the boosting approach to machine learning an overview · the boosting approach to machine learning...
TRANSCRIPT

Nonlinear Estimation and Classification, Springer, 2003.
The Boosting Approach to Machine LearningAn Overview
Robert E. SchapireAT&T Labs � Research
Shannon Laboratory180 Park Avenue, Room A203Florham Park, NJ 07932 USA
www.research.att.com/�schapire
December 19, 2001
Abstract
Boosting is a general method for improving the accuracy of any givenlearning algorithm. Focusing primarily on the AdaBoost algorithm, thischapter overviews some of the recent work on boosting including analysesof AdaBoost’s training error and generalization error; boosting’s connectionto game theory and linear programming; the relationship between boostingand logistic regression; extensions of AdaBoost for multiclass classificationproblems; methods of incorporating human knowledge into boosting; andexperimental and applied work using boosting.
1 Introduction
Machine learning studies automatic techniques for learning to make accurate pre-dictions based on past observations. For example, suppose that we would like tobuild an email filter that can distinguish spam (junk) email from non-spam. Themachine-learning approach to this problem would be the following: Start by gath-ering as many examples as posible of both spam and non-spam emails. Next, feedthese examples, together with labels indicating if they arespam or not, to yourfavorite machine-learning algorithm which will automatically produce a classifi-cation or prediction rule. Given a new, unlabeled email, such a rule attempts topredict if it is spam or not. The goal, of course, is to generate a rule that makes themost accurate predictions possible on new test examples.
1

Building a highly accurate prediction rule is certainly a difficult task. On theother hand, it is not hard at all to come up with very rough rules of thumb thatare only moderately accurate. An example of such a rule is something like thefollowing: “If the phrase ‘buy now’ occurs in the email, thenpredict it is spam.”Such a rule will not even come close to covering all spam messages; for instance,it really says nothing about what to predict if ‘buy now’ doesnot occur in themessage. On the other hand, this rule will make predictions that are significantlybetter than random guessing.
Boosting, the machine-learning method that is the subject of this chapter, isbased on the observation that finding many rough rules of thumb can be a lot easierthan finding a single, highly accurate prediction rule. To apply the boosting ap-proach, we start with a method or algorithm for finding the rough rules of thumb.The boosting algorithm calls this “weak” or “base” learningalgorithm repeatedly,each time feeding it a different subset of the training examples (or, to be more pre-cise, a different distribution or weighting over the training examples1). Each timeit is called, the base learning algorithm generates a new weak prediction rule, andafter many rounds, the boosting algorithm must combine these weak rules into asingle prediction rule that, hopefully, will be much more accurate than any one ofthe weak rules.
To make this approach work, there are two fundamental questions that must beanswered: first, how should each distribution be chosen on each round, and second,how should the weak rules be combined into a single rule? Regarding the choiceof distribution, the technique that we advocate is to place the most weight on theexamples most often misclassified by the preceding weak rules; this has the effectof forcing the base learner to focus its attention on the “hardest” examples. Asfor combining the weak rules, simply taking a (weighted) majority vote of theirpredictions is natural and effective.
There is also the question of what to use for the base learningalgorithm, butthis question we purposely leave unanswered so that we will end up with a generalboosting procedure that can be combined with any base learning algorithm.
Boostingrefers to a general and provably effective method of producing a veryaccurate prediction rule by combining rough and moderatelyinaccurate rules ofthumb in a manner similar to that suggested above. This chapter presents anoverview of some of the recent work on boosting, focusing especially on the Ada-Boost algorithm which has undergone intense theoretical study and empirical test-ing.
1A distribution over training examples can be used to generate a subset of the training examplessimply by sampling repeatedly from the distribution.
2

Given:�� � � � �� � � � � � ��� � �� � where�� , �� � � ��� � ��
Initialize � � ��� � ��� .For � � �� � � � � � :� Train base learner using distribution�� .� Get base classifier�� � � � .� Choose�� � .� Update: ��� � ��� � � � ��� !" �������� �� � ��#�
where#� is a normalization factor (chosen so that��� � will be a distribu-
tion).
Output the final classifier:
$ �� � � %&'( ) *+�, � ���� �� �- �Figure 1: The boosting algorithm AdaBoost.
2 AdaBoost
Working in Valiant’s PAC (probably approximately correct)learning model [75],Kearns and Valiant [41, 42] were the first to pose the questionof whether a “weak”learning algorithm that performs just slightly better thanrandom guessing can be“boosted” into an arbitrarily accurate “strong” learning algorithm. Schapire [66]came up with the first provable polynomial-time boosting algorithm in 1989. Ayear later, Freund [26] developed a much more efficient boosting algorithm which,although optimal in a certain sense, nevertheless sufferedlike Schapire’s algorithmfrom certain practical drawbacks. The first experiments with these early boostingalgorithms were carried out by Drucker, Schapire and Simard[22] on an OCR task.
The AdaBoost algorithm, introduced in 1995 by Freund and Schapire [32],solved many of the practical difficulties of the earlier boosting algorithms, and isthe focus of this paper. Pseudocode for AdaBoost is given in Fig. 1 in the slightlygeneralized form given by Schapire and Singer [70]. The algorithm takes as inputa training set
�� � � � �� � � � � � ��� � �� � where each�� belongs to somedomainorinstance space , and eachlabel �� is in some label set� . For most of this paper,we assume� � ��� � ��; in Section 7, we discuss extensions to the multiclasscase. AdaBoost calls a givenweakor base learning algorithmrepeatedly in a series
3

of rounds� � �� � � � � � . One of the main ideas of the algorithm is to maintain adistribution or set of weights over the training set. The weight of this distribution ontraining example
�on round� is denoted�� ���. Initially, all weights are set equally,
but on each round, the weights of incorrectly classified examples are increased sothat the base learner is forced to focus on the hard examples in the training set.
The base learner’s job is to find abase classifier�� � � � appropriatefor the distribution��. (Base classifiers were also called rules of thumb or weakprediction rules in Section 1.) In the simplest case, the range of each�� is binary,i.e., restricted to ��� � ��; the base learner’s job then is to minimize theerror�� � ������ ��� �� � � �� �� � �
Once the base classifier�� has been received, AdaBoost chooses a parameter�� � that intuitively measures the importance that it assigns to��. In the figure,we have deliberately left the choice of�� unspecified. For binary�� , we typicallyset �� � � ( �� � ���� � (1)
as in the original description of AdaBoost given by Freund and Schapire [32]. Moreon choosing�� follows in Section 3. The distribution�� is then updated using therule shown in the figure. Thefinal or combined classifier
$is a weighted majority
vote of the� base classifiers where�� is the weight assigned to�� .3 Analyzing the training error
The most basic theoretical property of AdaBoost concerns its ability to reducethe training error, i.e., the fraction of mistakes on the training set. Specifically,Schapire and Singer [70], in generalizing a theorem of Freund and Schapire [32],show that the training error of the final classifier is boundedas follows:�� � � $ �� � � �� �� � � �� +� !" ����� ��� �� � �� #� (2)
where henceforth we define � �� � � +� ���� �� � (3)
so that$ ��� � %&'( �� �� ��. (For simplicity of notation, we write� � and� � as
shorthand for���, � and� *�, �, respectively.) The inequality follows from the factthat ���� � �� � � � � if �� �� $ ��� �. The equality can be proved straightforwardly byunraveling the recursive definition of�� .
4

Eq. (2) suggests that the training error can be reduced most rapidly (in a greedyway) by choosing�� and�� on each round to minimize#� � +� � � ��� !" �������� �� � �� � (4)
In the case of binary classifiers, this leads to the choice of�� given in Eq. (1) andgives a bound on the training error of
�� #� � �� ��� �� �� � �� �� � �� � � � �� � � !" )�� +� � � - (5)
where we define� � � ��� � ��. This bound was first proved by Freund andSchapire [32]. Thus, if each base classifier is slightly better than random so that� � � � for some� � �, then the training error drops exponentially fast in� sincethe bound in Eq. (5) is at most��* � . This bound, combined with the boundson generalization error given below prove that AdaBoost is indeed a boosting al-gorithm in the sense that it can efficiently convert a true weak learning algorithm(that can always generate a classifier with a weak edge for anydistribution) intoa strong learning algorithm (that can generate a classifier with an arbitrarily lowerror rate, given sufficient data).
Eq. (2) points to the fact that, at heart, AdaBoost is a procedure for finding alinear combination� of base classifiers which attempts to minimize+� !" ����� �� � �� � +� !" )��� +� ���� �� � �- � (6)
Essentially, on each round, AdaBoost chooses�� (by calling the base learner) andthen sets�� to add one more term to the accumulating weighted sum of base classi-fiers in such a way that the sum of exponentials above will be maximally reduced.In other words, AdaBoost is doing a kind of steepest descent search to minimizeEq. (6) where the search is constrained at each step to followcoordinate direc-tions (where we identify coordinates with the weights assigned to base classifiers).This view of boosting and its generalization are examined inconsiderable detailby Duffy and Helmbold [23], Mason et al. [51, 52] and Friedman[35]. See alsoSection 6.
Schapire and Singer [70] discuss the choice of�� and �� in the case that��is real-valued (rather than binary). In this case,�� �� � can be interpreted as a“confidence-rated prediction” in which the sign of�� �� � is the predicted label,while the magnitude �� �� � gives a measure of confidence. Here, Schapire andSinger advocate choosing�� and�� so as to minimize
#� (Eq. (4)) on each round.
5

4 Generalization error
In studying and designing learning algorithms, we are of course interested in per-formance on examplesnot seen during training, i.e., in the generalization error, thetopic of this section. Unlike Section 3 where the training examples were arbitrary,here we assume that all examples (both train and test) are generated i.i.d. fromsome unknown distribution on � � . The generalization error is the probabilityof misclassifying a new example, while the test error is the fraction of mistakes ona newly sampled test set (thus, generalization error is expected test error). Also,for simplicity, we restrict our attention to binary base classifiers.
Freund and Schapire [32] showed how to bound the generalization error of thefinal classifier in terms of its training error, the size� of the sample, the VC-dimension2 � of the base classifier space and the number of rounds� of boosting.Specifically, they used techniques from Baum and Haussler [5] to show that thegeneralization error, with high probability, is at most3
��� �$ ��� �� � � � �� ��� � �� �where
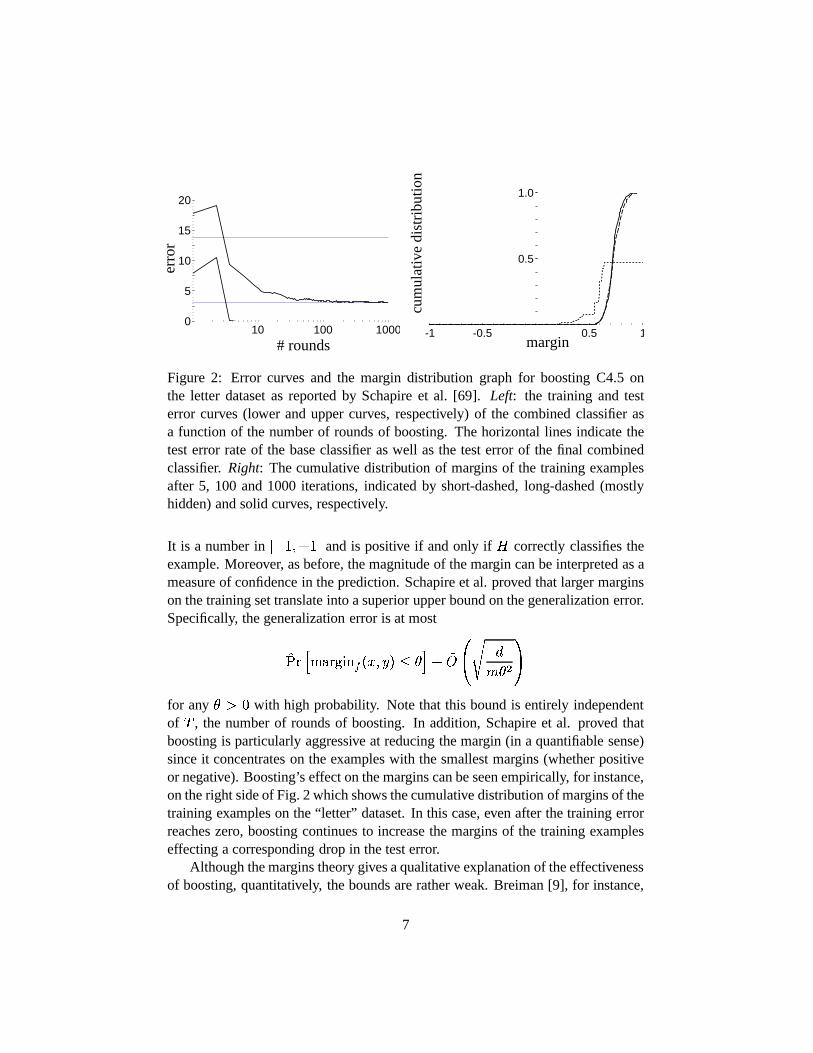
��� �� denotes empirical probability on the training sample. Thisbound sug-gests that boosting will overfit if run for too many rounds, i.e., as� becomes large.In fact, this sometimes does happen. However, in early experiments, several au-thors [8, 21, 59] observed empirically that boosting often doesnot overfit, evenwhen run for thousands of rounds. Moreover, it was observed that AdaBoost wouldsometimes continue to drive down the generalization error long after the trainingerror had reached zero, clearly contradicting the spirit ofthe bound above. Forinstance, the left side of Fig. 2 shows the training and test curves of running boost-ing on top of Quinlan’s C4.5 decision-tree learning algorithm [60] on the “letter”dataset.
In response to these empirical findings, Schapire et al. [69], following the workof Bartlett [3], gave an alternative analysis in terms of themarginsof the trainingexamples. The margin of example
�� � � � is defined to be
���'&(� �� � � � � � � �� �+� �� � � +� ���� �� �+� �� �2The Vapnik-Chervonenkis (VC) dimension is a standard measure of the “complexity” of a space
of binary functions. See, for instance, refs. [6, 76] for itsdefinition and relation to learning theory.3The “soft-Oh” notation � ���
, here used rather informally, is meant to hide all logarithmic andconstant factors (in the same way that standard “big-Oh” notation hides only constant factors).
6
10 100 10000
5
10
15
20
erro
r
# rounds-1 -0.5 0.5 1
0.5
1.0
cum
ulat
ive
dist
ribut
ion
margin
Figure 2: Error curves and the margin distribution graph forboosting C4.5 onthe letter dataset as reported by Schapire et al. [69].Left: the training and testerror curves (lower and upper curves, respectively) of the combined classifier asa function of the number of rounds of boosting. The horizontal lines indicate thetest error rate of the base classifier as well as the test errorof the final combinedclassifier.Right: The cumulative distribution of margins of the training examplesafter 5, 100 and 1000 iterations, indicated by short-dashed, long-dashed (mostlyhidden) and solid curves, respectively.
It is a number in���� � �� and is positive if and only if$
correctly classifies theexample. Moreover, as before, the magnitude of the margin can be interpreted as ameasure of confidence in the prediction. Schapire et al. proved that larger marginson the training set translate into a superior upper bound on the generalization error.Specifically, the generalization error is at most
��� ����'&(� �� � � � � �� � �� ��� �� � �for any � � � with high probability. Note that this bound is entirely independentof � , the number of rounds of boosting. In addition, Schapire et al. proved thatboosting is particularly aggressive at reducing the margin(in a quantifiable sense)since it concentrates on the examples with the smallest margins (whether positiveor negative). Boosting’s effect on the margins can be seen empirically, for instance,on the right side of Fig. 2 which shows the cumulative distribution of margins of thetraining examples on the “letter” dataset. In this case, even after the training errorreaches zero, boosting continues to increase the margins ofthe training exampleseffecting a corresponding drop in the test error.
Although the margins theory gives a qualitative explanation of the effectivenessof boosting, quantitatively, the bounds are rather weak. Breiman [9], for instance,
7

shows empirically that one classifier can have a margin distribution that is uni-formly better than that of another classifier, and yet be inferior in test accuracy. Onthe other hand, Koltchinskii, Panchenko and Lozano [44, 45,46, 58] have recentlyproved new margin-theoretic bounds that are tight enough togive useful quantita-tive predictions.
Attempts (not always successful) to use the insights gleaned from the theoryof margins have been made by several authors [9, 37, 50]. In addition, the margintheory points to a strong connection between boosting and the support-vector ma-chines of Vapnik and others [7, 14, 77] which explicitly attempt to maximize theminimum margin.
5 A connection to game theory and linear programming
The behavior of AdaBoost can also be understood in a game-theoretic setting asexplored by Freund and Schapire [31, 33] (see also Grove and Schuurmans [37]and Breiman [9]). In classical game theory, it is possible toput any two-person,zero-sum game in the form of a matrix� . To play the game, one player chooses arow
�and the other player chooses a column� . The loss to the row player (which
is the same as the payoff to the column player) is� �� . More generally, the twosides may play randomly, choosing distributions� and� over rows or columns,respectively. The expected loss then is����.
Boosting can be viewed as repeated play of a particular game matrix. Assumethat the base classifiers are binary, and let� � � � � ���� �� � be the entire baseclassifier space (which we assume for now to be finite). For a fixed training set�� � � � �� � � � � � ��� � �� �, the game matrix� has� rows and� columns where
� �� � � if �� �� � � � ��� otherwise.
The row player now is the boosting algorithm, and the column player is the baselearner. The boosting algorithm’s choice of a distribution�� over training exam-ples becomes a distribution� over rows of� , while the base learner’s choice of abase classifier�� becomes the choice of a column� of � .
As an example of the connection between boosting and game theory, considervon Neumann’s famous minmax theorem which states that��! � &(� ���� � � &(� ��! ����for any matrix� . When applied to the matrix just defined and reinterpreted inthe boosting setting, this can be shown to have the followingmeaning: If, for any
8

distribution over examples, there exists a base classifier with error at most��� � � ,then there exists a convex combination of base classifiers with a margin of at least�� on all training examples. AdaBoost seeks to find such a final classifier withhigh margin on all examples by combining many base classifiers; so in a sense, theminmax theorem tells us that AdaBoost at least has the potential for success since,given a “good” base learner, there must exist a good combination of base classi-fiers. Going much further, AdaBoost can be shown to be a special case of a moregeneral algorithm for playing repeated games, or for approximately solving matrixgames. This shows that, asymptotically, the distribution over training examples aswell as the weights over base classifiers in the final classifier have game-theoreticintepretations as approximate minmax or maxmin strategies.
The problem of solving (finding optimal strategies for) a zero-sum game iswell known to be solvable using linear programming. Thus, this formulation of theboosting problem as a game also connects boosting to linear,and more generallyconvex, programming. This connection has led to new algorithms and insights asexplored by Ratsch et al. [62], Grove and Schuurmans [37] and Demiriz, Bennettand Shawe-Taylor [17].
In another direction, Schapire [68] describes and analyzesthe generalizationof both AdaBoost and Freund’s earlier “boost-by-majority”algorithm [26] to abroader family of repeated games called “drifting games.”
6 Boosting and logistic regression
Classification generally is the problem of predicting the label � of an example�with the intention of minimizing the probability of an incorrect prediction. How-ever, it is often useful to estimate theprobability of a particular label. Friedman,Hastie and Tibshirani [34] suggested a method for using the output of AdaBoost tomake reasonable estimates of such probabilities. Specifically, they suggested usinga logistic function, and estimating
��� �� � � � � � � �� �� ��� �� � � ��� �� � (7)
where, as usual,� �� � is the weighted average of base classifiers produced by Ada-Boost (Eq. (3)). The rationale for this choice is the close connection between thelog loss (negative log likelihood) of such a model, namely,+� ( �� � ���� � �� � �� (8)
9

and the function that, we have already noted, AdaBoost attempts to minimize:+� ���� � �� � � � (9)
Specifically, it can be verified that Eq. (8) is upper bounded by Eq. (9). In addition,if we add the constant� � ( �
to Eq. (8) (which does not affect its minimization),then it can be verified that the resulting function and the onein Eq. (9) have iden-tical Taylor expansions around zero up to second order; thus, their behavior nearzero is very similar. Finally, it can be shown that, for any distribution over pairs�� � � �, the expectations � �( �� � ��� � �� ���and � ����� �� ��are minimized by the same (unconstrained) function� , namely,� �� � � � ( ��� �� � � � � �� � �� � �� � � � �Thus, for all these reasons, minimizing Eq. (9), as is done byAdaBoost, can beviewed as a method of approximately minimizing the negativelog likelihood givenin Eq. (8). Therefore, we may expect Eq. (7) to give a reasonable probabilityestimate.
Of course, as Friedman, Hastie and Tibshirani point out, rather than minimiz-ing the exponential loss in Eq. (6), we could attempt insteadto directly minimizethe logistic loss in Eq. (8). To this end, they propose their LogitBoost algorithm.A different, more direct modification of AdaBoost for logistic loss was proposedby Collins, Schapire and Singer [13]. Following up on work byKivinen and War-muth [43] and Lafferty [47], they derive this algorithm using a unification of logis-tic regression and boosting based on Bregman distances. This work further con-nects boosting to the maximum-entropy literature, particularly the iterative-scalingfamily of algorithms [15, 16]. They also give unified proofs of convergence tooptimality for a family of new and old algorithms, includingAdaBoost, for boththe exponential loss used by AdaBoost and the logistic loss used for logistic re-gression. See also the later work of Lebanon and Lafferty [48] who showed thatlogistic regression and boosting are in fact solving the same constrained optimiza-tion problem, except that in boosting, certain normalization constraints have beendropped.
For logistic regression, we attempt to minimize the loss function+� ( �� � ���� � �� � �� (10)
10

which is the same as in Eq. (8) except for an inconsequential change of constantsin the exponent. The modification of AdaBoost proposed by Collins, Schapire andSinger to handle this loss function is particularly simple.In AdaBoost, unravelingthe definition of�� given in Fig. 1 shows that�� ��� is proportional (i.e., equal upto normalization) to !" ������� � ��� ��where we define �� �� � � �+��, � ��� ��� �� � �To minimize the loss function in Eq. (10), the only necessarymodification is toredefine�� ��� to be proportional to �� � !" ������ � ��� �� �A very similar algorithm is described by Duffy and Helmbold [23]. Note that ineach case, the weight on the examples, viewed as a vector, is proportional to thenegative gradient of the respective loss function. This is because both algorithmsare doing a kind of functional gradient descent, an observation that is spelled outand exploited by Breiman [9], Duffy and Helmbold [23], Masonet al. [51, 52] andFriedman [35].
Besides logistic regression, there have been a number of approaches taken toapply boosting to more general regression problems in whichthe labels�� are realnumbers and the goal is to produce real-valued predictions that are close to these la-bels. Some of these, such as those of Ridgeway [63] and Freundand Schapire [32],attempt to reduce the regression problem to a classificationproblem. Others, suchas those of Friedman [35] and Duffy and Helmbold [24] use the functional gradientdescent view of boosting to derive algorithms that directlyminimize a loss func-tion appropriate for regression. Another boosting-based approach to regressionwas proposed by Drucker [20].
7 Multiclass classification
There are several methods of extending AdaBoost to the multiclass case. The moststraightforward generalization [32], called AdaBoost.M1, is adequate when thebase learner is strong enough to achieve reasonably high accuracy, even on thehard distributions created by AdaBoost. However, this method fails if the baselearner cannot achieve at least 50% accuracy when run on these hard distributions.
11

For the latter case, several more sophisticated methods have been developed.These generally work by reducing the multiclass problem to alarger binary prob-lem. Schapire and Singer’s [70] algorithm AdaBoost.MH works by creating a setof binary problems, for each example� and each possible label� , of the form:“For example�, is the correct label� or is it one of the other labels?” Freundand Schapire’s [32] algorithm AdaBoost.M2 (which is a special case of Schapireand Singer’s [70] AdaBoost.MR algorithm) instead creates binary problems, foreach example� with correct label� and eachincorrect label � � of the form: “Forexample�, is the correct label� or � �?”
These methods require additional effort in the design of thebase learning algo-rithm. A different technique [67], which incorporates Dietterich and Bakiri’s [19]method of error-correcting output codes, achieves similarprovable bounds to thoseof AdaBoost.MH and AdaBoost.M2, but can be used with any baselearner thatcan handle simple, binary labeled data. Schapire and Singer[70] and Allwein,Schapire and Singer [2] give yet another method of combiningboosting with error-correcting output codes.
8 Incorporating human knowledge
Boosting, like many machine-learning methods, is entirelydata-driven in the sensethat the classifier it generates is derived exclusively fromthe evidence present inthe training data itself. When data is abundant, this approach makes sense. How-ever, in some applications, data may be severely limited, but there may be humanknowledge that, in principle, might compensate for the lackof data.
In its standard form, boosting does not allow for the direct incorporation of suchprior knowledge. Nevertheless, Rochery et al. [64, 65] describe a modification ofboosting that combines and balances human expertise with available training data.The aim of the approach is to allow the human’s rough judgments to be refined,reinforced and adjusted by the statistics of the training data, but in a manner thatdoes not permit the data to entirely overwhelm human judgments.
The first step in this approach is for a human expert to construct by hand arule � mapping each instance� to an estimated probability�
�� � �� � �� that isinterpreted as the guessed probability that instance� will appear with label� �.There are various methods for constructing such a function� , and the hope is thatthis difficult-to-build function need not be highly accurate for the approach to beeffective.
Rochery et al.’s basic idea is to replace the logistic loss function in Eq. (10)
12

with one that incorporates prior knowledge, namely,+� ( �� � ���� � �� � �� � � +� �� �� ��� � �
�� � ��� �� � � �where
�� �
� � � � � � ( �� �� � � �� � � � ( ��� � � �� �� � � �� is binary relative
entropy. The first term is the same as that in Eq. (10). The second term gives ameasure of the distance from the model built by boosting to the human’s model.Thus, we balance the conditional likelihood of the data against the distance fromour model to the human’s model. The relative importance of the two terms iscontrolled by the parameter� .
9 Experiments and applications
Practically, AdaBoost has many advantages. It is fast, simple and easy to pro-gram. It has no parameters to tune (except for the number of round� ). It requiresno prior knowledge about the base learner and so can be flexibly combined withanymethod for finding base classifiers. Finally, it comes with a set of theoreticalguarantees given sufficient data and a base learner that can reliably provide onlymoderately accurate base classifiers. This is a shift in mindset for the learning-system designer: instead of trying to design a learning algorithm that is accurateover the entire space, we can instead focus on finding base learning algorithms thatonly need to be better than random.
On the other hand, some caveats are certainly in order. The actual performanceof boosting on a particular problem is clearly dependent on the data and the baselearner. Consistent with theory, boosting can fail to perform well given insufficientdata, overly complex base classifiers or base classifiers that are too weak. Boostingseems to be especially susceptible to noise [18] (more on this in Sectionsec:exps).
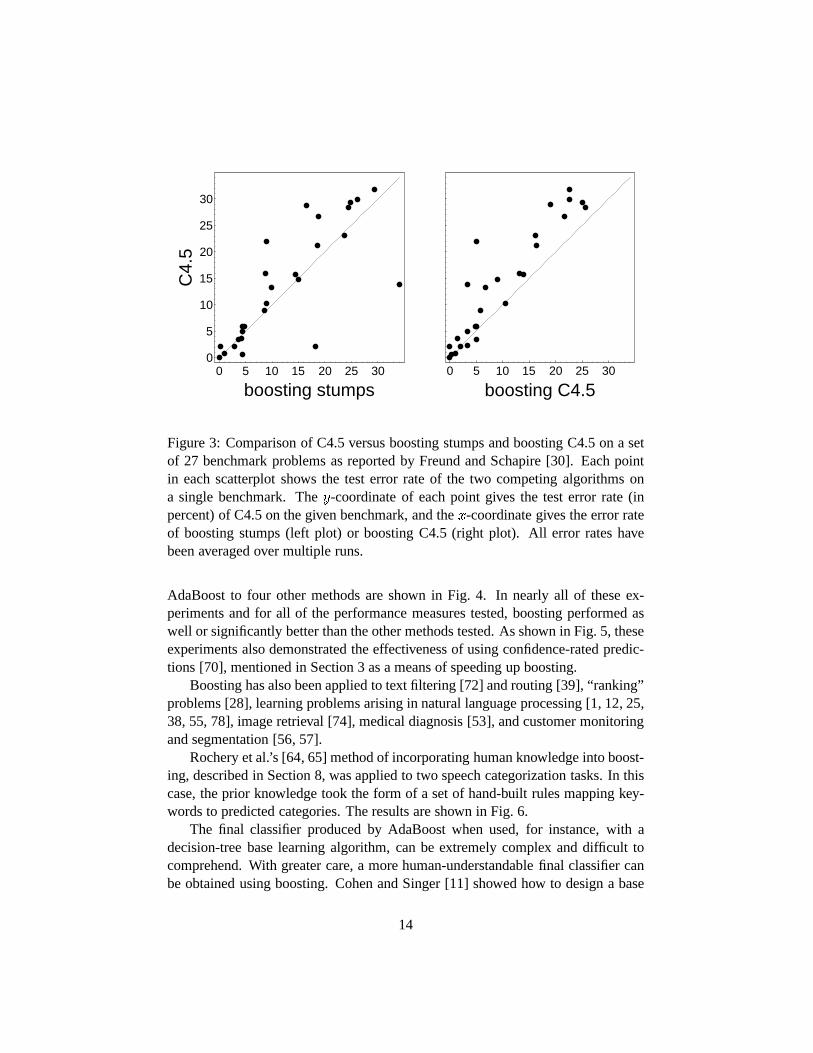
AdaBoost has been tested empirically by many researchers, including [4, 18,21, 40, 49, 59, 73]. For instance, Freund and Schapire [30] tested AdaBoost on aset of UCI benchmark datasets [54] using C4.5 [60] as a base learning algorithm,as well as an algorithm that finds the best “decision stump” orsingle-test decisiontree. Some of the results of these experiments are shown in Fig. 3. As can be seenfrom this figure, even boosting the weak decision stumps can usually give as goodresults as C4.5, while boosting C4.5 generally gives the decision-tree algorithm asignificant improvement in performance.
In another set of experiments, Schapire and Singer [71] usedboosting for textcategorization tasks. For this work, base classifiers were used that test on the pres-ence or absence of a word or phrase. Some results of these experiments comparing
13
0 5 10 15 20 25 300
5
10
15
20
25
30C
4.5
0 5 10 15 20 25 300
5
10
15
20
25
30
boosting stumps boosting C4.5
Figure 3: Comparison of C4.5 versus boosting stumps and boosting C4.5 on a setof 27 benchmark problems as reported by Freund and Schapire [30]. Each pointin each scatterplot shows the test error rate of the two competing algorithms ona single benchmark. The�-coordinate of each point gives the test error rate (inpercent) of C4.5 on the given benchmark, and the�-coordinate gives the error rateof boosting stumps (left plot) or boosting C4.5 (right plot). All error rates havebeen averaged over multiple runs.
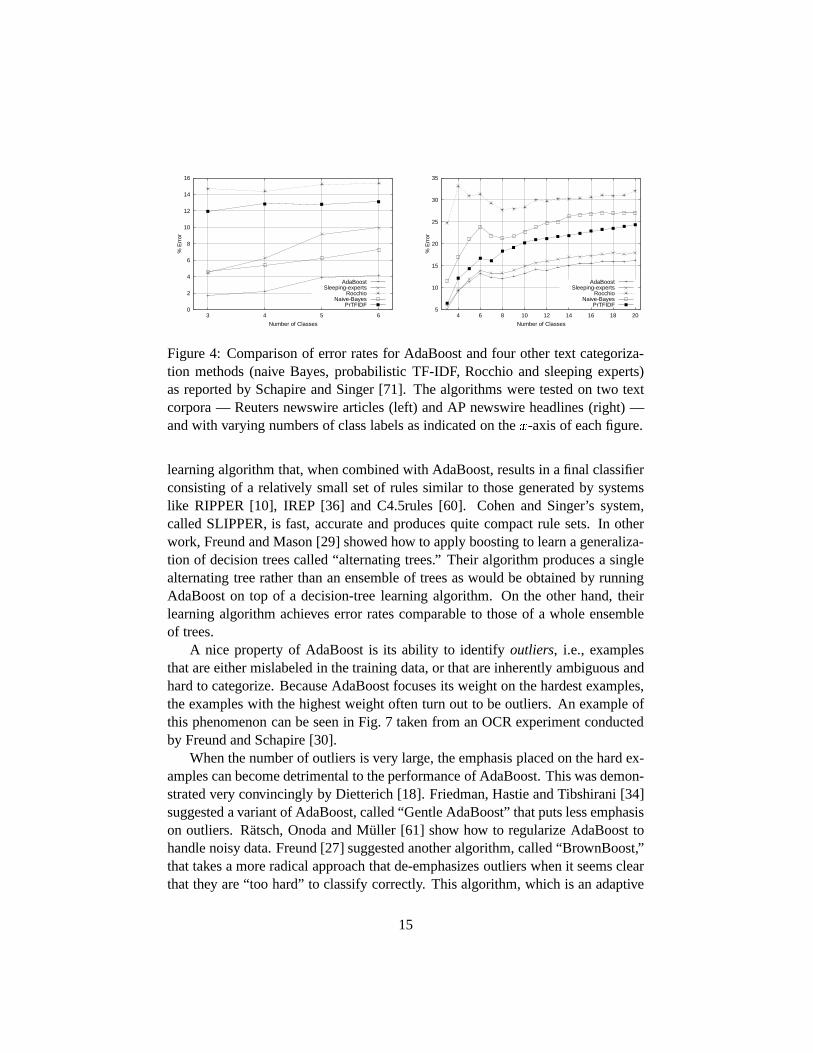
AdaBoost to four other methods are shown in Fig. 4. In nearly all of these ex-periments and for all of the performance measures tested, boosting performed aswell or significantly better than the other methods tested. As shown in Fig. 5, theseexperiments also demonstrated the effectiveness of using confidence-rated predic-tions [70], mentioned in Section 3 as a means of speeding up boosting.
Boosting has also been applied to text filtering [72] and routing [39], “ranking”problems [28], learning problems arising in natural language processing [1, 12, 25,38, 55, 78], image retrieval [74], medical diagnosis [53], and customer monitoringand segmentation [56, 57].
Rochery et al.’s [64, 65] method of incorporating human knowledge into boost-ing, described in Section 8, was applied to two speech categorization tasks. In thiscase, the prior knowledge took the form of a set of hand-builtrules mapping key-words to predicted categories. The results are shown in Fig.6.
The final classifier produced by AdaBoost when used, for instance, with adecision-tree base learning algorithm, can be extremely complex and difficult tocomprehend. With greater care, a more human-understandable final classifier canbe obtained using boosting. Cohen and Singer [11] showed howto design a base
14
0
2
4
6
8
10
12
14
16
3 4 5 6
% E
rror
Number of Classes
AdaBoostSleeping-experts
RocchioNaive-Bayes
PrTFIDF5
10
15
20
25
30
35
4 6 8 10 12 14 16 18 20
% E
rror
Number of Classes
AdaBoostSleeping-experts
RocchioNaive-Bayes
PrTFIDF
Figure 4: Comparison of error rates for AdaBoost and four other text categoriza-tion methods (naive Bayes, probabilistic TF-IDF, Rocchio and sleeping experts)as reported by Schapire and Singer [71]. The algorithms weretested on two textcorpora — Reuters newswire articles (left) and AP newswire headlines (right) —and with varying numbers of class labels as indicated on the�-axis of each figure.
learning algorithm that, when combined with AdaBoost, results in a final classifierconsisting of a relatively small set of rules similar to those generated by systemslike RIPPER [10], IREP [36] and C4.5rules [60]. Cohen and Singer’s system,called SLIPPER, is fast, accurate and produces quite compact rule sets. In otherwork, Freund and Mason [29] showed how to apply boosting to learn a generaliza-tion of decision trees called “alternating trees.” Their algorithm produces a singlealternating tree rather than an ensemble of trees as would beobtained by runningAdaBoost on top of a decision-tree learning algorithm. On the other hand, theirlearning algorithm achieves error rates comparable to those of a whole ensembleof trees.
A nice property of AdaBoost is its ability to identifyoutliers, i.e., examplesthat are either mislabeled in the training data, or that are inherently ambiguous andhard to categorize. Because AdaBoost focuses its weight on the hardest examples,the examples with the highest weight often turn out to be outliers. An example ofthis phenomenon can be seen in Fig. 7 taken from an OCR experiment conductedby Freund and Schapire [30].
When the number of outliers is very large, the emphasis placed on the hard ex-amples can become detrimental to the performance of AdaBoost. This was demon-strated very convincingly by Dietterich [18]. Friedman, Hastie and Tibshirani [34]suggested a variant of AdaBoost, called “Gentle AdaBoost” that puts less emphasison outliers. Ratsch, Onoda and Muller [61] show how to regularize AdaBoost tohandle noisy data. Freund [27] suggested another algorithm, called “BrownBoost,”that takes a more radical approach that de-emphasizes outliers when it seems clearthat they are “too hard” to classify correctly. This algorithm, which is an adaptive
15

10
20
30
40
50
60
70
1 10 100 1000 10000
% E
rror
Number of rounds
discrete AdaBoost.MRdiscrete AdaBoost.MH
real AdaBoost.MH
10
20
30
40
50
60
70
1 10 100 1000 10000
% E
rror
Number of rounds
discrete AdaBoost.MRdiscrete AdaBoost.MH
real AdaBoost.MH
Figure 5: Comparison of the training (left) and test (right)error using three boost-ing methods on a six-class text classification problem from the TREC-AP collec-tion, as reported by Schapire and Singer [70, 71]. Discrete AdaBoost.MH anddiscrete AdaBoost.MR are multiclass versions of AdaBoost that require binary( ��� � ��-valued) base classifiers, while real AdaBoost.MH is a multiclass ver-sion that uses “confidence-rated” (i.e., real-valued) baseclassifiers.
version of Freund’s [26] “boost-by-majority” algorithm, demonstrates an intrigu-ing connection between boosting and Brownian motion.
10 Conclusion
In this overview, we have seen that there have emerged a greatmany views orinterpretations of AdaBoost. First and foremost, AdaBoostis a genuine boostingalgorithm: given access to a true weak learning algorithm that always performs alittle bit better than random guessing on every distribution over the training set, wecan prove arbitrarily good bounds on the training error and generalization error ofAdaBoost.
Besides this original view, AdaBoost has been interpreted as a procedure basedon functional gradient descent, as an approximation of logistic regression and asa repeated-game playing algorithm. AdaBoost has also been shown to be re-lated to many other topics, such as game theory and linear programming, Breg-man distances, support-vector machines, Brownian motion,logistic regression andmaximum-entropy methods such as iterative scaling.
All of these connections and interpretations have greatly enhanced our under-standing of boosting and contributed to its extension in ever more practical di-rections, such as to logistic regression and other loss-minimization problems, tomulticlass problems, to incorporate regularization and toallow the integration ofprior background knowledge.
16

0 200 400 600 800 1000 1200 1400 160074
76
78
80
82
84
86
88
90
92
# Training Sentences
Cla
ssifi
catio
n A
ccur
acy
(%)
data
knowledge
knowledge + data
0 500 1000 1500 2000 2500 300045
50
55
60
65
70
75
80
85
90
# Training Examples
Cla
ssifi
catio
n A
ccur
acy
(%)
data
knowledge
knowledge + data
Figure 6: Comparison of percent classification accuracy on two spoken languagetasks (“How may I help you” on the left and “Help desk” on the right) as a func-tion of the number of training examples using data and knowledge separately ortogether, as reported by Rochery et al. [64, 65].
We also have discussed a few of the growing number of applications of Ada-Boost to practical machine learning problems, such as text and speech categoriza-tion.
References
[1] Steven Abney, Robert E. Schapire, and Yoram Singer. Boosting applied to taggingand PP attachment. InProceedings of the Joint SIGDAT Conference on EmpiricalMethods in Natural Language Processing and Very Large Corpora, 1999.
[2] Erin L. Allwein, Robert E. Schapire, and Yoram Singer. Reducing multiclass tobinary: A unifying approach for margin classifiers.Journal of Machine LearningResearch, 1:113–141, 2000.
[3] Peter L. Bartlett. The sample complexity of pattern classification with neural net-works: the size of the weights is more important than the sizeof the network.IEEETransactions on Information Theory, 44(2):525–536, March 1998.
[4] Eric Bauer and Ron Kohavi. An empirical comparison of voting classification algo-rithms: Bagging, boosting, and variants.Machine Learning, 36(1/2):105–139, 1999.
[5] Eric B. Baum and David Haussler. What size net gives validgeneralization?NeuralComputation, 1(1):151–160, 1989.
[6] Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K. Warmuth.Learnability and the Vapnik-Chervonenkis dimension.Journal of the Association forComputing Machinery, 36(4):929–965, October 1989.
17

4:1/0.27,4/0.17 5:0/0.26,5/0.17 7:4/0.25,9/0.18 1:9/0.15,7/0.15 2:0/0.29,2/0.19 9:7/0.25,9/0.17
3:5/0.28,3/0.28 9:7/0.19,9/0.19 4:1/0.23,4/0.23 4:1/0.21,4/0.20 4:9/0.16,4/0.16 9:9/0.17,4/0.17
4:4/0.18,9/0.16 4:4/0.21,1/0.18 7:7/0.24,9/0.21 9:9/0.25,7/0.22 4:4/0.19,9/0.16 9:9/0.20,7/0.17
Figure 7: A sample of the examples that have the largest weight on an OCR task asreported by Freund and Schapire [30]. These examples were chosen after 4 roundsof boosting (top line), 12 rounds (middle) and 25 rounds (bottom). Underneatheach image is a line of the form�:
� ��� �,� �� , where� is the label of the exam-ple,
� � and� are the labels that get the highest and second highest vote from the
combined classifier at that point in the run of the algorithm,and� �, � are thecorresponding normalized scores.
[7] Bernhard E. Boser, Isabelle M. Guyon, and Vladimir N. Vapnik. A training algorithmfor optimal margin classifiers. InProceedings of the Fifth Annual ACM Workshop onComputational Learning Theory, pages 144–152, 1992.
[8] Leo Breiman. Arcing classifiers.The Annals of Statistics, 26(3):801–849, 1998.
[9] Leo Breiman. Prediction games and arcing classifiers.Neural Computation,11(7):1493–1517, 1999.
[10] William Cohen. Fast effective rule induction. InProceedings of the Twelfth Interna-tional Conference on Machine Learning, pages 115–123, 1995.
[11] William W. Cohen and Yoram Singer. A simple, fast, and effective rule learner. InProceedings of the Sixteenth National Conference on Artificial Intelligence, 1999.
[12] Michael Collins. Discriminative reranking for natural language parsing. InProceed-ings of the Seventeenth International Conference on Machine Learning, 2000.
[13] Michael Collins, Robert E. Schapire, and Yoram Singer.Logistic regression, Ada-Boost and Bregman distances.Machine Learning, to appear.
[14] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine Learning,20(3):273–297, September 1995.
18

[15] J. N. Darroch and D. Ratcliff. Generalized iterative scaling for log-linear models.The Annals of Mathematical Statistics, 43(5):1470–1480, 1972.
[16] Stephen Della Pietra, Vincent Della Pietra, and John Lafferty. Inducing featuresof random fields. IEEE Transactions Pattern Analysis and Machine Intelligence,19(4):1–13, April 1997.
[17] Ayhan Demiriz, Kristin P. Bennett, and John Shawe-Taylor. Linear programmingboosting via column generation.Machine Learning, 46(1/2/3):225–254, 2002.
[18] Thomas G. Dietterich. An experimental comparison of three methods for construct-ing ensembles of decision trees: Bagging, boosting, and randomization. MachineLearning, 40(2):139–158, 2000.
[19] Thomas G. Dietterich and Ghulum Bakiri. Solving multiclass learning problems viaerror-correcting output codes.Journal of Artificial Intelligence Research, 2:263–286,January 1995.
[20] Harris Drucker. Improving regressors using boosting techniques. InMachine Learn-ing: Proceedings of the Fourteenth International Conference, pages 107–115, 1997.
[21] Harris Drucker and Corinna Cortes. Boosting decision trees. InAdvances in NeuralInformation Processing Systems 8, pages 479–485, 1996.
[22] Harris Drucker, Robert Schapire, and Patrice Simard. Boosting performance in neuralnetworks. International Journal of Pattern Recognition and Artificial Intelligence,7(4):705–719, 1993.
[23] Nigel Duffy and David Helmbold. Potential boosters? InAdvances in Neural Infor-mation Processing Systems 11, 1999.
[24] Nigel Duffy and David Helmbold. Boosting methods for regression.Machine Learn-ing, 49(2/3), 2002.
[25] Gerard Escudero, Lluis Marquez, and German Rigau. Boosting applied to wordsense disambiguation. InProceedings of the 12th European Conference on MachineLearning, pages 129–141, 2000.
[26] Yoav Freund. Boosting a weak learning algorithm by majority. Information andComputation, 121(2):256–285, 1995.
[27] Yoav Freund. An adaptive version of the boost by majority algorithm. MachineLearning, 43(3):293–318, June 2001.
[28] Yoav Freund, Raj Iyer, Robert E. Schapire, and Yoram Singer. An efficient boost-ing algorithm for combining preferences. InMachine Learning: Proceedings of theFifteenth International Conference, 1998.
[29] Yoav Freund and Llew Mason. The alternating decision tree learning algorithm. InMachine Learning: Proceedings of the Sixteenth International Conference, pages124–133, 1999.
19

[30] Yoav Freund and Robert E. Schapire. Experiments with a new boosting algorithm. InMachine Learning: Proceedings of the Thirteenth International Conference, pages148–156, 1996.
[31] Yoav Freund and Robert E. Schapire. Game theory, on-line prediction and boosting.In Proceedings of the Ninth Annual Conference on Computational Learning Theory,pages 325–332, 1996.
[32] Yoav Freund and Robert E. Schapire. A decision-theoretic generalization of on-linelearning and an application to boosting.Journal of Computer and System Sciences,55(1):119–139, August 1997.
[33] Yoav Freund and Robert E. Schapire. Adaptive game playing using multiplicativeweights.Games and Economic Behavior, 29:79–103, 1999.
[34] Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Additive logistic regression:A statistical view of boosting.The Annals of Statistics, 38(2):337–374, April 2000.
[35] Jerome H. Friedman. Greedy function approximation: A gradient boosting machine.The Annals of Statistics, 29(5), October 2001.
[36] Johannes Furnkranz and Gerhard Widmer. Incremental reduced error pruning. InMachine Learning: Proceedings of the Eleventh International Conference, pages 70–77, 1994.
[37] Adam J. Grove and Dale Schuurmans. Boosting in the limit: Maximizing the mar-gin of learned ensembles. InProceedings of the Fifteenth National Conference onArtificial Intelligence, 1998.
[38] Masahiko Haruno, Satoshi Shirai, and Yoshifumi Ooyama. Using decision trees toconstruct a practical parser.Machine Learning, 34:131–149, 1999.
[39] Raj D. Iyer, David D. Lewis, Robert E. Schapire, Yoram Singer, and Amit Singhal.Boosting for document routing. InProceedings of the Ninth International Conferenceon Information and Knowledge Management, 2000.
[40] Jeffrey C. Jackson and Mark W. Craven. Learning sparse perceptrons. InAdvancesin Neural Information Processing Systems 8, pages 654–660, 1996.
[41] Michael Kearns and Leslie G. Valiant. Learning Booleanformulae or finite automatais as hard as factoring. Technical Report TR-14-88, HarvardUniversity Aiken Com-putation Laboratory, August 1988.
[42] Michael Kearns and Leslie G. Valiant. Cryptographic limitations on learning Booleanformulae and finite automata.Journal of the Association for Computing Machinery,41(1):67–95, January 1994.
[43] Jyrki Kivinen and Manfred K. Warmuth. Boosting as entropy projection. InProceed-ings of the Twelfth Annual Conference on Computational Learning Theory, pages134–144, 1999.
20

[44] V. Koltchinskii and D. Panchenko. Empirical margin distributions and bounding thegeneralization error of combined classifiers.The Annals of Statistics, 30(1), February2002.
[45] Vladimir Koltchinskii, Dmitriy Panchenko, and Fernando Lozano. Further explana-tion of the effectiveness of voting methods: The game between margins and weights.In Proceedings 14th Annual Conference on Computational Learning Theory and 5thEuropean Conference on Computational Learning Theory, pages 241–255, 2001.
[46] Vladimir Koltchinskii, Dmitriy Panchenko, and Fernando Lozano. Some new boundson the generalization error of combined classifiers. InAdvances in Neural Informa-tion Processing Systems 13, 2001.
[47] John Lafferty. Additive models, boosting and inference for generalized divergences.In Proceedings of the Twelfth Annual Conference on Computational Learning The-ory, pages 125–133, 1999.
[48] Guy Lebanon and John Lafferty. Boosting and maximum likelihood for exponentialmodels. InAdvances in Neural Information Processing Systems 14, 2002.
[49] Richard Maclin and David Opitz. An empirical evaluation of bagging and boost-ing. In Proceedings of the Fourteenth National Conference on Artificial Intelligence,pages 546–551, 1997.
[50] Llew Mason, Peter Bartlett, and Jonathan Baxter. Direct optimization of marginsimproves generalization in combined classifiers. InAdvances in Neural InformationProcessing Systems 12, 2000.
[51] Llew Mason, Jonathan Baxter, Peter Bartlett, and Marcus Frean. Functional gradi-ent techniques for combining hypotheses. In Alexander J. Smola, Peter J. Bartlett,Bernhard Scholkopf, and Dale Schuurmans, editors,Advances in Large Margin Clas-sifiers. MIT Press, 1999.
[52] Llew Mason, Jonathan Baxter, Peter Bartlett, and Marcus Frean. Boosting algorithmsas gradient descent. InAdvances in Neural Information Processing Systems 12, 2000.
[53] Stefano Merler, Cesare Furlanello, Barbara Larcher, and Andrea Sboner. Tuning cost-sensitive boosting and its application to melanoma diagnosis. In Multiple ClassifierSystems: Proceedings of the 2nd International Workshop, pages 32–42, 2001.
[54] C. J. Merz and P. M. Murphy. UCI repository of machine learning databases, 1999.www.ics.uci.edu/�mlearn/MLRepository.html.
[55] Pedro J. Moreno, Beth Logan, and Bhiksha Raj. A boostingapproach for confidencescoring. InProceedings of the 7th European Conference on Speech Communicationand Technology, 2001.
[56] Michael C. Mozer, Richard Wolniewicz, David B. Grimes,Eric Johnson, and HowardKaushansky. Predicting subscriber dissatisfaction and improving retention in thewireless telecommunications industry.IEEE Transactions on Neural Networks,11:690–696, 2000.
21

[57] Takashi Onoda, Gunnar Ratsch, and Klaus-Robert Muller. Applying support vectormachines and boosting to a non-intrusive monitoring systemfor household electricappliances with inverters. InProceedings of the Second ICSC Symposium on NeuralComputation, 2000.
[58] Dmitriy Panchenko. New zero-error bounds for voting algorithms. Unpublishedmanuscript, 2001.
[59] J. R. Quinlan. Bagging, boosting, and C4.5. InProceedings of the Thirteenth Na-tional Conference on Artificial Intelligence, pages 725–730, 1996.
[60] J. Ross Quinlan.C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
[61] G. Ratsch, T. Onoda, and K.-R. Muller. Soft margins for AdaBoost.Machine Learn-ing, 42(3):287–320, 2001.
[62] Gunnar Ratsch, Manfred Warmuth, Sebastian Mika, Takashi Onoda, Steven Lemm,and Klaus-Robert Muller. Barrier boosting. InProceedings of the Thirteenth AnnualConference on Computational Learning Theory, pages 170–179, 2000.
[63] Greg Ridgeway, David Madigan, and Thomas Richardson. Boosting methodologyfor regression problems. InProceedings of the International Workshop on AI andStatistics, pages 152–161, 1999.
[64] M. Rochery, R. Schapire, M. Rahim, N. Gupta, G. Riccardi, S. Bangalore, H. Al-shawi, and S. Douglas. Combining prior knowledge and boosting for call classifica-tion in spoken language dialogue. Unpublished manuscript,2001.
[65] Marie Rochery, Robert Schapire, Mazin Rahim, and Narendra Gupta. BoosTexter fortext categorization in spoken language dialogue. Unpublished manuscript, 2001.
[66] Robert E. Schapire. The strength of weak learnability.Machine Learning, 5(2):197–227, 1990.
[67] Robert E. Schapire. Using output codes to boost multiclass learning problems. InMachine Learning: Proceedings of the Fourteenth International Conference, pages313–321, 1997.
[68] Robert E. Schapire. Drifting games.Machine Learning, 43(3):265–291, June 2001.
[69] Robert E. Schapire, Yoav Freund, Peter Bartlett, and Wee Sun Lee. Boosting themargin: A new explanation for the effectiveness of voting methods. The Annals ofStatistics, 26(5):1651–1686, October 1998.
[70] Robert E. Schapire and Yoram Singer. Improved boostingalgorithms usingconfidence-rated predictions.Machine Learning, 37(3):297–336, December 1999.
[71] Robert E. Schapire and Yoram Singer. BoosTexter: A boosting-based system for textcategorization.Machine Learning, 39(2/3):135–168, May/June 2000.
[72] Robert E. Schapire, Yoram Singer, and Amit Singhal. Boosting and Rocchio ap-plied to text filtering. InProceedings of the 21st Annual International Conference onResearch and Development in Information Retrieval, 1998.
22

[73] Holger Schwenk and Yoshua Bengio. Training methods foradaptive boosting ofneural networks. InAdvances in Neural Information Processing Systems 10, pages647–653, 1998.
[74] Kinh Tieu and Paul Viola. Boosting image retrieval. InProceedings of the IEEEConference on Computer Vision and Pattern Recognition, 2000.
[75] L. G. Valiant. A theory of the learnable.Communications of the ACM, 27(11):1134–1142, November 1984.
[76] V. N. Vapnik and A. Ya. Chervonenkis. On the uniform convergence of relativefrequencies of events to their probabilities.Theory of Probability and its applications,XVI(2):264–280, 1971.
[77] Vladimir N. Vapnik. The Nature of Statistical Learning Theory. Springer, 1995.
[78] Marilyn A. Walker, Owen Rambow, and Monica Rogati. SPoT: A trainable sentenceplanner. InProceedings of the 2nd Annual Meeting of the North American Chapterof the Associataion for Computational Linguistics, 2001.
23