tp1: programmation cuda “cuda devices and threading · p.bakowski 2 analyse d ’un circuit/...
TRANSCRIPT

P.Bakowski 1
TP1: Programmation CUDATP1: Programmation CUDA
““CUDA devices andCUDA devices and threadingthreading””
P. BakowskiP. Bakowski

P.Bakowski 2
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidia
..Dans le premier exercice nous allons analyser les Dans le premier exercice nous allons analyser les fonctionnalitfonctionnalitéés offertes par la carte graphique s offertes par la carte graphique nVidianVidiainstallinstalléée dans votre ordinateur.e dans votre ordinateur.
Il sIl s’’agit dagit d’é’écrire un programme qui sollicite lcrire un programme qui sollicite l’’environnement environnement «« runtimeruntime »» de CUDA et lui demander les paramde CUDA et lui demander les paramèètres du tres du circuit graphique circuit graphique –– GPU. GPU.
Ces paramCes paramèètres sont communiqutres sont communiquéés par le biais de la s par le biais de la structure:structure:
struct struct cudaDevicePropcudaDeviceProp
et la fonction: et la fonction:
cudaGetDeviceProperties(&deviceProp,devicecudaGetDeviceProperties(&deviceProp,device););

P.Bakowski 3
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidia
..struct cudaDevicePropstruct cudaDeviceProp
{{
char name[256];char name[256];
size_t totalGlobalMem;size_t totalGlobalMem;
size_t sharedMemPerBlock;size_t sharedMemPerBlock;
int regsPerBlock;int regsPerBlock;
int warpSize;int warpSize;
size_t memPitch;size_t memPitch;
int maxThreadsPerBlock;int maxThreadsPerBlock;
int maxThreadsDim[3];int maxThreadsDim[3];
int maxGridSize[3];int maxGridSize[3];
size_t totalConstMem;size_t totalConstMem;
int major;int major;
int minor;int minor;
int clockRate;int clockRate;
size_t textureAlignment;size_t textureAlignment;
int deviceOverlap;int deviceOverlap;
int multiProcessorCount;int multiProcessorCount;
int kernelExecTimeoutEnabled;int kernelExecTimeoutEnabled;
}}

P.Bakowski 4
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidia
..struct cudaDevicePropstruct cudaDeviceProp
{{
char name[256];char name[256];
size_t totalGlobalMem;size_t totalGlobalMem;
size_t sharedMemPerBlock;size_t sharedMemPerBlock;
int regsPerBlock;int regsPerBlock;
int warpSize;int warpSize;
size_t memPitch;size_t memPitch;
int maxThreadsPerBlock;int maxThreadsPerBlock;
int maxThreadsDim[3];int maxThreadsDim[3];
int maxGridSize[3];int maxGridSize[3];
size_t totalConstMem;size_t totalConstMem;
int major;int major;
int minor;int minor;
int clockRate;int clockRate;
size_t textureAlignment;size_t textureAlignment;
int deviceOverlap;int deviceOverlap;
int multiProcessorCount;int multiProcessorCount;
int kernelExecTimeoutEnabled;int kernelExecTimeoutEnabled;
}}

P.Bakowski 5
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidia
..struct cudaDevicePropstruct cudaDeviceProp
{{
char name[256];char name[256];
size_t totalGlobalMem;size_t totalGlobalMem;
size_t sharedMemPerBlock;size_t sharedMemPerBlock;
int regsPerBlock;int regsPerBlock;
int warpSize;int warpSize;
size_t memPitch;size_t memPitch;
int maxThreadsPerBlock;int maxThreadsPerBlock;
int maxThreadsDim[3];int maxThreadsDim[3];
int maxGridSize[3];int maxGridSize[3];
size_t totalConstMem;size_t totalConstMem;
int major;int major;
int minor;int minor;
int clockRate; // in KHzint clockRate; // in KHz
size_t textureAlignment;size_t textureAlignment;
int deviceOverlap;int deviceOverlap;
int multiProcessorCount;int multiProcessorCount;
int kernelExecTimeoutEnabled;int kernelExecTimeoutEnabled;
}}
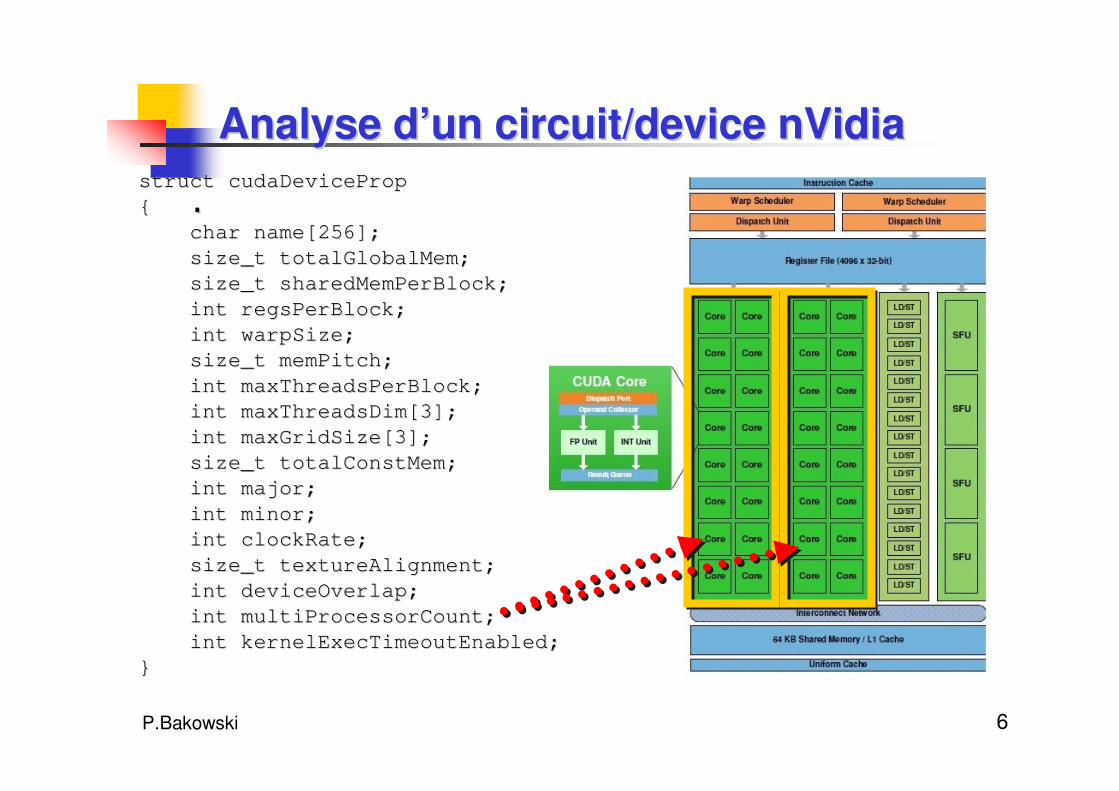
P.Bakowski 6
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidia
..struct cudaDevicePropstruct cudaDeviceProp
{{
char name[256];char name[256];
size_t totalGlobalMem;size_t totalGlobalMem;
size_t sharedMemPerBlock;size_t sharedMemPerBlock;
int regsPerBlock;int regsPerBlock;
int warpSize;int warpSize;
size_t memPitch;size_t memPitch;
int maxThreadsPerBlock;int maxThreadsPerBlock;
int maxThreadsDim[3];int maxThreadsDim[3];
int maxGridSize[3];int maxGridSize[3];
size_t totalConstMem;size_t totalConstMem;
int major;int major;
int minor;int minor;
int clockRate;int clockRate;
size_t textureAlignment;size_t textureAlignment;
int deviceOverlap;int deviceOverlap;
int multiProcessorCount;int multiProcessorCount;
int kernelExecTimeoutEnabled;int kernelExecTimeoutEnabled;
}}

P.Bakowski 7
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidiaMultiprocessorsMultiprocessors corescores Compute CapabilityCompute Capability
GeForce GTX 480 GeForce GTX 480 15 15 480 480 2.0 2.0 GeForce GTX 470 GeForce GTX 470 14 14 448 448 2.0 2.0 GeForce GTX 465 GeForce GTX 465 11 11 352 352 2.0 2.0 GeForce GTX 295 GeForce GTX 295 22××30 30 22××240 240 1.3 1.3 GeForce GTX 280/GTXGeForce GTX 280/GTX 285 30 285 30 240 240 1.3 1.3 GeForce GTX 260 GeForce GTX 260 24 24 192 192 1.3 1.3 GeForce 210 GeForce 210 2 2 16 16 1.2 1.2 GeForce GT 240 GeForce GT 240 12 12 96 96 1.2 1.2 GeForce GT 220 GeForce GT 220 6 6 48 48 1.2 1.2 GeForce GT 130 GeForce GT 130 12 12 96 96 1.1 1.1 GeForce GT 120 GeForce GT 120 4 4 32 32 1.1 1.1 GeForce GTS 250 GeForce GTS 250 16 16 128 128 1.1 1.1 GeForce 9800 GX2 GeForce 9800 GX2 22××16 16 22××128 128 1.1 1.1 GeForce 9800 GTX GeForce 9800 GTX 16 16 128 128 1.1 1.1 GeForce 8800 GT GeForce 8800 GT 14 14 112 112 1.1 1.1 GeForce 8800 GTS GeForce 8800 GTS 12 12 96 96 1.0 1.0 GeForce 8600 GT/GTS GeForce 8600 GT/GTS 4 4 32 32 1.11.1

P.Bakowski 8
Analyse du GPU (Exo0)Analyse du GPU (Exo0)
Exercice 0:Exercice 0:Ecrire un programme qui permet dEcrire un programme qui permet d’’afficher:afficher:Le nom du circuitLe nom du circuitLa taille de la mLa taille de la méémoire globalemoire globaleLa taille de la mLa taille de la méémoire partagmoire partagéée (dans un bloc)e (dans un bloc)Le nombre de registres par blocLe nombre de registres par blocLe nombre de Le nombre de threadsthreads par blocpar blocVersion: majeure, mineureVersion: majeure, mineureFrFrééquence horloge (en KHz)quence horloge (en KHz)Le nombre de multiprocesseursLe nombre de multiprocesseurs

P.Bakowski 9
Analyse dAnalyse d’’un circuit/un circuit/devicedevice nVidianVidia
Quelques Quelques ééllééments du programme:ments du programme:
#include <stdio.h>#include <stdio.h> #include <stdlib.h>#include <stdlib.h>
#include <cuda.h>#include <cuda.h> #include <cuda_runtime.h>#include <cuda_runtime.h>
int main(){int main(){
cudaDeviceProp deviceProp;cudaDeviceProp deviceProp;
int device=0;int device=0;
cudaGetDeviceProperties(&deviceProp, device );cudaGetDeviceProperties(&deviceProp, device );
////
Attention:Attention:Le code source doit être enregistrLe code source doit être enregistréé avec extension .cu; avec extension .cu; la compilation nla compilation néécessite lcessite l’’utilisation du script nvcc.utilisation du script nvcc.
%nvcc %nvcc ––o exo0 exo0.cuo exo0 exo0.cu

P.Bakowski 10
Addition des vecteurs, premier Addition des vecteurs, premier kernelkernel
Dans cet exercice nous allons Dans cet exercice nous allons éécrire notre premier crire notre premier kernelkernel –– fonction exfonction exéécutcutéée par le GPU.e par le GPU.Le programme est composLe programme est composéé de plusieurs parties:de plusieurs parties:
Le Le kernelkernel éévoquvoquéé comme fonction globale:comme fonction globale:__global__ __global__ addVectaddVect(..)(..)
La fonction principale main() avec:La fonction principale main() avec:allocation de la mallocation de la méémoire globale du GPUmoire globale du GPUtransfert des arguments dans cette mtransfert des arguments dans cette méémoiremoireappel du appel du kernelkernel avec un triple chevron avec un triple chevron
<<<..>>><<<..>>>transfert des rtransfert des réésultats de la msultats de la méémoire GPUmoire GPU

P.Bakowski 11
Le Le kernelkernel__global__ void __global__ void addVect(floataddVect(float* in1,float* in2,float* out)* in1,float* in2,float* out)
{{
int i = int i = threadIdx.xthreadIdx.x;;
out[i] = in1[i] + in2[i];out[i] = in1[i] + in2[i];
}}
La variable La variable threadIdx.xthreadIdx.x est une variable automatique est une variable automatique fournie par le compilateur; elle donne lfournie par le compilateur; elle donne l’’index du thread index du thread exexéécutant la fonction.cutant la fonction.
threadIdx.xthreadIdx.x=0=0
addVectaddVect
threadIdx.xthreadIdx.x=1=1
threadIdx.xthreadIdx.x=N=N--22
threadIdx.xthreadIdx.x=N=N--11

P.Bakowski 12
Allocation de la mAllocation de la méémoire GPUmoire GPU
float* Cv1;float* Cv1;
cudaMalloc((void **)&Cv1,memsize);cudaMalloc((void **)&Cv1,memsize);
float* Cv2;float* Cv2;
cudaMalloc((void **)&Cv2,memsize);cudaMalloc((void **)&Cv2,memsize);
float* Cres;float* Cres;
cudaMalloc((void **)&Cres,memsize);cudaMalloc((void **)&Cres,memsize);
Attention:Attention:
A la fin dA la fin d’’exexéécution la mcution la méémoire moire GPU doit être libGPU doit être libéérréée par: e par:
cudaFreecudaFree(Cv1); (Cv1); cudaFreecudaFree(Cv2); (Cv2);
cudaFreecudaFree(Cres);(Cres);

P.Bakowski 13
Transfert des donnTransfert des donnéées et appel du es et appel du kernelkernel
cudaMemcpy(Cv1,v1,memsize,cudaMemcpyHostToDevice);cudaMemcpy(Cv1,v1,memsize,cudaMemcpyHostToDevice);
cudaMemcpy(Cv2,v2,memsize,cudaMemcpyHostToDevice);cudaMemcpy(Cv2,v2,memsize,cudaMemcpyHostToDevice);
addVect<<<1,vsize>>>(Cv1,Cv2,Cres);addVect<<<1,vsize>>>(Cv1,Cv2,Cres);
cudaMemcpy(res,Cres,memsize,cudaMemcpyDeviceToHost);cudaMemcpy(res,Cres,memsize,cudaMemcpyDeviceToHost);
addVectaddVect
<<<1,vsize>>><<<1,vsize>>>
1 bloc, 1 bloc, vsizevsize kernelskernels

P.Bakowski 14
Addition des vecteurs (Exo1a)Addition des vecteurs (Exo1a)
Exercice 1a:Exercice 1a:Ecrire une application complEcrire une application complèète avec le te avec le kernelkernel qui qui additionne deux vecteurs.additionne deux vecteurs.Les valeurs des vecteurs peuvent être prLes valeurs des vecteurs peuvent être prééparparéées sous la es sous la forme de constantes:forme de constantes:Par exemple:Par exemple:
float v1[]={1,2,3,4,5,6,7,8,9,10};float v1[]={1,2,3,4,5,6,7,8,9,10};
float float
v2[]={10.9,11.8,12.7,13.6,14.5,15.4,16.3,17.2,18.1,19.0};v2[]={10.9,11.8,12.7,13.6,14.5,15.4,16.3,17.2,18.1,19.0};
AprAprèès le retour du s le retour du kernelkernel afficher les rafficher les réésultats.sultats.

P.Bakowski 15
Addition des vecteurs (Exo1b)Addition des vecteurs (Exo1b)
Exercice 1b:Exercice 1b:Ecrire la même application en mettant en Ecrire la même application en mettant en œœuvre le uvre le mméécanisme de blocs: Exemple de modifications canisme de blocs: Exemple de modifications àà faire:faire:
#define BLN 5#define BLN 5
Appel du Appel du kernelkernel::addVect<<<addVect<<<BLNBLN,vsize,vsize/BLN/BLN>>>(Cv1,Cv2,Cres);>>>(Cv1,Cv2,Cres);
Calcul de lCalcul de l’’indexe dans le indexe dans le kernelkernel::int i = int i = threadIdx.xthreadIdx.x + + blockIdx.xblockIdx.x**blockDim.xblockDim.x;;
blockIdx.xblockIdx.x=0=0 blockIdx.xblockIdx.x=4=4
x*x*blockDim.xblockDim.x=2=2

P.Bakowski 16
Multiplication des matricesMultiplication des matrices
La multiplication des matrices, nLa multiplication des matrices, néécessitant des opcessitant des opéérations rations de la multiplication et de lde la multiplication et de l’’addition sur plusieurs addition sur plusieurs ééllééments ments indindéépendant, permet dpendant, permet d’’exploiter pleinement la puissance exploiter pleinement la puissance des circuits GPU.des circuits GPU.
ii jj 0*1 + 1*3 = 30*1 + 1*3 = 3

P.Bakowski 17
Multiplication des matricesMultiplication des matrices
LL’’organisation de threads en deux dimensions se prête trorganisation de threads en deux dimensions se prête trèès s bien pour calculer les points dans la matrice des rbien pour calculer les points dans la matrice des réésultats. sultats. Nous allons donc utiliser les structures prNous allons donc utiliser les structures prééddééfinies de typefinies de typedim3 dim3
dim3 dimBlock(DIM,DIM);
dim3 dimGrid(1,1);
Chaque case de la matrice est traitChaque case de la matrice est traitéée par un thread.e par un thread.Chaque thread Chaque thread àà deux identificateurs:deux identificateurs:threadIdx.xthreadIdx.x et et threadIdx.ythreadIdx.y

P.Bakowski 18
Multiplication des matrices Multiplication des matrices -- kernelkernel
La fonction du La fonction du kernelkernel rréécupcupèère les arguments suivantes:re les arguments suivantes:
// allocation on GPU// allocation on GPU
cudaMalloc((voidcudaMalloc((void **)&dev_A,DIM*DIM*sizeof(float));**)&dev_A,DIM*DIM*sizeof(float));
cudaMalloc((voidcudaMalloc((void **)&dev_B,DIM*DIM*sizeof(float));**)&dev_B,DIM*DIM*sizeof(float));
cudaMalloc((voidcudaMalloc((void **)&dev_C,DIM*DIM*sizeof(float));**)&dev_C,DIM*DIM*sizeof(float));
// data transfer to GPU// data transfer to GPU
int int sizematsizemat= = DIM*DIM*sizeof(float),DIM*DIM*sizeof(float),
cudaMemcpy(dev_A,buffAcudaMemcpy(dev_A,buffA, , sizematsizemat,, cudaMemcpyHostToDevicecudaMemcpyHostToDevice););
cudaMemcpycudaMemcpy((dev_B,buffBdev_B,buffB, , sizematsizemat, , cudaMemcpyHostToDevicecudaMemcpyHostToDevice););

P.Bakowski 19
Multiplication des matrices Multiplication des matrices -- kernelkernel
Elle est appelElle est appeléée par:e par:dim3 dim3 dimBlock(DIM,DIMdimBlock(DIM,DIM);); dim3 dim3 dimGriddimGrid(1,1);(1,1);
matrix_mulmatrix_mul<<<<<<dimGrid,dimBlockdimGrid,dimBlock>>>(>>>(dev_A,dev_B,dev_C,DIMdev_A,dev_B,dev_C,DIM););
Son code est:Son code est:__global__ void__global__ void matrix_mul(floatmatrix_mul(float* dev_A,float* dev_B,* dev_A,float* dev_B,
float* dev_C,float* dev_C, int Width)int Width)
{{
int int txtx = = threadIdx.xthreadIdx.x;; int int tyty = = threadIdx.ythreadIdx.y;;
float float PvaluePvalue =0;=0;
for(int k=0;k<Width;++k)for(int k=0;k<Width;++k)
{{
float float AelAel==dev_A[tydev_A[ty*Width + k]; *Width + k];
float float BelBel=dev_B[k*Width +=dev_B[k*Width +txtx]; ];
PvaluePvalue += += AelAel**BelBel;;
}} dev_Cdev_C[[tyty**WidthWidth++txtx]= ]= PvaluePvalue;;
}}

P.Bakowski 20
Multiplication des matrices Multiplication des matrices -- CPUCPU
CiCi--dessous le code de multiplication des matrices rdessous le code de multiplication des matrices rééalisaliséépour le CPU. pour le CPU. Ici le traitement des cases sont rIci le traitement des cases sont rééalisaliséés ss sééquentiellement quentiellement par 2 boucles for, une pour la dimension verticale (i) et une par 2 boucles for, une pour la dimension verticale (i) et une pour la dimension horizontale (j).pour la dimension horizontale (j).
for(int i=0;i<DIM;i++)for(int i=0;i<DIM;i++)
for(int j=0;j<DIM;j++)for(int j=0;j<DIM;j++)
for(int k=0;k<DIM;k++)for(int k=0;k<DIM;k++)
buffC[jbuffC[j + i*DIM] += + i*DIM] += buffA[k+jbuffA[k+j*DIM]**DIM]*buffB[j+kbuffB[j+k*DIM];*DIM];

P.Bakowski 21
Analyse des performancesAnalyse des performances
Avec CUDA lAvec CUDA l’’analyse de performances peut être ranalyse de performances peut être rééalisaliséée e par les mpar les méécanismes dcanismes d’é’évvéénements.nements.Les Les éévvéénements peuvent être initialisnements peuvent être initialiséés par:s par:
float float elapsedTimeelapsedTime;;
cudaEvent_t start,stop; // declarationcudaEvent_t start,stop; // declaration
cudaEventCreate(&start); // creationcudaEventCreate(&start); // creation
cudaEventCreate(&stop);cudaEventCreate(&stop);
cudaEventRecord(cudaEventRecord(startstart,0); // activation,0); // activation
// execution// execution
cudaEventRecord(cudaEventRecord(stopstop,0);,0);
cudaEventSynchronize(stop);cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime,start,stop);cudaEventElapsedTime(&elapsedTime,start,stop);
// display // display elapsedTimeelapsedTime

P.Bakowski 22
Sujet: comparaison des performances Sujet: comparaison des performances
Sujet:Sujet:Ecrire une application de multiplication des matrices avec 2 Ecrire une application de multiplication des matrices avec 2 modes de fonctionnement: mode GPU et mode CPUmodes de fonctionnement: mode GPU et mode CPUComparer le temps dComparer le temps d’’exexéécution cution àà ll’’aide des aide des éévvéénements.nements.Pour obtenir les rPour obtenir les réésultats probants utiliser les matrices sultats probants utiliser les matrices carrcarréées de taille (DIM) minimum de 64*64. Le contenu des es de taille (DIM) minimum de 64*64. Le contenu des matrices peut être initialismatrices peut être initialiséé par la fonction rand():par la fonction rand():
float* random_block(int size)float* random_block(int size)
{{
float *float *ptrptr;;
ptrptr = (float *)malloc(size*sizeof(float));= (float *)malloc(size*sizeof(float));
for (int i=0;i<size;i++)for (int i=0;i<size;i++)
ptr[iptr[i] = rand();] = rand();
return return ptrptr;;
}}

P.Bakowski 23
RRéésumsuméé
Dans ce TP nous avons Dans ce TP nous avons éétuditudiéé les principales les principales caractcaractééristiques fonctionnels des unitristiques fonctionnels des unitéés GPU.s GPU.
Nous avons Nous avons éétuditudiéé et et éécrit quelques exemples crit quelques exemples simples de programmation CUDA incluant:simples de programmation CUDA incluant:
analyse danalyse d’’un un «« devicedevice »» CUDACUDA
éécriture dcriture d’’un un kernelkernel simplesimple
éécriture dcriture d’’un un kernelkernel àà deux dimensions de deux dimensions de traitementtraitement
analyse des performances basanalyse des performances baséée sur les e sur les éévvéénements CUDAnements CUDA