web searching and graph similarity vincent blondel and paul van dooren* cesame, universite...
Post on 18-Dec-2015
216 views
TRANSCRIPT


Web searching and graph similarityVincent Blondel and Paul Van Dooren*
CESAME, Universite Catholique de Louvainhttp://www.inma.ucl.ac.be/
* Thanks to P. Sennelart GAMM, 2003

The web graph
Nodes = web pages, Edges = hyperlinks between pages
3 billion (Google searched 3,083,324,625 webpages in 2002)
Average of 7 outgoing links

The web graph
Nodes = web pages, Edges = hyperlinks between pages
3 billion (Google searched 3,083,324,625 webpages in 2002)
Average of 7 outgoing links
Growth of a few %
every month

Outline
1. Structure of the web
2. Methods for searching the web
(Google PageRank and Kleinberg Hits)
3. Similarity in graphs
4. Application to synonym extraction (Blondel-Sennelart)

Structure of the web
Experiments : two crawls over 200 million pages in 1999
found a giant strongly connected component (core)
• Contains most prominent sites• It contains 30% of all pages• Average distance between nodes is 16• Small world
Ref : Broder et al., Graph structure in the web, WWW9, 2000

The web is a bowtie
Ref : The web is a bowtie, Nature, May 11, 2000
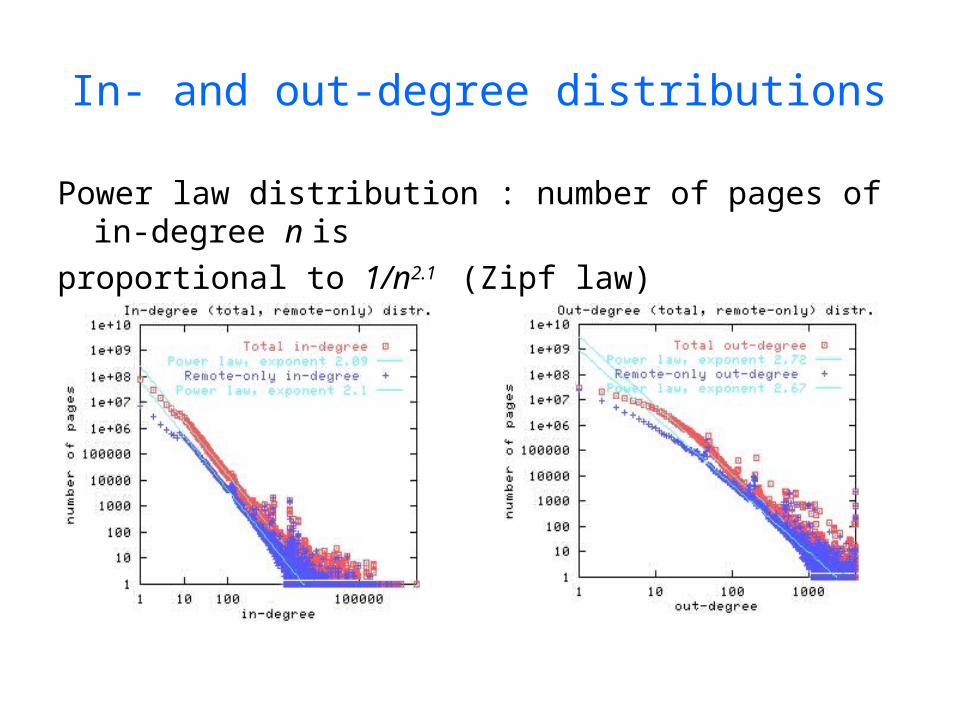
In- and out-degree distributions
Power law distribution : number of pages of in-degree n is
proportional to 1/n2.1 (Zipf law)

A score for every page
The score of a page is high if the page has many incoming
links coming from pages with high page score
One browses from page to page by following outgoing links
with equal probability. Score = frequency a page is visited.

A score for every page
The score of a page is high if the page has many incoming
links coming from pages with high page score
One browses from page to page by following outgoing links
with equal probability. Score = frequency a page is visited.
… some pages may have no outgoing links
… many pages have zero frequency

PageRank : teleporting random score
The surfer follows a path by choosing an outgoing link with probability p/dout(i) or teleports to a random web page with probability 0<1-p <1.
Put the transition probability of i to j in a matrix M (bij=1 if i→j)
mij = p bij /dout(i) + (1-p)/n
then the vector x of probability distribution on the nodes of the graph
is the steady state vector of the iteration xk+1=Mxk i.e. the dominanteigenvector of the matrix M (unique because of Perron-Frobenius)
PageRank of node i is the (relative) size of element i of this vector

Matlab News and Notes, October 2002
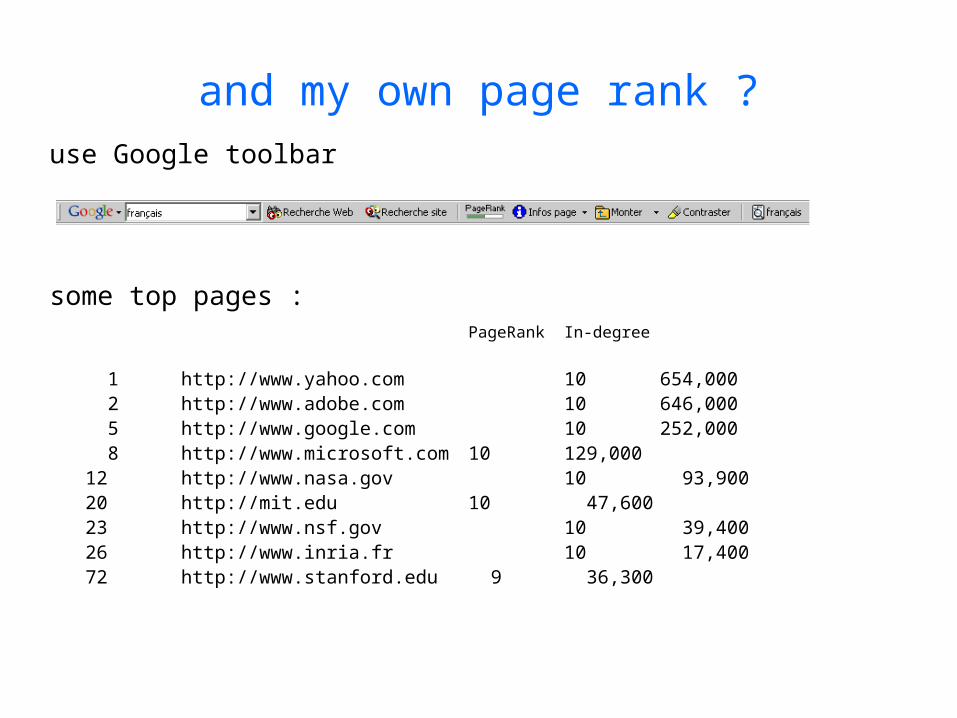
and my own page rank ?use Google toolbar
some top pages :PageRank In-degree
1 http://www.yahoo.com 10 654,000 2 http://www.adobe.com 10 646,000
5 http://www.google.com 10 252,000 8 http://www.microsoft.com 10 129,00012 http://www.nasa.gov 10 93,90020 http://mit.edu 10 47,60023 http://www.nsf.gov 10 39,40026 http://www.inria.fr 10 17,40072 http://www.stanford.edu 9 36,300

Kleinberg’s structure graph
The score of a page is high if the page has
many incoming links
The score is high if the incoming links are
from pages that have high scores

Kleinberg’s structure graph
The score of a page is high if the page has
many incoming links
The score is high if the incoming links are
from pages that have high scores
This inspired Kleinberg’s “structure graph”
hub authority

Good authorities for “University Belgium”

A good hub for “University Belgium”

Hub and authority scores
Web pages have a hub score hj and an authority score aj which are
mutually reinforcing :
pages with large hj point to pages with high aj
pages with large aj are pointed to by pages with high hj
hj ← Σ i:(j→i) ai
aj ← Σ i:(i→j) hi
or, using the adjacency matrix B of the graph (bij=1 if j→i is an edge)
h 0 B h h 1
a k+1 BT 0 a k a 0 1
Use limiting vector a (dominant eigenvector of BTB) to rank pages
= =


Extension to another structure graph
Give three scores to each web page : begin b, center c, end e
b c e
Use again mutual reinforcement to define the iteration
bj ← Σ i:(j→i) ci
cj ← Σ i:(i→j) bi + Σ i:(j→i) ei
ej ← Σ i:(i→j) ci
Defines a limiting vector for the iteration
b 0 B 0
xk+1 = M xk, x0= 1 where x = c , M = BT 0 B e 0 BT 0

Towards arbitrary graphs
For the graph • → • A = and M =
For the graph •→ • → • A = and M =
Formula for M for two arbitrary graphs GA and GB :
M= A B + AT BT
With xk =vec(Xk) iteration xk+1 = M xk is equivalent to Xk+1 = BXk AT+BT Xk A
0 1
0 0
0 B
BT 0
0 1 0
0 0 1
0 0 0
0 B 0
BT 0 B
0 BT 0

Convergence ?
The (normalized) sequence
Zk+1 = (BZk AT+BT Zk A)/ ||BZk AT+BT
Zk A||2
has two fixed points Zeven and Zodd for every Z0>0
Similarity matrix S = lim k→∞ Z2k , Z0 =1
Si,j is the similarity score between Vj (A) and Vi (B)
Properties
• ρS=BSAT+BTSA, ρ=||BSAT+BTSA||2• Fixed point of largest 1-norm• Robust fixed point for M+ε1• Linear convergence (power method for sparse M)

Bow tie example
S= S=
if m>n if n>m
not satisfactory
ρ 0
0 0
: :
0 0
0 1
: :
0 1
0 ρ
1 0
: :
1 0
0 0
: :
0 0 graph B 2
1
n+1 n+m+1
graph A
1 • → • 2
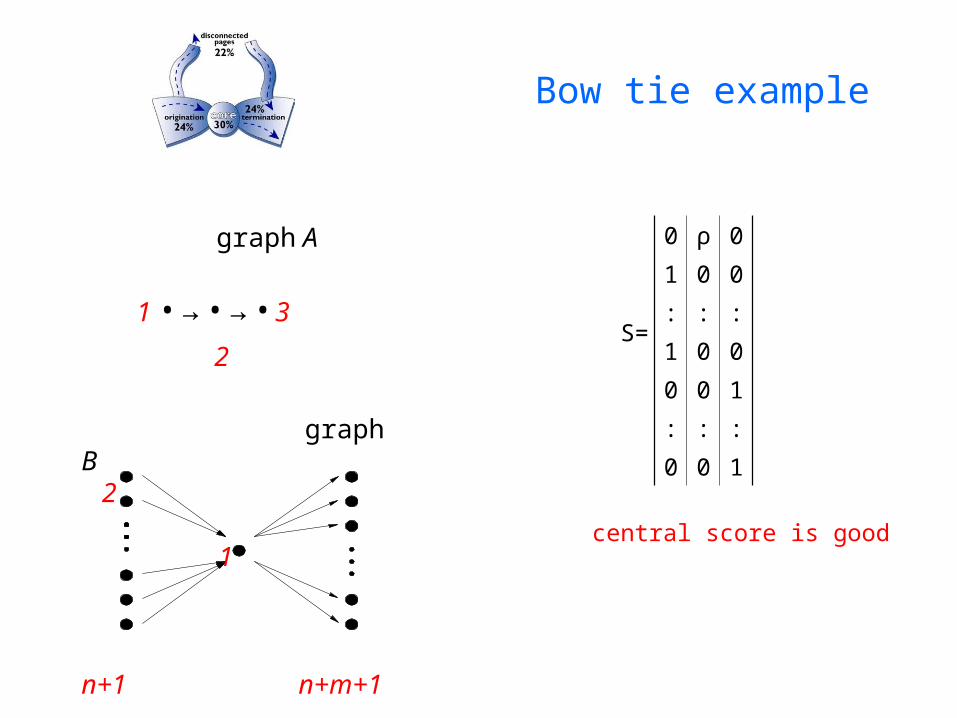
Bow tie example
S=
central score is good
graph B 2
1
n+1 n+m+1
graph A
1 • → • → • 3
2
0 ρ 0
1 0 0
: : :
1 0 0
0 0 1
: : :
0 0 1

Other properties
• Central score is a dominant eigenvector of BBT+BTB
(cfr. hub score of BBT and authority score of BTB)
• Similarity matrix of a graph with itself is square and semi-definite.
Path graph • → • → • Cycle graph
.4 0 0
0 .8 0
0 0 .4
1 1 1
1 1 1
1 1 1

The dictionary graph
OPTED, based on Webster’s unabridged dictionary
http://msowww.anu.edu.au/~ralph/OPTED
Nodes = words present in the dictionary : 112,169 nodes
Edge (u,v) if v appears in the definition of u : 1,398,424 edges
Average of 12 edges per node
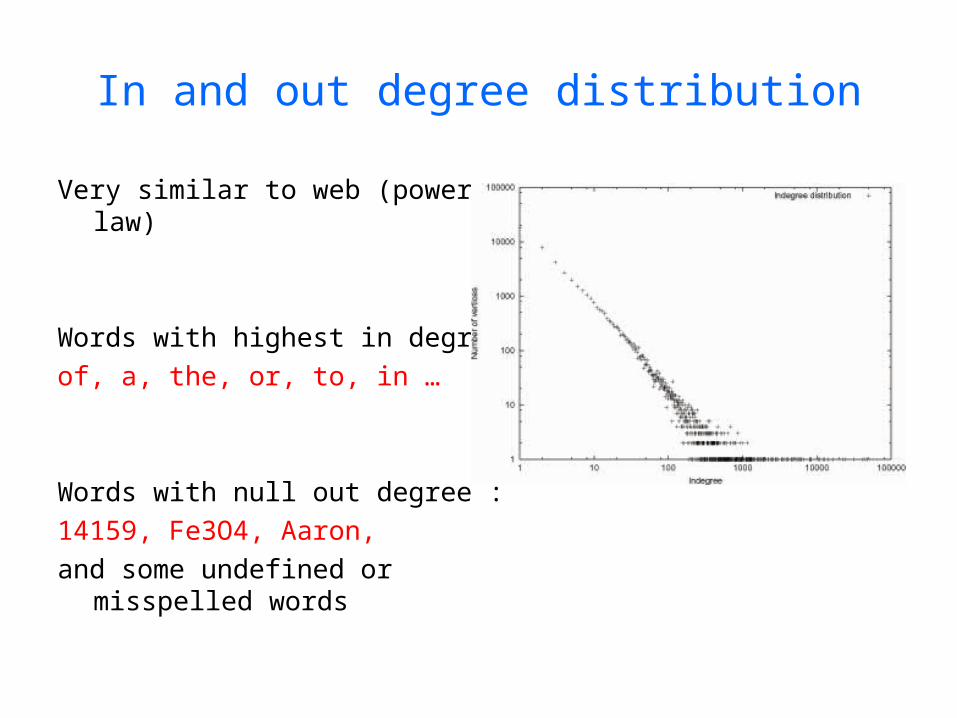
In and out degree distribution
Very similar to web (power law)
Words with highest in degree :
of, a, the, or, to, in …
Words with null out degree :
14159, Fe3O4, Aaron,
and some undefined or misspelled words
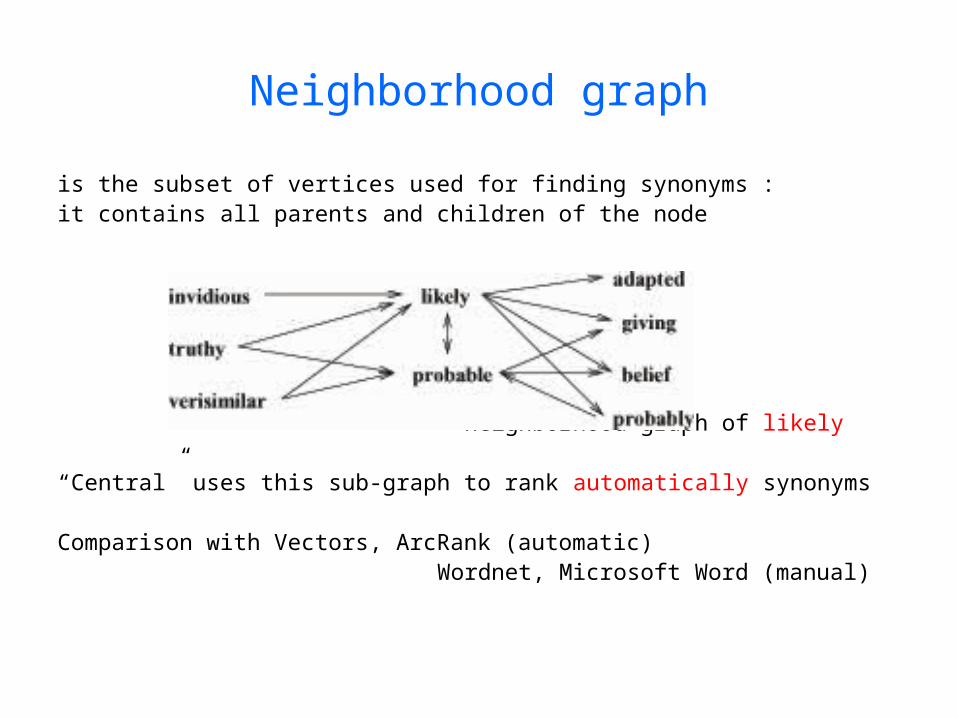
Neighborhood graph
is the subset of vertices used for finding synonyms : it contains all parents and children of the node
neighborhood graph of likely
“Central” uses this sub-graph to rank automatically synonyms
Comparison with Vectors, ArcRank (automatic) Wordnet, Microsoft Word (manual)

Disappear
Vectors Central ArcRanc Wordnet Microsoft
1 vanish vanish epidemic vanish vanish
2 wear pass disappearing go away cease to exist
3 die die port end fade away
4 sail wear dissipate finish die out
5 faint faint cease terminate go
6 light fade eat cease evaporate
7 port sail gradually wane
8 absorb light instrumental expire
9 appear dissipate darkness withdraw
10 cease cease efface pass away
Mark 3.6 6.3 1.2 7.5 8.6
Std Dev 1.8 1.7 1.2 1.4 1.3
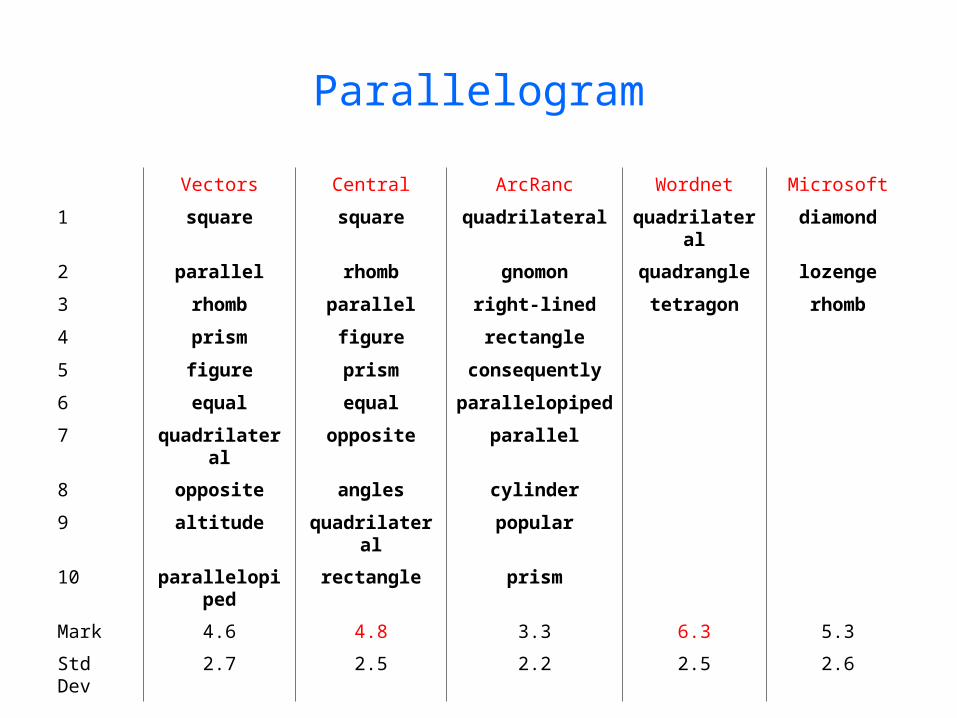
Parallelogram
Vectors Central ArcRanc Wordnet Microsoft
1 square square quadrilateral quadrilateral diamond
2 parallel rhomb gnomon quadrangle lozenge
3 rhomb parallel right-lined tetragon rhomb
4 prism figure rectangle
5 figure prism consequently
6 equal equal parallelopiped
7 quadrilateral opposite parallel
8 opposite angles cylinder
9 altitude quadrilateral popular
10 parallelopiped rectangle prism
Mark 4.6 4.8 3.3 6.3 5.3
Std Dev 2.7 2.5 2.2 2.5 2.6
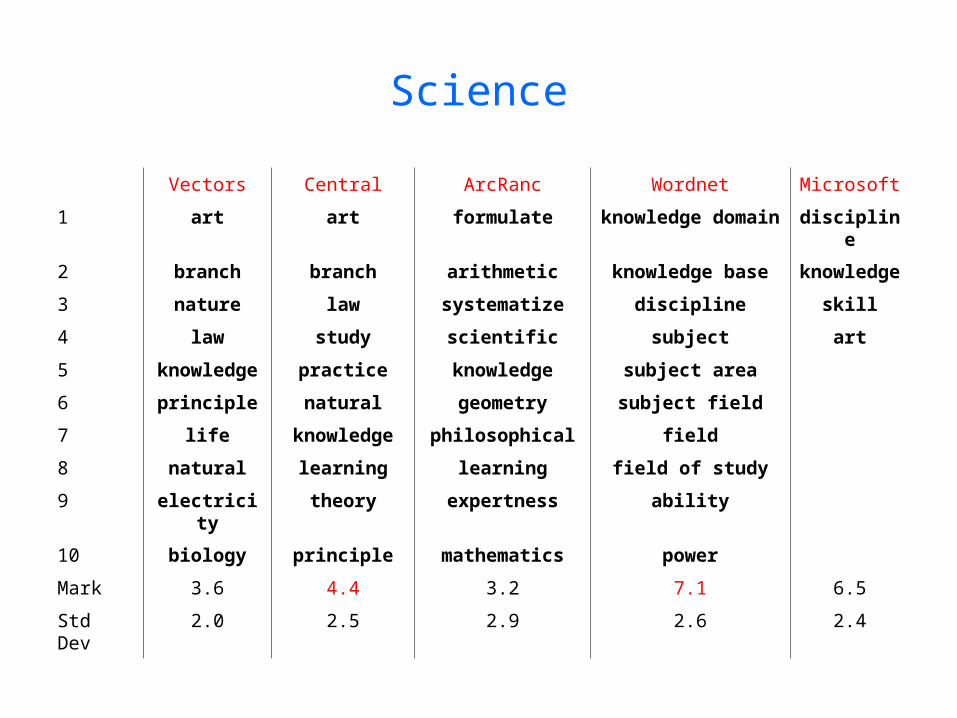
Science
Vectors Central ArcRanc Wordnet Microsoft
1 art art formulate knowledge domain discipline
2 branch branch arithmetic knowledge base knowledge
3 nature law systematize discipline skill
4 law study scientific subject art
5 knowledge practice knowledge subject area
6 principle natural geometry subject field
7 life knowledge philosophical field
8 natural learning learning field of study
9 electricity theory expertness ability
10 biology principle mathematics power
Mark 3.6 4.4 3.2 7.1 6.5
Std Dev 2.0 2.5 2.9 2.6 2.4
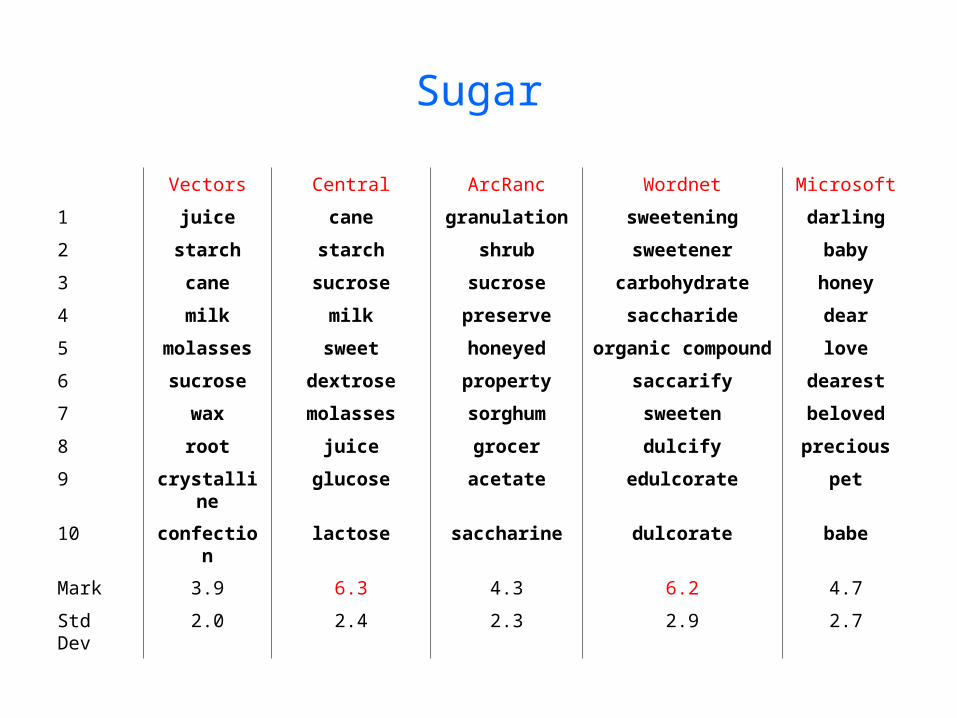
Sugar
Vectors Central ArcRanc Wordnet Microsoft
1 juice cane granulation sweetening darling
2 starch starch shrub sweetener baby
3 cane sucrose sucrose carbohydrate honey
4 milk milk preserve saccharide dear
5 molasses sweet honeyed organic compound love
6 sucrose dextrose property saccarify dearest
7 wax molasses sorghum sweeten beloved
8 root juice grocer dulcify precious
9 crystalline glucose acetate edulcorate pet
10 confection lactose saccharine dulcorate babe
Mark 3.9 6.3 4.3 6.2 4.7
Std Dev 2.0 2.4 2.3 2.9 2.7

Conclusion
• New notion of similarity between vertices of a graph
• Easy to compute : start from X0 = 1 and take even normalizediterates of Xk+1=BXkAT+BTXkA
• Potential use for data-mining, classification, clustering
• Successful implementation for the french dictionary “Le petit Robert”
• Applications in texts, internet, reference lists, telephone networks, bipartite graphs… (Melnik, Widom, …)
• Different from sub-graph problems !