the stanford wordnet project - srinysmith/slides/aic-seminars/090129-snow.pdf · the stanford...
TRANSCRIPT

Rion Snow
The Stanford Wordnet Project:Automating the Acquisition of World Knowledge

What I’m going to talk about
• Acquiring structured knowledge• Manual vs. machine learning approaches
• Application to biomedical semantic search
• Taxonomy induction• Integrating input from multiple extraction algorithms
• Automatic integration with existing taxonomies
• Implicit word sense disambiguation

The problem
• Most textual information exists in natural, unstructured form.
• Machines can’t read natural language!
• Machines can reason over structured tuples.
• How can we extract structured tuples from natural text?
3

Semantic Networks as Knowledge Repositories
4
“A small portion of the author’s semantic network.”– Douglas Hofstadter, Gödel, Escher, Bach
Can we learn semantic networks automatically?

Extracting Structured Knowledge
“Curtis Carlson, Ph.D., is SRI's president and CEO”
“SRI's headquarters are in Menlo Park”
“SRI International...is one of the world’s largest contract research institutes”
SRI International IS-A research institute
Curtis Carlson IS-A presidentCurtis Carlson IS-A CEOCurtis Carlson HAS-A Ph.D.
SRI HAS-A headquartersheadquarters LOC-IN Menlo Park
Each article can contain hundreds or thousands of items of knowledge...

Goal: Machine-readable summaries
6
Subject Relation Object
p53 is_a protein
Bax is_a protein
p53 has_function apoptosis
Bax has_function induction
apoptosis involved_in cell_death
Bax is_in mitochondrialouter membrane
Bax is_in cytoplasm
apoptosis related_to caspase activation
... ... ...
Textual abstract: Summary for human
Structured knowledge extraction: Summary for machine

Application: Question Answering
7
Audience Query Semantic Formulation
Soccer Moms
Which elementary schools near zip code 94043 have after-school programs?
X is_a elementary school
X is_near zip code 94043
X has_a after-school program
Graduate Student
Which research institutes are located in Menlo Park?
X is_a research institute
X located_in Menlo Park
BiomedicalResearcher
What in the plasma membrane is
involved in replication?
X located_in plasma membrane
X involved_in replication
JournalistWhich newspapers
endorsed Hillary Clinton in the primaries?
X is_a newspaper
X endorsed Hillary Clinton

One way to get there: manual curation
• At least one biomedical journal now asks authors to submit machine-readable “structured digital abstracts”...
8
“Welcome to the first issue of FEBS Letters with structured digital abstracts. A common complaint among researchers in the postgenomic era of orgiastic data production is our inability to cope with the scientific output...”
“Finally: The digital, democratic age of scientific abstracts”, Superti-Furgaa et al., April 2008.
63 papers annotated with SDAs from April 2008 - December 2008.
Little or no adoption by other journals (though many seem to think it’s a good idea).

Structured Digital Abstracts
9

Attempts at manual curation
10
Many manually constructed knowledge bases exist....
Benefit“Gold standard” relations
DrawbacksCostly to build and maintain
Brittle, difficult to adapt to new problemsRapidly outpaced by unstructured text

Motivation: Information overload
11
Guess how many biomedical research articles have been published since January 1, 2009?
How many research articles did you read in January?

Motivation: Information overload
12
On average, more than 2,000 articles published per day!
How many articles did you read yesterday?

Personal information overload
13
My January RSS Feeds: ~400 new items / day

Alternative: Heuristic-based knowledge extraction from semi-structured data
14
Subject Relation Object
Menlo Park is_in United States
Menlo Park is_in California
Menlo Park is_in San Mateo County
Menlo Park was_incorporated March 23, 1874
... ... ...
Can be applied to many data sources, e.g.:

Alternative: Heuristic-based knowledge extraction from semi-structured data
15
YAGO
These approaches are used by several projects, including: Benefit
High precision over many different relations(>90% precision)
DrawbacksOnly useful for semi-structured data; can’t
be applied to natural text
Existing Structured Knowledge Bases
Manually populatedPopulated by heuristic
extraction / crowdsourcing
YAGO

Machine learning to the rescue!
17
Our approach: use existing high-quality structured knowledge as training data over natural text corpora.
The Stanford Wordnet Project
Training Data
Classifiers,Taxonomy Induction
Natural Text Corpora

WordNet: A “Hyperdictionary”
Used for many NLP tasks:
- Word Similarity Measures - Word Sense Disambiguation - Query Expansion - Targeted Advertising: Google’s AdSense - Image Classification (Torralba et al.)- Textual Inference (Schoenmackers et al.)- Contradiction Detection (Ritter et al.)
Hyponymy (is-a), meronymy (part-of), and other relations for over 100,000 distinct word senses.

The Stanford Wordnet Project
Available now:
Augmented Wordnets– 400,000 added synsets
Sense-clustered Wordnets– Between 1%-30%
sense reduction
http://ai.stanford.edu/~rion/swn

Previous work in theAutomatic Acquisition of IS-A relations
* (Hearst, 1992) proposes 6 hand-designed lexico-syntactic patterns for IS-A recognition
* (Turney et al, 2004) uses a feature set of 128 “common short phrases” to infer a variety of semantic relationships from analogy questions

Hand-Designed Lexico-Syntactic Patterns
(Hearst, 1992): Automatic Acquisition of IS-A relations
Ex: “Exotic fruits, such as jackfruit, durian, and lychee, can often be found at your local asian market.”
IMPLIES: “Jackfruit, durian, and lychee are kinds of exotic fruit.”
Hearst 1: “Y such as X ((, X)* (, and/or) X)”Hearst 2: “such Y as X…”Hearst 3: “X… or other Y”Hearst 4: “X… and other Y”Hearst 5: “Y including X…”Hearst 6: “Y, especially X…”
Our approach: Starting with a set of known hyponym/hypernym pairs, learn the relevant patterns from the rich “lexico-syntactic pattern space” of syntactic dependency paths.

Automating the Pattern Discovery Process
Steps in Algorithm
1. Choose the target relationship R.
2. Begin with a ‘seed set’ of word pairs exhibiting R.
3. Find all sentences in a corpus containing a pair from the seed set.
4. Each time you find a target pair, “record the lexico-syntactic environment” in that sentence – then find the commonalities.
Example Step:
1. R = the noun hypernym relation.
2. Noun hyponym/hypernym pairs from WordNet.
3. ~6,000,000 sentences from Tipster 1-3 and Trec 5 newswire corpora, and Wikipedia encylopedia corpus.
4. …see next slide!

Recording the Lexico-Syntactic Environment with MINIPAR Syntactic Dependency Paths
MINIPAR: A principle-based dependency parser (Lin, 1998)
Extracted dependency path:
-N:s:VBE, “be” VBE:pred:N
Example Word Pair: “oxygen / element”Example Sentence: “Oxygen is the most abundant element on the moon.”
Minipar Parse:

Each of Hearst’s patterns can be captured by a syntactic dependency path in MINIPAR:
Hearst Pattern
Y such as X…
Such Y as X…
X… and other Y
MINIPAR Representation
-N:pcomp-n:Prep,such_as,such_as,-Prep:mod:N
-N:pcomp-n:Prep,as,as,-Prep:mod:N,(such,PreDet:pre:N)}
(and,U:punc:N),N:conj:N, (other,A:mod:N)

Hypernym Precision / Recall for all Features

Using Discovered Patterns to Find Novel Hyponym/Hypernym Pairs
Example of a discovered high-precision Path:-N:desc:V,call,call,-V:vrel:N: “<hypernym> ‘called’ <hyponym>”
Learned from cases such as:
“sarcoma / cancer”: …an uncommon bone cancer called osteogenic sarcoma and to…“deuterium / atom” ….heavy water rich in the doubly heavy hydrogen atom called deuterium.
May be used to discover new hypernym pairs not in WordNet:
“efflorescence / condition”: …and a condition called efflorescence are other reasons for… “’neal_inc / company” …The company, now called O'Neal Inc., was sole distributor of E-Ferol…“hat_creek_outfit / ranch” …run a small ranch called the Hat Creek Outfit.“tardive_dyskinesia / problem”: ... irreversible problem called tardive dyskinesia…“hiv-1 / aids_virus” …infected by the AIDS virus, called HIV-1.“bateau_mouche / attraction” …local sightseeing attraction called the Bateau Mouche...“kibbutz_malkiyya / collective_farm” …an Israeli collective farm called Kibbutz Malkiyya…
But 200,000 patterns are better than one!

Noun pairs as feature vectors
• Feature vector for each noun pair• Each entry corresponds to a dependency path count
Training set: ~600,000 noun pairs, of which ~15,000 are labeled by WN as positive hyponym/hypernym examples
Feature Lexicon: ~200,000 dependency paths

Classifiers vs. WordNet
Our best hypernym classifier model yields a 54% F-Score improvement over WordNet on a hand-labeled test set.

Freebase Relation Induction
2700 relations > 10 inst.
5.2 million instances3.7 million entities
Training Set
Corpus 2.3 million articles31.5 million sents
Work with Steven Bills and Mike Mintz
preliminary results:10,000 new links @ 82% precision20,000 new links @ 81% precision30,000 new links @ 75% precision40,000 new links @ 70% precision

Biomedical Relationship Induction
Prob.
1.00
1.00
0.99
0.63
0.86
0.92
0.93
0.38
...
Subject Relation Object
p53 is_a protein
Bax is_a protein
p53 has_function apoptosis
Bax has_function induction
apoptosis involved_in cell_death
Bax is_in mitochondrialouter membrane
Bax is_in cytoplasm
apoptosis related_to caspase activation
... ... ...
“Automatic Generation of One Million Structured Digital Abstracts”,(Srinivasan, Snow, et al, BCATS 2007)
Joint work with Balaji Srinivasan

Biomedical Relationship Induction
Corpus
Training Set
LearnedRelations
1013678 articles
300+ journals
1003397304 sents
327 relations
1441397 training7433198 terms
XPath counts matrix
1 1
1
Relation matrix Y
Y
!
Learned Relations0.99 0.92 0.01 0.010.02 0.05 0.08 0.030.03 0.97 0.06 0.99
Path CoeffsGO cell. comp.
AUC = .94Mouse Anatomy
AUC = .73
Accuracy (AUC) increases w/ # of training pairs for each relation
!
!
!
!
!
!!
!
!!
!
!
!
!
2 3 4 5 6
0.7
00
.75
0.8
00
.85
0.9
00
.95
1.0
0
log10(train counts)
10!
fold
cro
ss!
va
lida
ted
AU
C10-f
old
CV
AU
C
log10 (# of training pairs)
31

Query for things localized to membrane
Application: Biomedical search
32

Query for things localized to membrane...
Basic Queries
How do we know RhoA is localized to membrane?33

Supporting Evidence
34

Alternate Phrasings: “RhoA is_localized_to membrane”
...delocalizes RhoA...from the membrane...
...the levels of RhoA...in the membrane...
...extraction...of RhoA from the membrane...
...RhoA is localized to the plasma membrane...
...RhoA...a plasma membrane activator of PLD...
...RhoA...was dissociated from...plasma membrane
...translocation of RhoA from the cytosol to the membrane...
35

Complex Queries
Where are RhoA and beta-catenin colocalized?

Complex Queries
Complex query results
Both proteins localized to cytosol

Taxonomy Induction
What if we want to infer multiple types of relationships simultaneously?
How can we exploit inherent interrelated structure in taxonomic lexical relations?
– if X is a kind of Z, and Y is similar to X, then when can we infer that Y is a kind of Z?
We present a method for taxonomy induction independent of any particular relationship extraction algorithm.
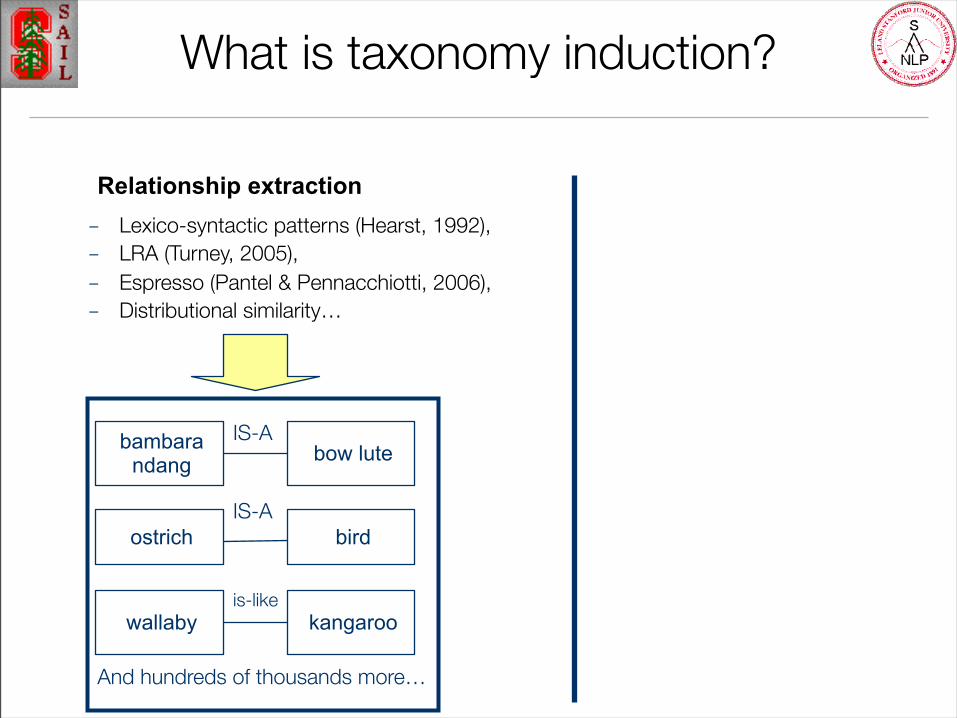
What is taxonomy induction?
bambarandang bow lute
IS-A
ostrichIS-A
wallaby kangaroois-like
bird
And hundreds of thousands more…
– Lexico-syntactic patterns (Hearst, 1992), – LRA (Turney, 2005), – Espresso (Pantel & Pennacchiotti, 2006),– Distributional similarity…
Relationship extraction

What is taxonomy induction?
bambarandang bow lute
IS-A
ostrichIS-A
wallaby kangaroois-like
TaxonomyInductionbird
And hundreds of thousands more…
A structured, consistent taxonomy of sense-disambiguated synsets
Relationship extraction– Lexico-syntactic patterns (Hearst, 1992), – LRA (Turney, 2005), – Espresso (Pantel & Pennacchiotti, 2006),– Distributional similarity…

Why taxonomy induction?
• Joint inference over multiple pairwise classifications improves precision of relationship extraction
• Implicit sense-disambiguation of lexical relations (“ontologizing”)
• Infer domain-specific taxonomies from corpora

Taxonomy Induction from Heterogenous Evidence
Hypernym classifier Distributional similarity Structured data
WordNet Freebase Gazetteers
“Semi-structured” data Wikipedia lists List induction42
We have all this evidence... how do we combine it?

Hypernym classification:
Continental is the second US carrier overall…
Continental is the first major US airline…
carrier (0.44)western (0.38)realist (0.25)partner (0.20)subsidiary (0.18)airline (0.18)american (0.17) …
Continentalis a kind of…
operating system (0.14)system (0.03)SunOS
…in the SunOS system…
…SunOS operating system…
is a kind of…

Predicted Hypernym
carrier 0.44western 0.38realist 0.25partner 0.20
subsidiary 0.18airline 0.18
Continental is a kind of…
In WN2.1 there are 11 senses of carrier, 3 senses of realist, 2 senses of airline; how do we decide where to add continental?

Predicted Hypernym
carrier 0.44western 0.38realist 0.25partner 0.20
subsidiary 0.18airline 0.18
• Naïve algorithm:
• Choose the first sense of the most likely link.
• Result: “continental is a kind of carrier#n#1”:
• Gloss: someone whose employment involves carrying something; "the bonds were transmitted by carrier“.
In WN2.1 there are 11 senses of carrier, 3 senses of realist, 2 senses of airline; how do we decide where to add continental?
Continental is a kind of…

Predicted Hypernym
carrier 0.44western 0.38realist 0.25partner 0.20
subsidiary 0.18airline 0.18
• Naïve algorithm:
• Choose the first sense of the most likely link.
• Result: “continental is a kind of carrier#n#1”:
• Gloss: someone whose employment involves carrying something; "the bonds were transmitted by carrier“.
In WN2.1 there are 11 senses of carrier, 3 senses of realist, 2 senses of airline; how do we decide where to add continental?
WRONG!
Continental is a kind of…

British AirwaysAmerican Airlines
United AirlinesAir France
KLMAir CanadaLufthansa
US Airways
Coordinate term classification:
Distributional Similarity“You shall know the meaning of a word by the company it keeps.” -- J.R. Firth, 1957
SunOSAIXUnixLinux
Unix SystemDOS
operating systemNT
cortisolepinephrine
glucocorticoidnorepinephrinecatecholamine
leptinACTH
prolactin
…Unix commands...
…running AIX…
…Linux platform…
…US Airways flight...
… KLM announced…
…Lufthansa fares…
…cortisol injection...
…leptin release…
…ACTH levels…
From (Ravichandran et al., 2005): distributional similarity for a lexicon of 655,495 nouns, gathered from a corpus of 70 million web pages (138 GB)

SunOS is similar to…
Naïve result: “sunos is a kind of bird_genus#n#1”.
Gloss: “a genus of birds”.
Term is a kind of aix 0.37 bird genus
unix 0.29 OSlinux 0.27 unixux 0.22 wife
unix system 0.18 OSdos 0.18 exec. dept.
operatingsystem
0.18 software
nt 0.15 NGOmacintosh 0.15 fabric

Term is a kind of aix 0.37 bird genus
unix 0.29 OSlinux 0.27 unixux 0.22 wife
unix system 0.18 OSdos 0.18 exec. dept.
operatingsystem
0.18 software
nt 0.15 NGOmacintosh 0.15 fabric
Naïve result: “sunos is a kind of bird_genus#n#1”.
Gloss: “a genus of birds”.
WRONG!
SunOS is similar to…

Definition of (m,n)-cousins:
if two synsets have a distance of (m,n) to their least common ancestor.

Visualization of Taxonomy Prediction from Distributional Similarity
P(Cmn(x,y) | sim(x,y) = 0.20) P(Cmn(x,y) | sim(x,y) = 0.80)

How can we exploit global information about multiple relations?
• Taxonomic constraints: explicit descriptions of relation interdependence.
• ISA transitivity constraint• If X ISA Y and Y ISA Z, then X ISA Z.
• Coordinate term / semantic class constraint• If X is-similar-to Y, there is some Z such that X
ISA Z and Y ISA Z.

Example of ISA Transitivity:
Consider adding continental (c) as the hyponym of “airline” in WordNet:
airline#1: (a hose that carries air under pressure)
airline#2: (a commercial enterprise that provides scheduled flights for passengers)

Intuition of our solution:
• For each potential relation R• For each pair of synsets that R might relate
• Calculate the set of implied relations I(R)• Compute the likelihood of a taxonomy with I(R)
• Insert R joining the synset pair resulting in the most likely taxonomy
• Implicit sense-disambiguation of lexical relations:• Choose the synset that maximizes taxonomy
likelihood

Our model for taxonomy likelihood
• Basic event: The probability of a relation in taxonomy T:
• We define the probability of a taxonomy T as the joint probability of T containing or not containing each of all possible relations.

Two Independence Assumptions
• “Naïve bayes assumption”: features are independent given the taxonomy T:
• “Hidden state assumption”: the dependence of evidence on the taxonomy is mediated entirely by the corresponding relation

Likelihood function for taxonomies:
• Which has the property that, for some new taxonomy T’ containing the new set I(R):
• Objective: find

Filling in the gaps of WordNet
58
Hypernym Hyponyms in WordNet 2.1
Not in WN 2.1, but added by our algorithm
hormone insulinprogesterone
leptinpregnenolone
quality combustibilitynavigabilityarability
affordabilityreusabilityextensibility
markup language
HTML SGML
XMLXHTML
company “East India Company”
MicrosoftIBM

Results Summary
• We’ve produced several new Wordnets • New Wordnets available with up to 400,000 novel synsets• Stanford Wordnet has 23% relative F-score improvement over
WordNet 2.1 in hand-labeled test set
• Available for download at: http://ai.stanford.edu/~rion/swn
• After adding 10,000 new hyponym synsets:• 84% fine-grained precision• 96% coarse-grained precision
• Significant error reduction vs. baseline method• 70% error reduction at 10,000 links• 41% error reduction at 20,000 links

Other topics I’ve been working on
• Mechanical Turk for NLP annotation• ~10,000 labels / day, ~1,000 labels / dollar
• Learning selectional preferences• State-of-the-art performance for WSD
• Merging sense hierarchies• Creating hierarchies with arbitrarily coarse-grained
sense distinctions

Thanks!
• Our augmented Wordnets are available for download at:
http://ai.stanford.edu/~rion/swn