thread cluster memory schedulingsafari/pubs/kim_micro10_talk.pdf · overview: thread cluster memory...
TRANSCRIPT

Thread Cluster Memory Scheduling:
Exploiting Differences in Memory Access Behavior
Yoongu KimMichael PapamichaelOnur MutluMor Harchol-Balter

Motivation
• Memory is a shared resource
• Threads’ requests contend for memory
– Degradation in single thread performance
– Can even lead to starvation
• How to schedule memory requests to increase both system throughput and fairness?
2
Core Core
Core CoreMemory

1
3
5
7
9
11
13
15
17
8 8.2 8.4 8.6 8.8 9
Max
imu
m S
low
do
wn
Weighted Speedup
FRFCFS
STFM
PAR-BS
ATLAS
Previous Scheduling Algorithms are Biased
3
System throughput bias
Fairness bias
No previous memory scheduling algorithm provides both the best fairness and system throughput
Better system throughput
Bet
ter
fair
ne
ss

Take turns accessing memory
Why do Previous Algorithms Fail?
4
Fairness biased approach
thread C
thread B
thread A
less memory intensive
higherpriority
Prioritize less memory-intensive threads
Throughput biased approach
Good for throughput
starvation unfairness
thread C thread Bthread A
Does not starve
not prioritized reduced throughput
Single policy for all threads is insufficient

thread
thread
thread
thread
Insight: Achieving Best of Both Worlds
5
thread
higherpriority
thread
thread
thread
Prioritize memory-non-intensive threads
For Throughput
Unfairness caused by memory-intensive being prioritized over each other
• Shuffle threads
Memory-intensive threads have different vulnerability to interference
• Shuffle asymmetrically
For Fairness

OutlineMotivation & Insights
Overview
Algorithm
Bringing it All Together
Evaluation
Conclusion
6

Overview: Thread Cluster Memory Scheduling
1. Group threads into two clusters2. Prioritize non-intensive cluster3. Different policies for each cluster
7
thread
Threads in the system
thread
thread
thread
thread
thread
thread
Non-intensive cluster
Intensive cluster
thread
thread
thread
Memory-non-intensive
Memory-intensive
Prioritized
higherpriority
higherpriority
Throughput
Fairness

OutlineMotivation & Insights
Overview
Algorithm
Bringing it All Together
Evaluation
Conclusion
8

TCM Outline
9
1. Clustering

Clustering Threads
Step1 Sort threads by MPKI (misses per kiloinstruction)
10
thre
ad
thre
ad
thre
ad
thre
ad
thre
ad
thre
ad
higher MPKI
Tα < 10%
ClusterThreshold
Intensive clusterαT
Non-intensivecluster
T = Total memory bandwidth usage
Step2 Memory bandwidth usage αT divides clusters

TCM Outline
11
1. Clustering
2. Between Clusters

Prioritize non-intensive cluster
• Increases system throughput
– Non-intensive threads have greater potential for making progress
• Does not degrade fairness
– Non-intensive threads are “light”
– Rarely interfere with intensive threads
Prioritization Between Clusters
12
>priority

TCM Outline
13
1. Clustering
2. Between Clusters
3. Non-Intensive Cluster
Throughput

Prioritize threads according to MPKI
• Increases system throughput
– Least intensive thread has the greatest potential for making progress in the processor
Non-Intensive Cluster
14
thread
thread
thread
thread
higherpriority lowest MPKI
highest MPKI
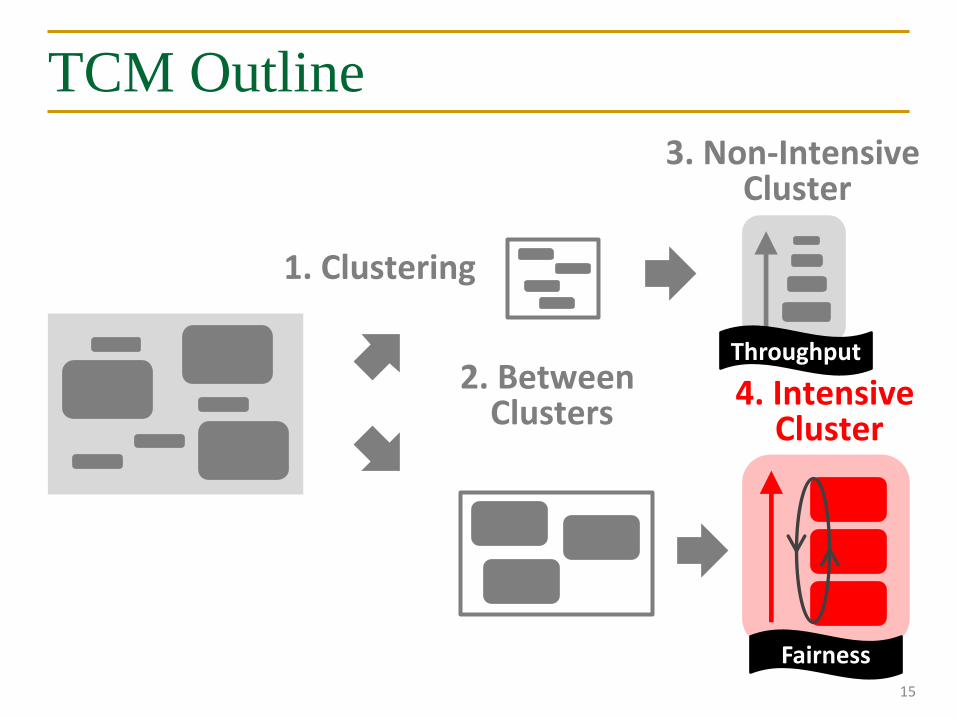
TCM Outline
15
1. Clustering
2. Between Clusters
3. Non-Intensive Cluster
4. Intensive Cluster
Throughput
Fairness

Periodically shuffle the priority of threads
• Is treating all threads equally good enough?
• BUT: Equal turns ≠ Same slowdown
Intensive Cluster
16
Increases fairness
Most prioritizedhigherpriority
thread
thread
thread

02468
101214
random-access streamingSl
ow
do
wn
Case Study: A Tale of Two ThreadsCase Study: Two intensive threads contending
1. random-access
2. streaming
17
Prioritize random-access Prioritize streaming
random-access thread is more easily slowed down
02468
101214
random-access streaming
Slo
wd
ow
n
7xprioritized
1x
11x
prioritized1x
Which is slowed down more easily?

Why are Threads Different?
18
Bank 1 Bank 2 Bank 3 Bank 4 Memory
rows

Why are Threads Different?
19
random-access
Bank 1 Bank 2 Bank 3 Bank 4 Memory
rows
•All requests parallel•High bank-level parallelism
activated row
reqreq
reqreq

Why are Threads Different?
20
streaming
Bank 1 Bank 2 Bank 3 Bank 4 Memory
rows
req
req
reqreq
•All requests Same row•High row-buffer locality
random-access
•All requests parallel•High bank-level parallelism
activated row

Why are Threads Different?
21
random-access streaming
Bank 1 Bank 2 Bank 3 Bank 4 Memory
rows
•All requests parallel•High bank-level parallelism
•All requests Same row•High row-buffer locality
stuck
Vulnerable to interference
reqreq
req
req
req
req
reqreq

TCM Outline
22
1. Clustering
2. Between Clusters
3. Non-Intensive Cluster
4. Intensive Cluster
Fairness
Throughput

Niceness
How to quantify difference between threads?
23
Vulnerability to interference
Bank-level parallelism
Causes interference
Row-buffer locality
+ Niceness -
NicenessHigh Low

Shuffling: Round-Robin vs. Niceness-Aware
1. Round-Robin shuffling
2. Niceness-Aware shuffling
24
What can go wrong?

Shuffling: Round-Robin vs. Niceness-Aware
1. Round-Robin shuffling
2. Niceness-Aware shuffling
25
Most prioritized
ShuffleInterval
Priority
Time
Nice thread
Least nice thread
What can go wrong?
A
B
C
D
D A B C D
A
B
D
C
B
C
A
D
C
D
B
A
D
A
C
B
GOOD: Each thread prioritized once

Shuffling: Round-Robin vs. Niceness-Aware
1. Round-Robin shuffling
2. Niceness-Aware shuffling
26
Most prioritized
ShuffleInterval
Priority
Time
Nice thread
Least nice thread
What can go wrong?
A
B
C
D
D A B C D
A
B
D
C
B
C
A
D
C
D
B
A
D
A
C
B
BAD: Nice threads receive lots of interference
GOOD: Each thread prioritized once

Shuffling: Round-Robin vs. Niceness-Aware
1. Round-Robin shuffling
2. Niceness-Aware shuffling
27

Shuffling: Round-Robin vs. Niceness-Aware
1. Round-Robin shuffling
2. Niceness-Aware shuffling
28
Most prioritized
ShuffleInterval
Priority
Time
Nice thread
Least nice threadA
B
C
D
D C B A D
D
A
C
B
B
A
C
D
A
D
B
C
D
A
C
B
GOOD: Each thread prioritized once

Shuffling: Round-Robin vs. Niceness-Aware
1. Round-Robin shuffling
2. Niceness-Aware shuffling
29
Most prioritized
ShuffleInterval
Priority
Time
Nice thread
Least nice threadA
B
C
D
D C B A D
D
A
C
B
B
A
C
D
A
D
B
C
D
A
C
B
GOOD: Each thread prioritized once
GOOD: Least nice thread stays mostly deprioritized

TCM Outline
30
1. Clustering
2. Between Clusters
3. Non-Intensive Cluster
4. Intensive Cluster
Fairness
Throughput

OutlineMotivation & Insights
Overview
Algorithm
Bringing it All Together
Evaluation
Conclusion
31
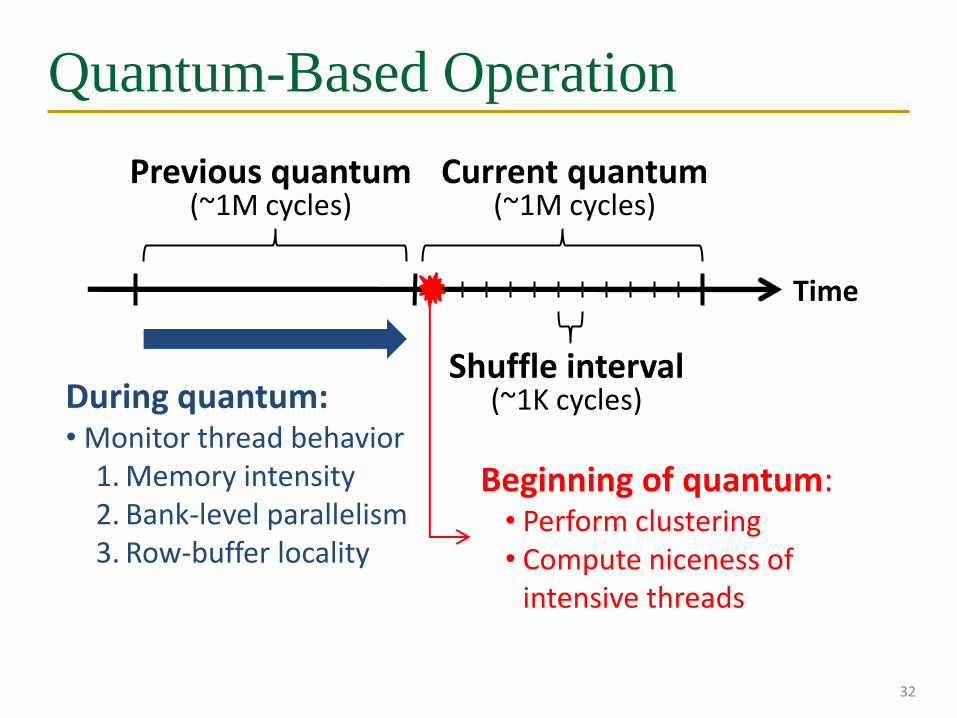
Quantum-Based Operation
32
Time
Previous quantum (~1M cycles)
During quantum:• Monitor thread behavior
1. Memory intensity2. Bank-level parallelism3. Row-buffer locality
Beginning of quantum:• Perform clustering• Compute niceness of
intensive threads
Current quantum(~1M cycles)
Shuffle interval(~1K cycles)

TCM Scheduling Algorithm
1. Highest-rank: Requests from higher ranked threads prioritized
• Non-Intensive cluster > Intensive cluster
• Non-Intensive cluster: lower intensity higher rank
• Intensive cluster: rank shuffling
2.Row-hit: Row-buffer hit requests are prioritized
3.Oldest: Older requests are prioritized
33

Implementation Costs
Required storage at memory controller (24 cores)
• No computation is on the critical path
34
Thread memory behavior Storage
MPKI ~0.2kb
Bank-level parallelism ~0.6kb
Row-buffer locality ~2.9kb
Total < 4kbits

OutlineMotivation & Insights
Overview
Algorithm
Bringing it All Together
Evaluation
Conclusion
35
Fairness
Throughput

Metrics & Methodology
• MetricsSystem throughput
36
i
alone
i
shared
i
IPC
IPCSpeedupWeighted
shared
i
alone
iiIPC
IPCSlowdownMaximum max
Unfairness
• Methodology– Core model
• 4 GHz processor, 128-entry instruction window
• 512 KB/core L2 cache
– Memory model: DDR2
– 96 multiprogrammed SPEC CPU2006 workloads

Previous Work
FRFCFS [Rixner et al., ISCA00]: Prioritizes row-buffer hits
– Thread-oblivious Low throughput & Low fairness
STFM [Mutlu et al., MICRO07]: Equalizes thread slowdowns
– Non-intensive threads not prioritized Low throughput
PAR-BS [Mutlu et al., ISCA08]: Prioritizes oldest batch of requests while preserving bank-level parallelism
– Non-intensive threads not always prioritized Low throughput
ATLAS [Kim et al., HPCA10]: Prioritizes threads with less memory service
– Most intensive thread starves Low fairness
37

Results: Fairness vs. Throughput
FRFCFS
STFM
PAR-BS
ATLAS
TCM
4
6
8
10
12
14
16
7.5 8 8.5 9 9.5 10
Max
imu
m S
low
do
wn
Weighted Speedup
38
Better system throughput
Bet
ter
fair
ne
ss
5%
39%
8%
5%
TCM provides best fairness and system throughput
Averaged over 96 workloads

Results: Fairness-Throughput Tradeoff
FRFCFS
2
4
6
8
10
12
12 13 14 15 16
Max
imu
m S
low
do
wn
Weighted Speedup
39
When configuration parameter is varied…
Adjusting ClusterThreshold
TCM allows robust fairness-throughput tradeoff
STFM
PAR-BS
ATLAS
TCM
Better system throughput
Bet
ter
fair
ne
ss

Operating System Support
• ClusterThreshold is a tunable knob
– OS can trade off between fairness and throughput
• Enforcing thread weights
– OS assigns weights to threads
– TCM enforces thread weights within each cluster
40

OutlineMotivation & Insights
Overview
Algorithm
Bringing it All Together
Evaluation
Conclusion
41
Fairness
Throughput

Conclusion
42
• No previous memory scheduling algorithm provides both high system throughput and fairness
– Problem: They use a single policy for all threads
• TCM groups threads into two clusters
1. Prioritize non-intensive cluster throughput
2. Shuffle priorities in intensive cluster fairness
3. Shuffling should favor nice threads fairness
• TCM provides the best system throughput and fairness

THANK YOU
43

Thread Cluster Memory Scheduling:
Exploiting Differences in Memory Access Behavior
Yoongu KimMichael PapamichaelOnur MutluMor Harchol-Balter

Thread Weight Support
• Even if heaviest weighted thread happens to be the most intensive thread…
– Not prioritized over the least intensive thread
45

Harmonic Speedup
46
Better system throughput
Bet
ter
fair
ne
ss
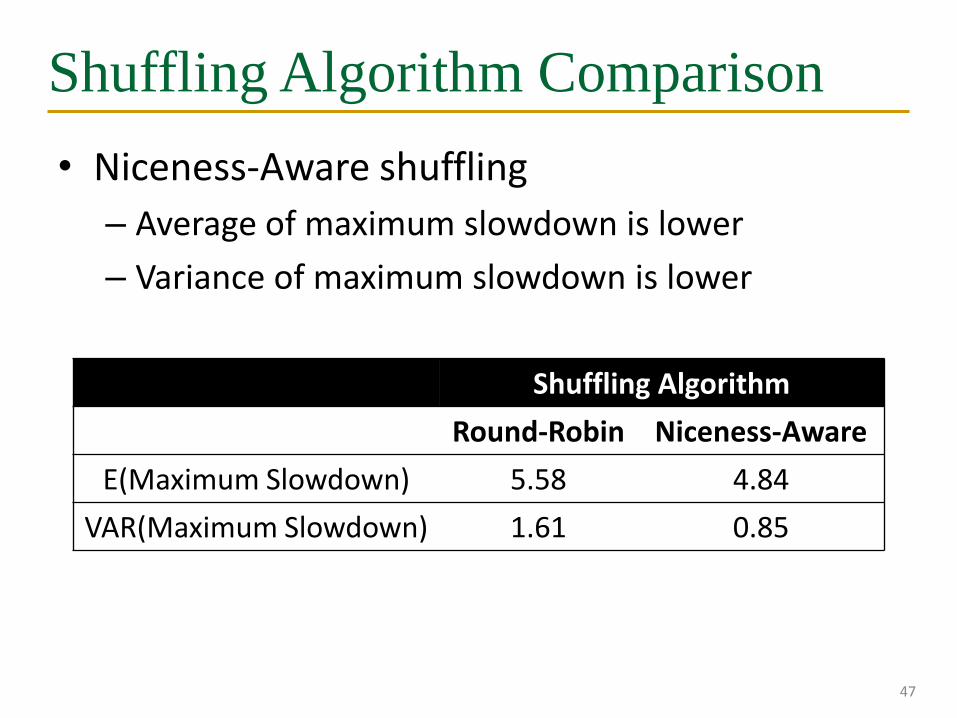
Shuffling Algorithm Comparison
• Niceness-Aware shuffling
– Average of maximum slowdown is lower
– Variance of maximum slowdown is lower
47
Shuffling Algorithm
Round-Robin Niceness-Aware
E(Maximum Slowdown) 5.58 4.84
VAR(Maximum Slowdown) 1.61 0.85

Sensitivity Results
48
ShuffleInterval (cycles)
500 600 700 800
System Throughput 14.2 14.3 14.2 14.7
Maximum Slowdown 6.0 5.4 5.9 5.5
Number of Cores
4 8 16 24 32
System Throughput(compared to ATLAS)
0% 3% 2% 1% 1%
Maximum Slowdown(compared to ATLAS)
-4% -30% -29% -30% -41%