text data understandingdatamining.uos.ac.kr/wp-content/uploads/2019/02/chap3.pdf · 2019-04-16 ·...
TRANSCRIPT

Chap 03Text Data Understanding
서울시립대학교김윤나
1

Text Data Management and Analysis
Index
• Introduction
• History and State of the Art in NLP
• NLP and Text Information Systems
• Text Representation
• Statistical Language Models
2

Text Data Management and Analysis
Introduction
• NLP(Natural Language Processing)
• 텍스트에서의미있는정보를분석, 추출하고이해하는일
련의기술집합
• Lexical, Syntactic, Semantic, Pragmatic, Discourse analysis
3

Text Data Management and Analysis
History and State of Art in NLP
Time
~1950s Research in NLPIt was hard for computer to understand NLP
1960s Bar-Hillel : fully-automatic high-quality translation could not be accomplished without knowledge
1960s & 1970s Only have limited application impact with the failure to scale up
1970s – 1980s Attention to story understanding
1980s Attention to statistical approaches
… …
Page 42-434

Text Data Management and Analysis
NLP and Text Information Systems
• Because of required robustness and efficiency in TIS applications, in
general, robust shallow NLP techniques tend to be more useful than
fragile deep analysis techniques.
• While improved NLP techniques should in general enable improved TIS
task performance, lack of NLP capability isn’t necessarily a major
barrier for some application tasks, notably text retrieval, which is a
relatively easy task as compared with a more difficult task such as
machine translation where deep understanding of natural language is
clearly required.
5

Text Data Management and Analysis
NLP and Text Information Systems
6

Text Data Management and Analysis
NLP and Text Information Systems
• Pattern-based way of solving a problem has turned
out to be quite powerful.
• <2 important differences with Eliza System>
• The rules in a machine learning system would not be exact or
strict, but stochastic.
• Instead of having human to supply rules, the “soft” rules may
be learned automatically from the training data with only
minimum help from users.
7

Text Data Management and Analysis
Text Representation
8

Text Data Management and Analysis
Text Representation
Represent such a sentence as a string of characters.
It can’t allow us to perform semantic analysis, which is often needed for many applications of text mining.
9

Text Data Management and Analysis
Text Representation
Performing word segmentation to obtain a sequence of words.Easily discover the most frequent words in this document.Representing text data as a sequence of words opens up a lot of interesting analysis possibilities.
Slightly less general than a string of characters.Ex) Chinese not easy to identify all the word boundaries with no space in between words.To solve problem, we have to rely on some special techniques. (not only based on whitespace)
10

Text Data Management and Analysis
Text Representation
Add Part-Of-Speech(POS) tags to the words.Ex) what kind of nouns are associated with what kind of verbs…We add POS as an additional way of representing text data.
Representing text as both words and POS tags enriches the representation of text data, enabling a deeper, more principled analysis.
11

Text Data Management and Analysis
Text Representation
Be parsing the sentence to obtain a syntactic structure.
12

Text Data Management and Analysis
Text Representation
Will add more entities and relations, through entity-relation recognition.
Not easy to identify all the entities with the right types and might make mistakes.Relations are even harder to find.
13

Text Data Management and Analysis
Text Representation
If we move further to a logic representation, we have predicates and inference rules.
Can’t do that all the time for all kinds of sentences since it may take significant computation time or a large amount of training data.
14

Text Data Management and Analysis
Text Representation
Add another level of representation of the intent of this sentence.This would allow us to analyze even more interesting things about the observer or the author of this sentence.
15

Text Data Management and Analysis
Text Representation
More sophisticated NLP techniques
<cons> <pros>Tradeoff16

Text Data Management and Analysis
Text Representation
• In text data analysis and text mining, humans play a very
import role.
• Patterns that are extracted from text data can be
interpreted by humans, and then humans can guide the
computers to do more accurate analysis by annotating more
data, guiding machine learning programs to make them
work more effectively.
17
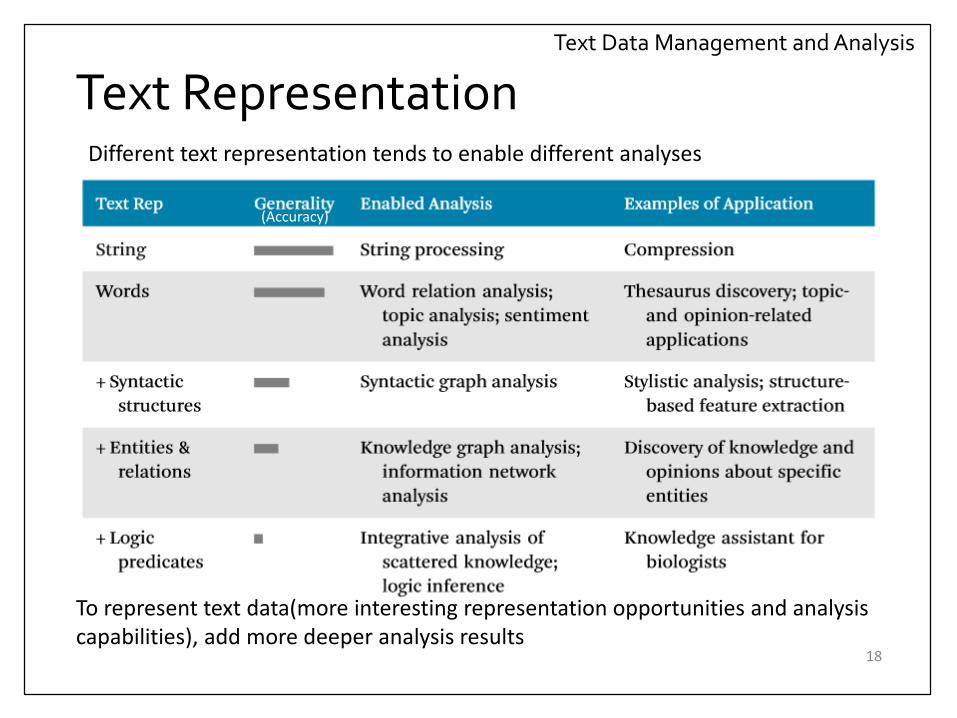
Text Data Management and Analysis
Text RepresentationDifferent text representation tends to enable different analyses
To represent text data(more interesting representation opportunities and analysis capabilities), add more deeper analysis results
(Accuracy)
18

Text Data Management and Analysis
Text Representation
Add additional representation
Very Robust and General
No word boundaries needed
General and relatively robust
use graph mining algorithms to analyze
Integrate analysis of scattered knowledge
Able to manage all the relevant knowledge from literature
19

Text Data Management and Analysis
Statistical Language Models
• a probability distribution over word sequences.
• gives any sequence of words a potentially different
probability.
• In general conversation • 𝑝 𝑇ℎ𝑒 𝑒𝑞𝑢𝑎𝑡𝑖𝑜𝑛 ℎ𝑎𝑠 𝑎 𝑠𝑜𝑙𝑢𝑡𝑖𝑜𝑛 < 𝑝(𝑇𝑜𝑑𝑎𝑦 𝑖𝑠 𝑊𝑒𝑑𝑒𝑠𝑑𝑎𝑦)
• At mathematics conference
• 𝑝 𝑇ℎ𝑒 𝑒𝑞𝑢𝑎𝑡𝑖𝑜𝑛 ℎ𝑎𝑠 𝑎 𝑠𝑜𝑙𝑢𝑡𝑖𝑜𝑛 > 𝑝(𝑇𝑜𝑑𝑎𝑦 𝑖𝑠 𝑊𝑒𝑑𝑒𝑠𝑑𝑎𝑦)
20

Text Data Management and Analysis
Statistical Language Models
• Given a language model, we can sample word sequences
according to the distribution.
• Use a model to “generate” text
• 𝐴 𝑙𝑎𝑛𝑔𝑢𝑎𝑔𝑒 𝑚𝑜𝑑𝑒𝑙 = 𝑎 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑖𝑣𝑒 𝑚𝑜𝑑𝑒𝑙 𝑓𝑜𝑟 𝑡𝑒𝑥𝑡
• Language model provides a principled way to quantify the
uncertainties associated with the use of natural language.
Allows to answer many interesting questions related to text analysis and information retrieval.
21

Text Data Management and Analysis
Statistical Language Models
• Enumerating all the possible sequences of words
and give a probability to each sequence
Too complex to estimate
• Need to make assumptions to simplify the model
• Simplest language model : unigram language
22

Text Data Management and Analysis
Statistical Language Models
• Unigram language model
• Assume that a word sequence results from generating each
word independently.
• The probability of a sequence of words would be equal to the
product of the probability of each word.
• Given a language model 𝜃, 𝑝 𝐷1 𝜃) ≠ 𝑝(𝐷2|𝜃)
• 𝑝 𝐷1 𝜃)↑ 𝑝 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 ↑
Word sequence 𝑤𝑖 ∈ 𝑉(𝑠𝑒𝑡 𝑜𝑓 𝑤𝑜𝑟𝑑𝑠)
23

Text Data Management and Analysis
Statistical Language Models
<Two examples of unigram language models, representing two different topics>
• D : text mining paper, 𝑝 𝐷 𝜃1 > 𝑝(𝐷|𝜃2)
• D’ : blog article about diet control, 𝑝 𝐷′ 𝜃1 < 𝑝(𝐷′|𝜃2)
𝑝 𝐷 𝜃1 > 𝑝 𝐷′ 𝜃1 𝑎𝑛𝑑 𝑝 𝐷 𝜃2 < 𝑝(𝐷′|𝜃2)
“text mining” “health”
24

Text Data Management and Analysis
Statistical Language Models
• D : observed document
• 𝜃 : unigram language model
• Estimate the probabilities of each word 𝑤, 𝑝 𝑤 𝜃 !!
• Maximum Likelihood(ML) estimator
• To estimate the probabilities of each word
• Seeks a model 𝜃 = argmax𝜃 𝑝(𝐷|𝜃)
• ML estimate of a unigram language model gives each word a
probability equal to its relative frequency in D
𝑝 𝑤 𝜃 =𝑐 𝑤,𝐷
|𝐷|
count of word w
25

Text Data Management and Analysis
Statistical Language Models
• Estimate is optimal in observed data, but how
about in an application?
• In general, the maximum likelihood estimate would assign
zero probability to any unseen token in observed data
• Techniques for improving the maximum likelihood estimator
called “Smoothing”. (Later mentioned)
26

Text Data Management and Analysis
Statistical Language Models
• A unigram language model is already very useful
for text analysis.
functional words : highest probabilities
content words:Differ dramatically depending on the data Can be used to discriminate the topics in different text samples
27

Text Data Management and Analysis
Statistical Language Models
• A unigram language models can also be used to
perform semantic analysis of word relations.
• Use to find what words are semantically associated with a
word.
• Need to filter out such common words.
• To filter out, general English model would serve the purpose
well. We use the background language model to model to
normalize the model and obtain a probability ratio for each
word.
28