ИТМО machine learning 2015. Рекомендательные системы
TRANSCRIPT


Рекомендательные системы
Андрей Данильченко
НИУ ИТМО, 16 ноября 2015

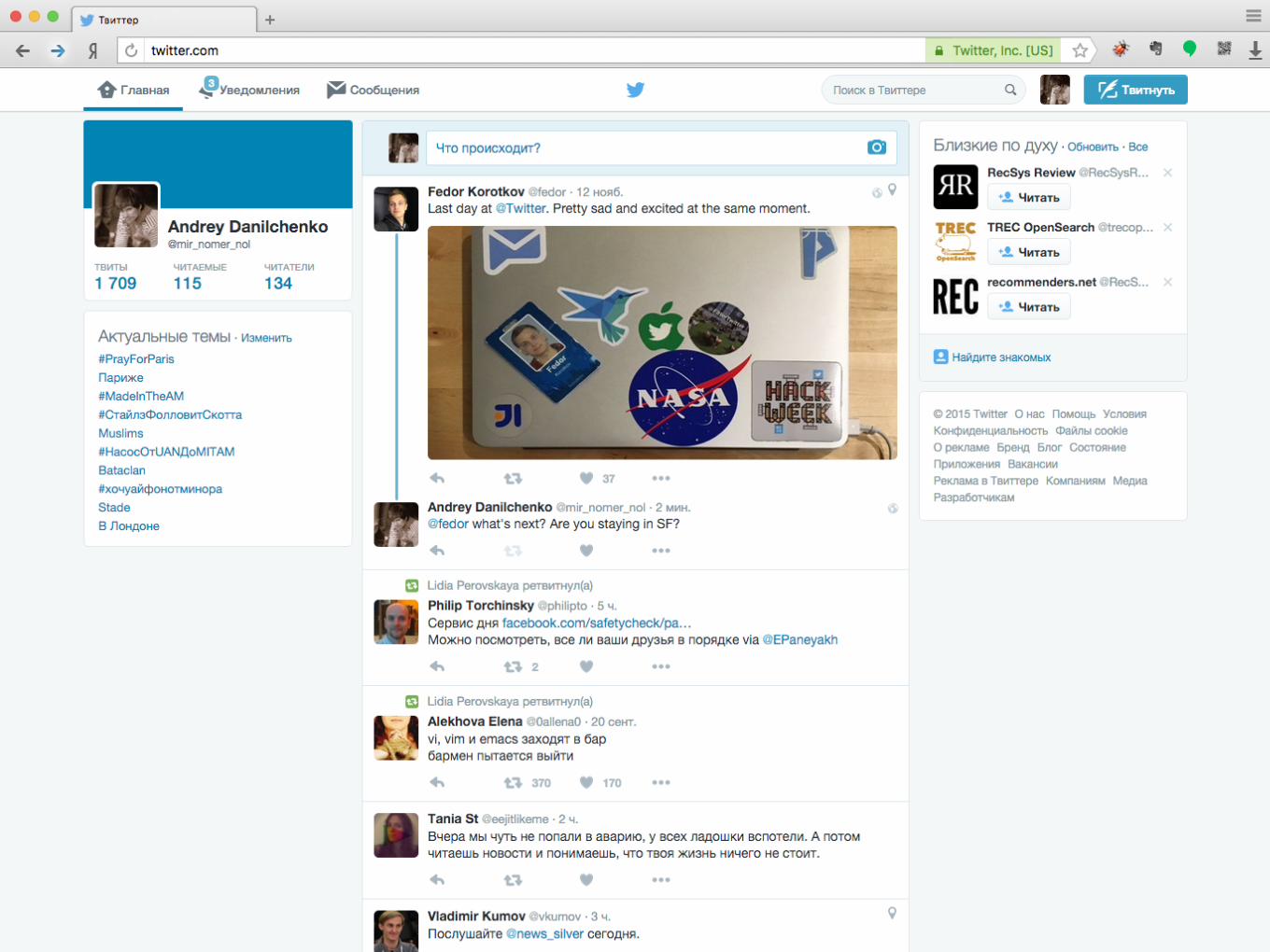
Что такое рекомендательная система?

4

5

7
8

9

F. Ricci “Recommender Systems Handbook”
│ Recommender Systems are software tools and techniques providing suggestions for items to be of use to a user
10

по данным google scholar (от 2015-11-14)
Количество статей в области
12

Какие бывают рекомендательные системы?

Классификация RS
Available data
User history Content
Collaborative Content-based
Hybrid
Tags &
Metadata

Данные
• Рейтинги (explicit feedback)
• унарные (like) • бинарные (like/dislike) • числовые (stars)
• История действий пользователя (implicit feedback)
• Тэги, метаданные
• Комментарии, отзывы
• Друзья

Рекомендательные задачи
16
• Predict
• Recommend
• Similar

Как построить простую рекомендательную систему?
17

User-based kNN
Как продукт оценили похожие пользователи?
r̂ui =1
Ni u( )rvi
v∈Ni (u)∑
Взвесим вклад каждого
r̂ui =wuvrvi
v∈Ni (u)∑
wuvv∈Ni (u)∑
И нормализуем рейтинги
r̂ui = h−1
wuvh rvi( )v∈Ni (u)∑
wuvv∈Ni (u)∑
$
%
&&&
'
(
)))

Как посчитать расстояние?
Косинусное расстояние
Корреляция Пирсона
cos(u,v) =ruirvi
i∈Iuv
∑
r2uii∈Iu
∑ rvj2
j∈Iv
∑
PC(u,v) =(rui − ru )(rvi − rv )
i∈Iuv
∑
(rui − ru )2
i∈Iu
∑ (rvj − rv )2
j∈Iv
∑
Поправленное косинусное расстояние (adjusted cosine)
AC(u,v) =(rui − ri )(rvi − ri )
i∈Iuv
∑
(rui − ri )2
i∈Iu
∑ (rvj − rj )2
j∈Iv
∑

Как нормализовать рейтинги?
20
h rui( ) = rui − ru
h rui( ) = rui − ruσ u
h rui( ) =j ∈ Iu : ruj ≤ rui{ }
Iu
Mean centering
Z-score
Percentile score

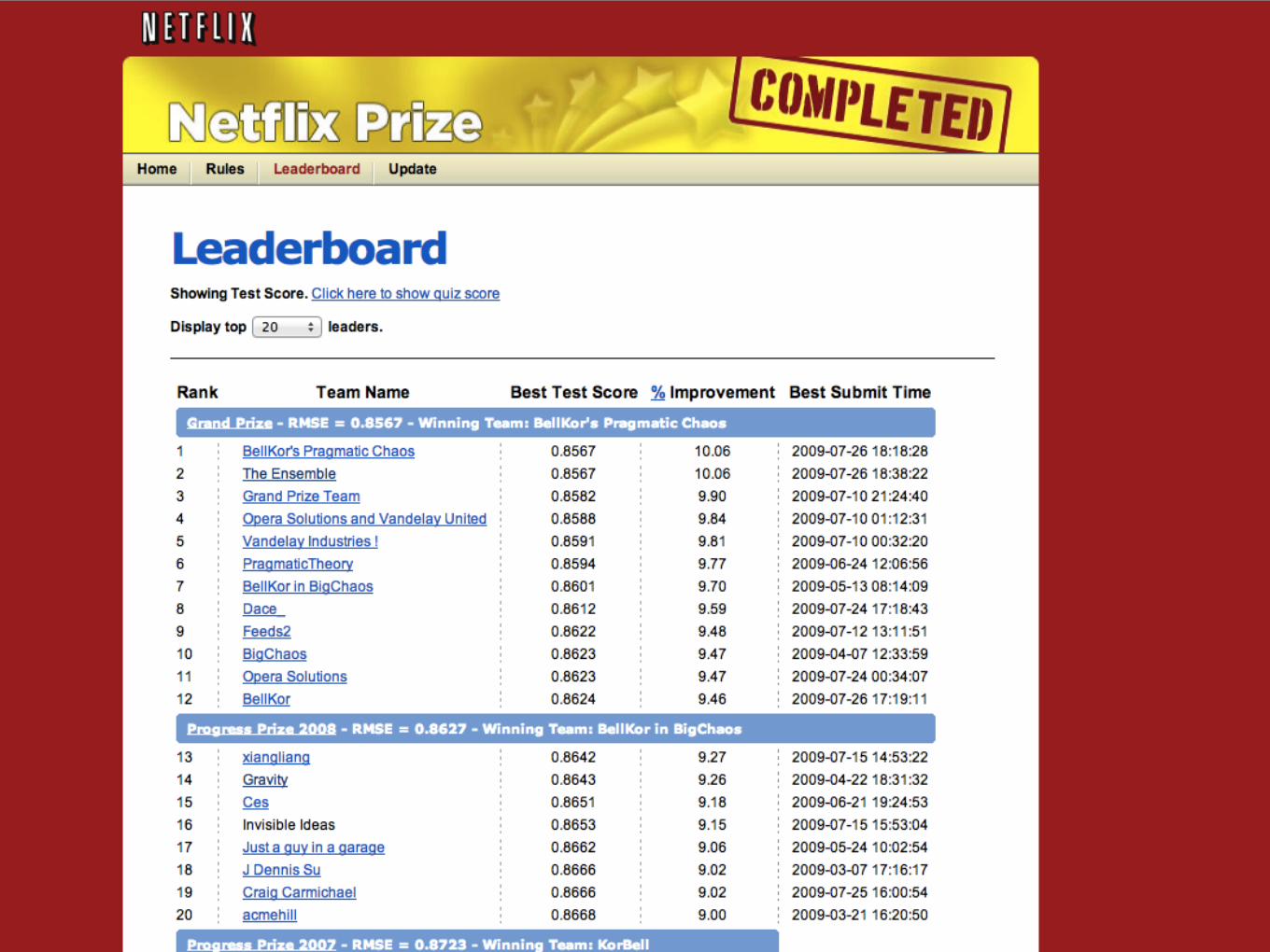
Как выиграть Netflix Prize?

http://sifter.org/~simon/journal/20061211.html

Singular Value Decomposition
Теорема: если в матрице λ оставить k наибольших элементов, то полученное произведение A’ будет наилучшим среди всех матриц ранга k приближением матрицы A.

Baseline predictors
Модель:
r̂uiu = µ + bu + bi
argminb*
ruiu −µ − bu − bi( )(u,i)∈R∑
2+λ bu
2 +u∈U∑ bi
2
i∈I∑
$
%&
'
()
Функция ошибки:

SVD
Модель:
Функция ошибки:
r̂ui = µ + bu + bi + puTqi
argminp*q*b*
rui −µ − bu − bi − puTqi( )
(u,i)∈R∑
2+λ pu
2+ qi
2+ bu
2 + bi2( )

Optimization by SGD
Модель:
Функция ошибки:
r̂ui = µ + bu + bi + puTqi
argminp*q*b*
rui −µ − bu − bi − puTqi( )
(u,i)∈R∑
2+λ pu
2+ qi
2+ bu
2 + bi2( )
bu ← bu +γ1 eui −λ1bu( )bi ← bi +γ1 eui −λ1bi( )pu ← pu +γ2 euiqi −λ2pu( )qu ← qi +γ2 eui pu −λ2qi( )
Шаг стохастического градиентного спуска:

Alternating Least Squares P-step: обновление при фиксированных векторах item-ов
pu = λnuI + Au( )−1 duAu =Q[u]
TQ[u]= qiqiT
i: u,i( )∈R∑
du =Q[u]T ru = ruiqi
i: u,i( )∈R∑
Q-step: обновление при фиксированных векторах пользователей
qi = λniI + Ai( )−1 diAi = P[i]
T P[i]= pupuT
u: u,i( )∈R∑
di = P[i]T ri = rui pu
u: u,i( )∈R∑

Что делать с implicit feedback?

Как использовать implicit feedback?
Идея: rating => (preference, confidence)
pui ∈ {0,1}
cui ∈ℜ+
∀(u, i)∈ R
cui =1+αrui
pui =1
pui = 0 иначе
или
cui =1+α log 1+ruiβ( )

Обучение модели
argminx*y*
cui pui − xuT yi( )
(u,i)∑
2+λ xu
2
u∑ + yi
2
i∑
#
$%
&
'(
Функция ошибки:
xu = λI +Y TCuY( )−1Y TCup(u)
yi = λI + XTCiX( )−1XTCi p(i)
Это сводится к уравнениям для ALS:

Обучение модели
argminx*y*
cui pui − xuT yi( )
(u,i)∑
2+λ xu
2
u∑ + yi
2
i∑
#
$%
&
'(
Функция ошибки:
xu = λI +Y TCuY( )−1Y TCup(u)
yi = λI + XTCiX( )−1XTCi p(i)
Это сводится к уравнениям для ALS:
Но есть проблема!

в матрице всего ненулевых элементов,
В матрице всего ненулевых элементов,
Ускорение iALS
Идея:
Y TCuY =Y TY +Y T Cu − I( )YCu − I
Cup(u)
Y TY
O f 2N + f 3 U( )
nu
nu
а не зависит от пользователя!
Итого: обновляем вектора пользователей за

Интуиция iALS
xu = λI +Y TCuY( )−1Y TCup(u) = λI + Au( )−1 du
A0 = c0yiT yi
i∑ d0 = c0p0yi
i∑
Au = A0 + (cui − c0 )yiT yi
(u,i)∈N (u)∑
du = d0 + cui pui − c0p0( ) yiu,i( )∈N (u)∑
Введем «нулевого» пользователя без фидбека:
Тогда для остальных пользователей выводим:
Выпишем ALS-шаг в упрощенной форме:

Как выбирать c0 и p0?
∀(u, i)∈ N
cui =1+αrui
pui =1
pui = 0 иначе
Как и раньше:

Как выбирать c0 и p0?
∀(u, i)∈ N
cui =1+αrui
pui =1
pui = 0 иначе
Как и раньше:
c0 =1
p0 = 0

Как объяснять рекомендации?

Если вам нравится X, то попробуйте Y…
Вам понравится Y!
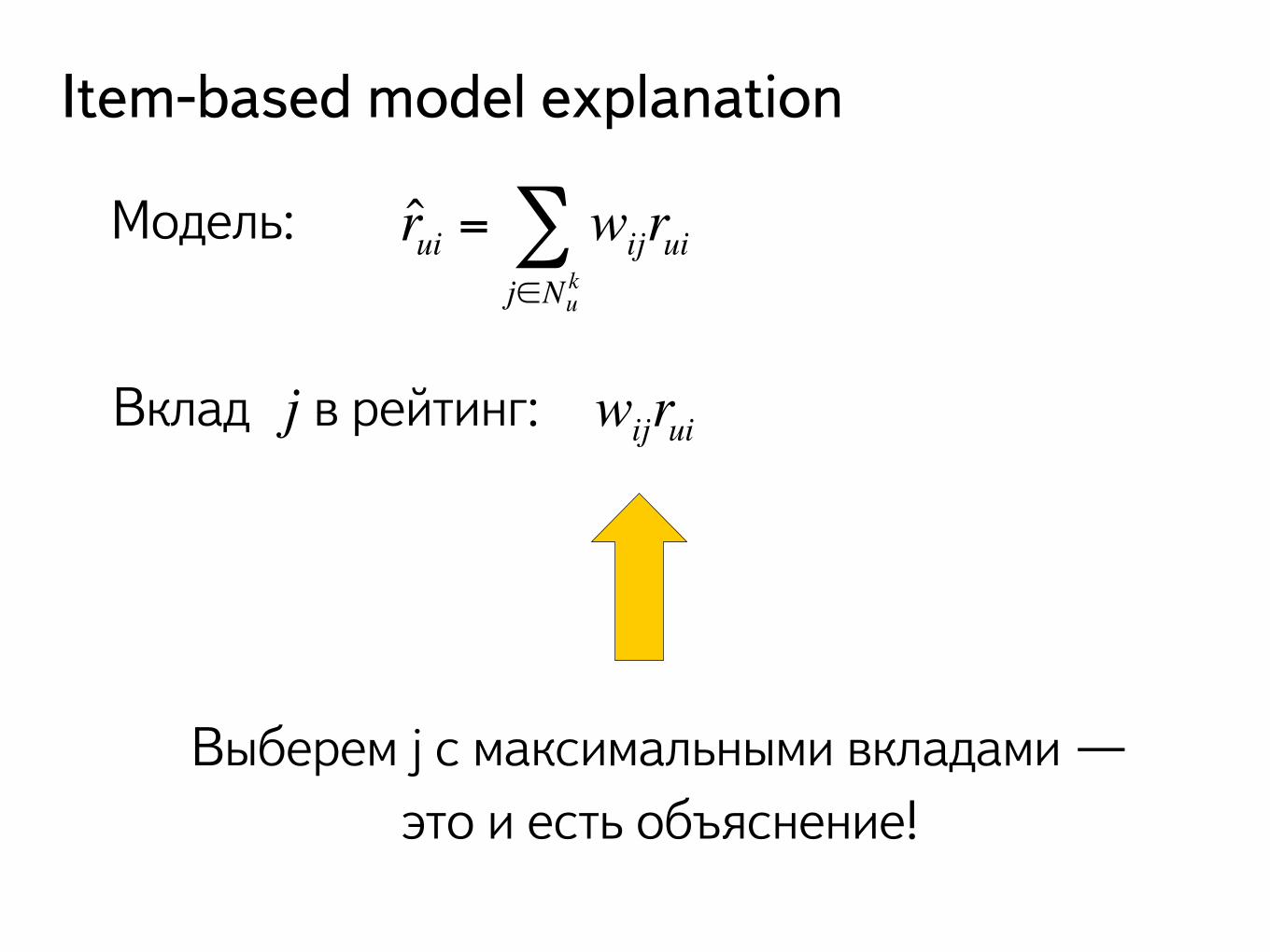
Item-based model explanation
Модель: r̂ui = wijruij∈Nu
k∑
Вклад в рейтинг: wijrui
Выберем j с максимальными вкладами — это и есть объяснение!
j

ALS explanation
Модель: r̂ui = yiT xu = yiT λI +Y TY( )−1Y Tr u( )
r̂ui = siju
u,i( )∈R∑ ruj
Wu = Y TY +λI( )−1
siju = yi
TW uyj
Выберем j с максимальными вкладами — это и есть объяснение!
Тогда перепишем модель как
Вклад в рейтинг: sijurujj

ALS explanation
Модель: r̂ui = yiT xu = yiT λI +Y TY( )−1Y Tr u( )
r̂ui = Vuqi( )T Vuqj( )ruju,i( )∈R∑
Wu = Y TY +λI( )−1
siju = yi
TW uyj
Перепишем модель как
Wu =VuTVu
VuТогда можно рассматривать как шаблон пользовательского мнения про item-ы

iALS explanation
Модель: p̂ui = yiT xu = yiT λI +Y TCuY( )−1Y TCup(u)
p̂ui = siju
pui>0∑ cuj puj
Wu = Y TCuY +λI( )−1
siju = yi
TW uyj
Выберем j с максимальными вкладами — это и есть объяснение!
Тогда перепишем модель как
Вклад в рейтинг: sijucuj puj = sij
ucujj

Как измерить качество?

Prediction quality
RMSE = 1| R |
rui − r̂ui( )u,i∈R∑
2
MAE = 1R
rui − r̂uiu,i∈R∑

Classification quality
Истинный ответ 0 Истинный ответ 1
Предсказали 0 TN FN
Предсказали 1 FP TP
Confusion matrix:
P = TPTP +FP
R = TPTP +FN
F1 =2
1P+1R
Precision:
Recall:

More on classification quality
AP = P(k)Δr(k)k=1
n
∑
MAP =AP(q)
q∈Q∑
Q
Average precision:
Mean average precision:
MAP — средняя точность на позициях, где есть попадания в top k.

Ranking quality (NDPM)
C+ = sgn rui − ruj( )sgn r̂ui − r̂uj( )ij∑
C− = sgn rui − ruj( )sgn r̂uj − r̂ui( )ij∑
Cu = sgn2 rui − ruj( )ij∑
Cs = sgn2 r̂ui − r̂uj( )ij∑
Cu0 =Cu − C+ +C−( )
NDPM =C− + 1
2Cu0
Cu

Ranking quality (NDCG)
DCGu = r1 +ri
log2 ii=2
n
∑
NDCGu =DCGu
IDCGu
NDCG =NDCGu
U
Пусть для каждого пользователя и item-а задана «релевантность» r

Как оптимизировать ранжирование?
48

│ Давайте смотреть на порядок пар!

BPR: problem setting
Для пользователей u из U и фильмов i из I составим обучающее множество как тройки:
DS = {(u, i, j) : i ∈ Iu+ ^ j ∈ I \ Iu
+}
где Iu+ — фильмы с implicit feedback для данного пользователя
>u — полный порядок на фильмах, причем выполняются свойства:
∀i, j ∈ I : i ≠ j⇒ i >u j∨ j >u i∀i, j ∈ I : i >u j ^ j >u i⇒ i = j∀i, j,k ∈ I : i >u j ^ j >u k⇒ i >u k
полнота
антисимметричность
транзитивность

Байесовская формулировка
p Θ |>u( )∝ p >u |Θ( ) p Θ( )
p Θ |>u( )u∈U∏ = p i >u j |Θ( )δ (u,i, j )∈DS( )
u,i, j∈U×I×I∏ ⋅
⋅ 1− p i >u j |Θ( )( )δ (u,i, j )∉DS( )
Тогда для всех пользователей запишем:
p Θ |>u( )u∈U∏ = p i >u j |Θ( )
u,i, j∈Ds∏
Тогда по свойствам порядка это можно упростить:

Preference model
p i >u j |Θ( ) =σ (x̂uij (Θ))
Окончательно определим модель как:
Здесь x̂uij — «встроенная» модель, которая отслеживает
связь между u, i и j. Например,
- матричное разложение
- модель kNN

BPR-Opt
p Θ( ) = N(0,ΣΘ )Предположим, наконец, априорное распределение параметров:
Тогда весь алгоритм: BPR−Opt := ln p Θ |>u( )= ln p >u |Θ( ) p(Θ)= ln σ x̂uij Θ( )( ) p Θ( )
(u,i, j )∈Ds∏
= ln(u,i, j )∈Ds∑ σ x̂uij Θ( )( )+ ln p Θ( )
= ln(u,i, j )∈Ds∑ σ x̂uij Θ( )( )−λΘ Θ
2

LearnBPR
1. Инициализируем параметры Θ 2. Пока не достигнута сходимость:
1. Выберем пример из Ds
3. Вернем финальные параметры
Θ←Θ+αexp(−x̂uij )1+ exp(−x̂uij )
⋅∂∂Θ
x̂uij +λΘΘ&
'((
)
*++2.

Еще раз о модели рейтинга
Распишем x̂uij = x̂ui − x̂uj
В случае разложения матриц
x̂ui = wu,hi = wuf hiff =1
k
∑
Тогда производные распишутся как
∂x̂uij∂θ
=
(hif − hjf )
wuf
−wuf
0
если θ = wuf
если θ = hifесли θ = hjfиначе

А разве что-то еще осталось?
56

If you like this lecture you will like these books

Удачи!
Андрей Данильченко Яндекс discovery products [email protected]
http://www.4ducks.ru/itmo-ml-course-2015-recsys-lecture.html