný
0,138 7,024 8,9780,138 6,024 7,9780,325 7,999 11,0030,125 6,569 8,4330,175 7,399 9,6030,438 8,258 11,7440,238 4,717 7,2850,438 3,258 6,7430,238 7,717 10,2850,175 5,398 7,6030,325 3,998 7,003
t0,975;10 2,634s0
2 1,376
ANOVA pre výsledky regresie Celkový súčet štvorcov dát yi (celková variácia y)
( ) ��==
=−=n
ii
n
iiCELK y
nyyyS
11
22 1 kde ,
Súčet štvorcov odchýlok modelu (časť celkovej variácie y, vysvetlená modelom):
( )�=
−=n
iiMOD yyS
1
22 ˆ
Reziduálny súčet štvorcov (nevysvetlená časť variácie y):
( ) ��� �=== =
=−=���
����
�−=
n
i
n
iii
n
i
k
jkiki iRES yyfbyS
1
2
1
2
1
2
0
2 ˆ ε
Ak máme dobre spočítané parametre modelu a chyby majú nulové stredné hodnoty a sú nezávislé, potom
222RESMODCELK SSS +=
Za predpokladu normálneho rozdelenia chýb budú mať navyše súčty štvorcov rozdelenia chi-kvadrát takto:
voľnostistupňami 1 s voľnostistupňami s
voľnostistupňami 1 s
2
2
2
−−
−
knSkS
nS
RES
MOD
CELK
Za predpokladu nulovej hypotézy, že náš model vôbec nič nevysvetľuje, máme tri odhady pre s0
2:

Testy základných štatistických hypotéz 46
1
1
222
0
222
0
222
0
−−==
==
−==
knSss
kSss
nSss
RESRES
MODMOD
CELKCELK
V prípade, že je náš model dobrý, bude s2RES podstatne menšie ako s2
MOD (a s2CELK).
Pomer
2
2
RES
MOD
ssF =
má rozdelenie F s k a n-k-1 stupňami voľnosti: Porovnaním s kritickou hodnotou F rozdelenia dostávame test významnosti modelu, alebo možno uviesť hladinu významnosti použitím kvantilovej funkcie pre F-rozdelenie.
Výsledky sa tradične zapisujú do tabuľky analýzy rozptylu:
Zdroj variácie
Súčet štvorcov
Stupne voľnosti
Stredný štvorec
F P
Model 2MODS k 2
MODs
Chyby 2RESS n-k-1 2
RESs 2
2
RES
MOD
ssF = )( 2
2
1,RES
MODknk s
sF −−
Spolu 2CELKS n-1 2
CELKs
Koeficient determinácie
2
2
2
22 1
CELK
RES
CELK
MOD
SS
SSR −==
R2 číselne vyjadruje časť variácie, ktorú sa podarilo vysvetliť modelom. Nie je to ale dobrá miera vhodnosti modelu. Pre porovnanie rôznych modelov možno použiť upravený koeficient determinácie (index determinácie):
)1(1
111 22
22 R
knn
ssRCELK
RESd −
−−−−=−=
(ale ani toto nie je zvlášť užitočný spôsob porovnávania rôznych modelov).
Koeficient viacnásobnej korelácie
2RR =
sa občas uvádza, ale je podobne málo užitočný ako koeficient determinácie.
Pokračovanie príkladu Pre naše dáta vyzerá tabuľka analýzy rozptylu takto:
Zdroj variáSŠ s.v. str. štvore F PModel 27,51 1 27,51Chyby 13,76269 9 1,529188 17,98994 0,00216963Spolu 41,27269 10 4,127269

Testy základných štatistických hypotéz 47
Už by sme skoro boli hotoví, ale pridáme ešte trocha regresnej diagnostiky:
Zvyšky vs. model
-3,00
-2,00
-1,00
0,00
1,00
2,00
3,00
0 2 4 6 8 10 12
1. Zvyšky proti predpovediam modelu:
Chceme vidieť, že zvyšky sú rozložené okolo nuly pravidelne a ich rozptyl sa pozdĺž osi x nemení.
Nepravidelné rozloženie je príznakom neadekvátnosti modelu. Ak sa rozptyl pozdĺž osi x výrazne mení, znamená to, že sa mení variancia chýb a musíme použiť váženú regresiu alebo transformovať dáta.
Kvantilový graf zvyškov
y = 1,1541x + 2E-14
-3,00
-2,00
-1,00
0,00
1,00
2,00
3,00
-2 -1 0 1 2
2. Kvantilový graf zvyškov:
Tu chceme vidieť body rozložené pozdĺž priamky, bez dlhých chvostov s inou smernicou na začiatku alebo na konci a bez izolovaných bodov.
Pre natrénovanie oka si zase môžete nechať nakresliť niekoľko simulovaných súborov dát.