tibco accelerator for apache spark quick start · document tibco accelerator for apache spark –...
TRANSCRIPT

t
t
p
:
/
/
w
w
w
.
t
i
b
c
o
.
c
o
m
TIBCO Accelerator for Apache
Spark
Quick Start
23 August 2016
Version 1.0.0
This document outlines basic tasks required to get up and running using the
TIBCO Accelerator for Apache Spark
Document
TIBCO Accelerator for Apache Spark – Quick Start 2
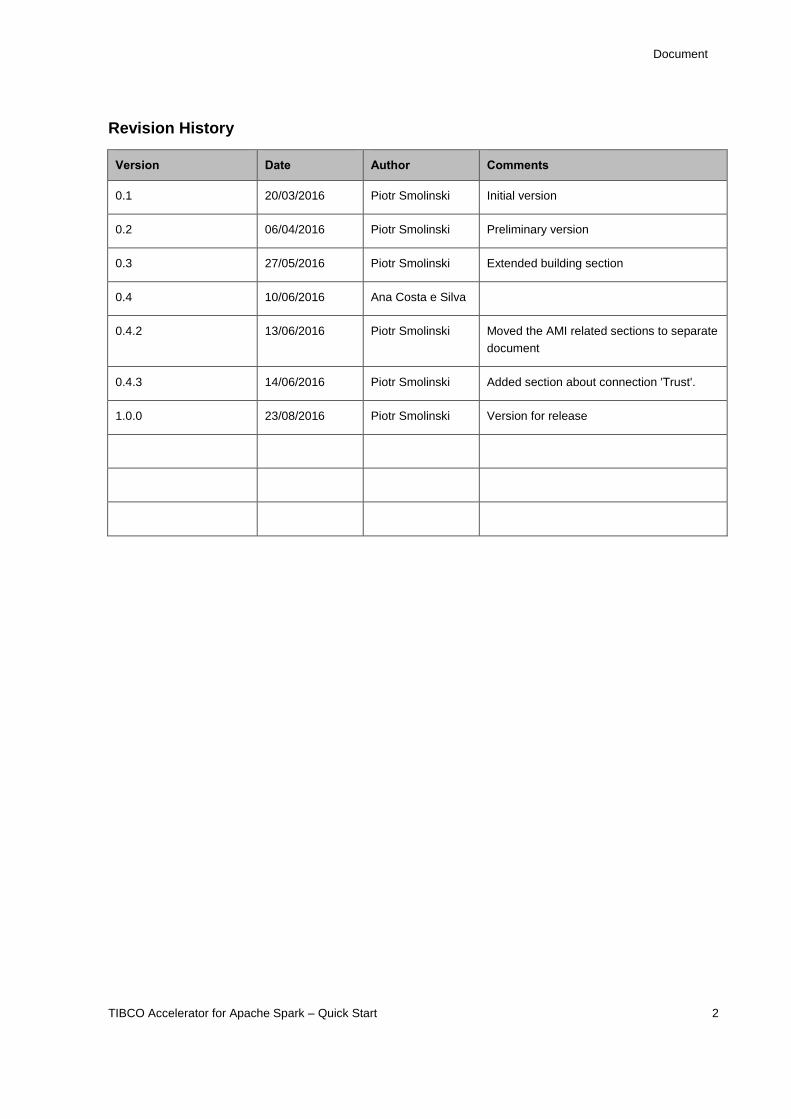
Revision History
Version Date Author Comments
0.1 20/03/2016 Piotr Smolinski Initial version
0.2 06/04/2016 Piotr Smolinski Preliminary version
0.3 27/05/2016 Piotr Smolinski Extended building section
0.4 10/06/2016 Ana Costa e Silva
0.4.2 13/06/2016 Piotr Smolinski Moved the AMI related sections to separate
document
0.4.3 14/06/2016 Piotr Smolinski Added section about connection 'Trust'.
1.0.0 23/08/2016 Piotr Smolinski Version for release

Document
TIBCO Accelerator for Apache Spark – Quick Start 3
Copyright Notice
COPYRIGHT© 2016 TIBCO Software Inc. This document is unpublished and the foregoing notice is
affixed to protect TIBCO Software Inc. in the event of inadvertent publication. All rights reserved. No
part of this document may be reproduced in any form, including photocopying or transmission
electronically to any computer, without prior written consent of TIBCO Software Inc. The information
contained in this document is confidential and proprietary to TIBCO Software Inc. and may not be used
or disclosed except as expressly authorized in writing by TIBCO Software Inc. Copyright protection
includes material generated from our software programs displayed on the screen, such as icons, screen
displays, and the like.
Trademarks
Technologies described herein are either covered by existing patents or patent applications are in
progress. All brand and product names are trademarks or registered trademarks of their respective
holders and are hereby acknowledged.
Confidentiality
The information in this document is subject to change without notice. This document contains
information that is confidential and proprietary to TIBCO Software Inc. and may not be copied,
published, or disclosed to others, or used for any purposes other than review, without written
authorization of an officer of TIBCO Software Inc. Submission of this document does not represent a
commitment to implement any portion of this specification in the products of the submitters.
Content Warranty
The information in this document is subject to change without notice. THIS DOCUMENT IS PROVIDED
"AS IS" AND TIBCO MAKES NO WARRANTY, EXPRESS, IMPLIED, OR STATUTORY, INCLUDING
BUT NOT LIMITED TO ALL WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A
PARTICULAR PURPOSE. TIBCO Software Inc. shall not be liable for errors contained herein or for
incidental or consequential damages in connection with the furnishing, performance or use of this
material.
For more information, please contact:
TIBCO Software Inc.
3303 Hillview Avenue
Palo Alto, CA 94304
USA

Document
TIBCO Accelerator for Apache Spark – Quick Start 4
Table of Contents
TABLE OF CONTENTS 4
TABLE OF FIGURES 7
TABLE OF TABLES 9
1 101.1 111.2
111.3 112
112.1 122.2
122.3 132.4
143 143.1
153.2 163.2.1
163.2.2 163.2.3
163.2.4 173.3
173.4 183.5
183.6 183.7
193.8 193.9
203.10 213.10.1
213.10.2 223.11
223.12 224
234.1 244.2
244.3 254.4
254.5 264.6
265 285.1
295.1.1 295.2
295.3 305.4
305.5 315.5.1
315.5.2 325.5.3
335.5.4 335.5.5
345.5.6 355.5.7
355.6 365.6.1
365.6.2 375.6.3
385.6.4 395.6.5
405.7 415.7.1
415.7.2 426
446.1 456.1.1
456.1.2 466.1.3
466.1.4 466.1.5
466.2 466.2.1
466.2.2 476.2.3
476.2.4 476.2.5
476.2.6 476.2.7
477 487.1
497.2 497.3
497.4 507.5

Document
TIBCO Accelerator for Apache Spark – Quick Start 5
517.5.1 517.5.2
51

Document
TIBCO Accelerator for Apache Spark – Quick Start 6
Table of Figures
Figure 1: Accelerator Component Diagram 13
Figure 2: TSSS address setting 23
Figure 3: Parameters for HTTP and HDFS 24
Figure 4: Sample warning about Spark SQL custom table 24
Figure 5: IronPython scripts warning 24
Figure 6: IronPython scripts trust dialog 25
Figure 7: Spark SQL data connection properties 25
Figure 8: Spark SQL custom queries 26
Figure 9: Spark SQL custom query enabling 26
Figure 10: Current traffic dashboard in LiveView Web 28
Figure 11: Avro data in transit 28
Figure 12: Target Parquet files 29
Figure 13: Totals 30
Figure 14: Drill-down 30
Figure 15: Categories 31
Figure 16: Basket analysis 32
Figure 17: Cross/Up-sell 32
Figure 18: Geographically 33
Figure 19: Play Page 34
Figure 20: Predictors and responses 35
Figure 21: Training in Spark 36
Figure 22: Evaluate model quality 37
Figure 23: Variable importance 38
Figure 24: Custom threshold 39
Figure 25: Bundle models into campaigns 40
Figure 26: Launch campaigns 41
Figure 27: empty.txt deployed 41
Figure 28: models-b.txt deployed 42
Figure 29: models-c.txt deployed 42

Document
TIBCO Accelerator for Apache Spark – Quick Start 7

Document
TIBCO Accelerator for Apache Spark – Quick Start 8
Table of Tables
Table 1: Open source software 47
Table 2: TIBCO products 48
Table 3: Java Components 48
Table 4: Windows environment variables 49
Table 5: Linux environment variables 49

Document
TIBCO Accelerator for Apache Spark – Quick Start 9

Document
TIBCO Accelerator for Apache Spark – Quick Start 10
1 Preface
1.1 Purpose of Document
This document provides brief description of concepts and launching the TIBCO Accelerator for Apache
Spark. It discusses the signature demo.
1.2 Scope
This document outlines the following:
● Required software
● Installation requirements
● Post-install steps
● Running the demo
● Using the simulator
● Recommended demo scripts
1.3 Referenced Documents
Document Reference
TIBCO Accelerator for Apache Spark Functional
Specification

Document
TIBCO Accelerator for Apache Spark – Quick Start 11
2 Overview
2.1 Business Scenario
With growth of Big Data solutions there is more and more need to use solutions focused on scalability.
The traditional Big Data assumes the data already exists and needs to be processed. This approach is
called Data at Rest.
The event processing aspects, both Complex Event Processing and Event Stream Processing, are
inherently related to the message passing called Data in Motion.
Passing quickly small amounts of data raises challenges significantly different from the typical problems
solved by massive data processing platforms. The popular Big Data solutions like Hadoop are optimized
to defer the data movement to the latest possible time and to execute most of the logic in where the
data is stored. It significantly increases data processing throughput, but at the same time reduces data
mobility.
The approach where the collected data is analysed and visualised brings vital information to the
decision makers. The process is typically based on historical data that leads to decision being made on
potentially stale data. At the same time the results of the past data processing require significant human
processing like implementation and deployment of decision rules. This adds further delay and increases
operational cost.
Contemporary enterprises expect to be able:
● To act on the fire hose of incoming events
● Execute analytics on the data as soon as it arrives
● Deploy the predictive models with minimal operational latency
TIBCO is a real time integration solutions vendor and provides proven solutions for event
processing. The Big Data solutions generate special challenges for event processing:
● Horizontally scalability for moving data
● Analytics friendly storage of the data
● Native support for execution of analytics models
The Big Data accelerator uses large retailer transaction monitoring and propensity prediction
scenario to show how these challenges can be addresses with mix of TIBCO and open source
products.
2.2 Benefits and Business Value
The Big Data accelerator offers an easy to use interface for business experts to analyse Spark data and
produce predictive models that allow them to identify the clients that are more likely to be interested in a
specific product, so we can make targeted offers. Models regarding different products are then
combined by them into campaigns, which are launched in real time at the click of a button. Any Spark
complexity is efficiently handled behind the scenes, allowing the drivers of the solution to focus on

Document
TIBCO Accelerator for Apache Spark – Quick Start 12
business rather than nuts and bolts. Furthermore, the set up can be adapted to diverse use cases that
require real time action. This is because the models learn from the data they receive and specialise in
learning to distinguish one type of observations from the rest. For example, we can train them to
distinguish fraudulent from non-fraudulent transactions, claims that an insurer should pay immediately
from those that require further analysis, sensor readings that indicate an industrial equipment is likely to
break from those that indicate the environment is safe, crowd monitoring moments that require an
intervention from those that are under control as is).
The key for real time deployment is speed. Contrary to most popular solutions, TIBCO products offer
real time integration and reporting.
The Big Data accelerator shows an easy way to combine Fast Data with Big Data. With the proper
approach the delay between data collection and analytics availability can be significantly reduced
leading to faster trend detection and not just timely but also better decisions.
At the same time, the combination of event processing products and live data mart executes vital
performance indicators computation in the real time and exposes them immediately to operational
teams. Accurate real-time indicators, like anomaly detection or less than optimal model predictions, can
be handled by automated processes to mitigate losses and increase profit.
At micro scale timely tracking customer behaviour combined with statistical models derived from
massive data increases ability to hit the opportunity window.
The proposed solution grows with business. It is inherently scalable while it still retains real-time
intelligence.
2.3 Technical Scenario
The Accelerator combines TIBCO portfolio with open source solutions. It demonstrates ability to convert
the Fast Data to Big Data (or Data in Motion to Data at Rest).
The example retailer has large number of stores and POS terminals. The whole traffic is handled by the
centralized solution. The transaction information with attached customer identification (loyalty card) is
delivered using Apache Kafka message bus. Kafka is an extremely horizontally scalable messaging
solution. The advantage over TIBCO EMS is that it can be natively scaled out and in depending on the
workload.
The messages are processed by the event processing layer implemented with TIBCO StreamBase
CEP. The events are enriched with customer history kept in Apache HBase. HBase is another
horizontally scalable solution. It is a column-oriented datastore with primary access by unique key. Its
design allows achieving a constant-cost access to the customer data within a millisecond-range latency.
HBase, in the proposed solution, keeps customer transaction history. It provides lock-free constant-cost
access for both reading past transactions and appending new ones.
The StreamBase application also does transaction data enrichment by identifying categories for each
purchased item. The categorized transactions are used to build a customer numerical profile that is in
turn processed by statistical models. As a result, customer propensity to accept each of actual offers is
evaluated. The offer with best score is sent back to the POS.
On the server side the categorized transaction information is retained to track sales performance and
react on changing trends.

Document
TIBCO Accelerator for Apache Spark – Quick Start 13
The transaction information accompanied with the offer sent to the customer is passed to the data
analytics store in HDFS. HDFS is key component of Hadoop. It is distributed filesystem optimized to
reliably store and process huge amounts of data. The HDFS is good at storing data at rest, but it
performs poorly when the data is still moving. In particular, the reliable writes of small chunks of data to
HDFS are too slow to be directly used in event processing applications.
To store data efficiently in HDFS, the accelerator uses a staging approach. First, the data is sent to the
Flume component. Flume aggregates data in batches and stores them in append-friendly Avro format.
In order to improve the data access for analytics tasks, Spark is used to convert Avro files to analytics-
friendly Parquet format in ETL process.
The data stored in the HDFS cluster is used for customer behaviour modelling. TIBCO’s Spotfire
component coordinates data visualisation, model training and deployment. Spotfire communicates with
Spark to aggregate the data and to process the data for model training. The actual data access and
transformation is performed by the Apache Spark component. The models are built with H2O. H2O is
an open source data analytics solution designed for distributed model processing.
With Spotfire, the business expert orchestrates model creation and submits the best models for hot-
deployment. To do that Spotfire communicates with the Zookeeper component, which keeps the
runtime configuration settings and passes the changes to all active instances of StreamBase, which
closes the processing loop.
2.4 Components
Figure 1: Accelerator Component Diagram

Document
TIBCO Accelerator for Apache Spark – Quick Start 14
3 Building the accelerator
Now, you have downloaded the accelerator source code from its homepage:
https://community.tibco.com/wiki/accelerator-apache-spark
Obviously the accelerator needs to be executed in the wider context. This includes cluster integration.
This section describes how to compile and deploy the accelerator components. Here are the
prerequisities:
● TIBCO StreamBase 7.6.3
● TIBCO Spotfire 7.5.0
o Apache Spark SQL adapter (Spotfire Connectors component)
o Apache Spark ODBC driver (Spotfire Drivers component)
● Apache Spark (tested with 1.5.2)
● Apache Kafka (tested with 0.9.0.1)
● Apache Hadoop (tested with 2.7.2)
● Apache HBase (tested with 1.2.0)
● Apache Flume (tested with 1.6.0)
● Apache Zookeeper (tested with 3.4.8)
● Apache Maven (3.3.x, the development environment used 3.3.3)
The components in the project are of the following flavors:
● Java libraries - generally built with maven
o core spark library and REST endpoint
o Flume extension
o Zookeeper utilities
● StreamBase applications - executed directly with sbd or lv-server
o event processor
o dashboard
o simulator
● Spotfire visualization - DXP file to be open in Spotfire
3.1 Building the java and streambase libraries
The java libraries are built with basic maven command:

Document
TIBCO Accelerator for Apache Spark – Quick Start 15
mvn clean package
Once the project is built, the result artifacts are available in the target directories inside each subproject.
3.2 Preparing the HDFS
The accelerator uses HDFS to:
● store the data for analytics (Parquet)
● store the events on the way to data (Avro)
● maintain reference data (model features and products catalogue)
● maintain the raw models and models metadata
All the paths must be accessible and writable by the user running the accelerator.
The accelerator assumes that the HDFS is configured and accessible from the machine running the
code.
3.2.1 Data prepared for analytics
The default location:
hdfs://demo.sample/apps/demo/transactions
The directory is created by the ETL job executed by the Spark component. In the preparation step make
sure the directory can be created.
3.2.2 Event log
The default location:
hdfs://demo.sample/apps/demo/transactionsLog
This directory is filled by Flume. The requirement is that the user running Flume must be able to write to
this directory and the user running Spark must be able to read the files. Spark reads the Avro files and
in the ETL job it creates the Parquet structure.
3.2.3 Reference data
The event processing application and Spark server require some shared reference data. The two tables
are products (product to category mapping) and features (list of model input features). These tables
have to be uploaded to HDFS and they must be readable by both StreamBase and Spark applications.
hdfs://demo.sample/apps/demo/config/products.txt
hdfs://demo.sample/apps/demo/config/features.txt
The files are available in the simulator project:
spark-demo-simulator/src/main/python/products.txt
spark-demo-simulator/src/main/python/features.txt
Use "hadoop fs -put" command to upload them to HDFS and make sure that they are available to the
user running StreamBase and Spark.
Example:

Document
TIBCO Accelerator for Apache Spark – Quick Start 16
hadoop fs -put -f products.txt hdfs://demo.sample/apps/demo/config/products.txt
hadoop fs -put -f features.txt hdfs://demo.sample/apps/demo/config/features.txt
3.2.4 Models and model metadata
The models are also deployed in HDFS. The reason is that HDFS provides a shared location for all
components within the accelerator. Spotfire uses shell scripts via TSSS to access the shared directory
and directs Spark to store the model generation results. StreamBase reads model metadata files from
the configured location and then loads the model POJOs.
The default root directory for model management is:
hdfs://demo.sample/apps/demo/models
The directory contains several subdirectories:
● results - model training job results; for each model training job there is tab-separated text file
containing information line for each generated models
● pojo - generated H2O POJO classes; the directory contains subdirectory for each model
training job
● roc - directory stores ROC points generated by H2O for each training job
● varimp - variable importance scores obtained from model training jobs
● sets - directory containing model metadata as tab-separated files describing deployable model
and its parameters
The results, pojo, roc and varimp are written by Spark application as result of the model training. The
sets directory is populated by Spotfire using system scripts launched by TSSS.
3.3 Preparing the HBase
HBase provides in the accelerator a convenient place to store customer's history. HBase is used solely
by event processing StreamBase application.
Before the StreamBase application is started, the table has to be created in the provided HBase cluster.
In order to do that launch the HBase shell (use your local credentials):
$HBASE_HOME/bin/hbase shell
Once connected to the master server create the table Customers with single column family
Transactions that keeps the update history up to some reasonable limit (200 in our case):
create 'Customers', { NAME => "Transactions", VERSIONS => 200 }
The created table can be erased/truncated by running the command:
truncate 'Customers'
The list of created tables can be obtained using "list" command and the information about the table
configuration can be queried using "describe 'Customers'" command,

Document
TIBCO Accelerator for Apache Spark – Quick Start 17
3.4 Preparing the Kafka topics
The accelerator uses three topics to pass the messages:
● Transactions - entry topic passing incoming transactions
● Notifications - response messages; this is default topic, the requestor may override the target
destination
● ToFlume - topic to pass the messages from StreamBase to Flume; the accelerator does not use
the Flume adapter directly in order to guarantee the data delivery to HDFS
The topics have to be created before the StreamBase application and Flume agent are started. For
simplicity in the demo all the topics are created with 3 partitions, but with only one replica as the simple
installation uses only one broker.
In order to list all the defined topics use the following command:
$KAFKA_HOME/bin/kafka-topics.sh \
--zookeeper localhost \
--list
The command user to create topic:
$KAFKA_HOME/bin/kafka-topics.sh \
--zookeeper localhost \
--create \
--topic Transactions \
--replication-factor 1 \
--partitions 3
All other topics (Notifications and ToFlume) were created with similar command.
3.5 Deploying the Flume agent
The Flume component reads the JSON messages produced by StreamBase event processing
application and writes them as Avro to HDFS. The Flume agent requires agent configuration file (flume-
conf.properties) and Avro schema (predictions.avsc).
The java extension provides generic code that converts the incoming JSON messages to Avro binary
format compliant with provided schema.
In order to deploy the Flume agent, copy flume-conf.properties and predictions.avsc to the Flume
configuration directory ($FLUME_HOME/conf). The spark-demo-flume.jar file should be copied to
$FLUME_HOME/lib directory.
In order to launch the Flume agent use the following command:
$FLUME_HOME/bin/flume-ng \
agent \
--name demo \
--conf $FLUME_HOME/conf \
-f $FLUME_HOME/conf/flume-conf.properties
3.6 Configuring Zookeeper
The java part for the Zookeeper is small utility allowing to access Zookeeper ensemble from the shell

Document
TIBCO Accelerator for Apache Spark – Quick Start 18
scripts. The existing zkCli.sh command is a wrapper around the text console. As such it is focused on
interactivity and not composability. As such it for example does not allow for empty or multiline z-node
content. To avoid that, two commands were created that handle the z-node content via stdin and stdout:
ZNodeGet and ZNodeSet. Both commands assume parent nodes exist.
To add the commands, copy the spark-demo-zookeeper.jar to $ZOOKEEPER_HOME/lib and the
zkGet.sh and zkSet.sh scripts to the $ZOOKEEPER_HOME/bin directory.
The accelerator configuration is assumed to exist in demo.sample:2181/demo z-node tree. The
configuration structure should be created before the StreamBase application and Spotfire visualization
are launched.
echo -n "" | ./zkSet.sh /demo
echo -n "" | ./zkSet.sh /demo/config
echo hdfs://demo.sample/apps/demo/config/features.txt | ./zkSet.sh /demo/config/features
echo hdfs://demo.sample/apps/demo/config/products.txt | ./zkSet.sh /demo/config/products
echo -n "" | ./zkSet.sh /demo/config/h2oModel
Note: echo -n "" command sends empty string as node content. Skipping the -n switch sends line end
character at the end of the content.
3.7 Deploying the realtime dashboard
At this moment the base structure for the accelerator has been created (some Spotfire related
components will be deployed later).
The next step is launching the event processing application. The event processing application depends
on LDM dashboard availability, so the spark-demo-ldm has to be launched first.
After the project is built with Maven, the target directory contains tar.gz archive with the project. Upload
the archive to the target environment and unpack it.
Note: It is recommended to create directories /var/log/demo and /var/run/demo and grant user running
the demo write privileges. In the unpacked projects create symbolic links to these directories with
names log and run respectively. If they are not created, the launch command will create local
directories.
Important: The Dashboard requires LV Web component that has to be installed as part of the
deployment process. Copy the lvweb.war to lv-user-webapps directory.
To start the project in the bin directory execute the control script with start command
AMBDA_Dashboard.sh start
The component should start gracefully. In case of issues verify the logs in the log directory. In order to
open the dashboard, point your web browser to:
http://demo.sample:10080/lvweb
3.8 Deploying the event processing component
The event processing StreamBase component is the working horse for the Fast Data story. At the
moment it is single StreamBase process showing the product connectivity options.
The project containing the component is spark-demo-streambase. The Maven build job creates,
similarly as for the dashboard, the tar.gz archive. Upload the component to the target server and

Document
TIBCO Accelerator for Apache Spark – Quick Start 19
unpack it. Create the symbolic links to log and run directories.
To start the process in the bin directory execute the control script with start command
AMBDA_EventProcessor.sh start
The component relies on other components availability:
● Dashboard
● HBase
● Kafka
● Zookeeper
The Flume agent is decoupled. After starting the process verify the logs.
3.9 Deploying the simulator
The traffic simulator is the last StreamBase component. Similar to the Dashboard and Event Processor
it is built as archive. The subproject implementing the simulator is spark-demo-datagenerator. After
building upload the archive to the server, unpack it and make sure the log and run directories are
created
To start the process in the bin directory execute the control script with start command
AMBDA_Simulator.sh start
The component is controlled by HTTP REST-like interface exposed by Dashboard.
The access is done unix-style by reading and setting given URLs. The GET operation retrieves the
parameter value in plain text, PUT updates it. Because the control is exposed via Dashboard, it is easy
to build a HTML5 application deployed on the LDM server that displays some charts and controls the
simulation execution.
At the moment the commands are executed with CUrl tool. Below are some samples.
time compression - factor against wall clock; it tells the simulator how to advance the simulation time.
Default value is 1. To advace one hour every second use 3600:
curl http://demo.sample:10080/simulator/call/settings/timeCompression
echo 3600 | curl -XPUT -d @-
http://demo.sample:10080/simulator/call/settings/timeCompression
messages per tick - iteration count for every metronome tick. Every iteration advances the clock
uniformly by (tick interval)/(messages per tick) and the tick interval is 0.2. Default value for messages
per tick is 1 that corresponds to 5 messages per second. In order to get 200/sec use value 40.
curl http://demo.sample:10080/simulator/call/settings/messagesPerTick
echo 40 | curl -XPUT -d @- http://demo.sample:10080/simulator/call/settings/messagesPerTick
status - simulator status. Either stopped (default) or running. To start simulation set the status to
running. To suspend, set the status to stopped. Stopping and starting does not reset the clock.
curl http://demo.sample:10080/simulator/call/settings/status
echo running | curl -XPUT -d @- http://demo.sample:10080/simulator/call/settings/status
echo stopped | curl -XPUT -d @- http://demo.sample:10080/simulator/call/settings/status

Document
TIBCO Accelerator for Apache Spark – Quick Start 20
current time - simulation time, use yyyy-MM-dd HH:mm:ss.SSS format. Default value is local time
when any change was executed. This can be set to arbitrary value.
curl http://demo.sample:10080/simulator/call/settings/currentTime
echo "2014-01-01 00:00:00.000" | curl -XPUT -d @-
http://demo.sample:10080/simulator/call/settings/currentTime
The simulator is currently non-persistent. If it is restarted, it will have back time compression 1.0, 1
message per tick (5 per second) and it will be stopped. Of course no simulation/scheduling state will be
retained.
If there are no configuration issues, changing the status of the simulator to running should result in
messages going through the system. That means transaction messages should be sent to Kafka and
consumed by Event Processing.
After the messages are going through, there should be new entries showing up in HBase table, and
notification messages on the Kafka bus. The entries in LDM should be visible in LV Web Dashboard. In
the end Flume should start writing Avro messages to HDFS.
3.10 Deploying the Spark service
The spark-demo-core component provides core logic related to the Big Data story. The component is
started as REST service exposed via Jetty server. In addition it starts Hive/Thrift endpoint used by
Spark SQL connectors.
In order to deploy the service, upload the spark-demo-rest.tar.gz and unpack it. Similarly as before
create the log and run directories/symlinks.
To start the service in the bin directory execute the control script with start command
AMBDA_DataService.sh start
The initial run of the service may partially fail complaining about missing Parquet directory. This is
expected and it is Spark service responsibility to do the ETL job transforming events collected as Avro
files into Parquet formatted data. If there is already some data collected, launch the following
HTTP/REST command:
curl http://demo.sample:9060/etl
Before this command is executed, the data cannot be hosted. In order to verify all is up and running,
test the service with ranges query:
curl http://demo.sample:9060/ranges
This query should return some data known to the service.
3.10.1 Additional tables
Some reference data is needed to enrich the data available from event. The accelerator assumes this
dataset is provided externally, although it can be subject of similar process as the event data. The data
used in the accelerator is already prepared in Parquet format in file spark-demo-reference.tar.gz.
Unpack this file and upload the content to HDFS:
hadoop fs -copyFromLocal -f reference /apps/demo
Once done, there should be directory tree created:

Document
TIBCO Accelerator for Apache Spark – Quick Start 21
[demo@demo ~]$ hadoop fs -ls /apps/demo/reference
Found 3 items
drwxr-xr-x - demo supergroup 0 2016-04-20 09:46 /apps/demo/reference/customer-
demographic-info
drwxr-xr-x - demo supergroup 0 2016-04-20 09:50 /apps/demo/reference/customerId-
segments
drwxr-xr-x - demo supergroup 0 2016-04-20 09:53 /apps/demo/reference/stores
These directories need to be registered in Spark metastore. Launch beeline (from $SPARK_HOME/bin)
and connect to the running spark-demo-rest application:
/opt/java/spark-1.5.2/bin/beeline -u jdbc:hive2://localhost:10001
Next register the tables:
CREATE TABLE customer_demographic_info USING parquet OPTIONS (path
"hdfs://demo.sample/apps/demo/reference/customer-demographic-info");
CREATE TABLE customerId_segments USING parquet OPTIONS (path
"hdfs://demo.sample/apps/demo/reference/customerId-segments");
CREATE TABLE stores USING parquet OPTIONS (path
"hdfs://demo.sample/apps/demo/reference/stores");
3.10.2 Expose the transaction data
The ETL-ed transaction content is also exposed as table using Spark SQL. Once the data is available in
Avro files (can be preloaded), from the shell execute the ETL command:
curl http://demo.sample:9060/etl
After the Avro files are converted to Parquet, the table can be exposed using beeline interface. Launch
the beeline and execute the table definition script:
CREATE TABLE titems USING parquet OPTIONS (path
"hdfs://demo.sample/apps/demo/transactions");
3.11 TERR dependencies
The scripts that will be launched from Spotfire require some additional environment settings. Firstly, the
RCurl package has to be installed. In order to do that, launch TERR console. In the demo environment:
/opt/tibco/tsss-7.5/SplusServer/engines/Terr/bin/TERR
Install the RCurl package:
install.packages("RCurl")
Should the installation fail, please referrer to the TSSS knowledge base.
Secondly, the AMBDA_Scripts directory has to be deployed. Upload spark-demo-terr.tar.gz archive
and unpack it. Spotfire expects the scripts to be available in /home/demo/AMBDA_Scripts directory.
3.12 Done
At this moment the accelerator environment should be functional. It may be desirable to register init.d
scripts to launch the Simulator, Dashboard, EventProcessor and DataService automatically.

Document
TIBCO Accelerator for Apache Spark – Quick Start 22

Document
TIBCO Accelerator for Apache Spark – Quick Start 23
4 Connecting from Spotfire
Once the server components are operative, the Spotfire client side has to be configured. The Spotfire
component in the Accelerator provides example of data analytics solution including model management.
The visualization shows several possible integrations channels that can be applied between Spotfire
client and Big Data cluster:
● TSSS-side scripting with TERR and shell scripts (accessing HDFS and Zookeeper)
● HTTP calls via TERR and RCurl
● HTTP calls via IronPython
● Spark platform data access using Spark SQL Adapter
The goal was to show various approaches and evaluate their strengths and weak points.
In order to access the server, the following ports must be available on the server platform:
● TSSS (default: 8080)
● custom HTTP endpoint for Spark (9060)
● Spark SQL Thrift endpoint (10001)
The visualization requires Spotfire Analyst 7.5.0 with Spotfire Connectors 4.5.0 (provides Spark SQL
Adapter) and Spotfire Drivers 1.1.0 (provides Spark SQL ODBC driver).
4.1 General settings (mandatory)
The visualization addresses the server components using symbolic name demo.sample. It is
recommended to add the public IP of the provisioned server environment to the hosts file. In order to
do that, edit the c:\windows\system32\drivers\etc\hosts file as user with administrator privileges.
Example line to be added to the file:
54.93.63.79 demo.sample
Note: The demo.sample name has to be understood also on the server environment as the local
system name.
4.2 Hadoop (optional)
Note: This step applies to client access to Hadoop from Windows environment hosting Spotfire part of
the accelerator. It is needed only if the same environment is used later to build server side part of the
solution based on the accelerator. This section requires also prior installation of Hadoop libraries in the
Spotfire environment.
Pure demo does not require direct access to the HDFS. It can be required to access Hadoop filesystem
from the development environment, though. When user has to connect to HDFS from Spotfire
environment, some additional following settings have to be configured.
1) Set the HADOOP_USER_NAME environment variable to demo (superuser for this

Document
TIBCO Accelerator for Apache Spark – Quick Start 24
environment)
2) Set the fs.defaultFS property in core-site.xml to hdfs://demo.sample
<property>
<name>fs.defaultFS</name>
<value>hdfs://demo.sample/</value>
</property>
3) Set the dfs.client.use.datanode.hostname property in hdfs-site.xml to true
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
In addition subsequent ports should be exposed from the cluster: 8020 (HDFS name node) and 50010
(HDFS data node).
4.3 Spotfire remote Data Functions (mandatory)
Spotfire accesses the server using a hybrid TERR (TIBCO Enterprise Runtime for R), HTTP and Spark
SQL solution. TERR is primarily used as a gateway to service shell scripts. In order to execute functions
inside TSSS, the default remote Data Functions endpoint has to be updated
Figure 2: TSSS address setting
In order to change the default URL, launch Spotfire (without opening DXP) and then navigate to menu
Tools > Options > Data Functions. Activate the Custom URL option and provide the actual endpoint:
http://demo.sample:8080/SplusServer
Note that the address is case-sensitive.
4.4 Local TERR packages (optional)
In the provided Spotfire visualization all calls using RCurl package are executed from the TSSS
environment. The configuration of RCurl package on server environment was already described in
section 3.11 TERR dependencies. The HTTP endpoints can be also accessed from TERR running
locally. This approach reduces number of network layers to pass, but requires additional activity on the
client environment where Spotfire is running. Similar steps as on the server environment have to be
executed. In order to enable RCurl in local TERR, within Spotfire navigate to the menu Tools > TERR
tools > Launch TERR Console. Next install the package using the following command:

Document
TIBCO Accelerator for Apache Spark – Quick Start 25
install.packages("RCurl")
4.5 Server environment reference (optional)
The Accelerator DXP file uses local settings to reference the target environment. These settings can be
changed when necessary in the first tab of the visualization (Settings). When the demo.sample name
is properly resolved both in the server and client systems, there is no need to change this part.
Figure 3: Parameters for HTTP and HDFS
4.6 Launching DXP file and enabling "Trust"
When a foreign DXP file is opened in a local environment and it contains potentially harmful active
content, Spotfire prevents it from execution. In the Accelerator such active content contains IronPython
scripts and custom queries to Apache Spark SQL.
During first launch Spotfire refuses opening the tables from Spark. This happens due to the security
restrictions. Accept all the warnings.
Figure 4: Sample warning about Spark SQL custom table
After all Spark SQL warnings are accepted, Spotfire displays dialog about IronPython scripts.
Figure 5: IronPython scripts warning
Accept the warning and in the subsequent dialog click "Trust All".

Document
TIBCO Accelerator for Apache Spark – Quick Start 26
Figure 6: IronPython scripts trust dialog
At this moment the custom queries can be reenabled. Navigate to menu Edit > Data Connection
Properties.
Figure 7: Spark SQL data connection properties
Select Settings and in the next dialog select Edit. Now for every table in Views in Connection list,
right click the item and activate Edit Custom Query. In the next dialog, just click OK, which establishes
trust relation between Spofire and the query definition.

Document
TIBCO Accelerator for Apache Spark – Quick Start 27
Figure 8: Spark SQL custom queries
Figure 9: Spark SQL custom query enabling

Document
TIBCO Accelerator for Apache Spark – Quick Start 28
5 Running the demo
5.1 Submit the traffic
The accelerator provides the real-time traffic simulator controlled using REST interface. The module is
in the longer term intended to be accessed from web interface. In the 1.0 version the component is
controlled using CUrl commands.
In order to submit the data, the desired message rate and time compression have to be set. A good
initial setting is 1 hour to 1 second time compression and 20 transactions per second.
The time compression is set by providing 3600 compression rate to the simulator settings. In order to
apply it run the following command:
echo 3600 | curl -XPUT -d @-
http://demo.sample:10080/simulator/call/settings/timeCompression
The simulator in the default configuration executes message injection in 200ms intervals, i.e. 5 times
per second. In order to send 20 messages per second, the number of messages per interval has to be
set to 4:
echo 4 | curl -XPUT -d @- http://demo.sample:10080/simulator/call/settings/messagesPerTick
The data traffic is enabled by setting the simulator status to running. The simulator injects the
messages according to the known reference data.
echo running | curl -XPUT -d @- http://demo.sample:10080/simulator/call/settings/status
The traffic injection can be suspended any time by setting the status to stopped. Subsequent status
change to running resumes the simulation from the point where it was suspended.
echo stopped | curl -XPUT -d @- http://demo.sample:10080/simulator/call/settings/status
5.1.1 Legacy approach
In order to send traffic to the message bus, login to the SSH shell as user demo and go to
AMBDA_Generator directory. In that directory run the following command:
nohup zcat sorted-0010.txt.gz </dev/null 2>/dev/null \
| ./publish-kafka.sh -t Transactions -r 20 \
> publish-kafka.out 2>&1 &
It launches a background process that reads pregenerated transactions saved in sorted-0010.txt.gz file
and sends them to Transactions topic.
This legacy procedure does not allow for simulation suspending and resuming.
5.2 Showing the live changes
In the web browser go to http://demo.sample:10080/lvweb.

Document
TIBCO Accelerator for Apache Spark – Quick Start 29
Figure 10: Current traffic dashboard in LiveView Web
The top table contains the current ledger of transactions flowing through the system. Clicking on the
transaction allows to drill down into transaction content in the bottom table.
5.3 Flume collection
The transactions processed by the event processing layer need to be stored in HDFS. In the accelerator
the events are passed via Kafka to Flume. Usage of Kafka prevents from data loss during data transfer
to HDFS. Flume saves the data in event-friendly appendable Avro format and optimizes HDFS write
process.
Figure 11: Avro data in transit
5.4 ETL process
The data in Avro can be already directly accessed using analytic processes. The nature of the reliable
write process, however, leads to suboptimal data structure. In particular the process leads to creation of
many relatively small files. No data loss guarantee results on the other hand in possible duplicates.
Therefore it is recommended to execute data postprocessing using ETL. In the demo the process is

Document
TIBCO Accelerator for Apache Spark – Quick Start 30
implemented as Spark job. For the demonstration purpose the ETL process is applied to the whole
dataset. In real implementations the data should be processed incrementally. After ETL the data is
saved in Parquet format using partitioning to improve querying efficiency.
Figure 12: Target Parquet files
5.5 Data Discovery
The Spotfire component contains three sections. The Index page contains an explanation of the
document’s structure with links to all the pages.
The first section is called Discover Big Data and it serves as an environment that enables answering
business questions in a visual way, including needs of Big Data Reporting and Discovery. This section
is composed of 6 pages.
5.5.1 Discover Big Data: Totals
The top of this page shows a preview of the data, which has a set of 10K lines and the respective
content. Such a preview can be useful for inspiring strategies for analysing the data. Below, we show
some KPIs and how they evolve over time. By clicking on the X and Y axes selectors, the user can
choose different KPIs.

Document
TIBCO Accelerator for Apache Spark – Quick Start 31
Figure 13: Totals
5.5.2 Discover Big Data: Drill-down
Figure 14: Drill-down
This section proposes a drill into the data. There are four market segments in the data. When the user
chooses some or all of them in the pie chart, a tree map subdividing the respective total revenue by
product appears. When selecting one or many products, below appears a time series of the respective

Document
TIBCO Accelerator for Apache Spark – Quick Start 32
revenues. The user may as such navigate the different dimensions of the data or choose different
dimensions in any of the visualisations.
5.5.3 Discover Big Data: Categories
As again a way of discovering the shape of the data, here is offered a drill-down by product categories.
At the top, a tree map shows the importance on sales and price of each product. The visualisations at
the bottom show some KPIs now and over time. By default, they encompass the whole business, but
they respond to choices of one or many products in tree map.
Figure 15: Categories
5.5.4 Discover Big Data: Basket analysis
Here, upon making a choice on the left hand list, we get a tree map that show the importance of all
other products that were sold in the same baskets that contained the product of choice. This is a nice
way of perceiving how customers buy products together and can help understand which variables
should be included in models. The controls on the right allow choosing different metrics and
dimensions.

Document
TIBCO Accelerator for Apache Spark – Quick Start 33
Figure 16: Basket analysis
5.5.5 Discover Big Data: Client CrossSell
Similar to the previous page, here are shown the products that clients who bought the chosen product
have also bought, whether in the same basket or in any moment in time. This is useful when drawing
cross/up-sell campaigns.
Figure 17: Cross/Up-sell

Document
TIBCO Accelerator for Apache Spark – Quick Start 34
5.5.6 Discover Big Data: Geos
This page shows how revenue and average price are distributed by shop and by region. It leverages
Spotfire’s ability to draw great maps.
Figure 18: Geographically
5.5.7 Discover Big Data: Play Page
The last page on this section allows the user to use Spotfire’s recommendation engine in order to draw
inspiration for new analyses that bring out business value. Here, the user can choose on the left hand
side a month of data to load into memory. Afterwards, a press of the Light-Bulb Icon at the top launches
the Recommendation Engine. As he/she chooses variables on the left hand pane, Spotfire populates a
selection of recommended visualisations for that type of data with the data that has been loaded. The
user can choose the one he/she feels better brings out the required insight and create a new dashboard
with just a few clicks. This page can be duplicated as many times as required.

Document
TIBCO Accelerator for Apache Spark – Quick Start 35
Figure 19: Play Page
5.6 Model building
The second section of the Spotfire component is called Model Big Data and supports the business in
the task of Modelling Big Data. This section is composed of 5 pages. The Accelerator currently supports
the Random Forest Classification model, which is a type of model that is valid on any type of data.
Therefore, it can be run by a business person. The goal is to make models that support promotions of a
particular product or groups of products.
5.6.1 Model Big Data: Data Prep
In this page, the user decides which months to use for training the models and which months to use for
testing them. For training, we recommend taking enough months to encompass at least one full
seasonal cycle, for example one full year. Maybe very old data is less relevant to current customer
behaviour. If that is the case, you may not want to include much old data. For testing, you should use at
least 1 to 3 months of data, preferably the more recent.
The chosen ranges are loaded using an aggregation job in Spark. Once the ranges are selected the
model training job can be launched.

Document
TIBCO Accelerator for Apache Spark – Quick Start 36
Figure 20: Predictors and responses
5.6.2 Model Big Data: Model Training
In this page, the user names the groups of products that will be modelled. He/she then uses the central
list to selects the products to make a promotion for. On the right-hand pane, the user launches the job
of making a model for it in Spark. H2O is called to run a Random Forest model over the data that is
stored in HDFS. This model aims at finding a way to distinguish those customers that are likely to have
an interest in a specific product, and therefore are good targets for a promotion, from those that are not.
Pressing the Check Status button allows seeing when the job has finished. It can be pressed many
times. Press the Refresh results button when the job is “done”.
When this latter button is pressed, Spotfire reaches to Spark via TERR to obtain the latest results of
model building exercise. This result includes the components identified in section 3.2.4.:
● results - model training job results; for each model training job there is tab-separated text file
containing information line for each generated models
● pojo - generated H2O POJO classes; the directory contains subdirectory for each model
training job
● roc - directory stores ROC points generated by H2O for each training job
● varimp - variable importance scores obtained from model training jobs
● sets - directory containing model metadata as tab-separated files describing deployable model
and its parameters
These results are analysed in the following pages.

Document
TIBCO Accelerator for Apache Spark – Quick Start 37
Figure 21: Training in Spark
5.6.3 Model Big Data: Evaluate model quality
On the left hand pane, the user chooses which model to evaluate. One can choose the current model or
any past model. The choice populates the chart with the respective ROC curve.
Evaluating model quality involves seeing if its results allow better decisions than a random choice, e.g.
than tossing a coin. The model in the accelerator aims at separating one type of clients from the
remainder, namely the ones who may be interested in the chosen product. For any given client, if we
chose what type they were at random, the model’s ROC curve (Receiver Operating Characteristic)
would likely be close to the red line in the chart. If the model were perfect and got every decision right,
the model’s ROC Curve would be given by the green line. The blue line gives the position of the actual
ROC Curve of the chosen model. The total area between the blue and the red line is called A.U.C.
(Area Under the Curve) and gives a measure of how much better the current model is when compared
with making a choice at random. The left hand table shows the A.U.C. of all models, which gives the
user an idea of how good models are expected to be. Models with enough A.U.C. can be user
approved. Previously approved models can also have their approval revoked in this page. All following
pages just show approved models. It is important to bear in mind that approval of a model should not be
final before the variable importance page is analysed, which happens on the next page.

Document
TIBCO Accelerator for Apache Spark – Quick Start 38
Figure 22: Evaluate model quality
5.6.4 Model Big Data: Variable importance
On the left hand pane, the user chooses which model to continue analysing. Only previously approved
models appear here.
A combination of visualizing the ranking of the features as well as the detail of the individual features is
important for a number of reasons:
1 Validation of the model’s quality. Maybe your best feature is so good because it is part of the answer
and should therefore be excluded.
2 Validation of the data’s quality. Were you expecting a different feature to have more power than what
is showing? Perhaps there are data quality issues causing a lack of relevance, or maybe outliers
introduced a bias. These quality issues can be quickly spotted in a visualization, for example a
histogram of the numeric features.
3 Correlation is not causation. It is necessary to ask questions that lead to a better understanding of the
reality being predicted.
4 Surprising top features. Sometimes predictors expected to be irrelevant turn out to have huge
predictive ability. This knowledge, when shared with the business, will inevitably lead to better
decisions.
5 Inspiration for new features. Sometimes the most informative features are the reason to delve into
new related information as a source of other rich features.
6 Computational efficiency. Features with very low predictive power can be removed from the model as
long as the prediction accuracy on the test dataset stays high. This ensures a more lightweight model
with a higher degree of freedom, better interpretability, and potentially faster calculations when applying
it to current data, in batch or real time.

Document
TIBCO Accelerator for Apache Spark – Quick Start 39
This type of considerations is more important in some usecases than in others.
It is important to bear in mind that approval of a model should not be final before the variable
importance page is analysed. If any issues are spotted, the user can revoke previously approved
models.
Figure 23: Variable importance
5.6.5 Model Big Data: Custom Threshold
This page is entirely optional. When a model run is in real time, a measure is calculated of how likely a
given customer is to say yes to a promotion of your specific product. In order to decide to send him or
her a promotion, this metric is compared against a Threshold. This Threshold is defined by default to
maximise the F1-score. The F1-score balances two types of desirable characteristics this type of
models can have:
* Precision: of all the people the model would send a promotion to, what proportion accepts it;
* Recall: of all the people that would have said yes to a promotion, how many did the model recognise.
F1 weighs these two dimensions equally. If you are happy with this choice, you can ignore this page.
However, the user may have their own way of defining a desired Threshold and can use this page to set
it. For example, they may want to maximise just precision or just recall, or to weigh them differently.
Table 2a can be used to select other known model performance metrics.
In 2b, one may select a Threshold manually. This is useful if it is important to control the proportion of
customers that are identified as target, in case this must be weighed against the size of a team who will
manually treat each case (e.g. telemarketing calls). The Proportion Selection (% of customer base)
figure populates against this choice.
In 2c, you may create your own model performance metric. For example, attribute a monetary cost to

Document
TIBCO Accelerator for Apache Spark – Quick Start 40
sending a promotion that is not converted and/or a monetary gain to a promotion that is converted. You
can do this by typing your own formula in "here" on the Y-axis of the chart and then selecting the
Threshold that maximises it. All the data needed for a custom calculation is available in the data that
feeds the chart.
In area 3, the user chooses the Threshold of choice and saves it by pressing Use.
Figure 24: Custom threshold
5.7 Deploy Marketing Campaigns
This final part is made of 2 pages that support the business in the task of running marketing campaigns
that deploy the models learnt in the previous sections. Each model targets one product. The models are
deployed to the event processing layer are model sets that we call campaigns or marketing campaigns.
Campaigns launch promotions for groups of products at once by bundling models and their respective
thresholds together.
5.7.1 Deploy: Bundle models into campaigns
Sections 1 and 2 of this page require user action, whilst the remainder just provide information. In
Section 1, the user chooses to either create a new campaign which takes on the name he/she chooses
to give it just below, or chooses to load an existing campaign for analysis by choosing one from table a)
to the immediate right. The models that are part of the new or existing campaign appear in table b) on
the right hand middle section of the page. The user can now use Section 2 to change the models that
are part of a campaign. This can be done by choosing to add new models, which he/she collects from
table c). Or by deleting existing models from the current campaign. When done, the user can save the
new settings of the existing campaign. The button at the bottom “Refresh available model list” ensures
that all the more recently run models appear in list c).

Document
TIBCO Accelerator for Apache Spark – Quick Start 41
Figure 25: Bundle models into campaigns
5.7.2 Deploy: Launch campaigns
The left hand side of this page allows user action, whilst the right presents resulting information. The
button “Which campaigns are currently running in real time?” show the names of the campaigns that are
running now. These names appear as StreamBase will see them. The button “Refresh list of available
campaigns” will update table a) so it includes all past campaigns, including the ones that have just been
created. When the user chooses a campaign from this table, table b) reflects the models that are part of
it. Finally, the button “Deploy the new selected campaign” can be pressed to launch a new campaign in
real time.

Document
TIBCO Accelerator for Apache Spark – Quick Start 42
Figure 26: Launch campaigns
The effects of the deployed model change can be observed in the transaction log.
Figure 27: empty.txt deployed

Document
TIBCO Accelerator for Apache Spark – Quick Start 43
Figure 28: models-b.txt deployed
Figure 29: models-c.txt deployed

Document
TIBCO Accelerator for Apache Spark – Quick Start 44
6 Components
The solution consists of several interconnected tools. This chapter briefly discusses their roles and
interactions.
6.1 Accelerator components
6.1.1 EventProcessor
The EventProcessor is StreamBase CEP application. This component is central to the event processing
with Fast Data story. The application consumes transaction messages from Kafka topic and applies
regular event processing to them showing several possible techniques:
● in-memory enrichment
● state delegation
● filtering
● transformation
● model execution
● decisioning
● process tracking
● persistence
The transactions contain very little data. In particular the category information is missing, so this
information is taken from in-memory inventory categorization dictionary.
According to the assumed model, the customer is described by his/her purchase history. In order to
keep the solution scalable, the state is moved out of the event processing layer. All customer
transactions are stored in HBase. The constant-cost data access by key allows reducing the effective
latency to acceptable value. The field value versioning helps reducing the network traffic. As a result
there are two quick interactions with HBase: one read by key and one append by key.
Having the new transaction and customer history, it is possible to select the transactions relevant to the
featurization process dropping to old transactions or duplicates. Then the application converts the
transactions into features same way as was done in the model training process.
Once the new transaction is described using variables compatible with the model(s) it is evaluated. The
model evaluation results not passing the threshold are discarded and from the remaining results, the
one with best score is selected as the actual offer.
The notification is sent to the event originator. The result of the transaction processing (including the
offer) is sent to Flume via Kafka topic.
The event processor captures the offers sent to customers and tracks the scoring. In the current demo
both parts are collocated, but in real application they would be implemented as two layers connected by
Kafka layer.

Document
TIBCO Accelerator for Apache Spark – Quick Start 45
The transactions and relevant data are sent to the Live DataMart.
6.1.2 Realtime Dashboard
The demo operational dashboard is Live DataMart instance. The intended purpose is to keep up-to-date
ledger of recent data. The DataMart does not keep the whole event history.
At the moment it contains transactions data and transaction content that is visible in LiveView Web
application. The user can drill-down from transactions to transaction content.
6.1.3 Data service
The Big Data resides in HDFS. It is typically too large to load in single process. The data service is a
Spark application that exposes REST/HTTP interface (and Spark SQL, too). The application provides
services:
● Access to preregistered views (like ranges or available categories)
● ETL process converting Avro to Parquet
● Featurization result preview
● Model training execution (with Sparkling Water)
6.1.4 Spotfire
Spotfire is main analytics and model lifecycle dashboard. It is used to:
● Inspect the HDFS data
● Prepare the models
● Review the trained models
● Build configurations
● Deploy models
6.1.5 Traffic simulator
Traffic simulator is a Jython (Java Python) application injecting transactions that can be consumed by
event processing layer. The application sends events to Kafka topic.
6.2 Infrastructure components
6.2.1 TSSS
TIBCO Spotfire Statistics Services provides runtime to execute data functions on the server side (in the
cluster). In the accelerator it works as a gateway to set of scripts. In particular it mediates:
● HDFS file listing
● Zookeeper queries and updates
Some TERR data functions are executed locally in Spotfire. They are mostly local data processing

Document
TIBCO Accelerator for Apache Spark – Quick Start 46
functions.
6.2.2 Kafka
Kafka is horizontally scalable message broker. It supports multiple consumers for each topic and
inherent topic partitioning. Typically each topic is defined with relatively big number of partitions. When
the traffic is low, only a couple of brokers are necessary to handle it. When the workload grows the
partitions can be spread across the cluster by adding new brokers. Kafka guarantees sequential
delivery within topic/partition. In the typical design the consumers scale well, too. Each consumer
processes messages from a distinct subset of partitions (single partition in particular). Kafka uses
unique consumption state decoupling. Unlike in JMS, the brokers usually do not keep the consumption
state, which significantly reduces design complexity.
6.2.3 HDFS
HDFS is Hadoop component providing reliable distributed file system. The HDFS is sequential read
optimized and provides mechanisms for local data processing (according to “bring code to data”).
HDFS does not support well random data access and frequent writes of small data chunks.
HDFS if perfect choice for data that is created once and no longer modified.
6.2.4 YARN
YARN is resource allocation framework in Hadoop. It coordinates distributed jobs. In the first release of
the accelerator YARN is not used, but it is essential component to typical Big Data solutions.
6.2.5 HBase
HBase is a NoSQL column-oriented database. While typically running on HDFS, it fills the gap for the
HDFS weaknesses. HBase is optimized for key-based data access sharing similar concepts with TIBCO
ActiveSpaces. HBase is durable, supports field versioning and column addressing for both reads and
writes.
HBase is a poor choice for sequential data processing and queries without primary key.
6.2.6 Flume
Flume is event aggregation framework. It provides reliable mechanism bridging the Data in Motion to
Data at Rest. In particular it solves a problem of reliable persistence of streams of events in HDFS.
Flume aggregates events if larger batches and executes coarse-grained writes.
6.2.7 Zookeeper
Zookeeper is cluster coordination solution. It provides quorum-based single source of truth. Zookeeper
provides small set of filesystem-like primitive operations that can be used to build higher-order
constructs, like:
● Leader election
● Distributes locking
● Shared state

Document
TIBCO Accelerator for Apache Spark – Quick Start 47
● Notifications
In the current version accelerator uses Zookeeper to maintain solution runtime configuration and to
notify processes about configuration changes. The event processing layer stores Kafka
consumption offsets in Zookeeper.
Zookeeper is a key component of many distributed products. In particular it is coordination
component for Kafka and HBase.

Document
TIBCO Accelerator for Apache Spark – Quick Start 48
7 Installation
7.1 Platform
The typical deployment platform for Hadoop and related projects is Linux. The accelerator was
deployed on CentOS 6.5.
7.2 Open source software
The following software is required to deploy the accelerator. The versions used in the projects are
typically relatively new, but most of the features should be also available in slightly older versions.
Table 1: Open source software
Software Version Website and notes
Apache Hadoop 2.7.2 http://hadoop.apache.org/
Any version 2.6.x and higher
Apache Kafka 0.9.0.1 http://kafka.apache.org/
Any version from 0.8.2.2
Apache HBase 1.2.0 http://hbase.apache.org/
Apache Flume 1.6.0 http://flume.apache.org/
Apache Zookeeper 3.4.8 http://zookeeper.apache.org/
Apache Spark 1.5.2 http://spark.apache.org/
1.5 branch
H2O, Sparkling Water 1.5.12 http://www.h2o.ai/download/sparkling-water/spark15
Most recent version for Spark 1.5.x.
Note about Spark and H2O: The current branch of Spark (1.6.x) introduced many new features, but at
the same time these new features caused behaviour change and introduced bugs affecting parts of
accelerator. Because of that the Spark version used in the accelerator is recent 1.5.x branch. To use
H2O with Spark Sparkling Water component is required in version matching Spark.
7.3 TIBCO products
The accelerator focuses on interoperability between event processing and data analytics in the Big Data
environments. The event processing product of choice is StreamBase supported with Live DataMart
(LDM) and LiveView Web (LVW) for operational dashboard. The analytics and model lifecycle part is
covered by Spotfire and TIBCO Spotfire Statistics Services (TSSS).

Document
TIBCO Accelerator for Apache Spark – Quick Start 49
Table 2: TIBCO products
Software Version Notes
StreamBase CEP 7.6.3
StreamBase Adapter
for Apache Flume
7.6.3
StreamBase Adapter
for H2O
Live DataMart 2.1.2
LiveView Web 1.0.2
Spotfire 7.5.0
TIBCO Spotfire
Statistics Services
7.5.0
Spotfire Adapter for
Spark SQL
TIBCO Enterprise
Runtime for R
(TERR)
4.1
Spark SQL ODBC
driver
OEM from Simba
7.4 Infrastructure and build tools
The server part of the accelerator is Java based with Spark related code written in Scala. The compiled
components are built with Maven. The current version of traffic simulator is based on Jython.
Table 3: Java Components
Software Version Notes
Eclipse Mars 4.5 SR2 Used to develop the components
Scala IDE 4.4.x Plugin for Eclipse: http://scala-ide.org/
JDK Oracle JDK 1.8.0_45 Both for design and runtime environment
Maven 3.3.9 Design environment
Jython 2.7.0 Used to submit the messages

Document
TIBCO Accelerator for Apache Spark – Quick Start 50
7.5 Environment variables
7.5.1 Design time environment
A MS Windows VM platform was used to develop the solution and run Spotfire visualizations.
Table 4: Windows environment variables
Variable Value Notes
JAVA_HOME c:\java\jdk_1.8.0_45
M2_HOME c:\java\maven-3.3.9
JYTHON_HOME c:\java\jython-2.7.0
STREAMBASE_HOME c:\tibco\sb-cep\7.6
PATH %JAVA_HOME%\bin
%M2_HOME%\bin
%JYTHON_HOME%\bin
%STREAMBASE_HOME%\bin
7.5.2 Runtime environment
The runtime environment is CentOS 6.5. The following environment variables are relevant:
Table 5: Linux environment variables
Variable Value Notes
JAVA_HOME /opt/java/jdk1.8.0_73
HADOOP_HOME /opt/java/hadoop-2.7.2
HADOOP_USER_NAME demo
JYTHON_HOME /opt/java/jython-2.7.0
KAFKA_HOME /opt/java/kafka_2.10-0.9.0.1
SPARK_HOME /opt/java/spark-1.5.2
STREAMBASE_HOME /opt/tibco/sb-cep/7.6
ZOOKEEPER_HOME /opt/java/zookeeper-3.4.8
PATH $HOME/bin
$HADOOP_HOME/bin

Document
TIBCO Accelerator for Apache Spark – Quick Start 51
$JAVA_HOME/bin
$JYTHON_HOME/bin
$KAFKA_HOME/bin
$SPARK_HOME/bin
$STREAMBASE_HOME/bin
$ZOOKEEPER_HOME/bin