画像認識向け 3 次元 積層 アクセラレータ・アーキテクチャの検討
DESCRIPTION
画像認識向け 3 次元 積層 アクセラレータ・アーキテクチャの検討. 九州大学大学院システム情報科学府* 九州大学大学院システム情報科学研究院** 上野伸也 * Gauthier Lovic Eric** 井上弘士** 村上和彰**. 概要. 画像認識技術 アクセラレータに よる高性能・低消費エネルギー化 アプリケーション分析 アクセラレータ・アーキテクチャ検討 性能・消費エネルギー評価 まとめ. 画像認識技術. 機械が人間に代わって,物事を理解,認識,判断 応用 分野 産業,医療,セキュリティ,安全技術, etc. 画像認識を行う機器への要求 - PowerPoint PPT PresentationTRANSCRIPT
画像認識向け 3 次元積層アクセラレータ・アーキテクチャの検討
九州大学大学院システム情報科学府 * 九州大学大学院システム情報科学研究院 **
上野伸也 * Gauthier Lovic Eric** 井上弘士 ** 村上和彰 **
1

概要• 画像認識技術• アクセラレータによる高性能・低消費エネ
ルギー化• アプリケーション分析• アクセラレータ・アーキテクチャ検討• 性能・消費エネルギー評価• まとめ
2

画像認識技術
• 機械が人間に代わって,物事を理解,認識,判断
• 応用分野– 産業,医療,セキュリティ,安全技術, etc.
• 画像認識を行う機器への要求– 高性能– 低消費エネルギー– ソフトウェア処理
http://www.honda.co.jp/news/2004/4040824a.html車載カメラによる夜間の歩行者認識技術
「インテリジェント・ナイトビジョンシステム」 (Honda)3
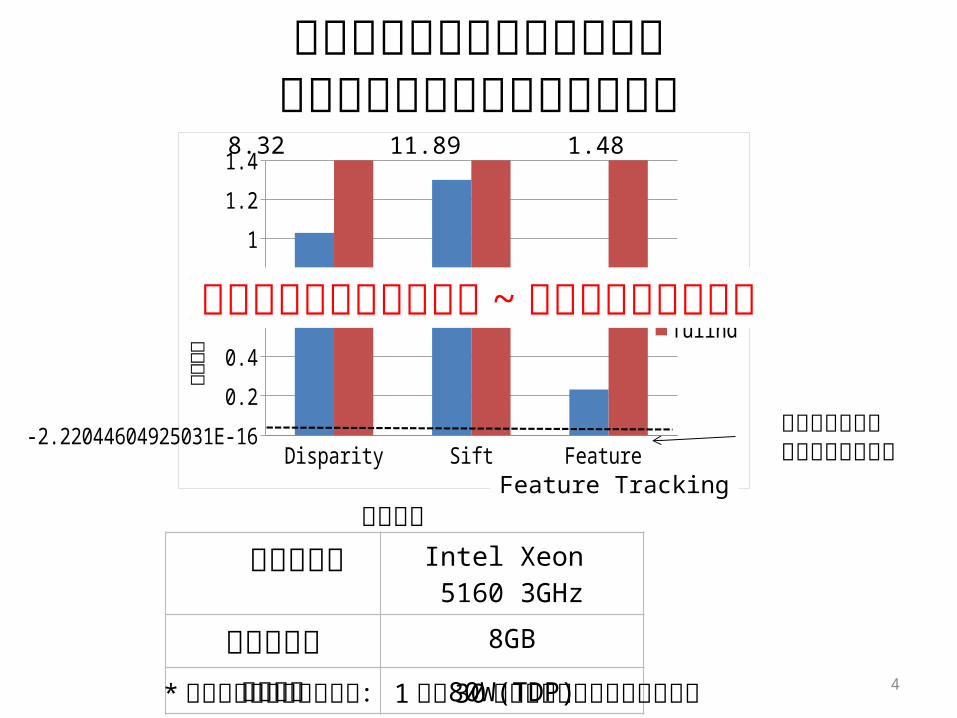
画像認識アプリケーションのリアルタイム実行に必要な性能
4
プロセッサ
Intel Xeon 5160 3GHz
メモリ容量 8GB
消費電力 80W(TDP)
Disparity Sift Feature Tracking
-2.22044604925031E-16
0.2
0.4
0.6
0.8
1
1.2
1.4
vgafullhd
実行
時間
(sec)
1.4811.898.32
リアルタイム性を満たす実行時間
実行環境
汎用プロセッサの数十倍 ~ 数百倍の性能が必要
Feature Tracking
* リアルタイム性を満たす: 1 秒間 30 枚の画像に対して処理を行う

ホストCPU 主記憶 アクセラ
レータ
アクセラレータによる高性能・低消費エネルギー化
5
インターコネクト
出典 http://www.itmweb.com
Cell/B.E Tesla S1070
出典: http://www.elsa-jp.co.jp/products/hpc/tesla/s1070/index.html
Cell/B.E ,GPU , etc
スレッド / データレベル並列性を利用して高性能・低消費エネルギー化
288GFLOPS210W
933GFLOPS1123W
*Xeon 5160 24GFLOPS 80W
アクセラレータの性能向上阻害要因 ・メモリ容量の不足 ・大規模化に伴う配線長の増加
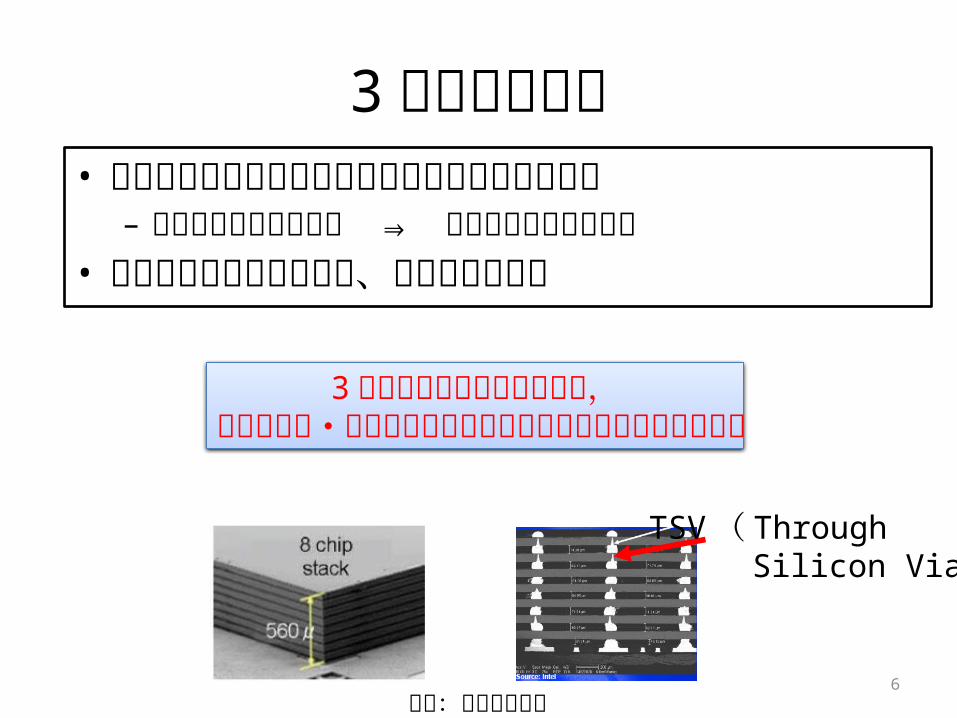
3 次元積層技術• 異なるプロセスを経て製造されたダイ同士の積層– 大容量のメモリを積層 ⇒ メモリ容量不足の緩和
• グローバル配線長の削減、チップ面積縮小
6出典:米インテル社
TSV ( Through Silicon Vias )
3 次元積層を利用することで,より高性能・低消費エネルギーなアクセラレータを実現可能

概要• 画像認識技術• アクセラレータによる高性能・低消費エネ
ルギー化• アプリケーション分析• アクセラレータ・アーキテクチャ検討• 性能・消費エネルギー評価• まとめ
7

対象プログラムの決定
• SD-VBS[1]– Venkata らによる画像処理
ベンチマークプログラムセット
– 画像認識に対応するプログラム• SIFT• Image Segmentation• SVM• Disparity Map• Feature Tracking
処理プログラム
画像変換
画像解析
画像認識
画像合成
画像理解
SIFT ○ ○
Image Segmentation ○ ○
SVM ○
Image Stitch ○ ○ ○
Texture Synthesis ○ ○ ○
Feature Tracking ○ ○ ○
Disparity Map ○ ○ ○
SD-VBS の各プログラムが含む処理
•画像認識アプリケーションに良く用いられる•計算量が大きい
[1]S. K. Venkata , et al. “SD-VBS: The San Diego Vision Benchmark Suite,”Proc . IISWC , pp.55-pp.64 , Oct. 2009 8

vga fullhd02468
101214
その他の処理
画像の読み込み
初期値の設定など
極値検出
DoG 画像の生成
画像平滑化
画像認識アプリケーション分析~ SIFT ~
• 入力画像から SIFT 特徴の特徴点を検出するプログラム– 物体認識、画像分類、特徴点追跡に用いられる
9ガウシアンフィルタ処理, DoG 画像生成,極値検出に注目
ガウシアンフィルタによる画像平滑化
DoG 画像の生成
極値検出
主曲率によるキーポイントの削除
低コントラストに基づくキーポイントの削除
ガウシアンフィルタ
実行
時間
(sec
)
SIFT の処理フロー 各処理の実行時間
*Intel Xeon 5160 3GHz で実行

ガウシアンフィルタによる画像平滑化
10
1. スケールを変化 ( )させながらそれぞれ画像平滑化
2. 入力画像を 2 分の 1 にダウンサンプリング3. 画像サイズが一定値以下になるまで 1.2 .
の処理を繰り返し
002
00 2,...,,, kk
各平滑化画像の生成は並列に行うことが可能
入力画像
入力画像
平滑化画像
L(2σ0)
L(σ0)
平滑化画像
平滑化画像
L(k*kσ0)
L(kσ0)
ダウンサンプリング
入力画像
平滑化画像
平滑化画像
平滑化画像
平滑化画像L(2σ0)
L(k*kσ0)
L(kσ0)
L(σ0)
1オクターブ
ガウシアンフィルタ処理

ガウシアンフィルタ処理
10 20 9 20 13 18 6 1517 8 2 21 18 15 1 2121 1 2 12 11 3 8 2112 6 22 19 19 15 8 144 20 12 3 18 14 20 224 12 8 2 3 8 16 74 22 18 21 21 3 8 222 22 7 15 18 11 20 117 15 9 17 1 14 13 14
7 8 10 11 11 9 9 69 10 11 13 14 12 11 99 11 12 14 14 12 12 109 11 12 14 14 14 14 118 11 12 12 13 14 14 118 12 13 12 12 13 14 108 13 15 14 13 13 13 108 12 14 14 13 13 12 105 8 9 9 9 9 9 7
入力画像 平滑化画像
平滑化
ガウシアンフィルタ
1. 注目画素をガウシアンフィルタの中心とする2. 画素値 ×ガウシアンフィルタ係数3. 2 の結果を合計4. 結果を対応する場所に記入5. 1 ~ 4 を全画素に対して行う
11
256
36
256
24
256
24256
24
256
24
256
16
256
16256
16256
16256
16
256
16256
16
256
4
256
4256
4
256
4
256
4256
4
256
4
256
16
256
4
256
1
256
1
256
1
256
1

DoG 画像の生成と極値検出
12
スケール 極値検出対象画像
•3 枚 1組で比較を行う•注目画素と 26近傍画素で比較•注目画素が極値がどうか判定•極値の場合、当該画素を キーポイント候補に加える•全画素に対して行う
並列に求めることが可能
平滑化画像DoG 画像
平滑化画像との差分を求める

分析結果まとめ( 並列度・入力データ数・演算の種類・ DFG の深さ )
13
並列度入力データ
数演算の種類と回数 DFG の深さ
画像平滑化 2Nk^2
積算 Nk^2回
和算 Nk^2-1回
DoG 生成 2 減算 1回
1
極値検出 27 比較演算 26回
1 ~ 26X :オクターブ数Y: :スケール数Zi : iオクターブ目の入力画素数Nk :スケール k におけるガウシアンフィルタのウィンドウサイズ
X
iiZY
1
並列性・演算に関する特性
X
iiZY
1
)1(
X
iiZY
1
)3(
1log2 2 kN
概要• 画像認識技術• アクセラレータによる高性能・低消費エネ
ルギー化• アプリケーション分析• アクセラレータ・アーキテクチャ検討• 性能・消費エネルギー評価• まとめ
14

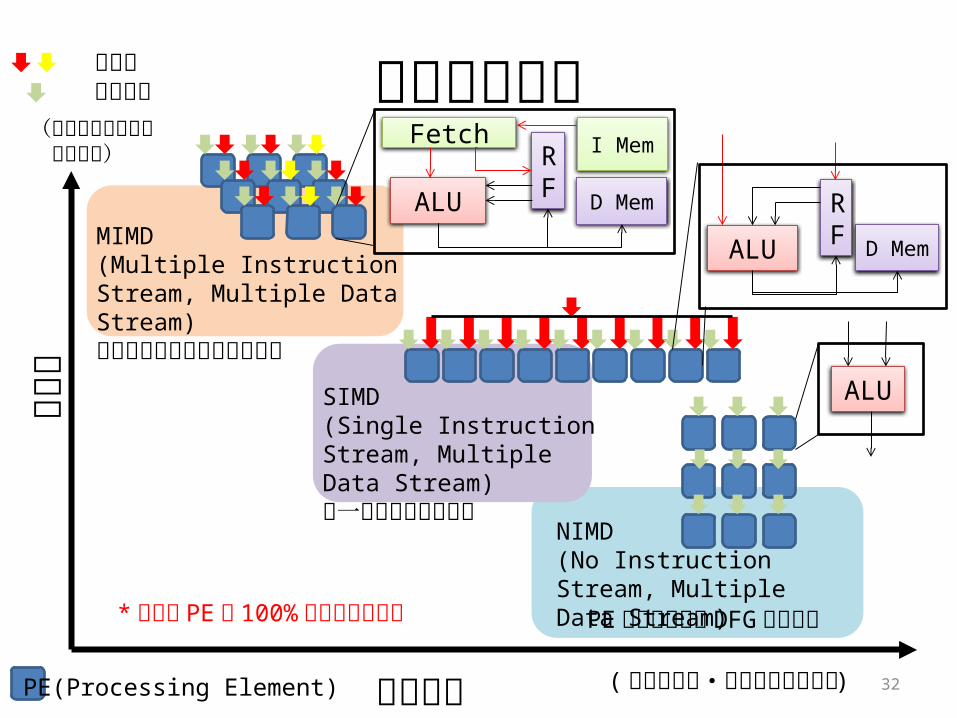
加速実行方式
15
汎用
性
MIMD(Multiple Instruction Stream, Multiple Data Stream)異なる命令を並列に実行可能
SIMD(Single Instruction Stream, Multiple Data Stream)同一命令を並列に実行
NIMD(No Instruction Stream, Multiple Data Stream)
PE アレイ上での DFG直接実行
電力効率PE(Processing Element)
命令流データ流
( より高性能・低消費エネルギー )
(より性能低下要因が少ない)
* 全ての PE が 100%動作すると仮定
命令フェッチ機構の簡略化
・命令フェッチ機構の省略・レジスタファイルの省略

各処理に適した加速実行方式
16
汎用
性
MIMD(Multiple Instruction Stream, Multiple Data Stream)異なる命令を並列に実行可能
SIMD(Single Instruction Stream, Multiple Data Stream)同一命令を並列に実行
NIMD(No Instruction Stream, Multiple Data Stream)
PE アレイ上での DFG直接実行
電力効率PE(Processing Element)
命令流データ流
( より高性能・低消費エネルギー )
(より性能低下要因が少ない)
* 全ての PE が 100%動作すると仮定
極値検出
DoG 画像の生成ガウシアンフィルタによる画像平滑化

実行方式切り替え可能なNIMD/MIMD型アクセラレータ
ALU アレイ構成用ネットワーク
プロセッサ・コアとメモリ・コアは密に結合
17
メモリ間オンチップネットワーク
Inst. Mem.
Data Mem.
Router
メモリコアRegister File
ALU ALU
プロセッサコア
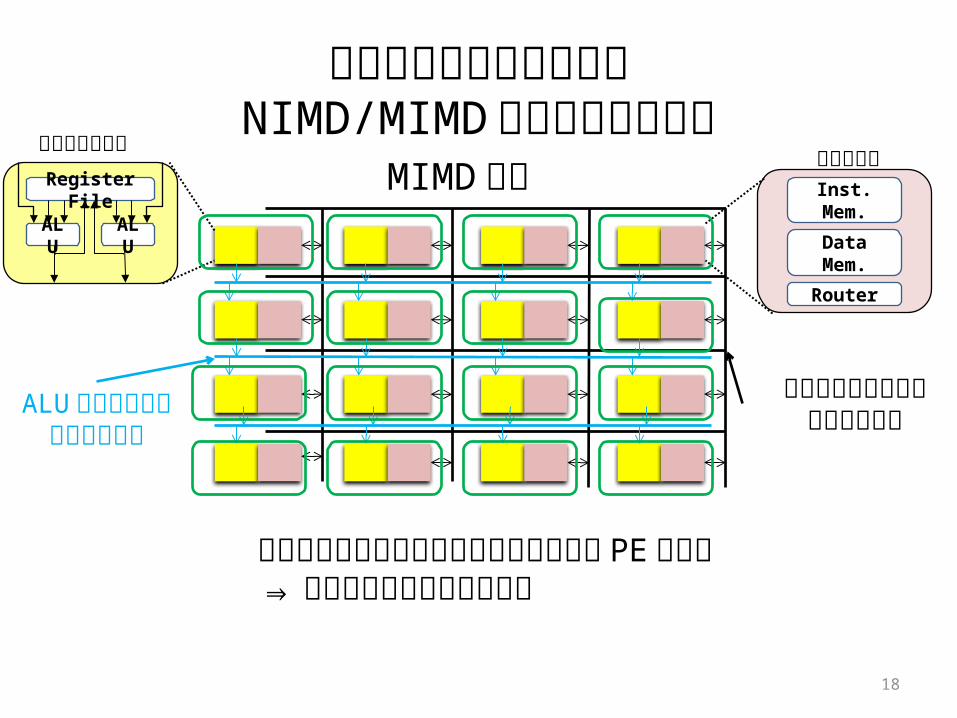
実行方式切り替え可能なNIMD/MIMD型アクセラレータ
メモリ間オンチップネットワーク
Inst. Mem.
Data Mem.
Router
メモリコアRegister File
ALU ALU
18
プロセッサコア MIMD 実行
プロセッサコアとメモリコアが結合して PE を構成⇒複数スレッドを並列に実行
ALU アレイ構成用ネットワーク

実行方式切り替え可能なNIMD/MIMD型アクセラレータ
問題点:ALU 間の配線長が長い ⇒ プロセッサコア間のデータ通信時間 / 消費エネルギー増加
NIMD 実行
19
メモリが隣接⇒単純な NIMD方式より ALU 間の距離が長い
× × × ×
+ +
+ALU アレイ構成用ネットワーク
Register File
ALU ALU
プロセッサコア
メモリ間オンチップネットワーク
Inst. Mem.
Data Mem.
Router
メモリコア
停止

3 次元積層NIMD/MIMD型アクセラレータ
20
Register File
プロセッサコア
ALU ALU
Inst. Mem.
Data Mem.
Router
ALU アレイ構成用オンチップ・ネットワーク
コア間データ通信用オンチップ・ネットワーク
メモリコア
メモリレイヤ
プロセッサ・レイヤ密に演算器
を集積
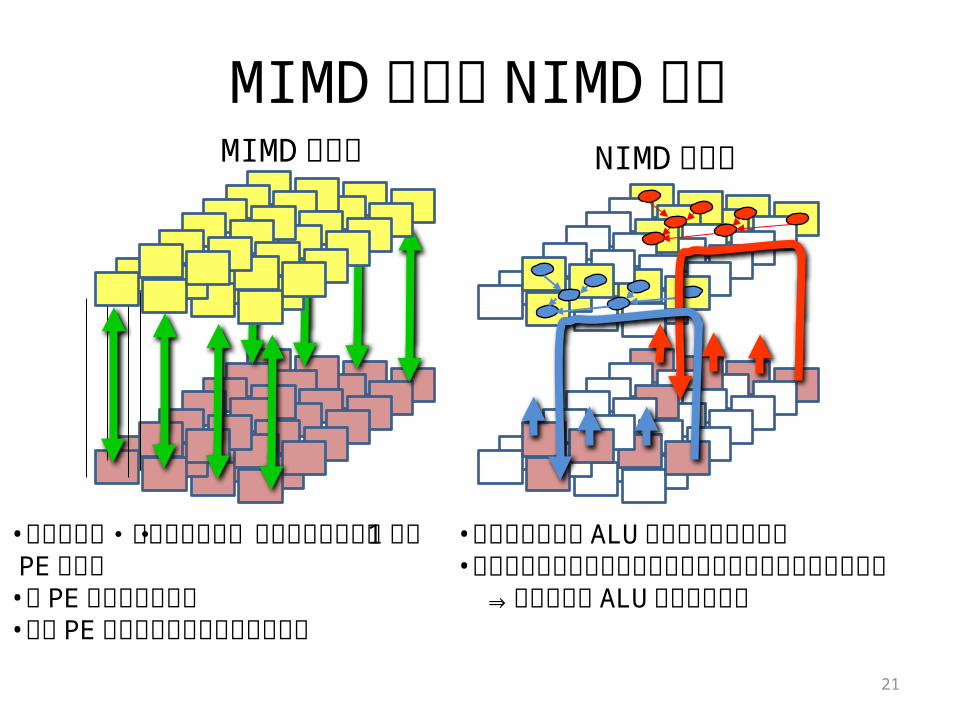
MIMD 実行と NIMD 実行
21
NIMD 実行時
•メモリコアから ALU アレイへデータ供給•プロセッサコアとデータの入出力を行うメモリコアを変更 ⇒様々な形の ALU アレイを実現
•プロセッサ・コアとメモリ・コアのペアにより 1個の PE を構成•各 PEは独立して動作•最大 PE 数のスレッド並列実行が可能
MIMD 実行時
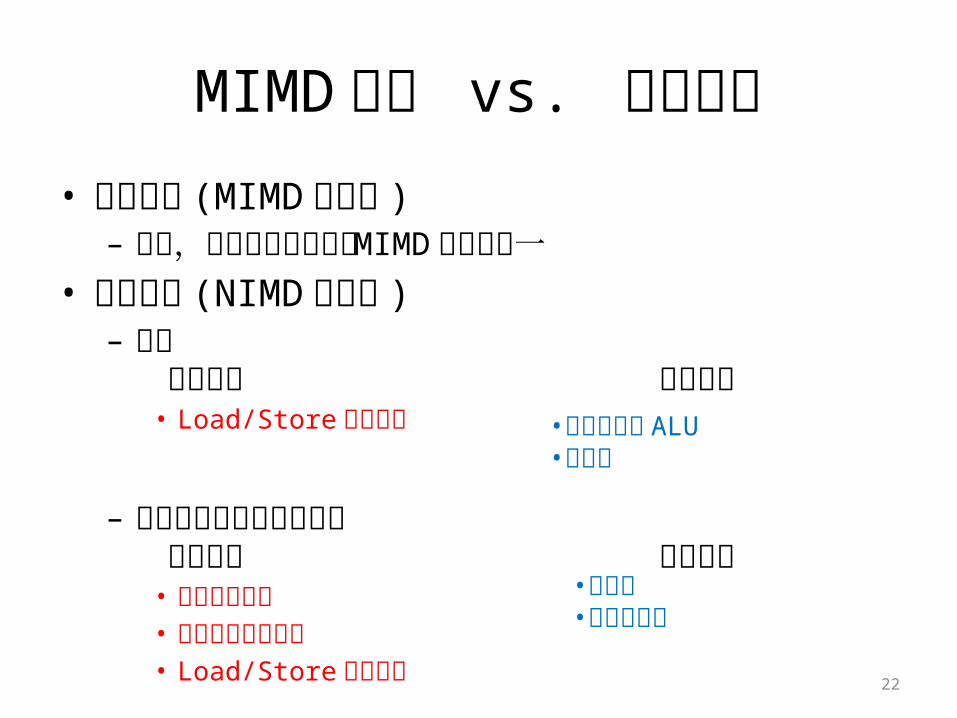
MIMD方式 vs. 提案手法• 提案手法 (MIMD 実行時 )– 性能,消費エネルギーはMIMD方式と同一
• 提案手法 (NIMD 実行時 )– 性能
向上要因 低下要因 • Load/Store命令削減
– 消費エネルギー削減効果 向上要因 低下要因• 命令フェッチ• レジスタファイル• Load/Store命令実行 22
•再構成•コア間通信
•動作しない ALU•再構成
概要• 画像認識技術• アクセラレータによる高性能・低消費エネ
ルギー化• アプリケーション分析• アクセラレータ・アーキテクチャ検討• 性能・消費エネルギー評価• まとめ
23
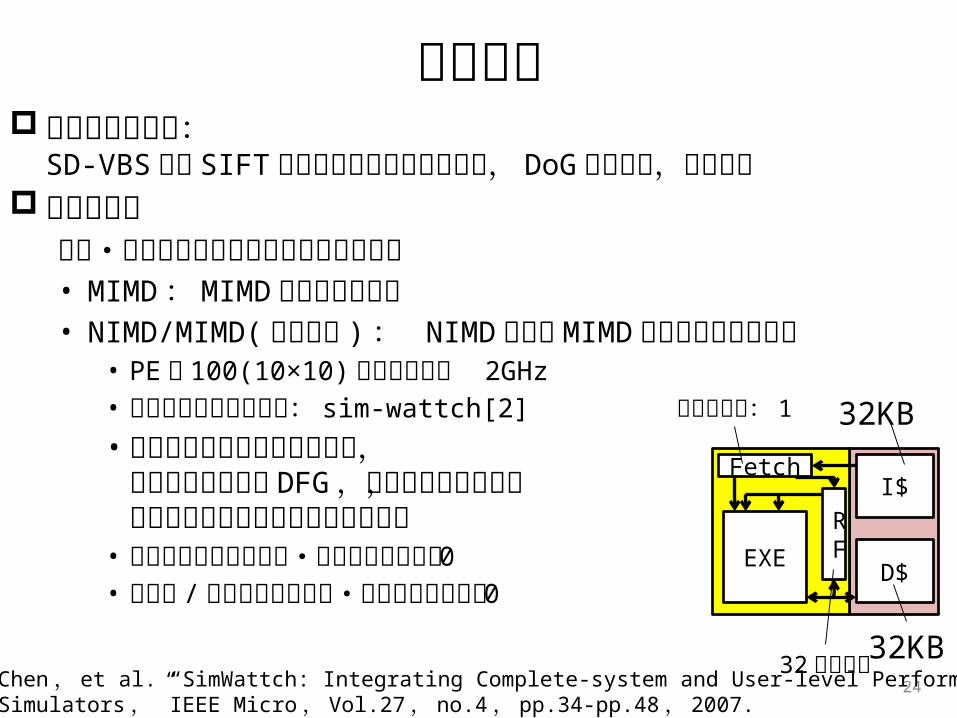
評価環境 実行プログラム:
SD-VBS より SIFT のガウシアンフィルタ処理, DoG 画像生成,極値検出
評価モデル性能・消費エネルギーモデルを用いて評価• MIMD : MIMD方式のみで実行• NIMD/MIMD(提案手法 ) : NIMD方式と MIMD方式を切り替え可
能• PE 数 100(10×10) ,動作周波数 2GHz• 消費電力シミュレータ: sim-wattch[2]• アルゴリズムから実行演算数,
マッピング可能な DFG ,イタレーション数,データキャッシュアクセス数を計算
• メモリアクセスの時間・消費エネルギーは 0• 再構成 / コア間通信の時間・消費エネルギーは 0
24
Fetch
RF
I$
D$EXE
32KB
32KB32 エントリ
命令発行幅: 1
[2]Jianwei Chen , et al. “SimWattch: Integrating Complete-system and User-level Performance and Power Simulators ,” IEEE Micro , Vol.27 , no.4 , pp.34-pp.48 , 2007.
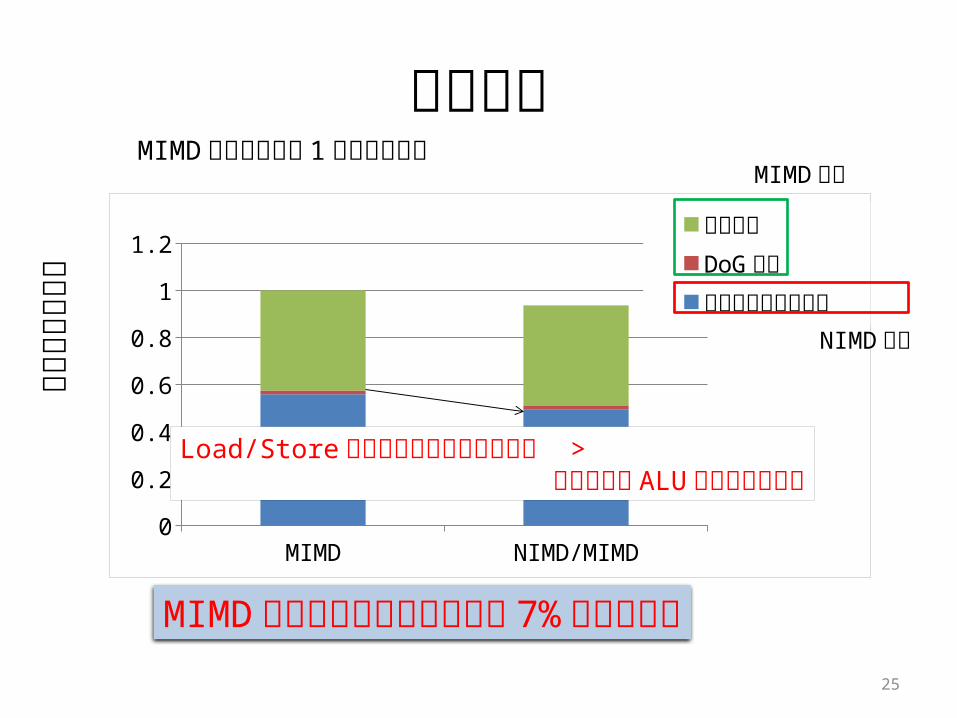
性能評価
25
正規
化実
行時
間
MIMD の実行時間を 1 として正規化
MIMD方式のみの実行に比べ約 7% の性能向上
MIMD NIMD/MIMD0
0.2
0.4
0.6
0.8
1
1.2 極値検出
DoG 画像
NIMD 実行
MIMD 実行
Load/Store命令数削減による性能向上 > 動作しない ALU による性能低下
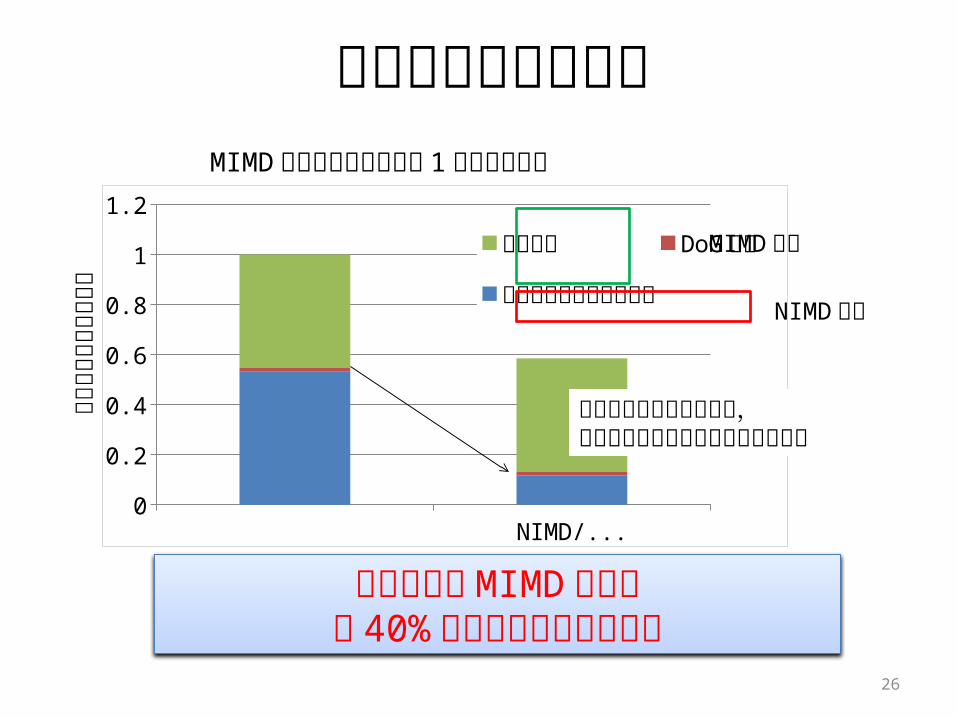
MIMD の消費エネルギーを 1 として正規化
消費エネルギー評価
26
正規
化消
費エ
ネル
ギー
提案手法はMIMD に比べ約 40% の消費エネルギー削減
MIMD NIMD/MIMD0
0.2
0.4
0.6
0.8
1
1.2極値検出DoG 画像ガウシアンフィルタ処理 NIMD 実行
MIMD 実行
命令フェッチ機構の省略,レジスタファイルの省略による効果

まとめ• 画像認識アプリケーションの特性解析– 処理によっては高性能 / 低消費エネルギーとな
る実行方式が異なる• 実行方式切り替え可能な NIMD/MIMD型
アクセラレータの提案– 3 次元実装技術を用いてより密に演算器を集積
• 性能 / 消費エネルギー評価– MIMD方式のみに比べ
7% の性能向上, 40% の消費エネルギー削減27
御清聴ありがとうございました
28
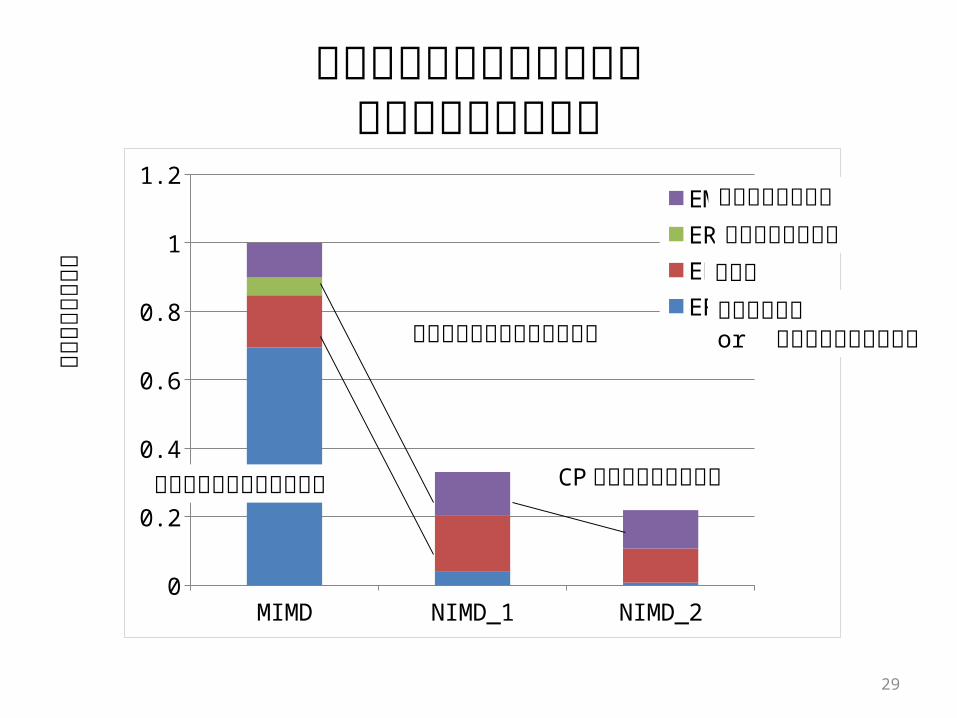
ガウシアンフィルタ処理の消費エネルギー内訳
MIMD NIMD_1 NIMD_20
0.2
0.4
0.6
0.8
1
1.2EMEREEEF
29
消費
エネ
ルギ
ー比
フロントエンドの削減効果
レジスタファイルの削減効果
データキャッシュレジスタファイル演算器
命令フェッチor データストリーム制御
CP動作回数の削減効果
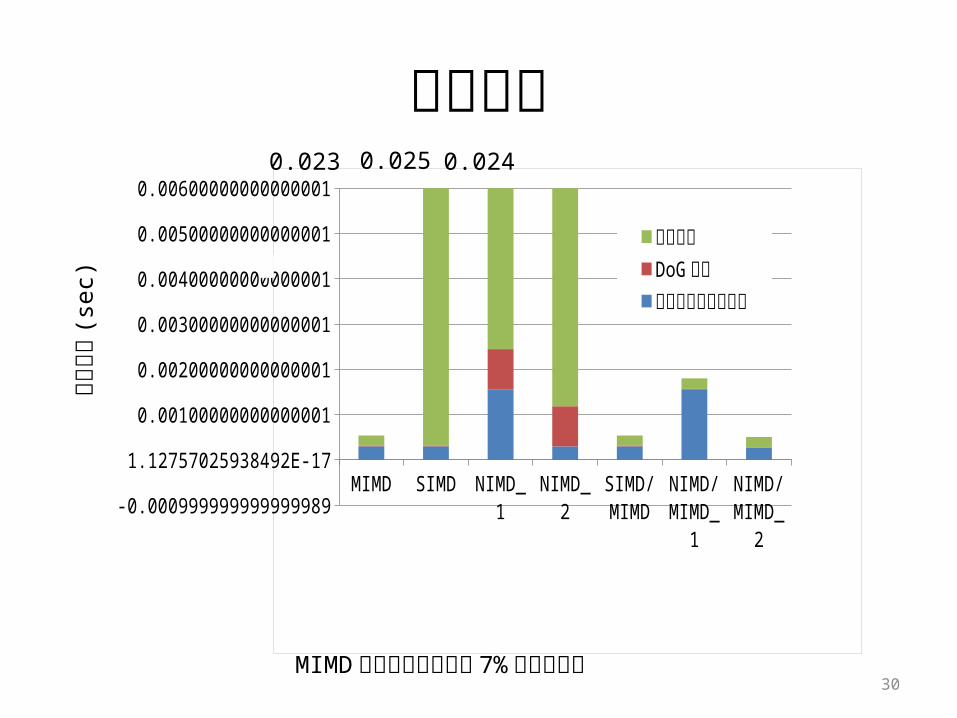
性能評価
30
MIMD SIMD NIMD_1 NIMD_2 SIMD/MIMD
NIMD/MIMD_1
NIMD/MIMD_2-0.000999999999999989
1.12757025938492E-17
0.00100000000000001
0.00200000000000001
0.00300000000000001
0.00400000000000001
0.00500000000000001
0.00600000000000001
極値検出
DoG 画像
0.023 0.025 0.024
実行
時間
(sec
)
MIMD方式のみに比べ約 7% の性能向上

消費エネルギー評価
31
MIMD SIMD NIMD_1 NIMD_2 SIMD/MIMD
NIMD/MIMD_1
NIMD/MIMD_2
0
0.2
0.4
0.6
0.8
1
1.2極値検出DoG 画像ガウシアンフィルタ処理
MIMD のみに比べ,約 40% の消費エネルギー削減
加速実行方式
32
汎用
性
MIMD(Multiple Instruction Stream, Multiple Data Stream)異なる命令を並列に実行可能
SIMD(Single Instruction Stream, Multiple Data Stream)同一命令を並列に実行
NIMD(No Instruction Stream, Multiple Data Stream)
PE アレイ上での DFG直接実行
電力効率PE(Processing Element)
命令流データ流
( より高性能・低消費エネルギー )
FetchRF
I Mem
D MemALU
D Mem
RFALU
ALU
(より性能低下要因が少ない)
* 全ての PE が 100%動作すると仮定
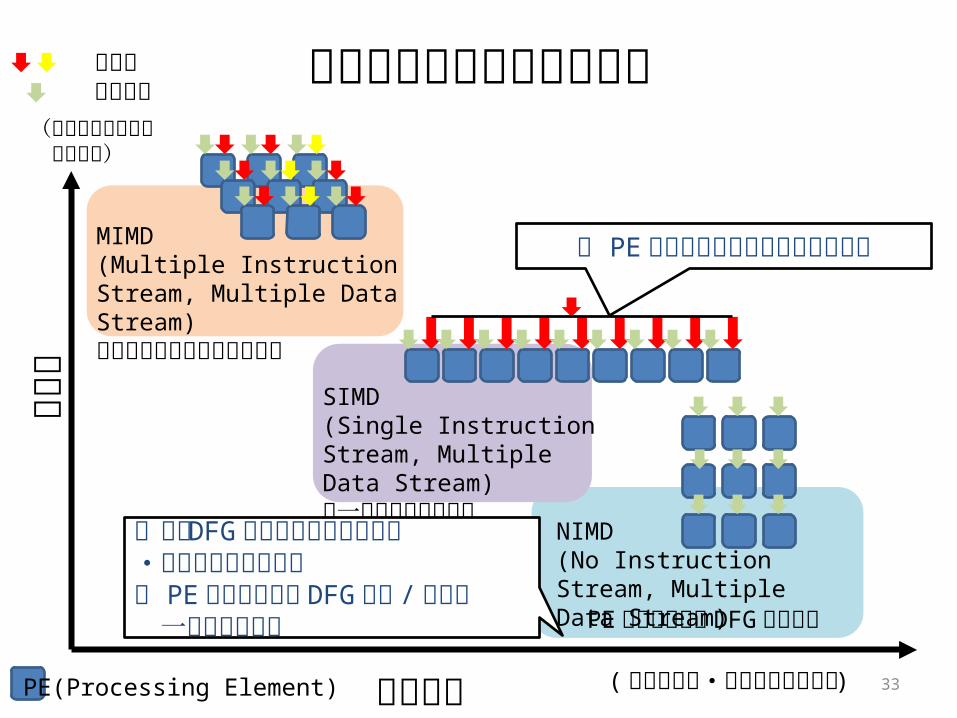
各実行方式の性能低下要因
33
汎用
性
(より性能低下要因が少ない)
MIMD(Multiple Instruction Stream, Multiple Data Stream)異なる命令を並列に実行可能
SIMD(Single Instruction Stream, Multiple Data Stream)同一命令を並列に実行
NIMD(No Instruction Stream, Multiple Data Stream)
PE アレイ上での DFG直接実行
電力効率PE(Processing Element)
命令流データ流
( より高性能・低消費エネルギー )
・実行 DFG が頻繁に変更する処理・分岐命令を含む処理・ PE アレイと実行 DFG の幅 /深
さが 一致しない処理
・ PE 間で異なる命令を実行する処理
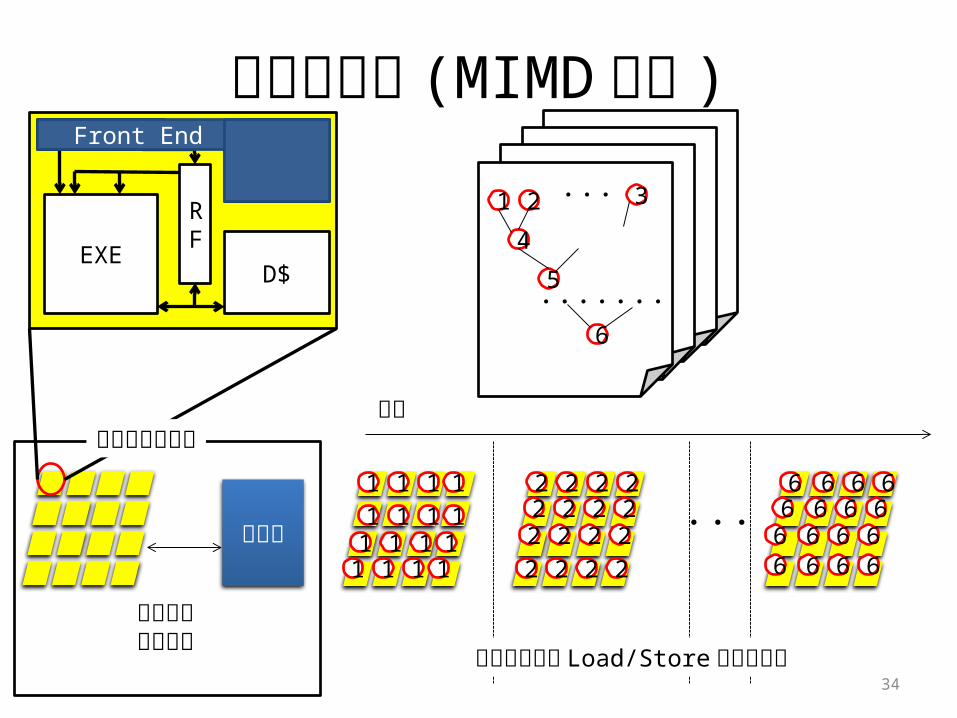
実行モデル (MIMD方式 )
メモリ
データの読み書き
34
Fetch
RF
I$
D$EXE
Front End
1 2
4
5
・・・ 3
6・・・・・・・
アクセラレータ時間
1 1 1 11 1 1 1
1 1 1 11 1 1 1
2 2 2 22 2 2 22 2 2 22 2 2 2
6 6 6 66 6 6 6
6 6 6 66 6 6 6
・・・
必要に応じて Load/Store命令を発行

実行モデル (SIMD方式 )
メモリ
データの読み書き
アクセラレータ
CP命令の
ブロードキャスト
RF
D$EXE
From SIMD コントロールユニット
1 2
4
5
・・・ 3
6・・・・・・・
時間
1 1 1 11 1 1 1
1 1 1 11 1 1 1
2 2 2 22 2 2 22 2 2 22 2 2 2
6 6 6 66 6 6 6
6 6 6 66 6 6 6
・・・
CP CP CP1 2 6
35
N iteration
必要に応じて Load/Store命令を発行
ブロードキャストするため,動作周波数は
MIMD に比べ低い

実行モデル (NIMD方式 )
CP
メモリ
アクセラレータ
再構成情報 入出力制御
パイプライン方式で実行
36
D$EXE
From CP
From PE
1 2
4
5
・・・ 3
6・・・・・・・
時間
CP
再構成情報
CP CP
入出力制御 入出力制御
コア間通信がクリティカルパス動作周波数が低下
Load/Store命令が不要動作しない PE が存在

性能モデリング
MIMD SIMD NIMD
MM
EXE
fIPCN
I
MMM
LS StallfIPCN
I
SS
EXE
fIPCN
I
SSS
LS StallfIPCN
I
X
i N
ii
f
DMAXIter
1
1_
StrStallN
N
reconf
f
CCX
EXET
MEMT
confTRe
IEXE :アルゴリズムの実現に最低限必要な命令数ILS :ロード / ストア命令数 Nx :動作 PE 数の平均StallX :メモリアクセスのストール時間 (sec) X :再構成回数IPC : PE が 1CC で実行可能な命令数CCReconf :再構成 1回の平均 CC Iteri : i回目構成時のイタレーション数MAX_Di : i回目構成時の DFG深さ最大値 fx : XIMD方式における周波数
37
confMEMEXE TTT Re)( 実行時間

消費エネルギーモデリング
38
MIMD SIMD NIMD
X
iNCPNi
reconf
fEIter
EX
1
)(FrontMfEI )(
))(
)((
BroadS
SCPSS
fEN
fEN
I
EXEMfEI )(
RFMRF fEAC )(3RFSRF fEAC )(3
X
iComNiComi fENIter
1_ ))((
EXESfEI )(
X
iEXENiPEi fENIter
1_ ))((
)
)(( $
memmiss
DMLS
ER
fEI
)
)(( $
memmiss
DSLS
ER
fEI
))((
))2((
$
1__
memmissDN
X
iioutiini
ERfE
NNIter
FE
EE
RE
ME
MREF)( EEEE 総消費エネルギー
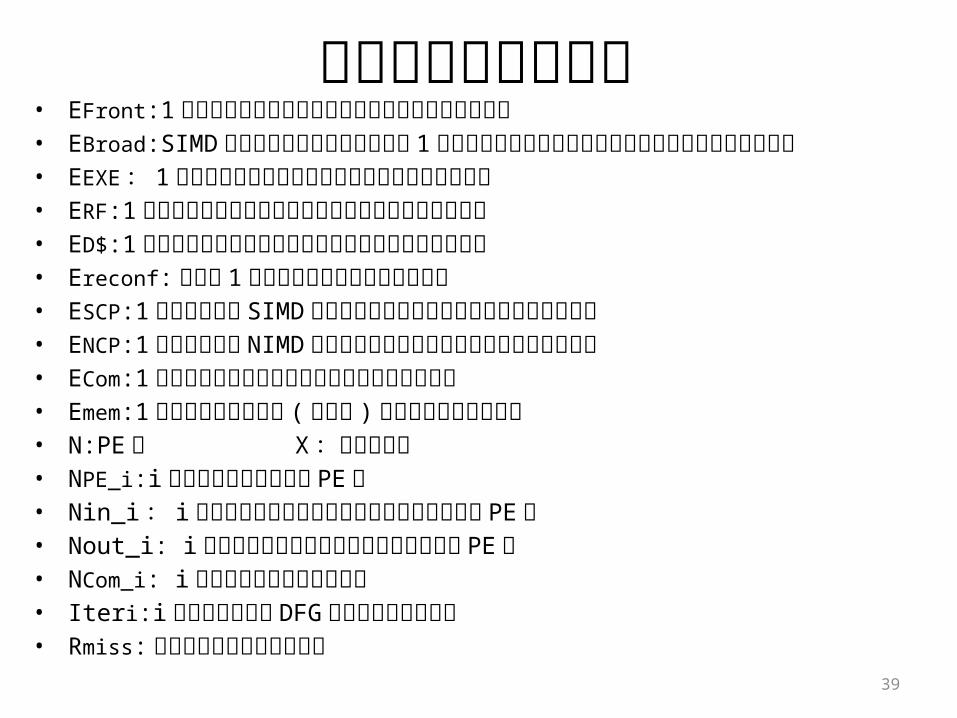
各パラメータの説明• EFront:1動作あたりのフロントエンドの平均消費エネルギー• EBroad:SIMD コントロールプロセッサから 1 コアへ命令をブロードキャスト
時の平均消費エネルギー• EEXE : 1動作あたりの命令実行部分の平均消費エネルギー• ERF:1動作あたりのレジスタファイルの平均消費エネルギー• ED$:1動作あたりのデータキャッシュの平均消費エネルギー• Ereconf:再構成 1回あたりの平均消費エネルギー• ESCP:1動作あたりの SIMD コントロールユニットの平均消費エネルギー• ENCP:1動作あたりの NIMD コントロールユニットの平均消費エネルギー• ECom:1動作あたりのコア間通信の平均消費エネルギー• Emem:1動作あたりのメモリ ( 主記憶 ) の平均消費エネルギー• N:PE 数 X :再構成回数• NPE_i:i回目の構成で動作する PE 数• Nin_i : i回目の構成でメモリからデータを入力される PE 数• Nout_i: i回目の構成でメモリへデータを出力する PE 数• NCom_i: i回目の構成のコア間通信数• Iteri:i回目に構成した DFG のイタレーション数• Rmiss: データキャッシュのミス率 39

モデリングによる評価• 目的– 提案手法の高性能・低消費エネルギー化効果を明確にす
る• 評価指標– 性能– 消費エネルギー
• 比較対象– MIMD方式のみ– NIMD方式のみ– NIMD方式のみ (PE アレイの深さと幅を変更 )– 提案手法 (MIMD方式と NIMD方式を切り替え +PE アレイ
の深さと幅を変更 ) 40

アプリケーション分析結果
41
W=(11,15,17,21,27) の 5種類入力画素 (288×288) のとき各 W につき N=552,420
入力画素 (288×288) のときK= 441,936
× ×+
+
+
× ×+
× ×+
・・・・・・
2W^2
1log2 2 W
ガウシアンフィルタ処理
DoG 画像の生成 極値検出
N Iter
ation
s
・・・- - - - -・・・
比較演算
L Ite
ratio
ns
・・・
52
入力画素 (288×288) のときL= 220,968
K
データレベル並列性が高い スレッドレベル並列性が高い依存関係の深い 同一計算のくり返し

スケール数 5 5 5 5 5
入力画素(縦 )
288 144 72 36 18
入力画素(横 )
288 144 72 36 18
並列度 414720
103680 25920 6480 1620 55242
0
Cif: 画像平滑化
スケール数 5 5 5 5 5
入力画素(縦 )
480 240 120 60 30
入力画素(横 )
480 240 120 60 30
並列度 1152000 288000 72000 18000 4500 153450
0
vga: 画像平滑化
fullhd: 画像平滑化スケール数 5 5 5 5 5 5 5
入力画素(縦 )
1080 540 270 135 68 34 17
入力画素(横 )
1080 540 270 135 68 34 17
並列度 5832000
1458000
3645009112
52312
0 5780 1445 7775970
cif vga fullhd
オクターブ数
5 5 7
スケール数 5 5 5
入力画素数 288*288
480*480
1080*1080
ウィンドウサイズ: 11,15,17,21,27
実際の実行における並列度
42

画像平滑化処理の並列性
43
10 20 9 20 13 18 6 1517 8 2 21 18 15 1 2121 1 2 12 11 3 8 2112 6 22 19 19 15 8 144 20 12 3 18 14 20 224 12 8 2 3 8 16 74 22 18 21 21 3 8 222 22 7 15 18 11 20 117 15 9 17 1 14 13 14
7 8 10 11 11 9 9 69 10 11 13 14 12 11 99 11 12 14 14 12 12 109 11 12 14 14 14 14 118 11 12 12 13 14 14 118 12 13 12 12 13 14 108 13 15 14 13 13 13 108 12 14 14 13 13 12 105 8 9 9 9 9 9 7
平滑化
求める値平滑化を行うために必要なデータ
画素の平滑化は全て並列に実行可能
ガウシアンフィルタ
入力画像
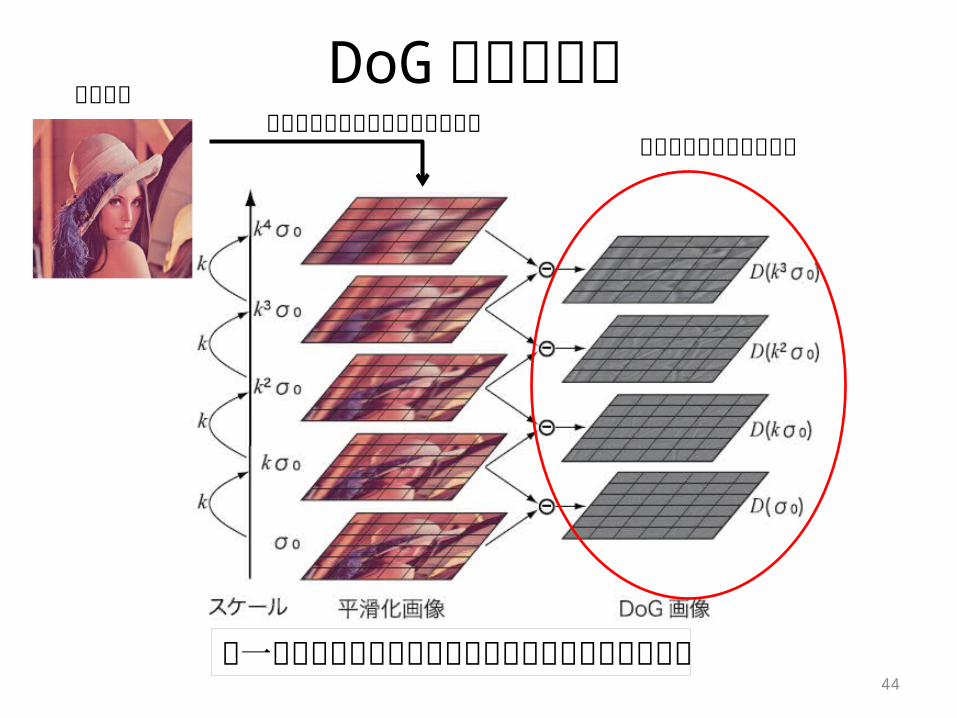
DoG 画像の生成入力画像
ガウシアンフィルタによる平滑化
44
同一オクターブ内の隣接した平滑化画像の差分を取る
並列に求めることが可能

特性解析 (DoG 画像の生成 )
45
7 8 10 11 11 99 10 11 13 14 129 11 12 14 14 129 11 12 14 14 148 11 12 12 13 148 12 13 12 12 138 13 15 14 13 13
平滑化画像 A
10 11 11 9 9 611 13 14 12 11 912 12 13 14 14 1113 12 12 13 14 1015 14 13 13 13 1014 14 13 13 12 109 9 9 9 9 7
平滑化画像 B
DoG 画像
-3 -3 -1 2 2 3-2 -3 -3 1 3 3-3 -1 -1 0 0 3-4 -1 0 1 0 4-7 -3 -1 -1 0 4-6 -2 0 -1 0 3-1 4 6 5 4 6
求める値
必要なデータ -
•各画素値は並列に求めることが可能•メモリ参照の空間的局所性は高い•メモリ参照の時間的局所性は低い•演算は減算のみ
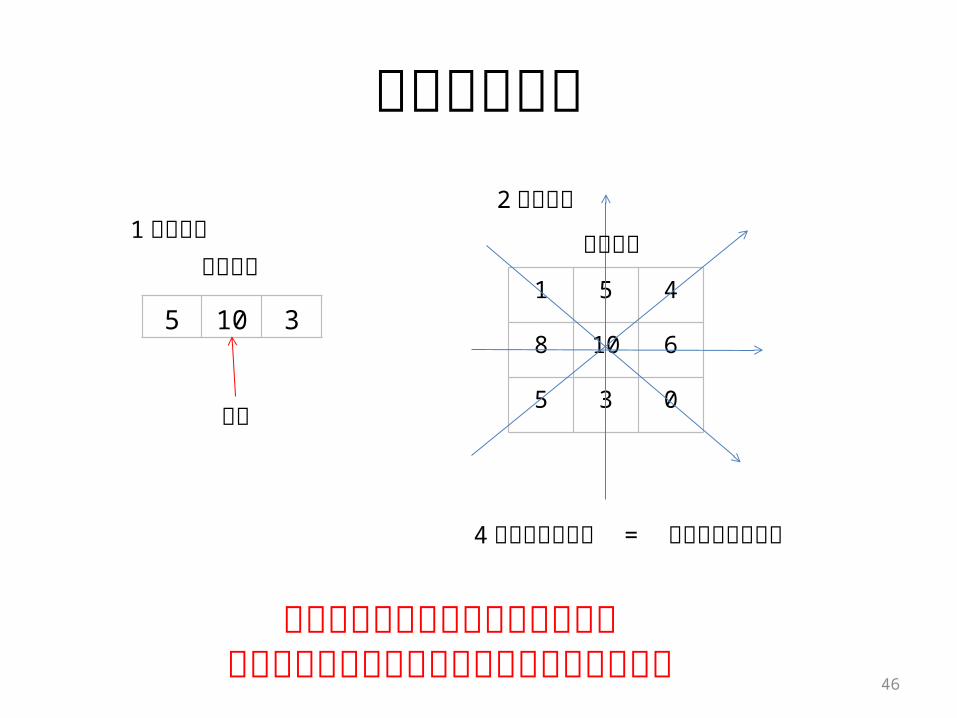
極値検出方法
1 次元の例
5 10 31 5 4
8 10 6
5 3 0
2 次元の例
極値
4方向全てで極値 = 中央の画素は極値
対象とする画素値が極値検出対象となっている全画素の中で最大もしくは最小
対象画像対象画像
46