unsupervised lexicon-based resolution of unknown words for full morphological analysis meni adler,...
Post on 18-Dec-2015
215 views
TRANSCRIPT

Unsupervised Lexicon-Based Resolution of Unknown Words for Full Morphological AnalysisMeni Adler, Yoav Goldberg, David Gabay, Michael Elhadad
Ben-Gurion University
ACL 2008, Columbus, Ohio

Unknown Words - English
The draje of the tagement starts rikking with Befa.
Morphologyunknown word analysis1 prob1
…
analysisn probn
analysisi probi
Syntax
Motivation

Unknown Words - English
The draje of the tagement starts rikking with Befa.
Morphology tagement, rikking, Befa
Syntax: The draje of the tagement starts rikking with Befa.
Motivation

Unknowns Resolution Method in English Baseline Method
PN tag for capitalized words Uniform distribution over open-class tags
Evaluation 12 open-class tags 45% of capitalized unknowns Overall, 70% of the unknowns were tagged
correctly
Motivation

Unknowns Resolution Method in Hebrew
The baseline method resolves:
only 5% of the Hebrew unknown tokens!
Why?
How can we improve?
Motivation

Unknown Words - Hebrew
The draje of the tagement starts rikking with Befa.
עם בפה דרג הטגמנט התחיל לנפן
drj htgmnt hthil lnpn `m bfh
Motivation

Unknown Words - Hebrew
drj htgmnt hthil lngn `m bfh Morphology
No capitalization: PN always candidate Many open-class tags (> 3,000)
Syntax Unmarked function words
preposition, definite article, conjunction, pronominal pronoun. the drj of drj
Function words ambiguity htgmnt: VBP/VBI, DEF+MM `m: PREP (with), NN (people) bfh: PREP+NN/PN/JJ/VB, PREP+DEF+NN/JJ…
Motivation

Outline
Characteristics of Hebrew Unknowns Previous Work Unsupervised Lexicon-based Approaches
Letters Model Pattern Model Linear-context Model
Evaluation Conclusion
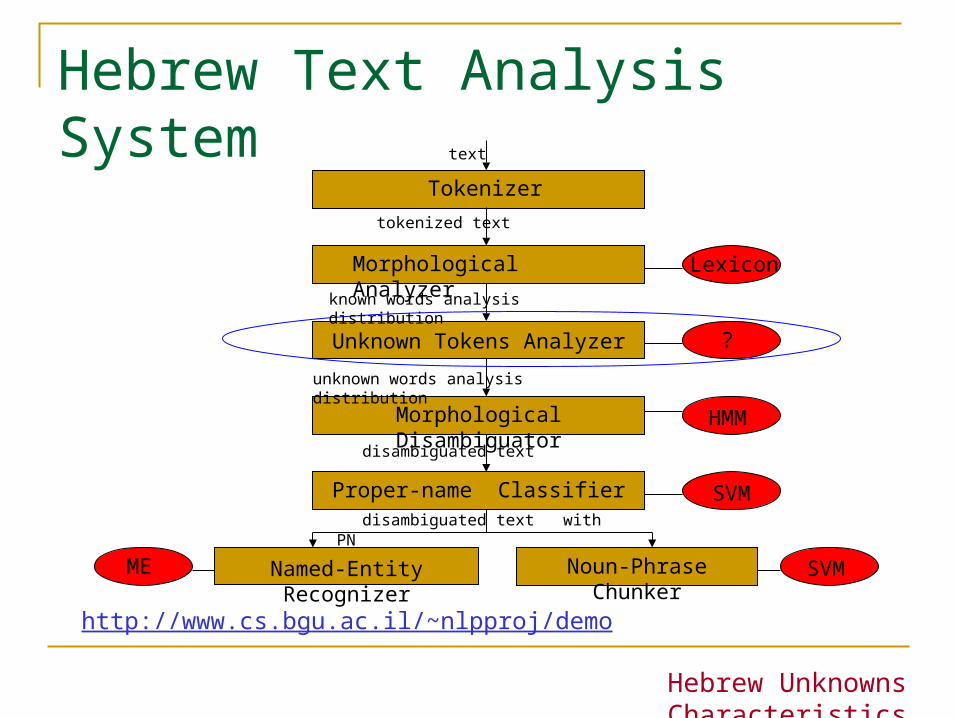
Hebrew Text Analysis System
Hebrew Unknowns Characteristics
Unknown Tokens Analyzer
Tokenizer
Morphological Analyzer
Morphological Disambiguator
Proper-name Classifier
Named-Entity Recognizer Noun-Phrase Chunker SVMME
Lexicon
SVM
HMM
?
http://www.cs.bgu.ac.il/~nlpproj/demo
text
tokenized text
known words analysis distribution
unknown words analysis distribution
disambiguated text
disambiguated text with PN

Hebrew Unknowns
Unknown tokens Tokens which are not recognized by the lexicon
NN: פרזנטור (presenter) VB: התחרדן (got warm under the sun)
Unknown analyses The set of analyses suggested by the lexicon does not
contain the correct analysis for a given token PN: שמעון פרס (Shimon Peres, that a dorm
cut…) RB: לעומתי (opposition, compared with me)
Hebrew Unknowns Characteristics

Hebrew Unknowns - Evidence Unknown Tokens (4%)
Only 50% of the unknown tokens are PN Selection of default PN POS is not sufficient More than 30% of the unknown tokens are Neologism Neologism detection
Unknown Analyses (3.5%) 60% of the unknown analyses are proper name Other POS cover 15% of the unknowns (only 1.1% of
the tokens) PN classifier is sufficient for unknown analyses
Hebrew Unknowns Characteristics

Hebrew Unknown Tokens Analysis Objectives
Given an unknown token, extract all possible morphological analyses, and assign likelihood for each analysis
Example: (got warm in the sun) התחרדן
verb.singular.masculine.third.past 0.6 Proper noun 0.2 noun.def.singular.masculine 0.1 noun.singular.masculine.absolute 0.05 noun.singular.masculine.construct 0.001 …
Hebrew Unknowns Characteristics

Previous Work - English
Heuristics [Weischedel et al. 95]
Tag-specific heuristics Spelling features: capitalization, hyphens, suffixes
Guessing rules learned from raw text [Mikheev 97]
HMM with tag-suffix transitions [Thede & Harper 99]
Previous Work

Previous Work - Arabic
Root-pattern-features for morphological analysis and generation of Arabic dialects [Habash & Rambow 06]
Combination of lexicon-based and character-based tagger [Mansour et al. 07]
Previous Work

Our Approach
Resources A large amount of unlabeled data (unsupervised) A comprehensive lexicon (lexicon-based)
Hypothesis Characteristics of unknown tokens are similar to known tokens
Method Tag distribution model, based on morphological analysis of the
known tokens in the corpus:
Letters model Pattern model Linear-context model
Unsupervised Lexicon-based Approach

Notation
Token A sequence of characters bounded with spaces
bcl בצל
Prefixes The prefixes according to each analysis
Preposition+noun (under a shadow): ב b
Base-word Token without prefixes (for each analysis)
Noun (an onion) בצל bcl Preposition+noun (under a shadow): צל cl
Unsupervised Lexicon-based Approach

Letters Model
For each possible analyses of a given token: Features
Positioned uni-, bi- and trigram letters of the base-word The prefixes of the base-word The length of the base-word
Value A full set of the morphological properties (as given by the
lexicon)
Unsupervised Lexicon-based Approach
Raw-text corpus
Lexicon
ME Letters Model

Letters Model – An example
Known token: בצל bcl Analyses
An onion Base-word: bcl Features
Grams: b:1 c:2 l:3 b:-3 c:-2 l:-1 bc:1 cl:2 bc:-2 cl:-1 bcl:1 bcl:-1 Prefix: none Length of base-word: 3
Value noun.singular.masculine.absolute
Under a shadow Features
Grams: c:1 l:2 c:-1 l:-2 cl:1 cl:-1 Prefix: b Length of base-word: 2
Value preposition+noun.singular.masculine.absolute
Unsupervised Lexicon-based Approach

Pattern Model
Word formation in Hebrew is based on root+template and/or affixation.
Based on [Nir 93], we defined 40 common neologism formation patterns, e.g. Verb
Template: miCCeC מחזר, tiCCeC תארך Noun
Suffixation: ut שיפוטיות, iya בידוריה Template: tiCCoCet תפרוסת, miCCaCa מגננה
Adjective Suffixation: ali סטודנטיאלי, oni טלויזיוני
Adverb Suffixation: it לעומתית
Unsupervised Lexicon-based Approach

Pattern Model
For each possible analyses of a given token: Features
For each pattern, 1 – if the token fits the pattern, 0- otherwise ‘no pattern’ feature
Value A full set of the morphological properties (as given by the
lexicon)
Unsupervised Lexicon-based Approach
Raw-text corpus
Lexicon
ME Pattern Model
Patterns
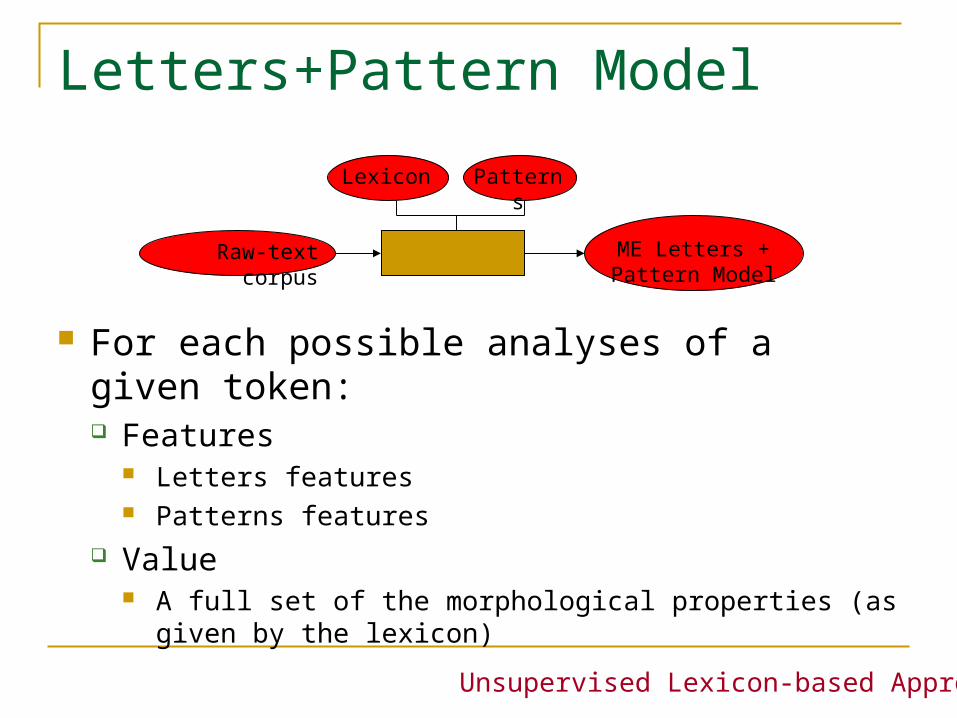
Letters+Pattern Model
For each possible analyses of a given token: Features
Letters features Patterns features
Value A full set of the morphological properties (as given by
the lexicon)
Unsupervised Lexicon-based Approach
Raw-text corpus
Lexicon
ME Letters + Pattern Model
Patterns

Linear-context ModelThe draje of the tagement starts rikking with Befa.
P(t|w) is hard to estimate for unknown tokens P(noun| draje), P(adjective| draje), P(verb| draje)
Alternatively, P(t|c), can be learned for known contexts P(noun| The, of), P(adjective| The, of), P(verb| The, of)
Observed Context Information Lexical distribution
Word given context P(w|c) - P(drage|The,of) Context given word P(c|w) - P(The, of | drage) Relative frequencies over all the words in the corpus
Morpho-lexical distribution of known tokens P(t|wi), - P(determiner|The)…, P(preposition|of)… Similar words alg. [Levinger et al. 95] [Adler 07] [Goldberg et al. 08]
Unsupervised Lexicon-based Approach

Linear-context Model
Expectation
Unsupervised Lexicon-based Approach
Notation: w – known word, c – context of a known word, t - tag
Initial Conditions
raw-text corpus p(w|c), p(c|w)
lexicon p(t|w)
Maximization
p(t|c) =
∑wp(t|w)p(w|c)
p(t|w) =
∑cp(t|c)p(c|w)

Evaluation
Resources Lexicon: MILA Corpus
Train: unlabeled 42M tokens corpus Test: annotated news articles of 90K token
instances (3% unknown tokens, 2% unknown analyses)
PN Classifier
Evaluation

Evaluation - Models
Baseline Most frequent tag - proper name - for all possible
segmentations of the token Letters model Pattern model Letters + Pattern model Letters, Linear-context Pattern, Linear-context Letters + Pattern, Linear-context
Evaluation

Evaluation - Criteria
Suggested Analysis Set Coverage of correct analysis Ambiguity level (average number of analyses) Average probability of correct analysis
Disambiguation accuracy Number of correct analyses, picked in the complete
system

Evaluation – Full Morphological Analysis
ModelAnalysis SetFull
Morph CoverageAmbiguityProbability
Baseline50.81.50.4857.3
Letters76.75.90.3269.1
Pattern82.820.40.166.8
Letters + Pattern84.110.40.2569.8
Linear-context, Letters80.77.940.3069.7
Linear-context, Pattern84.421.70.1266.5
Linear-context, Letters + Pattern
85.2120.2468.8
Evaluation

Evaluation – Word Segmentation and POS Tagging
ModelAnalysis SetSEG
POS CoverageAmbiguityProbability
Baseline52.91.50.5260.6
Letters8040.3977.6
Pattern87.48.70.1976
Letters+Pattern86.76.20.3278.5
Linear-context, Letters83.84.50.3778.2
Linear-context, Pattern88.78.80.2175.8
Linear-context, Letter+Pattern
87.86.50.3277.5
Evaluation

Evaluation - Conclusion
Error reduction > 30% over a competitive baseline, for a large-scale dataset of 90K tokens Full morphological disambiguation: 79% accuracy Word segmentation and POS tagging: 70% accuracy
Unsupervised linear-context model is as effective as a model which uses hand-crafted patterns
Effective combination of textual observation from unlabeled data and lexicon
Effective combination of ME model for tag distribution and SVM model for PN classification
Overall, error reduction of 5% for the whole disambiguation system
Evaluation

Summary
The characteristics of known words can help resolve unknown words
Unsupervised (unlabeled data) lexicon-based approach
Language independent algorithm for computing the distribution p(t|w) for unknown words
Nature of agglutinated prefixes in Hebrew [Ben-Eliahu et al. 2008]

tnqs (thanks) תנקס foreign 0.4 propernoun 0.3 noun.plural.feminine.absolute 0.2 verb.singular.feminine.3.future 0.08 verb.singular.masculine.2.future 0.02