unambiguity regularization for unsupervised learning of probabilistic grammars kewei tuvasant...
TRANSCRIPT

Unambiguity Regularization for Unsupervised Learning of Probabilistic Grammars
Kewei Tu Vasant HonavarDepartments of Statistics and
Computer ScienceUniversity of California, Los
Angeles
Department of Computer ScienceIowa State University

2
Overview Unambiguity Regularization
A novel approach for unsupervised natural language grammar learning
Based on the observation that natural language is remarkably unambiguous
Includes standard EM, Viterbi EM and so-called softmax-EM as special cases

3
Outline Background Motivation Formulation and algorithms Experimental results

4
Background Unsupervised learning of probabilistic grammars
Learning a probabilistic grammar from unannotated sentences
A square is above the triangle.A triangle rolls.The square rolls.A triangle is above the square.A circle touches a square.……
A square is above the triangle.A triangle rolls.The square rolls.A triangle is above the square.A circle touches a square.……
S ® NP VPNP ® Det NVP ® Vt NP (0.3) | Vi PP (0.2) | rolls (0.2) | bounces(0.1)……
S ® NP VPNP ® Det NVP ® Vt NP (0.3) | Vi PP (0.2) | rolls (0.2) | bounces(0.1)……
Training Corpus Probabilistic GrammarInduction

5
Background Unsupervised learning of probabilistic grammars
Typically done by assuming a fixed set of grammar rules and optimizing the rule probabilities
Various prior information can be incorporated into the objective function to improve learning e.g., rule sparsity, symbol correlation, etc.
Our approach: Unambiguity regularization Utilizes a novel type of prior information: the
unambiguity of natural languages

6
The Ambiguity of Natural Language Ambiguities are ubiquitous in natural languages
NL sentences can often be parsed in more than one way
Example [Manning and Schutze (1999)]
The post office will hold out discounts and service concessions as incentives.
Noun? Verb? Modifies “hold out” or “concessions”?
Given a complete CNF grammar of 26 nonterminals, the total number of possible parses is .

7
The Unambiguity of Natural Language Although each NL sentence has a large number of
possible parses, the probability mass is concentrated on a very small number of parses

8
Comparison with non-NL grammars
NL Grammar
Random Grammar
Max-Likelihood Grammar Learned by EM

9
Incorporate Unambiguity Bias into Learning How to measure the ambiguity
Entropy of the parse given the sentence and the grammar
How to add it into the objective function Use a prior distribution that prefers low ambiguity
Intractable Learning

10
Incorporate Unambiguity Bias into Learning How to measure the ambiguity
Entropy of the parse given the sentence and the grammar
How to add it into the objective function Use posterior regularization [Ganchev et al. (2010)]
An auxiliary distribution
Log posterior of the grammar given the training sentences
KL-divergence between q and the posterior distribution of the parses
Entropy of the parses based on q
A constant that controls the strength of regularization

11
Optimization Coordinate Ascent
Fix and optimize Exactly the M-step of EM
Fix and optimize Depends on the value of
When σ = 0
Exactly the E-step of EM
p q

12
Optimization Coordinate Ascent
Fix and optimize Exactly the M-step of EM
Fix and optimize Depends on the value of
When σ ≥ 1
Exactly the E-step of Viterbi EM
p q

13
Optimization Coordinate Ascent
Fix and optimize Exactly the M-step of EM
Fix and optimize Depends on the value of
When 0 < σ < 1
Softmax of the posterior distribution of the parses
p q
Softmax-EM

14
Softmax-EM Implementation
Simply exponentiate all the grammar rule probabilities before the E-step of EM
Does not increase the computational complexity of the E-step

15
The value of Choosing a fixed value of
Too small: not enough to induce unambiguity Too large: the learned grammar might be excessively
unambiguous Annealing
Start with a large value of Strongly push the learner away from the highly
ambiguous initial grammar Gradually reduce the value of
Avoid inducing excessive unambiguity

16
Mean-field Variational Inference So far: maximum a posteriori estimation (MAP) Variational inference approximates the posterior of the
grammar Leads to more accurate predictions than MAP Can accommodate prior distributions that MAP cannot
We have also derived a mean-field variational inference version of unambiguity regularization Very similar to the derivation of the MAP version

17
Experiments Unsupervised learning of the dependency model with
valence (DMV) [Klein and Manning, 2004]
Data: WSJ (sect 2-21 for training, sect 23 for testing) Trained on the gold-standard POS tags of the
sentences of length ≤ 10 with punctuation stripped off
18
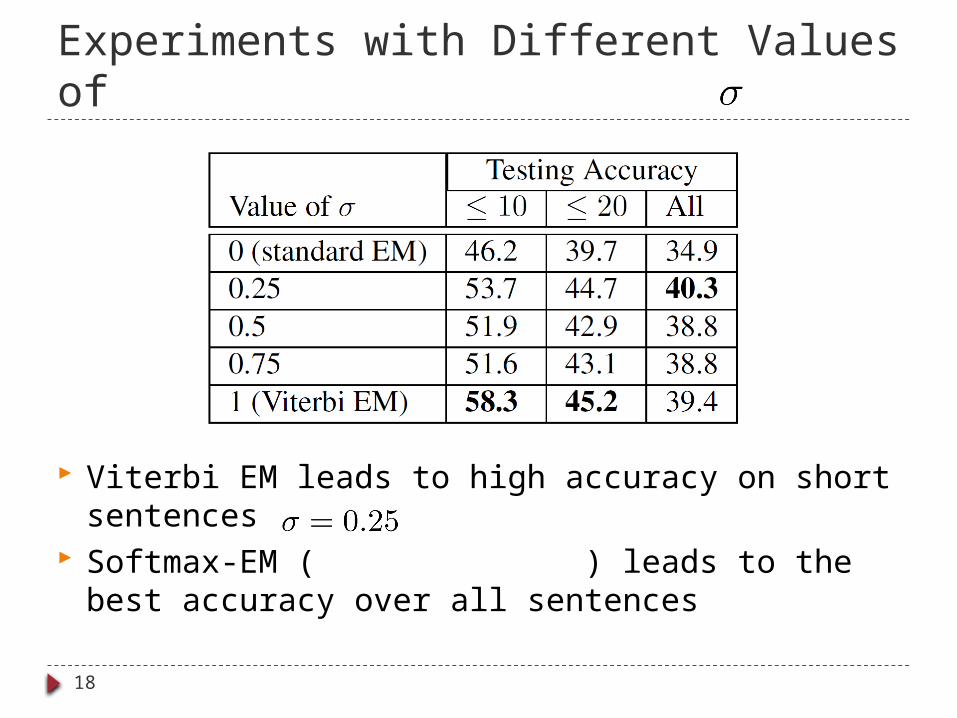
Experiments with Different Values of
Viterbi EM leads to high accuracy on short sentences Softmax-EM ( ) leads to the best accuracy over
all sentences

19
Experiments with Annealing and Prior Annealing the value of from 1 to 0 in 100 iterations Adding Dirichlet priors ( ) over rule probabilities
using variational inference Compared with the best results previously published for
learning DMV

20
Experiments on Extended Models Applying unambiguity regularization on E-DMV, an
extension of DMV [Gillenwater et al., 2010]
Compared with the best results previously published for learning extended dependency models

21
Experiments on More Languages Examining the effect of unambiguity regularization with the
DMV model on the corpora of eight additional languages.
Unambiguity regularization improves learning on eight out of the nine languages, but with different optimal values of .
Annealing the value of leads to better average performance than using any fixed value of .

22
Related Work Some previous work also manipulates the entropy of
hidden variables Deterministic annealing [Rose, 1998; Smith and Eisner, 2004]
Minimum entropy regularization [Grandvalet and Bengio, 2005; Smith and Eisner, 2007]
Unambiguity regularization differs from them in Motivation: the unambiguity of NL grammars Algorithm:
a simple extension of EM exponent >1 in the E-step decreasing the exponent in annealing

23
Conclusion Unambiguity regularization
Motivation The unambiguity of natural languages
Formulation Regularize the entropy of the parses of training
sentences Algorithms
Standard EM, Viterbi EM, softmax-EM Annealing the value of
Experiments Unambiguity regularization is beneficial to learning By incorporating annealing, it outperforms the current
state-of-the-art

Thank you!
Q&A