threads and scheduling
DESCRIPTION
6. Threads and Scheduling. Announcements. Homework Set #2 due Friday at 11 am - extension Program Assignment #1 due Thursday Feb. 10 at 11 am Read chapters 6 and 7. Program #1: Threads - addenda. draw the picture of user space threads versus kernel space threads - PowerPoint PPT PresentationTRANSCRIPT

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-1
Copyright © 2004 Pearson Education, Inc.
Threads and Scheduling
6

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-2
Copyright © 2004 Pearson Education, Inc.
Announcements
• Homework Set #2 due Friday at 11 am - extension
• Program Assignment #1 due Thursday Feb. 10 at 11 am
• Read chapters 6 and 7

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-3
Copyright © 2004 Pearson Education, Inc.
Program #1: Threads - addenda
• draw the picture of user space threads versus kernel space threads• user space threads yield voluntarily to switch between threads• because it’s user space, the CPU doesn’t know about these threads• your program just looks like a single-threaded process to CPU• Inside that process, use library to create and delete threads, wait a
thread, and yield a thread• this is what you’re building• Advantage: can implement threads on any OS, faster - no trap to
kernel, no context switch• Disadvantage: only voluntary scheduling, no preemption, blocked I/O
on one user thread blocks all threads

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-4
Copyright © 2004 Pearson Education, Inc.
Program #1: Threads - addenda
• each process keeps a thread table• analogous to process table of PCB’s kept by OS
kernel for each process• Key question: how do we switch between threads?
– need to save thread state and change the PC
• PA #1 does it like this– scheduler is a global user thread, while your threads a
and b are user, but local (hence on the stack)– stack pointer, frame pointer

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-5
Copyright © 2004 Pearson Education, Inc.

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-6
Copyright © 2004 Pearson Education, Inc.
What is a Process?• A process is a
program actively executing from main memory– has a Program
Counter (PC) and execution state associated with it
• CPU registers keep state
• OS keeps process state in memory
• it’s alive!
– has an address space associated with it
• a limited set of (virtual) addresses that can be accessed by the executing code
Code
Data
MainMemory
ProgramP1
binary CPUExecutionProgram
Counter (PC)
Registers
ALU
Fetch Codeand Data
Write Data
Process
Heap
Stack

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-7
Copyright © 2004 Pearson Education, Inc.
How is a Process Structured in Memory?
• Run-time memory image
• Essentially code, data, stack, and heap
• Code and data loaded from executable file
• Stack grows downward, heap grows upward
User stack
Heap
Read/write .data, .bss
Read-only .init, .text, .rodata
Unallocated
Run-time memory
address 0
max address

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-8
Copyright © 2004 Pearson Education, Inc.
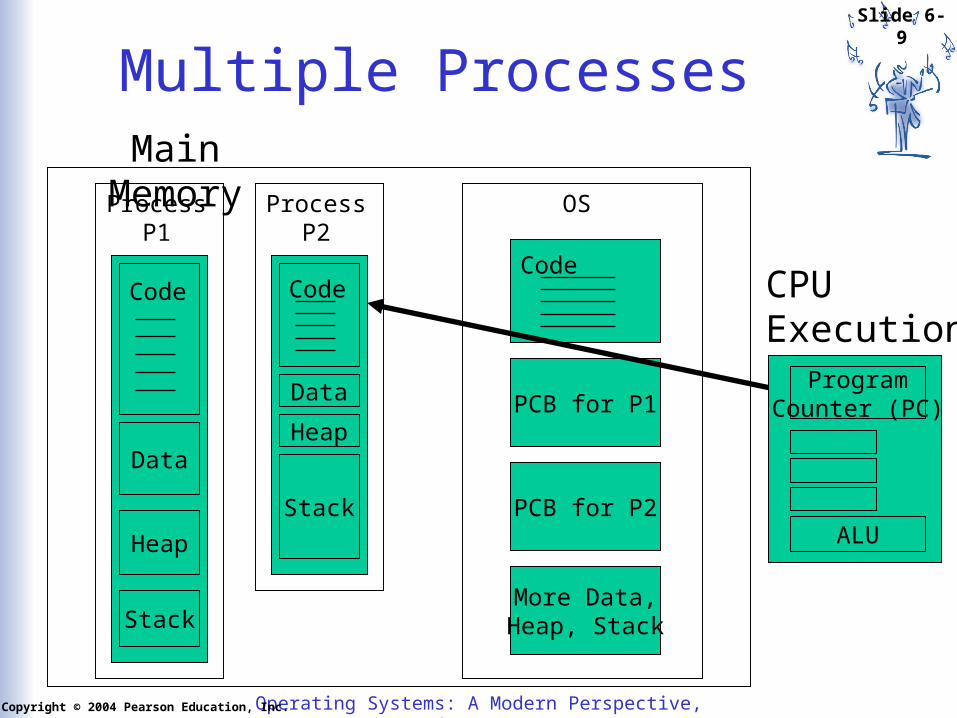
Multiple ProcessesMain Memory
Code
Data
ProcessP1
Heap
Stack
Code
Data
ProcessP2
Heap
Stack
• Process state, e.g. ready, running, or waiting
• accounting info, e.g. process ID
• Program Counter
• CPU registers• CPU-
scheduling info, e.g. priority
• Memory management info, e.g. base and limit registers, page tables
• I/O status info, e.g. list of open files
Code
More Data,Heap, Stack
OS
PCB for P2
PCB for P1
Operating Systems: A Modern Perspective, Chapter 6
Slide 6-9
Copyright © 2004 Pearson Education, Inc.
Multiple ProcessesMain Memory
Code
Data
ProcessP1
Heap
Stack
Code
Data
ProcessP2
Heap
Stack
Code
More Data,Heap, Stack
OS
PCB for P2
PCB for P1
CPUExecution
ProgramCounter (PC)
ALU

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-10
Copyright © 2004 Pearson Education, Inc.
Context Switching
ProcessManager
InterruptHandler
P1
P2
Pn
Executable Memory
Initialization1
23
45
7Interrupt
8
9
6
• Each time a process is switched out, its context must be saved, e.g. in the PCB
• Each time a process is switched in, its context is restored
• This usually requires copying of registers

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-11
Copyright © 2004 Pearson Education, Inc.
Threads
• A thread is a logical flow of execution that runs within the context of a process– has its own program counter (PC), register
state, and stack– shares the memory address space with other
threads in the same process,• share the same code and data and resources (e.g.
open files)

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-12
Copyright © 2004 Pearson Education, Inc.
Threads
• Why would you want multithreaded processes?– reduced context switch overhead
• In Solaris, context switching between processes is 5x slower than switching between threads
– shared resources => less memory consumption => more threads can be supported, especially for a scalable system, e.g. Web server must handle thousands of connections
– inter-thread communication is easier and faster than inter-process communication
– thread also called a lightweight process

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-13
Copyright © 2004 Pearson Education, Inc.
Threads
• Process P1 is multithreaded
• Process P2 is single threaded
• The OS is multiprogrammed
• If there is preemptive timeslicing, the system is multitasked
Main Memory
CodeData
Process P1’s Address Space
HeapCode
Data
ProcessP2
Heap
Stack
Stack
PC1
Reg.State
Thread 1
Stack
PC2
Reg.State
Thread 2
Stack
PC3
Reg.State
Thread 3

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-14
Copyright © 2004 Pearson Education, Inc.
Processes &Threads
Add
ress
Spa
ceA
ddre
ss S
pace
MapMap
Sta
ck
State
Pro
gram
Sta
tic d
ata
Res
ourc
es
Sta
ck
State
MapMap

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-15
Copyright © 2004 Pearson Education, Inc.
Thread-Safe/Reentrant Code
• If two threads share and execute the same code, then the code needs to be thread-safe– the use of global variables is not thread safe– the use of static variables is not thread safe– the use of local variables is thread safe
• need to govern access to persistent data like global/static variables with locking and synchronization mechanisms
• reentrant is a special case of thread-safe:– reentrant code does not have any references to global
variables– thread-safe code protects and synchronizes access to
global variables

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-16
Copyright © 2004 Pearson Education, Inc.
User-Space and Kernel Threads
• pthreads is a POSIX user space threading API– provides interface to create, delete threads in the same process– threads will synchronize with each other via this package– no need to involve the OS– implementations of pthreads API differ underneath the API
• Kernel threads are supported by the OS– kernel must be involved in switching threads– mapping of user-level threads to kernel threads is usually one-to-
one

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-17
Copyright © 2004 Pearson Education, Inc.
Model of Process Execution
ReadyList
ReadyList SchedulerScheduler CPUCPU
ResourceManager
ResourceManager
ResourcesResources
Preemption or voluntary yield
Allocate Request
DoneNewProcess job
jobjob
jobjob
“Ready”“Running”
“Blocked”
Operating Systems: A Modern Perspective, Chapter 6
Slide 6-18
Copyright © 2004 Pearson Education, Inc.
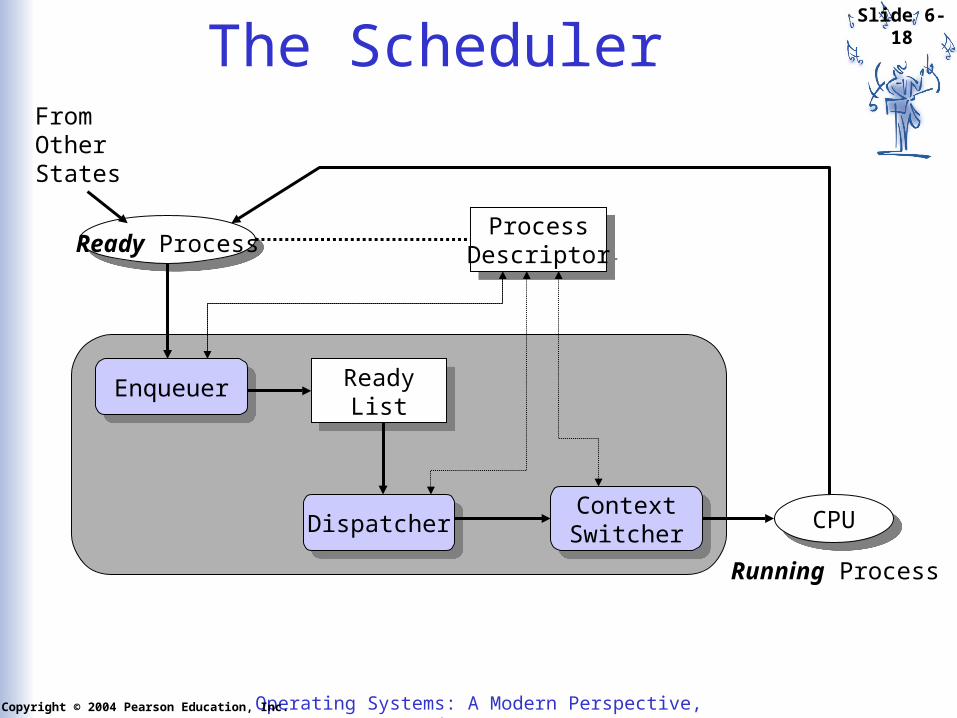
The Scheduler
Ready Process
EnqueuerEnqueuer ReadyList
ReadyList
DispatcherDispatcher ContextSwitcher
ContextSwitcher
ProcessDescriptor
ProcessDescriptor
CPUCPU
FromOtherStates
Running Process

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-19
Copyright © 2004 Pearson Education, Inc.
Invoking the Scheduler
• Need a mechanism to call the scheduler
• Voluntary call– Process blocks itself– Calls the scheduler
• Involuntary call– External force (interrupt) blocks the process– Calls the scheduler

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-20
Copyright © 2004 Pearson Education, Inc.
Voluntary CPU Sharing
yield(pi.pc, pj.pc) { memory[pi.pc] = PC; PC = memory[pj.pc];}
• pi can be “automatically” determined from the processor status registers
yield(*, pj.pc) { memory[pi.pc] = PC; PC = memory[pj.pc];}

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-21
Copyright © 2004 Pearson Education, Inc.
More on Yield
yield(*, pj.pc);. . .yield(*, pi.pc);. . .yield(*, pj.pc);. . .
• pi and pj can resume one another’s execution
• Suppose pj is the scheduler:// p_i yields to scheduleryield(*, pj.pc);// scheduler chooses pk
yield(*, pk.pc);// pk yields to scheduleryield(*, pj.pc);// scheduler chooses ...

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-22
Copyright © 2004 Pearson Education, Inc.
Voluntary Sharing
• Every process periodically yields to the scheduler• Relies on correct process behavior
– process can fail to yield: infinite loop either intentionally (while(1)) or due to logical error (while(!DONE))
• Malicious• Accidental
– process can yield to soon: unfairness for the “nice” processes who give up the CPU, while others do not
– process can fail to yield in time:• another process urgently needs the CPU to read incoming data
flowing into a bounded buffer, but doesn’t get the CPU in time to prevent the buffer from overflowing and dropping information
• Need a mechanism to override running process

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-23
Copyright © 2004 Pearson Education, Inc.
Involuntary CPU Sharing
• Interval timer– Device to produce a periodic interrupt– Programmable period
IntervalTimer() { InterruptCount--; if(InterruptCount <= 0) { InterruptRequest = TRUE; InterruptCount = K; }}
SetInterval(programmableValue) { K = programmableValue: InterruptCount = K; }}

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-24
Copyright © 2004 Pearson Education, Inc.
Involuntary CPU Sharing (cont)
• Interval timer device handler– Keeps an in-memory clock up-to-date (see Chap 4 lab
exercise)– Invokes the scheduler
IntervalTimerHandler() { Time++; // update the clock TimeToSchedule--; if(TimeToSchedule <= 0) { <invoke scheduler>; TimeToSchedule = TimeSlice; }}

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-25
Copyright © 2004 Pearson Education, Inc.
Contemporary Scheduling
• Involuntary CPU sharing – timer interrupts– Time quantum determined by interval timer –
usually fixed size for every process using the system
– Sometimes called the time slice length

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-26
Copyright © 2004 Pearson Education, Inc.
Choosing a Process to Run
• Mechanism never changes
• Strategy = policy the dispatcher uses to select a process from the ready list
• Different policies for different requirements
Ready Process
EnqueueEnqueue ReadyList
ReadyList
DispatchDispatch ContextSwitch
ContextSwitch
ProcessDescriptor
ProcessDescriptor
CPUCPU
Running Process

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-27
Copyright © 2004 Pearson Education, Inc.
Policy Considerations
• Policy can control/influence:– CPU utilization– Average time a process waits for service– Average amount of time to complete a job
• Could strive for any of:– Equitability– Favor very short or long jobs– Meet priority requirements– Meet deadlines

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-28
Copyright © 2004 Pearson Education, Inc.
Optimal Scheduling• Suppose the scheduler knows each process
pi’s service time, pi -- or it can estimate each pi :
• Policy can optimize on any criteria, e.g.,– CPU utilization– Waiting time– Deadline
• To find an optimal schedule:– Have a finite, fixed # of pi
– Know pi for each pi
– Enumerate all schedules, then choose the best

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-29
Copyright © 2004 Pearson Education, Inc.
However ...
• The (pi) are almost certainly just estimates
• General algorithm to choose optimal schedule is O(n2)
• Other processes may arrive while these processes are being serviced
• Usually, optimal schedule is only a theoretical benchmark – scheduling policies try to approximate an optimal schedule

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-30
Copyright © 2004 Pearson Education, Inc.
Model of Process Execution
ReadyList
ReadyList SchedulerScheduler CPUCPU
ResourceManager
ResourceManager
ResourcesResources
Preemption or voluntary yield
Allocate Request
DoneNewProcess job
jobjob
jobjob
“Ready”“Running”
“Blocked”

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-31
Copyright © 2004 Pearson Education, Inc.
Talking About Scheduling ...• Let P = {pi | 0 i < n} = set of processes
• Let S(pi) {running, ready, blocked}
• Let (pi) = Time process needs to be in running state (the service time)
• Let W(pi) = Time pi is in ready state before first transition to running (wait time)
• Let TTRnd(pi) = Time from pi first enter ready to last exit ready (turnaround time)
• Batch Throughput rate = inverse of avg TTRnd
• Timesharing response time = W(pi)

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-32
Copyright © 2004 Pearson Education, Inc.
Simplified Model
ReadyList
ReadyList SchedulerScheduler CPUCPU
ResourceManager
ResourceManager
ResourcesResources
Allocate Request
DoneNewProcess job
jobjob
jobjob
“Ready”“Running”
“Blocked”
• Simplified, but still provide analysis result
• Easy to analyze performance
• No issue of voluntary/involuntary sharing
Preemption or voluntary yield

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-33
Copyright © 2004 Pearson Education, Inc.
Estimating CPU Utilization
ReadyList
ReadyList SchedulerScheduler CPUCPU DoneNew
Process
System pi per second
Each pi uses 1/ units ofthe CPU
Let = the average rate at which processes are placed in the Ready List, arrival rate
Let = the average service rate 1/ = the average (pi)

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-34
Copyright © 2004 Pearson Education, Inc.
Estimating CPU Utilization
ReadyList
ReadyList SchedulerScheduler CPUCPU DoneNew
Process
Let = the average rate at which processes are placed in the Ready List, arrival rate
Let = the average service rate 1/ = the average (pi)
Let = the fraction of the time that the CPU is expected to be busy = # pi that arrive per unit time * avg time each spends on CPU = * 1/ = /
• Notice must have < (i.e., < 1)• What if approaches 1?
Operating Systems: A Modern Perspective, Chapter 6
Slide 6-35
Copyright © 2004 Pearson Education, Inc.
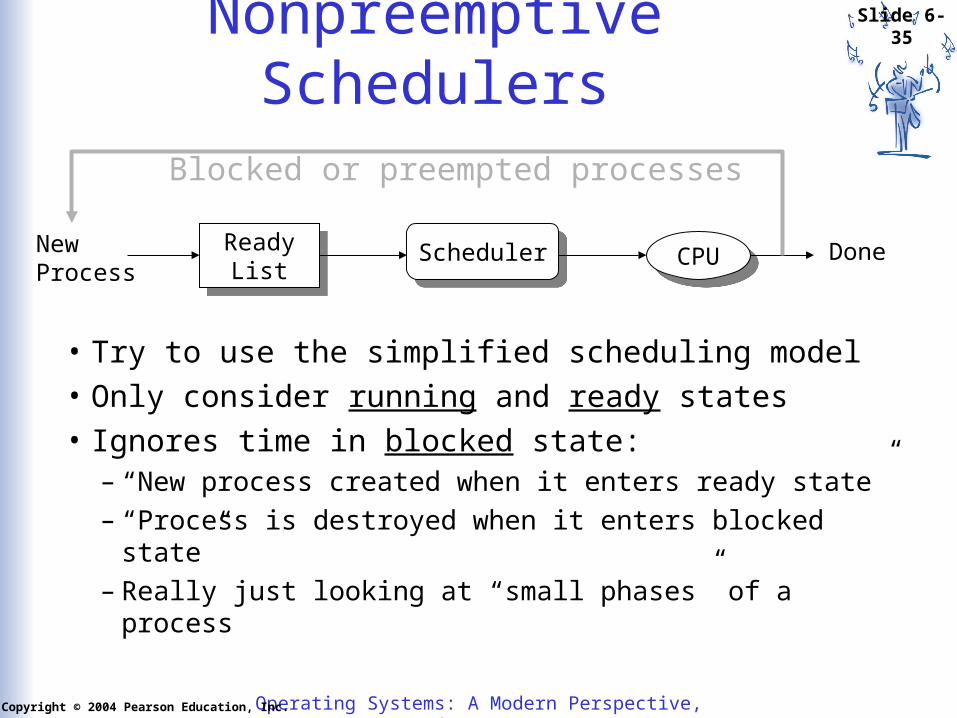
Nonpreemptive Schedulers
ReadyList
ReadyList SchedulerScheduler CPUCPU DoneNew
Process
• Try to use the simplified scheduling model
• Only consider running and ready states
• Ignores time in blocked state:– “New process created when it enters ready state”– “Process is destroyed when it enters blocked state”– Really just looking at “small phases” of a process
Blocked or preempted processes

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-36
Copyright © 2004 Pearson Education, Inc.
First-Come-First-Servedi (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p0) = (p0) = 350 W(p0) = 0
0 350

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-37
Copyright © 2004 Pearson Education, Inc.
First-Come-First-Servedi (pi)0 3501 1252 4753 2504 75
p0 p1
TTRnd(p0) = (p0) = 350TTRnd(p1) = ((p1) +TTRnd(p0)) = 125+350 = 475
W(p0) = 0W(p1) = TTRnd(p0) = 350
475350

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-38
Copyright © 2004 Pearson Education, Inc.
First-Come-First-Servedi (pi)0 3501 1252 4753 2504 75
p0 p1 p2
TTRnd(p0) = (p0) = 350TTRnd(p1) = ((p1) +TTRnd(p0)) = 125+350 = 475TTRnd(p2) = ((p2) +TTRnd(p1)) = 475+475 = 950
W(p0) = 0W(p1) = TTRnd(p0) = 350W(p2) = TTRnd(p1) = 475
475 950

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-39
Copyright © 2004 Pearson Education, Inc.
First-Come-First-Servedi (pi)0 3501 1252 4753 2504 75
p0 p1 p2 p3
TTRnd(p0) = (p0) = 350TTRnd(p1) = ((p1) +TTRnd(p0)) = 125+350 = 475TTRnd(p2) = ((p2) +TTRnd(p1)) = 475+475 = 950TTRnd(p3) = ((p3) +TTRnd(p2)) = 250+950 = 1200
W(p0) = 0W(p1) = TTRnd(p0) = 350W(p2) = TTRnd(p1) = 475W(p3) = TTRnd(p2) = 950
1200950

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-40
Copyright © 2004 Pearson Education, Inc.
First-Come-First-Servedi (pi)0 3501 1252 4753 2504 75
p0 p1 p2 p3 p4
TTRnd(p0) = (p0) = 350TTRnd(p1) = ((p1) +TTRnd(p0)) = 125+350 = 475TTRnd(p2) = ((p2) +TTRnd(p1)) = 475+475 = 950TTRnd(p3) = ((p3) +TTRnd(p2)) = 250+950 = 1200TTRnd(p4) = ((p4) +TTRnd(p3)) = 75+1200 = 1275
W(p0) = 0W(p1) = TTRnd(p0) = 350W(p2) = TTRnd(p1) = 475W(p3) = TTRnd(p2) = 950W(p4) = TTRnd(p3) = 1200
1200 1275

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-41
Copyright © 2004 Pearson Education, Inc.
FCFS Average Wait Time
i (pi)0 3501 1252 4753 2504 75
p0 p1 p2 p3 p4
TTRnd(p0) = (p0) = 350TTRnd(p1) = ((p1) +TTRnd(p0)) = 125+350 = 475TTRnd(p2) = ((p2) +TTRnd(p1)) = 475+475 = 950TTRnd(p3) = ((p3) +TTRnd(p2)) = 250+950 = 1200TTRnd(p4) = ((p4) +TTRnd(p3)) = 75+1200 = 1275
W(p0) = 0W(p1) = TTRnd(p0) = 350W(p2) = TTRnd(p1) = 475W(p3) = TTRnd(p2) = 950W(p4) = TTRnd(p3) = 1200
Wavg = (0+350+475+950+1200)/5 = 2974/5 = 595
127512009004753500
•Easy to implement•Ignores service time, etc•Not a great performer

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-42
Copyright © 2004 Pearson Education, Inc.
Predicting Wait Time in FCFS
• In FCFS, when a process arrives, all in ready list will be processed before this job
• Let be the service rate
• Let L be the ready list length
• Wavg(p) = L*1/1/L
• Compare predicted wait with actual in earlier examples

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-43
Copyright © 2004 Pearson Education, Inc.
Shortest Job Nexti (pi)0 3501 1252 4753 2504 75
p4
TTRnd(p4) = (p4) = 75 W(p4) = 0
750

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-44
Copyright © 2004 Pearson Education, Inc.
Shortest Job Nexti (pi)0 3501 1252 4753 2504 75
p1p4
TTRnd(p1) = (p1)+(p4) = 125+75 = 200
TTRnd(p4) = (p4) = 75
W(p1) = 75
W(p4) = 0
200750

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-45
Copyright © 2004 Pearson Education, Inc.
Shortest Job Nexti (pi)0 3501 1252 4753 2504 75
p1 p3p4
TTRnd(p1) = (p1)+(p4) = 125+75 = 200
TTRnd(p3) = (p3)+(p1)+(p4) = 250+125+75 = 450TTRnd(p4) = (p4) = 75
W(p1) = 75
W(p3) = 200W(p4) = 0
450200750

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-46
Copyright © 2004 Pearson Education, Inc.
Shortest Job Nexti (pi)0 3501 1252 4753 2504 75
p0p1 p3p4
TTRnd(p0) = (p0)+(p3)+(p1)+(p4) = 350+250+125+75 = 800TTRnd(p1) = (p1)+(p4) = 125+75 = 200
TTRnd(p3) = (p3)+(p1)+(p4) = 250+125+75 = 450TTRnd(p4) = (p4) = 75
W(p0) = 450W(p1) = 75
W(p3) = 200W(p4) = 0
800450200750

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-47
Copyright © 2004 Pearson Education, Inc.
Shortest Job Nexti (pi)0 3501 1252 4753 2504 75
p0p1 p2p3p4
TTRnd(p0) = (p0)+(p3)+(p1)+(p4) = 350+250+125+75 = 800TTRnd(p1) = (p1)+(p4) = 125+75 = 200TTRnd(p2) = (p2)+(p0)+(p3)+(p1)+(p4) = 475+350+250+125+75 = 1275TTRnd(p3) = (p3)+(p1)+(p4) = 250+125+75 = 450TTRnd(p4) = (p4) = 75
W(p0) = 450W(p1) = 75W(p2) = 800
W(p3) = 200W(p4) = 0
1275800450200750

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-48
Copyright © 2004 Pearson Education, Inc.
Shortest Job Nexti (pi)0 3501 1252 4753 2504 75
p0p1 p2p3p4
TTRnd(p0) = (p0)+(p3)+(p1)+(p4) = 350+250+125+75 = 800TTRnd(p1) = (p1)+(p4) = 125+75 = 200TTRnd(p2) = (p2)+(p0)+(p3)+(p1)+(p4) = 475+350+250+125+75 = 1275TTRnd(p3) = (p3)+(p1)+(p4) = 250+125+75 = 450TTRnd(p4) = (p4) = 75
W(p0) = 450W(p1) = 75W(p2) = 800
W(p3) = 200W(p4) = 0
Wavg = (450+75+800+200+0)/5 = 1525/5 = 305
1275800450200750
•Minimizes wait time•May starve large jobs•Must know service times

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-49
Copyright © 2004 Pearson Education, Inc.
Priority Schedulingi (pi) Pri0 350 51 125 22 475 33 250 14 75 4
p0p1 p2p3 p4
TTRnd(p0) = (p0)+(p4)+(p2)+(p1) )+(p3) = 350+75+475+125+250 = 1275TTRnd(p1) = (p1)+(p3) = 125+250 = 375TTRnd(p2) = (p2)+(p1)+(p3) = 475+125+250 = 850TTRnd(p3) = (p3) = 250TTRnd(p4) = (p4)+ (p2)+ (p1)+(p3) = 75+475+125+250 = 925
W(p0) = 925W(p1) = 250W(p2) = 375
W(p3) = 0W(p4) = 850
Wavg = (925+250+375+0+850)/5 = 2400/5 = 480
12759258503752500
•Reflects importance of external use•May cause starvation•Can address starvation with aging

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-50
Copyright © 2004 Pearson Education, Inc.
Deadline Schedulingi (pi) Deadline0 350 5751 125 5502 475 10503 250 (none)4 75 200
p0p1 p2 p3p4
12751050550200
0
•Allocates service by deadline•May not be feasible
p0p1 p2 p3p4
p0 p1 p2 p3p4
575

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-51
Copyright © 2004 Pearson Education, Inc.
Preemptive Schedulers
ReadyList
ReadyList SchedulerScheduler CPUCPU
Preemption or voluntary yield
DoneNewProcess
• Highest priority process is guaranteed to be running at all times– Or at least at the beginning of a time slice
• Dominant form of contemporary scheduling
• But complex to build & analyze

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-52
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
W(p0) = 0
0 50

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-53
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
W(p0) = 0W(p1) = 50
1000p1

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-54
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
W(p0) = 0W(p1) = 50W(p2) = 100
1000p2p1

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-55
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150
2001000p3p2p1

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-56
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
2001000p4p3p2p1

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-57
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
3002001000p0p4p3p2p1

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-58
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p4) =
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
4754003002001000p4p0p4p3p2p1 p1 p2 p3

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-59
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p1) =
TTRnd(p4) =
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
4754003002001000p4 p1p0p4p3p2p1 p1 p2 p3 p0
550

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-60
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p1) =
TTRnd(p3) = TTRnd(p4) =
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
4754003002001000p4 p1p0p4p3p2p1 p1 p2 p3 p0 p3p2
p0 p3p2 p0 p3p2
550 650
650 750 850 950

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-61
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p0) = TTRnd(p1) =
TTRnd(p3) = TTRnd(p4) =
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
4754003002001000p4 p1p0p4p3p2p1 p1 p2 p3 p0 p3p2
p0 p3p2 p0 p3p2 p0 p2 p0
550 650
650 750 850 950 1050

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-62
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p0) = TTRnd(p1) = TTRnd(p2) = TTRnd(p3) = TTRnd(p4) =
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
4754003002001000p4 p1p0p4p3p2p1 p1 p2 p3 p0 p3p2
p0 p3p2 p0 p3p2 p0 p2 p0 p2 p2 p2 p2
550 650
650 750 850 950 1050 1150 1250 1275

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-63
Copyright © 2004 Pearson Education, Inc.
Round Robin (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p0) = TTRnd(p1) = TTRnd(p2) = TTRnd(p3) = TTRnd(p4) =
W(p0) = 0W(p1) = 50W(p2) = 100W(p3) = 150W(p4) = 200
Wavg = (0+50+100+150+200)/5 = 500/5 = 100
4754003002001000
•Equitable•Most widely-used•Fits naturally with interval timer
p4 p1p0p4p3p2p1 p1 p2 p3 p0 p3p2
p0 p3p2 p0 p3p2 p0 p2 p0 p2 p2 p2 p2
550 650
650 750 850 950 1050 1150 1250 1275
TTRnd_avg = (1100+550+1275+950+475)/5 = 4350/5 = 870

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-64
Copyright © 2004 Pearson Education, Inc.
RR with Overhead=10 (TQ=50)i (pi)0 3501 1252 4753 2504 75
p0
TTRnd(p0) = TTRnd(p1) = TTRnd(p2) = TTRnd(p3) = TTRnd(p4) =
W(p0) = 0W(p1) = 60W(p2) = 120W(p3) = 180W(p4) = 240
Wavg = (0+60+120+180+240)/5 = 600/5 = 120
5404803602401200
•Overhead must be considered
p4 p1p0p4p3p2p1 p1 p2 p3 p0 p3p2
p0 p3p2 p0 p3p2 p0 p2 p0 p2 p2 p2 p2
575 790
910 1030 1150 1270 1390 1510 1535
TTRnd_avg = (1320+660+1535+1140+565)/5 = 5220/5 = 1044
635 670
790

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-65
Copyright © 2004 Pearson Education, Inc.
Multi-Level Queues
Ready List0Ready List0
Ready List1Ready List1
Ready List2Ready List2
Ready List3Ready List3
SchedulerScheduler CPUCPU
Preemption or voluntary yield
DoneNewProcess
•All processes at level i run before any process at level j•At a level, use another policy, e.g. RR

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-66
Copyright © 2004 Pearson Education, Inc.
Contemporary Scheduling• Involuntary CPU sharing -- timer interrupts
– Time quantum determined by interval timer -- usually fixed for every process using the system
– Sometimes called the time slice length
• Priority-based process (job) selection– Select the highest priority process– Priority reflects policy
• With preemption
• Usually a variant of Multi-Level Queues

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-67
Copyright © 2004 Pearson Education, Inc.
BSD 4.4 Scheduling
• Involuntary CPU Sharing
• Preemptive algorithms
• 32 Multi-Level Queues– Queues 0-7 are reserved for system functions– Queues 8-31 are for user space functions– nice influences (but does not dictate) queue
level

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-68
Copyright © 2004 Pearson Education, Inc.
Windows NT/2K Scheduling
• Involuntary CPU Sharing across threads
• Preemptive algorithms
• 32 Multi-Level Queues– Highest 16 levels are “real-time”– Next lower 15 are for system/user threads
• Range determined by process base priority
– Lowest level is for the idle thread

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-69
Copyright © 2004 Pearson Education, Inc.
Bank Teller Simulation
Tellers at the Bank
T1T1
T2T2
TnTn
…
Model of Tellers at the Bank
Cus
tom
ers
Arr
ival
s

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-70
Copyright © 2004 Pearson Education, Inc.
Simulation Kernel Loop
simulated_time = 0;while (true) {
event = select_next_event();if (event->time > simulated_time)
simulated_time = event->time;evaluate(event->function, …);
}

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-71
Copyright © 2004 Pearson Education, Inc.
Simulation Kernel Loop(2)void runKernel(int quitTime){ Event *thisEvent; // Stop by running to elapsed time, or by causing quit execute if(quitTime <= 0) quitTime = 9999999; simTime = 0; while(simTime < quitTime) { // Get the next event if(eventList == NIL) { // No more events to process break; } thisEvent = eventList; eventList = thisEvent->next; simTime = thisEvent->getTime(); // Set the time // Execute this event thisEvent->fire(); delete(thisEvent); };}

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-72
Copyright © 2004 Pearson Education, Inc.

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-73
Copyright © 2004 Pearson Education, Inc.
Simple State Diagram
ReadyBlocked
Running
Start
Schedule
Request
Done
Request
Allocate

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-74
Copyright © 2004 Pearson Education, Inc.
UNIX State Transition Diagram
Runnable
UninterruptibleSleep
Running
Start
Schedule
Request
Done
I/O Request
Allocate
zombie
Wait byparent
Sleeping
Traced or Stopped
Request
I/O Complete Resume

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-75
Copyright © 2004 Pearson Education, Inc.
Windows NT Thread States
Initialized
CreateThread
Ready
Activate
Sele
ct
Standby
Running
Terminated
Waiting
Transition
Reinitialize
Exit
Pre
empt
Dispatch
WaitWait Complete
Wait Complete
Dispatch

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-76
Copyright © 2004 Pearson Education, Inc.
Resources
R = {Rj | 0 j < m} = resource typesC = {cj 0 | RjR (0 j < m)} = units of Rj available
Reusable resource: After a unit of the resource has been allocated, it must ultimately be released back to the system. E.g., CPU, primary memory, disk space, … The maximum value for cj is the number of units of that resource
Consumable resource: There is no need to release a resource after it has been acquired. E.g., a message, input data, … Notice that cj is unbounded.
Resource: Anything that a process can request, then be blocked because that thing is not available.
Operating Systems: A Modern Perspective, Chapter 6
Slide 6-77
Copyright © 2004 Pearson Education, Inc.
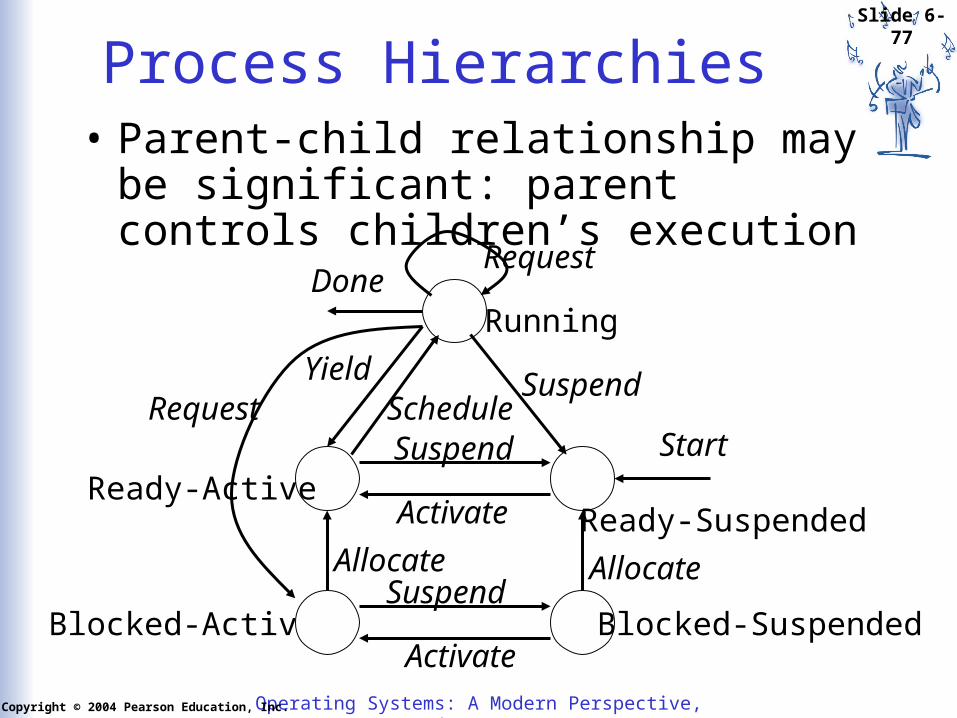
Process Hierarchies• Parent-child relationship may be significant:
parent controls children’s execution
Ready-Active
Blocked-Active
Running
StartSchedule
RequestDone
Request
AllocateReady-Suspended
Blocked-Suspended
SuspendYield
AllocateSuspend
Suspend
Activate
Activate

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-78
Copyright © 2004 Pearson Education, Inc.
UNIX Organization
System Call InterfaceSystem Call Interface
FileManager
MemoryManager
DeviceManager
ProtectionProtectionDeadlockDeadlock
SynchronizationSynchronization
ProcessDescription
ProcessDescription
CPUCPU Other H/WOther H/W
SchedulerScheduler ResourceManager
ResourceManagerResource
Manager
ResourceManagerResource
Manager
ResourceManager
MemoryMemoryDevicesDevices
LibrariesLibraries ProcessProcess
ProcessProcess
ProcessProcess
Monolithic Kernel

Operating Systems: A Modern Perspective, Chapter 6
Slide 6-79
Copyright © 2004 Pearson Education, Inc.
Windows NT Organization
Processor(s) Main Memory Devices
LibrariesLibraries
ProcessProcess
ProcessProcess
ProcessProcess
SubsystemSubsystemUser
SubsystemSubsystem SubsystemSubsystem
Hardware Abstraction LayerHardware Abstraction LayerNT Kernel
NT ExecutiveI/O SubsystemI/O Subsystem
TT
TT
TT T T
T