universidade federal de sergipe centro de … · infelizmente minha memória não é das melhores e...
TRANSCRIPT

0
UNIVERSIDADE FEDERAL DE SERGIPE CENTRO DE CIÊNCIAS EXATAS E TECNOLÓGICAS PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA
COMPUTAÇÃO
PERFORMANCE ANALYSIS OF VIRTUALIZATION
TECHNOLOGIES IN HIGH PERFORMANCE COMPUTING
ENVIRONMENTS
DAVID WILLIANS DOS SANTOS CAVALCANTI BESERRA
SÃO CRISTÓVÃO/SE
2016

1
UNIVERSIDADE FEDERAL DE SERGIPE CENTRO DE CIÊNCIAS EXATAS E TECNOLÓGICAS PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA
COMPUTAÇÃO
DAVID WILLIANS DOS SANTOS CAVALCANTI BESERRA
PERFORMANCE ANALYSIS OF VIRTUALIZATION
TECHNOLOGIES IN HIGH PERFORMANCE COMPUTING
ENVIRONMENTS
Dissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação (PROCC) da Universidade Federal do Sergipe (UFS) como parte de requisito para obtenção do título de Mestre em Ciência da Computação.
Orientador: Prof. Dr. Edward David Moreno Ordonez
SÃO CRISTÓVÃO/SE
2016

2
DAVID WILLIANS DOS SANTOS CAVALCANTI BESERRA
PERFORMANCE ANALYSIS OF VIRTUALIZATION
TECHNOLOGIES IN HIGH PERFORMANCE COMPUTING
ENVIRONMENTS
Dissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação (PROCC) da Universidade Federal do Sergipe (UFS) como parte de requisito para obtenção do título de Mestre em Ciência da Computação.
BANCA EXAMINADORA
Prof. Dr. Edward David Moreno Ordonez, Presidente
Universidade Federal de Sergipe (UFS)
Prof. Dr. Admilson de Ribamar Lima Ribeiro, Membro
Universidade Federal de Sergipe (UFS)
Prof. Dr. Luciana Arantes, Membro
Université Pierre et Marie Curie (UPMC)

3
PERFORMANCE ANALYSIS OF VIRTUALIZATION
TECHNOLOGIES IN HIGH PERFORMANCE COMPUTING
ENVIRONMENTS
Este exemplar corresponde à Dissertação de Mestrado, sendo o Exame de Defesa do mestrando DAVID WILLIANS DOS SANTOS CAVALCANTI BESERRA para ser aprovada pela Banca Examinadora.
São Cristóvão - SE, 19 de 09 de 2016
__________________________________________
Prof. Dr. Edward David Moreno Ordonez,
Orientador, UFS
__________________________________________
Prof. Dr. Admilson de Ribamar Lima Ribeiro,
Examinador, UFS
__________________________________________
Prof. Dr. Luciana Arantes,
Examinadora, UPMC

FICHA CATALOGRÁFICA ELABORADA PELA BIBLIOTECA CENTRALUNIVERSIDADE FEDERAL DE SERGIPE
B554pBeserra, David Willians dos Santos Cavalcanti Performance analysis of virtualization technologies in high performance computing enviroments = análise do desempenho de tecnologias de virtualização para ambientes de computação de alto desempenho / David Willians dos Santos Cavalcanti Beserra ; orientador Edward David Moreno Ordonez. - São Cristóvão, 2016. 79 f. : il.
Dissertação (Mestrado em Ciência da Computação) - Universidade Federal de Sergipe, 2016.
1. Computação de alto desempenho. 2. Computação em nuvem. 3. Sistemas de computação virtual. l. Ordonez, Edward David Moreno, orient. lI. Título.
CDU 004.051

AGRADECIMENTOS
Como quase tudo o que faço na vida, esta seção de agradecimentos está sendo escrita em caráter
emergencial, próximo de extrapolar o limite de tempo disponível. Porém - como quase sempre -
o faço por bons motivos, por motivos felizes. Também adianto que, apesar da pressa que tenho
ao escrever esse texto, jamais poderia (nem desejaria) abster-me de fazê-lo, pois para mim é a
etapa mais gratificante (trocadilho infame, eu sei) do processo de redação.
Dito isto, há uma série de pessoas as quais eu devo a alegria de ter concluído e defendido com
sucesso essa dissertação. Infelizmente minha memória não é das melhores e não consegui
lembrar o nome de todos nesse momento. Mas pode ter a certeza de que caso eu não tenha me
lembrado de você agora e acabe lembrando depois, certamente sentir-me-ei muito mal pelo lapso
de memória e continuarei sendo-lhe grato da mesma maneira.
Assim, gostaria de agradecer primeiramente a minha família por todo o apoio e paciência que
tiveram durante todo esse processo. Sou grato, e muito, pelo amor, pelo esforço e pelas lágrimas
que derramaram junto comigo, tanto nos momentos de dor excruciante e apatia aparentemente
sem fim, quanto nos de felicidade soberana. Como evitar chorar agora? Não há como! Ao menos
não há ninguém no CRI da Univ. Paris 1 nesse momento para ver.
Além de minha família, desejo expressar aqui a minha gratidão às hordas de amigos que
estiveram comigo nessa luta. Primeiramente, agradeço a Laurinha pela amizade e apoio
contínuos, por estar sempre “ali” quando de seu ombro amigo precisei e pelos momentos deveras
engraçados - com piadas nem um pouco politicamente corretas - que compartilhamos e que
ajudaram-me a encontrar aquele sorriso perdido que achava que já não mais o encontraria e me
ajudou a seguir em frente.
Agradeço ao meu bom amigo Jhonny (originalmente conhecido como Felipe Oliveira) pelo
apoio, pelos cafés e pelos momentos the zueira never ends . Agradeço também a Liliane

Romualdo pelo suporte indispensável desde quando este trabalho era apenas um sonho até o
momento em que esse sonho gerou um novo sonho ainda maior onde vivo agora. Sem o seu
trabalho em minha vida, o meu trabalho para o mundo seria impossível.
Agradeço ao meu amigo, “mano-vei”, companheiro de pesquisa, safadita e rubro-negro devotado
Jymmy Barreto. Meu irmão, o que seria desse trabalho hoje sem a sua ajuda? (Por favor não
responda, pois podem acabar querendo revogar o meu título de mestre para repassarem-no a
você). Obrigado pela entrega, pela doação, pelas conversas, pelas caronas e pelos cafés.
Também deixo aqui registrada a confissão de que morro de inveja de Amora gostar mais de você
do que de mim.
Ao lembrar de Jymmy é impossível não lembrar daquela que nos apresentou: Patrícia Takako
Endo. Obrigado Patrícia, pela decisiva participação em todos os trabalhos publicados a partir dos
resultados da pesquisa relatada neste documento. Agradeço pela verdadeira doação em
momentos onde nem para si mesma tinha tempo. E agradeço também desde já pelas futuras
ajudas, pois nossa parceria está apenas em seus primórdios ;).
Agradeço ao excelentíssimo senhor Victor Gabriel Galvan Doble (seu argentino xxxxdinho! <3)
pela amizade sincera, pelo apoio constante nos bons e nos maus momentos e pelas lições
ensinadas. Meu caro Gabriel, lhe digo em suas próprias palavras de um português bem
meia-boca: “você é um cara!” Que possamos nos encontrar de novo um dia e que você enfim
entenda que Pelé é melhor que Maradona e que não há time de futebol nesse universo tão bom
como o meu amado Sport Club do Recife.
Agradeço aos meus companheiros do pensionato de Dona Goreth, aos amigos do PROCC e da
UFS pelos momentos divertidos no período em que vivi em Aracaju. Agradeço também a todos
aqueles que contribuíram na vaquinha que possibilitou a minha participação no IEEE SMC 2015,
em Hong Kong. Esse trabalho é uma evolução e ampliação do trabalho lá apresentado.

Agradeço ao Prof. Adimilson de Ribamar Lima Ribeiro e a Profa. Luciana Arantes pelos
relevantes comentários proferidos em relação a esse trabalho, bem como pela disposição e tempo
dedicados à sua leitura e avaliação. Agradeço também ao Prof. Marco Túlio Chella pelo seu
apoio e compreensão no momento em que disso necessitei. Além de bom professor, excelente
humano.
Expresso também meus reiterados e eternos agradecimentos a todos os meus antigos mestres por
todo o saber e coragem de seguir em frente na jornada do aprendizado que me legaram. Com um
carinho mais que especial, agradeço a Profa. Márcia, que me alfabetizou; a Profa. Iranilde
Valente de Arruda, que me convenceu de que ler e aprender são coisas boas e ao Prof. Alberto
Araújo, que me formou enquanto pesquisador, sendo meu primeiro orientador e parceiro de
pesquisa por 6 anos. Se eu tenho umas ideias meio malucas hoje, certamente ele tem alguma
culpa (e muito mérito) no cartório.
Por fim, deixo registrados os meus agradecimentos especiais ao Prof. Edward David Moreno
Ordonez, meu orientador no mestrado e meu amigo pessoal. Professor, obrigado pela confiança
de permitir que eu conduzisse parte da pesquisa à distância quando não tínhamos nos visto antes
mais do que 5 minutos. Obrigado pelo apoio em todas as etapas da pesquisa, pela luta constante
por recursos para sustentar o trabalho desenvolvido. Obrigado também pela enorme paciência
demonstrada com esse ser hiper-ansioso que aqui se apresenta (eu sei que nem de longe foi fácil
manter-se paciente todo esse período). Obrigado pelo incentivo de buscar sempre a melhor
oportunidade possível e não me contentar apenas com o mínimo. Obrigado pela felicidade
genuína demonstrada ao ver-me conseguir realizar meus sonhos pouco a pouco. Obrigado pelas
lições de vida, pelos conselhos, pela amizade e por todas as portas que me abriu. Obrigado pela
sua humanidade. Sempre me lembrarei do senhor com muito carinho e gratidão.
Paris, 01 de novembro de 2016

ABSTRACT High Performance Computing (HPC) aggregates computing power in order to solve large and complex problems in different knowledge areas, such as science and engineering, ranging from 3D real-time medical images to simulation of the universe. Nowadays, HPC users can utilize virtualized Cloud infrastructures as a low-cost alternative to deploy their applications. Despite of Cloud infrastructures can be used as HPC platforms, many issues from virtualization overhead have kept them almost unrelated. In this work, we analyze the performance of some virtualization solutions - Linux Containers (LXC), Docker, VirtualBox and KVM - under HPC activities. For our experiments, we consider CPU, (physical network and internal buses) communication and disk I/O performance. Results show that different virtualization technologies can impact distinctly in performance according to hardware resource type used by HPC application and resource sharing conditions adopted. RESUMO Computação de Alto Desempenho (CAD) agrega poder computacional com o objetivo de solucionar problemas complexos e de grande escala em diferentes áreas do conhecimento, como ciência e engenharias, variando desde aplicações medias 3D ate a simulação do universo. Atualmente, os usuários de CAD podem utilizar infraestruturas de Nuvem como uma alternativa de baixo custo para a execução de suas aplicações. Apesar de ser possível utilizar as infraestruturas de nuvem como plataformas de CAD, muitas questões referentes as sobrecargas decorrentes do uso de virtualização permanecem sem resposta. Nesse trabalho foi analisado o desempenho de algumas ferramentas de virtualização - Linux Containers (LXC), Docker, VirtualBox e KVM – em atividades de CAD. Durante os experimentos foram avaliados os desempenhos da UCP, da infraestrutura de comunicação (rede física e barramentos internos) e de E/S de dados em disco. Os resultados indicam que cada tecnologia de virtualização impacta diferentemente no desempenho do sistema observado em função do tipo de recurso de hardware utilizado e das condições de compartilhamento do recurso adotadas.

4
LIST OF FIGURES 2.1 Main virtualization types.............................................................................................. 16
2.1. VirtualBox architecture .............................................................................................. 17
4. Measurement methodology.......................................................................................... 27
4. Measurement activities................................................................................................. 28
4.3 HPCC execution modes: (a) single, (b) star, and (c) MPI........................................... 32
4.4 VMs (or containers) communication inside the same physical host............................ 38
4.4 Scenario 1: without Interprocess communication ....................................................... 39
4.4 Scenario 2: cooperation with Interprocess communication in 1 or more abstraction 40
5.2 HPL results................................................................................................................... 45
5.2 DGEMM and FFT results in single and star modes..................................................... 46
5.2 Local memory access performance....………………………...................................... 46
5.2 Local interprocess communication ……..................................................................... 47
5.2 HPL and FFT results.................................................................................................... 48
5.2 RandomAccess (mpi) .................................................................................................. 48
5.2 Interprocess communication results – NOR................................................................ 49
5.2 HPL aggregated performance (same host)................................................................... 50
5.2 HPL local clusters performance (same host)............................................................... 50
5.2 Effects of resource sharing on performance with 2 instances running concurrently... 51
5.2 Effects of resource sharing on performance with 4 instances running concurrently... 52
5.2 Interprocess communication bandwidth (same host) ................................................. 53
5.2 Interprocess communication latency (same host) ....................................................... 53
5.2 Interprocess communication bandwidth (cluster) ...................................................... 54
5.2 Interprocess communication latency (cluster) ............................................................ 54
5.2 HPL cluster performance (using network) .................................................................. 55

5
5.2 Writing speed without interprocess communication (1K size file) ............................ 55
5.2 Reading speed without interprocesses communication (1K file size) ........................ 56
5.2 Writing speed without interprocesses communication (128M size file) .................... 57
5.2 Reading speed with processes communication (128M size file) ................................ 57
5.2 Writing speed with interprocess communication (1K file size) .................................. 58
5.2 Reading speed with interprocess communication (1K file size) ................................. 59
5.2 Writing speed with interprocess communication (128Mb file size) ........................... 59
5.2 Reading bandwidth with interprocess communication (128Mb file size) .................. 60
5.3 HPL aggregated performance (same host) .................................................................. 61
5.3 HPL cooperative performance (same host) ................................................................. 62
5.3 Performance of 1 HPL instance running in a single container using all resources of the environment ...........................................................................................................
63
5.3 Effects of resource sharing on performance with 2 instances running concurrently in a single container.....................................................................................................
63
5.3 Effects of resource sharing on performance with 4 instances running concurrently in a single container ....................................................................................................
64
5.3 Effects of resource sharing on performance with 4 instances running concurrently in 2 dual-processor containers .......................................................... ..........................
65
5.3 Effects of resource sharing on performance with 4 instances running concurrently in 4 single-processor containers ..................................................................................
66
5.3 Interprocess communication bandwidth (same host) .................................................. 67
5.3 Zoom on interprocess communication bandwidth results for 1c4p configuration (same host) ..................................................................................................................
67
5.3 Interprocess communication latency (same host) ....................................................... 68
5.3 Interprocess communication bandwidth (cluster) ...................................................... 68
5.3 Interprocess communication latency (cluster) ............................................................ 69

6
LIST OF TABLES
4.2 Metrics x stages ........................................................................................................... 31 4.3 Benchmarks adopted ............................................................................................... 31 4.3 HPCC classification – Luszczek ………………......................................................... 32
4.3 HPCC classification – Zhao ……………….………................................................... 32
4.3 Benchmark classification adopted…….…………….................................................. 33
4.3 Benchmarks x stages .........……………….………..................................................... 34
4.3 Benchmarks x metrics (M) ……………….………..................................................... 34
4.4 Single-server environments ……………….……….................................................... 36
4.4 Factors and levels ……………….………................................................................... 38
4.4 ARM-based environments ……………….………..................................................... 41
4.4 Articles published with results of the master dissertation …………………………. 73
4.4 Other articles published during the masters course…………......………………….. 73

7
LIST OF ACRONYMS
API Application Programming Interface
ARM Advanced RISC Machine
BLAS Basic Linear Algebra System
CAPES Coordenação de Aperfeiçoamento de Pessoal de Nível Superior
CGroups Control Groups
CPU Central Processing Unit
CV Coefficient of Variation
DFT Discrete Fourier Transform
FIO Flexible IO
FLOPS FLoating-point Operations Per Second
FV Full Virtualization
GB Gigabyte
GB/s Gigabytes per Second
GPL General Public Licence
GPU Graphics Processing Unit
GUI Graphical User Interface
GUPS Giga Updates Per Second
HA High Availability
HDFS Hadoop Distributed File System
HPC High Performance Computing
HPC High Performance Computing
HPCC HPC Challenge Benchmark
HPL High-Performance Linpack
I/O Input/Output
IEEE Institute of Electrical and Electronics Engineers
IoT Internet of Things
KVM Kernel-based Virtual Machine
LXC Linux Containers

8
MB/s megabytes per second
Mbps Megabits per second
MPI Message Passing Interface
NetPIPE Network Protocol Independent Performance Evaluator
NIC network interface controller
NOR Naturally Ordered Ring
OS Operating System
PC Personal Computer
POSIX Portable Operating System Interface
PV Paravirtualization
QEMU Quick Emulator
QoS Quality of Service
ROR Randomly Ordered Ring
SAN Storage-Area Network
SLA Service Level Agreement
SoC Systems-on-a-Chip
TCP Transmission Control Protocol
UDP User Datagram Protocol
UFPE Federal University of Pernambuco
UFRPE Federal Rural University of Pernambuco
UFS Federal University of Sergipe
UPE University of Pernambuco
VM Virtual Machine
VMM Virtual Machine Monitor

9
TABLE OF CONTENTS
1 INTRODUCTION .......................................................................................................... 12 2 A SMALL SURVEY IN VIRTUALIZATION TECHNOLOGY............................ 15
2.1 Hypervisors ............................................................................................................... 15
2.1.1 KVM ............................................................................................................... 16
2.1.2 VirtualBox....................................................................................................... 17
2.2 OS-level Virtualization............................................................................................. 18
2.2.1 LXC ................................................................................................................ 18
2.2.2 Docker ............................................................................................................ 18 3 RELATED WORKS...................................................................................................... 19
3.1 Fundamental Requirements to Use Virtualization in HPC Scenarios...................... 19
3.2 Studies About Virtualization and HPC Focused in Computationally Intensive
Applications on x86 Architecture ...................................................................................
19
3.2.1 Performance Analysis of Hypervisor-Based Solutions for HPC Purposes…. 20
3.2.2 Performance Analysis of OS-level Solutions for HPC Purposes.................... 21
3.3 Studies About Virtualization and HPC Focused in I/O-Intensive Applications on
x86 Architecture...............................................................................................................
22
3.4 Virtualization in Single-board Computers for HPC Purposes.................................. 23
4 EXPERIMENTAL DESIGN........................................................................................ 27
4.1 Goals......................................................................................................................... 28
4.1.1 Stage 1 and its Goals....................................................................................... 28
4.1.2 Stage 2 and its Goals....................................................................................... 29
4.1.3 Stage 3 and its Goals....................................................................................... 29
4.2 Metrics...................................................................................................................... 30
4.3 Benchmarks............................................................................................................... 31
4.4 Experiments Performed............................................................................................ 34

10
4.4.1 Experiments on Stage 1.................................................................................. 35
4.4.1.1 Infrastructure ..................................................................................... 35
4.4.2 Experiments on Stage 2 ................................................................................. 36
4.4.2.1 Virtualization Overheads on CPU-bound Applications
Performance.....................................................................................................
36
4.4.2.2 Effects of Resource Sharing on Performance .................................... 37
4.4.2.3 Virtualization Overheads on Communication Performance .............. 37
4.4.2.4 Virtualization Overheads on I/O-bound Tasks
Performance.....................................................................................................
38
4.4.2.5 Infrastructure...................................................................................... 39
4.4.3 Experiments on Stage 3 ................................................................................. 40
4.4.3.1 Virtualization Overheads on CPU-bound Applications
Performance.....................................................................................................
41
4.4.3.2 Effects of Resource Sharing on Performance .................................... 41
4.4.3.3 Virtualization Overheads on Communication Performance .............. 41
4.4.3.4 Infrastructure....................................................................................... 41
4.5 Why Choose These Virtualization Tools................................................................ 42
5 RESULTS........................................................................................................................ 44
5.1 Results of Stage 1...................................................................................................... 45
5.1.1 Local Resources Usage................................................................................... 46
5.1.1.1 Processing........................................................................................... 46
5.1.1.2 Local Memory Access........................................................................ 47
5.1.1.3 Local Interprocess Communication.................................................... 47
5.1.2 Global Resource Usage (Cluster
Environment)............................................................................................................
47
5.1.2.1 Global Processing............................................................................... 47
5.1.2.2 Global Memory Access...................................................................... 47
5.1.2.3 Global Interprocess Communication.................................................. 48
5.2 Results of Stage 2...................................................................................................... 49
5.2.1 Virtualization Overheads on CPU-bound Applications Performance............ 49
5.2.2 Effects of Resource Sharing on Performance................................................. 51
5.2.3 Virtualization Overheads on Communication Performance........................... 52

11
5.2.4 Virtualization Overheads on I/O-bound Tasks Performance.......................... 55
5.2.4.1 Scenario 1: without Communication among Processes...................... 55
5.2.4.2 Scenario 2: With Interprocess Communication.................................. 58
5.3 Results of Stage 3...................................................................................................... 59
5.3.1 Virtualization Overheads on CPU-bound Applications Performance............ 59
5.3.2 Effects of Resource Sharing on Performance................................................. 62
5.3.2.1 Overloads Due to Virtualization and Resource Sharing on
Performance of a Single Container Using all Hardware Resources
Available……………………………………………………………………..
62
5.3.2.2 Overloads Due to Virtualization and Resource Sharing on
Performance of Containers Running
Concurrently....................................................................................................
65
5.3.3 Virtualization Overheads on Communication Performance........................... 66
6 CONCLUSIONS AND PERSPECTIVES................................................................... 70
6.1 Conclusions Regarding Experiments Conducted on Stage 1................................... 70
6.2 Conclusions Regarding Experiments Conducted on Stage 2................................... 71
6.3 Conclusions Regarding Experiments Conducted on Stage 3................................... 71
6.4 Future Woks …………………………………..…………..................................... 72
6.5 Published Works on Conferences and Journals …………..................................... 73
REFERENCES................................................................................................................... 74

12
CHAPTER 1
INTRODUCTION
High Performance Computing (HPC) is a generic term to applications that are
computationally intensive or data intensive in nature [Simons and Buell 2010],
[Somasundaram and Govindarajan 2014], ranging from floating-point computation in
microcontrollers to 3D real-time medical images and simulations of large-scale structures,
such as the Universe [Vogelsberger et al. 2014]. Traditionally, HPC applications are
executed in dedicated infrastructures in which resources are locally owned with private access
and composing complex structures with quasi-static configurations. This type of in-house
infrastructure is expensive and difficult to setup, maintain, and operate [Vecchiola et al.
2009].
As a low-cost and flexible alternative, HPC users have utilized cloud infrastructures
instead in-house clusters; with this, they can enjoy cloud benefits, such as high availability
(HA), operating system (OS) customization, lower wait queue time, and maintenance cost
reduction [Ye et al. 2010], [Marathe et al. 2014]. Some cloud providers, such as Amazon,
Google, and IBM, are already offering a platform for HPC services, allowing the creation of
clusters over their infrastructure. To offer and manage their resource in a practice way,
commonly cloud providers rely on virtualization technology.
In Cloud Computing environments, virtualization is a key technology for enabling its
operation and, despite virtualization brings many advantages to cloud computing, such as
resource sharing and facility to scale resources down and up; it also presents many challenges
for its full use for HPC purposes, such as an increment in the management complexity of
infrastructures and services [Abdul-Rahman et al. 2012] and overheads caused by the
virtualization layer, taking as example the occurrence of performance penalties due to
resource sharing, with virtualized environments presenting worst performance than non-
virtualized [Regola and Ducom 2010]. Nowadays, there are several virtualization techniques

13
and tools, and each technique can impact differently on HPC applications performance.
Beyond that, some of these virtualization tools (hypervisors) can use a mix of virtualization
techniques to improve its performance.
In this way, evaluate the performance of current virtualization technologies under HPC
applications is relevant, especially when considering Message Passing Interface (MPI)
applications running on Beowulf Clusters (the most common set of HPC structure and library
used to develop HPC applications) [Ye et al. 2010]. This kind of evaluation is also needed to
identify the virtualization bottlenecks and determine which combination of hypervisor and
virtualization technique is more suitable for HPC applications and its environments.
Besides the clusters of workstations are still considered the most important HPC
infrastructure (and maybe still will be in the next decade), there are new developments in the
current HPC scenario that promises a revolution in the way how HPC is used and recognized.
One of these developments was the introduction of systems-on-a-chip (SoC) in the market,
encapsulating CPU, GPU, RAM memory and other components at the same chip [Wolf et al.
2008]. The SoC technology is used as the principal component of single-board computers,
like Raspberry PI, Intel Galileo and Banana PI.
These single-board computers are considered as new developments itself and are
categorized as Embedded Systems for General Purpose; being used for a large range of
applications, from Computer Science teaching [Ali et al. 2013] to Internet of Things [Molano
et al. 2015]. Moreover, the single-board computers are also emerging as an alternative to
provide low cost HPC infrastructures which can be used in extreme scenarios and conditions,
like deserts or forests.
Today, there are already available clusters of single-board computers aiming provide
low cost HPC infrastructure for educational purposes [Cox et al. 2014] or to act as cheapest
GPU hosts [Montella et al. 2014]. The single-board computers are also being used to
implement small cloud environments for tests and for general purposes, using virtualization
technology [Abrahamsson et al. 2013] [Tso et al. 2013]. It is important notice that the
performance of the most important architectural components of the system as CPU, Network
and Disk, needs to be monitored and distinct virtualization techniques and tools can impact
differently on performance of the entire environment [Varrette et al. 2013].
So, in this new scenario some questions emerges, for instance: what is the relation
between performance and virtualization technology used, both in single-board computers both
in traditional x86 systems?; What are the bottlenecks of the main SoC architectures used in
conjunction with virtualization technology under single-board computers for HPC purposes?.

14
Therefore, in the same way that is needed to evaluate the performance of virtualization when
used in conjunction with traditional computer systems, it is also necessary to evaluate its
performance when used in conjunction with single-board computers.
In this work we evaluate the performance of virtualization technologies for HPC
purposes, both platforms (traditional workstations and single-board computers).. The goal of
this work is to determine what type of virtualization technologies is more suitable for each
hardware type, under certain application domains. The performance measurements and
subsequent comparative analysis will be conducted using traditional benchmarks of HPC
community.
This work is structured as follows: Section 2 presents virtualization basic concepts
needed to understand this work; Section 3 describes the related works; Section 4 presents our
main goals and the methodology used to perform our experiments; we present and discuss the
results in Section 5; and finally, Section 6 presents the conclusions obtained from this study,
as well a set of possible future works.

15
CHAPTER 2
A SMALL SURVEY IN VIRTUALIZATION TECHNOLOGY
Considering all current virtualization technologies, we can highlight two of them:
operating-system-level (OS-level) virtualization and hardware virtualization, that makes
use of Virtual Machine Monitors (VMMs), as known as hypervisors. We provide a brief
description of these technologies in the next subsections.
2.1 Hypervisors
The hardware virtualization can be classified as Type I or Type II. Each type considers
where the VMM is located in the system software stack. Type I hypervisors (1.a) execute over
hardware (such as VWware ESXi1) or modify the host OS in order to allow direct access to
the hardware through paravirtualization process (for instance, Xen2) [Fayyad-Kazan et al.
2013] [Walters et al. 2008].
On the other hand, the Type II (1.b) maintains a VMM working like a software inside
the host OS, creating complete abstractions and total isolation from the virtualized hardware
[Manohar 2013]. For that, all guest OS instructions are translated. This type of virtualization
is also known as full (or total) virtualization.
Besides full virtualization allows a guest OS running without kernel modifications, it
imposes high overload in VM performance, opposing the main request that virtualization
must attend to support HPC: do not cause impact in the system. Despite full virtualization
does not satisfy this requirement, it is safety because offers a full isolation between host and
virtual environments [Younge et al. 2011]. The performance penalties caused by full
virtualization can be mitigated by using hardware-assisted virtualization, a set of specific
instructions to deal with virtualization process that is present in almost all processors and in 1 https://www.vmware.com/products/vsphere-hypervisor 2 http://www.xenproject.org/

16
some I/O elements [Ye et al. 2010]. Commonly, this approach is used with full virtualization,
maintaining the advantages and diminishing the drawbacks.
Figure 1. Main virtualization types
On the other hand, when using paravirtualization, hardware devices are not emulated;
they are accessed through special paravirtualized drivers, obtaining a better performance
when compared to full virtualization techniques, even when it is assisted by hardware
[Nussbaum et al. 2009]. As said before, the main difference between paravirtualization and
full virtualization is that in paravirtualization the kernel of the guest OS must be modified in
order to provide new system calls. These modifications increases the performance because
reduces the CPU consumption, but at same time reduces the security, the reliability, and
increases the management difficulty.
One of the most widely used hypervirsors is the Kernel-based Virtual Machine (KVM)3,
a Linux integrated hypervisor that can operate as Type I and Type II, in a hybrid way. The
next subsection describes with more details the hypervisor-based tools evaluated in this study:
KVM and VirtualBox.
2.1.1 KVM
The Kernel based Virtual Machine (KVM) is an open source hypervisor integrated to
Linux kernel. This virtualization approach takes advantage of the Linux kernel development
as own evolution [Nussbaum et al. 2009]. In KVM, VMs are simple Linux processes, 3 http://www.linux-kvm.org/page/Main Page

17
instantiated by the OS process scheduler. The I/O management, including the virtual network
interface, is done by a modified version of the Quick Emulator full virtualization tool
(QEMU). All I/O requests done by a VM are forwarded to the QEMU that redirects them to
the host OS. Today, the development of the virtio driver, a paravirtualized I/O driver
framework for KVM made KVM a strong candidate for HPC applications [Regola and
Ducom 2010].
2.1.2 VirtualBox
VirtualBox is a virtualization system maintained by Oracle [Oracle 2013]. It is an Open
Source Software under GNU/GPL license that runs on many OS, such as Linux, Windows,
and Macintosh. VirtualBox offers paravirtualization for network resource through adapted
versions of virtio drivers from KVM.
According to its manual, VirtualBox was designed to be modular and flexible.
Basically, the hypervisor runs: a) VBoxSVC, a background process that is responsible for
bookkeeping, maintaining the state of all VMs, and for providing communication between
VirtualBox components; b) and the GUI process, that is a client application.
VirtualBox uses a layered architecture consisting of a set of kernel modules for running
VMs, an API for managing the guests, and a set of user programs and services, as shown in
Figure 2. Currently, there are some Cloud Computing solutions for scientific HPC running
over VirtualBox, like Cloud BioLinux, for provisioning on-demand infrastructures for high-
performance bioinformatics [Krampis et al. 2012].
Figure 2. VirtualBox architecture [Bob Netherton 2010]

18
2.2 OS-level Virtualization
In the OS-level virtualization (1.c), abstractions are created through containers. A
container shares its kernel with the host OS; in this way, its processes and file system are
completely accessible from the host. However, there is no overhead of running other
abstraction layer because OS-level virtualization does not needs a hypervisor [Soltesz et al.
2007]. LinuX Containers (LXC) is an example of OS-level virtualization. The next subsection
describes with more details the OS-level based tools used in this study: LXC and Docker.
2.2.1 LXC
Linux Containers (LXC) is a lightweight virtualization mechanism that does not require
emulation of physical hardware. The main usage of LXC is to run a complete copy of the
Linux OS in a container without the overhead of running a level-2 hypervisor. The container
shares the kernel with the host OS, so its processes and file system are completely visible
from the host. On the other hand, the container only sees its file system and process space.
The LXC takes the CGroups (control group) resource management facilities as its basis and
adds POSIX file capabilities to implement processes and network isolation [Oracle 2014].
2.2.2 Docker
Docker is a high-level container-solution family that leverages LXC, differing from that
by allowing the packging of an entire environment into container images by the using of an an
overlay filesystem [Joy 2015]. Another relevant difference is highlighted by Morabito:
“During the first releases Docker made use of LXC as execution driver, but starting with the
version 0.9, Docker.io has dropped LXC as default execution environment, replacing it with
their own libcontainer” [Morabito 2015]. With Docker, is possible create personalized images
that can be used as a base to the deployment of many concurrent containers. It is ideal for
production environments as commercial public clouds [Morabito et al. 2015].

19
CHAPTER 3
RELATED WORKS
This section presents a set of representative state-of-art literature that contributed to
develop this research. This section was divided into subsections and each subsection deals
with a specific subset of related works according to each step of the research.
3.1 Fundamental Requirements to Use Virtualization in HPC Scenarios
Some fundamental requirements must be fulfilled for HPC virtualization. Firstly,
virtualization overhead cannot yield significant impacts under system performance. This is a
critical point for HPC [Ye et al. 2010]. Virtualization must maximize the use of physical
available resources [Nussbaum et al. 2009], avoiding resources underutilization [Johnson et
al. 2011]. Third requirement defines that virtualization must improve environment
administration, allowing fast start and destroy of VMs and flexible distribution of hardware
resources. Fourth requirement states that virtualization must increases virtualization
reliability, enabling mechanisms of redundancy and fail recovery ( [Ye et al. 2010], [Mergen
et al. 2006]).
Besides, virtualization should not decrease environment security through VMs
application isolation [Ye et al. 2010]. Above list of requirements is not exhaustive, but can be
considered as relevant starting point for analyzing virtualization tools under HPC.
3.2 Studies About Virtualization and HPC Focused in Computationally
Intensive Applications on x86 Architecture This section was also divided into subsections and each subsection deals with an
specific subset of related works according to each step of the research.

20
3.2.1 Performance Analysis of Hypervisor-Based Solutions for HPC Purposes
Some works already evaluated the performance of virtualization for HPC applications,
such in [Younge et al. 2011], where it was performed an performance analysis of open source
hypervisors (Xen, KVM, and VirtualBox) running some benchmarks in virtual clusters and
was proposed a hypervisor ranking for HPC applications, concluding that KVM and
VitualBox present the best global performance and management facility, with KVM excelling
in regard to computation capability and memory expandability. Authors also observed that,
different from Xen, KVM presents little performance oscillations, that is considered a key
characteristic in Cloud environments according [Napper and Bientinesi 2009].
In the same way, in [Luszczek et al. 2012] was conduced a study comparing KVM
against VirtualBox and VMware Player also concluding that KVM is the most suitable
virtualization tool for HPC. However, in both works the authors do not use a variable amount
of computers on tests and do not observe the effects of paravirtualization instructions over
systems performance. Inclusive, their work do not clarify if Xen cluster used
paravirtualization or not. This may cause influences on cluster performance. Other works,
such as [Bakhshayeshi et al. 2014], [Xavier et al. 2013] and [Karman et al. 2014] fail at the
same points. Regarding [Karman et al. 2014], its main contribution is a new HPCC test
classification, used on this work.
In other hand, some works evaluated the effects of the paravirtualization on the
performance of HPC applications. A relevant example of this class of study is the work of
Nussbaum and its partners [Nussbaum et al. 2009], that analyses the impact of
paravirtualization instructions for KVM and Xen environments hosted in a single server
taking into consideration metrics like CPU and network performance as well CPU
consumption data usage by VMs during tests. In regarding to network performance, authors in
[Nussbaum et al. 2009] considered a common scenario in Cloud Computing environments, in
which VMs share the same host and send a great number of packets. In this scenario, KVM
presented aggregated bandwidth better than Xen because KVM network emulation has a
better host CPU utilization when processing data, but do not extend their analysis for a cluster
environment.
In the same way [Ye et al. 2010] compares the performance of Xen hypervisor in cluster
environments using or not using the paravirtualization instructions and concluding that
paravirtualization instructions increases the performance, specially for network devices and
operations, but do not extend their work to other hypervisors; Similarly, Beserra and partners
[Beserra et al. 2014] analyzed VirtualBox performance for HPC applications, with focus on

21
effects of choosing host operating system on performance of virtualized clusters, also
analyzing the effects of paravirtualization instructions over performance, but their work lacks
of a comparison against another hypervisors. This work differs from previous others because
our analysis is in a high scale, measuring the scalability, using more than 1 hypervisor and
taking into consideration the effect of paravirtualization instructions usage on performance.
3.2.2 Performance Analysis of OS-level Solutions for HPC Purposes
However, these works cited in the previous subsection did not consider OS-level
virtualization technologies based on containers. Containers can offer advantages for HPC,
such as a short bootstrap time, and a less disk space usage. Authors in [Seo et al. 2014] noted
containers present a bootstrap duration 11 times smaller than KVM, and the disk usage is also
smaller; while 50 VMs (KVM running Ubuntu) can be stored in a disk with 500Gb, more than
100 containers use less than a half of this space. Beyond that, container technology can also
improve the service availability; for instance, work presented by [Guedes et al. 2014]
achieved a five 9’s availability in a web cache cluster scenario with 1:1 VM and disk over
container-based OS virtualization.
In other hand, authors in [Che et al. 2010] compared the performance of OpenVZ, Xen,
and KVM using VMs as web servers. OpenVZ presented results better than native in some
situations; however the KVM paravirtualization instructions were not activated. This
configuration could collaborate to KVM inferior performance, since KVM with
paravirtualization instructions can obtain better performances than Xen [Nussbaum et al.
2009], [Younge et al. 2011].
Authors in [Xavier et al. 2013] innovate when analyzing the performance of main OS-
level virtualization solutions running HPC applications. They compare OpenVZ, LXC, and
VServer against Xen performance considering CPU, disk, and network. All containers
solutions and Xen presented an equivalent processing capacity, with all solutions presenting
performance close to a native environment. The network performance analysis considered
bandwidth and delay according to packet size and their results indicated that LXC and
VServer have better performances, with smaller delay and bigger bandwidth for any size of
packet. “Since the HPC applications were tested, thus far, LXC demonstrates to be the most
suitable of the container-based systems for HPC” [Xavier et al. 2013].
The work presented in [Felter et al. 2014] compares the performance of KVM and a
Linux container-based solution, Docker (strongly based in LXC), in relation to non-

22
virtualized environments. Authors evaluated CPU, memory, storage and networking
resources, and observed Docker performance is equal or better than KVM in all cases they
tested. Both technologies introduce negligible overhead for CPU and memory performance,
however they need some improvements to support I/O intensive applications.
So, the next stage of this work was a performance comparison of KVM against LXC.
KVM was chosen because it has the best performance and is the best hypervisor-based
virtualizaton solution according to literature [Younge et al. 2011], [Felter et al. 2014]; and
LXC because it can become a de facto standard to system containerization, with the
possibility to converge with OpenVZ to compose the same tool [Dua et al. 2014].
We extend the work done by [Nussbaum et al. 2009], verifying how resource sharing
among multiple VMs can impact the performance (ie. how the execution of some
applications in parallel, under the same hardware resources, can reduces the performance of
each application on running when compared to the performance of the same applications
runnig alone), as well as analyzing the CPU usage by guests (containers and VMs) according
to different resource types.
We also analyze the network performance in function of size packets in a similar way to
[Xavier et al. 2013] and, for all experiment results, we take in consideration statistics analysis
(such as variation and standard deviation) - aspect that is not contemplated in [Xavier et al.
2013]. Additionally, different from all previous works, we also evaluate the intranode
interprocess communication performance. In this way, we fulfill some lacks of existing
works in literature and contribute to the state-of-the-art evolution.
3.3 Studies About Virtualization and HPC Focused in I/O-Intensive
Applications on x86 Architecture
Regarding to I/O performance issues, authors in [Morabito et al. 2015] compare KVM,
LXC, Docker and OSv using benchmarking tools to measure CPU, memory, disk I/O, and
network I/O performance. Overall, according to authors, results showed that containers
achieve generally better performance when compared with traditional VMs. To measure disk
I/O performance, authors used Bonnie++ tool4 and results showed that LXC and Docker offer
very similar performance and close to a bare metal environment. However, this work does not
consider different size of files, neither cooperation among processes.
4 https://sourceforge.net/projects/bonnie/

23
Authors in [Felter et al. 2014] compare the performance of KVM and Docker, in
relation to non-virtualized environments. Authors evaluated CPU, memory, storage and
networking resources. Regarding to intensive I/O operations performance analyses, authors
used FIO (Flexible IO)5 tool to generate I/O workload in a SAN-like storage. They also
evaluated the performance of virtualization tools under writing and reading operations in
MyQSL databases. They observed that Docker performance is equal or better than KVM in all
cases they tested. However, such as [Morabito et al. 2015], authors do not consider different
sizes of file, neither the resource competition impact on virtual environments.
Authors in [Gomes Xavier et al. 2014] analyses the containers performance under HPC
environments with I/O-bound applications using MapReduce. They evaluated LXC, OpenVZ
and VServer. First, authors used the micro benchmark TestDFSIO to identify performance
bottlenecks in Hadoop Distributed File System (HDFS) configurations, giving an insight in
terms of I/O performance of MapReduce clusters. Further, the authors used WordCount and
Terasort6 benckmarks to perform performance evaluation in a HDFS file system. Authors
concluded that LXC offers the best combination between performance and resource isolation.
However, authors do not compares the performance of container-based virtualization
solutions against VM-based virtualization solutions. Moreover, authors do not consider
resource competition impact on virtual environments.
Authors in [Preeth et al. 2015] evaluated Docker performance based on hardware
utilization. The I/O performance was evaluated with Bonnie++ and the authors observed that
Docker presents the same disk usage than a native environment. However, authors did not
compare Docker performance against other virtualization tools.
For our work, in addition to related works, we decided to verify how resource sharing
among multiple VMs can impact in the performance of HPC I/O-bound applications running
in virtualized environments implemented with traditional VM-based virtualization tools, and
container-based virtualized tools. We also performed a statistical analysis to obtain media and
standard variation for the entire set of experiments performed. This is a significantly
difference between our work from other recent ones, as [Preeth et al. 2015] and [Felter et al.
2014]. In this way, our work contributes to evolute the current state-of-the-art to other
baseline.
5 http://freecode.com/projects/fio 6 http://sortbenchmark.org/

24
3.4 Virtualization in Single-board Computers for HPC Purposes
The use of single-board computers for HPC purposes and related activities is a recent
trend, being first single-board computer cluster - Iridis-PI- developed by a team from
University of Southamptom in 2013 the [Cox et al. 2014]. The Iridis-Pi cluster was assembled
with 64 Raspberry Pi Model B acting as compute nodes (1 acting as the clusterhead) and
housed in a rack assembled with Lego pieces. The Iridis-PI cluster nodes are interconnected in
a common Ethernet Switch. This cluster was designed to reach educational goals and offer a
small cluster environment for tests and not to be considered as a serious alternative for HPC
infrastructure. However, the authors benchmarked the cluster to measure and evaluate its
performance on CPU computing capacity, network throughput and latency and the capacity
for I/O operations with Hadoop filesystem.
The results indicated some performance bottlenecks in Iridis-PI cluster: due low RAM
memory available into nodes, the cluster is limited to scaling for smaller problems; The peak
computing performance is also limited due this factor and due the less network throughput
(near of 100 Mb/s), delivering a computing performance near of 1.14 Gflops using 64 nodes.
Besides the pioneering of Iridis-PI cluster initiate, the authors had no compared the
performance of Raspberry Pi nodes against other single-board computers nodes. The authors
do not evaluated other important aspects of a computer system, like memory bandwidth and
the effects of parallelism into a single node; they would can had obtained these information
running other benchmarks. The authors do not evaluated the performance of any virtulization
techniques in Raspberry Pi.
Still in 2013 was registered the use of single-board computers to create small cloud
computing environments [Abrahamsson et al. 2013] [Tso et al. 2013]. A team from University
of Glasgow developed a small cloud environment - PiCloud - to emulate all layers of a Cloud
stack and for use in educational activities [Tso et al. 2013]. Their cloud was also assembled
using 56 Raspberry Pi housed in LEGO racks. The node interconnection was provided with
an OpenFlow switch. The virtualization layer was provided with LXC and each server hosted
3 containers; being the other virtualization tools alternatives discarded because were
considered by the authors as memory intensive and this feature is not suitable the memory
capacity of a Raspberry Pi (at that time). Besides be an interesting work in an educational
perspective, do not contributes so much to understand what are the possible applications and
performance bottlenecks of this kind of environment, because the cloud environment designed
and assembled by them was not evaluated with any benchmark or real application. Moreover,

25
it is also relevant notice that virtualization impacts on performance was not considered too,
and being the virtualization a key feature in cloud environments, is crucial evaluate its
impacts on performance.
Taking the PiCloud in account, a research team from Free University of Bozen-Bolzano
developed their own cloud environment alternative: the Bolzano Raspberry Pi Cloud
[Abrahamsson et al. 2013]. This cloud environment differs from PiCloud in some aspects: is
hosted in a structure specially designed for this purpose by the Design department of the same
university; achieves a new scaling capacity by use of 300 Raspberry Pi nodes; is not
concentrated in only a single switch and do not use virtualization technology, being more
similar to a conventional data center for web services purposes than a cloud environment.
However, in that work the authors did not any performance analysis of the cloud built. The
authors point to the possibility of experiment their cloud environment with mobile and self-
sufficient “cloud in a box” system using solar panels and satellite up-links to the cluster in the
future, and this idea brings with it the possibility of use cloud environments (and HPC cloud
environments) in isolated places.
Some works in the subsequent years had evaluate the performance of single-board
computers for many purposes, such as [Kruger and Hancke 2014] that evaluated the
performance of single-board computers and development boards taking in account an IoT
scenario. Other works already compared some computer-board alternatives with the use of a
real web single application [Halfacre 2012] and with a single benchmark to measure the
performance in intensive integer numbers computing [van der Hoeven 2013], but with no
specific focus on HPC activities: focusing just on energy-consumption issues, with the results
indicating that the ratio Performance/Watts of Raspberry Pi is far from the same ratio
obtained in traditional workstations [Jarus et al. 2013].
Regarding HPC purposes, in [Kaewkasi and Srisuruk 2014] was carried out a
performance analysis to verify if is possible use single-borad computers for big data
applications, with the authors concluding that this technology is still immature for these
purposes due its low processing capacity. However, another study showed the opposite:
single-board computers can be used for some applications in big data, but in their tests
performance was limited due low network throughput (around 100 Mb/s) [Anwar et al. 2014].
In [Ashari and Riasetiawan 2015] the performance of an ARM-based cluster was compared
with a PC-based cluster performance. However, also in that study no virtualization technology
was used and evaluated.

26
An interesting initiative to provide a new usage of single-board computers for HPC
purposes was presented in [Montella et al. 2014]. In that paper the authors describes an
architecture that consists of some Raspberry Pi units grouped in clusters and accessing GPUs
hosted in a workstation. The goal was improve the performance of single-board computers by
using virtualized slices of GPUs, with a specific solution for GPU virtualization: gVirtus.
In a common way the related works cited here present some lacks: do not evaluate the
performance obtained versus energy consumption of virtualization tools for HPC purposes;
when using virtualization, do not extend the performance evaluation for more than 1
virtualization tool; do not conduct performance evaluations in the environments using the
classical benchmark suites of HPC community, implying in not englobing all critical aspects
of an computer architecture, like memory bandwidth as example; do not purpose a model to
predict the performance of the environment based in real measurements and for a large scale
and never used Gigabit NICs when benchmarking HPC environments, missing the fact that in
HPC environments the maximum network bandwidth achieved has profound impact on
performance of the entire environment. So, in the last part of this research proposed in this
document is proposed to evaluate the performance of some already available virtualization
tools for ARM architecture - LXC and Docker - with traditional HPC benchmarks and using
single-board clusters with Gigabit NICs. The experimental design proposed to be used to
answer these issues is delineated with more details in the next section.

27
CHAPTER 4
EXPERIMENTAL DESIGN
This section describes the experimental design adopted on this research. The research
was splitted in three distinct stages. Each stage has its own goals collaborating to reach the
main goal. The infrastructure used varies because each step of this study was performed in
partnership with other universities. The first stage was performed in partnership with the
Federal Rural University of Pernambuco (UFRPE) and the second stage was performed in
partnership with the Federal University of Pernambuco (UFPE) and the University of
Pernambuco (UPE). The last stage was conducted in the Federal University of Sergipe
(UFS).
We adopted the methodology proposed in [Sousa et al. 2012] as a guide to plan and
execute this research. The methodology is based on four main activities: Measurement
planning, Measurements, Statistical treatment and Performance analysis (Figure 3). The first
activity (and the most important) is to planning all measurement experiments that will be done
on the environments evaluated, defining how our measurement should be performed in order
to collect metrics we are interested. In this activity, we also need to decide which
benchmarking tool we will use and how we will store the measured data.
Figure 3. Measurement methodology, adapted from [Sousa et al. 2012].

28
The second activity is the taking of measurements, an activity splitted into sub-activities
(the measurement activity is expanded in Figure 4). The third activity is the statistical
treatment of the data collected from the measurements performed previously, by applying of
statistical methods to provide accurate information about the experiments. The fourth and last
activity is the performance analysis itself, by comparing of all collected and treated data and
pointing the relations between the variables observed.
Figure 4. Measurement activities, adapted from[ [Sousa et al. 2012].
4.1 Goals The main goal of this research is to analyze the performance of current virtualization
technologies - hypervisor-based and OS-level - in HPC environments composed by x86_64
and ARM processors in order to discover which technology suits the best each architecture.
To achieve this goal we divided the research in 3 stages, each stage with different
infrastructures and local objectives. The next subsections explain the goals of each stage in
details.
4.1.1 Stage 1 and its Goals This stage consisted in analyses the performance of hypervisor-based virtualization
tools (KVM and VirtualBox) that have features of both Type 1 and Type II virtualization
techniques in order to discover which technology suits the best for HPC applications in
x86_64-based environments. Follows the goals of this step:

29
1. To determine the effects of paravirtualization instructions available on KVM
on performance of HPC applications;
2. To determine the effects of paravirtualization instructions available on
VirtualBox on performance of HPC applications;
3. To determine which hypervisor-based virtualization solution performs better
for HPC in function of resource used (for instance: CPU, Memory, Network), using or not
paravirtualization instructions; and,
4. To determine how the performance of KVM and VirtualBox tools evolutes in
function of the amount of nodes used on environment.
4.1.2 Stage 2 and its Goals On this stage, the performance of a hypervisor-based virtualization tool - KVM – was
compared against the performance of an OS-level virtualization tool - LXC -, considering the
following specific goals:
1. To determine the overhead caused by virtualization on CPU-bound
applications performance, regarding virtualization technology adopted;
2. To determine the overhead caused by resource sharing on performance of the
shared resources in function of the sharing type;
3. To determine how the type of virtualization technology adopted affects the
Interprocess communication performance, considering:
(a) Communications using only intranode communication mechanisms;
(b) Communications using a physical network interface;
4. To determine the overhead caused by virtualization on I/O-bound applications
performance, regarding virtualization technology adopted; and,
5. To determine how resource sharing in virtualizated environments affects I/O-
bound applications performance.
4.1.3 Stage 3 and its Goals In turn, the Stage 3 consists in analyses and compare the performance of OS-level
virtualization tools LXC and Docker for HPC applications running in ARM-based
environments, considering the following specific goals:

30
1. To determine the overhead caused by virtualization on CPU-bound
applications performance;
2. To determine the overhead caused by resource sharing on performance of the
shared resources in function of the sharing type; and,
3. To determine how virtualization affects the interprocess communication
performance, considering:
(a) Communications using only intranode communication mechanisms;
(b) Communications using a physical network interface;
4.1 Metrics We choose some metrics to reach the targeted goals. The metrics adopted differ in
function of the goal targeted. Follows the metrics used on this research:
1. Amount of floating-point computations that can be performed by a processor in
a given time, measured in FLoating-point Operations Per Second (FLOPS) and its multiples;
2. Memory bandwidth, measured in gigabytes per second (GB/s);
3. Amount of updates in random access memory in a given time, measured in
Giga Updates Per Second (GUPS);
4. Communication latency between MPI process pairs, measured in nanoseconds;
5. Communication bandwidth between MPI process pairs, measured in Megabits
per second (Mbps);
6. Disk write speed, measured in Megabytes per second (MB/s); and,
7. Disk read speed, measured in Megabytes per second (MB/s).
Metric 1 was used to measure the capacity of the systems evaluated in terms of
processing capacity. The metrics 2 and 3 were used to measure the access capacity on main
memory. The metrics 4 and 5 were used to measure the interprocess communication capacity
in the systems evaluated. In turn, metrics 6 and 7 were used to measure the I/O capacity of the
systems evaluated.
Table 1 shows the association between stages and metrics adopted for each stage of this
research. The metrics vary in function of the research stage. These variations occurred due
differences in the infrastructures used and due variations on the time available to use each
infrastructure on our research.

31
Table 1. Metrics x stages
4.3 Benchmarks The first benchmark we used was the High Performance Computing Challenge
Benchmark (HPCC) [Luszczek et al. 2006]. This benchmark suite is a set of 7 standard tests
for HPC developed by scientific community. HPCC evaluates the performance of processor,
main memory, local interprocess communication mechanisms, and network communication.
Table 2 describes each HPCC test:
Table 2. Benckmarks adopted
HPCC has 3 execution modes: single, star, and mpi (Figure 5). The single mode
executes the HPCC in a single processor; in the star mode, all processors execute separated
copies of HPCC without interprocess communication; and in the mpi mode, all processors
execute the HPCC in parallel with explicit data communication [Ye et al. 2010]. HPCC
requires the Message Passing Interface (MPI) and the Basic Linear Algebra System (BLAS);
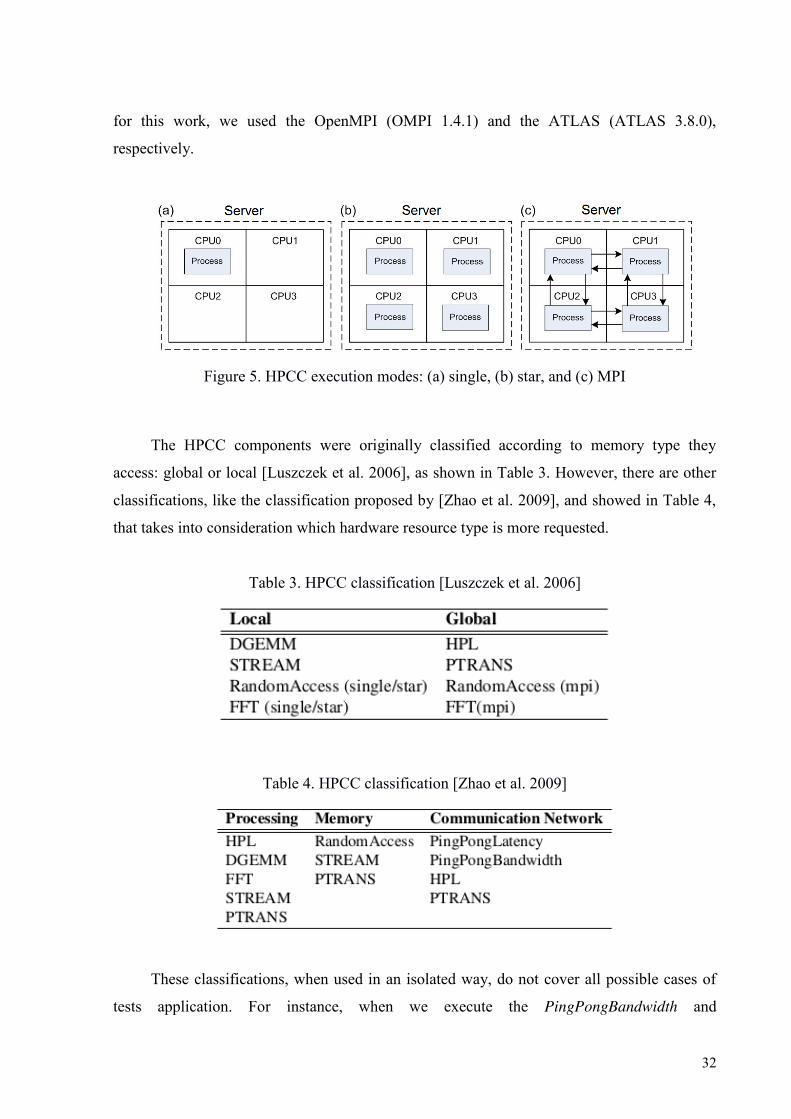
32
for this work, we used the OpenMPI (OMPI 1.4.1) and the ATLAS (ATLAS 3.8.0),
respectively.
Figure 5. HPCC execution modes: (a) single, (b) star, and (c) MPI
The HPCC components were originally classified according to memory type they
access: global or local [Luszczek et al. 2006], as shown in Table 3. However, there are other
classifications, like the classification proposed by [Zhao et al. 2009], and showed in Table 4,
that takes into consideration which hardware resource type is more requested.
Table 3. HPCC classification [Luszczek et al. 2006]
Table 4. HPCC classification [Zhao et al. 2009]
These classifications, when used in an isolated way, do not cover all possible cases of
tests application. For instance, when we execute the PingPongBandwidth and

33
PingPongLatency tests in a single server, we do not measure the network communication
performance, but the local interprocess communication performance of the server. Similar
argument can be applied to memory access measurements with RandomAccess in mpi mode.
Since STREAM and DGEMM execute only in star mode, they can obtain only local capacity
measurements.
Based on this argument, we utilized a new classification that merges the previous
classifications and also includes NetPIPE and fs_test. This classification (Table 5) groups the
HPCC tests by resource type more used (processing, memory or communication) and by the
accessed memory type (global or local). The communication between processes allocated in
the same server is now noticed as different of communication between processes allocated in
distinct servers, which uses the network for the communication.
Table 5. Benchmark classification adopted
The main benchmark of HPCC suite is the HPL, because it is the default benchmark
used by the TOP500 supercomputing site to elaborate a semiannual list containing the most
powerful supercomputers of the world [Napper and Bientinesi 2009].
To run the HPL benchmark adequately, we need to specify the value of N, the topology
of the processors grid (PxQ) and other configurable parameters. The N size is crucial for
achieving a good performance with HPL. In order to improve our experiment setup, we use a
web mechanism7, named Tuning HPL, to generate automatically the configurations.
The main goal when analysing the inter-proccess communication performance on this
research is to understand how the communication bandwidth and delay are impacted by the
additional virtualization layer. For this, we also choose use the Network Protocol Independent Performance Evaluator (NetPIPE) benchmark. NetPIPE monitors network
overheads using protocols, like TCP, UDP and MPI. It performs simple ping-pong tests,
7 http://www.advancedclustering.com/act-kb/tune-hpl-dat-file/

34
sending and receiving messages of increasing size between a couple of processes, whether
across a cluster connected by a Ethernet network or within a single multicore system.
To measure the performance on I/O-bound operations we used the fs_test tool8. This
tool is commonly used to evaluate a filesystem performance working with the MPI-I/O
library, an extension of MPI for I/O operations. The fs_test benchmark reports a specified
data-pattern, measuring the bandwidth achieved in writing and reading operations. Once MPI
and derivatives are critical for our scenarios, we chose fs_test for this work. Table 7 presents
an association between the metrics and benchmarks adopted in this research and Table 6
presents an association between the metrics adopted and the research stages.
Table 6. Benchmarks x stages
Table 7. Benchmarks x metrics (M)
4.4 Experiments Performed This section describes the experimental process adopted for this research. For each stage
was used a different set of benchmarks. Each stage also differs from each other regarding 8 http://institute.lanl.gov/data/software/#mpi-io

35
objectives and experiments conducted. Due this we splited this section in subsections that
explain in details the experimental procedure adopted for each stage.
4.4.1 Experiments on Stage 1 Our experiments were conducted in 5 different scenarios: firstly, the experiments were
executed in native environment. In this case, the available RAM was limited to 4GB in order
to obtain a fair comparison with virtualized environment. The last 4 scenarios were
configured under virtualized environments with KVM and VirtualBox. In this case, we
configured 1 VM per host, and each VM was allocated with 2 virtual CPUs and 4G RAM.
The remaining 4G RAM was dedicated to server exclusive use.
It was decided to use 4 virtualized environment because we are also interested to verify
the paravirtualization effects in HPC activities performance. In this way, the 4 virtualization
environments are:
• KVM with Full Virtualization (KVM-FV): virtualized cluster with KVM using full
virtualization and hardware-assisted;
• KVM with Paravirtualization (KVM-PV): virtualized cluster with KVM using virtio
paravirtualization to I/O devices;
• VirtualBox with Full Virtualization (VBox-FV): virtualized cluster with VirtualBox
using full virtualization and hardware-assisted; and
• VirtualBox with Paravirtualization (VBox-PV): virtualized cluster with VirtualBox
using paravirtualization to I/O devices.
HPCC benchmarks were executed 32 times, for all tests, environments and conditions.
In all tests, the two measurements with higher and lower value were excluded as outliers; with
the other 30, we computed the media and standard deviation.
4.4.1.1 Infrastructure
Experiments were executed in 8 HP Compaq 6005 machines with AMD Athlon II X2
220 processors operating in 2.8 GHz. This processor has a set of specific instructions to
virtualization, the AMD-v. These 8 computers have 8 GB DDR3 RAM with 1066 MHz. We
used Gigabit Ethernet network adapters and switches. We built the clusters used in this
experiment with Rocks Cluster 6.1 64bits OS (a Linux based OS developed to simplify the

36
creation process of high performance clusters). The hosts were configured with CentOS 6.6
64bit
4.4.2 Experiments on Stage 2
To reach all of the goals targeted for the Stage 2 of this research, we evaluated the
environments described in Table 8, taking into consideration two possible scenarios of
execution:
1. There is no communication between benchmark processes in execution;
2. The processes communicate with each other in a cooperative way.
All environments were implemented in KVM and LXC and, even the number of nodes
varies, all they had the same number of CPU cores and RAM. All environments used entire
available resources and were implemented in a single server. The Native environment was
composed of only 1 physical node with 4 processor cores and 3096MB of memory; the
virtual-1 had 1 VM with 4 cores and 3096MB of memory; the virtual-2 had 2 VMs with 2
cores per VM and 1536MB of memory per VM; and the virtual-4 had 4 VMs with 1 core per
VM and 768MB of memory per VM.
All benchmarks were executed 32 times, for all tests, environments and conditions. In
all tests, the two measurements with higher and lower value were excluded as outliers; with
the other 30, we computed the media and standard deviation. Next, we describe each
environment detail according to the goals aforementioned. The next sub-sections explain with
more details the experimental procedures to reach each goal targeted for the Stage 2.
Table 8. Single-server environments
4.4.2.1 Virtualization Overheads on CPU-bound Applications Performance To evaluate the CPU performance when there is no interprocess communication, we
instantiated 1 copy of HPL benchmark for each available processor. For instance, in the
Native environment, we instantiated 4 HPL copies, each one executing in a distinct processor;

37
while in the Virtual-4 environment, each VM had 1 HPL copy. So, as we had 4 VMs, we also
had 4 HPL copies running. Here, we observed the aggregated performance (the sum of all
individual HPL copies). On the other hand, when them have working in a cooperative way,
using explicit interprocess communications; we ran only 1 HPL instance, using all available
processors. The VMs in Virtual-2 and Virtual-4 environments were grouped in a cluster, with
1 HPL copy in execution
4.4.2.2 Effects of Resource Sharing on Performance
In this experiment we ran a copy of HPL benchmark in a VM of each type used in
Virtual-2 and Virtual-4 environments. The results obtained in these tests were compared with
those obtained individually by each VM of the same type when running concurrently with
other VMs the same type. In theory, equal VMs have the same performances in the same
activities. This test is an expansion of [Beserra et al. 2015a] work.
It is important to ensure that two users who contracted a particular Cloud service are
able to dispose the same performance. If the service (in this case instances of virtual resources
hosted on the same server) is not provided with a constant performance for all customers, then
it does not provide a good quality of service (QoS), which implies negative impacts for users
and in judicial problems for Cloud providers. So, it is imperative that the OS host be able to
allocate resources equally among the VMs [Nussbaum et al. 2009].
4.4.2.3 Virtualization Overheads on Communication Performance
We used NetPIPE to verify the ocurrence of virtualization overheads in intranode
interprocesses communications. First, we ran NetPIPE in Native and Virtual-1 environments;
then, we ran NetPIPE in pairs of processes running in Virtual-2 environment, with each
proccess in a distinct VM, to verify the virtualization effects in interprocesses communication
between VMs hosted in the same server. In this experiment, VMs did not use physical
network, they used internal server mechanisms, as shown in Figure 6. This experiment is
relevant since the internal communication mechanisms can vary according to virtualization
approach employed, and it can also influence the performance.
The physical network performance is a critical component in cluster environments.
When a communication enfolds different servers or VMs hosted in different servers, the
physical network is used, increasing the communication delay. To evaluate the network
performance, we executed NetPIPE with processes allocated in different physical servers,
measuring the performance according to packet size. To determine how the physical network

38
virtualization affects real applications, we also ran the HPL benchmark in virtual clusters
hosted in distinct servers
Figure 6. Communications among VMs inside the same physical host
4.4.2.4 Virtualization Overheads on I/O-bound Tasks Performance As said previously, our goal is to evaluate the performance of KVM and LXM
virtualization technologies under HPC I/O bound applications. For that, we choose the
following metrics:
• Data writing speed in files; and
• Data reading speed in files.
As factor, we used the filesize with two levels (1Kb and 128Mb), in order to analyze if
the filesize impact in the behavior of virtualization tools when using small and big archives;
and we also defined two communication patterns among processes (with communication
and without communication), as shown in Table 9.
Table 9. Factors and levels
We used the same 4 environments shown in 8 to evaluate KVM and LXC under I/O-
bound tasks. Next, to reach all of the goals targeted regarding I/O performance, we evaluated
the environments described in Table 8 taking into consideration two possible scenarios of
execution:

39
• Scenario 1: There is no communication among benchmark processes in execution;
• Scenario 2: There is communication among processes and they operate in a
cooperative way.
To evaluate the performance when there is no interprocess communication (scenario
1), we instantiated 1 copy of fs_test benchmark for each available processor (7). For instance,
in the native environment (7.a), we instantiated 4 fs_test copies, each one executing in a
distinct processor; while in the Virt-4 environment (7.c), each VM had 1 fs_test copy. So, as
we had 4 VMs, we also had 4 fs_test copies running. Here, we observed the aggregated
performance (the sum of all individual fs_test copies performance in reading and writing
operations).
Figure 7. Scenario 1: without interprocess communication
On the other hand, we have the case when they are working in a cooperative way, using
explicit interprocess communications (8); in this scenario, we ran only 1 fs_test instance,
using all available processors. The VMs in Virt-2 and Virt-4 environments (8.b and 8.c) were
grouped in a classical Beowulf cluster, with 1 fs_test copy in execution.
4.4.2.5 Infrastructure The experiments were executed in 2 HP EliteDesk 800 G1 (F4K58LT) computers
equipped with Intel R CoreTM i7-4770 processors operating in 3.4 GHz, with 8 GB DDR3
SDRAM memory operating in 1600 MHz. The processor used has a set of specific
instructions for virtualization: VT-x technology. We used Gigabit Ethernet network adapters

40
and switches to interconnect the servers when needed. Both hosts and clusters used in this
experiment were configured with Ubuntu 14.04.2 LTS 64 bit.
Figure 8. Scenario 2: cooperation with interprocess communication in 1 or more abstractions
4.4.3 Experiments on Stage 3 To reach all of the goals targeted for the Stage 3 of this research, we evaluated the
environments described in Table 10, taking into consideration two possible scenarios of
execution:
1. There is no communication between benchmark processes in execution;
2. The processes communicate with each other in a cooperative way.
All environments were implemented in LXC and Docker and, even the number of
nodes varies, all they had the same number of CPU cores and RAM. All environments used
entire available resources and were implemented in a single server. The Native-ARM
environment was composed of only 1 physical node with 4 processor cores and 1024MB of
memory available; the vARM-1 had 1 container with 4 cores and 1024MB of memory
available; the vARM-2 had 2 container with 2 cores per container and 512MB of memory per
container; and the vARM-4 had 4 container with 1 core per VM and 256MB of memory per
container.
All benchmarks were executed 32 times, for all tests, environments and conditions. In
all tests, the two measurements with higher and lower value were excluded as outliers; with
the other 30, we computed the media and standard deviation. Next, we describe each

41
environment detail according to the goals aforementioned. The next sub- sections explain with
more details the experimental procedures to reach each goal targeted for the Stage 2.
Table 10. ARM-based environments
4.4.3.1 Virtualization Overheads on CPU-bound Applications Performance To evaluate the CPU performance when there is no interprocess communication, we
instantiated 1 copy of HPL benchmark for each available processor. For instance, in the
Native environment, we instantiated 4 HPL copies, each one executing in a distinct processor;
while in the vARM-4 environment, each container had 1 HPL copy. So, as we had 4
containers, we also had 4 HPL copies running. Here, we observed the aggregated performance
(the sum of all individual HPL copies). On the other hand, when them have working in a
cooperative way, using explicit interprocess communications; we ran only 1 HPL instance,
using all available processors. The containers in vARM-2 and vARM-4 environments were
grouped in a cluster, with 1 HPL copy in execution.
Table 11. Configurations used to evaluate the effects of resource sharing
Each environment was benchmarked with a specific configuration description that
associates the cardinality of abstractions/nodes in execution, processing resources available
and HPL instances running simultaneously on the environment. The correspondence between
environments and configurations adopted is shown in Table 11. On this Table: ’c’ means
’containers’; ’p’ means ’processors’; and ’i’ means ’instances’. The numbers before the letters
indicates the cardinality of each element. For instance, 1c4p4i means the environment has 1

42
container (or physical host when in Native environment) with 4 processors available and 4
instances running simultaneously.
4.4.3.2 Effects of Resource Sharing on Performance In this experiment we ran a copy of HPL benchmark in a container of each type used in
vARM-1, vARM-2 and vARM-4 environments. The results obtained in these tests were
compared with those obtained individually by each container of the same type when running
concurrently with other containers the same type. In theory, equal containers have the same
performances in the same activities. The correspondences between environments and
configurations adopted are shown in Table 12 and its nomenclature is the same of the 11.
Table 12. Configurations used to evaluate the effects of resource sharing
4.4.3.3 Virtualization Overheads on Communication Performance
We used NetPIPE to verify the occurrence of virtualization overheads in intranode
interprocesses communications. First, we ran NetPIPE in Native and vARM-1 environments;
then, we ran NetPIPE in pairs of processes running in vARM-2 environment, with each
process in a distinct container, to verify the virtualization effects in interprocesses
communication between containers hosted in the same server. In this experiment, containers
did not use physical network, they used internal server mechanisms, as shown in Figure 6.
This experiment is relevant since the internal communication mechanisms can vary according
to virtualization approach employed, and it can also influence the performance.
The physical network performance is a critical component in cluster environments.
When a communication enfolds different servers or VMs hosted in different servers, the
physical network is used, increasing the communication delay. To evaluate the network
performance, we executed NetPIPE with processes allocated in different physical servers,
measuring the performance according to packet size. To determine how the physical network
virtualization affects real applications, we also ran the HPL benchmark in virtual clusters
hosted in distinct servers.

43
4.4.3.4 Infrastructure The experiments in embedded systems will be conducted in a Banana Pi Model 2 (BPI-
M2) single-board computer equipped with a Cortex A31S processor operating in 1 Ghz, with
1 GB DDR3 SDRAM memory operating in 1600 MHz. Each Banana-PI has a Gigabit
Ethernet network adapter and the nodes were interconnected in a Gigabit switch. All hosts and
clusters used in this experiment were configured with Debian Jessie Linux. We choose
Banana Pi because it has a Gigabit NIC, while Raspberry Pi has only a Fast Ethernet adapter
and for HPC clusters the network throughput is a very important aspect to be considered.
Because this we taken the decision of use Banana Pi in our research.
4.5 Why choose These Virtualization Tools?
In this work, the initial focus was conduct a performance analysis of KVM and
VirtualBox hypervisors running in traditional workstations, because both are hybrid systems
with support for hardware-assisted virtualization and paravirtualization drivers for network
devices [Younge et al. 2011], [Bakhshayeshi et al. 2014]. These hypervisors were chosen
because its provides a virtualization layer with minimal modifications on the host OS and in a
more safety way, unlike other hypervisors, such as Xen [Younge et al. 2011], [Bakhshayeshi
et al. 2014]. Next, it was evaluated the performance of OS-level virtualization against
hypervisor-based virtualization in workstations. After, this last analysis will be extend for
single-board computers. So, for these last steps we chosen use LXC and Docker due these
tools be considered as the de facto pattern in terms of OS-level virtualization tools [Beserra et
al. 2015a] and because both works also in traditional x86 systems both in arm-based systems
as the single-board-computers platforms [Abrahamsson et al. 2013].

44
CHAPTER 5
RESULTS
This section presents the results obtained in this research. The results were divided into
subsections each one presenting the results of a specific stage of this research. The results
obtained on the Stage 1 were published in the IEEE 2015 Conference in Systems, Man and
Cybernetics (ranked as B2 in the Brazilian Qualis/CAPES) [Beserra et al. 2015b].
The results obtained on the Stage 2 were published were published in the Ninth
International Conference on Complex, Intelligent, and Software Intensive Systems (ranked as
B3 in the Brazilian Qualis/CAPES) [Beserra et al. 2015a]; in the International Journal on Grid
Computing and Utility; and in the IEEE 2016 Conference in Systems, Man and Cybernetics.
The results obtained on the Stage 3 remains unpublished. However we plan submit these
results for a journal or conference ranked in the Qualis/CAPES.
5.1 Results of Stage 1 This subsection presents the results obtained from tests applied according to
methodology presented in Section 4, in order to reach the goals targeted for the Stage 1 of this
research. On this step of the research was assessed performance of two hypervisors under
HPC processing: KVM and VirtualBox. Particular focus was employed on paravirtualization
instructions performance impact.
The results are divided in two sections: local resource usage, in which access data is
stored in local memory; and global resources usage, in which resource are shared in a cluster
environment.
5.1.1 Local Resources Usage
This Subsection presents the results from tests accessing only data stored in local
memory. As the communication network is not used, there is no performance difference

45
between environments with paravirtualized (PV) and full virtualized (FV) network interface.
Due this, we present only results from PV configuration. The results are organized per
resource type more used.
5.1.1.1 Processing
The local processing capacity was measured using three tests: HPL, DGEMM and FTT.
Of these, DGEMM and FFT only can run in single and star modes; and HPL only in mpi
mode. The results for each test are presented in Figures 9, 10-(a), and 10-(b), respectively.
In HPL test, KVM achieved a near-native performance and performed 14% better than
VirtualBox. For DGEMM test, none of environments presented significant performance
variation between single and star modes; it indicates that both hypervisors are able to execute
multiple processes in parallel without significant performance loss. The KVMbased
environment presented a performance 5% lower than Native environment, and 10% higher
than VirtualBox-based environment.
Figure 9. HPL results
Regarding to the FFT test, there was a performance loss when we changed from single
to star mode. However, since this loss occurred in all environments, we cannot state that it
was caused by the virtualization. In a general way, the KVM-based environment presented the
performance very similar to the Native environment and 30% higher than VirtualBox-based
environment.

46
(a) DGEMM (b) FFT
Figure 10. DGEMM and FFT results in single and star modes
5.1.1.2 Local Memory Access
The local memory access capacity was measured using two tests: STREAM e
RandomAccess. The results are shown in Figures 11-(a) and 11-(b).
Regarding to STREAM test, it was observed that the VirtualBox-based environment
presented a performance 25% lower than a native environment in single mode, while the
KVM-based environment had a similar performance. In star mode, both hypervisors presented
similar performance with losses related to single mode, indicating that saturation was not
caused by the virtualization.
(a) STREAM (b) RandomAccess
Figure 11. Local memory access performance
The RandomAccess test results indicates that virtualization is not able to offer similar
performance to a native environment when compared the data update in memory. The KVM-
based environment in single mode obtained the same performance than a native environment
in star mode. In other hand, the native environment suffered a 32% degradation when
compared to itself running the RandomAccess test in single mode.

47
5.1.1.3 Local interprocess Communication The communication capacity between processes in the same server was measured with
b_eff test and PTRANS test. The b_eff results regarding to bandwidth and latency, and are
shown in Figure 12. Since PTRANS results were similar to b eff, we decided not to include it.
For all interprocess communication patterns tested, the KVM-based environments presented
performance close to native, and between 20% and 40% superior to VirtualBox-based
environments.
(a) Bandwidht (b) Latency
Figure 12. Local interprocess communication
5.1.2 Global Resource Usage (Cluster Environment) To reach all of the goals targeted for the Stage 3 of this research, we evaluated the
environments described in Table 12
5.1.2.1 Global Processing The global processing capacity was measured using two tests: HPL and FFT. The
results are presented in Figures 13-(a) and 13-(b). By using paravirtualization, the KVM-
based environment performs close to the native environment in both tests. Other
configurations presented degradation when the number of VMs increases, specially
VirtualBox.
5.1.2.2 Global Memory Access
The global memory access capacity was measured using RandomAccess test. The results
are presented in Figure 14. When running in a cluster with 8 computer nodes, the best result
obtained by the virtualized environments was still 300% lower than the native-environment. It
imply that applications that access frequently the memory in distributed environment are
severely affected by the virtualization at the time when the system size increases. Despite

48
KVM cannot perform as well as the native environment, the KVM paravirtualization
instructions decreased the virtualization overload; it does not occur with VirtualBox.
(a) HPL (b) FFT
Figure 13. HPL and FTT results
Figure 14. RandomAccess (mpi)
5.1.2.3 Global Interprocess Communication Due the fact of the network performance running MPI processes in ROR pattern
presented a similar behavior of NOR pattern, we are showing only results related to the NOR
mode of b_eff test.
The results obtained for bandwidth and latency are presented in the Figures 15- (a) and
15-(b) respectively. In all tests, the KVM-based environment performance with
paravirtualization instructions activated is similar to the native performance, while the
VirtualBox is lower.

49
(a) NOR Bandwidth (b) NOR Latency
Figure 15. Interprocess communication results - NOR
5.2 Results of Stage 2 This subsection presents the results obtained on the second stage of this research. On
this step of the research we conducted a performance evaluation between two virtualization
tools: KVM and LXC. Results were grouped according goals targeted and experimental
method used.
5.2.1 Virtualization Overheads on CPU-bound Applications Performance
In this Sub-section, we present the results of HPL benchmark executed in a single
server. Figure 16 shows results of CPU performance when executing HPL benchmark with no
interprocess communication. We can observe LXC presented aggregated performance higher
than KVM in Virtual-1 environment, and close to Native environment. Statistically, all
variations were irrelevant (lower than 5%) for all environments and virtualization
technologies.
When we divided physical resources in multiple virtual environments, both
virtualization technologies presented a worse performance. This gradual decreasing affects
KVM more poignantly because is needed to maintain multiple and isolated systems in
simultaneous execution, increasing the overhead in host CPU. During Virtual-4 execution, for
instance, the overhead of host CPU exceeds 100%, while LXC maintains the CPU usage
within availability limits. These results indicate that, despite VT-X instructions set,
administrative controls to provide emulation of CPU instructions and resource isolation
between systems cause considerable overhead on performance.

50
Figure 16. HPL aggregated performance (same host)
Figure 17 shows the CPU performance results when MPI processes are working in a
cooperative way. We can note LXC environments were constant and close to native, even
when resources were shared among multiple containers. It was possible because the host
system needs few resources to create and maintain a container [Xavier et al. 2013], [Felter et
al. 2014]. On the other hand, KVM environments presented gradual performance reduction
while we increased the number of VMs sharing the same host. It occurs because KVM needs
more resources to maintain VMs, and when the system is divided in more than one logic
node, processes will communicate by using network protocols, increasing the processing and
the communication latency. .
Figure 17. HPL local clusters performance (same host)

51
5.2.2 Effects of Resource Sharing on Performance In this Sub-section, we present the results of HPL benchmark executed in the
environments running concurrently some instances of virtual abstractions. Figure 18 shows
the CPU performance benchmark results of 1 virtual resource instance running isolated
against 2 instances of the same type running simultaneously at the same host server. Figure 19
shows a similar comparison, but with 4 instances of the same type. .
Figure 18. Effects of resource sharing on performance with 2 instances running
concurrently
In both cases, we can observe the occurrence of some performance contraction in
virtualized shared resources, with different reduction rates for each virtualization tool. In the
case of KVM, when running 2 VMs of the same type simultaneously, the performance of each
VM decreased about 11.5% in relation to same VM running alone. When running
simultaneously 4 VMs of the same type that we used in the Virtual-4 environment, the
reduction rate relative to a isolated VM jumped to 20%.
This probably occurred due to an overhead in processor of the host server, which
provided and maintained multiple virtual resources at the same time. In this case, to avoid
performance losses and a subsequent service quality below of predetermined levels in the
Service Level Agreement (SLA), is necessary to provide a threshold for native host resource
usage flexible in function of the amount of allocated VMs; it is possible to develop an
appropriate SLA that will allow both providers and users enjoy a stable service with respect to
performance.

52
On other hand, when we repeated the experiments for LXC, we observed a fixed value
of 11.5% pair to both sharing scenarios. This is good, because allows that any problems
regarding performance can be solved with a static threshold, enabling the creation of a more
simply SLA. .
Regarding to the performance variation on the virtualized resources, KVM behaved in a
similar way to that observed in previous tests and showed a stable performance with no
significant oscillations. The LXC, on the other hand, showed higher variations, but still
presenting only a few statistical significance.
This indicates that both virtualization technologies are useful for balancing virtual
resources if the environment manager adds an adequately threshold policy regarding to
physical server resources usage. Probably, if more resources were allocated to the virtual
server at a point where the physical resources are overloaded, it will be very unlikely that the
OS host has the capability to split the resources equally among multiple virtual environments,
as observed in previous experiments [Mello 2010]. .
Figure 19. Effects of resource sharing on performance with 4 instances running concurrently
5.2.3 Virtualization Overheads on Communication Performance Figure 20 shows results of NetPIPE execution in a single server. We can observe that in
Virtual-1 environment both virtualization technologies achieved communication bandwidth
similar to the one achieved by Native environment, and the performance variations were
insignificant. However, when we divided the physical server in multiple virtual environments,
the communication bandwidth achieved was reduced for both virtualization tools, especially
KVM. .

53
Figure 20. Interprocess communication bandwidth (same host)
Since Virtual-2 environment was configured in a cluster, it was needed to use network
protocols to perform the communication between NetPIPE processes, increasing the CPU
usage in the host, and also contributing to decreased bandwidth. For KVM, we can note an
additional reduction of bandwidth; it occurred because the host uses more CPU to emulate
two network interfaces simultaneously, as well as whole virtual communication environment
in an isolated way.
Figure 21. Interprocess communication latency (same host)
This tendency is endorsed when we observe delay communication results in Figure 21.
We found high values of delay when we have more requests to process. With exception of

54
Native, all environments presented considerable variations for both virtualization tools.
Figures 22 and 23 show results of NetPIPE execution in two servers. All environments
presented similar performance with little variations for communication bandwidth, as well as
for delay.
Figure 22. Interprocess communication bandwidth (cluster)
To finish our communication analysis, we verified how network virtualization affects
the HPC application performance. For that, we executed HPL in cluster environment with two
servers, as shown in Figure 24. Both environments presented similar performance, however
KVM cluster showed less variations than LXC.
Figure 23. Interprocess communication latency (cluster)

55
Figure 24. HPL cluster performance (using network)
5.2.4 Virtualization Overheads on I/O-bound Tasks Performance
Results obtained after execute benchmarks in all environments are presented in this
Section, divided into two sub-section according to scenarios defined in 4.4.2 section.
5.2.4.1 Scenario 1: without Communication among Processes
This subsection presents results obtained in reading and writing operations in 1K and
128M sized files in a context without communication among processes.
Figure 25 presents the performance in writing operations using 1K size files. We can
observe that LXC performance in Virt-1 environment was similar to Native environment; and
KVM performance was worse than both for all environments configuration.
Figure 25. Writing speed without Interprocess communication (1K size file)

56
Observing the performance obtained by individual instances, we can note that KVM
instances presented less variation than LXC and Native environments. This KVM behavior
occurred due its disk writing mechanism, that initially bufferizes data in host memory; in this
way, when the writing is effectively done in disk, all data are writing simultaneously,
avoiding performance instability.
Figure 26. Reading speed without interprocesses communication (1K file size)
The reading speed obtained for small files is shown in Figure 26. In this case, the Virt-
1-LXC environment presented performance similar to Native. We can also observe that
environments configured with LXC tends to deteriorate when the number of containers per
host increases. On the other hand, the KVM maintains approximately the same performance at
the same conditions. However, its performance is always worse than LXC and native
environment.
For all cases of reading operations, we can observe that while the number of
abstraction9 maintained by the host increases, the standard deviation of individual instances
performance decreases, revealing a less variation in measurements. We ca explain this
behavior as follow: when we increase the number of VMs, we increase the VM competition,
but at same time we decrease the resource concurrence intra-VMs (i.e., there is less processes
to be treated per VM).
Figure 27 shows the writing speed in 128M size files. We can note that LXC did not
present performance bottlenecks when the number of container was increased, and its writing
9 The number of abstraction corresponds to the number of containers or VMs, depending on virtualization type, LXC or KVM, respectively.
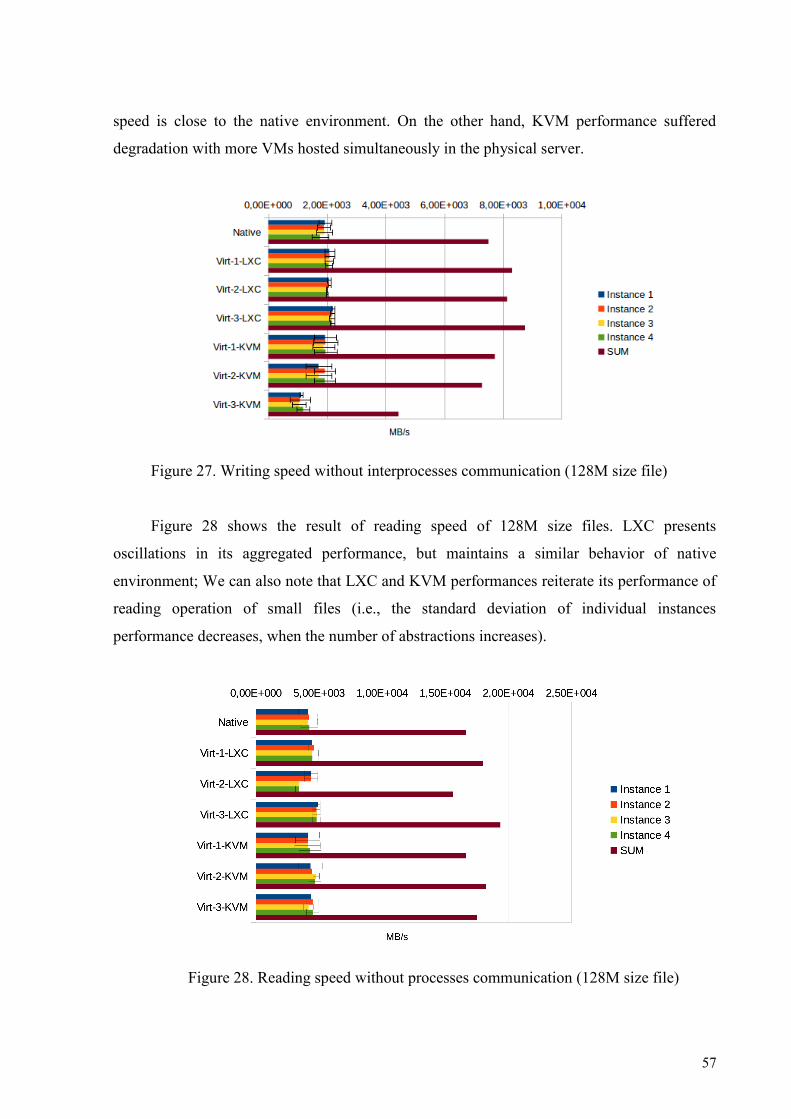
57
speed is close to the native environment. On the other hand, KVM performance suffered
degradation with more VMs hosted simultaneously in the physical server.
Figure 27. Writing speed without interprocesses communication (128M size file)
Figure 28 shows the result of reading speed of 128M size files. LXC presents
oscillations in its aggregated performance, but maintains a similar behavior of native
environment; We can also note that LXC and KVM performances reiterate its performance of
reading operation of small files (i.e., the standard deviation of individual instances
performance decreases, when the number of abstractions increases).
Figure 28. Reading speed without processes communication (128M size file)

58
Figure 29. Writing speed with Interprocess communication (1K file size)
5.2.4.2 Scenario 2: with Interprocess Communication This sub-section presents results of scenario 2, where there is interprocess
communication in a cooperative way, as showed in Figure 8. In this test, besides the
performance, we also collected the maximum and the minimum speeds of writing and reading
measured by the own fs_test tool.
Figure 29 shows the writing speed of small files (1K size). We can observe that for
Native, Virt-1-LXC and Virt-1-KVM, the median, minimum and maximum performances
were similar. On the other hand, when the number of abstractions increased, the performance
decreased significantly. This reduction occurred due the explicit communication among
abstractions (interprocess messages exchange), which increases the communication delay and
reduces the performance.
Figure 30 shows the performance of reading operations in small files. We can note that
there is an expected behavior, in which more abstractions result in a worse performance. We
can also observe that the reading performance is better than writing performance; it occurs
because the unique available disk is not used with the same intensity (a 1K size file fits on the
cache, speeding up the reading operation).
Figure 31 shows the result obtained in writing speed of 128M size files, with the
processes of a single fs_test instance working in a cooperative way. We can observe that the
performance of virtual environments in writing operations in 128M size file is much better
than in 1K files.
When comparing with 1K size files results, we can note that the standard deviation was
smaller; it happened because the execution time exclusively for writing operation in disk
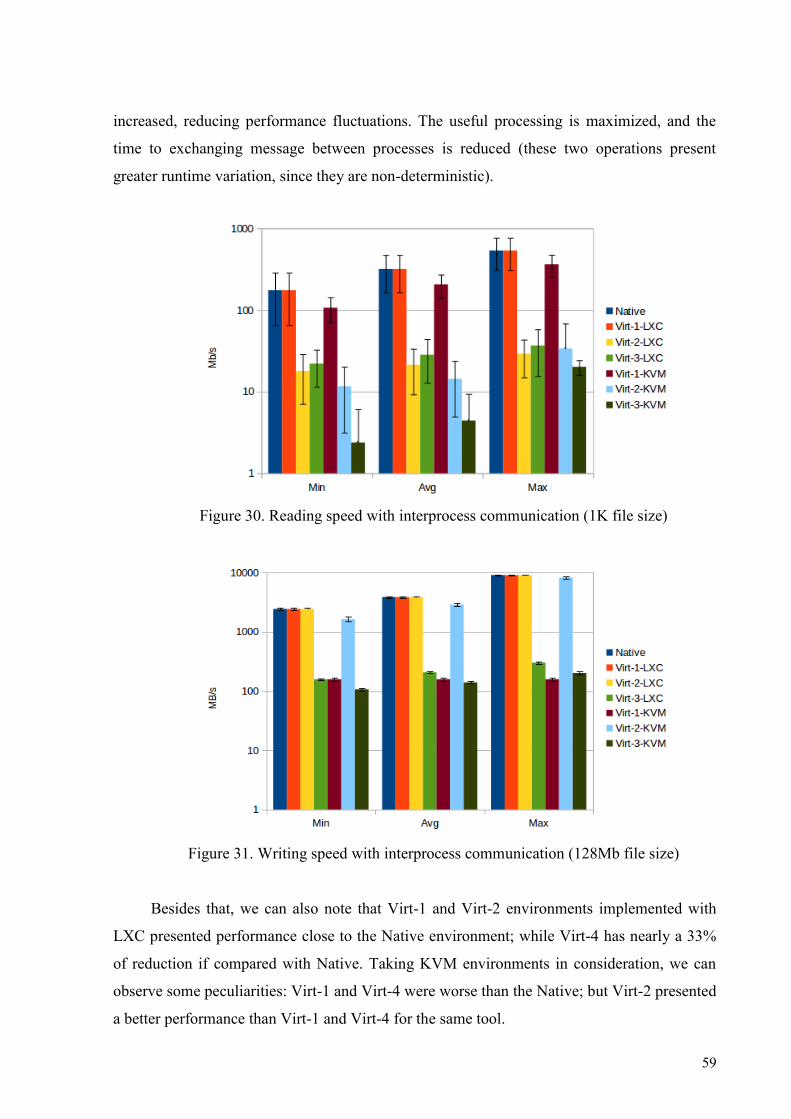
59
increased, reducing performance fluctuations. The useful processing is maximized, and the
time to exchanging message between processes is reduced (these two operations present
greater runtime variation, since they are non-deterministic).
Figure 30. Reading speed with interprocess communication (1K file size)
Figure 31. Writing speed with interprocess communication (128Mb file size)
Besides that, we can also note that Virt-1 and Virt-2 environments implemented with
LXC presented performance close to the Native environment; while Virt-4 has nearly a 33%
of reduction if compared with Native. Taking KVM environments in consideration, we can
observe some peculiarities: Virt-1 and Virt-4 were worse than the Native; but Virt-2 presented
a better performance than Virt-1 and Virt-4 for the same tool.

60
When we have only two VMs sharing resources of a same host, there is an efficient
resource switching between VMs; and additionally since each VM has its own kernel and due
KVM buffer system for writing and reading, KVM obtain a substantial performance
increment. On the other hand, when we have four VMs in a host, the resource switching
becomes inefficient. And, when we have just one VM, there is no resource switching, and just
one kernel and one buffer system that are shared by multiple process of the only instance.
Figure 32 shows the result of reading speed of 128M size files, with the processes of a
single fs_test instance working in a cooperative way. We observed that performance of all
environments was decreased when we increased the number of abstractions on the host.
Figure 32. Reading bandwidth with interprocess communication (128Mb file size)
5.3 Results of Stage 3 This subsection presents the results obtained on the third stage of this research which
consisted in analyze and compare the performance of OS-level virtualization tools LXC and
Docker for HPC applications running in ARM-based environments,. The results were grouped
according goals targeted and experimental method used.
5.3.1 Virtualization Overheads on CPU-bound Applications Performance
On this subsection we present the results obtained after run some instances of HPL
benchmark in a single server. We evaluated all configurations where is possible run 4
instances of HPL benchmark concurrently. Figure 33 shows results of CPU performance

61
when executing HPL benchmark with no interprocess communication. In Figure 33 is
possible see the performance of each HPL instance individually and the aggregated
performance obtained.
Figure 33. HPL aggregated performance (same host)
We notice that all configurations evaluated and implemented with virtualization
techniques have similar average performance for all concurrent instances, presenting a
maximum standard deviation near of 3,73%. Environments implemented with Docker
presented an average standard deviation superior 25,3% from that presented by environments
implemented with LXC (considering all configurations evaluated). The causes of the
differences noticed on the performance variability of both virtualization tools are still not
clear. However some possible causes are the distinct container management library used in
Docker and LXC [Morabito et al. 2015] or different version of software packages installed in
containers.
In turn, the regularity on the performance of individual instances imply in a similar
average aggregated performance in all virtualized environments. Thus, we can conjecture that
both virtualization tools presents equal performance on CPU-bound applications, since these
applications runs without need transfer data among processes. Virtualized environments
presented performance 3,67% below than Native environment.
Besides media and standard deviation we also computed the Coefficient of Variation
(CV). It may be interpreted as data variability about the mean. Smaller values for CV
indicates a more homogeneous data set and a 50% is the accepted limit value to a CV for most
cases [Guedes and Janeiro 2005]. We also computed the CV for the average performance of

62
each individual instance, obtaining a maximum CV of 11,2% (for the instance 4 running in
Docker-1c4p4i configuration). This ensures that data collected on this step of our research are
homogeneous and the standard deviation noticed by us are valid.
Figure 34. HPL cooperative performance (same host)
Figure 34 shows the CPU performance results when MPI processes are working in a
cooperative way. We can note LXC and Docker environments were constant and close to
Native, even when resources were shared among multiple containers. It was possible because
the host system needs few resources to create and maintain a container [Xavier et al. 2013],
[Felter et al. 2014]. The standard deviation registered is statistically negligible, implying all
environments evaluated does not presents notable oscillations on its performances. The
highest sample CV was near of 3,62%, ensuring that data collected on this step of our
research are homogeneous and the standard deviations noticed by us are valid.
5.3.2 Effects of Resource Sharing on Performance
In this section, we present the results from experiments that aimed help us to analyzing
the effects of resource sharing on performance of CPU-bound applications.
5.3.2.1 Overloads Due to Virtualization and Resource Sharing on Performance of a Single Container Using all Hardware Resources Available
Figure 35 shows the results obtained after ran a single HPL instance in containers using
all hardware resources available, as well as in a non-virtualized environment. On this context
both environments obtained similar performance and its performance was also similar to
performance obtained for the Native environment. On this experiment, the performance

63
differences observed indicates the overhead caused only by virtualization. The standard
deviation observed was negligible (less than 2 %).
Figure 35. Performance of 1 HPL instance running in a single container using all
resources of the environment
In turn, Figure 36 shows the results obtained after ran 2 HPL instances in containers
using all hardware resources available, as well as in a non-virtualized environment. The
performance of each concurrent instance was compared regarding with the performance of a
single HPL instance running without competition for hardware resources.
Figure 36. Effects of resource sharing on performance with 2 instances running
concurrently in a single container

64
All environments evaluated presented reduction on its performance due resource
sharing. We observed that Native environment presented an average performance reduction
near of 3,94%, while environment implemented with LXC presented a performance reduction
of 2,97% and the environment implemented with Docker presented a performance reduction
of 3,09%. Considering the performance average and standard deviation values obtained for
each instance and environment evaluated we can conclude that resource sharing affected
performance of all environments equally.
In turn, Figure 37 shows the results obtained after ran 4 HPL instances in contain-ers
using all hardware resources available, as well as in a non-virtualized environment.The
performance of each concurrent instance was compared regarding with the performance of a
single HPL instance running without competition for hardware resources.
Figure 37. Effects of resource sharing on performance with 4 instances running
concurrently in a single container
The rate of performance loss due resource sharing grows up in all environments
evaluated when compared with the results obtained after ran 4 concurrent HPL instances.
Native environment had performance loss near of 9,43% while the environment implemented
with LXC presented performance loss near of 10,81% and Docker presented performance loss
near of 12,37%. Considering the performance average and standard deviation values obtained
for each instance and environment evaluated we can conclude that resource sharing affected
performance of all environments equally. We also observed that the improvement of HPL
instances collaborates to reduces the performance on virtualized environments with a

65
reduction rate near of 239% in Native, 363% in LXC and 400% in Docker; when compared
with the results obtained for 2 HPL instances running concurrently.
5.3.2.2 Overloads Due to Virtualization and Resource Sharing on Performance of Containers Running Concurrently
In this Sub-section, we present the results of HPL benchmark executed in the
environments running concurrently some instances of virtual abstractions. Figure 38 shows
the CPU performance benchmark results of 1 virtual resource instance running isolated
against 2 instances of the same type running simultaneously at the same host server. Figure 39
shows a similar comparison, but with 4 instances of the same type.
Figure 38. Effects of resource sharing on performance with 4 instances running
concurrently in 2 dual-processor containers
In both cases, we can observe the occurrence of some performance contraction in
virtualized shared resources, with similar reduction rates for each virtualization tool. When
running 2 containers of the same type simultaneously on Virtual-2 environment, the
performance of each container decreased about 9,04% when the environments were
implemented with LXC and 7,57% when implemented with Docker, in relation to same
container running alone. When running simultaneously 4 containers of the same type that we
used in the Virtual-4 environment, the reduction rate relative to a isolated container jumped to
11,7% in LXC and 10,8% in Docker.
This probably occurred due to an overhead in processor of the host server, which
provided and maintained multiple virtual resources at the same time. In this case, to avoid
performance losses and a subsequent service quality below of predetermined levels in the

66
Service Level Agreement (SLA), is necessary to provide a threshold for native host resource
usage flexible in function of the amount of allocated containers; it is possible to develop an
appropriate SLA that will allow both providers and users enjoy a stable service with respect to
performance.
Figure 39. Effects of resource sharing on performance with 4 instances running
concurrently in 4 single-processor containers
5.3.3 Virtualization Overheads on Communication Performance
Figure 40 shows results of NetPIPE execution in a single server. We can observe that in
1c4p configuration on Virtual-1 environment both virtualization tools achieved
communication bandwidth similar to the one achieved by Native environment, and the
performance variations were insignificant for most packet data sizes used. So, due to this we
do not show any error bars on the Figure 40 to avoid pollute it.
However, the most significant performance variations occurred during the transmission
of larger data packets between a process to other and due to this we display the graph with
error bars in a zoom window in the interval containing the largest data packets used (See
Figure 41). Major performance variations noticed on this range of message length values may
occur due to unknown non-deterministic factors or due the split of a large message in 2 or
more data packets, if the size of the message sent exceeds a certain threshold.
When we divided the physical server in multiple virtual environments, the
communication bandwidth achieved was reduced for both virtualization tools, with Docker
overcoming LXC performance slightly. Since Virtual-2 environment was configured in a
cluster, it was needed to use network protocols to perform the communication between
NetPIPE processes, increasing the CPU usage in the host, and also contributing to decreased

67
bandwidth. The performance differences between Docker and LXC on Virtual-2 environment
occurred probably due differences in the packages and libraries used on containers
implemented with these tools.
Figure 40. Interprocess communication bandwidth (same host)
Figure 41. Zoom on interprocess communication bandwidth results for 1c4p
configuration (same host)
This tendency is endorsed when we observe delay communication results in Figure 42.
We found high values of delay when we have more requests to process. The performance
variations were insignificant for most packet data sizes used (less than 2%). We observed a
slightly higher network latency of LXC regarding Docker and we believe that this may also
have influenced the communication bandwidth observed in environments implemented with
both tools.
Figures 43 and 44 show results of NetPIPE execution in two servers. All environments
presented similar performance with little variations for communication bandwidth, as well as
for delay. Once more time LXC presented performance slightly lower than Docker in terms of

68
both communication bandwidth and in terms of network latency. The standard deviation
obtained is below 5%, which was statistically insignificant.
Figure 42. Interprocess communication latency (same host)
Figure 43. Interprocess communication bandwidth (cluster)

69
Figure 44. Interprocess communication latency (cluster)

70
CHAPTER 6
CONCLUSIONS AND PERSPECTIVES
This section presents the conclusions obtained after conduction of experimental
measurements and analysis of all data from all stages of this research. To facilities the
comprehension this section was divided into subsections according each stage of this research.
Nowadays, HPC users can utilize virtualized Cloud infrastructures as a low-cost
alternative to deploy their applications. Despite of Cloud infrastructures can be used as HPC
platforms, many issues from virtualization overhead have kept them almost unrelated. Due to
this, on this research was analyzed the performance of some virtualization solutions - Linux
Containers (LXC), Docker, VirtualBox and KVM - under HPC activities.
For our experiments, we consider some metrics and used distinct benchmarks both in
ARM-based and x86-based environments. For instance, we considered on our experiments
metrics like CPU,(network and inter-process) communication and I/O performance. Results
show that different virtualization technologies can impact distinctly in performance according
to hardware resource type used by HPC application and resource sharing conditions adopted.
6.1 Conclusions Regarding Experiments Conducted on Stage 1 On this step of the research was assessed performance of two hypervisors under HPC
processing: KVM and VirtualBox. Particular focus was employed on paravirtualization
instructions performance impact. All conducted tests resulted on best performance of KVM
hypervisor, with near native behaviour on scenarios where paravirtualized instructions were
employed. An exception was observed in the RandomAccess, in which both hypervisors
performed poorly. However, even in this scenario, KVM performed better than VirtualBox
and the use of paravirtualization instruction set improved the performance. Meanwhile, tests
showed VirtualBox performance for HPC is very poor, even using the paravirtualization

71
instructions. The major performance bottlenecks observed in both hypervisors were local
memory bandwidth and interprocess communication, both for a single host or to a cluster
environment.
6.2 Conclusions Regarding Experiments Conducted on Stage 2 This step of the research conducted a performance evaluation between two
virtualization tools: KVM and LXC. According to our experiments, we observed LXC is
more suitable for HPC than KVM. Considering a simple case of use, when virtual
environments use all server resources for only one VM or container, both systems presented
similar processing performance. However, in a more complex (and more common) scenario,
in which physical resources are divided among multiple and logic environments, both
decrease their performances, especially KVM.
For cluster environments, in which processes work in a cooperative way and there is
communication between processes, we can see the difference more clearly. Regarding to
variations on applications performance, LXC was better again, presenting less performance
fluctuations for most of tests. This is an important aspect to be considered, because in Cloud
Computing environments, if customers are paying for a specific Cloud service, then one
expects that all customers receive services with equal performance (or at least with a minimal
level previously agreed), otherwise Cloud provider can suffer an agreement penalty and
consequently, financial losses [Napper and Bientinesi 2009].
We can conclude that in Cloud Computing environments, in which physical resources
are splitted in multiple logic spaces, KVM does not present a good performance, and LXC can
be considered the most suitable solution for HPC applications.
Despite container-based solution is a good alternative to overcome the overhead issues
came from virtualization, during our experiment executions, we have faced to some open
issues, specifically for LXC. We observed LXC may not provide sufficient isolation at this
time, allowing guest systems to compromise the host system under certain conditions10.
Moreover, lxc-halt times-out and when we tried to upgrade to “Jessie” it brokes the
container11.
10 https://wiki.debian.org/LXC 11 http://lwn.net/Articles/588309/

72
6.3 Conclusions Regarding Experiments Conducted on Stage 3 This step of the research conducted a performance evaluation between two OS-level
virtualization tools: LXC and Docker. According to our experiments, we observed both tools
are suitable for HPC. Considering a simple case of use, when virtual environments use all
server resources for only container, both systems presented similar processing performance.
In a most complex and common scenario, in which physical resources are divided among
multiple and logic environments, both decrease their performances, especially LXC. But, even
on this case the performance is similar to performance obtained in non-virtualized
environments. All environments achieved similar performance also in terms of capacity for
communication between processes.
It is possible to show the existence of some challenges of technical nature that
occurred during the execution of this stage of research, just as occurred during the stage 2. he
OS-level virtualization technologies are still in the early days of its use in ARM-based
systems, and that implies a series of unforeseen events during the implementation of
functional virtualized environments using this type of technology. Among the main
challenges encountered we can include the configuration process of network interfaces on
containers. This task was particularly difficult in Docker because there is no support for its
overlay mode (which allows hosted containers on different servers to communicate using
bridges). The alternative found was to allow direct access from the server network interface
for containers Docker. In this case, all scripts had to be run from the container and not from
the host server.
Another challenge faced was the lack of support of Linux distributions currently
available to ARM systems for NFS (Network File System). This type of file system is key to
Linux environments dedicated to HPC because it allows file sharing (and object codes of MPI
programs) in a cluster environment. In its absence it was necessary to copy the executable
HPL manually for containers and host servers. Although it is enough for small-scale testing, it
is not suitable for large-scale systems because it allows the emergence of inconsistencies on
the files and results in difficulties in the environmental management.
6.4 Future Works
As future works, we plan to evaluate these virtualization technologies regarding the I/O
performance for traditional Hard Drives (HD), as well as for SSD devices, and to Graphical

73
Processing Unit (GPU) for single server and cluster environments. Other aspect that can be
developed in future, is to analyze how federated and/or hybrid Clouds could be benefited by
sharing their resources to execute HPC applications. These future analysis will be conducted
both in x86 and ARM architectures and focusing in pervasive grids
6.5 Published Works on Conferences and Journals
In the course of this research some articles describing the results presented in this
master dissertation were published or accepted for publication in journals and conferences. A
list of these publications are shown in Table 13:
Table 13. Articles published with results of the master dissertation
In addition to published scientific articles related to the results presented in this
dissertation, we also published the following works, which were obtained from
interinstitutional collaborations and developed in parallel to this research, as part of this
master´s course. A list of these publications is shown in Table 14.
Table 14. Other articles published during the masters course
Work title Publication vehicle Year Type Performance Evaluation of Hypervisors for HPC Applications
IEEE International Conference on Systems, Man, and Cybernetics
2015 Conference
Performance Analysis of LXC for HPC Environments
International Conference on Complex, Intelligent, and Software Intensive Systems
2015 Conference
Performance Analysis of Linux Containers for High Performance Computing Applications
International Journal of Grid and Utility Computing
2016 Journal
Performance Evaluation of a Lightweight Virtualization Solution for HPC I/O Scenarios
IEEE International Conference on Systems, Man, and Cybernetics
2016 Conference
Work title Publication vehicle Year Type Um Método de Escalonamento de VMs HPC que Equilibra Desempenho e Consumo Energético em Nuvens
Workshop em Clouds e Aplicações
2015 Conference
Proposta de Experimento Didático para Compreensão das Limitações do Uso de Nuvens Computacionais para CAD
International Journal of Computer Architecture Education
2016 Journal
A Virtual Machine Scheduler Based on CPU and I/O-bound Features for Energy-aware in High Performance Computing Clouds
Computers & Electrical Engineering
2016 Journal

74
REFERENCES
Abdul-Rahman, O., Munetomo, M., & Akama, K. (2012, July). Toward a genetic algorithm based flexible approach for the management of virtualized application environments in cloud platforms. In 2012 21st International Conference on Computer Communications and Networks (ICCCN) (pp. 1-9). IEEE.
Abrahamsson, P., Helmer, S., Phaphoom, N., Nicolodi, L., Preda, N., Miori, L., ... & Bugoloni, S. (2013, December). Affordable and energy-efficient cloud computing clusters: the bolzano raspberry pi cloud cluster experiment. In Cloud Computing Technology and Science (CloudCom), 2013 IEEE 5th International Conference on (Vol. 2, pp. 170-175). IEEE.
Ali, M., Vlaskamp, J. H. A., Eddin, N. N., Falconer, B., & Oram, C. (2013, September). Technical development and socioeconomic implications of the Raspberry Pi as a learning tool in developing countries. In Computer Science and Electronic Engineering Conference (CEEC), 2013 5th (pp. 103-108). IEEE.
Anwar, A., Krish, K. R., & Butt, A. R. (2014, September). On the use of microservers in supporting hadoop applications. In 2014 IEEE International Conference on Cluster Computing (CLUSTER) (pp. 66-74). IEEE.
Ashari, A., & Riasetiawan, M. (2015). High Performance Computing on Cluster and Multicore Architecture. TELKOMNIKA (Telecommunication Computing Electronics and Control), 13(4), 1408-1413.
Bakhshayeshi, R., Akbari, M. K., & Javan, M. S. (2014, February). Performance analysis of virtualized environments using HPC Challenge benchmark suite and Analytic Hierarchy Process. In Intelligent Systems (ICIS), 2014 Iranian Conference on (pp. 1-6). IEEE.
Beserra, D., Moreno, E. D., Endo, P. T., Barreto, J., Sadok, D., & Fernandes, S. (2015, July). Performance analysis of LXC for HPC environments. In Complex, Intelligent, and Software Intensive Systems (CISIS), 2015 Ninth International Conference on (pp. 358-363). IEEE.
Beserra, D., Oliveira, F., Araujo, J., Fernandes, F., Araújo, A., Endo, P., ... & Moreno, E. D. (2015, October). Performance Evaluation of Hypervisors for HPC Applications. In Systems, Man, and Cybernetics (SMC), 2015 IEEE International Conference on (pp. 846-851). IEEE.
Beserra, D., da Silva, R. P., Camboim, K., Borba, A., Araujo, J., & de Araujo, A. E. P. (2014). Análise do desempenho de sistemas operacionais hospedeiros de clusters virtualizados com o virtualbox. SBRC 2014-WCGA.

75
Bob Netherton, Gary Combs, (2010). Inside oracle vm virtualbox. In Oracle Solaris 10 System Virtualization Essentials. Oracle.
Che, J., Shi, C., Yu, Y., & Lin, W. (2010, December). A synthetical performance evaluation of openvz, xen and kvm. In Services Computing Conference (APSCC), 2010 IEEE Asia-Pacific (pp. 587-594). IEEE.
Cox, S. J., Cox, J. T., Boardman, R. P., Johnston, S. J., Scott, M., & O’brien, N. S. (2014). Iridis-pi: a low-cost, compact demonstration cluster. Cluster Computing, 17(2), 349-358.
Dua, R., Raja, A. R., & Kakadia, D. (2014, March). Virtualization vs containerization to support paas. In Cloud Engineering (IC2E), 2014 IEEE International Conference on (pp. 610-614). IEEE.
Fayyad-Kazan, H., Perneel, L., & Timmerman, M. (2013). Full and para-virtualization with Xen: a performance comparison. Journal of Emerging Trends in Computing and Information Sciences, 4(9).
Felter, W., Ferreira, A., Rajamony, R., & Rubio, J. (2015, March). An updated performance comparison of virtual machines and linux containers. In Performance Analysis of Systems and Software (ISPASS), 2015 IEEE International Symposium On (pp. 171-172). IEEE.
Xavier, M. G., Neves, M. V., & De Rose, C. A. F. (2014, February). A performance comparison of container-based virtualization systems for mapreduce clusters. In 2014 22nd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (pp. 299-306). IEEE.
Guedes, E. A., Silva, L. E., & Maciel, P. R. (2014, June). Performability analysis of i/o bound application on container-based server virtualization cluster. In 2014 IEEE Symposium on Computers and Communications (ISCC) (pp. 1-7). IEEE.
Guedes, T. A., M. A. A. C. and Janeiro, V. (2005). Estatística descritiva. Universidade Estadual de Maringá.
Halfacre, G. (2012). Raspberry pi review. Jarus, M., Varrette, S., Oleksiak, A., & Bouvry, P. (2013, April). Performance evaluation and
energy efficiency of high-density HPC platforms based on Intel, AMD and ARM processors. In European Conference on Energy Efficiency in Large Scale Distributed Systems (pp. 182-200). Springer Berlin Heidelberg.
Johnson, E., Garrity, P., Yates, T., & Brown, R. A. (2011, September). Performance of a virtual cluster in a general-purpose teaching laboratory. In 2011 IEEE International Conference on Cluster Computing (pp. 600-604). IEEE.
Joy, A. M. (2015, March). Performance comparison between linux containers and virtual machines. In Computer Engineering and Applications (ICACEA), 2015 International Conference on Advances in (pp. 342-346). IEEE.
Kaewkasi, C., & Srisuruk, W. (2014, July). A study of big data processing constraints on a low-power hadoop cluster. In Computer Science and Engineering Conference (ICSEC), 2014 International (pp. 267-272). IEEE.
Karman, R., Beserra, D., Endo, P., & Galdino, S. (2014). Análise de Desempenho do Virtualizador KVM com o HPCC em Aplicações de CAD. SBRC 2014-WCGA.
Krampis, K., Booth, T., Chapman, B., Tiwari, B., Bicak, M., Field, D., & Nelson, K. E. (2012). Cloud BioLinux: pre-configured and on-demand bioinformatics computing for the genomics community. BMC bioinformatics, 13(1), 1.

76
Kruger, C. P., & Hancke, G. P. (2014, July). Benchmarking Internet of things devices. In 2014 12th IEEE International Conference on Industrial Informatics (INDIN) (pp. 611-616). IEEE.
Luszczek, P., Meek, E., Moore, S., Terpstra, D., Weaver, V. M., & Dongarra, J. (2011, August). Evaluation of the HPC challenge benchmarks in virtualized environments. In European Conference on Parallel Processing (pp. 436-445). Springer Berlin Heidelberg.
Luszczek, P. R., Bailey, D. H., Dongarra, J. J., Kepner, J., Lucas, R. F., Rabenseifner, R., & Takahashi, D. (2006, November). The HPC Challenge (HPCC) benchmark suite. In Proceedings of the 2006 ACM/IEEE conference on Supercomputing (p. 213).
Manohar, N. (2013). A Survey of Virtualization Techniques in Cloud Computing. In Proceedings of International Conference on VLSI, Communication, Advanced Devices, Signals & Systems and Networking (VCASAN-2013) (pp. 461-470). Springer India.
Marathe, A., Harris, R., Lowenthal, D., De Supinski, B. R., Rountree, B., & Schulz, M. (2014, June). Exploiting redundancy for cost-effective, time-constrained execution of HPC applications on amazon EC2. In Proceedings of the 23rd international symposium on High-performance parallel and distributed computing (pp. 279-290). ACM.
Mello, T. Schulze, B. P. R. M. A. (2010). Uma análise de recursos virtualizados em ambientes de hpc. In Proceedings of XXVIII of Brazilian Symposium on Computer Networks - IX Workshop in Clouds and Applications, pages 17–30. SBC.
Mergen, M. F., Uhlig, V., Krieger, O., & Xenidis, J. (2006). Virtualization for high-performance computing. ACM SIGOPS Operating Systems Review, 40(2), 8-11.
Molano, J. I. R., Betancourt, D., & Gómez, G. (2015, August). Internet of Things: A Prototype Architecture Using a Raspberry Pi. In International Conference on Knowledge Management in Organizations (pp. 618-631). Springer International Publishing.
Montella, R., Giunta, G., & Laccetti, G. (2014). Virtualizing high-end GPGPUs on ARM clusters for the next generation of high performance cloud computing. Cluster computing, 17(1), 139-152.
Morabito, R. (2015, December). Power Consumption of Virtualization Technologies: an Empirical Investigation. In 2015 IEEE/ACM 8th International Conference on Utility and Cloud Computing (UCC) (pp. 522-527). IEEE.
Morabito, R., Kjällman, J., & Komu, M. (2015, March). Hypervisors vs. lightweight virtualization: a performance comparison. In Cloud Engineering (IC2E), 2015 IEEE International Conference on (pp. 386-393). IEEE.
Napper, J., & Bientinesi, P. (2009, May). Can cloud computing reach the top500?. In Proceedings of the combined workshops on UnConventional high performance computing workshop plus memory access workshop (pp. 17-20). ACM.
Nussbaum, L., Anhalt, F., Mornard, O., & Gelas, J. P. (2009, July). Linux-based virtualization for HPC clusters. In Montreal Linux Symposium.
Oracle (2013). Oracle VM Virtualbox: User manual. Online. Available in: https://www.virtualbox.org/manual/UserManual.html. Accessed in 26-August-2014.
Oracle (2014). Oracle® linux administrator’s solutions guide for release 6 - chapter 9 linux container.

77
Preeth, E. N., Mulerickal, F. J. P., Paul, B., & Sastri, Y. (2015, November). Evaluation of Docker containers based on hardware utilization. In 2015 International Conference on Control Communication & Computing India (ICCC) (pp. 697-700). IEEE.
Regola, N., & Ducom, J. C. (2010, November). Recommendations for virtualization technologies in high performance computing. In Cloud Computing Technology and Science (CloudCom), 2010 IEEE Second International Conference on (pp. 409-416). IEEE.
Seo, K. T., Hwang, H. S., Moon, I. Y., Kwon, O. Y., & Kim, B. J. (2014). Performance comparison analysis of linux container and virtual machine for building cloud. Advanced Science and Technology Letters, 66, 105-111.
Simons, J. E., & Buell, J. (2010). Virtualizing high performance computing. ACM SIGOPS Operating Systems Review, 44(4), 136-145.
Soltesz, S., Pötzl, H., Fiuczynski, M. E., Bavier, A., & Peterson, L. (2007, March). Container-based operating system virtualization: a scalable, high-performance alternative to hypervisors. In ACM SIGOPS Operating Systems Review (Vol. 41, No. 3, pp. 275-287). ACM.
Somasundaram, T. S., & Govindarajan, K. (2014). CLOUDRB: A framework for scheduling and managing High-Performance Computing (HPC) applications in science cloud. Future Generation Computer Systems, 34, 47-65.
Sousa, E. T., Maciel, P. R., Medeiros, E. M., de Souza, D. S., Lins, F. A., & Tavares, E. A. (2012, July). Evaluating eucalyptus virtual machine instance types: A study considering distinct workload demand. In Third International Conference on Cloud Computing, GRIDs, and Virtualization (pp. 130-135).
Tso, F. P., White, D. R., Jouet, S., Singer, J., & Pezaros, D. P. (2013, July). The glasgow raspberry pi cloud: A scale model for cloud computing infrastructures. In 2013 IEEE 33rd International Conference on Distributed Computing Systems Workshops (pp. 108-112). IEEE.
van der Hoeven, R. (2013). Raspberry pi performance.
Varrette, S., Guzek, M., Plugaru, V., Besseron, X., & Bouvry, P. (2013, October). Hpc performance and energy-efficiency of xen, kvm and vmware hypervisors. In 2013 25th International Symposium on Computer Architecture and High Performance Computing (pp. 89-96). IEEE.
Vecchiola, C., Pandey, S., & Buyya, R. (2009, December). High-performance cloud computing: A view of scientific applications. In 2009 10th International Symposium on Pervasive Systems, Algorithms, and Networks (pp. 4-16). IEEE.
Vogelsberger, M., Genel, S., Springel, V., Torrey, P., Sijacki, D., Xu, D., ... & Hernquist, L. (2014). Properties of galaxies reproduced by a hydrodynamic simulation. arXiv preprint arXiv:1405.1418.
Walters, J. P., Chaudhary, V., Cha, M., Guercio Jr, S., & Gallo, S. (2008, March). A comparison of virtualization technologies for HPC. In 22nd International Conference on Advanced Information Networking and Applications (aina 2008) (pp. 861-868). IEEE.
Soltesz, S., Pötzl, H., Fiuczynski, M. E., Bavier, A., & Peterson, L. (2007, March). Container-based operating system virtualization: a scalable, high-performance alternative to hypervisors. In ACM SIGOPS Operating Systems Review (Vol. 41, No. 3, pp. 275-287). ACM.

78
Wolf, W., Jerraya, A. A., & Martin, G. (2008). Multiprocessor system-on-chip (MPSoC) technology. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 27(10), 1701-1713.
Xavier, M. G., Neves, M. V., Rossi, F. D., Ferreto, T. C., Lange, T., & De Rose, C. A. (2013, February). Performance evaluation of container-based virtualization for high performance computing environments. In 2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (pp. 233-240). IEEE.
Ye, K., Jiang, X., Chen, S., Huang, D., & Wang, B. (2010, September). Analyzing and modeling the performance in xen-based virtual cluster environment. In High Performance Computing and Communications (HPCC), 2010 12th IEEE International Conference on (pp. 273-280). IEEE.
Younge, A. J., Henschel, R., Brown, J. T., Von Laszewski, G., Qiu, J., & Fox, G. C. (2011, July). Analysis of virtualization technologies for high performance computing environments. In Cloud Computing (CLOUD), 2011 IEEE International Conference on (pp. 9-16). IEEE.
Zhao, T., Ding, Y., March, V., Dong, S., & See, S. (2009, August). Research on the performance of xVM virtual machine based on HPCC. In 2009 Fourth ChinaGrid Annual Conference (pp. 216-221). IEEE.