warp processors frank vahid (task leader) department of computer science and engineering university...
Post on 19-Dec-2015
218 views
TRANSCRIPT

Warp Processors
Frank Vahid (Task Leader)Department of Computer Science and Engineering
University of California, RiversideAssociate Director, Center for Embedded Computer Systems, UC Irvine
Task ID: 1331.001 July 2005 – June 2008
Ph.D. students: Greg Stitt Ph.D. expected June 2007Ann Gordon-Ross Ph.D. expected June 2007
David Sheldon Ph.D. expected 2009Ryan Mannion Ph.D. expected 2009Scott Sirowy Ph.D. expected 2010
Industrial Liaisons: Brian W. Einloth, Motorola
Serge Rutman, Dave Clark, Darshan Patra, IntelJeff Welser, Scott Lekuch, IBM

Frank Vahid, UCR2
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (with
Freescale) Consider desktop/server domains (with IBM)

Frank Vahid, UCR3
Microprocessors plus FPGAs
Xilinx Virtex II Pro. Source: Xilinx Altera Excalibur. Source: Altera
Cray XD1. Source: FPGA journal, Apr’05
Speedups of 10x-1000x Embedded, desktop, and
supercomputing More platforms w/ uP
and FPGA Xilinx, Altera, … Cray, SGI Mitrionics IBM Cell (research)

Frank Vahid, UCR4
“Traditional” Compilation for uP/FPGAs
Specialized language or compiler
SystemC, NapaC, HandelC,
Spark, ROCCC, CatapultC, Streams-C, DEFACTO, …
Commercial success still limited
Sw developers reluctant to change languages/tools
But still very promising
Libraries/Object Code
Libraries/Object Code
Updated BinaryHigh-level Code
DecompilationSynthesis
BitstreamBitstream
uP FPGA
Linker
HardwareHardwareSoftwareSoftware
Non-Standard Software Tool Flow
Updated BinarySpecialized Language
DecompilationSpecialized Compiler

Frank Vahid, UCR5
Warp Processing – “Invisible” Synthesis
Libraries/Object Code
Libraries/Object Code
Updated BinaryHigh-Level Code
DecompilationSynthesis
BitstreamBitstream
uP FPGA
Linker
HardwareHardwareSoftwareSoftware
2002 – Sought to make synthesis more “invisible” Began “Synthesis
from Binaries” project
DecompilationSynthesis
DecompilationCompiler
Updated BinaryHigh-level CodeLibraries/
Object Code
Libraries/Object Code
Updated BinarySoftware Binary
HardwareHardwareSoftwareSoftware
Move compilation before synthesis
Standard Software Tool Flow

Frank Vahid, UCR6
Warp Processing – Dynamic Synthesis
Libraries/Object Code
Libraries/Object Code
Updated BinaryHigh-Level Code
DecompilationSynthesis
BitstreamBitstream
uP FPGA
Linker
HardwareHardwareSoftwareSoftwareDecompilationSynthesis
DecompilationCompiler
Updated BinaryHigh-level CodeLibraries/
Object Code
Libraries/Object Code
Updated BinarySoftware Binary
HardwareHardwareSoftwareSoftware
Obtained circuits were competitive
2003: Runtime? Like binary translation
(x86 to VLIW), more aggressive
Benefits Language/tool
independent Library code OK Portable binaries Dynamic optimizations
FPGA becomes transparent performance hardware, like memory
Warp processor looks like standard uP but invisibly synthesizes hardware
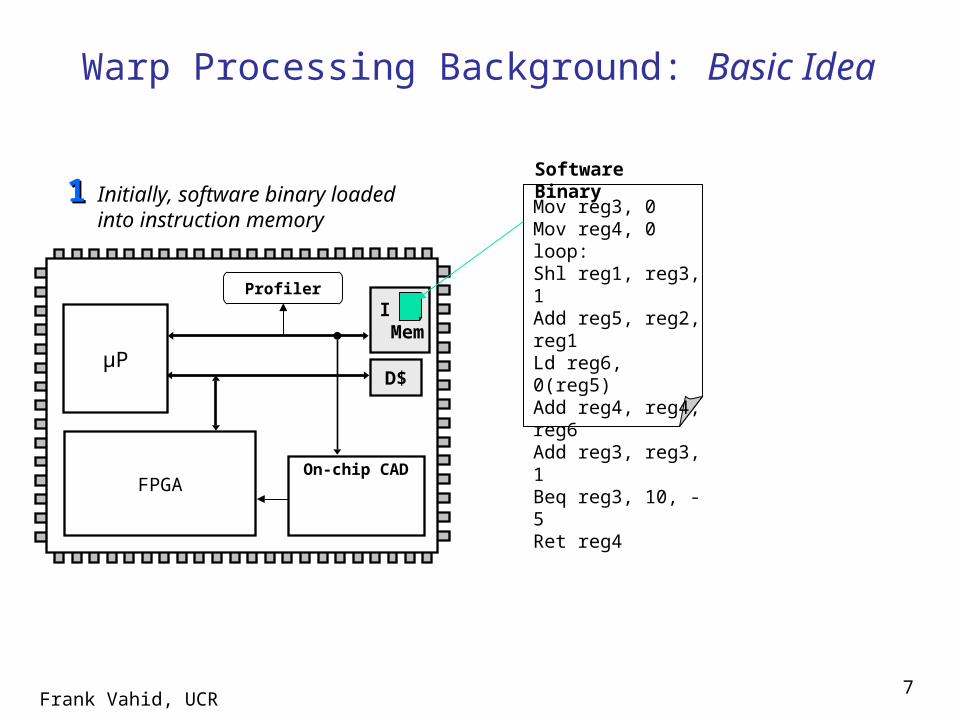
Frank Vahid, UCR7
µP
FPGAOn-chip CAD
Warp Processing Background: Basic Idea
Profiler
Initially, software binary loaded into instruction memory
11
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary

Frank Vahid, UCR8
µP
FPGAOn-chip CAD
Warp Processing Background: Basic Idea
ProfilerI Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryMicroprocessor executes
instructions in software binary
22
Time EnergyµP

Frank Vahid, UCR9
µP
FPGAOn-chip CAD
Warp Processing Background: Basic Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryProfiler monitors instructions
and detects critical regions in binary
33
Time Energy
Profiler
add
add
add
add
add
add
add
add
add
add
beq
beq
beq
beq
beq
beq
beq
beq
beq
beq
Critical Loop Detected
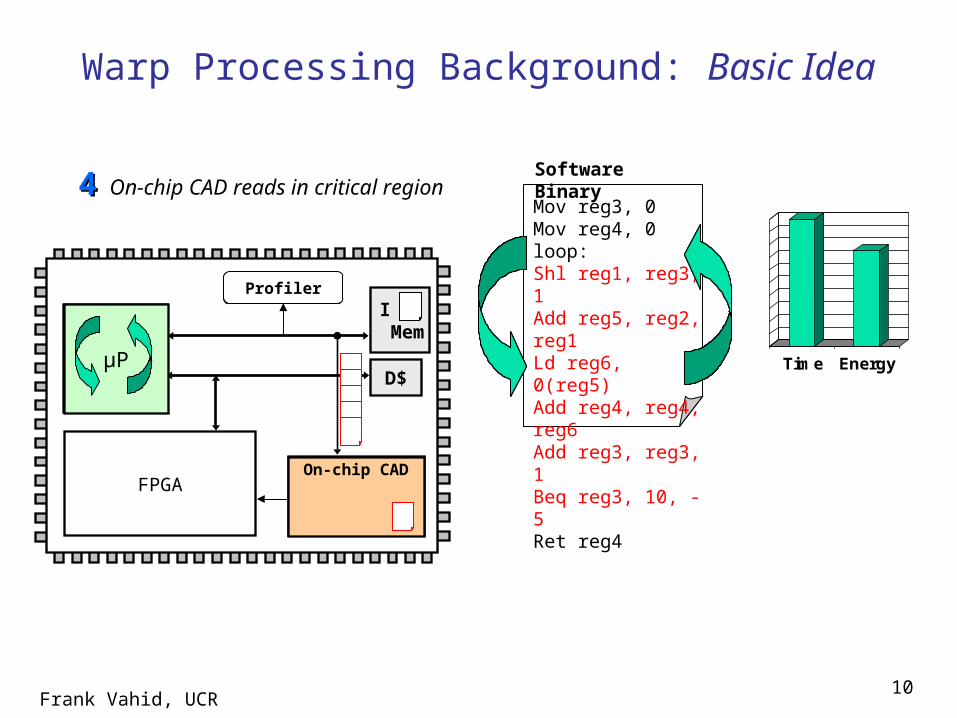
Frank Vahid, UCR10
µP
FPGAOn-chip CAD
Warp Processing Background: Basic Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD reads in critical
region44
Time Energy
Profiler
On-chip CAD

Frank Vahid, UCR11
µP
FPGADynamic Part. Module (DPM)
Warp Processing Background: Basic Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD converts critical region
into control data flow graph (CDFG)55
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
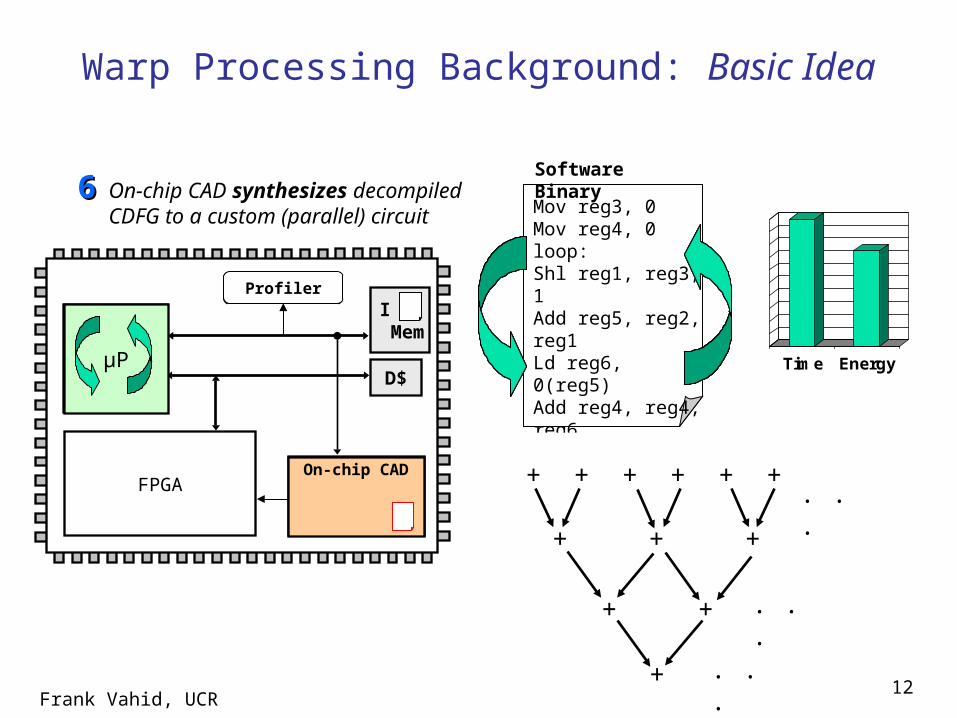
Frank Vahid, UCR12
µP
FPGADynamic Part. Module (DPM)
Warp Processing Background: Basic Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD synthesizes
decompiled CDFG to a custom (parallel) circuit
66
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .

Frank Vahid, UCR13
µP
FPGADynamic Part. Module (DPM)
Warp Processing Background: Basic Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD maps circuit onto
FPGA77
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA
Frank Vahid, UCR14
µP
FPGADynamic Part. Module (DPM)
Warp Processing Background: Basic Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary88
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA
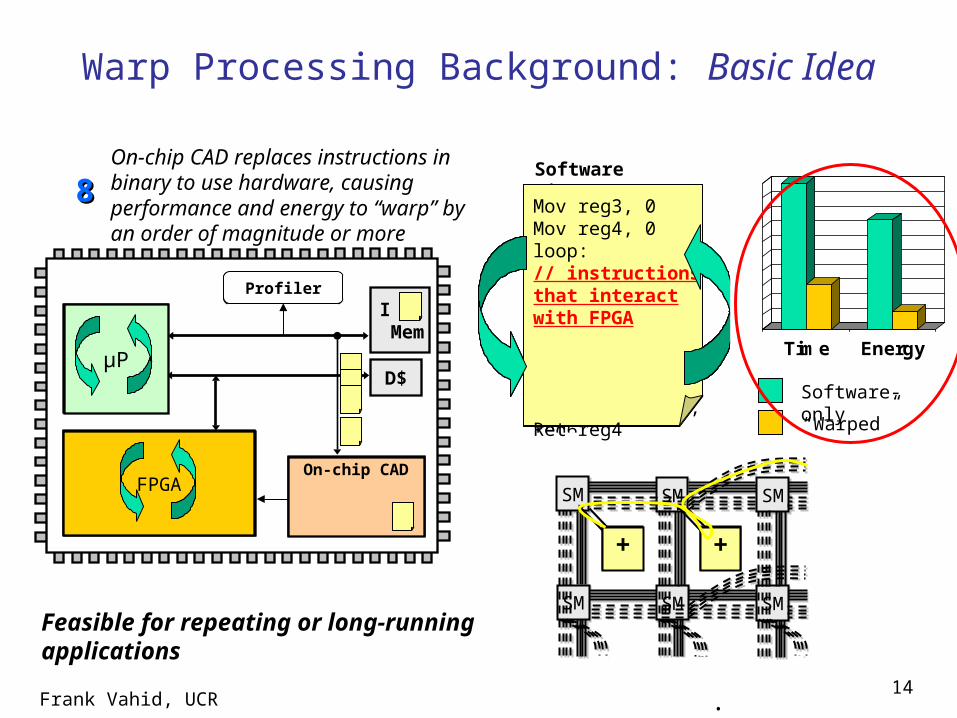
On-chip CAD replaces instructions in binary to use hardware, causing performance and energy to “warp” by an order of magnitude or more
Mov reg3, 0Mov reg4, 0loop:// instructions that interact with FPGA
Ret reg4
FPGA
Time Energy
Software-only“Warped”
Feasible for repeating or long-running applications

Frank Vahid, UCR15
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (with
Freescale) Consider desktop/server domains (with IBM)

Frank Vahid, UCR16
Synthesis from Binaries can be Surprisingly Competitive
0123456789
101112131415
Spee
dup
From C source
From binary
Only small difference in speedup
With aggressive decompilation Previous techniques, plus newly-created ones

Frank Vahid, UCR17
Decompilation is Effective Even with High Compiler-Optimization Levels
Average Speedup of 10 Examples
0
5
10
15
20
25
30
Publication: New Decompilation Techniques for Binary-level Co-processor Generation. G. Stitt, F. Vahid. IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Nov. 2005.
Do compiler optimizations generate binaries harder to effectively decompile?
(Surprisingly) found opposite – optimized code even better

Frank Vahid, UCR18
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (with
Freescale) Consider desktop/server domains (with IBM)

Frank Vahid, UCR19
Several Month Study with Freescale
Optimized H.264 Proprietary code
Different from reference code 10x faster 16,000 lines ~90% time in 45
distinct functions rather than 2-3
Function Name Instr %TimeCumulative SpeedupMotionComp_00 33 6.76% 1.1InvTransform4x4 63 12.53% 1.1FindHorizontalBS 47 16.68% 1.2GetBits 51 20.78% 1.3FindVerticalBS 44 24.70% 1.3MotionCompChromaFullXFullY24 28.61% 1.4FilterHorizontalLuma 557 32.52% 1.5FilterVerticalLuma 481 35.84% 1.6FilterHorizontalChroma133 38.96% 1.6CombineCoefsZerosInvQuantScan69 42.02% 1.7memset 20 44.87% 1.8MotionCompensate 167 47.66% 1.9FilterVerticalChroma 121 50.32% 2.0MotionCompChromaFracXFracY48 52.98% 2.1ReadLeadingZerosAndOne56 55.58% 2.3DecodeCoeffTokenNormal93 57.54% 2.4DeblockingFilterLumaRow272 59.42% 2.5DecodeZeros 79 61.29% 2.6MotionComp_23 279 62.96% 2.7DecodeBlockCoefLevels56 64.57% 2.8MotionComp_21 281 66.17% 3.0FindBoundaryStrengthPMB44 67.66% 3.1
Frank Vahid, UCR20
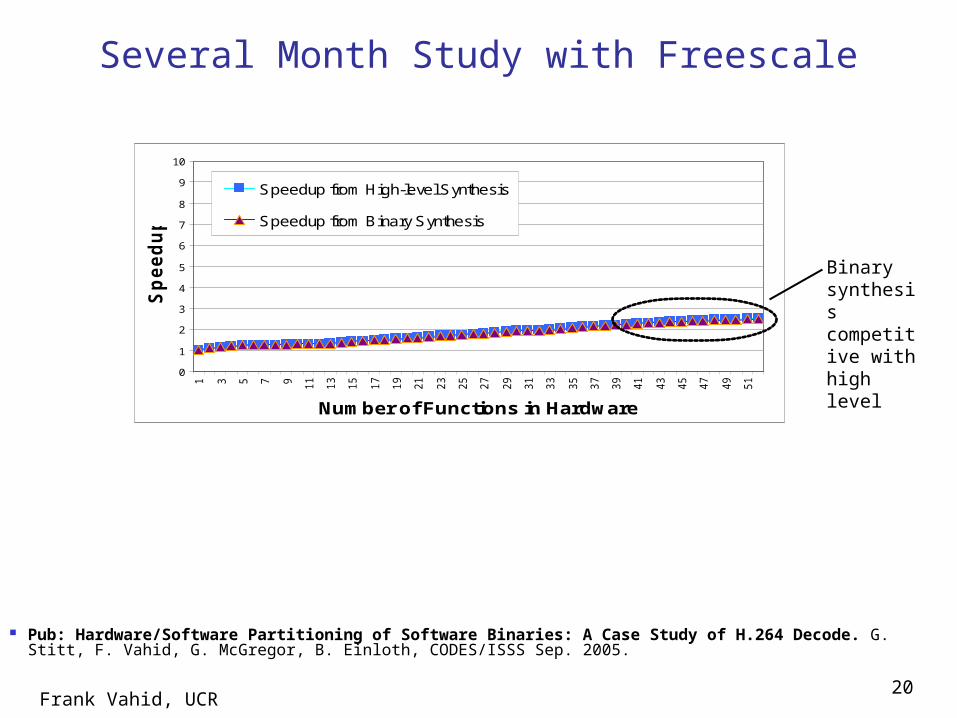
Several Month Study with Freescale
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11
13
15
17
19
21
23
25
27
29
31
33
35
37
39
41
43
45
47
49
51
Number of Functions in Hardware
Sp
ee
du
p
Speedup from High-level Synthesis
Speedup from Binary Synthesis
Binary synthesis competitive with high level
Pub: Hardware/Software Partitioning of Software Binaries: A Case Study of H.264 Decode. G. Stitt, F. Vahid, G. McGregor, B. Einloth, CODES/ISSS Sep. 2005.

Frank Vahid, UCR21
However – Ideal Speedup Much Larger
How bring both approaches closer to ideal? Unanticipated sub-task
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11
13
15
17
19
21
23
25
27
29
31
33
35
37
39
41
43
45
47
49
51
Number of Functions in Hardware
Sp
ee
du
p
Speedup from High-level Synthesis
Speedup from Binary Synthesis
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11
13
15
17
19
21
23
25
27
29
31
33
35
37
39
41
43
45
47
49
51
Number of Functions in Hardware
Sp
ee
du
pIdeal Speedup (Zero-time Hw Execution)
Speedup from High-Level Synthesis
Speedup from Binary Synthesis
Large difference between ideal speedup and actual speedup

Frank Vahid, UCR22
C-Level Coding Guidelines
Are there simple coding guidelines that improve synthesized hardware?
Orthogonal to synthesis from high-level or binary issue
Studied dozens of embedded applications and identified bottlenecks
Memory bandwidth Use of pointers Software algorithms
Defined ~10 basic guidelines
(e.g., avoid function pointers, use constants, …)
573 1616 842
0123456789
10
g3fax mpeg2 jpeg brev fir crc
Sp
eed
up
Sw
Hw/sw with original code
Hw/sw with guidelines
-30%
-20%
-10%
0%
10%
20%
30%
Performance Overhead
Size Overhead
0
2
4
6
8
101 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
Number of Functions in Hardware
Sp
eed
up
Ideal Speedup (Zero-time Hw Execution)Speedup After Rewrite (High-level)Speedup After Rewrite (Binary)Speedup from High-Level SynthesisSpeedup from Binary Synthesis
Closer to ideal
Pub: A Code Refinement Methodology for Performance-Improved Synthesis from C . G. Stitt, F. Vahid, W. Najjar. IEEE/ACM Int. Conf. on Computer-Aided Design (ICCAD), Nov. 2006.

Frank Vahid, UCR23
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (with
Freescale) Consider desktop/server domains (with IBM)
Frank Vahid, UCR24
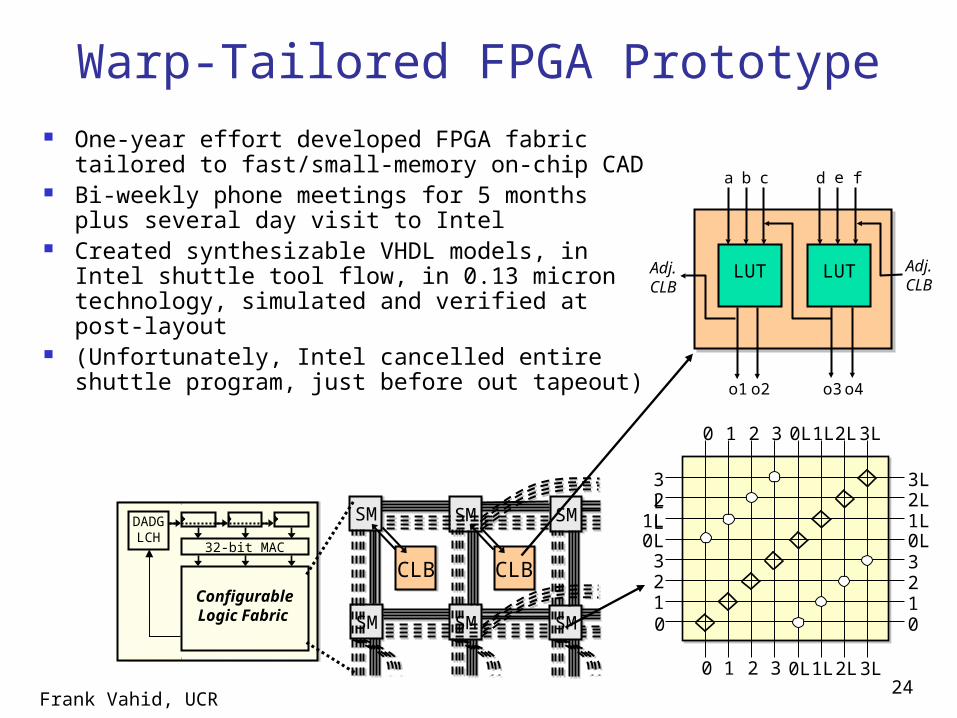
Warp-Tailored FPGA Prototype One-year effort developed FPGA fabric
tailored to fast/small-memory on-chip CAD Bi-weekly phone meetings for 5 months
plus several day visit to Intel Created synthesizable VHDL models, in
Intel shuttle tool flow, in 0.13 micron technology, simulated and verified at post-layout
(Unfortunately, Intel cancelled entire shuttle program, just before out tapeout)
DADGLCH
Configurable Logic Fabric
32-bit MAC
SM
CLB
SM
SM
SM
SM
SM
CLB
SM
CLB
SM
SM
SM
SM
SM
CLB
LUTLUT
a b c d e f
o1 o2 o3o4
Adj.CLB
Adj.CLB
0
0L
1
1L2L
2
3L
3
0123
0L1L2L
3L
0123
0L1L2L3L
0 1 2 3 0L1L2L3L

Frank Vahid, UCR25
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (with
Freescale) Consider desktop/server domains (with IBM)

Frank Vahid, UCR26
Smart Buffers
State-of-the-art FPGA compilers use several advanced methods e.g., ROCCC
Riverside Optimizing Compiler for Configurable Computing [Guo, Buyukkurt, Najjar, LCTES 2004]
SmartBuffer Compiler analyzes memory access
patterns Determines size of window and stride
Creates custom self-updating buffer, "pushes" data into datapath
Helps alleviate memory bottleneck problem
Smart Buffer
Block RAM
InputAddress
Generator
Datapath
Block RAM
OutputAddress
Generator
Task Trigge
rWrite Buffer

Frank Vahid, UCR27
Smart Buffers
A[0] A[1] A[2] A[3] A[4] A[5] A[6] A[7] A[8] ….
1st iteration window
2nd iteration window
3rd iteration window
Void fir() { for (int i=0; i < 50; i ++) { B[i] = C0 * A[i] + C1 *A[i+1] + C2 * A[i+2] + C3 * A[i+3]; }}
A[0] A[1] A[2] A[3]
A[1] A[2] A[3] A[4]
A[2] A[3] A[4] A[5]
Smart Buffer
Killed
Killed
*Elements in bold are read from memory
Etc.

Frank Vahid, UCR28
Recovering Arrays from Binaries
Arrays and memory access patterns needed Array recovery from binaries
Search loops for memory accesses with linear patterns
Other access patterns are possible but rare (e.g., array[i*i]) Array bounds determined from loop bounds and induction
variables

Frank Vahid, UCR29
Recovery of Arrays
+
Determine induction variable: reg3 Find array address calculations
Element size specified by shift or multiplication amount
Find base address from reg2 definition
Reg2 corresponds to array base address
Determine array bounds from loop bounds
for ( ) { reg3=0;reg3 < 10;reg3++
long array[10];
for (reg3=0; reg3 < 10; reg++)
reg4 += array[reg3];
<<
reg3
2
+
reg2
Memory Read
1
reg3
reg4
+
reg4
}
Frank Vahid, UCR30
Recovery of Arrays
i*element_size*width j*element_size
+
base
+
addr
for (i=0; i < 10; i++) {
for (j=0; j < 10; j++) {
}
}
i*element_size*width+base
j*element_size
+
addr
for (i=0; i < 10; i++) {
for (j=0; j < 10; j++) {
}
}
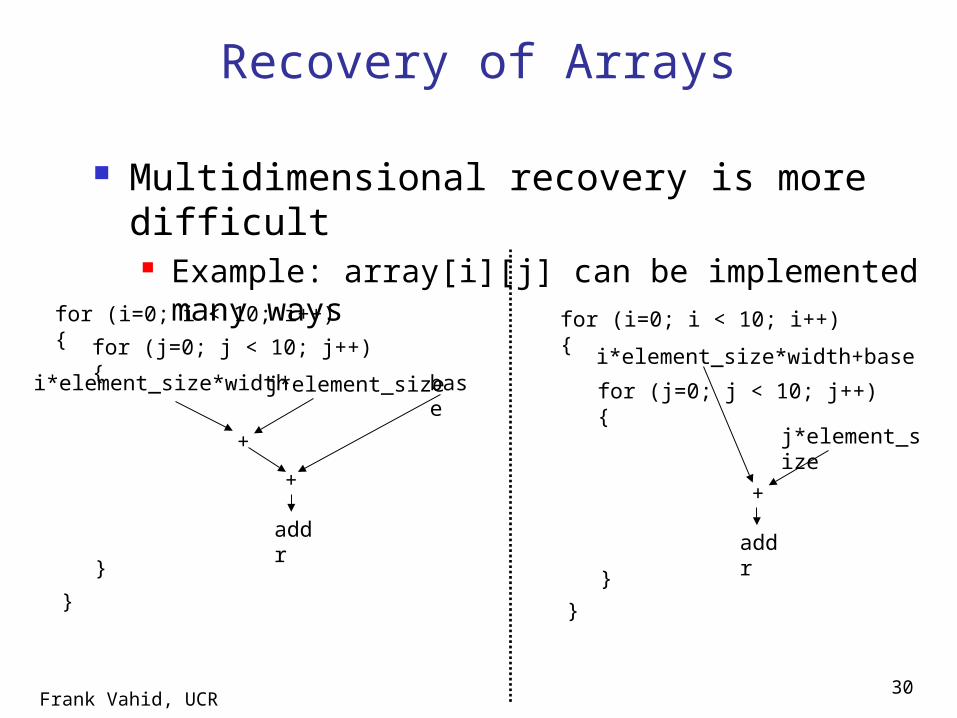
Multidimensional recovery is more difficult Example: array[i][j] can be implemented many
ways

Frank Vahid, UCR31
Recovery of Arrays
Multidimensional array recovery Use heuristics to find row major ordering
calculations Compilers can implement RMO in many ways
Dependent on the optimization potential of the application
Hard to check every possible way Check for common possibilities So far able to recover multidimensional arrays for all
but one example Success with dozens of benchmarks
Bounds of each array dimension determined from bounds of inner and outer loop
Frank Vahid, UCR32
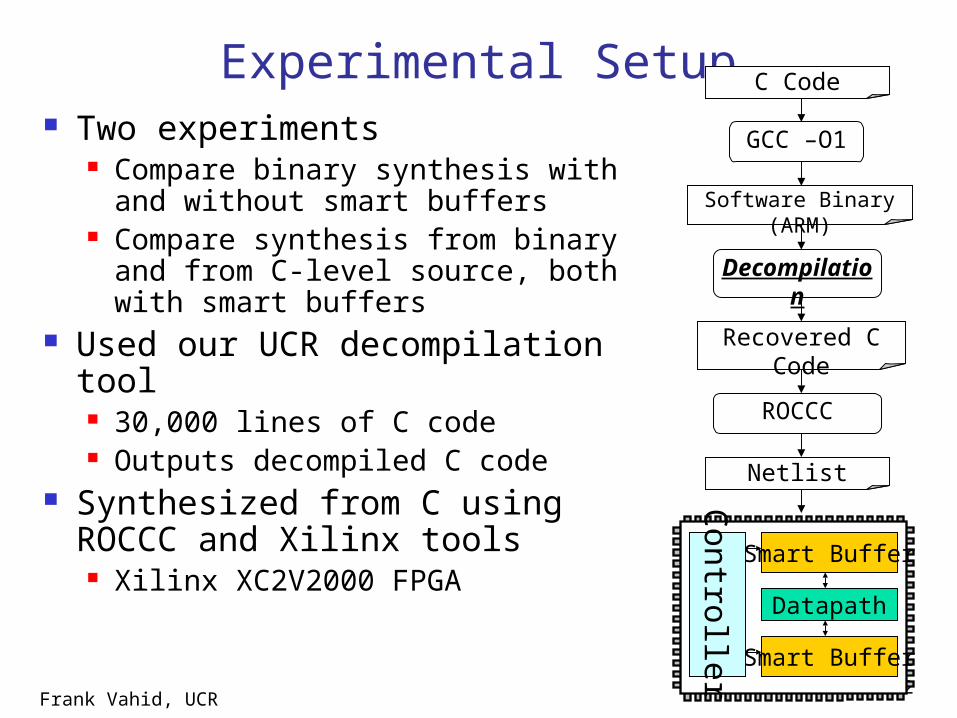
Experimental Setup Two experiments
Compare binary synthesis with and without smart buffers
Compare synthesis from binary and from C-level source, both with smart buffers
Used our UCR decompilation tool 30,000 lines of C code Outputs decompiled C code
Synthesized from C using ROCCC and Xilinx tools Xilinx XC2V2000 FPGA
Software Binary (ARM)
C Code
GCC –O1
Decompilation
Recovered C Code
ROCCC
Controller
Smart Buffer
Datapath
Smart Buffer
Netlist

Frank Vahid, UCR33
Binary Synthesis with and without SmartBuffer
Used examples from past ROCCC work SmartBuffer: Significant speedups
Shows criticality of memory bottleneck problem
Example Cycles Clock Time Cycles Clock Time Speedupbit_correlator 258 118 2.2 258 118 2.2 1.0fir 577 125 4.6 129 125 1.0 4.5udiv8 281 190 1.5 281 190 1.5 1.0prewitt 172086 123 1399.1 64516 123 524.5 2.7mf9 8194 57 143.0 258 57 4.5 31.8moravec 969264 66 14663.6 195072 66 2951.2 5.0
Avg: 7.6
W/O Smart Buffers With Smart Buffers

Frank Vahid, UCR34
Synthesis from Binary versus from Original C
From C vs. from binary – nearly same results One example even better (due to gcc optimization) Area overhead due to strength-reduced operators
and extra registers
Example Cycles Clock Time Area Cycles Clock Time Area %TimeImprovement %AreaOverhead
bit_correlator 258 118 2.19 15 258 118 2.19 15 0% 0%fir 129 125 1.03 359 129 125 1.03 371 0% 3%udiv8 281 190 1.48 398 281 190 1.48 398 0% 0%prewitt 64516 123 525 2690 64516 123 525 4250 0% 58%mf9 258 57 4.5 1048 258 57 4.5 1048 0% 0%moravec 195072 66 2951 680 195072 70 2791 676 -6% -1%
Avg: -1% 10%
Synthesis from C Code Synthesis from Binary
ROCCC gcc –O1, decompile, ROCCC
Pub: Techniques for Synthesizing Binaries to an Advanced Register/Memory Structure. G. Stitt, Z. Guo, F. Vahid, and W. Najjar. ACM/SIGDA Symp. on Field Programmable Gate Arrays (FPGA), Feb. 2005, pp. 118-124.

Frank Vahid, UCR35
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (w/
Freescale) Consider desktop/server domains (with IBM)

Frank Vahid, UCR36
Domain-Specific FPGA Question: To what extent can
customizing FPGA fabric impact delay and area?
Relevant for FPGA fabrics forming part of ASIC or SoC, for sub-circuits subject to change
Used VPR (Versatile Place & Route) for Xilinx Spartan-like fabrics
Varied LUT sizes, LUTs per CLB, and switch matrix parameters
Pseudo-exhaustive exploration on 9 MCNC circuit benchmarks
Pareto points show interesting delay/area tradeoffs
dsip
0.0000
100.0000
200.0000
300.0000
400.0000
500.0000
600.0000
700.0000
800.0000
0.0000 2.0000 4.0000 6.0000 8.0000
area
de
lay
SM
CLB
SM
SM
SM
SM
SM
CLB
SM
CLB
SM
SM
SM
SM
SM
CLB

Frank Vahid, UCR37
Domain-Specific FPGA Compared customized
fabric to best average fabric
Three experiments: Delay only, Area only, Delay*Area
Benefits understated – avg is for 9 benchmarks, not larger set for which off-the-shelf FPGA fabrics are designed
Delay – up to 50% gain, at cost of area
Area – up to 60% gain, plus delay benefits
Customized Delay versus Best Average Delay Fabric
0
0.5
1
1.5
2
2.5
C7552 bigkey clmb dsip mm30a mm4a s15850 s38417 s38584
Benchmarks
Delay
Area
Customized Area versus Best Average Area
0
0.2
0.4
0.6
0.8
1
1.2
C7552 bigkey clmb dsip mm30a mm4a s15850 s38417 s38584
Benchmarks
Delay
Area

Frank Vahid, UCR38
Task Description Warp processing background
Idea: Invisibly move binary regions from microprocessor to FPGA 10x speedups or more, energy gains too
Task– Mature warp technology Years 1/2
Automatic high-level construct recovery from binaries
In-depth case studies (with Freescale) Warp-tailored FPGA prototype (with Intel)
Year 2/3 Reduce memory bottleneck by using smart buffer Investigate domain-specific-FPGA concepts (with
Freescale) Consider desktop/server domains (with IBM)

Frank Vahid, UCR39
Consider Desktop/Server Domains
Investigated warp processing for SPEC benchmarks
But little speedup from hw/sw partitioning Due to data structures, file I/O, library functions, ...
Server benchmark Studied Apache server Too disk intensive, could not attain significant
speedups Multiprocessing benchmarks
Promising direction for warp processing
Frank Vahid, UCR40
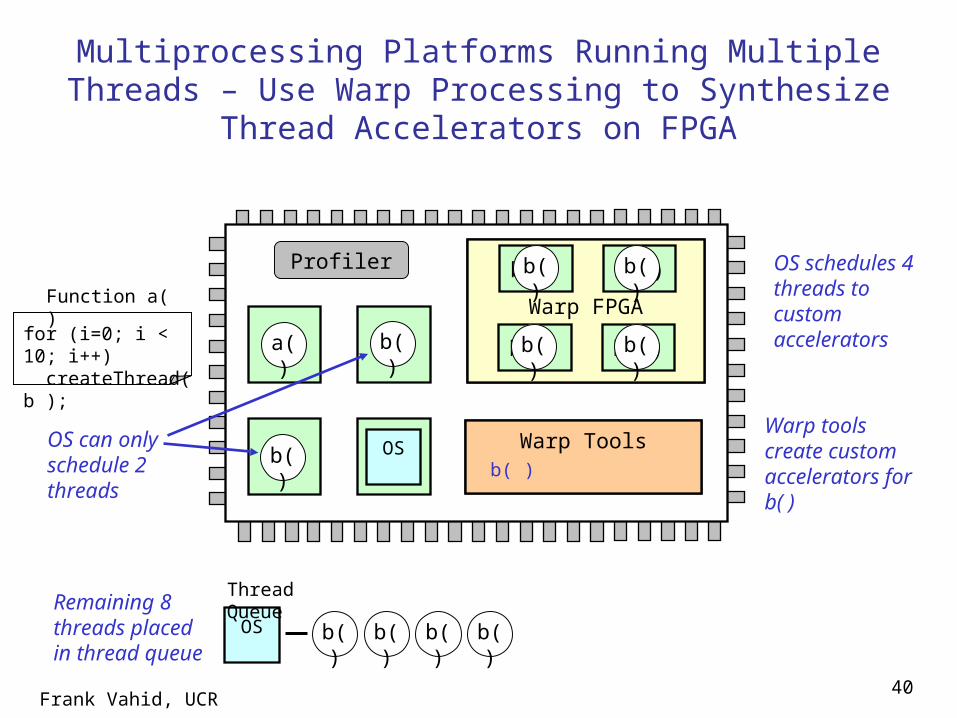
Multiprocessing Platforms Running Multiple Threads – Use Warp Processing to Synthesize Thread Accelerators
on FPGA
Profiler
µP
Warp Tools
Warp FPGA
µP
µP µPOS
a( ) b( )
b( )
for (i=0; i < 10; i++) createThread( b );
Function a( )
OS
Thread Queue
b( ) b( ) b( ) b( )b( ) b( )b( )b( )
Warp Toolsb( )
Warp FPGA
b( )
b( )
b( )
b( )b( )
b( ) b( )
b( )
OS can only schedule 2 threads
Remaining 8 threads placed in thread queue
Warp tools create custom accelerators for b( )
OS schedules 4 threads to custom accelerators
Frank Vahid, UCR41
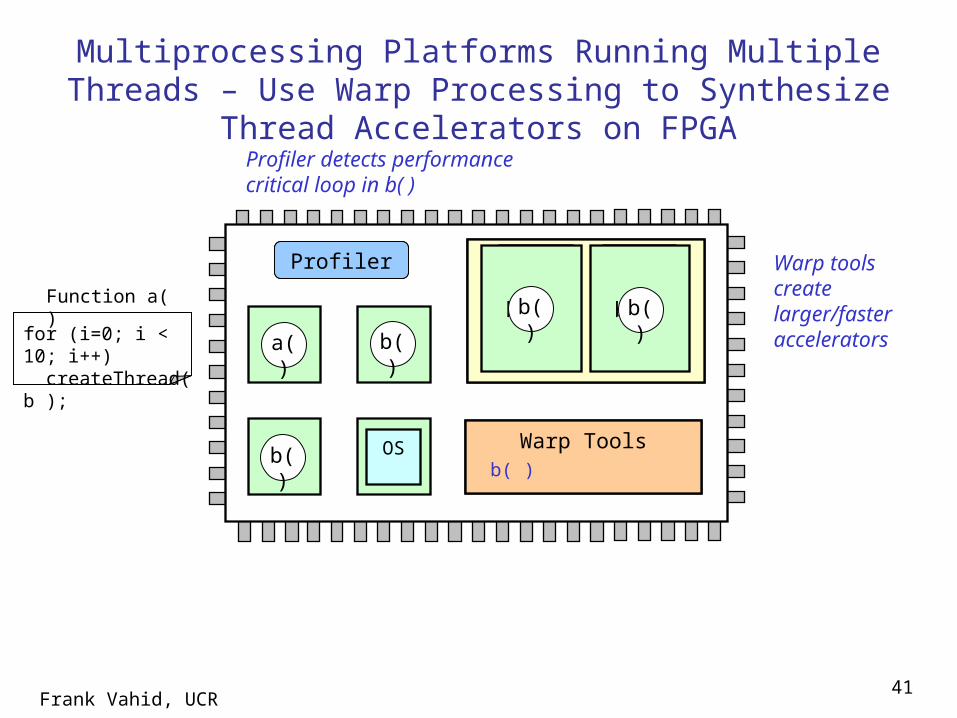
Multiprocessing Platforms Running Multiple Threads – Use Warp Processing to Synthesize Thread Accelerators
on FPGA
Profiler
µP
Warp Tools
Warp FPGA
µP
µP µPOS
a( ) b( )
b( )
for (i=0; i < 10; i++) createThread( b );
Function a( )
Warp Toolsb( )
Profiler
Profiler detects performance critical loop in b( )
Warp FPGA
b( )
b( )
b( )
b( ) Warp tools create larger/faster accelerators
b( )b( ) b( )b( )

Frank Vahid, UCR42
Warp Processing to Synthesize Thread Accelerators on FPGA
307.7 501.9
020406080
100120140
Spe
edup
(4-u
P) 4-uP
8-uP
16-uP
32-uP
64-uP
Warp
Multi-threaded warp 120x faster than 4-uP (ARM) system
Created simulation framework >10,000 lines of code Plus SimpleScalar
Apps must be long-running (e.g., scientific apps running for days) or repeating for synthesis times to be acceptable

Frank Vahid, UCR43
Multiprocessor Warp Processing – Additional Benefits due to Custom Communication
µP µP
µP µP
NoC – Network on a Chip provides communication between multiple cores
Problem: Best topology is application dependent
Bus Mesh
Bus Mesh
App1
App2

Frank Vahid, UCR44
Warp Processing – Custom Communication
FPGA
NoC – Network on a Chip provides communication between multiple cores
Problem: Best topology is application dependent
Bus Mesh
Bus Mesh
App1
App2
µP µP
µP µP
Warp processing can dynamically choose topology
FPGA
µP µP
µP µP
FPGA
µP µP
µP µP
Collaboration with Rakesh Kumar University of Illinois, Urbana-Champaign “Amoebic Computing”

Frank Vahid, UCR45
µP
Cache
Warp Processing Enables Expandable Logic Concept
RAM
Expandable RAM
uP
Performance
Profiler
µP
Cache
Warp Tools
DMA
FPGAFPGA
FPGA FPGA
RAM Expandable RAM – System detects RAM during start, improves performance invisibly
Expandable Logic – Warp tools detect amount of FPGA, invisibly adapt application to use less/more hardware.
Expandable Logic
Planning MICRO submission
Frank Vahid, UCR46
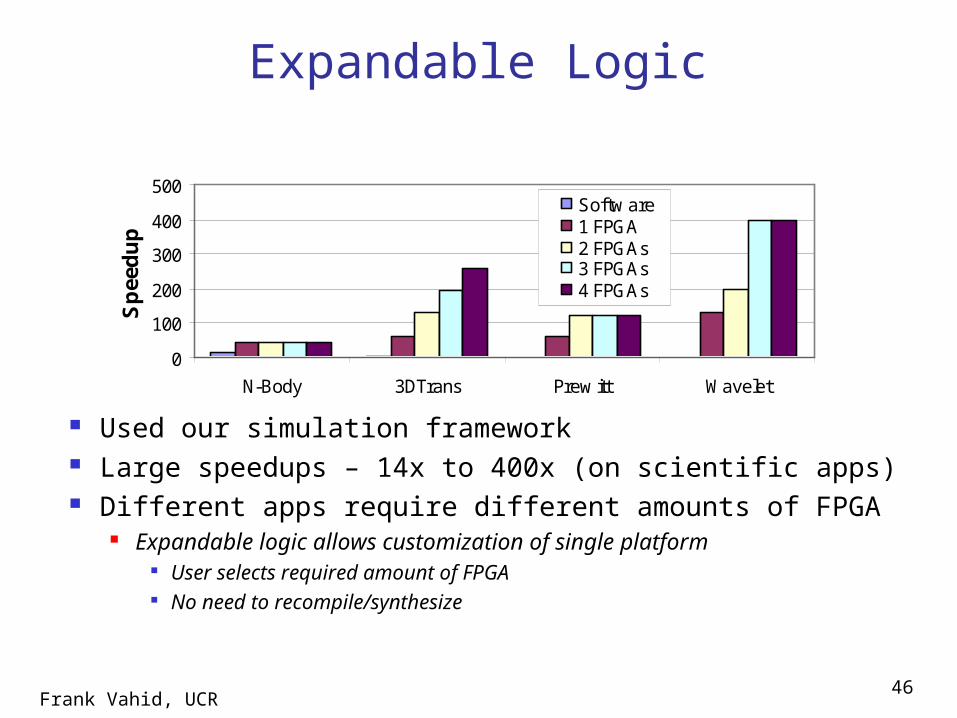
Expandable Logic
Used our simulation framework Large speedups – 14x to 400x (on scientific apps) Different apps require different amounts of FPGA
Expandable logic allows customization of single platform User selects required amount of FPGA No need to recompile/synthesize
0
100
200
300
400
500
N-Body 3DTrans Prew itt Wavelet
Sp
eed
up
Softw are1 FPGA2 FPGAs3 FPGAs4 FPGAs

Frank Vahid, UCR47
Current/Future: IBM’s Cell and FPGAs
Investigating use of FPGAs to supplement Cell
Q: Can Cell-aware code be migrated to FPGA for further speedups?
Q: Can multithreaded Cell-unaware code be compiled to Cell/FPGA hybrid for better speedups than Cell alone?

Frank Vahid, UCR48
Current/Future: Distribution Format for Clever Circuits for FPGAs?
Code written for microprocessor doesn’t always synthesize into best circuit
Designers create clever circuits to implement algorithms (dozens of publications yearly, e.g., FCCM)
Can those algorithms be captured in high-level format suitable for compilation to variety of platforms? With big FPGA, small FPGA, or none at all? NSF project, overlaps with SRC warp processing
project

Frank Vahid, UCR49
Industrial Interactions Year 2 / 3
Freescale Research visit: F. Vahid to Freescale, Chicago, Spring’06. Talk and
full-day research discussion with several engineers. Internships –Scott Sirowy, summer 2006 in Austin (also 2005)
Intel Chip prototype: Participated in Intel’s Research Shuttle to build
prototype warp FPGA fabric – continued bi-weekly phone meetings with Intel engineers, visit to Intel by PI Vahid and R. Lysecky (now prof. at UofA), several day visit to Intel by Lysecky to simulate design, ready for tapout. June’06–Intel cancelled entire shuttle program as part of larger cutbacks.
Research discussions via email with liaison Darshan Patra (Oregon). IBM
Internship: Ryan Mannion, summer and fall 2006 in Yorktown Heights. Caleb Leak, summer 2007 being considered.
Platform: IBM’s Scott Lekuch and Kai Schleupen 2-day visit to UCR to set up Cell development platform having FPGAs.
Technical discussion: Numerous ongoing email and phone interactions with S. Lekuch regarding our research on Cell/FPGA platform.
Several interactions with Xilinx also

Frank Vahid, UCR50
Patents
“Warp Processing” patent Filed with USPTO summer 2004 Several actions since Still pending
SRC has non-exclusive royalty-free license

Frank Vahid, UCR51
Year 1 / 2 publications
New Decompilation Techniques for Binary-level Co-processor Generation. G. Stitt, F. Vahid. IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2005.
Fast Configurable-Cache Tuning with a Unified Second-Level Cache. A. Gordon-Ross, F. Vahid, N. Dutt. Int. Symp. on Low-Power Electronics and Design (ISLPED), 2005.
Hardware/Software Partitioning of Software Binaries: A Case Study of H.264 Decode. G. Stitt, F. Vahid, G. McGregor, B. Einloth. International Conference on Hardware/Software Codesign and System Synthesis (CODES/ISSS), 2005. (Co-authored paper with Freescale)
Frequent Loop Detection Using Efficient Non-Intrusive On-Chip Hardware. A. Gordon-Ross and F. Vahid. IEEE Trans. on Computers, Special Issue- Best of Embedded Systems, Microarchitecture, and Compilation Techniques in Memory of B. Ramakrishna (Bob) Rau, Oct. 2005.
A Study of the Scalability of On-Chip Routing for Just-in-Time FPGA Compilation. R. Lysecky, F. Vahid and S. Tan. IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM), 2005.
A First Look at the Interplay of Code Reordering and Configurable Caches. A. Gordon-Ross, F. Vahid, N. Dutt. Great Lakes Symposium on VLSI (GLSVLSI), April 2005.
A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning. R. Lysecky and F. Vahid. Design Automation and Test in Europe (DATE), March 2005.
A Decompilation Approach to Partitioning Software for Microprocessor/FPGA Platforms. G. Stitt and F. Vahid. Design Automation and Test in Europe (DATE), March 2005.

Frank Vahid, UCR52
Year 2 / 3 publications Binary Synthesis. G. Stitt and F. Vahid. ACM Transactions on Design Automation of
Electronic Systems (TODAES), 2007 (to appear). Integrated Coupling and Clock Frequency Assignment. S. Sirowy and F. Vahid.
International Embedded Systems Symposium (IESS), 2007. Soft-Core Processor Customization Using the Design of Experiments Paradigm. D.
Sheldon, F. Vahid and S. Lonardi. Design Automation and Test in Europe, 2007. A One-Shot Configurable-Cache Tuner for Improved Energy and Performance. A
Gordon-Ross, P. Viana, F. Vahid and W. Najjar. Design Automation and Test in Europe, 2007. Two Level Microprocessor-Accelerator Partitioning. S. Sirowy, Y. Wu, S. Lonardi and
F. Vahid. Design Automation and Test in Europe, 2007. Clock-Frequency Partitioning for Multiple Clock Domains Systems-on-a-Chip. S.
Sirowy, Y. Wu, S. Lonardi and F. Vahid Conjoining Soft-Core FPGA Processors. D. Sheldon, R. Kumar, F. Vahid, D.M. Tullsen, R.
Lysecky. IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Nov. 2006. A Code Refinement Methodology for Performance-Improved Synthesis from C. G.
Stitt, F. Vahid, W. Najjar. IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Nov. 2006.
Application-Specific Customization of Parameterized FPGA Soft-Core Processors. D. Sheldon, R. Kumar, R. Lysecky, F. Vahid, D.M. Tullsen. IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Nov. 2006.
Warp Processors. R. Lysecky, G. Stitt, F. Vahid. ACM Transactions on Design Automation of Electronic Systems (TODAES), July 2006, pp. 659-681.
Configurable Cache Subsetting for Fast Cache Tuning. P. Viana, A. Gordon-Ross, E. Keogh, E. Barros, F. Vahid. IEEE/ACM Design Automation Conference (DAC), July 2006.
Techniques for Synthesizing Binaries to an Advanced Register/Memory Structure. G. Stitt, Z. Guo, F. Vahid, and W. Najjar. ACM/SIGDA Symp. on Field Programmable Gate Arrays (FPGA), Feb. 2005, pp. 118-124.