theory of computing, part 1. 1introduction 2theoretical background biochemistry/molecular biology...
TRANSCRIPT

Theory of computing, part 1

1 Introduction
2 Theoretical background Biochemistry/molecular biology
3 Theoretical background computer science
4 History of the field
5 Splicing systems
6 P systems
7 Hairpins
8 Detection techniques
9 Micro technology introduction
10 Microchips and fluidics
11 Self assembly
12 Regulatory networks
13 Molecular motors
14 DNA nanowires
15 Protein computers
16 DNA computing - summery
17 Presentation of essay and discussion
Course outline

Old computers

Abacus

Abacus

Born December 26, 1791 in Teignmouth, Devonshire UK,
Died 1871, London; Known to some as the Father of
Computing for his contributions to the basic design of
the computer through his Analytical machine..
The difference engine (1832)

The ENIAC machine occupied a room 30x50 feet. The
controls are at the left, and a small part of the
output device is seen at the right.
ENIAC (1946)

The IBM 360 was a revolutionary advance in
computer system architecture, enabling a family
of computers covering a wide range of price and
performance.
ENIAC (1946)

Books

Books

Introduction

Finite state machines (automata)
Pattern recognition
Simple circuits (e.g. elevators, sliding doors)
Automata with stack memory (pushdown autom.)
Parsing computer languages
Automata with limited tape memory
Automata with infinite tape memory
Called `Turing machines’,
Most powerful model possible
Capable of solving anything that is solvable
Models of computing

Regular grammars
Context free grammars
Context sensitive grammars
Unrestricted grammars
Chomsky hierarchy of grammars

Computers can be made to recognize, or accept, the
strings of a language.
There is a correspondence between the power of the
computing model and the complexity of languages
that it can recognize!
Finite automata only accept regular grammars.
Push down automata can also accept context free
grammars.
Turing machines can accept all grammars.
Computers can recognise languages
Languages

A set is a collection of things called its elements. If
x is an element of set S, we can write this:
x S A set can be represented by naming all its elements,
for example:
S = {x, y, z}
There is no particular order or arrangement of the
elements, and it doesn’t matter if some appear more
than once. These are all the same set:
{x, y, z}={y, x, z}={y, y, x, z, z}
Sets

A set with no elements is called the empty set, or
a null set. It is denoted by ={}. If every element of set A is also an element of
set B, then A is called a subset of B :
A B The union of two sets is the set with all elements
which appear in either set:
C = A B The intersection of two sets is the set with all
the elements which appear in both sets:
C = A B
Combining sets

A string a sequence of symbols that are placed
next to each other in juxtaposition
The set of symbols which make up a string are
taken from a finite set called an alphabet
E.g. {a, b, c} is the alphabet for the string
abbacb.
A string with no elements is called an empty
string and is denoted . If Σ is an alphabet, the infinite set of all
strings made up from Σ is denoted Σ*.
E.g., if Σ ={a}, then Σ *={, a, aa, aaa, …}
Alphabet and strings

A language is a set of strings.
If Σ is an alphabet, then a language over Σ
is a collection of strings whose components
come from Σ.
So Σ* is the biggest possible language over
Σ, and every other language over Σ is a
subset of Σ*.
Languages

Four simple examples of languages over an
alphabet Σ are the sets , {}, Σ, and Σ*.
For example, if Σ={a} then these four simple
languages over Σ are
, {}, {a}, and {, a, aa, aaa, …}.
Recall {} is the empty string while is the empty set. Σ* is an infinite set.
Examples of languages

The alphabet is Σ = {a,b,c,d,e…x,y,z}
The English language is made of strings
formed from Σ: e.g. fun, excitement.
We could define the English Language as the
set of strings over Σ which appear in the
Oxford English dictionary (but it is clearly
not a unique definition).
Example: English

The natural operation of concatenation
of strings places two strings in
juxtaposition.
For example, if then the concatenation
of the two strings aab and ba is the
string aabba.
Use the name cat to denote this
operation. cat(aab, ba) = aabba.
Concatenation

Languages are sets of strings, so they
can be combined by the usual set
operations of union, intersection,
difference, and complement.
Also we can combine two languages L
and M by forming the set of all
concatenations of strings in L with
strings in M.
Combining languages

This new language is called the product of L
and M and is denoted by L M.
A formal definition can be given as follows:
L M = {cat(s, t) | s L and t M}
For example, if L = {ab, ac} and M = {a, bc,
abc}, then the product L•M is the language
L M = {aba, abbc, ababc, aca, acbc, acabc}
Products of languages

The following simple properties hold for any
language L:
L {} = {} L = L
L = L =
The product is not commutative. In other
words, we can find two languages L and M such
that
L M M L
The product is associative. In other words,
if L, M, and N are languages, then
L (M N) = (L M) N
Properties of products

If L is a language, then the product
L L is denoted by L2.
The language product Ln for every n {0, 1, 2, …} is as follows:
L0 = {}
Ln = L Ln-1 if n > 0
Powers of languages

For example, if L = {a, bb} then the first
few powers of L are
L0 = {}
L1 = L = {a, bb}
L2 = L L = {aa, abb, bba, bbbb}
L3 = L L2 = {aaa, aabb, abba, abbbb,
bbaa, bbabb, bbbba, bbbbbb}
Example

If L is a language over Σ (i.e. L Σ*) then the closure of L is the language
denoted by L* and is defined as follows:
L* = L0 L1 L2 …
The positive closure of L is the language
denoted by L+ and defined as follows:
L+ = L1 L2 L3 …
Closure of a language

It follows that L* = L+ {}. But it’s not necessarily true that
L+ = L* - {}
For example, if we let our alphabet
be Σ = {a} and our language be L =
{, a}, then
L+ = L*
Can you find a condition on a
language L such that
L+ = L* - {}?
L* vs. L+

The closure of Σ coincides with our
definition of Σ* as the set of all
strings over Σ. In other words, we have
a nice representation of Σ* as follows:
Σ* = Σ0 Σ1 Σ2 ….
Closure of an alphabet

Let L and M be languages over the
alphabet Σ. Then:
a) {}* = * = {}
b) L* = L* L* = (L*)*
c) L if and only if L+ = L*
d) (L* M*)* = (L* M*)* = (L M)*
e) L (M L)* = (L M)* L
Properties of closure

Grammars

A grammar is a set of rules used to
define the structure of the strings in a
language.
If L is a language over an alphabet Σ,
then a grammar for L consists of a set of
grammar rules of the following form:
where and denote strings of symbols taken from Σ and from a set of grammar
symbols (non-terminals) that is disjoint
from Σ
Grammars

A grammar rule is often called a production, and it can be read in any of
several ways as follows:
replace by
produces
rewrites to
reduces to
Productions

Every grammar has a special grammar symbol
called a start symbol, and there must be at
least one production with left side
consisting of only the start symbol.
For example, if S is the start symbol for a
grammar, then there must be at least one
production of the form
S
Where to begin ……

1. An alphabet N of grammar symbols called
non-terminals. (Usually upper case
letters.)
2. An alphabet T of symbols called
terminals. (Identical to the alphabet of
the resulting language.)
3. A specific non-terminal called the start
symbol. (Usually S. )
4. A finite set of productions of the form , where and are strings over the alphabet N T
The 4 parts of a grammar

Let Σ = {a, b, c}. Then a grammar for the
language Σ* can be described by the
following four productions:
S
S aS
S bS
S cS
Or in shorthand:
S | aS | bS | cS
S can be replaced by either , or aS, or bS, or cS.
Example

If G is a grammar, then the language of G
is the set of language strings derived
from the start symbol of G. The language
of G is denoted by:
L(G)
Grammar specifies the language

If G is a grammar with start symbol S and
set of language strings T, then the
language of G is the following set:
L(G) = {s | s T* and S + s}
Grammar specifies the language

If the language is finite, then a grammar can
consist of all productions of the form
S w
for each string w in the language.
For example, the language {a, ab} can be
described by the grammar S a | ab.
Finite languages

If the language is infinite, then some
production or sequence of productions must be
used repeatedly to construct the derivations.
Notice that there is no bound on the length of
strings in an infinite language.
Therefore there is no bound on the number of
derivation steps used to derive the strings.
If the grammar has n productions, then any
derivation consisting of n + 1 steps must use
some production twice
Infinite languages

For example, the infinite language {anb | n
0 } can be described by the grammar,
S b | aS
To derive the string anb, use the production
S aS
repeatedly --n times to be exact-- and then
stop the derivation by using the production
S b
The production S aS allows us to say
If S derives w, then it also derives aw
Infinite languages

A production is called recursive if its
left side occurs on its right side.
For example, the production S aS is
recursive.
A production S is indirectly
recursive if S derives (in two or more
steps) a sentential form that contains
S.
Recursion

For example, suppose we have the
following grammar:
S b | aA
A c | bS
The productions S aA and A bS are
both indirectly recursive
S aA abS
A bS baA
Indirect recursion

A grammar is recursive if it contains
either a recursive production or an
indirectly recursive production.
A grammar for an infinite language must
be recursive!
However, a given language can have many
grammars which could produce it.
Recursion

Suppose M and N are languages. We can
describe them with grammars have disjoint
sets of nonterminals.
Assign the start symbols for the grammars of
M and N to be A and B, respectively:
M : A N : B
… …
Then we have the following rules for creating
new languages and grammars:
Combining grammars

The union of the two languages, M N, starts with the two productions
S A | B
followed by the grammars of M and N
A
…
B
…
Combining grammars, union rule

Similarly, the language M N starts with the production
S AB
followed by, as above,
A
…
B
…
Combining grammars, product rule

Finally, the grammar for the closure of a
language, M*, starts with the production
S AS |
followed by the grammar of M
A
…
Combining grammars, closure rule

Suppose we want to write a grammar for the
following language:
L = {, a, b, aa, bb, ..., an, bn, ..}
L is the union of the two languages
M = { an | n N}
N = { bn | n N}
Example, union

Thus we can write a grammar for L as follows:
S A | B union rule,
A | aA grammar for M,
B | bB grammar for N.
Example, union

Suppose we want to write a grammar for the
following language:
L = { ambn | m,n N}
L is the product of the two languages
M = {am | m N}
N = {bn | n N}
Example, product

Thus we can write a grammar for L
as follows:
S AB
product rule,
A | aA grammar for M
B | bB grammar for N
Example, product

Suppose we want to construct the
language L of all possible strings made
up from zero or more occurrences of aa
or bb.
L = {aa, bb}* = M*
M = {aa, bb}
Example, closure

So we can write a grammar for L as follows:
S AS | closure rule,A aa | bb grammar for {aa, bb}.
Example, closure

We can simplify this grammar:
Replace the occurrence of A in S
AS by the right side of A aa to
obtain the production S aaS.
Replace A in S AS by the right
side of A bb to obtain the
production S bbS.
This allows us to write the the
grammar in simplified form as:
S aaS | bbS |
An equivalent grammar

Language Grammar
{a, ab, abb, abbb} S a | ab | abb | abbb
{, a, aa, aaa, …} S aS |
{b, bbb, bbbbb, … b2n+1} S bbS | b
{b, abc, aabcc, …, anbcn} S aSc | b
{ac, abc, abbc, …, abnc} S aBc
B bB |
Some simple grammars

Regular languages

There are many possible ways of describing the
regular languages:
Languages that are accepted by some finite
automaton
Languages that are inductively formed from
combining very simple languages
Those described by a regular expression
Any language produced by a grammar with a
special, very restricted form
What is a regular language?

We start with a very simple basis of
languages and build more complex ones by
combining them in particular ways:
Basis: , {} and {a} are regular
languages for all a Σ.
Induction: If L and M are regular
languages, then the following languages
are also regular:
L M, L M and L*
Building a regular language

For example, the basis of the definition
gives us the following four regular
languages over the alphabet Σ = {a,b}:
, {}, {a}, {b}
Sample building blocks

Regular languages over {a, b}.
Language {, b}
We can write it as the union of the two
regular languages {} and {b}:
{,b} = {} {b}
Example 1

Language {a, ab }
We can write it as the product of the
two regular languages {a} and {, b}:
{a, ab} = {a} {, b}
Example 2

Language {, b, bb, …, bn,…}
It's just the closure of the regular
language {b}:
{b}* = {, b, bb, ..., bn ,...}
Example 3

{a, ab, abb, ..., abn, ...}
= {a} {, b, bb, ..., bn, ... }
= {a} {b}*
Example 4

{, a, b, aa, bb, ..., an, …, bm, ...}
= {a}* {b}*
Example 5

A regular expression is basically a
shorthand way of showing how a regular
language is built from the basis
The symbols are nearly identical to
those used to construct the languages,
and any given expression has a language
closely associated with it
For each regular expression E there is
a regular language L(E)
Regular expressions

The symbols of the regular expressions are
distinct from those of the languages
Regular expression Language
L () =
L () = {}
a L {a} = {a}
Basis of regular Basis of regular
expressions languages
Regular expressions versus languages

There are two binary operations on regular expressions
(+ and ) and one unary operator (*)
Regular expression Language
R + S L (R + S ) = L (R ) L (S )
R S , R S L (R S ) = L (R ) L (S )
R* L (R* ) = L (R )*
These are closely associated with the union, product and
closure operations on the corresponding languages
Operators on regular expressions

Like the languages they represent, regular
expressions can be manipulated inductively to
form new regular expressions
Basis: , and a are regular expressions for all a Σ.
Induction: If R and S are regular expressions,
then the following expressions are also regular:
(R), R + S, R S and R*
Building regular expressions

For example, here are a few of the infinitely
many regular expressions over the alphabet Σ
= {a, b }:
, , a, b
+ b, b*, a + (b a), (a + b) a,
a b*, a* + b*
Regular expressions

To avoid using too many parentheses, we
assume that the operations have the
following hierarchy:
* highest (do it first)
+ lowest (do it last)
For example, the regular expression
a + b a*
can be written in fully parenthesized form
as
(a + (b (a*)))
Order of operations

Use juxtaposition instead of whenever no confusion arises. For example, we can
write the preceding expression as
a + ba*
This expression is basically shorthand
for the regular language
{a} ({b} ({a}*))
So you can see why it is useful to write
an expression instead!
Implicit products

Find the language of the regular expression
a + bc*
L(a + bc*) = L(a) L(bc*)
= L(a) (L(b) L(c*))
= L(a) (L(b) L(c)*)
= {a} ({b} {c}*)
= {a} ({b) {, c, c2, ., cn,…})
= {a} {b, bc, bc2, .. .... bcn,…}
= {a, b, bc, bc2, ..., bcn, ...}.
Example

Many infinite languages are easily seen to
be regular. For example, the language
{a, aa, aaa, ..., an, ... }
is regular because it can be written as the
regular language {a} {a}*, which is
represented by the regular expression aa*.
Regular language

The slightly more complicated language
{, a, b, ab, abb, abbb, ..., abn, ...}
is also regular because it can be represented
by the regular expression
+ b + ab*
However, not all infinite languages are
regular!
Regular language

Distinct regular expressions do not always
represent distinct languages.
For example, the regular expressions a + b
and b + a are different, but they both
represent the same language,
L(a + b) = L(b + a) = {a, b}
Regular language

We say that regular expressions R and
S are equal if
L(R) = L(S)
and we denote this equality by
writing the following familiar
relation:
R = S
Regular language

For example, we know that
L (a + b) = {a, b} = {b, a} = L (b + a)
Therefore we can write
a + b = b + a
We also have the equality
(a + b) + (a + b) = a + b
Regular language

Properties of regular language
Additive (+) properties:
R + T = T + R
R + = + R= R
R + R = R
(R +S) +T = R + (S+ T)
These follow simply from the
properties of the union of sets

Properties of regular language
Product (•) properties
R = R =
R = R = R
(RS)T =R(ST)
Distributive properties
R(S + T) = RS + RT
(S + T)R = SR +TR

* = * =
R* = R*R* = (R*)* = R+R*
RR* = R*R
R(SR)* = (RS)* R
(R+S)* = (R*S*)* = (R* + S*)* = R*(SR*)*
Closure properties

Show that ( + a + b)* = a*(ba*)*
( + a + b)* = (a + b)* (+ property)
= a*(ba*)* (closure property)
Example

Regular grammars

A regular grammar is one where each
production takes one of the following
forms:
S
S w
S T
S wT
where the capital letters are non-
terminals and w is a non-empty string
of terminals
Regular grammar

Only one nonterminal can appear on the
right side of a production. It must
appear at the right end of the right
side.
Therefore the productions
A aBc and S TU
are not part of a regular grammar, but
the production A abcA is.
Regular grammar
Finite automata

Introduction
Deterministic finite automata (DFA’s)
Non-deterministic finite automata (NFA’s)
NFA’s to DFA’s
Simplifying DFA’s
Regular expressions finite automata
Outline

Consider the control system for a
one-way swinging door:
There are two states: Open and
Closed
It has two inputs, person detected
at position A and person detected
at position B
If the door is closed, it should
open only if a person is detected
at A but not B
Door should close only if no one is
detected
A B
Automatic one way door

Open Closed
A, no B
No A or B
A and BA, no BB, no A
A and BB, no ANo A or B
Control schematic

A finite automaton is usually represented
like this as a directed graph
Two parts of a directed graph:
The states (also called nodes or
vertices)
The edges with arrows which
represent the allowed transitions
One state is usually picked out as the
starting point
For so-called ‘accepting automata,’ some
states are chosen to be final states
Finite automaton

The input data are represented by a string
over some alphabet and it determines how the
machine progresses from state to state.
Beginning in the start state, the characters
of the input string cause the machine to
change from one state to another.
Accepting automata give only yes or no
answers, depending on whether they end up in
a ‘final state.’ Strings which end in a
final state are accepted by the automaton.
Strings and automata

The labeled graph in the figure above represents a FA over the alphabet Σ = {a, b} with start state 0 and final state 3.
Final states are denoted by a double circle.
Example

The previous graph was an example of a
deterministic finite automaton – every node
had two edges (a and b) coming out
A DFA over a finite alphabet Σ is a finite
directed graph with the property that each
node emits one labeled edge for each distinct
element of Σ.
Deterministic finite automata (DFA’s)

A DFA accepts a string w in Σ* if there is a
path from the start state to some final state
such that w is the concatenation of the labels
on the edges of the path.
Otherwise, the DFA rejects w .
The set of all strings accepted by a DFA M is
called the language of M and is denoted by
L(M)
More formally

Construct a DFA to recognize the regular
languages represented by the regular
expression (a + b)* over alphabet Σ = {a, b}.
This is the set {a, b}* of all strings over
{a, b}. This can be recognised by
Example: (a+b)*

Find a DFA to recognize the language
represented by the regular expression
a(a + b)* over the alphabet Σ = {a, b}.
This is the set of all strings in Σ*
which begin with a. One possible DFA
is:
Example: a(a+b)*

Build a DFA to recognize the regular language
represented by the regular expression
(a + b)*abb over the alphabet Σ = {a, b}.
The language is the set of strings that begin
with anything, but must end with the string
abb.
Effectively, we’re looking for strings which
have a particular pattern to them
Example: pattern recognition

The diagram below shows a DFA to recognize this language.
If in state 1: the last character was a
If in state 2 : the last two symbols were ab
If in state 3: the last three were abb
Solution: (a+b)*abb

State transition function

We can also represent a DFA by a state transition
function, which we'll denote by T, where any state
transition of the form
is represented by: T(i,a) = j
To describe a full DFA we need to know:
what states there are,
which are the start and final ones,
the set of transitions between them.
State transition function

The class of regular languages is
exactly the same as the class of
languages accepted by DFAs!
Kleene (1956)
For any regular language, we can find
a DFA which recognizes it!
Regular languages

DFA’s are very often used for pattern matching,
e.g. searching for words/structures in strings
This is used often in UNIX, particularly by the
grep command, which searches for combinations of
strings and wildcards (*, ?)
grep stands for Global (search for) Regular
Expressions Parser
DFA’s are also used to design and check simple
circuits, verifying protocols, etc.
They are of use whenever significant memory is
not required
Applications of DFA’s

DFA’s are called deterministic because
following any input string, we know exactly
which state its in and the path it took to
get there
For NFA’s, sometimes there is more than one
direction we can go with the same input
character
Non-determinism can occur, because following
a particular string, one could be in many
possible states, or taken different paths to
end at the same state!
Non-deterministic finite automata

A non-deterministic finite automaton (NFA)
over an alphabet Σ is a finite directed graph
with each node having zero or more edges,
Each edge is labelled either with a letter
from Σ or with .
Multiple edges may be emitted from the same
node with the same label.
Some letters may not have an edge associated
with them. Strings following such paths are
not recognised.
NFA’s

If an edge is labelled with the empty string , then we can travel the edge without consuming an
input letter. Effectively we could be in either
state, and so the possible paths could branch.
If there are two edges with the same label, we
can take either path.
NFA’s recognise a string if any one of its many
possible states following it is a final state
Otherwise, it rejects it.
Non-determinism
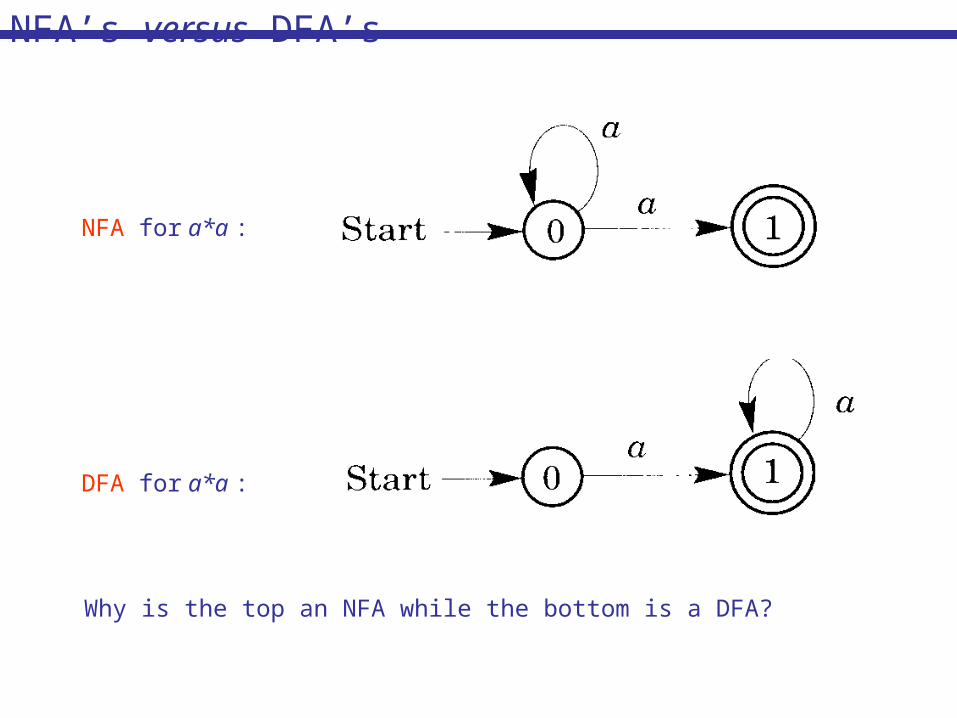
DFA for a*a :
Why is the top an NFA while the bottom is a DFA?
NFA for a*a :
NFA’s versus DFA’s

Draw two NFAs to recognize the language of the
regular expression ab + a*a.
This NFA has a edge, which allows us to travel to state 2 without consuming an input letter.
The upper path corresponds to ab and the lower one
to a*a
Example
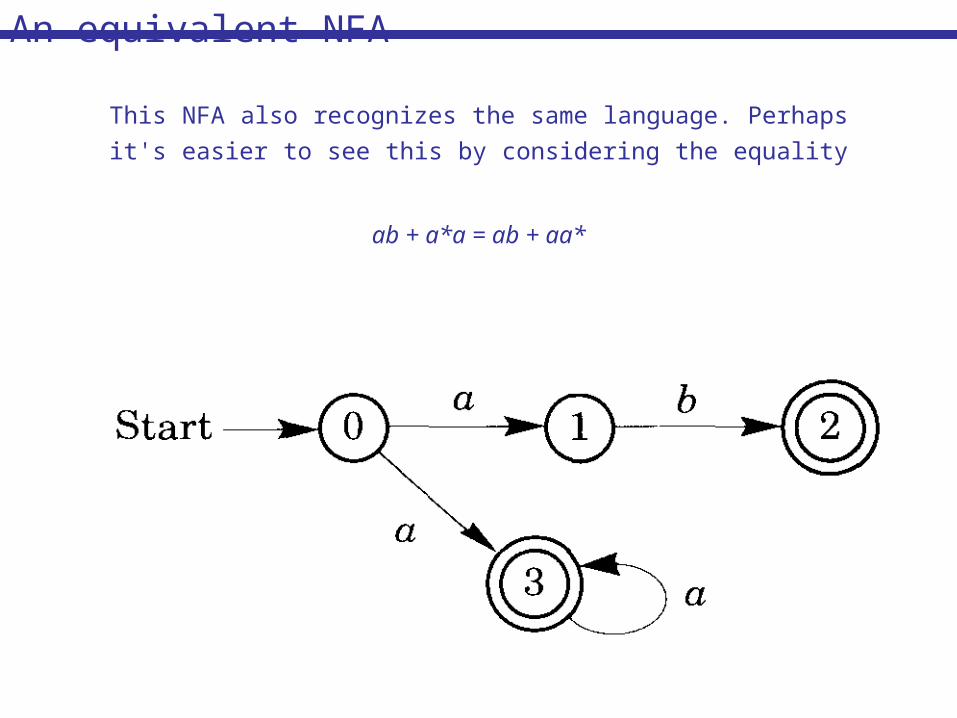
This NFA also recognizes the same language. Perhaps
it's easier to see this by considering the equality
ab + a*a = ab + aa*
An equivalent NFA

Since there may be non-determinism, we'll let the
values of this function be sets of states.
For example, if there are no edges from state k
labelled with a, we'll write
T(k, a) =
If there are three edges from state k, all labelled
with a, going to states i, j and k, we'll write
T(k, a) = {i, j, k}
NFA transition functions

All digital computers are deterministic; quantum
computers may be another story!
The usual mechanism for deterministic computers is
to try one particular path and to backtrack to the
last decision point if that path proves poor.
Parallel computers make non-determinism almost
realizable. We can let each process make a random
choice at each branch point, thereby exploring
many possible trees.
Comments on non-determinism

The class of regular languages is exactly the
same as the class of languages accepted by NFAs!
Rabin and Scott (1959)
Just like for DFA’s!
Every NFA has an equivalent DFA which recognises
the same language.
Some facts

We prove the equivalence of NFA’s and DFA’s by showing
how, for any NFA, to construct a DFA which recognises
the same language
Generally the DFA will have more possible states than
the NFA. If the NFA has n states, then the DFA could
have as many as 2n states!
Example: NFA has three states {A}, {B}, {C}
the DFA could have eight: {}, {A}, {B}, {C},
{A, B}, {A, C}, {B, C}, {A, B, C}
These correspond to the possible states the NFA could
be in after any string
From NFA’s to DFA’s

Begin in the NFA start state, which could be a
multiple state if its connected to any by
Determine the set of possible NFA states you could be
in after receiving each character. Each set is a new
DFA state, and is connected to the start by that
character.
Repeat for each new DFA state, exploring the possible
results for each character until the system is closed
DFA final states are any that contain a NFA final
state
DFA construction

The start state is A, but following an a you could be in A
or B; following a b you could only be in state A
A B Ca b
a,b
A A,Ba b
b
A,C
ab
a
NFA
DFA
Example (a+b)*ab

Regular expressions represent the regular languages.
DFA’s recognize the regular languages.
NFA’s also recognize the regular languages.
Summary

So far, we’ve introduced two kinds of automata:
deterministic and non-deterministic.
We’ve shown that we can find a DFA to recognise
anything language that a given NFA recognises.
We’ve asserted that both DFA’s and NFA’s recognise
the regular languages, which themselves are
represented by regular expressions.
We prove this by construction, by showing how any
regular expression can be made into a NFA and vice
versa.
Finite automata

Given a regular expression, we can find an automata
which recognises its language.
Start the algorithm with a machine that has a start
state, a single final state, and an edge labelled
with the given regular expression as follows:
Regular expressions finite automata

1. If an edge is labelled with , then erase the edge.
2. Transform any diagram like
into the diagram
Four step algoritm

3. Transform any diagram like
into the diagram
Four step algoritm

4. Transform any diagram like
into the diagram
Four step algoritm

Construct a NFA for the regular expression, a* + ab
Start with
Apply rule 2
a* + ab
ab
a*
Example a*+ab

ab
a
a
a b
Apply rule 4 to a*
Apply rule 3 to ab
Example a*+ab

1 Create a new start state s, and draw a
new edge labelled with from s to the original start state.
2 Create a new final state f, and draw new
edges labelled with from all the
original final states to f
Finite automata regular expressions

3 For each pair of states i and j that have
more than one edge from i to j, replace all
the edges from i to j by a single edge
labelled with the regular expression formed
by the sum of the labels on each of the
edges from i to j.
4 Construct a sequence of new machines by
eliminating one state at a time until the
only states remaining are s and the f.
Finite automata regular expressions

As each state is eliminated, a new machine is
constructed from the previous machine as follows:
Let old(i,j) denote the label on edge i,j of the current machine. If no edge exists, label
it .
Assume that we wish to eliminate state k. For
each pair of edges i,k (incoming edge) and
k,j (outgoing edge) we create a new edge label new(i, j)
Eliminating states

The label of this new edge is given by:
new(i,j) = old(i,j) + old(i, k) old(k, k)* old(k,j)
All other edges, not involving state k, remain the
same:
new(i, j) = old(i, j)
After eliminating all states except s and f, we wind up
with a two-state machine with the single edge s, f labelled with the desired regular expression new(s, f)
Eliminate state k

Initial DFA
Steps 1 and 2
Add start and final states
Example

Eliminate state 2
(No path to f)
Eliminate state 0
Eliminate state 1
Final regular expression
Example

Sometimes our constructions lead to more
complicated automata than we need, having more
states than are really necessary
Next, we look for ways of making DFA’s with a
minimum number of states
Myhill-Nerode theorem:
‘Every regular expression has a unique* minimum
state DFA’
* up to a simple renaming of the states
Finding simpler automata

Two steps to minimizing DFA:
1 Discover which, if any, pairs of states are
indistinguishable. Two states, s and t, are
equivalent if for all possible strings w,
T(s,w) and T(t,w) are both either final or
non-final.
2 Combine all equivalent states into a single
state, modifying the transition functions
appropriately.
Finding minimum state DFA
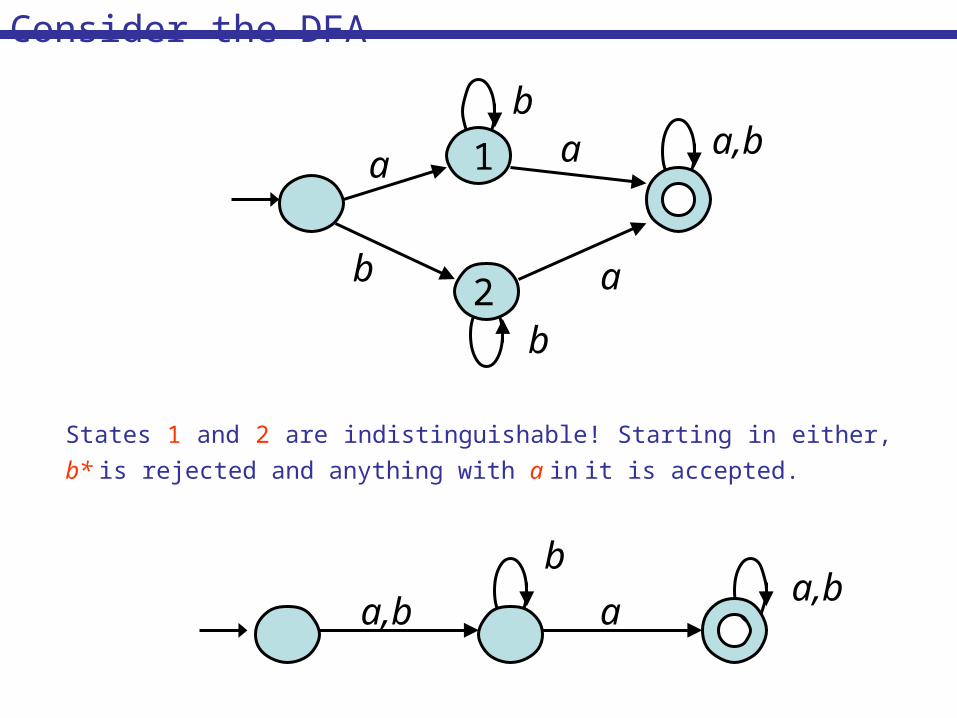
States 1 and 2 are indistinguishable! Starting in either,
b* is rejected and anything with a in it is accepted.
a ab
b a
b
1
2
a,b
aa,b a,b
b
Consider the DFA

1. Remove all inaccessible states, where no path
exists to them from start.
2. Construct a grid of pairs of states.
3. Begin by marking those pairs which are clearly
distinguishable, where one is final and the other
non-final.
4. Next eliminate all pairs, which on the same
input, lead to a distinguishable pair of states.
Repeat until you have considered all pairs.
5. The remaining pairs are indistinguishable.
Part 1, finding indistinguishable pairs

1. Construct a new DFA where any pairs of
indistinguishable states form a single state
in the new DFA.
2. The start state will be the state containing
the original start state.
3. The final states will be those which contain
original final states.
4. The transitions will be the full set of
transitions from the original states (these
should all be consistent.)
Part 2, construct minimum DFA
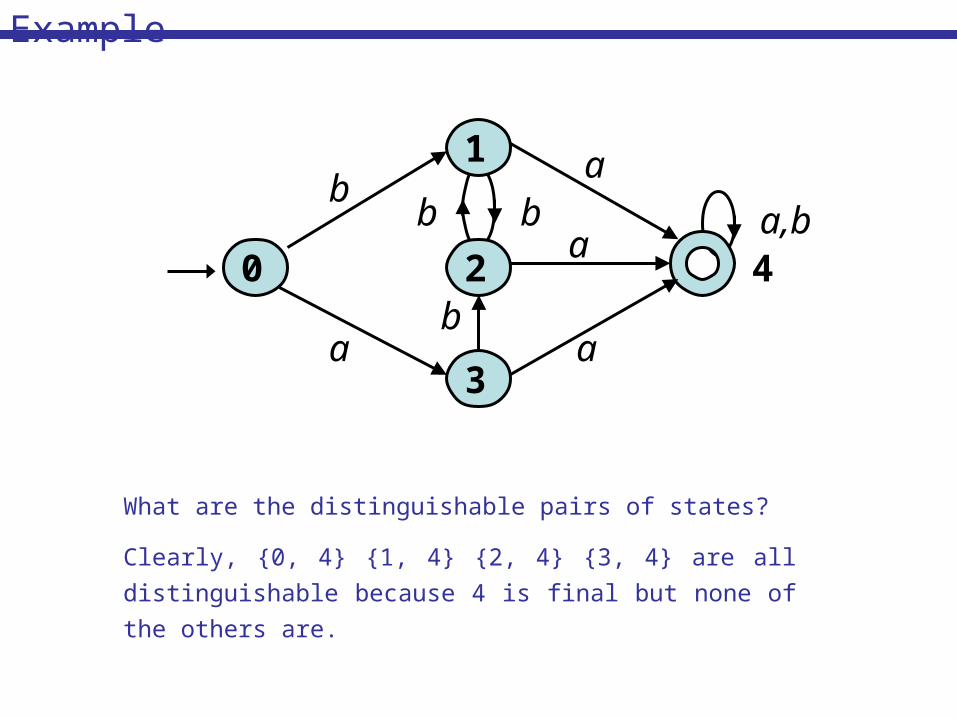
a
a
a,b
a
a
b b b
0
3
2
1
4
What are the distinguishable pairs of states?
Clearly, {0, 4} {1, 4} {2, 4} {3, 4} are all
distinguishable because 4 is final but none of
the others are.
b
Example

We eliminate these as possible
indistinguishable pairs.
Next consider {0, 1}. With input
a, this becomes {3, 4} which is
distinguishable, so {0, 1} is as
well.
Similarly, we can show {0, 2} and
{0, 3} are also distinguishable,
leading to the modified grid…
1234
? ? ? ? ? ?x x x x
0 1 2 3
1234
xx ? x ? ?x x x x
0 1 2 3
Grid of pairs of state

We are left with
{1, 2} given a {4, 4}
given b {2, 1}
{2, 3} given a {4, 4}
given b {1, 2}
{1, 3} given a {4, 4}
given b {2, 2}
These do not lead to pairs we know to
be distinguishable, and are therefore
indistinguishable!
Remaining pairs

States 1, 2, and 3 are all indistinguishable, thus
the minimal DFA will have three states:
{0} {1, 2, 3} {4}
Since originally T(0, a) = 3 and T(0, b) = 1, the
new transitions are T(0, a) = T(0, b) = {1,2,3}
Similarly,
T({1,2,3}, a) = 4 and T({1,2,3}, b) = {1,2,3}
Finally, as before,
T(4, a) = 4 and T(4, b) = 4
Construct minimal DFA

The resulting DFA is much simpler:
aa,b a,b
b
0 1, 2, 3 4
This recognises regular expressions of the form, (a +
b) b* a (a + b)*
This is the simplest DFA which will recognise this
language!
Resulting minimal DFA

We now have many equivalent ways of representing
regular languages: DFA’s, NFA’s, regular expressions
and regular grammars.
We can also now simply(?!) move between these
various representations.
We’ll see next lecture that the automata
representation leads to a simple way of recognising
some languages which are not regular.
We’ll also begin to consider more powerful language
types and correspondingly more powerful computing
models!
conclusions

M = (Q, Σ, δ, q0, F)
Q = states a finite setΣ = alphabet a finite setδ = transition function a total function in Q Σ
Qq0 = initial/starting state q0 Q
F = final states F Q
Formal definition