universitatea “alexandru ioan cuza” iaŞi …adiftene/licenta/licenta2012_pitumihai.pdfetc.)...
TRANSCRIPT

UNIVERSITATEA “ALEXANDRU IOAN CUZA” IAŞI
FACULTATEA DE INFORMATICĂ
LUCRARE DE LICENȚĂ
Tehnici de adnotare automată a imaginilor
propusă de
Mihai Pîțu
Sesiunea: Iulie, 2012
Coordonator științific
Dr. Adrian Iftene

1
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
UNIVERSITATEA “ALEXANDRU IOAN CUZA” IAŞI
FACULTATEA DE INFORMATICĂ
Tehnici de adnotare automată a imaginilor
Mihai Pîțu
Sesiunea: Iulie, 2012
Coordonator științific
Dr. Adrian Iftene

2
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Declaraţie privind originalitate şi respectarea drepturilor de autor
Prin prezenta declar că Lucrarea de licenţă cu titlul „Tehnici de adnotare automată a
imaginilor” este scrisă de mine și nu a mai fost prezentată niciodată la altă facultate sau instituție
de învățământ superior din țară sau străinătate. De asemenea, declar că toate sursele utilizate,
inclusiv cele preluate de pe Internet, sau indicate în lucrare, cu respectarea regulilor de evitare a
plagiatului:
toate fragmentele de text reproduse exact, chiar și în traducere proprie din altă limbă, sunt
scrise între ghilimele și dețin referința precisă a sursei;
reformularea în cuvinte proprii a textelor scrise de către alți autori deține referința precisă;
codul sursă, imagini etc. preluate din proiecte open-source sau alte surse sunt utilizate cu
respectarea drepturilor de autor și dețin referințe precise;
rezumarea ideilor altor autori precizează referința precisă la textul original.
Iași,
Absolvent: Mihai Pîțu
_______________

3
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Declaraţie de consimţământ
Prin prezenta declar că Lucrarea de licenţă cu titlul „Tehnici de adnotare automată a
imaginilor”, codul sursă al programelor şi celelalte conţinuturi (grafice, multimedia, date de test
etc.) care însoţesc această lucrare să fie utilizate în cadrul Facultăţii de Informatică. De asemenea,
sunt de acord ca Facultatea de Informatică de la Universitatea Alexandru Ioan Cuza Iaşi să
utilizeze, modifice, reproducă şi să distribuie în scopuri necomerciale programele-calculator,
format executabil şi sursă, realizate de mine în cadrul prezentei lucrări de licenţă.
Iași,
Absolvent: Mihai Pîțu
_______________________

4
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Acord privind proprietatea dreptului de autor
Facultatea de Informatică este de acord ca drepturile de autor asupra programelor-
calculator, format executabil şi sursă, să aparţină autorului prezentei lucrări, Mihai Pîțu.
Încheierea acestui acord este necesară din următoarele motive:
Iași,
Decan: Dr. Adrian Iftene Absolvent: Mihai Pîțu
_______________________ _______________________

5
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Cuprins
1. Introducere ..................................................................................................................................... 6
1.1. Motivație ....................................................................................................................................... 6
1.2. Competiția ImageCLEF – Annotation Task ................................................................................... 7
1.3. Concluziile capitolului ................................................................................................................... 9
2. Definiții și exemple ........................................................................................................................10
2.1. Extragerea trăsăturilor imaginilor folosind PEF (Profile Entropy Features) ...................................10
2.2. Clasificarea datelor folosind SVM (Support vector machines) .......................................................11
2.3. Ontologii ......................................................................................................................................14
2.4. Codebooks - dicționare de cuvinte vizuale ....................................................................................14
2.5. Extragerea cuvintelor vizuale........................................................................................................16
2.6. Exploatarea tag-urilor definite de utilizatori ..................................................................................22
2.7. Exploatarea coloristicii imaginilor - Momentele culorilor .............................................................23
2.8. Detectarea fețelor .........................................................................................................................25
2.9. Concluziile capitolului ..................................................................................................................26
3. Abordări în sistemele existente .....................................................................................................27
3.1. Participări la ImageCLEF 2009 Annotation Task ..........................................................................27
3.2. Participări la ImageCLEF 2011 Annotation Task ..........................................................................28
3.3. Concluziile capitolului ..................................................................................................................29
4. Descrierea sistemului ....................................................................................................................30
4.1. Cerințe .........................................................................................................................................30
4.2. Detalii de implementare ................................................................................................................31
4.3. Extragerea trăsăturilor imaginilor .................................................................................................32
4.4. Clasificarea imaginilor de test .......................................................................................................34
4.5. Postprocesare ...............................................................................................................................38
4.6. Evaluare .......................................................................................................................................39
4.7. Concluziile capitolului ..................................................................................................................41
5. Contribuții personale, rezultate și direcții de viitor .....................................................................42
Bibliografie .............................................................................................................................................43

6
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
1. Introducere
1.1. Motivație
Procesarea automată a imaginilor cu ajutorul agenților constituie o ramură provocatoare a
inteligenței artificiale, cu impact important asupra unor arii largi de aplicații cum ar fi indexarea
și căutarea de imagini după categorii pe Web, recunoașterea de modele în domenii precum
medicina, rețele sociale, construcții și altele. Sistemele actuale de căutare de imagini, Google
Image sau Bing Images se bazează pe descrieri și adnotări textuale ale imaginilor, fără a analiza
conținutul acestora, așadar acestea nu pot fi folosite pentru căutare în colecții de imagin i
neadnotate.
Viziunea calculatoarelor (Computer Vision) este un domeniu de actualitate cu aplicații în
lumea aplicațiilor 3D, robotică sau aplicații Web. Tehnicile folosite pentru a proiecta un software
care să înțeleagă obiectele sau mediul dintr-o anumită imagine sunt strâns legate de algoritmii
folosiți în Machine Learning (învățarea automată a mașinilor), antrenând mai întâi programul prin
exemple. Pentru procesarea imaginilor algoritmii existenți fac parte din categoria metodelor de
învățare supervizată. Această metodă presupune un set de date de intrare prelucrat (imagini care
au conținutul cunoscut) suficient de semnificativ astfel încât să se poată deduce o funcție numită
clasificator (dacă output-ul este discret) sau funcție de regresie (dacă output-ul este continuu).
Tehnici precum: Support Vector Machines1 (SVM) [1], Generative Models
2, Boosting
3, multiple
instance learning, active learning și altele au fost folosite pentru a clasifica și indexa imagini până
în prezent.
1 http://www.support-vector-machines.org/ 2 http://en.wikipedia.org/wiki/Generative_model 3 http://www.cs.princeton.edu/~schapire/boost.html

7
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
1.2. Competiția ImageCLEF – Annotation Task
ImageCLEF reprezintă o competiție organizată de CLEF4
(Cross Language Evaluation
Forum) cu aplicații în domeniul CBIR5 - Regăsirea bazată pe conținutul imaginilor (Content-
Based Image Retrieval); acest lucru presupune „regăsirea” de imagini dintr-o colecție mare de
date folosind doar informațiile vizuale conținute de aceste imagini, pe baza unor interogări
textuale. Organizatorii au propus mai multe sarcini precum: CBIR cu interogări în diferite limbi
internaționale; Medical CBIR presupune regăsirea de imagini similare privind o anumită temă
medicală; Adnotarea automată de fotografii (Annotation task); Adnotarea automată de fotografii
cu temă medicală.
Nevoia adnotării automate de imagini a apărut datorită creșterii exponențiale de informații
vizuale pe Web și nu numai, așadar sunt necesare sisteme care să indexeze, să caute pe baza
conținutului sau să organizeze aceste informații vizuale. Aceste sisteme sunt încă imperfecte, iar
din acest motiv nu sunt încă acceptate pe scară largă. În competiția ImageCLEF - Annotation
Task organizată în 2011 (rezultate – Tabelul 1), participanții au trebuit să adnoteze un set de test
de 10,000 de imagini publice de pe site-ul de partajare a imaginilor, Flickr6, folosind 99 de
concepte vizuale predefinite. Această sarcină putea fi rezolvată folosind următoarele abordări:
1. Adnotarea automată folosind doar informații vizuale (V)
2. Adnotarea automată bazată pe meta-datele imaginii sau adnotările manuale ale
utilizatorilor (T)
3. Abordări multi-modale, ce implică o combinație între abordările de mai sus (M)
Câteva dintre cauzele dificultății adnotării imaginilor sunt:
Diversitatea conceptelor la nivelul unei singure imagini
Subiectivitatea adnotării conceptelor prezente (precum sentimentele) în datele de
antrenament
Volumul de date dezechilibrat (sunt mai multe exemple relevante pentru un anumit
concept decât pentru altul, în setul de antrenament)
4 http://clef-campaign.org/ 5 http://en.wikipedia.org/wiki/Content-based_image_retrieval
6 http://imageclef.org/2012/photo-flickr/

8
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Calitatea imaginii
Colecția de imagini de test au avut adnotări manuale pentru cele 99 de concepte. Aceste
concepte variază de la diferite scene în care a fost făcută fotografia (în aer liber, din interior,
panoramic, macro, etc.), obiecte prezente în imagine (animale, persoane, etc.), reprezentarea
imaginii (portret, pictură, etc.) până la calitatea imaginii (neclară, supraexpusă, subexpusă, etc.).
În anul 2011 au fost evaluate și sentimentele prezente în imagine – Figura 1 (clasificate după
modelul din [2]), față de competițiile din anii trecuți.
Figura 1: Sentimentele transmise de imagini au fost asignate manual folosindu-se aplicația MTurk7 [3]
Grupul Locul F-measure
ISIS 1 0.62
LIRIS 14 0.57
TUBFI 17 0.56
CEALIST 42 0.50
LAPI 70 0.39
Tabelul 1: Rezultate pentru o parte din echipele participante la ImageCLEF 2011
În competiția ImageCLEF - Annotation Task organizată în 2012, organizatorii au stabilit 94
de concepte8 grupate în 18 categorii:
Momentul zilei: zi, noapte
7 www.mturk.com 8 http://imageclef.org/2012/photo-flickr/concepts

9
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Corpuri cerești: soare, lună, stele
Vreme: cer senin, cer acoperit de nori, cer parțial acoperit de nori, curcubeu
Combustie: flăcări, fum, artificii
Iluminare: umbre, reflecție, siluetă, efect de lentile,
Panoramă: munte, deșert, pădure, ţărm de mare, oraș, rural, graffiti
Apă: subacvatic, ocean, lac, râu, alte contexte în care apare apa
Floră: copaci, plante, flori, iarbă
Faună: pisică, câine, cal, pește, pasăre, insectă, păianjen, reptilă, rozătoare
Număr de persoane: nicio persoană, o persoană, două persoane, trei persoane, grup
mic, grup mare
Sexul persoanei: masculin, feminin
Relațiile dintre persoane: familie sau prieteni, colegi de muncă, străini
Calitatea imaginii: fără estompare, estompare parțială, estompare completă, estompare
de mișcare, artefacte
Stilul imaginii: imagine în imagine, distorsiune circulară, text pe imagine, alb-negru
Vizualizarea: portret, macro, în interiorul unei clădiri, în exteriorul unei clădiri
Cadru: viața de oraș, petrecere, acasă, recreere, mâncare
Sentimente: bucuros, calm, inactiv, melancolic, neplăcut, înfricoșător, activ, euforic,
amuzant
Tipul de transport: bicicletă, mașină, camion, tren, transport pe apă, transport aerian
Problema subiectivității și a faptului că este posibil ca o imagine să nu fie adnotată cu toate
conceptele existente în imagine (de exemplu, în setul de imagini de training, doar 40% sunt
adnotate cu sentimente) rămâne și în competiția din acest an.
1.3. Concluziile capitolului
În acest capitol am făcut o scurtă introducere în domeniul Computer Vision și a problemei
adnotării automate de imagini, prin prisma participării la competiția ImageCLEF 2012
Annotation Task. Această competiție presupune detectarea unui număr de 94 de concepte
prestabilite într-un set de imagini de test, pe baza unui set de imagini de antrenare.

10
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
2. Definiții și exemple
2.1. Extragerea trăsăturilor imaginilor folosind PEF (Profile Entropy Features)
Pentru a clasifica conținutul unei imagini, se calculează un descriptor de imagine (capabil
să surprindă particularitățile fiecărei imagini) folosind anumite caracteristici extrase din imagine.
Majoritatea tehnicilor implementate până în prezent se bazează pe distribuția culorilor în imagine
(color histogram9). O nouă tehnică propusă în [4] numită Profile Entropy Features (PEF) are
avantajul combinării caracteristicilor texturii cu formele prezente în imagine, precum și o viteză
sporită în execuție.
Această tehnică presupune normalizarea10
imaginii RGB actualizând canalele Red, Green
și Blue astfel: r = R/l, g=G/l, b=1-r-g, unde l=(R+G+B)/3.
reprezintă proiecția ortogonală a
pixelilor pe axa orizontală X, respectiv
, proiecția ortogonală a pixelilor pe axa verticală Y,
unde op este operatorul de proiecție, care poate fi media aritmetică sau media armonică a
valorilor luminanţei (en. luminance11
) pentru fiecare pixel. Apoi pentru fiecare canal roșu, verde,
albastru și operator op se calculează
( ) (
) , unde I este imaginea dată, pdf
reprezintă funcția probabilităților distribuite12
pe N intervale (N = √ , S = lungimea unei linii de
pixeli sau a unei coloane de pixeli), definită în [5]. Se folosesc apoi componentele entropiei
normalizate:
( ) (
( ))
, ( )
(
( ))
, ( )
( ( ))
,
Unde H este funcția entropie pentru histograme:
( ) ∑ ( )
9 http://www.jatit.org/volumes/research-papers/Vol6No1/13Vol6No1.pdf
10 http://www.aishack.in/2010/01/normalized-rgb/ 11 http://www.drdrbill.com/downloads/optics/photometry/Luminance.pdf 12
http://mathworld.wolfram.com/ProbabilityDensityFunction.html

11
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Acest algoritm se repetă pentru fiecare din cele 3 regiuni (Figura 2) din imagine împărțite
în mod egal din imaginea originală.
Figura 2: Împărțirea imaginii originale în regiuni pentru a surprinde textura imaginilor panoramice (partea
de sus, de obicei cerul, partea de mijloc, obiectul din imagine, iar partea de jos, gazon, apă, etc.)
În final, caracteristicile PEF reprezintă concatenarea valorilor , și ,
rezultând un vector de 45 de elemente (3 canale RGB * 5 trăsături * 3 regiuni).
2.2. Clasificarea datelor folosind SVM (Support vector machines)
SVM13
(Mașini cu vectori suport) constitute o tehnică eficientă de clasificare a datelor.
Această tehnică presupune un set de date pentru antrenare (training) și un set de date de test14
.
Fiecare instanță din setul de antrenament este deja clasificată ca aparținând unei anumite clase, iar
acest set de date este folosit pentru a creea un model care este capabil să eticheteze instanțele din
setul de test ca aparținând unei anumite clase. Așadar pentru un set de date de învățare S, o
instanță este de forma (xi, yi), i {1, 2, …, l}, xi ϵ Rn and yi {-1, 1}, iar acest set este liniar
separabil dacă există astfel încât ( ) . SVM caută soluția problemei
de optimizare [6]:
minw,b,ξ
w
Tw + C ∑
yi (wT (w) + b) 1 - ,
13 http://www.support-vector-machines.org 14
Introducere Învățare automată: http://robotics.stanford.edu/~nilsson/MLBOOK.pdf
12
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
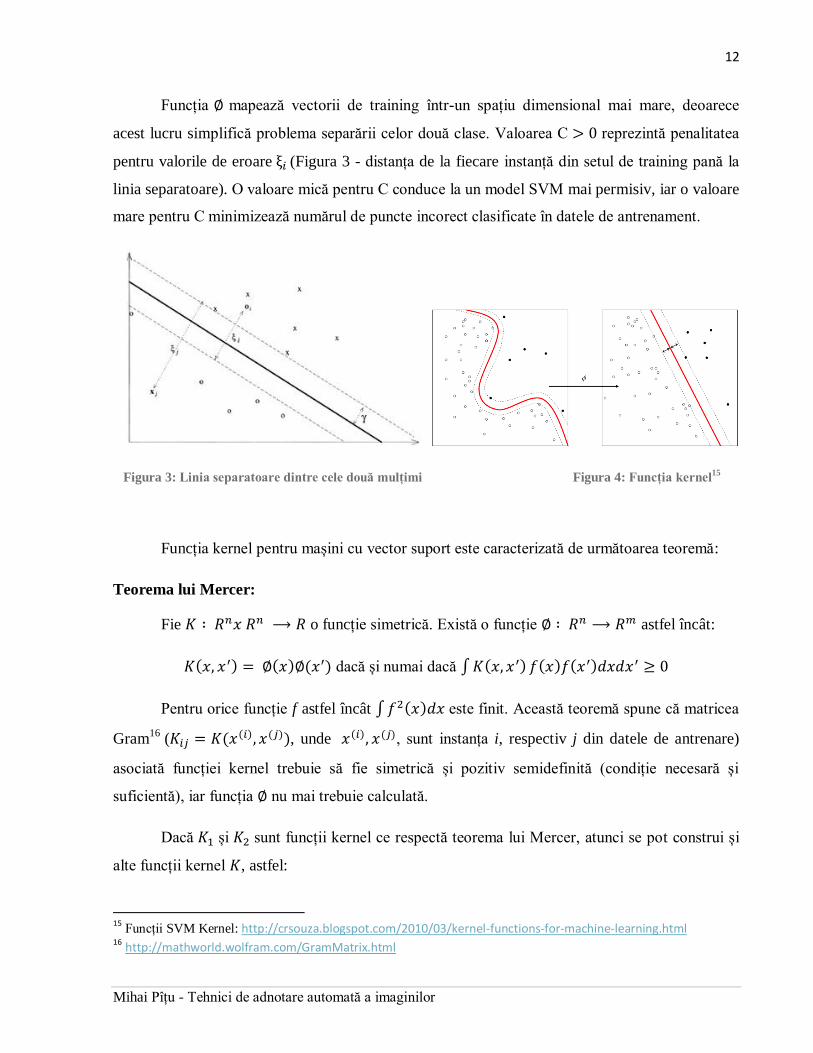
Funcția mapează vectorii de training într-un spațiu dimensional mai mare, deoarece
acest lucru simplifică problema separării celor două clase. Valoarea C reprezintă penalitatea
pentru valorile de eroare (Figura 3 - distanța de la fiecare instanță din setul de training pană la
linia separatoare). O valoare mică pentru C conduce la un model SVM mai permisiv, iar o valoare
mare pentru C minimizează numărul de puncte incorect clasificate în datele de antrenament.
Figura 3: Linia separatoare dintre cele două mulțimi Figura 4: Funcția kernel15
Funcția kernel pentru mașini cu vector suport este caracterizată de următoarea teoremă:
Teorema lui Mercer:
Fie o funcție simetrică. Există o funcție astfel încât:
( ) ( ) ( ) dacă și numai dacă ∫ ( ) ( ) ( )
Pentru orice funcție f astfel încât ∫ ( ) este finit. Această teoremă spune că matricea
Gram16
( ( ( ) ( )), unde ( ) ( ), sunt instanța i, respectiv j din datele de antrenare)
asociată funcției kernel trebuie să fie simetrică și pozitiv semidefinită (condiție necesară și
suficientă), iar funcția nu mai trebuie calculată.
Dacă și sunt funcții kernel ce respectă teorema lui Mercer, atunci se pot construi și
alte funcții kernel , astfel:
15 Funcții SVM Kernel: http://crsouza.blogspot.com/2010/03/kernel-functions-for-machine-learning.html 16
http://mathworld.wolfram.com/GramMatrix.html

13
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
( ) ( ) ( )
( ) ( ), unde a ϵ
( ) ( ) ( )
Pentru o clasificare non-liniară, se folosesc și alte funcții pentru a separa mulțimile numite
kernel-uri (Figura 4). Dintre acestea cele mai folosite sunt:
Linear: ( )
Polinomial: ( ) ( ) , unde d este gradul polinomului
RBF: ( ) (
) (sau ( ) ( ) ) unde ||p|| = poziția
unui punct într-un spațiu Euclidian17
Sigmoid: r ( ) ( ), unde tanh este funcția tangentă hiperbolică18
Chi-square: χ2(x, y) = ∑
( )
( )
, acest kernel vine de la distribuția chi-square
19 și
a dat rezultate bune pentru clasificarea de imagini în sistemele actuale.
Parametrii γ, d și r sunt de obicei diferiți de la o problemă la alta.
Pentru a învăța un clasificator SVM folosind un set de date de training, se urmează următorii
pași20
:
1. Se transformă datele de intrare (trăsăturile imaginii) în formatul svmLight21
.
2. Se scalează datele de intrare: acest pas este important pentru a evita lucrul cu numere mari
și pentru a evita debalansarea problemei (de exemplu în cazul folosirii kernelului RBF).
Valorile atributelor trebuie să fie în intervalul [-1, 1] sau [0, 1]. Această scalare trebuie
făcută și pe datele de test.
3. Se alege un kernel pentru clasificator (pentru început ar trebui considerat RBF, apoi
pentru clasificarea de imagini se poate considera kernelul χ2).
17 http://xlinux.nist.gov/dads/HTML/euclidndstnc.html 18
http://en.wikipedia.org/wiki/Hyperbolic_function 19 http://mathworld.wolfram.com/Chi-SquaredDistribution.html 20 http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf 21
http://svmlight.joachims.org/

14
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
4. Se folosește cross-validation pentru a găsi cei mai buni parametrii C și γ deoarece acești
parametri sunt diferiți în funcție de problemă. Tehnica de cross-validation (secțiunea 4.5)
presupune selectarea unui set de test din datele de training pentru a verifica acuratețea
clasificării. Acest lucru previne problema supraestimării.
5. Se folosesc parametrii C și γ generați de cross-validation pentru a antrena întreg setul de
intrare.
În domeniul clasificării imaginilor, apare problema apartenenței unei imagini la mai multe
clase (o imagine poate conține mai multe concepte, de exemplu elemente de natură cât și oameni,
etc.). Acest lucru presupune un tip de clasificare diferit de cel tradițional, iar una din cele mai
folosite tehnici este clasificarea binară. Această clasificare este o extensie a metodei One-
Against-All [7] și presupune etichetarea imaginilor ce conțin exemple relevante pentru un
concept dat, ca fiind exemple pozitive, restul imaginilor din setul de date training fiind etichetate
ca fiind exemple negative. Se antrenează câte un Svm pentru fiecare concept prezent în datele de
training.
2.3. Ontologii
O ontologie (în informatică) definește o structură formală a lucrurilor și a relațiilor dintre
ele. Folosind o mulțime de concepte structurate într-o ontologie, se pot face presupuneri asupra
altor concepte similare cu unul asignat deja. De exemplu, dacă într-o imagine se află nori, se
poate infera că fotografia este făcută spre cer, sau că imaginea este de tip panoramă. Acest lucru
poate fi folosit pentru a genera și alte adnotări pentru o imagine în care s-a identificat cel puțin un
concept. În setul de date de antrenare oferit de Image CLEF, imaginile adnotate respectă în
relațiile semantice dintre concepte, de exemplu, dacă o imagine a fost adnotată cu
weather_lightning, aceasta va conține (cu probabilitate mare) și conceptul view_outdoor.
2.4. Codebooks - dicționare de cuvinte vizuale
Pentru a evita folosirea multor proprietăți vizuale ale imaginii (lucru care îngreunează
clasificarea), se folosesc așa numitele transformări codebook. Se definește întâi o mulțime de
cuvinte vizuale (en. codewords – un set de exemple sau parametrii ce poate fi comparat cu un

15
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
pattern similar – Figura 5), apoi se folosește o distribuție a frecvențelor codeword-urilor ca un set
compact de trăsături ce reprezintă imaginea. Astfel, un codeword este reprezentativ pentru mai
mulți descriptori vizuali similari. Această abordare a fost inspirată din metoda „sacului de
cuvinte” (bag of words22) din domeniul procesării limbajului natural23, în care se definește un set
de cuvinte cu ajutorul căruia se construiesc tabele de frecvențe pentru diferite documente text.
Figura 5: Modelul codebook: o imagine reprezentată sub forma unei mulțimi de regiuni (bag-of-regions),
fiecare regiune fiind reprezentată de cel mai bun codeword din vocabularul (codebook-ul) predefinit
Pentru a construi un codebook, se extrag trăsături dintr-un set de imagini de antrenament.
Una din cele mai folosite metode pentru a defini codewords este “rețeaua de pătrate” (Figura 5),
în care imaginea este segmentată, obținându-se astfel patch-uri locale ce descriu diferite texturi
prezente în imagine. O altă tehnică pentru a obține codewords este folosirea algoritmilor (ex.
SIFT, SURF, Harris-Laplace) ce identifică puncte de interes locale și definesc descriptori
(vectori) de lungime fixă în jurul acestor puncte de interes (Figura 6). Acești descriptori ar trebui
să fie invarianți24
la rotiri, scalări, schimbări în iluminare sau alte transformări, astfel încât în
momentul în care se dorește compararea acestora, proprietățile lor să rămână neschimbate.
Avantajul construirii unui codebook este în primul rând viteza procedeului de potrivire a
imaginilor și faptul că acest proces se face folosind cele mai importante cuvinte vizuale în raport
cu imaginea.
22 http://www.cs.huji.ac.il/~daphna/course/student%20lectures/noam%20aigerman.pdf 23 http://en.wikipedia.org/wiki/Natural_language_processing 24
http://books.google.ro/books?id=dp2xHfJz2d0C&printsec=frontcover&hl=ro#v=onepage&q&f=false

16
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Figura 6: Patch-uri extrase folosind SURF Figura 7: Patch-uri extrase folosind SURF din două clustere
(sursa [8])
Construcția unui codebook presupune folosirea algoritmului de clustering, k-means –
Tabelul 2. Algoritmul minimizează numărul inițial de trăsături la un număr de clustere k
predefinit. Se asignează apoi fiecărei trăsături un singur codeword (centru de cluster)
reprezentativ, tehnică denumită și hard-assignment25
- Figura 7.
Init: selectează k centre de clustere aleatoriu
Repeat:
-Asignează puncte din mulțimi către cei mai apropiați clusteri
-Actualizează centrul clusterului folosind media distanței
euclidiene a punctelor clusterului.
-Șterge centrele clusterilor: reactualizează aleator
Until: Nicio schimbare
Tabelul 2: Algoritmul k-means26
2.5. Extragerea cuvintelor vizuale
Cercetările din ultimii ani din domeniul Computer Vision și-au îndreptat atenția către
extragerea de trăsături locale ale imaginilor deoarece acestea tind să captureze mai bine semantica
imaginilor decât cele globale (histograme de culori, intensități, texturi, etc.) și să asigure
invarianța la transformări afine. Aceste trăsături locale sunt asociate cu diferite modele prezente
în anumite părți ale imaginii (puncte, margini sau mici patch-uri). După ce aceste puncte de
25 http://nlp.stanford.edu/IR-book/html/htmledition/flat-clustering-1.html 26
https://www.ai-class.com/course/video/videolecture/68

17
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
interes au fost identificate în imagine, se calculează diferite măsurători în vecinătate, construindu-
se astfel descriptori.
Top-Surf27
este o librărie capabilă să extragă puncte de interes folosind SURF (Speeded
Up Robust Features) [9] și să identifice cuvintele vizuale prezente în imagine pe baza unui
dicționar de cuvinte vizuale (codebook) preconstruit.
SURF (Speeded Up Robust Features) este un algoritm inspirat din descriptorul SIFT28
(Scale-invariant feature transform) care optimizează partea de construcție a descriptorului vizual.
SURF folosește o măsură bazată pe distribuția trăsăturilor de tip Haar29
și matricea Hessiană30
a
imaginii pentru a detecta punctele de interes31
. În cazul SURF, punctele de interes sunt extrase
din punctele de extrem peste întreg spațiul de scalări folosind determinatul matricei Hessiene [8]:
(( ) ) [ ( ) ( )
( ) ( )]
Unde ( ) , se referă la convoluția (derivarea) imaginii de ordinul 2 cu kernelul
Gaussian, la scalarea . În plus, imaginea este analizată la mai multe scalări pentru a obține
invarianță la modificări ale dimensiunii (Figura 8), iar descriptorul conține orientarea dominantă
pentru fiecare punct de interes pentru a obține invarianță la rotire (Figura 9).
Figura 8: Construcția spațiului de scalare folosind metoda reprezentării piramidale32
. Scalările sunt obținute
prin aplicări succesive ale unui filtru Gaussian [9]
27 http://press.liacs.nl/researchdownloads/topsurf/ 28 http://www.cs.berkeley.edu/~malik/cs294/lowe-ijcv04.pdf 29
http://grail.cs.washington.edu/pub/stoll/wavelet1.pdf 30 http://www.math.vt.edu/people/dlr/m2k_svb11_hesian.pdf 31 http://nichol.as/papers/Schmid/Evaluation%20of%20Interest%20Point%20Detectors.pdf 32
http://web.mit.edu/persci/people/adelson/pub_pdfs/pyramid83.pdf

18
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Figura 9: Selecția orientării descriptorului. Se calculează o sumă a intensităților pixelilor (roșu) cuprinși de
fereastra glisantă (gri) formându-se vectori orientați. Vectorul cu modul cel mai mare determină orientarea
descriptorului [9]
Numărul de puncte de interes găsite poate să varieze între 0 și câteva mii, în funcție de
dimensiunea sau detaliile imaginii (de exemplu dacă imaginea este monocoloră, niciun punct de
interes nu va fi returnat). Într-un experiment prezentat în [24], într-o imagine se găsesc în medie
176 de puncte de interes cu o deviație standard de 85.3 (experiment realizat pe 100,000 de
imagini redimensionate la o rezoluție de 256x256 pixeli). Deoarece fiecărui punct de interes îi
corespunde un descriptor (ce conține un vector de 64 de elemente în cazul SURF33
, 128 de
elemente în cazul SIFT) se pune problema potrivirii acestor descriptori (Figura 10) cu cei prezenți
într-o bază de date, acest lucru fiind posibil folosind, de exemplu, ca măsură distanța euclidiană
dintre doi vectori.
Pentru construcția codebook-ului, au fost extrase 33.5 milioane de puncte de interes dintr-
o bază de date cu imagini, fiecare punct de interes fiind considerat o locație în R64
. Apoi se aplică
o metodă de clusterizare34
astfel încât fiecare punct de interes să aparțină unui singur cluster,
această tehnică aplicându-se de mai multe ori. Centrele acestor clustere reprezintă cuvintele
dicționarului vizual nou creat.
33 http://www.vision.ee.ethz.ch/~surf/eccv06.pdf 34
http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/

19
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Figura 10: Descriptorul Top-Surf. Cele mai frecvente 100 de cuvinte vizuale
Asemenea abordărilor în ceea ce privește procesarea limbajului natural, acestor cuvinte
vizuale li se pot atribui greutăți în funcție de importanța lor în documente (de exemplu cuvintele
vizuale ce au o frecvență ridicată de apariție în toate documentele, pot fi considerate mai puțin
importante (stop-words35
) decât cele care apar cu frecvență mare în documente specifice). O
măsură ce s-a dovedit de succes [11] în acest sens este tehnica tf-idf weighting. Frecvența unui
termen (term frequency - tf) reprezintă numărul de apariții al unui cuvânt (vizual) într-un
document, care poate fi normalizat pentru a preveni discriminarea documentelor cu număr mai
mic de cuvinte. Frecvența inversă a unui termen într-un document (Inverse document frequency -
idf) este o măsură care determină dacă un cuvânt este rar într-un set de documente.
( )
Unde t este un cuvânt vizual, #D – cardinalitatea mulțimii de documente D, iar d un document din
D.
( ) ( ) ( ) (tf-idf weighting)
35
http://en.wikipedia.org/wiki/Stop_words

20
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Folosind această măsură, fiecare cuvânt vizual din descriptorul Top-Surf va primi un scor, iar
distanța dintre doi descriptori (vectori din RN) poate fi calculată folosind similaritatea cosinus
36
sau diferența absolută.
Formula de calcul a similarității cosinus dintre doi vectori poate fi derivată din definiția
produsului scalar:
( ) ( )
| | | |
∑
√∑ ( ) √∑ ( )
Unde d1 * d2 reprezintă produsul scalar (intersecția) dintre cei doi descriptori, iar ||d|| reprezintă
norma vectorului d. Deoarece descriptorii sunt formați din greutăți tf-idf (strict pozitive) pentru
fiecare cuvânt vizual, scorul de similaritate cosinus va aparține intervalului [0, 1] (unghiul dintre
cei doi vectori nu depășește 90 grade), 1 pentru descriptori identici, 0 pentru descriptori absolut
diferiți.
O altă tehnică folosită pentru a compara doi descriptori este diferența absolută37
, definită
astfel:
( ) ∑
Unde |r| reprezintă modulul numărului real r, care în acest caz este egal cu diferența absolută a
scorurilor tf-idf pentru cel de-al i-lea cuvânt vizual din cei doi descriptori. Această măsură tinde
să discrimineze descriptorii cu lungimi de cuvinte vizuale diferite. Scorul calculat de distanța
absolută aparține intervalului [0, ) (0 pentru descriptori absolut identici).
Mărimea descriptorului returnat de algoritmul SURF constituie o motivație pentru
proiectarea Top-Surf (pentru o colecție de 100,000 de imagini descriptorii SURF necesită
aproximativ 4.5Gb, iar descriptorii Top-Surf – Figura 10, aproximativ 80Mb). Pentru o imagine a
cărui descriptor Top-Surf trebuie calculat, se extrag mai întâi punctele de interes SURF, acestea
fiind agregate într-o histogramă de frecvențe, căutând cărui cuvânt vizual din codebook îi
36 http://www.ir-facility.org/scoring-and-ranking-techniques-tf-idf-term-weighting-and-cosine-similarity 37
http://users.cis.fiu.edu/~lli003/Music/cla/42.pdf
21
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
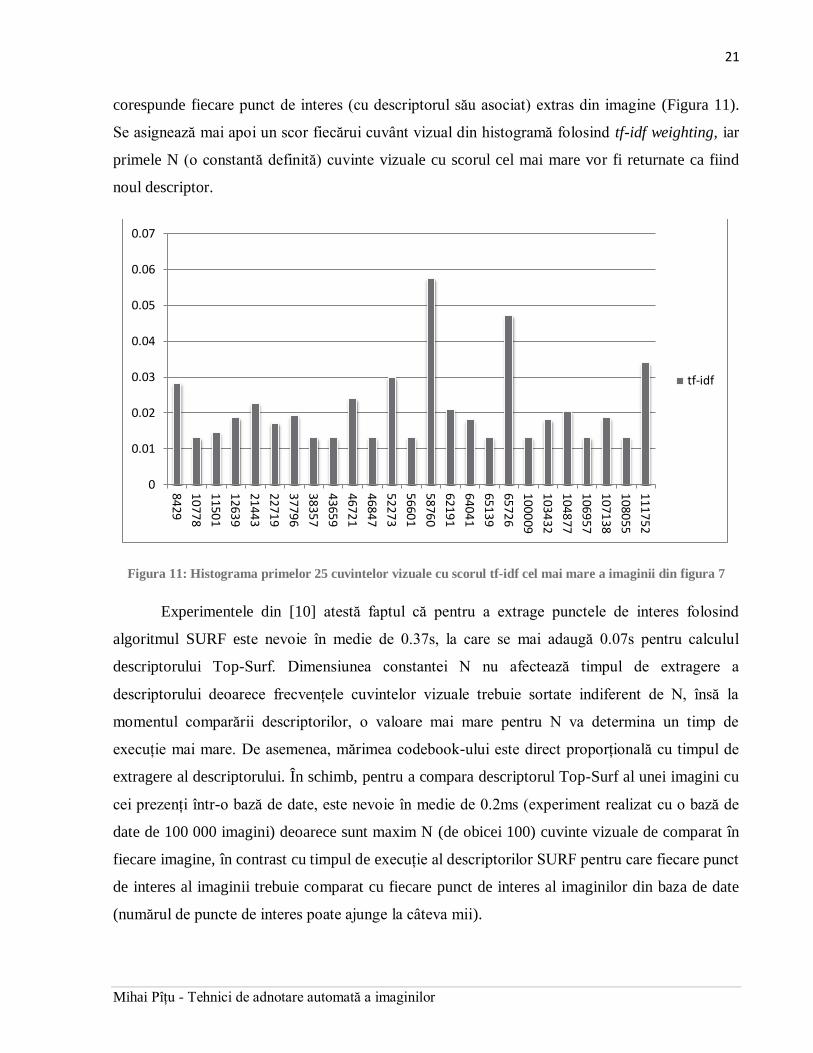
corespunde fiecare punct de interes (cu descriptorul său asociat) extras din imagine (Figura 11).
Se asignează mai apoi un scor fiecărui cuvânt vizual din histogramă folosind tf-idf weighting, iar
primele N (o constantă definită) cuvinte vizuale cu scorul cel mai mare vor fi returnate ca fiind
noul descriptor.
Figura 11: Histograma primelor 25 cuvintelor vizuale cu scorul tf-idf cel mai mare a imaginii din figura 7
Experimentele din [10] atestă faptul că pentru a extrage punctele de interes folosind
algoritmul SURF este nevoie în medie de 0.37s, la care se mai adaugă 0.07s pentru calculul
descriptorului Top-Surf. Dimensiunea constantei N nu afectează timpul de extragere a
descriptorului deoarece frecvențele cuvintelor vizuale trebuie sortate indiferent de N, însă la
momentul comparării descriptorilor, o valoare mai mare pentru N va determina un timp de
execuție mai mare. De asemenea, mărimea codebook-ului este direct proporțională cu timpul de
extragere al descriptorului. În schimb, pentru a compara descriptorul Top-Surf al unei imagini cu
cei prezenți într-o bază de date, este nevoie în medie de 0.2ms (experiment realizat cu o bază de
date de 100 000 imagini) deoarece sunt maxim N (de obicei 100) cuvinte vizuale de comparat în
fiecare imagine, în contrast cu timpul de execuție al descriptorilor SURF pentru care fiecare punct
de interes al imaginii trebuie comparat cu fiecare punct de interes al imaginilor din baza de date
(numărul de puncte de interes poate ajunge la câteva mii).
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
8429
10778
11501
12639
21443
22719
37796
38357
43659
46721
46847
52273
56601
58760
62191
64041
65139
65726
100009
103432
104877
106957
107138
108055
111752
tf-idf

22
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
2.6. Exploatarea tag-urilor definite de utilizatori
În unele situații, informația vizuală nu este de ajuns pentru a da o interpretare semantică a
conținutului imaginii. Atunci când sunt definite adnotări făcute de o persoană (tag-uri diferite de
conceptele prezentate în secțiunea 1.2) putem exploata semantica acestora pentru a îmbunătăți
“judecata” sistemului bazat pe informații vizuale. Problemele ce apar la aceste abordări sunt
legate de faptul că numărul de tag-uri (Figura 12) este relativ mic (sau 0) pentru o imagine
(comparativ cu un document text), pot fi dintr-o multitudine de limbi, unele sunt subiective sau
irelevante și pot fi alcătuite din mai multe cuvinte (de exemplu, rarebook, artgallery,
selectivecolor, etc.) sau abrevieri (exemplu: b.w.). Aceste probleme împiedică buna funcționare a
metodelor tradiționale folosite la procesarea limbajului natural.
Figura 12: Fotografie adnotată de un utilizator Flickr cu tag-urile: book, oldbook, rarebook, latin, greek,
library, bornin1550, deadlanguage, libro
Grupul CEALIST [12] propune în participarea la ImageCLEF 2011 o măsură de similaritate
dintre fiecare tag și conceptele vizuale pe baza ontologiei Wordnet38
și a teoriilor privind rețelele
sociale. Autorii din [13] au demonstrat faptul că o clasificare bazată pe teoria modelului spațial
vectorial39
ce folosește măsuri precum tf (frecvența unui termen) sau idf (frecvența inversă a unui
termen) este inadecvată pentru analiza tag-urilor propuse de utilizatori din cauza problemelor
prezentate în paragraful anterior. De exemplu, pentru conceptul însorit (en. sunny), cele mai
frecvente tag-uri (experiment realizat la competiția ImageCLEF 2011) au fost: albastru (en.
blue), Cannon, Nikon, nori (en. clouds), însă există și concepte pentru care frecvența tag-urilor
38 http://wordnet.princeton.edu/ 39
http://cogsys.imm.dtu.dk/thor/projects/multimedia/textmining/node5.html

23
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
corespunde cu semnificația conceptului. De asemenea, aceeași autori propun un kernel SVM
liniar bazat pe cele mai frecvente tag-uri prezente în setul de antrenare, idee întâlnită și în
abordările din [14] sau [15].
Această abordare presupune construcția unui vocabular de cuvinte ce conține tag-urile atașate
imaginilor de antrenare, ce apar de cel puțin k ori (în experimentele din [13] s-a folosit k=3,
respectiv k=16). Acest proces filtrează în mare parte tag-urile irelevante și rare, rezultând un
număr de n tag-uri, ce vor fi folosite pentru a asigna fiecărei imagini un vector binar n-
dimensional, a cărei i componentă va fi 1 dacă imaginea este adnotată cu tag-ul i din vocabular și
0, altfel. Kernelul liniar SVM ce clasifică astfel de vectori este următorul:
( )
Unde este produsul scalar dintre vectorul binar transpus și vectorul . Kernelul KG
numără câte tag-uri sunt partajate de cei doi vectori (corespondenți celor două imagini de
comparat). Acest kernel conduce la o reprezentare multi-dimensională rară (multe valori nule
între imagini), iar acest lucru poate afecta performanțelor clasificatorului, însă în combinație cu
alte kernel-uri s-a arătat o îmbunătățire semnificativă a rezultatelor.
2.7. Exploatarea coloristicii imaginilor - Momentele culorilor
Momentele culorilor [16] (en. Color moments) reprezintă o măsură bazată pe
caracteristicile culorilor (distribuțiile culorilor) din imagine, care a fost folosită cu succes în
domeniul CBIR (Content-Based Image Retrieval).
Această metodă a fost dovedită a fi mai performantă (de aceeași autori din [16] și de
experimentele din această lucrare) decât metodele convenționale bazate pe distribuția culorilor
(e.g. histograme de culori). Construcția unei histograme de culori H(I) presupune
redimensionarea imaginii astfel încât fiecare imagine din baza de date (în contextul CBIR) să
conțină același număr de pixeli, iar apoi culorile din imagine să fie discretizate astfel încât fiecare
interval din histogramă este numărul de apariții al culorii j in imaginea I. Cu toate acestea,
histograma de culori nu este invariantă la modificări sensibile precum transformări afine,
distorsiuni sau modificări ale iluminării (Figura 13).

24
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Figura 13: Histogramele de culori pentru aceeași imagine însă cu iluminări diferite
Această măsură se bazează pe presupunerea că distribuția culorilor într-o imagine poate fi
văzută ca o distribuție de probabilități peste o imagine. Acest lucru se face pe baza analizei
tendinței centrale (statistică descriptivă) a distribuției culorilor folosind media, a împrăștierii
valorilor culorilor folosind deviația standard și a asimetriei (skewness) distribuției culorilor în
imagine. Pentru a caracteriza o culoare prezentă în imagine se poate folosi modelul de culori40
RGB (roșu, verde, albastru) sau HSV (nuanță, saturație, luminozitate), fiecare model fiind
reprezentabil într-un sistem 3-dimensional (cartezian pentru modelul RGB, cilindric pentru
modelul HSV). Așadar fiecare dimensiune a modelului de culori ales, este caracterizată de 3
măsuri ale distribuției culorii (media, deviația standard și asimetria), rezultând un vector de 9
momente ce va caracteriza imaginea din punct de vedere coloristic.
∑
Unde este valoarea pixelului j din imagine în dimensiunea i a modelului de culori ales, iar N
este numărul de pixeli din imagine. este media valorilor culorilor din imagine pentru
dimensiunea i a modelului de culori.
40
http://software.intel.com/sites/products/documentation/hpc/ipp/ippi/ippi_ch6/ch6_color_models.html

25
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
√
∑( )
Unde este deviația standard a distribuției culorilor pentru dimensiunea i a modelului de culori.
√
∑( )
Unde este asimetria distribuția culorilor pentru dimensiunea i a modelului de culori.
Pentru a compara vectorii descriptivi ai imaginilor se poate folosi distanța euclidiană sau
funcția de similaritate dintre două imagini , respectiv :
( ) ∑( |
| |
| |
|)
Unde i reprezintă dimensiunea curentă a modelului de culori, sunt ponderi ce pot fi ajustate
pentru a obține diferite rezultate (de exemplu, dacă este folosit modelul HSV, nuanța culorii poate
avea o pondere și o importanță mai mare decât valoarea (intensitatea) culorii).
2.8. Detectarea fețelor
Unele concepte definite în secțiunea 1.2 au legătură cu prezența oamenilor în imagini
(Numărul de persoane: nicio persoană, o persoană, două persoane, trei persoane; portret, etc.).
Deși aceste concepte nu sunt strict legate de apariția fețelor în imagine, există o probabilitate
mare legată de faptul că dacă o persoană se află în imagine, aceasta să apară cu fața. Cu toate
acestea, aproximativ 30% din imaginile din setul de antrenare propus de organizatorii
ImageCLEF 2012 ce conțin fețe, nu sunt adnotate utilizând conceptul portret.
Algoritmul de detectare a fețelor propus de Voila și Jones41
presupune antrenarea unei
cascade de clasificatori (mai mulți clasificatori în care al (k+1)-lea clasificator este dependent de
41
http://research.microsoft.com/en-us/um/people/viola/Pubs/Detect/violaJones_CVPR2001.pdf

26
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
output-ul clasificatorului k) de tip AdaBoost pentru extragerea (alegerea) de trăsături de tip
Haar42
. În a doua imagine din figura 14, se observă faptul că suma intensităților pixelilor din jurul
ochilor este mai mare decât suma intensităților pixelilor de sub ochi (totodată, aceeași trăsătură
Haar ar putea fi detectată în zona gurii, acest lucru întărind presupunerea că este vorba de o față
umană), iar în a treia imagine se observă că suma intensităților pixelilor din jurul nasului este mai
mare decât suma intensităților pixelilor de pe nas. Aceste trăsături sunt considerate a fi unice
pentru fața umană.
Figura 14: Cele mai frecvente trăsături de tip Haar la fețele oamenilor [17]
În final, fiecare clasificator „slab” este agregat într-un clasificator „tare”43
, capabil să
detecteze fețele umane. Imaginea este scanată la mai multe scalări pentru a detecta fețe, iar
procesul poate fi optimizat folosind imagini integrale44
. Algoritmul este foarte rapid și precis, ce
poate avea o rată de detecție de peste 95% dacă sunt aleși parametrii optimi.
2.9. Concluziile capitolului
În acest capitol am prezentat formal algoritmii și definițiile pe care se bazează această
lucrare, atât din punct de vedere teoretic, cât și al implementării. Pentru etapa de învățare
automată am definit (sumar) mașinile cu vectori suport (secțiunea 2.2), iar pentru etapa de
extragere a trăsăturilor imaginii, algoritmii: Profile Entropy Features (pentru a surprinde textura și
formele imaginii), cuvinte vizuale folosind TopSurf (pentru trăsăturile locale), momentele
culorilor (coloristica imaginii) și abordarea textuală folosind tag-urilor definite de utilizatori.
42 http://dtpapers.googlecode.com/files/01544911.pdf 43 http://en.wikipedia.org/wiki/Boosting 44
http://www.cse.yorku.ca/~kosta/CompVis_Notes/integral_representations.pdf

27
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
3. Abordări în sistemele existente
3.1. Participări la ImageCLEF 2009 Annotation Task
În participarea UAIC la competiția ImageCLEF45
Annotation Task din 2009 [18] s-a
propus un sistem alcătuit din patru mari componente: prima componentă identifică fețele
oamenilor (în cazul în care există în imagine - componentă utilă pentru categoriile ce conțin
persoane), a doua componentă calculează similitudinea dintre imaginea de adnotat și fiecare
imagine din setul de antrenament, a treia componentă extrage informații din fișierul Exif46
asociat
imaginii, iar a patra componentă asignează o valoare implicită în funcție de gradul de apariție în
setul datelor de training.
În cadrul aceleiași competiție, în [19] H. Glotin et al. propune un sistem care explorează
proprietățile unei imagini folosind mai multe abordări, printre care cea mai performantă s-a
dovedit următoarea: imaginea se segmentează în 3 regiuni orizontale (câte o treime fiecare), iar
pentru fiecare regiune se calculează histograma culorilor în spațiul HSV. Această abordare are
rezultate bune pentru concepte panoramice precum: cerul, vegetația, oceanul, etc. Se antrenează
un clasificator SVM optimizat pentru performanțe multivariate47
, deoarece problema adnotării
este dezechilibrată (numărul de date pentru învățare diferă de la un concept la altul).
În participarea universității din Amsterdam [14] (clasată pe locul întâi la competiția din
2009), se descriu mai multe abordări cu privire la recunoașterea conceptelor, având în vedere că
un obiect este greu de recunoscut dacă se schimbă perspectiva din care este observat (fotografiat).
Pentru a acoperi acest aspect, se folosesc detectorii Harris-Laplace48
pentru punctele de interes,
pe mai multe scalări ale imaginii (pentru a obține invarianță la scalare). Pentru concepte
omogene, detectorii Harris-Laplace sunt ineficienți, se folosesc strategii de random și dense
sampling [25]. Al doilea pas în implementarea echipei ISIS a fost extragerea de puncte SIFT, din
diferite spații de culori. Pentru a reduce numărul de caracteristici ale imaginii, se folosesc
transformări codebook. Pentru partea de clasificare, se folosește librăria LIBSVM, utilizându-se
kernelul χ2 (Chi-square kernel).
45
http://www.imageclef.org/ 46 http://en.wikipedia.org/wiki/Exchangeable_image_file_format 47 http://svmlight.joachims.org/svm_perf.html 48
http://en.wikipedia.org/wiki/Harris_affine_region_detector

28
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Grupul XRCE [20] (clasat pe locul doi în competiția din 2009) propune o metodă bazată
pe utilizarea ontologiilor în momentul clasificării, lucru derivat din diversitatea conceptelor din
datele de test (din competiția organizată în 2009). Acest lucru a fost folosit în adnotarea imaginii
cu mai multe etichete și nu în etapa de training, în felul următor: după ce funcția clasificator
asignează probabilități fiecărei etichete, se face o post-procesare pentru a se asigura consistența
datelor clasificate cu cele din ontologie. Pentru a extrage trăsăturile locale ale imaginii, s-a folosit
algoritmul SIFT și statisticile locale RGB. Dimensiunea vectorului de trăsături a fost redusă la 50
de elemente, folosind PCA (Principal Component Analysis).
Aceste trăsături sunt clasificate folosind tehnica vocabularelor vizuale [10]. Constrângerile
ontologiei au fost implementate astfel: pentru concepte (detectate în imagine) care sunt disjuncte,
probabilitățile lor sunt normalizate astfel încât suma lor să fie 1; pentru un concept părinte
probabilitatea este mai mare sau egală cu probabilitatea maximă a copiilor; pentru un concept
care implică un alt concept, se normalizează doar dacă cele două intră în conflict. Pentru a
verifica adnotările făcute, se folosesc metodele Equal Error Rate (ERR) și Area under Curve
(AUC).
3.2. Participări la ImageCLEF 2011 Annotation Task
Grupul TUBFI [15] reprezintă departamentul de Machine Learning al institutului de
tehnologie FIRST din Berlin, ce a participat la competiția ImageCLEF Annotation Task din 2011
cu 4 rulări informații vizuale și o rulare multi-modală. Pentru abordarea folosind doar informații
vizuale, aceștia au folosit descriptorii Harris-Laplace, SIFT și RGB-SIFT (descriptorul dezvoltat
de grupul universității din Amsterdam [14]), agregate în modele „sacul de cuvinte vizuale” (Bag
of visual words). Abordarea multi-modală exploatează semantica adnotărilor date de utilizatorii
Flickr folosind o funcție kernel personalizată ce calculează distanța dintre două seturi de adnotări
peste un vocabular selectat de cuvinte (se folosesc doar cele mai frecvente cuvinte prezente în
setul de training).
Grupul LIRIS [21] a reprezentat universitatea din Lyon la competiția ImageCLEF
Annotation Task din 2011, cu două rulări folosind doar informații textuale și două rulări multi-
modale. În abordarea bazată pe informații vizuale, aceștia au construit o măsură care calculează

29
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
distanța semantică dintre o adnotare făcută de utilizator și un dicționar construit de aceștia, care
conține cuvinte specifice fiecărui concept, folosind librăria WordNet. O altă metodă s-a bazat pe
setul de cuvinte ANEW49
(ce conține scoruri privind emoțiile generate de cuvinte) care calculează
valența și nivelul de apropiere către un anumit sentiment pentru fiecare cuvânt asociat imaginii de
test. În abordarea bazată pe informațiile vizuale, grupul LIRIS a folosit diferite proprietăți ale
imaginii precum culoarea, textura, precum și caracteristici locale extrase folosind SIFT. Pentru
etapa de clasificare, aceștia au utilizat diferite strategii precum Adaboost și SVMs.
Grupul „Laboratorul de Analiză și Prelucrarea Imaginilor” [22] au reprezentat
Universitatea Politehnică din București, iar aceștia au participat la competiția din 2011 cu două
rulări folosind doar informații vizuale. Aceștia au dezvoltat un descriptor capabil să rețină
geometria contururilor din imagine și relațiile dintre ele, extrăgând apoi câteva proprietăți
statistice ce vor fi asociate imaginii împreună cu histogramele de culori. Imaginile au fost
redimensionate la o dimensiune de maxim 300 de pixeli (pe lungime sau lățime) pentru a scădea
timpul de execuție, iar apoi au fost extrase liniile din imagine folosind un detector de muchii
Canny50
la 4 scalări diferite, fiecare linie fiind caracterizată de un număr de trăsături. În final
imaginea este caracterizată de un vector de 916 elemente (extras în circa 40 de secunde utilizând
un procesor de 2.6 GHz), iar pentru etapa de clasificare autorii au folosit metoda LDA51
(Linear
Discriminant Analysis).
3.3. Concluziile capitolului
În sistemele prezentate în acest capitol, am analizat unele din cele mai bune abordări
propuse până acum în domeniul adnotării automate a imaginilor, pentru a reliefa calitățile sau
defectele acestora și pentru a descrie stadiul actual al cercetărilor din acest domeniu.
49 http://csea.phhp.ufl.edu/media/anewmessage.html 50 http://fourier.eng.hmc.edu/e161/lectures/canny/node1.html 51
http://research.cs.tamu.edu/prism/lectures/pr/pr_l10.pdf

30
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
4. Descrierea sistemului
4.1. Cerințe
Sistemul propus este capabil să adnoteze automat un set de imagini folosind conceptele
definite în secțiunea 1.2, principalul scop al acestuia fiind participarea la ImageCLEF 2012. Baza
de date ImageCLEF 2012 conține 15,000 de imagini de antrenare și 10,000 de imagini de test
(Figura 15) (imagini preluate de pe site-ul de partajare a fotografiilor Flickr52
; imaginile de test și
antrenare constituie un subset al colecției de imagini MIR FLICKR53
). Pentru competiția din
acest an se pot înainta un număr de 5 rulări ale sistemului propus pe setul de imagini de test.
Datele de antrenare au fost lansate de către organizatori cu două luni înaintea termenului-limită
(30.6.2012), iar datele de test cu 6 săptămâni înaintea termenului-limită.
Figura 15: Exemple de imagini de antrenare/test
O altă utilizare pentru acest sistem ar putea fi adnotarea automată a unui set mare de
imagini, utilizare pentru care am propus o arhitectură client-server.
52 http://www.flickr.com/ 53
http://press.liacs.nl/mirflickr/
31
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
4.2. Detalii de implementare
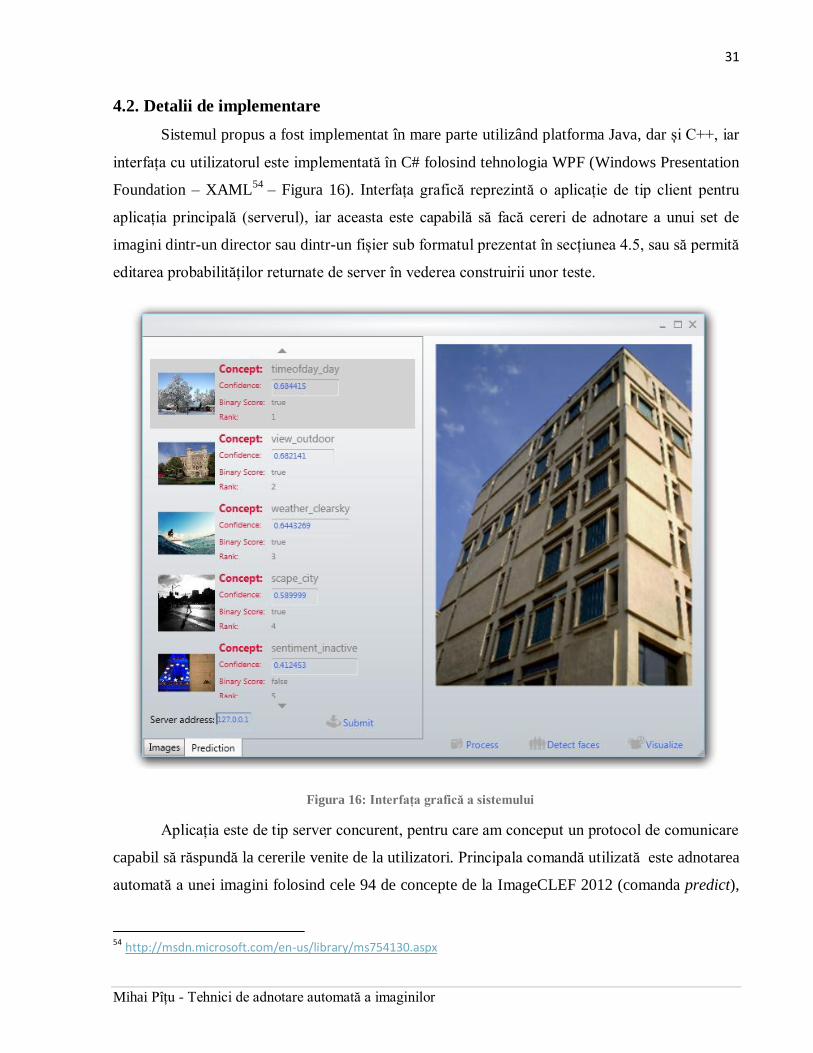
Sistemul propus a fost implementat în mare parte utilizând platforma Java, dar și C++, iar
interfața cu utilizatorul este implementată în C# folosind tehnologia WPF (Windows Presentation
Foundation – XAML54
– Figura 16). Interfața grafică reprezintă o aplicație de tip client pentru
aplicația principală (serverul), iar aceasta este capabilă să facă cereri de adnotare a unui set de
imagini dintr-un director sau dintr-un fișier sub formatul prezentat în secțiunea 4.5, sau să permită
editarea probabilităților returnate de server în vederea construirii unor teste.
Figura 16: Interfața grafică a sistemului
Aplicația este de tip server concurent, pentru care am conceput un protocol de comunicare
capabil să răspundă la cererile venite de la utilizatori. Principala comandă utilizată este adnotarea
automată a unei imagini folosind cele 94 de concepte de la ImageCLEF 2012 (comanda predict),
54
http://msdn.microsoft.com/en-us/library/ms754130.aspx

32
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
însă protocolul suportă și cereri pentru a vizualiza descriptorul Top-Surf (comanda visualize),
cereri pentru detecția fețelor folosind librăria OpenCV55
(comanda facedetection) sau
posibilitatea de a trimite serverului corectări privind adnotarea conceptelor (comanda post).
4.3. Extragerea trăsăturilor imaginilor
Pentru abordarea vizuală, am implementat descriptorul global prezentat formal în
secțiunea 2.1 (Profile Entropy Features), descriptorul local prezentat în secțiunea 2.5 folosind
librăria Top-Surf și descriptorul de culori prezentat în secțiunea 2.7. Extragerea acestor
descriptori se face în aprox. 2 secunde (pe un procesor i7 Turbo Boost: 1.73GHz – 2.88GHz)
Acești descriptori au fost datele de intrare pentru Mașinile cu vectori suport (Support Vector
Machine SVM – secțiunea 2.2). În figura 17 am descris diagrama de pachete a aplicației
principale (serverul), care are o structură modulară, astfel încât se pot adăuga și testa și alți
algoritmi pentru extragerea trăsăturilor imaginilor.
Figura 17: Diagrama de pachete a aplicației principale
55
http://opencv.willowgarage.com/wiki/

33
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Pentru algoritmul de extragere a cuvintelor vizuale (TopSurf) am creat o interfață JNI56
(Java Native Interface) care asigură comunicarea dintre librăria dinamică nativă TopSurf (scrisă
în C++ de B. Thomee57
în 2010) și aplicația Java scrisă de mine. Deoarece librăria necesită un
spațiu relativ mare de adrese de memorie (în testele pentru ImageCLEF 2012 am folosit un
dicționar preconstruit de 300,000 de cuvinte vizuale), am decis să folosesc compilez librăria
dinamică pentru platforma x64. De asemenea, parametrul de redimensionare al imaginilor folosit
în acest sistem este de 512 pixeli și folosesc primele 256 de cuvinte vizuale returnate de
descriptorul TopSurf.
Descriptorul PEF (Profile Entropy Features) a fost implementat de mine după
specificațiile din secțiunea 2.1, în care m-am folosit de librăria JAI58
(Java Advanced Imaging)
pentru acces rapid la pixelii imaginilor.
Pentru algoritmul din secțiunea 2.6 am construit un dicționar de tag-uri definite de
utilizatori cu k=16 (numărul minim de apariții al unui tag în adnotările imaginilor de antrenare)
deoarece acest prag elimină mai multe cuvinte irelevante asociate imaginilor. De asemenea, am
folosit serviciul online Bing Translator59
(serviciu de traduce și detectare a limbilor străine)
deoarece multe dintre tag-urile definite de utilizatori sunt în altă limbă decât engleza (spaniolă,
arabă, etc.). Acest lucru a fost posibil datorită serviciului de detectare a limbii (dacă tag-ul definit
de utilizator este diferit de limba engleză se încearcă traducerea) și existența unei librării60
Java
care implementează protocolul de comunicare cu acest serviciu. După această etapă, am aplicat
un algoritm61
de obținere a rădăcinii cuvântului (en. stemming; de exemplu, tag-urile: stemmer,
stemming, stemmed au ca rădăcină cuvântul stem.) pentru a nu trata diferit tag-urile provenite din
același cuvânt.
Pentru exploatarea coloristicii imaginilor am implementat algoritmul de extragere a
momentelor culorilor (secțiunea 2.7) și am folosit modelul de culori HSV (deoarece în urma
testelor, prin folosirea acestui model se obțin rezultate mai bune), iar pentru funcția de
56 http://java.sun.com/docs/books/jni/ 57 http://www.liacs.nl/~bthomee/ 58
http://java.sun.com/javase/technologies/desktop/media/jai/ 59 http://www.microsofttranslator.com/ 60 http://code.google.com/p/microsoft-translator-java-api/ 61
implementare: http://tartarus.org/~martin/PorterStemmer/java.txt

34
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
similaritate , am folosit (o pondere mai mare pentru
parametrul de nuanță din modelul HSV).
4.4. Clasificarea imaginilor de test
Deoarece cerințele acestui sistem (Figura 17) au fost legate de faptul că o imagine poate fi
adnotată cu mai multe concepte (multi-label classification 62
), am ales să antrenez câte un
clasificator SVM pentru fiecare dintre cele 94 de concepte, iar outputul mașinilor cu vector suport
(SVMs) va fi postprocesat asigurându-se astfel consistența relațiilor dintre adnotările făcute
automat. O altă abordare63
pe care am implementat-o (dar cu rezultate slabe) pentru a rezolva
problema clasificării multi-label a fost următoarea: fiecare combinație de clase găsită în imaginile
de antrenament a fost considerată o singură clasă pentru fiecare din instanțe (imagini care au
aceleași combinații de concepte). Această abordare generează un număr mare de clase
(combinații de concepte), cu un număr mic de instanțe reprezentative pentru fiecare din clasele
respective.
Pentru implementarea mașinilor cu vector suport am folosit librăria Libsvm64
(versiunea
3.11 cu mici modificări pentru a asigura compatibilitatea cu sistemul propus) utilizând kernelul
preconstruit (en. Precomputed) (distanțele dintre imagini se calculează separat) ce necesită
construcția unei matrice Gram65
cu formatul din Tabelul 3:
Pentru un set de date de antrenare de 3 instanțe și un set de date de
test de 1 instanță definite ca în exemplul următor:
15 1:1 2:1 3:1 4:1
45 2:3 4:3
25 3:1
15 1:1 3:1
Dacă se folosește kernelul linear, noile date de antrenare/test vor fi:
62
http://en.wikipedia.org/wiki/Multi-label_classification 63 Abordare inspirată din: http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/multilabel/ 64 http://www.csie.ntu.edu.tw/~cjlin/libsvm/ 65
http://www.encyclopediaofmath.org/index.php/Gram_matrix

35
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
15 0:1 1:4 2:6 3:1
45 0:2 1:6 2:18 3:0
25 0:3 1:1 2:0 3:1
15 0:? 1:2 2:0 3:1
? poate fi orice valoare.
Orice subset al acestor date este de asemenea valid. De exemplu:
25 0:3 1:1 2:0 3:1
45 0:2 1:6 2:18 3:0
Tabelul 3: Formatul libsvm pentru kernel-ul preconstruit, sursa: Libsvm Readme
O funcție kernel (folosită în cazul mașinilor cu vector suport) este o funcție continuă,
simetrică și pozitiv semi-definită (Teorema lui Mercer – Secțiunea 2.2), iar aceasta poate fi
gândită ca o funcție ce descrie apropierea (similaritatea) între două imagini. Pe baza descriptorilor
vizuali descriși mai sus, am propus o funcție kernel ce combină toți cei patru descriptori:
( ) ( ) ( ) ( ) ( )
Unde , (astfel încât ) sunt contribuții pentru
funcțiile kernel:
( ) ( ( ) ( )), sau ( ) ( ( ( ) ( )))
unde este funcția de similaritate cosinus (iar este distanța absolută)
definită în secțiunea 2.5, ( ) este descriptorul TopSurf definit în aceeași secțiune, iar
este parametrul de regularizare. În majoritatea testelor am folosit similaritatea cosinus.
( ) ( ) este kernel-ul RBF ce calculează distanța dintre
descriptorii PEF (secțiunea 2.1).
( ) ( ) ( )
este kernel-ul definit în secțiunea 2.6 ce numără câte tag-uri definite
de utilizatori (asociate imaginilor respectiv, ) sunt partajate, iar rezultatul este
normalizat cu numărul de tag-uri prezente în vocabularul preconstruit.
( ) ( ( )) este kernel-ul bazat pe momentele culorii (secțiunea
2.7), fiind funcția de similaritate din aceași secțiune, iar este parametrul de
regularizare.

36
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Funcțiile , , și (definite pe intervalul ) respectă teorema lui Mercer, deci
respectă de asemenea teorema lui Mercer (necesară pentru a asigura convergența
mașinilor cu vector suport).
O altă problemă întâlnită la setul de imagini de antrenare oferit de organizatorii
ImageCLEF este faptul că numărul de exemple de imagini pentru fiecare concept diferă mult de
la un concept la altul (datele de antrenare nu sunt balansate66
). De exemplu, pentru conceptul
weather_rainbow există 33 de exemple pozitive (din cele 15,000 de imagini), pentru conceptul
fauna_horse există 64 de exemple pozitive, iar în schimb pentru conceptul quantity_none există
10335 de exemple pozitive. Acest lucru îngreunează problema clasificării, din motive evidente.
Pentru a rezolva această problemă am ajustat parametrii de „greutate”67
(en. weights) pentru
conceptul deficient în exemple, însă de asemenea, am implementat o strategie de selectare a
imaginilor de antrenare (en. sampling68
) cu care am îmbunătățit performanțele sistemului –
Tabelul 4.
int mins = smallClass.size();
int maxs = bigClass.size();
int n = maxs / (mins * binFold);
if (n > maxBinFold)
n = maxBinFold;
if (n == 0)
n = 1;
int r = (maxs / n);
for (int j = 0; j < n - 1; j++)
i = sampleOnceBinary(...);
r = maxs - i;
sampleOnceBinary(...);
Tabelul 4: Strategia de sampling. Din întreg setul de imagini de antrenare se aleg ca fiind exemple pozitive cele
adnotate folosind conceptul concept1, restul de imagini fiind considerate exemple negative. Clasa cu numărul
mai mic de exemple este antrenată separat cu m subseturi de exemple din clasa cu numărul mai mare de
exemple. De exemplu, pentru binFold=3, maxBinFold=10, iar numărul total de imagini n=15000, pentru
conceptul quality_partialblur, care are 3549 de exemple, se vor antrena 3 SVM-uri separate, în care exemplele
pozitive sunt cele 3549 de imagini, iar exemplele negative sunt , pe rând, câte 3817 din imaginile rămase.
66 http://www.dice.ucl.ac.be/Proceedings/esann/esannpdf/es2011-29.pdf 67 http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f410 68
http://pages.stern.nyu.edu/~fprovost/Papers/skew.PDF

37
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Pentru a decide prezența unui concept c într-o imagine de test, după ce a fost aplicată
strategia de sampling, toate cele m SVM-uri trebuie să prezică clasa pozitivă (apartenența la clasa
pozitivă), altfel conceptul c nu este prezent în imaginea de test. Aplicarea acestei strategii a fost
posibilă deoarece după calculul matricei Gram, se pot antrena folosind Libsvm și subseturi ale
acestei matrice (Tabelul 2). Astfel, calculul matricei Gram (Tabelul 5) se face o singură dată
(operație costisitoare ca memorie și timp – necesită aprox. 10GB de memorie RAM pentru setul
de antrenament de 15,000 de imagini și aprox. 15 minute pe un procesor i7 Turbo Boost
(frecvența variază între 1.73GHz și 2.8 GHz)).
for (int i = 0; i < allImagesFeatures.size(); i++) {
gramMatrix.y[i] = (double) allImagesFeatures.get(i).getAnnotations();
gramMatrix.x[i][0] = new svm_node();
gramMatrix.x[i][0].index = 0;
gramMatrix.x[i][0].value = i + 1;
gramMatrix.x[i][i + 1] = new svm_node();
gramMatrix.x[i][i + 1].index = i + 1;
gramMatrix.x[i][i + 1].value = compute(allImagesFeatures.get(i),
allImagesFeatures.get(i)); //calculul funcției kernel ( )
for (int j = i + 1; j < gramMatrix.l; j++) {
gramMatrix.x[i][j + 1] = new svm_node();
gramMatrix.x[i][j + 1].index = j + 1;
gramMatrix.x[i][j + 1].value = compute(allImagesFeatures.get(i),
allImagesFeatures.get(j));
//deoarece matricea este simetrică, ( ) ( )
gramMatrix.x[j][i + 1] = new svm_node();
gramMatrix.x[j][i + 1].index = i + 1;
gramMatrix.x[j][i + 1].value = gramMatrix.x[i][j + 1].value;
}
}
Tabelul 5: Calculul matricei Gram.
Deoarece sistemul antrenează separat 94 de SVM-uri pentru fiecare concept, am propus o
implementare concurentă a algoritmului de antrenare, astfel etapa de antrenament se poate
desfășura eficient, folosind mai multe fire de execuție.

38
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
4.5. Postprocesare
Deoarece se antrenează câte un clasificator pentru fiecare concept, există posibilitatea
încălcării regulilor ontologiei de concepte (de exemplu, imaginea de test să fie adnotată simultan
cu quality_noblur, quality_partialblur, concepte care sunt prin definiție, opuse).
Pentru a elimina aceste ambiguități, am implementat un algoritm care construiește, pe
baza adnotărilor imaginilor de antrenament, perechi de concepte exclusive. S-au găsit astfel (în
setul de 15,000 de imagini de antrenament) 879 de combinații de concepte exclusive – concepte
(care apar de 0 ori simultan într-o imagine de antrenament) (de exemplu: quantity_one -
quantity_two, sentiment_melancholic - sentiment_funny, transport_car - transport_water, etc.).
Folosind aceste combinații de concepte exclusive, am eliminat conceptele din setul de predicții
pozitive (returnat de mașinile cu vector suport) astfel: dacă două concepte exclusive
aparțin simultan setului de predicții pozitive și setului de concepte exclusive , conceptul a
cărui încredere (probabilitate) este mai mică decăt a celuilalt concept, este eliminat (îi este setată
o probabilitate sub pragul de încredere (0.5)):
( ) ( ) ( )
Similar, se pot obține concepte ce implică alte concepte. Pentru aceasta, se caută folosind
setul de imagini de antrenament, conceptele a căror apariții implică și apariția altor concepte, în
p% din cazuri (de exemplu, în 90% din cazurile în care apare conceptul scale_mountainhill, va
aparea și conceptul view_outdoor, sau în cazurile în care apare conceptul relation_coworkers, va
aparea și conceptul age_adult). Etapa de postprocesare folosind acest raționament constă în a
adăuga la setul de predicții pozitive (returnat de mașinile cu vector suport) și conceptele
implicate de acestea, asociendu-le o probabilitate apropiată (pentru un concept p mulțimea Imp(p)
este mulțimea de concepte implicate de conceptul p):
( )
O altă etapă de postprocesare aplicată în acest sistem, a fost detecția fețelor de oameni în
imagini (pentru a corecta, eventual, predicția conceptelor ce implică detecția numărului de
persoane: nicio persoană, o persoană, două persoane, trei persoane, grup mic, grup mare, sau dacă
este vorba de o imagine de tip portret). Pentru detecția fețelor (secțiunea 2.8.) am folosit librăria

39
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
OpenCV (implementarea Java69
), deoarece aceasta conține o implementare eficientă a
algoritmului Voila – Jones (timpul de detecție a fețelor într-o imagine de test depinde de
dimensiunea imaginii, însă acest lucru se face în aprox. 300ms, în funcție și de parametrii aleși
pentru algoritm). Algoritmul presupune setarea unui număr de parametrii pe care i-am ales în
funcție de acuratețea cu care s-a detectat fețele oamenilor în urma unor teste pe imaginile de
antrenament. Astfel, pentru parametrul scaleFactor (parametru care scalează ferestrele de scanare
a fețelor) am ales 1.15, pentru parametrul minNeighbors (numărul minim de ferestre de scanare
detectate care alcătuiesc un obiect) am ales 7, iar pentru a respinge regiunile din imagine care
conțin zgomot, am folosit CV_HAAR_DO_CANNY_PRUNING care aplică algoritmul Canny de
detecție liniilor deoarece optimizează procesul de detecție a fețelor. În final, probabilitatea de
apariție a unuia din conceptele enumerate mai sus, este media dintre o probabilitate mare (0.9) de
apariție a conceptului dacă se detectează fețe în imagine și probabilitatea returnată de SVM (de
exemplu, dacă se detectează o singură față în imagine iar probabilitatea returnată de SVM este 0.4
pentru conceptul quantity_one, probabilitatea finală va fi
, iar probabilitatea
celelalte concepte – quantity_none, quantity_two, quantity_three, quantity_smallgroup,
quantity_biggroup, va fi setată sub pragul de încredere 0.5).
4.6. Evaluare
În implementarea mea am căutat parametrii optimali pentru (și
alții) folosind tehnica de grid search70
(căutare exhaustivă într-un subset de parametrii ai unui
algoritm de învățare automată) și cross-validation71
(se împarte setul de antrenament în n părți,
preferabil fiecare parte să conțină un număr proporțional de exemple pozitive și negative, după
care se antrenează clasificatorul folosind n-1 părți, iar cea de-a n parte se testează folosind noul
clasificator, calculându-se în același timp performanța sistemului (acuratețea, f-measure,72
etc.).
Se repetă procedeul astfel încât fiecare dintre cele n părți să fie testate o singură dată. S-a
demonstrat [23] că pentru n=5, n=10, n=20, etc. se calculează, folosind această metodă, o
69
http://code.google.com/p/javacv/ 70 http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf 71 http://www.cs.cmu.edu/~schneide/tut5/node42.html 72
http://trec.nist.gov/pubs/trec15/appendices/CE.MEASURES06.pdf

40
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
valoare a performanței sistemului apropiată de valoarea reală). Pentru evaluarea performanțelor
sistemului, am folosit F-measure (măsură folosită și în evaluarea ImageCLEF 2012):
, unde
Această măsură este folosită frecvent în cazul sistemelor Content-Based Image Retrieval,
variabilele tp (true positives – imaginile relevante returnate de sistem), tn (true negatives –
imaginile corect nereturnate de sistem), fp (false positives – imaginile incorect returnate de
sistem) și fn (false negatives – imaginile relevante nereturnate de sistem) asigură o evaluare
corectă a unui astfel de sistem. Cu toate acestea, deoarece timpul a fost limitat pentru teste, este
posibil ca algoritmul să nu fi găsit soluția optimă (am efectuat rulări cu diferiți parametrii în
decursul a câtorva săptămâni, deoarece pentru a antrena sistemul cu un set de parametrii este
nevoie de aprox. 3 ore (depinde însă de dificultățile numerice întâlnite de SVM), fără a adăuga
timpul de extragere a trăsăturilor imaginilor de antrenament și test (deoarece acest lucru s-a făcut
o singură dată), pe același procesor i7 Turbo Boost cu 12GB de memorie RAM).
Formatul de prezentare al rulărilor este același cu cel folosit la TREC73
, iar acesta este
compus dintr-un singur fișier sub formatul din Tabelul 6:
[identificator imagine] [scor de încredere pentru conceptul 0] [scor binar
pentru conceptul 0] ... [scor de încredere pentru conceptul n-1] [scor binar
pentru conceptul N-1]
Tabelul 6: formatul de prezentare al unei imagini74
Pentru competiția din acest an am alcătuit un număr de 5 rulări, cu următoarele
proprietăți:
submission1: Abordarea a fost în totalitate bazată pe informații vizuale (descriptorii
vizuali folosind contribuțiile: ), cu parametrul
SVM, C=20, același pentru fiecare din cei 94 de clasificatori
submission2: Abordare multi-modală (folosind contribuțiile:
), cu parametrul C diferențiat pentru fiecare concept, iar strategia de
73 http://trec.nist.gov/evals.html 74
http://www.imageclef.org/2012/photo-flickr/annotation

41
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
sampling a fost aplicată la acele concepte a căror performanță a fost mai bună folosind
această strategie, în urma testelor de grid search
submission3:Aceeași abordare ca la submission2, însă strategie de sampling și de
aplicarea a parametrilor de greutate SVM a fost folosită pentru toți clasificatorii
submission4:Abordare multi-modală (folosind contribuțiile:
), cu parametrul C diferențiat pentru fiecare concept și
aplicarea strategiei de sampling
submission5: Abordare multi-modală (folosind contribuțiile:
), cu parametrul C=20, același pentru fiecare clasificator și fără etapa de
postprocesare
În urma experimentelor de grid search efectuate, cele mai bune performanțele ale sistemului
propus au fost în jurul scorului F-measure de 0.53. Aceste performanțe sunt similare cu cele
obținute de sistemele actuale [3] (sistemele din jumătatea superioară a topului alcătuit la
competiția ImageCLEF 2011 Annotation Task). Există concepte pentru care sistemul are rezultate
foarte bune (momentele zilei, vreme, floră, faună, corpuri cerești, etc.) și concepte pentru care
sistemul are rezultate mai puțin bune (relații între persoane, calitatea imaginii, cadru, sentimente,
etc.), lucru explicabil datorită naturii descriptorilor vizuali descriși în această lucrare.
4.7. Concluziile capitolului
În acest capitol am prezentat implementarea și structura sistemului propus, cum s-a
realizat extragerea de trăsături ale imaginilor, combinarea trăsăturilor extrase cu un algoritm de
învățare automată (mașini cu vector suport), algoritmi de postprocesare folosiți pentru a asigura
consistența adnotărilor făcute, precum și evaluarea performanțele obținute.

42
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
5. Contribuții personale, rezultate și direcții de viitor
În sistemul prezentat în această lucrare, am combinat în mod original mai mulți algoritmi
performanți folosiți în sistemele actuale și am obținut rezultate comparabile cu cele din sistemele
existente, contribuția personală majoră fiind agregarea acestor algoritmi cu mașinile cu vector
suport pentru care am definit o funcție kernel capabilă să aprecieze distanța semantică dintre
imagini. Prin participarea la competiția din acest an am dorit să testez diferite abordări (bazate
doar pe informații vizuale sau multi-modale), pentru a constata îmbunătățirea performanțelor
folosind semantica tag-urilor definite de utilizatori, a trăsăturilor locale ale imaginilor (prin
utilizarea descriptorului TopSurf), a coloristicii imaginilor (momentele culorilor), sau a texturii
din imagine (descriptorul PEF).
Acest sistem poate fi extins (datorită structurii modulare a acestuia) cu alți algoritmi de
extragere a trăsăturilor imaginilor, în vederea continuării lucrului și a avansării stadiului
cercetărilor (state-of-the-art) în domeniul Computer Vision. O altă abordare care ar putea avea
succes, ar fi folosirea diferențiată a setărilor parametrilor de contribuție pentru kernelul SVM
, în funcție de conceptul pentru care se antrenează clasificatorul (de
exemplu, pentru conceptele ce exprimă sentimente se intuiește o pondere mai mare a coloristicii
imaginilor, pentru concepte panoramice, o pondere mai mare pentru descriptorul de textură, etc.).
În acest sistem am implementat această abordare, însă aceasta nu a putut fi testată riguros din
cauza limitărilor tehnice (memorie RAM). De asemenea, această aplicație ar putea fi folosită de
utilizatorii ce doresc să adnoteze colecții mari de imagini, ușurând problema regăsirii imaginilor
într-o bază de date.

43
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
Bibliografie
[1] S. Tong, E. Chang. “Support vector machine active learning for image retrieval”, 2001
[2] J. Russell. “A Circumplex Model of Affect”, 1980
[3] S. Nowak, K. Nagel, J. Liebetrau. “The CLEF 2011 Photo Annotation and Concept-based
Retrieval Tasks”, 2011
[4] H. Glotin, Z.Q. Zhao, S. Ayache. “Efficient Image Concept Indexing by Harmonic &
Arithmetic Profiles Entropy”, 2009
[5] R. Moddemeijer. “On estimation of entropy and mutual information of continuous
distributions”, 1989
[6] C. Nello, J. Shawe-Taylor. “An Introduction to Support Vector Machines and other kernel-
based learning methods”, 2000
[7] A. Gidudu, G. Hulley, T. Marwala. “Image Classification Using SVMs: One-against-One Vs.
One-against-All”, 2007
[8] C. Evans, “Notes on the OpenSURF Library”, 2009
[9] H. Bay, A. Ess, T. Tuytelaars, L. Van Gool. “Speeded-up robust features (SURF). Computer
Vision and Image Understanding”, 2008
[10] G. Csurka, C. Dance, L. Fan, J. Willamowski, C. Bray, “Visual Categorization with Bags of
Keypoints”, 2004
[11] G. Salton, M. McGill. “Introduction to modern information retrieval”, 1983
[12] A. Znaidia, H. Le Borgne. “CEA LISTs participation to Visual Concept Detection Task of
ImageCLEF”, 2011
[13] M. Guillaumin, J. Verbeek, C. Schmid. “Multimodal semi-supervised learning for image
classication.”, 2010
[14] K. van de Sande, T. Gevers, A. Smeulders. “The University of Amsterdam’s Concept
Detection System at ImageCLEF 2009”, 2009
[15] A. Binder, W. Samek, M. Kawanabe. “The joint submission of the TU Berlin and Fraunhofer
FIRST (TUBFI) to the ImageCLEF2011 Photo Annotation Task”, 2011
[16] M. Stricker, M. Orengo, “Similarity of color images“, 1995
[17] P. Viola, M. Jones. “Rapid object detection using boosted cascade of simple features”, 2001

44
Mihai Pîțu - Tehnici de adnotare automată a imaginilor
[18] A. Iftene, L. Vamanu, C. Croitor. “UAIC at ImageCLEF 2009 Photo Annotation Task”,
2009
[19] H. Glotin, A. Fakeri-Tabrizi, P. Mulhem, M. Ferecatu. “Comparison of Various AVEIR
Visual Concept Detectors with an Index of Carefulness”, 2009
[20] J. Ah-Pine1, S. Clinchant, G. Csurka, Y. Liu. “XRCE’s Participation in ImageCLEF”, 2009
[21] N. Liu, Y. Zhang, E. Dellandrea, S. Bres, L. Chen. “LIRIS-Imagine at ImageCLEF 2011
Photo Annotation task”, 2011
[22] C. Rasche, C. Vertan. „Testing a method for statistical image classification in image
retrieval”, 2011
[23] I. Witten, E. Frank, M. Hall. “Data Mining – Practical Machine Learning Tools and
Techniques, Third Edition”, 2011
[24] B. Thomee, E. Bakker, M. Lew. “Top-Surf: A visual words toolkit”, 2010
[25] T. Tuytelaars, K. Mikolajczyk. “Local Invariant Feature Detectors: A Survey”, 2008
[26] J. van Gemert, C. Snoek, C. Veenman, A. Smeulders, J.M. Geusebroek. “Comparing
Compact Codebooks for Visual Categorization”, 2008