trinity: architecture and early experience · • lanl yellow network – mutrino ... ssp =...
TRANSCRIPT

Trinity:ArchitectureandEarlyExperience
Scott Hemmert, Shaun Dawson, Si Hammond, Daryl Grunau, Rob Hoekstra, Mike Glass, Jim Lujan, Dave Morton, Hai Ah Nam, Paul
Peltz Jr., Mahesh Rajan, Alfred Torrez, Manuel Vigil, Cornell Wright
CrayUsersGroup,May2016
SAND2016-4374C

NA T I ONA L NUC L EA R S EC UR I TY A DMI N IS TRA T I ON OF F I C E OF D E F EN S E P ROG RAM S
ASCPlatformTimeline
Jan 2016
Adv
ance
d Te
chno
logy
Syst
ems
(ATS
)
Fiscal Year
‘13 ‘14 ‘15 ‘16 ‘17 ‘18
UseRetire
‘20‘19 ‘21
Com
mod
ity
Tech
nolo
gySy
stem
s (C
TS)
Procure& Deploy
Sequoia(LLNL)
ATS1– Trinity(LANL/SNL)
ATS2– Sierra(LLNL)
Tri-labLinuxCapacityClusterII(TLCCII)
CTS1
CTS2
‘22
System
Delivery
ATS3 – Crossroads (LANL/SNL)
ATS4– (LLNL)
‘23
ATS5 – (LANL/SNL)

TrinityProjectDrivers
• Satisfythemissionneedformorecapableplatforms– Trinityisdesignedtosupportthelargest,mostdemandingASCapplications– Increasesingeometricandphysicsfidelitieswhilesatisfyinganalysts’time-to- solution
expectations– Fosteracompetitiveenvironmentandinfluencenextgenerationarchitecturesinthe
HPCindustry
• Trinityisenablingnewarchitecturefeaturesinaproductioncomputingenvironment– Trinity’sarchitecturewillintroducenewchallengesforcodeteams:transitionfrom
multi-coretomany-core,high-speedon-chipmemorysubsystem,widerSIMD/vectorunits
– Tightlycoupledsolidstatestorageservesasa“burstbuffer”forcheckpoint/restartfileI/O&dataanalytics,enablingimprovedtime-to-solutionefficiencies
– Advancedpowermanagementfeaturesenablemeasurementandcontrolatthesystem,node,andcomponentlevels,allowingexplorationofapplicationperformance/wattandreducingtotalcostofownership
• MissionNeedRequirementsareprimarilydrivingmemorycapacity– Over2PBofaggregatemainmemory 3

TrinityArchitecture

TrinityPlatform
• TrinityisasinglesystemthatcontainsbothIntelHaswellandKnightsLandingprocessors– Haswell partitionsatisfiesFY16missionneeds(wellsuitedtoexistingcodes).
– KNLpartitiondeliveredinFY16resultsinasystemsignificantlymorecapablethancurrentplatformsandprovidestheapplicationdeveloperswithanattractivenext-generationtarget(andsignificantchallenges)
– AriesinterconnectwiththeDragonflynetworktopology
• BasedonmatureCrayXC30architecturewithTrinityintroducingnewarchitecturalfeatures– IntelKnightsLanding(KNL)processors– BurstBufferstoragenodes– Advancedpowermanagementsystemsoswareenhancements
5

TrinityArchitecture
6
Compute(Intel“Haswell”)9436Nodes(~11PF)
Compute(IntelXeonPhi)>9500Nodes
~40PFTotalPerformanceand2.1PiBofTotalMemory
GatewayNodes Lustre Routers(222total,114Haswell)
BurstBuffer(576total,300Haswell)
2x648PortIBSwitches
39PBFileSystem
39PBFileSystem
78PBUsable~1.6TB/sec– 2Filesystems
CraySonexion© StorageSystem
CrayDevelopment&LoginNodes
40GigENetwork
GigENetwork
GigE
40GigEFDRIB
3.69PBRaw3.28TB/sBW

CrayAriesInterconnect
7
x00 01 02 03 04 05 06 07
10 11 12 13 14 15 16 17
20 21 22 23 24 25 26 27
30 31 32 33 34 35 36 37
40 41 42 43 44 45 46 47
50 51 52 53 54 55 56 57
GreenLinks(15x1)To15Other
BladesinChassis,1TileEachLink
(5.25GB/sperlink)
BlackLinks(5x3)To5Other
ChassisinGroup,3TilesEachLink
(15.75GB/sperlink)
BlueLinks(10x1)ToOtherGroups,10GlobalLinks
(4.7GB/sperlink)
CrayAriesBlade 1.Chassis
16BladesPerChassis16Aries,64Nodes
All-to-allElectricalBackplane
2.Group
6ChassisPerGroup96Aries,384Nodes
ElectricalCables,2-DAll-to-All
3.Global
G0 G1 G2 G3 G4
Upto241GroupsUpto23136Aries,92544Nodes
OpticalCables,All-to-AllbetweenGroups
Gemini:2nodes,62.9GB/sroutingbwAries 4nodes,204.5GB/sroutingbw
Arieshasadvancedadaptiverouting
xNICA
HostA
NICB
HostB
NICC
HostC
NICD
HostD

TrinityHaswell ComputeNode
Haswell16Core588GF
PCIe-3x1
6
Node
DDR4DIMM16GBs
DDR4DIMM16GBs
DDR4DIMM16GBs
DDR4DIMM16GBs
QPI
SouthbridgeChip
QPI
Haswell16Core588GF
DDR4DIMM16GBs
DDR4DIMM16GBs
DDR4DIMM16GBs
DDR4DIMM16GBs
128GB,DDR42133
8

TrinityKNLComputeNodeSingleSocket- SelfHostedNode
PCIe-3x1
6Node
SingleSocket- SelfHostedNode
96GBDDR42400–Memory
SouthbridgeChip
DMI2
~PCIe-2x4
16GBOnPkgMem
>3TFKNL(72cores)
9

TestBedSystems
• Gadget– SoftwareDevelopmentTestbed• ApplicationRegressionTestbeds– Configuration• 100Haswell ComputeNodes• 720TB/15GB/sSonexion2000Filesystem• 6BurstBufferNodes
– Trinitite• LANLYellowNetwork
–Mutrino• SandiaSRNNetwork
10

EarlyApplicationPerformance

CapabilityImprovement
• Definedastheproductofanincreaseinproblemsize,and/orcomplexity,andanapplicationspecificruntimespeedupfactoroverbaselinemeasurementonNNSA’sCielo (aCrayXE6)
• Threeapplicationschosen– SierraNalu
• SIERRA/Nalu isalowMachCFDcodethatsolvesawidevarietyofvariabledensityacousticallyincompressibleflowsspanningfromlaminartoturbulentflowregimes.
– Qbox• Qbox isafirst-principlesmoleculardynamicscodeusedtocomputetheproperties
ofmaterialsattheatomisticscale.
– PARTISN• ThePARTISNparticletransportcode[6]providesneutrontransportsolutionson
orthogonalmeshesinone,two,andthreedimensions.
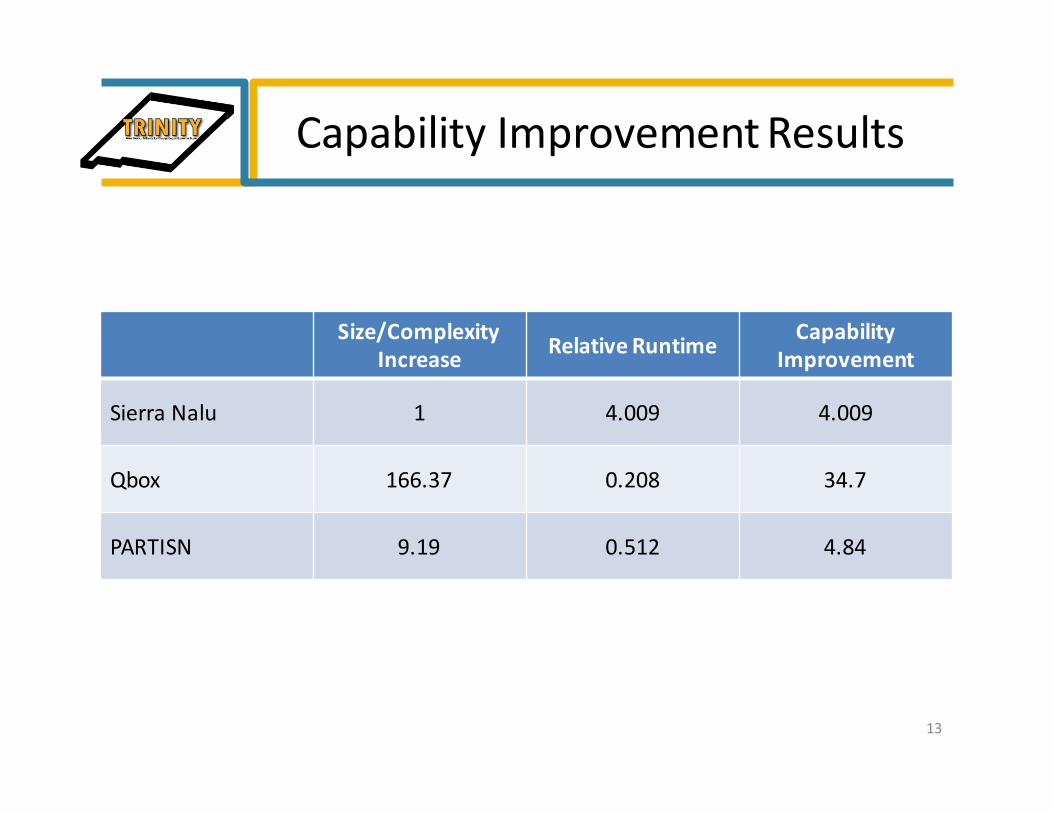
CapabilityImprovementResults
Size/ComplexityIncrease RelativeRuntime Capability
Improvement
SierraNalu 1 4.009 4.009
Qbox 166.37 0.208 34.7
PARTISN 9.19 0.512 4.84
13

SystemSustainedPerformance
14
Target=400
ApplicationName MPITasks Threads NodesUsed ReferenceTflops Time(s) Pi
miniFE (TotalCGTime) 49152 1 1536 1065.151 49.5116 0.014005964
miniGhost (Totaltime) 49152 1 1536 3350.20032 17.7 0.122949267
AMG(GMRESSolve wallTime) 49152 1 1536 1364.51 66.233779 0.013412384
UMT (cumulativeWorkTime) 49184 1 1537 18409.4 454.057 0.026378822
SNAP(solve time) 12288 2 768 4729.66 177 0.034793285
miniDFT (Benchmark_time) 2016 1 63 9180.11 377.77 0.385726849
GTC(NERSC_TIME) 19200 1 300 19911.348 868.439 0.076425817
MILC(NERSC_TIME) 12288 1 384 15036.5 393.597 0.099486409
Geometricmean= 0.052990429
SSP= 500.0176846

FileSystem

FileSystemConfiguration
16
Lustre Routers(222total,114Haswell)
2x648PortIBSwitches
39PBFileSystem
39PBFileSystem
78PBUsable~1.6TB/sec– 2Filesystems
CraySonexion© StorageSystem

N-NPerformance
• IOR,32processespernode,Eachprocesswriting1GiB• Targeted1filesystemfortheseruns• Maxwrite:401GiB/sMaxRead:420GiB/s
0
50
100
150
200
250
300
350
400
450
32
64128
256
5121024204840968192
16384
32768
65536
GiB/s
ProcessorCount
N-NWrite
4MTransferSize
8MTransferSize
0
50
100
150
200
250
300
350
400
450
32
64128
256
5121024204840968192
16384
32768
65536
GiB/s
ProcessorCount
N-NRead
4MTransferSize
8MTransferSize

N-1Performance
• IOR,32processespernode,Eachprocesswriting1GiB instrided pattern• TargetdirectorystripwidthsettoOSTcount• TargetdirectorystripesizematchedIORtransfersize• Targeted1filesystemfortheseruns• Maxwrite:301GiB/sMaxRead:330GiB/s
0
50
100
150
200
250
300
350
32
64
128
256
512
1024204840968192
16384
32768
65536
GiB/s
ProcessorCount
N-1Write
4MTransferSize
8MTransferSize
0
50
100
150
200
250
300
350
32
64
128
256
512
1024204840968192
16384
32768
65536
Gib/s
ProcessorCount
N-1Read
4MTransferSize
8MTransferSize

MetadataPerformance
• TestedLustreDNEphase1capabilityusing10metadataserverseachservingonedirectory
• mdtest,32procs pernode• Create,stat,delete1millionfiles

DataWarp/BurstBuffer

BurstBufferConfiguration
BurstBuffer(576total,300Haswell)
3.69PBRaw3.28TB/sBW

BurstBufferswillimproveProductivity andEnableMemoryHierarchyResearch
22
Operated by Los Alamos National Security, LLC for the U.S. Department of Energy's NNSA
UNCLASSIFIED - LA-UR-15-26608
Slide 61
Burst Buffers will improve Productivity and Enable Memory Hierarchy Research
• Burst Buffer will improve operational efficiency by reducing defensive IO time
• Burst Buffer fills a gap in the Memory and Storage Hierarchy and enables research into related programming models
# Technology Drivers: – Solid State Disk (SSD) cost decreasing – Lower cost of bandwidth than hard disk drive
# Trinity Operational Plans:
– SSD based 3 PB Burst Buffer – 3.28 TB/Sec (2x speed of Parallel File
System)
• TechnologyDrivers:– SolidStateDisk(SSD)costdecreasing– Lowercostofbandwidththanharddiskdrive
• TrinityOperationalPlans:– SSDbased3PBBurstBuffer– 3.28TB/Sec(2xspeedofParallelFileSystem)
• BurstBufferwillimproveoperationalefficiencybyreducingdefensiveIOtime
• BurstBufferfillsagapintheMemoryandStorageHierarchyandenablesresearchintorelatedprogrammingmodels

BurstBuffer– morethancheckpoint
• UseCases:– Checkpoint
• In-jobdrain,pre-jobstage,post-jobdrain– Dataanalysisandvisualization
• In-transit• Post-processing• Ensemblesofdata
– DataCache• Demandload• Datastaged
– Outofcoredata• Dataintensiveworkloadsthatexceedmemorycapacity
23

DataWarpDetails
• DataWarpnodesbuiltfromCrayservicenodes– 16-coreIntelSandyBridgewith64GiB memory– TwoIntelP3608SSDcards(4TBpercard)
• Capacityoverprovisionedtogetto10drivewritesperdayendurance(standardis3DWPD)
• Usagemodes– Stripedscratch– Stripedprivate– Paging(possiblefuturemode)– Cache(possiblefuturemode)
• Integratedwithworkloadmanager– Stagein/Stageout(singlejoblifetime)– Persistentallocations(accessiblebymultiplejobs)
24

DataWarpN-N
25
• TestConfiguration:– 1readerorwriterprocesspernode– 32GiB totaldatareadorwrittenpernode– TheDataWarpallocationstripedacrossall300DataWarpnodes
BlockSize BlockSize

DataWarpN-1
26
BlockSizeBlockSize
• TestConfiguration:– 1readerorwriterprocesspernode– 32GiB totaldatareadorwrittenpernode– TheDataWarpallocationstripedacrossall300DataWarpnodes

SystemManagementandIntegration
27

ACES/CrayCollaboration
• CLE6.0/SMW8.0(Rhine/Redwood)– CompleteoverhauloftheImagingandProvisioningSystem
• EarlyReleasesandCollaboration– BetatestingwithCrayinJune2015– LANLwasabletoprovideearlyfeedbacktoCray– HelpedCraydevelopamorematureandsecureproduct

EarlyExperienceswithCLE6.0
• TrinityfirsttodeployCLE6.0/SMW8.0• HowisCLE6.0different?– UtilizesAnsible fornodeconfiguration– UtilizesindustrystandardLinuxtools– Configuratortooltomanagesystemconfiguration

EarlyExperienceswithCLE6.0
• Pre-ReleaseEvaluationandPreparation– Significanttimeinvestmentrequiredforaninstall– SMWandBootRAIDmustbereformatted(noupgradepath)
– Configurator• QuestionandAnswerinterfaceforfillingoutsystemconfiguration
• Tediousandcumbersometouse– Worksheetsinlaterbetaversions
• Canbepreparedaheadoftime• Foralargesystemthistakesaconsiderableamountoftime• BetterthanusingConfigurator

EarlyExperienceswithCLE6.0
• ConfigurationManagement– UsingAnsible effectively
• UseCray’sAnsiblesite-hookstofullyprescribethemachine– Canbreakthebootprocess– Causesthebootprocesstorunlonger– Onlyrunsatboottime
• SeparateLocalAnsibleplaysdevelopedbyadmins– Canberunviacron oratjobepilogues– Cray’sAnsible playsarelengthyandresource-intensive
• PlayingnicelywithCray’sAnsibleplays– DifficulttomanagefilesthatCrayalsowantstomanage– Workaroundsinplace,butisstillanongoingissue

EarlyExperienceswithCLE6.0
• ExternalLoginNodes– ReplacementforBright– UtilizesOpenStack– CommonalityBetweenInternalloginandeLogin• BuildseLogin imagesfromsamesource• UsesthesameProgrammingEnvironment
– OpenStackConcerns• HardertomanageanddebugOpenStack• SecuringOpenStackcanbeachallenge

IntegratingNewTechnologies
• Sonexion2000– Lustre Appliance– FirstdeploymentofDistributedNamespace(DNEPhase1)• MultipleMDTforbettermetadataperformance• DirectoriesonMDTscreatedforusersonacasebycasebasis
– ContinuallyworkingwithSeagatetofixissues• DataWarp– LearninghowtomanageDataWarp– Debuggingwhenthingsgowrongisachallenge– ManychallengesintegratingDataWarpwithAdaptive’sMoabscheduler

CurrentChallenges
• Debuggingbootfailures– ItisalmostalwaysAnsible thatfails– SometimesrerunningAnsiblewillfixit– SomeAnsible logsareonlyontheendnode
• Ifthenode’sssh isnotconfiguredyetitcanbedifficulttogettothelogs
• Cray’sxtconcanworkbutonlyifthereisapasswordset• DataWarpatScale– Testingdonemostlyonsmallersystems– Seeingissueswithstage-outperformancetoLustre– CommunicationissueswithMoabandDataWarp underhighload• Currentlyssh,butaRESTfulinterfacehasbeenrequested

OngoingCollaborationwithCray
• CLE6.0UP00toCLE6.0UP01– UP01willbethefirstpublicreleaseofCLE6.0/SMW8.0
–Manyofthebugsandenhancementsrequestedwillbeinthenewrelease
– UP01requiredforKNLdeploymentinPhase2– InstallationofUP01onLANLTDSsystemsendofMay

TrinityCenterofExcellence

TrinityAdvancedTechnologySystem
Slide37
COMPUTENODESIntel“Haswell”XeonE5-
2698v3IntelXeonPhi“Knights
Landing”
9436nodes >9500nodesDual socket,16cores/socket,
2.3GHz1socket,60+cores,>3Tflops/KNL
128GB DDR4 96GBDDR4+16GBHBM
#6onTop500November2015
8.1PFlops(11PFPeak)
CrayAries‘Dragonfly’InterconnectAdvancedAdaptiveRouting
All-to-allbackplane&betweengroups
CraySonexionStorageSystem
78PBUsable,~1.6TB/s
CrayDataWarp576BurstBufferNodes
3.7PB,~3.3TB/s

Trinity- Performance(Portable)Challenges
Slide38
COMPUTENODESIntel“Haswell”XeonE5-
2698v3IntelXeonPhi“Knights
Landing”
9436nodes >9500nodesDual socket,16cores/socket,
2.3GHz1socket,60+cores,>3Tflops/KNL
128GB DDR4 96GBDDR4+16GBHBM
#6onTop500November2015
8.1PFlops(11PFPeak)
CrayAries‘Dragonfly’InterconnectAdvancedAdaptiveRouting
All-to-allbackplane&betweengroups
CraySonexionStorageSystem
78PBUsable,~1.6TB/s
CrayDataWarp576BurstBufferNodes
3.7PB,~3.3TB/s
• Enabling (not hindering) Vectorization
• Increase parallelism, cores/threads• High Bandwidth Memory• Burst Buffer – reduce I/O overhead

AccesstoEarlyHW/SW
Slide39
• ApplicationRegressionTestBedsx2(Cray)~100nodes(June2015),SoftwareDev.Testbed <100nodes– PhaseI,upgradesforPhaseII
• WhiteBoxes(Intel)~fewnodes(Sept2015/April2016)

COECollaborations
Slide40
• Cray– JohnLevesque(50%)– JimSchwarzmeier (20%)– GeneWagenbreth (100%)- new– MikeDavis(SNL),MikeBerry(LANL)
on-siteanalyst– SMEs(Performance&Tools)– Acceptanceteam
• Intel– RonGreen,on-siteanalyst(SNL/LANL)– DiscoverySession,Dungeons- SMEs
• ASCcodesareoftenexportcontrolled,largeandcomplex=alotofpaperwork
• Embeddedvendorsupport/expertiseisneeded=UScitizenship
• Originalprojectsfocusonasinglecode/lab

CoEProjects/Highlights
Slide41
• SNL– FocusedonpreparingtheSierraengineeringanalysissuiteforTrinity– ProxyCodes:miniAero (explicitAerodynamics),miniFE(implicitFE),
miniFENL,BDDC(DomainDecomp.Solver)– ‘Super’DungeonSessionincluding
• Morerealisticcode/stack– NALU(proxyapplicationforFEMassemblyforlowMachCFD)+Trilinosmulti-gridsolver,Kokkos + BDDC
• 6weekspreparationleadinguptoDungeonsession• ExposeIntelto‘real’codes&issues– longcompiletimes,longtoolsanalysistimes,compilerissues,MKLissues.
• Greatforrelationship/collaborationbuilding– MoreembeddedsupportfromCray(GeneWagenbreth,March2016)

CoE Projects/Highlights
Slide42
• LLNL– DevelopedProxyCode:Quicksilver(MonteCarlotransport)• Dynamicneutrontransportproblem(MPIorMPI+threads)• Useinperformanceportabilityactivities• Proxycodesarenotanexampleofefficientsourcecode,ratherarepresentationofalargerapplication
– DiscoverySessions(x2)withproxyapplications&performanceportableabstractionlayer

CoE Projects/Highlights
Slide43
• LANL– Fullapplicationexploration– verylarge,multi-physics,multi-material
AMRapplication(MPI-only)• Discoverysession(Intel)&Deepdive(Cray)– on-site• PrototypingSPMDinradiationdiffusionpackageasanoptionincodethreading
implementation• Addressingperformancebottlenecksinsolverslibrary(HYPRE)&code• Addressingtechnicaldebt
– BroadeningscopeofCOEprojectstoincludedeterministicSntransport(fullapplicationandproxy)
– Discoverysessions&deepdiveactivities

Vectorization
44
0%
20%
40%
60%
80%
100%InstructionsEx
ecuted
Logical
Branching
MaskHandling
Scatter
Gather
DataMove
VectorFMA
AVX-512
AVX-Std
AVX-512Vectorization LevelsinDOEBenchmarksandMini-Apps

ExperiencesonKNL
45
• Forsomeapplications,greaterimprovementthanthehardwarespecificationsmovingbetweenmemory
• StrongestapplicationperformanceforsomekernelsonanyGA-hardwarewehaveeverseen
• API(memkind)bringupgoingwellbutweexpectthistobelow-level(usersdonotlikethisandwantithiddenaway)
• LotsunderNDAbutresultswillmostlikelybeshownatISC’16
• InitialworkonKNLwithmini-applicationsandsomeperformancekernels(fromTrillinos)goingverywell
Mem Kind:http://memkind.github.io/memkind/memkind_arch_20150318.pdf

Questions?
46