text mining 2people.tuke.sk/jan.paralic/prezentacie/mz/mz6.pdf• otvorené štandardy- existuje...
TRANSCRIPT

Objavovanie znalostí v textoch TU Košice
TEXT MINING 2
Objavovanie znalostí v textochPeter Bednár

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Proces objavovania znalostí v textoch
1. Stanovenie obchodného alebo výskumného cieľa
2. Identifikácia relevantných textových dát
3. Integrovanie a predspracovanie textov do vhodnej reprezentácie
4. Použitie metód pre extrahovanie znalostí na predspracovaných
dátach - modelovanie
5. Vyhodnotenie výsledkov
6. Využitie výsledkov
2

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Identifikácia relevantných textových dát
• V dokumentových súboroch rôznych formátov (.txt, .doc, .docx, .pdf,
...)
• Ako súčasť databázových záznamov informačných systémov (ERP,
CRM, QMS, SCM, ...)
• Na webe v podobe HTML stránok, wiki, a pod. (intranete alebo
Internete)
• Na sociálnom webe v podobe správ, komentárov, hodnotení,
krátkych popisov, blogov a pod. (Facebook, Twitter, LinkedIn,
YouTube, Instagram, Pinterest, ...)
• Z obsahu komunikácie (e-mail, sms, chat, automatický prepis audio
hovoru)
3

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Prístup k dátam
• Na webe cez internetové protokoly HTTP, FTP
• Pomocou SQL, ak sú dáta uložené v relačnej databáze
– Napr. pri integrovaní dát z ERP
• Prostredníctvom webových služieb
– Návratová hodnota pri volaní služieb je väčšinou zakódovaná vo
formáte XML, alebo JSON (Javascript Object Notation)
• Je potrebné získať oprávnenie k prístupu, ak sú dáta zabezpečené
– meno/heslo, bezpečnostné certifikáty
4

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Formáty textových dát (1)
• Proprietárne formáty - poskytovateľ softvéru nemusí zverejniť
špecifikáciu formátu
– Dáta môžu byť len čiastočne čitateľné, problémy s verziami
– Napr. staršie MS Office formáty .doc, .xls, .ppt
• Otvorené štandardy - existuje voľne dostupná špecifikácia
– HTML, XML, JSON
– Formát elektronickej pošty
– Súborové formáty .docx (novší MS Office formát), .odt
(OpenOffice formát), .pdf, .rtf
– Často sú štandardizované medzinárodnými organizáciami RFC,
ISO/IEC, OASIS
5

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Formáty textových dát (2)
• Dokumenty môžu byť komprimované, alebo spojené do archívu -
.zip, .gz, .bz2, .rar, .tar
– znova môžu byť problematické proprietárne formáty
• Na webe a pri elektronickej pošte sa formáty rozlišujú podľa MIME
(Multipurpose Internet Mail Extensions) štandardu
– MIME spravuje organizácia IANA (Internet Assigned Numbers
Authority)
– Popis formátov zahŕňa odporúčanú súborovú príponu a
jedinečné označenie typu, ktoré sa uvádza v hlavičke HTTP
protokolu, alebo v prílohe pošty
– Aktuálny zoznam formátov:
http://www.iana.org/assignments/media-types/
6

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Kódovanie textu (1)
• Samotný text je uložený v počítači ako postupnosť čísel, pričom
existuje viacero tabuliek, ktoré každému znaku priradzujú číslo
• Základná prekladová tabuľka pre latinku je ASCII (American
Standard Code for Information Interchange)
– Ide o 7-bitové kódovanie (128 znakov), obsahuje medzeru a 94
znakov pre tlačenie (veľké a malé písmená latinskej abecedy a
interpunkčné znaky)
• Pre slovenskú abecedu sa používa viacero 8-bitových tabuliek (256
znakov), najčastejšie:
– ISO/IEC norma ISO 8859-2
– Windows 1250 zavedená Microsoftom
7

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Kódovanie textu (2)
• Aby sa zjednotila reprezentácia textov pre všetky abecedy a
znakové sady, bol navrhnutý štandard Unicode
• Unicode 8.0 definuje kódovanie pre viac než 120 000 znakov ktoré
pokrývajú 129 moderných a historických systémov písma (hláskové
aj znakové)
• Pre Unicode existuje viacero kódovaní:
– UTF-8 - schéma s premenlivým počtom bytov na znak od 1 do 6,
prvých 128 znakov je rovnakých ako ASCII
– UTF-16 - schéma s premenlivým počtom bytov, 2 alebo 4 na
jeden znak
8

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Harmonizácia dát (1)
• Zo vstupného formátu vyextrahujeme čistý text
– Pri značkovaných formátoch (XML, HTML, .rtf) odstránime
vložené formátovacie a štrukturálne značky
– Zjednotíme kódovanie textu (napr. na UTF-8)
– Snažíme sa čo najviac zachovať:
• Členenie textu na kapitoly, odseky, nadpisy a pod. Slová,
ktoré sa vyskytujú v nadpisoch alebo abstrakte, môžu mať
väčšiu váhu pri popise obsahu dokumentu.
• Typografické informácie - konce riadkov, strán, odsadenie,
odrážky
9

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Harmonizácia dát (2)
• Zo vstupného formátu vyextrahujeme metainformácie
– Bibliografické údaje napr. informácie o autorovi, dátum
publikovania, pôvodný zdroj alebo umiestnenie dokumentu,
zdrojový formát dokumentu a pod.
– Metaúdaje vložené autorom, ktoré dodatočne charakterizujú
obsah, ako napr. kľúčové slová, zaradenie dokumentu do
kategórií a pod.
– Linky, ktoré odkazujú na súvisiace dokumenty
• Snažíme sa čo najviac zjednotiť štruktúru metainformácií, tak aby
bola spoločná pre rôzne vstupné formáty
10

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Harmonizácia dát – príklad (1)
Dokument v PDF
formáte:
Extrahovaný čistý text:
Manažment znalostí(1)
OBSAH PREDNÁŠKY
* Základné informácie o predmete
* Dáta, informácie, znalosti
* Manažment znalostí
* Vyhľadávanie informácií z množiny textových dokumentov
- Proces vyhľadávania informácií (information retrieval – IR)
- Formálna definícia IR modelu
* Klasické modely pre IR
- Boolovský model
Manažment znalostí (1) Ján Paralič (people.tuke.sk/jan_paralic)
Základné informácie o predmete
...
11
Extrahované metainformácie:
autor: Jan Paralic
dátum vytvorenia: 18.9.2015
zdroj: http://people.tuke.sk/jan.paralic/prezentacie/MZ/MZ1.pdf
zdrojový formát: application/pdf
názov: Objavovanie znalosti
téma: Seminar UI

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Harmonizácia dát – príklad (2)
12
JSON objekt získaný z Twitter služby:
{"coordinates": null,"created_at": "Thu Oct 21 16:02:46 +0000 2015","id": 0123456789, "entities": {
"urls": [],"user_mentions": [ ],"hashtags": [ {
"name": "FridayReads","id": 123654789, …} ]
}, "text": "I’m loving 'The Sound of Things Falling' by Juan
Gabriel Vasquez #FridayReads","user": {
"name": "lenadunham","id": 987456321,…
},…
}
Extrahovaný čistý text:
I’m loving 'The Sound of Things Falling' by Juan
Gabriel Vasquez #FridayReads
Extrahované metainformácie
autor: lenadunhan
dátum vytvorenia: 21.10.2015
zdroj:https://api.twitter.com/1.1/statuses/show.json?id=
0123456789zdrojový formát: application/json
kľúčové slová: FridayReads

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Integrácia dát – centralizovaný CMS
• Harmonizované dokumenty je výhodné integrovať do systému pre
manažment obsahu (CMS - Content Management System), ktorý by
mal poskytovať:
– Jednotný prístup k spravovaným dátam
• Priamy prístup k vyextrahovanému čistému textu v
zjednotenom kódovaní
• Prístup k metainformáciám v zjednotenej štruktúre
– Možnosť vyhľadávania a filtrovania textových dát podľa obsahu
a/alebo metainformácií
13

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Integrácia dát - príklad
14
CMSHarmonizácia
textových dát
Dokumentové
súbory
ERP, CRM
záznamy
Komentáre
zákazníkov
Správy
zákazníkov
Firemná
pošta
Prepis hovorov zo
zákazníckeho
centra
Jednotný
prístup k dátam
Vnútorné
prostredie firmy

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Predspracovanie textových dát
• Pred aplikovaním metód text miningu je potrebné previesť text do
štruktúrovanej reprezentácie
• Čím viac informácií reprezentácia obsahuje
– Tým jednoznačnejšie reprezentuje význam textu, ale
– Predspracovanie je zložitejšie, je viac jazykovo závislé, vyžaduje
viac jazykových zdrojov (napr. slovníkov, korpusov, pravidiel) a
môže byť menej robustné voči chybám v texte
• Pre dané dáta a úlohu text miningu je potrebné zvoliť vhodný
kompromis
15

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Reprezentácia textov - rozdelenie
• Nezohľadňuje sa poradie slov
– Vektorová reprezentácia dokumentov, kde termy tvoria iba
jednotlivé slová
• Čiastočne sa zohľadňuje poradie slov
– Vektorová reprezentácia dokumentov, kde termy tvoria jednotlivé
slová a niektoré slovné spojenia
• Zohľadňuje sa poradie slov
– Postupnosť slov a ich príznaky
– Syntaktická reprezentácia textov, ktorá priamo obsahuje
gramatické vzťahy medzi slovami
16

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Jazykové úrovne pri predspracovaní
• Nezohľadňuje sa poradie slov
– Lexikálna analýza + čiastočná morfologická analýza
• Čiastočne sa zohľadňuje poradie slov
– Lexikálna analýza + čiastočná morfologická analýza + čiastočná
syntaktická analýza
• Zohľadňuje sa poradie slov
– Lexikálna analýza + morfologická analýza + syntaktická analýza
17

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Metódy pre predspracovanie textu
• Lexikálna analýza
– Tokenizácia – rozdelenie na základné lexikálne jednotky
– Segmentácia textu – rozdelenie na vety, vyjadrenia
• Morfologická analýza
– Stemming – prevedenie tvarov na koreň slova
– Lematizácia – prevedenie tvarov na základný tvar slova
– Morfologické značkovanie – priradenie slovného druhu (sloveso,
podstatné meno, predložka, atď.) a morfologických kategórií
(rod, pád, číslo, vid, atď.)
• Syntaktická analýza
– Syntaktické parsovanie – rozdelenie vety na frázy, priradenie
syntaktických rolí (podmet, prísudok, predmet, atď.)
18
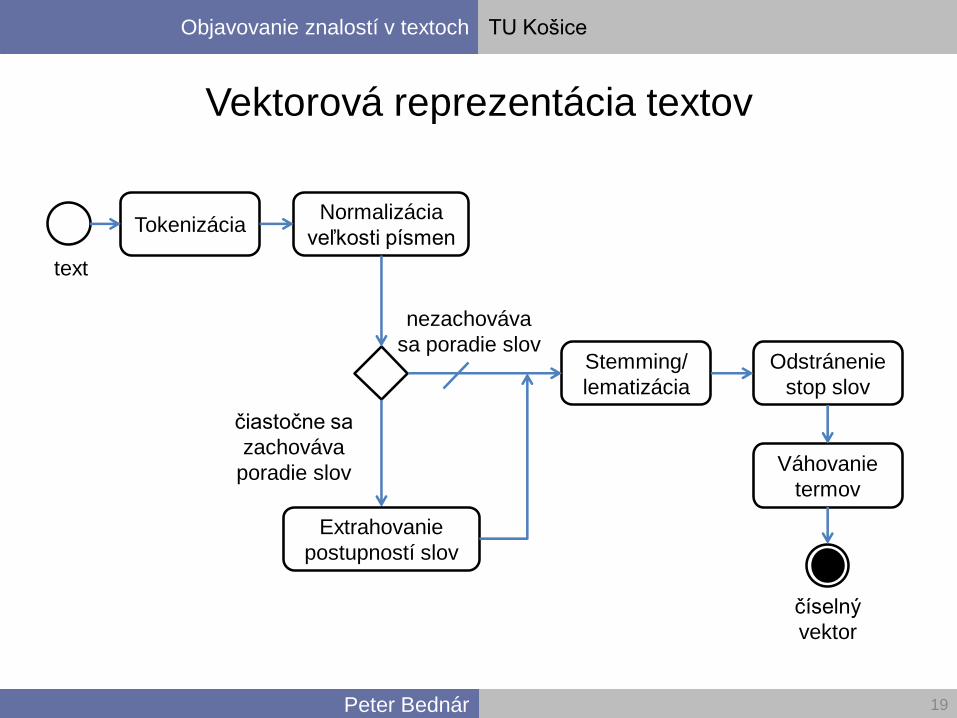
Objavovanie znalostí v textoch TU Košice
Peter Bednár
Vektorová reprezentácia textov
19
Tokenizácia
Stemming/
lematizácia
Normalizácia
veľkosti písmen
Odstránenie
stop slov
Extrahovanie
postupností slov
nezachováva
sa poradie slov
čiastočne sa
zachováva
poradie slov Váhovanie
termov
text
číselný
vektor

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Tokenizácia
• Rozdelenie textu na základné lexikálne jednotky - tokeny, ako napr.
slová, interpunkčné znaky, číselné údaje, dátumy, internetové
adresy a pod.
• Vstup: postupnosť znakov
• Výstup: postupnosť tokenov
• Pre európske jazyky sú slová oddelené medzerou alebo
interpunkčnými znakmi - – ( ) , . ; : / „ “ ? ! …
– Najčastejšie sa text rozdelí pomocou regulárnych výrazov
– Výnimky sa následne ošetria podľa slovníka
• Skratky, názvy, zložené výrazy
• viac - menej → viac-menej
20

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Tokenizácia - regulárne výrazy (1)
• Umožňujú kompaktne zapísať vzor pre postupnosť znakov
• Výskyt znaku
. (bodka) - ľubovoľný znak
[množina] - znak z množiny
[^množina] - ľubovoľný znak okrem množiny
\\ spätná lomka, \t tabulátor, \n nový riadok, \” úvodzovky
• Opakovanie znakov:
? - znak sa vyskytol 0 alebo raz
* - znak sa vyskytol ľubovoľný počet krát (aj 0)
+ - znak sa vyskytol raz alebo viackrát
{min, max} - znak sa vyskytol minimálne min a maximálne
max krát, alebo {počet opakovaní}
21

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Tokenizácia - regulárne výrazy (2)
• Kombinovanie výrazov
výraz1 | výraz2 – výraz1 alebo výraz2
(výraz) – zátvorky ohraničujú výraz pri kombinovaní
• Príklady:
[a-záéíĺóŕúýčďľňšťžäô]+ – slovo v slovenskej abecede, všetky
písmená malé, napr. vŕba
[1-9][0-9]*(\.[0-9]*)? (€|EUR) – číselná hodnota v eurách, napr.
10.25 EUR
[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)*@([a-zA-Z0-9_-]+\.)+[a-z]{2,6} –
emailová adresa, napr. [email protected]
22

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Extrahovanie termov
• Cieľom je previesť tokeny na termy, ktoré budú zahrnuté do
vektorovej reprezentácie
• Vstup: postupnosť tokenov
• Výstup: postupnosť termov
1. Znormujeme veľkosť písmen (výnimkou môžu byť názvy a skratky,
kde má striedanie veľkých a malých písmen význam)
2. Prevedieme slovo na jeho základný tvar (tzv. lemu - lematizácia)
alebo koreň slova (tzv. stem - stemming), t.j. všetky tvary toho istého
slova budú namapované na jeden term
3. Odstránime neplnovýznamové slová (spojky, predložky, častice,
zámená, čísla), keďže pri zanedbaní poradia nemajú veľký vplyv na
reprezentáciu významu
23

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Stemming
• Pre daný jazyk sa navrhnú pravidlá, ktoré prevedú rôzne tvary slova
na ich spoločný koreň odstránením prípon a predpôn
• Relatívne presná metóda pre jazyky s jednoduchšou morfológiou,
napr. pre angličtinu {clos-ing, clos-es, clos-er, clos-e} →clos+0
• Stemming nemusí byť jednoznačný, t.j. slová s rôznym významom
môžu byť namapované na ten istý koreň
• Koreň už nemusí byť slovom (nemusí byť úplne zrozumiteľný)
• Pravidlá majú tvar [podmienka] S1 → S2: ak je splnená podmienka
(napr. ak slovo končí na -s alebo obsahuje spoluhlásku), potom
nahraď predponu/príponu S1 reťazcom S2
• Pre angličtinu sa najčastejšie používa Porterov stemmer
24

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Porterov stemmer - príklady pravidiel
1a - Odstránenie prípon -s, -es
S → cats → cat
IES → I ponies → poni,
SSES → SS caresses → caress
1b - Odstránenie prípon -d, -e, -ing
EED → EE agreed → agree
ED → plastered → plaster
ING → plastering → plaster
1c - Zmena prípony y na i
Y → I ponny → ponni
2 - Zmena prípon
ATIONAL → ATE relational → relate
25

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Lematizácia
• Každé slovo sa prevedie na základný tvar - lemu (neurčitok pre
slovesá, 1. pád jednotného čísla pre podstatné mená, atď.)
• Napr.: pekná → pekný, prípadov → prípad
• Slovenčina má veľa prípon, nepravidelné slová, rôzne alternácie v
základe slova (napr. otec, otcovi - bez e)
• Pre jazyky so zložitou morfológiou sa používa kombinácia pravidiel
a morfologického slovníka, ktorý mapuje tvary slova na ich základný
tvar
• Lematizácia môže byť nejednoznačná
– Jeden tvar môže byť namapovaný na viacero lem (napr. mier →
mier, alebo mieriť)
26

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Odstránenie stop slov
• Ak zanedbáme poradie slov, najdôležitejšie pre reprezentáciu
významu textu sú slovesá, podstatné mená a prídavné mená
• Odstránením neplnovýznamových slov sa zníži rozmer
príznakového priestoru (neplnovýznamové slová spôsobujú pri
modelovaní dátový šum)
• Odstránia sa slová zo slovníka tzv. stop slov
– Spojky, predložky, častice, zámená, pomocné slovesá
– Napr. pre slovenčinu: a, aby, aj, ako, ale, alebo, ani, áno, asi,
bez, by, byť, cez, čo, či, dnes, do, další, ešte, ho, i, iba, ja, je,
jeho, jej, k, kam, každý ...
• Môžu sa odstrániť aj čísla, dátumy, a pod., ako napr. 1 000, 26.10.
2015
27

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Extrahovanie postupností slov
• Niektoré mená a názvy a veľa odborných termínov je tvorených
viacerými slovami (mennými frázami) - mali by byť indexované ako
jeden term, aby sa zachoval ich význam
• Postupnosti slov je možné vyextrahovať štatisticky spočítaním
frekventovaných n-gramov, t.j. n za sebou idúcich slov
– Jazykovo nezávislá metóda
– Vyextrahované postupnosti nemusia byť gramaticky správne
frázy
– Extrahovanie gramatických fráz si vyžaduje zložitejšiu
morfologickú a syntaktickú analýzu
28

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Extrahovanie n-gramov – príklad (1)
• Príklady bigramov vyextrahovaných z 250 článkov denníka SME
95 v roku 45 v usa
89 o tom 42 v stredu
89 sa v 40 budúci rok
82 v novembri 39 a v
65 centrálna banka 39 centrálnej banky
57 v eurozóne 39 v piatok
56 na úrovni 38 v rámci
53 by sa 37 roku 2013
53 mld eur 37 v treťom
51 v utorok ...
29

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Extrahovanie n-gramov – príklad (2)
• Príklady trigramov vyextrahovaných z 250 článkov denníka SME
33 v roku 2013 21 v roku 2014
32 o tom agentúra 19 domáci produkt hdp
31 v budúcom roku 19 európska centrálna banka
28 na budúci rok 19 hrubý domáci produkt
28 s tým že 19 informovala o tom
24 v porovnaní s 17 centrálna banka ecb
23 hrubého domáceho produktu 17 domáceho produktu hdp
...
• So stúpajúcim n sa znižuje frekvencia n-gramov, ale zvyšuje sa
podiel ustálených slovných spojení
30

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Google n-gram corpus
• Google poskytuje viacero korpusov n-gramov vygenerovaných z
rôznych dátových množín indexovaných pre vyhľadávanie
• Korpus vygenerovaný z kolekcie kníh Google Book:
http://storage.googleapis.com/books/ngrams/books/datasetsv2.html
– Pokrýva angličtinu, čínštinu, francúzštinu, nemčinu, hebrejčinu,
taliančinu, ruštinu a španielčinu
– Korpus obsahuje frekvencie výskytov 1-gramov (jednotlivých
slov), 2-, 3-, 4- a 5-gramov
– Je možné získať všetky n-gramy, alebo iba podmnožinu n-
gramov, ktoré tvoria gramatické frázy zo slov vybraných slovných
druhov (napr. menné frázy tvorené iba prídavnými a podstatnými
menami)
31

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Vektorová reprezentácia - príklad
Vstupný text:
Hodnota denného dovozu dosiahla iba 10 059 mil. barelov.
1. Tokenizácia:
Hodnota denného dovozu dosiahla iba 10 059 mil. barelov .
2. Normalizácia veľkosti písmen
hodnota denného dovozu dosiahla iba 10 059 mil. barelov .
3. Lematizácia
hodnota denný dovoz dosiahnuť iba 10 059 mil. barel .
4. Odstránenie stop slov
hodnota denný dovoz dosiahnuť barel
{barel , denný, dovoz, dosiahnuť, hodnota}
32

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Syntaktická reprezentácia textov
33
TokenizáciaSegmentácia na
vety/vyjadrenia
text
syntaktická
reprezentácia
Morfologické
značkovanie
Syntaktické
parsovanie

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Morfologické značkovanie
• Pri morfologickom značkovaní sa každému slovu priradí jeho slovný
druh (podstatné meno, prídavné meno, sloveso, príslovka,
predložka, zámeno, spojka, častica, citoslovce, atď.) a ďalšie
morfologické kategórie (rod, pád, číslo, vid, životnosť atď.)
• Na základe poradia slov a morfologických značiek sa potom
identifikujú syntaktické vzťahy
• Na automatické značkovanie sa používajú štatistické metódy
(hlavne skryté Markovove modely - HMM) – dosahujú presnosť 90-
98% podľa zložitosti morfológie jazyka
34

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Syntaktické parsovanie
• Pri syntaktickom parsovaní sa identifikujú gramatické vzťahy medzi
slovami a vetné členy (podmet, prísudok, predmet, prívlastok, atď.)
• Na automatické parsovanie sa používajú manuálne vytvorené
pravidlá (gramatiky), alebo štatistické metódy – dosahujú presnosť
80-89% podľa jazyka
• V súčasnosti je populárna reprezentácia pomocou závislostných
stromov, ktorá je výhodná pre jazyky s voľným slovosledom (napr.
pre slovenčinu)
35

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Syntaktická reprezentácia - závislostné stromy
• Každému slovu vo vete zodpovedá jeden uzol + koreň stromu
• Orientované hrany medzi uzlami reprezentujú gramatické vzťahy a
sú označené funkciou podradeného slova (počiatočný uzol) voči
nadradenému slovu (koncový uzol hrany), napr.:
36
Oracle kúpil Sun
pod
pr
pred

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Syntaktická reprezentácia – príklad (1)
37
Hodnota denného dovozu dosiahla iba 10 059 mil. barelov
PM
1p, jč,
žr
PrM
2p, jč,
mr
PM
2p, jč,
mr, nž
S
dok
jč, žr
ZČ Čsl Čsl
2p, mč,
mr
PM
2p, mč,
mr, nž
Slovné druhy
PM podstatné meno, PrM prídavné meno, S sloveso, ZČ zvýrazňovacia častica, Čsl
číslovka
Morfologické kategórie
1p, 2p – pád, jč, mč – jednotné/množné číslo, žr, mr – ženský/mužský rod, nž –
neživotné, dok – dokonavý slovesný vid, atď.

Objavovanie znalostí v textoch TU Košice
Peter Bednár
Syntaktická reprezentácia – príklad (2)
38
Hodnota
pod pred
pr
denného dovozu dosiahla iba 10 059 mil. barelov
atr
atr
atr
atr
pč
Syntaktické funkcie
pr – prísudok, pod – podmet, pred – predmet, atr – atribút rozvitého člena, pč –
pomocný člen