web crawling & crawler
TRANSCRIPT

IN THE NAME OF GOD
1

WEB CRAWLING
PRESENTED BY:
Amir Masoud Sefidian
Shahid Rajaee Teacher Training UniversityFaculty of Computer Engineering
2

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
3

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle
• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
4

• Web crawling is the process by which we gather pages from the Web, in order to index them and support a search.
• Web crawler is a computer program that browses the World Wide Web in a methodical, automated manner.
• Objective of crawling:Quickly and efficiently gather as many useful web pages and link structure that interconnects them.
Creates and repopulates search engines data by navigating the web, downloading documents and files.
5
Other Names:
web robotsWEB SpidErharvesterBotsIndexersweb agentwanderer

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
6

• Our goal is not to describe how to build the crawler for a full-scale commercial web search engine.
• We focus on a range of issues that are generic to crawling from the student project scale to substantial research projects.
7

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
8

Features a crawler must provide:• Robustness:
• Crawlers must be designed to be resilient to spider traps:• Infinitely deep directory structures: http://foo.com/bar/foo/bar/foo/...• Pages filled a large number of characters.
• Politeness:Crawlers should respects Web servers implicit and explicit policies:
• Explicit politeness: specifications from webmasters on what portions of site can be crawled.• Implicit politeness: even with no specification, avoid hitting any site too often.
Features a crawler should provide:
• Distributed: execute in a distributed fashion across multiple machines.
• Scalable:
should permit scaling up the crawl rate by adding extra machines and bandwidth.
• Performance and efficiency:
Efficient use of various system resources including processor, storage and network bandwidth.
• Quality:The crawler should be biased towards fetching “useful” pages first.
• Freshness:
In many applications, the crawler should operate in continuous mode: it should obtain fresh copies of previously fetched pages. A search engine crawler, for instance, can thus ensure that the search engine’s index contains a fairly current representation of each indexed web page.
• Extensible:
Crawlers should be designed to be extensible in many ways to cope with new data formats (e.g.XML-based formats), new fetch protocols (e.g. ftp)and so on. This demands that the crawler architecture be modular.
9
Desiderata for web crawlers

Basic properties any non-professional crawler should satisfy:
1. Only one connection should be open to any given host at a time.
2. Awaiting time of a few seconds should occur between successive requests to a host.
3. Politeness restrictions should be obeyed.
Reference point:
Fetching a billion pages (a small fraction of the static Web at present) in a month-long crawl requires fetching several hundred pages each second.
Multi-thread design
The MERCATOR crawler has formed the basis of a number of research and commercial crawlers.
10

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
11

Basic operation of any hypertext crawler
• The crawler begins with one or more URLs that constitute a seed set.
• Picks a URL from seed set, then fetches the web page at that URL. The fetched page to extract the text and the links from the page.
• The extracted text is fed to a text indexer.
• The extracted links (URLs) are then added to a URL frontier, which at all times consists of URLs whose corresponding pages have yet to be fetched by the crawler.
• Initially URL frontier = SEED SET
• As pages are fetched, the corresponding URLs are deleted from the URL frontier.
• In continuous crawling, the URL of a fetched page is added back to the frontier for fetching again in the future.
• The entire process may be viewed as traversing the web graph.
12

CRAWLING THE WEB
13

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
14
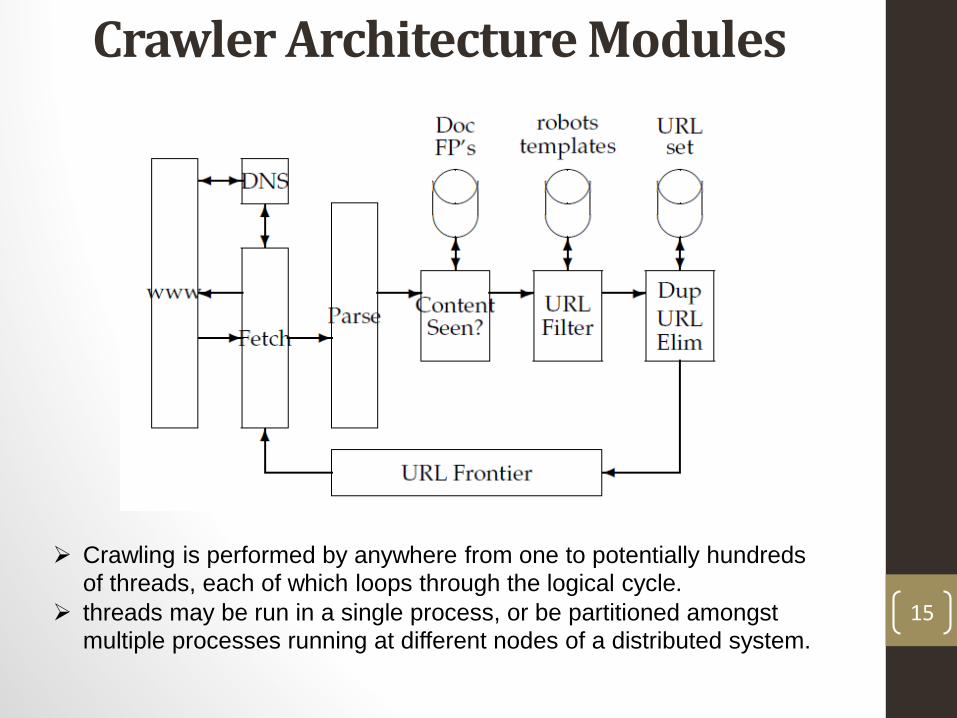
Crawler Architecture Modules
Crawling is performed by anywhere from one to potentially hundreds
of threads, each of which loops through the logical cycle. threads may be run in a single process, or be partitioned amongst
multiple processes running at different nodes of a distributed system.
15
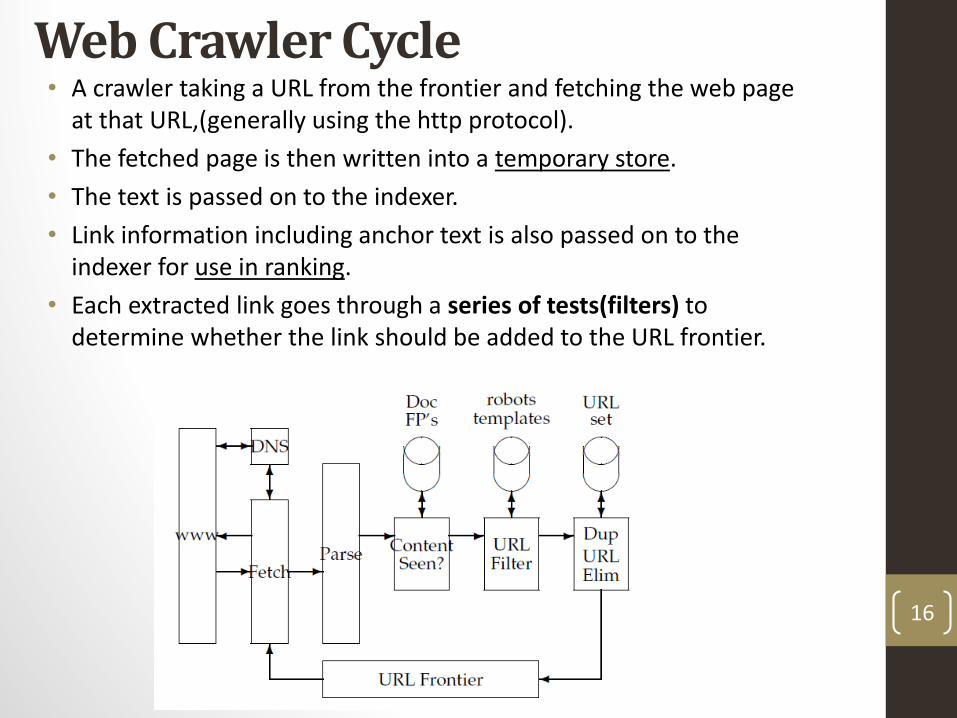
Web Crawler Cycle• A crawler taking a URL from the frontier and fetching the web page
at that URL,(generally using the http protocol).
• The fetched page is then written into a temporary store.
• The text is passed on to the indexer.
• Link information including anchor text is also passed on to the indexer for use in ranking.
• Each extracted link goes through a series of tests(filters) to determine whether the link should be added to the URL frontier.
16

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle
• URL Tests
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
17

URL Tests• Tests to determine whether the link should be added to the URL
frontier:
• 1) 40% of the pages on the Web are duplicates of other pages. Tests whether a web page with the same content has already been seen at another URL. How Test?
• simplest implementation: simple fingerprint such as a checksum (placed in a store labeled "Doc FP’s" in Figure).
• more sophisticated test: use shingles.
• 2) A URL filter is used to determine whether the extracted URL should be excluded from the frontier based on one of several tests.
• Crawler may seek to exclude certain domains (say, all .com URLs).
• Test could be inclusive rather than exclusive.
• Off-limits areas to crawling, under a standard known as the Robots Exclusion Protocol, placing a robots.txt at the root of the URL hierarchy at the site.
• Caching robots.txt
18

URL Normalization & Duplicate Elimination
• Often the HTML encoding of a link from a web page p indicates the target of that link relative to the page p.
• A relative link encoded thus in the HTML of the page en.wikipedia.org/wiki/Main_Page:
• <a href=“/wiki/Wikipedia:General_disclaimer“ title="Wikipedia:Generaldisclaimer">Disclaimers</a>
• http://en.wikipedia.org/wiki/Wikipedia:General_disclaimer.
• The URL is checked for duplicate elimination:
• if the URL is already in the frontier or (in the case of a non-continuous crawl) already crawled, we do not add it to the frontier.
19

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
20

Housekeeping Tasks
Certain housekeeping tasks are typically performed by a dedicated thread: Generally is quiescent except that it wakes up once every few
seconds to:
log crawl progress statistics every few seconds (URLs crawled, frontier size, etc.)
Decide whether to terminate the crawl or (once every few hours of crawling) checkpoint the crawl.
In checkpointing, a snapshot of the crawler’s state is committed to disk.
In the event of a catastrophic crawler failure, the crawl is restarted from the most recent checkpoint.
21

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
22

Distributing the crawler• Crawler could run under different processes, each at a different
node of a distributed crawling system:
• is essential for scaling.
• it can also be of use in a geographically distributed crawler system where each node crawls hosts “near” it.
• Partitioning the hosts being crawled amongst the crawler nodes can be done by:
• 1) hash function.
• 2) some more specifically tailored policy.
• How do the various nodes of a distributed crawler communicate and share URLs?Use a host splitter to dispatch each surviving URL to the crawler node responsible for the URL.
23

Distributed Crawler Architecture
24

25
Host Splitter

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
26

DNS resolution
Each web server (and indeed any host connected to the internet) has a unique IP address (sequence of four bytes generally represented as four integers separated by dots).
DNS(Domain Name Service) resolution or DNS lookup:Process of translating a URL in textual form to an IP address www.wikipedia.org 207.142.131.248
Program that wishes to perform this translation (in our case, a component of the web crawler) contacts a DNS server that returns the translated IP address.DNS resolution is a well-known bottleneck in web crawling:1) DNS resolution may entail multiple requests and round-trips across the internet, requiring seconds and sometimes even longer.
URLs for which we have recently performed DNS lookups (recently asked names) are likely to be found in the DNS cache avoiding the need to go to the DNS servers on the internet.
Standard remedy CASHING
27

DNS resolution(countinue)
2) lookup implementations in are generally synchronous:Once a request is made to the Domain Name Service, other crawler threads at that node are blocked until the first request is completed.
Solution:• Most web crawlers implement their own DNS resolver as a component
of the crawler.• Thread i executing the resolver code sends a message to the DNS server
and then performs a timed wait.• it resumes either when being signaled by another thread or when a set
time quantum expires.• A single separate thread listens on the standard for incoming response
packets from the name service.• A crawler thread that resumes because its wait time quantum has
expired retries for a fixed number of attempts, sending out a new message to the DNS server and performing a timed wait each time.
• The time quantum of the wait increases exponentially with each of these attempts 28

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
29

The URL frontier
Maintains the URLs in the frontier and regurgitates them in some order whenever a crawler thread seeks a URL.
Two important considerations govern the order in which URLs are returnedby the frontier:
1) Prioritization: high-quality pages that change frequently should be prioritized for frequent crawling.Priority of URLs in URL frontier is function of(combination is necessary):
• Change rate.• Quality.
2) Politeness: • Crawler must avoid repeated fetch requests to a host within a short
time span.• The likelihood of this is exacerbated because of a form of locality of
reference: many URLs link to other URLs at the same host.• A common heuristic is to insert a gap between successive fetch
requests to a host30

The URL frontier
A polite and prioritizing implementation of a URL frontier:1. only one connection is open at a
time to any host. 2. a waiting time of a few seconds
occurs between successive requests to a host and
3. high-priority pages are crawled preferentially.
The two major sub-modules: F front queues : implement
prioritization B back queues : implement
politeness
All of queues are FIFO
31
31

Front Queues
32
prioritizer assigns an integer priority i between 1 and F based on its fetch history to the URL(taking into account the rate at which the web page at this URL has changed between previous crawls).a document that has more frequent change has higher priority
URL with assigned priority i, will append to the ith of the front queues.
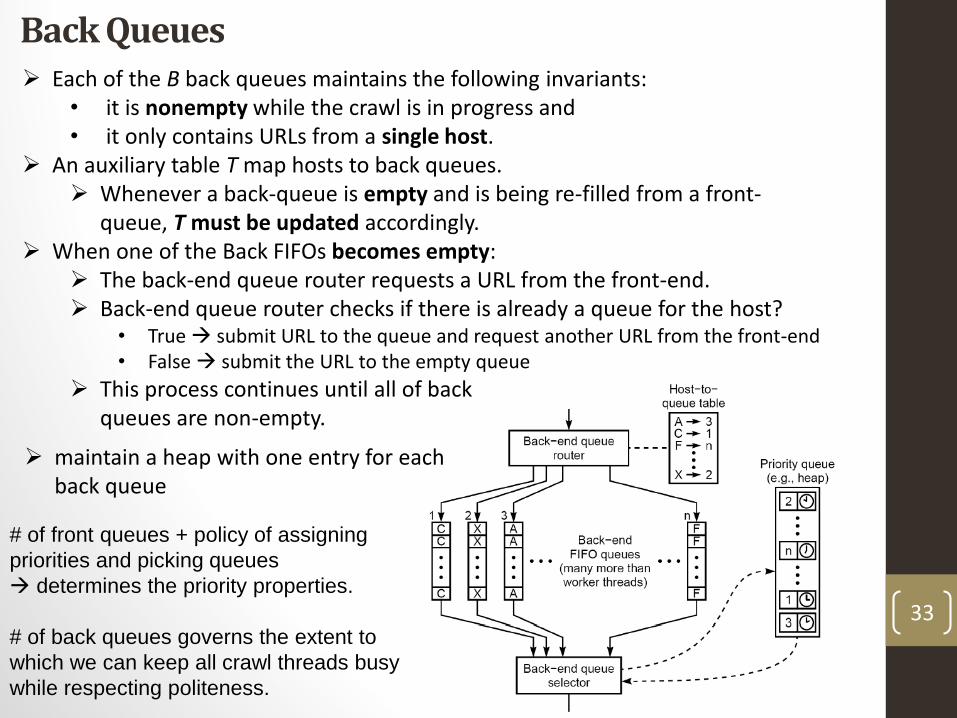
Back Queues Each of the B back queues maintains the following invariants:
• it is nonempty while the crawl is in progress and • it only contains URLs from a single host.
An auxiliary table T map hosts to back queues. Whenever a back-queue is empty and is being re-filled from a front-
queue, T must be updated accordingly. When one of the Back FIFOs becomes empty:
The back-end queue router requests a URL from the front-end. Back-end queue router checks if there is already a queue for the host?
• True submit URL to the queue and request another URL from the front-end• False submit the URL to the empty queue
33
This process continues until all of back queues are non-empty.
# of front queues + policy of assigning
priorities and picking queues
determines the priority properties.
# of back queues governs the extent to
which we can keep all crawl threads busy
while respecting politeness.
maintain a heap with one entry for each back queue

Today’s Lecture Content
• What is Web Crawling(Crawler) and Objective of crawling
• Our goal in this presentation
• Listing desiderata for web crawlers
• Basic operation of any hypertext crawler
• Crawler Architecture Modules & Working Cycle• URL Tests
• Housekeeping Tasks
• Distributed web crawler
• DNS resolution
• URL Frontier details
• Several Types of Crawlers
34

35
Several Types of Crawlers
BFS or DFS CrawlingCrawl their crawl space, until reaching a certain size or time limit.
Repetitive (Continuous) Crawlingrevisiting URL to ensure freshness
Targeted (Focused) CrawlingAttempt to crawl pages pertaining to some topic, while minimizing
number of off topic pages that are collected.
Deep (Hidden) Web CrawlingPrivate sites(need to login)Scripted pagesThe data that which is present in the data base may only be
downloaded through the medium of appropriate request or forms.

36

37
QUESTION??...