Лекция №7 "Машина опорных векторов"
TRANSCRIPT

Лекция 7Машина опорных векторов
Николай Анохин
6 ноября 2014 г.

План занятия
SVM
Функции ядра
SGD
1 / 29

Постановка задачи
Пусть дан набор объектов D = {(xi , yi )}, xi ∈ X , yi ∈ Y, i ∈ 1, . . . ,N,полученный из неизвестной закономерности y = f (x). Необходимовыбрать из семейства параметрических функций
H = {h(x, θ) : X ×Θ→ Y}
такую h∗(x) = h(x, θ∗), которая наиболее точно апроксимирует f (x).
ЗадачиI Регрессия: Y = [a, b] ⊂ RI Классификация: |Y| < C
2 / 29

SVM
3 / 29

Мотивация
4 / 29

Обобщенные линейные модели
Обучающая выборка
X = (x1, . . . , xN)
Значения целевой переменной
t1, . . . , tN ; tj ∈ {−1,+1}
Функция принятия решения
y(x) = w>φ(x) + b
Разделяющая плоскость (РП)
yi (xi)ti > 0
Решений много: как выбрать?
5 / 29

Максимальный зазор
Margin – наименьшее расстояниемежду РП и обучающим объектом.
dj =|y(xj)|‖w‖
=tjy(xj)
‖w‖=
=tj(w>φ(xj) + b)
‖w‖Оптимальная РП
arg maxw,b
[1
‖w‖minj
tj(w>φ(xj) + b)
]
6 / 29

Задача оптимизации
Расстояние от точки xj до РП
dj =tj(w>φ(xj) + b)
‖w‖
Для точки xj , лежащей на минимальном расстоянии от РП положим
tj(w>φ(xj) + b) = 1
Задача оптимизации
1
2‖w‖2 → min
w,b
при условияхtj(w
>φ(xj) + b) ≥ 1, ∀j ∈ 1, . . . ,N
7 / 29

Метод множителей Лагранжа a = (a1, . . . , aN)>, ai ≥ 0.
L(w, b, a) =1
2‖w‖2 −
N∑j=1
aj [tj(w>φ(xj) + b)− 1]
Дифференцируем по w и b
w =N∑j=1
aj tjφ(xj), 0 =N∑j=1
aj tj
Подставляем w и b в лагранжиан
8 / 29

Сопряженная задача
Сорпяженная задача
L̃(a) =N∑j=1
aj −1
2
N∑i=1
N∑j=1
aiaj ti tjφ(xi )>φ(xj)→ max
a
при условияхaj ≥ 0, ∀j ∈ 1, . . . ,N
N∑j=1
aj tj = 0
НаблюденияI k(xi , xj) = φ(xi )>φ(xj) – неотрицательно-определенная функцияI лагранжиан L̃(a) – выпуклая и ограниченная сверху функция
9 / 29

Классификация
Функция принятия решения
y(x) = w>φ(x) + b =N∑j=1
aj tjφ(xj)>φ(x) + b =
N∑j=1
aj tjk(xj , x) + b
Условия Karush-Kuhn-Tucker
aj ≥ 0
tjy(xj)− 1 ≥ 0
aj{tjy(xj)− 1} = 0
Опорным векторам xj ∈ S соответствуют aj > 0
b =1
Ns
∑i∈S
ti −∑j∈S
aj tjk(xi, xj)
10 / 29

Линейно-разделимый случай
ЗадачаДана обучающая выборка
x1 x2 tx1 1 −2 1x2 1 2 −1
Найти оптимальную разделяющую плоскость, используясопряженную задачу оптимизации
11 / 29

Линейно-неразделимый случай
12 / 29

Смягчение ограничений
Переменные ξj ≥ 0 (slacks):
ξj =
{0, если y(xj)tj ≥ 1
|tj − y(xj)|, иначе
Задача оптимизации
CN∑j=1
ξj +1
2‖w‖2 → min
w,b
13 / 29

Сопряженная задача
Сорпяженная задача
L̃(a) =N∑j=1
aj −1
2
N∑i=1
N∑j=1
aiaj ti tjφ(xi )>φ(xj)→ max
a
при условиях0 ≤ aj ≤ C , ∀j ∈ 1, . . . ,N
N∑j=1
aj tj = 0
НаблюденияI aj = 0 – правильно проклассифицированные объектыI aj = C – опорные векторы внутри отступаI 0 < aj < C – опорные векторы на границе
14 / 29

Классификация
Функция принятия решения
y(x) =N∑j=1
aj tjk(xj , x) + b
Константа b
b =1
NM
∑i∈M
ti −∑j∈S
aj tjk(xi, xj)
15 / 29
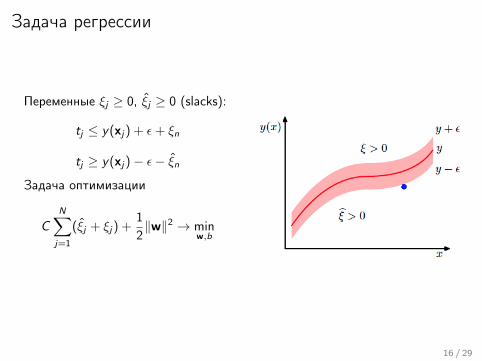
Задача регрессии
Переменные ξj ≥ 0, ξ̂j ≥ 0 (slacks):
tj ≤ y(xj) + ε+ ξn
tj ≥ y(xj)− ε− ξ̂nЗадача оптимизации
CN∑j=1
(ξ̂j + ξj) +1
2‖w‖2 → min
w,b
16 / 29

Численные методы оптимизации
I Chunking (Vapnik, 1982)I Decomposition (Osuna, 1996)I Sequential Minimal Optimization (Platt, 1999)
17 / 29

Функции ядра
18 / 29

Функции ядра
φ(x) – функция преобразования x из исходного пространства вспрямляющее пространство
Проблема: количество признаков может быть очень велико
Идея Kernel TrickВ процессе тренировки и применения SVM исходные векторы xиспользуются только как аргументы в скалярном произведенииk(xi , xj) = φ(xi )>φ(xj). Но в этом случае можно избежатьвычисления ϕ(x)!
19 / 29

Теорема Мерсера
ТеоремаФункция k(x, z) является ядром тогда и только тогда, когда она
I симметричнаk(x, z) = k(z, x)
I неотрицательно определена∫x∈X
∫z∈X
k(x, z)g(x)g(z)dxdz > 0, ∀g(x) : X→ R
ЗадачаПусть x ∈ R2, а преобразование φ(x)
φ(x) = (1,√
2x1,√
2x2, x21 ,√
2x1x2, x22 ).
Проверить, что функция k(x, z) = (1 + x>z)2 является функциейядра для данного преобразования.
20 / 29

Некоторые стандартные функции ядра
I Линейное ядроk(x, z) = x>z
I Полиномиальное ядро степени d
k(x, z) = (x>z + r)d
I Radial Basis Function
k(x, z) = e−γ|x−z|2
I Sigmoidk(x, z) = tanh(γx>z + r)
21 / 29

Опять ирисы
22 / 29

SGD
23 / 29

Связь с линейными моделями
Задача оптимизации
N∑j=1
ξj +1
2‖w‖2 ∼
N∑j=1
E (y(xj), tj) + λ‖w‖2 → minw,b
Hinge loss
E (yj , tj) =
{1− yj tj , если yj tj < 1
0, иначе
24 / 29

Stochastic Gradient Descent
Градиентный спуск
wk+1 = wk − η(k)1
N
N∑n=1
∇wl(xn,w, tn)
Стохастический градиентный спуск
wk+1 = wk − η(k)∇wl(xk,w, tk)
Усредненный стохастический градиентный спуск w̄k = 1k
∑kj=1 wj
wk+1 = wk − η(k)∇wl(xk,w, tk), w̄k+1 =k
k + 1w̄k +
1
k + 1wk+1
Сходимость:∑
k η2k <∞,
∑k ηk =∞
25 / 29

SGD tips
I Использовать SGD, когда обучение модели занимает слишкоммного времени
I Перемешать тренировочную выборкуI Следить за training error и validation errorI Поверять, правильно ли вычисляется градиент
Q(z ,w + δ) ≈ Q(z ,w) + δg
I Подобрать η0 на небольшой выборке
ηk = η0(1 + η0λk)−1, λ – параметр регуляризации
26 / 29

SVM – итоги
+ Нелинейная разделяющая поверхность+ Глобальая оптимизация+ Разреженное решение+ Хорошая обобщающая способность- Не поддерживает p(Ck |x)
- Чувствительность к выбросам- Нет алгоритма выбора ядра- Медленное обучение
27 / 29

Эксперименты над SVMВ задаче рассматриваются 4 алгоритма генерации обучающихвыборок. Требуется разработать функцию, автоматическиподбирающую параметры модели SVM в зависимости от полученнойвыборки.
Инструкция по выполнению задания
1. Скачать код http://bit.ly/1y26EF4
2. Запустить хелп, при желании изучить
$ python svm.py -h$ python svm.py cc -h
3. Запустить какой-нибудь пример, разобраться с картинкой
$ python svm.py gauss
4. Работать над кодом (функция select_model)
28 / 29

Вопросы
29 / 29