zero-shot learning by convex combination of semantic embeddings mohammad norouzi, tomas mikolov,...
TRANSCRIPT

Zero-Shot Learning byConvex Combination of Semantic Embeddings
Mohammad Norouzi, Tomas Mikolov, Samy Bengio, Yoram Singer, Jonathon Shlens, Andrea Frome, Greg S. Corrado, Jeffrey Dean


Image Annotation
Lion Tiger
Apple
Orange
(100,000+ classes)

Labeled Datasets
Lion Tiger
…
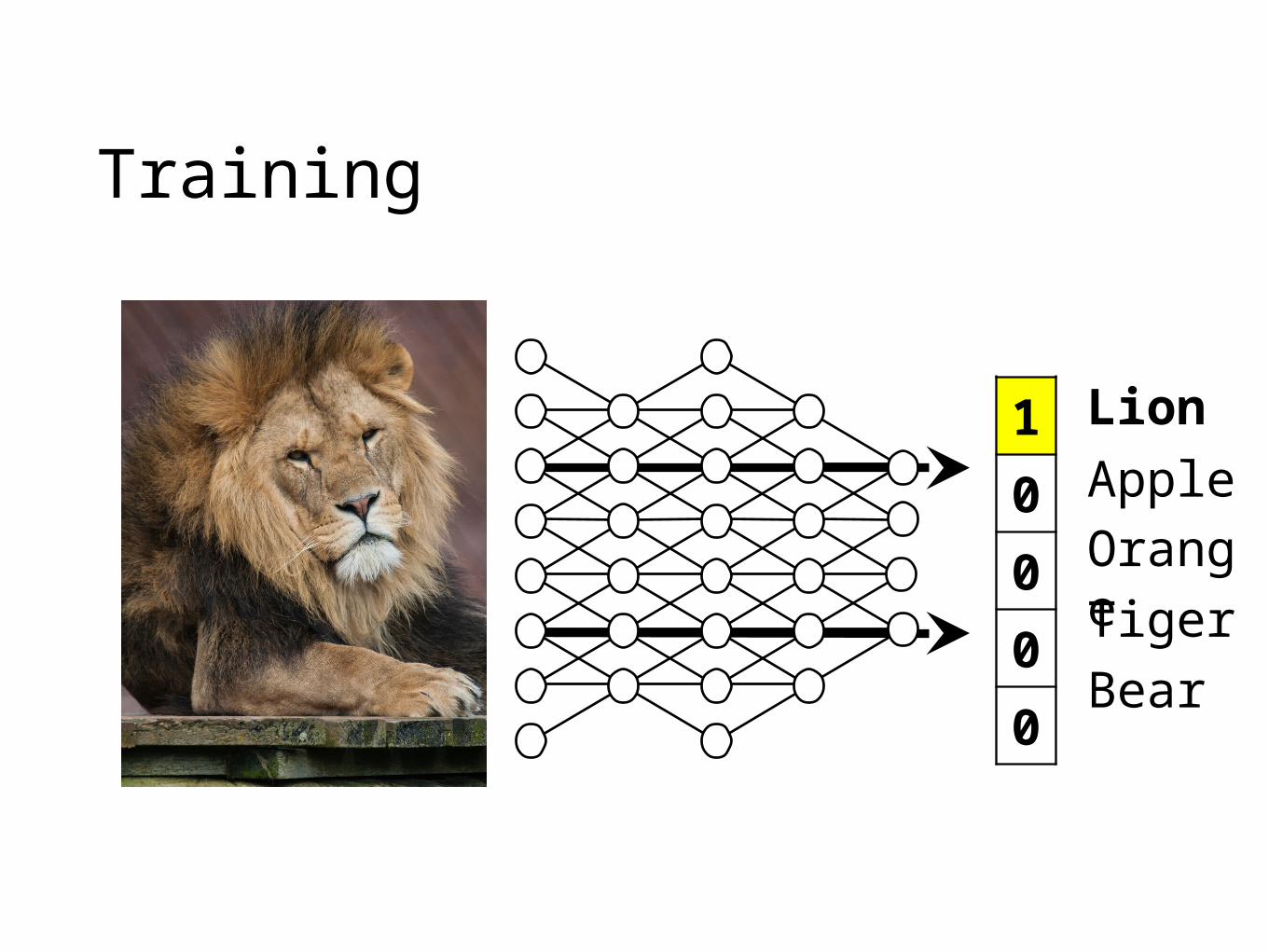
Training
10000
Tiger
Apple
Lion
Orange
Bear
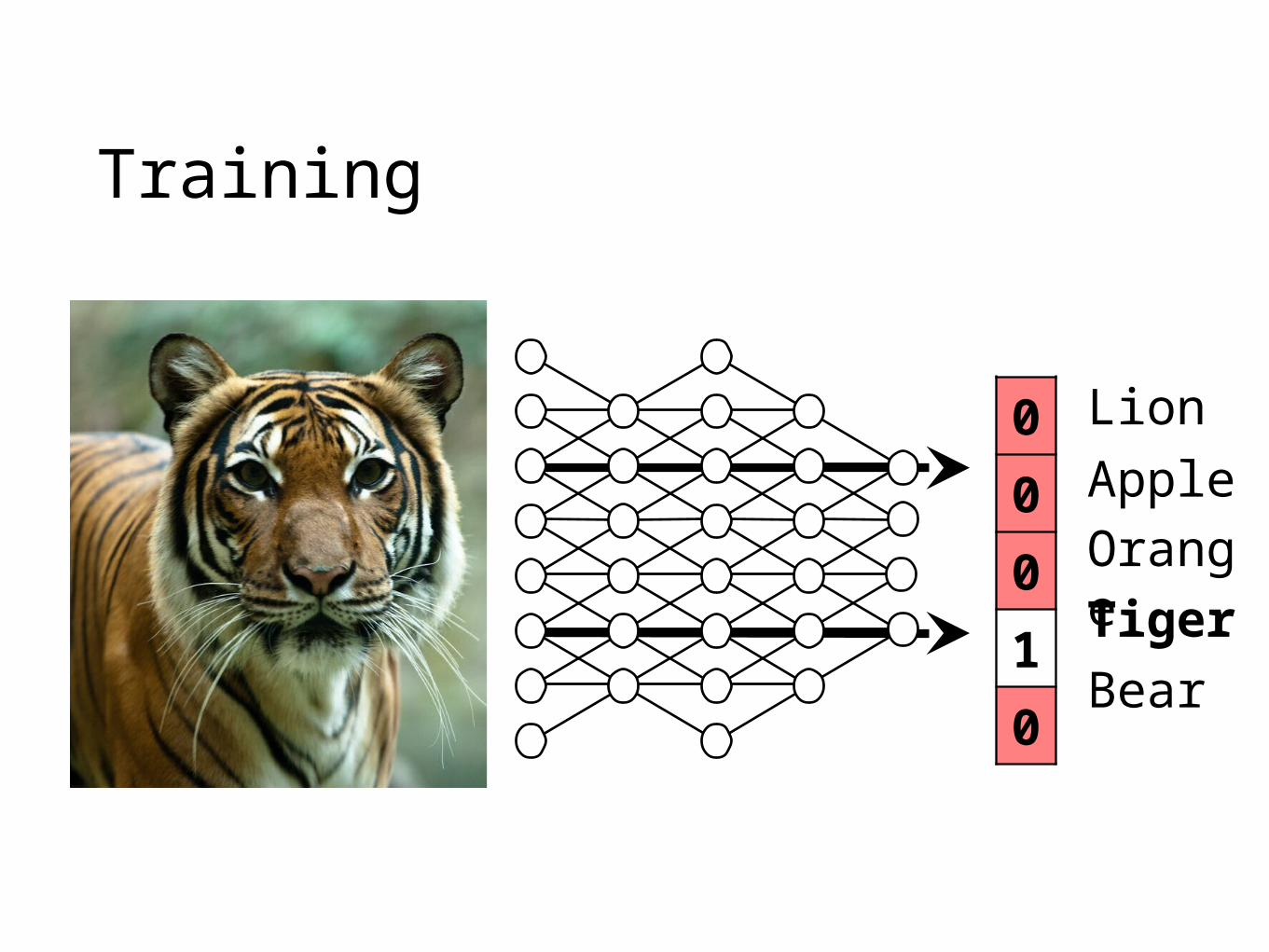
Training
00010
Tiger
Apple
Lion
Orange
Bear

Testing
Lion? Tiger?
Generalize to Unseen Images

How to Generalize to Unseen Labels
Training:
► Lion
► Apple
► Orange
► Tiger
► Bear
Test:
► Wolf
► Cougar
► Grapefruit
“Side information”
“Represenation of new classes”

One-Shot Learning
Wolf Cougar
[Erik G. Learned-Miller et al. Learning from one example through shared densities on transforms, 2000]
[Li Fei-Fei et al. One-shot learning of object categories, 06]

Zero-Shot Learning by Supervised Attributes
•Mammal, quadruped, white / gray / black, big pointed ears, not spotted, …
•Mammal, quadruped, brown / gray, wild, long tail, not spotted, …
Wolf
Cougar
[Ali Farhadi et al. Describing objects by their attributes, 09]
[Christoph Lampert et al. Learning to detect unseen object classes by between-class attribute transfer, 09]

Zero-Shot Learning by Unsupervised Embeddings•Dog – Bear
•Cat – Tiger – Lion
•Orange – Lemon
Use embedding of labels in a vector space and a notion of semantic similarity in that space
Wolf
Cougar
Grapefruit
[Richard Socher et al. Zero-shot learning through cross-modal transfer, 13]
[Andrea Frome, Greg S. Corrado, Jon Shlens et al.DeViSE: A Deep Visual-Semantic Embedding Model, 13]
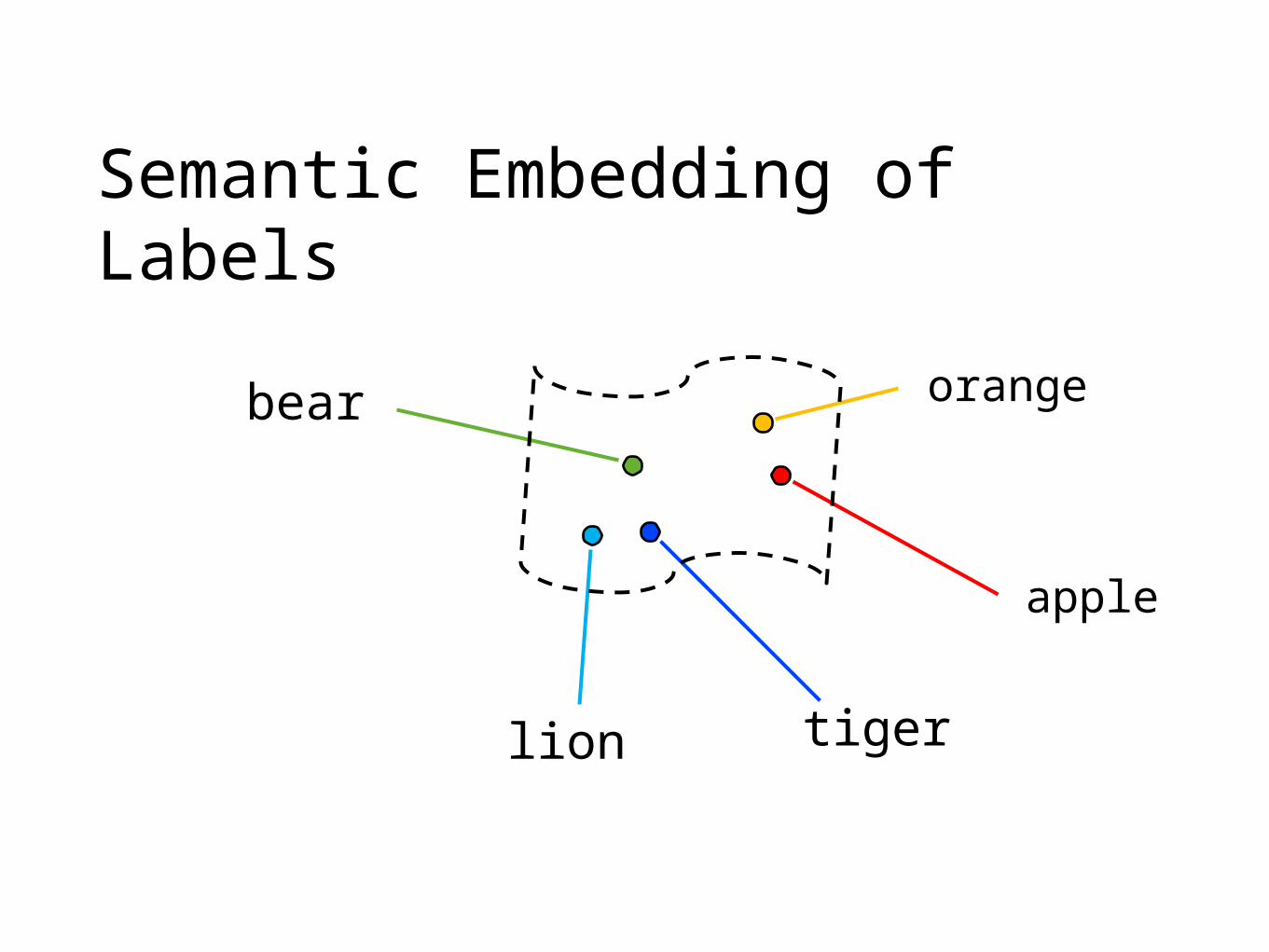
Semantic Embedding of Labels
apple
orange
tigerlion
bear
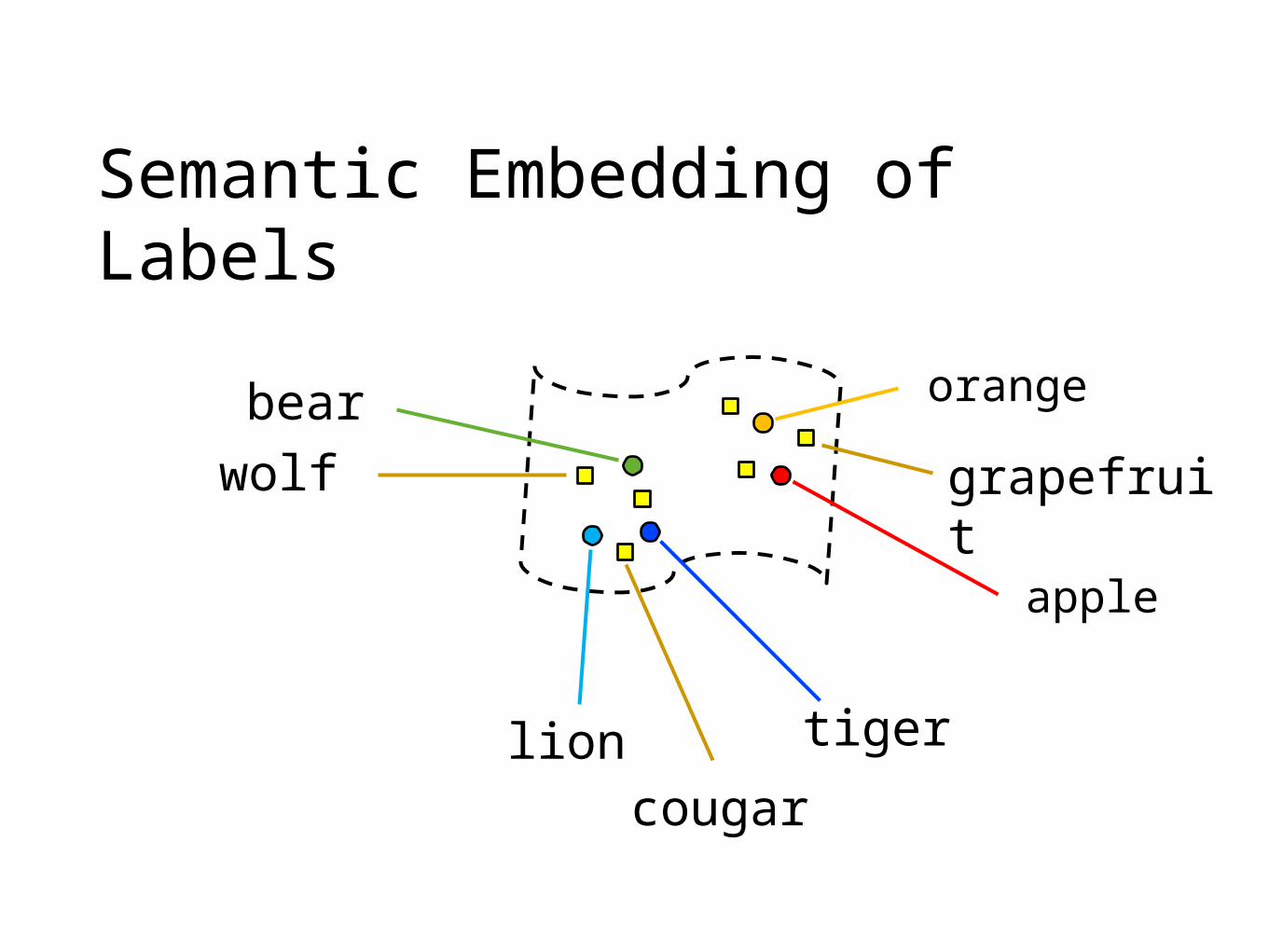
Semantic Embedding of Labels
cougar
grapefruitwolf
tiger
apple
orange
lion
bear
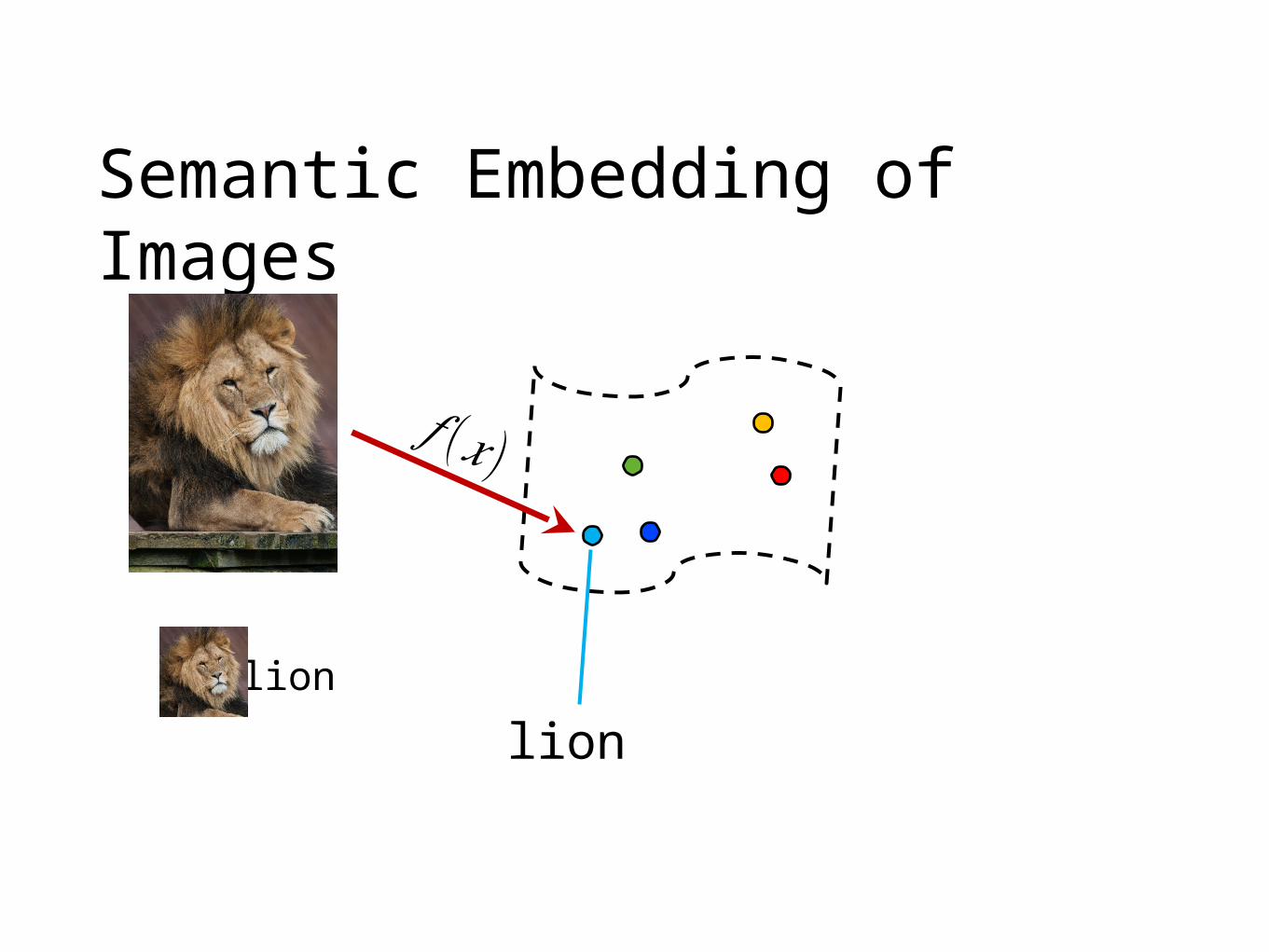
Semantic Embedding of Images
𝑓 (𝑥)
lion lion
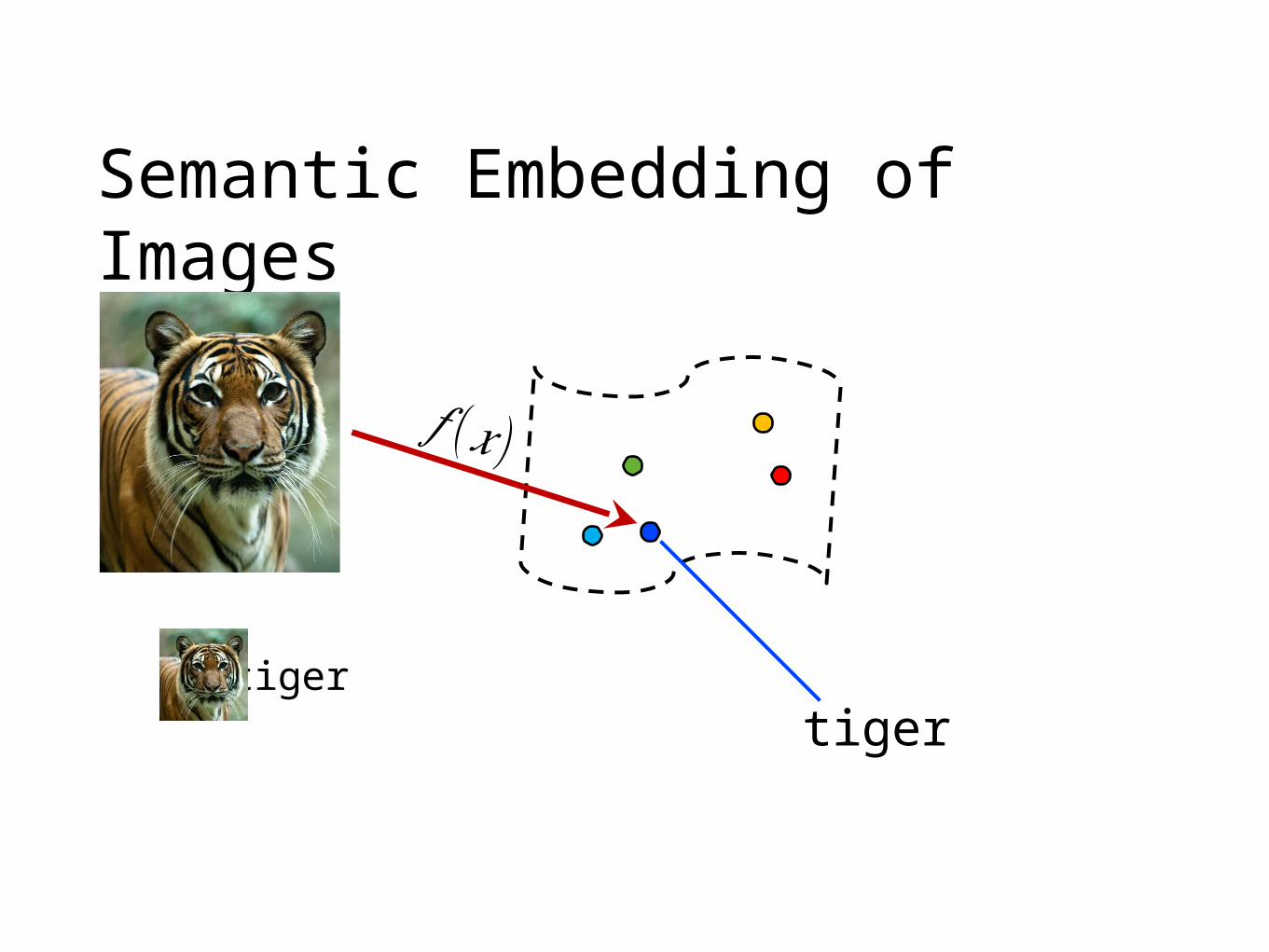
Semantic Embedding of Images
tiger
𝑓 (𝑥)
tiger

Semantic Embedding of Images
cougar
► How to define the semantic embedding of labels► How to project images into that space► We use kNN search for label retrieval
𝑓 (𝑥)

Unsupervised Label Embedding
Word with similar context will get similar vectors
We apply Skip-gram to Wikipedia articles [Tomas Mikolov et al. Efficient estimation of word representations in vector space, 13] (word2vec)
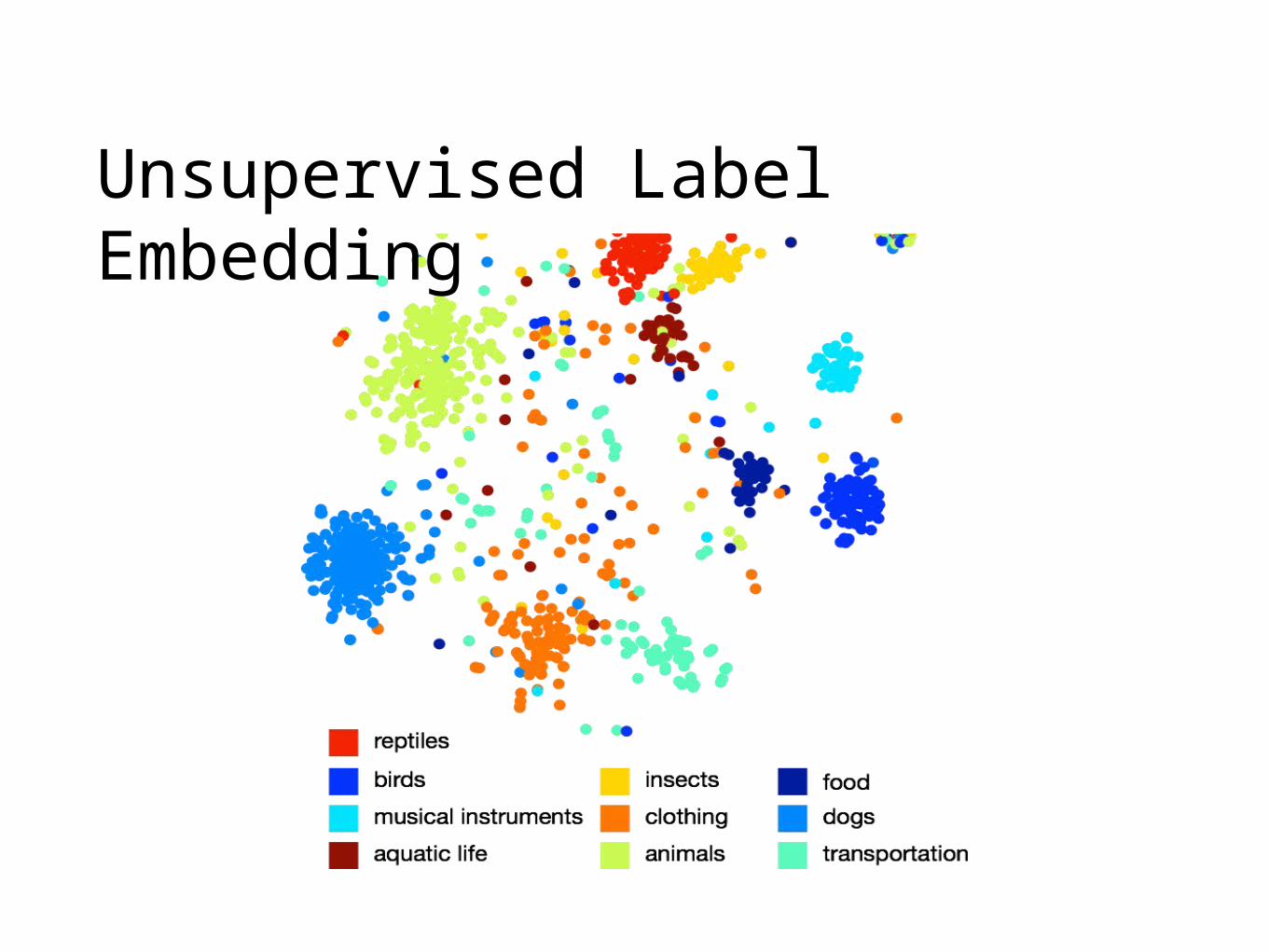
Unsupervised Label Embedding

ConSE: Convex Combination of Semantic Embeddings
Tiger
Apple
Lion
Orange
Bear
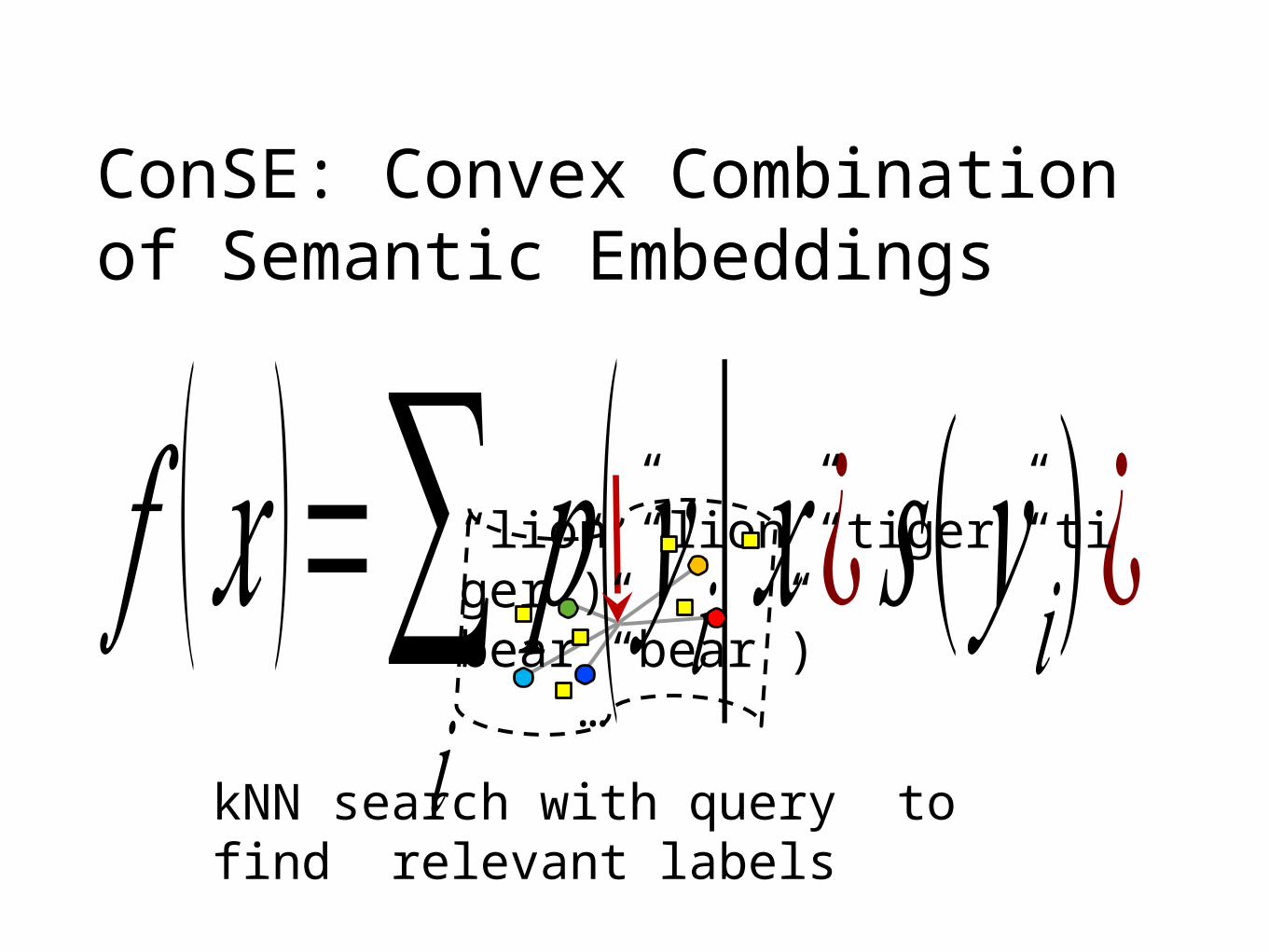
ConSE: Convex Combination of Semantic Embeddings
𝑓 (𝑥 )=∑𝑖
𝑝 (𝑦 𝑖|𝑥 ¿𝑠 (𝑦 𝑖)¿kNN search with query to find relevant labels
“lion”“lion”“tiger”“tiger”) bear”“bear”) …
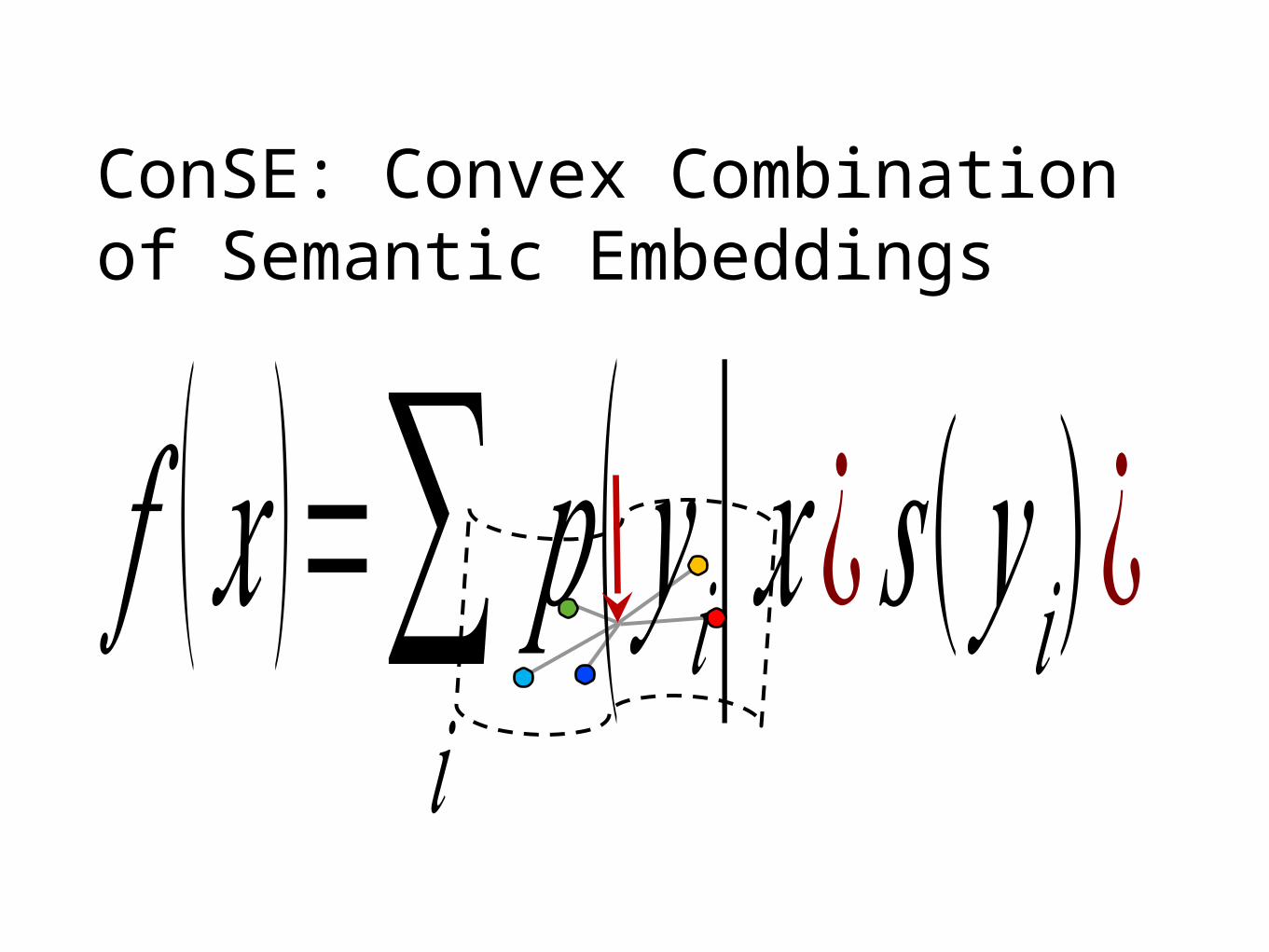
ConSE: Convex Combination of Semantic Embeddings
𝑓 (𝑥 )=∑𝑖
𝑝 (𝑦 𝑖|𝑥 ¿𝑠 (𝑦 𝑖)¿

ConSE(T): Convex Combination of Semantic Embeddings
A parameter to only select top predictions is among top probabilitiesWhen , then

ConSE(T): Convex Combination of Semantic Embeddings
► No extra training is needed
► For training images as long as then
► The output of is likely to stay on the manifold of labels when top predictions are close in the sematic space (similar to LLE)

Alternative Embedding Models (1)
► Train a regression model on the training set
[Richard Socher et al. Zero-shot learning through cross-modal transfer, 13]

Alternative Embedding Models (2)
► Train a ranking model on the training set so that is closer to than
Triplet ranking hinge loss
[Andrea Frome, Greg S. Corrado, Jon Shlens et al. DeViSE: A Deep Visual-Semantic Embedding Model, 13]
Our main baseline

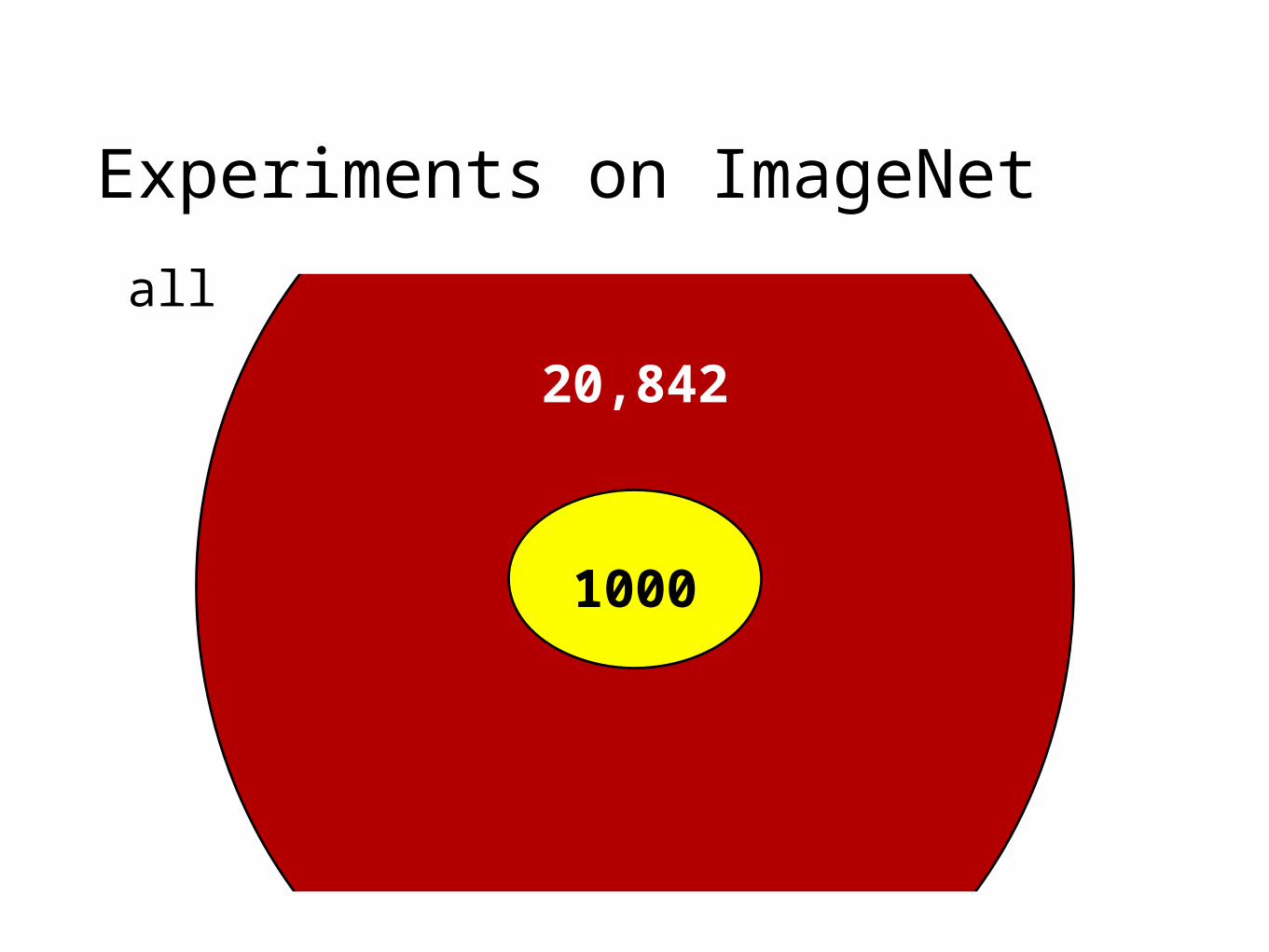
Experiments on ImageNet
21,841 labels in total
1000 labels for training
20,842 labels for zero-shot classification

Experiments on ImageNet
manta ray
stingray
wing chair
swivel chair

[Tomas Mikolov et al. Efficient estimation of word representations in vector space, 13]
D space
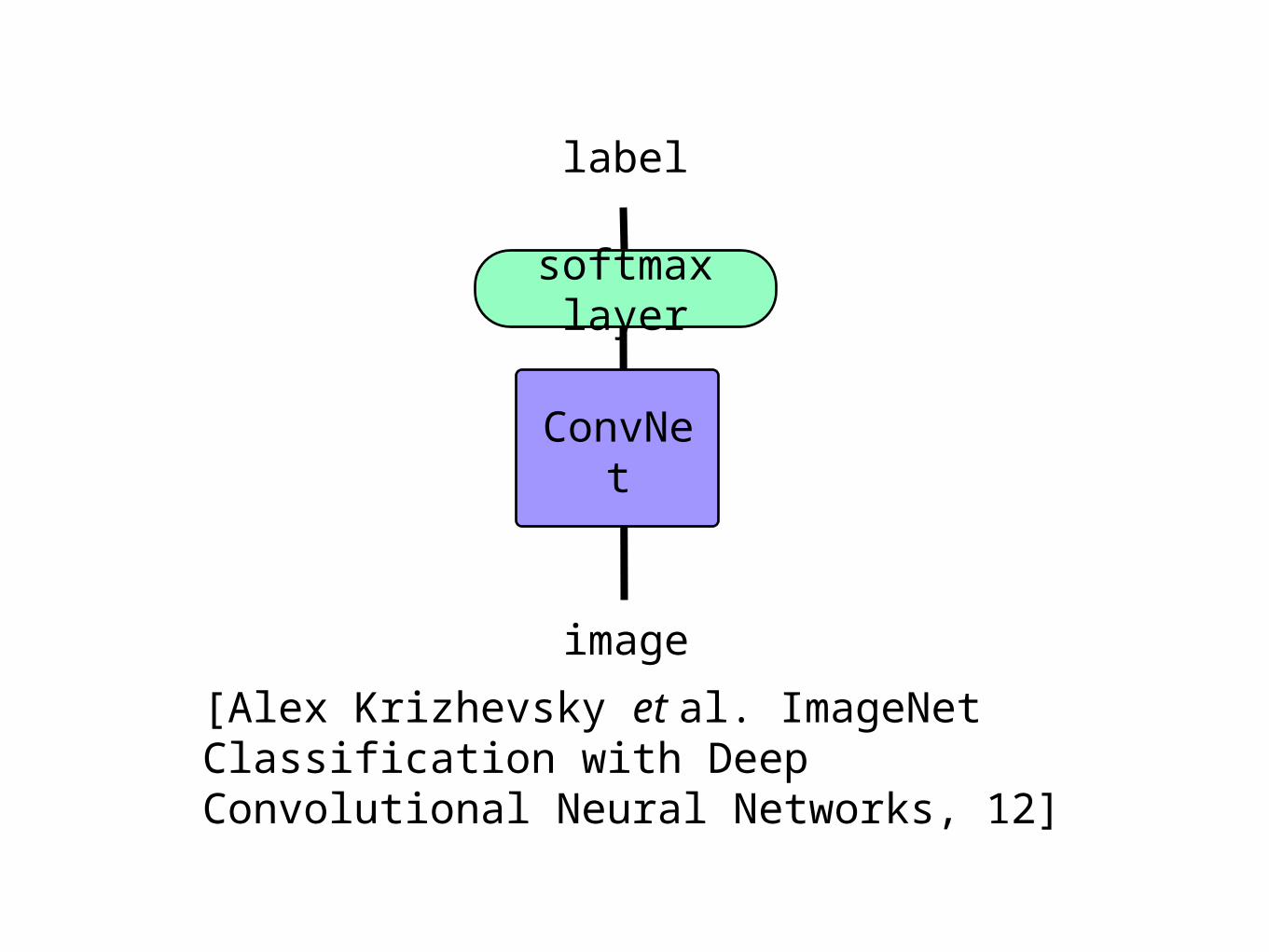
softmax layer
image
label
ConvNet
[Alex Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks, 12]
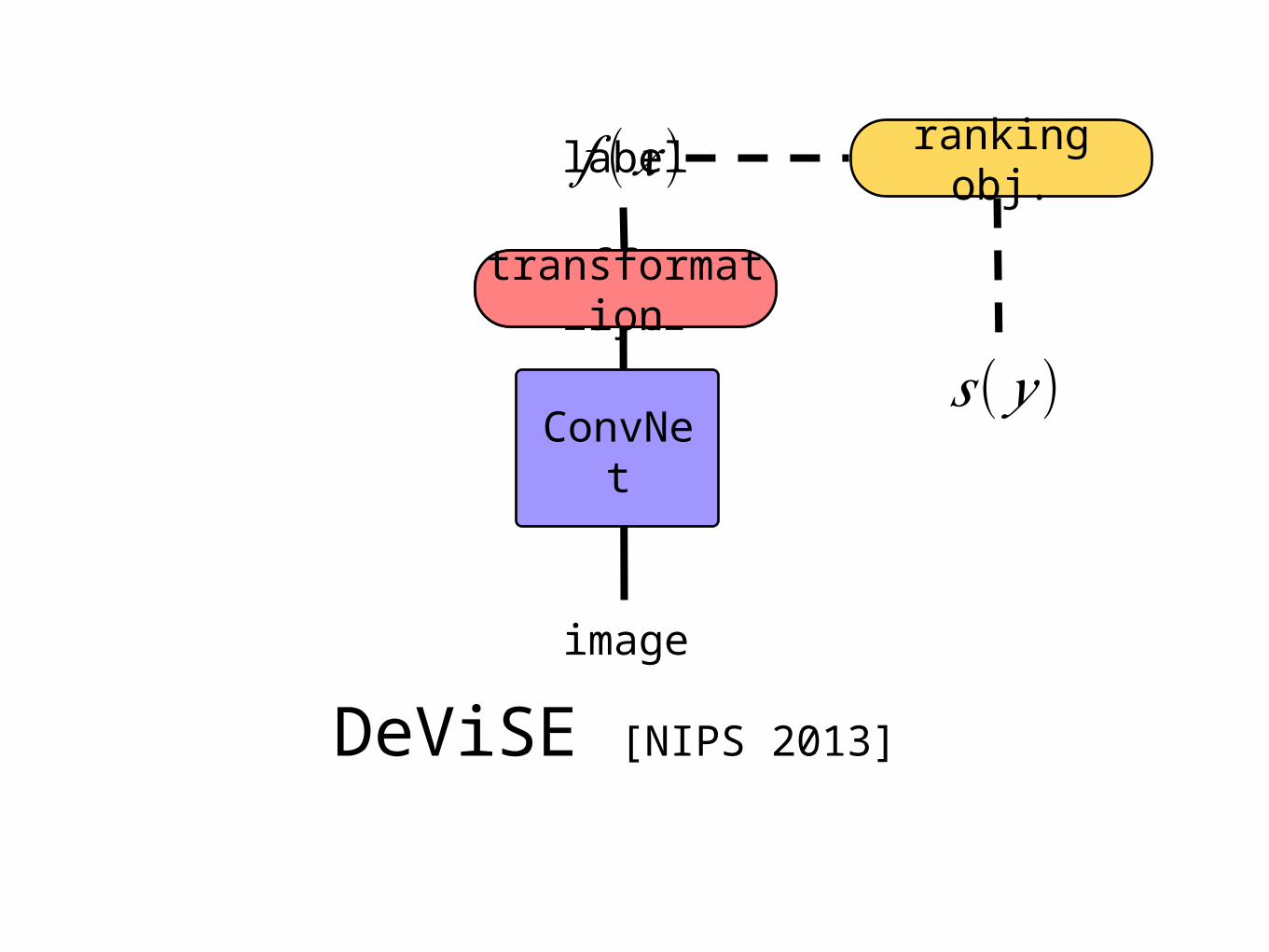
softmax layer
image
label
ConvNet
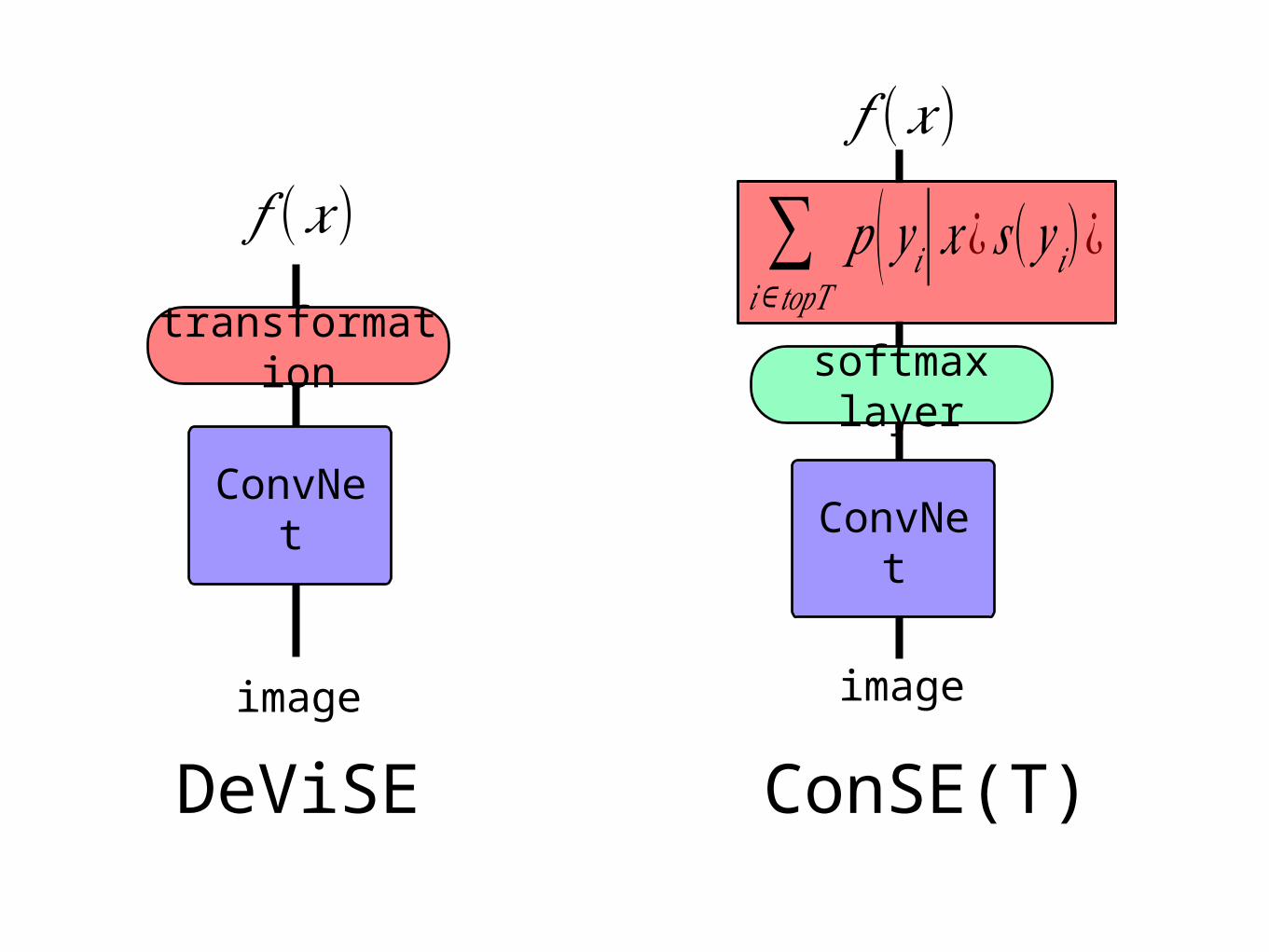
DeViSE [NIPS 2013]
transformation
𝑓 (𝑥) ranking obj.
𝑠(𝑦 )
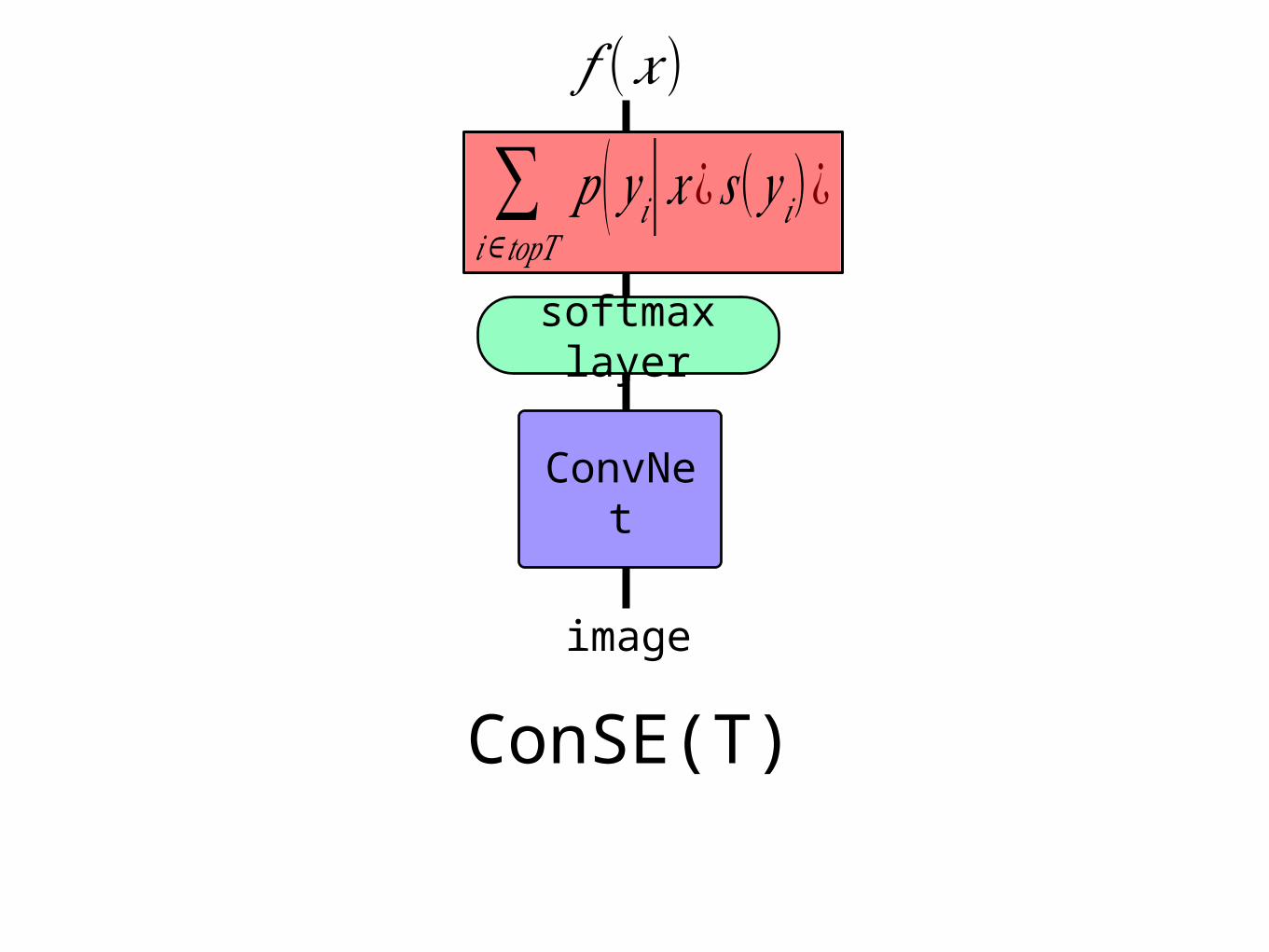
ConSE(T)
image
ConvNet
∑𝑖∈𝑡𝑜𝑝𝑇
𝑝 ( 𝑦 𝑖|𝑥¿ 𝑠(𝑦 𝑖)¿
𝑓 (𝑥)
softmax layer
ConSE(T)
image
ConvNet
∑𝑖∈𝑡𝑜𝑝𝑇
𝑝 ( 𝑦 𝑖|𝑥¿ 𝑠(𝑦 𝑖)¿
𝑓 (𝑥)
softmax layer
image
ConvNet
DeViSE
transformation
𝑓 (𝑥)

Experiments on ImageNet
Training Set: ImageNet 1K
1000

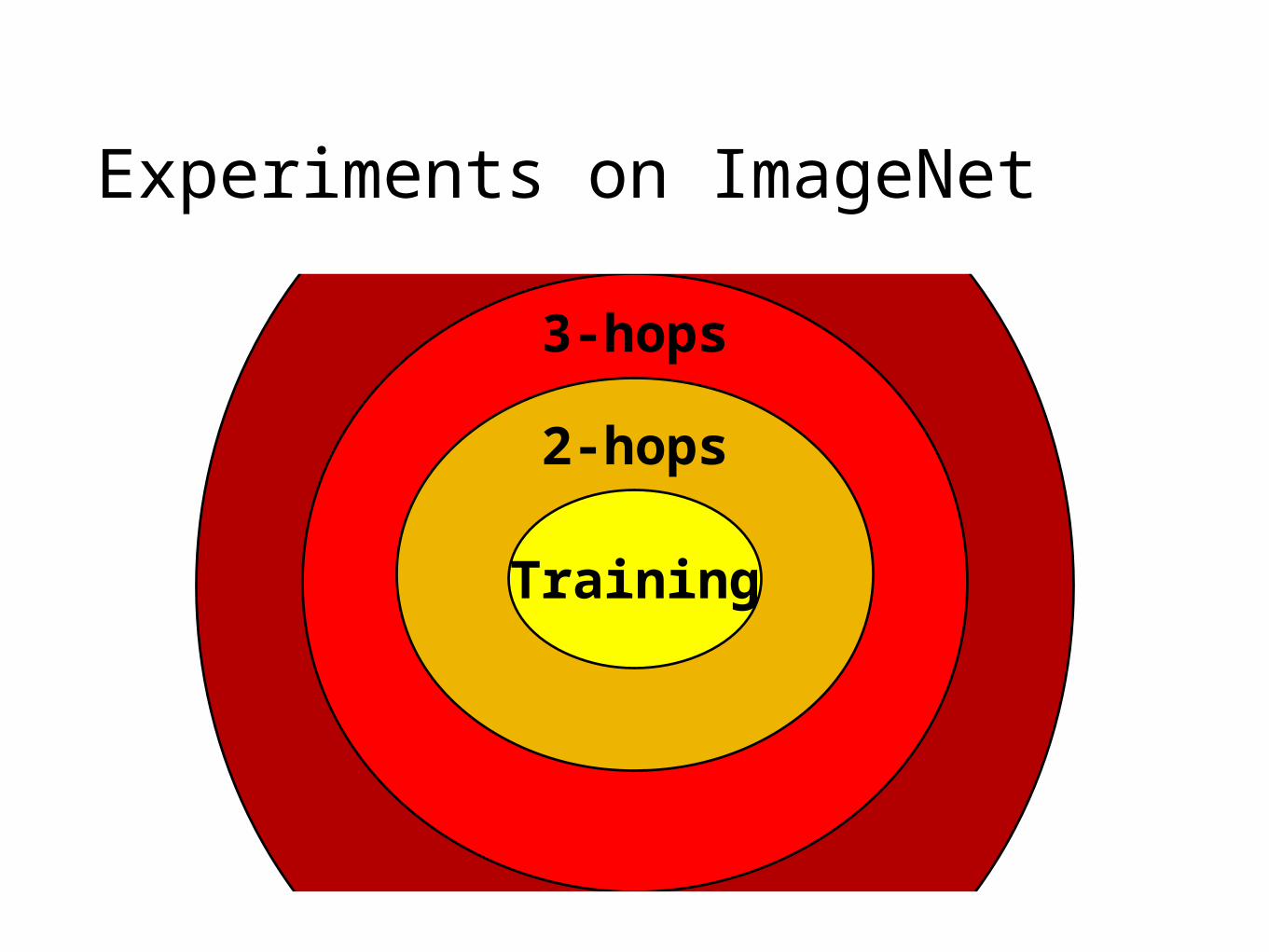
Experiments on ImageNet
1000
1549
2-hops: 1 or 2 tree hops away from training labels

Experiments on ImageNet
1000
7860
3-hops
Experiments on ImageNet
1000
20,842
all
Experiments on ImageNet
Training
2-hops
3-hops
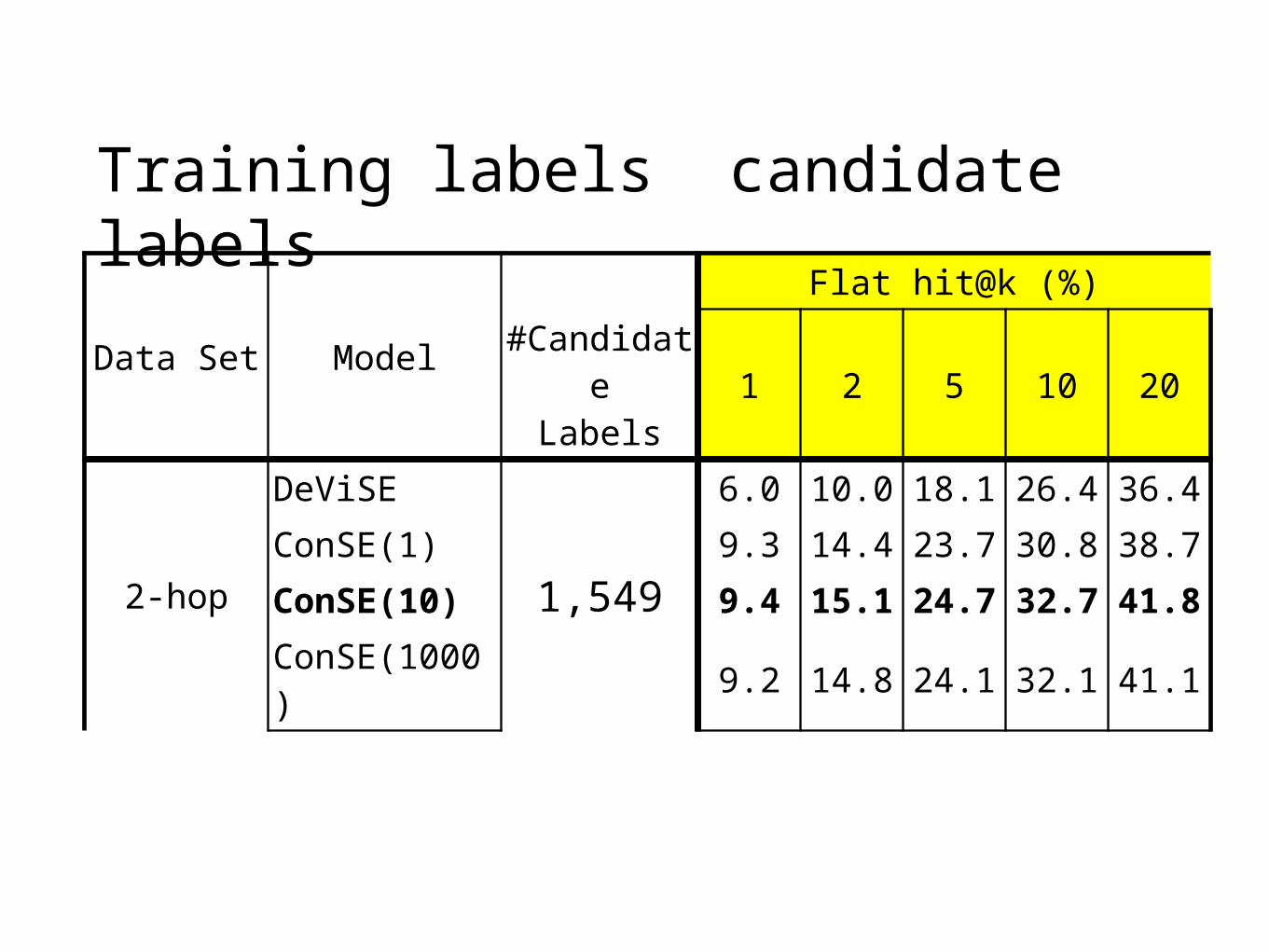
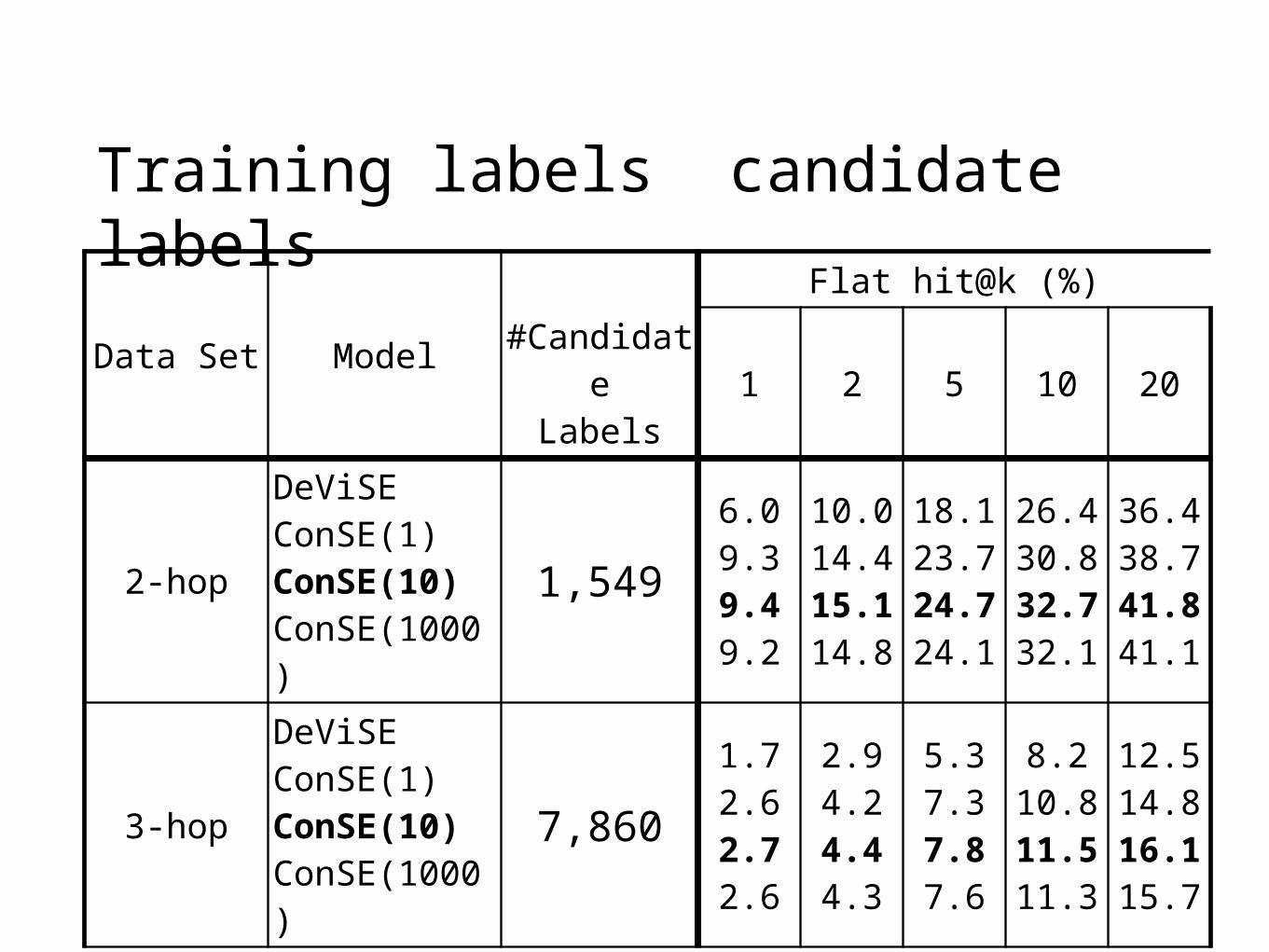
Training labels candidate labels
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
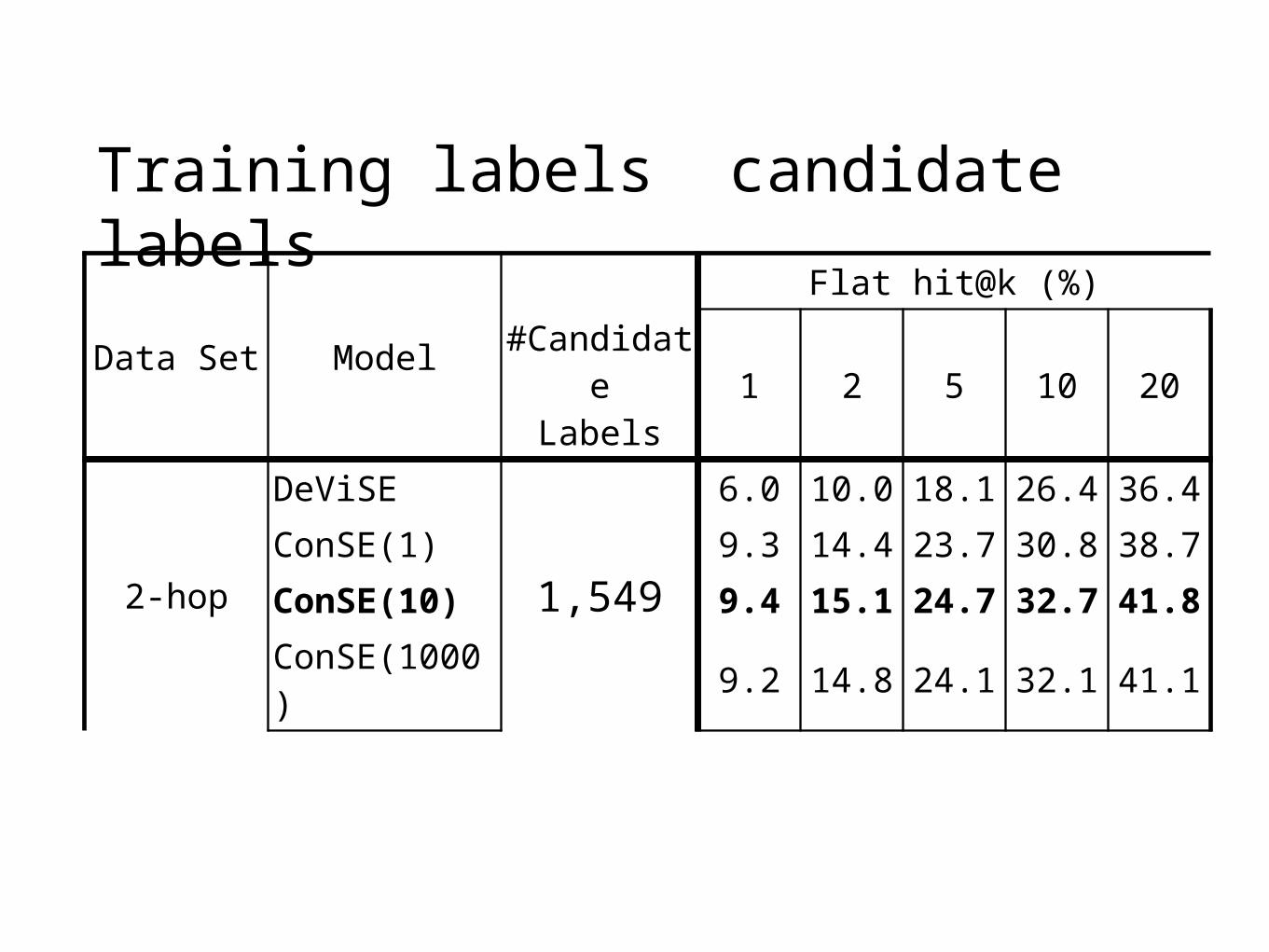
2-hop
DeViSE
1,549
6.0 10.0 18.1 26.4 36.4ConSE(1) 9.3 14.4 23.7 30.8 38.7
ConSE(10) 9.4 15.1 24.7 32.7 41.8
ConSE(1000) 9.2 14.8 24.1 32.1 41.1
Training labels candidate labels
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSE
1,549
6.0 10.0 18.1 26.4 36.4ConSE(1) 9.3 14.4 23.7 30.8 38.7
ConSE(10) 9.4 15.1 24.7 32.7 41.8
ConSE(1000) 9.2 14.8 24.1 32.1 41.1
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSE
1,549
6.0 10.0 18.1 26.4 36.4ConSE(1) 9.3 14.4 23.7 30.8 38.7
ConSE(10) 9.4 15.1 24.7 32.7 41.8
ConSE(1000) 9.2 14.8 24.1 32.1 41.1
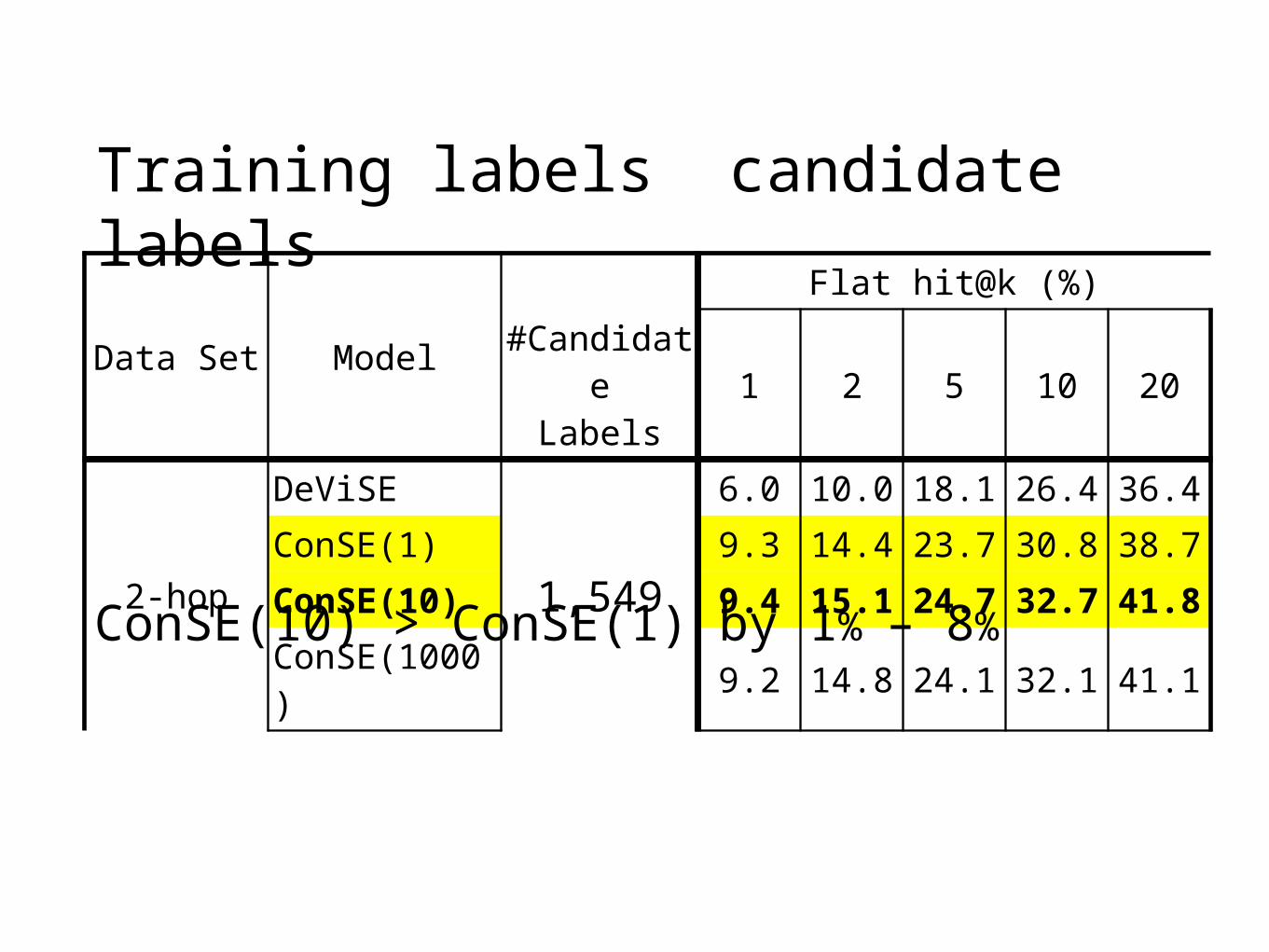
Training labels candidate labels
ConSE(10) > ConSE(1) by 1% – 8%
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSE
1,549
6.0 10.0 18.1 26.4 36.4ConSE(1) 9.3 14.4 23.7 30.8 38.7
ConSE(10) 9.4 15.1 24.7 32.7 41.8
ConSE(1000) 9.2 14.8 24.1 32.1 41.1
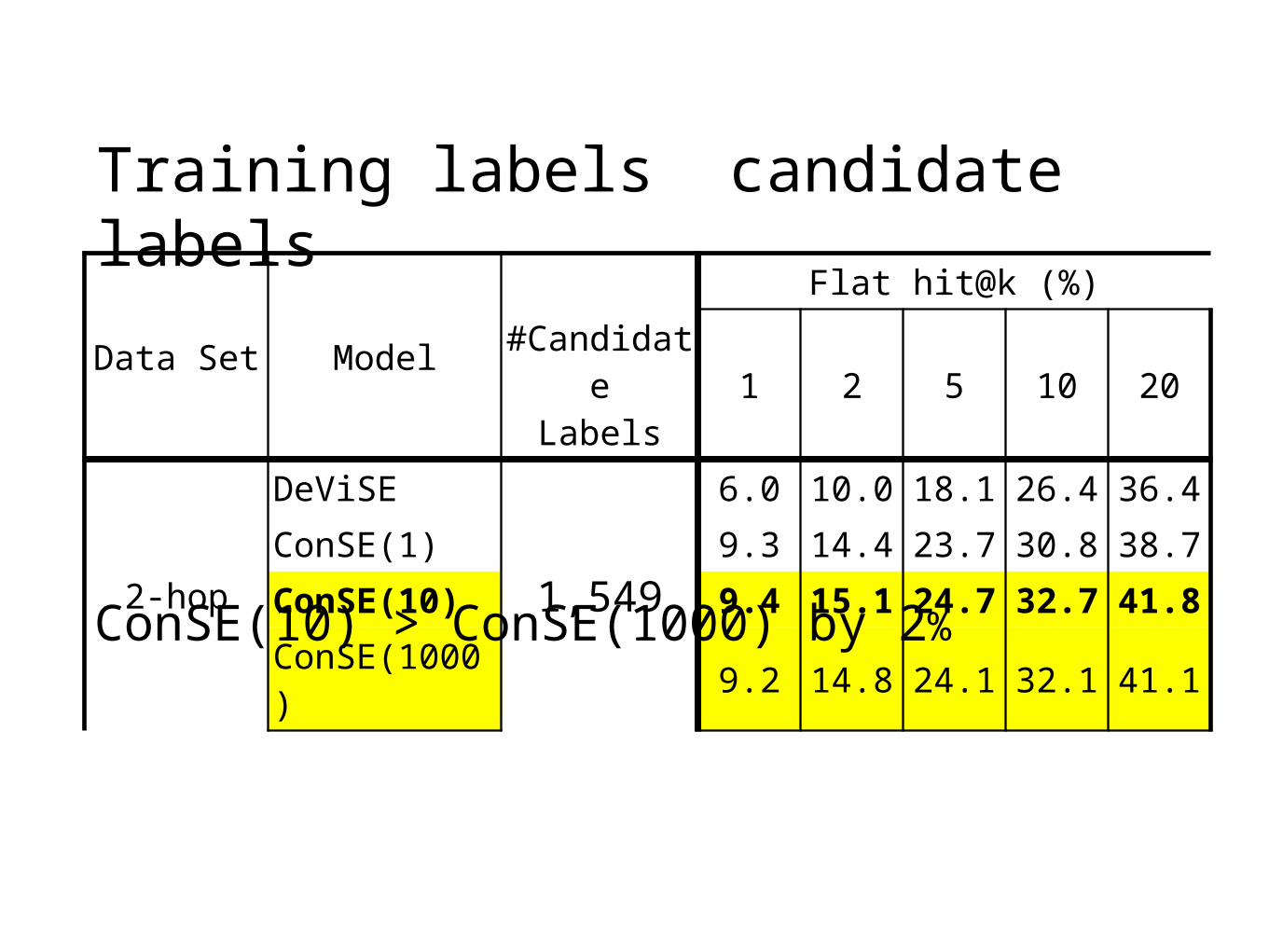
Training labels candidate labels
ConSE(10) > ConSE(1000) by 2%
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSE
1,549
6.0 10.0 18.1 26.4 36.4ConSE(1) 9.3 14.4 23.7 30.8 38.7
ConSE(10) 9.4 15.1 24.7 32.7 41.8
ConSE(1000) 9.2 14.8 24.1 32.1 41.1
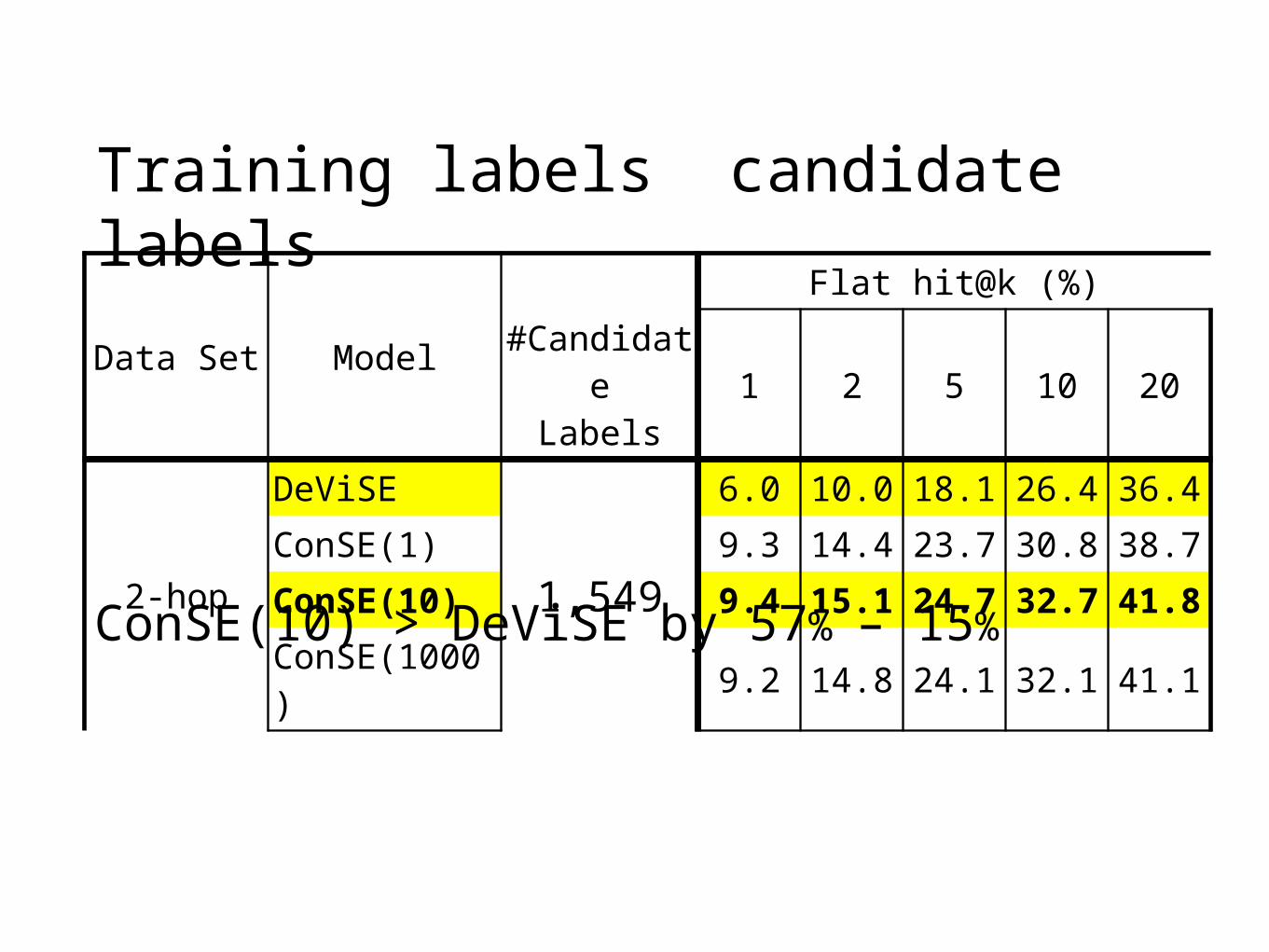
Training labels candidate labels
ConSE(10) > DeViSE by 57% – 15%
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSEConSE(1)ConSE(10)ConSE(1000)
1,549
6.09.39.49.2
10.014.415.114.8
18.123.724.724.1
26.430.832.732.1
36.438.741.841.1
3-hop
DeViSEConSE(1)ConSE(10)ConSE(1000)
7,860
1.72.62.72.6
2.94.24.44.3
5.37.37.87.6
8.210.811.511.3
12.514.816.115.7
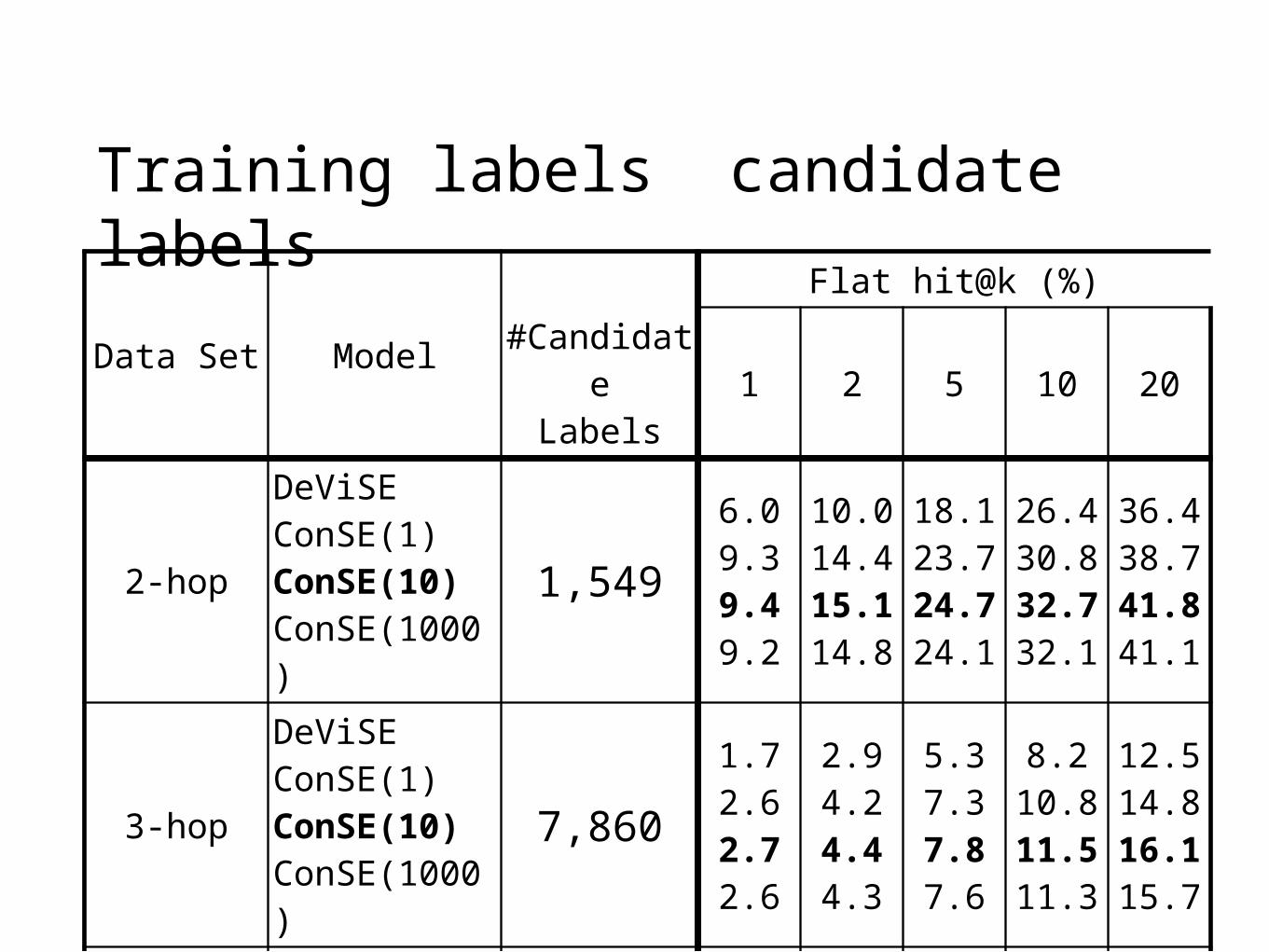
Training labels candidate labels
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSEConSE(1)ConSE(10)ConSE(1000)
1,549
6.09.39.49.2
10.014.415.114.8
18.123.724.724.1
26.430.832.732.1
36.438.741.841.1
3-hop
DeViSEConSE(1)ConSE(10)ConSE(1000)
7,860
1.72.62.72.6
2.94.24.44.3
5.37.37.87.6
8.210.811.511.3
12.514.816.115.7
ImageNet 21K
DeViSEConSE(1)ConSE(10)ConSE(1000)
20,842
0.81.31.41.3
1.42.12.22.1
2.53.63.93.8
3.95.45.85.6
6.07.68.38.1
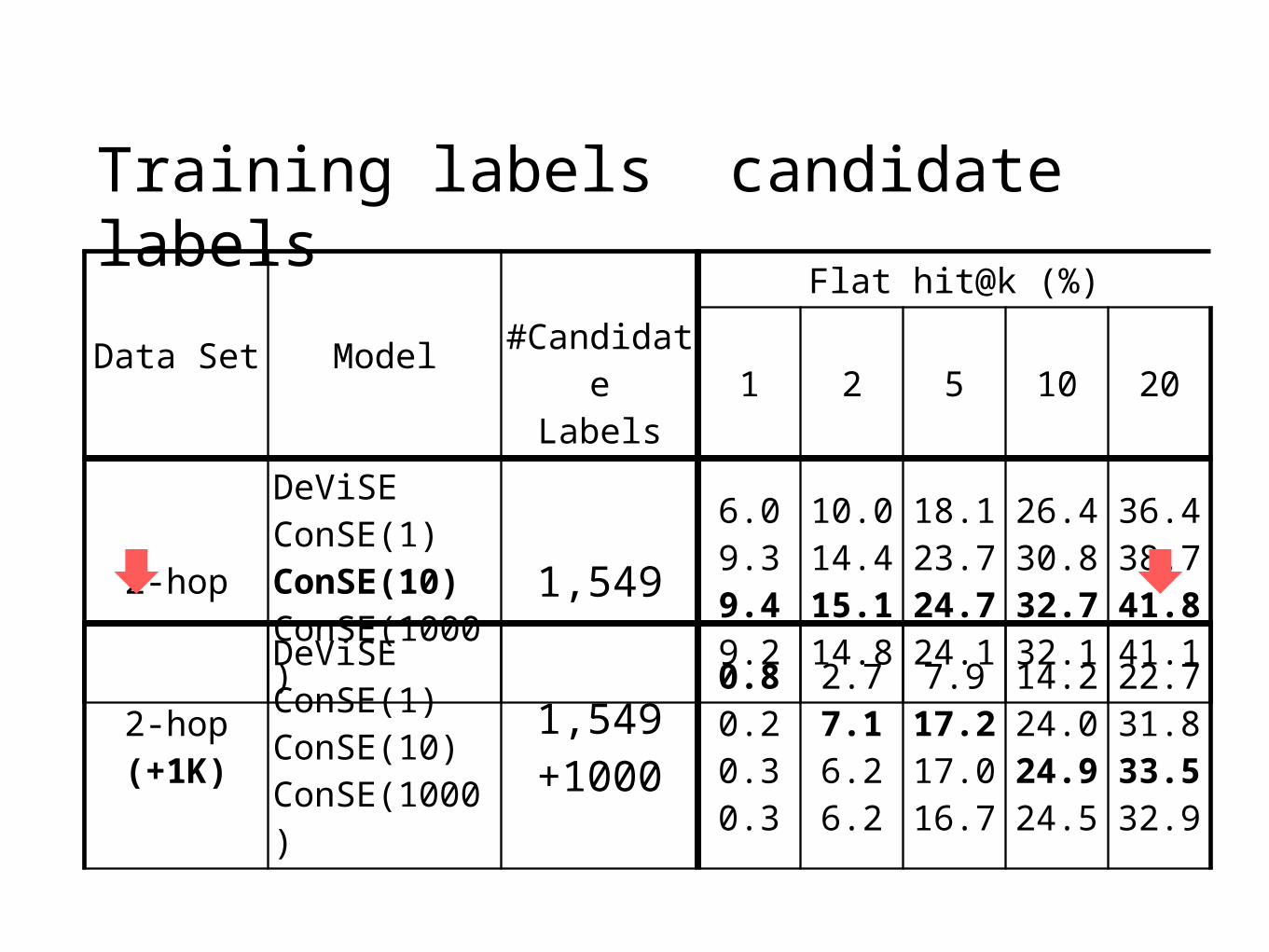
Training labels candidate labels
Data Set Model #Candidate
Labels
Flat hit@k (%)
1 2 5 10 20
2-hop
DeViSEConSE(1)ConSE(10)ConSE(1000)
1,549
6.09.39.49.2
10.014.415.114.8
18.123.724.724.1
26.430.832.732.1
36.438.741.841.1
Training labels candidate labels
2-hop(+1K)
DeViSEConSE(1)ConSE(10)ConSE(1000)
1,549+1000
0.80.20.30.3
2.77.16.26.2
7.917.217.016.7
14.224.024.924.5
22.731.833.532.9
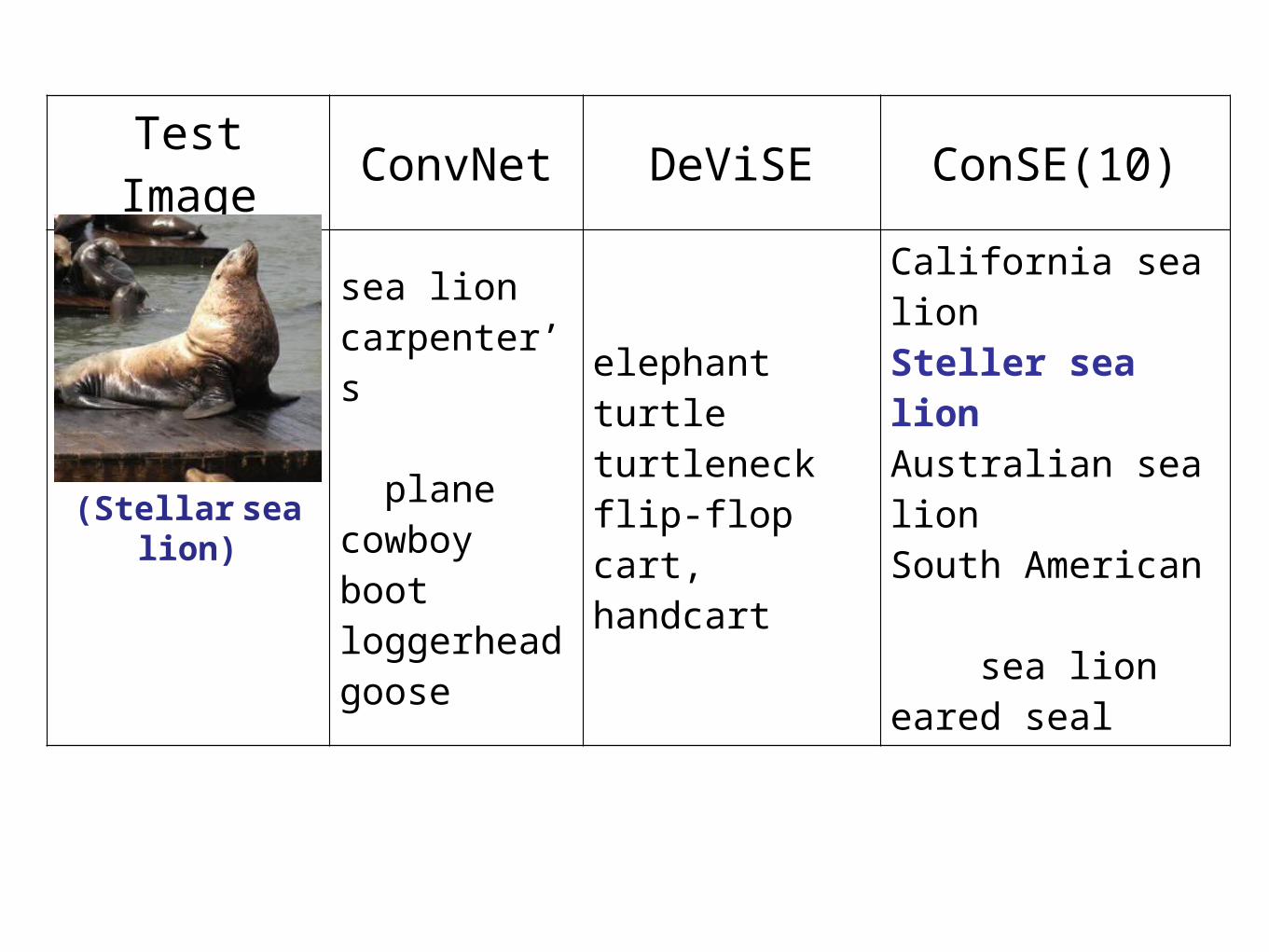
Test Image ConvNet DeViSE ConSE(10)
sea lioncarpenter’s planecowboy bootloggerheadgoose
elephantturtleturtleneckflip-flopcart, handcart
California sea lionSteller sea lionAustralian sea lionSouth American sea lioneared seal
(Stellar sea lion)

Test Image ConvNet DeViSE ConSE(10)
sea lioncarpenter’s planecowboy bootloggerheadgoose
elephantturtleturtleneckflip-flopcart, handcart
California sea lionSteller sea lionAustralian sea lionSouth American sea lioneared seal
hamsterbroccoliPomeranianCapuchinweasel
golden hamsterrhesus monkeypipeshakerAmerican mink
golden hamsterrodent, gnawerEurasian hamsterrhesus monkeyrabbit, coney, cony
(Stellar sea lion)
(golden hamst.)

Test Image ConvNet DeViSE ConSE(10)
wigfur coatSalukiAfghan houndstole
water spanieltea gownbridal gownspanieltights, leotards
business suitdress, frockhairpiece, false hairswimsuitkit, outfit
Ostrichblack storkvulturecranepeacock
heronowl, bird of nighthawkraptorfinch
flightless bird, ratitePeafowlcommon spoonbillNew World vultureGreek partridge
(dress, frock)
(flightless bird)
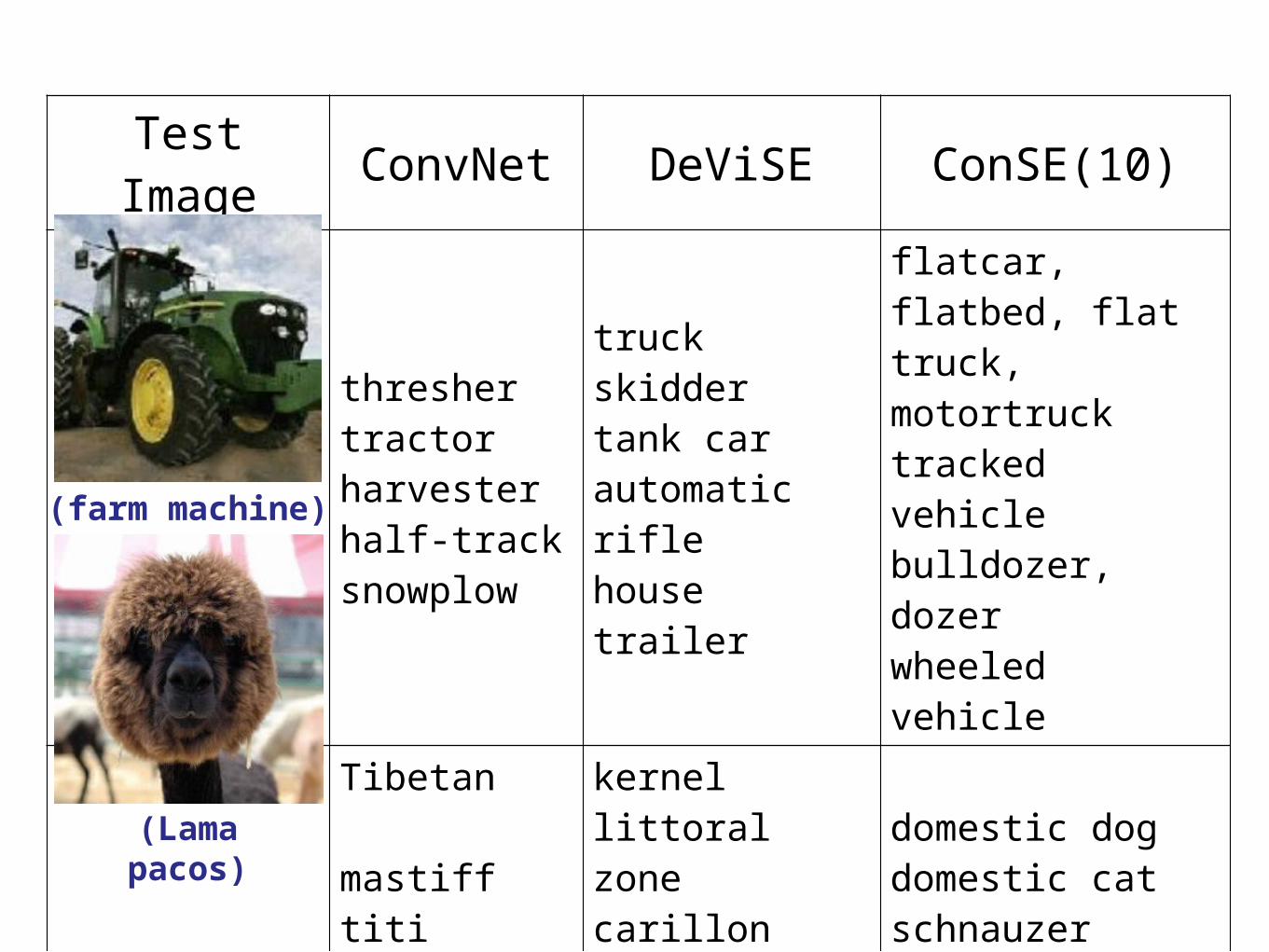
Test Image ConvNet DeViSE ConSE(10)
threshertractorharvesterhalf-tracksnowplow
truckskiddertank carautomatic riflehouse trailer
flatcar, flatbed, flattruck, motortrucktracked vehiclebulldozer, dozerwheeled vehicle
Tibetan mastifftiti monkeyKoalallamachow-chow
kernellittoral zonecarillonCabernet Sauvignonpoodle dog
domestic dogdomestic catschnauzerBelgian sheepdogdomestic llama
(Lama pacos)
(farm machine)

Why ConSE > DeViSE zero-shot learning?
► ConSE < DeViSE on the training set
► In DeViSE the function is unrestricted, so it can project images out of the manifold of labels
► In ConSE the projection is much more restricted. We have to stay on the manifold, so the projection function is much more regularized

Conclusion
ConSE: A deterministic way to embed images in a semantic embedding space using probabilistic predictions of a classifier
Experiments suggest that this model performs very well for zero-shot learning compared to regression based algorithms

Thank you!Liger?