world wide web information retrieval using web connectivity
TRANSCRIPT

i
World Wide Web Information Retrieval Using Web
Connectivity Information
Jiafei Sun
Directed by Wen-Chen Hu
Committee Members
Gerry V. Dozier
Dean Hendrix
A Project Report
Submitted to the Advisory Committee
In Partial Fulfillment of the
Requirements for the
Degree of
Master of Computer Science and Software Engineering
Auburn University
May 12, 2001

ii
PROJECT ABSTRACT
Gathering, processing and distributing information from the World Wide Web
will be a vital technology for the next century. Web search techniques have played a
critical role in the development of information systems. Due to the diverse nature of web
documents, traditional search techniques must be improved. Hyperlink structure based
methods have proved to be powerful ways of exploring the relationships between web
documents.
In this project, a prototype web search engine was developed to exploit the link
structure of web documents, based on the use of the Companion algorithm. The prototype
consists of a web spider, local database, and search software.
The system was written using the Java programming language. Our spider crawls
and downloads web pages using Lynx, then saves the hyperlinks into an Oracle database.
JDBC is used to implement the database processing. Search software makes a vicinity
graph for the query URL and returns the most related pages after calculating the hub and
authority weights. Finally, HTML web pages provide user interfaces and communicate
with CGI using the Perl language.

iii
ACKNOWLEDGMENTS
The author would like to express thanks to all of the members of his M.S.
committee for their useful comments on the thesis, assistance in scheduling the defense
date and kind help during the final defense period. The author would like to express his
deepest appreciation to Dr. Wen-Chen Hu, his thesis mentor, for the depth of the training
and the appropriate guidance he has provided. The author would also like to
acknowledge the Department of Computer Science and Software Engineering of Auburn
University for financial support. Finally, thanks especially go to the author’s wife
Qifang, his son, Alex, and his father and mother for their support and love.

iv
TABLE OF CONTENTS
LIST OF FIGURES …………………………………………………………………… vi LIST OF TABLES ………………………………………………………………….... viii CHAPTER 1 INTRODUCTION …………………………………………………….. 1 1.1 World Wide Web and Web Searches .………………………………… 1
1.2 Disadvantages of the Current Search Engines …………………………..2
1.3 Project Outline.…………………………………………………………..3
1.4 Report Organization ….………………………………………………... 5
CHAPTER 2 RELATED TECHNOLOGIES USED IN THIS PROJECT ………….. 6
2.1 Web Search Services ………………………………………………….. 6
2.2 Web Spiders …………………………………………………………… 8
2.3 Database and Web-database Connectivity …………………………… 10
2.4 Data Mining ……………………..…………………………………… . 14
CHAPTER 3 SYSTEM DEVELOPMENT …………………………………………. 17
3.1 System Overview ……………….…………………………………….. 17
3.2 The Spider ………………………………………………….…………. 19
3.3 Indexing …………….. ………………….…………………………… . 23
3.4 System Interface………………………………………………………. 25

v
CHAPTER 4 RELATED-PAGE ALGORITHMS …………………………………. 30
4.1 Building the Vicinity Graph ………………………………………….. 31
4.2 Duplicate Elimination …..………………………………………………34
4.3 Edge Weight Assignment ……………….……………………………..36
4.4 Hub and Authority Score Computation ………………………………..37
4.5 An Example ………………………. …………………………………..40
CHAPTER 5. EXPERIMENTAL RESULTS …………………….………………….. 44
5.1 The Spider ………………………………………………………………44
5.2 Checking the Downloads ……………………………………………….47
5.3 Searching and Ranking ………………………………………………...50
CHAPTER 6. CONCLUSIONS ………………………………..…………………….. 57
REFERENCES ……………………………………………………………………….. 58

vi
LIST OF FIGURES
Figure 2.1 Search engine structure ……………………..…………………………… 7
Figure 2.2 JDBC – Architecture overview ………………………………………… 11
Figure 3.1 Program architecture …………………………………………………… 18
Figure 3.2 The pictures of class node and node1 ………………………………..… 22
Figure 3.3 Project interface ………………………………………………………… 26
Figure 3.4 The spider interface …………………………………………………. …. 27
Figure 3.5 The interface for checking the downloads …..………………………….. 28
Figure 3.6 The interface for the search engine ………………………………………. 29
Figure 4.1 A vicinity graph example ………………………………………………... 33
Figure 4.2 Search results of the query: http//www.eng.auburn.edu/hu/ .………..…… 42
Figure 5.1 The interface of the spider with seed URL http://www.eng.auburn.edu/ .…45
Figure 5.2 The crawling results of the spider from the seed URL
http://www.eng.auburn.edu/ ………………………………………….46
Figure 5.3 The interface for checking the download …………………………….……48
Figure 5.4 Checking the downloads …………………………………………………..49
Figure 5.5 Search results of the query: URL = http://www.oasis.auburn.edu/,
B=500, BF=500, F=500, FB=500………………………………………51

vii
Figure 5.6 Search results of the query: URL = http://www.lib.auburn.edu/,
B=500, BF=500, F=500, and FB=500………………………………….52
Figure 5.7 Search results for the query http://www.eng.auburn.edu/ ………………….54
Figure 5.8 Search results for the query http://aos.auburn.edu/ ………………………...55

viii
LIST OF TABLES
Table 1.1 Output of the Companion algorithm given http://www.auburn.edu/ ………4
Table 4.1 The authority and hub values for the vicinity graph shown in Fig 4.1 …… 33
Table 4.2 URLs and their parent and child URLs………… ……………………..… 41

1
Chapter 1 Introduction
The gathering, processing and distribution of information from the World Wide
Web will be a key technology for the next century. As the Internet has tens of millions of
sites, web search techniques play a critical role in the development of information
systems. This chapter will introduce the web and the techniques needed to search it and
look at the problems involved, and an overview of this project will be given.
1.1 The World Wide Web and Web Searches
The web is a system with universally accepted standards for storing, retrieving,
formatting, and displaying information via a client/server architecture. The web handles
all types of digital information, including text, hypermedia, graphics and sound, by way
of graphical user interfaces, making it very easy to use.
The web is based on a standard hypertext language (HTML), which formats
documents and incorporates dynamic hypertext links to other documents stored on the
same or different computers. Clicking on a hypertext link transports the user to another
document. Users are able to navigate around the web with no restrictions, free to follow

2
their own logic, needs, or interests, by specifying a uniform resource locator (URL)
which points to the address of a specific resource on the web.
The WWW hosts a plethora of information with millions of web pages. The
publicly indexable Web contained an estimated 800 million pages as of February 1999,
encompassing about 15 terabytes of information or about 6 terabytes of text after
removing HTML tabs, comments, and extra white space. This huge number of web pages
has been increasing by a million pages a day [1].
1.2 Disadvantage of the Current Search Engines
As there are so many web pages and so much information, search engines have
been developed to help retrieve desired information. Search engines are programs that
return a list of web sites or pages (designated by URLs) that match some user-selected
criteria. To use one of the publicly available search sites, the user navigates to a search
engine site and types in the subject of their search.
When the web first became available to the public, the only way to navigate it was
by surfing with the browser. Users began with a known page and traveled via its
hypertext links, browsing until they found the information they were seeking. When there
were only a few hundred HTTP servers on the Internet, this method was adequate for
most users. Most of these machines contained centrally managed collections of
documents by students and professional researchers who were aware of the major
repositories of information in their fields. However, the rapid growth of the web, both in

3
terms of the number of pages and the kinds of resources available, resulted in a need for
better ways of organizing information on the web.
Although search engines greatly help people to find some interesting web sites, at
present they suffer from several disadvantages. One is that users have to formulate
queries that specify the information they need, which is prone to errors. Another is that
all search engines do keyword searches against a database, but various factors influence
the results obtained from each. The size of the database, frequency of updates, search
capability and design, and speed may lead to significantly different results.
1.3 Project Outline
Recent work in information retrieval on the web has recognized that the hyperlink
structure can be very valuable for locating information [2,3,4,5]. This assumes that if
there is a link from page v to page w, then the author of v is recommending page w, and
links often connect related pages. In this project, the hyperlink structure contained in a
web page is used to identify related pages, overcoming the above disadvantages.
A related web page is one that addresses the same topic as the original page, but is not
necessarily semantically identical. For example, given http://www.nytimes.com/, the tool
should find other newspapers and news organizations in the web. Traditional web search
engines take a query as input and produce a set of (hopefully) relevant pages that match
the query terms. In this project, the input to the search process is not a set of query terms,
but the URL of a page, and the output is a set of related web pages. Of course, in contrast

4
to search engines, this approach requires that the user has already found a page of
interest.
This project is based on the use of Companion algorithm, which uses only the
hyperlink structure of the web to identify the related web pages. For example, Table1.1
shows the output of the Companion algorithm when given http://www.auburn.edu/ as
input.
Table1.1 Output of the Companion algorithm given http://www.auburn.edu/
URL Hub Authority Rank(A)
http://www.auburn.edu/ 7.0 2.0 7.0
http://www.lib.auburn.edu/ 3.0 1.0 4.0
http://www.auburn.edu/student_info/bulletin/ 0.0 1.0 4.0
http://www.auburn.edu/main/calendar.html 0.0 4.0 4.0
http://oasis.auburn.edu/ 0.0 1.0 4.0
http://aos.auburn.edu/ 0.0 1.0 4.0
http://www.auburn.edu/main/au_campus_directory.html 0.0 1.0 4.0
http://www.eng.auburn.edu/ 4.0 0.0 0.0
This project was designed to use a spider to exploit the hyperlink structure of the web
pages and save their URLs to the Oracle database, then find related pages by applying the
Companion algorithm. This algorithm only uses information about the links that appear
on each page and the order in which the links appear. They neither examine the content
of pages, nor do they examine patterns of how users tend to navigate among pages.

5
The Companion algorithm is derived from the HITS algorithm proposed by Kleiberg
for ranking search engine queries [6,7]. Kleinberg suggested that the HITS algorithm
could also be used for finding related pages, and provided anecdotal evidence that it
might work well. In this project, the algorithm was extended to exploit not only links but
also their order on a page.
1.4 Report Organization
Chapter 2 explains some related technologies used in this project. Chapter 3
describes the system structure. It covers the project architecture, the design and
development details of various components such as the spider, database, and common
gateway interface (CGI). Chapter 4 presents the Companion Algorithm and how to
implement each step of the algorithm in detail. Chapter 5 presents the system interface
and the results obtained by the new search engine for the related pages. Finally, Chapter 6
gives our conclusions as to the effectiveness of this approach.

6
Chapter 2. Related Technologies Used in this Project
To build a search engine, we need several different components. This chapter
introduces some related technologies we will use in this project.
2.1 Web Search Services
The Internet contains millions of sites at this point; growth is exponential and
bibliographic control does not exist. To find the proverbial needle in this immense
haystack, it is necessary to use web search techniques. Basically, there are currently two
different ways to search the web, namely search directories and search engines. Search
directories, such as Yahoo, present information to users in a hierarchically structured
format. There are numerous broad categories from which a user can select, each of which
is further divided into subcategories. Directories are the best choice for general
browsing. However, to locate specific information, it is preferable to specify the search
terms and use a search engine. In this project, a search engine is used to find related web
pages.
There are three main parts to a search engine as shown in Figure 2.1:

7
Figure 2.1 Search engine structure.
1. The crawler, also known as a “spider” or “robot,” is a program that automatically
scans various web sites. Crawlers follow the links on a site to find other relevant
pages.
2. The index is created to organize URLs, keywords, links, and text. Indexing builds
a data structure that will allow quick searching of the text.

8
3. The search software goes through the index to find web pages with key word
matches or other matching techniques and ranks the pages in terms of relevance
when a user submits a search query.
The search engine sends out "robots" or "spiders" into the World Wide Web to locate
new pages for their database. As a spider visits a web site it finds the hyperlinks it
contains, leading it to other pages within the web site and to related pages on the wider
web. The search engine will then index the subpages or important product pages. In this
chapter, these different components will be discussed in detail.
2.2 Web Spiders
A search engine does not actually scan the web when it receives a request from a
user. Rather, it looks up the keywords, phrases or links in its own database, which has
been compiled using spiders that continuously travel across the web looking for new
pages, updating existing entries and creating links to them.
There are two algorithms which may be used to direct the way a spider conducts a
search: one is depth-first and the other is breath-first. A depth-first search is a
generalization of a preorder traversal search, while a breadth-first search is like an order-
level search in the tree. Depth-first searches create relatively comprehensive databases on
a few subjects, while breadth-first searches build databases that touch more lightly on a
wider variety of documents. For example, to create a subject specific index, it is better to
select a known relevant group of pages to explore, rather than one initial document, thus

9
employing a depth-first strategy with an upper bound on the degree of depth. This would
prevent the search from becoming lost in inevitable digressions when exploring a largely
unknown space in some depth. On the other hand, if an index needs to be built for
sampling a wide variety of the web, it is better to choose a breadth-first strategy. The
breadth-first algorithm is used in this project because related pages are spread over a wide
variety of web documents.
A spider scans various web sites and extracts URLs, keywords, links, text, etc. It is
also able to follow the links on a web site to find other relevant pages. In this project, the
link structure is used to explore the relation between web pages while at the pages that
are possibly related to the user’s query are simultaneously collected to form a vicinity
graph of the web. The query term is first submitted to a text based search engine, then the
spider is used to find all the links on each returned page. Thus, the spider is used here to
crawl the web pages and obtain the vicinity related page collection that is used for the
Companion algorithm, which will be explained in detail in the Chapter 4.
The spider can be implemented in several languages, including C, C++, Perl, and
Java. Java is an innovative programming language that enables programs called applets to
be embedded in Internet web pages. Java also permits the use of application programs
that can run normally on any computer that supports the language. A Java program does
not execute directly on any computer, but runs on a standardized hypothetical computer
called the Java virtual machine, which is emulated inside the computer by a program. The
Java source code is converted by a Java compiler to a binary program consisting of byte
codes. Byte codes are machine instructions for the Java virtual machine. When a Java
program is executed, a program called the Java interpreter inspects and deciphers the byte

10
codes for it, checks to ensure that it has not been tampered with and is safe to execute,
and then executes the actions that the byte codes specify within the Java virtual machine.
A Java interpreter can run stand-alone, or it can be part of a web browser such as
Netscape Navigator or Microsoft Internet Explorer, where it can be invoked
automatically to run applets in a web page.
2.3 Database and Web-database Connectivity
Another advantage to using the Java language is that JavaSoft’s database connectivity
specification (JDBC) can then be used to connect to the Oracle database, which it uses to
save the information collected from the web pages which have been visited. The JDBC
application programming interface (API) is a Java API which can be used to access
virtually any kind of tabular data. It consists of a set of classes and interfaces written in
the Java programming language that provide a standard API for tool/database developers
and makes it possible to write industrial strength database applications using an all-Java
API. The Java API makes it easy to send search and query language (SQL) statements to
relational database systems and supports all dialects of SQL. The value of the JDBC API
is that an application can access virtually any data source and run on any platform that
supports the Java Virtual Machine. The JDBC API is used to invoke SQL commands
directly. A JDBC driver makes it possible to:
1. Establish a connection with a data source.
2. Send queries and update statements to the data source.
3. Process the results.

11
Figure 2.2 is an overview of the architecture of JDBC.
Fig 2.2 JDBC - Architecture Overview
The JDBC API works very well in this capacity and is easier to use than any other
database connectivity APIs. However, it is also designed to be a base upon which to build
alternate interfaces and tools. Since the JDBC API is complete and powerful enough to
be used as a base, it has had various kinds of alternate APIs developed on top of it,
including the following:

12
1. An embedded SQL for Java. JDBC requires that SQL statements be passed as
uninterpreted strings to Java. An embedded SQL preprocessor provides type
checking at the time of compiling and allows a programmer to mix SQL
statements with Java programming language statements.
2. A direct mapping of relational database tables to Java classes. In this object-
relational mapping, a table becomes a class, each row of the table becomes an
instance of that class, and each column value corresponds to an attribute of that
instance. The programmer can then operate directly on Java objects.
A database is an organized collection of related data, designed, built and populated
with data for a specific purpose, and represents some aspect of the real world. A database
management system (DBMS) is a collection of programs that enables user to create and
maintain a database. A database system provides a number of benefits:
1. Controlling redundancy
2. Restricting unauthorized access
3. Providing persistent storage for objects and data structure
4. Providing up-to-data information to all users
5. Providing multiple user interfaces and sharing data among multiple transactions
6. Representing complex relationships among data
7. Enforcing integrity constraints
8. Providing backup and recovery
Defining a database involves specifying the data types, structure, and constraints for
the data stored in the database. Constructing the database is a process of storing the data
themselves in some storage medium that is controlled by the DBMS. Manipulating a

13
database includes functions such as querying the database to retrieve specific data,
updating the database to reflect changes in the database and generating reports from the
database.
Database systems can be based on several different approaches: hierarchical, network,
relational, and object-relational models. Previously, relational databases (RDBMS)
dominated the marketplace, with vendors such as Oracle, Sybase, Informix, and Ingress.
In this model, data are represented as rows in tables and operators are provided to
generate new tables from the old ones. Recently, Object-Oriented (OO) DBMSs have
come to the fore and play more and more important roles. In order to compete with
OODBMS, RDBMS vendors provide hybrid products, such as Universal Servers,
offering OO/multimedia capabilities and Oracle 8’s user-defined data types.
Oracle 8i is one of the latest products from Oracle Corporation. It is an extremely
powerful, portable and scaleable database for developing, deploying and managing
applications within the enterprise and on the Internet. It was designed to support very
large and high volume transaction processing and data warehousing applications.
The major new feature of Oracle 8i is the inclusion of Java and Internet capabilities in
the database. Developers can now create an application in Java, PL/SQL, C or C++.
Another major feature of Oracle 8i is the Internet File System (IFS), which enables the
database to store and manage the relational and nonrelational data files. Oracle 8i comes
with Oracle inter Mediate which can manage and access multi-media data, including
audio, video, image, text, and spatial information. All these allow the database to be used
to host Internet applications and content, in addition to serving as repositories for
traditional relational data in workgroup and enterprise files.

14
2.4 Data Mining
The success of computerized data management has resulted in the accumulation of
huge amounts of data in several organizations. There is a growing perception that
analyses of these large databases can turn this “passive data” into useful “actionable
information”. The recent emergence of data mining, which is also referred to as
knowledge discovery in databases, is a testimony to this trend.
The objective of data mining is to identify the topics of unstructured Web documents.
In addition to answering specific queries (information retrieval), data mining techniques
also support unsupervised or supervised categorization that classifies a document for
inclusion in an indexed text database. Data mining methods can be divide into two
categories: the probabilistic approach and the deterministic approach.
The non-deterministic models are based on the assumption that web documents are
better described with statistical models because of the diversity and unstructured
character of hypertext documents. Statistical methods usually deal with only the text
portion of the document. The applications of the statistical models appear in both
supervised learning (also known as classification), and unsupervised learning (also
known as clustering). In the first situation, the learner first receives training data where
each term is tagged with a label from a finite discrete set. The algorithm is first trained
using this data set and then exposed to unlabeled data for a guess of possible labels. In the
case of unsupervised learning, on the other hand, the algorithm does not receive any
training data but instead is presented with a set of unlabeled documents. It is expected to

15
discover a hierarchy among these documents based on a measure of similarity between
documents. Using the tree analogy, related documents will appear close to each other
near the leaf level of the hierarchy, while dissimilar documents do not merge until they
are close to the root.
The strength of the probabilistic methods lies in the fact they can systematically
model the text information in a document and they are more effective in analyzing larger
documents, where the noise effect is lower. The drawback to probabilistic approaches,
however, lies in their inability to model meta-data such as hyperlinks. Also, the
complexity of the models sometimes degrades their execution speed. Finally, since a
particular web page can be authored in any language, dialect, or style by an individual
with any background, culture, motivation, interest or level of education, accurate
statistical models are very difficult to establish and sometimes a compromise must be
made between speed and complexity.
Deterministic methods in data mining take a different approach. Here, more effort is
spent exploring the structure of the documents, including the link structure. The
hyperlinks of the web offer rich latent information that does not usually appear in a text
document. An important application which takes advantage of this is the Hyperlink
Induced Topic Search (HITS) [8,9,10].
The Hyperlink Induced Topic Search, or HITS, does not crawl the web but relies on a
search engine. The data that the HITS method processes comes from a search engine and
the ranking is performed on a subgraph of the web that includes pages that match the
query from a search engine and pages citing or cited by these pages. The iteration process
of the HITS algorithm has been shown to produce equivalent results to those obtained

16
through a power series iteration. The main drawback of the basic HITS algorithm is that
all the edges of the graph are of the same weight and this can lead to topic contamination
during the expansion of the subgraph with cited and citing pages of the results from the
search engine query. An improved method, called the Automatic Resource Compilation
(or ARC) [11], incorporates a variable edge weight with an add-on penalty function that
favors occurrence of the keywords near the anchor text. Since the HITS and ARC
algorithms depend on a search engine query result, it is slower than the Google search
engine, which simulates a random walk on the Web graph with the purpose of estimating
the page ranking of the pages in the Web graph related to a specific query. However,
strategies such as caching a pre-crawled graph can greatly improve the performance. The
Related-Page Algorithm is developed from HITS, but is different in several important
ways. This algorithm will be discussed in detail in Chapter 4.

17
Chapter 3 System Development
In this chapter, implementation of the project will be described. There are three main
parts of the project. The first is the spider, the second involves saving objects to the
database, and the final step includes making the vicinity graph, calculating the hub and
authority values and returning the results list of the best URLs.
3.1 System Overview
Figure 3.1 shows an architectural diagram of the project. The first phase is mainly
concerned with searching and obtaining hyperlinks from related WebPages and saving
these URLs and their parents and children information into the database. For their
research, Jeffrey Dean and Monika Henzinger [5] were fortunate to have access to
Compaq’s Connectivity Server. The Connectivity Server provides high-speed access to
the graph structure of 180 million URLs (nodes) and the links (edges) that connect them.
The entire graph structure is stored on a Compaq AlphaServer 4100 with 8 GB of main
memory and dual 466 MHz Alpha processors. Because neither this kind of server nor the
large amount of memory needed to save the graph structure is available for this project,

18
Figure 3.1 Program architecture
Figure 3.1 Program architecture
we were only able to simulate this process. We created a small web source and saved the
information the spider retrieved to a local database. To do this, our spider was first used
to crawl web pages from a seed URL. To get a sufficient number of related URLs, we
sent several web addresses, which tend to refer to each other, such as
http://www.auburn.edu/ and http://www.lib.auburn.edu/ as seeds from which to the spider
to collect several hundred related URLs. We saved this set to the local database. It
should be mentioned that it is possible to crawl and save URL information from the entire
Web into a database, if there is enough memory and time available.
The second phase involves retrieval of the information stored in the local database
and subsequently applies the Companion algorithm. A query is submitted to a Web
User interface
Spider Downloading
Database
Vicinity Graph
Ranking
Related pages
Users
Query interface

19
interface, which is then sent to the database through CGI/Perl script and a JDBC
program. The web URLs that are nearby to the query are retrieved and the vicinity graph
is built according different layer and the relation of parent and children. After assigning
edge weights and calculating the Hub and Authority scores, the most highly related pages
are returned depending on the sorting results. These steps are examined in more detail in
the following sections.
3.2 The Spider
A spider, also known as a crawler, is a program that automatically scans various web
sites and extracts URLs, keywords, links, text, etc. A spider also follows the links on a
site to find other relevant pages. It is used to crawl web pages to collect a number of
URLs, which are then saved into a database. Our spider was used only to extract URLs
from web pages and collected their parents and children information. These sources were
saved to a local database and are used to calculate the Companion Algorithm.
The spider starts from a seed URL given by the user. This seed URL is also the first
URL in the crawling list. The spider checks the URL, making sure that the URL has not
already been visited, and then inserts it into the crawling list and analyzes the Web
document. The number of hyperlinks from web pages that can be inserted into the
crawling list is specified via the “Number of Web pages downloaded”.
The spider is implemented by using the Java programming language and Lynx.
The program is launched using the command:
java MySpider seed file1 numberOfWebPages

20
Lynx is a general-purpose command line/terminal type distributed information browser.
It can be used to interactively (through a keyboard) access information on the WWW and
display HTML documents containing links to files residing on the local system with a
variety of options. For example:
lynx –dump –source <url> > filename
Option –dump: stores the formatted output of the document to either standard output or
to a file specified in the command line.
Option –source: works the same as –dump but outputs the HTML source file instead of
formatted text.
The MySpider class has a non-argument constructor and four member functions. The
main function is quite simple. Its purpose is to create a MySpider object and take user
inputs, which are URL variables, and specify the number of sites to search. This part of
the main function code is :
MySpider Spider = new MySpider();
try{
…
for (int k = 0; k < Num; k++){
Spider.Search(k, URL);
Spider.SetNode1();
Spider.inSertToDB();
}
…
}

21
…
finally{
Spider.r.exit(0);
}
The constructor creates three vector objects. One vector, URLT, stores the URLs
(crawling list) retrieved from the seed URL and its following pages. Vector Vnode stores
the objects, which include parents and children of the seed URL, from the class node.
public class node{
protected Vector parents;
protected String url;
protected Vector children;
…
}
The third vector, Vnode1, stores the objects of node1.
public class node1{
protected String parent;
protected String url;
protected String child;
…
}
Figure 3.2 shows the different structures of node and node1.

22
p1 p1 url c1
c1
p2 url c2 p2 url c2
p3 p3 url none
node node1
Figure 3.2 The pictures of class node and node1.
It also creates a Runtime object. The major function is the search function. It takes the
URL and the number of sites, an integer number, as input, reads the whole web
document, captures the URL names, and stores the data into vectors. It uses lynx
commands and the seed URL to dump the HTML source files. The code is
command = “lynx –dump –sourec” + url;
p = r.exec (command);
After storing URLs in the vector URLT, the search function also creates node class
objects, sets parents and children, and saves the objects into vector Vnode.
The setNode1() function changes the objects of class node to objects of class node1,
which are easily inserted into the database. The inSertToDB() function uses the database
utility function DButility.execQuery(query) to insert the information (parent, URL, child)
into the database.

23
3.3 Indexing
Our database is designed to be simple and illustrative. One table address is created to
store the hyperlink information. Each record has three fields: the URL, its parent, and its
child.
The address table was created by DropCreateTable.class, which includes the code:
stmt.execute ("CREATE TABLE address (parents VARCHAR2(300), url
VARCHAR2(300), children VARCHAR2(300))");
In this project, JDBC is used to implement the database processing. First, after the
related pages have been crawled, the URLs and their parents and children are stored in
the database. Second, it is necessary to check the pages downloaded on the web interface.
Finally, the parent and children information of the URL is retrieved from the database, a
vicinity graph is built, and the Companion algorithm used to find the related pages.
JDBC is used to connect Java and the database. The system is implemented by using
the Java programming language and JDBC. To access the correct database, the JDBC
program needs an appropriate driver to connect to the DBMS. The DriverManager is the
class responsible for selecting database drivers and creating a new database connection.
The following codes make it possible to set up a connection using a JDBC-ODBC bridge
driver:
DriverManager.registerDriver (new oracle.jdbc.driver.OracleDriver());
OracleConnection con = (OracleConnection) DriverManager.

24
getConnection(“jdbc:oracle:oci8:@csedb”,”ops$username”,”password”);
To execute an SQL statement, a statement object has to be created. The connection
object that was obtained from the call to DriverManager.getConnection, can be used to
create statement objects.
Statement stmt = con.creatStatement();
There are two functions in the class Dbutility. The execUpdate () function first
connects to the database using the above statements. Then the function takes the query as
its argument, for example: insert statement query or other query. The statement (query)
is executed to update the database. The recordCount is returned after updating. The
other function is execQuery (), which also takes the query as its argument. After
retrieving information from the database, the results are saved in an object of the form
ResultSet (rs). Finally, the function returns a two dimensional array String[][] which
contains all the information of parent, URL, and child. These two functions are used in
the Spider and Search classes to communicate with the database.
The Companion algorithm is used to find the related pages of the query URL. We
will discuss this part in detail in Chapter 4.

25
3.4 System Interface
The project interface is shown in Fig 3.3. There are three parts in this interface:
(i) My Spider, (ii) Checking the download, and (iii) My Search Engine.
Figure 3.4 is the interface of My Spider. Users first enter the seed URL and the
number of web pages to collect, then press the StartCrawling button. The spider software
will search the web pages starting from the seed URL and save the URLs and their
parents and children into the database. At the same time the spider also prints the search
results on the screen.
Figure 3.5 is the interface used to monitor the download. It is used to check the
information saved in the database. The number of URLs to be checked is entered in the
“URL number” box, then the “search” button is clicked. The software will retrieve the
URLs from the database and print the results in the table shown in the window.
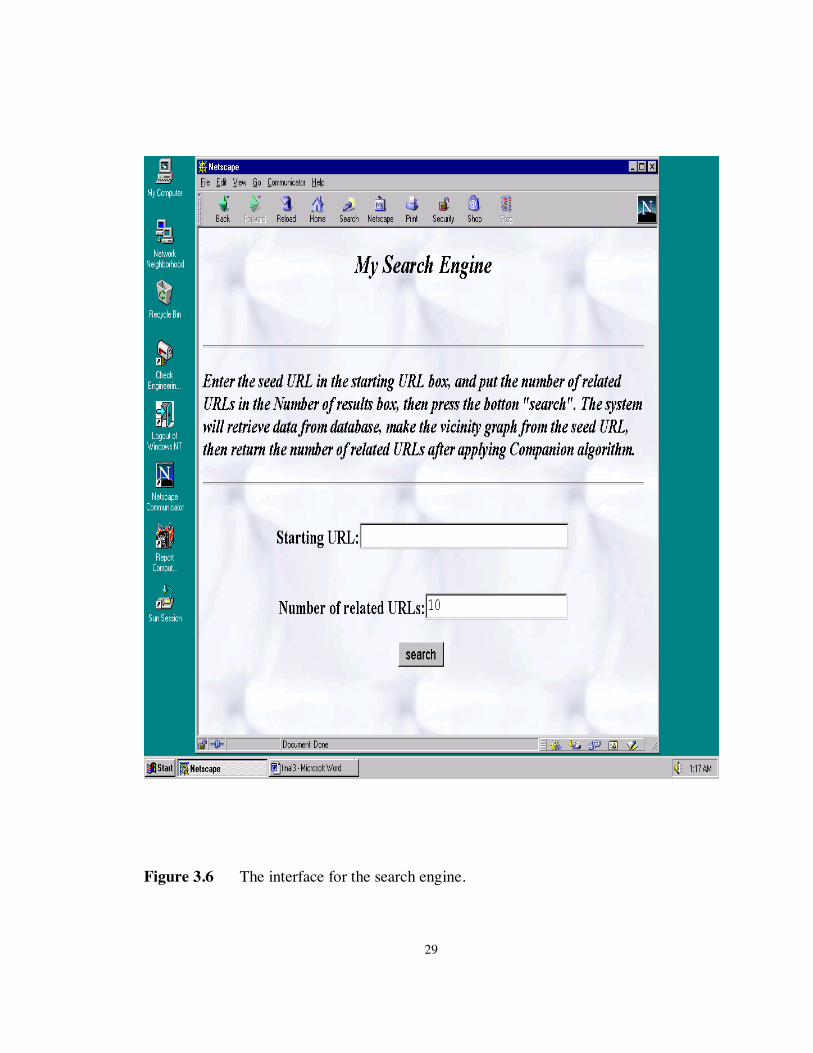
Figure 3.6 is the interface for the Search Engine. The query URL is entered in the
“Starting URL” box, and the number of related URLs entered in the “Number of results”
box, then the “search” button is clicked. The system will retrieve data from the database,
make a vicinity graph for the seed URL, then return the number of related URLs after
applying the Companion algorithm.

26
Figure 3.3 Project interface

27
Figure 3.4 The Spider interface

28
Figure 3.5 The interface for checking the download
29
Figure 3.6 The interface for the search engine.

30
Chapter 4 Related Page Algorithms
This chapter describes a Related Page Algorithm known as the Companion algorithm
[5]. This algorithm only exploits the hyperlink structure (i.e. graph connectivity) and does
not examine information about the content or usage of pages. In this chapter, the terms
“parent” and “child” are used to describe relationships between web pages. If there is a
hyperlink from page w to page v, we say that w is a parent of v and that v is a child of w.
The Companion algorithm takes as input a starting URL u and consists of four steps:
1. Build a vicinity graph for u.
2. Eliminate duplicates and near-duplicates from this graph.
3. Compute edge weights based on host to host connections.
4. Compute a hub score and an authority score for each node in the graph and
return the top ranked authority nodes. This phase of the algorithm uses a
modified version of the HITS algorithm originally proposed by Kleinberg
[6,7].
These steps are described in more detail in the subsections below.

31
4.1 Building the Vicinity Graph
Given a query URL u, it is possible to build a directed graph of nodes that are near to
u in the web graph. Graph nodes correspond to web pages and graph edges correspond to
hyperlinks. The graph consists of the following nodes (and the edges between these
nodes):
• u,
• up to B parents of u, and for each parent up to BF of its children different from u,
• up to F children of u, and for each child up to FB of its parents different from u.
Here is how we choose these nodes in detail:
Back (B), and back-forward (BF) nodes: If u has more than B parents, add B random
parents to the graph; otherwise add all of u’s parents. If a parent x of u has more than BF
+1 children, add up to BF/2 children pointed to by the BF/2 links on x immediately
preceding the link to u and up to BF/2 children pointed to by the BF/2 links on x
immediately succeeding the link to u (ignoring duplicate links). If page x has fewer than
BF children, we add all of its children to the graph. Note that this exploits the order of
links on page x. Thus, a rough graph of this step when B=3 and BF =4 looks like the
following:
A C D T W V X Y u Z G

32
Here A, C and D are the parents of u and T, W, V, X, Y, Z, and G are forward children of
these parents.
Forward (F), and forward-back (FB) nodes: If u has more than F children, add the
children pointed to by the first F links of u; otherwise, add all of u’s children. If a child
of u has more than BF parents, add the BF parents; otherwise, add all of the child’s
parents. For the case where F=3 and FB=4, the graph looks like the following:
P Q R S u E N T
C H I L M
The graph here shows that C, H, I, L, and M are the children of u. In addition to u, P, Q,
R, and S are the FB parents of C, and E, N, and T are the FB parents of L. u is the only
parent of H, I, and M. If there is a hyperlink from a page represented by node v in the
graph to a page represented by node w, and v and w do not belong to the same host, then
there is a directed edge from v to w in the graph. Edges between nodes on the same host
are omitted.

33
Example: Fig 4.1 shows an example of a vicinity graph construction.
B1 B2 B3
C1 C2 C3
D1 D2 D3
Fig 4.1 A vicinity graph example
As many different situations as possible were included in the vicinity graph. The relations
shown in Table 4.1 were used to substitute these nodes in the graph.
Table 4.1 The authority and hub values for the vicinity graph shown in Fig 4.1
B1: http://www.usa.com a=1 h=2
B2: http://www.china.com a=1 h=2
B3: http://www.eng.auburn.edu a=1 h=1
C1: http://www.voa.com /special a=2 h=1
C2: http://www.eng.auburn.edu/hu a=2 h=2
C3: http://www.auburn.edu/sun a=2 h=1
D1: http://www.auburn.edu a=2 h=2
D2: http://www.abc.com a=2 h=1
D3: http://www.cnn.com a=2 h=2

34
The arrow points to the node from its parent. We will discuss the program used to make
the vicinity graph in section 4.2.
4.2 Duplicate Elimination
After building this graph, the near-duplicates are combined. Two nodes are
considered to be near-duplicates if (a) they each have more than 10 links and (b) they
have at least 95% of their links in common. When two near-duplicates are combined,
their two nodes are replaced by a node whose links are the union of the links of the two
near-duplicates. This duplicate elimination phase is important because many pages are
duplicated across hosts (for example mirror sites or different aliases for the same page),
and allowing them to remain separate can greatly distort the search results obtained.
Given a query URL u, a directed graph is built of nodes that are near to u in the web
graph. The graph consists of the node u, B parents of u and for each parent up to BF of its
children other than u., up to F children of u, and for each child up to FB of its parents
other than u. Before making the vicinity graph, it is necessary to determine which nodes
are near u. Here, the Search class provides several functions. The function setNode()
takes the query URL u, and the number of B, F, BF, and FB as arguments. After
retrieving the results [][] from the database, we declare a vector array:
Vector [] Varray = new Vector [5];
Each vector of Varray element is used to save one layer of nodes near u. Varray[0] is for
B, Varray[1] for the URL itself, Varray[2] for F, Varray[3] for BF, and Varray[4] for FB.

35
The following code was used for the situation when u has more than B parents, as
mentioned in Chapter 3. B random parents are added to the graph.
Random R = new Random();
while ( Url.getParentSize () > B){
i = R.nextInt();
if (i < Url.getParentSize())
Url.removeParentAt(i);
}
Each object of node in every Vector of Varray thus saves the information concerning its
own URL, parents, and children retrieved from the database.
The vicinity graph was made with vector Gp which contains linklist. Each linklist
saves the URL as its head, while other nodes are used to save children of this URL. The
class Linklist implements a linkable interface, and includes constructor() and several
insert(), remove(), and length() member functions.
The makeGraph (Vector [] data) function searches all vector arrays, which are the
nodes near to u. Then the function saves all the information on the children of each URL
into each linkedlist headed by this URL, and returns a vector. The following is an
example of a piece of code for the makeGraph function.
for(int i=0;i<Gp1.length;i++){
for(int j=0;j<(Gp1[i]).size();j++){
node n = (node)((Gp1[i]).elementAt(j));
LinkedList list = new LinkedList();
String url = n.getUrl();

36
Linkable head = new LinkableString(url);
list.insertAtHead(head);
int m = 0;
while( m< n.getChildrenSize()){
String child = n.getChild(m);
Linkable lt = new LinkableString(child);
list.insertAtTail(lt);
m++;
}
Gp.addElement(list);
}
}
The remaining part of the makeGraph function performs the duplicate elimination.
4.3 Edge Weight Assignment
In this stage, a weight is assigned to each edge, using the edge weighting scheme of
Bharat and Henzinger [12]. An edge between two nodes on the same host (the host can be
determined from the URL-string) has weight 0. If there are k edges from documents on a
first host to a single document on a second host, each edge is given an authority weight of
1/k. This weight is used when computing the authority score of the document on the
second host. If there are l edges from a single document on the first host to a set of

37
documents on a second host, each edge has a hub weight of 1/l. This scaling prevents a
single host from having too much influence on the computation.
The resulting weighted graph is referred to as the vicinity graph of u.
The assignWeight() function inside the Search class takes the Gp vector as argument,
then calculates the Authority Weight and Hub Weight for each edge. Inside this function,
the host is retrieved from each owner. By using several loops, the problem of k edges
from documents on a first host to a single document on a second host, as discussed above,
can be solved. Finally the information in the vector returned by the assignWeight()
function represents the vicinity graph of u.
4.4 Hub and Authority Score Computation
In this step, the imp algorithm [12] computes hub and authority scores by using the
vicinity graph. The imp algorithm is a straightforward extension of the HITS algorithm
incorporating edge weights.
The reasoning behind the HITS algorithm is that a document that points to many
others is a good hub, and a document that many documents point to is a good authority. It
therefore follows that a document that points to many good authorities is an even better
hub, and similarly a document pointed to by many good hubs is an even better authority.
The HITS computation repeatedly updates hub and authority scores so that documents
with high authority scores are expected to have relevant content, whereas documents with

38
high hub scores are expected to contain links to sites with relevant content. The
computation of hub and authority scores is performed as follows:
Initialize all elements of the hub vector H to 1.0.
Initialize all elements of the authority vector A to 1.0.
While the vectors H and A have not converged:
For all nodes n in the vicinity graph N,
A[n] : = ! (n", n) # edges(N) H[n"] × authority_weight(n", n)
For all n in N,
H[n] : = ! (n", n) # edges(N) H[n"]× hub_weight(n", n)
This example will be examined in detail in Chapter 5 (test for the Companion
Algorithm).
Note that the algorithm does not claim to find all relevant pages, since there may be
some that have good content but have not been linked to by many authors of other sites.
The Companion algorithm then returns the nodes with the highest authority scores
(excluding u itself) as the pages that are most related to the start page u.
In the software, before computing the Hub and Authority scores, we declare class
nodeWeight:
public class nodeWeight{
private String host;
private String owner;

39
private double auth;
private double hub;
public Vector Hhub;
public double A;
}
For each URL in the vicinity graph, a nodeW object is created of class nodeWeight (host,
owner). The auth in the object is used to save authority weight, hub is used to save Hub
weight, and the vector Hhub is used to save all the hosts pointing to the URL. These hosts
in the Hhub vector are used to calculate A. Here, A is the A[n] value referred to in
Chapter 3. The Companion Algorithms is then used. Inside the assignWeight function,
the two vectors Relav and Auth are used to save ! H and ! A for each URL.
• Calculation of Hub: In the vicinity graph (vector Gp), each URL of a head node in
the linkedlist is checked to see how many URLs in the list are pointed to by this
head, and the result saved to vector Relav after removing sites with the same host,
both pointing to it and pointed to by it. Because all elements of the hub vector are
initialized to 1.0, the number of elements in the vector Relav is the H value for
this URL.
• Calculation of Auth: In the vicinity graph, a loop is included to check each URL
inside the linkedlist to see how many heads point to this URL, then the vector
Auth is used to save this value after removing the sites with the same host which
point to it. Because all elements of the Auth vector are initialized to 1.0, the
number of the elements in the vector Auth is the A value for this URL.The key
point of the Companion algorithm is that a URL which points to more URLs is a

40
good Hub, while a URL which is point to by more URLs is a good authority.
These two factors can be combined by function calA().
The cA value is the A[n] which is ! (n", n) # edges(N) H[n"] × authority_weight(n", n). The
Companion algorithm then returns the nodes with higher authority scores as the pages
that are most closely related to the start page u.
The other two functions in the Search class are used to rank the related pages. The
VtoArray () function converts the final vector to an array for sorting, and the
Bubble_Sort() function sorts the array depending on the A value in the nodeWeight
object.
4.5 An Example
To test the Companion Algorithm, we used the example in Fig 4.1 to calculate the
Hub and Authority scores by running our system. The graph was saved into the database
by inserting the parent and child relationships shown in Table 4.2. Every line (“parent url
child”) represents one relation in the node1 class object.
After saving Table 4.2 into the database, the related pages were retrieved by entering
the following query.
> java Search http://www.eng.auburn.edu/hu/
The program built the graph, calculated the Authority Weight by using the Companion
Algorithm, and then returned the related pages ranked according to their A values. Figure
4.2 shows the results, with the Authority Weight for each node in the vicinity graph.

41
Table 4.2 URLs and their Parent and child URLs (format: parent URL, space, URL,
space, child URL).
http://www.voa.com/special http://www.usa.com http://www.china.com
none http://www.usa.com http://www.auburn.edu
http://www.usa.com http://www.china.com http://www.eng.auburn.edu
none http://www.china.com http://www.voa.com/special
none http://www.china.com http://www.eng.auburn.edu/hu
http://www.china.com http://www.eng.auburn.edu http://www.auburn.edu/sun
http://www.china.com http://www.voa.com/special http://www.usa.com
http://www.auburn.edu http://www.voa.com/special none
http://www.china.com http://www.eng.auburn.edu/hu http://www.auburn.edu/sun
http://www.voa.com/special http://www.eng.auburn.edu/hu http://www.cnn.com
http://www.abc.com http://www.eng.auburn.edu/hu http://www.auburn.edu
http://www.eng.auburn.edu http://www.auburn.edu/sun http://www.cnn.com
http://www.eng.auburn.edu/hu http://www.auburn.edu/sun none
http://www.cnn.com http://www.auburn.edu/sun none
http://www.usa.com http://www.auburn.edu http://www.voa.com/special
http://www.eng.auburn.edu/hu http://www.auburn.edu http://www.abc.com
http://www.auburn.edu http://www.abc.com http://www.eng.auburn.edu/hu
http://www.cnn.com http://www.abc.com none
http://www.eng.auburn.edu/hu http://www.cnn.com http://www.abc.com
http://www.auburn.edu/sun http://www.cnn.com http://www.auburn.edu/sun
From these test results, we can see:
1. The results (authority weight A) from the program running the Companion
Algorithm are the same as those obtained by manual calculation. For example:
http://www.abc.com/ points to one other node, so its hub =1.0. Two other nodes,

42
http://www.auburn.edu/ and http://www.cnn.com/, point to it, so the auth value of
http://www.abc.com/ is 2. When calculating A[n] for http://www.abc.com/, we need
Figure 4.2 Search results of the query: http://www.eng.auburn.edu/hu/. The A is the
value A[n] which is used for Ranking.

43
to combine (!) the authority value of http://www.auburn.edu/, which is 2, and
http://www.cnn.com/, which is 2. The A[n] for http://www.abc.com/ is calculated by
multiplying hub for http://www.abc.com/ times the authority of http://www.auburn.edu/
plus the hub for http://www.abc.com/ times the authority of http://www.cnn.com/. That
is, 1×2 +1×2 =4. This confirms that our program executes the Algorithm correctly.
2. The program successfully executed the Duplicate Elimination step. For example,
for http://www.eng.auburn.edu/hu, a is 2 rather than 3. If the fact that
http://www.auburn.edu and http://www.auburn.edu/sun share the same host had not been
taken into account, the a value for http://www.eng.auburn.edu would be 3.
3. In this testing process, the B, BF, F and FB values were each set to 10. Thus, the
vicinity graph includes all the nodes listed here. It is not possible to discern the effect of
these values on the Companion Algorithm. This issue will be discussed in detail in the
next chapter.

44
Chapter 5 Experimental Results
Our experiments were conducted using an Ultra 5 Sun Workstation, which is part of
the engineering network, running Solaris 2.6. Perl5, JDK 1.1.7, and Oracle 8.1.1 were
among the tools used for this project.
5.1 The Spider
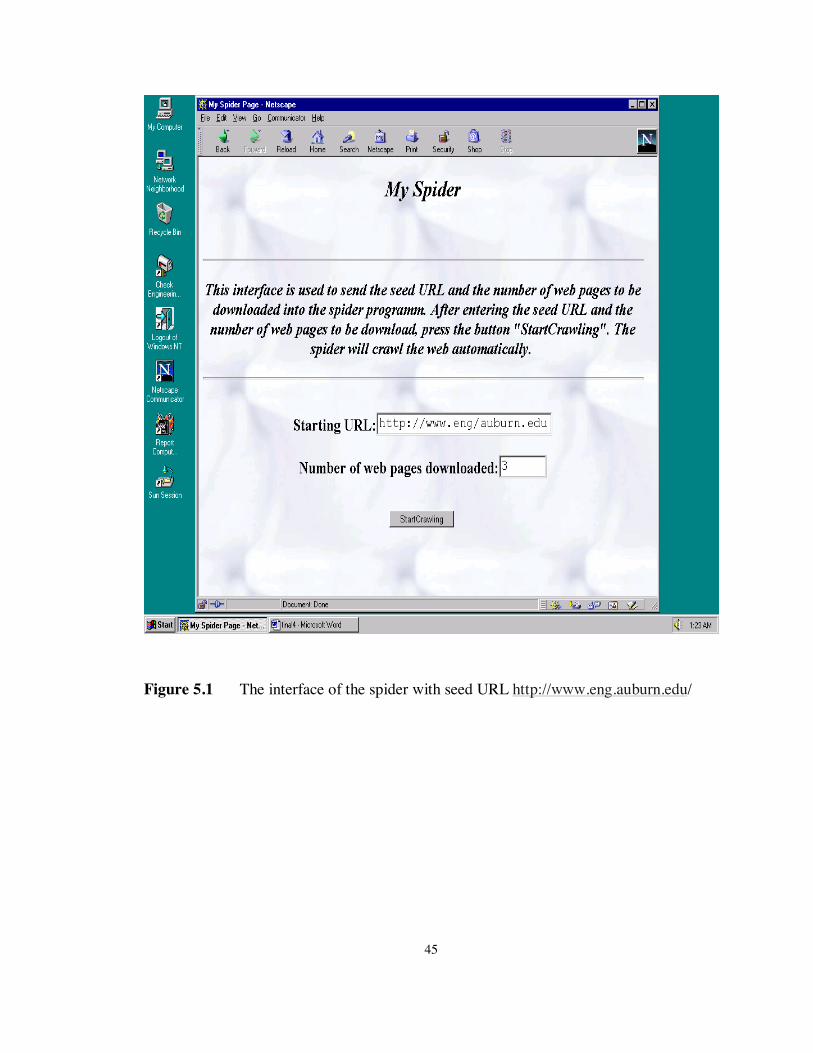
In this experiment, real web pages were explored by our spider to first build up a
database, then queries were made to retrieve data from this database and the Companion
algorithm was applied. First, the spider searched the Web and downloaded URLs and
parents and children relations. Fig 5.1 shows the interface of the spider with seed URL
http://www.eng.auburn.edu/, and Fig 5.2 shows the crawling results obtained.
45
Figure 5.1 The interface of the spider with seed URL http://www.eng.auburn.edu/

46
Figure 5.2 The crawling results of the spider from the seed URL
http://www.eng.auburn.edu/
Lacking the resources of other research groups [5], the scale of this research was
necessarily more limited. However, several seed URLs were selected which share some
relationships to build up our database. The following five URLs were selected as seed
URLs for our spider to use to download URLs.

47
http://www.auburn.edu/
http://www.lib.auburn.edu/
http://www.eng.auburn.edu/
http://www.theplainsman.com
http://www.oasis.edu/
The web page of each URL was searched and three further pages the spider crawled to
from this page were also searched, and the URLs obtained from these pages were saved
to the database named “address”. In this way, about 600 lines of data of URL
relationships retrieved from these pages were saved in the database.
5.2 Checking the Download
After inserting the data into the Oracle database, we were able to check the
content of the database by checking the download interface. By using the “Checking
Download” interface, the user can enter the number of URLs checked (Fig 5.3). Then the
system returns the URLs saved in the database. Figure 5.4 shows the URLs saved in the
database.

48
Figure 5.3 The interface for checking the downloads

49
Figure 5.4 Checking the downloads.

50
5.3 Searching and Ranking
The experimental results were obtained by running the command
> java Search retrievingURL B BF F FB
where B, BF, F, and FB are the number of nodes in a specified layer of the vicinity graph.
They represent “Go back,” “Go back-forward,” “Go forward,” and “Go forward-back.”
Example 1: Figure 5.5 shows the results of the query obtained from the command:
java Search http://www.oasis.auburn.edu 500 500 500 500
With these B, BF, F, FB values, all the nodes inside the database were included. The
search program gives http://www.auburn.edu/ as the closest related page.

51
Figure 5.5 Search results of the query: URL = http://www.oasis.auburn.edu/, B=500,
BF=500, F=500, FB=500.
Example 2: The second experiment was conducted using the query:
java http://www.lib.auburn.edu/ 500 500 500 500
The sorted results are saved in Fig 5.6, with the closest related page identified as
http://www.univrel.edu/.

52
Figure 5.6 Search results of the query: URL = http://www.lib.auburn.edu/, B=500,
BF=500, F=500, and FB=500.
From these Figures, we find one query sometime returns several related URLs with the
same value for the authority. For example, the query http://www.oasis.auburn.edu/
returns both http://www.auburn.edu/ and http://www.lib.auburn.edu/ with 12 as the
authority. The reason might be that our database information is limited. When the
number of URLs in the database is increased, this problem is likely to disappear.

53
To investigate the effects of different B, BF, F, and FB values, 300 and 100 were also
used for these values in the query http://www.oasis.auburn.edu/.
java http://www.oasis.auburn.edu 300 300 300 300
java http://www.oasis.auburn.edu 100 100 100 100
java http://www.oasis.auburn.edu 100 5 100 5
The results for these experiments are the same. This implies that we cannot test the B,
BF, F, FB effect from our limited resources. When a large database is available, these
variables will have an effect on the authority. Dean and Henzinger proposed [5] that
using a large value for B (2000) and a small value for BF (8) works better in practice than
using moderate values for each (say, 50 and 50).
Figure 5.7 shows the search results for the query http://www.eng.auburn.edu .
The system returns http://aos.auburn.edu/ as the highest rank. To test if it is reversible,
we sent http://aos.auburn.edu/ as the query. Figure 5.8 shows the results. Comparing
both figures, we can see the related pages are irreversible. Because the related pages
depend on the links, and different web pages have different links, these results are
reasonable.

54
Figure 5.7 Search results for the query http://www.eng.auburn.edu/
Given the limitations of our small database, it is difficult to directly compare our
search engine with other search engines. For broad topics such as news, football etc,
other search engines give several hundreds or even thousands of addresses. Even for the
query “Auburn University”, the http://www.excite.com/ returns 195,540 web sites. One
page usually leads to a hundred more pages. To check all these pages is not feasible with

55
Figure 5.8 Search result of the query http://aos.auburn.edu/
our limited database. However, this project has successfully demonstrated the use of the
Companion algorithm to rank the URLs which are returned in a search.
The Companion algorithm used the HITS algorithm as a starting point, but improved
on it in several ways. For example, our vicinity graph is structured to exclude grandparent
nodes but to include nodes that share a child with u. These nodes are believed to be more
likely to be related to u than the grandparent nodes. We also exploited the order of the
links on a page to determine which “siblings” of u to include. The other improvement is

56
the techniques whereby nodes in our vicinity graph that have a large number of duplicate
links are merged.

57
Chapter 6. Conclusions
1. The ranking web page can be obtained by using only hyperlink information from
each web page.
2. This project presented a Companion algorithm for finding related pages in the
World Wide Web. The algorithms developed can be implemented efficiently and
are suitable for use within a large-scale web service providing a related pages
feature.
3. The B, F, BF, FB values obtained from the vicinity graph for the certain query
have an effect on the performance of the search engine.
4. The disadvantage of this project is that our database was too small to test more of
the parameters concerned with this algorithm. This should be solved when it is
possible to access a server with a larger database.

58
References
1. Steve Lawrence and C. Lee Giles, Accessibility of information on the web,
Nature, Vol. 400, pages 107-109, 1999.
2. P. Pirolli, J. Pitkow, and R. Rao. Silk from a sow’s ear: Extracting usable
structures from the web. In Proceedings of the Conference on Human Factors in
Computing Systems (CUI 96), pages 118-125, April 1996.
3. J. Carriere and R. Kazman. Webquery: Searching and visualizing the web
through connectivity. In Proceedings of the Sixth International World Wide Web
Conference [1], pages 701-711.
4. Loren Terveen and Will Hill. Evaluating emergent collaboration on the web. In
Proceedings of ACM CSCW’98 Conference on Computer-Supported Cooperative
Work, Social Filtering, Social Influences, pages 355-362, 1998.
5. Jeffrey Dean and Monika R. Henzinger. Finding Related Pages in the World Wide
Web (1999). In Proceedings of 8th www conference, Toroto, Canada.1999
6. J. Kleinberg. Authoritative sources in a hyperlinked environment. In Proceedings
of the Seventh International World Wide Web Conference [2], pages 259-270.
7. J. Kleinberg. Authoritative sources in a hyperlinked environment. In
Proceedings of the 9th Annual ACM-SIAM Symposium on Discrete Algorithms,
pages 668-677, January 1998.

59
8. J. Kleinberg. Authoritative sources in a hyperlinked environment. Proc. 9th ACM-
SIAM Symposium on Discrete Algorithms, 1998. Extended version in Journal of
the ACM 46 (1999).
9. J. Kleinberg, S. R. Kumar, P. Raghavan, S. Rajagopalan, A. Tomkins. The web
as a graph: measurements, models and methods. Invited survey at the
International Conference on Combinatorics and Computing, 1999.
10. S. Chakrabarti, et al. Mining the Web’s link structure. IEEE Computer, (32) 8,
pages 60-67, August 1999.
11. S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, P. Raghavan, S. Rajagopalan.
Automatic resource list compilation by analyzing hyperlink structure and
associated text. In Proc. 7th International World Wide Web Conference, 1998.
12. K. Bharat and M. Henzinger. Improved algorithms for topic distillation in
hyperlinked environments. In Proceedings of the 21st International ACM SSIGIR
Conference on Research and Development in Information Retrieval (SIFIR ’98),
pages 104-111, 1998.