user's guide to websphere extreme scale -...
TRANSCRIPT

ibm.com/redbooks
User’s Guide to WebSphere eXtreme Scale
Daniel FroehlichNitin Gaur
Jonathan MarshallJohn Pape
Jennifer Zorza
Topology design and sizing
Application scenarios
JPA for data access
Front cover


User’s Guide to WebSphere eXtreme Scale
December 2008
International Technical Support Organization
SG24-7683-00

© Copyright International Business Machines Corporation 2008. All rights reserved.Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADPSchedule Contract with IBM Corp.
First Edition (December 2008)
This edition applies to WebSphere eXtreme Scale Version 6.1.
Note: Before using this information and the product it supports, read the information in “Notices” on page ix.

Contents
Notices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ixTrademarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
Preface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiThe team who wrote this book . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiBecome a published author . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiiiComments welcome. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii
Chapter 1. Introduction to WebSphere eXtreme Scale . . . . . . . . . . . . . . . . 11.1 The scalability challenge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Caches and a data grid as a solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Introduction to WebSphere eXtreme Scale . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.1 Transaction support . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3.2 Securability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.3 Extreme scalability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.4 High availability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4 Implementing WebSphere eXtreme Scale . . . . . . . . . . . . . . . . . . . . . . . . . 91.4.1 Possible entry points . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4.2 WebSphere eXtreme Scale decision tree . . . . . . . . . . . . . . . . . . . . . 10
1.5 Explaining the names—product evolution . . . . . . . . . . . . . . . . . . . . . . . . . 131.6 Comparing eXtreme Scale to in-memory databases. . . . . . . . . . . . . . . . . 15
1.6.1 Introducing IMDBs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.6.2 Explaining the difference. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Chapter 2. WebSphere eXtreme Scale architecture and topologies. . . . . 192.1 WebSphere eXtreme Scale architecture . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.1.1 Grid architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.1.2 WebSphere eXtreme Scale internal components . . . . . . . . . . . . . . . 232.1.3 Grid clients and servers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.1.4 WebSphere eXtreme Scale meta model . . . . . . . . . . . . . . . . . . . . . . 26
2.2 Catalog server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.2.1 Shard placement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.3 APIs used to access the grid. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.3.1 ObjectMap API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.3.2 EntityManager API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.4 A simple example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.5 Zones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.5.1 Zone-based routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.6 Scalability sizing considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
© Copyright IBM Corp. 2008. All rights reserved. iii

2.7 Common topology configurations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.7.1 Managed grid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.7.2 Stand-alone grid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.7.3 Local cache topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442.7.4 Collocated application and cache topology. . . . . . . . . . . . . . . . . . . . 442.7.5 Distributed cache topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452.7.6 Zone-based topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
Chapter 3. Application scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.1 Introducing the scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.1.1 Presenting a generic application architecture . . . . . . . . . . . . . . . . . . 503.1.2 Introducing the scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.1.3 Scenario characteristics overview. . . . . . . . . . . . . . . . . . . . . . . . . . . 563.1.4 Scenario descriptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.2 Side cache scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573.2.1 Variations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.2.2 Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.2.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.2.4 Topologies. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.3 Second level cache scenario. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.3.1 Variations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.3.2 Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.3.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.3.4 Topologies. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.4 Data access layer scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.4.1 Variations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.4.2 Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.4.3 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.4.4 Topologies. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.5 DataGrid computing scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.5.1 Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 663.5.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 663.5.3 Topologies. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.6 Dealing with stale caches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.6.1 Simply tolerate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 713.6.2 Use time-based eviction strategies . . . . . . . . . . . . . . . . . . . . . . . . . . 713.6.3 Cache polls the database for updates in regular intervals . . . . . . . . 713.6.4 Use JMS publish/subscribe to propagate changes . . . . . . . . . . . . . . 723.6.5 Make sure no external changes to the backing store occur . . . . . . . 753.6.6 Make sure all external change processes notify the grid . . . . . . . . . 753.6.7 Push the changes from the back end store up to the grid. . . . . . . . . 76
Chapter 4. Query engine. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
iv User’s Guide to WebSphere eXtreme Scale

4.1 Introducing Object Grid Query Language . . . . . . . . . . . . . . . . . . . . . . . . . 804.2 Considerations when using queries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.3 Translating SQL to OGQL examples. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
Chapter 5. eXtreme Scale in a Network Deployment environment . . . . . . 875.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.1.1 Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.1.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 915.1.3 Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.2 Introducing the sample application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.2.1 The problems solved. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.2.2 Application architecture and design . . . . . . . . . . . . . . . . . . . . . . . . . 945.2.3 Application component model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 945.2.4 Component details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.3 Introducing the sample topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 985.3.1 Operational model. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 985.3.2 Grid topology. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.4 Creating the sample topology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1015.4.1 Installing the products . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1015.4.2 Configuring the runtime environment . . . . . . . . . . . . . . . . . . . . . . . 109
5.5 The sample application in action . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1175.5.1 Explaining the code. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1175.5.2 Monitoring the grid while preloading . . . . . . . . . . . . . . . . . . . . . . . . 121
Chapter 6. eXtreme Scale in a stand-alone environment . . . . . . . . . . . . 1236.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.1.1 Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1246.1.2 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.2 Configuring the lab environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1266.2.1 Reviewing the selected topology. . . . . . . . . . . . . . . . . . . . . . . . . . . 1266.2.2 Installation of the product . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1266.2.3 Post-installation procedure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
6.3 Example scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1296.3.1 Configuring the grid as a simple side cache . . . . . . . . . . . . . . . . . . 1306.3.2 Configuring the grid as an extension of another grid . . . . . . . . . . . 139
Chapter 7. Using WebSphere eXtreme Scale with JPA . . . . . . . . . . . . . . 1477.1 Java Persistence API introduction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1487.2 WebSphere eXtreme Scale support for JPA . . . . . . . . . . . . . . . . . . . . . . 149
7.2.1 Using JPA for data access in WebSphere eXtreme Scale . . . . . . . 1517.2.2 Using WebSphere eXtreme Scale as a JPA cache . . . . . . . . . . . . 153
7.3 JPA data access with the sample application . . . . . . . . . . . . . . . . . . . . . 1557.4 Setting up the JPA Loader . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
7.4.1 Configure the sample application to use the JPAEntityLoader . . . . 158
Contents v

7.4.2 Enabling write-behind for the JPA Loader. . . . . . . . . . . . . . . . . . . . 1627.5 Setting up the time-based updater . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
7.5.1 Configuring the database with a timestamp field . . . . . . . . . . . . . . 1677.5.2 Update the JPA entity with a timestamp field . . . . . . . . . . . . . . . . . 1687.5.3 Add the time-based updater to the grid configuration . . . . . . . . . . . 168
7.6 Using the Client Loader in the sample application . . . . . . . . . . . . . . . . . 1707.7 Setting up eXtreme Scale as a JPA cache . . . . . . . . . . . . . . . . . . . . . . . 174
7.7.1 Steps to enable JPA caching with WebSphere eXtreme Scale . . . 1767.7.2 Configuration options for the eXtreme Scale cache . . . . . . . . . . . . 1787.7.3 Advanced eXtreme Scale configuration for the cache . . . . . . . . . . 1817.7.4 Monitoring the cache. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1837.7.5 Options for cache invalidation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
8.1 Using eXtreme Scale without application change . . . . . . . . . . . . . . . . . . 1888.2 HTTP session management overview. . . . . . . . . . . . . . . . . . . . . . . . . . . 188
8.2.1 HTTP session replication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1888.2.2 Extending HTTP session management with eXtreme Scale. . . . . . 1898.2.3 What benefits does eXtreme Scale provide? . . . . . . . . . . . . . . . . . 192
8.3 Introducing the example scenarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1938.4 Example: Setting up the application . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
8.4.1 Running addObjectgridSessionFilter. . . . . . . . . . . . . . . . . . . . . . . . 1948.5 Example: Using a collocated HTTP session store . . . . . . . . . . . . . . . . . 196
8.5.1 Understanding the grid configuration . . . . . . . . . . . . . . . . . . . . . . . 1988.5.2 Configuring the application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2008.5.3 Running the application. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
8.6 Example: Using a remote HTTP session store . . . . . . . . . . . . . . . . . . . . 2038.6.1 Understanding the grid configuration . . . . . . . . . . . . . . . . . . . . . . . 2048.6.2 Configuring the application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2048.6.3 Running the application. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
8.7 Configuration of the HTTP session management . . . . . . . . . . . . . . . . . . 2058.7.1 Configuring session management behavior . . . . . . . . . . . . . . . . . . 2068.7.2 Understanding the sample grid definitions . . . . . . . . . . . . . . . . . . . 207
8.8 Advanced profile and session data management . . . . . . . . . . . . . . . . . . 2118.8.1 Relevant terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2118.8.2 SessionHandle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2118.8.3 Why use SessionHandle? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2128.8.4 Native partitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2128.8.5 How to use SessionHandle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2138.8.6 Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
Appendix A. Loading and running the sample application . . . . . . . . . . . 215
vi User’s Guide to WebSphere eXtreme Scale

Installation concepts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216Using Rational Application Developer for testing . . . . . . . . . . . . . . . . . . . . . . 216An alternate test environment configuration. . . . . . . . . . . . . . . . . . . . . . . . . . 218
Appendix B. Setting up the database . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221Installing DB2 UDB V9.5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222Creating the database and tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222Defining the JDBC provider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224Creating the JDBC data source . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
Appendix C. Additional material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229Locating the Web material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229Using the Web material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
How to use the Web material . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
Related publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231IBM Redbooks publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231Online resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231How to get Redbooks publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233Help from IBM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
Contents vii

viii User’s Guide to WebSphere eXtreme Scale

Notices
This information was developed for products and services offered in the U.S.A.
IBM may not offer the products, services, or features discussed in this document in other countries. Consult your local IBM representative for information on the products and services currently available in your area. Any reference to an IBM product, program, or service is not intended to state or imply that only that IBM product, program, or service may be used. Any functionally equivalent product, program, or service that does not infringe any IBM intellectual property right may be used instead. However, it is the user's responsibility to evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in this document. The furnishing of this document does not give you any license to these patents. You can send license inquiries, in writing, to: IBM Director of Licensing, IBM Corporation, North Castle Drive, Armonk, NY 10504-1785 U.S.A.
The following paragraph does not apply to the United Kingdom or any other country where such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you.
This information could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. IBM may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time without notice.
Any references in this information to non-IBM Web sites are provided for convenience only and do not in any manner serve as an endorsement of those Web sites. The materials at those Web sites are not part of the materials for this IBM product and use of those Web sites is at your own risk.
IBM may use or distribute any of the information you supply in any way it believes appropriate without incurring any obligation to you.
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products.
This information contains examples of data and reports used in daily business operations. To illustrate them as completely as possible, the examples include the names of individuals, companies, brands, and products. All of these names are fictitious and any similarity to the names and addresses used by an actual business enterprise is entirely coincidental.
COPYRIGHT LICENSE:
This information contains sample application programs in source language, which illustrate programming techniques on various operating platforms. You may copy, modify, and distribute these sample programs in any form without payment to IBM, for the purposes of developing, using, marketing or distributing application programs conforming to the application programming interface for the operating platform for which the sample programs are written. These examples have not been thoroughly tested under all conditions. IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these programs.
© Copyright IBM Corp. 2009. All rights reserved. ix

Trademarks
IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. These and other IBM trademarked terms are marked on their first occurrence in this information with the appropriate symbol (® or ™), indicating US registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at http://www.ibm.com/legal/copytrade.shtml
The following terms are trademarks of the International Business Machines Corporation in the United States, other countries, or both:
DB2®developerWorks®eServer™IBM®
Rational®Redbooks®Redbooks (logo) ®Tivoli®
WebSphere®xSeries®z/OS®
The following terms are trademarks of other companies:
Oracle, JD Edwards, PeopleSoft, Siebel, and TopLink are registered trademarks of Oracle Corporation and/or its affiliates.
Hibernate, JBoss, and the Shadowman logo are trademarks or registered trademarks of Red Hat, Inc. in the U.S. and other countries.
EJB, J2EE, J2SE, Java, Java runtime environment, JavaServer, JDBC, JDK, JMX, JRE, JSP, JVM, and all Java-based trademarks are trademarks of Sun Microsystems, Inc. in the United States, other countries, or both.
Windows, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Linux is a trademark of Linus Torvalds in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.
x User’s Guide to WebSphere eXtreme Scale

Preface
WebSphere® eXtreme Scale provides a solution to scalability issues through caching and grid technology. It provides an enhanced quality of service in high performance computing environments.
This IBM® Redbooks® publication, User’s Guide to WebSphere eXtreme Scale, introduces WebSphere eXtreme Scale V6.1 and shows how to set up and use an eXtreme Scale environment. It begins with a discussion of the issues that would lead you to an eXtreme Scale solution. It then describes the architecture of eXtreme Scale to help you understand how the product works. It provides information about potential grid topologies, the APIs used by applications to access the grid, and application scenarios that explain how to effectively use the grid.
This book is intended for architects and implementers who want to implement WebSphere eXtreme Scale.
The team who wrote this book
This book was produced by a team of specialists from around the world working at the International Technical Support Organization (ITSO), Raleigh Center.
Daniel Froehlich is a Senior IT Architect with IBM Software Services for WebSphere, located in Germany. He has 18 years of experience in the application development field. His area of expertise include application architecture and performance management of mission critical business applications based on the IBM WebSphere product family. He holds a degree in Computer Science from RWTH Aachen University of Technology.
Nitin Gaur is Senior WebSphere IT Specialist with the IBM TechWorks Organization. Prior to teaming with TechWorks, Nitin spent several years with the WebSphere OEM and support team. In his nine years with IBM he has achieved an array of industry recognized certifications. As a technical leader he has been involved in writing various technical papers, industry journal articles and presentations at industry conferences. The range of the topics span from software architectures to improvement of management processes. He has written extensively on application virtualization, enterprise problem determination methodology, WebSphere Application Server, WebSphere Extended Deployment
© Copyright IBM Corp. 2008. All rights reserved. xi

best practices, and stack product integration with WebSphere Extended Deployment. Nitin lives in Austin, TX.
Jonathan Marshall is a Senior IT Specialist working in the UK as a WebSphere Technical Sales Specialist. He has 8 years of experience in IBM with WebSphere Application Server and related products. His areas of expertise include WebSphere Application Server, WebSphere Extended Deployment, WebSphere ESB and WebSphere Process Server. He has previously written developerWorks® articles including one on WebSphere eXtreme Scale. He holds a degree in Computer Science from the University of Warwick.
John Pape is an advisory software engineer in the United States. He has eight years of experience in WebSphere Application Server field; three of which with IBM. His areas of expertise include WebSphere Application Server, WebSphere Extended Deployment, and the Java™ Virtual Machine. He currently works with the WebSphere SWAT team. He holds a degree in Management Information Systems.
Jennifer Zorza is a WebSphere Product Introduction Specialist with the IBM Customer Programs team working in New York City. She has over six years of experience with WebSphere products on all platforms, including z/OS®. She earned her BS in Computer Science from the University of Michigan and her MBA from New York University- Stern School of Business.
Thanks to the following people for their contributions to this project:
Carla SadtlerInternational Technical Support Organization, Raleigh Center
Michael SchmittIBM Rochester
Kristi PetersonIBM Rochester
Art JolinIBM Raleigh
Chris D. JohnsonIBM Rochester
Joshua Dettinger IBM Rochester
Cheng-chieh (Jerry) ChengIBM Rochester
xii User’s Guide to WebSphere eXtreme Scale

Hendrik van RunIBM UK
Billy NewportIBM Rochester
Hao WangIBM Rochester
Become a published author
Join us for a two- to six-week residency program! Help write a book dealing with specific products or solutions, while getting hands-on experience with leading-edge technologies. You will have the opportunity to team with IBM technical professionals, Business Partners, and Clients.
Your efforts will help increase product acceptance and customer satisfaction. As a bonus, you will develop a network of contacts in IBM development labs, and increase your productivity and marketability.
Find out more about the residency program, browse the residency index, and apply online at:
ibm.com/redbooks/residencies.html
Comments welcome
Your comments are important to us!
We want our books to be as helpful as possible. Send us your comments about this book or other IBM Redbooks in one of the following ways:
� Use the online Contact us review Redbooks form found at:
ibm.com/redbooks
� Send your comments in an e-mail to:
� Mail your comments to:
IBM Corporation, International Technical Support OrganizationDept. HYTD Mail Station P0992455 South RoadPoughkeepsie, NY 12601-5400
Preface xiii

xiv User’s Guide to WebSphere eXtreme Scale

Chapter 1. Introduction to WebSphere eXtreme Scale
The IBM WebSphere eXtreme Scale product provides a high-performance, scalable cache framework. This chapter is an introduction to WebSphere eXtreme Scale.
We begin by explaining scalability challenges that exist in today’s environment and how WebSphere eXtreme Scale addresses this challenge. Then we show how caching and grid technologies can help to resolve this challenge. We continue with the introduction of WebSphere eXtreme Scale and the key features of the product. We then provide suggestions for how WebSphere eXtreme Scale can be implemented through possible entry points and a decision tree for adoption. We close this chapter with a brief discussion of the product history and a comparison of WebSphere eXtreme Scale to in-memory databases.
This chapter includes the following topics:
� “The scalability challenge” on page 2� “Caches and a data grid as a solution” on page 4� “Introduction to WebSphere eXtreme Scale” on page 6� “Implementing WebSphere eXtreme Scale” on page 9� “Explaining the names—product evolution” on page 13� “Comparing eXtreme Scale to in-memory databases” on page 15
1
© Copyright IBM Corp. 2008. All rights reserved. 1
1.1 The scalability challenge
In order to understand the scalability challenge addressed by WebSphere eXtreme Scale, let us first define and understand scalability. Scalability is the ability of a system to handle increasing load in a graceful manner. This implies that a system can be readily extended. For example, a system has linear scaling capabilities so that doubling the CPU capacity also doubles the maximum throughput that the system can handle. In general, there are two ways an IT system can be scaled:
� Horizontally, by adding additional hosts to a tier. This is also called scale out.
� Vertically, by enlarging the capabilities of a single system. For example, adding CPUs. This is also called scale up.
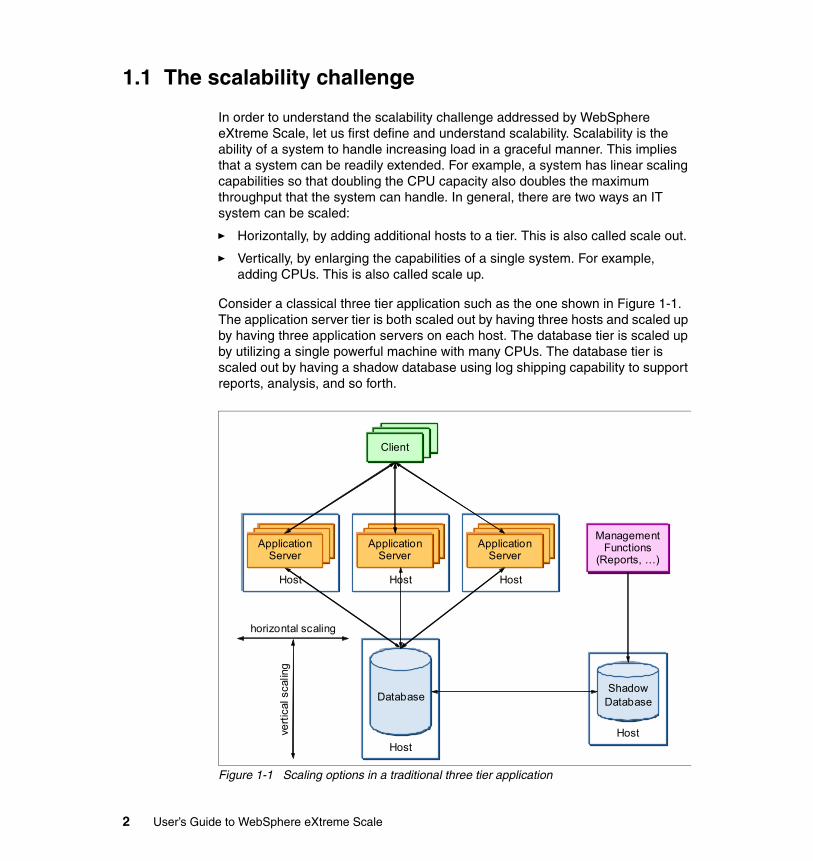
Consider a classical three tier application such as the one shown in Figure 1-1. The application server tier is both scaled out by having three hosts and scaled up by having three application servers on each host. The database tier is scaled up by utilizing a single powerful machine with many CPUs. The database tier is scaled out by having a shadow database using log shipping capability to support reports, analysis, and so forth.
Figure 1-1 Scaling options in a traditional three tier application
HostHost
HostHostHost
ClientClient
ApplicationServer
ShadowDatabase
Client
ManagementFunctions
(Reports, …)
Database
ApplicationServer
ApplicationServer
ApplicationServer
ApplicationServer
ApplicationServer
ApplicationServer
ApplicationServer
ApplicationServer
horizontal scaling
verti
cal s
calin
g
2 User’s Guide to WebSphere eXtreme Scale
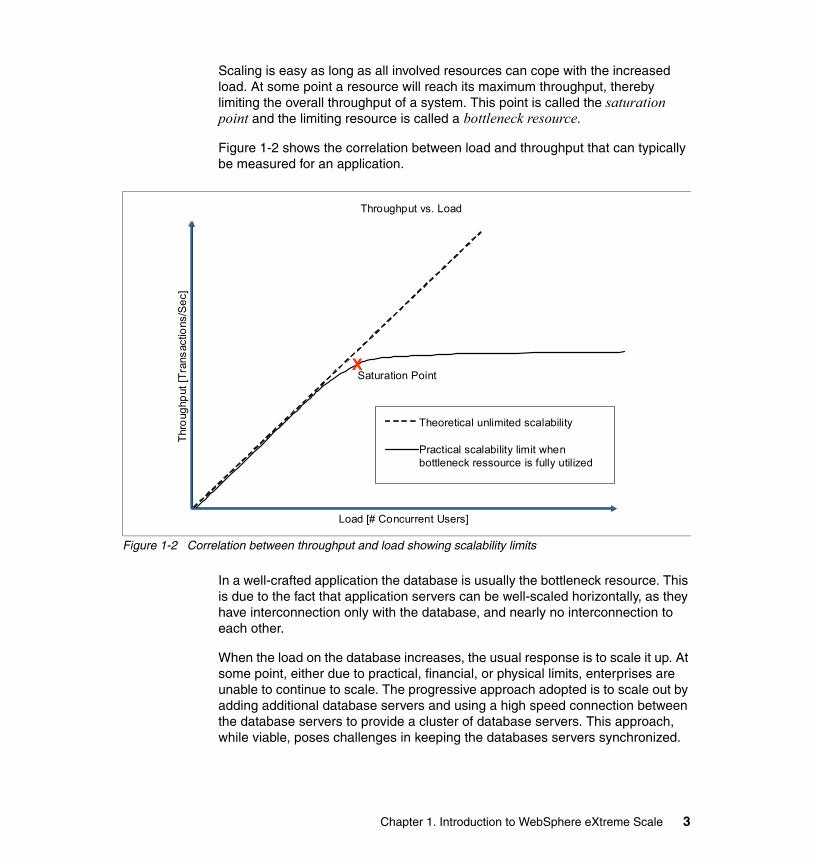
Scaling is easy as long as all involved resources can cope with the increased load. At some point a resource will reach its maximum throughput, thereby limiting the overall throughput of a system. This point is called the saturation point and the limiting resource is called a bottleneck resource.
Figure 1-2 shows the correlation between load and throughput that can typically be measured for an application.
Figure 1-2 Correlation between throughput and load showing scalability limits
In a well-crafted application the database is usually the bottleneck resource. This is due to the fact that application servers can be well-scaled horizontally, as they have interconnection only with the database, and nearly no interconnection to each other.
When the load on the database increases, the usual response is to scale it up. At some point, either due to practical, financial, or physical limits, enterprises are unable to continue to scale. The progressive approach adopted is to scale out by adding additional database servers and using a high speed connection between the database servers to provide a cluster of database servers. This approach, while viable, poses challenges in keeping the databases servers synchronized.
Thro
ughp
ut [T
rans
actio
ns/S
ec]
Load [# Concurrent Users]
XSaturation Point
Theoretical unlimited scalability
Practical scalability limit when bottleneck ressource is fully utilized
Throughput vs. Load
Chapter 1. Introduction to WebSphere eXtreme Scale 3

It is important to ensure that the databases are kept in synchronous for data integrity and crash recovery. For example, consider two concurrent transactions that modify the same row. When these transactions are executed by different database servers, communication is required to ensure the atomic, consistent, isolated, and durable attributes of database transaction are preserved. This communication can grow exponentially as the number of involved database servers increases, which ultimately limits the scalability of the database back end. In fact, while application server clusters with more than 100, or even 1000, hosts can be easily found, a database server cluster with more then 4 members is hard to find.
The scalability challenge then, is to provide scalable access to large amounts of data. In almost all application scenarios, scalability is treated as a competitive advantage. It directly impacts the business applications and the business unit that owns the applications. This is because applications that are scalable can easily accommodate growth and aid the business functions in analysis and business development.
1.2 Caches and a data grid as a solution
So how can the scalability challenge be solved? One feasible approach is somewhat obvious: when the database is the bottleneck, the number of requests that go to the database need to be reduced. This is accomplished by introducing caching capabilities into the application.
Every major business application usually incorporates some kind of caching technique. Application servers use some amount of local memory to store frequently accessed data. A cache, then, can simply extend that storage capability. It is generally considered to be a shock absorber to the database. As shown in Figure 1-3 on page 5, the cache sits between the application and the database to reduce the load.
Cache: A cache can be defined as a copy of frequently accessed data that is held in process memory. The intent of any caching mechanism is to reduce response time by reducing access time to data, and to increase scalability by reducing the number of requests to the database.
4 User’s Guide to WebSphere eXtreme Scale
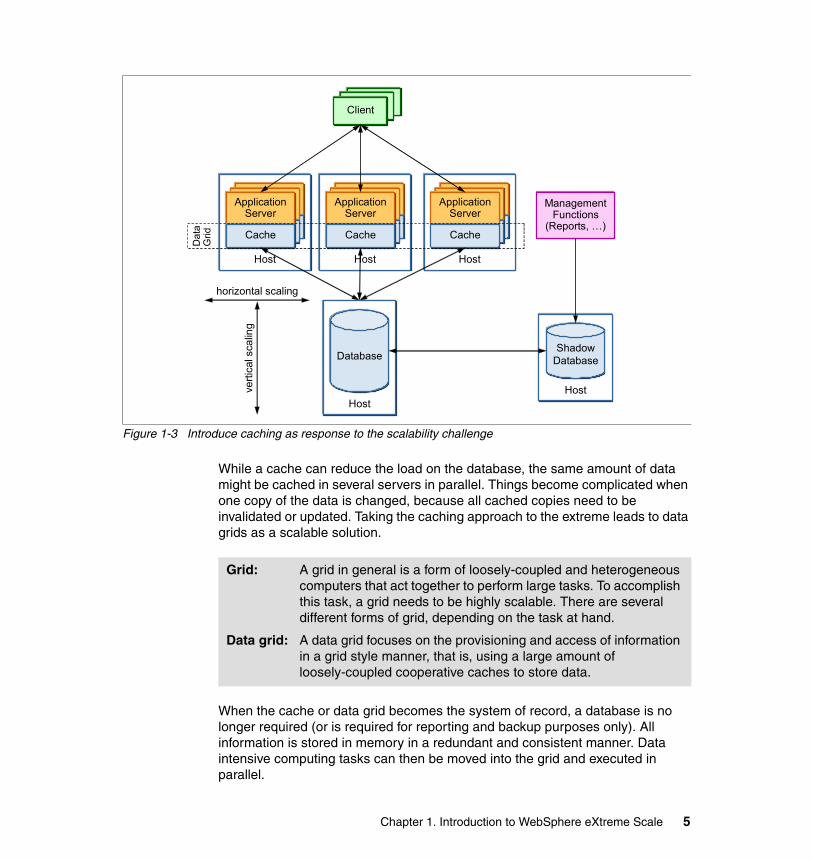
Figure 1-3 Introduce caching as response to the scalability challenge
While a cache can reduce the load on the database, the same amount of data might be cached in several servers in parallel. Things become complicated when one copy of the data is changed, because all cached copies need to be invalidated or updated. Taking the caching approach to the extreme leads to data grids as a scalable solution.
When the cache or data grid becomes the system of record, a database is no longer required (or is required for reporting and backup purposes only). All information is stored in memory in a redundant and consistent manner. Data intensive computing tasks can then be moved into the grid and executed in parallel.
Host
ClientClientClient
ApplicationServer
Cache
ApplicationServer
Cache
ApplicationServer
Cache
Host
ApplicationServer
Cache
ApplicationServer
Cache
ApplicationServer
Cache
Host
ApplicationServer
Cache
ApplicationServer
Cache
ApplicationServer
Cache
Dat
aG
rid
HostHost
ShadowDatabase
ManagementFunctions
(Reports, …)
Database
horizontal scaling
verti
cal s
calin
g
Grid: A grid in general is a form of loosely-coupled and heterogeneous computers that act together to perform large tasks. To accomplish this task, a grid needs to be highly scalable. There are several different forms of grid, depending on the task at hand.
Data grid: A data grid focuses on the provisioning and access of information in a grid style manner, that is, using a large amount of loosely-coupled cooperative caches to store data.
Chapter 1. Introduction to WebSphere eXtreme Scale 5

1.3 Introduction to WebSphere eXtreme Scale
WebSphere eXtreme Scale provides an extensible framework to simplify the caching of data used by an application. It can be used to build a highly scalable, fault tolerant data grid with nearly unlimited horizontal scaling capabilities. WebSphere eXtreme Scale is the IBM response to the scalability challenge associated with data access.
WebSphere eXtreme Scale enables infrastructure with the ability to deal with extreme levels of data processing and performance. When the data and resulting transactions experience incremental or exponential growth, the business performance does not suffer because the grid is easily extended by adding additional capacity (Java virtual machines and hardware).
The key features of WebSphere eXtreme Scale are as follows:
� Transaction support� Securability� Extreme scalability� High availability
These features are discussed in detail in the following sections.
1.3.1 Transaction support
Custom caching solutions usually use a java.util.Map to store data. Updates are simply put into the map. But what happens if a single user transaction updates several objects in the cache and in the end the whole transaction is rolled back because of some business exception? Are all changes rolled back in the cache, too? This is hard to get right the first time.
WebSphere eXtreme Scale has built-in transaction support for all changes made to the cached data. Changes are committed or rolled back in an atomic way. WebSphere eXtreme Scale augments the database and acts as an intermediary between the application and database. Transaction processing ensures that multiple individual operations that work in tandem are treated as a single unit of work. If even one individual operation fails, the entire transaction fails.
WebSphere eXtreme Scale uses transactions for the following reasons:
� To apply multiple changes as an atomic unit at commit time� To ensure consistency of all cached data� To isolate a thread from concurrent changes� To act as the unit of replication to make the changes durable.� To implement a life cycle for locks on change
6 User’s Guide to WebSphere eXtreme Scale

WebSphere eXtreme Scale implements transactions by handing out copies of cached objects to the application. All the changes to objects are tracked in a difference map. In the event of a successful commit, the changes are applied to the cached objects. A locking strategy ensures that the data has not been changed in between. Optimistic and pessimistic locking strategies are supported. Likewise, in event of a transaction rollback, the difference map is discarded and eventually existing locks on the entries are released.
Additional detailed information about transactions can be obtained from the following developerWorks article, available from the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/Ki
1.3.2 Securability
Depending on the sensitivity of the data that is stored in the cache, security is an important point to consider. Like with a database, fine grained control on which client is allowed which kind of access to data can be enforced.
WebSphere eXtreme Scale security includes the following features:
� Authentication
Authentication provides the ability to authenticate the identity of the requester or client. WebSphere eXtreme Scale supports both client-to-server and server-to-server authentication.
� Authorization
Authorization provides an adequate level of access control to authenticated clients. The authorization includes controlling operations such as reading, querying, and modifying the data in the grid, but also management operations such as replication of data and starting and stopping of grid containers.
� Transport security
Transport security ensures secure communications between the remote clients and grid servers. Currently, the transport security between the grid servers does not support SSL due to limitations imposed by HAManager, which uses reliable multicast messaging (RMM). Because the grid infrastructure is usually in a secured infrastructure protected with domain level and protocol level firewalls, the transport level security is not perceived to be a cause for concern.
� System security
System security includes overall system security for the access and operational management of the grid itself.
Chapter 1. Introduction to WebSphere eXtreme Scale 7

1.3.3 Extreme scalability
As the product name suggests, WebSphere eXtreme Scale supports substantial scale outs. It is designed to scale to thousands of grid containers. This is possible by using partitions to split large amounts of data into manageable chunks and distributing them across the grid containers. Clients directly access the partition that holds the requested data.
As explained in 1.1, “The scalability challenge” on page 2, the amount of communication between containers is the crucial limiting factor for scalability. The WebSphere eXtreme Scale grid containers hardly communicate with each other. This allows large linear scale outs such as application servers. Communication between grid containers occurs for two reasons:
� Availability management
Communication occurs to keep track of which containers are available. This communication is kept small by grouping the containers into chunks around 20 in size.
� Data replication
Communication occurs to ensure high availability of cached data. This is the only peer-to-peer communication between containers holding the same data.
WebSphere eXtreme Scale has been proven to run smoothly with more than 1000 Java virtual machines (JVMs) participating in a data grid managing half a terrabyte of data. Performance tests conducted in this setup did not identify any bottleneck. The scale out was only limited by available hardware.
1.3.4 High availability
When the grid becomes the system of record, high availability becomes an issue. It must guarantee that no loss of critical data will occur for a wide range of different failure cases. WebSphere eXtreme Scale accomplishes this guarantee by allowing for redundant copies of cache data called replicas. A given object can have a configurable number of replicas throughout the grid. A replica can be synchronous with the primary object (transactions only commit when all synchronous replicas are changed) or asynchronous (an update of replicas occurs after commit). Zones can be used to ensure replicas reside in different physical fire compartments or data centers to ensure availability in disaster scenarios.
8 User’s Guide to WebSphere eXtreme Scale

High availability requires careful planning, sizing, and configuration. More details on high availability and failure modes can be found in the ObjectGrid high availability wiki, available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/jS
1.4 Implementing WebSphere eXtreme Scale
After explaining the main features of WebSphere eXtreme Scale, we would like to discuss how it can be implemented into an existing IT infrastructure. We discuss the implementation by showing possible entry points and providing a decision tree based on typical problems an organization might face.
1.4.1 Possible entry points
Figure 1-4 on page 10 shows three possible entry points for adopting WebSphere eXtreme Scale. It can be used in ways ranging from a simple in-process cache to an enterprise-wide distributed data grid. The diagram also implies a road map. An organization can start with one of the lower entry points and evolve continuously into to the higher levels of grid computing.
The first entry point uses WebSphere eXtreme Scale as a sophisticated caching layer for an application. This proven and well supported IBM product can be used instead of investing in the custom development of a home-grown solution. The replacement or augmentation of an existing caching implementation that has reached its limits (for example, transactionality, scalability, or security) is also found in this category.
The second entry point uses WebSphere eXtreme Scale as a data grid to store large amounts of data. While a traditional database has a size limit, a data grid can be extended to accommodate a great quantity of data, even as the data that needs to be stored grows.
The third entry point uses the extreme scalability WebSphere eXtreme Scale supports to build an enterprise-wide complex data grid solution. It includes grid-style computing by bringing the algorithms to the data (as opposed to the traditional distributed computing approach where the algorithms retrieve the required data from the back end).
Chapter 1. Introduction to WebSphere eXtreme Scale 9
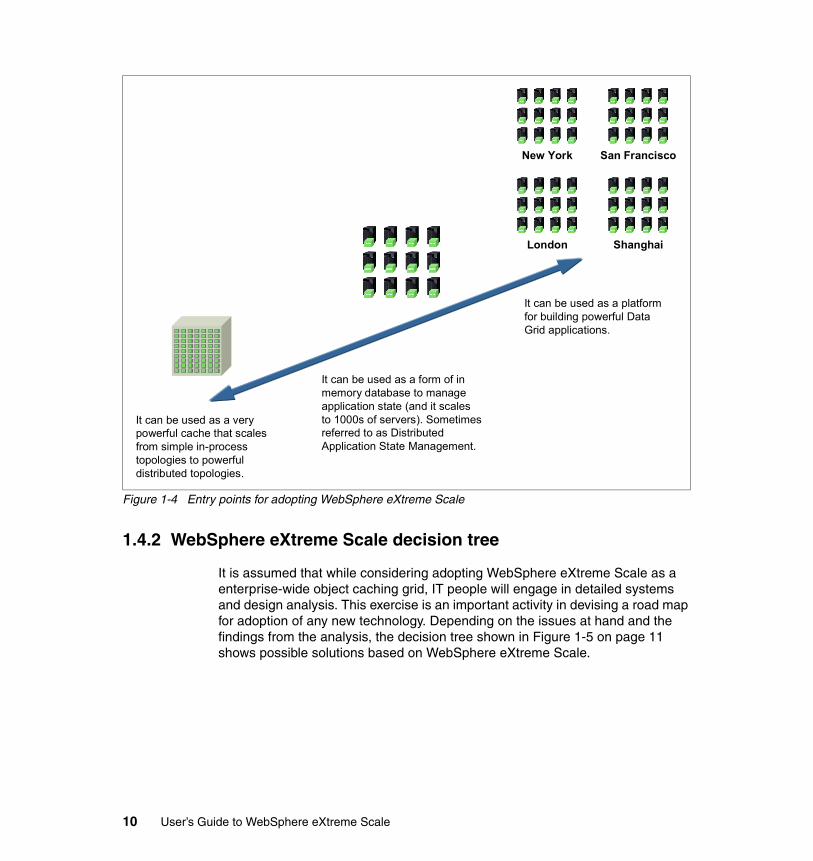
Figure 1-4 Entry points for adopting WebSphere eXtreme Scale
1.4.2 WebSphere eXtreme Scale decision tree
It is assumed that while considering adopting WebSphere eXtreme Scale as a enterprise-wide object caching grid, IT people will engage in detailed systems and design analysis. This exercise is an important activity in devising a road map for adoption of any new technology. Depending on the issues at hand and the findings from the analysis, the decision tree shown in Figure 1-5 on page 11 shows possible solutions based on WebSphere eXtreme Scale.
New York San Francisco
London Shanghai
It can be used as a verypowerful cache that scalesfrom simple in-process topologies to powerfuldistributed topologies.
It can be used as a form of inmemory database to manageapplication state (and it scalesto 1000s of servers). Sometimesreferred to as DistributedApplication State Management.
It can be used as a platformfor building powerful DataGrid applications.
10 User’s Guide to WebSphere eXtreme Scale
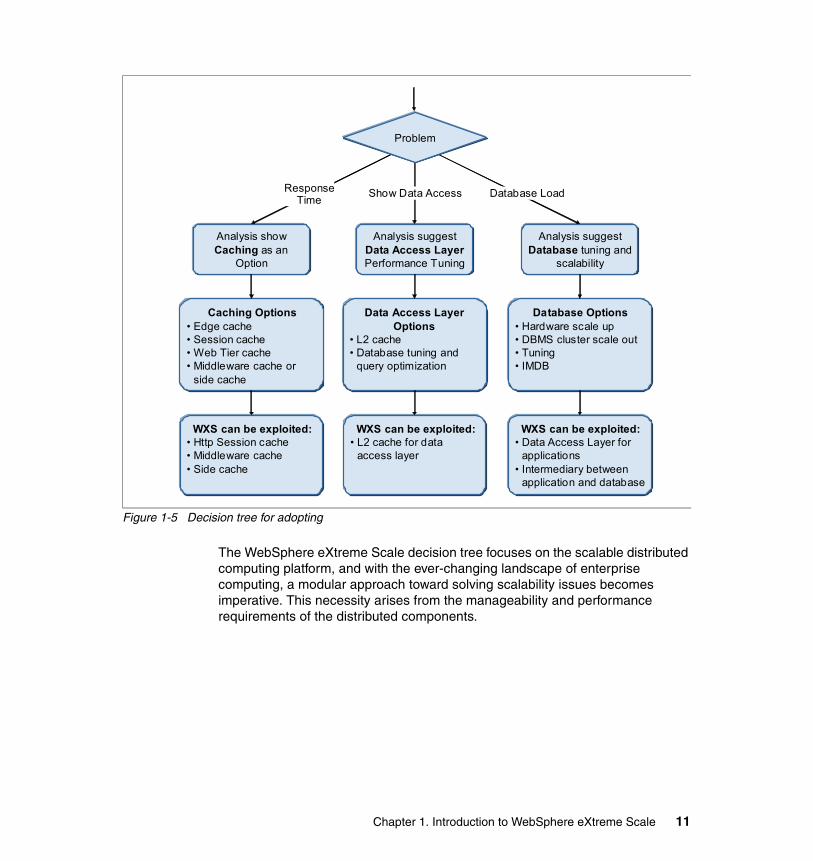
Figure 1-5 Decision tree for adopting
The WebSphere eXtreme Scale decision tree focuses on the scalable distributed computing platform, and with the ever-changing landscape of enterprise computing, a modular approach toward solving scalability issues becomes imperative. This necessity arises from the manageability and performance requirements of the distributed components.
WXS can be exploited:• Data Access Layer for
applications• Intermediary between
application and database
WXS can be exploited:• L2 cache for data
access layer
WXS can be exploited:• Http Session cache• Middleware cache• Side cache
Database Options• Hardware scale up• DBMS cluster scale out• Tuning• IMDB
Data Access LayerOptions
• L2 cache• Database tuning and
query optimization
Caching Options• Edge cache• Session cache• Web Tier cache• Middleware cache or
side cache
Analysis suggest Database tuning and
scalability
Analysis suggest Data Access Layer Performance Tuning
Analysis show Caching as an
Option
ResponseTime Show Data Access Database Load
Problem
Chapter 1. Introduction to WebSphere eXtreme Scale 11

The decision tree breaks down the problem components into following three broad categories.
� Caching
The intent of any caching mechanism is to improve performance by enabling easy access to data, which in the absence of a cache, would have to be fetched from a database. Repeated access to a database for data can be computationally expensive and may impact the overall application performance. Caching can also be employed as a front-end Web tier, and at the edge for static application contents. WebSphere eXtreme Scale can be employed to cache HTTP sessions, which are typically cached in the same address space as the application. The HTTP session and side cache scenario are discussed in detail in Chapter 3, “Application scenarios” on page 49.
� Data access layer (DAL)
Also known as the data persistence layer, the DAL provides access to persisted data stored in a database. The DAL is used by the applications to access the data. This layer relieves the application from dealing with the complexities inherent in this access. Because WebSphere eXtreme Scale stores the data in the form of an object in the grid, the DAL potentially acts as a loader, thereby managing the entity relationship (Object Relational Mapping [ORM]) and converting the raw data into java objects which can be stored in the Grid. The DAL can be either custom-built Java Connection Architecture (JCA)-based or standard JPA-based. Other commercial ORMs are also commonly used as DAL. There are various scenarios in which WebSphere eXtreme Scale can be used in conjunction with DAL, such as a L2 cache or even a layer above the ORM layer, as a DAL itself. More information about data access layer scenarios can be found in Chapter 3, “Application scenarios” on page 49.
� Database scalability
Traditionally, databases were notorious culprits in hindering scalability, and were considered incapable of meeting the needs of high-performance distributed computing design. With the new advancements in technology around the hardware that hosts the databases, network (10GigE, and so forth), and disk access technologies (Fibre Channel, and so forth), coupled with the advancements with the multi-processing DBMS technologies, the databases have risen to the scalability challenge. WebSphere eXtreme Scale as a data grid technology intends to enhance rather than replace the role of an enterprise database. WebSphere eXtreme Scale acts as an intermediary to the enterprise database. By reducing the access to the databases, it not only improves the application performance, but also relieves the database for business activities such as business intelligence analysis, data mining, data analysis, and so forth. This approach allows for an enterprise to save costs,
12 User’s Guide to WebSphere eXtreme Scale

as the focus from database scalability shifts to data grid scalability, and easily adapt to growth in data demand. WebSphere eXtreme Scale as a network-attached cache scenario is discussed in Chapter 3, “Application scenarios” on page 49.
The discussion above clearly illustrates the versatility of the WebSphere eXtreme Scale as a platform for extending scalability across all components of the enterprise architecture.
1.5 Explaining the names—product evolution
In 2008, the WebSphere Extended Deployment product names changed. This section describes the evolution of the product and its distinct place in WebSphere family of products.
Figure 1-6 outlines the evolution of the WebSphere Extended Deployment family of products.
Figure 1-6 WebSphere eXtreme Scale evolution timeline
WebSphere Extended Deployment (XD) V5.xDynamic Operations Extreme Computing
Extended Manageability
WebSphereVirtual Enterprise
(WVE) V6.1
WebSphereeXtreme Scale
(WXS) V6.1
WebSphereCompute Grid V6.1
WebSphere Extended Deployment (XD) V6.X
OperationsOptimizationComponent
Data GridComponent
Compute GridComponent
2004
2006
2008
Chapter 1. Introduction to WebSphere eXtreme Scale 13
WebSphere Extended Deployment was originally introduced in 2004 as a stand-alone product that exploited the rich manageability features of WebSphere Network Deployment to provide extensibility to heterogeneous application server environments. WebSphere Extended Deployment (XD) was a combined product that included Dynamic Operations, High Performance Computing and Business Grid, touting the principles of grid and autonomic computing.
WebSphere Extended Deployment, while an attractive value proposition, did not appeal to all segments of enterprise computing. The Java batch and development teams were unable to realize the full potential of WebSphere WebSphere Extended Deployment’s dynamic (renamed to Optimized) operations piece. The OLTP application infrastructure team of enterprise computing did not fully appreciate the value of Business (renamed to Compute) Grid. At the same time, a high end caching framework, or ObjectGrid, was added to the product to complement the partitioning facility in the DataGrid package.
Realizing that WebSphere Extended Deployment could be better understood by customers as separate functional areas, it was split into three distinct components in 2006 with V6.0. Each component could be adopted and procured independently, but yet were inter-operable at runtime. These distinct bundles were:
� WebSphere Extended Deployment Operations Optimization� WebSphere Extended Deployment Compute Grid� WebSphere Extended Deployment Data Grid
As these products evolved, they played a pioneering role in setting the stage for new batch and caching platforms. To underline the indepency of each component, a re-branding occurred in 2008, resulting in the following now-valid product names changes as shown in Table 1-1.
Table 1-1 2008 Rebranding name changes
Old Name New Name
WebSphere Extended Deployment Operations Optimization
WebSphere Virtual Enterprise
WebSphere Extended Deployment Compute Grid
WebSphere Compute Grid
WebSphere Extended Deployment Data Grid
WebSphere eXtreme Scale
Note: In 2008, ObjectGrid was renamed to WebSphere eXtreme Scale. You may see the two names used interchangeably throughout this Redbooks publication.
14 User’s Guide to WebSphere eXtreme Scale

1.6 Comparing eXtreme Scale to in-memory databases
Introducing a caching layer or data grid is not the only existing solution to address the scalability challenge described in 1.1, “The scalability challenge” on page 2. Another viable solution is an in-memory database (IMDB). This section compares a data grid solution to IMDBs.
1.6.1 Introducing IMDBs
An IMDB has all the system qualities of a traditional relational database management system (RDBMS), but resides in memory, eliminating the need for a database. While this notion of a purely in-memory database may please the technologists, it has never settled well with the business community, who usually own the data and the application. The reasons for this dissatisfaction are simple. A business has requirements and functions such as audits, history, legal requirements, operations and business analysis, all of which require data to be persisted for subsequent retrieval and mining.
IMDBs attempt to bring data closer to the application. An IMDB solution involves holding an entire database in memory, as a single entity. The application treats the IMDB layer as a database, while the IMDB is backed by a relational database. The advantage of this approach is the availability of data with faster access times.
IMDB solutions provide all the database-like enterprise service quality features such as ACID (Atomic, Consistent, Isolated, Durable) transactions, high availability, fail over, clustering, and SQL support.
While IMDB technology provides much needed relief to address costly scalability issues and business needs, it does have some limitations. An IMDB can only hold a finite amount of data, because the data has to fit into single address space. To address this issue, applications and data can be partitioned according to a relevant business need (for example, partitions based on customer location, with one installation for east coast customers and another for west coast customers).
Chapter 1. Introduction to WebSphere eXtreme Scale 15
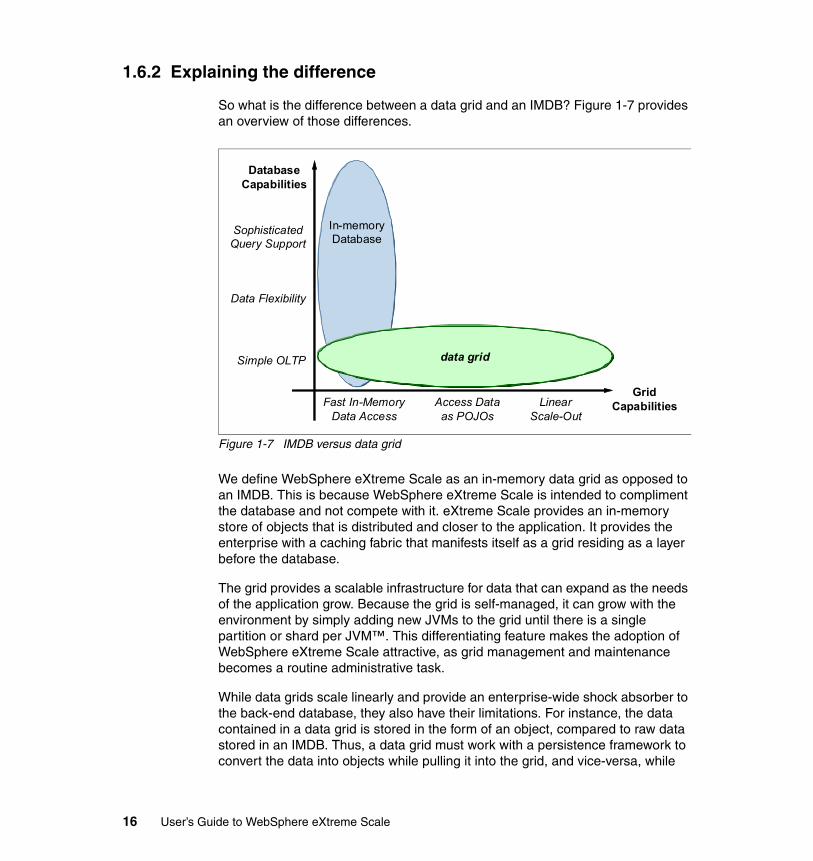
1.6.2 Explaining the difference
So what is the difference between a data grid and an IMDB? Figure 1-7 provides an overview of those differences.
Figure 1-7 IMDB versus data grid
We define WebSphere eXtreme Scale as an in-memory data grid as opposed to an IMDB. This is because WebSphere eXtreme Scale is intended to compliment the database and not compete with it. eXtreme Scale provides an in-memory store of objects that is distributed and closer to the application. It provides the enterprise with a caching fabric that manifests itself as a grid residing as a layer before the database.
The grid provides a scalable infrastructure for data that can expand as the needs of the application grow. Because the grid is self-managed, it can grow with the environment by simply adding new JVMs to the grid until there is a single partition or shard per JVM™. This differentiating feature makes the adoption of WebSphere eXtreme Scale attractive, as grid management and maintenance becomes a routine administrative task.
While data grids scale linearly and provide an enterprise-wide shock absorber to the back-end database, they also have their limitations. For instance, the data contained in a data grid is stored in the form of an object, compared to raw data stored in an IMDB. Thus, a data grid must work with a persistence framework to convert the data into objects while pulling it into the grid, and vice-versa, while
Fast In-MemoryData Access
Access Dataas POJOs
LinearScale-Out
GridCapabilities
SophisticatedQuery Support
Data Flexibility
Simple OLTP
DatabaseCapabilities
In-memoryDatabase
data grid
16 User’s Guide to WebSphere eXtreme Scale

writing it back to the database. This adds another framework to the overall solution, which may add additional architectural planning overhead. Also, data grids can only represent the data as single entity, and do not support SQL. Instead, WebSphere eXtreme Scale supports Object Grid Query Language (OGQL) which is similar to JPQL.
While data grids and IMDBs differ in their approach, it is important to understand the pros and cons of these data caching technologies when selecting an in-memory data cache solution.
Chapter 1. Introduction to WebSphere eXtreme Scale 17

18 User’s Guide to WebSphere eXtreme Scale

Chapter 2. WebSphere eXtreme Scale architecture and topologies
This chapter provides an overview of the architecture of the WebSphere eXtreme Scale product. It explains the terminology for the main components, which in turn provides a strong basis for defining eXtreme Scale topologies.
The topics in this chapter are as follows:
� “WebSphere eXtreme Scale architecture” on page 20� “APIs used to access the grid” on page 30� “A simple example” on page 34� “Zones” on page 36� “Zones” on page 36“Scalability sizing considerations” on page 41� “Common topology configurations” on page 43
2
© Copyright IBM Corp. 2008. All rights reserved. 19
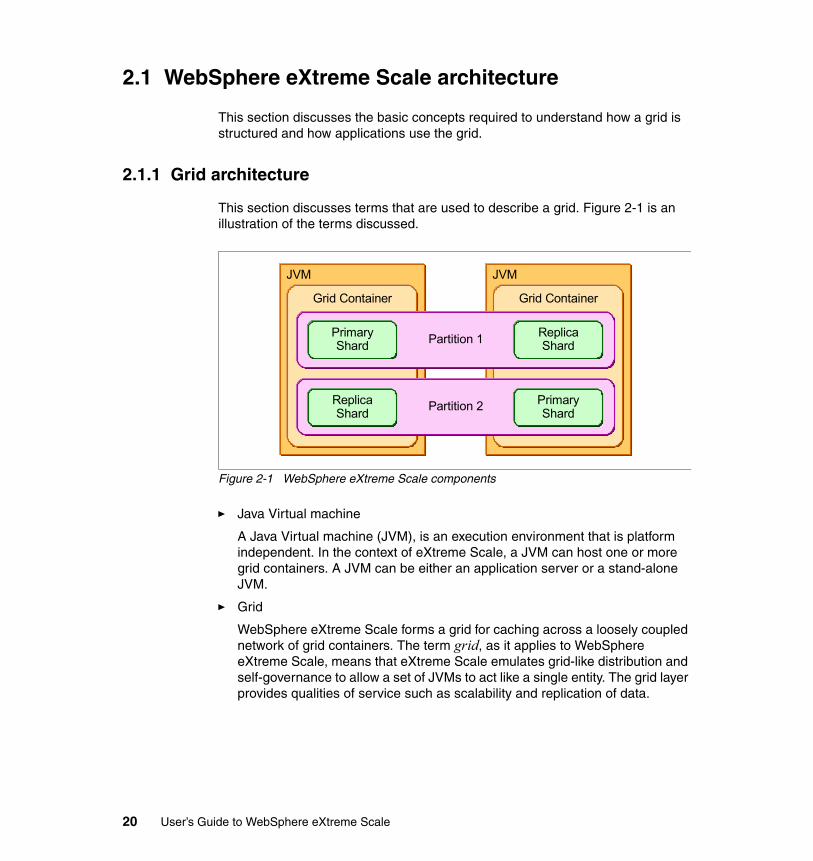
2.1 WebSphere eXtreme Scale architecture
This section discusses the basic concepts required to understand how a grid is structured and how applications use the grid.
2.1.1 Grid architecture
This section discusses terms that are used to describe a grid. Figure 2-1 is an illustration of the terms discussed.
Figure 2-1 WebSphere eXtreme Scale components
� Java Virtual machine
A Java Virtual machine (JVM), is an execution environment that is platform independent. In the context of eXtreme Scale, a JVM can host one or more grid containers. A JVM can be either an application server or a stand-alone JVM.
� Grid
WebSphere eXtreme Scale forms a grid for caching across a loosely coupled network of grid containers. The term grid, as it applies to WebSphere eXtreme Scale, means that eXtreme Scale emulates grid-like distribution and self-governance to allow a set of JVMs to act like a single entity. The grid layer provides qualities of service such as scalability and replication of data.
JVM
Grid Container
JVM
Grid Container
Partition 1PrimaryShard
Partition 2ReplicaShard
ReplicaShard
PrimaryShard
20 User’s Guide to WebSphere eXtreme Scale

� Grid containers
Much like a typical description of a container in a J2EE™ context, grid containers essentially provide the grid application services such as security, transaction support, JNDI lookup service, remote connectivity, and so forth. The grid containers house shard distribution and placement, and enable easy manageability of the grid infrastructure. Much like other containers (Web and EJB™ container, for example), a grid container can also take advantage of the configuration service provided by the WebSphere Application Server infrastructure in a managed environment.
� Partitions
Partitioning is the process of splitting data into smaller sections. Partitioning allows the grid to store more data than can be accommodated in a single JVM. The data is partitioned using an application-defined schema. The grid can have many partitions depending on the application, and these partitions must be factored in while configuring and designing for a scalable infrastructure.
� Shards
The term shard is used to define a single instance of a partition. Each partition has a primary shard and an optional set of replica shards. The shard distribution algorithms ensure that the primary and replica shards are never in the same container to ensure fault tolerance and high availability.
Figure 2-2 shows four partitions with a single replica each, making eight shards in total. All of the shards are located in two grid containers. In this case, we see that each grid container holds four shards.
Figure 2-2 Shards
Grid
Grid ContainercontainerA
Grid ContainercontainerB
Partition 1 Shard 1 ReplicaShard 1
Partition 4Shard 4 Replica Shard 4
Partition 3 Shard 3 ReplicaShard 3
Partition 2Shard 2 Replica Shard 2
Chapter 2. WebSphere eXtreme Scale architecture and topologies 21

Shard placement is the responsibility of catalog servers. As the grid membership changes and new JVMs are added to accommodate growth, the catalog server pulls shards from relatively overloaded containers and moves them to the new empty container. With this behavior, the grid can scale out, by simply adding additional JVMs. Conversely, when the grid membership changes due to failure or planned removal of JVMs, the catalog server will attempt to redistribute the shards that best fit the available JVMs. In such a case, the grid is said to scale in. The ability of WebSphere eXtreme Scale to scale in and scale out provides tremendous flexibility to the changing nature of infrastructure.
Note: A primary shard is sometimes referred to as the primary partition. While you may see those two terms used interchangeably, a partition is a collection of a primary and zero or more replica shards.
Leading practice: Calculate the number of JVMs required from the partitioning configuration.
When deciding on the number of JVMs required for a grid, a good rule of thumb is to start with the number of partitions needed multiplied by the number of replica shards per partition.
For example, if you have two partitions and each partition has one primary and one replica shard, then you would need at least four JVMs as a starting point for a highly available grid.
22 User’s Guide to WebSphere eXtreme Scale

2.1.2 WebSphere eXtreme Scale internal components
The following sections define the components you will find in WebSphere eXtreme Scale. Figure 2-3 is an illustration of the terms discussed.
Figure 2-3 WebSphere eXtreme Scale internal components
SessionWhen a user initially interacts with the grid, a session is established. A connection to a session can be made directly by a user or through a front-end application. Sessions are single threaded. When another user connects to the grid, another session is established.
Map A map is an interface that stores data as key/value pairs. There are no duplicate keys in a map. A map is considered an associative data structure, because it associates an object with a key.
ObjectMapAn ObjectMap is a type of map that is used to store a value for a key. That value can be either an object instance or a tuple.
� An object instance requires its corresponding class file to be in the JVM, because the bytecode is needed to resolve the object class.
� A tuple represents the attributes of an object. You do not need the class file present.
An ObjectMap is always located on a client, and is used in the context of a local session.
GridSession
ObjectMap
BackingMap
Chapter 2. WebSphere eXtreme Scale architecture and topologies 23
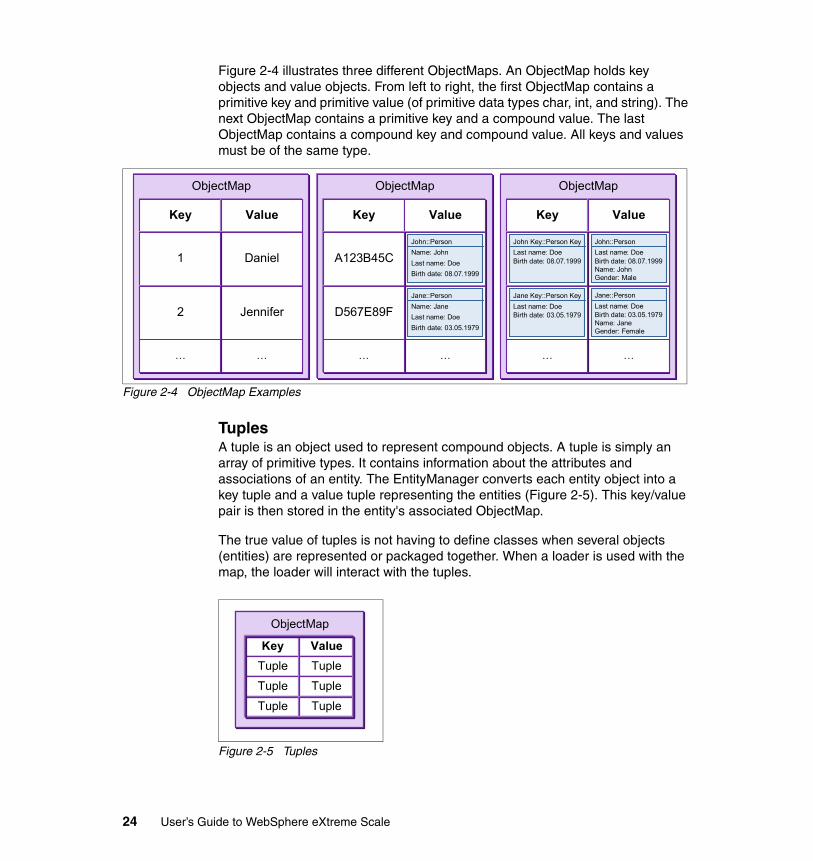
Figure 2-4 illustrates three different ObjectMaps. An ObjectMap holds key objects and value objects. From left to right, the first ObjectMap contains a primitive key and primitive value (of primitive data types char, int, and string). The next ObjectMap contains a primitive key and a compound value. The last ObjectMap contains a compound key and compound value. All keys and values must be of the same type.
Figure 2-4 ObjectMap Examples
TuplesA tuple is an object used to represent compound objects. A tuple is simply an array of primitive types. It contains information about the attributes and associations of an entity. The EntityManager converts each entity object into a key tuple and a value tuple representing the entities (Figure 2-5). This key/value pair is then stored in the entity's associated ObjectMap.
The true value of tuples is not having to define classes when several objects (entities) are represented or packaged together. When a loader is used with the map, the loader will interact with the tuples.
Figure 2-5 Tuples
ObjectMap
Key Value
John::PersonLast name: DoeBirth date: 08.07.1999Name: JohnGender: Male
Jane::PersonLast name: DoeBirth date: 03.05.1979Name: JaneGender: Female
…
John Key::Person KeyLast name: DoeBirth date: 08.07.1999
Jane Key::Person KeyLast name: DoeBirth date: 03.05.1979
…
ObjectMap
Key Value
John::PersonName: JohnLast name: DoeBirth date: 08.07.1999
Jane::PersonName: JaneLast name: DoeBirth date: 03.05.1979
…
A123B45C
D567E89F
…
ObjectMap
Key Value
Daniel
Jennifer
…
1
2
…
ObjectMap
KeyTuple
Tuple
Tuple
ValueTuple
Tuple
Tuple
24 User’s Guide to WebSphere eXtreme Scale
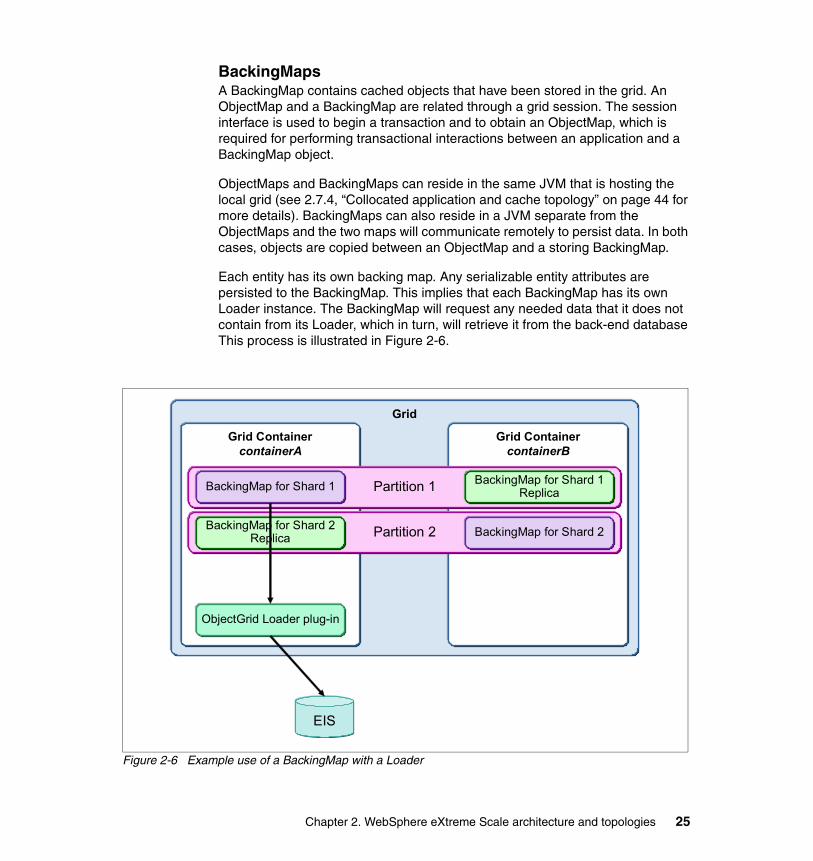
BackingMapsA BackingMap contains cached objects that have been stored in the grid. An ObjectMap and a BackingMap are related through a grid session. The session interface is used to begin a transaction and to obtain an ObjectMap, which is required for performing transactional interactions between an application and a BackingMap object.
ObjectMaps and BackingMaps can reside in the same JVM that is hosting the local grid (see 2.7.4, “Collocated application and cache topology” on page 44 for more details). BackingMaps can also reside in a JVM separate from the ObjectMaps and the two maps will communicate remotely to persist data. In both cases, objects are copied between an ObjectMap and a storing BackingMap.
Each entity has its own backing map. Any serializable entity attributes are persisted to the BackingMap. This implies that each BackingMap has its own Loader instance. The BackingMap will request any needed data that it does not contain from its Loader, which in turn, will retrieve it from the back-end database This process is illustrated in Figure 2-6.
Figure 2-6 Example use of a BackingMap with a Loader
Grid
Grid ContainercontainerA
Grid ContainercontainerB
Partition 1 BackingMap for Shard 1ReplicaBackingMap for Shard 1
ObjectGrid Loader plug-in
Partition 2BackingMap for Shard 2Replica BackingMap for Shard 2
EIS
Chapter 2. WebSphere eXtreme Scale architecture and topologies 25

2.1.3 Grid clients and servers
The following terms are used when discussing how an application interacts with the grid.
� ObjectGrid Instance
Applications must obtain an ObjectGrid instance to work with a grid. This is done so that the application can interact with the grid and perform various operations, such as create, retrieve, update, and delete the objects in the grid.
� Grid server
Catalog servers and the JVMs that host grid containers holding the cache are defined as grid servers. The catalog servers primary function is to serve routing information, while the other grid servers host the cache (stored in BackingMaps).
� Grid Client
Clients connect to a grid and are attached to the whole grid. Clients need to examine the key of application data to determine to which partition to route the request. Any entity that is attached to the grid with any kind of request becomes a client. A client contains an ObjectMap and may contain a near-cache copy of a BackingMap.
A grid client and server can have independent BackingMaps (far-cache and near-cache). The server-side, or far-cache, BackingMap is always shared between clients, while the client-side, or near-cache, BackingMap (if in use) is shared between all threads of the grid client. Clients can read data from multiple partitions in a single transaction. However, clients can only update a single partition in a transaction.
2.1.4 WebSphere eXtreme Scale meta model
This section explains the operational components that make up the eXtreme Scale and the relationship between these components. This model can be used in better understanding the WebSphere eXtreme Scale product itself, and can be instrumental in the design of a scalable topology. The WebSphere eXtreme Scale meta model can also be used for analysis of sizing requirements of the grid. Figure 2-7 on page 27 shows the relationship between various components of the grid.
Note: The terms “grid server” and “ObjectGrid server” are interchangeable.
Note: The terms “grid client” and “ObjectGrid client” are interchangeable.
26 User’s Guide to WebSphere eXtreme Scale
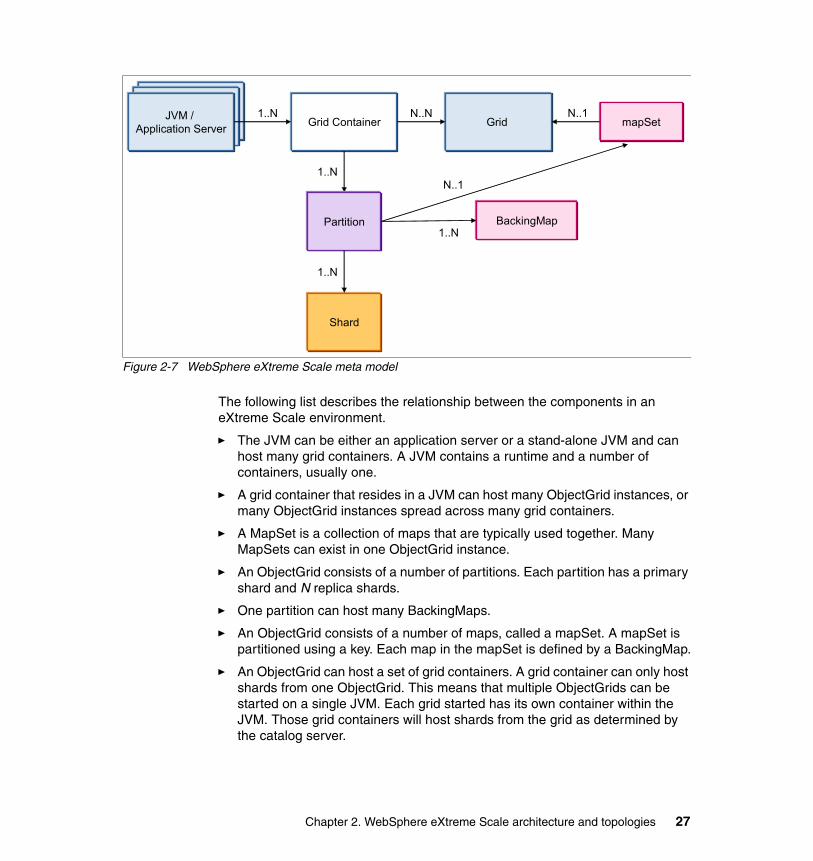
Figure 2-7 WebSphere eXtreme Scale meta model
The following list describes the relationship between the components in an eXtreme Scale environment.
� The JVM can be either an application server or a stand-alone JVM and can host many grid containers. A JVM contains a runtime and a number of containers, usually one.
� A grid container that resides in a JVM can host many ObjectGrid instances, or many ObjectGrid instances spread across many grid containers.
� A MapSet is a collection of maps that are typically used together. Many MapSets can exist in one ObjectGrid instance.
� An ObjectGrid consists of a number of partitions. Each partition has a primary shard and N replica shards.
� One partition can host many BackingMaps.
� An ObjectGrid consists of a number of maps, called a mapSet. A mapSet is partitioned using a key. Each map in the mapSet is defined by a BackingMap.
� An ObjectGrid can host a set of grid containers. A grid container can only host shards from one ObjectGrid. This means that multiple ObjectGrids can be started on a single JVM. Each grid started has its own container within the JVM. Those grid containers will host shards from the grid as determined by the catalog server.
JVM to Container –1 to many (1 to N)
JVM to Container –1 to many (1 to N)
JVM / Application Server Grid Container Grid mapSet
Shard
Partition BackingMap
1..N
1..N
1..N
1..N
N..N N..1
N..1
Chapter 2. WebSphere eXtreme Scale architecture and topologies 27

2.2 Catalog server
The catalog server is the engine that drives the grid operations. The catalog server maintains the healthy operation of grid servers and containers. The catalog server becomes the central nervous system of the grid operation by providing the following essential operation services:
� Location service to all the clients� Health management of the grid itself� Shard distribution and re-distribution� Policy and rule enforcement � High availability and group service
The client will begin its access to the grid by obtaining a routing table from the catalog servers, which enables the client to locate the primary partition shard and object. In the event of a JVM failure, or re-distribution of partitions due to a change in grid membership, the client is provided with an up-to-date routing table by one of the grid servers. This mechanism is maintained by an epoch time and version maintained with the routing table held by the client.
When a client is unable to get a response from any of the grid servers in a partition, the client will contact the catalog server again. If a catalog server is not available, the client fails.
When the grid server and container are not available, the peer server, or leader, in the same core group reports the failure to the catalog server. If the catalog server is down, the peer server is unable to report the failure. It is vital, then, to consider the high availability of catalog servers during the planning phases of the grid topology.
2.2.1 Shard placement
The catalog servers play an instrumental role in replication, distribution, and assignment of the shards to the grid containers. As the grid containers join the grid, they register themselves with the catalog server. Based on the total amount of registered JVMs, catalog servers are aware of grid participants and capacity. Catalog servers use this information to calculate the total number of primary shards and their replicas for each partition available for distribution.
Waterflow algorithmThe mechanism employed to re-distribute the partitions among the available JVMs available in the grid is based on an algorithm resembling the natural flow of water. As the name suggests, the waterflow model is based on distribution of objects between available containers. As the JVMs hosting grid containers leave
28 User’s Guide to WebSphere eXtreme Scale

and join the grid, the partitions’ primary shards and their replicas are re-distributed. This re-distribution of objects also conforms to specified zone rules (if any) and adheres to the distribution model that ensures high availability by not placing primary and replica on same JVM (or even the same machine).
It is important to understand the implications of the shard placement policy defined and enforced by the catalog servers. The waterflow algorithm ensures the equitable distribution of the total number of shards across the total number of available JVMs in a grid. Hence, WebSphere eXtreme Scale ensures that no one JVM is overloaded, when other JVMs are available to host shards, and enables fault tolerance when the primary shard disappears (due to JVM failure or crash) by promoting secondary or replica shard to primary shard.
To ensure high (or continuous) availability of a data partition, WebSphere eXtreme Scale employs the waterflow algorithm to ensure that the primary and replica shard of a partitions are never placed in the same JVM or even on the same machine.
Figure 2-8 shows four partitions, each with a primary and one replica shard, distributed across four JVMs.
Figure 2-8 Shards Placed with all available JVM
Grid
GridContainer 2
Partition 1(replica)
Partition 3
GridContainer 3
Partition 2
Partition 4(replica)
GridContainer 1
Partition 4
Partition 1
GridContainer 4
Partition 3(replica)
Partition 2 (replica)
Chapter 2. WebSphere eXtreme Scale architecture and topologies 29
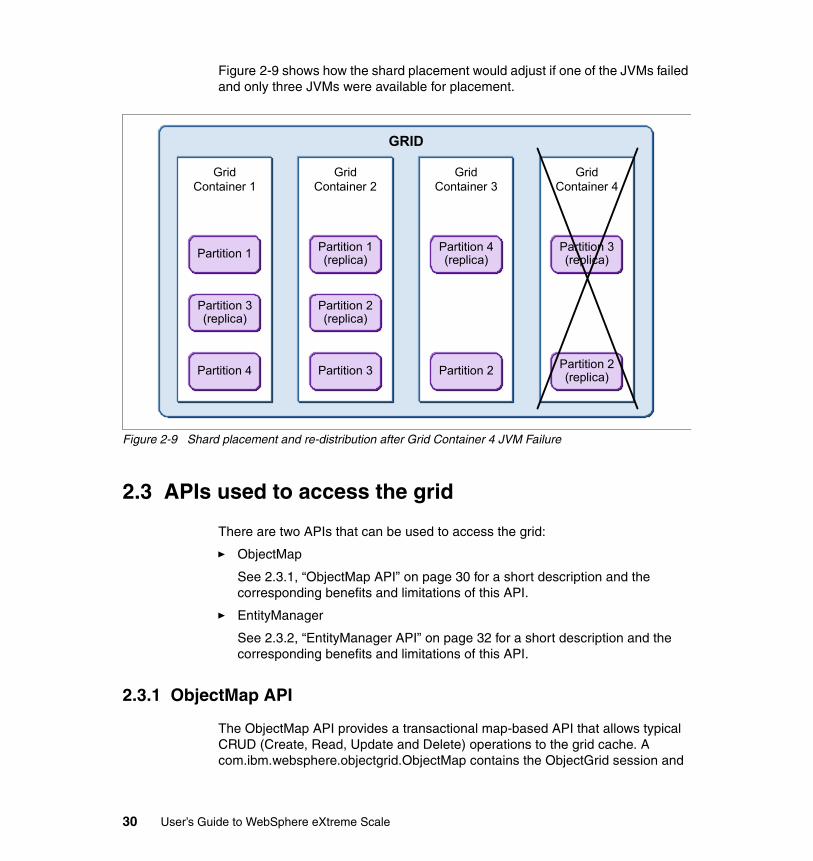
Figure 2-9 shows how the shard placement would adjust if one of the JVMs failed and only three JVMs were available for placement.
Figure 2-9 Shard placement and re-distribution after Grid Container 4 JVM Failure
2.3 APIs used to access the grid
There are two APIs that can be used to access the grid:
� ObjectMap
See 2.3.1, “ObjectMap API” on page 30 for a short description and the corresponding benefits and limitations of this API.
� EntityManager
See 2.3.2, “EntityManager API” on page 32 for a short description and the corresponding benefits and limitations of this API.
2.3.1 ObjectMap API
The ObjectMap API provides a transactional map-based API that allows typical CRUD (Create, Read, Update and Delete) operations to the grid cache. A com.ibm.websphere.objectgrid.ObjectMap contains the ObjectGrid session and
GRID
GridContainer 2
Partition 1(replica)
Partition 2(replica)
Partition 3
GridContainer 3
Partition 2
Partition 4(replica)
GridContainer 1
Partition 4
Partition 1
Partition 3(replica)
GridContainer 4
Partition 3(replica)
Partition 2(replica)
30 User’s Guide to WebSphere eXtreme Scale

the transaction data for the client application. That stored data is either targeted for or retrieved from the BackingMap. For more information about the ObjectMap programming API, see the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/Z4Ud
BenefitsObjectMaps provide a simple and intuitive approach for the application to store data. An ObjectMap is ideal for caching objects that have no relationships involved. ObjectMaps are like Java maps, allowing data to be stored as key/value pairs. Access is easy and fast with primary-key based access. Because ObjectMaps are like Java maps, they should be familiar to programmers who know java.util.map.
LimitationsObjectMaps are not ideal if object relationships are involved in your data storage scheme. There are also performance considerations, due to reliance on Java serialization.
Serialization versioningWebSphere eXtreme Scale depends heavily on Java object serialization to transfer object instances between JVMs. Keep in mind that the objects in the grid might exist there for a long time, perhaps for month and years. But new releases of an application occur much more frequently.
A new release may not able to read objects from the grid that have been placed there by a previous release. This can be caused by incompatible changes in the class (for example, changing the type of an attribute from “String” to “Integer”). A simple solution would be to completely bring down the grid for re-deployment and bring it back (hopefully with pre-loading) afterwards.
But there is a better solution. Java offers a sophisticated class versioning mechanism for serialization. A good starting point is the Java serialization specification, especially Chapter 5 “Versioning of Serializable Objects,” available at the following Web page:
http://java.sun.com/j2se/1.5.0/docs/guide/serialization/spec/serialTOC.html
Be sure to fully understand the concept of “compatible” and “incompatible” changes.
The API documentation is also worth reading and can be found at the following Web page:
http://java.sun.com/j2se/1.5.0/docs/api/java/io/Serializable.html
Chapter 2. WebSphere eXtreme Scale architecture and topologies 31

2.3.2 EntityManager API
The EntityManager API is a simple and intuitive programming model for interacting with the ObjectGrid cache. As an alternative to the ObjectMap API, objects are represented as entities, which allows relationships and may optimize performance. Relationships are defined in a schema or through Java annotations. The EntityManager API uses the existing Map-based infrastructure, but it converts entity objects to and from tuples before storing or reading them from the Map. An example of using the EntityManager API can be seen in Example 2-1.
For more information about the EntityManager programming API, see the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/PwEN
Example 2-1 EntityManager API example
import com.ibm.websphere.objectgrid.ObjectGrid;import com.ibm.websphere.objectgrid ObjectGridManagerFactory;import com.ibm.websphere.objectgrid.Session;import com.ibm.websphere.objectgrid.em.EntityManager;
public class EntityManagerExample {
static public void main(String [] args)throws Exception
{ ObjectGridManager ogManager = (ObjectGridManager) ObjectGridManagerFactory.getObjectGridManager(); ObjectGrid objectGrid = ogManager.createObjectGrid("Company");
Leading practices for serialization versioning:
� Ensure every class that is used to store objects in the grid (that is, keys and values) has an explicitly declared static final long serialVersionUID with a value generated on initial release.
� Establish a build process that can verify that a new version of your application can still deserialize all object types serialized by the previous version. This can be accomplished by storing serialized sample objects in the version control system, and de-serializing these objects at build time to verify integrity. This could be implemented as a JUnit Test, for example.
� Make sure the object classes are available to the grid container.
32 User’s Guide to WebSphere eXtreme Scale

Session session = objectGrid.getSession(); EntityManager em = session.getEntityManager(); EntityTransaction tran = em.getTransaction();
tran.begin(); Manager manager=new Manager("Joe"); Employee employee=new Employee("John", "Doe","50000"); employee.setManager(manager); employee.setSSN("012-34-5678");
// Persist the manager to the persistence context // Employee is automatically cascaded by default. em.persist(manager); tran.commit(); // Verify that we can find our employee tran.begin(); Employee emp=(Employee)em.find(Employee.class, ("012-34-5678"); tran.commit();
// Remove the employee entity tran.begin(); Employee employeetoremove =(Employee)em.find(Employee.class, ("012-34-5678"); em.remove(employeetoremove );
tran.commit();}
}
BenefitsThe EntityManager API is ideal when object relationships are involved. It provides an easy way to interact with a complex graph of related objects or Object graphs. There is a slight performance advantage over the ObjectMap API, as the EntityManager API uses tuple sets of only primitives with no reliance on serialization. There is optimized performance for queries and for loading objects from the back-end data source. The EntityManager API also may be easier to use due to its reliance on POJO-style programming which has been adopted by most enterprise application architectures.
LimitationsThe EntityManager requires the definition of schema in an entity.xml file. Applications may have to be re-architected to avoid complex relationships between objects and to ensure that there is an absolute relationship between a root and its branches (this relationship is known as constrained tree schema).
Chapter 2. WebSphere eXtreme Scale architecture and topologies 33
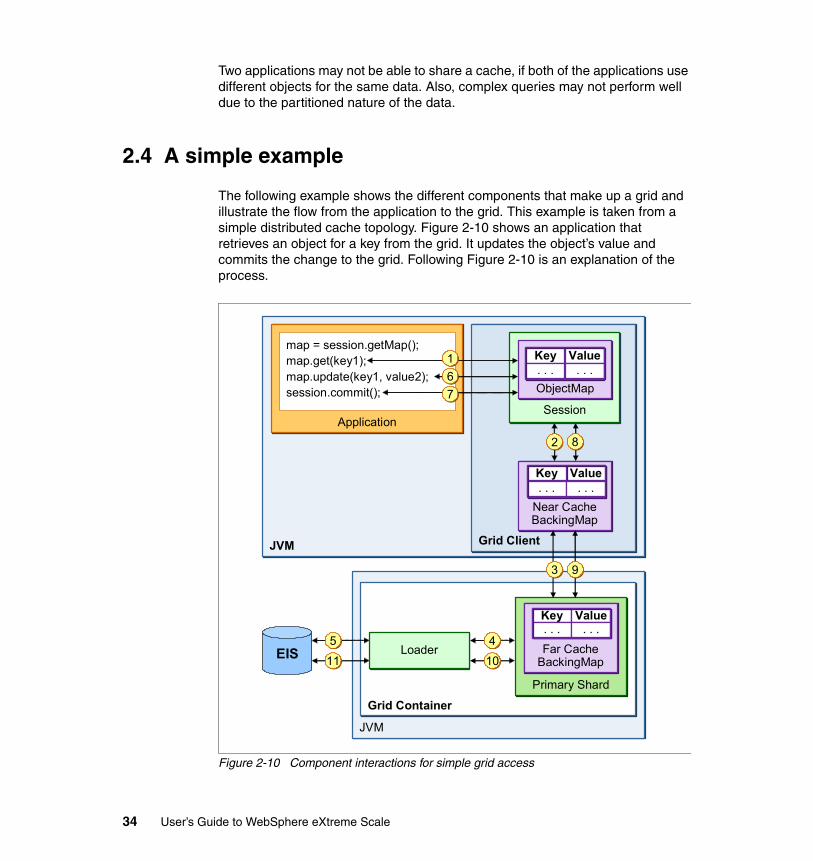
Two applications may not be able to share a cache, if both of the applications use different objects for the same data. Also, complex queries may not perform well due to the partitioned nature of the data.
2.4 A simple example
The following example shows the different components that make up a grid and illustrate the flow from the application to the grid. This example is taken from a simple distributed cache topology. Figure 2-10 shows an application that retrieves an object for a key from the grid. It updates the object’s value and commits the change to the grid. Following Figure 2-10 is an explanation of the process.
Figure 2-10 Component interactions for simple grid access
JVMJVM Grid ClientGrid Client
EIS
Near CacheBackingMapNear CacheBackingMap
ValueValueKeyKey. . .. . . . . .. . .
JVMJVM
Grid ContainerGrid ContainerPrimary ShardPrimary Shard
ApplicationApplication
map = session.getMap();map.get(key1);map.update(key1, value2);session.commit();
22 88
SessionSession
ObjectMapObjectMap
KeyKey. . .. . .
ValueValue. . .. . .
33 99
Far CacheBackingMapFar Cache
BackingMap
KeyKey. . .. . .
ValueValue. . .. . .
44
1010LoaderLoader
55
1111
116677
34 User’s Guide to WebSphere eXtreme Scale

1. The application requests an object from the grid for a given key. As this request is the first time that the object has been accessed, it is not yet present in the local session ObjectMap.
2. The grid client uses the ObjectMap to attempt to retrieve the object from the client near-cache (which is actually a local instance of a backing map). Assuming no other thread in the application has accessed this particular object, there is also a miss here.
3. The grid client determines the partition number in which the object for the key should reside. Usually, the primary shard of that partition is accessed. If readFromReplica was enabled, a replica shard might be accessed instead. If the grid container is collocated with the application in the same JVM or host, this adjustment could increase speed. In either case, the grid client connects to the selected shard and asks for the object.
4. The shard checks whether an object for the requested key is present in its backing map. This could have been achieved through preloading, but do not assume this status is not the case. In this case, the grid would return null, denoting the key is not available. The client would then be responsible for loading the data from the back-end datastore and using a put() to place it into the grid. In our example, a loader has been configured for the grid. This simplifies client programming, as only the grid needs to be accessed in order to retrieve and store what is needed from the back end datastore.
5. The loader is invoked to bring in the data from the back-end datastore, for example, using JDBC™, and the object is constructed. All previous calls store a copy of that object in its corresponding map and will return it to the caller. So, the object eventually arrives in the client.
6. The client changes the object for a given key and puts it back in the ObjectMap using the update() command. Note that the changes occur only in the session’s local copy of the object. Other sessions accessing that object cannot see this change yet.
7. The client commits the changes, which sets off a sequence of calls to propagate the changes into the grid and down to the back-end datastore.
8. The object is updated in the client near cache
9. The update is propagated to the backing map of the primary shard.
Note: You can also configure the grid to store a reference. Using a reference is faster and consumes less memory, but any change of the object is at once visible to all clients in the same JVM. Enabling reference is recommended only when the application can guarantee that the object will not be changed after read/commit.
Chapter 2. WebSphere eXtreme Scale architecture and topologies 35

10.The backing map updates the entry for the key. If replicas are configured, they are now contacted and informed of the update (not shown in this example). This can happen in synchronization (the operation will return only after the replica has been updated successfully) or asynchronization (the operation will return immediately). The backing map informs the loader to update the value. By default, this updating is also a synchronous operation. If write-behind is activated, this updating happens asynchronously. The client sees a successful update operation even when the back-end datastore is offline.
11.The Loader writes the changes to the back end, all calls unwind and return.
2.5 Zones
WebSphere eXtreme Scale introduced zone-based support in V6.1.0.3. Zone support provides much needed control of shard placement in the grid. Zone support is a significant competitive differentiator in the in-memory data grid (IMDG) space.
Zone support allows for rules-based shard placement, enabling high availability of the grid due to redundant placement of shards across physical locations. This notion is particularly appealing to enterprise environments that need data replication and availability across geographically dispersed data centers. In the past, these enterprise computing environments were limited due to the performance constraints imposed by networks and real-time data replication requirements. With the inclusion of Zone support, WebSphere eXtreme Scale offers better scalability by decoupling the grid environment. With Zone support, only the metadata shared by the catalog servers is synchronously replicated, while the data objects are copied asynchronously across networks. This not only enables better location awareness and access of objects, but also imposes fewer burdens on enterprise networks by eliminating the requirement of real time replication.
As long as catalog servers see zones being registered (as the zoned grid servers come alive), the primary and replica shards are striped across zones. Further, the zone rules described in the objectGridDeployment.xml file will dictate placement of synchronous or asynchronous replica shards in respective zones.
As a general practice, it is recommended that you place only synchronous replicas in same zone and asynchronous replicas in a different zone for optimal replication performance. This placement also would be optimal for scaling across geographies or data centers.
36 User’s Guide to WebSphere eXtreme Scale

Because core groups do not span zones, the catalog servers are placed one or two per data center or zones, and the catalog servers synchronize their object/shard routing information. A catalog service must be clustered for high availability in every zone. The catalog servers retain topology information of all of the containers in the ObjectGrid and controls balancing and routing for all clients.
Because catalog servers play a vital role in maintaining the catalog service and client routing, it is important to understand the concept of a catalog service quorum. A catalog service quorum is the minimum number of active catalog server members required for the grid system to operate correctly (that is, to accept membership registrations and changes to membership to ensure proper routing and shard placement).
This approach of ensuring the registration and consistency of grid servers is achieved only when a quorum is established between catalog servers. Writes to the catalog service state are committed only when the majority of the catalog servers participate in the transaction. Containers that are changing states cannot receive any commands, unless the catalog service transaction commits first. If the catalog service is hosted in a minority partition, that is, no quorum established, it accepts liveness messages. The catalog servers cannot, however, accept server registrations or membership changes, because the state is essentially frozen until the catalog service quorum is re-established. It is therefore recommended that you have catalog servers in odd numbers (preferably odd prime numbers).
Zone capability is useful to ensure that replicas and primaries are placed in different locations or zones for better fault tolerance. Normally, eXtreme Scale will not place a primary and replica shard on JVMs with the same IP address (with a user-configurable exception in development environments). This same notion of fault tolerance can now be extended to a grid that extends geographies. Zone rules can be configured and applied to ensure that the replica shards are placed in separate zones (in a different building or even in a different geography) from the zone that hosts the primary shard.
It is a standard practice to place a synchronous replica in the same zone (for high availability) and an asynchronous replica in a different zone. This configuration ensures high availability for a JVM failure in a local zone (synchronous replica), and ensures high availability in a complete data center failure (asynchronous replica).
This flexibility assures the availability of data to the application regardless of its zoned location. The catalog servers provide up-to-date routing information about the location of an object should the object not be found in the zone with the closest proximity to the application container.
Chapter 2. WebSphere eXtreme Scale architecture and topologies 37
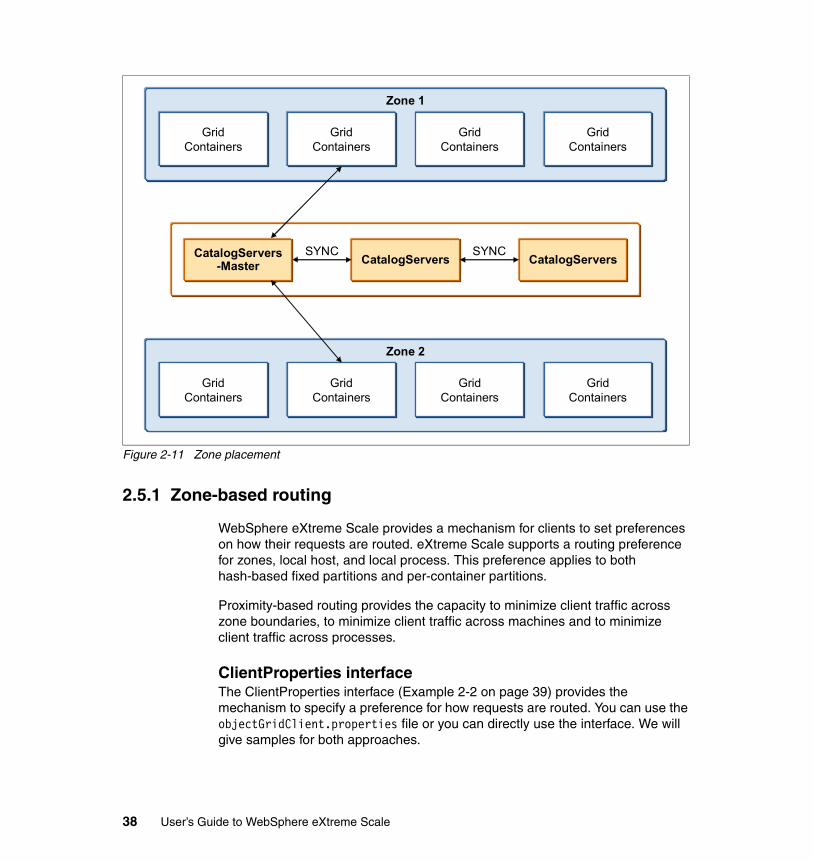
Figure 2-11 Zone placement
2.5.1 Zone-based routing
WebSphere eXtreme Scale provides a mechanism for clients to set preferences on how their requests are routed. eXtreme Scale supports a routing preference for zones, local host, and local process. This preference applies to both hash-based fixed partitions and per-container partitions.
Proximity-based routing provides the capacity to minimize client traffic across zone boundaries, to minimize client traffic across machines and to minimize client traffic across processes.
ClientProperties interfaceThe ClientProperties interface (Example 2-2 on page 39) provides the mechanism to specify a preference for how requests are routed. You can use the objectGridClient.properties file or you can directly use the interface. We will give samples for both approaches.
Zone 1
GridContainers
GridContainers
GridContainers
GridContainers
Zone 2
GridContainers
GridContainers
GridContainers
GridContainers
CatalogServers CatalogServersSYNC SYNCCatalogServers
-Master
38 User’s Guide to WebSphere eXtreme Scale

Example 2-2 ClientProperties
public interface ClientProperties { public void setPreferZones(String[] zones); public String[] getPreferZones();
void setPreferLocalProcess(boolean localProcess);void setPreferLocalHost(boolean localHost);public boolean isPreferLocalProcess();public boolean isPreferLocalHost();
}
The ClientProperties object is cached in the ClientClusterContext. You can retrieve or set the ClientProperties through ClientClusterContext.
ClientClusterContext With eXtreme Scale V6.1.0.3, two new methods have been added into the ClientClusterContext interface, as shown in Example 2-3:
Example 2-3 ClientClusterContext
public ClientProperties getClientProperties(String objectGridName);public void setClientProperties(String objectGridName, URL url);
� getClientProperties(ogName)
This method will retrieve the ClientProperties for this ObjectGrid. Each ObjectGrid can have a ClientProperties.
� SetClientProperties(ogName, url)
This method tells whether client properties file can be loaded with specific ObjectGrid.
Client properties file exampleThe first step is to create client properties file.
The sample objectGridClient.properties file is as shown in Example 2-4.
Example 2-4 objectGridClient.properties
# eXtreme Scale client configpreferLocalProcess = falsepreferLocalhost = falsepreferZones = Zone1, Zone2
The second step is to make client aware of the client properties file.
Chapter 2. WebSphere eXtreme Scale architecture and topologies 39

The default client property file name is objectGridClient.properties. eXtreme Scale searches for a client property file with this name during the client's startup and during client connect process in client classpath. If the file is found in the client classpath, it will be loaded automatically. If you use the default client properties file name, and if you also put that file in the root of your classpath, it will be loaded automatically and you do not need to do anything else.
If you use a different client properties file name, or if you put the client properties file outside of the classpath, you have two ways to make client aware of your properties file:
� Load the file in the application during your client connect process as shown in Example 2-5:
Example 2-5
ClientClusterContext ccc = manager.connect("localhost:2809", null, null); URL clientPropsURL = Thread.currentThread(). getContextClassLoader().getResource("etc/myObjectGridClient.properties"); ClientProperties props = ccc.setClientProperties("myOGName", clientPropsURL);
� Use the following system property to make client aware of your client properties file:
-Dcom.ibm.websphere.objectgrid.ClientProperties=<fileName>
Programming exampleExample 2-6 shows how to use getClientClusterContext, how to use getClientProperties, and how to set the routing preference to zones programmatically. This example also illustrates how you can override the preferences client property file sets programmatically.
Example 2-6 Setting zone based routing
ObjectGridManager manager = ObjectGridManagerFactory.getObjectGridManager(); ClientClusterContext ccc = manager.connect("localhost:2809", null, null); ClientProperties cp=ccc.getClientProperties("accounting"); String [] preferZones= new String[]{"Zone1", "Zone2"}; cp.setPreferZones(preferZones); ObjectGrid objectGrid = manager.getObjectGrid(ccc, "accounting"); Session session = objectGrid.getSession(); ObjectMap map = session.getMap("payroll"); session.begin(); map.insert("key", "value"); session.commit();
40 User’s Guide to WebSphere eXtreme Scale

Routing behaviorsWhen a client is set to prefer zones, the following routing behavior occurs:
1. eXtreme Scale looks for a target in the first zone in the preferred zones array. If a target is found and is available, eXtreme Scale routes to this target.
2. If the target is not available in that zone, eXtreme Scale tries the second zone in the preferred zones array. If a target is found, eXtreme Scale routes to that target.
3. If the target is not available in that zone, eXtreme Scale attempts to find an available target in each of the zones in the preferred zones array.
4. If eXtreme Scale cannot find an available target in any of the preferred zones, it routes the requests to other zones that are not in the preferred zones.
5. If eXtreme Scale cannot find an available target in any zone, it will throw a ServiceUnavailableException error.
When the preferZones preference is enabled, the preferLocalProcess and preferLocalhost settings are disabled automatically. Otherwise, the preferLocalProcess and preferLocalhost settings are enabled by default.
2.6 Scalability sizing considerations
WebSphere eXtreme Scale provides a scalable framework with a choice of runtime topologies to linearly extend (that is, the ability to grow the grid with increase in demand and data without increased overhead) the scalability of a data-driven transactional application. The discussion around performance, metrics, and sizing is beyond the scope of this Redbooks publication, but we are compelled to enumerate some significant sizing considerations. Sizing is an important topic, as stability and health of the grid is of paramount importance in ensuring a reliable enterprise caching platform. These carefully crafted imperatives are intended to serve as a guide during the initial design and planning phase of the WebSphere eXtreme Scale-enabled grid infrastructure.
Number of JVMsThis is probably the most common, yet still important consideration. While the eXtreme Scale grid offers linear scalability, insights into grid deployment, data size, and application patterns will suggest the size and volume of JVMs that will make up the grid. This insight is also an important data point to facilitate future growth of the grid. For instance, the grid deployment factors such as estimated partition size, number of partitions, number of synchronous and asynchronous replicas, desired availability, zoned deployment over geographies, and so forth, should be considered while deciding the total JVMs and size (in terms of memory allocation) of JVMs that make up the Grid.
Chapter 2. WebSphere eXtreme Scale architecture and topologies 41

Number of gridsThe decision to use one single grid for all enterprise applications hosted, or to allocate one dedicated grid instance for every application separately, is one that requires careful planning, analysis, thought, and deep insights into application patterns adopted. It is suggested as a leading practice that you dedicate a grid instance to every application. Some of most notable reasons for this suggested practice, are as follows:
� Isolation of data and infrastructure � Separation of grid boundary and maintaining grid independence� Chargeback based on usage in hosting environments� Scalability planning
Catalog serversAs discussed earlier, catalog servers play a central role in extreme scale grid management. It is therefore vital to plan for catalog server high availability and sizing requirements. As a rule of thumb, there should be at least two catalog servers for high availability. The decision on the number of catalog servers depends on overall grid size, desired high availability, and zones configuration.
Sizing for growthThe appeal of extreme Scale is the ability to scale linearly with growth. It is therefore vital to factor in the growth imperatives for ease of grid infrastructure administration and for accommodation of growth. Growth imperatives include decisions and considerations regarding grid topology, hardware requirements and availability, managed or stand-alone grid environment, and so forth. The driving factors are the resource (hardware and software) availability and the set of tasks involved in adding grid containers to expand the grid on demand. This imperative may also include the decision points and operational procedures required to add to the grid capacity.
It is important to plan the number of partitions you will need for both current capacity and future growth. Once you have deployed your applications you cannot simply add partitions or scale using more JVMs. A good guideline to follow is that at the end of your planning horizon, you should end up with 10 shards per partition.
42 User’s Guide to WebSphere eXtreme Scale

2.7 Common topology configurations
Before designing your topology, it is important to consider what type of software you will install on your servers to house your grid. There are two types of servers, stand-alone and managed (Network Deployment). You can use a combination of both type of servers.
2.7.1 Managed grid
You can use WebSphere Application Server Network Deployment servers to host your eXtreme Scale JVMs. The main benefit of this configuration is that you can more easily manage your environment using the administrative capabilities available in the WebSphere Network Deployment product. The clustering and high availability management features offered by the managed environment can be exploited. Grid extensibility becomes relatively easier in a managed environment, as creating grid servers to extend the grid is only a matter of a few clicks (as long as the capacity supports the grid expansion). Additionally, the commonly available monitoring tools that may already be employed to monitor the performance and availability of your environment can be used to monitor the grid servers.
2.7.2 Stand-alone grid
Stand-alone servers can use the client JVM of your choice to host the ObjectGrid. The main benefit of this configuration is the use of less expensive J2SE™ containers as grid servers that can hold the cache. Environments that already use J2SE for their applications may also be inclined to use J2SE/stand-alone containers. In this case, the inclusion of WebSphere eXtreme Scale as a platform may be the only new addition. While there are obvious cost advantages to using stand-alone servers, the downside is the possible lack of available management and monitoring solutions for the J2SE containers, which host the grid servers.
A common scenario that can be envisioned is the use of a Network Deployment managed environment to host enterprise applications and the use of a readily available J2SE runtime environment as the grid layer.
Regardless of which type of server is chosen, the core capability of WebSphere eXtreme Scale, which is a transactional, secure and scalable application cache fabric is available to be exploited. The issues around management and monitoring is environment-specific and a personal choice. Each topology discussed below can be implemented on either type of server or using a combination of servers of both types.
Chapter 2. WebSphere eXtreme Scale architecture and topologies 43
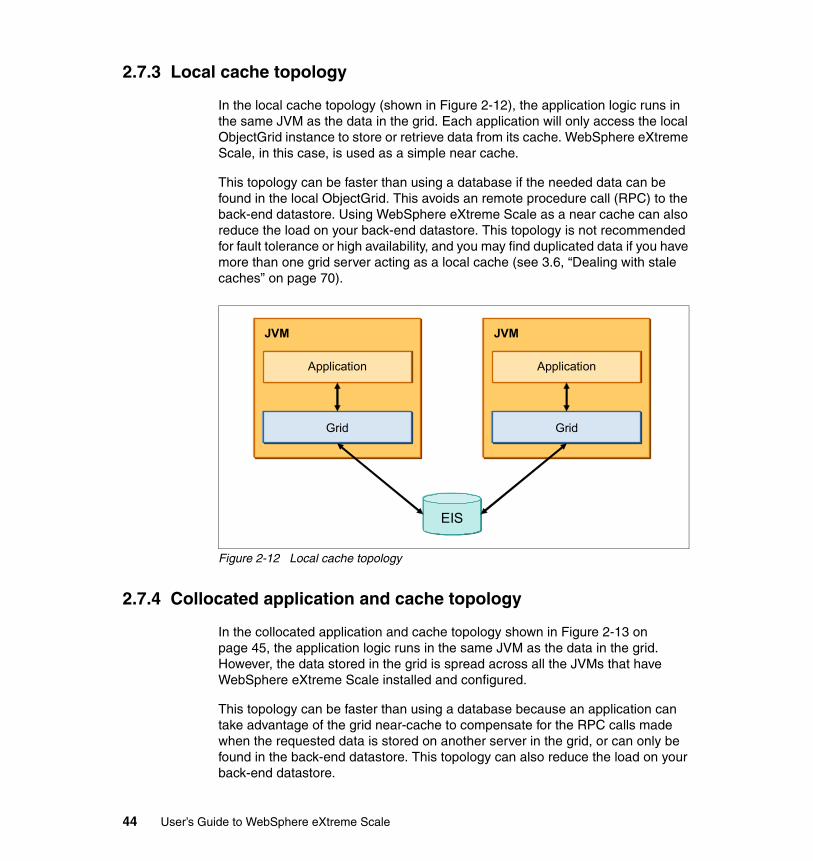
2.7.3 Local cache topology
In the local cache topology (shown in Figure 2-12), the application logic runs in the same JVM as the data in the grid. Each application will only access the local ObjectGrid instance to store or retrieve data from its cache. WebSphere eXtreme Scale, in this case, is used as a simple near cache.
This topology can be faster than using a database if the needed data can be found in the local ObjectGrid. This avoids an remote procedure call (RPC) to the back-end datastore. Using WebSphere eXtreme Scale as a near cache can also reduce the load on your back-end datastore. This topology is not recommended for fault tolerance or high availability, and you may find duplicated data if you have more than one grid server acting as a local cache (see 3.6, “Dealing with stale caches” on page 70).
Figure 2-12 Local cache topology
2.7.4 Collocated application and cache topology
In the collocated application and cache topology shown in Figure 2-13 on page 45, the application logic runs in the same JVM as the data in the grid. However, the data stored in the grid is spread across all the JVMs that have WebSphere eXtreme Scale installed and configured.
This topology can be faster than using a database because an application can take advantage of the grid near-cache to compensate for the RPC calls made when the requested data is stored on another server in the grid, or can only be found in the back-end datastore. This topology can also reduce the load on your back-end datastore.
EIS
JVM
ApplicationApplication
Grid
JVM
ApplicationApplication
Grid
44 User’s Guide to WebSphere eXtreme Scale
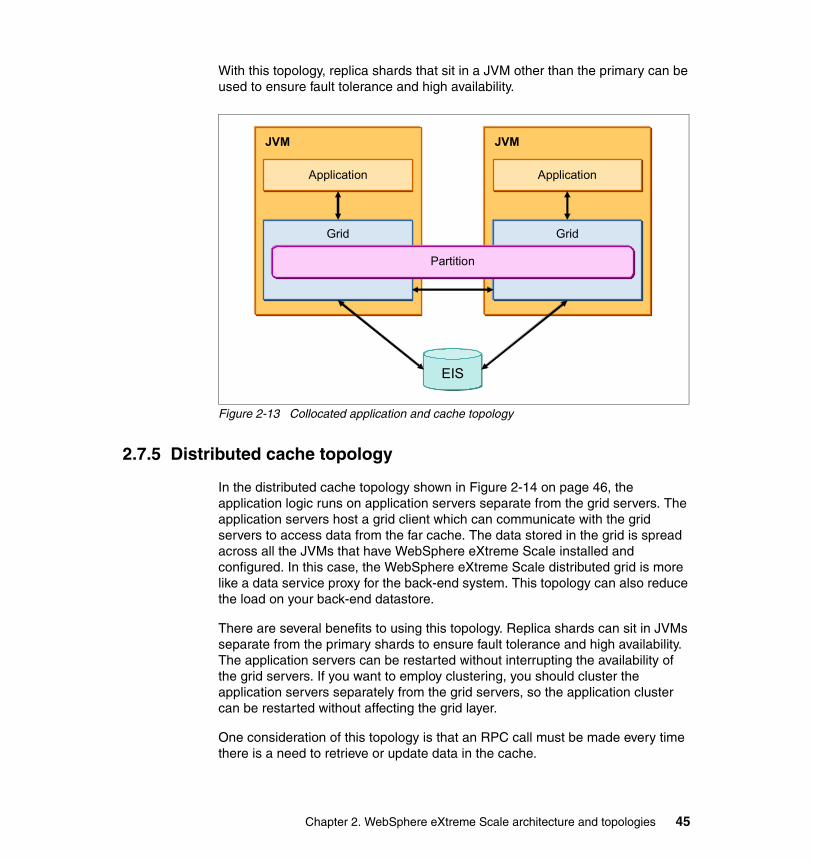
With this topology, replica shards that sit in a JVM other than the primary can be used to ensure fault tolerance and high availability.
Figure 2-13 Collocated application and cache topology
2.7.5 Distributed cache topology
In the distributed cache topology shown in Figure 2-14 on page 46, the application logic runs on application servers separate from the grid servers. The application servers host a grid client which can communicate with the grid servers to access data from the far cache. The data stored in the grid is spread across all the JVMs that have WebSphere eXtreme Scale installed and configured. In this case, the WebSphere eXtreme Scale distributed grid is more like a data service proxy for the back-end system. This topology can also reduce the load on your back-end datastore.
There are several benefits to using this topology. Replica shards can sit in JVMs separate from the primary shards to ensure fault tolerance and high availability. The application servers can be restarted without interrupting the availability of the grid servers. If you want to employ clustering, you should cluster the application servers separately from the grid servers, so the application cluster can be restarted without affecting the grid layer.
One consideration of this topology is that an RPC call must be made every time there is a need to retrieve or update data in the cache.
EIS
JVM
ApplicationApplication
Grid
JVM
ApplicationApplication
Grid
Partition
Chapter 2. WebSphere eXtreme Scale architecture and topologies 45
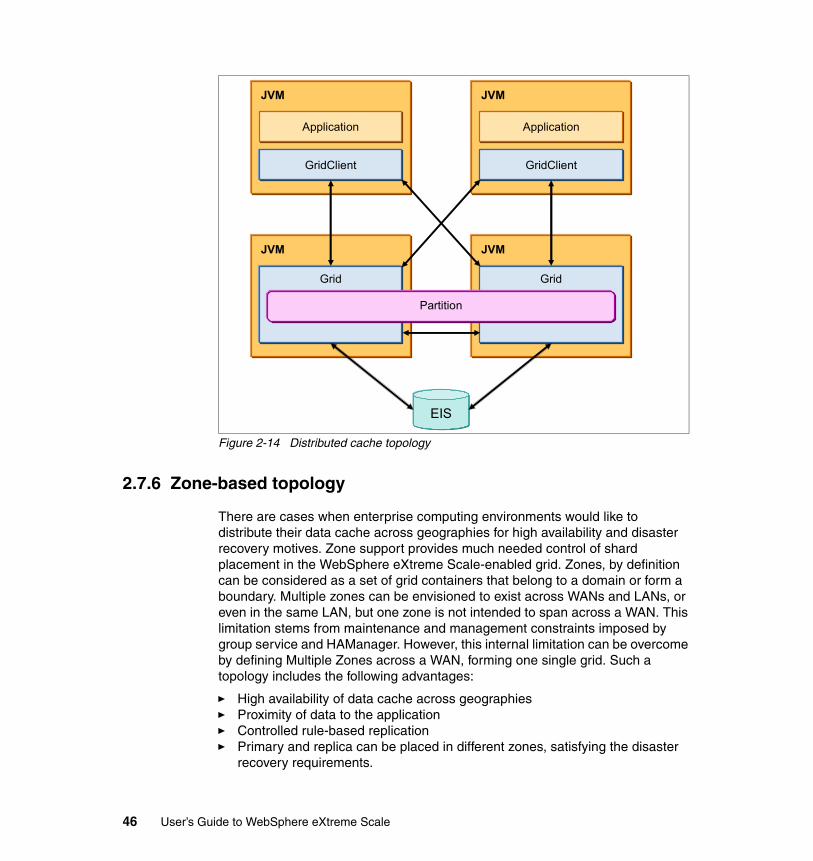
Figure 2-14 Distributed cache topology
2.7.6 Zone-based topology
There are cases when enterprise computing environments would like to distribute their data cache across geographies for high availability and disaster recovery motives. Zone support provides much needed control of shard placement in the WebSphere eXtreme Scale-enabled grid. Zones, by definition can be considered as a set of grid containers that belong to a domain or form a boundary. Multiple zones can be envisioned to exist across WANs and LANs, or even in the same LAN, but one zone is not intended to span across a WAN. This limitation stems from maintenance and management constraints imposed by group service and HAManager. However, this internal limitation can be overcome by defining Multiple Zones across a WAN, forming one single grid. Such a topology includes the following advantages:
� High availability of data cache across geographies� Proximity of data to the application� Controlled rule-based replication � Primary and replica can be placed in different zones, satisfying the disaster
recovery requirements.
JVM
ApplicationApplication
GridClient
EIS
JVM
Grid
JVM
Grid
Partition
JVM
ApplicationApplication
GridClient
46 User’s Guide to WebSphere eXtreme Scale
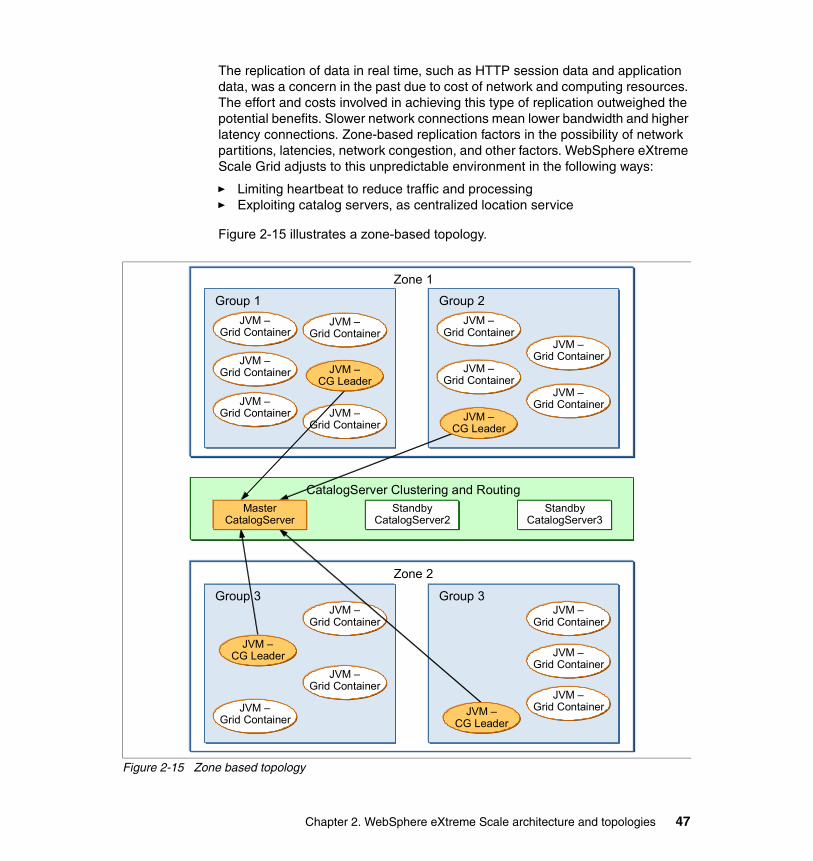
The replication of data in real time, such as HTTP session data and application data, was a concern in the past due to cost of network and computing resources. The effort and costs involved in achieving this type of replication outweighed the potential benefits. Slower network connections mean lower bandwidth and higher latency connections. Zone-based replication factors in the possibility of network partitions, latencies, network congestion, and other factors. WebSphere eXtreme Scale Grid adjusts to this unpredictable environment in the following ways:
� Limiting heartbeat to reduce traffic and processing� Exploiting catalog servers, as centralized location service
Figure 2-15 illustrates a zone-based topology.
Figure 2-15 Zone based topology
Zone 2
Zone 1
Group 1JVM –
Grid Container
JVM –Grid Container
JVM –Grid Container JVM –
Grid Container
JVM –Grid Container
Group 2JVM –
Grid Container
JVM –Grid Container
JVM –Grid Container
JVM –Grid Container
Group 3
JVM –Grid Container
JVM –Grid Container
JVM –Grid Container
Group 3JVM –
Grid Container
JVM –Grid Container
JVM –Grid Container
CatalogServer Clustering and RoutingStandby
CatalogServer2Standby
CatalogServer3Master
CatalogServer
JVM –CG Leader
JVM –CG Leader
JVM –CG Leader
JVM –CG Leader
Chapter 2. WebSphere eXtreme Scale architecture and topologies 47

48 User’s Guide to WebSphere eXtreme Scale

Chapter 3. Application scenarios
This chapter presents four different scenarios to show how WebSphere eXtreme Scale can be integrated with existing or new applications. It sets the stage by presenting a generic application architecture that is based on the IBM SOA Reference Architecture. Using this generic architecture as a foundation, it explains how WebSphere eXtreme Scale can be used.
For each scenario, a detailed description is provided, complete with possible variations, benefits, and limitations. Suggestions for suitable topologies to use with the scenario are also included.
This chapter concludes with a discussion on how to handle stale data in the cache. This issue is an important matter for every application that uses caching techniques to consider.
The following topics are covered in this chapter:
� “Introducing the scenarios” on page 50� “Side cache scenario” on page 57� “Second level cache scenario” on page 60� “Data access layer scenario” on page 61� “DataGrid computing scenario” on page 64� “Dealing with stale caches” on page 70
3
© Copyright IBM Corp. 2008. All rights reserved. 49

3.1 Introducing the scenarios
This chapter will introduce the WebSphere eXtreme Scale scenarios based on a generic application architecture. After introducing the architecture, we will derive the scenarios and show how they fit into an application.
3.1.1 Presenting a generic application architecture
Business applications are usually built of several different layered components. Each component layer has a well-defined responsibility, encapsulating certain logic (following the well-known IT principle of separation of duties). Figure 3-1 on page 51 is an architectural overview diagram which shows the generic application architecture. The architecture is based on IBM SOA Reference Architecture. It will be used to show the possible entry points for WebSphere eXtreme Scale.
See the following Web page for a general overview on SOA:
http://www.ibm.com/software/solutions/soa/
A good introduction into the reference architecture can be found in the IBM WebSphere Developer Technical Journal article Introducing the WebSphere Integration Reference Architecture, available at the following Web page:
http://www.ibm.com/developerworks/websphere/techjournal/0508_simmons/0508_simmons.html
Note: In a classic silo application, all components can be packed into a single J2EE Enterprise Application (EAR file) for deployment. In a multi-tier distributed environment, the components are deployed to different tiers in different EAR files. In a sophisticated SOA environment, each component offers its services and the interaction between components is established using a service integration bus.
50 User’s Guide to WebSphere eXtreme Scale
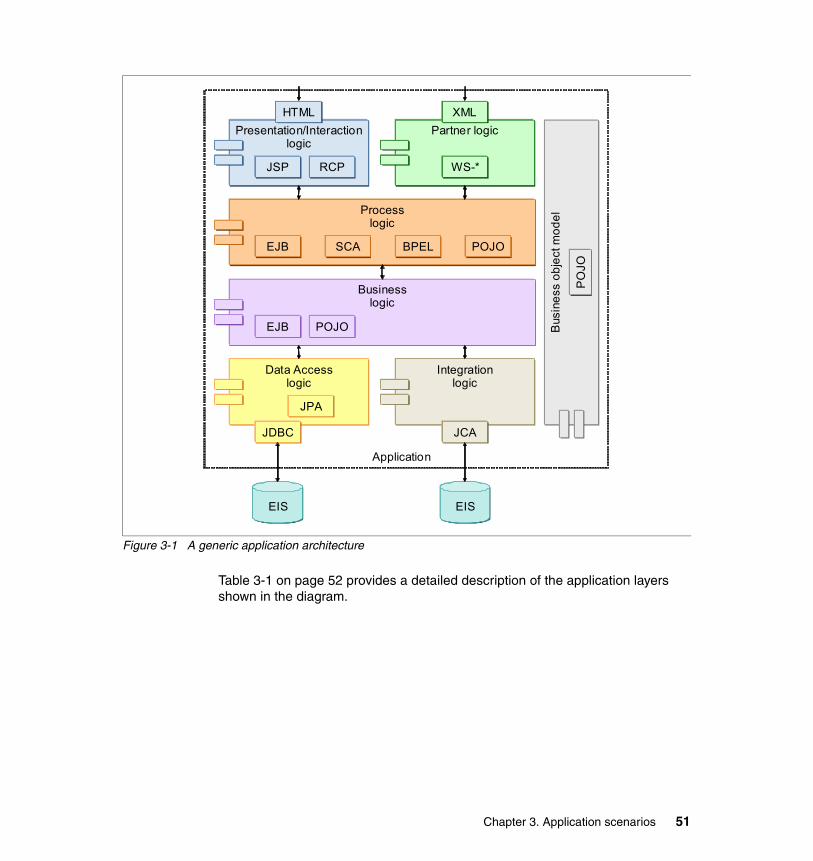
Figure 3-1 A generic application architecture
Table 3-1 on page 52 provides a detailed description of the application layers shown in the diagram.
Application
Presentation/Interactionlogic
RCPJSP
Partner logic
WS-*
Businesslogic
POJOEJB
Data Accesslogic
JPA
JDBC
Integrationlogic
JCA
Processlogic
SCAEJB POJOBPEL
HTML XML
EIS EIS
Bus
ines
s ob
ject
mod
el
PO
JO
Chapter 3. Application scenarios 51
Table 3-1 Descriptions of the architectural layers shown in Figure 3-1 on page 51
Layer Responsibility
Business object model
This layer contains business objects (such as Person, Account) that are used by all other layers. Often, the business objects also implement elementary and invariant business rules (that is, savings account cannot have a negative balance). The business object model might be deployed as a utility jar file.
Example Classes: AccountBO, PersonBO
Data access logic
This layer is responsible for retrieving and storing data in a database. It knows how to create business objects from results to queries against the database. The logic to modify the data might involve optimistic or pessimistic locking strategies. It is often implemented using some kind of persistence framework (for example, JPA) in conjunction with object/relational mapping technology to bridge the gap between a relational database and object oriented java. JDBC is frequently used to access a relational database. Because each data access request is self contained, services are usually stateless.
Example class: AccountManager.findAccountsWithNegativeBalanceBeyondLimit(...)
Integration logic
This layer is responsible for retrieving and storing data in a non-database back-end EIS system (such as a Customer Relationship Management or Accounting System). For example, it can contain mapping rules and aggregation logic to bridge the gap between an EIS object and an business object (that is, a Person object in the CRM system might have different attribute types than the business object model of the application, thus translation is required).
Often Java Connector Architecture (JCA) or other adapter technologies are used to connect to the back-end system. Message-oriented middleware such as WebSphere MQ provides the necessary connectivity. In larger enterprises, Enterprise Application Integration technology such as WebSphere ESB or WebSphere Message Broker can simplify implementation of this layer. Like the data logic layer, services are usually stateless.
Example classes: CRMManager.findLastContactDateForPerson(...)
Business logic
Complex business rules and algorithms are encapsulated in this layer. It uses data access or integration logic to get the required data and then applies the business logic to it. Thus, it provides the primitive building blocks for process logic. It is usually implemented in plain old Java objects, which can be accessed by a stateless session bean facade. As each invocation is self contained, services in this layer are usually stateless.
Example class: FraudFacade.evaluateFraudRiskBasedOnTransactionHistory(...)
52 User’s Guide to WebSphere eXtreme Scale
3.1.2 Introducing the scenarios
How does WebSphere eXtreme Scale fit into this generic application architecture? The type of integration depends on the layer. Therefore we will discuss several different scenarios:
� Side cache scenario� Second level cache for persistence frameworks� WebSphere eXtreme Scale as data access layer� DataGrid computing
As all layers need access to data, WebSphere eXtreme Scale can be used at every layer for caching in order to reduce response times. The first example of this caching is the side cache scenario.
Side cache scenarioA side cache scenario requires special caching logic code to be introduced into the application, or existing caching logic code augmented to use WebSphere eXtreme Scale. Every time data is needed, the grid is checked first. If the value is
Process logic
This layer implements business processes or application use cases. It orchestrates the business logic blocks into a whole process. Process logic can be a complete business process, or just a use case of an application. A process requires more complex communication between client and server. This communication can last several days or months. So the implementation is associated with some kind of state. In a SOA, it is externalized from the source code using Business Process Execution Language (BPEL) and executed using a BPEL container such as WebSphere Process Server.
Example class: CreateAccountPO.execute();
Presentation / Interaction logic
This layer enables a client to interact with the application. It is capable of presenting the data using a thin client (that is, Java Server Pages [JSP™]) or heavier clients (that is, Rich Client Platform (RCP). This layer often contains an implementation of the famous Model-View-Controller Design Pattern. Input validation might enforce simple business rules from the business object model.
Example classes: CreateAccountView, CreatAccountController
Partner logic Partner logic is used to interact with business partners. It is usually built on Web services technology. Like the integration logic, it contains mapping rules to adapt to differences in local business objects and remote business objects provided by the partner. Security aspects such as authentication and authorization are important, especially when services are offered to a partner.
Example classes: CreditRatingAgencyFacade.determineRatingForCustomer()
Layer Responsibility
Chapter 3. Application scenarios 53

not in the grid, the data is accessed using the existing mechanisms and then stored in the grid. The grid is located beside the application, hence the name. A special variation of this scenario is to use WebSphere eXtreme Scale to store HttpSession state information.
Naturally, the lower application layers are more likely to be an integration point for WebSphere eXtreme Scale because they are more data centric and thus benefit more from caching. We define two scenarios for this circumstance: the second level (L2) cache scenario and the WebSphere eXtreme Scale as a data access layer scenario.
Second level cache for persistence frameworksThis scenario is focused on data access layer implementations based on the persistence framework. Persistence frameworks frequently have a caching component to speed up the retrieval of objects. This caching component can be augmented to use WebSphere eXtreme Scale as a large and powerful second level cache. WebSphere eXtreme Scale provides out of the box support for the frameworks OpenJPA and Hibernate™. Integration into other frameworks can be implemented as long as the frameworks offer the necessary integration points.
For more information about OpenJPA, see the following Web page:
http://openjpa.apache.org/
For more information about Hibernate, see the following Web page:
http://www.hibernate.org/
WebSphere eXtreme Scale as data access layerIn this scenario, WebSphere eXtreme Scale is used as data access layer by the upper application layers. The WebSphere eXtreme Scale client APIs are used directly. The caching and data access logic becomes transparent as the grid provides the result regardless of whether it is in the cache or not. For certain entities, all rows might be located in the grid, providing extremely fast and scalable access. This scenario requires a loader to be implemented. WebSphere eXtreme Scale can be a natural extension to an existing data access layer.
The final scenario encompasses full scale grid style computing with extreme scalability and high availability.
DataGrid computingIn this scenario, the grid becomes the system of record. The back-end system is only used as a hardened data store for outages, and to support reporting and data warehouse access. The application is specially designed to use of an in-memory database to support extreme scalability and availability.
54 User’s Guide to WebSphere eXtreme Scale
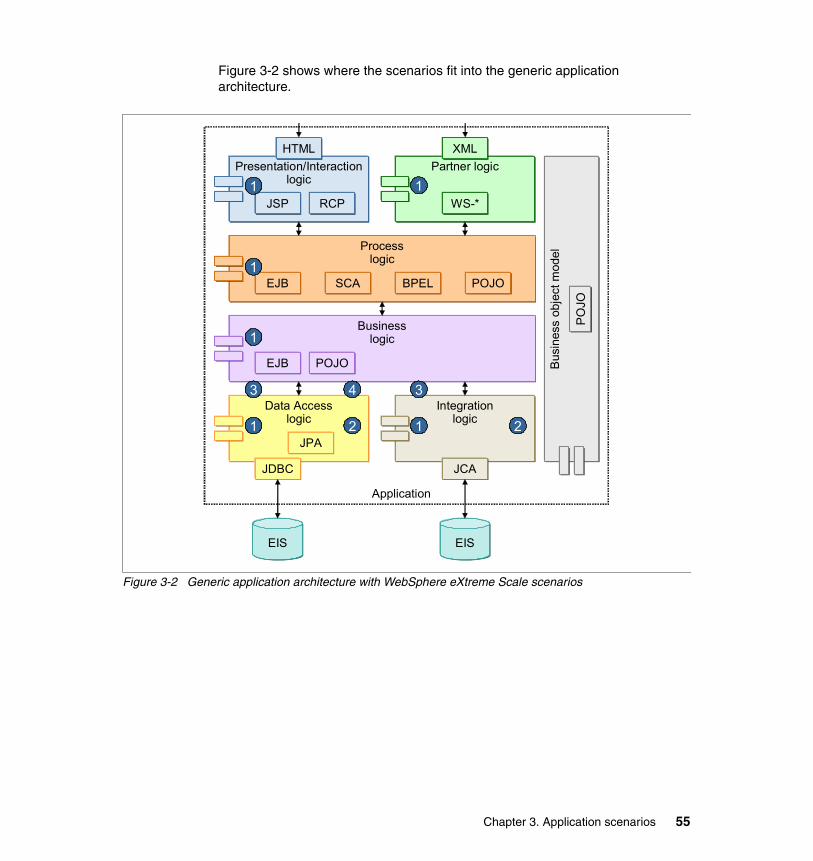
Figure 3-2 shows where the scenarios fit into the generic application architecture.
Figure 3-2 Generic application architecture with WebSphere eXtreme Scale scenarios
Application
Presentation/Interactionlogic
RCPJSP
Partner logic
WS-*
Businesslogic
POJOEJB
Data Accesslogic
JPA
JDBC
Integrationlogic
JCA
Processlogic
SCAEJB POJOBPEL
HTML XML
EIS EISB
usin
ess
obje
ct m
odel
PO
JO
1
1
1
1
43
1 2
3
1 2
Chapter 3. Application scenarios 55
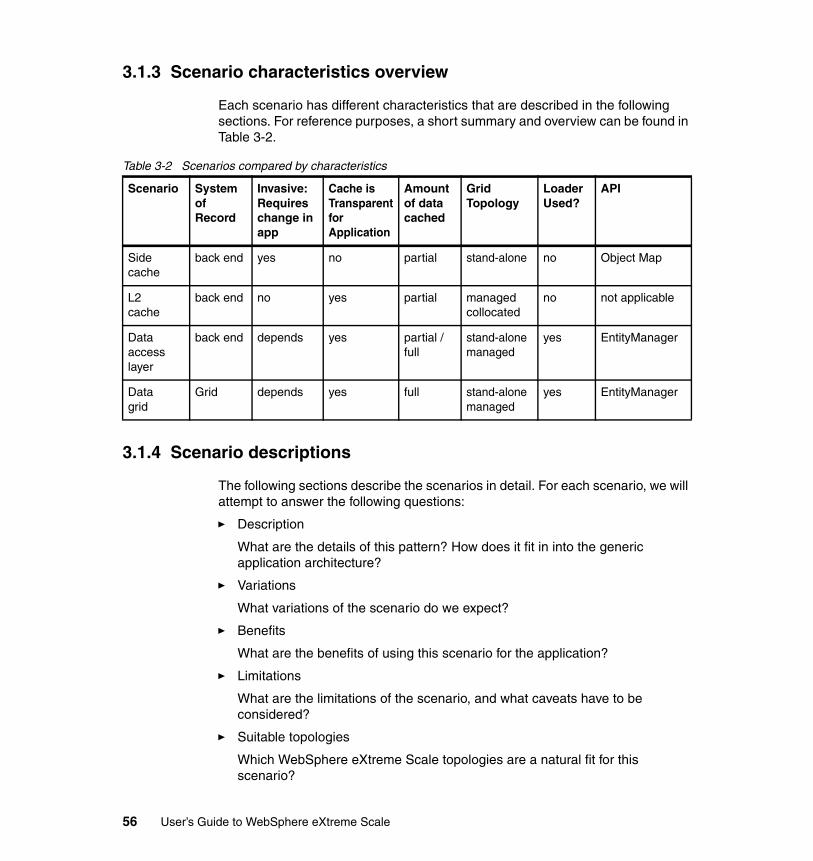
3.1.3 Scenario characteristics overview
Each scenario has different characteristics that are described in the following sections. For reference purposes, a short summary and overview can be found in Table 3-2.
Table 3-2 Scenarios compared by characteristics
3.1.4 Scenario descriptions
The following sections describe the scenarios in detail. For each scenario, we will attempt to answer the following questions:
� Description
What are the details of this pattern? How does it fit in into the generic application architecture?
� Variations
What variations of the scenario do we expect?
� Benefits
What are the benefits of using this scenario for the application?
� Limitations
What are the limitations of the scenario, and what caveats have to be considered?
� Suitable topologies
Which WebSphere eXtreme Scale topologies are a natural fit for this scenario?
Scenario System of Record
Invasive: Requires change in app
Cache is Transparent for Application
Amount of data cached
Grid Topology
Loader Used?
API
Side cache
back end yes no partial stand-alone no Object Map
L2 cache
back end no yes partial managed collocated
no not applicable
Data access layer
back end depends yes partial / full
stand-alone managed
yes EntityManager
Data grid
Grid depends yes full stand-alonemanaged
yes EntityManager
56 User’s Guide to WebSphere eXtreme Scale
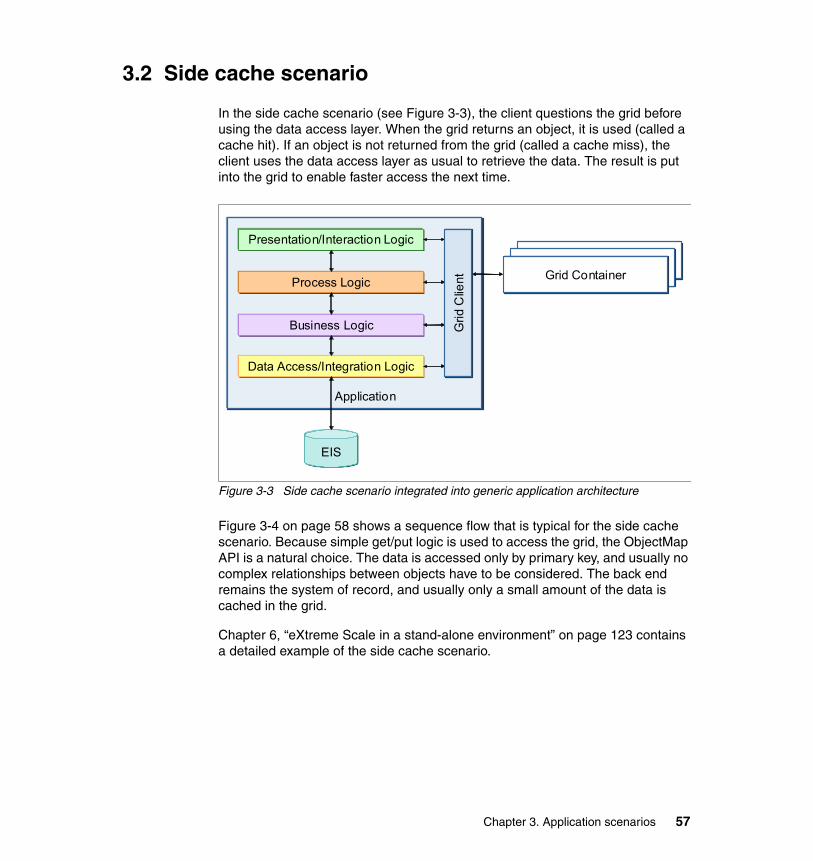
3.2 Side cache scenario
In the side cache scenario (see Figure 3-3), the client questions the grid before using the data access layer. When the grid returns an object, it is used (called a cache hit). If an object is not returned from the grid (called a cache miss), the client uses the data access layer as usual to retrieve the data. The result is put into the grid to enable faster access the next time.
Figure 3-3 Side cache scenario integrated into generic application architecture
Figure 3-4 on page 58 shows a sequence flow that is typical for the side cache scenario. Because simple get/put logic is used to access the grid, the ObjectMap API is a natural choice. The data is accessed only by primary key, and usually no complex relationships between objects have to be considered. The back end remains the system of record, and usually only a small amount of the data is cached in the grid.
Chapter 6, “eXtreme Scale in a stand-alone environment” on page 123 contains a detailed example of the side cache scenario.
EIS
Application
Grid ContainerGrid ContainerGrid ContainerGrid ContainerGrid ContainerGrid Container
Presentation/Interaction Logic
Business Logic
Data Access/Integration Logic
Process Logic
Grid
Clie
ntG
rid C
lient
Chapter 3. Application scenarios 57
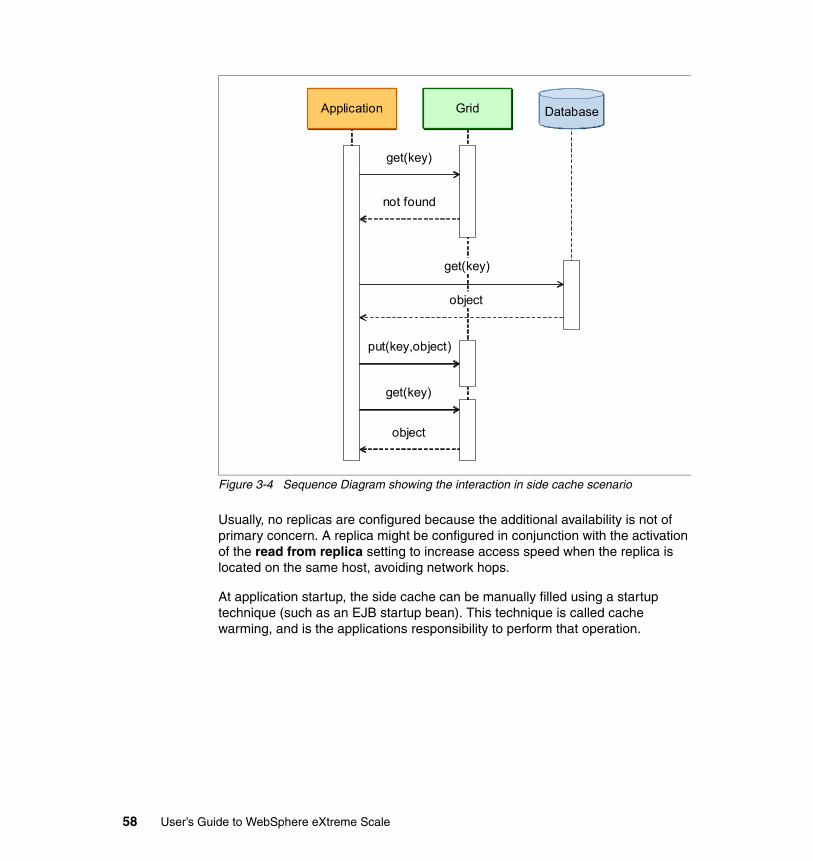
Figure 3-4 Sequence Diagram showing the interaction in side cache scenario
Usually, no replicas are configured because the additional availability is not of primary concern. A replica might be configured in conjunction with the activation of the read from replica setting to increase access speed when the replica is located on the same host, avoiding network hops.
At application startup, the side cache can be manually filled using a startup technique (such as an EJB startup bean). This technique is called cache warming, and is the applications responsibility to perform that operation.
get(key)
not found
get(key)
object
put(key,object)
get(key)
object
Application Grid Database
58 User’s Guide to WebSphere eXtreme Scale

3.2.1 Variations
A major variation of the side cache scenario is to use a side cache to store the application state. Stateful components often require fast but fail-safe persistence of state information to support high availability requirements. The HTTP session in the interaction layer is the prime example. Every request updates the session data. Instead of storing it in a database, a grid can be used. In case of session fail over, another cluster member has fast access to the state information, providing transparent compensation of a failed application server.
This variation is described in detail in Chapter 8, “Extended HTTP Session Management with WebSphere eXtreme Scale” on page 187.
3.2.2 Benefits
The primary benefit of using WebSphere eXtreme Scale in this scenario is that the cache contains less redundancy using partitioning. An object is stored only once in the cache, even if multiple clients use it. Thus, more memory can be used for caching, which increases the cache hit rate.
When the application already has some kind of caching logic, WebSphere eXtreme Scale can be easily integrated. If not, WebSphere eXtreme Scale is a perfect base for this logic, providing off the shelf solutions to non-trivial caching problems such as transaction handling.
3.2.3 Limitations
The side cache scenario supports access only on primary key bases. Complex queries cannot be supported, as the amount of data held in the grid is undefined, which would result in undefined query results.
When the grid container is not collocated with the application, near caches will be automatically created by WebSphere eXtreme Scale. Special attention has to be paid to handle stale data in these near caches.
Care has to be taken when a single transaction updates multiple partitions. This procedure is currently not supported by WebSphere eXtreme Scale. The easiest solution is to use multiple transactions, one for each partition.
Chapter 3. Application scenarios 59
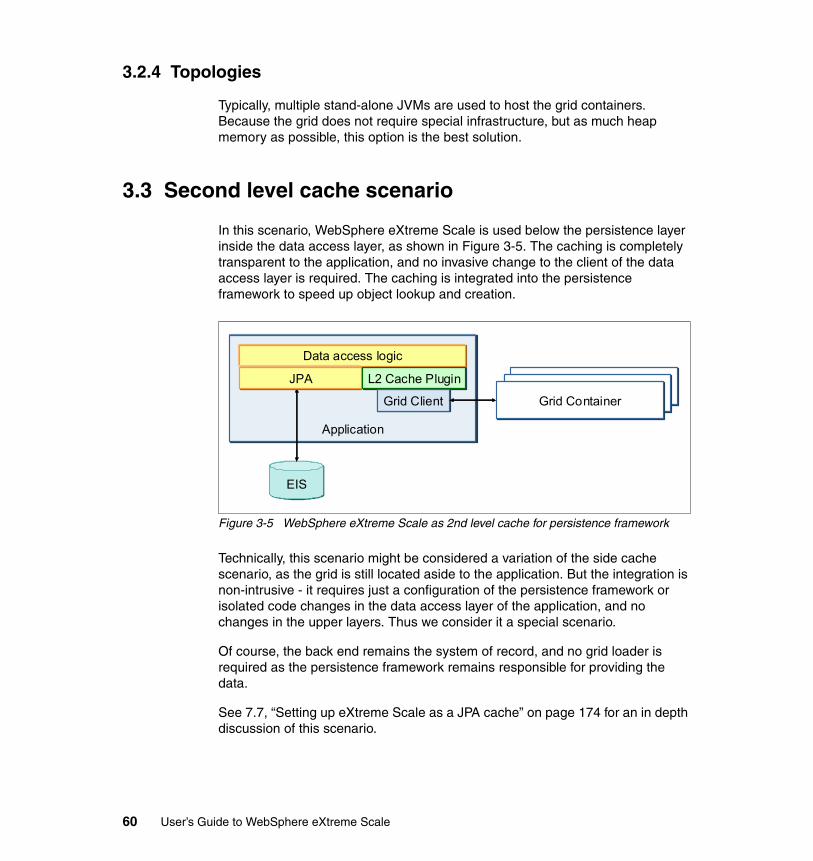
3.2.4 Topologies
Typically, multiple stand-alone JVMs are used to host the grid containers. Because the grid does not require special infrastructure, but as much heap memory as possible, this option is the best solution.
3.3 Second level cache scenario
In this scenario, WebSphere eXtreme Scale is used below the persistence layer inside the data access layer, as shown in Figure 3-5. The caching is completely transparent to the application, and no invasive change to the client of the data access layer is required. The caching is integrated into the persistence framework to speed up object lookup and creation.
Figure 3-5 WebSphere eXtreme Scale as 2nd level cache for persistence framework
Technically, this scenario might be considered a variation of the side cache scenario, as the grid is still located aside to the application. But the integration is non-intrusive - it requires just a configuration of the persistence framework or isolated code changes in the data access layer of the application, and no changes in the upper layers. Thus we consider it a special scenario.
Of course, the back end remains the system of record, and no grid loader is required as the persistence framework remains responsible for providing the data.
See 7.7, “Setting up eXtreme Scale as a JPA cache” on page 174 for an in depth discussion of this scenario.
EIS
Application
Grid ContainerGrid ContainerGrid ContainerGrid ContainerGrid ContainerGrid Container
Data access logic
JPA L2 Cache PluginL2 Cache Plugin
Grid ClientGrid Client
60 User’s Guide to WebSphere eXtreme Scale

3.3.1 Variations
Two variations of this scenario can be identified, depending on how it is implemented:
� Implementation by configuration
When a JPA implementation such as OpenJPA or Hibernate is used as the persistence framework, WebSphere eXtreme Scale can be simply configured as L2 cache to these frameworks.
� Custom implementation
For other persistence frameworks, an adapter has to be developed. Depending on the extension points the existing frameworks offers, this can be an easy or complex task.
3.3.2 Benefits
The application benefits from faster persistence access without major code changes. The L2 caches can be pre-loaded using a special API call.
3.3.3 Limitations
Usually the persistence layer interacts with the L2 cache after committing changes to the database. This interaction means that when the JVM dies after committing to the database and before updating the cache, the cache might become stale.
3.3.4 Topologies
As no special infrastructure is required for the grid container, a stand-alone topology is the preferred choice. It provides a maximum amount of memory available for caching.
3.4 Data access layer scenario
To use the grid-style computing WebSphere eXtreme Scale offers, the grid has to be used as a special data access layer for the upper layer. These layers will likely use the EntityManager API to access data. The grid is configured to use a loader to get data from the back-end system. Because the loader usually requires resources from the application, the grid is collocated to the application as show in Figure 3-6 on page 62.
Chapter 3. Application scenarios 61
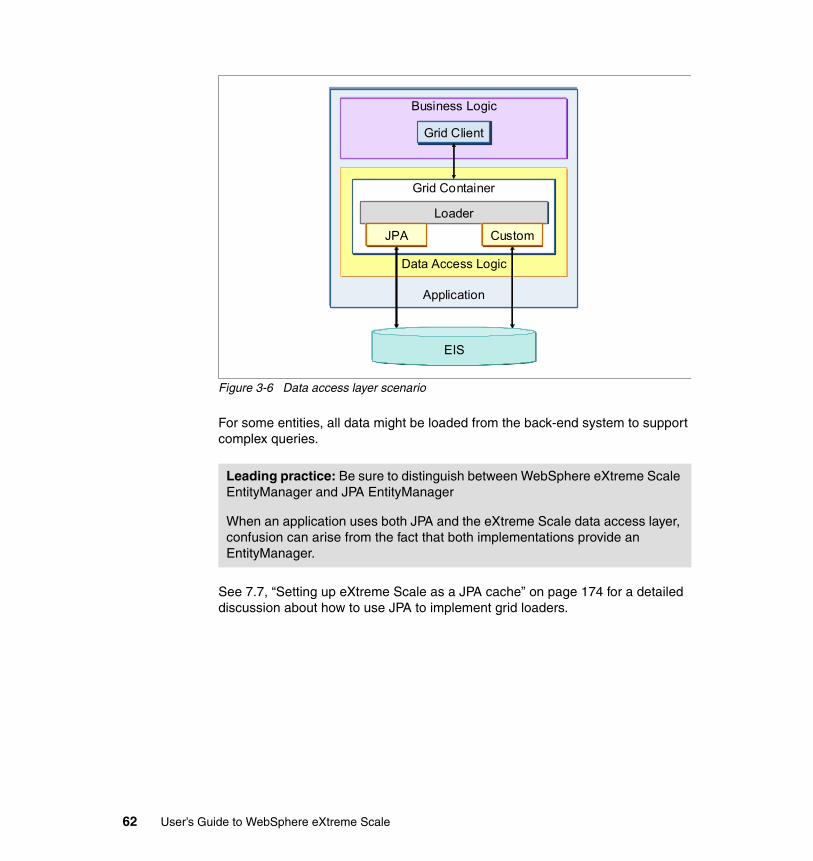
Figure 3-6 Data access layer scenario
For some entities, all data might be loaded from the back-end system to support complex queries.
See 7.7, “Setting up eXtreme Scale as a JPA cache” on page 174 for a detailed discussion about how to use JPA to implement grid loaders.
Leading practice: Be sure to distinguish between WebSphere eXtreme Scale EntityManager and JPA EntityManager
When an application uses both JPA and the eXtreme Scale data access layer, confusion can arise from the fact that both implementations provide an EntityManager.
Application
Business Logic
Grid ClientGrid Client
Data Access Logic
Grid ContainerGrid Container
EIS
LoaderLoader
JPA Custom
62 User’s Guide to WebSphere eXtreme Scale

3.4.1 Variations
Two variations of this scenario can be identified:
� Use JPA as loader implementation
The grid loader can be implemented based on a persistence framework such as JPA.
� Custom loader implementation
A custom loader might use JCA or the integration layer of the application to retrieve data from a non-relational back end. Even simple flat files might be easy to implement.
3.4.2 Benefits
Whether the data is in the cache or not becomes transparent to the application, it sees an extremely fast back-end access (assuming the cache is large enough to provide a good hit rate). For certain entities, pre-loading can be used to bring in all data from the back-end datastore into the cache. This pre-loading enables even complex queries against the data, without touching the back end at all.
The loader can be configured to asynchronously write back the changes to the back-end system. Configuring the loader decouples the application availability from back-end availability. Even when the back end is down, the application can write changes. They are buffered in the grid to be written back when the back-end system comes online again. Replicas of the data in the grid can be configured to ensure the data is not lost in case of grid container failure.
3.4.3 Limitations
When using write-behind caching, care has to be taken to handle error situations correctly. A write behind might fail (for example, the data has been changed in the back-end system and optimistic locking detects this change). These errors cannot be reported back to the client, as the client request already has been completed. We suggest that you handle this situation such as a failure of message processing in message oriented middleware. These systems provide an error/dead letter queue where such failed messages are stored. Operations staff or the application should provide procedures to check the failed messages and handle them correctly. WebSphere eXtreme Scale allows the same pattern: Failed write behind operations are stored in a special entity and can be retrieved from there.
The write-behind caching function (new in Extreme Scale V6.1.0.3) is discussed further in Chapter 7, “Using WebSphere eXtreme Scale with JPA” on page 147.
Chapter 3. Application scenarios 63
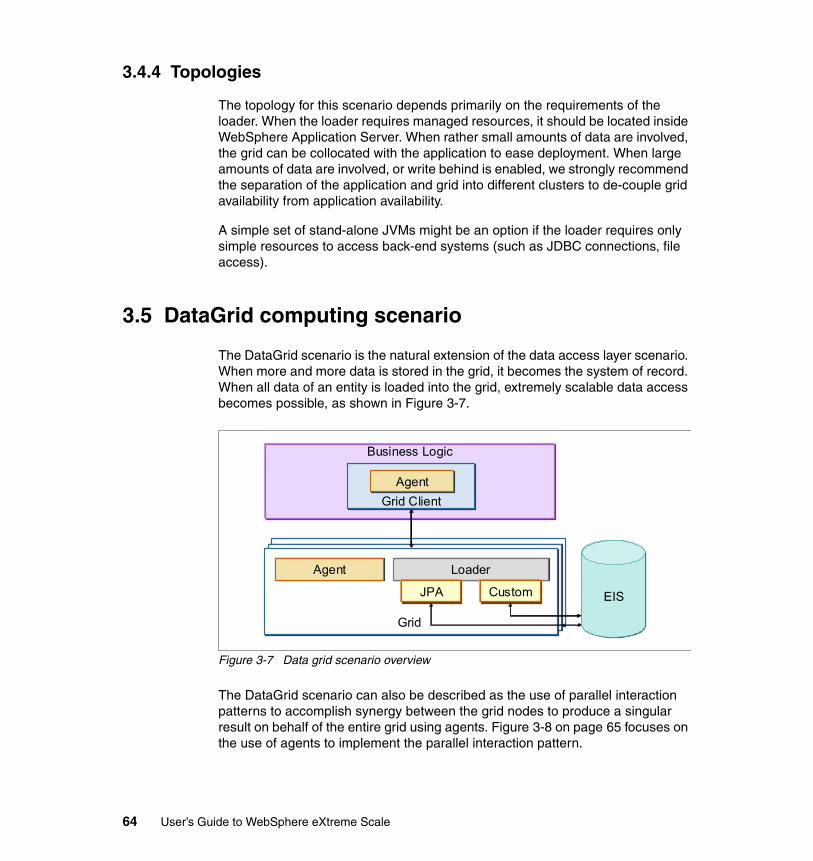
3.4.4 Topologies
The topology for this scenario depends primarily on the requirements of the loader. When the loader requires managed resources, it should be located inside WebSphere Application Server. When rather small amounts of data are involved, the grid can be collocated with the application to ease deployment. When large amounts of data are involved, or write behind is enabled, we strongly recommend the separation of the application and grid into different clusters to de-couple grid availability from application availability.
A simple set of stand-alone JVMs might be an option if the loader requires only simple resources to access back-end systems (such as JDBC connections, file access).
3.5 DataGrid computing scenario
The DataGrid scenario is the natural extension of the data access layer scenario. When more and more data is stored in the grid, it becomes the system of record. When all data of an entity is loaded into the grid, extremely scalable data access becomes possible, as shown in Figure 3-7.
Figure 3-7 Data grid scenario overview
The DataGrid scenario can also be described as the use of parallel interaction patterns to accomplish synergy between the grid nodes to produce a singular result on behalf of the entire grid using agents. Figure 3-8 on page 65 focuses on the use of agents to implement the parallel interaction pattern.
Business Logic
Grid Grid Grid Grid Grid Grid
LoaderLoaderAgentAgent
JPA Custom
Grid ClientGrid Client
EIS
AgentAgent
64 User’s Guide to WebSphere eXtreme Scale
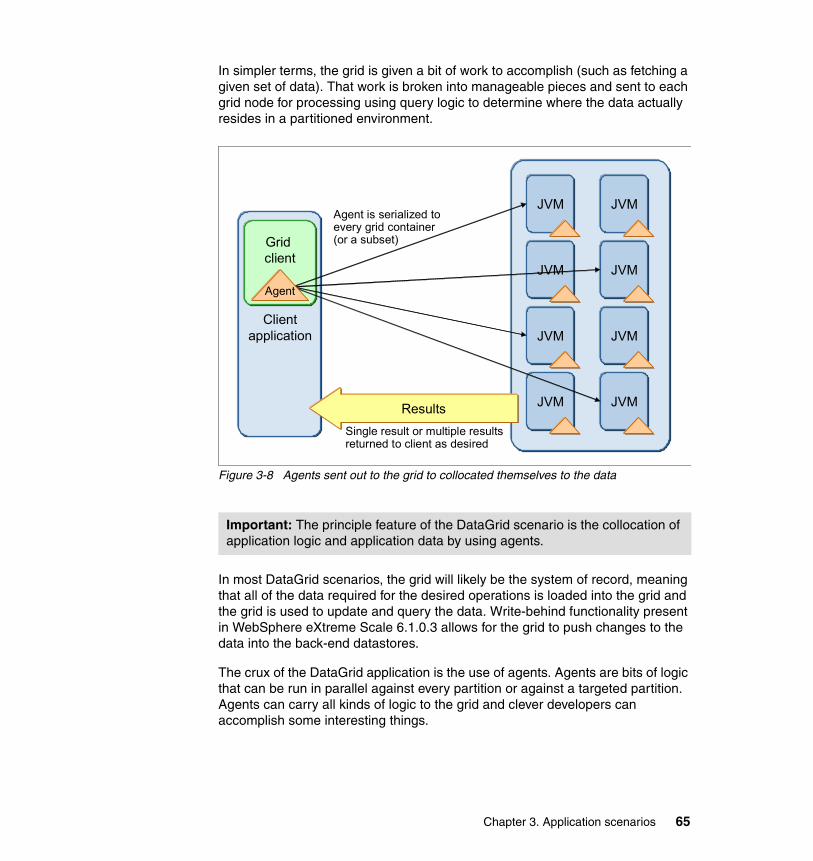
In simpler terms, the grid is given a bit of work to accomplish (such as fetching a given set of data). That work is broken into manageable pieces and sent to each grid node for processing using query logic to determine where the data actually resides in a partitioned environment.
Figure 3-8 Agents sent out to the grid to collocated themselves to the data
In most DataGrid scenarios, the grid will likely be the system of record, meaning that all of the data required for the desired operations is loaded into the grid and the grid is used to update and query the data. Write-behind functionality present in WebSphere eXtreme Scale 6.1.0.3 allows for the grid to push changes to the data into the back-end datastores.
The crux of the DataGrid application is the use of agents. Agents are bits of logic that can be run in parallel against every partition or against a targeted partition. Agents can carry all kinds of logic to the grid and clever developers can accomplish some interesting things.
Important: The principle feature of the DataGrid scenario is the collocation of application logic and application data by using agents.
Clientapplication
Grid client
Agent is serialized toevery grid container(or a subset)
Single result or multiple resultsreturned to client as desired
JVM JVM
JVM JVM
JVM JVM
JVM JVMResults
Agent
Chapter 3. Application scenarios 65

Agent creation and utilization is made possible with WebSphere eXtreme Scale’s DataGrid APIs. The DataGrid APIs provide a vehicle to run logic collocated with the data, query across partitions, and aggregate large result sets into a single result set (that is, the agent does the collation of the data into a single unit and returns it to the client).
Two major query patterns exist for DataGrid applications:
� Parallel Map
Allows the entries for a set of Entities or Objects to be processed and returns a result for each entry processed
� Parallel Reduction
Processes a subset of the entries and calculates a single result for the group of entries
Chapter 4, “Query engine” on page 79, contains a detailed discussion on the query engine of WebSphere eXtreme Scale.
3.5.1 Benefits
DataGrid applications exhibit several performance and efficiency benefits. Namely, the parallel nature of query agents allows for extremely large data sets to be queried quickly.
Because DataGrid applications generally do not touch the back-end datastores (except for write-behind scenarios) they produce little to no load on back-end datastores (that is, databases, adapters, and so forth.).
DataGrid applications use highly-scalable partitioned data. The partitions are hosted across all of the grid containers that make up the grid. More containers can be added to increase the capacity of the overall grid.
3.5.2 Limitations
If your DataGrid application does not use the grid as the system of record, it will be necessary to inform the grid of data changes in the back-end datastores. See 3.6, “Dealing with stale caches” on page 70 for a detailed discussion of this issue. It may also entail additional logic in the DataGrid application to decide whether to query the grid or the back-end datastore.
Note: DataGrids can scale linearly by adding new grid containers.
66 User’s Guide to WebSphere eXtreme Scale

Another caveat to the DataGrid is the inherent complexity that comes with dealing with partitioned data. Partitioning data intelligently in the grid requires thought and planning. Querying the grid is no different and the method that you choose to query the data effectively will be heavily influenced on the chosen design for the partitioning of your grid.
Note: Keep in mind that accessing the grid and performing queries over the data contained in the grid is not like using a database. In many cases it is not as straightforward as working with the database. This limitation is the trade-off for the linear scalability of the grid over the database solution.
Attention: If you need to query your DataGrid and you decide to query each partition individually (not using an agent), be aware that if you intend to change the data and write it back to the grid, you cannot write to multiple partitions within the same grid transaction. This course of action means that each partition’s data would have to be committed to the grid iteratively. This interaction restriction differs from the behavior seen in RDBMS systems. Again, this point illustrates that working with the grid is different than working with a database.
Chapter 3. Application scenarios 67
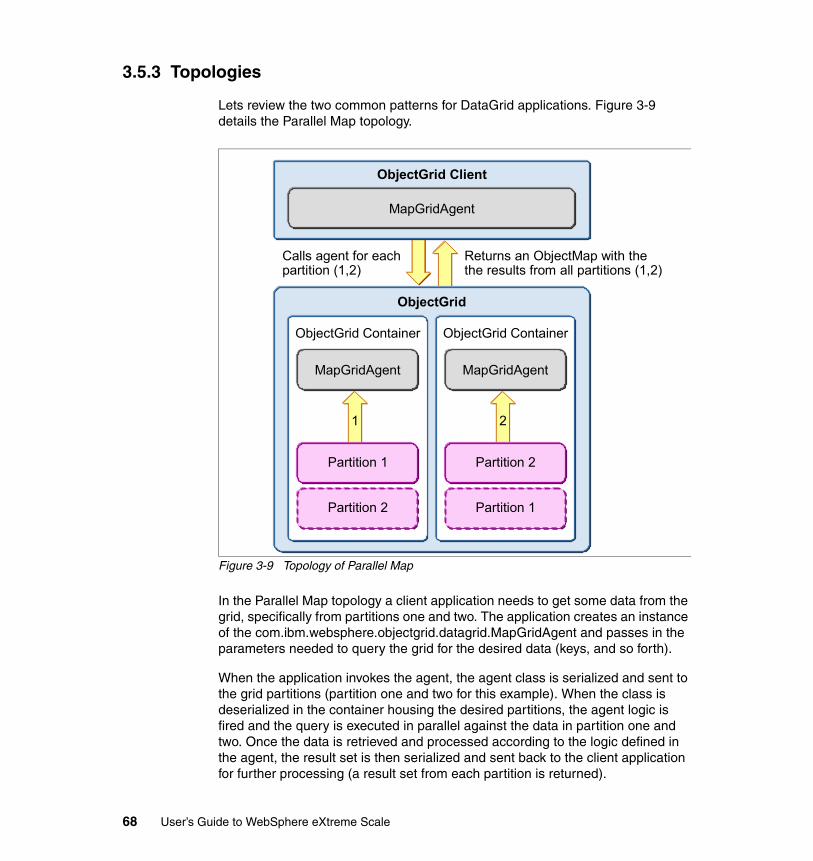
3.5.3 Topologies
Lets review the two common patterns for DataGrid applications. Figure 3-9 details the Parallel Map topology.
Figure 3-9 Topology of Parallel Map
In the Parallel Map topology a client application needs to get some data from the grid, specifically from partitions one and two. The application creates an instance of the com.ibm.websphere.objectgrid.datagrid.MapGridAgent and passes in the parameters needed to query the grid for the desired data (keys, and so forth).
When the application invokes the agent, the agent class is serialized and sent to the grid partitions (partition one and two for this example). When the class is deserialized in the container housing the desired partitions, the agent logic is fired and the query is executed in parallel against the data in partition one and two. Once the data is retrieved and processed according to the logic defined in the agent, the result set is then serialized and sent back to the client application for further processing (a result set from each partition is returned).
ObjectGrid
ObjectGrid Container
MapGridAgent
1
Partition 1
Partition 2
ObjectGrid Container
MapGridAgent
2
Partition 2
Partition 1
ObjectGrid Client
MapGridAgent
Calls agent for eachpartition (1,2)
Returns an ObjectMap with thethe results from all partitions (1,2)
68 User’s Guide to WebSphere eXtreme Scale
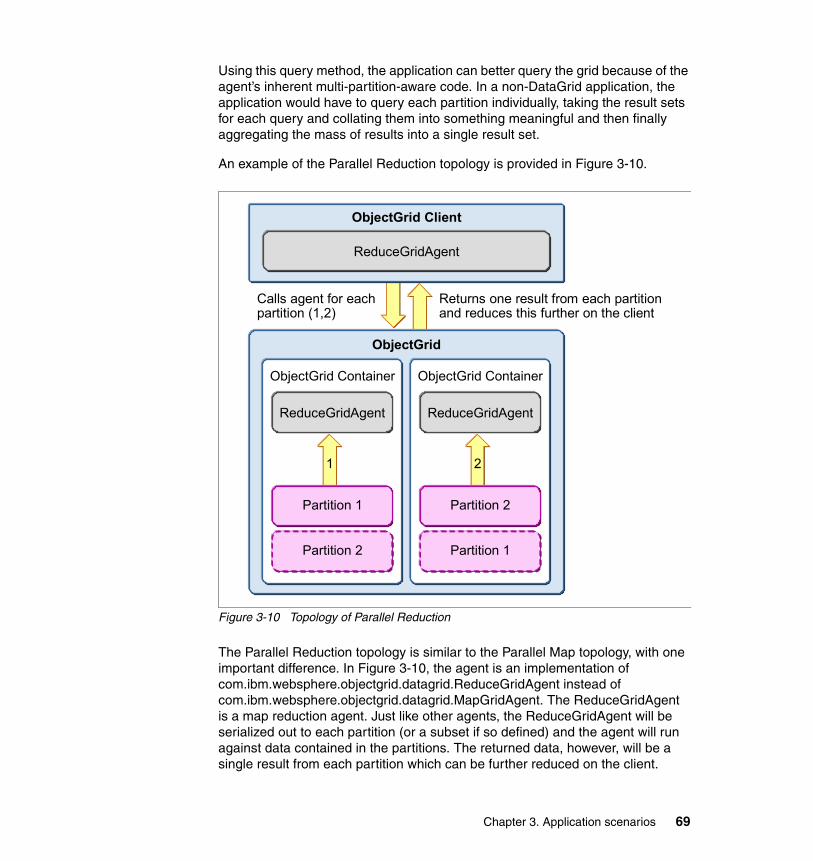
Using this query method, the application can better query the grid because of the agent’s inherent multi-partition-aware code. In a non-DataGrid application, the application would have to query each partition individually, taking the result sets for each query and collating them into something meaningful and then finally aggregating the mass of results into a single result set.
An example of the Parallel Reduction topology is provided in Figure 3-10.
Figure 3-10 Topology of Parallel Reduction
The Parallel Reduction topology is similar to the Parallel Map topology, with one important difference. In Figure 3-10, the agent is an implementation of com.ibm.websphere.objectgrid.datagrid.ReduceGridAgent instead of com.ibm.websphere.objectgrid.datagrid.MapGridAgent. The ReduceGridAgent is a map reduction agent. Just like other agents, the ReduceGridAgent will be serialized out to each partition (or a subset if so defined) and the agent will run against data contained in the partitions. The returned data, however, will be a single result from each partition which can be further reduced on the client.
ObjectGrid
ObjectGrid Container
ReduceGridAgent
1
Partition 1
Partition 2
ObjectGrid Container
ReduceGridAgent
2
Partition 2
Partition 1
ObjectGrid Client
ReduceGridAgent
Calls agent for eachpartition (1,2)
Returns one result from each partitionand reduces this further on the client
Chapter 3. Application scenarios 69

Because DataGrid applications deal with large grids, the topic of fault tolerance is likely to play a major role in the topology of the grid and its shards. The subject of replication zones is likely to arise. To learn more about zones, see the Developerworks article Zone Based Replication, available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/Jgb4
3.6 Dealing with stale caches
Whenever an application uses cache or grid functionality in conjunction with a hardened back-end datastore, the problem of stale data in the cache has to be considered. It might occur that the application reads old data from the cache, but the data has already been updated in the back end. This situation is called a dirty read because of a stale cache. This situation can have severe impacts for the application and the business it supports. It occurs frequently when a lot of external changes (that is, not managed by the application) are applied to the back-end datastore.
First of all, the requirements on cached data accuracy has to be determined by finding answers to the following questions:
� How acceptable is a dirty read? � What are the consequences if one occurs? � What is the maximum acceptable time between an update in the back-end
store and an update in the cache?
Note: Due to the large quantities of memory typically required by a DataGrid application, no grid shard is usually collocated with the application client code (that is, on the application server). The client code operates in a client mode only where it connects to a remote grid instance. It is possible, and sometimes advisable depending on the data needs, to use a near cache in the DataGrid application client. The near cache, in this instance, would be used to cache frequently queried data and prevent the cost incurred by serialization/deserializarion of the agent class and the remote procedure call out to the grid itself.
Important: Ensure that primary shards and replica shards are separated in a methodical and sensible way. Do not put replica shards on the same machine as the primary shard. WebSphere eXtreme Scale provides a mechanism to define zones in the grid. These zones allow for policy-based placement controls to be implemented (that is, maybe zone1 contains all primary shards whereas zone2 contains synchronous replicas or asychronous replicas).
70 User’s Guide to WebSphere eXtreme Scale

The answer to these questions depend on the type of data and the type of use cases the application drives against it. The answers can range from “dirty reads can occur and do not really matter” to “dirty reads are not acceptable in any case.”
For example, a social community Web application that uses a cache from which to read profile images of users can tolerate a dirty read quite easily. Showing an out of date image is a minor inconvenience, and probably not even noticed by other users.
A different example would be an online stock trading application that reads stock exchange rates from the cache for actual trades. A dirty read can result in a wrong price calculation, imposing a loss to the bank. That makes dirty reads intolerable, and the solution has to guarantee that they do not occur.
Accuracy requirements have to be established for each entity that is stored in the cache. Different entities might have different requirements for a single application.
In the following sections, we will discuss different options, and what WebSphere eXtreme Scales offers to deal with this issue.
3.6.1 Simply tolerate
If requirements permit, dirty reads can simply be accepted as a matter of fact.
3.6.2 Use time-based eviction strategies
Use a time-based eviction strategy (after 24 hours, every day at 04:00) to establish an upper bound for the dirty read time.
3.6.3 Cache polls the database for updates in regular intervals
The cache application polls the back-end store for the latest changes. This application can either invalidate the objects from the cache, or directly update it. Use information provided by the back-end store to determine changes. Examples can be a timestamp column “last modified” that denotes the point in time. In this
Note: This strategy can cause peak loads at the back end when a lot of invalidated data is re-read at a certain point in time. Or it can cause performance degradation because of a lot of cache misses after invalidation occurred.
Chapter 3. Application scenarios 71

case, it is easy to select all rows that have been changed since the last row. It is quite common for a business application to have a “last modified” timestamp for audit reason that can used right away.
If such a column is not already present, it might be introduced without changing the application by utilizing back-end store features to create and maintain this column. For example IBM DB2® UDB V9.5 supports a column defined as follows:
last_modified TIMESTAMP NOT NULLGENERATED ALWAYSFOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP
DB2 will ensure that the column last_modified is always updated.
Extreme Scale supports polling the database for changes out of the box for JPA using a TimeBasedDBUpdater. In 7.5, “Setting up the time-based updater” on page 165, you can find detailed instructions about how to use and configure it. The Class TimeBasedDBUpdater wiki also provides information about the Time-based updater. The wiki is available at the following Web page:
http://www.ibm.com/developerworks/wikis/objectgridprog/docs/api/com/ibm/websphere/objectgrid/jpa/dbupdate/TimeBasedDBUpdater.html
When JPA is not used, a simple WorkerThread can be spawned by the application to poll changes from the database and update the grid
3.6.4 Use JMS publish/subscribe to propagate changes
Stale data can arise when several clients use a near cache and have local copies for the same key, and then one client modifies this data. Per default, the other clients do not get notified of the modification, thus they have a stale object in their local cache.
Notes:
� This approach does not invalidate objects that have been deleted from the back end. Deleted objects are hard to select from a database for obvious reasons.
� Stale data can still exist with polling-based invalidation. There can be quite a large time period between the time data changes and the next poll, during which clients will get stale data.
72 User’s Guide to WebSphere eXtreme Scale

JMS Messaging, especially Publish/Subscribe using Topics can be used to pushes changes from the grid to near caches residing at the client. Extreme Scale supports this feature using the JMSObjectGridEventListener. See the Class JMSObjectGridEventListener wiki available at the following Web page:
http://www.ibm.com/developerworks/wikis/objectgridprog/docs/api/com/ibm/websphere/objectgrid/plugins/builtins/JMSObjectGridEventListener.html
An example usage of the JMSObjectGridEventListener is depicted in Figure 3-11 on page 74. It shows two grid clients of a single grid. Both clients have configured a near cache to store local data using the grid client config file as described in the Configuring an ObjectGrid client wiki available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/o4Eu
When client #1 updates the key, client #2 has stale data in the cache. A JMSObjectGridEventListener is configured in the publisher role so that it sends an invalidation event from the grid to the client using a JMS provider (for example, WebSphere MQ, or the service integration bus provided with WebSphere Application Server). Another JMSObjectGridEventListener is configured in the subscriber role to consume the event and invalidate the data in client #2.
Leading practice: Use small near caches with quick eviction strategy.
Stale near caches can be avoided by configuring a small cache size and an eviction strategy that promptly removes the objects from the near cache. Keep in mind that there is a large grid behind the near cache, and it is not expensive to get the data from the grid again. So the benefits from a near cache are pretty small. The grid has lower redundancy of objects to free more space for caching, and a clever replication mechanism to ensure availability and consistency. Take advantage of these mechanisms!
Chapter 3. Application scenarios 73
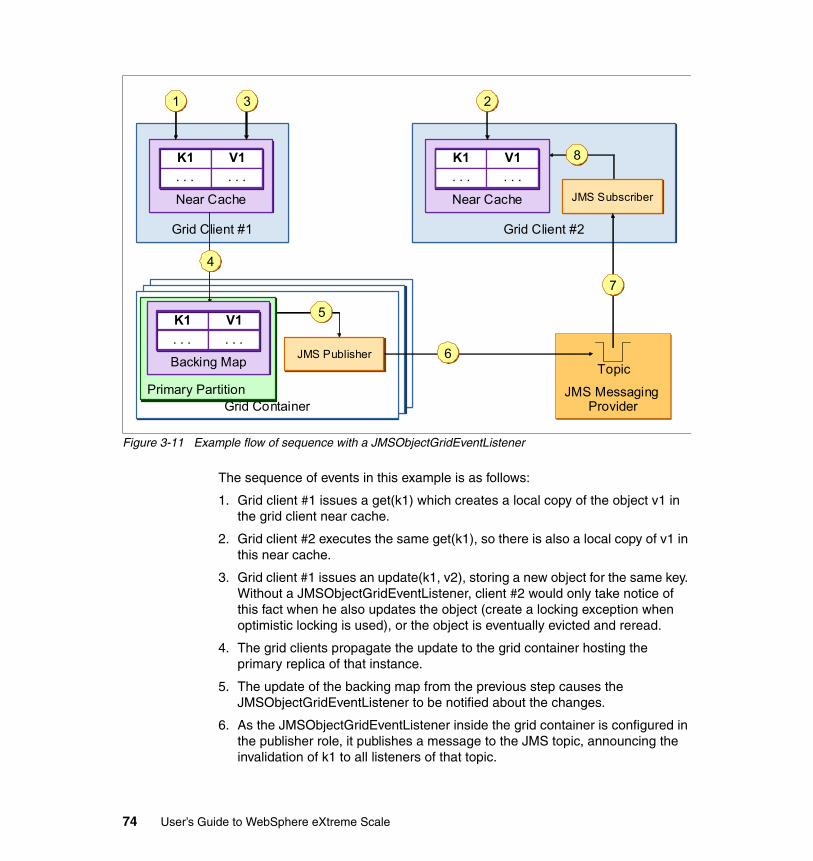
Figure 3-11 Example flow of sequence with a JMSObjectGridEventListener
The sequence of events in this example is as follows:
1. Grid client #1 issues a get(k1) which creates a local copy of the object v1 in the grid client near cache.
2. Grid client #2 executes the same get(k1), so there is also a local copy of v1 in this near cache.
3. Grid client #1 issues an update(k1, v2), storing a new object for the same key. Without a JMSObjectGridEventListener, client #2 would only take notice of this fact when he also updates the object (create a locking exception when optimistic locking is used), or the object is eventually evicted and reread.
4. The grid clients propagate the update to the grid container hosting the primary replica of that instance.
5. The update of the backing map from the previous step causes the JMSObjectGridEventListener to be notified about the changes.
6. As the JMSObjectGridEventListener inside the grid container is configured in the publisher role, it publishes a message to the JMS topic, announcing the invalidation of k1 to all listeners of that topic.
Grid Client #1Grid Client #1 Grid Client #2Grid Client #2
JMS SubscriberJMS Subscriber
Topic
JMS Messaging Provider
Topic
JMS Messaging Provider
Near CacheNear Cache
K1K1. . .. . .
V1V1. . .. . .
Near CacheNear Cache
K1K1. . .. . .
V1V1. . .. . .
77
Grid ContainerGrid ContainerPrimary PartitionPrimary Partition
55
44
88
3311 22
JMS PublisherJMS PublisherBacking MapBacking Map
K1K1. . .. . .
V1V1. . .. . .
66
74 User’s Guide to WebSphere eXtreme Scale

7. The JMS Provider pushes the message to all subscribers, especially client #2.
8. The JMSObjectGridEventListener is configured in the subscribe role, thus it receives and processes the invalidation message. Thus, the stale data v1 for k1 is removed from the near cache of client #2.
This is just one example usage of JMSObjectGridEventListener. Consider the following points:
� A JMS topic is used for communication. Many client can be subscribed to a topic. So with a single message to a topic, all clients can invalidate their data.
� The example publishes an invalidation message. The JMSObjectGridEventListener can be configured to push an update message containing the new object, so the subscriber can directly update the near cache instead of only invalidating it.
� Every grid member (client or server) can be in the publisher or subscriber role, or both. A valid configuration in the above example would be to configure Client #2 in subscriber and publisher role. This approach would result in the updates from client #2 being directly published to the JMS Topic.
� The JMSObjectGridEventListener can be used to synchronize any two grids. This approach can be useful when strong separation between grids (for example, data centers located in different geographies) prohibit tight coupling using IIOP, but data exchange using message oriented middleware is a valid option.
3.6.5 Make sure no external changes to the backing store occur
This approach prohibits external changes to be directly applied to the backing store. Instead, every change to the data is only allowed through applications that participate in the cache. This approach can be difficult if other components or applications that are not aware of the cache have write access to the backing store. For example, subsystems, interfaces to external systems, data cleansing scripts, and so forth would not be allowed to change data.
3.6.6 Make sure all external change processes notify the grid
Instead of prohibiting all external changes as in the previous approach, this approach envisions that the grid is notified of all external changes. Figure 3-12 on page 76 gives an example of this approach. All database scripts or other external modifications need to be equipped with a grid client that notifies the grid about changes. The easiest notification would be to invalidate the data in the cache. A more sophisticated solution might be able to directly update the data.
Chapter 3. Application scenarios 75

The downside of this approach is that it might be difficult to ensure that all scripts, applications, and so forth, are aware of the grid.
Figure 3-12 Notification of external changes to the grid
3.6.7 Push the changes from the back end store up to the grid
For SQL databases, post-insert, update, and delete triggers can be used to invalidate or update the grid as depicted in Figure 3-13 on page 77. This approach requires a grid client to be embedded into the database, which is not a problem as long as the database supports triggers that are implemented in java.
The triggers are usually executed before the transaction is committed. This circumstance can lead to an unnecessary cache invalidation when the transaction is rolled back in the end. But this invalidation is acceptable when dirty reads cannot be tolerated. It is better to have an unneccessary invalidation than a stale object.
Grid ContainerGrid Container
RDBMS
Backing MapBacking Map
KeyKey. . .. . .
ValueValue. . .. . .
TableTable
KeyKey. . .. . .
ValueValue. . .. . .
......……
......……
SQL ScriptSQL Script
UPDDELINS...
UPDDELINS...
Grid ClientGrid Client
76 User’s Guide to WebSphere eXtreme Scale
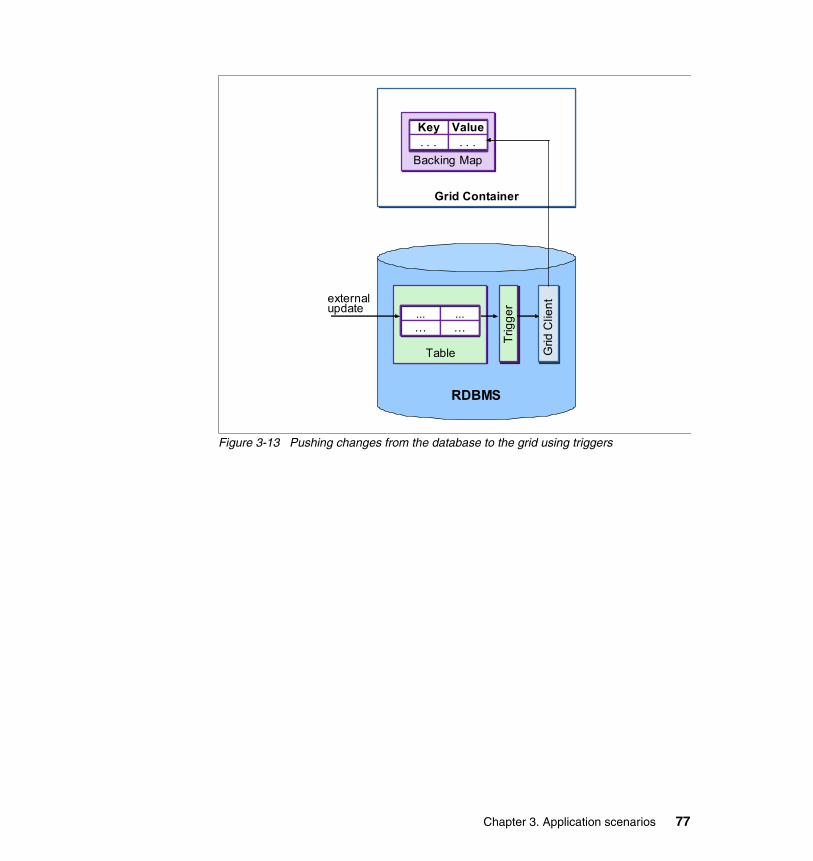
Figure 3-13 Pushing changes from the database to the grid using triggers
Grid ContainerGrid Container
RDBMS
Grid
Clie
ntG
rid C
lient
Backing MapBacking Map
KeyKey. . .. . .
ValueValue. . .. . .
TableTable
KeyKey. . .. . .
ValueValue. . .. . .
......……
......……
Trig
ger
Trig
gerexternal
update
Chapter 3. Application scenarios 77

78 User’s Guide to WebSphere eXtreme Scale

Chapter 4. Query engine
As more and more data is stored in a grid, it may make sense to access data not only by primary key, but to use more sophisticated queries against the data. If the grid is going to be a database shock absorber, it must support complex queries against the data. WebSphere eXtreme Scale provides a flexible query engine. This chapter discusses the current eXtreme Scale query capabilities.
The following topics are covered in this chapter:
� “Introducing Object Grid Query Language” on page 80� “Considerations when using queries” on page 82� “Translating SQL to OGQL examples” on page 86
4
© Copyright IBM Corp. 2008. All rights reserved. 79

4.1 Introducing Object Grid Query Language
WebSphere eXtreme Scale offers functionality to run SELECT type queries using Object Grid Query Language (OGQL). OGQL is based on Java Persistence Query Language (JPQL). Like JPQL, objects and attributes are used instead of tables and columns as used with SQL (Structured Query Language).
Executing queries against a grid requires schema information. When the entity manager API is used, the existing entity schema definition (using annotations or XML) will be used. When the object map API is used, the query schema has to be defined programmatically or through XML.
The query engine of WebSphere eXtreme Scale has the following capabilities, briefly mentioned here.
� Single and multi-valued results� Aggregate functions� Sorting and grouping� Joins� Conditional expressions with sub queries� Named and positional parameters� Index utilization� Path expression syntax for object navigation� Pagination
For a detailed explanation of each capability, see the ObjectGrid Query API wiki, available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/DIYd
To introduce the query language, a simple example can be found in Example 4-1. It shows a query that retrieves a list of Customer objects that have orders above a certain limit. Note that customers can have multiple orders.
Example 4-1 Query retrieving a list of customers with orders above a limit.
SELECT DISTINCT custFROM Customer cust JOIN cust.orders ordWHERE ord.state = 'Active' AND ord.totalPrice > ?1ORDER BY cust.lastName
80 User’s Guide to WebSphere eXtreme Scale

Example 4-2 shows a sample code snippet of how the EntityManager APIs can be used to execute the sample query. The lines in bold mark the query creation, and result retrieval.
Example 4-2 Sample code snippet using EntityManager query API to execute a query.
public Collection<Customer> findCustomersWithOrdersOverLimit(EntityManager em, double limit) throws Exception {
// Define Query String queryString = ...; // Query string from example above em.getTransaction().begin(); Query q = em.createQuery(queryString); q.setParameter(1, limit); q.setMaxResults(100);
// Execute query and retrieve results: Collection<Customer> result = new LinkedList<Customer>; Iterator iter = q.getResultIterator(); while(iter.hasNext()) { Customer c = (Customer)iter.next(); result.add(c); }
em.getTransaction().rollback(); return result;}
Note: Consider that OGQL is a subset of JPQL when developing your queries.
JPQL is a powerful language and is the driving force behind OGQL. It is conceivable that the future direction of the query API may lean away from OGQL and back towards the usage of JPQL with WebSphere eXtreme Scale, because of simplicity and ease of use.
Chapter 4. Query engine 81

4.2 Considerations when using queries
In this section, we elaborate on certain topics that need to be considered when implementing queries. Although the grid query language resembles SQL, the underlying concepts are quite different. The following sections highlight the differences.
PartitionsBy default, a query is executed against a single partition.1 When the data is divided into multiple partitions, the query does not work as it would normally work when querying a database. For scalability reasons, executing a query does not cause follow-up communications to other partitions and grid containers. The query will contain results only from the data located in the single partition that the client is connected to.
While it sounds like a big restriction, it can be easily mitigated by using agents to search all partitions in parallel.
Using JOINsRelational databases often use a JOIN statement to link associated child entities (for example, select persons and all their associated addresses). The first topic to consider when regarding JOINs is so important that we defined it as leading practice:
1 Per default, the query is executed against the partition the session is pinned to by previous operations. If it is not yet pinned because it is the first operation of a session, the partition has to be set explicitly using the Query.setPartition() method.
Leading practice: Avoid cartesian products in FROM clause, use JOIN instead.
Joining of entities occurs in memory. Be careful when using cartesian products (FROM entity1, entity2, entity3), as the resulting temporary data can easily become quite large. The local ObjectMap that is storing this data may not be able to hold the large amount of data that results from a cartesian product, causing an out of memory exception. Use JOINs to reduce the size and to reduce the query execution time dramatically (FROM entiy1 JOIN entity1.entity2). See 4.3, “Translating SQL to OGQL examples” on page 86 for a real-world example.
82 User’s Guide to WebSphere eXtreme Scale

Avoiding cartesian products has an impact on which syntax to use for expressing JOINs. In SQL, there are different notations available to express a JOIN operation. For example the JOIN criteria can either be included in the FROM clause, as shown in Example 4-3, or expressed in the WHERE clause, as shown in Example 4-4.
Example 4-3 Expressing a JOIN statement in SQL in the FROM clause
SELECT * FROM A JOIN B ON (b.fk = a.pk)
Example 4-4 Expressing a JOIN statement in SQL in the WHERE clause
SELECT * FROM A,B WHERE b.fk = a.pk
Using different syntax usually does not make a difference for a SQL database, as the query optimizer creates the same execution plan. But the syntax you use can make a huge difference for the grid when cartesian products are involved. In the given example, the second syntax involves a cartesian product which should be avoided when querying against the grid.
Another important thing to consider is that a query including JOINs is executed against a single partition. If the joined child data resides in a different partition, the child will not be included in the result. If an inner join is used, even the parent will not be included in the result set.
If it is required that a JOIN will retrieve all child objects, make sure the children are placed in the same partition as the parent. This task can be performed by placing the data into a single map set that shares the same partitioning key. Note that when an entity is a child to multiple parent entities (called multi-headed entities), it might become impossible to define the same partitioning key. This situation leads to the following leading practice:
Leading practice: Avoid multi headed entities.
When a child entity has relationships to several parents, it is called a multi- headed entity. Figure 4-1 on page 84 shows an example of such a situation. The Address entity is multi-headed, because it is a child of Order and of Customer entity.
When all entities have different primary keys, it might become impossible to define a single shared partition key for all the entities. The simplest solution is to avoid these kind of relationships all together. Another option is to simply include the child in the object graph and not to model them as a distinct entity. Although a single child object might be stored more than once in the grid, it simplifies querying.
Chapter 4. Query engine 83

Figure 4-1 Multi headed entities that should be avoided
Using agents As stated above, a query, by default, is only executed against a single partition. This issue can be resolved by using agents (such as MapGridAgent and ReduceGridAgent) to spread queries over all partitions simultaneously. See 3.5, “DataGrid computing scenario” on page 64 for information about using agents.
When using queries in conjunction with agents, it is important to know that aggregation functions, such as count(), will work only on the local partition and the total result has to be computed by applying the function to the results from the agent.
Limiting query resultsIn SQL, you often limit the result set size to avoid being overloaded with a huge result set. This task can be accomplished by using the setFirstResult() and setMaxResults() to control the size of the result.
Special care has to be taken when using agents. All elements from the agent result are sent to the client, no matter how large or small that set of results may be.
Order
OrdIDTypeBalance
Customer
CustIDFirstNameLastName
0..* 0..*
Address
AdrIDLine1Line2ZIPCity
1..* 1..*
84 User’s Guide to WebSphere eXtreme Scale

Using indexesAs with relational databases, indexes are important to speed up queries. WebSphere eXtreme Scale supports indexes on any attributes of the data. They can be either configured in the XML configuration or using the @index annotation for entities. For more information, see the Using indexing for non-key data access wiki, available at the following Web page.
http://www-128.ibm.com/developerworks/wikis/x/QIAF
However, only one index can be defined per attribute and indexes cannot be defined on associations.
As with relational databases, there is a cost associated with an index. An index is stored in memory and has to considered when calculating heap sizes for a grid container. Also, an index has to be kept up to date when data is changed, which will require CPU cycles. Therefore, having too many indexes can be slow.
Query optimization SQL databases usually include a highly sophisticated query optimizer to find an optimal query execution plan. Often, SQL developers rely on the optimizer to work out the details. For example, the ordering of the WHERE conditions usually is not important, as the optimizer will try to evaluate the most selective conditions first, based on statistical data.
WebSphere eXtreme Scale does not include any query optimization component. Based on the query string, a straight forward execution plan is created and executed. The FROM clause is evaluated from left to right, so all entities with low cardinality should be placed first. The same applies to WHERE clauses, meaning all conditions with high selectivity and which are supported by an index should be placed first. Also, no statistics gathering is performed.
Rollback transactions should be used when performing a read-only query to avoid expensive commit processing (known as walking the graph).
Leading practice: Check the query execution plan for performance.
As it is a best practice to check the query execution plan that a relational database will create, it is recommended to review the query plan of a grid query to ensure efficient execution. This task can be performed by logging the plan from the application (see Example 4-5 on page 86) or by enabling the trace setting QueryEnginePlan=debug=enabled.
Chapter 4. Query engine 85

Example 4-5 Code snippet to log the query plan
public void search(...) { String queryText = ...; Query query = ...
if (log.isDebug()) { log.debug(“Going to execute query "+queryText +" with plan “ + query.getPlan()); }}
4.3 Translating SQL to OGQL examples
This example shows a simple SQL query translated into OGQL, taking the above considerations into account. It is based on an a simple entity relationship model where an OWNER can have many ADDRESS entries. Example 4-6 shows an SQL Query retrieving all OWNERs having an address on Tiger Street.
Example 4-6 Sample SQL Query selecting all Owners living in Tiger Street.
SELECT own.*FROM ITSO.OWNER AS own, ITSO.ADDRESS AS adrWHERE adr.custnobiz = own.custnoAND adr.addr1 = 'Tiger Street'
Translating the above example in OGQL is straight forward. Only the cartesian product needs to be translated into a JOIN statement. Also, an index on the attribute addr1 is recommended to support this query. This translation results in the query string shown in Example 4-7
Example 4-7 Sample query translated into OGQL
SELECT OBJECT(own)FROM Owner AS ownJOIN own.bizAddresses AS adrWHERE adr.addressLine1 = ?1
86 User’s Guide to WebSphere eXtreme Scale

Chapter 5. eXtreme Scale in a Network Deployment environment
WebSphere eXtreme Scale fits perfectly into an environment managed by WebSphere Application Server Network Deployment, allowing all the services, such as transaction management, security and monitoring, to be used by grid components.
After a brief overview of the benefits and limitations of WebSphere eXtreme Scale in a managed environment, this chapter will introduce the sample application and topology used to demonstrate the features. Then it provides detailed instructions on how to install and configure the sample environment. This chapter concludes by showing details of the sample application in action.
This chapter includes the following topics:
� “Overview” on page 88� “Introducing the sample application” on page 93� “Introducing the sample topology” on page 98� “Creating the sample topology” on page 101� “The sample application in action” on page 117
5
© Copyright IBM Corp. 2008. All rights reserved. 87

5.1 Overview
Before digging into the details on how to install and configure WebSphere eXtreme Scale in conjunction with WebSphere Application Server, we would like to show the benefits and limitations of that environment and give certain points that need to be considered.
5.1.1 Benefits
Using WebSphere eXtreme Scale in a managed environment has a lot of advantages, which are described below.
Simplified connection to the gridIn a stand-alone environment, connecting the grid requires knowledge of the host name and port of the catalog servers. In a managed environment, this requirement can be simplified by defining a custom property that points to the catalog servers. Example 5-1 shows a code snippet how this simplification can be done.
Example 5-1 Connecting to a grid without specifying a catalog server host and port
//Use ObjectGridManagerFactory to get the reference to the ObjectGridManager APIObjectGridManager om = ObjectGridManagerFactory.getObjectGridManager();
//Obtain the client context assuming "caalog.service.cluster" property is defined:ClientClusterContext context = om.connect( ServerFactory.getServerProperties().getCatalogServiceBootstrap(), null, null);
//Get the ObjectGrid instance:ObjectGrid ivObjectGrid= objectGridManager.getObjectGrid(context,"objectgridName");
In 5.4.2, “Configuring the runtime environment” on page 109, we show how to actually configure this mechanism. More Information can be found in the Installation for a WebSphere Extended Deployment J2EE application wiki available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/1C
88 User’s Guide to WebSphere eXtreme Scale

Example 5-2 Source code snippet showing how to wait for a grid to come online
public void waitForObjectGridtoComeOnline(ObjectGrid grid) throws Exception {
int timeout = 60000;long startTime = System.currentTimeMillis();StateManager stateMan = StateManagerFactory.getStateManager();AvailabilityState state = stateMan.getObjectGridState(grid);while (!state.equals(AvailabilityState.ONLINE)
&& (System.currentTimeMillis() - startTime < timeout)) {state = stateMan.getObjectGridState(grid);Thread.sleep(250); // avoid tight loop
}if (!state.equals(AvailabilityState.ONLINE)) {
throw new Exception( "ObjectGrid "+grid+" did not come online after "+timeout+" msecs");
}}
Simplified grid container managementWhen a J2EE application contains grid configuration files in the META-INF/ Directory of the ear, the grid is automatically configured according to that configuration.
Managed environment for loader implementationsImplementing custom loaders often requires special resources to gain access to the back-end information system. In an environment managed by WebSphere Application Server, a loader implementation can use all available J2EE resources. For example, JDBC connections, JMS providers, or JCA adapters can
Leading practice: Check grid availability state before using it.
When connecting to the grid, the grid may not yet fully online. This situation can happen when preloading large amounts of data takes a long time, or replication rules require a certain number of containers to be started before the grid comes online.
We recommend querying the grid state in conjunction with wait and retry logic when obtaining the initial reference to the grid. This querying is ideally done in a startup bean to ensure the grid is available before application request processing starts.
A sample code snippet to query the grid state is shown in Example 5-2.
Chapter 5. eXtreme Scale in a Network Deployment environment 89

be used in a custom loader implementation using connection pooling, lookup and discovery (JNDI) and security (providing necessary authentications and authorizations).
Simplified administration and managementIn a managed environment, WebSphere Application Server takes care of deployment. It ensures that all nodes are synchronized and have the same version of the application and its artifacts.
The WebSphere administrative console can be used to manage grid containers like application servers, which simplifies administration and management.
Transparent transaction demarcationWebSphere eXtreme Scale offers transactional access to a grid. In a stand-alone environment, it is the responsibility of the grid client to begin and end the transaction. This transaction requires additional programming effort.
In a managed environment, the WebSphereTransactionCallBack can be used to delegate the transaction handling to the J2EE container. Thus, no extra code is required in the grid client. Every time a J2EE container-managed transaction starts or ends (rollback or commit), a grid transaction is started or ended, ensuring that the grid transaction is parallel to the J2EE transaction.
Details and instructions can be found in the WebSphereTransactionCallback plug-in wiki, available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/XAb4
Use PMI for monitoringWebSphere Application Server provides a sophisticated performance monitoring infrastructure (PMI). It can be used to gather performance statistics of all components inside an application server.
WebSphere eXtreme Scale takes advantage of this infrastructure to collect performance statistics relevant to the grid. Metrics provided include the following:
� Actual cache size� Cache hit rate� Transaction response time� Loader update response time
More detailed information about this topic can be found in the Monitoring ObjectGrid performance with WebSphere Application Server performance monitoring infrastructure (PMI) wiki, available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/FIMF
90 User’s Guide to WebSphere eXtreme Scale

Catalog serviceWhen using WebSphere eXtreme scale, a catalog service is started automatically within the deployment manager process. No manual startup is required
5.1.2 Limitations
There are limitations when using WebSphere eXtreme Scale in a WebSphere Application Server environment. The following topics should be considered.
Larger footprintThe grid in a managed environment has to share available memory with an application server or application components, which means that less memory is available for storing objects in the grid.
Collocated application can reduce grid availabilityWhen the grid container is collocated with the enterprise application in the same application server, the grid container becomes more vulnerable. Issues in the application (for example, memory leaks, deadlock situations) can bring the grid container down.
To increase high availability, we recommend separating the application and the grid into different clusters.
Distributed transactions are not supportedWebSphere eXtreme scale does not support distributed transactions (XA) using 2-phase commit protocol. The transaction plug-in will not enlist the grid transaction with the transaction manager, and therefore, if the grid fails to commit, any other resources that are managed by the XA transaction will not roll back.
Leading practice: Use a dedicated WebSphere cluster for catalog servers.
For high availability reasons it is recommended that you use a cluster of catalog services. Best results can be achieved by having at least three catalog servers located in different physical locations. Three, because it is a prime number which provides a quorum in a split network situation. We recommend using a distinct WebSphere cluster to host the catalog servers in order to decouple this critical grid infrastructure from other WebSphere infrastructure.
In 5.4.2, “Configuring the runtime environment” on page 109, we include detailed instructions about how to configure this type of setup.
Chapter 5. eXtreme Scale in a Network Deployment environment 91

5.1.3 Considerations
The following sections detail factors that need to be considered when using WebSphere eXtreme Scale in conjunction with WebSphere Application Server.
Topology selectionWebSphere Application Server offers a large variety of deployment topologies to support many scalability and high availability requirements. The grid requirements place an additional constraint on this topology. The overall target topology should be carefully planned to match all requirements.
Chapter 2, “WebSphere eXtreme Scale architecture and topologies” on page 19 contains information about grid topologies.
WebSphere topologies are described in WebSphere Application Server V6 Scalability and Performance Handbook, SG24-6392.
Configuration filesAn EJB module or WAR module using a grid must have corresponding grid XML configuration files in its META-INF directory. Depending on what configuration files are found by the WebSphere eXtreme Scale runtime environment, the application will be run in one of the following two modes:
� Client only
When only an objectGrid.xml file is detected, the application will be a grid client only. The grid configuration from the XML file will be used for the client near-cache configuration.
You can override this situation by programmatically specifying the location of a different grid client configuration file in the ObjectGridManager.createObjectGrid() Operation. No grid container will be started for this application. The grid client will contact the catalog server to connect to suitable grid containers.
� Collocated grid container
When the META-INF directory also contains an objectGridDeployment.xml file, a grid container will automatically be started inside the application server. The grid container registers with the catalog server and becomes eligible for shard placement. Independently of the application mode, an entity.xml file is required when entity manager API is used without annotations.
Note: Configuration file names are case sensitive. If the grid container does not start automatically, be sure to check the file name spelling.
92 User’s Guide to WebSphere eXtreme Scale

ClassloadersJ2EE application can have complicated class loading rules, resulting in a hierarchy of class loaders for a given module. When sharing objects through the grid, this hierarchy can result in problems such as ClassCastExceptions, because different classloaders are involved. See the Installation for a WebSphere Extended Deployment J2EE application wiki available at the following Web page for detailed recommendations:
http://www-128.ibm.com/developerworks/wikis/x/1C
5.2 Introducing the sample application
One of the key features introduced in WebSphere eXtreme Scale version 6.1.0.3 is the write-behind functionality. Write-behind functionality means that updates made to data in the grid are automatically buffered and asynchronously written back to the hardened data store (database) through a configured loader plug-in. This capability can significantly reduce the amount of load on the back end. In this section, we will explore a sample application called ITSOSample that uses a loader plug-in for both pre-loading and write-behind operations.
We first explain the problems this application tries to solve and give an overview of its architecture and design. We conclude with detailed descriptions of important application components.
5.2.1 The problems solved
The ITSOSample does not try to solve all data-related business cases but it does address several common use-cases that are likely to emerge in business scenarios. The problems solved by ITSOSample could be listed as follows:
� The need to pre-load data into the caching mechanism
Often applications will need more than a side cache mechanism that provides data to the application in a “cache miss on first request, cache hit on next request” method. Rather, they need a warm up mechanism that provides the data as soon as the application is ready for it. The warming of the cache produces additional load on the back end system. If it is not desirable to have this operation going on in the application (for example, for applications deployed on mainframes where MIP usage is a concern), this operation can be pushed to a loader.
Note: When dealing with class loading issues, WebSphere Application Server offers the class loader viewer to gain insight into the situation. In the administrative console, select Troubleshooting → Class Loader Viewer.
Chapter 5. eXtreme Scale in a Network Deployment environment 93

� The need to use the grid cache as the system of record and communicate changes in the data to the back end datastore
If the data requirements of an application place exceedingly demanding load on the back-end datastores, the business may call for a scenario that uses the cache mechanism as the system of record over the back-end datastore. This is done to relieve the pressure on the datastore and place it on the grid where it is more easily managed and spread out among the partitions. By using the write-behind functionality of WebSphere eXtreme Scale 6.1.0.3, updates to the data contained in the grid can be systematically pushed back down to the datastore underneath the grid. Clever implementations of the write-behind functionality can yield smart, batched, and parallel updates to the database.
� The need to query large amounts of data efficiently
Large amounts of data are more effectively queried in parallel and the partitioned nature of the WebSphere eXtreme Scale makes for a highly conducive environment for parallel query mechanisms. The agent framework used by WebSphere eXtreme Scale can do more than just queries. The developer of the agent can use the agent to push logic and lists of keys to every partition for any number of clever operations (that is, batch updates, data manipulation, exporting of partition data).
The ITSOSample demonstrates solutions for several key data-oriented application business and technical requirements.
5.2.2 Application architecture and design
ITSOSample is a J2EE Web application that uses a servlet to clear, preload, and query data from the grid. The application also uses Java Persistence API (JPA) to manage the persistence operations between the grid and the database.
The ITSOSample application is split into a client-side application called ItsoSampleClient, and a server-side application called ItsoSampleServer. The client-side application contains logic for the Web application that the user will interact with, along with a utility JAR containing the JPA entity classes. The server-side application contains the utility JAR and the objectGrid.xml and objectGridDeployment.xml files to define the grid topology
5.2.3 Application component model
The application code for the ITSOSample is fairly straightforward. The application demonstrates several key usage patterns that common business applications may wish to implement. The ITSOSample application demonstrates technologies such as Java Persistence APIs, WebSphere eXtreme Scale APIs, and grid
94 User’s Guide to WebSphere eXtreme Scale

loading mechanisms such as the ClientLoader. In the application, the RunSVTTest servlet uses a class called WorkerBee to manage the delegation of work to several other classes in the application. We can also see parallel grid-style computing (that is, ParallelQueryAgent) in this servlet. Also, the WorkerBee class demonstrates how to preload the grid instance from a database using the ClientLoader class included with WebSphere eXtreme Scale 6.1.0.3. See 7.2.1, “Using JPA for data access in WebSphere eXtreme Scale” on page 151 for more information.
In the next section, we explore the important parts of the application.
5.2.4 Component details
In the previous section we noted several key classes that the ITSOSample uses to interact with WebSphere eXtreme Scale to demonstrate its capabilities. This section explores exactly what these key classes do and how they accomplish their tasks.
EntityManager: interacting with the gridThere are two APIs in which client code (or plug-in code) directly interacts with the grid for the purposes of putting and getting data from the grid:
� ObjectMap API � EntityManager API
In ITSOSample, the servlet class responsible for the grid interaction uses the EntityManager API to query data in the grid instance. The code sample in Example 5-3 on page 95, taken from ItsoSampleClient, depicts the usage of the EntityManager API in the query agent, ParallelQueryAgent.
In Example 5-3 on page 95, we can see a simple demonstration of obtaining a reference to the EntityManager object through a Session reference, and then using the EntityManager reference to create a query to be used to search data in the grid, partition by partition. Code involving the EntityManager APIs is marked in bold. The code in italics is responsible for executing the query and returning an Iterator object that can be used to peruse the result set. In this example, the Iterator is passed into a method called dumpOwner(). The dumpOwner() method contains code that prints out details about the Owner objects to the console.
Example 5-3 Sample code depicting EntityManager API usage
EntityManager entityManager = session.getEntityManager();BackingMap map = grid.getMap("Owner");int numOfPartitions = map.getPartitionManager().getNumOfPartitions();error = true;
Chapter 5. eXtreme Scale in a Network Deployment environment 95

for(int partition=0;partition<numOfPartitions;partition++){entityManager.getTransaction().begin();Query query = entityManager.createQuery(theQuery);query.setPartition(partition);Iterator<Owner> ownerIterator = query.getResultIterator();if (!ownerIterator.hasNext()) {
entityManager.getTransaction().commit();System.out.println("<p>No records found on query: "
+ theQuery +" for partition "+partition +"</p>");} else{
error = false; //at least one set of owners was foundboolean dumpOwnerError = dumpOwner(ownerIterator);entityManager.getTransaction().commit();if(error == false){
error = dumpOwnerError;}
}}
Loading with JPA: pre-loading and persistenceOne of the simplest ways to preload a grid is to use the JPA. JPA is explored in much more detail in Chapter 7, “Using WebSphere eXtreme Scale with JPA” on page 147. For now, all we need to understand is that JPA is an attractive framework for use in a grid loader plug-in.
Because our grid instance is basically a large bank for objects and deals only with these objects, JPA is able to simplify the way that we can get data out of a database or other datastore and into object form to be inserted into our grid. Without the use of JPA in your loader, you would need to query the data out of your database, turn them into objects, and then use the ObjectMap or EntityManager APIs to push the data into the grid.
An example of JPA usage, taken from ItsoSampleClient, is shown in Example 5-4 on page 96. The sample code comes from the WorkerBee class, specifically from a method that clears a table used for our lab example. The JPA code is marked bold.
Example 5-4 Sample code depicting JPA usage to clear database tables
javax.persistence.EntityManager em = null;try {
javax.persistence.EntityManagerFactory emf = Persistence.createEntityManagerFactory(dbType);
em = emf.createEntityManager();em.getTransaction().begin();
96 User’s Guide to WebSphere eXtreme Scale

em.createNativeQuery("delete from itso.Account").executeUpdate();em.createNativeQuery("delete from itso.Owner").executeUpdate();em.createNativeQuery("delete from itso.Address").executeUpdate();em.createNativeQuery("delete from itso.Owner_account").executeUpdate();em.createNativeQuery("delete from itso.OWNER_ADDRESS").executeUpdate();em.getTransaction().commit();
} catch (Exception ex) {System.out.println("Exception doing database clear: " + ex);ex.printStackTrace();return "Exception doing database clear: " + ex;
}System.out.println("Cleared the database.");
Query Agents: mining for dataOne of the major benefits of utilizing WebSphere eXtreme Scale is the ability to scale out your data into hundreds of containers and execute queries on the data in parallel producing a single result set. This interaction represents a paradigm shift in thinking from using grids as large cache instances to true grid-style interaction patterns and data-oriented application models.
With WebSphere eXtreme Scale we can use agents to push query logic to each shard in the grid and execute the query logic on the JVM containing the data. The result is extremely fast queries on huge data sets and a single result set being returned to the invoking application.
A traditional approach would execute the query against many different tables, perhaps even different database instances. These queries might involve setting up confusing joins and matching extensive criterion in SQL predicates to find the data required. This would most likely produce a large result set that needs to be iterated through by the application.
Example 5-5 on page 97 demonstrates a portion of the ParallelQueryAgent class that executes a query over all partitions and returns a single result set to the invoker. The bold lines are responsible for creating the EntityManager query object and passing it into a new ParallelQueryAgent instance.
Example 5-5 Example code depicting a parallel query
if(useAgentQuery){Query query =
ParallelQueryAgentFactory.instance().createQuery(session,theQuery);Iterator<Owner> ownerIterator = query.getResultIterator();if (!ownerIterator.hasNext()) {
System.out.println("<p>No records found on query: "+ theQuery + "</p>");
Chapter 5. eXtreme Scale in a Network Deployment environment 97

error = true;}else{
boolean dumpError = dumpOwner(ownerIterator);if(error == false){error = dumpError;}
}} else{....
5.3 Introducing the sample topology
The sample application described above needs a topology on which to run. This section describes the sample topology created for this Redbooks publication to demonstrate WebSphere eXtreme Scale in a managed environment. We discuss the operational model that describes which components are installed and running on which hosts. Finally, we explain the grid topology.
5.3.1 Operational model
The basic operational model of the sample topology is show in Figure 5-1 on page 99. It is a cell of four nodes. There are two clusters, each of which extends over all of the nodes. As each cluster has four members, this leads to a total of eight application server JVMs.
The first cluster named AppCluster hosts the application ItsoSampleClient that uses the grid. The second cluster named GridCluster hosts the ItsoSampleServer application and the grid itself.
This topology does not contain a Web server as a typical installation would. It was left out to focus on WebSphere eXtreme Scale installation.
98 User’s Guide to WebSphere eXtreme Scale
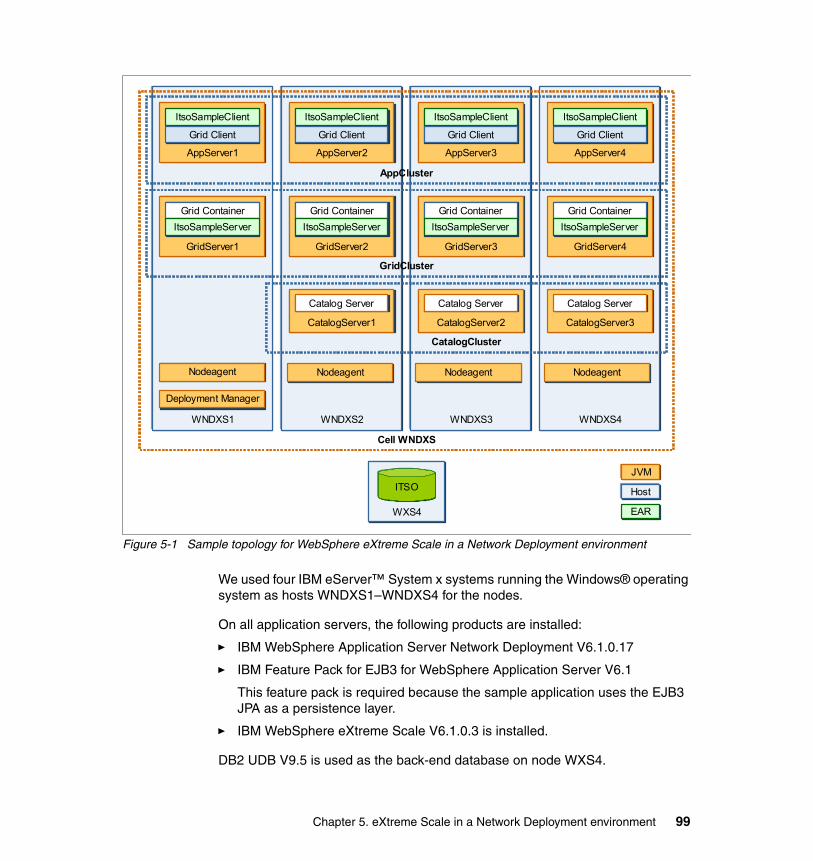
Figure 5-1 Sample topology for WebSphere eXtreme Scale in a Network Deployment environment
We used four IBM eServer™ System x systems running the Windows® operating system as hosts WNDXS1–WNDXS4 for the nodes.
On all application servers, the following products are installed:
� IBM WebSphere Application Server Network Deployment V6.1.0.17
� IBM Feature Pack for EJB3 for WebSphere Application Server V6.1
This feature pack is required because the sample application uses the EJB3 JPA as a persistence layer.
� IBM WebSphere eXtreme Scale V6.1.0.3 is installed.
DB2 UDB V9.5 is used as the back-end database on node WXS4.
WNDXS2 WNDXS3 WNDXS4
CatalogServer1CatalogServer1
Catalog ServerCatalog Server
WNDXS1
AppServer1AppServer1
ItsoSampleClientItsoSampleClient
Grid ClientGrid Client
AppServer2AppServer2
ItsoSampleClientItsoSampleClient
Grid ClientGrid Client
AppServer3AppServer3
ItsoSampleClientItsoSampleClient
Grid ClientGrid Client
AppServer4AppServer4
ItsoSampleClientItsoSampleClient
Grid ClientGrid Client
GridServer1GridServer1
Grid ContainerGrid Container
GridServer2GridServer2
Grid ContainerGrid Container
GridServer3GridServer3
Grid ContainerGrid Container
GridServer4GridServer4
Grid ContainerGrid Container
EAREAR
Host
JVM
WXS4
ITSO
Deployment ManagerDeployment Manager
CatalogServer2CatalogServer2
Catalog ServerCatalog Server
CatalogServer3CatalogServer3
Catalog ServerCatalog Server
NodeagentNodeagent
AppCluster
GridCluster
CatalogCluster
Cell WNDXS
ItsoSampleServerItsoSampleServer ItsoSampleServerItsoSampleServer ItsoSampleServerItsoSampleServer ItsoSampleServerItsoSampleServer
NodeagentNodeagent NodeagentNodeagent NodeagentNodeagent
Chapter 5. eXtreme Scale in a Network Deployment environment 99

5.3.2 Grid topology
The grid, called BranchGrid, is hosted inside the application servers of the cluster named GridCluster. We configured 8 partitions to accommodate possible future growth. We also configured one optional synchronous replica for each primary shard.
A possible placement is shown in Figure 5-2. Note that actual shard placement may vary, depending on what the catalog server decides.
Figure 5-2 Grid topology for sample Network Deployment environment
This configuration is reflected in the objectGridDeployment.xml located in ItsoSampleServer.ear/ItsoSampleWeb.war/META-INF/. Example 5-6 shows the essential part of it.
Example 5-6 Essential part of objectGridDeployment.xml for sample topology
<objectgridDeployment objectgridName="BranchGrid"> <mapSet name="AccountMS" numberOfPartitions="8" minSyncReplicas="0" maxSyncReplicas="1" maxAsyncReplicas="0" replicaReadEnabled="false" numInitialContainers="1"> <map ref="Account" /> <map ref="Owner" /> <map ref="Address" /> </mapSet> </objectgridDeployment>
BranchGridBranchGrid
GC1@WNDXS1
PS0PS0
PS4PS4
RS1RS1
RS5RS5
GC2@WNDXS2GC2@WNDXS2
PS1PS1 RS2RS2
PS5PS5 RS6RS6
GC4@WNDXS4GC4@WNDXS4
RS0RS0PS3PS3
RS4RS4PS7PS7
GC3@WNDXS3GC3@WNDXS3
PS2PS2 RS3RS3
PS6PS6 RS7RS7
Primary ShardPrimary Shard
Replica ShardReplica Shard
Grid Container
GridGrid
100 User’s Guide to WebSphere eXtreme Scale

5.4 Creating the sample topology
This section describes the necessary steps to create the sample topology described in the previous sections.
5.4.1 Installing the products
The following steps are required for all nodes of the topology:
1. Install IBM WebSphere Application Server Network Deployment V6.1.0.17 and create the necessary profiles.
2. Install Feature Pack for EJB 3.0.
3. Install IBM WebSphere eXtreme Scale V6.1.0.3.
4. Federate the profiles created in step 1 into the cell.
After these products are installed, they can be configured to match the desired topology. This includes the creation of clusters and catalog servers. The configuration will be described in 5.4.2, “Configuring the runtime environment” on page 109. The sample scenario also requires a database as a back end system. The installation and configuration steps required for the database are described in Appendix B, “Setting up the database” on page 221.
Pre-installation tips:
� Make sure the installation prerequisites for the operating systems are met. Specifically, that all required operating system fixes are applied.
� The network communication between all nodes is working properly. That is, each node can successfully ping all other nodes.
� Do not create any profiles before applying the fix packs. Certain defects in V6.1.0.0 will create problems with the cell certificates, causing the communication between the application servers to fail. This can be avoided by first getting to the latest fix level, then creating the profiles.
� A good starting point for more instructions on how to install WebSphere eXtreme Scale can be found at the following Web page:
http://www.ibm.com/software/webservers/appserv/extremescale
� More information about Feature Pack EJB3 can be reached from the article Utility: Feature Pack for EJB 3.0 for WebSphere Application Server V6.1, available at the following Web page:
http://www-01.ibm.com/support/docview.wss?rs=177&uid=swg21287579
Chapter 5. eXtreme Scale in a Network Deployment environment 101

Installing WebSphere Application Server Network DeploymentThe steps to install WebSphere Application Server Network Deployment V6.1.0.17 are as follows.
1. Install WebSphere Application Server Network Deployment V6.1.0 on each host.
2. Install the latest version of WebSphere Update Installer, available at the following Web page:
http://www-01.ibm.com/support/docview.wss?rs=180&uid=swg24012718
If you need more detailed information about downloading and installing WebSphere Application Server products and fixes, visit the following Web page:
http://www.ibm.com/software/webservers/appserv/was/support/
3. Use the Update Installer to install the latest available fix pack, V6.1.0.17 in this case. The fix packs can be found at the Support site at the following Web page:
http://www-01.ibm.com/software/webservers/appserv/was/support/download.html
4. Using the profile creation wizard, create a deployment manager profile named Dmgr01 on node WNDXS1. Start the deployment manager and make sure it comes up as shown in Figure 5-3 on page 103. You can check the status of the node in the administrative console by selecting System Administration → Nodes.
Note: These steps must be repeated for every node in the topology.
102 User’s Guide to WebSphere eXtreme Scale

Figure 5-3 Sample topology after initial WebSphere Installation
5. Stop the deployment manager, and create an empty default profile named AppSrv01 on all hosts.
Installing Feature Pack for EJB 3.0The next step is to install the Feature Pack for EJB 3.0 and update it to the appropriate maintenance level.
1. Install Feature Pack for EJB 3.0 for WebSphere Application Server V6.1 on all nodes. When asked about profile augmentation, augment all existing profiles.
2. Apply the latest fix pack, in this case, Feature Pack for EJB 3.0 Fix Pack 17, on all nodes using the Update Installer. The Feature Pack fix packs are available on the same page as the corresponding WebSphere Application Server fix pack site:
http://www-01.ibm.com/software/webservers/appserv/was/support/download.html
Important: Do not federate the profiles into the cell at this step. It will be done after all production installation is completed.
The reason for this approach is that eXtreme Scale installation and EJB3 feature pack installation require profile augmentation, and profile augmentation is not allowed for a federated node.
Chapter 5. eXtreme Scale in a Network Deployment environment 103

Fix Pack 17 can be found at the following Web page:
http://www-01.ibm.com/support/docview.wss?rs=180&uid=swg24019101
Installing WebSphere eXtreme ScaleAfter the Network Deployment installation has been completed, WebSphere eXtreme Scale can be installed on top of it.
The following steps have to be performed for each host:
1. Ensure that all WebSphere processes are stopped on all hosts, especially the deployment manager process on host WNDXS1.
2. Run the installation for WebSphere Extended Deployment Data Grid V6.1.0.0. Make sure that when the installation wizards asks which profiles to augment, all existing profiles are selected, as shown in Figure 5-4.
Leading practice: Match the Feature Pack fix level to the base product fix level
When applying fixes to feature packs, make sure that the fix level of the feature pack matches the fix level of the base product you are using. Otherwise, you might get undefined product behavior.
Note: The product recently has been renamed from WebSphere Extended Deployment Data Grid to WebSphere eXtreme Scale. At the time of writing, the name change is not yet reflected in the product itself. Thus the following steps and figures show the name WebSphere Extended Deployment Data Grid. For a more detailed discussion about this topic, refer to 1.5, “Explaining the names—product evolution” on page 13.
104 User’s Guide to WebSphere eXtreme Scale
Figure 5-4 Select the profiles to be augmented for eXtreme Scale
The centralized installation manager CIM component is required only for configurations including WebSphere Virtual Enterprise, which is out of the scope of this Redbooks publication. Therefore, it is de-selected, as shown in Figure 5-5 on page 106.
Chapter 5. eXtreme Scale in a Network Deployment environment 105
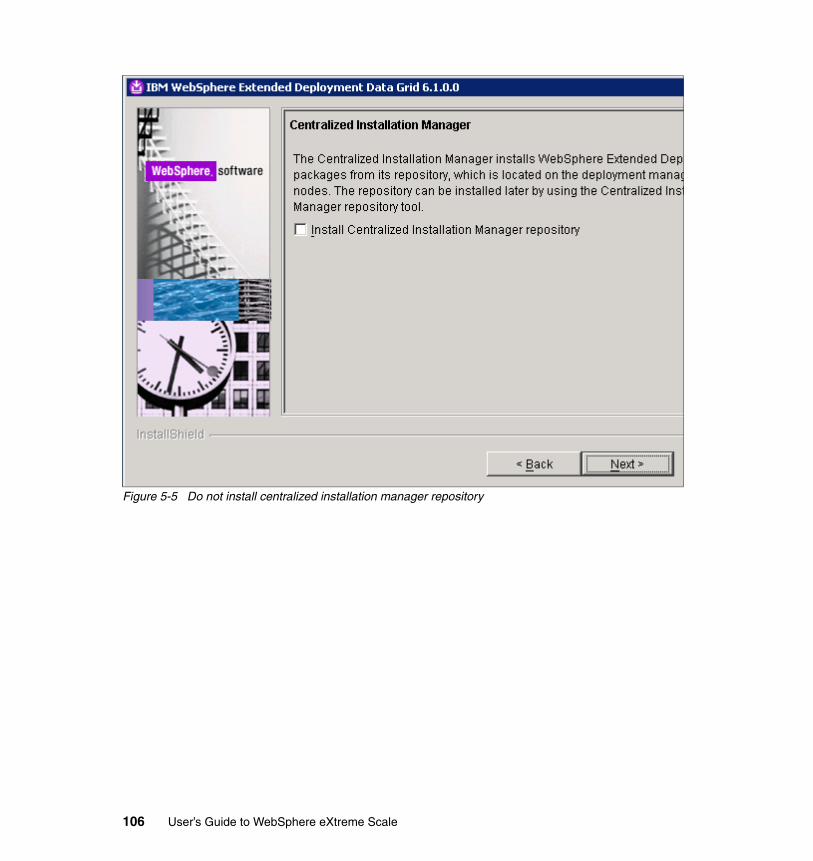
Figure 5-5 Do not install centralized installation manager repository
106 User’s Guide to WebSphere eXtreme Scale
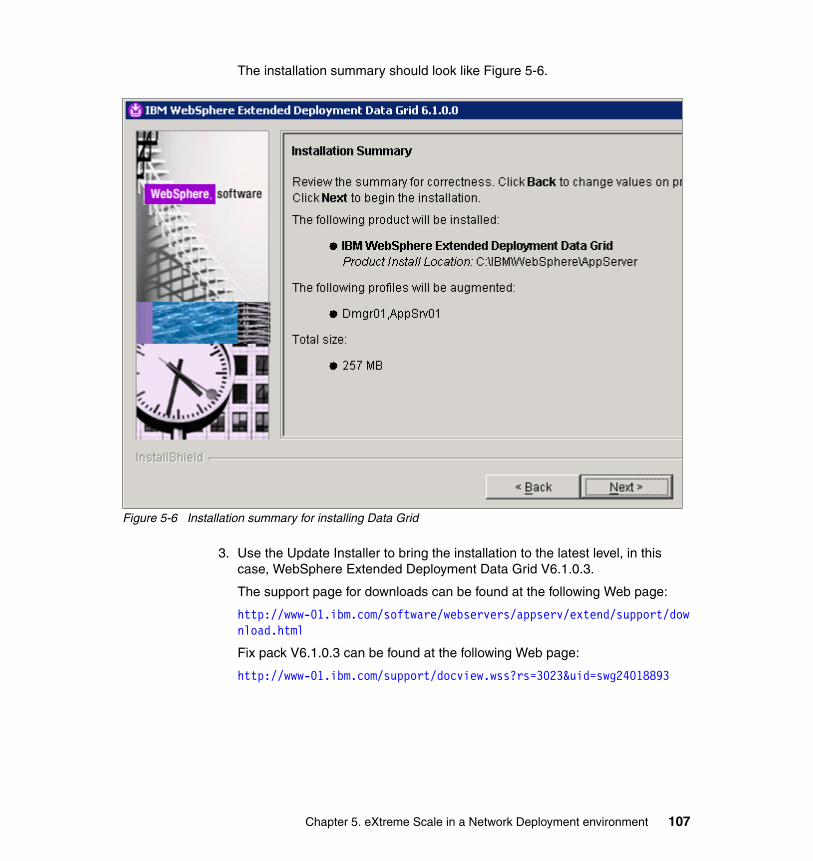
The installation summary should look like Figure 5-6.
Figure 5-6 Installation summary for installing Data Grid
3. Use the Update Installer to bring the installation to the latest level, in this case, WebSphere Extended Deployment Data Grid V6.1.0.3.
The support page for downloads can be found at the following Web page:
http://www-01.ibm.com/software/webservers/appserv/extend/support/download.html
Fix pack V6.1.0.3 can be found at the following Web page:
http://www-01.ibm.com/support/docview.wss?rs=3023&uid=swg24018893
Chapter 5. eXtreme Scale in a Network Deployment environment 107

Federating the nodes into the cellAfter having completed all product installations and updates, federate the nodes into the cell as follows:
1. Ensure deployment manager is running on host WNDXS1. If it is not, start it using the <WAS_HOME>\profiles\Dmgr01\bin\startManager script.
2. Federate each node into the cell using the <WAS_HOME>\profiles\AppSrv01\bin\addNode command. This must be done one at a time, as the deployment manager does not support concurrent addNode operations.
3. Make sure all node agents are up and running and the cell is completely in sync. You can check this from the administrative console by selecting System Administration → Nodes. The result should look like Figure 5-7. The Version column shows all required products and version levels.
Figure 5-7 Sample topology after installing all products and federating the nodes
108 User’s Guide to WebSphere eXtreme Scale

5.4.2 Configuring the runtime environment
After WebSphere eXtreme Scale V6.1.0.3 has been installed on all nodes, the configuration has to be done.
Creating the clustersThe sample topology requires three clusters:
� AppCluster, containing the application acting as the grid client� GridCluster, containing the grid containers� CatalogCluster, to host the catalog services
The necessary steps to create a cluster are described in detail in WebSphere Application Server V6.1: System Management and Configuration, SG24-7304. We will briefly summarize the necessary steps here:
1. Log on to administrative console and select Servers → Clusters → New.
2. At the Step 1 window, Name the cluster AppCluster.
3. Create a first cluster member on node WNDXS1.
You can create all required application servers at this point. That is fine as long as you would like to go with all the defaults. If you want to change certain settings (for example, log file size) on all applications servers, there are two possible ways to accomplish this:
– Create a new template (Application Servers → Templates) with the modified settings and use it for all servers.
– Create the first server from the default template, then change the settings and add the missing members using the first member as a template.
Note: When installing the products on a large number of nodes, time can be saved by using the WebSphere Installation Factory to get the desired version with one single install, without the requirement to manually apply fixes. WebSphere eXtended Deployment components like DataGrid are supported when a special plug-in is used. See the following Web page for more details:
http://www-1.ibm.com/support/docview.wss?rs=180&uid=swg24009108
Chapter 5. eXtreme Scale in a Network Deployment environment 109

We followed the latter approach, as shown in Figure 5-8.
Figure 5-8 Create the new AppCluster cluster with one member
110 User’s Guide to WebSphere eXtreme Scale

4. Create the remaining cluster members on nodes WNDXS2 to WNDXS4 from the administrative console by selecting Servers → Clusters → Cluster Members → New.
The final list of application servers should look like Figure 5-9.
Figure 5-9 List of application servers
5. Repeat steps 1–4 to create a cluster called GridCluster on nodes WNDXS1 to WNDXS4.
6. Repeat steps 1–4 to create a cluster called CatalogCluster on nodes WNDXS2 to WNDXS4.
Activating catalog servers in CatalogClusterThe goal of this step is to de-activate the catalog server that is create by default in the deployment manager. The sample topology has a cluster that should host the catalog servers.
The location of catalog servers is defined by a custom cell property named catalog.services.cluster. If the property does not exist, a catalog server is created in the deployment manager. The value contains a comma separated list to identify the catalog servers.
Chapter 5. eXtreme Scale in a Network Deployment environment 111

For each catalog server, the following information must be defined, using colons as separator:
� Server name comprised of cell\node\server� Host name� Client port for grid clients to communicate with the catalog server� Peer port for other catalog servers to connect� Bootstrap port of the server (Application Servers → Ports)
For the sample topology, the required value is show in Example 5-7. It creates three catalog servers on the nodes WNDXS2–WNDXS4.
Example 5-7 Cell custom property value named catalog.services.cluster to enable catalog services
WNDXSCell\WNDXS2Node01\CatalogServer1:WNDXS2.itso.ral.ibm.com:6600:6601:9812,WNDXSCell\WNDXS3Node01\CatalogServer2:WNDXS3.itso.ral.ibm.com:6600:6601:9813,WNDXSCell\WNDXS4Node01\CatalogServer3:WNDXS4.itso.ral.ibm.com:6600:6601:9810
To configure this custom property from the administrative console, select System Administration → Cell → Custom Property → New. Create a property named catalog.services.cluster with the value shown in Example 5-7.
A change in catalog service location requires a restart of all processes that might be attached. In the example, we restarted the whole cell including the deployment manager and node agents.
To start the catalog servers, the cluster CatalogCluster has to be started. Do this in the administrative console by selecting Servers → Clusters → Start.
Leading practice: Start all catalog servers in parallel
The catalog service is critical infrastructure to the grid. It is based on grid technology itself, using the grid replication mechanisms to ensure data availability. The internal partitioning configuration requires at least one replica to be available. When only a single cluster member is started, this rule cannot be established and the catalog server will not start. Example 5-9 shows messages that can be observed in the SystemOut.log of the affected catalog server in such a situation.
Therefore, we recommend always starting the whole catalog service cluster at once.
112 User’s Guide to WebSphere eXtreme Scale

To verify the configuration was successful, the system out log of each catalog server can be checked for messages shown in Example 5-8.
Example 5-8 Messages indicating a successful grid catalog server cluster start
CWOBJ8106I: master catalog server cluster activated with cluster CatalogCluster[WNDXSCell quorumMet=true, 1 master: 0 standbys]
CWOBJ8000I: Registration is successful with zone (DefaultZone) and coregroup of (WNDXSCellDefaultCoreGroup).
CWOBJ1001I: ObjectGrid Server WNDXSCell\WNDXS2Node01\CatalogServer1 is ready to process requests.
CWOBJ8109I: Updated catalog server cluster CatalogCluster[WNDXSCell quorumMet=true, 1 master: 1 standbys] from server WNDXSCell\WNDXS2Node01\CatalogServer1 with entry CatalogServerEntry[1220651474343, master:true, domainName=WNDXSCell]
Example 5-9 shows the messages you will see when the catalog service cannot start due to missing cluster members.
Example 5-9 Messages when catalog service cannot start due to missing other member
CWOBJ2514I: Waiting for ObjectGrid server activation to complete.CWOBJ8401I: Waiting for a server replica to be started. Start another server(s) immediately.CWOBJ1668W: Request is coming to the server that has not completely started.CWOBJ1668W: Request is coming to the server that has not completely started.
Deploying the applicationsAfter all the infrastructure has been created, the final step is to deploy the applications. This is done through administrative console by selecting Applications → Enterprise Applications → New. No special settings are required. The ItsoSampleClient.ear should be mapped to the AppCluster, the ItsoSampleServer.ear to the GridCluster. If Web servers are being used, the client application should be mapped to both the AppCluster and the Web server.
Before starting the application, make sure that all changes are saved and the cell is completely synchronized.
Chapter 5. eXtreme Scale in a Network Deployment environment 113

The ITSOSampleClient application needs the test.itso.og.agent.ParallelQueryAgent in the server class path. Perform the following steps:
1. On all systems hosting a grid server:
a. Create new subdirectory <WAS_HOME>\lib\ITSO.
b. Then, use the following command to perform the copy:
xcopy <WAS_HOME>\profiles\AppSrv01\installedApps\WNDXS1Cell01\ItsoSampleClient.ear\ItsoSampleClientWeb.war\WEB-INF\classes\* <WAS_HOME>\lib\ITSO /s
2. In the administrative console select Environment → Shared Libraries. Then, follow these steps:
a. Set the scope to the cluster, GridCluster.
b. Create a new entry called ItsoSampleLib, and specify the following for the classpath:
Classpath = ${WAS_INSTALL_ROOT}/lib/ITSO
3. Navigate to Applications → Enterprise Applications.
a. Click ItsoSampleServer to open the configuration page.
b. Select Shared library references.
c. Select ItsoSampleServer, and click Reference shared libraries.
d. In the Available box, select ItsoSampleLib and click >>. Click OK.
e. Repeat steps a through d for ItsoSampleServerWar.
Starting and verifying the applications
The GridCluster should be started first to ensure the grid is online for the application. When the application server starts the ItsoSampleServer application, the grid configuration file is detected and the grid is created as shown in Example 5-10.
Example 5-10 Log Messages indicating the successful start of the sample grid
[9/5/08 20:49:04:562 EDT] 00000026 WebGroup A SRVE0169I: Loading Web Module: ItsoSampleWeb.[9/5/08 20:49:04:578 EDT] 00000022 ServerAgent I CWOBJ7201I: Detected the addition of new server (WNDXSCell\WNDXS1Node01\GridMember1,WNDXSCell\WNDXS2Node01\CatalogServer1,WNDXSCell\WNDXS3Node01\CatalogServer2,WNDXSCell\WNDXS4Node01\CatalogServer3) in core group (DefaultCoreGroup).
114 User’s Guide to WebSphere eXtreme Scale

[9/5/08 20:49:04:640 EDT] 0000002a EMFactoryCont I CWOBJ3002I: Initializing entity metadata for ObjectGrid: BranchGrid[9/5/08 20:49:05:328 EDT] 00000029 ReplicatedPar I CWOBJ1511I: BranchGrid:IBM_SYSTEM_ENTITYMANAGER_MAPSET:0 (primary) is open for business.[9/5/08 20:49:05:515 EDT] 0000002a EMFactoryImpl I CWOBJ3003I: Entity registered: Account[9/5/08 20:49:05:531 EDT] 0000002a EMFactoryImpl I CWOBJ3003I: Entity registered: Owner[9/5/08 20:49:05:531 EDT] 0000002a EMFactoryImpl I CWOBJ3003I: Entity registered: Address[9/5/08 20:49:05:546 EDT] 0000002a EMFactoryCont I CWOBJ3001I: The ObjectGrid EntityManager service is available to process requests for ObjectGrid: BranchGrid and container or server: Container-0
When the grid cluster is up and running, start the AppCluster to launch the front end of the sample application. Figure 5-10 on page 116 shows the URL used to invoke the Web application.
Chapter 5. eXtreme Scale in a Network Deployment environment 115
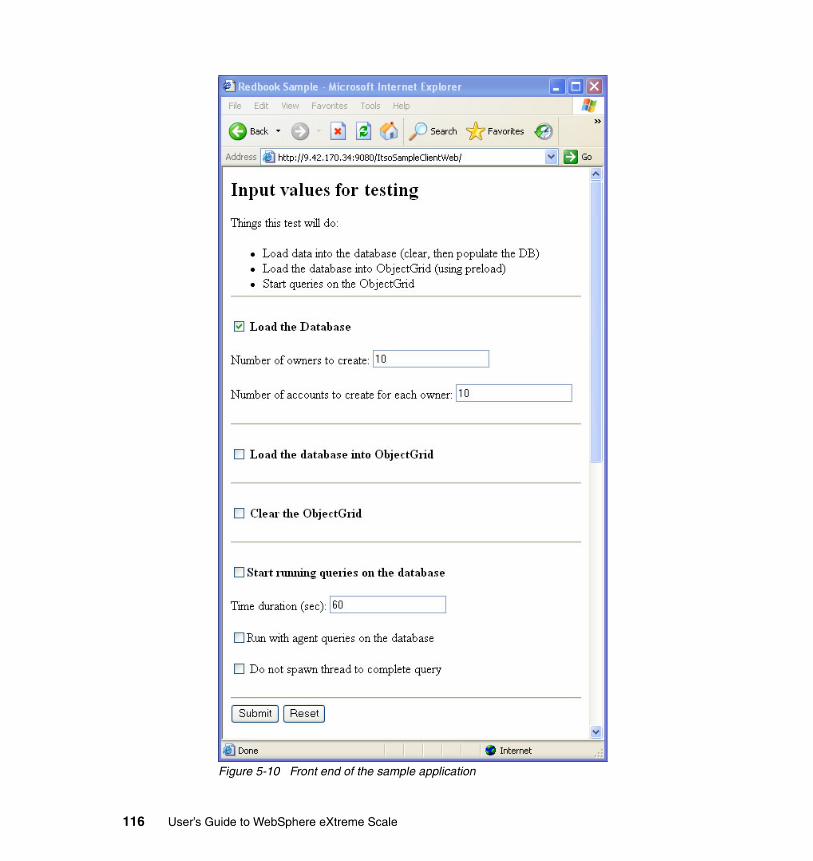
Figure 5-10 Front end of the sample application
116 User’s Guide to WebSphere eXtreme Scale

To verify successful deployment, use the Load the Database option, which creates rows in the database. Example 5-11 shows a sample response of the load data operation.
Example 5-11 Results of loading the database
AppServer1 - September 9, 2008 3:03:11 PM EDT - Loading DB2openJPA database with: 10 Owners: 10 Personal Accounts: Successfully cleared and loaded the database.
After that, the database can be loaded into the grid which results in a message such as that shown in Example 5-12
Example 5-12 Load the data in the grid
AppServer1 - September 9, 2008 3:04:43 PM EDT - Preloading ObjectGrid: Successfully preloaded the objectGrid
5.5 The sample application in action
In order to appreciate the ITSOSample example, let us take a look at the operations it provides.
5.5.1 Explaining the code
In this section, we examine three pieces of functionality from ITSOSample:
� Using the loader plug-in included with WebSphere eXtreme Scale version 6.1.0.3 to preload the grid at startup
� Executing queries in parallel against the grid partitions
� Using the loader plug-in included with WebSphere eXtreme Scale version 6.1.0.3 to reload the grid on demand
Using the ClientLoader to populate the gridIn the ITSOSample, the WorkerBee class is responsible for populating the grid with the data contained in the database instance. Example 5-13 on page 118 demonstrates the code responsible for loading the grid using the ClientLoader object. The ClientLoader class is included with WebSphere eXtreme Scale 6.1.0.3 and uses the JPA framework to retrieve data from the underlying database. The ClientLoader class then converts the records into objects and injects them into the grid using the EntityManager APIs.
Chapter 5. eXtreme Scale in a Network Deployment environment 117

Example 5-13 Loading the grid using the ClientLoader object
ClientLoader c = ClientLoaderFactory.getClientLoader();stateMan.setObjectGridState(AvailabilityState.PRELOAD, grid);c.load(grid, "Owner", dbType, null ,Owner.class, null,
null, preload, null);//Check that data actually exists in the grid
if( ClientLoaderFactory.getClientLoaderSession(grid.getSession()).getEntityManager().find(Owner.class, new Integer(0)) == null){
throw new RuntimeException("No data found in object grid.");}stateMan.setObjectGridState(AvailabilityState.ONLINE, grid);System.out.println("Loaded Owner.");
The following points pertain to Example 5-13:
� The first bold line sets the state of the grid to the preload state. A grid in the preload state will reject requests that do not come from the client that is preloading the grid. A random shard is chosen to house and respond to requests for the current state.
� The second bold line begins loading the data into the grid. The load() method of the ClientLoader class takes a number of parameters. The notable parameters are the ObjectGrid reference, the name of the backing map, the JPA persistence unit definition name (found in the persistance.xml file used by the JPA framework), and the class name of the object implementing the data (in this case, Owner.class).
� The last bold line resets the availability state flag on the grid to online so that the grid can begin to service requests for data.
We discuss the ClientLoader in more detail in 7.2.1, “Using JPA for data access in WebSphere eXtreme Scale” on page 151.
118 User’s Guide to WebSphere eXtreme Scale

Executing queries in parallelNow let us take a look at the code that is executed during parallel queries. Example 5-14 shows the entire reduce() method that is run on every partition by the agent manager.
Example 5-14 Sample code showing the reduce() method of the ParallelQueryAgent class
public Object reduce(Session session, ObjectMap map) { // Create the query and setup the parameters Query localQuery = session.getEntityManager().createQuery(queryString); localQuery.setFirstResult(firstResult); localQuery.setMaxResults(maxResults); if(namedParameters != null) { for(Iterator i=namedParameters.entrySet().iterator();i.hasNext();) { Entry curEntry = (Entry) i.next(); localQuery.setParameter((String)curEntry.getKey(), curEntry.getValue()); }
} else if(posParameters != null) { int numParams = posParameters.size(); for(int i=0;i<numParams;i++) { localQuery.setParameter(i, posParameters.get(i)); } }
// Run the query against the local session and return the results Iterator i = localQuery.getResultIterator(); return getResultAsList(session, map, i);
}
To better explain the sequence of events that occur in the code we will break the code down in to smaller chunks.
In the first section (shown in Example 5-15), we can see the code creating a new Query object using the value contained in the queryString variable. The first line of code creates an EntityManager query using the string contained in the variable queryString. The next two lines simply set the minimum and maximum amount of records to return.
Example 5-15 Creating a new Query object
Query localQuery = session.getEntityManager().createQuery(queryString);localQuery.setFirstResult(firstResult); localQuery.setMaxResults(maxResults);
Chapter 5. eXtreme Scale in a Network Deployment environment 119

In Example 5-16, the code checks to see whether or not named parameters or positional parameters have been used. Named parameters are set on the query by name whereas positional parameters are referred to by a zero-based index value.
Example 5-16 Checking named parameters
if(namedParameters != null) {for(Iterator i=namedParameters.entrySet().iterator();i.hasNext();) {
Entry curEntry = (Entry) i.next();localQuery.setParameter(
(String)curEntry.getKey(), curEntry.getValue());}
}
The code in Example 5-17 makes the same check as in Example 5-16 but handles the case for the positional parameters.
Example 5-17 Checking positional parameters
else if(posParameters != null) {int numParams = posParameters.size();for(int i=0;i<numParams;i++) {
localQuery.setParameter(i, posParameters.get(i));}
}
The code in Example 5-18 triggers the execution of the query and returns to the invoking code.
Example 5-18 Trigger the execution
// Run the query against the local session and return the resultsIterator i = localQuery.getResultIterator();return getResultAsList(session, map, i);
Detailed information about parallel queries can be found in the developerWorks article Highly scalable grid-style computing and data processing with the ObjectGrid component of WebSphere Extended Deployment, available from the following Web page:
http://www.ibm.com/developerworks/websphere/techjournal/0712_marshall/0712_marshall.html
120 User’s Guide to WebSphere eXtreme Scale

5.5.2 Monitoring the grid while preloading
The preloading can be monitored using the Performance Viewer located in the administrative console by enabling the module for ObjectGridMaps. Figure 5-11 shows a sample diagram when preloading was initiated using the sample client. Note the sharp increase of the number of map entries, and also for the memory usage.
Figure 5-11 Performance viewer showing preloading in action
Chapter 5. eXtreme Scale in a Network Deployment environment 121

122 User’s Guide to WebSphere eXtreme Scale

Chapter 6. eXtreme Scale in a stand-alone environment
WebSphere eXtreme Scale has several flexible deployment options. One of these deployment options is installing WebSphere eXtreme Scale into a stand-alone Java2 Standard Edition environment (J2SE). The stand-alone deployment option differs from the WebSphere Network Deployment-managed option in that it lacks Java Enterprise Edition support and does not benefit from the management and monitoring environment that WebSphere Network Deployment provides. It does, however, provide a simple footprint and runtime for hosting grid containers and catalog servers.
The following topics are discussed in this chapter:
� “Overview” on page 124� “Configuring the lab environment” on page 126� “Example scenarios” on page 129
6
© Copyright IBM Corp. 2008. All rights reserved. 123

6.1 Overview
In the following sections, we discuss the benefits and limitations of implementing WebSphere eXtreme Scale in a stand-alone environment. These factors should be considered when deciding the best deployment option for your needs.
6.1.1 Benefits
There are both benefits and limitations to any deployment option. By using the stand-alone deployment option we are leveraging the following benefits.
� Simplicity
The stand-alone deployment option brings the least complex installation and configuration option. The deployment is merely a basic runtime of ObjectGrid libraries and a Java virtual machine.
� Minimum memory overhead
By eliminating the WebSphere Application Server runtime footprint from the memory requirements of the grid container, we are able to maximize the amount of memory that can be used for the storage of objects in the grid instances.
6.1.2 Limitations
There are several limitations that need to be considered when choosing the stand-alone deployment option:
� Administration
The stand-alone deployment option does not provide JVM management in a visual manner like the WebSphere administration console included with WebSphere Application Server. The administration console provides the ability to start and stop JVM’s as well as depict the current status of the JVM (running or stopped). However, the xsadmin tooling provided in WebSphere eXtreme Scale version 6.1.0.3 provides some level of diagnostic and management capabilities. We discuss the xsadmin tooling in a later section.
� Monitoring
The stand-alone deployment option lacks graphical monitoring functionality provided through the WebSphere administration console that is used in the WebSphere-managed deployment options. However, it is not devoid of monitoring capabilities. The xsadmin tooling can be used to monitor grid container utilization and to locate and monitor the locations of primary replicas inside the grid. A JMX™ console application or an application that
124 User’s Guide to WebSphere eXtreme Scale

use MX4J application programming interfaces (APIs) can monitor the grid containers through the use of a Management Gateway Process. Details regarding the Management Gateway Process can be found in the Management gateway process overview wiki, available from the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/6oIF
� Java virtual machine
WebSphere eXtreme Scale version 6.1 ships with the IBM JDK™. After installation of the stand-alone environment, this JDK will be available for use. If you wish to use a JDK other than the included JDK (for example, using ObjectGrid embedded into a non-WebSphere Application Server runtime), you need to be aware of ORB limitations from these non-IBM JDKs. Details on how to overcome these limitations can be found in the Using a non-IBM JDK or JRE with ObjectGrid wiki, available from the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/niQ
� Java Enterprise Edition managed resources
WebSphere eXtreme Scale in a stand-alone J2SE environment will not have access to managed resources such as JDBC connection pooling mechanisms, JNDI calls, JCA adapters, and so forth.
Chapter 6. eXtreme Scale in a stand-alone environment 125
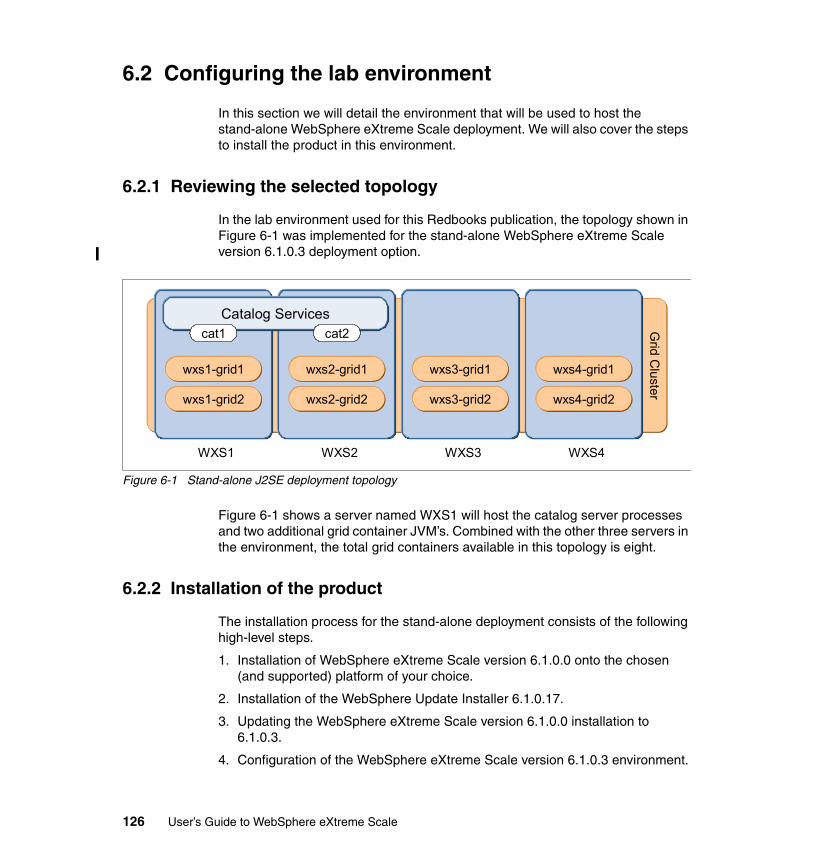
6.2 Configuring the lab environment
In this section we will detail the environment that will be used to host the stand-alone WebSphere eXtreme Scale deployment. We will also cover the steps to install the product in this environment.
6.2.1 Reviewing the selected topology
In the lab environment used for this Redbooks publication, the topology shown in Figure 6-1 was implemented for the stand-alone WebSphere eXtreme Scale version 6.1.0.3 deployment option.
Figure 6-1 Stand-alone J2SE deployment topology
Figure 6-1 shows a server named WXS1 will host the catalog server processes and two additional grid container JVM’s. Combined with the other three servers in the environment, the total grid containers available in this topology is eight.
6.2.2 Installation of the product
The installation process for the stand-alone deployment consists of the following high-level steps.
1. Installation of WebSphere eXtreme Scale version 6.1.0.0 onto the chosen (and supported) platform of your choice.
2. Installation of the WebSphere Update Installer 6.1.0.17.
3. Updating the WebSphere eXtreme Scale version 6.1.0.0 installation to 6.1.0.3.
4. Configuration of the WebSphere eXtreme Scale version 6.1.0.3 environment.
WXS1 WXS4WXS3WXS2
wxs1-grid1
wxs1-grid2
wxs2-grid1
wxs2-grid2
Catalog Servicescat1 cat2
wxs3-grid1
wxs3-grid2
wxs4-grid1
wxs4-grid2
Grid C
luster
126 User’s Guide to WebSphere eXtreme Scale

The installation process installs the required libraries that are needed to interact with the grid, a middleware agent process, an IBM Java virtual machine and Java runtime environment™, and sample applications show-casing features of WebSphere eXtreme Scale (including xsadmin, a grid diagnostic and management tool).
For a detailed list of the steps required for installing WebSphere eXtreme Scale in a stand-alone (non-WebSphere) environment consult the “Installing the product” chapter of the WebSphere eXtreme Scale documentation, available at the following Web page:
http://publib.boulder.ibm.com/infocenter/wxdinfo/v6r1/topic/com.ibm.websphere.dataint.doc/info/install/tinstallxdsteps.html
The installation steps located in the Web page above describe the installation procedure for installing WebSphere eXtreme Scale onto the WebSphere Application Server runtime. When the installer or WebSphere eXtreme Scale is started and it does not find an existing WebSphere Application Server installation, it will proceed to show the screens necessary to install the product as a stand-alone deployment. For a stand-alone deployment, all that is required for installation is the install path.
At this point, we have installed the base WebSphere eXtreme Scale product and now need to install the WebSphere UpdateInstaller product. The latest version of the WebSphere Update Installer can be downloaded from the following Web page:
http://www-01.ibm.com/support/docview.wss?rs=180&uid=swg24012718
For our lab environment, WebSphere UpdateInstaller version 6.1.0.17 was used.
After installing the WebSphere Update Installer, we can use it to install the 6.1.0.3 fix pack for WebSphere eXtreme Scale using the instructions on the IBM Support site at the following Web page:
http://www-01.ibm.com/support/docview.wss?rs=3023&uid=swg24018893
The URL provided includes the fix pack download as well.
Tip: IBM recommends, as a leading practice, using the packaged IBM JRE™ with WebSphere eXtreme Scale.
Tip: For easier management, it is recommended to use a consistent installation path across all of your stand-alone WebSphere Extended Deployment DataGrid installations.
Chapter 6. eXtreme Scale in a stand-alone environment 127

Once the installation of fix pack 6.1.0.3 is complete, we can confirm our installation by checking the version information of the WebSphere eXtreme Scale code. We do this by navigating to c:\<install_path>\ObjectGrid\lib. When in this directory, we can execute the Java command shown in Example 6-1.
Example 6-1 Executing the version command
C:\<install_path>\ObjectGrid\lib>java -jar objectgrid.jar version
ObjectGrid Standalone v2.3 WXD610 [cf30831.34618] [$LastChangedDate: 2008-07-2501:26:12 -0400 (Fri, 25 Jul 2008) $]
Example 6-1 shows the current version of the product installed. The bolded text “WXD610” means WebSphere eXtreme Scale 6.1.0. The remaining characters inside the square brackets indicate the fix pack level and internal build codes. In the example, “cf3” means cumulative fix three or fix pack three.
In summary, we have installed the WebSphere eXtreme Scale base product, installed the WebSphere UpdateInstaller, and updated the WebSphere eXtreme Scale base product to version 6.1.0.3.
6.2.3 Post-installation procedure
After installing WebSphere eXtreme Scale, there a couple of steps that need to be completed before we are ready to start grid containers and host a grid. First, we need to alter the setupCmdLine.bat/sh located in the bin directory to contain the JAVA_HOME variable declaration. Example 6-2 shows the version of the setupCmdLine.bat/sh file as shipped with WebSphere eXtreme Scale.
Example 6-2 setupCmdLine
@REM THIS PRODUCT CONTAINS RESTRICTED MATERIALS OF IBM@REM 5724-J34, 5655-P28 (C) COPYRIGHT International Business Machines Corp., 2006@REM All Rights Reserved * Licensed Materials - Property of IBM@REM US Government Users Restricted Rights - Use, duplication or disclosure@REM restricted by GSA ADP Schedule Contract with IBM Corp.
SET CUR_DIR=%cd%cd /d "%~dp0.."SET OBJECTGRID_HOME=%cd%cd /d "%CUR_DIR%"
if not defined JAVA_HOME echo Set the JAVA_HOME environment variable.
128 User’s Guide to WebSphere eXtreme Scale

Example 6-3 shows the changes required to set the JAVA_HOME variable needed by WebSphere eXtreme Scale to locate the JRE to be used for the grid runtime. The new line is in bold for clarity.
Example 6-3 Changes to setupCmdLine for JAVA_HOME
@REM THIS PRODUCT CONTAINS RESTRICTED MATERIALS OF IBM@REM 5724-J34, 5655-P28 (C) COPYRIGHT International Business Machines Corp., 2006@REM All Rights Reserved * Licensed Materials - Property of IBM@REM US Government Users Restricted Rights - Use, duplication or disclosure@REM restricted by GSA ADP Schedule Contract with IBM Corp.
SET JAVA_HOME="C:\WebSphere\XD\java"SET CUR_DIR=%cd%cd /d "%~dp0.."SET OBJECTGRID_HOME=%cd%cd /d "%CUR_DIR%"if not defined JAVA_HOME echo Set the JAVA_HOME environment variable.
As an alternative to editing the setupCmdLine.bat/sh file, we could also simply export the environment entry JAVA_HOME in the current shell before running any WebSphere eXtreme Scale commands, as shown in Example 6-4.
Example 6-4 Alternative - Set JAVA_HOME in the current shell
c:\<install_path>set JAVA_HOME=<install_path>\java
6.3 Example scenarios
Now that we have a functional environment, we can deploy a grid. In the following sections, we demonstrate two uses of the stand-alone WebSphere eXtreme Scale environment:
� The first example, described in 6.3.1, “Configuring the grid as a simple side cache” on page 130, is for a simple side cache pattern with no preloading or write-behind. This pattern demonstrates one of the easiest entry points into WebSphere eXtreme Scale.
� The second example, described in 6.3.2, “Configuring the grid as an extension of another grid” on page 139, shows how to extend an existing grid by supplementing it with inexpensive JVMs from the J2SE environment in order to provide more capacity.
Chapter 6. eXtreme Scale in a stand-alone environment 129
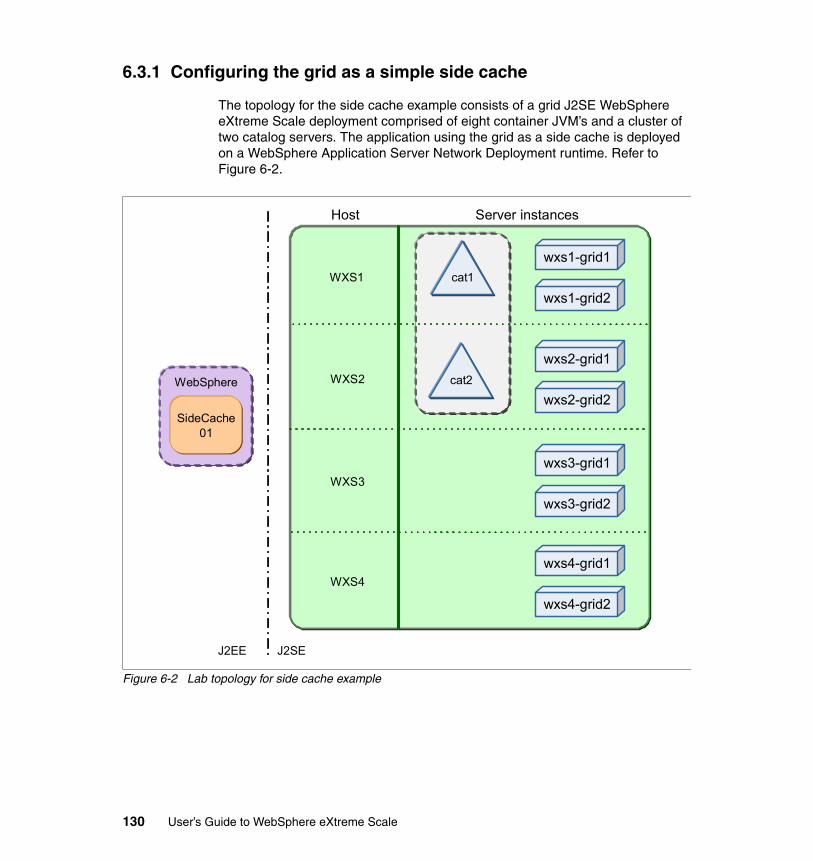
6.3.1 Configuring the grid as a simple side cache
The topology for the side cache example consists of a grid J2SE WebSphere eXtreme Scale deployment comprised of eight container JVM’s and a cluster of two catalog servers. The application using the grid as a side cache is deployed on a WebSphere Application Server Network Deployment runtime. Refer to Figure 6-2.
Figure 6-2 Lab topology for side cache example
SideCache01
cat1
cat2
J2SEJ2EE
Host Server instances
WXS1
WXS4
WXS2
WXS3
WebSphere
wxs1-grid1
wxs1-grid2
wxs2-grid1
wxs2-grid2
wxs3-grid1
wxs3-grid2
wxs4-grid1
wxs4-grid2
130 User’s Guide to WebSphere eXtreme Scale

Starting the catalog serversBefore starting any grid containers, we need to start the catalog servers.
For this example we start two catalog servers only. In our example, the catalog servers are named cat1 and cat2. On server WXS1, we start catalog server cat1 with the command shown in Example 6-5.
Example 6-5 Starting the cat1 catalog server
C:\<install_path>\ObjectGrid\bin>startOgServer.bat cat1 -catalogserviceendpoints cat1:wxs1:6600:6601,cat2:wxs2:6600:6601
On server WXS2, we start catalog server cat2 with the command shown in Example 6-6.
Example 6-6 Starting the cat1 catalog server
C:\<install_path>\ObjectGrid\bin>startOgServer.bat cat2 -catalogserviceendpoints cat1:wxs1:6600:6601,cat2:wxs2:6600:6601
Both servers take the same list for the -catalogserviceendpoint argument. This is because all servers in the cluster must use the same list of peers if inter-server communication is to be successful.
Important: Catalog servers can be a single point of failure. It is absolutely imperative to run multiple catalog servers. Due to quorum policies, it is recommended to have an odd number of catalog servers with a minimum number of three. Because this environment was a test environment, we were able to use fewer catalogs than recommended.
Important:
When starting clustered catalog servers, the servers must be started near simultaneously. This is due to the fact that the catalog servers will wait for the entire group of catalog servers (defined at startup using the -catalogservicesendpoints argument) to become available before completing the startup process.
Start at least two catalog servers within 120 seconds of each other so that the grid and server data can be stored into more than one server. Wait for at least two catalog servers to be active to proceed to the next step. Otherwise, you may see messages that say that a client is routed to a server that has not completely started yet. This is not a defect, but exists to enforce quality of service
Chapter 6. eXtreme Scale in a stand-alone environment 131

Disabling the catalog server cluster quorumBy default the Catalog server cluster quorum is enabled. You can disable this quorum by using the flag -quorum false during starting catalog servers.
Setting the heartbeat frequency level Three heartbeat settings can be tuned to affect how aggressively the availability of the containers is monitored for failover purposes. These settings use the following three commonly used heartbeat frequency levels:
� Level 0 uses a 30-second failure detection time.� Level -1 uses a 5-second failure detection time. � Level 1 uses a 180-second failure detection time.
By the default, eXtreme Scale sets the heartbeat frequency to Level 0.
If you want a more aggressive failover and highly responsive system, specify -heartbeat -1 when you start the catalog server. This will make the failover occur faster but adds overhead to the system due to the additional system heartbeat traffic.
If you want the system to have less overhead and to be more resource friendly, start the catalog server with -heartbeat 1. Doing so will make failover occur slower but will generate less heartbeat traffic.
Starting the container JVMsThe application that will use the grid as a side cache will store Person objects in the grid using the ObjectMap APIs. The Person object is just an arbitrary Java bean that was written for this example. Any customer of standard Java object could be used.
Because we are using a custom Java object (Person), a JAR file that contains the Person.class file has to be included in the classpath of each container when it is started, as shown in Example 6-7.
Example 6-7 JAR file with the custom objects included in the class path
C:\<install_path>\ObjectGrid\bin>startOgServer.bat wxs1-grid1 -catalogserviceendpoints wxs1:2809,wxs2:2809 -objectgridfile c:\gridcfg\JSESample_noloader\objectGrid.xml -deploymentpolicyfile c:\gridcfg\JSESample_noloader\objectGridDeployment.xml -jvmargs -cp c:\gridcfg\JSESample_noloader\dataobjects.jar
The bold text in Example 6-7 is responsible for adding the required JAR file to the JVM’s classpath. This addition is required because Java object serialization is used when moving objects in and out of the grid containers.
132 User’s Guide to WebSphere eXtreme Scale

Example 6-7 on page 132 also demonstrates the commands we can use to start all of our container JVM’s. The command line remains the same except for the first argument, which is the chosen server name. All containers that will be used to host the side cache grid should use the same configuration files. Also, we must make sure that all the servers involved (that is, WXS1,WXS2,WXS3,WXS4) have access to the JAR file mentioned previously (dataobjects.jar).
Custom HA manager portBy default, eXtreme Scale automatically creates and verifies an available port for HAManager. In this release it also enables you to specify the HAManager port by using -haManagerPort when you start the ObjectGrid server.
Reviewing the grid configuration filesBefore we continue let us take a look at the objectGrid.xml and objectGridDeployment.xml files that are being used by our container JVM’s.
Example 6-8 displays the contents of the objectGrid.xml configuration file. This configuration file is responsible for defining all of the objectGrid and backingMap elements that will make up the side cache grid. In this example, we are calling our grid instance “CacheGrid”. Our grid contains a single backing map definition named “cachedata”.
Example 6-8 objectGrid.xml
<?xml version="1.0" encoding="UTF-8"?><objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ibm.com/ws/objectgrid/config ../objectGrid.xsd" xmlns="http://ibm.com/ws/objectgrid/config">
<objectGrids> <objectGrid name="CacheGrid"> <backingMap name="cachedata" timeToLive="900" /> </objectGrid> </objectGrids>
</objectGridConfig>
Chapter 6. eXtreme Scale in a stand-alone environment 133

Example 6-9 on page 134 details the objectGridDeployment.xml configuration file. This file is responsible for defining policies for shard placement and partition configuration.
In this example we have defined four partitions for the grid called CacheGrid. This value is defined with the numberOfPartitions property of the objectgridDeployment XML element. The number of asynchronous and synchronous replica shards for each partition is configurable on the objectgridDeployment element as well. In our example we have defined that we should have between one and four synchronous replica shards (minSyncReplicas=1 and maxSyncReplicas=4) and a maximum of four asynchronous replica shards.
Example 6-9 objectGridDeployment.xml
<?xml version="1.0" encoding="UTF-8"?><deploymentPolicy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ibm.com/ws/objectgrid/deploymentPolicy ../deploymentPolicy.xsd" xmlns="http://ibm.com/ws/objectgrid/deploymentPolicy">
<objectgridDeployment objectgridName="CacheGrid"> <mapSet name="PrimaryMapSet" numberOfPartitions="4" minSyncReplicas="1" maxSyncReplicas="4" maxAsyncReplicas="4"> <map ref="cachedata" /> </mapSet> </objectgridDeployment>
</deploymentPolicy>
Now that we have started all of our container JVM’s, lets take a look at the sample application, ITSOSideCache.
The applicationThe application, ITSOSideCache, is a JEE Web application that simulates a typical side cache pattern of cache hits and cache misses. The application consists of two JavaServer™ Pages (JSP) and a single servlet that are responsible for managing the cache interaction.
134 User’s Guide to WebSphere eXtreme Scale

The ITSOSideCache application is provided in the additional Web material for this book. For instructions about how to download this material, see Appendix C, “Additional material” on page 229. Extract the ITSOSideCache.zip file from the download material and perform the following steps to prepare it for use:
1. Open the ITSOSideCache.zip file and locate the ITSOSideCacheWeb.war file.
2. Open the ITSOSideCacheWeb.war file and locate the WEB-INF directory.
3. Within the WEB-INF directory, edit member web.xml.
4. Locate the <init-param> parameter and change this parameter setting as follows:
<param-value>9.42.171.30:2809</param-value>
Modify the IP address, in this case 9.42.171.30, to match the host name where you run the catalog server. The port number, 2809, needs to match the catalog server port. If it does not, modify the port number as well to match your catalog server port.
5. Save the changes, replacing the altered member in the ITSOSideCache.zip file.
6. Rename ITSOSideCache.zip to ITSOSideCache.ear.
7. Install the application in a WebSphere Application Server stand-alone server.
After deploying the application to a WebSphere Application Server runtime and browsing to the context root of the application, you can review the index page (Figure 6-3).
In our example the URL is http://localhost:9080/itso.
Figure 6-3 index.jsp for side cache sample application
Chapter 6. eXtreme Scale in a stand-alone environment 135

The details on what the application will do is detailed at a high level in the previous figure. If we click the provided link, we can see the application work. Figure 6-4 displays the output that is shown after clicking the link on the index page the first time after the application is started. Notice that the page tells us that the data was retrieved from the data store (database, adapter, flat file, and so forth.)
Figure 6-4 First results from datastore
Figure 6-5 displays the output when the page is hit again (refreshed).
Figure 6-5 Second results from side cache
In Figure 6-5, the line “Method of obtaining data: from cache” indicates that the data was found in the side cache, or grid. This application demonstrates a simplified example. Let us take a look at the application code that does the interaction.
136 User’s Guide to WebSphere eXtreme Scale

The codeBecause ITSOSideCache is a simple Web application all the work for interaction with the cache is done through one servlet, specifically the doGet() method. The code for the doGet() method is shown in Example 6-10.
Example 6-10 Example doGet() method code for cache interaction servlet class
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {//request comes in for a Person record with ID 1234try {
Session s = grid.getSession();ObjectMap map = s.getMap("cachedata");System.out.println("Consulting with cache to determine if value exists");if (map.containsKey(new Integer(1234))){
/** this condition means that the cache contains* the data we want, we just need to get it*/System.out.println("Cache indicates that value is present, retrieving");s.begin();Person p = (Person)map.get(new Integer(1234));s.commit();System.out.println("Value obtained, marshalling into view");/* * we'll stuff this record in a request attribute * and send it to a JSP for viewing */request.setAttribute("results", p);request.setAttribute("method", "from cache");RequestDispatcher rd = request.getRequestDispatcher("result.jsp");rd.forward(request, response);
} else {/* * this condition means that the cache does NOT have the * data, so we should go get it and put it in the grid */System.out.println("Cache indicates that value is not present");/* * go off and fetch a record from the backend * system (I.e. database or otherwise) -- we'll fake ours * for this example */System.out.println("Going off to get record from backend....");Person person = new Person(1234, "John", "Doe", "RTP");
Chapter 6. eXtreme Scale in a stand-alone environment 137

/* * now put it in the grid for next time */s.begin();map.insert(person.getPersonIDasInteger(), person);s.commit();System.out.println("Add value to cache");//return the recordSystem.out.println("Value obtained, marshalling into view");request.setAttribute("results", person);request.setAttribute("method", "from datastore");RequestDispatcher rd = request.getRequestDispatcher("result.jsp");rd.forward(request, response);
}} catch (Exception e) {
e.printStackTrace();} }
The code in Example 6-10 on page 137 is fairly straightforward. A simulated request for a Person object with an id of 1234 is passed to the servlet. From there, the servlet establishes communication with the grid instance. (In the init() method of the servlet the reference to the variable named “grid” was established.) It proceeds to determine if the desired value resides in the side cache. If the value is present, the servlet simply retrieves the value and processes it into the request object and then forwards the requester to the results.jsp Web page. If the value was not found in the side cache, the application proceeds to produce a fabricated Person object with the desired values, places the Person object into the side cache for later retrieval, and then forwards the user to the result.jsp Web page as before. For reference, the init() method of the servlet is provided in Example 6-11.
Example 6-11 Example init() method code for cache interaction servlet class
public void init() throws ServletException {System.out.println("init'ing CacheInteractionManagerServlet");ObjectGridManager og_mgr = ObjectGridManagerFactory.getObjectGridManager();try {
System.out.println("Trying to contact the catalog services @ " +getInitParameter("cluster"));
//catalog server cluster enpoints are defined in a servlet init param for this //exampleClientClusterContext ccc = og_mgr.connect(getInitParameter("cluster"),null, null);//connect to the configured catalog server clusterSystem.out.println("Catalog services contacted successfully!");
138 User’s Guide to WebSphere eXtreme Scale

grid = og_mgr.getObjectGrid(ccc, "CacheGrid");if (grid == null){//the grid is not yet available, we should start it
//failed to get the remote grid instanceSystem.out.println("The distributed grid does not appear to be available --
grid = null");} else {
//the distributed grid reference was obtained successfullySystem.out.println("The distributed grid IS available - using it");try {
Session session = grid.getSession();ObjectMap cacheMap = session.getMap("cachedata");System.out.println("Clearing out the cachedata backingMap");cacheMap.clear(); //clear the contents of this map out
} catch (Exception e) {e.printStackTrace();
} }} catch (ConnectException e) {
e.printStackTrace();System.out.println("Catalog services were not found @ " +
getInitParameter("cluster"));//handle the ConnectException case
}System.out.println("Side cache application ready for requests.");}
As we have seen, creating a simple side cache interaction with WebSphere eXtreme Scale is fairly straightforward and simple. Now we will look at another usage scenario for our J2SE grid environment.
6.3.2 Configuring the grid as an extension of another grid
In many scenarios, the amount of data to be contained in the grid will grow to a point in which the grid, as configured, cannot contain it all in memory. In this case, it may be desirable to use cheap JVM’s from a J2SE stand-alone WebSphere eXtreme Scale deployment. Utilizing JVM’s from the stand-alone deployment can provide a cheaper alternative to creating more grid containers on a WebSphere-managed WebSphere eXtreme Scale deployment due to licensing considerations.
Chapter 6. eXtreme Scale in a stand-alone environment 139
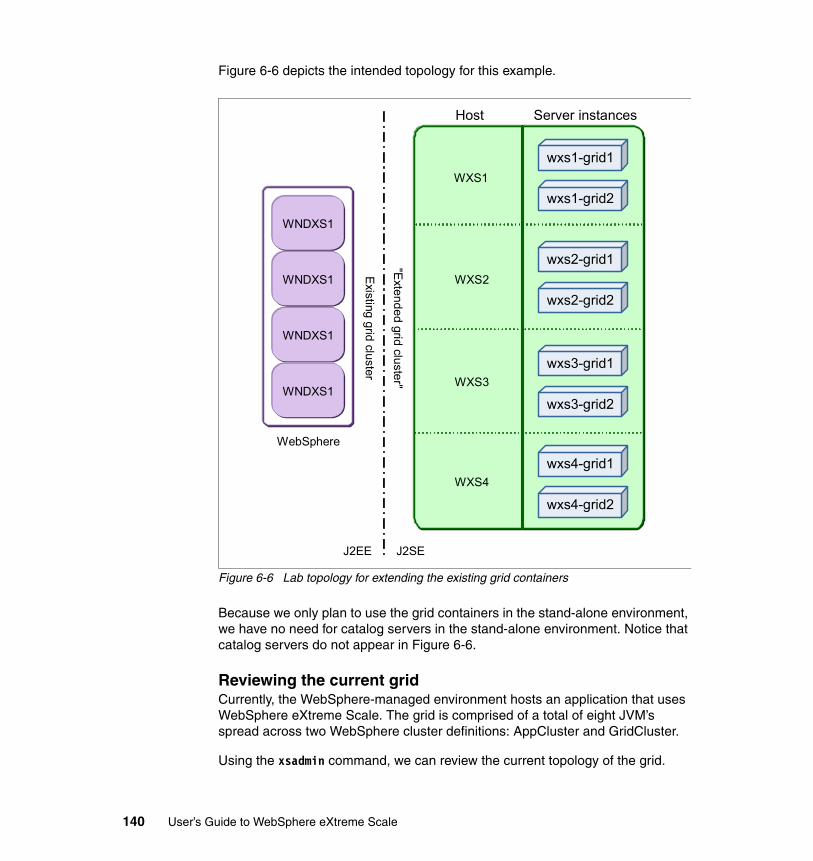
Figure 6-6 depicts the intended topology for this example.
Figure 6-6 Lab topology for extending the existing grid containers
Because we only plan to use the grid containers in the stand-alone environment, we have no need for catalog servers in the stand-alone environment. Notice that catalog servers do not appear in Figure 6-6.
Reviewing the current gridCurrently, the WebSphere-managed environment hosts an application that uses WebSphere eXtreme Scale. The grid is comprised of a total of eight JVM’s spread across two WebSphere cluster definitions: AppCluster and GridCluster.
Using the xsadmin command, we can review the current topology of the grid.
J2SEJ2EE
WebSphere
Host Server instances
WXS1
WXS4
WXS2
WXS3
wxs1-grid1
wxs1-grid2
wxs2-grid1
wxs2-grid2
wxs3-grid1
wxs3-grid2
wxs4-grid1
wxs4-grid2
WNDXS1
WNDXS1
WNDXS1
WNDXS1
"Extended grid cluster"
Existing grid cluster
140 User’s Guide to WebSphere eXtreme Scale

The resulting output from the xsadmin command in Example 6-12 displays the details regarding the current placement of the grid shard amongst the available containers. In our example we have eight containers available to host the EntityManagerXMLSampleObjectGrid grid instance.
Example 6-12 Using xsadmin to view the grid topology
C:\<was_install_root\profiles\Dmgr01\bin>xsadmin.bat -dmgr -g EntityManagerXMLSampleObjectGrid -m ENTITY_MAPSET_MANAGER -containers
This administrative utility is provided as a sample only and is not to be considered a fully supported component of the WebSphere eXtreme Scale product
Connecting to Catalog service at localhost:9809*** Show all online containersHost: WNDXS3.itso.ral.ibm.com Container: Container-10, Server:WNDXSCell\WNDXS3Node01\GridMember3, Zone:DefaultZone P:0 Primary P:6 SynchronousReplica P:1 AsynchronousReplica P:7 AsynchronousReplica Container: Container-11, Server:WNDXSCell\WNDXS3Node01\GridMember4, Zone:DefaultZone P:0 SynchronousReplica P:1 SynchronousReplica P:3 SynchronousReplica P:5 SynchronousReplica Container: Container-6, Server:WNDXSCell\WNDXS3Node01\AppServer3, Zone:DefaultZone P:4 SynchronousReplica P:7 SynchronousReplica P:0 AsynchronousReplica P:5 AsynchronousReplica
Host: WNDXS1.itso.ral.ibm.com Container: Container-4, Server:WNDXSCell\WNDXS1Node01\AppServer1, Zone:DefaultZone P:3 Primary P:5 Primary P:7 Primary
Chapter 6. eXtreme Scale in a stand-alone environment 141

P:0 SynchronousReplica Container: Container-8, Server:WNDXSCell\WNDXS1Node01\GridMember1, Zone:DefaultZone P:1 Primary P:6 Primary P:3 SynchronousReplica P:2 AsynchronousReplica
Host: WNDXS4.itso.ral.ibm.com Container: Container-7, Server:WNDXSCell\WNDXS4Node01\AppServer4, Zone:DefaultZone P:2 SynchronousReplica P:4 SynchronousReplica P:7 SynchronousReplica P:6 AsynchronousReplica
Host: WNDXS2.itso.ral.ibm.com Container: Container-5, Server:WNDXSCell\WNDXS2Node01\AppServer2, Zone:DefaultZone P:2 Primary P:4 Primary P:5 SynchronousReplica P:6 SynchronousReplica Container: Container-9, Server:WNDXSCell\WNDXS2Node01\GridMember2, Zone:DefaultZone P:1 SynchronousReplica P:2 SynchronousReplica P:3 AsynchronousReplica P:4 AsynchronousReplica
Num containers matching = 8 Total known containers = 8 Total known hosts = 4
Starting the container JVMsIn the next few steps will increase the number of available containers for this grid instance (and all other grid instances configured) to a total of 16 JVM’s. We will accomplish this by starting eight container JVM’s on the stand-alone environment and pointing these containers to the catalog server in the WebSphere-managed environment (currently the default of the Deployment Manager process).
142 User’s Guide to WebSphere eXtreme Scale

To start the grid containers we can use a command such as the one shown in Example 6-13.
Example 6-13 Starting the grid containers
C:\<install_path>\ObjectGrid\bin>startOgServer.bat wxs1-grid1 -catalogserviceendpoints wndxs1:9809 -objectgridfile c:\gridcfg\JEESample_loader\objectGrid.xml -deploymentpolicyfile c:\gridcfg\JEESample_loader\objectGridDeployment.xml -jvmargs -cp c:\gridcfg\JEESample_loader
Notice that this command is similar to the previous example, side cache. The only difference in this command is that we are pointing the container JVM to the catalog server in the WebSphere-managed environment. Of course, we are using a different set of configuration XML files that match those being used in the existing grid containers. Also, we have included a directory in the classpath of the container JVM to pick up required files and class definitions required for things such as loaders to work correctly.
After starting seven more servers across our stand-alone environment, we can execute the same xsadmin command as before to see how the grid dynamic has changed.
From Example 6-14, we can see that we have successfully increased our grid capacity from eight JVM’s residing entirely inside the WebSphere-managed environment to 16 JVM’s located in both a WebSphere-managed environment and a stand-alone J2SE environment.
Example 6-14 Reviewing the topology
C:\<was_install_root>\profiles\Dmgr01\bin>xsadmin.bat -dmgr -g EntityManagerXMLSampleObjectGrid -m ENTITY_MAPSET_MANAGER -containers
This administrative utility is provided as a sample only and is not to be considered a fully supported component of the WebSphere eXtreme Scale product
Connecting to Catalog service at localhost:9809*** Show all online containersHost: WXS3 Container: Container-24, Server:wxs3-grid1, Zone:DefaultZone P:7 SynchronousReplica P:1 AsynchronousReplica Container: Container-25, Server:wxs3-grid2, Zone:DefaultZone P:2 Primary P:7 AsynchronousReplica
Chapter 6. eXtreme Scale in a stand-alone environment 143

Host: WXS2 Container: Container-22, Server:wxs2-grid1, Zone:DefaultZone P:6 Primary P:4 SynchronousReplica Container: Container-23, Server:wxs2-grid2, Zone:DefaultZone P:7 Primary P:0 SynchronousReplica
Host: WXS4 Container: Container-26, Server:wxs4-grid1, Zone:DefaultZone P:1 SynchronousReplica P:4 SynchronousReplica Container: Container-27, Server:wxs4-grid2, Zone:DefaultZone P:1 SynchronousReplica P:3 SynchronousReplica
Host: WNDXS3.itso.ral.ibm.com Container: Container-10, Server:WNDXSCell\WNDXS3Node01\GridMember3, Zone:DefaultZone P:0 Primary P:6 SynchronousReplica Container: Container-11, Server:WNDXSCell\WNDXS3Node01\GridMember4, Zone:DefaultZone P:0 SynchronousReplica P:5 SynchronousReplica Container: Container-6, Server:WNDXSCell\WNDXS3Node01\AppServer3, Zone:DefaultZone P:0 AsynchronousReplica P:5 AsynchronousReplica
Host: WNDXS1.itso.ral.ibm.com Container: Container-4, Server:WNDXSCell\WNDXS1Node01\AppServer1, Zone:DefaultZone P:3 Primary P:5 Primary Container: Container-8, Server:WNDXSCell\WNDXS1Node01\GridMember1, Zone:DefaultZone P:3 SynchronousReplica P:2 AsynchronousReplica
Host: WXS1 Container: Container-20, Server:wxs1-grid1, Zone:DefaultZone P:1 Primary P:2 SynchronousReplica
144 User’s Guide to WebSphere eXtreme Scale

Container: Container-21, Server:wxs1-grid2, Zone:DefaultZone P:4 Primary P:3 AsynchronousReplica
Host: WNDXS4.itso.ral.ibm.com Container: Container-7, Server:WNDXSCell\WNDXS4Node01\AppServer4, Zone:DefaultZone P:7 SynchronousReplica P:6 AsynchronousReplica
Host: WNDXS2.itso.ral.ibm.com Container: Container-5, Server:WNDXSCell\WNDXS2Node01\AppServer2, Zone:DefaultZone P:5 SynchronousReplica P:6 SynchronousReplica Container: Container-9, Server:WNDXSCell\WNDXS2Node01\GridMember2, Zone:DefaultZone P:2 SynchronousReplica P:4 AsynchronousReplica
Num containers matching = 16 Total known containers = 16 Total known hosts = 8
Special consideration must normally be given to extending a grid that resides in a WebSphere-managed environment and contains a loader plug-in. If the loader plug-in requires the usage of JEE resources like data sources, JCA adapters, and message queues, it must be noted that these resources will not be available in the stand-alone environment due to the lack of an application server runtime.
Chapter 6. eXtreme Scale in a stand-alone environment 145

146 User’s Guide to WebSphere eXtreme Scale

Chapter 7. Using WebSphere eXtreme Scale with JPA
This chapter describes the functionality that WebSphere eXtreme Scale provides to benefit from JPA for data access. It covers the following two major use-cases:
� Providing eXtreme Scale data access through JPA� Providing a caching implementation for JPA
We will also be looking at the sample application and extending its functionality to demonstrate how to use the JPA Loader implementations.
This chapter includes the following topics:
� “Java Persistence API introduction” on page 148� “WebSphere eXtreme Scale support for JPA” on page 149� “JPA data access with the sample application” on page 155� “Setting up the JPA Loader” on page 156� “Setting up the time-based updater” on page 165� “Using the Client Loader in the sample application” on page 170� “Setting up eXtreme Scale as a JPA cache” on page 174
7
© Copyright IBM Corp. 2008. All rights reserved. 147

7.1 Java Persistence API introduction
The Java Persistence API (JPA) 1.0 is a new standard introduced to Java Enterprise Edition (JEE) 5.0 as part of the EJB 3.0 specification. It is part of the overall simplification of JEE, in this case dramatically simplifying persistence. JPA is the successor to entity EJBs and provides greater portability, performance and general ease-of-use.
JPA allows the persistence of plain old Java objects (POJOs), called entities, to a database simply by adding annotations to the Java class. This topic is beyond the scope of this Redbooks publication. For more information, see Redbooks publication WebSphere Application Server Version 6.1 Feature Pack for EJB 3.0, SG24-7611. It will suffice here to show an example of a JPA entity.
Example 7-1 shows the Account entity from the sample application described in 5.2, “Introducing the sample application” on page 93. This is a great example of a POJO being annotated as both an eXtreme Scale entity (as designated by the eXtreme Scale @Entity annotation) and a JPA entity. It shows the commonality and reuse between eXtreme Scale and JPA.
Example 7-1 Account entity from sample application
@[email protected]@Table(name="ACCOUNT", schema="itso")public class Account implements Serializable {
private static final long serialVersionUID = -3514273682447644159L;
@[email protected]@Column(name = "ID")String accountId;
@Column(name = "BALANCE")int balance;
@[email protected](optional = false, fetch = javax.persistence.FetchType.EAGER )@JoinColumn(name = "CUSTNO", referencedColumnName = "CUSTNO", nullable=true) Owner owner;
@ManyToOne
148 User’s Guide to WebSphere eXtreme Scale

@javax.persistence.ManyToOne(optional = false, fetch = javax.persistence.FetchType.EAGER )@JoinColumn(name = "CUSTNOBiz", referencedColumnName = "CUSTNO", nullable=true) Owner bizOwner;
//getters and setters}
The JPA annotations that have been added to the eXtreme Scale entity define:
� The @javax.persistence.Entity� The schema and table details� Which instance variables map to which table fields
This example demonstrates that JPA is a good match with WebSphere eXtreme Scale, which excels at storing Java objects. Once we have defined an entity for both eXtreme Scale and JPA we can seamlessly use it to persist to both, and allow the loading tools we are about to discuss to manage the persistence and life-cycle.
7.2 WebSphere eXtreme Scale support for JPA
WebSphere eXtreme Scale version 6.1.0.3 introduced strong database integration with JPA. The aim of this integration is to allow the developer to combine the strong productivity benefits of JPA: speed to develop, ease of deployment, and runtime performance, with the power of WebSphere eXtreme Scale. The aim has been to provide the user with the functionality with minimal development or code-change.
JPA, as its name suggests, is just a standard programming interface. The functionality offered by WebSphere eXtreme Scale is for the Apache OpenJPA implementation of JPA, available from Apache at the following Web page:
http://openjpa.apache.org/
OpenJPA is also the basis of the Feature Pack for EJB 3.0 for WebSphere Application Server v6.1. It is this feature pack on WebSphere Application Server that has been used throughout this Redbooks publication for the sample application. See 5.3, “Introducing the sample topology” on page 98.
Chapter 7. Using WebSphere eXtreme Scale with JPA 149
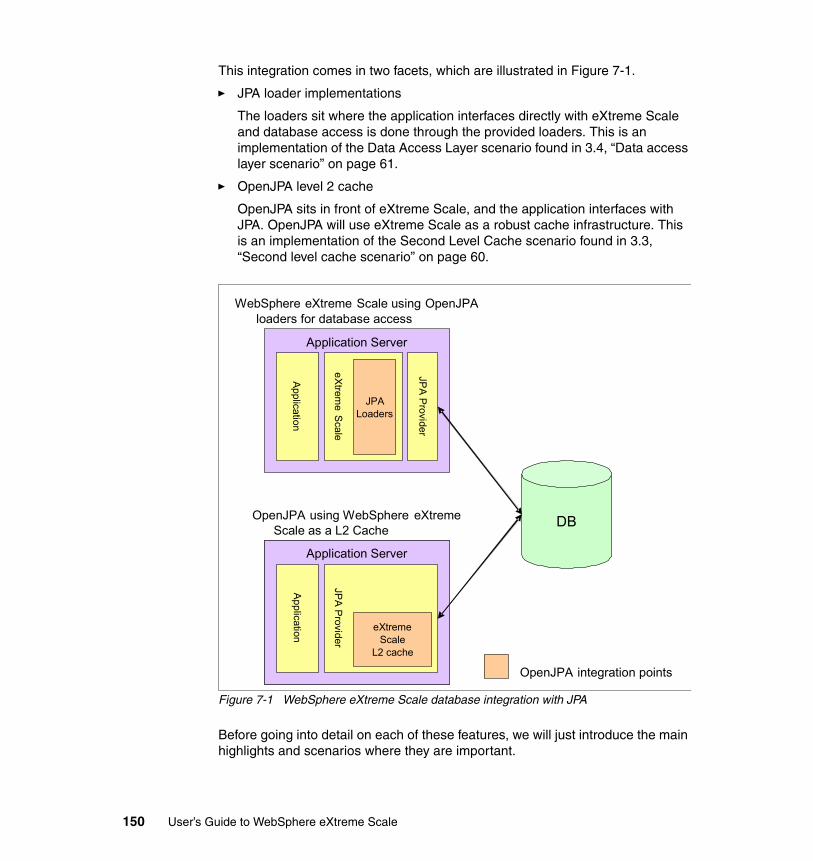
This integration comes in two facets, which are illustrated in Figure 7-1.
� JPA loader implementations
The loaders sit where the application interfaces directly with eXtreme Scale and database access is done through the provided loaders. This is an implementation of the Data Access Layer scenario found in 3.4, “Data access layer scenario” on page 61.
� OpenJPA level 2 cache
OpenJPA sits in front of eXtreme Scale, and the application interfaces with JPA. OpenJPA will use eXtreme Scale as a robust cache infrastructure. This is an implementation of the Second Level Cache scenario found in 3.3, “Second level cache scenario” on page 60.
Figure 7-1 WebSphere eXtreme Scale database integration with JPA
Before going into detail on each of these features, we will just introduce the main highlights and scenarios where they are important.
DB
Application Server
Application
eXtreme
Scale
JPA
Provider
JPALoaders
Application Server
Application
JPA
Provider
eXtremeScale
L2 cache
Application Server
Application
JPA
Provider
eXtremeScale
L2 cache
OpenJPA integration points
WebSphere eXtreme Scale using OpenJPAloaders for database access
OpenJPA using WebSphere eXtremeScale as a L2 Cache
150 User’s Guide to WebSphere eXtreme Scale

7.2.1 Using JPA for data access in WebSphere eXtreme Scale
WebSphere eXtreme Scale provides the following features to use OpenJPA to interact with a database. These are all specific implementations of the Data Access Scenario found in 3.4, “Data access layer scenario” on page 61.
� JPA loader
There are two JPA loaders. They are JPA implementations of the eXtreme Scale generic Loader interface. This interface provides a means to write to and read from a database from the eXtreme Scale grid using JPA entities.
The JPA Loader functionality can be used in either a write-through or a write-behind capacity. Write-through is the default behavior and ensures every update to the grid is immediately persisted to the database. Write-behind will batch updates for either a period of time or a number of updates before persisting to the database.
� Time-based Updater
This provides a polling mechanism to periodically check a database for any changes to the data and update the grid accordingly. This is an important function to help manage stale caches. For further information about options for dealing with stale cache information, see 3.6, “Dealing with stale caches” on page 70.
� Client Loader
The Client Loader implementation provides an implementation to easily preload and populate a grid by providing a JPA query.
These are illustrated in Figure 7-2 on page 152.
Chapter 7. Using WebSphere eXtreme Scale with JPA 151
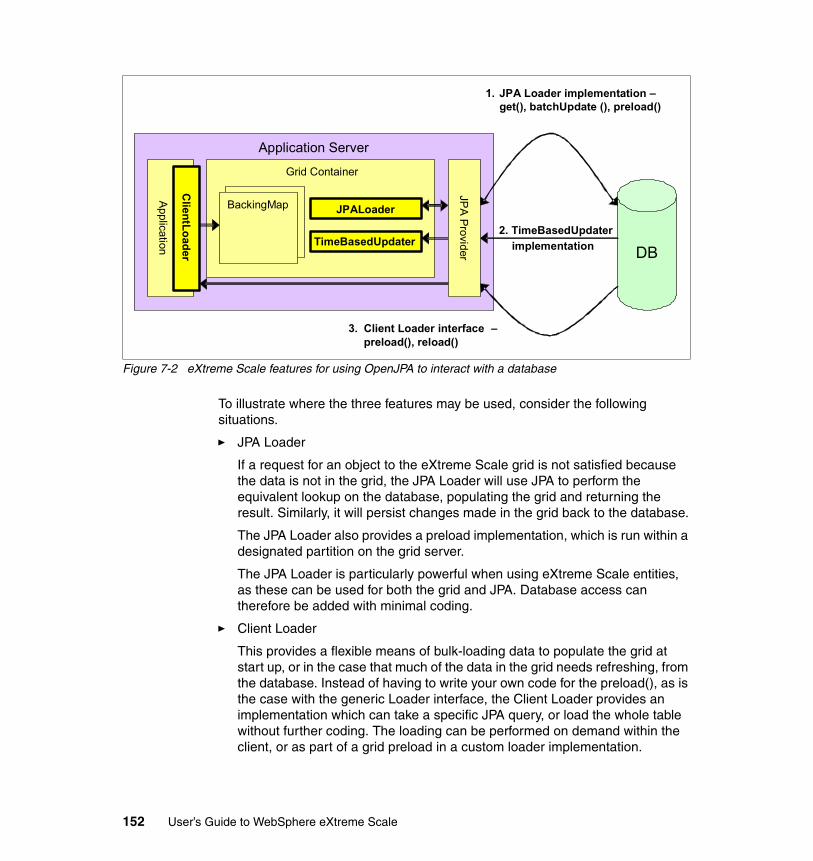
Figure 7-2 eXtreme Scale features for using OpenJPA to interact with a database
To illustrate where the three features may be used, consider the following situations.
� JPA Loader
If a request for an object to the eXtreme Scale grid is not satisfied because the data is not in the grid, the JPA Loader will use JPA to perform the equivalent lookup on the database, populating the grid and returning the result. Similarly, it will persist changes made in the grid back to the database.
The JPA Loader also provides a preload implementation, which is run within a designated partition on the grid server.
The JPA Loader is particularly powerful when using eXtreme Scale entities, as these can be used for both the grid and JPA. Database access can therefore be added with minimal coding.
� Client Loader
This provides a flexible means of bulk-loading data to populate the grid at start up, or in the case that much of the data in the grid needs refreshing, from the database. Instead of having to write your own code for the preload(), as is the case with the generic Loader interface, the Client Loader provides an implementation which can take a specific JPA query, or load the whole table without further coding. The loading can be performed on demand within the client, or as part of a grid preload in a custom loader implementation.
Application ServerApplication Server
Application
Grid Container
DBDB
JPALoader
ClientLoader
TimeBasedUpdater
BackingMapBackingMap
1.
JPA
Provider
3. Client Loader interface –preload(), reload()
2. TimeBasedUpdaterimplementation
JPA Loader implementation –get(), batchUpdate (), preload()
152 User’s Guide to WebSphere eXtreme Scale

� Time-based Updater
A means to update the grid is essential if the grid does not have exclusive access to the database. If another application can update data on the database, the Time-based Updater can check for these updates and notify the grid accordingly. It can invalidate or refresh the stale data.
Naturally, the three features could be used together to provide a robust data access layer for eXtreme Scale based upon JPA.
7.2.2 Using WebSphere eXtreme Scale as a JPA cache
The other facet of the eXtreme Scale JPA functionality is the ability to plug in eXtreme Scale as a cache for JPA. As with all data access, JPA performance can be significantly improved through the use of caching. The good news is that this can be achieved without having to change any application code. Instead, WebSphere eXtreme Scale can be set up as a cache purely through configuration files and deployment descriptors.
WebSphere eXtreme Scale provides persistence cache implementations specifically for OpenJPA and Hibernate. We are going to focus on the OpenJPA implementation as it is the basis for Feature Pack for EJB 3.0 for WebSphere Application Server v6.1.
WebSphere eXtreme Scale provides two cache implementations for OpenJPA:
� DataCache � QueryCache
The DataCache is an implementation of a level 2 cache (see 3.3, “Second level cache scenario” on page 60). That is, it will store retrieved JPA entities in the grid and when the application next attempts to retrieve the same entity, it will first check the cache and return the entity from there. Because this can be a distributed cache, all users and instances of the application could use the same cache. This is illustrated in Figure 7-3 on page 154.
Chapter 7. Using WebSphere eXtreme Scale with JPA 153
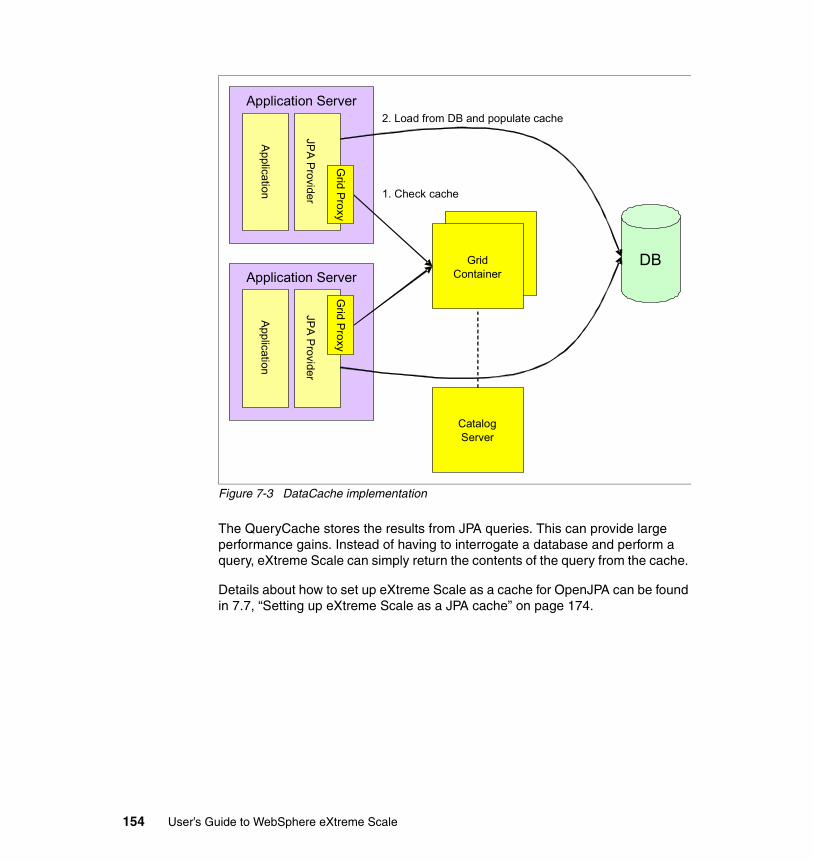
Figure 7-3 DataCache implementation
The QueryCache stores the results from JPA queries. This can provide large performance gains. Instead of having to interrogate a database and perform a query, eXtreme Scale can simply return the contents of the query from the cache.
Details about how to set up eXtreme Scale as a cache for OpenJPA can be found in 7.7, “Setting up eXtreme Scale as a JPA cache” on page 174.
eXtremeScale
Cluster
eXtremeScale
Cluster DBDB
Application Server
Application
JPA
Provider
GridContainer
GridContainer
CatalogServer
CatalogServer
Application ServerApplication Server
Application
JPA
Provider
1. Check cache
2. Load from DB and populate cache
Grid P
roxyG
rid Proxy
154 User’s Guide to WebSphere eXtreme Scale
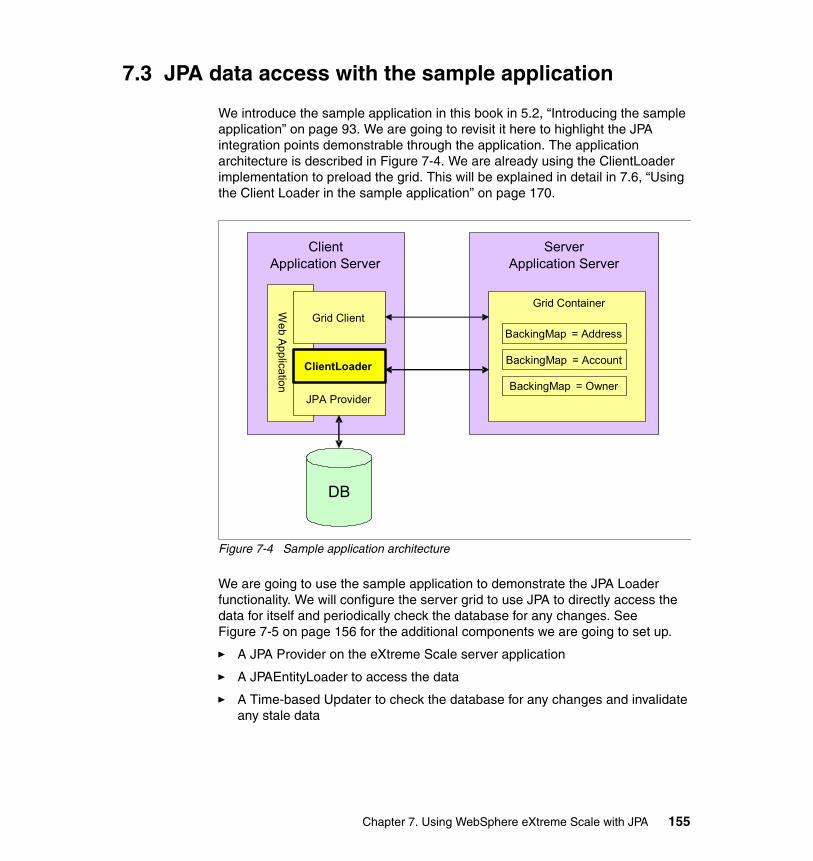
7.3 JPA data access with the sample application
We introduce the sample application in this book in 5.2, “Introducing the sample application” on page 93. We are going to revisit it here to highlight the JPA integration points demonstrable through the application. The application architecture is described in Figure 7-4. We are already using the ClientLoader implementation to preload the grid. This will be explained in detail in 7.6, “Using the Client Loader in the sample application” on page 170.
Figure 7-4 Sample application architecture
We are going to use the sample application to demonstrate the JPA Loader functionality. We will configure the server grid to use JPA to directly access the data for itself and periodically check the database for any changes. See Figure 7-5 on page 156 for the additional components we are going to set up.
� A JPA Provider on the eXtreme Scale server application
� A JPAEntityLoader to access the data
� A Time-based Updater to check the database for any changes and invalidate any stale data
ClientApplication Server
ServerApplication Server
Web A
pplication
Grid Container
DB
BackingMap = OwnerJPA Provider
ClientLoader BackingMap = Account
BackingMap = AddressGrid Client
Chapter 7. Using WebSphere eXtreme Scale with JPA 155
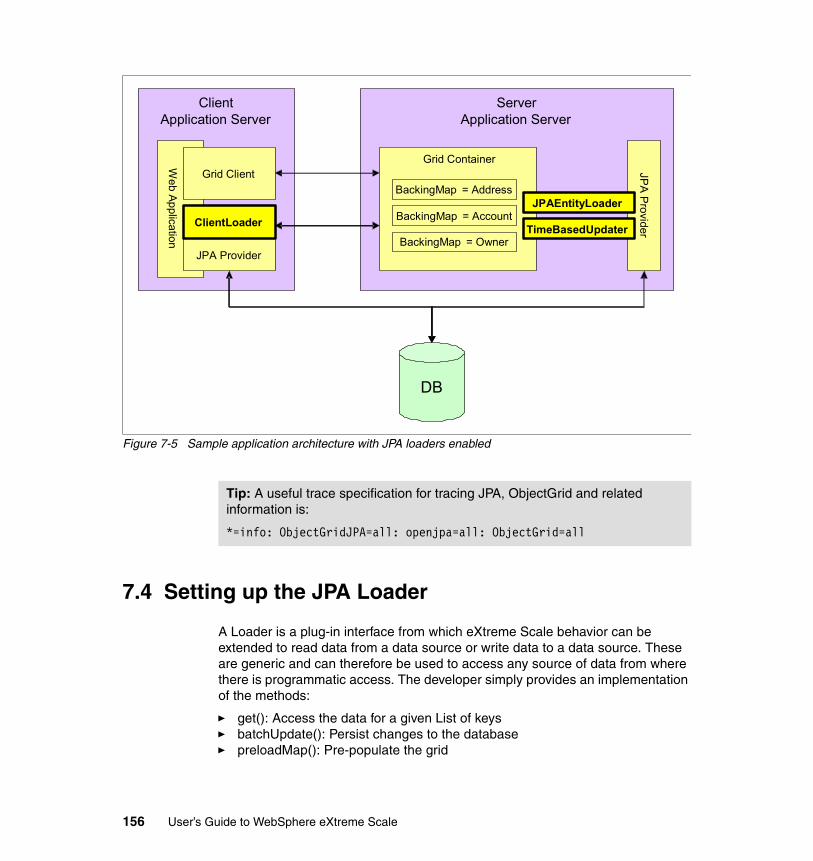
Figure 7-5 Sample application architecture with JPA loaders enabled
7.4 Setting up the JPA Loader
A Loader is a plug-in interface from which eXtreme Scale behavior can be extended to read data from a data source or write data to a data source. These are generic and can therefore be used to access any source of data from where there is programmatic access. The developer simply provides an implementation of the methods:
� get(): Access the data for a given List of keys� batchUpdate(): Persist changes to the database� preloadMap(): Pre-populate the grid
ClientApplication Server
ServerApplication Server
Web A
pplication
Grid Container
DB
BackingMap = OwnerJPA Provider
ClientLoader BackingMap = Account
BackingMap = AddressGrid Client JP
A P
rovider
JPAEntityLoader
TimeBasedUpdater
Tip: A useful trace specification for tracing JPA, ObjectGrid and related information is:
*=info: ObjectGridJPA=all: openjpa=all: ObjectGrid=all
156 User’s Guide to WebSphere eXtreme Scale
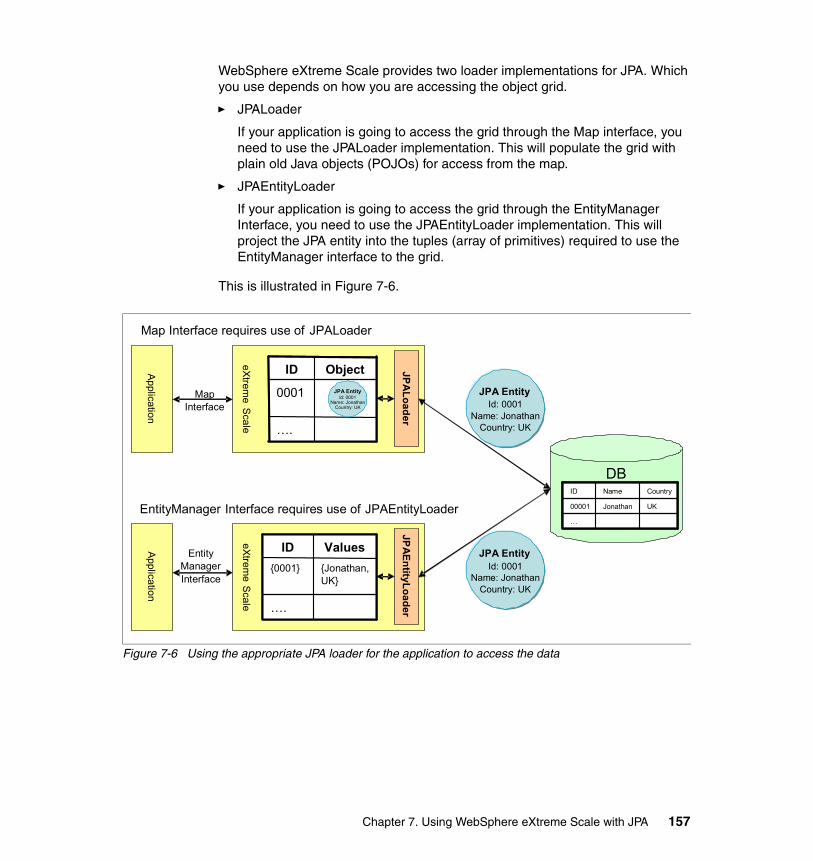
WebSphere eXtreme Scale provides two loader implementations for JPA. Which you use depends on how you are accessing the object grid.
� JPALoader
If your application is going to access the grid through the Map interface, you need to use the JPALoader implementation. This will populate the grid with plain old Java objects (POJOs) for access from the map.
� JPAEntityLoader
If your application is going to access the grid through the EntityManager Interface, you need to use the JPAEntityLoader implementation. This will project the JPA entity into the tuples (array of primitives) required to use the EntityManager interface to the grid.
This is illustrated in Figure 7-6.
Figure 7-6 Using the appropriate JPA loader for the application to access the data
DBDB
Application
Application
eXtreme
Scale
eXtreme
Scale
JPALoader
JPA EntityId: 0001
Name: JonathanCountry: UK….
0001
ObjectID
….
0001
ObjectIDJPA Entity
Id: 0001Name: Jonathan
Country: UK
Application
Application
eXtreme
ScaleeXtrem
eS
cale
JPAEntityLoader
JPA EntityId: 0001
Name: JonathanCountry: UK
….
{Jonathan, UK}
{0001}
ValuesID
….
{Jonathan,UK}
{0001}
ValuesID
EntityManager Interface requires use of JPAEntityLoader
Map Interface requires use of JPALoader
…
UKJonathan00001
CountryNameID
…
UKJonathan00001
CountryNameID
MapInterface
EntityManagerInterface
Chapter 7. Using WebSphere eXtreme Scale with JPA 157

Both Loader implementations have the same simple JPA requirements to access the database. They require the following configuration of eXtreme Scale and JPA:
� WebSphere eXtreme Scale configuration
Configure the object grid to use the JPALoader plug-in.
� JPA configuration and development
– JPA provider
In the sample, we are using Feature Pack for EJB 3.0 for WebSphere Application Server v6.1, which is based on OpenJPA.
– JPA Entities
These can be the same as the eXtreme Scale entities.
– JPA persistence unit for connectivity to the database
7.4.1 Configure the sample application to use the JPAEntityLoader
As the sample application makes use of the eXtreme Scale EntityManager API, we need to use the JPAEntityLoader implementation. We are going to set that up on the server application so that the grid can directly access the data instead of needing to be manually populated.
In order to use the JPA Loaders, we need to tell eXtreme Scale where the data is and what kind of data is stored in the database. This is done by adding two plug-in beans to the normal objectGrid.xml file as highlighted in Example 7-2.
Example 7-2 Sample objectGrid.xml configured to use the JPAEntityLoader
<?xml version="1.0" encoding="UTF-8"?><objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://ibm.com/ws/objectgrid/config ../objectGrid.xsd" xmlns="http://ibm.com/ws/objectgrid/config">
<objectGrids><objectGrid name="BranchGrid" entityMetadataXMLFile="entityMeta.xml">
1)<bean id="TransactionCallback" className="com.ibm.websphere.objectgrid.jpa.JPATxCallback">
<property name="persistenceUnitName" type="java.lang.String" value="DB2openJPA" />
</bean><backingMap name="Owner" pluginCollectionRef="Owner"/>
158 User’s Guide to WebSphere eXtreme Scale

<backingMap name="Account" pluginCollectionRef="Account"/><backingMap name="Address" pluginCollectionRef="Address"/>
</objectGrid></objectGrids>
<backingMapPluginCollections>
2)<backingMapPluginCollection id="Owner">
<bean id="Loader" className="com.ibm.websphere.objectgrid.jpa.JPAEntityLoader">
<property name="entityClassName" type="java.lang.String" value="test.itso.data.Owner"/>
</bean></backingMapPluginCollection><backingMapPluginCollection id="Account">
<bean id="Loader" className="com.ibm.websphere.objectgrid.jpa.JPAEntityLoader">
<property name="entityClassName" type="java.lang.String" value="test.itso.data.Account"/>
</bean></backingMapPluginCollection><backingMapPluginCollection id="Address">
<bean id="Loader" className="com.ibm.websphere.objectgrid.jpa.JPAEntityLoader">
<property name="entityClassName" type="java.lang.String" value="test.itso.data.Address"/>
</bean></backingMapPluginCollection>
</backingMapPluginCollections></objectGridConfig>
The two plug-ins configured here refer to:
� The JPA persistence unit, which describes how to connect to the database and provides access to the entity metadata. In the case of the sample application, we have already provided a persistence.xml file in the client application that contains this persistence unit information. This can be copied into the ItsoSampleWeb Web Content\META-INF directory to be used by that application.
This is mandatory in order to use a JPA Loader. As you can see, it is configured as a property on the JPATxCallback bean configuration. There is one per objectGrid configuration.
Chapter 7. Using WebSphere eXtreme Scale with JPA 159

� A JPA Loader, of type JPAEntityLoader, is configured for each backing map. We configure a JPA Loader by configuring a backingMapPluginCollection per backingMap where the ID is that of the plug-inCollectionRef of the backingMap.
In this example, the owner JPAEntityLoader is highlighted.
The JPA Loader plug-in beans take two properties:
– entityClassName
The entityClassName property is self-explanatory and describes which JPA entity is going to be used to manage the database persistence for the backingMap. In this case it is test.itso.data.Owner.
This property is mandatory for the JPALoader class, but is optional for the JPAEntityLoader class. This is because eXtreme Scale entities can be reused as JPA entities and does not need describing here.
– preloadPartition
The preloadPartition property enables or disables the preload of the database through JPA. It is optional for both JPA Loaders.
If set to -1, the preload is disabled. This is the default.
If set to 0 or greater, this defines which grid partition is going to be used to preload the data into the grid. Only a single partition is used to preload the data. If preloading to multiple partitions, the entries loaded, IDs hashed and distributed across the grid. We are not going to test the preload here, but if it is enabled, you will be able to see the database loaded into the grid at start up.
Having changed the configuration in our sample application to enable eXtreme Scale to use the JPA Loader, we are ready to go. We do not have to do anything specific to the JPA configuration. We can use the existing JPA provider, persistence unit configuration and the JPA entities that we have already defined and described in 7.3, “JPA data access with the sample application” on page 155.
Tip: The JPA Loader preload is not qualified in any way. It naturally should be used with caution as it will preload the entire database. If greater control is needed in the preload, such as preloading based on some query string, the ClientLoader as demonstrated in the sample application is more appropriate.
160 User’s Guide to WebSphere eXtreme Scale
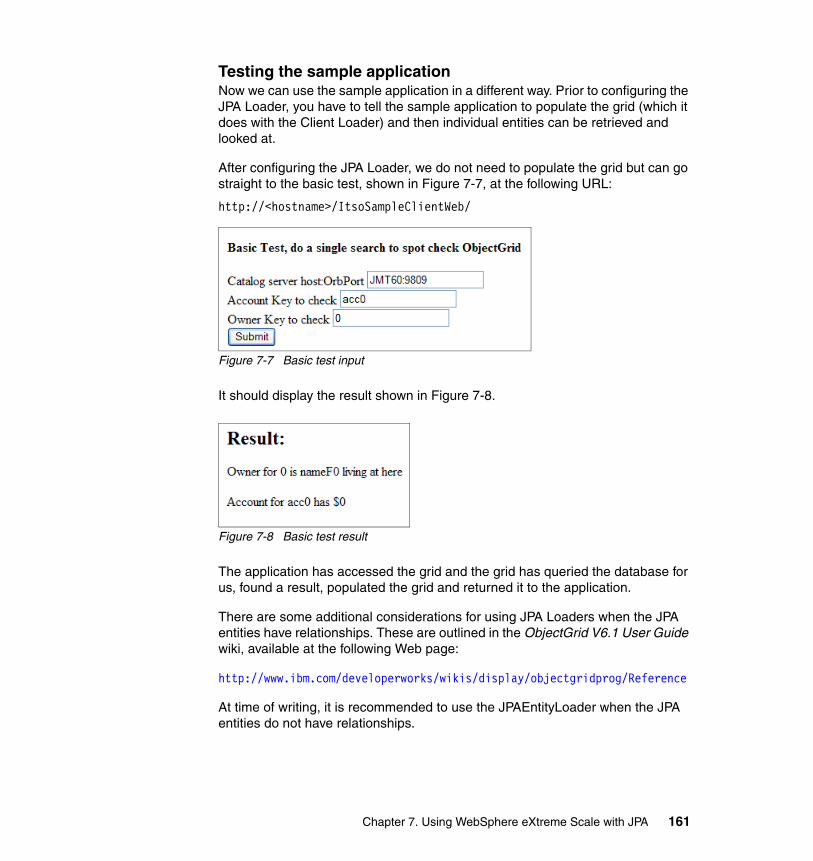
Testing the sample applicationNow we can use the sample application in a different way. Prior to configuring the JPA Loader, you have to tell the sample application to populate the grid (which it does with the Client Loader) and then individual entities can be retrieved and looked at.
After configuring the JPA Loader, we do not need to populate the grid but can go straight to the basic test, shown in Figure 7-7, at the following URL:
http://<hostname>/ItsoSampleClientWeb/
Figure 7-7 Basic test input
It should display the result shown in Figure 7-8.
Figure 7-8 Basic test result
The application has accessed the grid and the grid has queried the database for us, found a result, populated the grid and returned it to the application.
There are some additional considerations for using JPA Loaders when the JPA entities have relationships. These are outlined in the ObjectGrid V6.1 User Guide wiki, available at the following Web page:
http://www.ibm.com/developerworks/wikis/display/objectgridprog/Reference
At time of writing, it is recommended to use the JPAEntityLoader when the JPA entities do not have relationships.
Chapter 7. Using WebSphere eXtreme Scale with JPA 161

7.4.2 Enabling write-behind for the JPA Loader
By default, all loaders, including JPA Loaders, will immediately perform an update to the database when a change is made to the grid. This is called the write-through scenario.
WebSphere eXtreme Scale version 6.1.0.3 introduced write-behind functionality. This is where updates are batched up before persisting to a database.
There are a number of good reasons why this may be preferable.
� Performance
Each application transaction to the grid will be quicker, as the transaction will not have to wait for the data to be persisted to the back end.
� Isolation of back-end failures
If the back-end database fails, this normally affects the availability of an application but in this case, the application can keep running. The write-behind functionality has a built-in retry mechanism, which can persist the data when the back-end comes back online.
� Reduce load on back end
Instead of multiple small database accesses, eXtreme Scale acts as a buffer for the updates. They will be more efficiently batched into fewer, larger updates. This can greatly improve the scalability of a database.
Note: At time of writing with eXtreme Scale v6.1.0.4, there was an issue with the runtime enhancement of JPA entities. That is the process by which persistence functionality is added to the entity POJO. This is applied to JPA classes when they are first started in an application server, or Java application.
The problem was that eXtreme Scale loaded the class first instead of OpenJPA. If OpenJPA does not load the class, it does not run the enhancer against it. This will be fixed, but until then, the workaround is to use a build-time enhancement using the wsenhancer.bat/.sh command with the Feature Pack for EJB 3 for WebSphere Application Server or the PCEnhancer tool from OpenJPA.
162 User’s Guide to WebSphere eXtreme Scale

Figure 7-9 Illustration of write-through versus write-through
The write-behind functionality is enabled for a given backing map and applies to all loaders. We demonstrate it here with the JPA Loader.
Example 7-3 shows a portion of the objectGrid.xml definition file, which configures the write-behind on the Owner backing map. In this case, the write-behind is configured to make updates based on two criteria:
� Time-based update
It will perform an update to the database if 60 seconds have elapsed since the last database update.
This can be configured to the required number of seconds between updates. If no value is provided, the default is 300 seconds.
� Count-based update
It will perform an update if a count of 100 updates to the grid have occurred since the last database update.
If no value is provided, the default count is 1000.
Example 7-3 Portion of the objectGrid.xml enabling write-behind
<backingMap name="Owner" writeBehind="T60;C100" pluginCollectionRef="Owner"/>
If you enable trace for the object grid using ObjectGrid=all, you can observe the output shown in Example 7-4 on page 164 where it shows the write-behind thread counting elapsed time and performed updates with any outstanding changes.
Application Server
Application
Grid Container
DB
JPA Loader
QueueMap
BackingMap
JPA
Provider
1. Write -through
2. Write-behind
BatchUpdate
Chapter 7. Using WebSphere eXtreme Scale with JPA 163

Example 7-4 From trace log file
[15/09/08 13:08:42:453 BST] 0000006f WriteBehindLo 1 WBLoader - 59907ms passed since the last update. Will update the database.[15/09/08 13:08:42:468 BST] 0000006f WriteBehindLo 1 WBLoader - pushed 2 changes to real loader.
Handling write-behind failureWhile there are some strong benefits to the write-behind functionality, there are also some additional considerations. Where there is a failure writing to the back end, the application transaction will have already been committed. A good example is adding a new entry to the backing map where the entry already exists in the database. The backing map transaction would successfully commit, but when the write-behind tries to write it to the database, it would fail with a duplicate key exception. There are other similar failure scenarios that we need to be able to handle.
There is a special map that stores these failed write-behind updates. This serves as an event queue for failed updates, which can be retrieved and handled accordingly. The name of the map that stores these failures uses the following naming convention:
IBM_WB_FAILED_UPDATES_<map name>
Example 7-5 shows sample code for accessing the failed write-behind update map and the failed keys and values.
Example 7-5 Sample code for handling failures
session.begin();ObjectMap failedMap = session.getMap(
WriteBehindLoaderConstants.WRITE_BEHIND_FAILED_UPDATES_MAP_PREFIX + “Owner");
Object key = null;
while(key = failedMap.getNextKey(ObjectMap.QUEUE_TIMEOUT_NONE)) {LogElement element = (LogElement) fMap.get(key);Object failedKey = element.getCacheEntry().getKey();Object failedValue = element.getAfterImage();fMap.remove(key);//Handle the failure key and value.
}session.commit();
164 User’s Guide to WebSphere eXtreme Scale

7.5 Setting up the time-based updater
In the previous section, we configured the sample application to use a JPA Loader. We can now use the JPA Loader to do another useful thing for us. WebSphere eXtreme Scale provides a time-based updater to periodically check a database for updates. If another application has made an update to the data, the updater can detect this update and do one of three things:
� Invalidate the stale data which will be removed� Update the stale data with fresh data� Add any recent insertions
It checks an extra field in the database. The latest commercial databases, such as DB2 v9.5 and Oracle® 10g, provide functionality to update a timestamp field whenever that row is changed. When you have a list of time stamps, a couple of simple queries can establish what has changed since you last looked.
The query in Example 7-6 supplies all rows that have changed in the period since we last checked the time stamp.
Example 7-6 Query to identify rows changed in database
SELECT o FROM Owner o where o.rowChgTs>?
After loading the changed rows, the query in Example 7-7 can get the time stamp of the last change on the database.
Example 7-7 Query to identify last change in the database
SELECT MAX(o.rowChgTs) FROM Owner o
This is illustrated in Figure 7-10 on page 166.
Chapter 7. Using WebSphere eXtreme Scale with JPA 165

Figure 7-10 Time-based Updater usage
This is what WebSphere eXtreme Scale does with the time-based Updater implementation. This functionality applies to any database where a specified field is incremented every time the row is accessed. We will set this up to work with the JPA Loader that we configured previously.
The time-based updater uses a heuristic to determine how often to poll the database table. This ensures that you are not polling too, which could be expensive on a large database table.
ServerApplication Server
Grid Container
DB
BackingMap = Owner
BackingMap = Account
BackingMap = Address
JPA
Provider
JPAEntityLoader
TimeBasedUpdater
1. What has changed since last access?SELECT o FROM Owner o where o.rowChgTs>?
2. Remember latest access timeSELECT MAX(o.rowChgTs ) FROM Owner o
.custno . rowChgTscustno
Owner
166 User’s Guide to WebSphere eXtreme Scale

It provides three options for refreshing the data in the grid:
� Invalidate stale data
This is the quickest of the three options. It would be ideal if you have a lot of stale data that would be expensive to load at once, and if you do not mind loading the data again when you need it.
� Update stale data
The updater will load the new data into the grid, which is good if you do not want to take the hit of individual requests reloading data.
� Checking the database for any additional inserts
This extends the previous option and inserts any new rows into the grid.
The options provided by the time-based updater allow for detection of changes to data and inserts but not for the deletion of data, as this would not show in the timestamp query. An alternative to this would be to provide a deleted field in the database, where applications would mark rows as deleted instead of removing them. This would be detected by the time-based updater.
To configure the Time-based Updater, the following must be done:
� Configure a JPA Loader� Configure the database with a timestamp field� Update entity with a new timestamp field� Set up the time-based updater in the objectGrid.xml file
7.5.1 Configuring the database with a timestamp field
The DDL provided with the sample application actually already defines a field, ROWCHGTS, that is automatically updated when the row is changed.
If the database table needs updating to include this field, Example 7-8 shows the SQL required for DB2 9.5 to augment a table with the timestamp field.
Example 7-8 SQL required to augment a table with the timestamp field
ALTER TABLE ITSO.OWNER ADD COLUMN ROWCHGTS TIMESTAMP NOT NULL GENERATED ALWAYS FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP;
As you can see, this field is set up to contain a generated time stamp that is incremented whenever that row is updated.
Chapter 7. Using WebSphere eXtreme Scale with JPA 167

7.5.2 Update the JPA entity with a timestamp field
Having created the additional field in the database, we need to create the corresponding variable in the JPA entity class. Example 7-9 shows the variable. It is annotated as a special timestamp field and we provide the name of the corresponding database column name, rowChgTs.
Add this field, with its getters and setters to the Owner class.
Example 7-9 Extra variable required in JPA entity
@com.ibm.websphere.objectgrid.jpa.dbupdate.annotation.Timestamp@Column(name = "ROWCHGTS", updatable = false, insertable = false)public Timestamp rowChgTs;
public Timestamp getRowChgTs() {return rowChgTs;
}
public void setRowChgTs(Timestamp rowChgTs) {this.rowChgTs = rowChgTs;
}
As mentioned, this is straight forward to set up for other databases as well. The WebSphere eXtreme Scale wiki contains reference as to how to set this up with Oracle and other databases.
7.5.3 Add the time-based updater to the grid configuration
We have now set up the database to track changes and we have edited our owner entity so that can access that information. We are now in a position to add the time-based updater to the eXtreme Scale grid configuration.
Having set up the JPAEntityLoader in 7.4, “Setting up the JPA Loader” on page 156, we need to augment that configuration with that of the time-based updater. Example 7-10 on page 169 shows how we have added this to the configuration of the Owner backing map.
168 User’s Guide to WebSphere eXtreme Scale

Example 7-10 Excerpt from objectGrid.xml with Time-based Updater configuration
<?xml version="1.0" encoding="UTF-8"?><objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://ibm.com/ws/objectgrid/config ../objectGrid.xsd"xmlns="http://ibm.com/ws/objectgrid/config">
<objectGrids><objectGrid name="BranchGrid" entityMetadataXMLFile="entityMeta.xml">
<bean id="TransactionCallback" className="com.ibm.websphere.objectgrid.jpa.JPATxCallback">
<property name="persistenceUnitName" type="java.lang.String" value="DB2openJPA" />
</bean>
<backingMap name="Owner" pluginCollectionRef="Owner"><timeBasedDBUpdate
timestampField="rowChgTs"persistenceUnitName="DB2openJPA"entityClass="test.itso.data.Owner"mode="UPDATE_ONLY"/>
</backingMap><backingMap name="Account" pluginCollectionRef="Account"/><backingMap name="Address" pluginCollectionRef="Address"/>
</objectGrid></objectGrids>
<backingMapPluginCollections>....</backingMapPluginCollections>
</objectGridConfig>
Chapter 7. Using WebSphere eXtreme Scale with JPA 169

The configuration should be provided for each backing map that we wish to keep up to date. It allows us to specify:
� entityClass
This is the class name of the entity we which to keep up to date
� timestampField
This maps to the timestamp instance variable that we added to the JPA entity
� persistenceUnitName
The JPA persistence unit that we have already defined
� mode
� What kind of update do we wish to perform on the grid. It can be one of three values:
– INVALIDATE_ONLY
This will remove the stale entries from the grid but the entities would need to be loaded if needed again.
– UPDATE_ONLY
This will update the grid with any entities that have changed.
– INSERT_UPDATE
As well as updating any stale entities in the grid, this will populate the grid with any new entities that have been added to the database since.
7.6 Using the Client Loader in the sample application
The ability to preload data is provided with the Loader interface, specifically the JPALoader and JPAEntityLoader implementations mentioned in the previous section. However, the JPA-specific implementations are restricted to preloading an entire database table for a corresponding JPA entity. It may well be that your application does not want to, or for reasons of size, cannot load an entire table.
A more versatile preload functionality is provided with the ClientLoader implementation, where custom queries can be executed. Unlike the JPALoader which sits behind eXtreme Scale, the Client Loader uses a JPA configuration within the client and populates the grid from there. This allows the application developer to still benefit from the convenience of the integration of JPA and eXtreme Scale entities. This is shown in Figure 7-11 on page 171.
170 User’s Guide to WebSphere eXtreme Scale
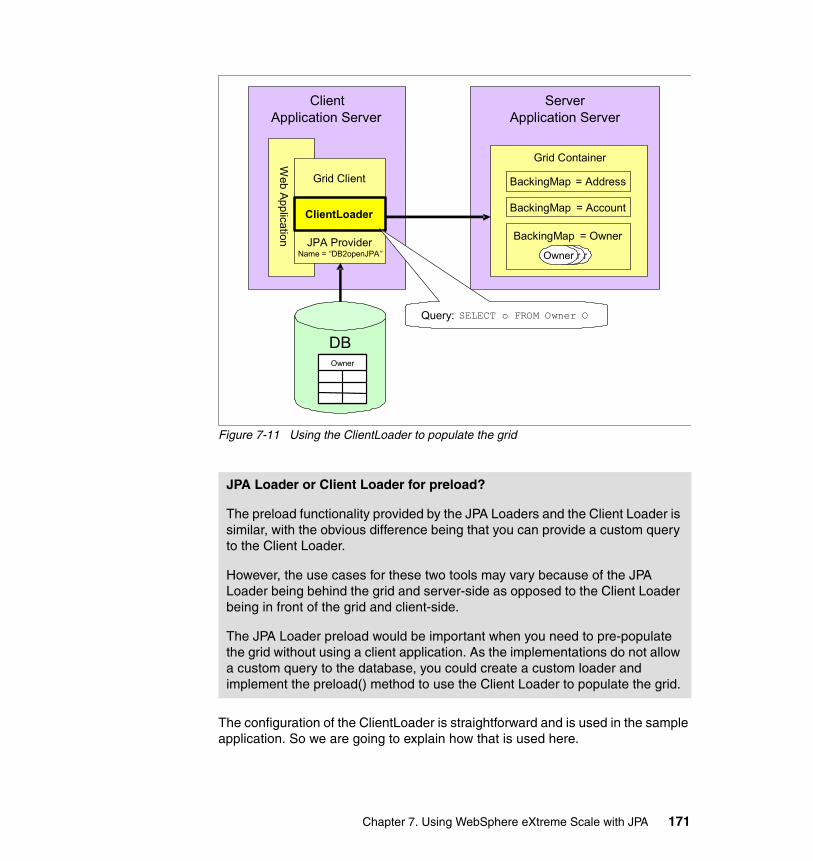
Figure 7-11 Using the ClientLoader to populate the grid
The configuration of the ClientLoader is straightforward and is used in the sample application. So we are going to explain how that is used here.
JPA Loader or Client Loader for preload?
The preload functionality provided by the JPA Loaders and the Client Loader is similar, with the obvious difference being that you can provide a custom query to the Client Loader.
However, the use cases for these two tools may vary because of the JPA Loader being behind the grid and server-side as opposed to the Client Loader being in front of the grid and client-side.
The JPA Loader preload would be important when you need to pre-populate the grid without using a client application. As the implementations do not allow a custom query to the database, you could create a custom loader and implement the preload() method to use the Client Loader to populate the grid.
DBDBOwnerOwner
ClientApplication Server
ServerApplication Server
Web A
pplication
Grid Container
BackingMap = Owner
Grid Client
JPA ProviderName = “DB2openJPA”
ClientLoader BackingMap = Account
BackingMap = Address
Query: SELECT o FROM Owner O
OwnerOwnerOwner
Chapter 7. Using WebSphere eXtreme Scale with JPA 171

Let us summarize the prerequisite configuration.
� JPA configuration is required on the client side.
To use it, the client must be configured as follows:
– JPA Provider
The sample application uses the Feature Pack for EJB 3.0 for WebSphere Application Server and provides a persistence.xml file which contains the definition of the persistence unit.
– JPA Entity definitions and relevant metadata
The sample application defines 3 entities: Account, Address, and Owner. All of these are both JPA entities and eXtreme Scale entities
� Application code.
Based on this configuration, the sample application can use the ClientLoader to populate the eXtreme Scale grid. For the actual code, see the loadObjectGrid method of the WorkerBee class. It is simplified here by way of example in Example 7-11.
Example 7-11 Application code
StateManager stateMan = StateManagerFactory.getStateManager();stateMan.setObjectGridState(AvailabilityState.PRELOAD, grid);
ClientLoader c = ClientLoaderFactory.getClientLoader();c.load(grid, "Owner", “DB2openJPA”, null ,Owner.class, null, null, preload, null);
stateMan.setObjectGridState(AvailabilityState.ONLINE, grid);
We can see some leading practices demonstrated by the example. Prior to using the ClientLoader, the grid is put into PRELOAD state. This takes the grid offline. Clients should therefore check the status of the grid prior to using it, but if not, the status check ensures the request will fail quickly. The grid is then populated and brought back into the ONLINE state.
172 User’s Guide to WebSphere eXtreme Scale

The options passed to the ClientLoader are as follows:
� grid
The ObjectGrid that we want to populate.
� Owner
The map that we want to populate.
� DB2openJPA
This is the name of the persistence unit that we want to use from our persistence.xml file.
� null
This can be a persistenceProps object, where we can supplement the persistence.xml file with additional properties.
� Owner.class
This is the class name of the JPA entity we will be placing in the grid. It is optional as, by default, the classname would be taken from the entity metadata file for the eXtreme Scale grid. It is not necessary in this scenario, as we are using the same POJO as both the eXtreme Scale and the JPA entity.
� null
This is the optional load SQL string to specify the data that you want to preload. In this example, it is null, so the query will equate to “SELECT o FROM Owner o”. An example in this scenario could be something such as the following:
SELECT o FROM Owner o WHERE o.customerNumber >= :lowNum AND o.customerNumber <= :highNum
� null
This is the query parameter map, which is not needed in the example application. But if we provide a query as shown in the previous point, we would need two values for the lowNum and highNum parameters.
� preload
This is a boolean value to define whether the load is going to provide a preload or not. If it is true, the preload will first clear the grid before loading the data.
� null
If required, this can be a ClientLoaderCallback implementation, which provides preStart() and postFinish() call back methods.
Chapter 7. Using WebSphere eXtreme Scale with JPA 173

7.7 Setting up eXtreme Scale as a JPA cache
Caching is always an important factor in designing well-performing and scalable server applications. Providing a way to manage that cache is also important, taking into account things such as cache availability, cache updates and invalidation, and on high performance applications, cache scalability. This is why WebSphere eXtreme Scale provides an excellent implementation of a level 2 cache for both Hibernate and Apache OpenJPA. We are going to cover the main steps required to set up eXtreme Scale as the level 2 cache for OpenJPA.
For further reference information about configuring caching for the feature pack, see the IBM information center article Configuring OpenJPA caching to improve performance, available at the following Web page:
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/topic/com.ibm.websphere.ejbfep.multiplatform.doc/info/ae/ae/tejb_datcacheconfig.html
The OpenJPA implementation provides the option to enable a data cache or a query cache or alternatively to plug in WebSphere eXtreme Scale to perform that caching role. This implementation does not change the behavior of the use of JPA or affect standards compliance. The caches are set up as properties of the JPA persistence unit in the persistence.xml file
<property name="openjpa.DataCache" value="true(CacheSize=5000...<property name="openjpa.QueryCache" value=("CacheSize=1000, ...
We are going to override the default cache with WebSphere eXtreme Scale.
WebSphere eXtreme Scale data cache and query cacheWebSphere eXtreme Scale provides an implementation for both the data cache and query cache functions in OpenJPA.
The data cache implementation works as would be expected from a side cache scenario. It can be plugged into OpenJPA, which in turn will check the grid cache every time it looks up an entity. If the entity is in the grid, it is returned. Otherwise, it is obtained from the database and stored in the grid.
The query cache is an extension of the data cache functionality. Instead of just providing a side cache for the JPA entities, it caches the results of a query. The query string and parameters are used to generate a unique key and the ID for the results of the query. This is illustrated in Figure 7-12 on page 175 where Owner entities 1 and 2 are returned by the query. The entities are stored in the data cache maps. There is a backing map set up for each table, in this case, Owner. The query is given a unique identifier and placed in the query cache together with a reference to the two entities we have retrieved and stored in the data cache.
174 User’s Guide to WebSphere eXtreme Scale
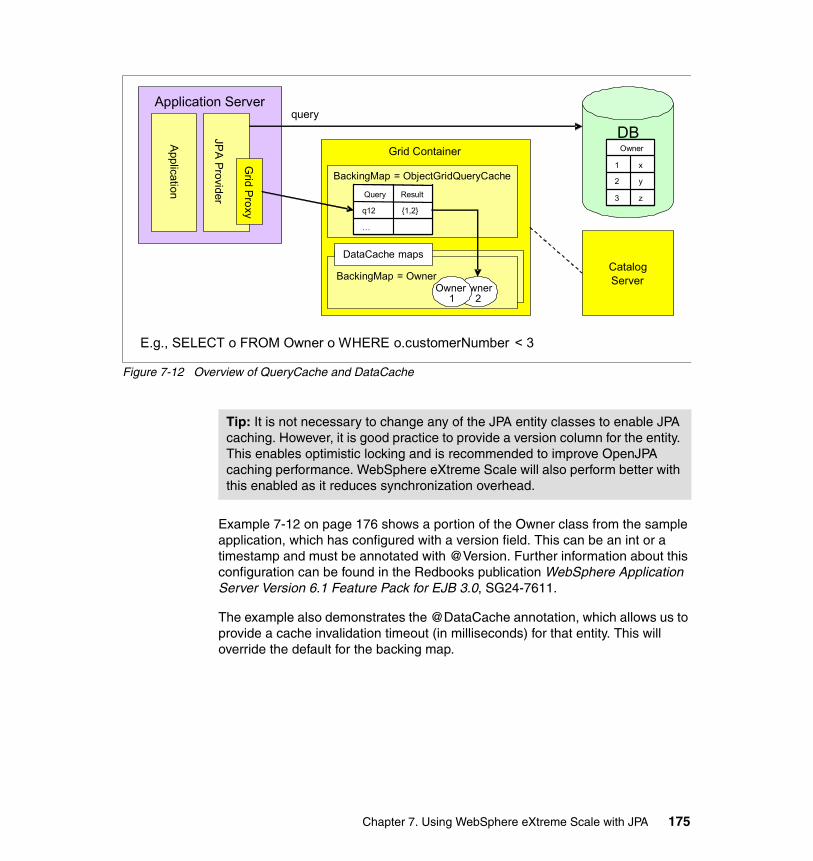
Figure 7-12 Overview of QueryCache and DataCache
Example 7-12 on page 176 shows a portion of the Owner class from the sample application, which has configured with a version field. This can be an int or a timestamp and must be annotated with @Version. Further information about this configuration can be found in the Redbooks publication WebSphere Application Server Version 6.1 Feature Pack for EJB 3.0, SG24-7611.
The example also demonstrates the @DataCache annotation, which allows us to provide a cache invalidation timeout (in milliseconds) for that entity. This will override the default for the backing map.
Grid Container
Application Server
Application
JPA
Provider
DB
z3
y2
x1
Owner
z3
y2
x1
Owner
BackingMap = ObjectGridQueryCacheResult
…
{1,2}q12
Query Result
…
{1,2}q12
Query
BackingMap = Owner BackingMap = Owner
Owner2
Owner1
DataCache maps
E.g., SELECT o FROM Owner o WHERE o.customerNumber < 3
query
CatalogServer
Grid P
roxy
Tip: It is not necessary to change any of the JPA entity classes to enable JPA caching. However, it is good practice to provide a version column for the entity. This enables optimistic locking and is recommended to improve OpenJPA caching performance. WebSphere eXtreme Scale will also perform better with this enabled as it reduces synchronization overhead.
Chapter 7. Using WebSphere eXtreme Scale with JPA 175

Example 7-12 Example based on sample application Owner class
@Entity@Table(name="OWNER", schema="itso")@DataCache(timeout=10000)public class Owner implements Serializable {
private static final long serialVersionUID = -4595963652402183419L;
@Id@Column(name = "CUSTNO")int customerNumber;
@Column(name = "FIRST")String firstName;
@Column(name = "LAST")String lastName;
@Versionint version;
//Other fields and getters and setters}
7.7.1 Steps to enable JPA caching with WebSphere eXtreme Scale
As already mentioned, it is easy to enable caching for the OpenJPA implementation. You need to configure the following items:
� The JPA provider� An eXtreme Scale grid
Before looking at the specifics of these configuration requirements, it is worth noting that the default caching settings are compelling and worth considering first. You need to enable the cache in the persistence.xml but do not need to provide any object grid descriptor files to use these defaults.
You can enable eXtreme Scale caching for OpenJPA by just adding the simple three properties to the persistence.xml file in the module using JPA, as shown in Example 7-13 on page 177. The cache is then ready to run. These settings will create both the data cache and the query cache.
176 User’s Guide to WebSphere eXtreme Scale

Example 7-13 Simple configuration of OpenJPA caching
<?xml version="1.0" encoding="UTF-8"?><persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="1.0" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="SampleDB"><jta-data-source>jdbc/SampleDB</jta-data-source><properties>
<!-- enable cache --><property name="openjpa.DataCache" value="com.ibm.websphere.objectgrid.openjpa.ObjectGridDataCache()"/><property name="openjpa.RemoteCommitProvider" value="sjvm" /><property name="openjpa.QueryCache" value="com.ibm.websphere.objectgrid.openjpa.ObjectGridQueryCache()"/></properties>
</persistence-unit>
</persistence>
The defaults are expressed in Figure 7-13 on page 178 and include the following settings:
� Number of partitions is set to 1.
� Number of replicas can be anything up to a maximum of 47, so this will be dictated by the number of server instances started. One replica is shown in the diagram, with two servers running primary and replica shards.
� Synchronous replication mode.
� Replica read is enabled, so that all shards can be read from.
� Expiration time-out (Time To Live) on the cache is set to 30 minutes.
Any subsequent configuration mentioned here will override this default behavior.
By way of explanation, the openjpa.RemoteCommitProvider property is mandatory when using the eXtreme Scale cache. It is for the OpenJPA to manage the distributed event notification when using its own cache in a distributed manner. Because we are overriding the implementation, we need to pass the parameter sjvm (for stand-alone JVM) to unenable that mechanism.
Chapter 7. Using WebSphere eXtreme Scale with JPA 177
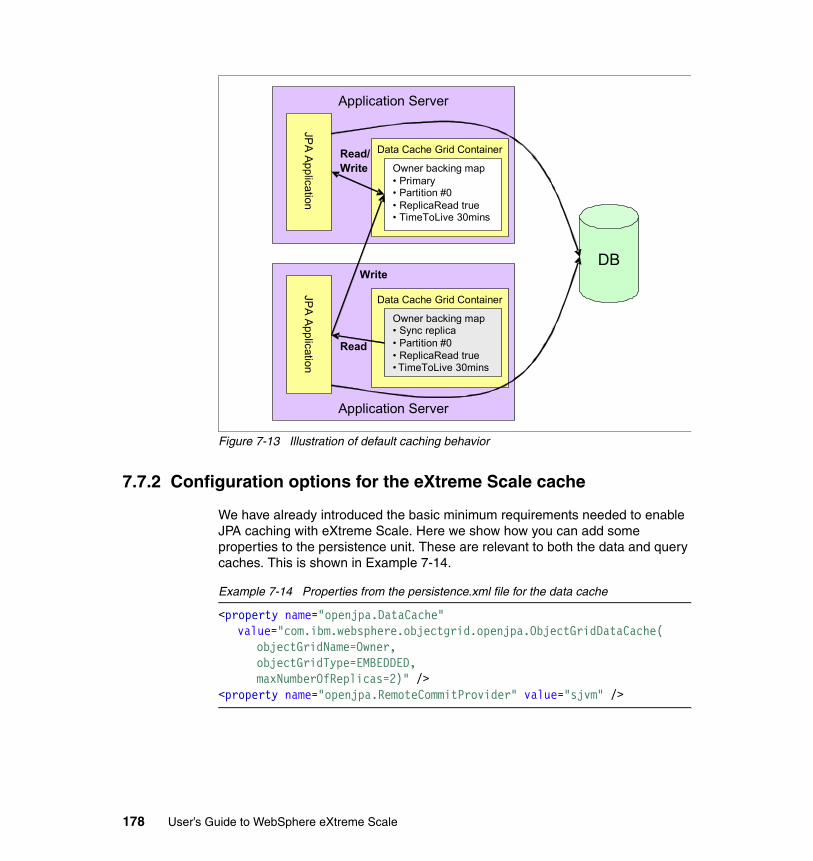
Figure 7-13 Illustration of default caching behavior
7.7.2 Configuration options for the eXtreme Scale cache
We have already introduced the basic minimum requirements needed to enable JPA caching with eXtreme Scale. Here we show how you can add some properties to the persistence unit. These are relevant to both the data and query caches. This is shown in Example 7-14.
Example 7-14 Properties from the persistence.xml file for the data cache
<property name="openjpa.DataCache"value="com.ibm.websphere.objectgrid.openjpa.ObjectGridDataCache(
objectGridName=Owner,objectGridType=EMBEDDED, maxNumberOfReplicas=2)" />
<property name="openjpa.RemoteCommitProvider" value="sjvm" />
DB
Application Server
JPA
Application
Data Cache Grid Container
Application Server
JPA
Application
Owner backing map• Primary• Partition #0• ReplicaRead true• TimeToLive 30mins
Data Cache Grid Container
Owner backing map• Sync replica• Partition #0• ReplicaRead true• TimeToLive 30mins
Read
Write
Read/Write
178 User’s Guide to WebSphere eXtreme Scale

These are the properties, shown in the example, that can be provided to tailor the use of the cache:
� objectGridName
The name of the objectgrid to use as the data cache for this persistence unit.
� objectGridType
This can be EMBEDDED, EMBEDDED_PARTITION, REMOTE. See below for descriptions.
� replicaMode: SYNC/ASYNC/NONE
This defaults to SYNC for EMBEDDED and ASYNC for EMBEDDED_PARTITION.
� replicaReadEnabled
Whether all replicas can be used to read from. This defaults to TRUE for EMBEDDED and FALSE for EMBEDDED_PARTITION.
� numberOfPartitions
This property is only relevant to define the number of partitions for EMBEDDED_PARTITION.
� maxUsedMemory: TRUE/FALSE
This property will enable the memory-based evictor to empty the cache if running out of heap space. The default is always true.
� maxNumberOfReplicas
If you need to change the maximum number of replicas from the default of 47. This would only need changing if using more than 47 JVMs.
Cache deployment topologiesThere are three different types of eXtreme Scale deployments referenced by the objectGridType property above:
� EMBEDDED
This is where the grid is collocated with the application and the grid is restricted to a single partition. This recommended deployment option is probably sufficient for most use cases. It has the limitation that the cache will be limited in size to the contents of a single partition or JVM, but this may not be an issue for normal data access. This is depicted in Example 7-14 on page 178.
Chapter 7. Using WebSphere eXtreme Scale with JPA 179

� EMBEDDED_PARTITION
This extends the functionality of EMBEDDED to provide flexibility to allow multiple partitions. This will entail more remote reads than the EMBEDDED scenario, so should only be considered when a significant amount of data needs to be cached to ensure overall application performance.
While EMBEDDED_PARTITION allows you to create multiple partitions, if you have a lot of data, there is a cut-off point where it is no longer worth running with a collocated grid. Also, the proportion of local reads will reduce as the size of the cache increases beyond the boundary capacity of a single JVM.
� REMOTE
As the name describes, this is communicating with a remote grid configuration. By default, this will attempt to obtain a grid from the catalog service. If you need to configure the location of the catalog service (for example, it is outside of WebSphere Application Server), you will need to provide the catalogServiceEndPoints property in the objectGridServer.properties file. While this provides excellent flexibility for configuring the grid, you must take into account the cost of remote calls to the grid. The objectGridDeployment.xml file will be ignored with this deployment as it is not needed.
Enabling the query cacheTo enable the query cache, a similar entry is added to the persistence.xml file (Example 7-15). The data and query caches can be enabled independently of each other and the query cache can take the same parameters as the data cache. However, if both are enabled, the query cache will take the same settings as the data cache.
Example 7-15 Properties from the persistence.xml file for the query cache
<property name="openjpa.QueryCache" value="com.ibm.websphere.objectgrid.openjpa.ObjectGridQueryCache()"/>
Tip: The recommended object grid type is EMBEDDED. It is a single partition that is replicated to all of the other servers. This is the fastest option as all cache reads can be local, although writes still have to be to the primary shard. While this is limited to a single partition, this will probably be sufficient for most data access scenarios. The JVM is protected from running out of memory with the memory-based eviction.
EMBEDDED_PARTITION should only be considered if you wish to cache more than a single JVM-worth of data and are happy to take the performance hit of remote calls.
180 User’s Guide to WebSphere eXtreme Scale

7.7.3 Advanced eXtreme Scale configuration for the cache
The persistence.xml configuration is the recommended approach for configuring the cache grid. However, if advanced configuration is needed, the grid configuration can be overridden with descriptors. In the case of the OpenJPA cache, the descriptors have the following specific naming requirements:
� openjpa-objectGrid.xml � openjpa-objectGridDeployment.xml
Each backing map that you wish to override must be called by the same name as the fully qualified JPA entity class that you want to cache. The key word ALL_ENTITY_MAPS is used to provide a new default setting for all maps. Individual map configurations can still be overridden by specifying them by name. Example 7-16 and Example 7-17 on page 182 provide sample configuration files to demonstrate overriding the grid configuration. The first is the grid definition, with a backing map for the Owner entity that we wish to cache.
Example 7-16 openjpa-objectGrid.xml
<?xml version="1.0" encoding="UTF-8"?><objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://ibm.com/ws/objectgrid/config ../objectGrid.xsd"xmlns="http://ibm.com/ws/objectgrid/config">
<objectGrids><objectGrid name="Owner"><backingMap name="test.itos.data.Owner"readOnly="false" copyKey="false" lockStrategy="NONE"copyMode="NO_COPY" evictionTriggers="MEMORY_USAGE_THRESHOLD"pluginCollectionRef="test.itso.data.Owner"></backingMap></objectGrid></objectGrids>
<backingMapPluginCollections><backingMapPluginCollection id="test.itso.data.Owner"><bean id="ObjectTransformer" className="com.ibm.ws.objectgrid.openjpa.ObjectGridPCDataObjectTransformer" /><bean id="Evictor" className="com.ibm.websphere.objectgrid.plugins.builtins.LRUEvictor"/></backingMapPluginCollection></backingMapPluginCollections>
</objectGridConfig>
Chapter 7. Using WebSphere eXtreme Scale with JPA 181

This is the deployment plan for the grid, where we define two partitions, four replicas and references for the Owner map and the ObjectGridQueryCache. The latter map is the BackingMap, which is automatically defined by the cache functionality.
Example 7-17 openjpa-objectGridDeployment.xml
<?xml version="1.0" encoding="UTF-8"?><deploymentPolicy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://ibm.com/ws/objectgrid/deploymentPolicy ../deploymentPolicy.xsd" xmlns="http://ibm.com/ws/objectgrid/deploymentPolicy">
<objectgridDeployment objectgridName="Owner"><mapSet name="MAPSET_Owner" numberOfPartitions="2"numInitialContainers="1" minSyncReplicas="0" maxSyncReplicas="4"maxAsyncReplicas="0" replicaReadEnabled="true">
<map ref="test.itso.data.Owner" /><map ref="ObjectGridQueryCache" />
</mapSet></objectgridDeployment>
</deploymentPolicy>
Tip: When running the EMBEDDED_PARTITION type of collocated cache, you will observe that all of the primary partitions will start up on the first application server to be used. (The grid itself is not instantiated until JPA is used within the application). This may not be an issue, especially if the application will be doing predominantly read operations. However, all writes will go to the primary partitions, potentially heavily loading a single server.
If you wish to spread the primary partitions out, you need to use the numInitialContainers setting to wait for a number of container servers to be up and running. The problem with that setting in this situation is that the application will need to be run on all servers to bring the grid online, with first applications to be used having to wait until the final application is used. In this situation, it would be appropriate to provide a Startup bean to ping the database using JPA. This would instantiate the cache across all servers.
182 User’s Guide to WebSphere eXtreme Scale

7.7.4 Monitoring the cache
You can review the deployment of the cache and assess its effectiveness through the Tivoli® Performance Viewer in the WebSphere administration console. An example is shown in Figure 7-14 on page 184. Once the eXtreme Scale cache has been used and instantiated, the object grid maps will have corresponding entries in the viewer. Select these and you can see how many entries are in the cache and the cache hit rate. The figure shows both the data cache and the query cache in use.
You can access the Tivoli Performance Viewer from Administration console → Monitoring and Tuning → Performance Viewer → Current Activity. You must enable the Performance Monitoring Infrastructure for the server, also found under Monitoring and Tuning.
Note: At the time of writing, there is a discrepancy between the objectGrid.xml and objectGridDeployment.xml configurations when setting up the Query Cache. By default, the ObjectGridQueryCache object grid configuration is created and so should not be in the objectGrid.xml. However, its counterpart in the deployment XML file is not created and needs to reference the map in the deployment map set in the objectGridDeployment.xml.
It is the intention that this configuration will not be necessary in future releases. Regardless, it is recommended to configure caching purely through the persistence.xml file and not require these grid descriptors.
Chapter 7. Using WebSphere eXtreme Scale with JPA 183
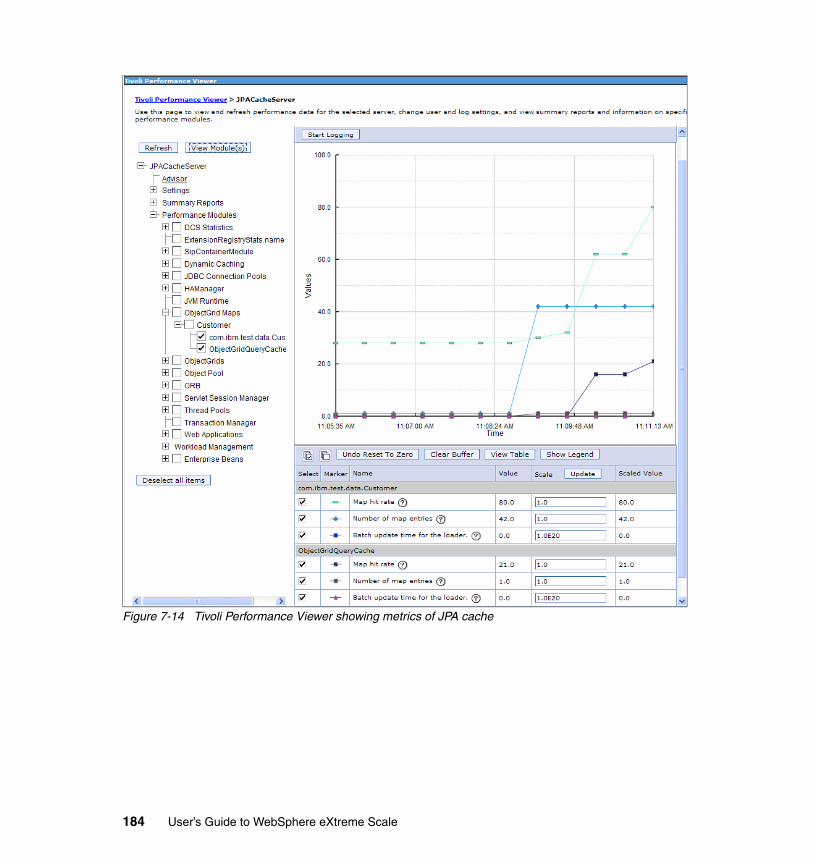
Figure 7-14 Tivoli Performance Viewer showing metrics of JPA cache
184 User’s Guide to WebSphere eXtreme Scale

7.7.5 Options for cache invalidation
The OpenJPA implementation also provides the @DataCache annotation, which allows the developer to provide a cache timeout for a given JPA entity. This annotation is declared on the entity, as shown in Example 7-18.
Example 7-18 Definition of the Owner entity with timeout configured
@Entity@Table(name="OWNER", schema="itso")@DataCache(timeout=30000)public class Owner implements Serializable {
A timeout setting of 30000 milliseconds equates to 30 seconds and is implemented using the Time To Live (TTL) evictor. (Because the evictor has a 15 second sleep, that means the time to live is up to 45 seconds).
All of the normal invalidation mechanisms that eXtreme Scale offers are available to us in the caching scenario. The normal eXtreme Scale evictors can be used to handle invalidations, such as the TTL evictor. See Example 7-19 for an example of evictor configuration.
Example 7-19 Portion of objectGrid.xml demonstrating evictor
<objectGrids><objectGrid name="Owner">
<backingMap name="Owner" ttlEvictorType="LAST_ACCESS_TIME" timeToLive="1800"/>
<backingMap name="Account" ttlEvictorType="CREATION_TIME" timeToLive="1200"/>
</objectGrid></objectGrids>
For more information, see the Evictors wiki at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/4oIF
At this time, the JPA Loaders cannot be used with the OpenJPA cache. This means it is not possible to use the time-based updater with the cache.
Chapter 7. Using WebSphere eXtreme Scale with JPA 185

186 User’s Guide to WebSphere eXtreme Scale

Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale
This chapter describes how WebSphere eXtreme Scale can be used without changing any application code to extend the capabilities of HTTP session management in both a WebSphere and non-WebSphere Application Server environment.
This chapter will introduce the main concepts behind implementing WebSphere eXtreme Scale HTTP session management. It includes the following topics:
� “Using eXtreme Scale without application change” on page 188� “HTTP session management overview” on page 188� “Introducing the example scenarios” on page 193� “Example: Setting up the application” on page 193� “Example: Using a collocated HTTP session store” on page 196� “Example: Using a remote HTTP session store” on page 203� “Configuration of the HTTP session management” on page 205
8
© Copyright IBM Corp. 2008. All rights reserved. 187

8.1 Using eXtreme Scale without application change
While WebSphere eXtreme Scale provides a number of programming APIs, it also provides a number of features that can be used without having to change your application. There are a number of scenarios in which you can use a grid simply through configuration and by providing XML configuration files. These are all variations of the side cache scenario outlined in 3.2, “Side cache scenario” on page 57. This is the non-invasive or declarative approach to using WebSphere eXtreme Scale.
You can use the following features through configuration:
� HTTP session management� OpenJPA cache� EJB container-managed persistence
In this section, we will be demonstrating the non-invasive use of WebSphere eXtreme Scale with HTTP session management.
8.2 HTTP session management overview
HTTP session management is a function offered by Java Enterprise Edition (JEE) application servers. It allows JEE applications to store state about a given user across many HTTP requests. The JEE specification provides an API to store and retrieve information specific to the given user. The traditional example for this is the Web site shopping cart, where transient data or state about intended purchases is stored until actually purchased.
All application servers provide this basic functionality but the qualities of service that underpin this can vary widely.
8.2.1 HTTP session replication
Most application servers provide some sort of session replication functionality. This means that HTTP session objects are made available to other application servers in the environment. This is normally done either by writing to a database or through memory-to-memory replication technology.
Sample application: For your convenience, the sample application discussed in the section, MySessionTest, is available as downloadable material. See Appendix C, “Additional material” on page 229.
188 User’s Guide to WebSphere eXtreme Scale

In the case of an application server failure or a request being routed to another application server, the session state will be copied to the appropriate application server and made available to the user. This prevents the user from having to log on again and repeat what they are doing.
However, there are compromises or limitations to the replication facilities provided out of the box with application servers. For example, in order to keep performance at a reasonable level, replication is typically done periodically, perhaps every 10 seconds. This gives you a failure window which may be unacceptable to your application.
For further information about HTTP session replication options in WebSphere Application Server, see the Redbooks publication WebSphere Application Server V6.1: System Management and Configuration, SG24-7304.
8.2.2 Extending HTTP session management with eXtreme Scale
WebSphere eXtreme Scale provides non-invasive integration for HTTP session management, so that the application does not have to be changed. It does this through an HTTP servlet filter, a standard part of the servlet specification.
As shown in Figure 8-1 on page 190, the HTTP servlet filter intercepts every request to the Web application. Before passing control to the application servlet or JSP, it wraps the HTTPServletRequest and HTTPServletResponse objects that the application developer uses to access the request’s session state. The eXtreme Scale HTTPSession object overrides the object normally provided by the default session manager. Therefore, there is no data duplication between the two session managers.
The filter ensures that the session data is synchronized with the grid. On each request, if HTTP session attributes have changed, they will be written back into the grid.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 189
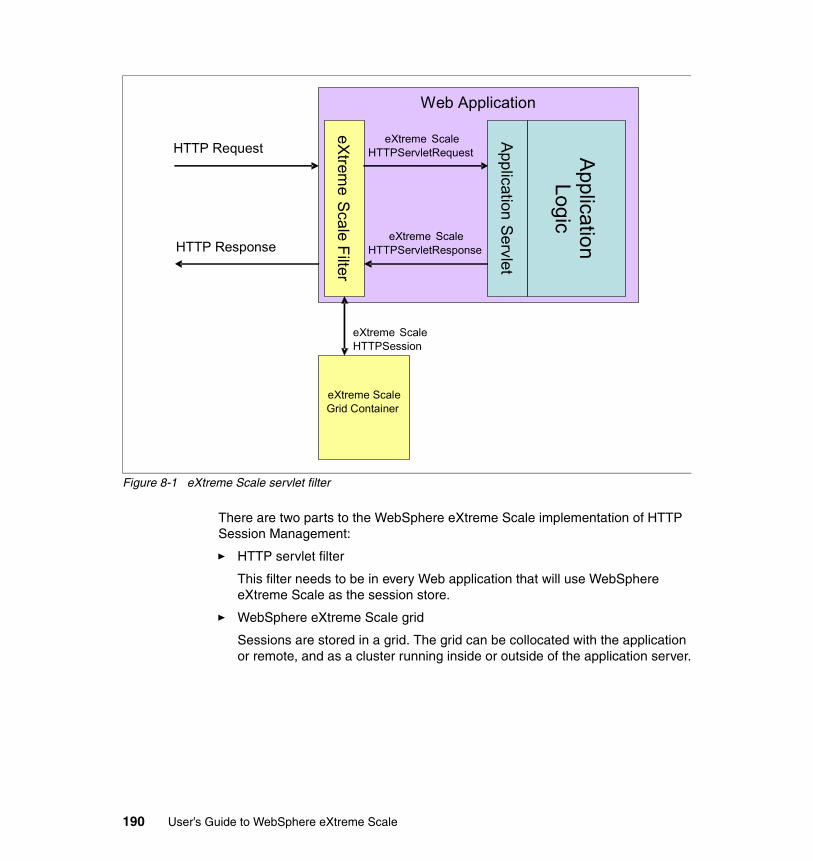
Figure 8-1 eXtreme Scale servlet filter
There are two parts to the WebSphere eXtreme Scale implementation of HTTP Session Management:
� HTTP servlet filter
This filter needs to be in every Web application that will use WebSphere eXtreme Scale as the session store.
� WebSphere eXtreme Scale grid
Sessions are stored in a grid. The grid can be collocated with the application or remote, and as a cluster running inside or outside of the application server.
Web Application
eXtrem
eScale Filter
HTTP Request
HTTP Response
eXtreme ScaleHTTPServletRequest
eXtreme ScaleHTTPServletResponse
Application Servlet
Application
Logic
eXtremeScaleGrid Container
eXtreme ScaleGrid Container
eXtreme ScaleHTTPSession
190 User’s Guide to WebSphere eXtreme Scale

The sample configuration files supplied with the product provide both the definition of the grid and a deployment file example:
– objectGrid.xml
This contains the definition of the grid itself: the maps, locking behavior, plug-ins, and so forth.
– objectGridDeployment.xml
This contains a description of the grid’s deployment: how many partitions, what replication strategy to use, and so on.
These files must be provided in the Web application’s META-INF directory. The names of the files are important. When WebSphere eXtreme Scale detects these files in the Web application, it will start the container for the HTTP sessions.
The sample files provided are shown in Figure 8-2.
Figure 8-2 Grid configuration files
The sample files that we will be using for the configuration of the grid are highlighted in the figure and provide a grid definition and cluster deployment definition for WebSphere eXtreme Scale version 6.1. The objectgrid.maps.xml and objectgrid.cluster.xml files provide grid definitions for version 6.0.
The build.xml and the splicer.properties are used for injecting properties into the Web application for use with WebSphere eXtreme Scale. These will be described shortly.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 191

8.2.3 What benefits does eXtreme Scale provide?
Using WebSphere eXtreme Scale for HTTP session management, you can benefit from the following advantages:
� High qualities of service
WebSphere eXtreme Scale provides faster and more robust replication than WebSphere Application Server. WebSphere eXtreme Scale provides an assured level of replication as it will retry saving a session object if the initial attempt fails. Additionally, HTTP session data can be replicated without the performance overhead seen when using the synchronous replication in WebSphere Application Server.
� Session data is not restricted to a WebSphere Application Server cell boundary
In WebSphere Application Server, sessions are typically restricted to a cell boundary. (It is possible to share sessions across a cell with a database but there are other management drawbacks to this).
Because WebSphere eXtreme Scale can run outside WebSphere Application Server, it is straight forward to set up a stand-alone grid cluster that many applications and cells could use.
� Cross application and platform access
It is possible to configure WebSphere eXtreme Scale to allow different applications to access the session object for the same user. Because it does not have a dependency on WebSphere Application Server, this replication can actually be from non-WebSphere Application Server environments such as WebSphere Application Server Community Edition (based on Apache Geronimo).
192 User’s Guide to WebSphere eXtreme Scale

8.3 Introducing the example scenarios
The following sections show how to configure an application to use WebSphere eXtreme Scale for HTTP session management and how to deploy that to two different configurations:
� A collocated HTTP session store
This is where the eXtreme Scale grid is running inside the same application server as the application and uses a catalog server that is, by default, running in the deployment manager.
� A remote HTTP session store
This is where the eXtreme Scale grid is running in a stand-alone configuration with its own catalog server and one or many container servers hold the session state. The application servlet filter connects remotely to the grid of containers.
8.4 Example: Setting up the application
Setting up an application to use WebSphere eXtreme Scale for HTTP Session management is trivial. It simply requires the following adjustments:
� Setting up the application to use the HTTP servlet filter provided by WebSphere eXtreme Scale
� Providing some configuration properties in the web.xml file of the Web module.
These tasks can be done automatically by using the addObjectgridSessionFilter.bat/.sh tool, or by using the custom Ant task provided. These tools simply inject the required properties into the web.xml file.
This example uses the stand-alone tool, but the Ant task would prove useful to combine this configuration step with the overall build of the application.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 193

8.4.1 Running addObjectgridSessionFilter
The addObjectgridSessionFilter.bat/.sh tool picks up properties from a file and puts them into the web.xml file. There is a sample of this property file called splicer.properties which is available at:
<WXS_HOME>/session/samples/splicer.properties
There are two key properties found in this file that we must address at this point:
� catalogHostPort (v6.1)
This dictates where the bootstrap port of the catalog server is. It is not needed and should be removed if running WebSphere eXtreme Scale within WebSphere Application Server, but is essential if running eXtreme Scale as stand-alone.
The property catalogHostPort needs to be set to the host:port of the remote catalog server. If there are a cluster of catalog servers, which is preferable in a resilient environment, you can provide a list of catalog servers in the following form:
host:port<,host:port>
� objectGridClusterConfigFileName (v6.0.x)
This property is for compatibility with version 6.0.x of WebSphere eXtreme Scale, then known as ObjectGrid. It refers to a file that defines the static cluster definition. This is no longer needed in version 6.1, which instead relies of the catalog server to define the cluster. This should be commented out in the properties file.
Apart from these properties, the defaults are fine to get started with. We will look at them in more detail later to understand what options there are for configuration and tuning.
To run the splicer application, run the following command:
<WXS_HOME>/session/bin/addObjectGridFilter.bat/.shUsage: addSessionObjectGridFilter
<location of ear file> <location of properties file>
For example:
addSessionObjectGridFilter MySessionTest.ear splicer.properties
The output will confirm that the web.xml file has been configured properly as shown in Figure 8-3 on page 195.
194 User’s Guide to WebSphere eXtreme Scale

Figure 8-3 Adding the grid servlet filter
Take a look at the web.xml file of the application and you will see the additional parameters configured in the web.xml. We have not finished configuring our application as it must also be provided with some information about the deployment of the grid. This is dependent on the deployment topology and will be addressed in the next two sections.
addObjectgridFilter MySessionTest.ear splicer.properties
CWWSM0023I: Reading properties file: splicer.propertiesCWWSM0021I: Reading archive: MySessionTest.ear
CWWSM0027I: Processing .war file: MySessionTestWebCWWSM0028I: Context parameters are:CWWSM0029I: Context name: shareSessionsAcrossWebApps Value: falseCWWSM0029I: Context name: sessionIDLength Value: 23CWWSM0029I: Context name: sessionTableSize Value: 1000CWWSM0029I: Context name: replicationInterval Value: 10CWWSM0029I: Context name: replicationType Value: asynchronousCWWSM0029I: Context name: defaultSessionTimeout Value: 30CWWSM0029I: Context name: affinityManager Value: com.ibm.ws.httpsession.NoAffinityManagerCWWSM0029I: Context name: catalogHostPort Value: JMT60CWWSM0029I: Context name: objectGridName Value: sessionCWWSM0029I: Context name: persistenceMechanism Value: ObjectGridStore
CWWSM0030I: Application splicing completed successfully.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 195

8.5 Example: Using a collocated HTTP session store
The first deployment scenario we are going to demonstrate is the Web application using a collocated WebSphere eXtreme Scale HTTP session store. The catalog server and containers are embedded in WebSphere Application Server and, in this scenario, the containers that hold the session data are in the same application servers as the Web applications. This is shown in Figure 8-4 on page 197.
The benefits specific to this topology are primarily performance and manageability.
� Performance is greatly improved by having the session store local. Once configured, we can benefit from all of the qualities of service offered by WebSphere eXtreme Scale such as replication.
� This deployment solution is easy to deploy and manage as it just requires a couple of deployment descriptors in the application to define the grid and describe how it is to be deployed. You do not need any separate processes running, or any additional management or monitoring infrastructure, making this is an easy and powerful deployment option.
While the figure only depicts a single catalog server, this can be easily clustered in the Network Deployment configuration to remove the single point of failure. This is described in more detail in Chapter 5, “eXtreme Scale in a Network Deployment environment” on page 87.
Best Practice: This is the recommended deployment topology for HTTP session management and is suitable for most uses of HTTP session management.
196 User’s Guide to WebSphere eXtreme Scale

Figure 8-4 Collocated HTTP session store
The request goes through the following steps when it arrives at the application server.
1. WebSphere Application Server provides a session ID if one does not exist. This determines the server affinity of the user, so that subsequent requests will return back to the same server
2. The WebSphere eXtreme Scale servlet filter intercepts the request and creates a new session object. The filter will store the state in one of the local container partitions. Therefore the session state will always be local to the HTTP request, where affinity is honored. The HTTPSession object is provided to the application servlet implementation, so all reads and any subsequent writes will be made directly to the grid.
3. In the collocated scenario, WebSphere eXtreme Scale actually requires two grid configurations. As well as storing session information, it stores partition information in a separate grid (see Example 8-1 on page 198). This information is used to perform a lookup and remote read of the session state if affinity is broken due to a reason such as a server failure.
DeploymentManager
Application Server
WebApp
Application Server
WebApp
Grid Container
WebServer
Grid Container
CatalogServer
eXtreme Scale cluster
FilterFilter
sessionsession.partition.info
sessionsession.partition.info
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 197

8.5.1 Understanding the grid configuration
To configure the collocated grid scenario, we are going to use the following sample configuration files provided with WebSphere eXtreme Scale:
� <WXS_HOME>/session/samples/objectGrid.xml� <WXS_HOME>/session/samples/objectGridDeployment.xml
The first file, objectGrid.xml, defines the grids that are needed for the session management. This is shown in shown in Example 8-1. This definition file should not need to be changed.
Example 8-1 Portion of objectGrid.xml describe grid configuration
<objectGrids><objectGrid name="session">
<backingMap name="logical.name" ... /><backingMap name="objectgrid.session.metadata" ... /><backingMap name="objectgrid.session.attribute" ... /><backingMap name="datagrid.session.global.ids" ... />
</objectGrid><objectGrid name="session.partition.info">
<backingMap name="partition.info" ... /><backingMap name="clone.info" ... />
</objectGrid></objectGrids>
There are two objectGrid definitions in the configuration:
� Session
The session grid stores session attributes and metadata related to it.
� Session.partition.info
The session.partition.info stores information that indicates which partition in the grid contains what data. This is important in the scenario where affinity is lost. In the normal pattern of operation, affinity is established to the server containing the primary store of the session state. In the case where this is lost, this grid provides the look up to other servers.
The second file, objectGridDeployment.xml, defines how the grids should be deployed in the application servers. The default settings will partition the grid and provide for a maximum of one synchronous replica. This is shown in Example 8-2 on page 199. We will look at these options in more detail in 8.7, “Configuration of the HTTP session management” on page 205. However, you do not need to change the defaults to run effectively.
198 User’s Guide to WebSphere eXtreme Scale

Example 8-2 Portion of objectGridDeployment.xml for grid deployment and clustering
<objectgridDeployment objectgridName="session.partition.info"><mapSet name="endPointMapSet"
numberOfPartitions="5" minSyncReplicas="0" maxSyncReplicas="1" maxAsyncReplicas="0" developmentMode="false" placementStrategy="FIXED_PARTITIONS">
<map ref="partition.info"/><map ref="clone.info"/>
</mapSet></objectgridDeployment> <objectgridDeployment objectgridName="session">
<mapSet name="mapSet2" numberOfPartitions="5" minSyncReplicas="0" maxSyncReplicas="1" maxAsyncReplicas="0" developmentMode="false" placementStrategy="PER_CONTAINER">
<map ref="logical.name"/><map ref="objectgrid.session.metadata"/><map ref="objectgrid.session.attribute"/><map ref="datagrid.session.global.ids"/>
</mapSet> </objectgridDeployment>
Tip: If you are testing on a single server, you will need to set the following value:
developmentMode = true
If developmentMode is equal to false (as shown in Example 8-2), WebSphere eXtreme Scale will not start a replica on the same physical server as it is typically preferable to spread replicas across different servers for greater availability.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 199

8.5.2 Configuring the application
We have looked at the two configuration files to run this scenario. To define the WebSphere eXtreme Scale HTTP session store in the Web application, we need to place these definition files in the Web application’s META-INF directory, as described in Figure 8-5.
Figure 8-5 Placing the configuration files in the Web application
The application should be ready to run now with the properties that we injected into the web.xml file in 8.4, “Example: Setting up the application” on page 193.
8.5.3 Running the application
The application requires that the WebSphere Application Server Network Deployment environment be configured as described in 5.4, “Creating the sample topology” on page 101. In addition, the application needs access to the sessionobjectgrid.jar file to run. This contains the servlet filter implementation and could be bundled with your application in the WEB-INF/lib directory. This is not provided in the sample application with this Redbooks publication, so you need to copy it to your WebSphere Application Server lib directory. It can be found in the following directory:
<WXS_HOME>/session/lib
The sample application, called MySessionTest.ear, is prepared for running in this environment. It is configured with the grid and web.xml settings and contains a JSP (called SessionTest.jsp) for testing session management.
Make sure the deployment manager is successfully started. By default, it will be running the catalog server. You can verify that the catalog server has correctly
200 User’s Guide to WebSphere eXtreme Scale

started in the SystemOut.log as it should contain a message similar to the following message:
ObjectGrid Server Cell01\CellManager01\dmgr is ready to process requests.
Deploy the application to an application server or cluster in WebSphere Application Server through the normal means in the administrative console from Applications → Install New Application. There are no special considerations at this point. Start the application server or cluster and you should see messages in the logs confirming that the grid is being started, as shown in Example 8-3.
Example 8-3 WebSphere eXtreme Scale start up messages in SystemOut.log
[26/08/08 15:31:30:508 BST] 00000021 ServerImpl I CWOBJ2501I: Launching ObjectGrid server Cell01\Node01\AppClusterMember1.[26/08/08 15:31:31:024 BST] 00000021 ServerAgent I CWOBJ1720I: HAManager Controller detected that ObjectGrid server is in the WebSphere environment, using WebSphere HAManager instead of initializing and starting standalone HAManager.[26/08/08 15:31:31:039 BST] 00000021 PeerManagerSe I CWOBJ7700I: Peer Manager service started successfully in server (Cell01\Node01\AppClusterMember1) with core group (DefaultCoreGroup).[26/08/08 15:31:31:149 BST] 00000021 ServerImpl I CWOBJ8000I: Registration is successful with zone (DefaultZone) and coregroup of (Cell01DefaultCoreGroup).[26/08/08 15:31:31:195 BST] 00000021 ServerImpl I CWOBJ1001I: ObjectGrid Server Cell01\Node01\AppClusterMember1 is ready to process requests.
Example 8-4 also shows some of the messages that will be shown as the catalog server designates the partitions and replicas to the application server instances.
Example 8-4 SystemOut.log indicating successful start
[26/08/08 15:31:38:164 BST] 00000026 ReplicatedPar I CWOBJ1511I: session:mapSet2:3 (primary) is open for business.[26/08/08 15:31:38:680 BST] 00000028 SynchronousRe I CWOBJ1511I: session:mapSet2:7 (synchronous replica) is open for business.
Run the application by going to the JSP URL:
http://localhost/MySessionTestWeb/SessionTest.jsp
The SessionTest.jsp will display session information such as time created and time last accessed. You can verify that the session management is working by refreshing the page. When refreshing, correct session management will show the
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 201
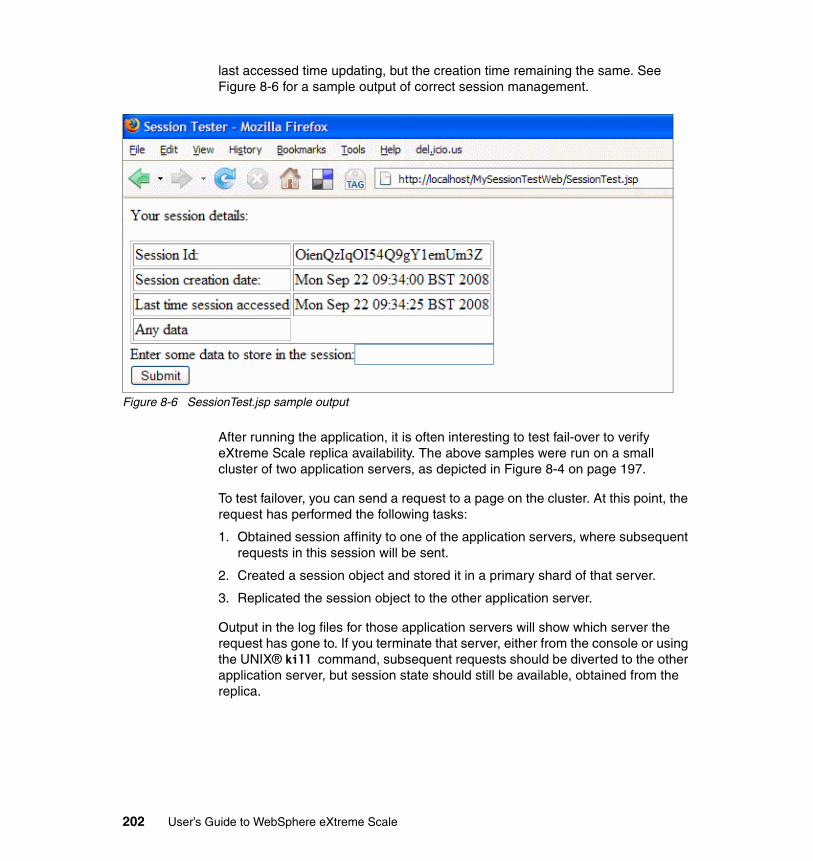
last accessed time updating, but the creation time remaining the same. See Figure 8-6 for a sample output of correct session management.
Figure 8-6 SessionTest.jsp sample output
After running the application, it is often interesting to test fail-over to verify eXtreme Scale replica availability. The above samples were run on a small cluster of two application servers, as depicted in Figure 8-4 on page 197.
To test failover, you can send a request to a page on the cluster. At this point, the request has performed the following tasks:
1. Obtained session affinity to one of the application servers, where subsequent requests in this session will be sent.
2. Created a session object and stored it in a primary shard of that server.
3. Replicated the session object to the other application server.
Output in the log files for those application servers will show which server the request has gone to. If you terminate that server, either from the console or using the UNIX® kill command, subsequent requests should be diverted to the other application server, but session state should still be available, obtained from the replica.
202 User’s Guide to WebSphere eXtreme Scale

8.6 Example: Using a remote HTTP session store
The second deployment scenario we are going to demonstrate is a Web application using a remote WebSphere eXtreme Scale HTTP session store. We will use a remote catalog server and remote grid containers and call them from the Web application inside WebSphere Application Server.
This scenario naturally has the overhead of remote calls and managing additional processes, so in what situations would this topology be preferable? The remote HTTP session configuration reduces the memory overhead for a given application server. It also provides additional flexibility for the following situations:
� Session state across different Web applications� Different application server versions� Different application server technologies altogether
Figure 8-7 illustrates this topology.
Figure 8-7 eXtreme Scale remote HTTP session store
DeploymentManager
ApplicationServer
WebApp
Grid Container “server1”
WebServer
CatalogServer
eXtreme S
cale cluster
Grid Container “server2”
Filter
session
session
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 203

8.6.1 Understanding the grid configuration
To configure the remote grid scenario, we are using the sample configuration files provided with WebSphere eXtreme Scale:
� <WXS_HOME>/session/samples/objectGridStandalone.xml� <WXS_HOME>/session/samples/objectGridDeploymentStandalone.xml
As you can see, these sample configuration files are created specifically for this scenario where the application is going to communicate with a remote, stand-alone HTTP session store.
The first file, objectGridStandalone.xml, defines the grid that is needed for the session management. A portion of this configuration is shown in Example 8-5, where the objectGrid session is defined to store all session attributes and metadata related to it.
Example 8-5 Portion of objectGrid.xml describe grid configuration
<objectGrids><objectGrid name="session">
<backingMap name="logical.name" ... /><backingMap name="objectgrid.session.metadata" ... /><backingMap name="objectgrid.session.attribute" ... /><backingMap name="datagrid.session.global.ids" ... />
</objectGrid></objectGrids>
Notice that we do not need the session.partition.info grid that we used in the collocated grid scenario in Example 8-1 on page 198. This is because we do not need to ensure that session state is in a specific (namely, a local) partition. We can just let eXtreme Scale do all the data placement for us in the grid.
The second file, objectGridDeploymentStandalone.xml, defines how this grid should be deployed. This is the same as any other stand-alone configuration and can be configured as desired.
8.6.2 Configuring the application
To allow the Web application to use the remote HTTP session store, we need to set up the web.xml as outlined in 8.4, “Example: Setting up the application” on page 193. This web.xml file contains the reference to the host and port of the remote catalog server. That is all that is needed to run this scenario. We do not need to provide the grid configuration because it is remote.
204 User’s Guide to WebSphere eXtreme Scale

8.6.3 Running the application
To run the application, take the following steps:
1. Start the remote WebSphere eXtreme Scale cluster by performing the following steps:
a. Start the catalog server in the normal way, for example
<WXS_HOME>\bin\startOgServer.bat catalogServer -listenerHost JMT60 -listenerPort 2809
b. Start one or more grid container servers with reference to the objectGrid.xml and objectGridStandalone.xml files.
<WXS_HOME>\bin\startOgServer.bat server1 -objectgridFile objectGridStandAlone.xml -deploymentPolicyFile objectGridDeploymentStandalone.xml -catalogServiceEndpoints JMT60:2809
In the code above, server1 is the name of the server and should be unique for each container server started. For example, server1, server2, and so on.
2. Set up the Network Deployment environment by performing the following steps.
a. Ensure eXtreme Scale is installed on the Network Deployment environment as described in 5.4, “Creating the sample topology” on page 101.
b. Deploy the application and start it.
8.7 Configuration of the HTTP session management
So far we have depended heavily on the sample configuration files, without really understanding the parameters that we have been using. In this section, we are going to look at the key parameters and further understand how WebSphere eXtreme Scale provides HTTP session management.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 205

8.7.1 Configuring session management behavior
We can change the behavior of the HTTP session management functionality provided by WebSphere eXtreme Scale through tuning the parameters that are injected into the web.xml file.
Web.xml propertiesThis section addresses the key properties.
� objectGridName
default: session
This property provides the name of the grid that the Web application is to use to store session state. This would need changing if many applications each needed their own use of WebSphere eXtreme Scale for HTTP session management. If Web applications were sharing session state across a grid, this should be the same name for all of those applications.
� objectGridClusterConfigFileName
As discussed, this property is for compatibility with version 6.0.x of WebSphere eXtreme Scale, then known as ObjectGrid. It refers to a file that defines the static cluster definition. This is no longer needed in version 6.1, which instead relies on the catalog server to define the cluster. This should be commented out in the properties file.
� catalogHostPort
This dictates where the bootstrap port of the catalog server is. It is not needed if running WebSphere eXtreme Scale within WebSphere Application Server, but is necessary if running stand-alone. If there is a cluster of catalog servers, which is preferable in a resilient environment, you can provide a list of catalog servers in the following form:
host:port<,host:port> replicationType default: asynchronous replicationInterval default: 10
The default settings for replication is similar to the defaults of the WebSphere Application Server HTTP session manager, namely asynchronous updates every 10 seconds.
Using synchronous replication has no performance overhead in the collocated grid scenario.
Leading practice: It is recommended that replicationType is changed to synchronous for WebSphere eXtreme Scale HTTP session management.
206 User’s Guide to WebSphere eXtreme Scale

In the remote grid scenario, it is acceptable to reduce the overhead of remote invocations by using asynchronous replicas. The session would have already been synchronously copied to the remote grid in the first place before placing in a replica. So asynchronous replication in this still situation still provides superior replication qualities of service.
Once set to synchronous, the replicationInterval property is not used.
� shareSessionsAcrossWebApps
default: false
This is pretty self-explanatory. If you wish to share session state across many applications or application server technologies, change the value of this setting to true.
By way of reminder, to share sessions, the applications must all reside on the same domain, for example www.ibm.com. This is because WebSphere Application Server relies on cookies, specifically the JSESSIONID cookie, to track the session ID. Cookies are naturally specific to a given Web domain.
For full reference information about these properties, see the Using ObjectGrid for HTTP session management wiki at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/uwEN
8.7.2 Understanding the sample grid definitions
Example 8-6 on page 208 shows the sample objectGrid.xml definition file for a collocated HTTP session store. We introduced the two grid definitions in this sample in 8.5, “Example: Using a collocated HTTP session store” on page 196.
Tip: The sample objectGrid.xml for HTTP session management should not need to be changed. Incorrect changes can break the session functionality. The objectGridDeployment.xml should also be ok but it may be desirable to change settings such as; minSyncReplicas, maxSyncReplicas, maxAsyncReplicas, developmentMode.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 207

The following information is provided for reference.
� ObjectGridEventListener is a plug-in configured on the session grid. It notifies the grid when the primary is up and running and available for use.
� A number of the backing maps use a copyMode of NO_COPY. This is not typically recommended to application developers as this allows direct access to editing the grid data regardless of transactions and locks. It is only safe to use with (largely) read-only data, or there will not be multiple users changing the same data, as in the scenario of HTTP session management. For more information see the Transaction mechanics in ObjectGrid wiki at the following Web page
http://www-128.ibm.com/developerworks/wikis/x/Ki
� The object.session.metadata backing map is used for storing metadata about the HTTP session, such as creation time and last access time. This backing map also uses a plug-in ObjectTransformer. This provides custom serialization, which can be significantly faster than Java serialization and is used for remote calls. It is recommended that you provide an ObjectTransformer where possible.
Example 8-6 Sample objectGrid.xml
<?xml version="1.0" encoding="UTF-8"?><objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ibm.com/ws/objectgrid/config ../objectGrid.xsd" xmlns="http://ibm.com/ws/objectgrid/config">
<objectGrids><objectGrid name="session.partition.info">
<backingMap name="partition.info" readOnly="false" lockStrategy="PESSIMISTIC" ttlEvictorType="NONE" copyMode="NO_COPY" numberOfBuckets="107"/>
<backingMap name="clone.info" readOnly="false" lockStrategy="PESSIMISTIC" ttlEvictorType="NONE" copyMode="NO_COPY" numberOfBuckets="107" lockTimeout="300"/>
</objectGrid>
<objectGrid name="session"><bean id="ObjectGridEventListener"
className="com.ibm.ws.session.store.objectgrid.ObjectgridHandleMgr"/><backingMap name="logical.name" readOnly="false"
lockStrategy="PESSIMISTIC" ttlEvictorType="NONE" numberOfBuckets="1" numberOfLockBuckets="1"/>
<backingMap name="objectgrid.session.metadata" pluginCollectionRef="objectgrid.session.metadata" readOnly="false" lockStrategy="PESSIMISTIC" ttlEvictorType="LAST_ACCESS_TIME" copyMode="NO_COPY" numberOfBuckets="10007"/>
208 User’s Guide to WebSphere eXtreme Scale

<backingMap name="objectgrid.session.attribute" pluginCollectionRef="objectgrid.session.attribute" readOnly="false" lockStrategy="OPTIMISTIC" ttlEvictorType="NONE" copyMode="NO_COPY" numberOfBuckets="10007"/>
<backingMap name="datagrid.session.global.ids" readOnly="false" lockStrategy="PESSIMISTIC" ttlEvictorType="NONE" copyMode="NO_COPY" numberOfBuckets="10007"/>
</objectGrid></objectGrids><backingMapPluginCollections>
<backingMapPluginCollection id="objectgrid.session.metadata"> <bean id="ObjectTransformer"
className="com.ibm.ws.session.store.objectgrid.MetadataMapTransformer"/>
</backingMapPluginCollection> <backingMapPluginCollection id="objectgrid.session.attribute">
<bean id="OptimisticCallback" className="com.ibm.websphere.objectgrid.plugins.builtins.NoVersioningOptimisticCallback"/>
</backingMapPluginCollection> </backingMapPluginCollections>
</objectGridConfig>
Example 8-7 shows the sample deployment configuration for the collocated HTTP session store scenario. This is a pretty standard deployment of WebSphere eXtreme Scale. We can see that this will create a maximum of just one synchronous replica. This can be tuned as desired.
Example 8-7 Sample objectGridDeployment.xml configuration
<?xml version="1.0" encoding="UTF-8"?><deploymentPolicy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://ibm.com/ws/objectgrid/deploymentPolicy ../deploymentPolicy.xsd" xmlns="http://ibm.com/ws/objectgrid/deploymentPolicy">
<objectgridDeployment objectgridName="session.partition.info"><mapSet name="endPointMapSet" numberOfPartitions="5" minSyncReplicas="0"
maxSyncReplicas="1" maxAsyncReplicas="0" developmentMode="false" placementStrategy="FIXED_PARTITIONS"><map ref="partition.info"/><map ref="clone.info"/>
</mapSet></objectgridDeployment> <objectgridDeployment objectgridName="session">
<mapSet name="mapSet2" numberOfPartitions="5" minSyncReplicas="0" maxSyncReplicas="1" maxAsyncReplicas="0" developmentMode="false" placementStrategy="PER_CONTAINER">
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 209

<map ref="logical.name"/><map ref="objectgrid.session.metadata"/><map ref="objectgrid.session.attribute"/><map ref="datagrid.session.global.ids"/>
</mapSet> </objectgridDeployment>
</deploymentPolicy>
There is an interesting property highlighted in the example. In WebSphere eXtreme Scale version 6.1.0.3, the property placementStrategy was exposed. This property has the following two values:
� FIXED_PARTITIONS
This property is the default and was the only behavior available for configuration prior to version 6.1.0.3. This means that the number of partitions defined, in this case five, is fixed for the whole grid, regardless of the number of container servers started. With a fixed number of partitions, they will be moved to other containers as they start using the Waterflow algorithm outlined in 2.5, “Zones” on page 36.
For example, start one server and all five partitions will reside on it. Start a second server, and two of the partitions can be moved to it. This behavior will naturally depend on other configuration factors, such as numInitialContainers, which defines how many container servers need to be running before the partitions are deployed and activated. This prevents unnecessary movement of partitions.
� PER_CONTAINER
This property establishes that a WebSphere eXtreme Scale grid can contain a dynamic number of partitions. In this case, it will be five partitions per application server. This is ideal in the HTTP session management scenario, where we want to ensure there are a set number of partitions available for local access.
The remaining properties can be found in the reference on the Deployment policy configuration reference wiki at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/Pokd
210 User’s Guide to WebSphere eXtreme Scale

8.8 Advanced profile and session data management
In the above section we discussed simple HTTP session management with WebSphere eXtreme Scale without any custom code change. In this section we introduce a new feature that allows you to have more control on session and profile data. With eXtreme Scale V6.1.0.4, a mechanism is provided to ensure that a client's related transactions are routed to the same partitions.
8.8.1 Relevant terms
The following terms apply to advanced profile and session data management:
Hash-based partitions Partitioning is based on data key's hash code on the fixed number of partitions, therefore, it is also called fixed number of partitions
Per-container partitions Partitions are created with each container's startup. The number of partitions depends on the number of containers; therefore, the number of partitions is not fixed.
First transaction The first transaction of many related transactions (1...n) that is used by a client for the same purpose
Subsequent transactions Transactions (2...n) after the first transaction in the many related transactions that is used by a client for the same purpose
Session reuse ratio (n–1)/n where n is the number of related transactions that is used by a client for the same purpose
SessionHandle An object contains partition information for the current session and can be re-applied to a new session of related subsequent transactions. It is usually used with the per container partitions to pin client's activities to the specific partition (that is, affinity).
8.8.2 SessionHandle
You can retrieve and set the SessionHandle from a Session object across a series of related transactions. When SessionHandle is not set in the transaction, eXtreme Scale will select a partition among all available partitions for the grid and set the SessionHandle in the user session automatically. You can retrieve this SessionHandle and set it in subsequent transactions.
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 211

Example 8-8 Using SessionHandle
public interface Session { public SessionHandle getSessionHandle(); public void setSessionHandle(SessionHandle target) throws TargetNotAvailableException;}
8.8.3 Why use SessionHandle?
Routing a user’s ObjectGrid interactions into a specific partition in multiple related transactions can provide better performance than routing requests according to hash-based partitions. There is a cost to determine the first SessionHandle because eXtreme Scale needs to obtain global dynamic information for all partitions in a grid. This information is not necessary for hash-based partition routing (a hash key decides which partition to take). However, there is a big performance boost for subsequent related transactions. The more related transactions there are, the better the performance.
Routing using the SessionHandle feature scales better than hash-based fixed partition routing. The per-container placement provides unlimited partitions for the grid, so a user's request can be routed to unlimited partitions instead of the fixed number of partitions in hash-based partitioning.
Because the number of partitions is dynamic, eXtreme Scale needs to collect global information of all current available partitions to do routing. In order to reduce the first-time cost, time-based bootstrapping is used, which can have up to 60 seconds of stale routing data. Furthermore, global versioning with epoch is used for the whole grid and the whole map set to check routing table changes to minimize traffic costs.
8.8.4 Native partitions
eXtreme Scale calls a partition as a native partition when the primary shard of this partition has not failed yet. After the primary shard of partition has failed over, eXtreme Scale marks this partition as not a native partition (or a foreign partition), and will not select this foreign partition for a new session.
Tip: When there is high ratio of session reuse (more than 60%) we suggest users use the SessionHandle feature.
212 User’s Guide to WebSphere eXtreme Scale

8.8.5 How to use SessionHandle
In order to use per-container placement, the deployment policy needs to have the placementStrategy attribute set to PER_CONTAINER. This tells the catalog service of the desired placement strategy and indicates that the numberOfPartitions attribute relates to the number of partitions per container rather than the number of partitions fixed in the grid.
Example 8-9 Setting the per-container placement strategy
<?xml version="1.0" encoding="UTF-8"?><deploymentPolicy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ibm.com/ws/objectgrid/deploymentPolicy ../deploymentPolicy.xsd" xmlns="http://ibm.com/ws/objectgrid/deploymentPolicy">
<objectgridDeployment objectgridName="siprouting"> <mapSet name="mapSet1" numberOfPartitions="3" minSyncReplicas="0" maxSyncReplicas="1" maxAsyncReplicas="0" placementStrategy="PER_CONTAINER"> <map ref="map1" /> <map ref="map2" /> <map ref="map3" /> </mapSet> </objectgridDeployment></deploymentPolicy>
As in the following sample code, you can retrieve a SessionHandle with session.getSessionHandle(). At the beginning of subsequent related transactions, set the SessionHandle with session.setSessionHandle(sessionHandle). You can terminate the sequence by setting SessionHandle to null.
Example 8-10 Using SessionHandle
ObjectGrid objectGrid = manager.getObjectGrid(ccc, "siprouting"); Session session = objectGrid.getSession(); ObjectMap map = session.getMap("map1"); session.begin(); map.insert("key", "value"); session.commit(); SessionHandle future=session.getSessionHandle();
Chapter 8. Extended HTTP Session Management with WebSphere eXtreme Scale 213

System.out.println("get future target at transaction 2="+ future); Session session2=objectGrid.getSession(); session2.begin(); session2.setSessionHandle(future); System.out.println("target="+ session2.getSessionHandle()); assertEquals("value", map.get("key")); session2.commit(); SessionHandle future2=session2.getSessionHandle(); System.out.println("get future target at transaction 3="+ future2); Session session3=objectGrid.getSession(); session3.begin(); session3.setSessionHandle(future2); assertEquals("value", map.get("key")); session3.commit(); future2=session3.getSessionHandle(); System.out.println("get future target at end of transaction 3="+ future2);
session3.setSessionHandle(null); SessionHandle t= session3.getSessionHandle(); System.out.println(" extract future target reset it="+ t);
In the above sample, the session is reused twice. SessionHandle is set to null in the last block to signal routing code to pick a new target.
8.8.6 Considerations
You can store SessionHandle into an HTTP session, JMS session, or even a database to manage any kind of session and profile data (including HTTP session data). You can then retrieve the SessionHandle and apply it into an eXtreme Scale session to retrieve and update data. WebSphere eXtreme Scale provides this generic and high-performance solution for advanced users to manage their data across many related transactions.
214 User’s Guide to WebSphere eXtreme Scale

Appendix A. Loading and running the sample application
In this appendix, we explain how to setup a test environment in order to unit test and develop applications that use WebSphere eXtreme Scale. Setting up the test environment is fairly simple. It entails many of the same steps that are used to deploy the stand-alone J2SE environment for WebSphere eXtreme Scale.
In this appendix, we discuss the following topics:
� “Installation concepts” on page 216� “Using Rational Application Developer for testing” on page 216� “An alternate test environment configuration” on page 218
A
© Copyright IBM Corp. 2008. All rights reserved. 215

Installation concepts
In order to develop Java applications that use WebSphere eXtreme Scale, you must collect the required JARs from a current WebSphere eXtreme Scale deployment and move them to the development workstation. The required JARs will depend on the type of application you are writing. Details on the required JARs for common development scenarios are located in the Packaging overview wiki available at the following Web page:
http://www-128.ibm.com/developerworks/wikis/x/CwEN
Using Rational Application Developer for testing
Developing Java applications is easy when using IBM Rational® Application Developer, an integrated development environment (IDE) for Java applications. Rational Application Developer includes support for WebSphere Application Server-based server runtimes as well as other server runtimes such as Tomcat and JBoss®. The following sections detail how to use the Rational tooling to make testing with WebSphere eXtreme Scale simple.
Whether the Java project is destined for a J2EE application server or a stand-alone application of some kind, the method for setting up the test environment is the same. Simply include the appropriate eXtreme Scale JARs in the project library definitions and you are ready to proceed.
For our example, we have created a simple J2EE web application and an EAR file to contain it (Figure A-1 on page 217).
216 User’s Guide to WebSphere eXtreme Scale
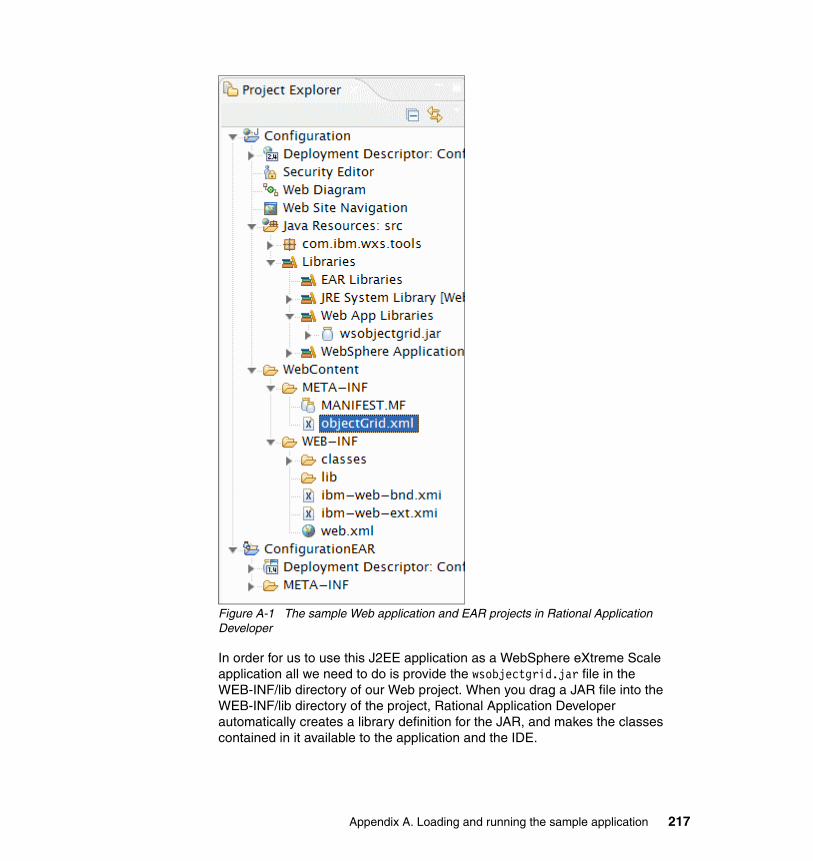
Figure A-1 The sample Web application and EAR projects in Rational Application Developer
In order for us to use this J2EE application as a WebSphere eXtreme Scale application all we need to do is provide the wsobjectgrid.jar file in the WEB-INF/lib directory of our Web project. When you drag a JAR file into the WEB-INF/lib directory of the project, Rational Application Developer automatically creates a library definition for the JAR, and makes the classes contained in it available to the application and the IDE.
Appendix A. Loading and running the sample application 217

When the application is deployed to the server runtime, the application will start and the server will act as a WebSphere eXtreme Scale container.
If we wanted to write an application that used the stream query capability we would just need to add the appropriate JAR files to the application build path as described earlier.
An alternate test environment configuration
In the previous section, we covered how to set up a simple, self-contained, grid instance and application combination. As an alternative means, you can deploy the WebSphere eXtreme Scale code onto your development machine and use Rational Application Developer to start and stop catalog server instances and container servers. Using this approach it is possible to more accurately depict scenarios in which the application to be written will act only as a client to the grid and will not house any grid instances (other than a near cache). To begin, install eXtreme Scale using the instructions in Chapter 6, “eXtreme Scale in a stand-alone environment” on page 123.
Next, determine how many grid server instances you would like to set up. To control the starting and stopping of these servers, we can set up external tools definitions that will point to scripts that will start and stop the servers (that is, startogserver.bat/sh).
To create an external tool definition, consult the Rational Application Developer help contents and search for “stand-alone external tools.” The first result should be the instructions on how to set up an external tool. For our situation, we can create a tool definition that looks like the one shown in Figure A-2 on page 219.
Note: Because WebSphere eXtreme Scale does not require any part of WebSphere Application Server and is completely self-contained, all you need to do is define the appropriate JARs as libraries for your application projects and you are ready to write your application.
218 User’s Guide to WebSphere eXtreme Scale
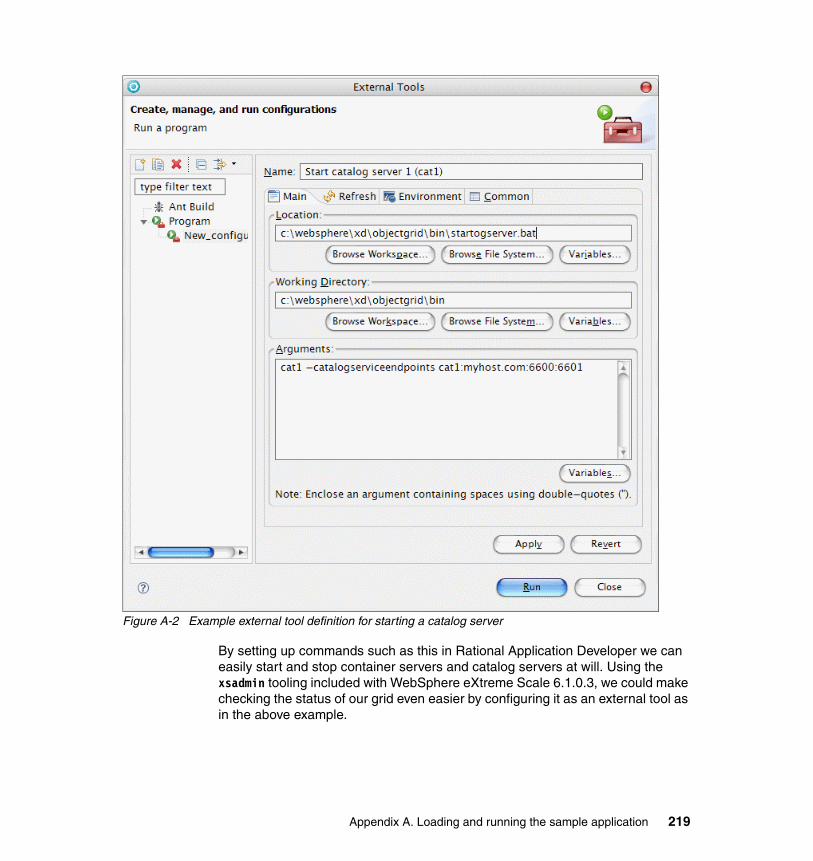
Figure A-2 Example external tool definition for starting a catalog server
By setting up commands such as this in Rational Application Developer we can easily start and stop container servers and catalog servers at will. Using the xsadmin tooling included with WebSphere eXtreme Scale 6.1.0.3, we could make checking the status of our grid even easier by configuring it as an external tool as in the above example.
Appendix A. Loading and running the sample application 219

220 User’s Guide to WebSphere eXtreme Scale

Appendix B. Setting up the database
This appendix provides instructions about how to set up the DB2 database that is required by the example application described in 5.2, “Introducing the sample application” on page 93.
B
Sample application: For information about obtaining the downloadable material see Appendix C, “Additional material” on page 229.
© Copyright IBM Corp. 2008. All rights reserved. 221

Installing DB2 UDB V9.5
The DB2 UDB2 V9.5 base installation on node WXS4 is an out-of-the-box installation. The DB2 Information Center provides detailed instructions for this in An overview of installing your DB2 server product (Windows) at the following Web page:
http://publib.boulder.ibm.com/infocenter/db2luw/v9r5/topic/com.ibm.db2.luw.qb.server.doc/doc/t0052773.html
Creating the database and tables
Before the tables can be created, a database has to be defined. We used the DB2 Control Center to create a database named ITSO.
When the database exists, the actual tables and indexes can be created. The sample application includes an SQL script that contains the required statements. The script is located in ItsoSampleServer.ear\META-INF\owner.ddl and can be executed using the DB2 Control Center.
After the tables have been created, we must ensure that the DB2 user ID the application server will use to connect to the database has enough privileges to use the new tables. The sample setup uses the user DB2USER that belongs to the group DBUSERS. We grant the privileges for connect, insert, update, and delete to the group DB2USERS. This can be done using DB2 Control Center by opening the Tables View, right-clicking on the table and selecting Privileges. In the dialog box add group “DB2USERS” and grant all rights as shown in Figure B-1 on page 223. Then click Apply.
222 User’s Guide to WebSphere eXtreme Scale
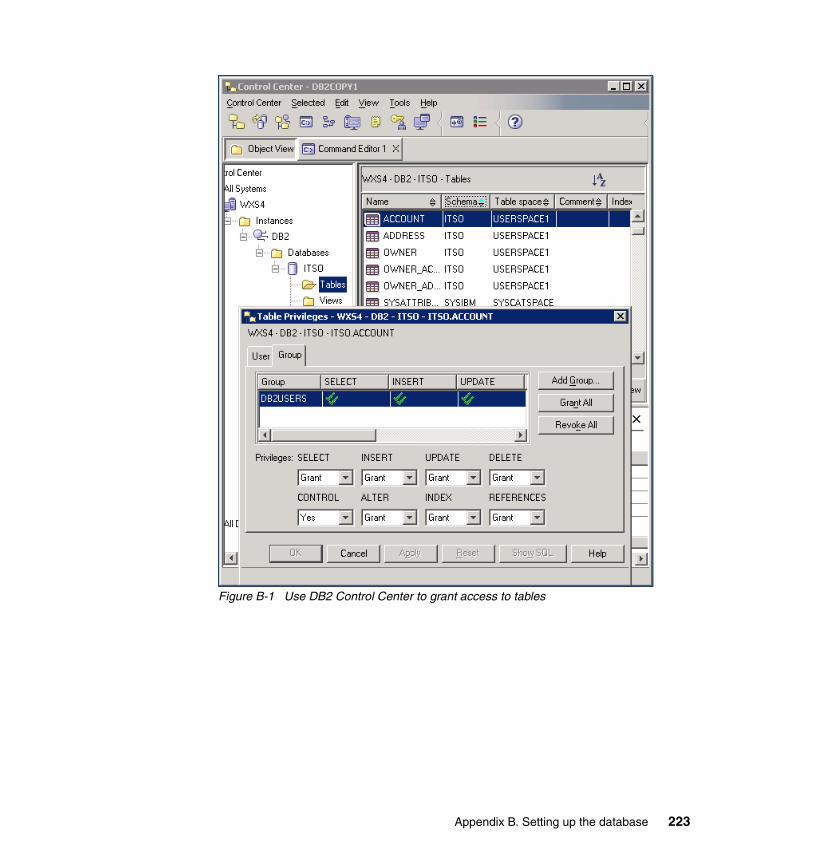
Figure B-1 Use DB2 Control Center to grant access to tables
Appendix B. Setting up the database 223

Defining the JDBC provider
When the DB2 setup is completed, the required WebSphere resources can be defined by following these steps:
1. Create the DB2 JDBC Provider using the WebSphere administrative console. Select Resources → JDBC → JDBC Providers → New operation at cell level scope. The exact procedure is described in the information center article JDBC providers, available at the following Web page:
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/topic/com.ibm.websphere.nd.doc/info/ae/ae/cdat_jdbcprov.html
Care has to be taken that the JDBC driver JAR files are located on every node. For the example, c:\ibm\db2jdbcdriver was used as the common path. The DB2jcc*.jar files were copied from the DB2 hosts DB2_HOME\java to this path.
2. Set the WebSphere variables for the DB2 driver. Figure B-2 shows the variables in the administrative console.
Figure B-2 WebSphere Variables for DB2 universal JDBC driver
3. Select Environment → WebSphere Variables to verify the settings for the sample topology.
224 User’s Guide to WebSphere eXtreme Scale
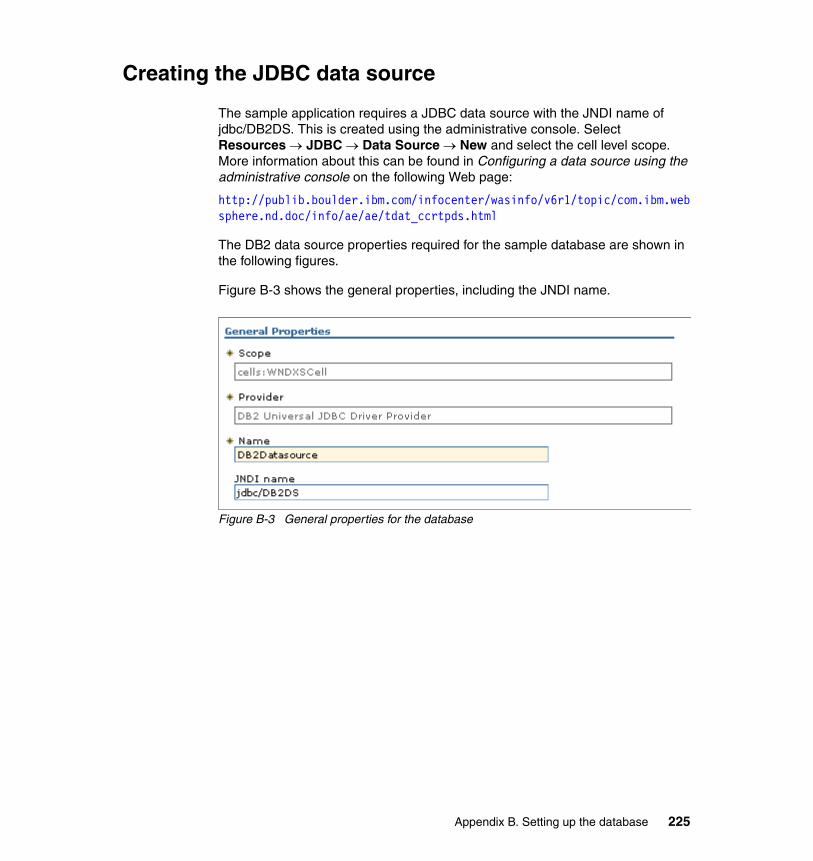
Creating the JDBC data source
The sample application requires a JDBC data source with the JNDI name of jdbc/DB2DS. This is created using the administrative console. Select Resources → JDBC → Data Source → New and select the cell level scope. More information about this can be found in Configuring a data source using the administrative console on the following Web page:
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/topic/com.ibm.websphere.nd.doc/info/ae/ae/tdat_ccrtpds.html
The DB2 data source properties required for the sample database are shown in the following figures.
Figure B-3 shows the general properties, including the JNDI name.
Figure B-3 General properties for the database
Appendix B. Setting up the database 225
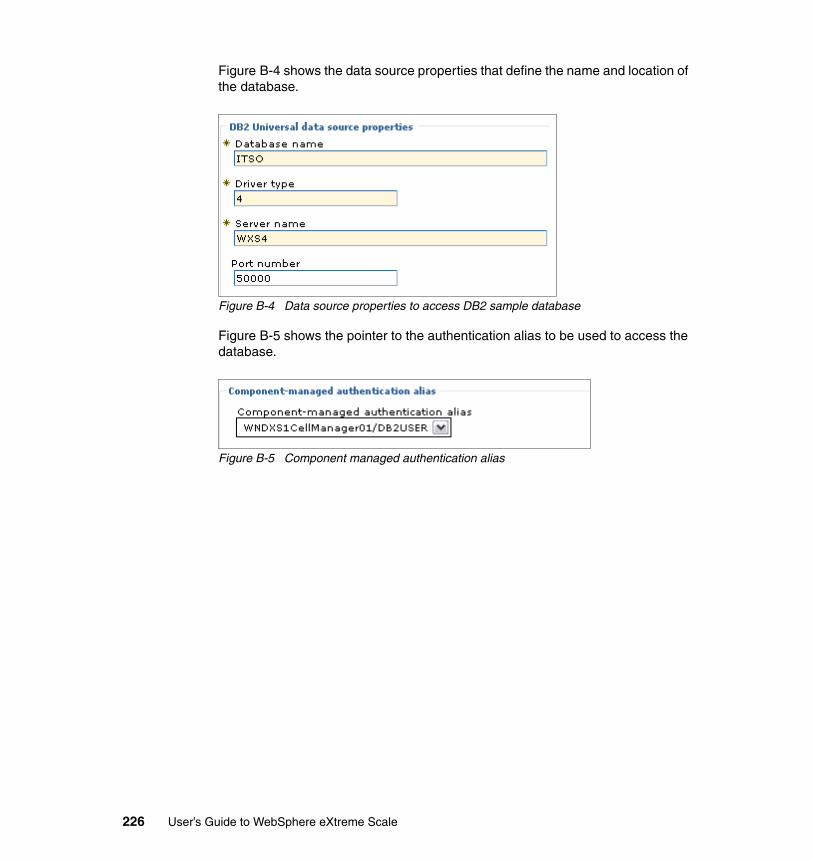
Figure B-4 shows the data source properties that define the name and location of the database.
Figure B-4 Data source properties to access DB2 sample database
Figure B-5 shows the pointer to the authentication alias to be used to access the database.
Figure B-5 Component managed authentication alias
226 User’s Guide to WebSphere eXtreme Scale
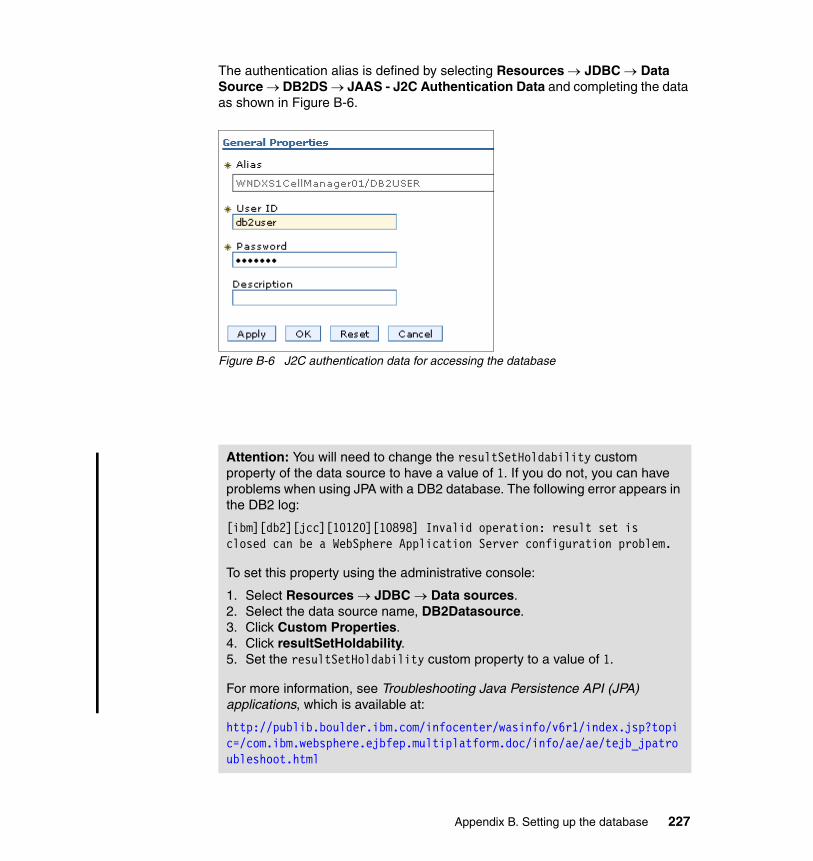
The authentication alias is defined by selecting Resources → JDBC → Data Source → DB2DS → JAAS - J2C Authentication Data and completing the data as shown in Figure B-6.
Figure B-6 J2C authentication data for accessing the database
Attention: You will need to change the resultSetHoldability custom property of the data source to have a value of 1. If you do not, you can have problems when using JPA with a DB2 database. The following error appears in the DB2 log:
[ibm][db2][jcc][10120][10898] Invalid operation: result set is closed can be a WebSphere Application Server configuration problem.
To set this property using the administrative console:
1. Select Resources → JDBC → Data sources.2. Select the data source name, DB2Datasource.3. Click Custom Properties.4. Click resultSetHoldability.5. Set the resultSetHoldability custom property to a value of 1.
For more information, see Troubleshooting Java Persistence API (JPA) applications, which is available at:
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/index.jsp?topic=/com.ibm.websphere.ejbfep.multiplatform.doc/info/ae/ae/tejb_jpatroubleshoot.html
Appendix B. Setting up the database 227

228 User’s Guide to WebSphere eXtreme Scale

Appendix C. Additional material
This book refers to additional material that you can download from the Internet as described in this appendix.
Locating the Web material
The Web material that is associated with this book is available in softcopy on the Internet from the IBM Redbooks Web server. Point your Web browser at:
ftp://www.redbooks.ibm.com/redbooks/SG247683
Alternatively, you can go to the IBM Redbooks Web site at:
ibm.com/redbooks
Select Additional materials and open the directory that corresponds with the IBM Redbooks form number, SG247683.
C
© Copyright IBM Corp. 2008. All rights reserved. 229

Using the Web material
The additional Web material that accompanies this book includes the following files:
File name Description
MySessionTest.ear Sample application used in Chapter 8, “Extended HTTP Session Management with WebSphere eXtreme Scale” on page 187.
ITSOSideCache.zip Sample application used in Chapter 6, “eXtreme Scale in a stand-alone environment” on page 123
ITSOSampleClient.ear Sample application used in Chapter 5, “eXtreme Scale in a Network Deployment environment” on page 87.
ITSOSampleServer.ear Sample application used in Chapter 5, “eXtreme Scale in a Network Deployment environment” on page 87.
How to use the Web material
The sample EAR files used during this project are provided for informational purposes. You can use these to browse the structure and code included in the sample applications. These were tested using Rational Application Developer 6.1.01.
To browse the samples, create a subdirectory (folder) on your workstation, and decompress the contents of the Web material zipped file into this folder.
Import the EAR files into a Rational Application Developer workspace and use the instructions in Appendix A, “Loading and running the sample application” on page 215 to add the appropriate JAR files from WebSphere eXtreme Scale to the project.
230 User’s Guide to WebSphere eXtreme Scale

Related publications
We consider the publications that we list in this section particularly suitable for a more detailed discussion of the topics that we cover in this book.
IBM Redbooks publications
For information about ordering these publications, see “How to get Redbooks publications” on page 233. Note that some of the documents referenced here might be available in softcopy only.
� WebSphere Application Server V6 Scalability and Performance Handbook, SG24-6392
� WebSphere Application Server V6.1: System Management and Configuration, SG24-7304
Online resources
These Web sites are also relevant as further information sources:
� WebSphere eXtreme Scale product home page
http://www.ibm.com/software/webservers/appserv/extremescale
� WebSphere eXtreme Scale wiki documentation
http://www-128.ibm.com/developerworks/wikis/x/_IMF
� WebSphere eXtreme Scale Information Center
http://publib.boulder.ibm.com/infocenter/wxdinfo/v6r1/topic/com.ibm.websphere.dataint.doc/info/welcome_61_dgxd.html
� WebSphere Application Server documentation
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/topic/com.ibm.websphere.nd.doc/info/welcome_nd.html
� WebSphere Application Server V6.1 Feature Pack for EJB 3.0 documentation
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r1/topic/com.ibm.websphere.ejbfep.multiplatform.doc/info/welcome_nd.html
© Copyright IBM Corp. 2008. All rights reserved. 231

� Utility: Feature Pack for EJB 3.0 for WebSphere Application Server V6.1
http://www-01.ibm.com/support/docview.wss?rs=177&uid=swg21287579
� Highly scalable grid-style computing and data processing with the ObjectGrid component of WebSphere Extended Deployment
http://www.ibm.com/developerworks/websphere/techjournal/0712_marshall/0712_marshall.html
� IBM DB2 Database for Linux®, UNIX, and Windows Information Center
http://publib.boulder.ibm.com/infocenter/db2luw/v9r5/topic/com.ibm.db2.luw.doc/welcome.html
� WebSphere Application Server Support
http://www.ibm.com/software/webservers/appserv/was/support/
� WebSphere Extended Deployment Support
http://www-01.ibm.com/software/webservers/appserv/extend/support/download.html
� Update Installer for WebSphere Application Server V6.1 and V6.0.2.21 (onward)
http://www-01.ibm.com/support/docview.wss?rs=180&uid=swg24012718
� 6.1.0.3: WebSphere Extended Deployment V6.1 Fix Pack 3 for multi-platforms
http://www-01.ibm.com/support/docview.wss?rs=3023&uid=swg24018893
� 6.1.0.17: WebSphere Application Server V6.1 Fix Pack 17 for Windows
http://www-01.ibm.com/support/docview.wss?rs=180&uid=swg24019101
� IBM Installation Factory for WebSphere Application Server V6.0 releases
http://www-1.ibm.com/support/docview.wss?rs=180&uid=swg24009108
� IBM WebSphere Developer Technical Journal: Introducing the WebSphere Integration Reference Architecture
http://www.ibm.com/developerworks/websphere/techjournal/0508_simmons/0508_simmons.html
� Apache OpenJPA
http://openjpa.apache.org/
� Hibernate
http://www.hibernate.org/
� Service Oriented Architecture
http://www.ibm.com/software/solutions/soa/
232 User’s Guide to WebSphere eXtreme Scale

� Java Object Serialization Specification version 1.5.0
http://java.sun.com/j2se/1.5.0/docs/guide/serialization/spec/serialTOC.html
� java.io Interface Serializable
http://java.sun.com/j2se/1.5.0/docs/api/java/io/Serializable.html
How to get Redbooks publications
You can search for, view, or download Redbooks, Redpapers, Technotes, draft publications and Additional materials, as well as order hardcopy Redbooks, at this Web site:
ibm.com/redbooks
Help from IBM
IBM Support and downloads
ibm.com/support
IBM Global Services
ibm.com/services
Related publications 233

234 User’s Guide to WebSphere eXtreme Scale

(0.2”spine)0.17”<
->0.473”
90<->
249 pages
User’s Guide to WebSphere eXtrem
e Scale



®
SG24-7683-00 0738432091
INTERNATIONAL TECHNICALSUPPORTORGANIZATION
BUILDING TECHNICALINFORMATION BASED ONPRACTICAL EXPERIENCE
IBM Redbooks are developed by the IBM International Technical Support Organization. Experts from IBM, Customers and Partners from around the world create timely technical information based on realistic scenarios. Specific recommendations are provided to help you implement IT solutions more effectively in your environment.
For more information:ibm.com/redbooks
®
User’s Guide to WebSphere eXtreme Scale
Topology design and sizing
Application scenarios
JPA for data access
WebSphere eXtreme Scale provides a solution to scalability issues through caching and grid technology. It provides an enhanced quality of service in high performance computing environments.
This IBM Redbooks publication, User’s Guide to WebSphere eXtreme Scale, introduces WebSphere eXtreme Scale V6.1 and shows how to set up and use an eXtreme Scale environment. It begins with a discussion of the issues that would lead you to an eXtreme Scale solution. It then describes the architecture of eXtreme Scale to help you understand how the product works. It provides information about potential grid topologies, the APIs used by applications to access the grid, and application scenarios that explain how to effectively use the grid.
This book is intended for architects and implementers who want to implement WebSphere eXtreme Scale.
Back cover