wlcg and its technical architecture
TRANSCRIPT

Lecture for GC3 Large Scale Computing Infrastructures - MINF4526 - UZH - 2012-12-05Room BIN-2.A.10, 12:00-14:00
Sigve Haug on behalf of DPNC Geneva and AEC/LHEP Bern - ATLAS 2012 - 1/11
World wide Large Hadron Collider (LHC) Computing Grid (WLCG)
WLCG and its
Technical Architecture
Sigve Haug - Albert Einstein Center for Fundamental Physics - University of Bern

Information on the guest lecturer
2

Lecture outline
3
1. Large Hadron Collider (LHC) and its Computing and Data requirements
1.1 LHC physics, detectors, trigger and data output 1.2 Computing and Data requirements
2. World wide LHC Computing Grid (WLCG)
2.1 Basic architecture 2.2 Infrastructure elements and implementation 2.3 Data management 2.4 WLCG in action
3. Future of WLCG
3.1 Some lessons 3.2 Some challenges

Sigve Haug on behalf of DPNC Geneva and AEC/LHEP Bern - ATLAS 2012 - 1/11
Part 1
The Large Hadron Collider and its
Computing and Data Requirements

1.1 Large Hadron Collider Physics
5
Main objectives in the LHCphysics program
• Discover the Higgs particle. Measure its properties.
• Probe the Standard Model (SM) of elementary particles in a new energy domain. Measure so-called cross sections and branching ratios
• Discover new physics beyond the SM (supersymmetry, dark matter, extra dimensions ...)
Most of the program was settled already back in the 1980s and 1990s.
LHC and its experiments. Today we use ATLAS as example

1.1 Cross Sections σ and Luminosity L
6
The number of events N in the detector
NTotal = L x σ ~ 109 s-1 NHiggs(150) ~ 0.5 s-1
Today we have produced O(104) Higgs particles. About 150 after selection.
Integrated luminosity
Month in YearJan Apr Jul Oct
]-1D
eliv
ered
Lum
inos
ity [f
b
0
5
10
15
20
25
30 = 7 TeVs2010 pp = 7 TeVs2011 pp = 8 TeVs2012 pp
ATLAS Online Luminosity
Cross section as function of machine energy

|η|<3.0|η|<3.0
1.1 Recorded Data Amount - ATLAS Example
The on-line trigger farm
The trigger system (a bit old)
• ~ 2.5k Computers• ~ 1M Lines of C++ and python• ~ 50 Developers• ~ 20 Releases per year• ~ 100 bugs per week
500-1000 events written to disk per second. This corresponds to ~ GB/s. ATLAS writes typically 10h/day 200 days a year. What is the total volume ? 7.2

1.2 Computing and Disk Requirements
8
About 100 PB disk, 70 PB tape and 785 kHS06 needed by ATLAS only. In total WLCG needs to provide about the double.

Sigve Haug on behalf of DPNC Geneva and AEC/LHEP Bern - ATLAS 2012 - 1/11
How to give ~10ʼ000 scientists all
over the globe access to petabytes of data coming from one
instrument ?
(and make everyone else happy)

Part 2
The World wide Large hadron collider Computing Grid
WLCG

2. WLCG
11
In short
• Technical Design Report (TDR) in 2005. The Distributed Computing Infrastructure (DCI) for LHC
• Now a grid with more than 170 computing centers in 36 countries, i.e. the worldʼs largest aggregation of clusters and storage installations.
• Contains O(100) PB of data distributed over the centers and several 105 cores to process this data.
• Provides thousands of scientists access to the data and the CPU
• Based on commodity hardware, some private network links and common research networks
Will continue to be the DCI for LHC the next 10 to 20 years
Sites in the World wide LHC Computing Grid

2. WLCG Initial Considerations
12
• Centralize everything ?
• Space, cooling and power not available at CERN back in 1999
• Member countries wanted 2/3 outside CERN
• Distribute everything ?
• High network capacity expectations, grid technologies emerging
• A lot of existing infrastructure and sites available around the globe
• Network reliability a big concern
• Something in between turned out to be feasible
• The so-called MONARC Model of LHC computing (with tiers)

2.1 WLCG Basic Architecture
13
20 (%)
11 (40%)
~ 130 (40%)
Many
2011 : ~250k cores and ~100 PB disk
(Tiers = Steps / Levels)

2.2 WLCG Network Infrastructure
14
There are dedicated“dark” fibers from Tier0 tothe 11 Tier1. The rest ispublic.
In Switzerland:
Level 3
CIXP
GEANT3lightpaths
GEANT3
AMS-IX
Swisscom
SwisscomTelia
Equinix
Swissix
CBF LinkDFN
Swissix
BelWü
CBF LinkGARR
Project
Provider
Network
IX
Dark!bers
SWITCHlan backbone node
Lightpaths
Internet transit
Internet exchange
Research and education network
SWITCHlan node with external peerings
CERN
UniGE
IBM
Skyguide
VSNetRERO
HES-SOAvdP
UniL
IMD
EESP
EHL
EPFL
HEIG-VD
UniFR
UniBEUniNE
EUresearchETH-Rat
SNFHSLU
VSNet
HFSJG
CSCSTI-EDU
HFT-SO
HES-SO
IWB
UniBASBSSE PSI
ENSI
WSL
Equinix
IBM
ETH
HSR
ITIS
NAZ
UZHmeteoCH
ZHAW
PHTG
FHSG UniSG
NTB HLI
HTWPMOD
SLF
EICLRG
LRG
LRG
LRG
SWITCHlan Backbone 2012
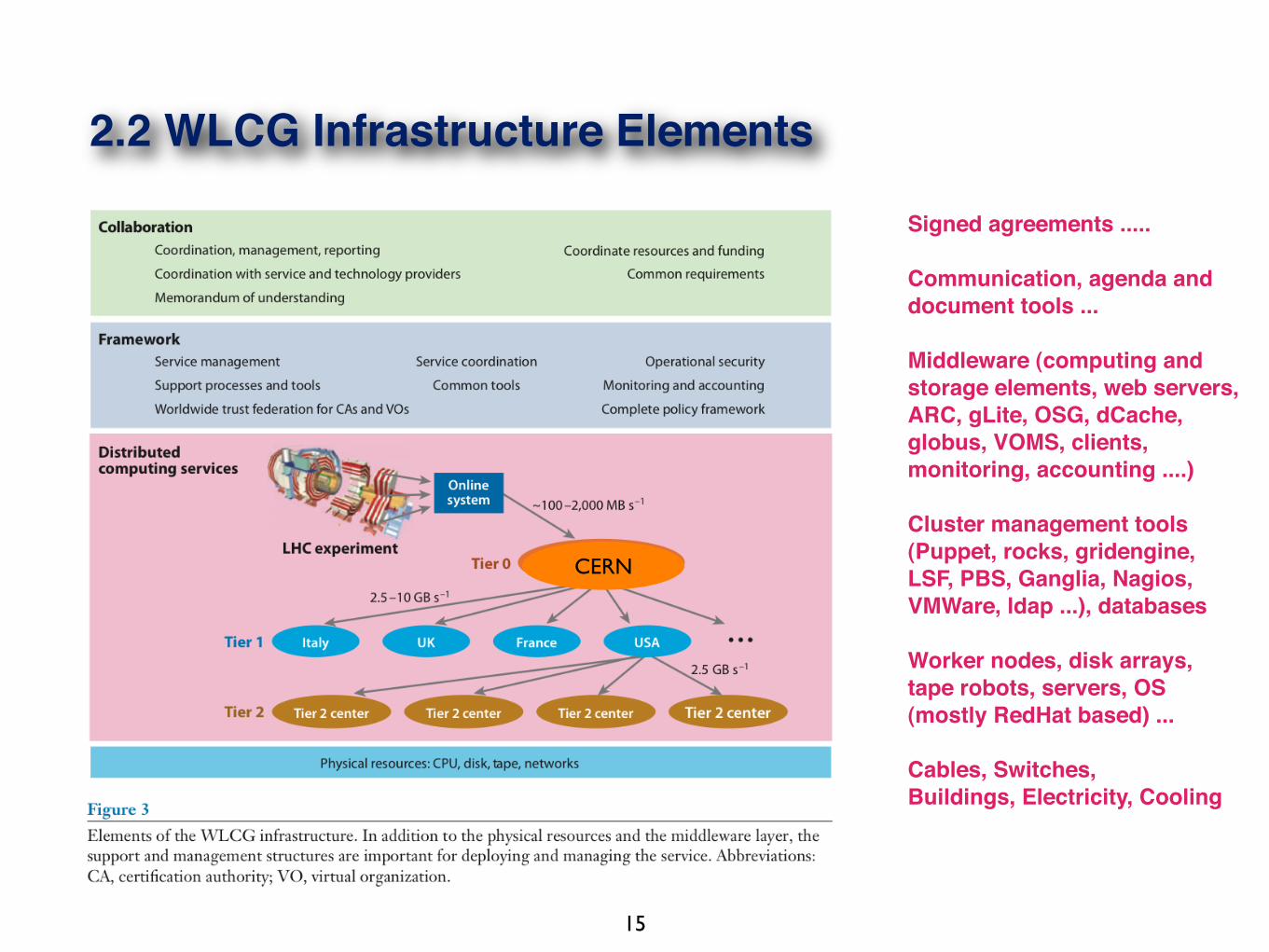
2.2 WLCG Infrastructure Elements
15
Based
Signed agreements .....
Communication, agenda and document tools ...
Middleware (computing and storage elements, web servers, ARC, gLite, OSG, dCache, globus, VOMS, clients, monitoring, accounting ....)
Cluster management tools (Puppet, rocks, gridengine, LSF, PBS, Ganglia, Nagios, VMWare, ldap ...), databases
Worker nodes, disk arrays, tape robots, servers, OS (mostly RedHat based) ...
Cables, Switches,Buildings, Electricity, Cooling
CERN

2.2 WLCG Implementation with Grid Middleware
16

Sigve Haug on behalf of DPNC Geneva and AEC/LHEP Bern - ATLAS 2012 - 1/11
Middleware and WLCG do not
provideDistributed Data Management
(DDM) based on Data Sets
Thus, each experiment hasdeveloped their own DDM systems

2.3 Experiment/ATLAS Data Organization
18
• Data are in files aggregated into data sets or containers
• If possible, files are kept large (several GB)
• Data sets often contain thousands of files with events recorded under “constant” conditions. Containers also contain data sets.
• Data sets are therefore smallest subject of
• Replication, movement and processing
• Meta data stored in data bases (MySQL, ORACLE) with http front-ends
• Replication list, file list per data set, location of file catalog
• Physics meta data also stored in data bases
• Look up place for the scientist based on a “Good Run List”

2.3 ATLAS Distributed Data Management System
19
• Relies on middleware (LFC, FTS, SRM, SE)
• Implements Datasets in Data Bases
• Python implementation
• Python agents at T1 sites
• User client to create sets, upload sets, retrieve sets, look up sets etc
• O(5000) datasets per day

2.3 WLCG/ATLAS Data Distribution
20
• Copy data set (raw data = “byte stream”) from experimental site to Tier 0
• Full copy to tape at Tier 0
• First reconstruction (raw data -> object/derived format)
• One full copy of raw distributed to Tier 1s. Derived data to every Tier 1.
• Tier 1s
• Reprocessing of data (when better meta data etc available)
• Distribution of derived data to Tier 2s
• Tier 3s and 4s
• Get data off the grid for local end analysis

ATLAS Production and Distributed Analysis System
21
• The experiments have their own• layers on top of the WLCG also
for job management.
• In ATLAS this is called PanDA.
• On one hand it has a production system for coordinated placement of jobs and submission
• On the other it has user clients for “chaotic” usage
• It handles about 1M jobs per day with 1k users of which 300 are heavy users.
Implemented in Python and MySQL and runs under Apache as a web service

The ARC model in the Nordic Cloud / Tier 1
22
• The pilot job model require “grid nodes”
• ARC sites normally donʼt have middleware on the worker nodes (non-grid nodes)
• ARC downloads input to the front-end which is then available via (parallel) local filesystem.
•
Implemented in Python (probably similar to GP3 ?)
• ARC submission service (here aCT) can automatically send jobs where files are cached (ACIX).
• ALL THIS IS USELESS IN THE PILOT MODEL.
• So some in ATLAS put the arc Control Tower between PaNDA and the clusters.
• ARC has a cache on the front-end and then automatically minimizes file transfers.

2.4 WLCG in Action
23
Demonstrations etc
• Real Time Monitor Visualization http://rtm.hep.ph.ic.ac.uk/webstart.php
• Submission with prun ()
• Accounting graphs (http://accounting.egi.eu/egi.php)

• 193 Journal Papers (CMS similar)
• 112 in 2012• 88 in 2011• 21 in 2010
• 389 Conference notes
• 124 in 2012• 163 in 2011• 101 in 2010
24
ATLAS Scientific Output (Status September)

Sigve Haug on behalf of DPNC Geneva and AEC/LHEP Bern - ATLAS 2012 - 1/11
Part 3
Future of WLCG

3.1 Some lessons
26
...
• Capacity and reliability of the network were underestimated. The constraints from the rigid MONARC model are not all necessary. Rigid data placement is not optimal.
• Generic work flows turned out to be too complex, not very usable
• A availability beyond 90-95% is unrealistic. All solutions should cope with services being down for some periods
• Aggregation of files (data sets) should not be smallest data unit. Some files are always missing. They should be taken from somewhere else.
...

3.2 Some expected challenges
27
...
• New CPU technologies (multi-cores, GPUs). Efficient usage of memory needed.
• Virtualization, hybrid and public clouds
...

28
The future of WLCG ...
33 TeV.
3000 fb-1 at 14 TeV
300 fb-1 at 14 TeV
... may be longer than the one of LHC

4 Summary
29
Who gives the summary ?
• ...
• ...
...

Selected literature
30
• Bird I., Computing for the Large Hadron Collider, Annu. Rev. Nucl. Part. Sci. 2011.61:99-118.
• Aderholz M., et al., Models of Networked Analysis at Regional Centers. MONARC phase 2 rep. CERN-LCB-2000-001 (2000)
• Managing ATLAS data on a petabyte scale with DQ2 http://iopscience.iop.org/1742-6596/119/6/062017/pdf/ jpconf8_119_062017.pdf

ADDITIONAL SLIDES
31

2.1 WLCG - TIER0 Data flow
32
Based on t

33
The ATLAS Event Data Model (EDM)
The Event Data Model defines a number of different data formats:• RAW:
◦ "ByteStream” format, ~1.6 MB/event• ESD (Event Summary Data):
◦ Full output of reconstruction in object (POOL/ROOT) format:■ Tracks (and their hits), Calo Clusters, Calo Cells, combined reconstruction objects etc.
◦ Nominal size 1 MB/event initially, to decrease as the understanding of the detector improves■ Compromise “being able to do everything on the ESD” and “not storage for oversize events”
• AOD (Analysis Object Data):◦ Summary of event reconstruction with “physics” (POOL/ROOT) objects:
■ electrons, muons, jets, etc.◦ Nominal size 100 kB/event (currently roughly double that)
• DPD (Derived Physics Data):◦ Skimmed/slimmed/thinned events + other useful “user” data derived from AODs and conditions data
■ DPerfD is mainly skimmed ESD◦ Nominally 10 kB/event on average
■ Large variations depending on physics channels• TAG:
◦ Database (or ROOT files) used to quickly select events in AOD and/or ESD files

34
The WLCG/ATLAS Operational Model
• Tier-0 (CERN):◦ Copy RAW data to CERN Castor for archival & Tier-1s for storage and reprocessing◦ Run first-pass calibration/alignment◦ Run first-pass reconstruction (within 48 hrs)◦ Distribute reconstruction output (ESDs, AODs, DPDs & TAGS) to Tier-1s
• Tier-1 (x10):◦ Store and take care of a fraction of RAW data (forever)◦ Run “slow” calibration/alignment procedures◦ Rerun reconstruction with better calib/align and/or algorithms◦ Distribute reconstruction output to Tier-2s◦ Keep current versions of ESDs and AODs on disk for analysis◦ Run large-scale event selection and analysis jobs for physics and detector groups◦ Looks like some user access will be granted, but limited and NO ACCESS TO TAPE or LONG
TERM STORAGE• Tier-2 (x~35):
◦ Run analysis jobs (mainly AOD and DPD)◦ Run simulation (and calibration/alignment when/where appropriate)◦ Keep current versions of AODs and samples of other data types on disk for analysis
• Tier-3:◦ Provide access to Grid resources and local storage for end-user data◦ Contribute CPU cycles for simulation and analysis if/when possible