web search engines rooted in information retrieval (ir) systems prepare a keyword index for corpus...
Post on 22-Dec-2015
223 views
TRANSCRIPT

Web search enginesRooted in Information Retrieval (IR) systems
•Prepare a keyword index for corpus
•Respond to keyword queries with a ranked list of documents.
ARCHIE•Earliest application of rudimentary IR systems to the Internet
•Title search across sites serving files over FTP

Mining the Web Chakrabarti and Ramakrishnan 2
Boolean queries: Examples Simple queries involving
relationships between terms and documents•Documents containing the word Java
•Documents containing the word Java but not the word coffee
Proximity queries•Documents containing the phrase Java
beans or the term API
•Documents where Java and island occur in the same sentence

Mining the Web Chakrabarti and Ramakrishnan 3
Document preprocessing Tokenization
•Filtering away tags
•Tokens regarded as nonempty sequence of characters excluding spaces and punctuations.
•Token represented by a suitable integer, tid, typically 32 bits
•Optional: stemming/conflation of words
•Result: document (did) transformed into a sequence of integers (tid, pos)

Mining the Web Chakrabarti and Ramakrishnan 4
Storing tokens Straight-forward implementation
using a relational database•Example figure
•Space scales to almost 10 times Accesses to table show common
pattern•reduce the storage by mapping tids to a
lexicographically sorted buffer of (did, pos) tuples.
• Indexing = transposing document-term matrix

Mining the Web Chakrabarti and Ramakrishnan 5
Two variants of the inverted index data structure, usually stored on disk. The simplerversion in the middle does not store term offset information; the version to the right stores termoffsets. The mapping from terms to documents and positions (written as “document/position”) maybe implemented using a B-tree or a hash-table.

Mining the Web Chakrabarti and Ramakrishnan 6
Storage For dynamic corpora
•Berkeley DB2 storage manager
•Can frequently add, modify and delete documents
For static collections• Index compression techniques (to be
discussed)

Mining the Web Chakrabarti and Ramakrishnan 7
Stopwords Function words and connectives Appear in large number of documents and
little use in pinpointing documents Indexing stopwords
• Stopwords not indexed For reducing index space and improving performance
• Replace stopwords with a placeholder (to remember the offset)
Issues• Queries containing only stopwords ruled out• Polysemous words that are stopwords in one
sense but not in others E.g.; can as a verb vs. can as a noun

Mining the Web Chakrabarti and Ramakrishnan 8
Stemming Conflating words to help match a query term with a
morphological variant in the corpus. Remove inflections that convey parts of speech,
tense and number E.g.: university and universal both stem to universe. Techniques
• morphological analysis (e.g., Porter's algorithm)
• dictionary lookup (e.g., WordNet). Stemming may increase recall but at the price of
precision• Abbreviations, polysemy and names coined in the technical
and commercial sectors
• E.g.: Stemming “ides” to “IDE”, “SOCKS” to “sock”, “gated” to “gate”, may be bad !

Mining the Web Chakrabarti and Ramakrishnan 9
Batch indexing and updates Incremental indexing
•Time-consuming due to random disk IO
•High level of disk block fragmentation Simple sort-merges.
•To replace the indexed update of variable-length postings
For a dynamic collection•single document-level change may need to
update hundreds to thousands of records.
•Solution : create an additional “stop-press” index.

Mining the Web Chakrabarti and Ramakrishnan 10
Maintaining indices over dynamic collections.

Mining the Web Chakrabarti and Ramakrishnan 11
Stop-press index Collection of document in flux
• Model document modification as deletion followed by insertion
• Documents in flux represented by a signed record (d,t,s)
• “s” specifies if “d” has been deleted or inserted. Getting the final answer to a query
• Main index returns a document set D0.• Stop-press index returns two document sets
D+ : documents not yet indexed in D0 matching the query D- : documents matching the query removed from the
collection since D0 was constructed.
Stop-press index getting too large• Rebuild the main index
signed (d, t, s) records are sorted in (t, d, s) order and merge-purged into the master (t, d) records
• Stop-press index can be emptied out.

Mining the Web Chakrabarti and Ramakrishnan 12
Index compression techniques Compressing the index so that much
of it can be held in memory•Required for high-performance IR
installations (as with Web search engines),
Redundancy in index storage•Storage of document IDs.
Delta encoding•Sort Doc IDs in increasing order•Store the first ID in full•Subsequently store only difference (gap)
from previous ID

Mining the Web Chakrabarti and Ramakrishnan 13
Encoding gaps Small gap must cost far fewer bits
than a document ID. Binary encoding
•Optimal when all symbols are equally likely
Unary code•optimal if probability of large gaps
decays exponentially

Mining the Web Chakrabarti and Ramakrishnan 14
Encoding gaps Gamma code
•Represent gap x as Unary code for followed by represented in binary ( bits)
Golomb codes•Further enhancement
logx 1
logx2 -x logx

Mining the Web Chakrabarti and Ramakrishnan 15
Lossy compression mechanisms
Trading off space for time collect documents into buckets
•Construct inverted index from terms to bucket IDs
•Document' IDs shrink to half their size. Cost: time overheads
•For each query, all documents in that bucket need to be scanned
Solution: index documents in each bucket separately•E.g.: Glimpse (http://webglimpse.org/)

Mining the Web Chakrabarti and Ramakrishnan 16
General dilemmas Messy updates vs. High compression
rate Storage allocation vs. Random I/Os Random I/O vs. large scale
implementation

Mining the Web Chakrabarti and Ramakrishnan 17
Relevance ranking Keyword queries
• In natural language
• Not precise, unlike SQL Boolean decision for response unacceptable
• Solution Rate each document for how likely it is to satisfy the
user's information need Sort in decreasing order of the score Present results in a ranked list.
No algorithmic way of ensuring that the ranking strategy always favors the information need• Query: only a part of the user's information need

Mining the Web Chakrabarti and Ramakrishnan 18
Responding to queries Set-valued response
•Response set may be very large (E.g., by recent estimates, over 12 million
Web pages contain the word java.)
Demanding selective query from user Guessing user's information need
and ranking responses Evaluating rankings

Mining the Web Chakrabarti and Ramakrishnan 19
Evaluating procedure Given benchmark
•Corpus of n documents D
•A set of queries Q
•For each query, an exhaustive set of relevant documents identified manually
Query submitted system•Ranked list of documents
retrieved
•compute a 0/1 relevance list iff otherwise.
Q q D Dq
)d ,,d ,(d n21
)r.., ,r ,(r n21
D d qi 1 ri 0 ri

Mining the Web Chakrabarti and Ramakrishnan 20
Recall and precision Recall at rank
•Fraction of all relevant documents included in .
• . Precision at rank
•Fraction of the top k responses that are actually relevant.
• .
1 k
)d ,,d ,(d n21
ki1
iq
r |D|
1 recall(k)
ki1
irk
1 k)precision(

Mining the Web Chakrabarti and Ramakrishnan 21
Other measures Average precision
• Sum of precision at each relevant hit position in the response list, divided by the total number of relevant documents
• . .
• avg.precision =1 iff engine retrieves all relevant documents and ranks them ahead of any irrelevant document
Interpolated precision• To combine precision values from multiple queries• Gives precision-vs.-recall curve for the benchmark.
For each query, take the maximum precision obtained for the query for any recall greater than or equal to
average them together for all queries Others like measures of authority, prestige etc
||k1k
q
)(*r |D|
1 ionavg.precis
D
kprecision

Mining the Web Chakrabarti and Ramakrishnan 22
Precision-Recall tradeoff Interpolated precision cannot increase with
recall• Interpolated precision at recall level 0 may be less
than 1 At level k = 0
• Precision (by convention) = 1, Recall = 0 Inspecting more documents
• Can increase recall• Precision may decrease
we will start encountering more and more irrelevant documents
Search engine with a good ranking function will generally show a negative relation between recall and precision.• Higher the curve, better the engine
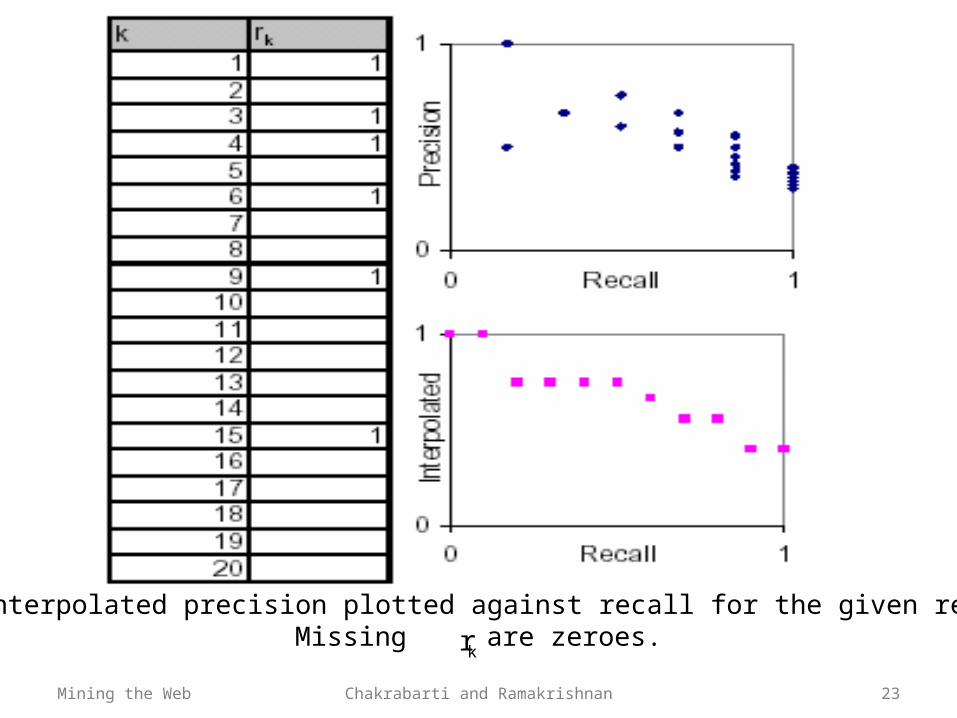
Mining the Web Chakrabarti and Ramakrishnan 23
Precision and interpolated precision plotted against recall for the given relevance vector.Missing are zeroes.
kr

Mining the Web Chakrabarti and Ramakrishnan 24
The vector space model Documents represented as vectors in
a multi-dimensional Euclidean space•Each axis = a term (token)
Coordinate of document d in direction of term t determined by:•Term frequency TF(d,t)
number of times term t occurs in document d, scaled in a variety of ways to normalize document length
• Inverse document frequency IDF(t) to scale down the coordinates of terms that
occur in many documents

Mining the Web Chakrabarti and Ramakrishnan 25
Term frequency .
. Cornell SMART system uses a
smoothed version
) n(d,
t)n(d, t)TF(d,
)) (n(d,max
t)n(d, t)TF(d,
)),(1log(1),(
0),(
tdntdTF
tdTF
otherwise
tdn 0),(

Mining the Web Chakrabarti and Ramakrishnan 26
Inverse document frequency Given
•D is the document collection and is the set of documents containing t
Formulae•mostly dampened functions of
•SMART .
|| tD
D
)||
||1log()(
tD
DtIDF
tD

Mining the Web Chakrabarti and Ramakrishnan 27
Vector space model Coordinate of document d in axis t
• .
•Transformed to in the TFIDF-space Query q
• Interpreted as a document
•Transformed to in the same TFIDF-space as d
)(),( tIDFtdTFdt
d
q

Mining the Web Chakrabarti and Ramakrishnan 28
Measures of proximity Distance measure
•Magnitude of the vector difference .
•Document vectors must be normalized to unit ( or ) length Else shorter documents dominate (since
queries are short)
Cosine similarity•cosine of the angle between and
Shorter documents are penalized
|| qd
1L
2L
d
q

Mining the Web Chakrabarti and Ramakrishnan 29
Relevance feedback Users learning how to modify queries
• Response list must have least some relevant documents
• Relevance feedback `correcting' the ranks to the user's taste automates the query refinement process
Rocchio's method• Folding-in user feedback
• To query vector Add a weighted sum of vectors for relevant documents
D+ Subtract a weighted sum of the irrelevant documents
D-
• .
q
D -D
d-dq'q

Mining the Web Chakrabarti and Ramakrishnan 30
Relevance feedback (contd.) Pseudo-relevance feedback
•D+ and D- generated automatically E.g.: Cornell SMART system top 10 documents reported by the first
round of query execution are included in D+
• typically set to 0; D- not used Not a commonly available feature
•Web users want instant gratification
•System complexity Executing the second round query slower
and expensive for major search engines

Mining the Web Chakrabarti and Ramakrishnan 31
Ranking by odds ratio R : Boolean random variable which
represents the relevance of document d w.r.t. query q.
Ranking documents by their odds ratio for relevance• .
Approximating probability of d by product of the probabilities of individual terms in d• .
•Approximately…
),|Pr(/)|Pr(
),|Pr(/)|Pr(
),Pr(/),,Pr(
),Pr(/),,Pr(
),|Pr(
),|Pr(
qRdqR
qRdqR
dqdqR
dqdqR
dqR
dqR
t t
t
qRx
qRx
qRd
qRd
),|Pr(
),|Pr(
),|Pr(
),|Pr(
dqt qtqt
qtqt
ab
ba
dqR
dqR
)1(
)1(
),|Pr(
),|Pr(
,,
,,

Mining the Web Chakrabarti and Ramakrishnan 32
Bayesian Inferencing
Bayesian inference network for relevance ranking. A document is relevant to the extent that setting its corresponding belief node to true lets us assign a high degree of belief in the node corresponding to the query.
Manual specification of mappings between terms to approximate concepts.

Mining the Web Chakrabarti and Ramakrishnan 33
Bayesian Inferencing (contd.) Four layers
1.Document layer
2.Representation layer
3.Query concept layer
4.Query
Each node is associated with a random Boolean variable, reflecting belief
Directed arcs signify that the belief of a node is a function of the belief of its immediate parents (and so on..)

Mining the Web Chakrabarti and Ramakrishnan 34
Bayesian Inferencing systems 2 & 3 same for basic vector-space IR
systems Verity's Search97
•Allows administrators and users to define hierarchies of concepts in files
Estimation of relevance of a document d w.r.t. the query q•Set the belief of the corresponding node to
1 •Set all other document beliefs to 0•Compute the belief of the query•Rank documents in decreasing order of
belief that they induce in the query

Mining the Web Chakrabarti and Ramakrishnan 35
Other issues Spamming
• Adding popular query terms to a page unrelated to those terms
• E.g.: Adding “Hawaii vacation rental” to a page about “Internet gambling”
• Little setback due to hyperlink-based ranking
Titles, headings, meta tags and anchor-text• TFIDF framework treats all terms the same
• Meta search engines: Assign weight age to text occurring in tags, meta-tags
• Using anchor-text on pages u which link to v Anchor-text on u offers valuable editorial judgment
about v as well.

Mining the Web Chakrabarti and Ramakrishnan 36
Other issues (contd..) Including phrases to rank complex
queries•Operators to specify word inclusions and
exclusions•With operators and phrases
queries/documents can no longer be treated as ordinary points in vector space
Dictionary of phrases•Could be cataloged manually•Could be derived from the corpus itself
using statistical techniques•Two separate indices:
one for single terms and another for phrases

Mining the Web Chakrabarti and Ramakrishnan 37
Corpus derived phrase dictionary
Two terms and Null hypothesis = occurrences of and are
independent To the extent the pair violates the null
hypothesis, it is likely to be a phrase
•Measuring violation with likelihood ratio of the hypothesis
•Pick phrases that violate the null hypothesis with large confidence
Contingency table built from statistics
1t
2t
1t
2t
) , ( ) , (
) , ( ) , (
2 1 11 2 1 10
2 1 01 2 1 00
t t k k t t k k
t t k k t t k k

Mining the Web Chakrabarti and Ramakrishnan 38
Corpus derived phrase dictionary
Hypotheses•Null hypothesis
•Alternative hypothesis
•Likelihood ratio
);(max
);(max0
kpH
kpH
p
p
11100100 )())1(())1(())1)(1((),,,;,( 212121211110010021kkkk ppppppppkkkkppH
11100100111001001110010011100100 ),,,;,,,( kkkk ppppkkkkppppH

Mining the Web Chakrabarti and Ramakrishnan 39
Approximate string matching Non-uniformity of word spellings
• dialects of English
• transliteration from other languages Two ways to reduce this problem.
1. Aggressive conflation mechanism to collapse variant spellings into the same token
2. Decompose terms into a sequence of q-grams or sequences of q characters

Mining the Web Chakrabarti and Ramakrishnan 40
Approximate string matching1. Aggressive conflation mechanism to
collapse variant spellings into the same token
• E.g.: Soundex : takes phonetics and pronunciation details into account
• used with great success in indexing and searching last names in census and telephone directory data.
2. Decompose terms into a sequence of q-grams or sequences of q characters
• Check for similarity in the grams• Looking up the inverted index : a two-stage affair:
• Smaller index of q-grams consulted to expand each query term into a set of slightly distorted query terms
• These terms are submitted to the regular index• Used by Google for spelling correction• Idea also adopted for eliminating near-duplicate
pages
)42( qq

Mining the Web Chakrabarti and Ramakrishnan 41
Meta-search systems• Take the search engine to the document
• Forward queries to many geographically distributed repositories
• Each has its own search service
• Consolidate their responses.
• Advantages• Perform non-trivial query rewriting
• Suit a single user query to many search engines with different query syntax
• Surprisingly small overlap between crawls
• Consolidating responses• Function goes beyond just eliminating duplicates• Search services do not provide standard ranks
which can be combined meaningfully

Mining the Web Chakrabarti and Ramakrishnan 42
Similarity search• Cluster hypothesis
•Documents similar to relevant documents are also likely to be relevant
• Handling “find similar” queries•Replication or duplication of pages
•Mirroring of sites

Mining the Web Chakrabarti and Ramakrishnan 43
Document similarity• Jaccard coefficient of similarity
between document and • T(d) = set of tokens in document d
• .
•Symmetric, reflexive, not a metric
•Forgives any number of occurrences and any permutations of the terms.
• is a metric
1d 2d
|)()(|
|)()(|),('
21
2121 dTdT
dTdTddr
),('1 21 ddr

Mining the Web Chakrabarti and Ramakrishnan 44
Estimating Jaccard coefficient with random permutations
1. Generate a set of m random permutations
2. for each do3. compute and 4. check if5. end for6. if equality was observed in k cases,
estimate.
m
kddr ),(' 21
)(min)(min 21 dTdT
)( 2d)( 1d

Mining the Web Chakrabarti and Ramakrishnan 45
Fast similarity search with random permutations
1. for each random permutation do2. create a file3. for each document d do4. write out to 5. end for6. sort using key s--this results in contiguous blocks
with fixed s containing all associated 7. create a file8. for each pair within a run of having a given
s do9. write out a document-pair record to g10. end for11. sort on key 12. end for13. merge for all in order, counting the
number of entries
),( 21 dd
sd
ddTs )),((min
f
f
f
g
f
),( 21 dd
g ),( 21 dd
g ),( 21 dd ),( 21 dd

Mining the Web Chakrabarti and Ramakrishnan 46
Eliminating near-duplicates via shingling
• “Find-similar” algorithm reports all duplicate/near-duplicate pages
• Eliminating duplicates• Maintain a checksum with every page in the corpus
• Eliminating near-duplicates• Represent each document as a set T(d) of q-grams
(shingles)
• Find Jaccard similarity between and
• Eliminate the pair from step 9 if it has similarity above a threshold
1d),( 21 ddr 2d

Mining the Web Chakrabarti and Ramakrishnan 47
Detecting locally similar sub-graphs of the Web
• Similarity search and duplicate elimination on the graph structure of the web
• To improve quality of hyperlink-assisted ranking
• Detecting mirrored sites• Approach 1 [Bottom-up Approach]
1. Start process with textual duplicate detection• cleaned URLs are listed and sorted to find duplicates/near-
duplicates• each set of equivalent URLs is assigned a unique token ID • each page is stripped of all text, and represented as a
sequence of outlink IDs
2. Continue using link sequence representation 3. Until no further collapse of multiple URLs are possible
• Approach 2 [Bottom-up Approach]1. identify single nodes which are near duplicates (using text-
shingling)2. extend single-node mirrors to two-node mirrors3. continue on to larger and larger graphs which are likely
mirrors of one another

Mining the Web Chakrabarti and Ramakrishnan 48
Detecting mirrored sites (contd.)• Approach 3 [Step before fetching all pages]
• Uses regularity in URL strings to identify host-pairs which are mirrors
• Preprocessing• Host are represented as sets of positional bigrams
• Convert host and path to all lowercase characters• Let any punctuation or digit sequence be a token
separator• Tokenize the URL into a sequence of tokens, (e.g.,
www6.infoseek.com gives www, infoseek, com)• Eliminate stop terms such as htm, html, txt, main, index,
home, bin, cgi• Form positional bigrams from the token sequence
• Two hosts are said to be mirrors if• A large fraction of paths are valid on both web sites• These common paths link to pages that are near-duplicates.