towards automated classification of discussion transcripts: a cognitive presence case
TRANSCRIPT

1
Towards Automated Content Analysis of Discussion Transcripts:
A Cognitive Presence Case
Vitomir Kovanović¹, Srećko Joksimović¹, Zak Waters²Dragan Gašević¹ , Kirsty Kitto², Marek Hatala³, and George Siemens⁴
¹ The University of Edinburgh
² Queensland University of Technology
³ Simon Fraser University
⁴ University of Texas at Arlington
April 27, 2016Edinburgh, UK
[email protected]://Vitomir.kovanovic.info@vkovanovic
Generously supported by

2Overall goal
and why it matters
Automate content analysis of online discussions for
the levels of cognitive presence
Benefits
Faster coding of messagesOperationalization of coding scheme
Monitor student progressSpeed-up research

3Online discussions
The key ingredient in distance education
Used all the timeAdopted by most online and blended
courses, often not in a productive manner.
Supported by social-constructivismThe social (co)construction of knowledge is
essential for social-constructivist pedagogies
adopted by most online instructors.
Produce large amounts of dataCalled gold mine of information about learning
processes, they can be used to understand how
people learn online.
Require a lot of work from instructorsThat is why social-constructivist
pedagogies work with up to ~ 30 students.
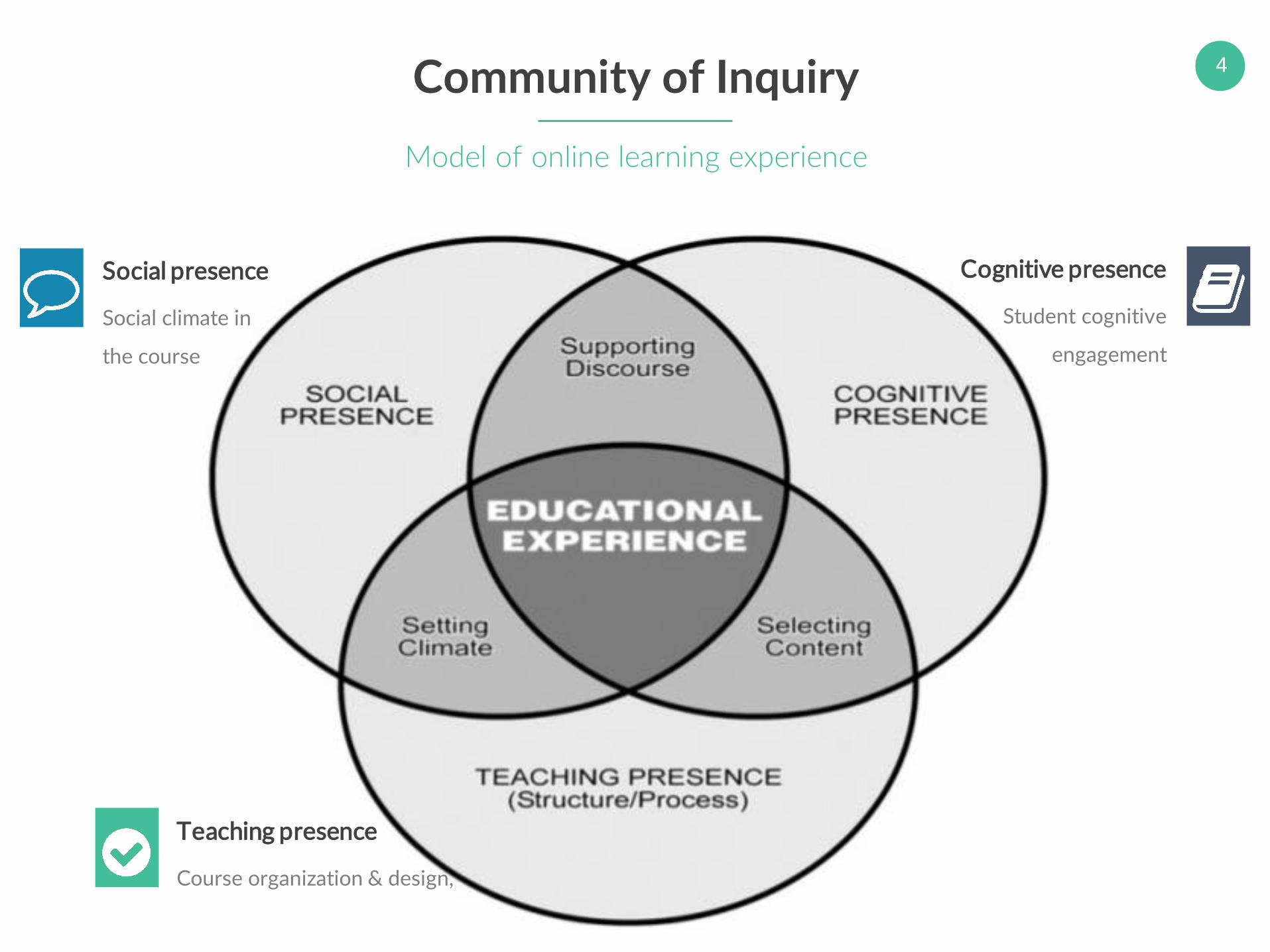
4Community of Inquiry
Model of online learning experience
Cognitive presence
Student cognitive
engagement
Social presence
Social climate in
the course
Teaching presence
Course organization & design,

5Cognitive presence
Central construct of the CoI model
Triggering event
Start of the learning cycle, sense of
puzzlement, dilemma.
Resolution
Application and testing of the
acquired knowledge
Exploration
Brainstorming of different ideas,
information gathering.
Integration
Synthesis of the relevant ideas and
information
“an extent to which the participants in any particular configuration of a community of
inquiry are able to construct meaning through sustained Communication”
(Garrison, Anderson, and Archer, 1999, p. 89)
Cognitive presence definition
Triggering event
Resolution
Exploration
Integration
Learning cycle

6Assessment of three presences
How we measure cognitive, social, and teaching presence
Two ways of assessing levels of three presences
1. Quantitative content analysis instrument
A coding scheme for each presence
2. CoI Survey instrument
34 Likert-scale questions

7Cognitive presence coding scheme

8Cognitive presence coding scheme

9Challenges of cognitive presence assessment
Content analysis instrument:1. Manual, labor intensive, time-
consuming,2. Requires expertise with CoI coding
schemes,
Survey instrument:1. Self-reported, perceived instead of
objective values,2. Selection bias, not all students
answer the survey,
3. No real-time feedback on student learning progress,4. Almost no impact on educational practice.

10Text classification
Build a classifier for coding cognitive presence
By automating coding of messages, we can overcome many
of the challenges identified with CoI model adoption.
Builds on previous text-mining work in education
We build on the previous work on the same topic
(Kovanovic et al. 2014, …
Abandon kitchen sink approach
We do not want bag-of-words overfitting approach
Five-class text classifier
Classifier needs to assign a cognitive presence class
1-Trigering event, 2 – Exploration, 3 – Integration, 4-
Resolution, 0 – Other (non cognitive).
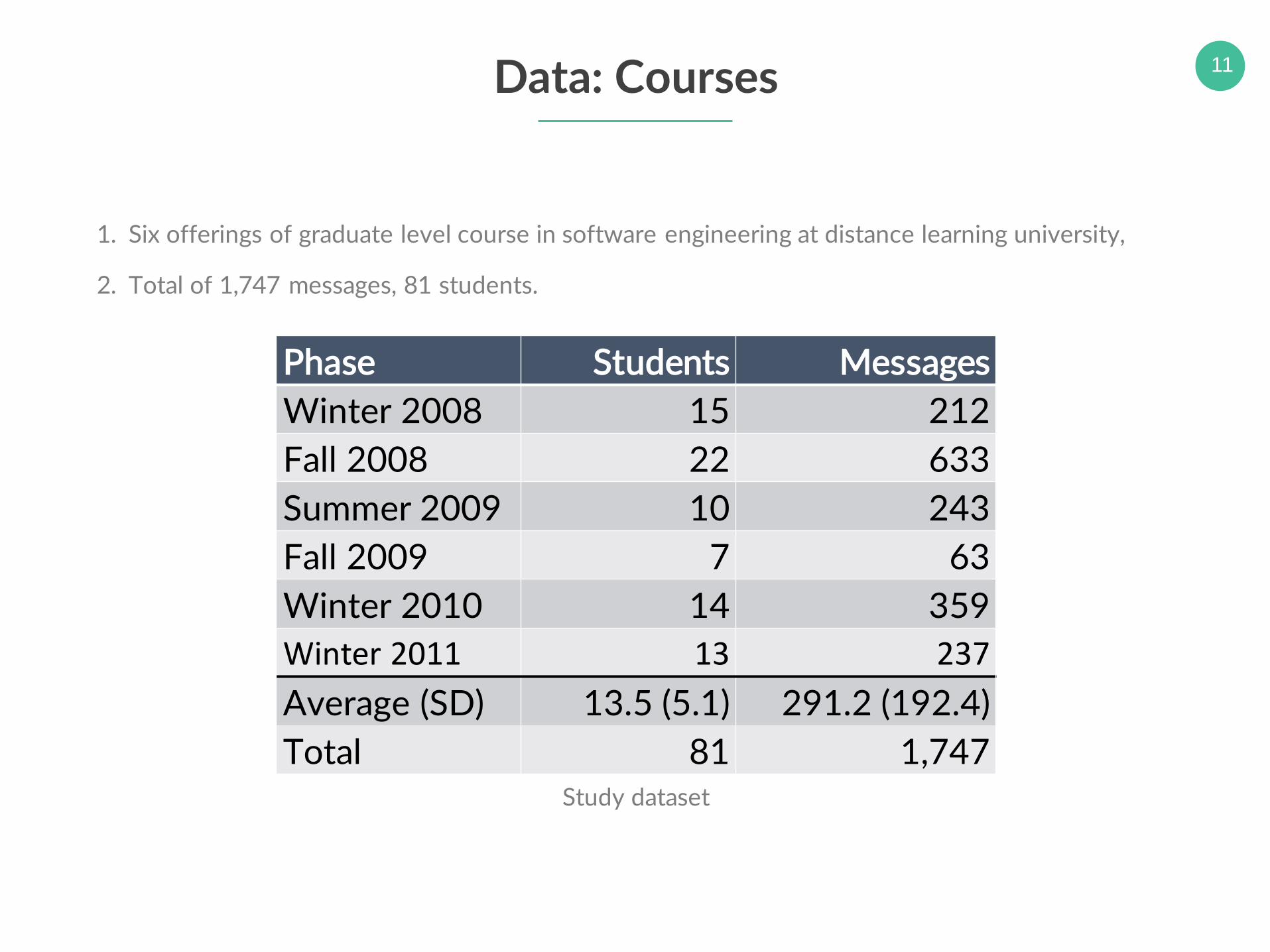
11Data: Courses
1. Six offerings of graduate level course in software engineering at distance learning university,
2. Total of 1,747 messages, 81 students.
Phase Students Messages
Winter 2008 15 212
Fall 2008 22 633
Summer 2009 10 243
Fall 2009 7 63
Winter 2010 14 359
Winter 2011 13 237
Average (SD) 13.5 (5.1) 291.2 (192.4)
Total 81 1,747Study dataset

12Data: Messages
1. Messages coded for level of cognitive presence on a scale 0-5.
2. Manually coded by two coders
(agreement = 98:1%; Cohen's κ = 0:974).
ID Phase Messages (%)
0 Other 140 8.01%
1 Triggering Event 308 17.63%
2 Exploration 684 39.17%
3 Integration 508 29.08%
4 Resolution 107 6.12%
All 1747 100%Message coding results

13SMOTE preprocessing
SMOTE preprocessing for class balancing. Dark blue– original instances which are preserved, light blue – synthetic
instances, red – original instances which are removed.
We generate new data points in minority classes by “syntactic resampling” using SMOTE technique.
To generate a new data point (Z) ∈ Rn:
• Pick a random data existing data point (X),
• Pick K (in our case 5) instances most similar to the given data point,
• Pick randomly one of the K neighbors (Y)
• Create a new data point Z as a linear combination: Z = X + rand(0,1)*Y

14Extracted features
205 features in total extracted
1 3
2 4
5
LIWC features
93 different counts indicative of different
psychological processes (e.g., affective, cognitive,
social, perceptual)
LSA similarity
Average coherence of message’s paragraphs to
each other. LSA space is built from Wikipedia
articles related to concepts extracted from the
topic start message (using TAGME).
Coh-Metrix features
108 metrics of text coherence
(and related metrics)
Named entity count
Number of concepts related to DBPedia
computer science category (using DBPedia
spotlight)
Discussion context features
1. Number of replies
2. Message depth
3. Cosine similarity to previous/next message
4. Thread start/end boolean indicators

15Random Forest classifier
• A state-of-the-art ensemble learning method:
• Builds a large collection of decision trees (i.e., forest) using a subset of features (i.e., columns)
• Reduces the variance without increasing the bias
• Final class for a data point: a simple majority vote across the forest.
• Two parameters:
1. ntree – the number of trees built
2. mtry – number of features used ntree = 6
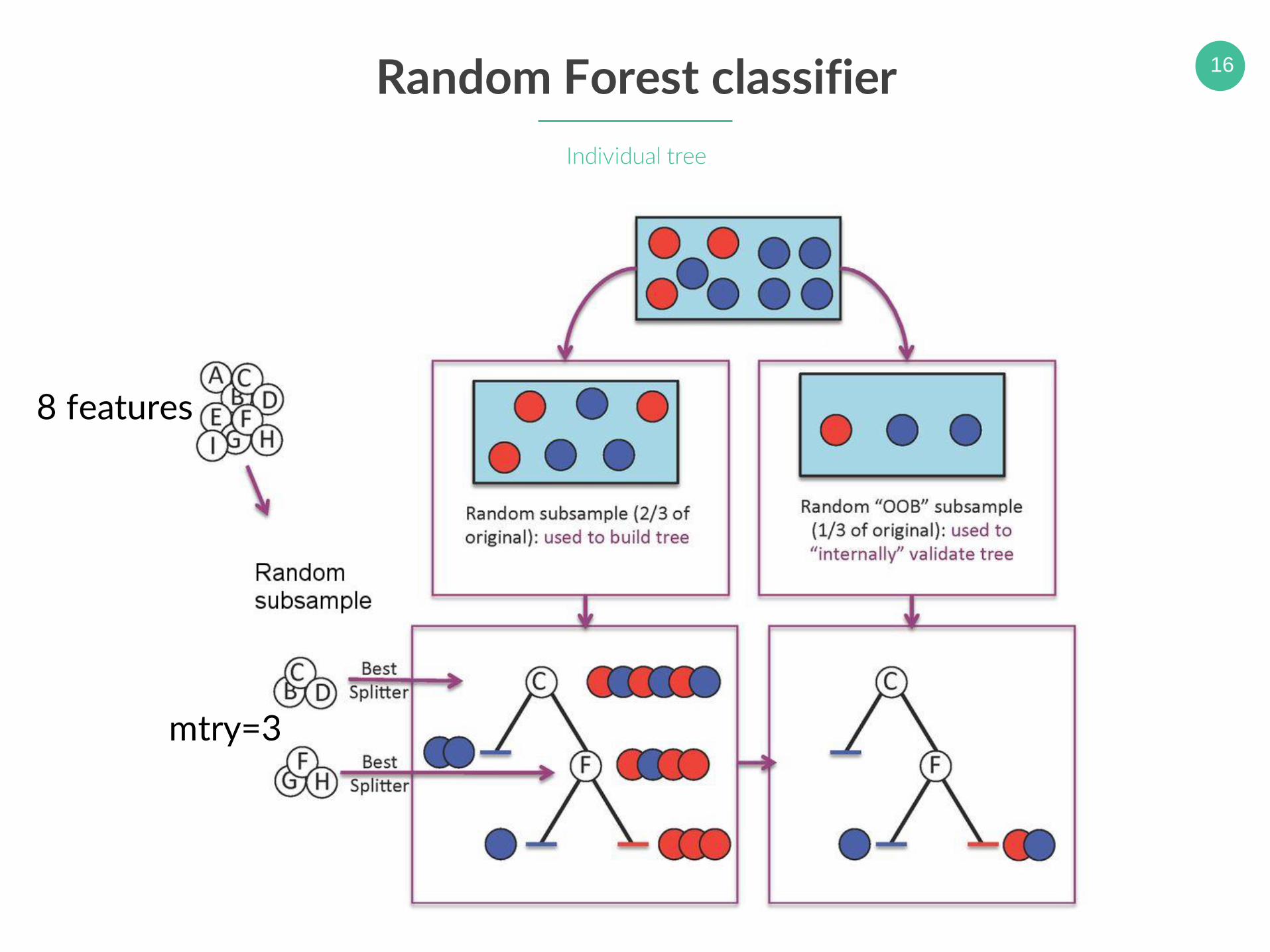
16Random Forest classifier
Individual tree
mtry=3
8 features

17Hyper-parameter tuning
• We split the data to train/test data in 3:1
ratio
• Two parameters
1. ntree – the number of trees built (we built 1,000)
2. mtry – number of features used(evaluated using 10-fold CV)
Values of mtry evaluated:{2, 12, 23, 34, 44, 55, 66, 76, 87, 98, 108, 119, 130, 140, 151, 162, 172, 183, 194, 205}.
mtry Accuracy (SD) Kappa (SD)
Min 194 0.68 (0.04) 0.59 (0.04)
Max 12 0.72 (0.04) 0.65 (0.05)
Difference 0.04 0.06
Hyper parameter tuning results
Hyper parameter tuning

18Implementation
Feature Extraction
• Coh-Metrix (McNamara, Graesser, McCarthy, & Cai, 2014)
• LIWC (Tausczik & Pennebaker, 2010)
• LSA similarity, Text Mining library for LSA (TML)
Algorithm implementation
• SMOTE algorithm implemented using WEKA
• Random Forest classifier using randomForest R package
• Repeated cross-validation using carret R package
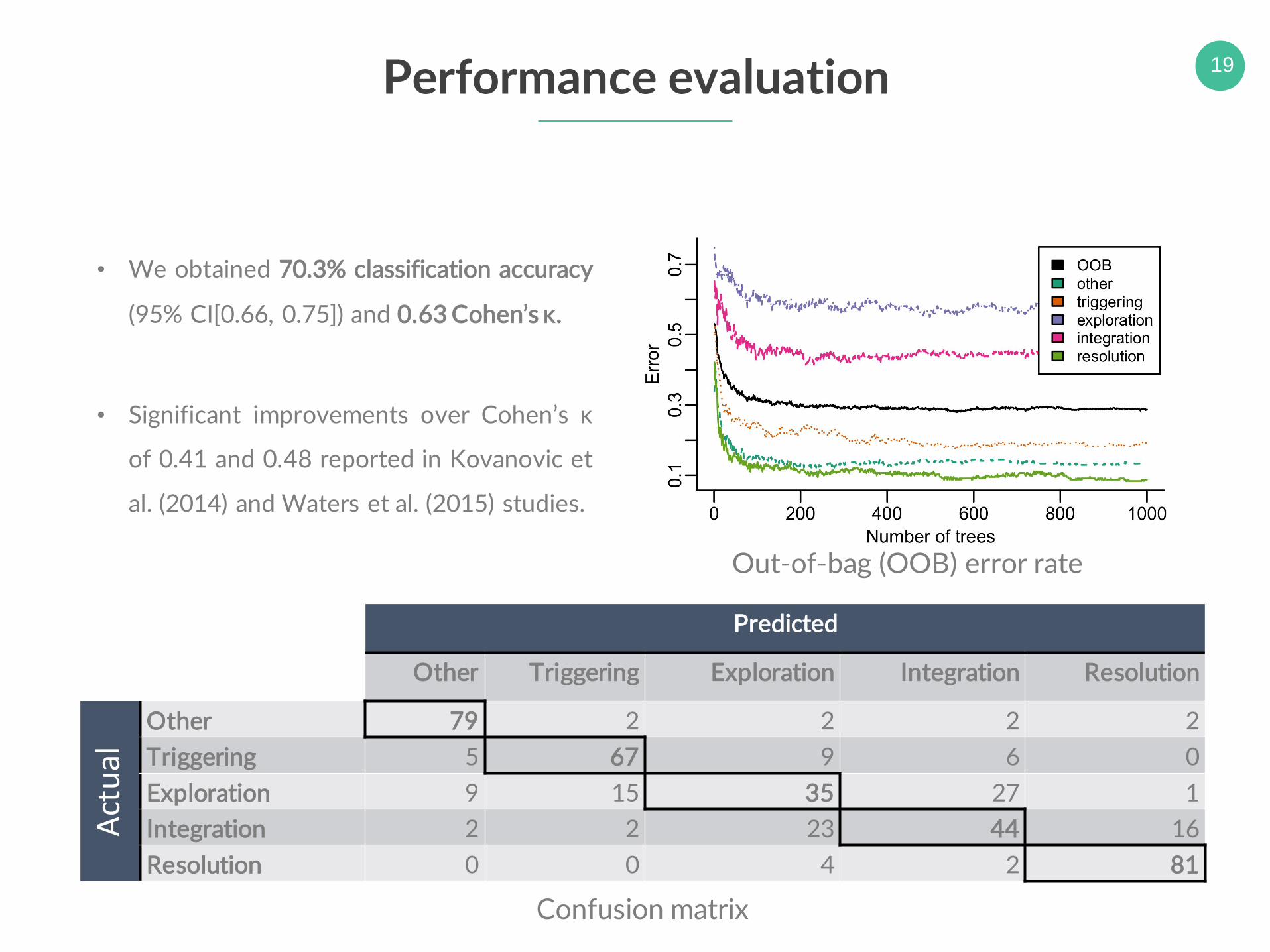
19Performance evaluation
• We obtained 70.3% classification accuracy
(95% CI[0.66, 0.75]) and 0.63 Cohen’s κ.
• Significant improvements over Cohen’s κ
of 0.41 and 0.48 reported in Kovanovic et
al. (2014) and Waters et al. (2015) studies.
Predicted
Other Triggering Exploration Integration Resolution
Act
ual
Other 79 2 2 2 2
Triggering 5 67 9 6 0
Exploration 9 15 35 27 1
Integration 2 2 23 44 16
Resolution 0 0 4 2 81
Confusion matrix
Out-of-bag (OOB) error rate

20Performance evaluation
• Much better performance than previous studies
• Slightly below commonly accepted 0.7 Cohen’s κ.
• Parameter optimization plays an important role (0.05 Cohen’s κ difference, 4% classification
accuracy).
• Feature space ~ 100x smaller than in the previous study
• Limits the chances for overfitting
• Features are more context-independent
• Particularly important for different pedagogical contexts (e.g., MOOC discussions)
• “Theory-driven” feature space
Confusion matrix

21Feature Importance
• A side product of Random Forest algorithm
• Mean Decrease Gini (MDG) measure of
feature contribution to reducing decision
tree impurity
• A long tail of feature importance
• Few features very important, most not so
much
• Provides more detailed operationalization of
CoI coding scheme.

22Feature importancePhase
# Variable Description MDG* Other TE Exp. Int. Res.
1 cm.DESWC Number of words 32.91 55.41 80.91 117.71 183.30 280.68
2 ner.entity.cnt Number of named entities 26.41 13.44 21.67 28.84 44.75 64.18
3 cm.LDTTRa Lexical diversity, all words 21.98 0.85 0.77 0.71 0.65 0.58
4 message.depth Position within a discussion 19.09 2.39 1.00 1.84 1.87 2.00
5 cm.LDTTRc Lexical diversity, content words 17.12 0.95 0.90 0.86 0.82 0.78
6 cm.LSAGN Avg. givenness of each sentence 16.63 0.10 0.14 0.18 0.21 0.24
7 liwc.Qmark Number of question marks 16.59 0.27 1.84 0.92 0.58 0.38
8 message.sim.prev Similarity with previous message 16.41 0.20 0.06 0.22 0.30 0.39
9 cm.LDVOCD Lexical diversity, VOCD 15.43 12.92 28.99 53.57 83.47 97.16
10 liwc.money Number of money-related words 14.38 0.21 0.32 0.32 0.65 0.99
11 cm.DESPL Avg. number of paragraphs 12.47 4.26 6.37 7.49 10.17 14.05
12 Message.sim.next Similarity with next message 11.74 0.08 0.34 0.20 0.22 0.22
13 Message.reply.cnt Number of replies 11.67 0.42 1.44 0.82 1.10 0.84
14 cm.DESSC Sentence count 11.67 4.28 6.36 7.49 10.17 14.29
15 lsa.similarity Avg. LSA sim. between sentences 9.69 0.29 0.47 0.54 0.62 0.67
16 cm.DESSL Avg. sentence length 9.60 11.88 13.62 16.69 19.36 21.73
17 cm.DESWLsyd SD of word syllables count 8.92 0.98 1.33 0.98 0.97 0.97
18 liwc.i Number of FPS* pronouns 8.84 4.33 2.82 2.37 2.51 2.19
19 cm.RDFKGL Flesch-Kincaid Grade level 8.29 7.68 10.30 10.19 11.13 11.99
20 cm.SMCAUSwn WordNet overlap between verbs 8.14 0.38 0.48 0.51 0.50 0.47
* MDG - Mean decrease Gini impurity index, FPS - first person singular

23Feature importancePhase
# Variable Description MDG* Other TE Exp. Int. Res.
1 cm.DESWC Number of words 32.91 55.41 80.91 117.71 183.30 280.68
2 ner.entity.cnt Number of named entities 26.41 13.44 21.67 28.84 44.75 64.18
3 cm.LDTTRa Lexical diversity, all words 21.98 0.85 0.77 0.71 0.65 0.58
4 message.depth Position within a discussion 19.09 2.39 1.00 1.84 1.87 2.00
5 cm.LDTTRc Lexical diversity, content words 17.12 0.95 0.90 0.86 0.82 0.78
6 cm.LSAGN Avg. givenness of each sentence 16.63 0.10 0.14 0.18 0.21 0.24
7 liwc.Qmark Number of question marks 16.59 0.27 1.84 0.92 0.58 0.38
8 message.sim.prev Similarity with previous message 16.41 0.20 0.06 0.22 0.30 0.39
9 cm.LDVOCD Lexical diversity, VOCD 15.43 12.92 28.99 53.57 83.47 97.16
10 liwc.money Number of money-related words 14.38 0.21 0.32 0.32 0.65 0.99
11 cm.DESPL Avg. number of paragraphs 12.47 4.26 6.37 7.49 10.17 14.05
12 Message.sim.next Similarity with next message 11.74 0.08 0.34 0.20 0.22 0.22
13 Message.reply.cnt Number of replies 11.67 0.42 1.44 0.82 1.10 0.84
14 cm.DESSC Sentence count 11.67 4.28 6.36 7.49 10.17 14.29
15 lsa.similarity Avg. LSA sim. between sentences 9.69 0.29 0.47 0.54 0.62 0.67
16 cm.DESSL Avg. sentence length 9.60 11.88 13.62 16.69 19.36 21.73
17 cm.DESWLsyd SD of word syllables count 8.92 0.98 1.33 0.98 0.97 0.97
18 liwc.i Number of FPS* pronouns 8.84 4.33 2.82 2.37 2.51 2.19
19 cm.RDFKGL Flesch-Kincaid Grade level 8.29 7.68 10.30 10.19 11.13 11.99
20 cm.SMCAUSwn WordNet overlap between verbs 8.14 0.38 0.48 0.51 0.50 0.47
* MDG - Mean decrease Gini impurity index, FPS - first person singular

24Operationalization of cognitive presence
Higher levels of cognitive presence actually mean…
The higher the cognitive presence (O -> TE -> E -> I -> R)
• The longer the message.
• The more concepts mentioned (more named entities).
• The lower the lexical diversity (both at content level and in general).
• The later its position in the thread. Except non-cognitive messages, they tend to occur closer to
the end as well.
• The higher the giveness of each sentence.
• The fewer the question marks. Except non-cognitive, they have the smallest number of question
marks.
• The higher the number of paragraphs and sentences.
• The higher the average length of sentence and their similarity to each other.
• The more money-related terms.
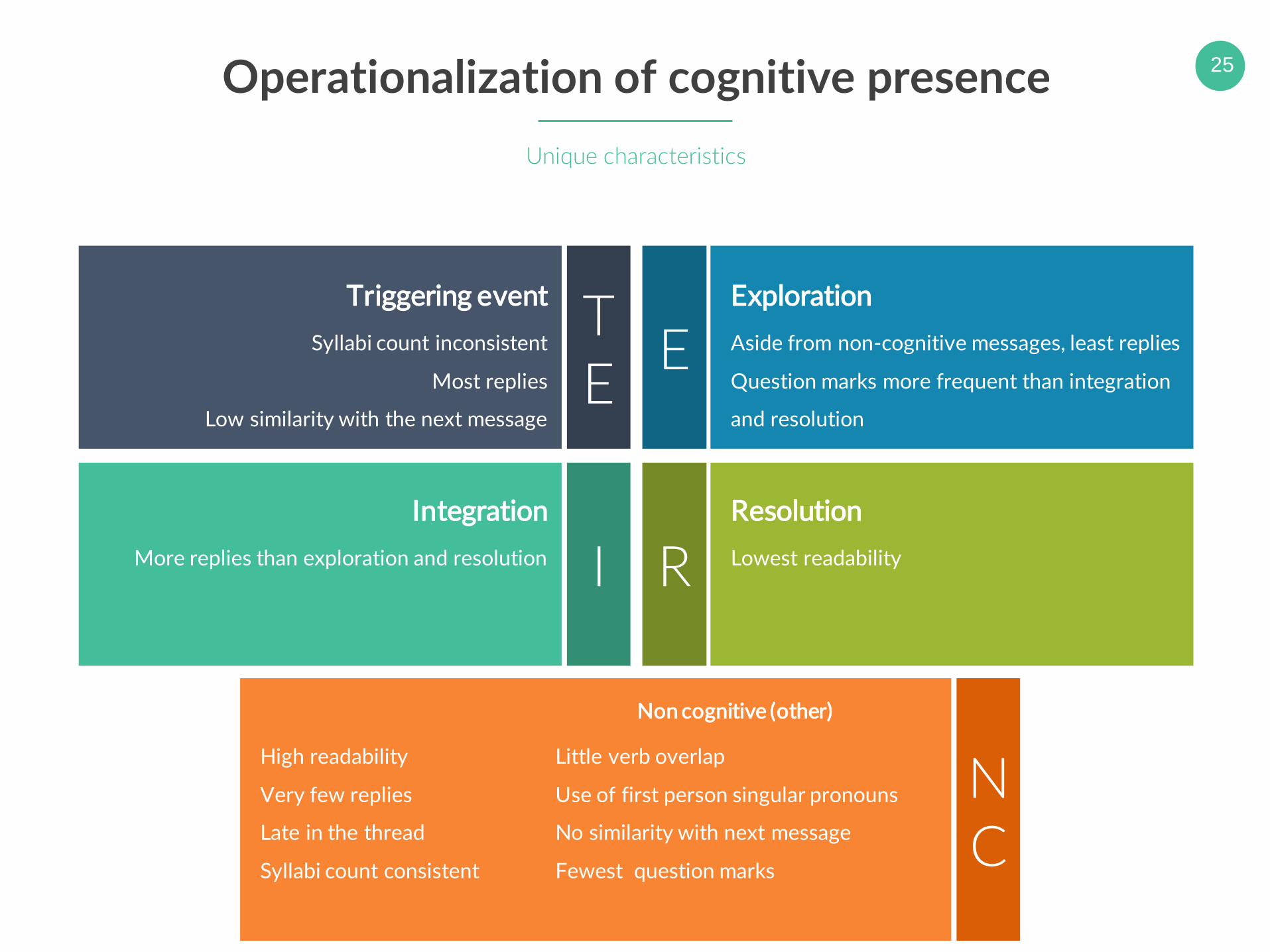
25Operationalization of cognitive presence
Unique characteristics
TE
Triggering event
Syllabi count inconsistent
Most replies
Low similarity with the next message
EExploration
Aside from non-cognitive messages, least replies
Question marks more frequent than integration
and resolution
IIntegration
More replies than exploration and resolution RResolution
Lowest readability
NC
Non cognitive (other)
High readability
Very few replies
Late in the thread
Syllabi count consistent
Little verb overlap
Use of first person singular pronouns
No similarity with next message
Fewest question marks

26Summary
Almost done
• We developed a classifier for automated coding of discussion messages for the levels of cognitive
presence
• We significantly improved the classification accuracy (Cohen’s κ = , Classification Accuracy = )
• The feature space ~ 100x smaller
• The feature space is also more generalizable
• We provided more detailed operationalization of the cognitive presence coding scheme
Future work:
• We are currently coding a dataset from two MOOC courses by the University of Edinburgh
• Evaluation of the classifier in the MOOC context

27Our plan
It will be a small and fun project

28Reality
But it is definitely not a small project

29The end
That is all folks
Thank you

30References
Garrison, D. R., Anderson, T., & Archer, W. (1999). Critical Inquiry in a Text-Based Environment:
Computer Conferencing in Higher Education. The Internet and Higher Education, 2(2–3), 87–105.
Kovanović, V., Joksimović, S., Gašević, D., & Hatala, M. (2014). Automated Content Analysis of
Online Discussion Transcripts. In Proceedings of the Workshops at the LAK 2014 Conference co-
located with 4th International Conference on Learning Analytics and Knowledge (LAK 2014).
Indianapolis, IN. Retrieved from http://ceur-ws.org/Vol-1137/
McNamara, D. S., Graesser, A. C., McCarthy, P. M., & Cai, Z. (2014). Automated Evaluation of Text
and Discourse with Coh-Metrix. Cambridge University Press.
Tausczik, Y. R., & Pennebaker, J. W. (2010). The Psychological Meaning of Words: LIWC and
Computerized Text Analysis Methods. Journal of Language and Social Psychology, 29(1), 24–54.
http://doi.org/10.1177/0261927X09351676
Waters, Z., Kovanović, V., Kitto, K., & Gašević, D. (2015). Structure matters: Adoption of structured
classification approach in the context of cognitive presence classification. In Proceedings of the
11th Asia Information Retrieval Societies Conference, AIRS 2015.