trabajo bdd
TRANSCRIPT

TRABAJO DE BASE DE DATOS DISTRIBUIDA
LINA VANESSA RUIDIAZ VISBAL
NASER YAMITD ROMERO DUARTE
RODRIGO CABRERA BENJUMEA
JAVIER SERRANO HERNANDEZ
JASSER MEJIA
GRUPO(2)
UNIVERSIDAD POPULAR DEL CESAR
FACULTAD DE INGENERIA Y TECNOLOGIA
VALLEDUPAR (CESAR)
2012

TRABAJO DE BASE DE DATOS DISTRIBUIDA
LINA VANESSA RUIDIAZ VISBAL
NASER YAMITD ROMERO DUARTE
RODRIGO CABRERA BENJUMEA
JAVIER SERRANO HERNANDEZ
JASSER MEJIA
ING: WILIAM MEJIA
GRUPO (2)
UNIVERSIDAD POPULAR DEL CESAR
FACULTAD DE INGENERIA Y TECNOLOGIA
VALLEDUPAR (CESAR)
2012

TABLA DE CONTENIDO
1. ¿QUE SON BASES DE DATOS DISTRIBUIDAS? 2. EJEMPLO DE UNA BASE DE DATOS DISTRIBUIDAS 3. COMPARACIÓN BDD Y BDC 4. ARQUITECTURA DE LAS BASES DE DATOS 5. TIPOS DE ALMACENAMIENTO
5.1 REPLICA 5.2 FRAGMENTACIÓN
5.2.1 FRAGMENTACIÓN HORIZONTAL 5.2.2 FRAGMENTACIÓN VERTICAL 5.2.3 FRAGMENTACIÓN MIXTA
5.3 REPLICA Y FRAGMENTACIÓN 6. NIVELES DE TRANSPARENCIA EN UNA BASE DE DATOS
DISTRIBUIDA 7. CARACTERÍSTICAS DE LAS BASE DE DATOS DISTRIBUIDA 8. VENTAJAS Y DESVENTAJAS
9. RECUPERACIÓN
10. LAS DOCE REGLA
11. ALTERNATIVAS PARA LA IMPLEMENTACION DE SMBD
12. LAS DOCE REGLAS 13. CONCLUSION 14. BIBLIOGRAFIA


INTRODUCCION
Una base de datos distribuida es una colección lógicamente interrelacionada de datos compartidos, físicamente distribuida en una red informática. Comenzó por una necesidad de almacenar información de forma masiva. Una de las primeras ideas surgió en 1970 por Edgard Frank Codd con el que definió el modelo y las reglas para poder evaluar un administrador de bases de datos relacionales.
• El motivo por el cual surgió el concepto de bases de datos distribuidos es
porque en el mundo de los negocios se ha dado una globalización y las empresas
cada vez están más descentralizadas físicamente. Para manejar estos datos se
necesitan componentes hardware para manejar y procesar los datos, como software
para controlar el flujo de información de manera más eficiente posible.
• Algunos aspectos a considerar es la seguridad, la eficiencia, y la distribución
lógica tanto física como digital de los datos, se debe de asegurar también la
disponibilidad de los datos a la hora de acezarlos.
• En un sistema de bases de datos distribuidas, existen varios factores que
deben tomar en consideración que definen la arquitectura del sistema, distribución,
heterogeneidad, y autonomía

1. ¿QUE SON BASES DE DATOS DISTRIBUIDAS?
Son un grupo de datos que pertenecen a un sistema pero a su vez esta repartido entre ordenadores de una misma red, ya sea a nivel local o cada uno en una diferente localización geográfica, cada sitio en la red es autónomo en sus capacidades de procesamiento y es capaz de realizar operaciones locales y en cada uno de estos ordenadores debe estar ejecutándose una aplicación a nivel global que permita la consulta de todos los datos como si se tratase de uno solo.
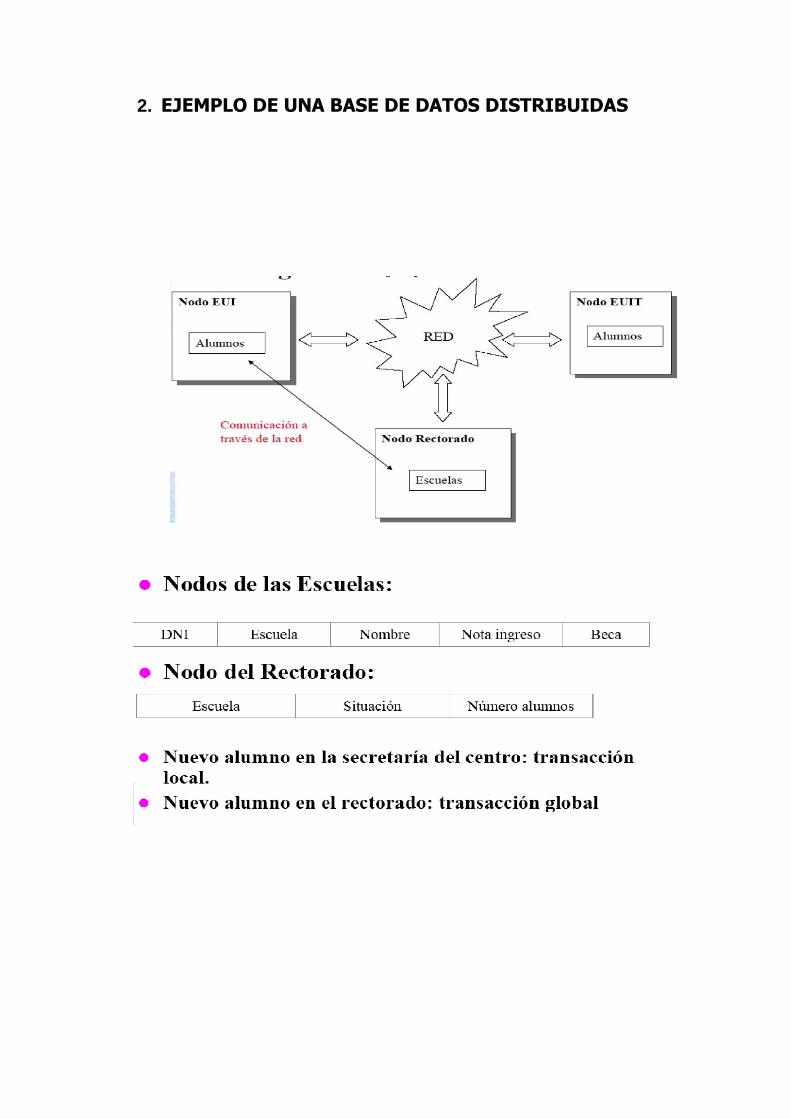
2. EJEMPLO DE UNA BASE DE DATOS DISTRIBUIDAS
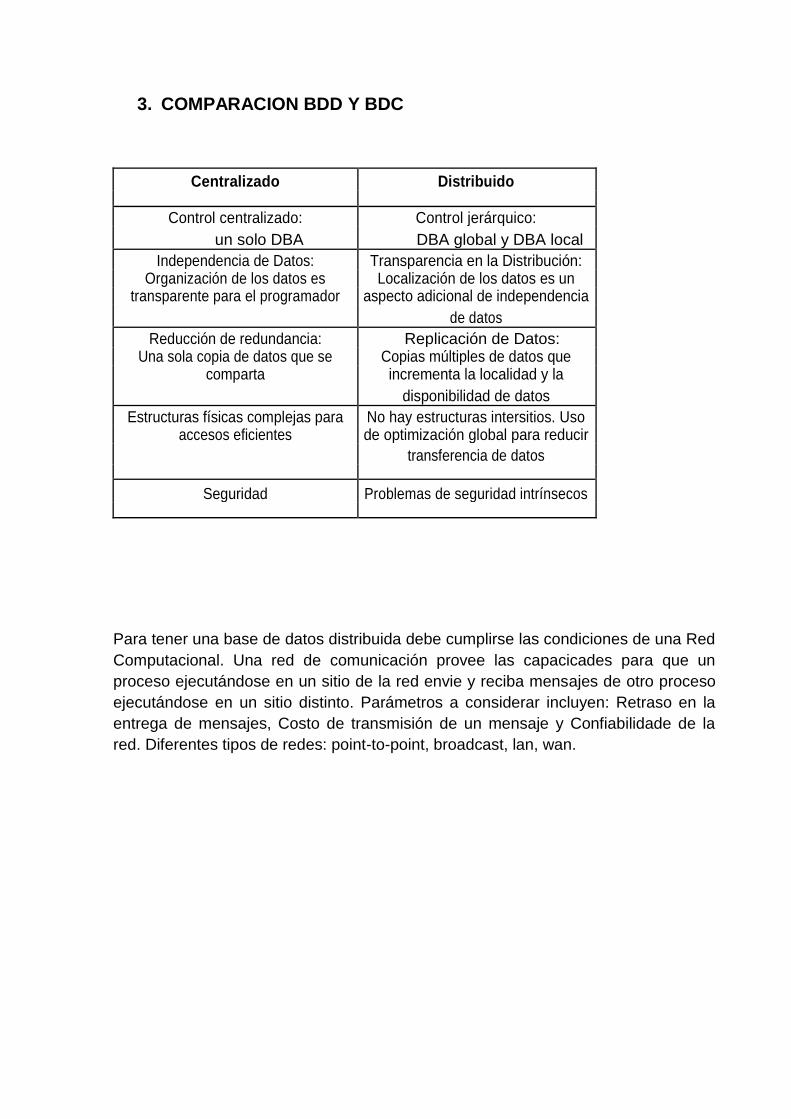
3. COMPARACION BDD Y BDC
Centralizado Distribuido
Control centralizado: Control jerárquico:
un solo DBA DBA global y DBA local
Independencia de Datos: Transparencia en la Distribución: Organización de los datos es Localización de los datos es un
transparente para el programador aspecto adicional de independencia
de datos
Reducción de redundancia: Replicación de Datos: Una sola copia de datos que se Copias múltiples de datos que
comparta incrementa la localidad y la
disponibilidad de datos
Estructuras físicas complejas para No hay estructuras intersitios. Uso accesos eficientes de optimización global para reducir
transferencia de datos
Seguridad Problemas de seguridad intrínsecos
Para tener una base de datos distribuida debe cumplirse las condiciones de una Red
Computacional. Una red de comunicación provee las capacicades para que un
proceso ejecutándose en un sitio de la red envie y reciba mensajes de otro proceso
ejecutándose en un sitio distinto. Parámetros a considerar incluyen: Retraso en la
entrega de mensajes, Costo de transmisión de un mensaje y Confiabilidade de la
red. Diferentes tipos de redes: point-to-point, broadcast, lan, wan.

4. ARQUITECTURA DE LAS BASES DE DATOS DISTRIBUIDA
ARQUITECTURA ANSI/SPARC
La arquitectura ANSI / SPARC se divide en 3 niveles: 1. EL NIVEL INTERNO. Es el que se ocupa de la forma como se
almacenan físicamente los datos.
2. EL NIVEL EXTERNO. Es el que se ocupa de la forma como los usuarios individuales perciben los datos.
3. EL NIVEL CONCEPTUAL. Es un nivel de mediación entre los otros dos, es decir define las estructuras de almacenamientos el Administrador de Base de Datos. No existe un equivalente de una arquitectura estándar para sistemas de manejo de bases de datos distribuidas, cada sistema ha adoptado su propia arquitectura. Se debe definir un modelo de referencia para un esquema de estandarización en bases de datos distribuidas, cuyo propósito es dividir el

trabajo en piezas y esas piezas se relacionan unas con otras. Se sigue los siguientes enfoques: 1. BASADO EN COMPONENTES. Se definen las componentes del sistema junto con las relaciones entre ellas. 2. BASADO EN FUNCIONES. Se identifican las diferentes clases de usuarios junto con la funcionalidad que el sistema ofrecerá para cada clase. 3. BASADO EN DATOS. Se identifican los diferentes tipos de descripción de datos y se especifica un marco de trabajo arquitectural el cual define las unidades funcionales que realizarán y/o usarán los datos de acuerdo con las diferentes vistas. Este es el enfoque seguido por el modelo ANSI/SPARC.
ARQUITECTURA DE UN SISTEMA DE MANEJO DE BASES DE DATOS DISTRIBUIDOS HOMOGÉNEOS
DATOSDISTRIBUIDOS HOMOGENEOS
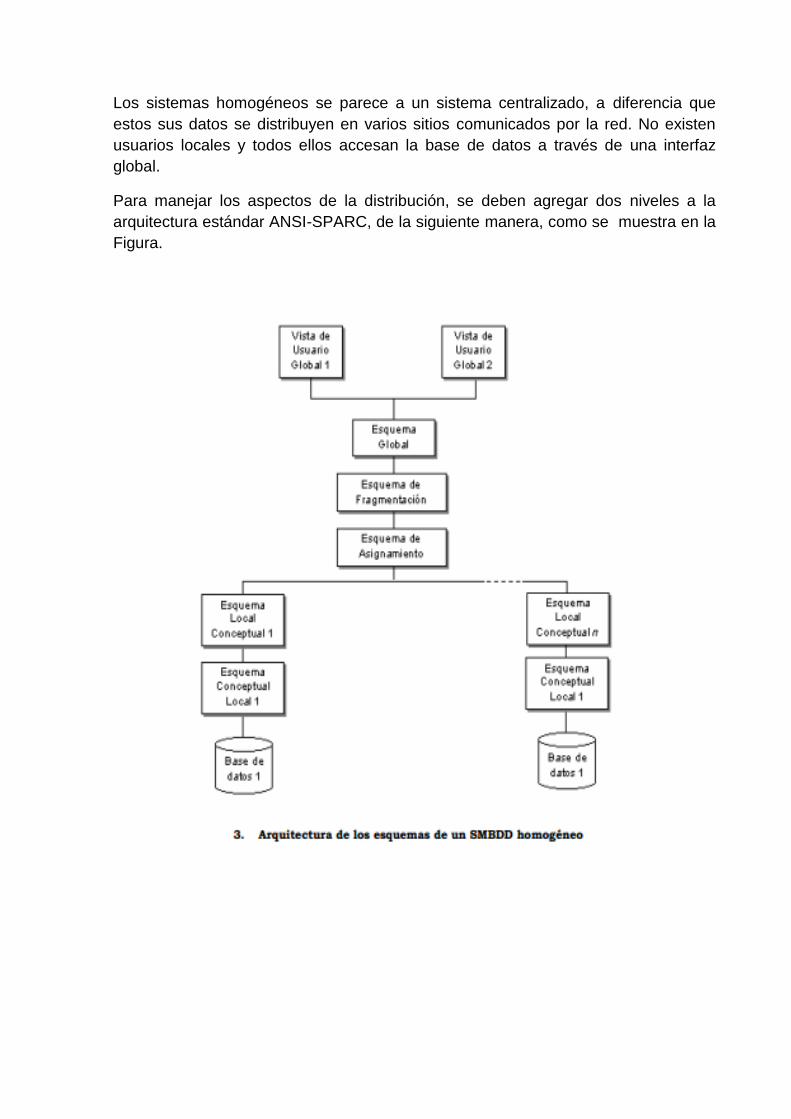
Los sistemas homogéneos se parece a un sistema centralizado, a diferencia que
estos sus datos se distribuyen en varios sitios comunicados por la red. No existen
usuarios locales y todos ellos accesan la base de datos a través de una interfaz
global.
Para manejar los aspectos de la distribución, se deben agregar dos niveles a la
arquitectura estándar ANSI-SPARC, de la siguiente manera, como se muestra en la
Figura.

EL ESQUEMA DE FRAGMENTACIÓN. Describe la forma en que las relaciones
globales se dividen entre las bases de datos locales.
EL ESQUEMA DE ASIGNAMIENTO. Especifica el lugar en el cual cada fragmento
es almacenado. De aquí, los fragmentos pueden migrar de un sitio a otro en
respuesta a cambios en los patrones de acceso
ARQUITECTURA DE UN SISTEMA DE MANEJO DE BASES DE
DATOS DISTRIBUIDOS HETEROGÉNEOS
Un sistema multi-bases de datos tiene múltiples SMBDs, que pueden ser de tipos
diferentes, y múltiples bases de datos existentes. Existen usuarios locales y
globales.

ARQUITECTURA BASADA EN COMPONENTES DE UN SISTEMA
DE MANEJO DE BASES DE DATOS DISTRIBUIDOS
Consiste en dos partes como son: el procesador de datos y el procesador de
usuario.
• El procesador de usuario es el encargado de procesar las solicitudes del usuario,
consiste en cuatro partes: un manejador de la interfaz con el usuario, un controlador
semántico de datos, un optimizador global de consultas y un supervisor de la
ejecución global.
• El procesador de datos existe en cada nodo de la base de datos distribuida. Utiliza
un esquema local conceptual y un esquema local interno, el procesador de datos
consiste de tres partes: un procesador de consultas locales, un manejador
de recuperación de fallas locales y un procesador de soporte para tiempo
de ejecución.

5. TIPOS DE ARCHIVOS
5.1. Replica El sistema conserva varias copias o réplicas idénticas de unatabla. Cada réplica se almacena en un nodo diferente.
Ventajas: Disponibilidad: El sistema sigue funcionando aún en caso de caída
de uno de los nodos. Aumento del paralelismo: Varios nodos pueden realizar consultas
en paralelo sobre la misma tabla. Cuantas más réplicas existan de la tabla, mayor serála posibilidad de que el dato buscado se encuentre en el nodo desde el que se realiza la consulta, minimizando con ello el tráfico de datos entre nodos.
Inconveniente: Aumento de la sobrecarga en las actualizaciones: El sistema
debe asegurar que todas las réplicas de la tabla sean consistentes. Cuandose realiza una actualización sobre una de las réplicas, los cambios deben propagarse a todas las réplicas de dicha tabla a lo largo del sistema distribuido.
5.2. Fragmentación
Existen tres tipos de fragmentacion la horizontal, la vertical y la mixta
5.2.1. Fragmentación Horizontal
Unatabla T se divide en subconjuntos, T1, T2, ...Tn. Los fragmentos se definen a
través de una operación de selección y su reconstrucción se realizará con una
operación de unión de los fragmentos componentes.
Cada fragmento se sitúa en un nodo.
Base de Datos DistribuidasPueden existir fragmentos no disjuntos: combinación de fragmentación y replicación.
Ejemplo:
Tabla inicial de alumnos
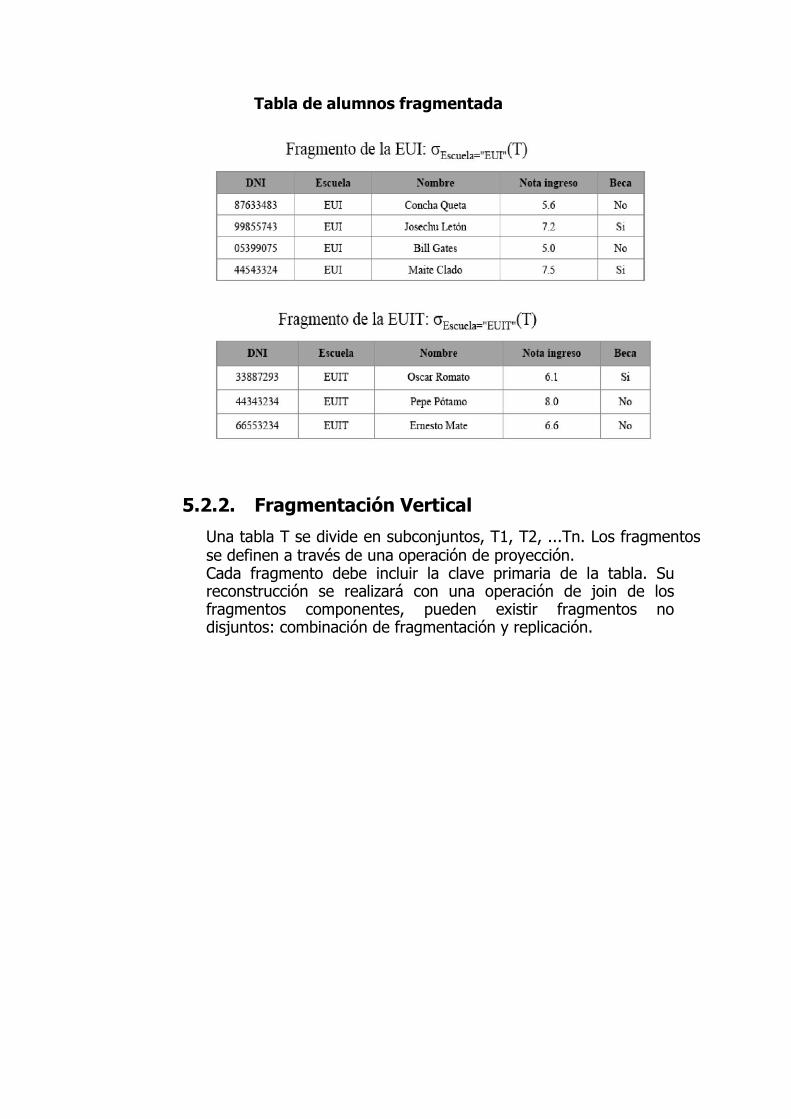
Tabla de alumnos fragmentada
5.2.2. Fragmentación Vertical
Una tabla T se divide en subconjuntos, T1, T2, ...Tn. Los fragmentos se definen a través de una operación de proyección. Cada fragmento debe incluir la clave primaria de la tabla. Su reconstrucción se realizará con una operación de join de los fragmentos componentes, pueden existir fragmentos no disjuntos: combinación de fragmentación y replicación.

Ejemplo:
3.-Fragmentación Mixta
Como el mismo nombre indica es una combinación de las dos
anteriores vistas he aquí un ejemplo apartir de una tabla fragmentada
horizontalmente.

5.3. REPLICA Y FRAGMENTACIÓN
Las técnicas de réplica y fragmentación se pueden aplicar sucesivamente a la
misma relación de partida. Un fragmento se puede replicar y a su vez esa
réplica ser fragmentada, para luego replicar alguno de esos fragmentos.
6. NIVELES DE TRANSPARENCIA EN UNA BASE DE DATOS DISTRIBUIDA
El propósito de establecer una arquitectura de un sistema de bases de datos
distribuidas es ofrecer un nivel de transparencia adecuado para el manejo de
la información.
La transparencia se define como la separación de la semántica de alto nivel de un
sistema de los aspectos de bajo nivel relacionados a la implementación del mismo.
Un nivel de transparencia adecuado permite ocultar los detalles de implementación a las capas de alto nivel de un sistema y a otros usuarios.
El sistema de bases de datos distribuido permite proporcionar independencia de
los datos.
La independencia de datos se puede dar en dos aspectos: lógica y física.
.1 Independencia lógica de datos. Se refiere a la inmunidad de las
aplicaciones de usuario a los cambios en la estructura lógica de la base de
datos. Esto permite que un cambio en la definición de un esquema no debe afectar a las aplicaciones de usuario. Por ejemplo, el agregar un
nuevo atributo a una relación, la creación de una nueva relación, el
reordenamiento lógico de algunos atributos. .2 Independencia física de datos. Se refiere al ocultamiento de los
detalles sobre las estructuras de almacenamiento a las aplicaciones de usuario. la descripción física de datos puede cambiar sin afectar a las aplicaciones de usuario. Por ejemplo, los datos pueden ser movidos de un disco a otro, o la organización de los datos puede cambiar.
La transparencia al nivel de red se refiere a que los datos en un SBDD se
accedan sobre una red de computadoras, sin embargo, las aplicaciones no
deben notar su existencia. La transparencia al nivel de red conlleva a dos
cosas:
.1Transparencia sobre la localización de datos. el comando que se usa es
independiente de la ubicación de los datos en la red y del lugar en donde la operación
se lleve a cabo. Por ejemplo, en Unix existen dos comandos para hacer

una copia de archivo. Cp se utiliza para copias locales y rcp se utiliza para copias remotas. En este caso no existe transparencia sobre la localización.
.2Transparencia sobre el esquema de nombramiento. Lo anterior se logra
proporcionando un nombre único a cada objeto en el sistema distribuido. Así, no se
debe mezclar la información de la localización con en el nombre de un objeto.
La transparencia sobre replicación de datos se refiere a que si existen réplicas de objetos de la base de datos, su existencia debe ser controlada por el sistema no por el usuario. Se debe tener en cuenta que cuando el usuario se encarga de manejar las réplicas en un sistema, el trabajo de éste es mínimo por lo que se puede
obtener una eficiencia mayor. Sin embargo, el usuario puede olvidarse de mantener la consistencia de las réplicas teniendo así datos diferentes.
La transparencia a nivel de fragmentación de datos permite que cuando los objetos de la bases de datos están fragmentados, el sistema tiene que manejar la
conversión de consultas de usuario definidas sobre relaciones globales a consultas definidas sobre fragmentos. Así también, será necesario mezclar las respuestas a consultas fragmentadas para obtener una sola respuesta a una consulta global. El acceso a una base de datos distribuida debe hacerse en forma transparente.
En resumen, la transparencia tiene como punto central la independencia de datos.
La responsabilidad sobre el manejo de transparencia debe estar compartida tanto por el sistema operativo, el sistema de manejo de bases de datos y el lenguaje de
acceso a la base de datos distribuida. Entre estos tres módulos se deben resolver los aspectos sobre el procesamiento distribuido de consultas y sobre el manejo de nombres de objetos distribuidos.

7. CARACTERÍSTICAS DE LAS BASE DE DATOS DISTRIBUIDA
• Los datos deben estar físicamente en más de un ordenador.
• Las sedes deben estar interconectadas mediante una red
• Los datos han de estar lógicamente integrados tanto en local como remoto
• En una única operación se puede acceder datos que se encuentran en más
de una sede
• Todas las acciones que necesiten realizarse sobre más de una sede serán
transparentes al usuario

8. VENTAJAS Y DESVANTAJAS
Ventajas y desventajas de un SGBDD
• Ventajas
o Reflejan mejor la estructura de la organización.
o Hacen que los datos puedan compartirse en mayor medida.
o Mejora la fiabilidad, la disponibilidad y las prestaciones.
o Puede ser más económico.
o Permite el crecimiento modular.
o Facilita la integración.
o Ayuda a las organizaciones a seguir siendo competitivas.
• Desventajas
o El costo.
o La complejidad –el diseño de la base de datos es más complicada.
o Falta de estándares en la comunicación.
o Falta de experiencia.
Diferencia entre un SGBDD homogéneo y heterogéneo
La diferencia es que los nodos del sistema homogéneo utilizan el mismo tipo de
SGBD mientras que un sistema heterogéneo puede utilizar diferentes tipos de
SGBD.
• SGBDD homogéneo
o Todos los nodos utilizan el mismo SGBD.
• SGBDD heterogéneo
o Los nodos pueden estar ejecutando diferentes SGBD, los cuales no tienen
porque están basados en un mismo modelo de datos subyacente, de modo que
el sistema puede estar compuesto de diferentes SGBD relacionales.
En qué circunstancias es preferible utilizar ambos tipos:
• Los homogéneos cuando la implementación de las bases de datos se realizan
en conjunto.

• Los heterogéneos cuando se tiene ya las bases de datos implementadas por
separado y se las quiere integrar para poder comunicarlas.
Funcionalidades de un SGBDD
• Servicios avanzados comunicaciones.
• Catalogo ampliado del sistema.
• Control avanzado de seguridad.
• Servicios avanzados de recuperación.
Sistema multi-base de datos
• Un sistema multi-base de datos (MDBS) es un SGBD distribuido en el que
cada nodo mantiene una completa autonomía.
• Un MDBS se instala transparentemente por encima de los sistemas de
archivos y bases de datos existentes, presentado a los usuarios una única base
de datos.
Niveles de transparencia de un SGBDD
• Transparencia de distribución.
• Transparencia de transacción.
• Transparencia de rendimiento.
• Transparencia de SGBD.
Seguridad
Los problemas de mayor importancia en seguridad son autenticación,
identificación, y refuerzo de los controles de acceso apropiados.
El sistema de seguridad de niveles múltiples consiste en que muchos usuarios
con distintos niveles de permisos para una misma base de datos con información
de distintos niveles. En las bases de datos distribuidas se han investigado dos
acercamientos a este modelo: data distribuida y control centralizado, y data y
control distribuidos.

9. PROCESAMIENTO DISTRIBUIDO DE CONSULTAS
El procesamiento de consultas es de suma importancia en bases de datos centralizadas. Sin embargo, en BDD éste adquiere una relevancia mayor. El objetivo es convertir transacciones de usuario en instrucciones para manipulación de datos. No obstante, el orden en que se realizan las transacciones afecta grandemente la velocidad de respuesta del sistema. Así, el procesamiento de consultas presenta un problema de optimización en el cual se determina el orden en el cual se hace la menor cantidad de operaciones. En BDD se tiene que considerar el procesamiento local de una consulta junto con el costo de transmisión de información al lugar en donde se solicitó la consulta.
Ejemplo de consulta distribuida
NODO1
EMPLEADO
• El contenido de la relación EMPLEADO es el siguiente:
• 10.000 tuplas.
• Cada tupla tiene 100 bytes de longitud.
• El campo COD tiene 9 bytes de longitud.
• El campo Depto tiene 4 bytes de longitud.
• El campo Nombre tiene 15 bytes de longitud.
• El campo Apellido tiene 15 bytes de longitud

10. RECUPERACION
En los entornos distribuidos de datos podemos encontrar lo siguientes:
Fallo de los nodos. Cuando un nodo falla, el sistema deberá continuar
trabajando con los nodos que aún funcionan. Si el nodo a recuperar es una
base de datos local, se deberán separar los datos entre los nodos restantes
antes de volver a unir de nuevo el sistema.
Copias múltiples de fragmentos de datos. El subsistema encargado
del control de concurrencia es el responsable de mantener la consistencia
en todas las copias que se realicen y el subsistema que realiza la
recuperación es el responsable de hacer copias consistentes de los datos
de los nodos que han fallado y que después se recuperarán.
Transacción distribuida correcta. Se pueden producir fallos durante
la ejecución de una transacción correcta si se plantea el caso de que al
acceder a alguno de los nodos que intervienen en la transacción, dicho
nodo falla.
Fallo de las conexiones de comunicaciones. El sistema debe ser capaz
de tratar los posibles fallos que se produzcan en las comunicaciones entre nodos. El caso mas extremo es el que se produce cuando se divide la red.
Esto puede producir la separación de dos o más particiones donde las
particiones de cada nodo pueden comunicarse entre si pero no con particiones de otros nodos. Para implementar las soluciones a estos problemas, supondremos que los datos se encuentran almacenados en un único nodo sin repetición. De ésta manera sólo existirá un único catálogo y un único DM (Data Manager) encargados del control y acceso a las distintas partes de los datos. Para mantener la consistencia de los datos en el entorno distribuido contaremos con los siguientes elementos:
Catálogo: Programa o conjunto de programas encargados de
controlar la ejecución concurrente de las transacciones.
CM (Cache Manager). Subsistema que se encarga de mover los datos
entre las memorias volátiles y no volátiles, en respuesta a las peticiones
de los niveles más altos del sistema de bases de datos. Sus operaciones
son Fetch(x) y Flush(x).
RM (Recovery Manager). Subsistema que asegura que la base de datos
contenga los efectos de la ejecución de transacciones correctas y ninguno
de incorrectas. Sus operaciones son Start, Commit, Abort, Read, Write,
que utilizan a su vez los servicios del CM.

DM (Data Manager). Unifica las llamadas a los servicios del CM y el RM.
TM (Transaction Manager). Subsistema encargado de determinar que
nodo deberá realizar cada operación a lo largo de una transacción.

Las operaciones de transacción que soporta una base de datos son: Start, Commit y Abort. Para comenzar una nueva transacción se utiliza la operación Start. Si aparece una operación commit, el sistema de gestión da por terminada la transacción con normalidad y sus efectos permanecen en la base de datos. Si, por el contrario, aparece una operación abort, el
sistema de gestión asume que la transacción no termina de forma normal y todas las modificaciones realizadas en la base de datos por la transacción deben de ser deshechas.
11. ALTERNATIVAS PARA LA IMPLEMENTACION DE SMBD
En la Figura 2.8 se presentan las diferentes dimensiones (factores) que se deben considerar para la implementación de un sistema manejador de base de datos. Las dimensiones son tres:
1. Distribución. Determina si las componentes del sistema están localizadas en la misma computadora o no.
2. Heterogeneidad. La heterogeneidad se puede presentar a varios niveles: hardware, sistema de comunicaciones, sistema operativo o SMBD. Para el caso de SMBD heterogéneos ésta se puede presentar debido al modelo de datos, al lenguaje de consultas o a los algoritmos para manejo de transacciones.
3. Autonomía. La autonomía se puede presentar a diferentes niveles:
Autonomía de diseño. La habilidad de un componente del SMBD para decidir cuestiones relacionadas a su propio diseño.
Autonomía de comunicación. La habilidad de un componente del SMBD para decidir como y cuando comunicarse con otros SMBD.
Autonomía de ejecución. La habilidad de un componente del SMBD para ejecutar operaciones locales de la manera que él quiera.
Desde el punto de vista funcional y de organización de datos, los sistemas de datos distribuidos están divididos en dos clases separadas, basados en dos filosofía totalmente diferentes y diseñados para satisfacer necesidades diferentes:

12. LAS DOCE REGLAS
El principio fundamental nos conduce a 12 reglas u objetivos:
1.- Autonomía local. Los sitios en un sistema distribuido deben ser autónomos.
– La autonomía local significa que todas las operaciones en un sitio dado están controladas por ese sitio; ningún sitio X debe depender de algún otro sitio Y para su operación satisfactoria.
– La seguridad, integridad y representación de almacenamiento de los datos locales permanecen bajo el control y jurisdicción del sitio local.
2.- No dependencia de un sitio central. La autonomía local implica que todos los sitios deben ser tratados como iguales.
– Por lo tanto, no debe haber particularmente ninguna dependencia de un sitio “maestro” central para algún servicio central, tal que todo el sistema dependa de ese sitio central.
– Razones por las cuales no debería haber un sitio central: • El sitio central puede ser un cuello de botella • El sistema sería vulnerable; es decir, si el sitio central falla,
también fallará todo el sistema
3.-Operación continua.
Una ventaja de los sistemas distribuidos es que deben proporcionar mayor confiabilidad y mayor disponibilidad.
– Confiabilidad. La probabilidad de que el sistema esté listo y funcionando en cualquier momento dado. Los SD no son una propuesta de todo o nada; pueden continuar operando cuando hay alguna falla en algún componente independiente.
Disponibilidad. La probabilidad de que el sistema esté listo y funcionando continuamente a lo largo de un período especificado

4. INDEPENDENCIA DE UBICACIÓN. CONOCIDA TAMBIÉN COMO
TRANSPARENCIA DE UBICACIÓN.
Los usuarios no tienen que saber dónde están almacenados físicamente los datos,
sino que deben ser capaces de comportarse como si todos los datos estuvieran
almacenados en su propio sitio local.
Esto simplifica los programas de los usuarios. En particular, permite que los datos emigren de un sitio a otro sin invalidar ninguno de estos programas o actividades
5. INDEPENDENCIA DE FRAGMENTACIÓN.
Un sistema soporta la fragmentación de datos cuando puede ser dividida en o partes o fragmentos, para efectos de almacenamiento físico.
– La fragmentación es necesaria por razones de rendimiento: los datos pueden estar almacenados en la ubicación donde son usados más frecuentemente para que la mayoría de las operaciones sean locales y se reduzca el tráfico en la red.
– Los usuarios deben comportarse como si los datos en realidad estuvieran sin fragmentación alguna.
6.- INDEPENDENCIA DE REPLICACIÓN.
El sistema soporta replicación de datos cuando un fragmento puede ser representado por muchas copias distintas, o réplicas, guardadas en muchos sitios distintos.
las réplicas son necesarias por dos razones principales:
1. Significan un mejor rendimiento (las aplicaciones pueden operar sobre las copias locales en lugar de tener que comunicarse con sitios remotos).

2. Pueden significar una mejor disponibilidad (un objeto replicado permanece disponible para su procesamiento, mientras esté disponible al menos una copia).
Por supuesto, la principal desventaja de las réplicas es que al actualizarlas es necesario actualizar todas: el problema de la propagación de la actualización.
7.- PROCESAMIENTO DISTRIBUIDO DE CONSULTAS.
En este aspecto debemos mencionar dos puntos amplios:
Primero consideremos la consulta “obtener los proveedores de tornillos en Valdepeñas”. Supongamos que el usuario está en la instalación de Ciudad Real y los datos están en el emplazamiento de Valdepeñas. Supongamos también que son n los registros de proveedor que satisfacen la solicitud. Si el sistema es relacional, la consulta implicará en esencia dos mensajes: uno para transmitir la solicitud de Ciudad Real a Valdepeñas, y otro para devolver el conjunto resultante de n registros de Valdepeñas a Ciudad Real. Si, por otro lado, el sistema no es relacional, sino de un registro a la vez, la consulta implicará en esencia 2n mensajes: n de Ciudad Real a Valdepeñas solicitando el siguiente registro, y n de Valdepeñas a Ciudad Real para devolver ese siguiente registro. Así, el ejemplo ilustra el punto de que un sistema relacional tendrá con toda probabilidad un mejor desempeño que uno no relacional (para cualquier consultaque solicite varios registros).
En segundo lugar, la optimización es todavía más importante en un sistema distribuido que en uno centralizado. Lo esencial es que, en una consulta como la anterior, donde están implicados varios sitios, habrá muchas maneras de trasladar los datos en la red para satisfacer la solicitud, y es crucial encontrar una estrategia eficiente, ya que de esta estrategia depende el tiempo de respuesta. Esta es otra razón más por la cual los sistemas distribuidos son siempre relacionales (pues las solicitudes relacionales son optimizables, mientras que las de un registro a la vez no lo son).

8.- MANEJO DISTRIBUIDO DE TRANSACCIONES. El manejo de transacciones tiene dos aspectos principales: el control de recuperación y el control de concurrencia, cada uno de los cuales requiere un tratamiento más amplio en el ambiente distribuido. Para explicar ese tratamiento más amplio es preciso introducir primero un término nuevo, “agente”. En un sistema distribuido, una sola transacción puede implicar la ejecución de código en vario sitios (en particular, puede implicar actualizaciones en varios sitios). Por tanto, se dice que cada transacción está compuesta de 50 varios agentes, donde un agente es el proceso ejecutado en nombre de una transacción dada en un determinado sitio. Y el sistema necesita saber cuándo dos agentes son parte de la misma transacción; por ejemplo, es obvio que no puede permitirse un bloqueo mutuo entre dos agentes que sean parte de la misma transacción.
Control del recuperación: para asegurar que una transacción dada sea atómica (todo o nada) en el ambiente distribuido, el sistema debe asegurarse de que todos los agentes orrespondientes a esa transacción se comprometan al unísono o bien que retrocedan al unísono. Este efecto puede lograrse mediante el protocolo de compromiso en dos fases. Control de concurrencia: esta función en un ambiente distribuido estará basada con toda seguridad en el bloque, como sucede en los sistemas no distribuidos. 9.- INDEPENDENCIA CON RESPECTO AL EQUIPO. Las instalaciones de cómputo en el mundo real, por lo regular incluyen varias máquinas diferentes y existe una verdadera necesidad de poder integrar los datos en todos esos sistemas y presentar al usuario una sola imagen del sistema. Por tanto, es conveniente poder ejecutar el mismo DBMS en diferentes equipos, y además lograr que esos diferentes equipos participen como socios iguales en un sistema distribuido. 10.- INDEPENDENCIA CON RESPECTO AL SISTEMA OPERATIVO. Este objetivo es en parte un corolario del anterior. Resulta obvia la conveniencia no sólo de poder ejecutar el mismo DBMS en diferentes equipos, sino también de poder ejecutarlo en diferentes sistemas operativos (incluso en diferentes sistemas operativos dentro del mismo equipo) y lograr que (por ejemplo) una versión MVS y una versión UNIX y una versión PC/DOS participen todas en el mismo sistema distribuido. 11.- INDEPENDENCIA CON RESPECTO A LA RED. Si el sistema ha de poder manejar múltiples sitios diferentes, con equipo distinto y diferentes sistemas operativos, resulta obvia la conveniencia de poder manejar también varias redes de comunicaciones distintas.

12.- INDEPENDENCIA CON RESPECTO AL DBMS. Bajo este título consideramos las implicaciones de relajar la suposición de homogeneidad estricta. Puede alegarse que esa suposición es quizá demasiado rígida. En realidad, no se equiere sino que los DBMS en los diferentes sitios manejen todos la misma interfaz; no necesitan ser por fuerza copias del mismo sistema. Por ejemplo, si tanto Ingres como Oracle manejaran la norma oficial de SQL, podría ser posible lograr una comunicación entre los dos en el contexto de un sistema distribuido. Dicho de otro modo, el sistema distribuido podría ser heterogéneo, al menos hasta cierto grado. Definitivamente sería deseable poder manejar la heterogeneidad. Una vez más, en la realidad las instalaciones de cómputo no sólo suelen emplear varias máquinas iferentes y varios sistemas operativos distintos, sino que también ejecutan diferentes DBMS; y sería agradable que todos esos DBMS distintos pudieran participar de alguna manera en un sistema distribuido. En otras palabras, el sistema distribuido ideal deberá ofrecer independencia respecto al DBMS.

13. CONCLUSIONES
Las bases de datos distribuidas son cada vez más usadas por las empresas y suponen una ventaja competitiva frente a los sistemas centralizados, siempre y cuando la empresa en cuestión tenga necesidad de usar una base de datos de este tipo. Lo más habitual es disponer de varias sedes y tener que manejar información común, para lo cual las bases de datos distribuidas son especialmente útiles.

14. BIBLIOGRAFIA
http://usuarios.lycos.es/jrodr35/
http://html.rincondelvago.com/bases-de-datos-
distribuidas_1.html
http://sacbeob.8m.com/tutoriales/bddistribuidas/index.htm
http://www.cs.cinvestav.mx/SC/prof_personal/adiaz/Disdb/Cap_
1.html