web archiving service: release 1 guide
TRANSCRIPT

Web Archiving Service: Release 1 Guide August 29, 2006
The following guide is derived from the help screens in Release 1 of the Web Archiving Service. Note that these instructions will change as new functionality is added in later releases.
Contents WAS Release 1 Features Overview of the Capture Process Selecting Sites to Capture Choosing Capture Settings WAS Default Capture Settings Reviewing Capture Results Improving Capture Results Getting Help
WAS Release 1 Features
The first Web Archiving Service release will provide the basic functionality needed to issue a simple web capture and display the results. The method for displaying results will be an interim solution for this release; expect a more integrated display with WAS Release 2.
User Actions: Login to WAS account View an activity summary including currently scheduled captures and
recently run captures Create a new site entry Create a new capture Select one or more web sites to capture Choose capture scope settings for host only or host + linked pages View basic capture reports View capture results using interim search and display solution View capture settings View help screens
Release 1 Constraints: Users will not yet be able to schedule repeating captures or combine
separate captures into collections.
Each curator will have a separate WAS account. Group accounts for collaborative features will be explored in later WAS releases. While we're aware that some curators ultimately plan to collaborate, we request that each curator provide separate feedback in early WAS releases.
WAS Release 1 Guide California Digital Library 1
Only a limited number of capture settings will be available.
Note that web sites captured during release 1 are being stored on a
staging server, not in a production environment. While CDL expects that we will be able to save the materials captured, we are not able to promise full preservation services until WAS Release 6. If you have immediate preservation needs for web resources, please contact [email protected] to make alternate arrangements.
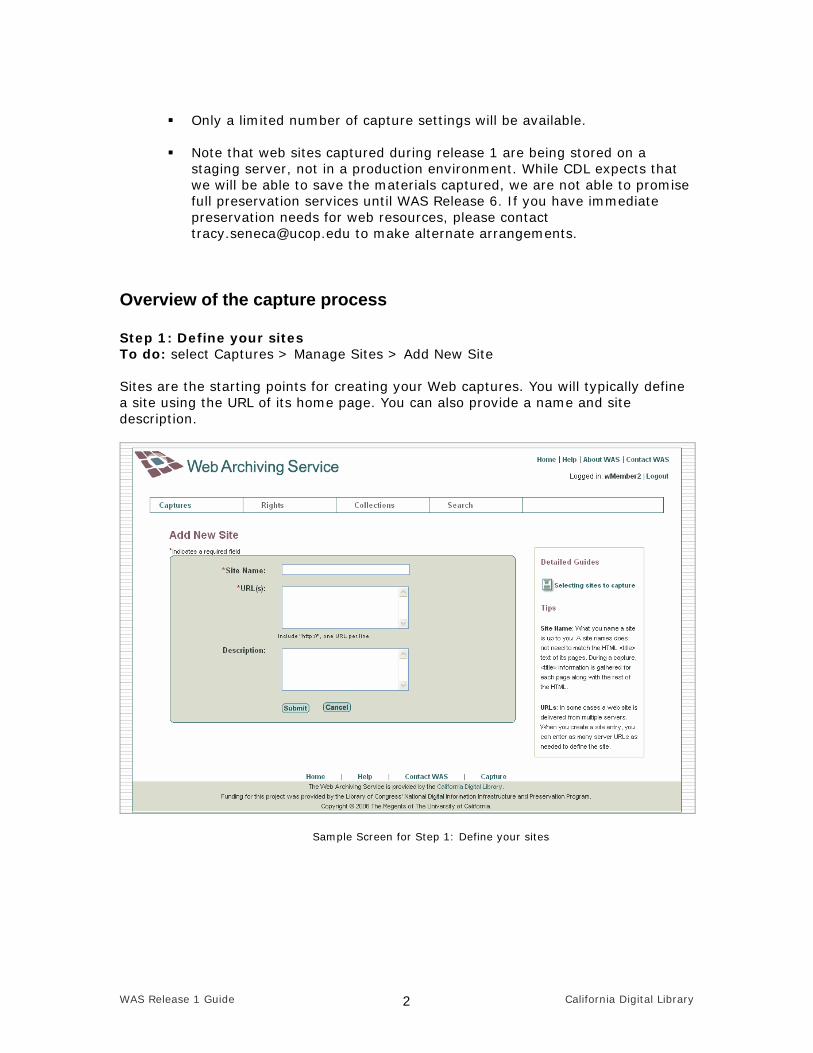
Overview of the capture process Step 1: Define your sites To do: select Captures > Manage Sites > Add New Site Sites are the starting points for creating your Web captures. You will typically define a site using the URL of its home page. You can also provide a name and site description.
Sample Screen for Step 1: Define your sites
WAS Release 1 Guide California Digital Library 2

Step 2: Define your captures To do: select Captures > Create Captures A capture is a group of similar sites whose content will be placed in an archive. A capture focusing on energy policy, for example, might include the Web sites of energy-related government agencies and utilities. When defining a capture, specify how the content of the sites is to be crawled. Capture settings can specify size limits, time limits, and whether to capture content from external links.
Sample screen for Step 2: Define your captures
Step 3: Run your captures To do: select Captures > Manage Captures During a capture run, the WAS automatically accesses content from the associated sites and stores it in an archive. Each execution of a capture is known as a capture job. It may take hours or days to complete a capture job depending on how busy the system is, how much content exists at the sites, and the capture limits you've chosen.
WAS Release 1 Guide California Digital Library 3

Sample screen for Step 3: Run your captures
Step 4: Review capture results To do: select Captures > View Results After a capture job is complete, you can browse and search the content that was archived. Content from each capture job is saved separately. You can also view reports covering details such as host, mimetype, and status log information. These reports let you check for errors and assess the effectiveness of captures. Screen images and further details are provided in the “Reviewing Capture Results” section of this document.
Selecting Sites to Capture The first step in creating a web capture is to enter information about the sites you wish to include. You will define each site separately, and will be able to include them in any future captures you create.
When investigating sites to capture, consider the following:
How much of the site do you want to capture? Explore the site to determine if you only want pages from that site or if you
also want to capture linked pages from other sites How many servers or hosts does the site consist of? In some cases, particularly sites the provide extensive multimedia or pdf files,
a web site is delivered from more than one server. When you create a WAS site entry, you'll be able to enter as many URLs as needed to define the site.
Is the site protected by a robot exclusion file?
WAS Release 1 Guide California Digital Library 4

In some cases, the site owner or administrator may have placed a file on the site prohibiting crawlers from capturing some or all of the site's content. To see if the site you want prohibits crawlers, try viewing the site's robots.txt file: (http://www.example.com/robots.txt).
Links: The Instructions for removing content from Google includes a clear explanation of how robot exclusions work. http://www.google.com/support/webmasters/bin/answer.py?answer=35301&topic=8459 The W3C Standard for Robot Exclusions contains a more detailed explanation. http://www.robotstxt.org/wc/norobots.html
Considerations for Release 1 You will not yet be able to limit your capture to specific directories within a
site. In future releases you will be able to enter more metadata about sites,
including information concerning copyright. General Web Crawler Considerations
Web crawlers have difficulty capturing dynamically generated sites. The Heritrix crawler can only capture URLs beginning with "http://". You
cannot capture ftp sites with the crawler.
Choosing Capture Settings For release 1, capture setting options are:
Name Create a name for this capture. Once a capture is saved, you can run it any number of times, so choose a name that will help you remember the purpose of this capture. Max Time The maxiumum amount of time the capture will run. If the capture reaches this time limit before finishing, you will still be able to view the content captured up to that point. Max Data The maximum size the capture is permitted to reach. If the capture reaches this size limit, you will still be able to view content captured up to that point. Scope This host only This setting will capture pages originating from the host names in the URLs you specified when you defined the site. The crawler will not follow external links unless they are embedded in the page (e.g. images rendered on the page).
WAS Release 1 Guide California Digital Library 5

Host + linked pages This setting will capture pages originating from the host names in the URLs you specified when you defined the site. The crawler will also gather pages immediately linked from those hosts. The crawler will not continue to explore or capture other sites past immediately linked pages. Site List (Also called a “seed list”) When selecting from your site list, be sure to choose sites that will ultimately belong in the same collection together. Usually these will be sites that are topically related. Also choose sites that will all work well using the same capture settings. For example, if you have 30 sites to capture, but only want external links captured for 4 of those sites, create a separate capture for those four sites using the "host + linked pages" scope option. Group the remaining sites together in a separate capture.
WAS Default Capture Settings Release 1 only allows minimal control over capture settings; here is information about some of the important default values CDL has selected for all crawls:
Scope settings All captures will default to "max-link-hops = 25" scope setting. This means that the crawler will follow links from the URL(s) you enter for the site, and continue gathering documents until it gets 25 links away from the starting point. This should provide a thorough capture of most sites. Politeness settings In this early stage of pilot testing, the WAS crawlers will be configured with the highest "politeness" settings. This means that the crawler will force a delay between requests to the same server, so that the content owner's site performance is not adversely affected by crawler activity. Robot Exclusions The WAS will honor robots exclusion files prohibiting crawlers from capturing web sites. Capture frequency All captures will run on a one-time-only basis. In future releases, you will be able to specify daily, weekly or monthly captures. For Release 1 you will need to re-execute captures you want to run more than once. Order.xml One of the results of a finished capture is the order.xml file. There are many more settings than mentioned in the list above, and the order.xml file contains a record of every setting Heritrix used to issue the capture, including all default settings.
WAS Release 1 Guide California Digital Library 6

Reviewing Capture Results Monitoring Capture Progress A web capture can take several hours to complete. Once captured, the content will be indexed and ingested into the repository. The WAS home page will tell you which captures are still running and which have recently completed. Capture Results To see capture results, you can select the "results" tab on the home page or choose Captures > View Results . Note that a capture can have multiple capture jobs - instances of that capture that were run on a particular date. If you have run the same capture multiple times, you will need to select the specific date for the capture job you want to review.
Select results by date to display
Reviewing Capture Reports In addition to displaying the captured web content, you will be able to review reports of the crawler's activity. These reports will convey stats about the capture, including the total size, total number of files gathered and more. These are all default reports produced by the Heritrix web crawler.
WAS Release 1 Guide California Digital Library 7
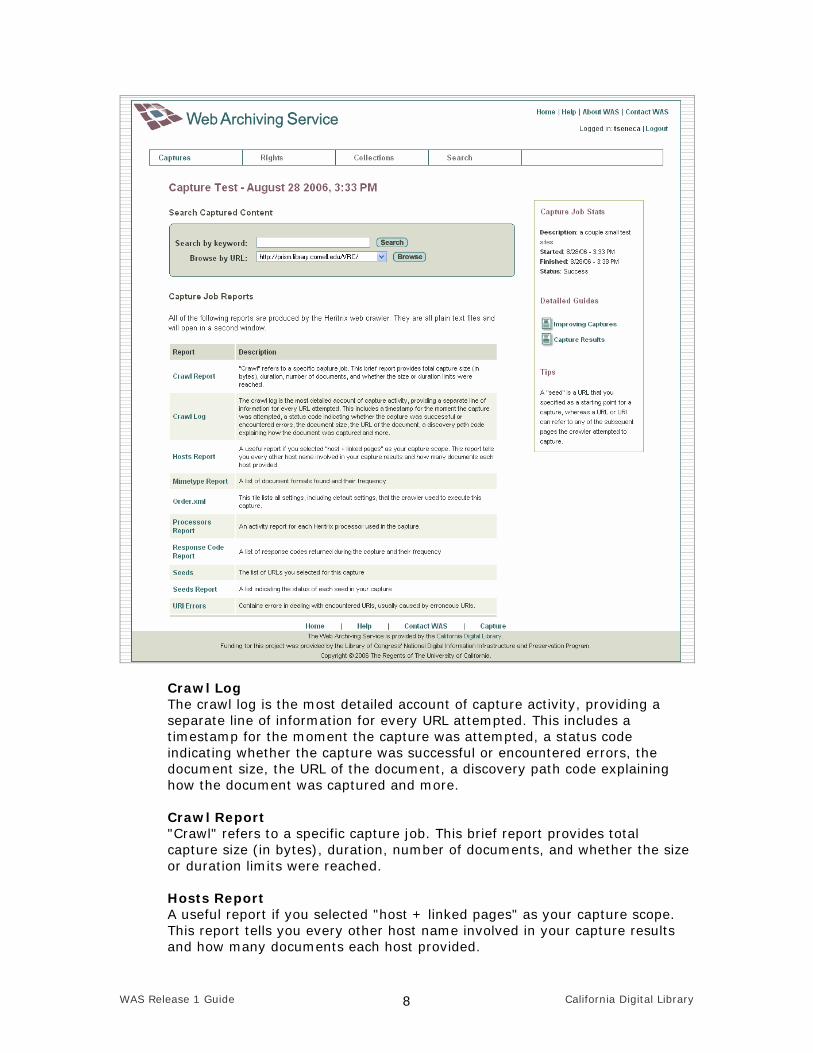
Crawl Log The crawl log is the most detailed account of capture activity, providing a separate line of information for every URL attempted. This includes a timestamp for the moment the capture was attempted, a status code indicating whether the capture was successful or encountered errors, the document size, the URL of the document, a discovery path code explaining how the document was captured and more. Crawl Report "Crawl" refers to a specific capture job. This brief report provides total capture size (in bytes), duration, number of documents, and whether the size or duration limits were reached. Hosts Report A useful report if you selected "host + linked pages" as your capture scope. This report tells you every other host name involved in your capture results and how many documents each host provided.
WAS Release 1 Guide California Digital Library 8

Mimetype Report A list of document formats found and their frequency. Order.xml This file lists all settings, including default settings, that the crawler used to execute this capture. Processors Report An activity report for each Heritrix processor used in the capture. Response Code Report.txt A list of response codes returned during the capture and their frequency. See the Heritrix user manual status codes list for further information. Seeds The list of URLs you selected for this capture. Seeds Report A list indicating the status of each seed in your capture. Uri Errors Contains errors in dealing with encountered URIs, usually caused by erroneous URIs.
Search and Display You can search archived web pages by keyword, or browse by the URLs you supplied for the capture. For Release 1 the WAS will use a third-party solution – the Internet Archive’s Wayback Machine - to search and render archived web content. The Wayback Machine interface has been left ‘as-is’ for Release 1.
WAS Release 1 Guide California Digital Library 9

Wayback Machine search results
WAS Release 1 Guide California Digital Library 10

Wayback Machine page display Links: Heritrix User Manual - Analysis of Jobs http://crawler.archive.org/articles/user_manual.html#analysis Release 1 will rely on the default Heritrix reports. The focus of Release 3 will be to make these reports more intuitive and integrated with the WAS interface.
Improving Capture Results What if your capture results don't contain the documents you expected to get? A number of different factors can influence the success of a web capture. Here are some problems to look for, and suggestions for how to respond to them.
Multiple site addresses If you have chosen a "host name only" capture setting, and one of your sites is served from multiple addresses, you will likely be missing key documents from that site. One way to tell if this is happening is to run a follow-up capture of the same site using the broader "host + linked pages" setting. This is often the only practical way to tell if there are multiple URLs required for a single site.
WAS Release 1 Guide California Digital Library 11

When the broader capture completes, look carefully at the "hosts.txt" report. This report lists all of the host names that supplied documents to the capture results. If the site requires multiple URLs, you will likely see a similar looking host name near the top of the list with a high number of documents.
Example: Arizona Department of Water Resources site: If you use the URL: http://www.azwater.gov, and limit that capture to the original hostname only, you will get 2233 documents. If you use the "host + linked pages" setting, you will get an additional 286 documents from http://www.water.az.gov. All of these documents are part of the Arizona Department of Water Resources site.
To insure that you get a more complete capture of the site without getting irrelevant material from other sites, edit the site entry to include the additional URL information, then re-execute the original capture with the narrower host only setting. This can improve captures since some sites will use multiple servers to deliver multimedia or pdf files. In other cases, a site may have changed addresses or issued an alias address, but will still contain hard-coded links to the old address. Robot Exclusion Files Another common explanation for incomplete capture results is the presence of robot exclusion files or rules. It can be hard to tell in advance if robots exclusion files will affect your capture. A robots.txt file can be placed in any subdirectory on a web site's server, or can be placed within the metadata of any specific html file. One way to tell which documents were impacted by robots exclusion files is to examine the crawl.log report. That report details every document that the crawler attempted to capture, and includes the error code for those that were unsuccessful. The error code for files prohibited by robots exclusion rules is -9988. (Note that we expect WAS Release 3 to make this type of analysis easier!).
Getting Help For technical support or to offer feedback, use the Contact WAS link at the top of any screen. If for some reason you cannot use that link, send email to: [email protected]. If you are reporting a problem, please provide any error message details, the name of capture or site affected, and any information that will help us duplicate the issue.
WAS Release 1 Guide California Digital Library 12

Web Archiving Service: Release 1 Glossary August 29, 2006
Capture
Noun: A set of configurations that can be used to initiate the capture process. A capture is a combination of selected web sites and the settings the crawler will use when crawling those sites
Verb: The process of copying digital information from the web to a repository for collection or archive purposes. The entire capture process involves three stages:
1. Crawl the web content 2. Ingest the web content into the repository 3. Index the content stored in the repository
Collection A group of resources related by common ownership or a common theme or subject matter. A web collection consists of one or more crawls that capture a group of related websites (e.g., candidate websites for state election campaigns).
Release Notes: The ability to create, edit and delete collections will be available with WAS Release 4.
Entry Point URL (EPU) A URL serving as one of the starting addresses a web crawler uses to capture content. Also called a seed URL.
Heritrix An open-source web crawler from the Internet Archive. Heritrix is a java-based crawler now widely adopted by a number of web archiving initiatives. As Heritrix gathers web content, it builds .arc files, which consist of the http headers and content for each object captured.
Host, Hostname A unique alphabetic name identifying a computer on the internet. Example: www.loc.gov. A website may consist of more than one host. A capture scope can be set to limit materials only to the hosts specified in the target site list.
WAS Glossary California Digital Library 1

Repository
The physical storage location and medium for one or more digital archives. The Web Archiving Service relies on the California Digital Library's Digital Preservation Repository (DPR)
Robot Exclusions A robot exclusion is a method that site administrators use to convey instructions to web crawlers. This can be a separate text file or a META tag placed within an individual page. A robots exclusion rule may prohibit all content from being captured, specific pages or specific directories.
A crawler can be configured to ignore robot exclusions; the WAS will honor robot exclusions by default.
Seed List One or more entry point URLs from which a web crawler begins capturing web resources. The URLs in a seed list should be topically related, and should all work well with the same crawler settings.
Site A distinct web site, usually associated with a single hostname. In the Web Archiving Service, a site is defined by a unique name, a description and one or more entry point URLs.
Status - Capture Ready: The capture settings have been saved, and the capture can be run.
Running: The crawler is currently executing this capture. Depending on the number of pages in the target sites, the capture may take several hours to complete.
You will not be able to edit or schedule a capture when it is already running.
WAS Glossary California Digital Library 2