words, voices and memories: the interaction of linguistic and indexical information in...
TRANSCRIPT

Words, Voices and Memories: the interaction of linguistic and indexical
information in cross-language speech perception
Steve Winters(in collaboration with
Susie Levi, David Pisoni and Karen Lichtman)Cognition and Cognitive Development Research Group
February 5, 2009

Leading Off…• A story about God and electricity.
• The moral of the story?
• Perceivers make use of whatever information is available to them to make sense of what they’re experiencing.
• And: perceptual boundaries are not necessarily limited by the intentions of production.
• “Any potential cue is an actual cue.” (Liberman, 1985)
• This observation is an essential feature of exemplar-based models of speech perception. (Johnson, 1997)

Exemplar Theory:Basic Precepts
1. Listeners store in memory every speech experience they have in their lifetime.
• Including all details of those experiences.
2. Speech tokens in memory (traces) are associated with different (linguistic, indexical) category labels.
3. New speech tokens (probes) are categorized on the basis of their similarity to exemplars in memory.
• Categories which are associated with the most similar exemplars receive the most activation.
4. The perceptual response to speech (the echo) is a weighted average of the activated exemplars.

Important!• Echoes are similar to, but more abstract than probes.
• General properties are not stored explicitly in memory; they just emerge during the processing of speech.
• Note: Francis Galton

Normalization Theory• In contrast, normalization theories of speech perception hold that listeners identify speech sounds on the basis of their defining properties.
• Mental representations of speech sounds are abstract and sparse
• [+voice], [-round], [+nasal]
• “Indexical” properties, such as a speaker’s identity, age, gender, etc., are “extra-linguistic” (Abercrombie, 1967)
• = “noise” in the signal that perception must sort through to get to the good stuff.

Received Wisdom• “...when we learn a new word we practically never remember most of the salient acoustic properties that must have been present in the signal that struck our ears; for example, we do not remember the voice quality, speed of utterance, and other properties directly linked to the unique circumstances surrounding every utterance.” -- Morris Halle (1985)
• Is this true?
• Are words and voice quality stored separately in memory?

Is this true?• No.
• Voice information does affect language processing.
1. Phoneme Classification
• (Mullennix and Pisoni, 1990)
2. Recognition Memory
• (Palmeri, Goldinger and Pisoni, 1993)
3. Spoken Word Intelligibility
• (Nygaard, Sommers and Pisoni, 1994)

Maybe the Other Way?• No.
• A familiar language facilitates voice identification.
• Forensic phonetics and the “voice line-up” task
• Thompson (1987)
• English > Spanish-accented English > Spanish
• Goggin, Thompson, Strube and Simental (1991)
• English, German, bilingual listeners
• familiar language > unfamiliar language
• Sullivan and Schlichting (2000)
• L2 learners of Swedish > no knowledge of Swedish

Testing Independence• Evidence indicates that the indexical and linguistic properties of speech are integrated in memory.
• Note: in previous research, both language and talkers were changed between listening conditions.
• Q: What happens when the language changes but the talker remains the same?

Experimental Plan• Experiment 1: Cross-language voice identification
• Train listeners to identify talkers in one language
• Test ability to generalize to new language
• Experiment 2: Cross-linguistic transfer task
• Train listeners to identify talkers in one language
• Test ability of listeners to recognize words (in noise) spoken by the same talkers in a different language.
• Experiment 3: Continuous word recognition task
• Listeners identify words--from a language they don’t know--as “old” or “new”
• words repeated in either same or different voices

Experiment 1: Hypotheses• Q: Can listeners generalize knowledge of talkers across languages?
• If linguistic and voice information are integrated in processing (and memory):
• Transfer of talker knowledge across languages should be incomplete
• Also: expect better talker identification accuracy for familiar language
• If language and voice information are processed separately:
• Complete transfer of talker knowledge should occur across languages

Experiment 1: Materials• 10 L1 German / L2 English talkers
• 5 male, 5 female
• Similar dialect
• Similar in perceived nativeness
• These talkers produced
• 360 CVC English words (e.g., buzz, cheek)
• 360 CVC German words (e.g., hoch, Rahm)

Listeners• 40 L1 English listeners
• No knowledge of German
• 20 were trained on English stimuli only
• 20 were trained on German stimuli only
• Had to show evidence of learning
• > 40% accuracy on half of testing sessions

test.tiff
Training Demo

Procedure: Training• 4 days of training
• 2 sessions per day (~30 min each)
• Each session involved:
• Familiarization: same 5 words from each talker
• Re-familiarization: same word from each talker
• Recognition: 5 words/talker, heard twice
• with feedback
• Testing: 10 words/speaker
• no feedback
x2

Procedure: Generalization• 5th day
• Familiarization: 3 words from each talker
• Re-familiarization: 1 word from each talker
• Testing (both languages)
• 10 novel words/talker in each language
• blocked by language
• counterbalanced for which language was first

test.tiff
Generalization Demo
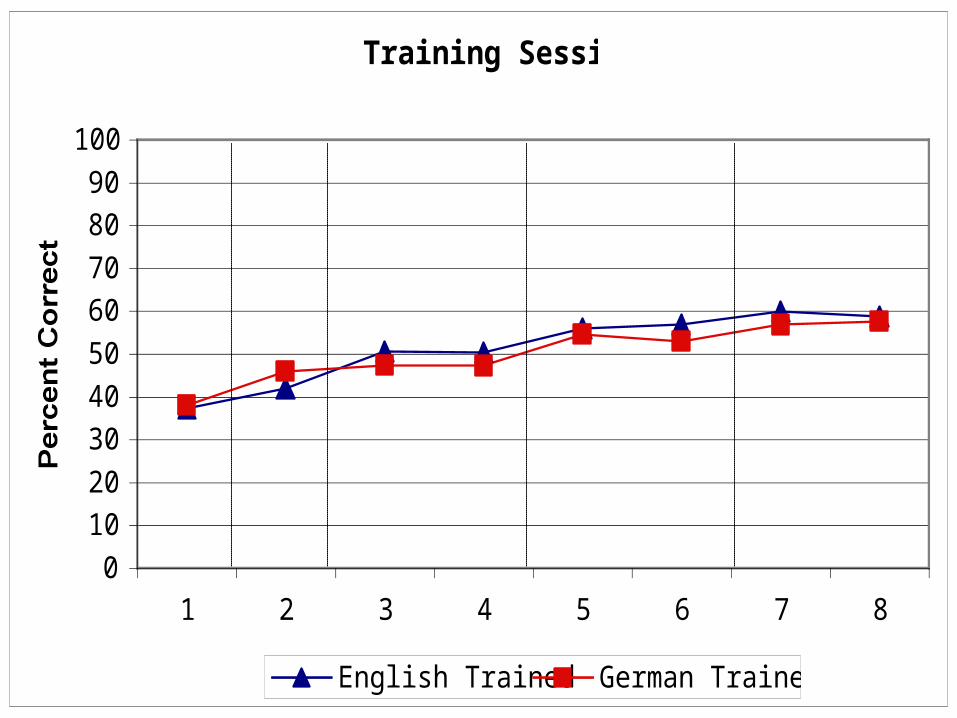
Training Results: no effect of language
Training Session
0
1020
3040
50
6070
8090
100
1 2 3 4 5 6 7 8
Percent Correct
English Trained German Trained
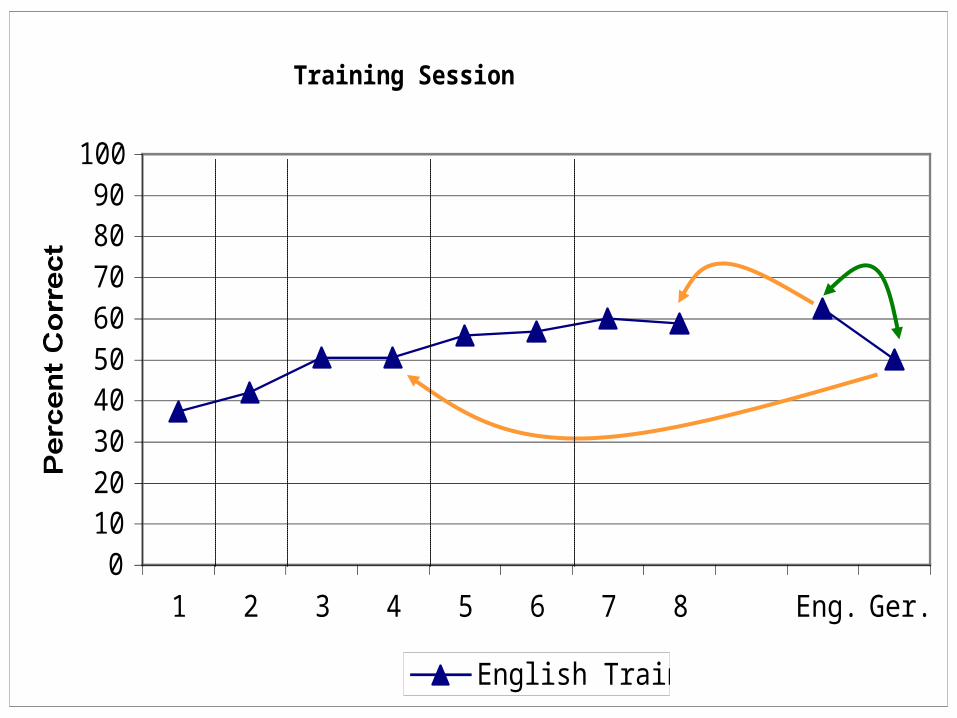
Generalization: English TrainedTraining Session Generalization
0102030405060708090
100
1 2 3 4 5 6 7 8 Eng. Ger.
Percent Correct
English Trained
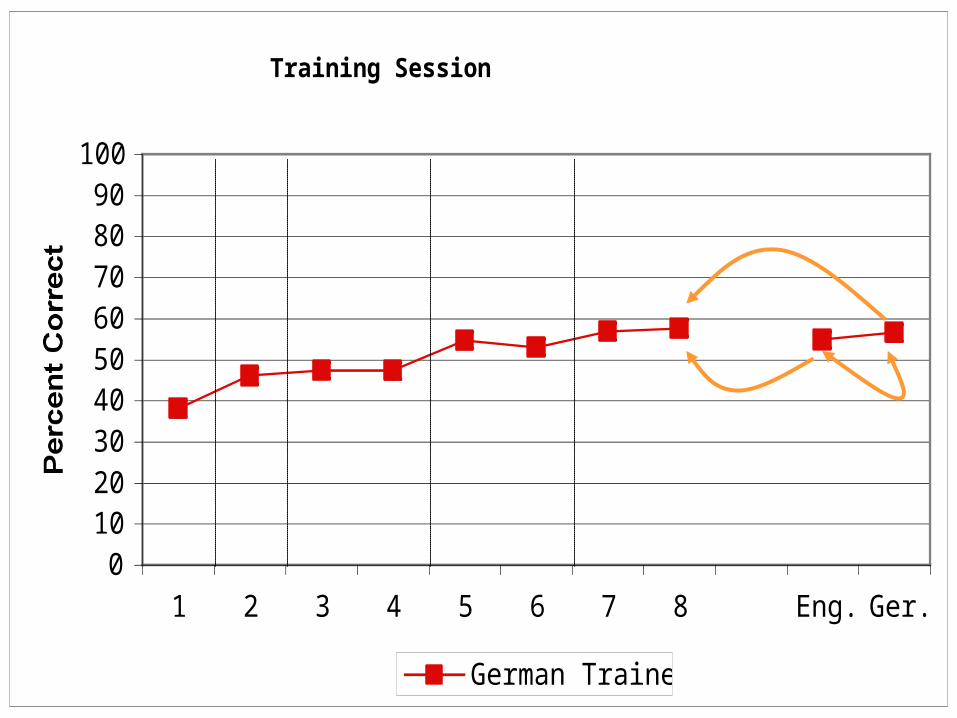
Generalization: German TrainedTraining Session Generalization
0102030405060708090
100
1 2 3 4 5 6 7 8 Eng. Ger.
Percent Correct
German Trained

Findings: Experiment 1
• Knowledge of bilinguals’ voices can generalize across languages
• Training language interacts with generalization
• = effect of language
• Listeners learn at the same rate regardless of their training language
• = no effect of language

Discussion• Evidence that talker identification is both language-independent and language-dependent.
• Q1: What are the language-independent properties of the signal?
• two possibilities: F0, duration
• Q2: Why the generalization asymmetry?
• A1: It’s easier to generalize to a familiar language.
• A2: Listeners may rely on language-dependent indexical cues only when they hear a language that they know.
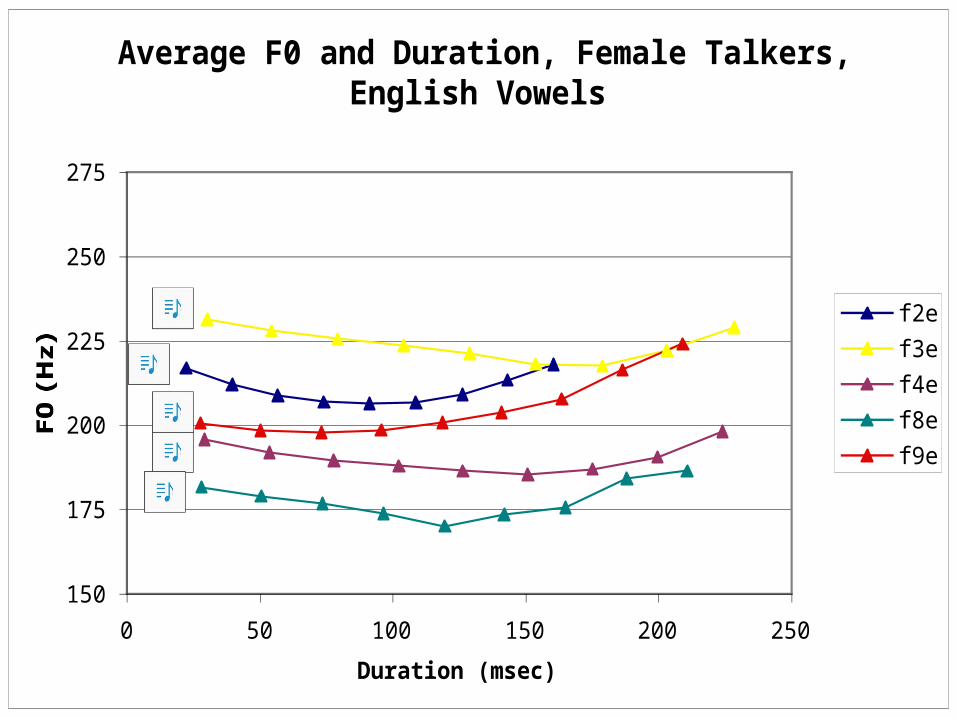
F0 chart #1: Female English
Average F0 and Duration, Female Talkers, English Vowels
150
175
200
225
250
275
0 50 100 150 200 250
Duration (msec)
F0 (Hz)
f2e
f3e
f4e
f8e
f9e
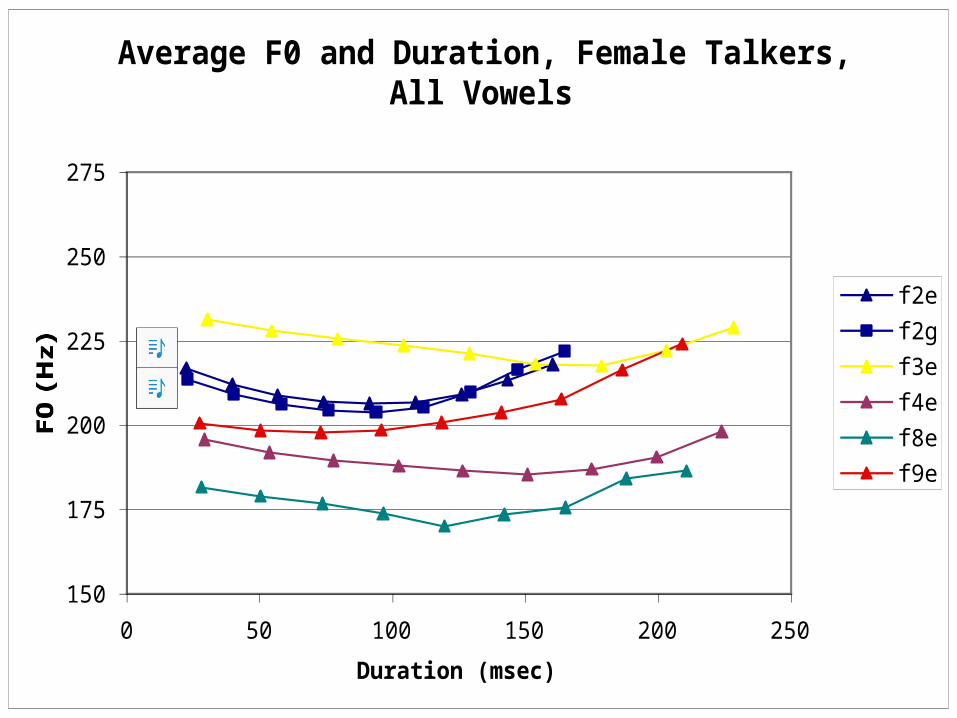
F0 Traces, Females, part 2
Average F0 and Duration, Female Talkers, All Vowels
150
175
200
225
250
275
0 50 100 150 200 250
Duration (msec)
F0 (Hz)
f2e
f2g
f3e
f4e
f8e
f9e
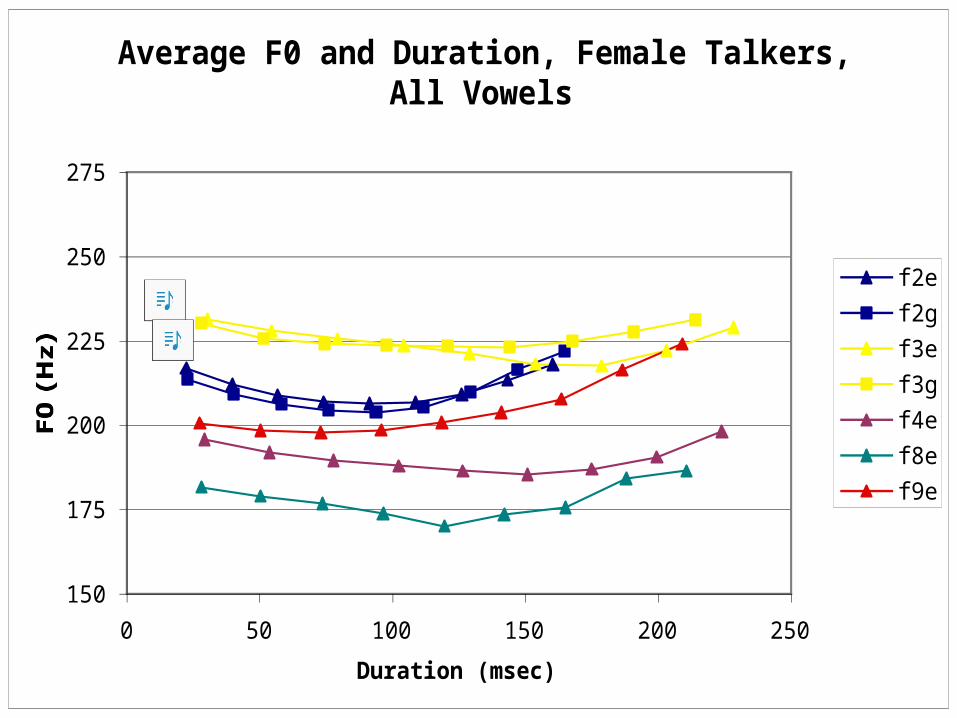
F0 Chart #3: Females
Average F0 and Duration, Female Talkers, All Vowels
150
175
200
225
250
275
0 50 100 150 200 250
Duration (msec)
F0 (Hz)
f2e
f2g
f3e
f3g
f4e
f8e
f9e
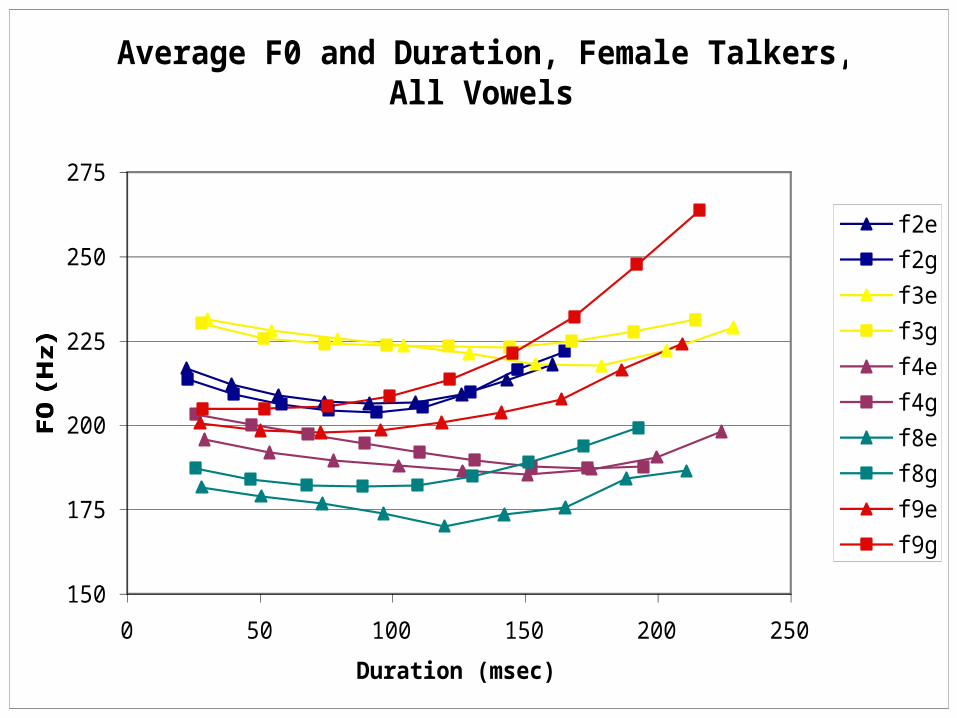
F0 Chart #4: Female All
Average F0 and Duration, Female Talkers, All Vowels
150
175
200
225
250
275
0 50 100 150 200 250
Duration (msec)
F0 (Hz)
f2e
f2g
f3e
f3g
f4e
f4g
f8e
f8g
f9e
f9g
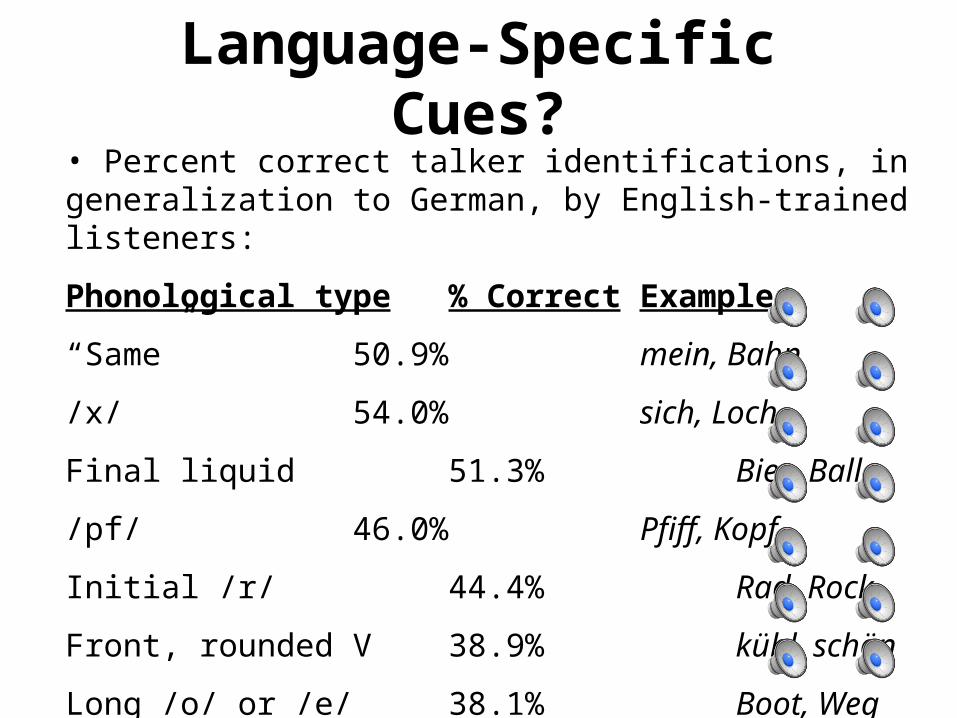
Language-Specific Cues?• Percent correct talker identifications, in generalization to German, by English-trained listeners:
Phonological type % Correct Examples
“Same” 50.9% mein, Bahn
/x/ 54.0% sich, Loch
Final liquid 51.3% Bier, Ball
/pf/ 46.0% Pfiff, Kopf
Initial /r/ 44.4% Rad, Rock
Front, rounded V 38.9% kühl, schön
Long /o/ or /e/ 38.1% Boot, Weg

Experiment 2• Q: Does knowledge of a talker in one language facilitate linguistic processing of that talker in another?
• Training task: talker identification
• English-speaking listeners (monolingual)
• Bilingual talkers, speaking in either English or German.
• Testing task: English word recognition in noise
• Three talker groups:
• Familiar bilinguals
• Unfamiliar bilinguals
• Native English talkers

Experiment 2: Motivation• Known: ability to identify a talker’s voice in English
facilitates recognition of words spoken by that talker in English. (Nygaard et al., 1994)
1. Exemplar-based account: linguistic representations include talker-specific information.
• Processing is facilitated by similarity to traces in memory.
2. Normalization account: listeners learn how to filter indexical properties of particular talkers.
• …thereby becoming more adept at revealing the linguistic core of the spoken word.

Experiment 2: Predictions• Known: listeners show complete generalization of talker knowledge from German to English. (Experiment 1)
• These listeners identify talkers based on language-independent information in speech.
• Exemplar-based prediction:
• Learning to identify talkers in German will not facilitate word recognition in English.
• (Listeners do not develop integrated representations.)
• Normalization prediction:
• Listeners filter same talker properties in both languages facilitation should occur across languages.

Experiment 2: Training• Listeners were trained to identify voices of either:
• Group 1 (five German female talkers)
• Group 2 (five German female talkers)
• Half trained in German; half trained in English
• Three days of training
• Two sessions per day
• Criterion: 40% correct on at least three training sessions.
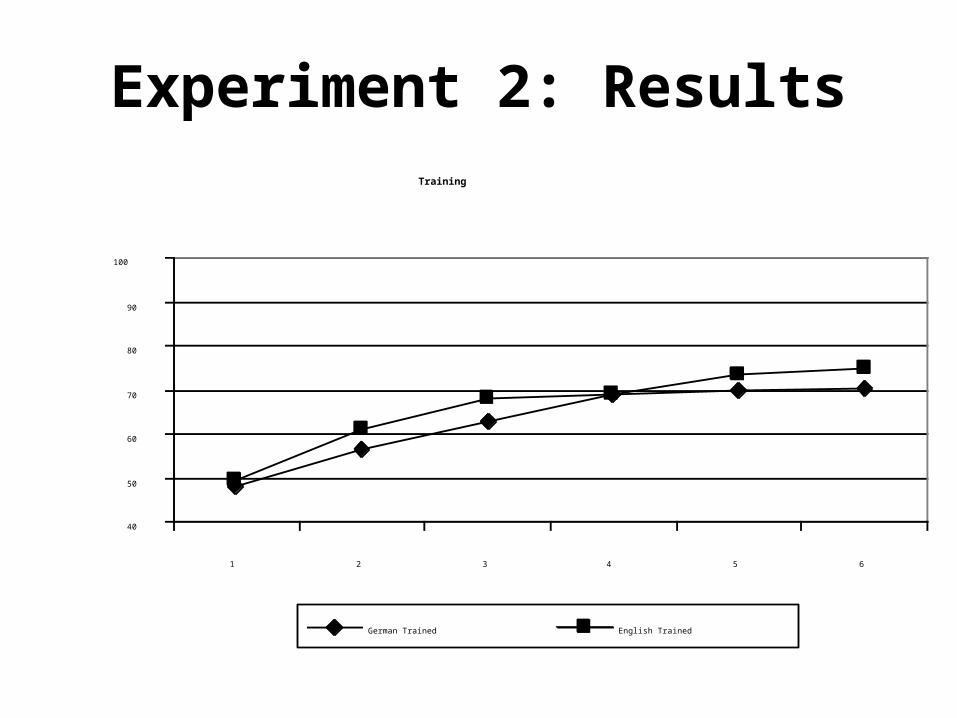
Experiment 2: ResultsTraining
40
50
60
70
80
90
100
1 2 3 4 5 6
Percent correct Talker
Identification
German Trained English Trained

Word Recognition Across Groups
Word Recognition, Untrained Listeners
0.4
0.42
0.44
0.46
0.48
0.5
English Group One Group Two
Talker Group
% Words Correct

10%
20%
30%
40%
50%
60%
Group 1 Group 2 Group 1 Group 2
Percent Whole Words Correctly Identified
Gp 1 Talkers Gp 2 Talkers
English Learners German Learners
Results:Word Recognition, all listeners
Interaction between listener and talker groups is not significant.

Splitting Hairs• Review of literature revealed that Nygaard et al. (1994) split listeners up into “good” and “poor” listeners.
• Good listeners =
• 70% correct or better in training.
• Poor listeners =
• < 70% correct in training.
• Splitting listeners in the same way yielded significant interactions in Experiment 2 data.

10%
20%
30%
40%
50%
60%
Group 1 Group 2 Group 1 Group 2
Percent Whole Words Correctly Identified
Gp 1 Talkers Gp 2 Talkers
Results:Word Recognition, English Listeners
Good Learners Poor Learners
Interaction (Good learners): p = .008; Interaction (Poor learners): p = .025.

10%
20%
30%
40%
50%
60%
Group 1 Group 2 Group 1 Group 2
Percent Whole Words Correctly Identified
Gp 1 Talkers Gp 2 Talkers
Results:Word Recognition, German Listeners
Good Learners Poor Learners
Interaction between listener and talker groups is not significant.

Discussion• (Good) English-trained listeners exhibited better word
recognition scores for familiar talkers.
• (Good) German-trained listeners did not.
• Familiar talker effect is based on rich, talker-specific linguistic representations…
• rather than a filtering of “extra-linguistic” talker information.
• Caveat: some listeners develop these representations better than others.

Patterns1. English-trained listeners displayed:
• Interactions between linguistic and talker categories in both experiments.
2. German-trained listeners:
• No interactions between linguistic and talker categories in either experiment.
• Implications:
• English-trained listeners can develop richly detailed, exemplar-like representations of speech.
• German-trained listeners develop sparser, language-independent representations of voices.

Experiment 3: Motivation• Experiments 1 and 2: voice identification training.
• German-trained listeners developed language-independent representations of voices.
• One explanation: listeners simply ignore the words.
1. meaningless to them
2. irrelevant to the task
• Q: Is there a double dissociation?
• Do English listeners ignore voices when listening to German words?

Experiment 3: Task• Task: continuous word recognition
• Listeners hear a series of words;
• Must decide if each word is “new” or a “repeat” of an earlier word in the list.
• The catch: some words are repeated in the same voice
• others are repeated in a different voice.
• Finding: same-voice repeats are easier to recognize.
• (Palmeri et al., 1993)
• Q: Is this also true in an unfamiliar language?

Experiment 3: Methods• Stimuli: German words only
• 5 male talkers in one series
• 5 female talkers in another series
• 160 (distinct) trials in each series
• 40 repeats in old voice
• 40 repeats in new voice
• Listeners: native English listeners
• 17 with no knowledge of German
• 19 German L2 learners
• Sample:
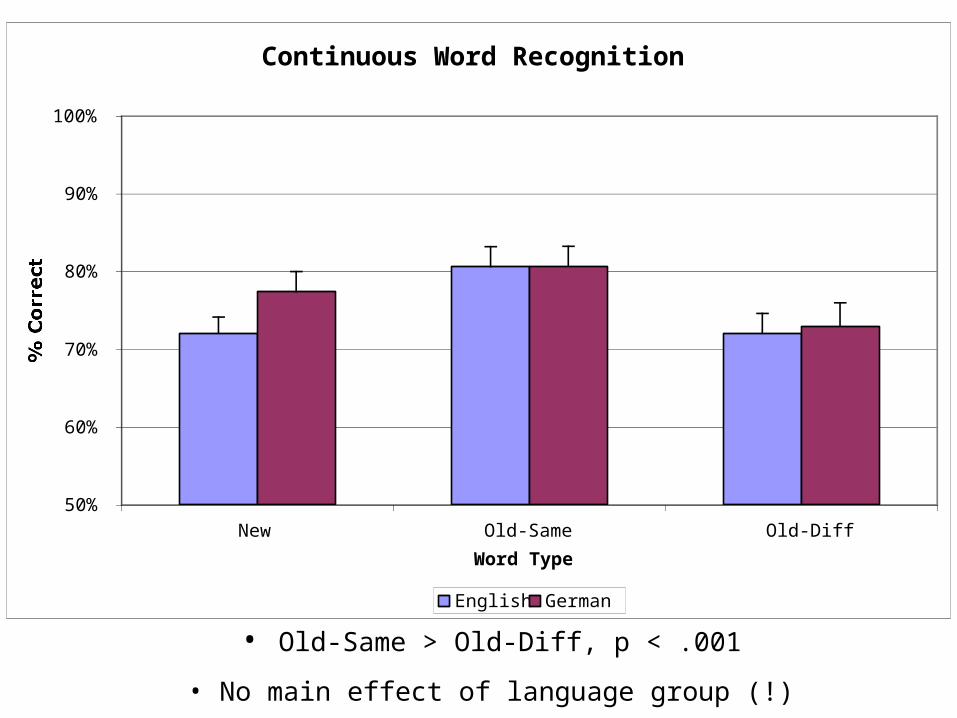
Raw Results
• Old-Same > Old-Diff, p < .001
• No main effect of language group (!)
Continuous Word Recognition
50%
60%
70%
80%
90%
100%
New Old-Same Old-Diff
Word Type
% Correct
English German
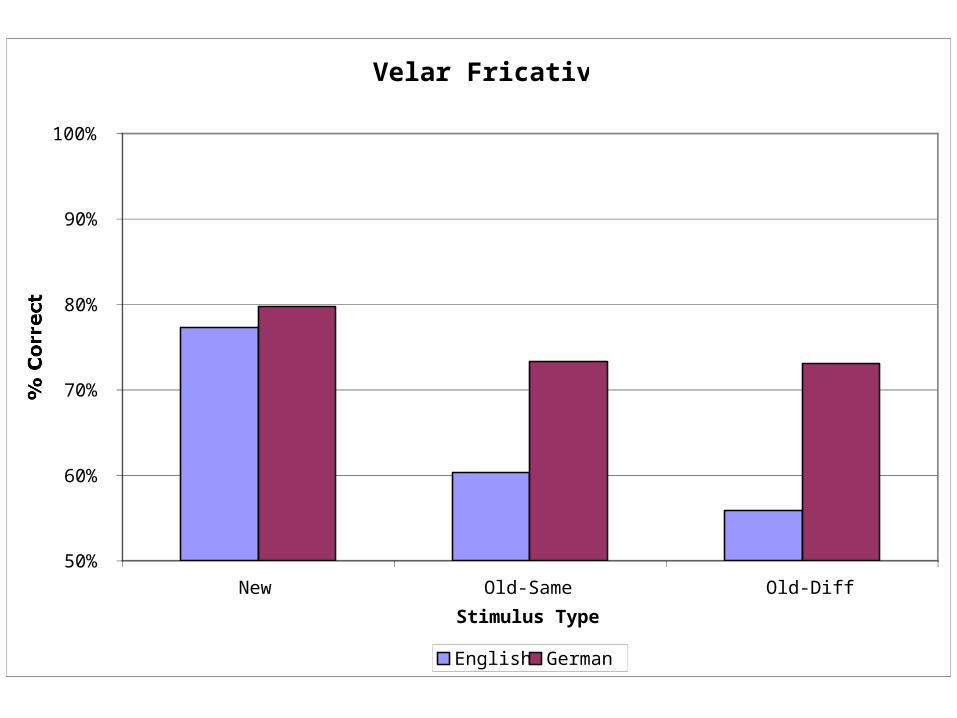
Velar Fricative DataVelar Fricative
50%
60%
70%
80%
90%
100%
New Old-Same Old-Diff
Stimulus Type
% Correct
English German
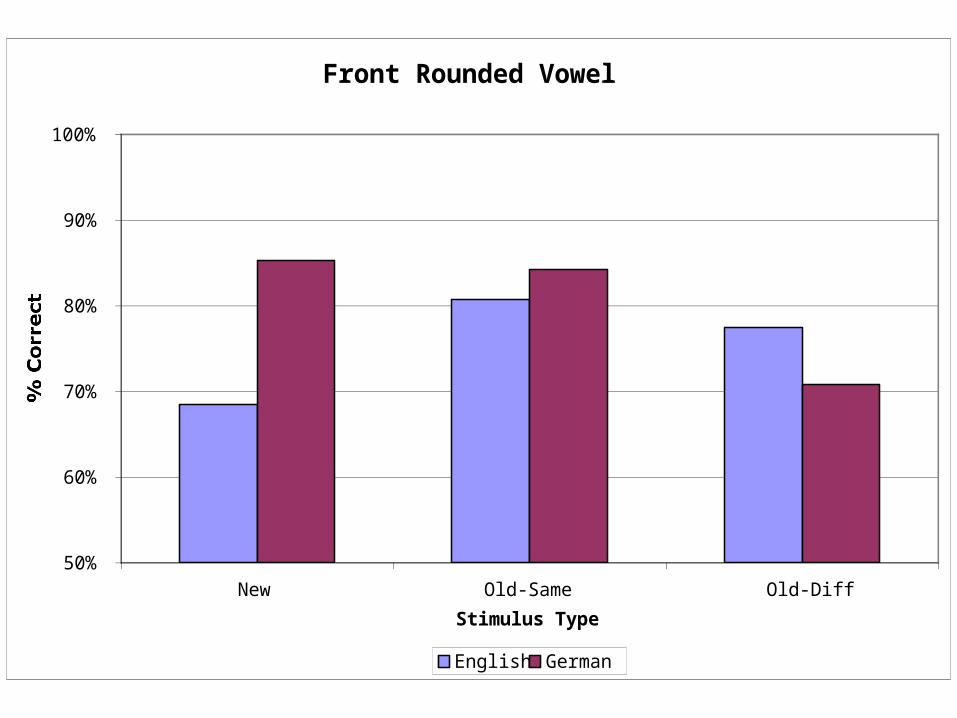
Front Rounded Vowel DataFront Rounded Vowel
50%
60%
70%
80%
90%
100%
New Old-Same Old-Diff
Stimulus Type
% Correct
English German

Conclusions1. Voice information affects word recognition even when
listeners hear words from a language they do not know.
2. L2 learners seem to encode exotic sounds more effectively than naïve listeners.
• Apparent interaction asymmetry:
• Linguistic information may be ignored
• Voice information may not

Thoughts for the future?• Perhaps we only store what we know how to label. (Pierrehumbert, 2001)
• An alternative task: continuous voice recognition
• New voice or old voice?
• Some old voices repeated with same word;
• Others repeated with different word.
• (Anecdotally: this is an extremely difficult task)

Future Directions: Thai• What (phonetic) properties do listeners use to identify voices across languages?
• Are there limitations on the amount and kinds of phonetic information listeners can store in memory?
• Ex: second language perception
• Next up: creation of Thai-English bilingual database
• Thai has:
• lexical tone distinctions
• three-way VOT distinctions
• 3 x 3 vowel space distinction

Future Directions: Thai• Talker identification training paradigm:
• Talker A is associated with Tone 1
• Talker B is associated with Tone 2
• Talker C is associated with Tone 3, etc.
• Generalization:
• Talker A is presented with not-Tone 1
• Talker B is presented with not-Tone 2, etc.
• How much is identification accuracy impaired in generalization?
• = How robust are the cognitive representations of the talkers’ voices?

Conclusions• These results pose something of a challenge to both
existing models of speech perception.
1. Generalization of talker knowledge across languages is possible.
• Extent depends on language of training.
2. Familiar talker facilitation of word recognition is based on talker-specific linguistic representations…
• Rather than a filtering of extra-linguistic indexical information.
3. Exemplar-like representations seem to depend on:
• the language being heard
• the information in the task which can be ignored


Future Directions• Theoretical possibility: you only store in exemplars what you know how to label. (Pierrehumbert, 2001)
• But then…how do you learn how to label it?
• Research Option #1: repeat experiments with bilinguals, who know category labels for both languages.
• Should get interactions both ways.
• Research Option #2: try languages which aren’t so phonetically similar.
• Ex: Chinese (tone), Japanese (F0 differences)


Study #1

Answer #1• Theories?
• Integral (exemplar) view: language should affect the perception of talker identity
• (talker identification process depends on the phonological particulars in different languages)
• Separable (formal) view: voice information is processed separately from language.
• Predicts transfer of knowledge across languages
• …because listeners attend to language-independent voice information.

Nobody’s Perfect• Do listeners really store every acoustic detail of spech
exemplars in memory?
• Some limitations to think about:
1. Storage space/forgetting
2. Categorical Perception: sound discrimination follows sound identification
• Note: this works best with speech sounds that exhibit rapid spectral changes (POA) rather than more gradual or stable spectral qualities (vowels)
3. Second Language (L2) speech perception
4. Development of first language (L1) speech perception

Questions• We know that linguistic and indexical information interact within a given language…
• But how language-dependent is a listener’s mental representation of a particular talker’s voice?
• If you know what a bilingual talker sounds like in one language…
• Can you identify them when they are speaking in a different language?
• o voice and linguistic information interact when listeners identify bilingual talkers across languages?
• (and are there any language-independent properties in the signal that listeners might attend to when identifying voices speaking in two different languages?)
• How much do we need to consider voice information in phonological representations of speech?

References• Garner, W.R. (1974) The Processing of Information and Structure. Erlbaum, Potomac, Wiley, New York.
• Garner and Felfoldy, 1970 W.R. Garner and G.L. Felfoldy, Integrality of stimulus dimensions in various types of information processing, Cognit. Psychol. 1 (1970), pp. 225–241.


Leading Off…• A story about God and electricity.
• The moral of the story?
• Perceivers will make use of whatever information is available to them to make sense of what they’re experiencing.
• “Any potential cue is an actual cue.” (Klatt, 1979)
• Any arbitrary detail may be perceived to contribute to the meaning of a ritualistic act.
• …especially if it’s consistent.
• The mind does not always draw the perceptual boundaries you expect it to draw.
• especially if the meaning of what it perceives is arbitrary.
• Also: any potential cue is an actual cue. (Klatt, 1979)
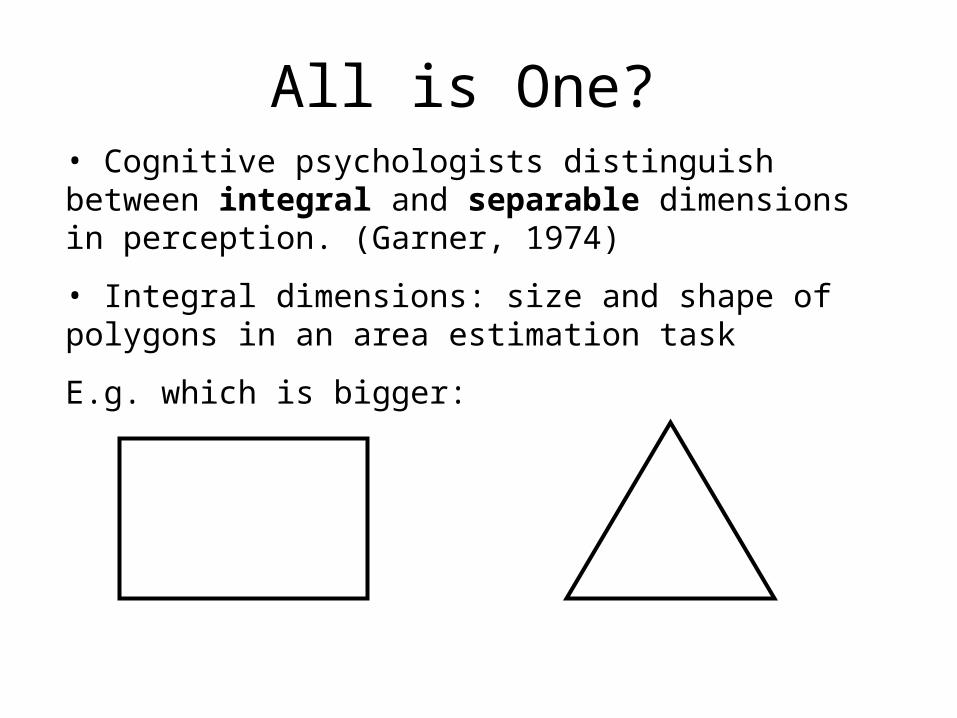
All is One?• Cognitive psychologists distinguish between integral and separable dimensions in perception. (Garner, 1974)
• Integral dimensions: size and shape of polygons in an area estimation task
E.g. which is bigger:

All is One?• Cognitive psychologists distinguish between integral and separable dimensions in perception.
• Separable dimensions: size and color of polygons in an area estimation task
E.g. which is bigger:

Linguistic Distinctions• In formal phonology, features of speech sounds have traditionally been represented as a set of separable dimensions. (Chomsky & Halle, 1968)
• [+voice], [-back], [-round], etc.
• This set has been modified somewhat over the years…
• But the basic set of distinctive features still operates independently of “micro-features”
• …such as the phonetic properties of different speakers’ voices
• or the environmental setting in which sounds are heard, etc.

Interactions and Exemplars• The interaction of voice and linguistic information in
speech perception seems to supports the predictions of exemplar theories of speech perception.

Two Theories• The normalization view:
• Categorization of speech sounds operates on the basis of properties in the signal.
• Linguistic and indexical properties are orthogonal.
• (=voice information is meaningless noise)
• The exemplar view:
• Categorization of speech sounds operates on the basis of exemplars in memory.
• Linguistic and indexical properties are not separated in cognitive representations…
• And may be integrated in processing.

Questions• We know that linguistic and indexical information interact within a given language…
• But how language-dependent is a listener’s mental representation of a particular talker’s voice?
• If you know what a bilingual talker sounds like in one language…
• Can you identify them when they are speaking in a different language?
• How much do we need to consider voice information in phonological representations of speech?

Game Plan• Study 1: identification of bilingual talkers across
languages
• Study 2: transfer of voice identification knowledge to a word identification task
• (across languages)
• Study 3: continuous word recognition in an unfamiliar language
• Wrap-up/future plans.

Experiment 2: Methods• For starters: a norming study.
• 32 monolingual, native English listeners
• 15 female talkers:
• Group 1: 5 native English talkers
• Group 2: 5 native German-English bilinguals
• Group 3: 5 native German-English bilinguals
• Task: identify words spoken in four levels of white noise by all three groups of talkers.
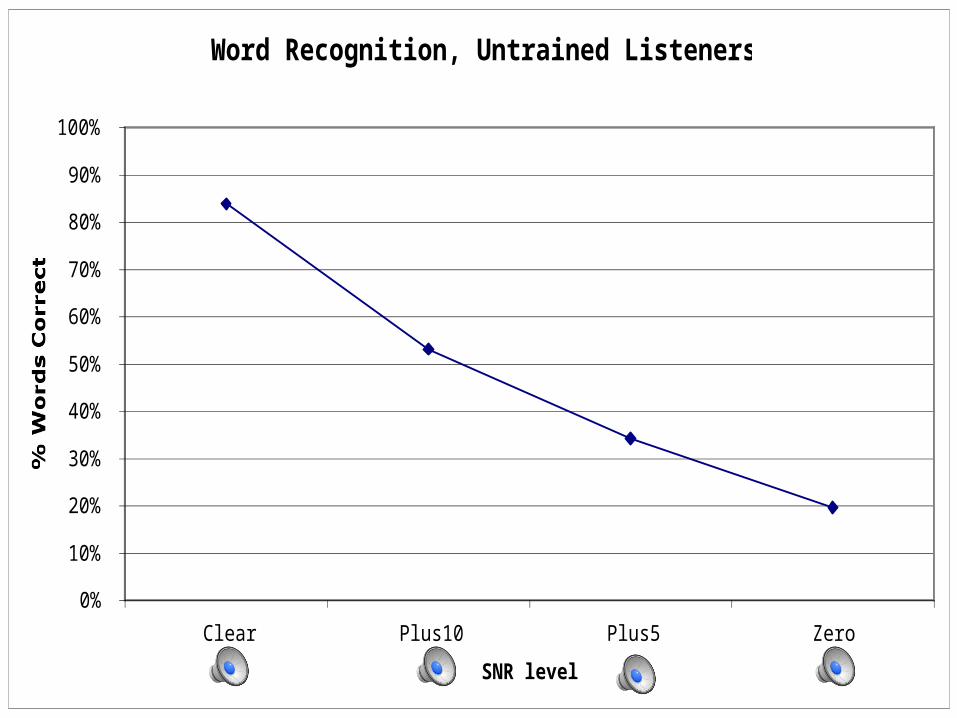
Baseline Word Recognition in English
• Graph and Demos
Word Recognition, Untrained Listeners
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Clear Plus10 Plus5 Zero
SNR level
% Words Correct