utilizando nosql para big data com dynamodb
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Felipe Garcia, Arquiteto de Soluções AWS
Junho 2016
Utilizando NoSQL para Big Data com
DynamoDBUma visão ”mão na massa” em como utilizar DynamoDb
para workloads Big Data

O Que Esperar Desta Sessão
• Foco no “como” e não “o que”
• Vamos ver implementações funcionais de algumas
arquiteturas de Big Data
• Aprenda como os serviços AWS abstraem muita
complexidade de arquiteturas Big Data sem sacrificar
poder e escala
• Demonstrar como combinações de serviços da AWS
podem ser utilizados para criar sistemas ricos para
análise de dados

O que é ”Big Data”?
• Como muitos jargões de tecnologia, “Big Data” tende
em ser definido de diferentes maneiras
• A maioria das definições, mencionará 2 dos 3Vs de Big
Data
• Volume
• Velocidade

Características de Big Data
• A quantidade de dados está aumentando em uma velocidade rápida
• Dados brutos de uma vasta fonte de dados estão cada vez mais sendo usados para
responder perguntas de negócio
• Arquivos de Log
• Como as suas aplicaçnoes estão sendo usadas e quem está usando
elas?
• Monitoramento de desempenho de aplicações
• Qual o impacto do desempenho de minhas aplicações em meu
negócio?
• Métricas de aplicação
• Como os usuários responderão a uma nova funcionalidade?
• Segurança
• Quem tem acesso a minha infraestrutura, o que eles tem aesso, e como
eles estão acessando? Alguma ameaça?

Características de Big Data
• O crescimento em volume de dados significa que o fluxo
de dados está se movendo em uma taxa muito maior:
• MB/s é normal
• GB/s está ficando cada vez mais comum
• Número de usuários conectados está crescendo em
uma taxa impressionante:
• Estima-se 75 bilhões de dispositivos conectados em 2020
• 105 ou 106 transações por segundo não são incomuns
em aplicações de Big Data
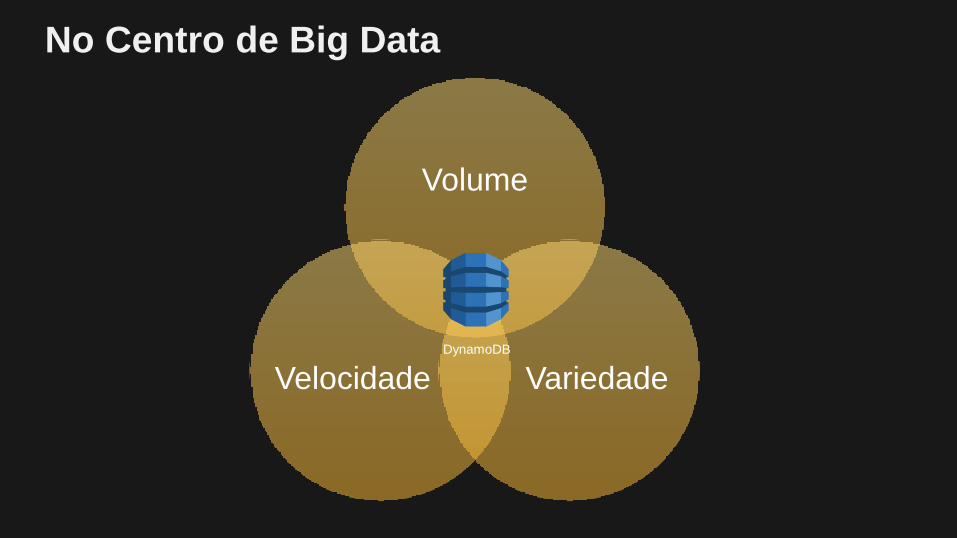
No Centro de Big Data
Volume
VariedadeVelocidadeDynamoDB

Processando Dados Transacionais
• DynamoDb é excelente para processamento
transacional
• Alta concorrência
• Consistência forte
• Atualização atômica de itens únicos
• Atualização condicional para de-duplicação e concorrência
otimista
• Suporta schemas chave/valor e JSON
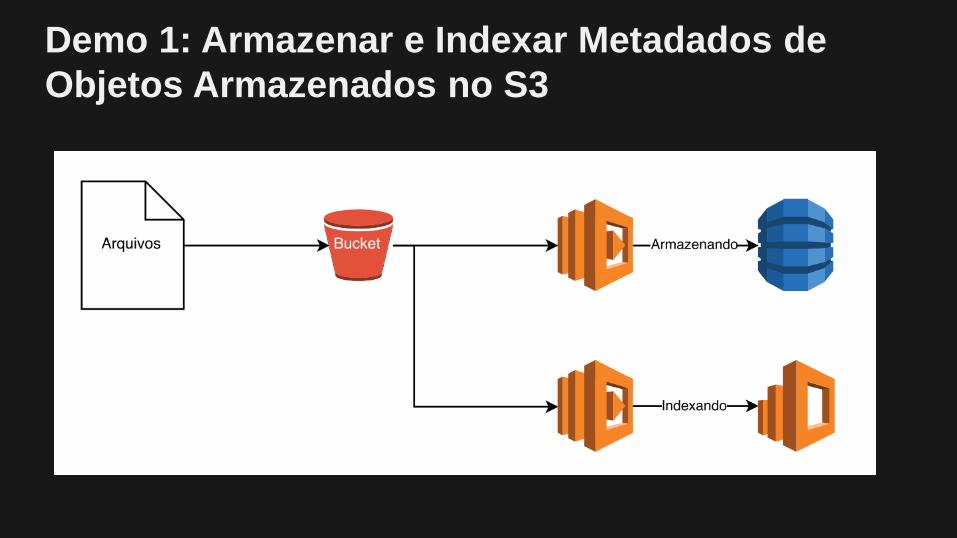
Demo 1: Armazenar e Indexar Metadados de
Objetos Armazenados no S3

Demo 1: Caso de Uso
Temos um grande número de arquivos de áudio
armazenandos no S3, e gostaríamos de torná-los
pesquisáveis
• Usar DynamoDb como base de dados primária dos
metadados
• Indexar e pesquisar o metadado usando Elasticsearch

Demo 1: Passos Para Implementar
1. Criar uma função Lambda que lê o metadado da tag
ID3 e insere em uma tabela no DynamoDb
2. Habilitar notificações no Bucket do S3 que armazena
os arquivos de áudio
3. Habilitar Streams na tabela do DynamoDb
4. Criar uma função Lambda que lê o metadado do
DynamoDb e indexa no Elasticsearch
5. Habilitar a Stream como origem de evento na função
Lambda

Demo 1: Principais Lições
1. DynamoDb + Elasticsearch = Banco de dados durável,
escalável, altamente disponível com funcionalidades
ricas de pesquisa
2. Utilize funções Lambda para responder a eventos do
S3, e Streams do DynamoDb sem ter que gerenciar
infraestrutura

Demo 2: Executar consultas em múltiplas
fontes de dados usando DynamoDb e EMR
com Hive

Demo 2: Caso de Uso
Queremos enriquecer os metadados armazenados no
DynamoDb com dados adicionais da fonte de dados
Million Song:
• Fonte de dados Million Song está armazenada em
formato texto
• Metadados da tag ID3 estão armazenados no
DynamoDb
• Usar Amazon EMR com Hive para unir as duas fontes
de dados em uma única consulta

Demo 2: Passos Para Implementar
1. Criar um cluster EMR com Hive
2. Criar uma tabela extarna Hive utilizando
DynamoDbStorageHandler
3. Criear uma tabela externa Hive utilizando a localização
dos arquivos de texto contendo os metadados do
projeto Million Song
4. Criar e executar a consulta Hive que faz a junção das
duas tabelas externas e grava os resultados no S3
5. Carregar os resultados do S3 no DynamoDb utilizando
Lambda

Demo 2: Principais Lições
1. Usar o Amazon EMR para rapidamente provisionar um
cluster Hadoop com Hive, e destruí-lo ao terminar os
processamentos
2. Uso de Hive com DynamoDb permite que itens nas
tabelas do DynamoDb sejam unidos e consultados com
uma grande variedade de fontes de dados
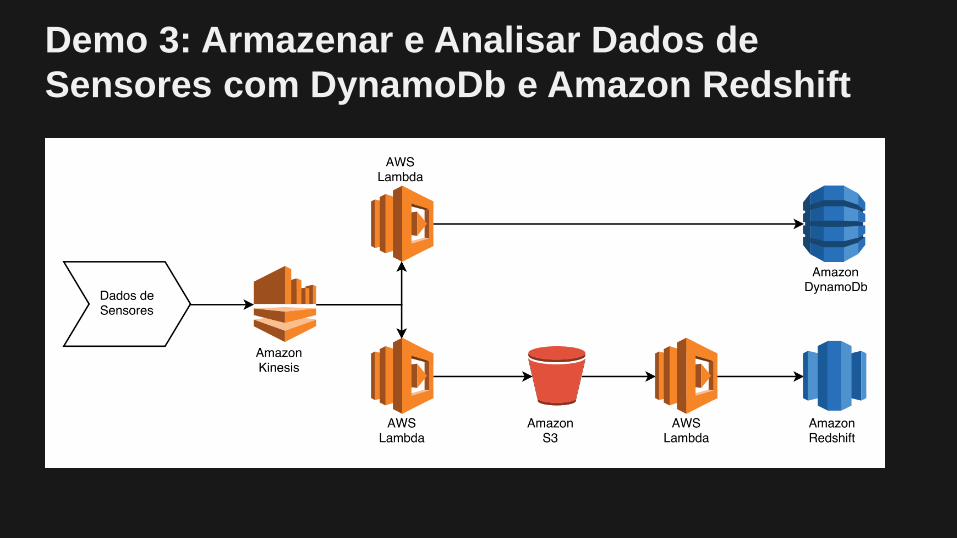
Demo 3: Armazenar e Analisar Dados de
Sensores com DynamoDb e Amazon Redshift

Demo 3: Caso de Uso
Um grande número de sensores estão realizando leituras
em intervalos regulares. Você precisa agregar os dados de
cada leitura em um data warehouse para análise:
• Usar Amazon Kinesis para ingerir novos dados brutos
• Armazenar leituras dos sensores no DynamoDb para
acesso rápido e criar dashboards em tempo real
• Carregar os dados do Amazon S3 no Amazon Redshift
utilizando AWS Lambda

Demo 3: Passos Para Implementar
1. Criar duas funções Lambda para ler dados da Stream
do Amazon Kinesis
2. Habilitar a Stream do Amazon Kinesis com uma origem
de eventos para cada função Lambda
3. Em uma função Lambda, grave os dados no
DynamoDb
4. Na outra função Lambda, grave os dados no S3
5. Use o projeto aws-lambda-redshift-loader para carregar
os dados do S3 dentro do Redshift

Demo 3: Principais Lições
1. Kinesis + Lambda + DynamoDb = Solução escalável,
durável e altamente disponível para ingestão de dados
de sensores com sobrecarga operacional baixissíma
2. DynamoDb é ideal para consultas de quase tempo real
de dados recentes dos sensores
3. Redshift é ideal para análises mais profundas de dados
dos sensores abrangendo períodos mais longos e
grandes quantidades de registros
4. Usar Lambda para carregar dados no Redshift fornece
uma maneira de executar ETL em intervalos frequentes

Sumário
• A versatilidade do DynamoDb faz com que ele seja um
componente importante em muitas arquiteturas de Big
Data
• Soluções de “Big Data” geralmente envolvem diferentes
ferramentas para armazenar, processar e analisar
• O ecosistema da AWS oferece um conjunto de serviços
ricos e poderosos que tornam possível a construção de
arquiteturas de Big data escaláveis e duráveis com
facilidade

Obrigado!