transforming your graph analytics with graphdb 8.3
TRANSCRIPT

Graph Analytics with GraphDB
Ontotext Webinar Oct 5 2017
Presentation Outline
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
2
Presentation Outline
FactForge Data Integration
3
DBpedia (the English version) 496M
Geonames (all geographic features on Earth) 150M
owlsameAs links between DBpedia and Geonames 471K
Company registry data (GLEI) 3M
Panama Papers DB (LinkedLeaks) 20M
Other datasets and ontologies WordNet WorldFacts FIBO
News metadata (2000 articlesday enriched by NOW) 473M
Total size (1611M explicit + 328M inferred statements) 1 939М
The New FactForge Statistics
4
DBpedia ndash freshly generated from Wikipedia Organisations 308459 (old 287307)
Persons 1314437 (old 1518283)
Locations 862148 (old 816120)
Geonames locations 11341387 (old 11834908)
5
News Metadata Metadata from Ontotextrsquos Dynamic Semantic Publishing platform
News stream from Google
Automatically generated as part of the NOWontotextcom semantic news showcase
News stream from Google since Feb 2015 about 50k newsmonth
Over 1M news articles at present
~70 tags (annotations) per news article
Tags link text mentions of concepts to the knowledge graph
Technically these are URIs for entities (people organizations locations etc) and key phrases
6
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Presentation Outline
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
2
Presentation Outline
FactForge Data Integration
3
DBpedia (the English version) 496M
Geonames (all geographic features on Earth) 150M
owlsameAs links between DBpedia and Geonames 471K
Company registry data (GLEI) 3M
Panama Papers DB (LinkedLeaks) 20M
Other datasets and ontologies WordNet WorldFacts FIBO
News metadata (2000 articlesday enriched by NOW) 473M
Total size (1611M explicit + 328M inferred statements) 1 939М
The New FactForge Statistics
4
DBpedia ndash freshly generated from Wikipedia Organisations 308459 (old 287307)
Persons 1314437 (old 1518283)
Locations 862148 (old 816120)
Geonames locations 11341387 (old 11834908)
5
News Metadata Metadata from Ontotextrsquos Dynamic Semantic Publishing platform
News stream from Google
Automatically generated as part of the NOWontotextcom semantic news showcase
News stream from Google since Feb 2015 about 50k newsmonth
Over 1M news articles at present
~70 tags (annotations) per news article
Tags link text mentions of concepts to the knowledge graph
Technically these are URIs for entities (people organizations locations etc) and key phrases
6
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

FactForge Data Integration
3
DBpedia (the English version) 496M
Geonames (all geographic features on Earth) 150M
owlsameAs links between DBpedia and Geonames 471K
Company registry data (GLEI) 3M
Panama Papers DB (LinkedLeaks) 20M
Other datasets and ontologies WordNet WorldFacts FIBO
News metadata (2000 articlesday enriched by NOW) 473M
Total size (1611M explicit + 328M inferred statements) 1 939М
The New FactForge Statistics
4
DBpedia ndash freshly generated from Wikipedia Organisations 308459 (old 287307)
Persons 1314437 (old 1518283)
Locations 862148 (old 816120)
Geonames locations 11341387 (old 11834908)
5
News Metadata Metadata from Ontotextrsquos Dynamic Semantic Publishing platform
News stream from Google
Automatically generated as part of the NOWontotextcom semantic news showcase
News stream from Google since Feb 2015 about 50k newsmonth
Over 1M news articles at present
~70 tags (annotations) per news article
Tags link text mentions of concepts to the knowledge graph
Technically these are URIs for entities (people organizations locations etc) and key phrases
6
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

The New FactForge Statistics
4
DBpedia ndash freshly generated from Wikipedia Organisations 308459 (old 287307)
Persons 1314437 (old 1518283)
Locations 862148 (old 816120)
Geonames locations 11341387 (old 11834908)
5
News Metadata Metadata from Ontotextrsquos Dynamic Semantic Publishing platform
News stream from Google
Automatically generated as part of the NOWontotextcom semantic news showcase
News stream from Google since Feb 2015 about 50k newsmonth
Over 1M news articles at present
~70 tags (annotations) per news article
Tags link text mentions of concepts to the knowledge graph
Technically these are URIs for entities (people organizations locations etc) and key phrases
6
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

5
News Metadata Metadata from Ontotextrsquos Dynamic Semantic Publishing platform
News stream from Google
Automatically generated as part of the NOWontotextcom semantic news showcase
News stream from Google since Feb 2015 about 50k newsmonth
Over 1M news articles at present
~70 tags (annotations) per news article
Tags link text mentions of concepts to the knowledge graph
Technically these are URIs for entities (people organizations locations etc) and key phrases
6
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

6
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

GDB WB Builtin Overview Class Relations
7
GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

GDB WB Builtin Class Instances amp Hierarchy
8
GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

GDB WB Builtin DomainRange Graph
9
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65
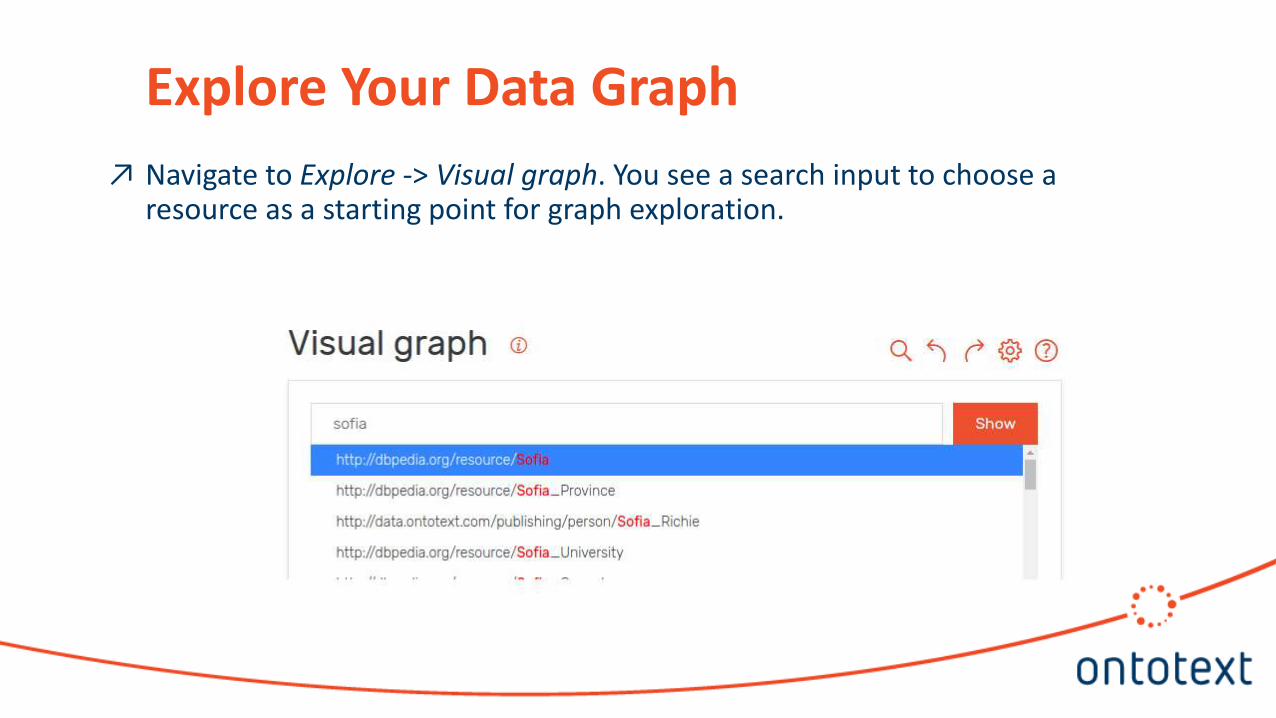
Explore Your Data Graph
Navigate to Explore -gt Visual graph You see a search input to choose a resource as a starting point for graph exploration
10
11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

11
Visualize the graph of Sofia
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65
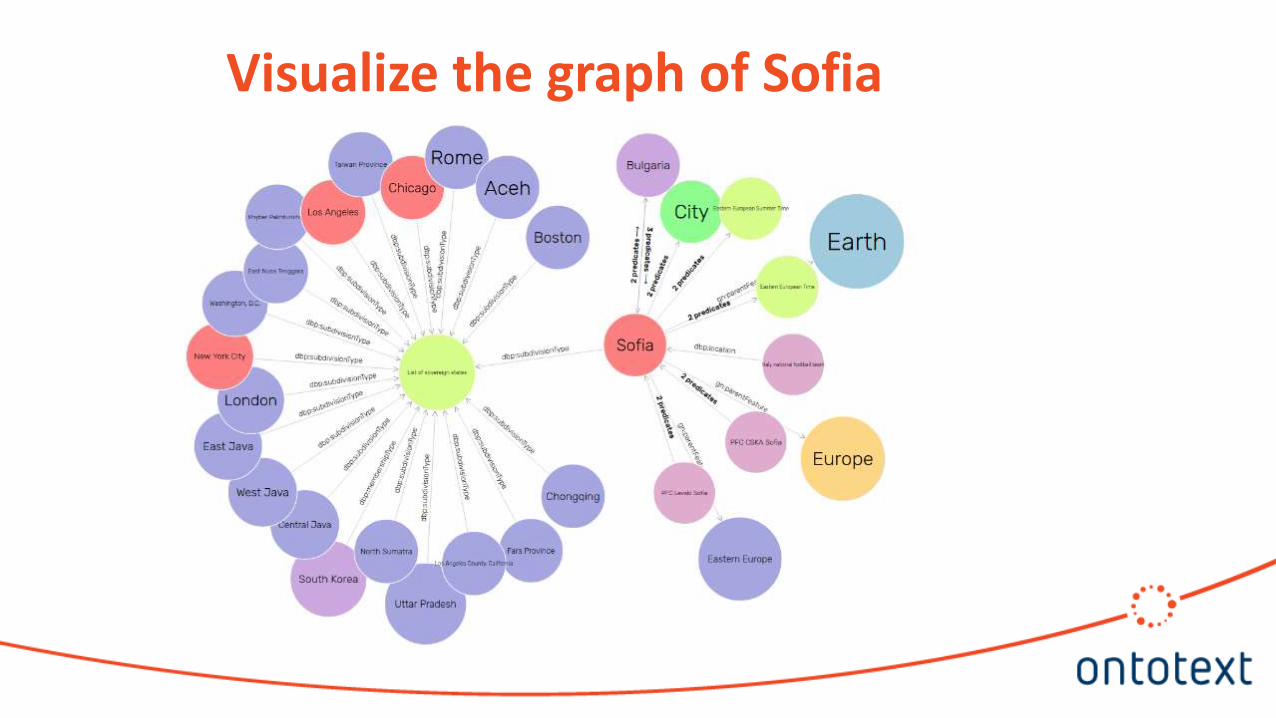
12
Visualize the graph of Sofia
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65
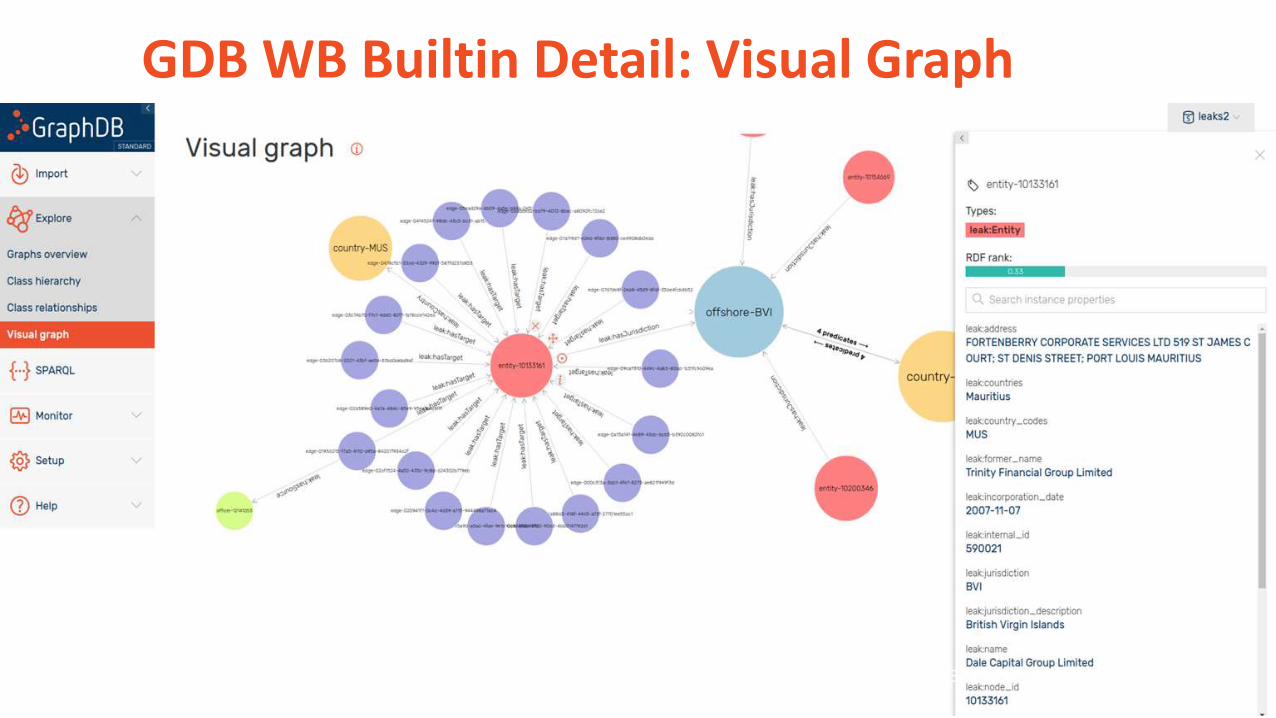
GDB WB Builtin Detail Visual Graph
13
14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

14
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

What is SPARQLSPARQL is a SQL-like query language forRDF graph data with the following query types
SELECT returns tabular results
CONSTRUCT creates a new RDF graph based on query results
ASK returns lsquoyesrsquo if the query has a solution otherwise lsquonorsquo
DESCRIBE returns RDF graph data about a resource useful when the query client does not know the structure of the RDF data in the data source
INSERT inserts triples into a graph
DELETE deletes triples from a graph
15
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65
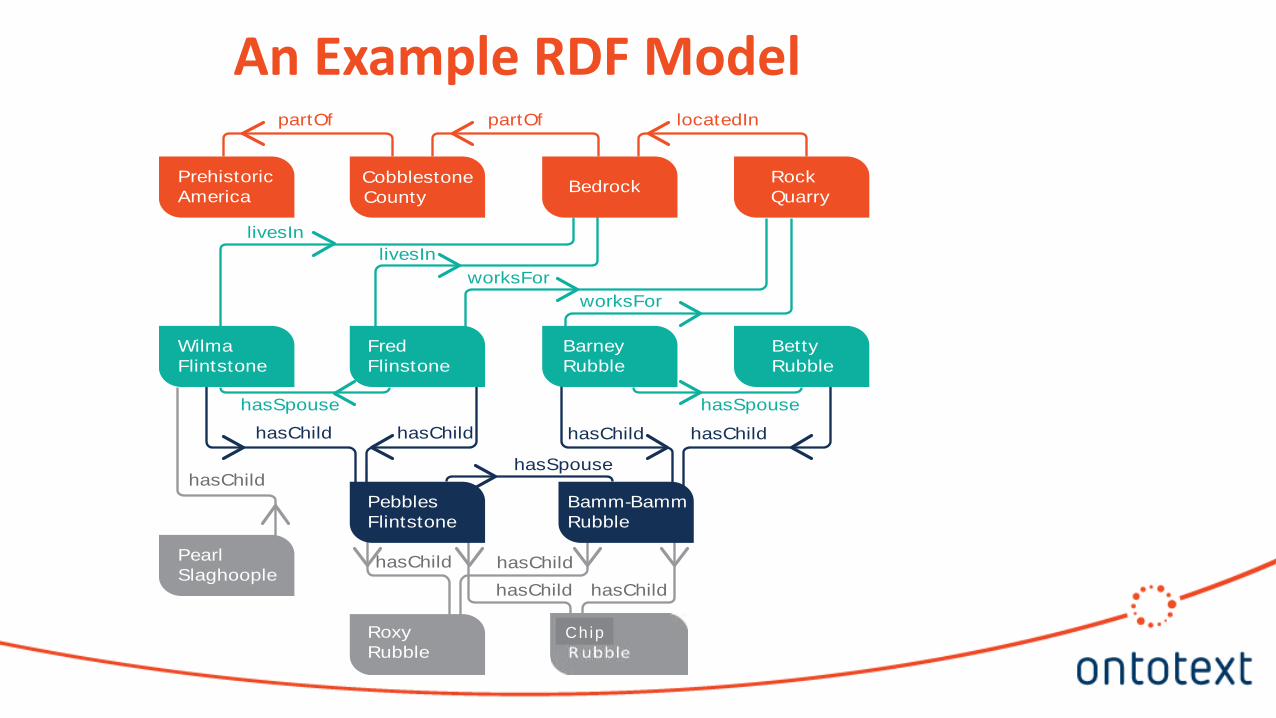
An Example RDF Model
hasSpouse
hasSpouse
hasSpouse
hasChild
hasChild hasChild
hasChild hasChild
hasChild hasChild hasChild hasChild
worksFor
livesIn
livesIn
worksFor
Wilma
Flintstone
Pebbles
Flintstone
Pearl
Slaghoople
Roxy
RubblePearl
Slaghoople
Bamm-Bamm
Rubble
Prehistoric
AmericaCobblestone
CountyBedrock
Rock
Quarry
partOf locatedIn
Fred
Flinstone
Barney
Rubble
Betty
Rubble
partOf
Chip
16
Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Using SPARQL to Insert TriplesTo create an RDF graph perform these steps
Define prefixes to URIs with the PREFIX keyword
Use INSERT DATA to signify you want to insert statements Write the subject-predicate-object statements (triples)
Execute this query
pebbles bamm-bamm
fred wilma
roxy chip
hasSpouse
hasChild hasChild
hasChild hasChild
PREFIX br lthttpbedrockgtINSERT DATA
brfred brhasSpouse brwilma brfred brhasChild brpebbles brwilma brhasChild brpebbles brpebbles brhasSpouse brbamm-bamm
brhasChild brroxy brchip
17
lsquobrrsquo refers to the namespace lsquohttpbedrockrsquo so that lsquobrFredrsquo
expands to lthttpbedrockFredgt a Universal Resource
Identifier (URI)
Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Using SPARQL to Select TriplesTo access the RDF graph you just created perform these steps Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select certain information and WHERE to signify your conditions restrictions and filters
Execute this query
PREFIX br lthttpbedrockgtSELECT subject predicate object
WHERE subject predicate object
Subject Predicate Object
brfred brhasChild brpebblesbrpebbles brhasChild brroxybrpebbles brhasChild brchipbrwilma brhasChild brpebbles
18
Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Using SPARQL to Find Fredrsquos Grandchildren
To find Fredrsquos grandchildren first find out if Fred has any grandchildren
Define prefixes to URIs with the PREFIX keyword
Use ASK to discover whether Fred has a grandchild and WHERE to signify your conditions
YESPREFIX br lthttpbedrockgtASKWHERE
brfred brhasChild child child brhasChild grandChild
19
Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Using SPARQL to Find Fredrsquos Grandchildren
Now that we know he has at least one grandchild perform these steps to find the grandchild(ren)
Define prefixes to URIs with the PREFIX keyword
Use SELECT to signify you want to select a grandchild and WHERE to signify your conditions
PREFIX br lthttpbedrockgtSELECT grandChild WHERE
brfred brhasChild child child brhasChild grandChild
grandChild
1 brroxy2 brchip
20
21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

21
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

GraphDBtrade Workbench is a web-based tool for
Management of repositories
Loading and exporting data
RDF graph exploration and visualization
Query writing and evaluation
Monitoring query execution and resource usage
Management of users and connectors
Management of clusters (Enterprise Edition)
GraphDBtrade Workbench
22
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65
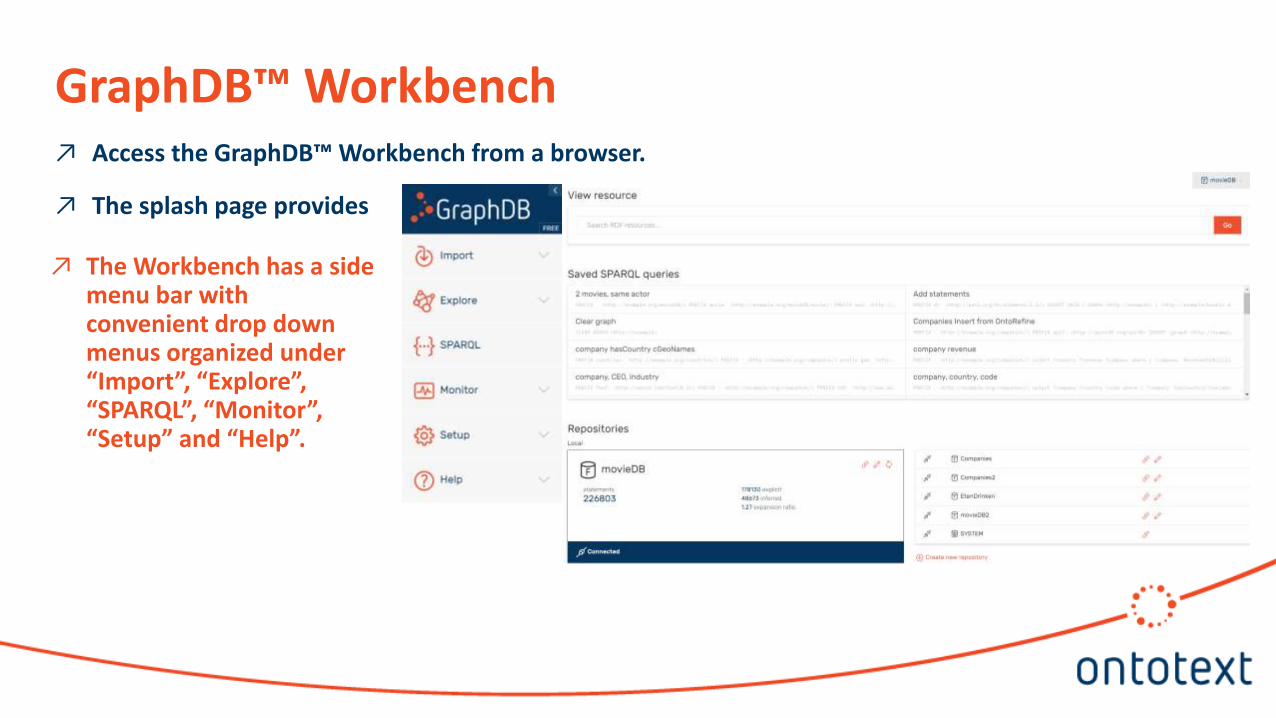
On the following slide is an example of the GraphDBtrade Workbench screen
Access the GraphDBtrade Workbench from a browser
The splash page provides a summary of the installed GraphDBtrade Workbench
GraphDBtrade Workbench
23
The Workbench has a side menu bar with convenient drop down menus organized under ldquoImportrdquo ldquoExplorerdquo ldquoSPARQLrdquo ldquoMonitorrdquo ldquoSetuprdquo and ldquoHelprdquo
Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Test the repository by
Selecting ldquoSPARQLrdquo
Submitting queries
GraphDBtrade Workbench Execute Queries
2 Query
24
SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

SPARQL Editing
GDB WB integrates the YASGUI editor Automatic prefix addition (best practice load prefixesttl) Autocompletion of URIs (classes properties entitieshellip)
25
FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

FactForge Saved Queries
FactForgequery F04
26
By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

By selecting the SPARQL menu the SPARQL query editor displays and
Allows you to render your query results as Table Pivot Table or Google Analytic Charts
Execute Queries With GraphDBtrade Workbench
27
28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

28
GraphDBtrade Workbench Query Editor
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65
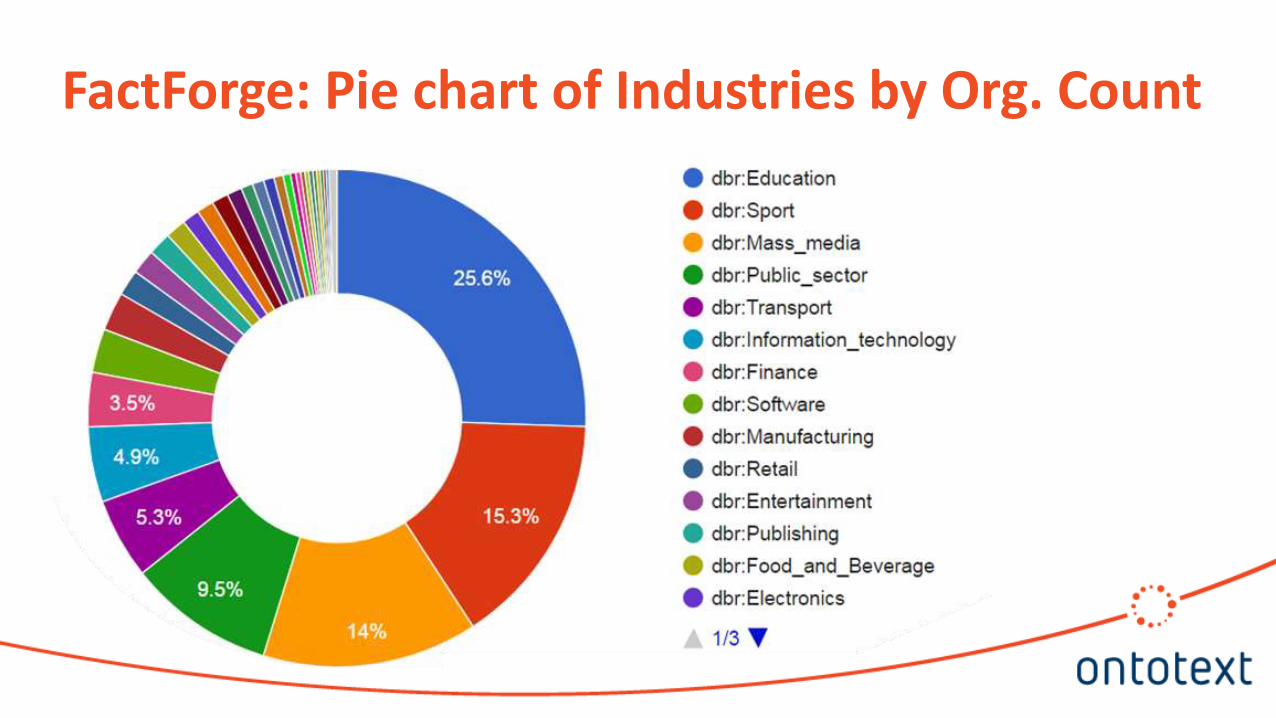
FactForge Pie chart of Industries by Org Count
29
Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Query Monitoring Abort Query
30
GraphDBtrade allows you to abort long queries that are executing
Eg you create a query that is long running and you would like to halt it and perhaps modify it and resubmit it and not wait until it completes
From the side menu panel select Monitor then Queries
SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

SPARQL editor switches inference and owlsameAs expansion
PREFIX dbr lthttpdbpediaorgresourcegtPREFIX dbo lthttpdbpediaorgontologygtselect where
dbrSofia p location location a dboLocation
31
owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

owlsameAs optimisation sameAs is useful in semantic data integration
Often independent agencies mint different URLs for the same entity
sameAs an equivalence relation declares them the same (ldquosmushingrdquo)
All statements of URL X in equivalence cluster are ldquocopiedrdquo to all Y in the same cluster
Such inference causes combinatorial explosion of statements
If unchecked decreases memory and query time performance
sameAs Optimisation Compact representation statements are made against clusters not against individual URLs
Backward chaining finds all solutions across cluster
Query results compacted by picking one representative from cluster (option disableSameAs=true)
disableSameAs=false = ldquoExpand results over equivalent URIsrdquo
32
33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

33
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
The Honey and the Sting of owlsameAs
34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

34
The Honey and the Sting of owlsameAs
E11 E22
E12 E21
E23
geonames727011
dbpediaSofia
geonames732800
dbpediaBulgaria
opencyc-enBulgaria
geo-ontparentFeature
35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

35
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Ontotext GraphDB Connectors
36
Provide fast full text range faceted search and aggregations
Utilize an external engine like Lucene Solr or Elasticsearch
Flexible schema mapping index only what you need
Real-time synchronization of data in GraphDB and the external engine
Connector management via SPARQL
Data querying amp update via SPARQL
Based on the GraphDB plug-in architecture
Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Geo-spatial Plug-In
37
Special handling of 2D geo-spatial data
Custom index and query re-writing
Expressive query constraints
Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Geo-spatial Extensions
Data must use the WGS84 ontologyhttpwwww3org200301geowgs84_pos
wgs84SpatialThingwgs84location
wgs84Point
rdfssubClassOf
wgs84long
Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Geo-spatial Extensions
39
GraphDB overrides RDF LIST syntax eg link omgeonearby(lat1 long1 50mi)
Geo-spatial plug-in re-writes this tolink geo-poslat link_lat
link geo-poslong link_long
distance between (link_lat link_long) and (lat1 long1) is less than or equal to 50 miles
Query extensions includeNearby (lat long distance)
Within (rectangle)
Within (polygon)
distance function
Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Geo-spatial Extensions
40
Powerful method to explore geo data
Provides query constraints otherwise not possible in SPARQL
Fast and efficient based on R-Trees
GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

GeoSPARQL Support
41
GeoSPARQL is a standard for representing and querying geospatial linked data from the Open Geospatial Consortium using the Geography Markup Language
A small topological ontology in RDFSOWL for representation
Simple Features RCC8 and DE-9IM (aka Egenhofer) topological relationship vocabularies and ontologies for qualitative reasoning
A SPARQL query interface using a set of Topological SPARQL extension functions for quantitative reasoning
42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

42
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

RDF Rank is a GraphDBtrade extension that
Is similar to PageRank and it identifies ldquoimportantrdquo nodes in an RDF graph based on their interconnectedness
Is accessed using the rankhasRDFRank system predicate
Incremental RDF Rank is useful for frequently changing data
For Example to select the top 100 important nodes in the RDF graph
RDF Rank
PREFIX rank lthttpwwwontotextcomowlimRDFRankgtSELECT n WHERE n rankhasRDFRank r ORDER BY DESC(r)LIMIT 100
RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

RDF Rank
RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

RDF Rank
Simple example - get the 100 most highly ranked resources
SELECT DISTINCT airport rrank
WHERE
SELECT dbrLondon geo-poslat lat geo-poslong long LIMIT 1
airport gdb-geonearby(lat long 50mi)
a dboAirport
rankhasRDFRank3 rrank
ORDER BY DESC(rrank)
46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

46
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Semantic Media MonitoringFor each entity
popularity trends
relevant news
related entities
knowledge graph information
Sep 2017 Graph Analytics with GraphDB Webinar
47
Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Graph Analytics with GraphDB Webinar
48
Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Semantic Media MonitoringPress-Clipping
We can trace references to a specific company in the news This is pretty much standard however we can deal with syntactic variations in the names
because state of the art Named Entity Recognition technology is used
Whatrsquos more important we distinguish correctly in which mention ldquoParisrdquo refers to which of the following Paris (the capital of France) Paris in Texas Paris Hilton or to Paris (the Greek hero)
We can trace and consolidate references to daughter companies
We have comprehensive industry classification The one from DBPedia but refined to accommodate identifier variations and specialization
(eg company classified as dbrBank will also be considered classified as dbrFinancialServices)
Sep 2017 Graph Analytics with GraphDB Webinar
49
Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Media Monitoring Queries
F6 News that mention a specific entity during specific period
F7 Most popular companies per industry
F8 Most popular companies per industry including children
Sep 2017 Graph Analytics with GraphDB Webinar
50
News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

News popularity ranking of companies
Rankings can be customized by specifying a geographic region news category (eg business sport lifestyle etc) and time period
Unique features It is based on live streaming news
Tracks also mentions of subsidiaries
Rank uses the industry sectors of DBPedia with several refinements About 40 top-industry sectors
Sectors are linked in a hierarchical taxonomy (all together 251 sectors)
Industry sectors are de-duplicated (all designators used in Wikipedia are about 9 000)
Sep 2017 Graph Analytics with GraphDB Webinar
51
Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Rank uses NOW FactForge and GraphDB
This ranking service is entirely based on FactForge FactForge allows public exploration and querying of a knowledge graph of more than 1 billion facts
which is loaded in GraphDB
GraphDB is a semantic graph database engine of Ontotext
Unlike FactForge this service is aimed at non-technical users as it does not require any knowledge of SPARQL or other technology
But it allows users to see the SPARQL query for each ranking and to customize it
Try rankontotextcom
Sep 2017 Graph Analytics with GraphDB Webinar
52
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
53
rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

rankontotextcom demonstratorSep 2017 Graph Analytics with GraphDB Webinar
54
55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

55
FactForge as a Playground
Visualizations
SPARQL Overview
GraphDBtrade Workbench
GraphDBtrade Plug-ins
RDFRank ndash Importance of node in the KG
Popularity Ranking of Companies
Node similarity in KG
Presentation Outline
Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Why
I want to search in knowledge graphs Because they are too big and I donrsquot have years to write ldquoproperrdquo SPARQL
I want to detect duplicates
I want to do entity resolution For disambiguation of entity references in text
For reconciliation or for linking or data integration
Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Adapt Information Retrieval (IR) ideas IRrsquos basic is the Vector space model
Documents are vectors in a geometrical space that has one dimension for each word Coordinates correspond to the number of times that the word appears in the document Imagine there are only 5 words used in all documents a ab acb ba bc Document content ldquoa bc ba a abcrdquo Document vector = lt20111gt Similarity is measure by the COS of the angle between the vectors Very popular and simple Read more at httpsenwikipediaorgwikiVector_space_model
How it can work
A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

A simple model Nodes are described by the outgoing edges ie ltpredicate objectgt pairs
Concern there are too many different PO-pairs in a big KG
For FactForge it would be a space with 100M+ dimensions hellip
Experiment with node similarity in FactForgenet
The basic assumption two nodes are more similar if they share more PO-pairs
Ie they are connected to the same other nodes with the same types of relationships
Weighted sum weight PO-pairs based on their ldquoinformation valuerdquo
More ldquopopularrdquo pairs are less informative known as TFIDF
Vector Space Model for Knowledge Graphs
Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Example Nodes sharing outgoing liks
idIOEW2389W idIOP235JKO
San Francisco
Aerospace
ldquoBFR LLCrdquonam
eldquoVenus Express Incrdquo
nam
e
Beta Inc
pare
nt shared edge
differentiating edge
ldquoVenus Express Incrdquo
Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Demonstration
1 Shared edges for a node
2 Shared edges for a node filtered by predicate
3 Similar nodes by count of shared edges
4 Similar nodes by count of shared edges typed
5 Shared pairs for a node by popularity
6 Node similarity as weighted sum of shared pairs
rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

rankontotextcom demonstratorSep 2017
61
Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Teaching time is 9 + 1 hours including Pre-class assignments (recorded sessions) Live Class Sessions Individual Consultation (optional)
Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Support and FAQrsquossupportontotextcom
Additional resources
OntotextCommunity Forum and Evaluation Support httpstackoverflowcomquestionstaggedgraphdbGraphDB Website and Documentation httpgraphdbontotextcomWhitepapers Fundamentals httpontotextcomknowledge-hubfundamentals
SPARQL OWL and RDFRDF httpwwww3orgTRrdf11-conceptsRDFS httpwwww3orgTRrdf-schemaSPARQL Overview httpwwww3orgTRsparql11-overviewSPARQL Query httpwwww3orgTRsparql11-querySPARQL Update httpwwww3orgTRsparql11-update
63
For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

For Further Information
64
Peio Popov North America Sales and Business Development
peiopopovontotextcom
19292390659
Ilian Uzunov Europe Sales and Business Development
Ilianuzunovontotextcom
359888772248
Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65

Thank you
Experience the technology with our demonstrators
NOW Semantic News Portal httpnowontotextcom
RANK News popularity ranking for companies httprankontotextcom
FactForge Hub for open data and news about People and Organizations
httpfactforgenet
65