traffic classification svm_im2015_10may2015
TRANSCRIPT

Yang Hong, Changcheng HuangDepartment of Systems and Computer Engineering,
Carleton University, Ottawa, Canada
Biswajit Nandy, Nabil SeddighSolana Networks
Ottawa, Ontario, Canada
14th IFIP/IEEE Symposium on Integrated Network and Service Management (IFIP/IEEE IM), Ottawa, Canada, May 2015, pp.458−466

Why Traffic Classification?
Different types of network/cloud applications impose inherently different QoS requirements low end-to-end delay for interactive applications
high throughput for file transfer applications
Network utilization needs to be optimized while ensuring performance for various applications
Network/cloud operators need to treat applications differently
2

Applications over Network Traffic
Network applications are classified into different categories
bulk data transfer
file transfer protocol
peer-to-peer downloads
cloud service
cloud computing
database transactions
real-time streaming
voice
video
Different applications running over network
3
Internet
ComputerGroup Database
Streaming Media
Web
FTP
E-Commence

Contributions of This Paper
Proposal of an iterative-tuning scheme to increase training speed of Support Vector Machine
(SVM) learning algorithms against multi-class classification problem
Theoretical analysis of iterative-tuning scheme to derive the equations to obtain SVM parameters
Application of iterative-tuning SVM to achieve a best trade-off between classification accuracy
and training speed
4

Outline
Related Work (Traffic Classification Approaches) Support Vector Machine (SVM) Overview SVM Multi-Class Formulation Iterative-Tuning SVM Performance Evaluation of SVM Classification Conclusions
5

Traffic Classification Approaches (1) Port-based Classification Perform application mapping using Internet Assigned
Numbers Authority (IANA) standardized port numbers Payload-based Classification Inspect packet header and payload to match it against
application pattern signatures Host-behavior-based Classification Capture behavioral information of a host to match it
against host-behavior signatures of applications Flow-features-based Classification Capture flow features to map different applications
with different statistical features
6

Traffic Classification Approaches (2) Port-based Classification insufficient for those applications which assign ports
dynamically or share popular ports Payload-based Classification can NOT accurately identify the traffic application if
the payload is encrypted Host-behavior-based Classification can NOT identify specific application sub-types
Flow-features-based Classification require a large scale of dataset SVM algorithm achieves the highest traffic
classification accuracy (this paper improves SVM) 7

Support Vector Machine (SVM) Overview
Construct separate hyper-plane for each traffic class with multiple flow-features
Maximize the distance between the closest training data samples of different classes in n-dimensional flow-feature space
Red circle represents a training sample of Class 1
blue square represents a training sample of Class 2
A new sample is classified into a class where it is closest to
Hyper-planes constructed by SVM fortwo different classes
8
BA
Class 1
Class 2

SVM Multi-Class Formulation (Primal Problem)
Notation: i is index of a class; m is number of classes; wi is a weight vector associated with class i; C is a general regularization parameter and C>0; k is index of a training sample; l is number of training samples; ξk is a non-negative constraint associated with the training sample; xk∈ℜn is a input vector (n is the number of flow-features) associated with the k-th training sample; yk∈1, . . . , m is the corresponding membership class for xk; The weight wi can be regarded as the inverse of the mean distance between an sample and all training samples of class i.
(1)
(2)
9
∑∑==
+l
kk
m
iiw
Cwki 11
2
, 21min ξ
ξ
,,,, kiexwxw kkikTik
Tyk
∀−≥− ξConstraints
( ) max max Ti ii i
D x D w x= = (3)
Maximum value Di predicts the membership class of a testing sample

SVM Multi-Class Formulation (Dual Problem)
Notation: see the previous slide #9
(4)
(5)
10
Constraints
(10)
∑∑∑= ==
+=Ωl
k
m
ikiki
m
ii ew
1 1,,
1
2)(21)(min ααα
α
,)0 ]2[, ]1[(1
,,, kiCm
ikikiki ∀=∀≤ ∑
=αα
∑∑==
==l
kkki
l
kkii xww
1,
1, )()( ααα (7)
,
( ) 0i k
αα
∂Ω=
∂ (8)Optimal solution:
.,,)()(,
,, ikexwg kik
Ti
kiki ∀+=
∂Ω∂
= ααα
(9)
,,minmax ,:,,,
kgg kiCikii
kkiki
∀−=<α
υ

Iterative-Tuning SVM
System diagram of iterative-tuning scheme
11
w(α)
Iterative Tuning
α Ω(α)
,1, 1 ,
( )k jk j k j j j
k
αα α γ λ
α−
+
∂Ω ′′ = ′ −
∂ ′
1, , ,[ ; ; ; ; ]k k i k m kα α α α′ = ∑−
=−=
1
1,,
m
ikikm αα
, ,
1
( ) ( ) Tmi k j i k j
ji k k
w wα αλ
α α=
∂ ′ ∂ ′ = ∂ ′ ∂ ′
∑ kki
ki xw=
∂∂
,
)(αα
Gauss-Newton algorithm provides faster convergence speed
(12)
(13) (14)
(16) (17)

Experimental Setup
12
Use NetFlow-V5 to collect network traffic trace Collect data over a 24-hour period Utilize 12 flow-features obtained from NetFlow-V5
flow-records as the basis for input to classification algorithms traffic classification achieves a better accuracy, if all
12 flow-features are selected NetFlow data trace consists of 241,223 TCP flows 3 testing datasets consist of 130,527 flows, 55,531
flows, and 55,165 flows belong to 3 different time periods respectively

Flow-Features For Traffic Classification
13
Feature ID Feature Name1 source port2 destination port
3 average packet size4 average bytes/sec (src→dst)5 average bytes/sec (dst→src)6 packet count (src→dst)7 packet count (dst→src)8 byte count (src→dst)9 byte count (dst→src)10 ratio of byte count (src→dst) / byte count (dst→src)11 SYN flag count12 flow duration
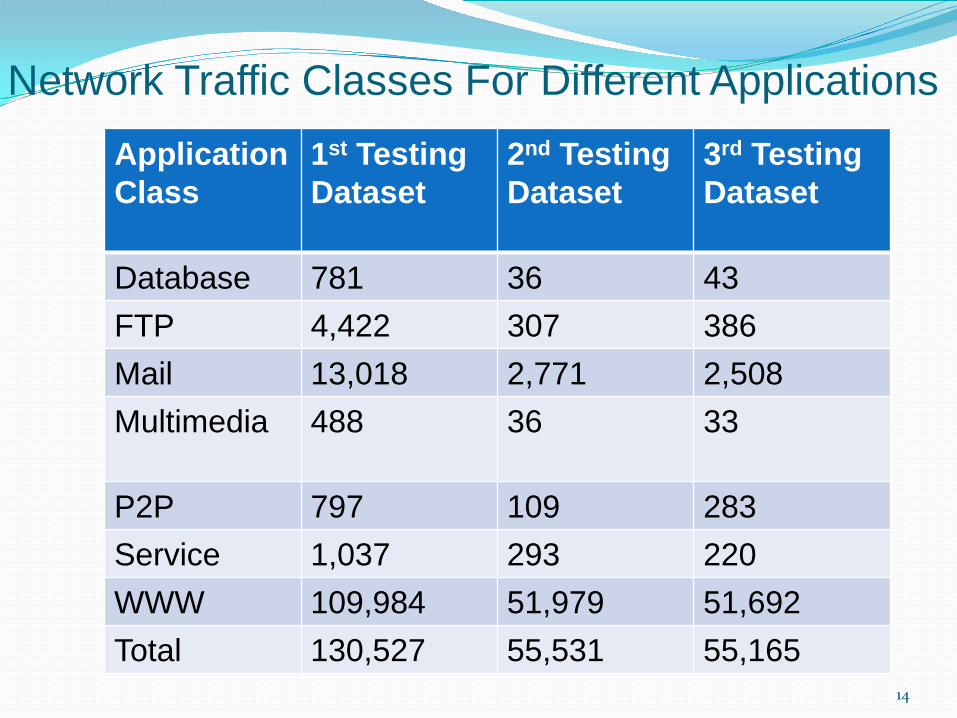
Network Traffic Classes For Different Applications
14
Application Class
1st Testing Dataset
2nd Testing Dataset
3rd Testing Dataset
Database 781 36 43FTP 4,422 307 386Mail 13,018 2,771 2,508Multimedia 488 36 33
P2P 797 109 283Service 1,037 293 220WWW 109,984 51,979 51,692Total 130,527 55,531 55,165

Comparison of SVM Classification Algorithms
15
SVM Type
Training time (ms)
Overall Accuracy
SVM-IT 187 98.66% (128776/130527)SVM-0 1,575 98.48% (128551/130527)SVM-1 2,698 98.68% (128804/130527)SVM-2 530 98.62% (128724/130527)SVM-3 1,388 98.2% (128172/130527)SVM-4 1,528 99.1% (129356/130527)SVM-5 7,534 98.56% (128644/130527)SVM-6 2,932 98.16% (128127/130527)SVM-7 5,911 98.5% (128571/130527)

Ratio of Classification Accuracy/Training time
Ratio of Accuracy/Training time (in logarithmic scale) provided by 9 different SVM classification algorithms for 1st testing dataset
16
0 1 2 3 4 5 6 7 8 9 100
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
SVM Type
log1
0[10
(Acc
urac
y/Ti
me)
]
SVM-ITSVM-0SVM-1SVM-2SVM-3SVM-4SVM-5SVM-6SVM-7
SVM-5 exhibits the lowest performance/cost ratio
iterative-tuning SVM provides the highest performance/cost ratio
achieving better trade-off between classification accuracy and training speed than other 8 SVMs

Classification Precision of Each Class (1)
17
All 9 SVMs can identify more than 99% of WWW traffic SVM-4 has highest precisions for identifying Database, FTP, and P2P traffic
SVM-3 exhibits higher precision for classifying Mailtraffic than other 8 SVMs
0.94
0.95
0.96
0.97
0.98
0.99
1
1.01
0 1 2 3 4 5 6 7 8 9 10
Clas
sific
atio
n Pr
ecisi
on
SVM Type
Overall
FTP
WWW

Classification Precision of Each Class (2)
18
Iterative-tuning SVM can identify 90% of Service traffic,more precisely than other 8 SVMs
SVM-5 can identify Multimedia traffic with greater precision than other 8 SVMs
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 1 2 3 4 5 6 7 8 9 10
Clas
sific
atio
n Pr
ecisi
on
SVM Type
Database
Multimedia
P2P
Service

Other Experimental Findings Benefit of SVM Classification over Port-based
Classification Port-based classification only obtains overall classification
accuracy as about 88%
SVM classification achieves overall classification accuracy as about 98%
Advantage and Disadvantage of Unbiased Training Datasetunbiased training dataset makes the classification precision
of each different class more balanced
there is no arbitrarily low precision for any particular class
overall accuracy decreases by nearly 2%19

Conclusions Propose iterative-tuning scheme to increase training
speed for SVM multi-class classification dual problem
Analyze working mechanism of iterative-tuning scheme to obtain dual parameter vector for SVM classification model
Iterative-tuning SVM is computationally more efficient than 8 typical SVMswhile exhibiting almost identical accuracy as those 8 SVMs
SVM classification based on flow-level information achieve accuracy higher than 98%
allow network/cloud operators to apply traffic classification for a range of issues including semi-real-time security monitoring and traffic engineering
20