100,000 genomes project and its potential for rare disease research
TRANSCRIPT

100,000 Genomes Project and its potential for rare disease research
Eamonn Sheridan
Professor of Clinical Genetics
University of Leeds

100,000 genomes project
• Launched 2012 by the Prime Minister
• Genomes England (DoH owned) will sequence 100,000 whole genomes by 2017
• Aims
– Create ethical and transparent programme based on consent
– Benefit patients and set up a genomic medicine service for the NHS
– Enable new scientific discovery and medical insights
– Kick start the development of a UK genomics industry

Rare diseases
• 50,000 genomes
– Three per patient • (proband + two relatives)
• Genome sequence not exome
• Deliver clinically meaningful results
– Analytical challenge
• Store data
– 200GB per genome
– Total 10-20 petabytes
– 30000-50000 CDs –tower 250-500m high
– Facebook 300PB!!
• Research in the 100,000 genomes project
– Genomics England Clinical Interpretation Partnerships (GeCIP)
– bring together researchers, clinicians and trainees from academia and the NHS
– main focus of GeCIP is on clinical interpretation • research will also be undertaken


Now with added:
Paed sepsis
Inherited cancer
Hepatology!!!!
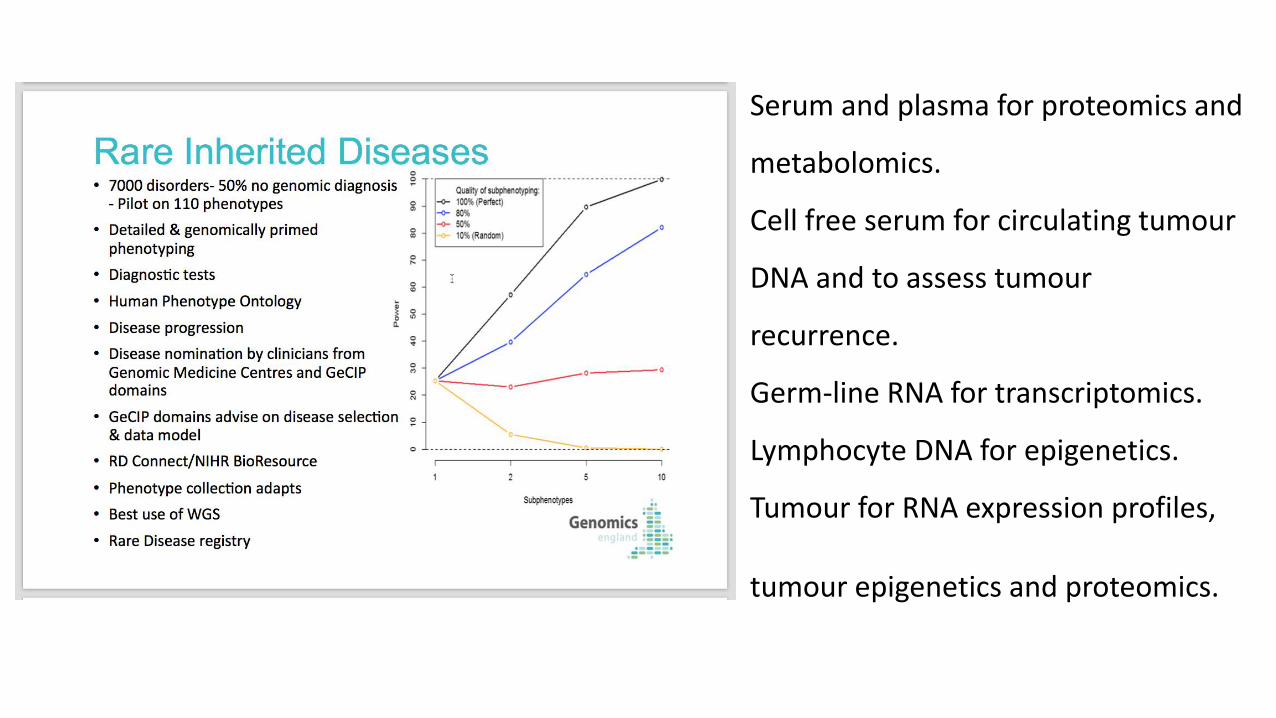
Serum and plasma for proteomics and
metabolomics.
Cell free serum for circulating tumour
DNA and to assess tumour
recurrence.
Germ-line RNA for transcriptomics.
Lymphocyte DNA for epigenetics.
Tumour for RNA expression profiles,
tumour epigenetics and proteomics.
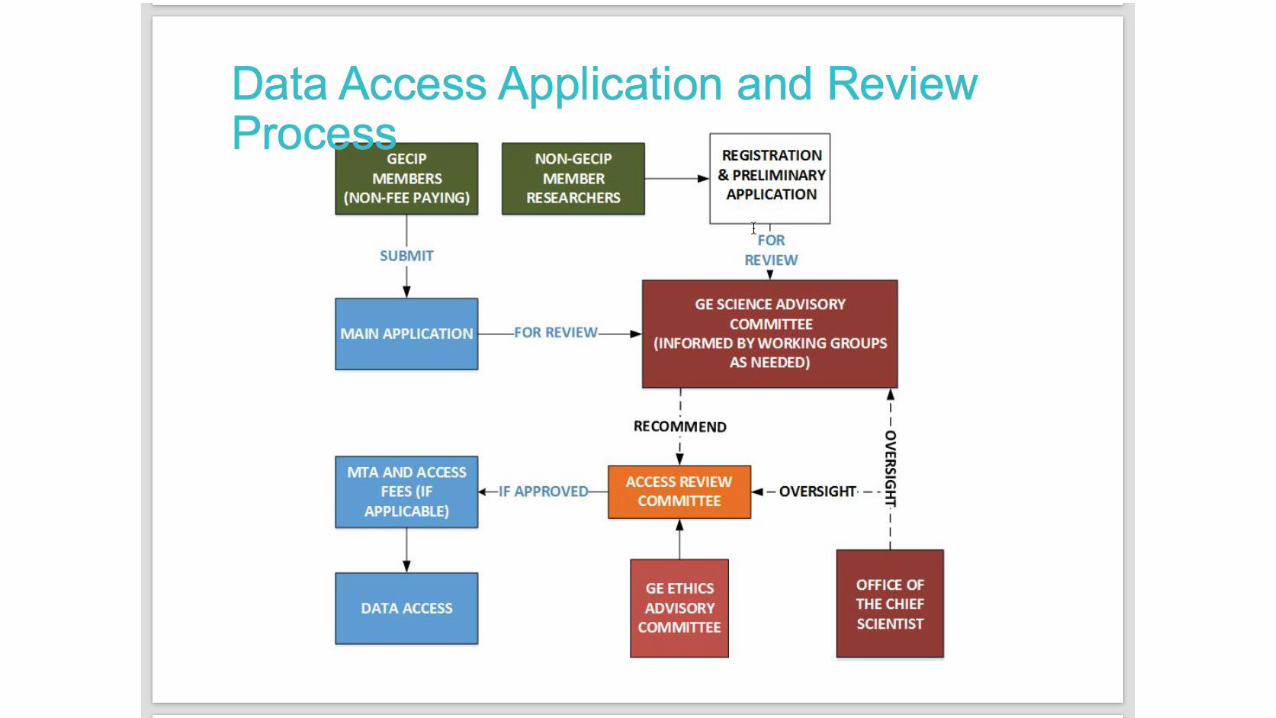

How is all this going to help research?
• Traditional approach to gene discovery
– Targetted at patients with pre-existing clinical diagnoses
– Eg De novo dominant Mutations in ARID1B cause Coffin Siris syndrome • Developmental delay, Absent speech,
Coarse facies, hypertrichosis, fingernail abnormalities, ACC
• Includes three patients with deletions of 6q25 including ARID1B
– Haploinsufficiency is the disease mechanism
Santen et al 2012
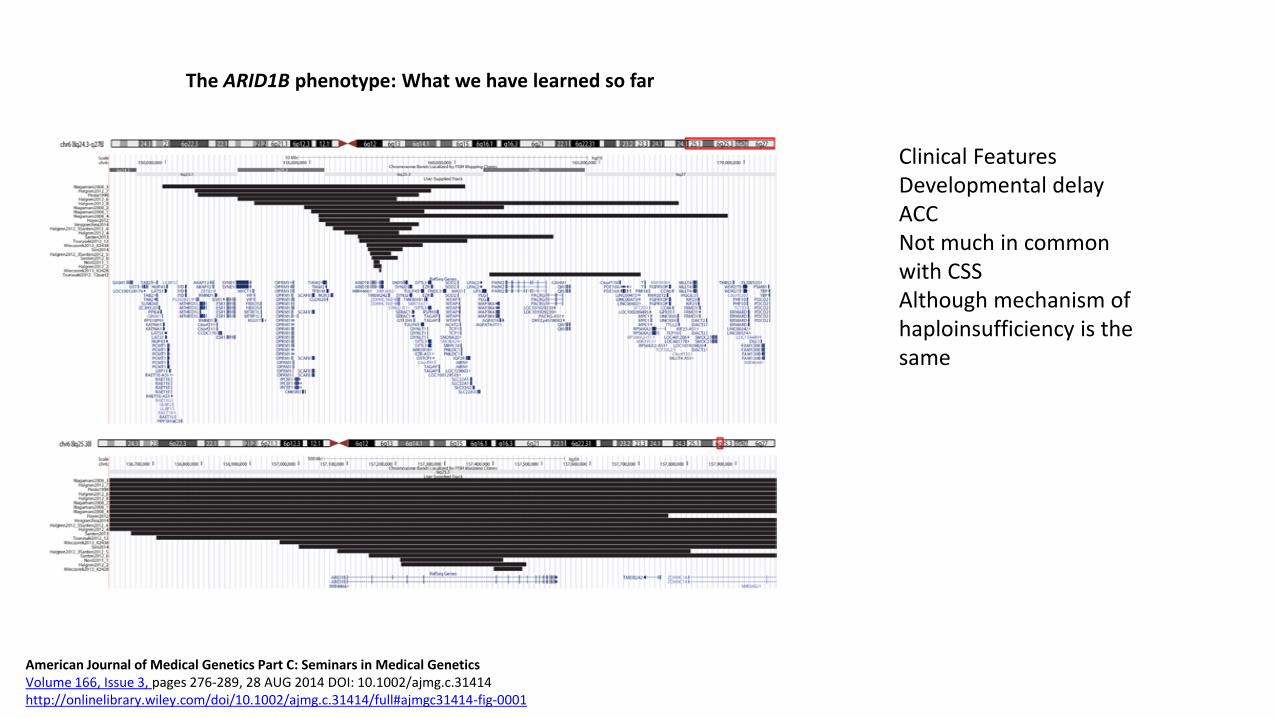
The ARID1B phenotype: What we have learned so far
American Journal of Medical Genetics Part C: Seminars in Medical Genetics Volume 166, Issue 3, pages 276-289, 28 AUG 2014 DOI: 10.1002/ajmg.c.31414 http://onlinelibrary.wiley.com/doi/10.1002/ajmg.c.31414/full#ajmgc31414-fig-0001
Clinical Features Developmental delay ACC Not much in common with CSS Although mechanism of haploinsufficiency is the same

ARID1B
• Subsequently reported in DDD as cause of 1% of delay in recruits
– Much broader phenotype in these patients
• Core CSS phenotype still valid predictor of mutations in ARID1B
– CSS is also caused by mutations in SMARCB1
The International Journal of Biochemistry & Cell Biology, Volume 52, 2014, 83–93
What about going beyond diagnosis?
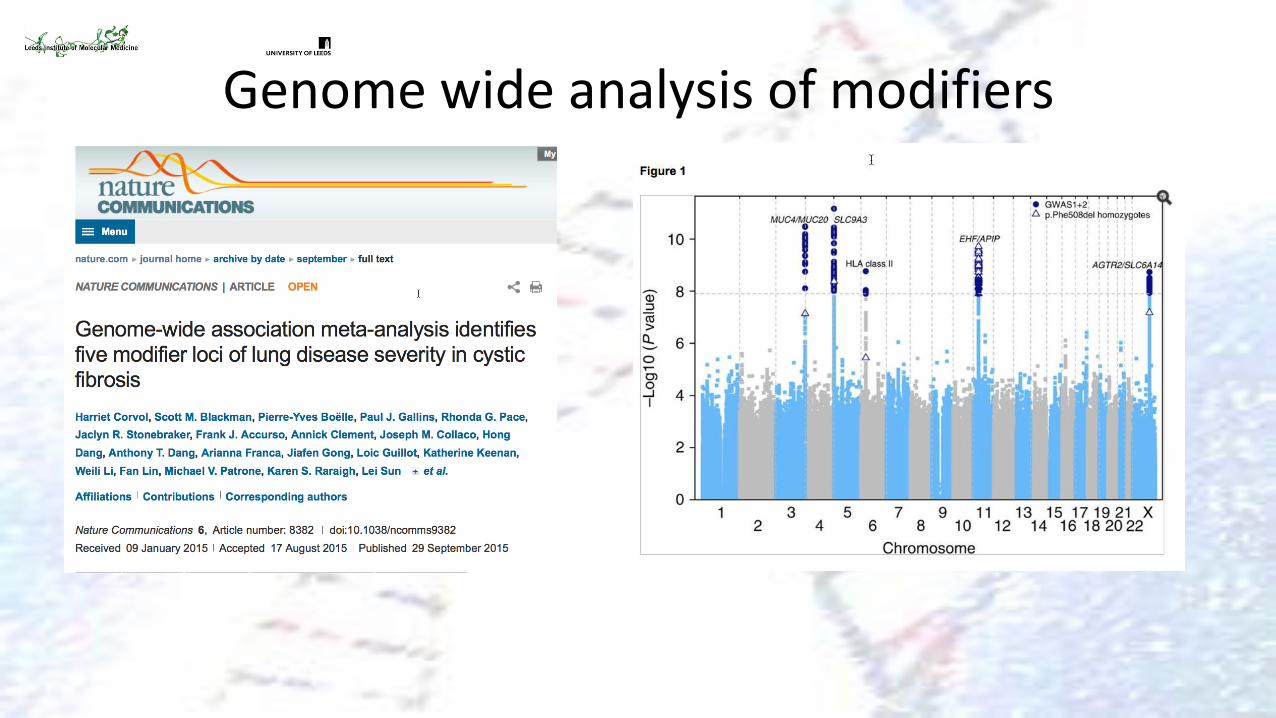
Genome wide analysis of modifiers

100,000 genomes
• Promiscuous approach to mutation discovery
• Linked to very deep phenotyping
– May broaden phenotypes
– Better identification of core components
– Better data on natural history • Presently often a snapshot
• All patients have detailed genome sequence available
• Can be re-interrogated in light of subsequent knowledge
– Technology
– Disease
– Natural history
– Pathogenetic pathways
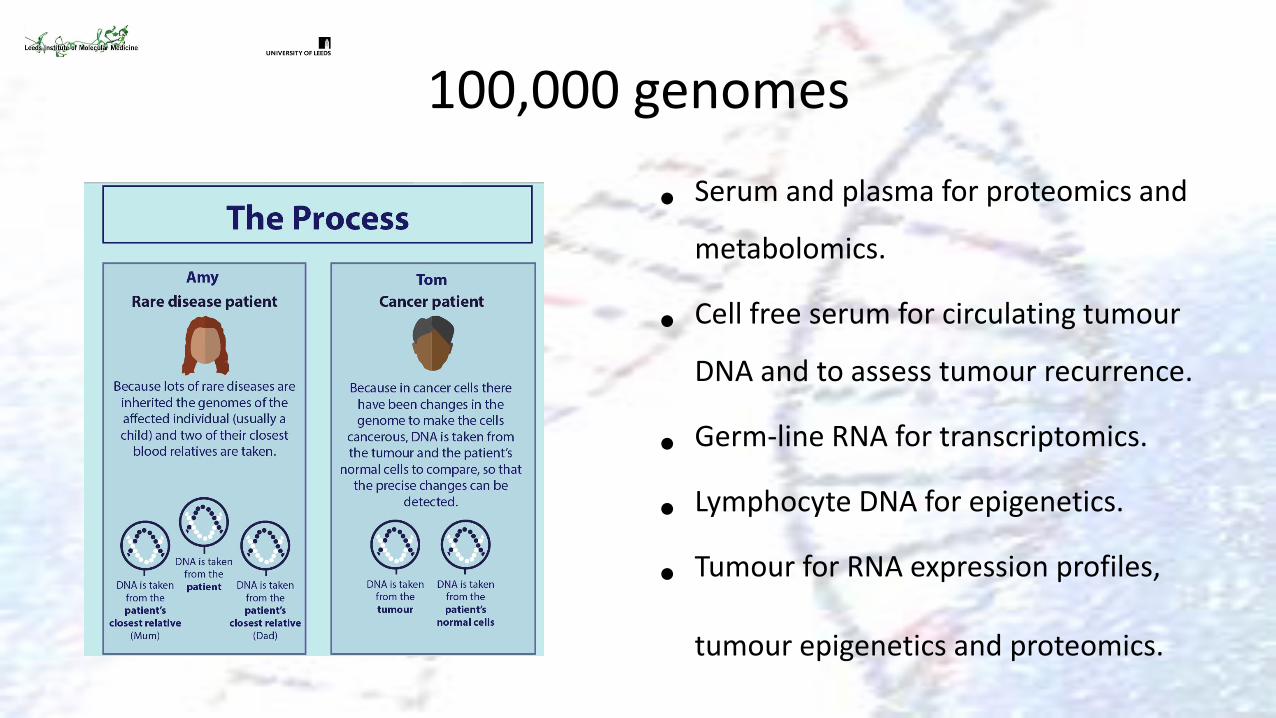
100,000 genomes
• Serum and plasma for proteomics and
metabolomics.
• Cell free serum for circulating tumour
DNA and to assess tumour recurrence.
• Germ-line RNA for transcriptomics.
• Lymphocyte DNA for epigenetics.
• Tumour for RNA expression profiles,
tumour epigenetics and proteomics.
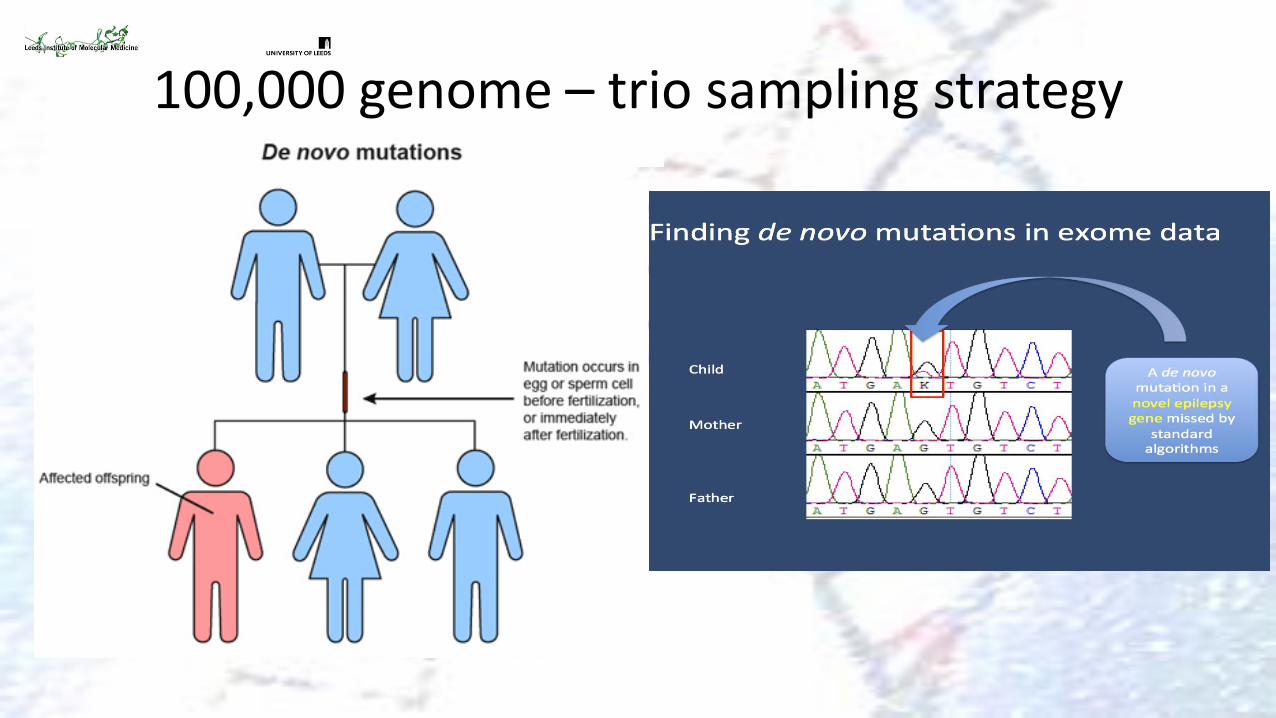
100,000 genome – trio sampling strategy
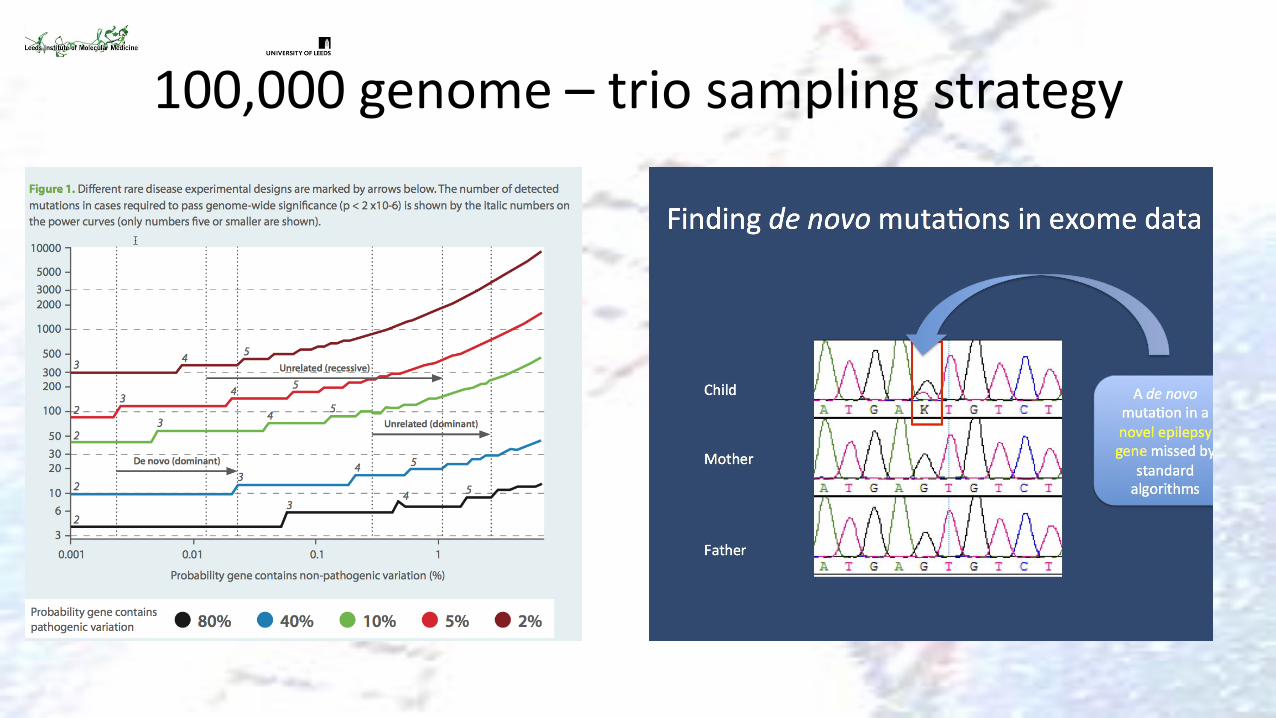
100,000 genome – trio sampling strategy

100,000 genomes – biological insight
• MPPH syndrome
• Early overgrowth (brain > somatic tissues)
• Progressive megalencephaly
• Ventriculomegaly/Hydrocephalus
• Cerebellar tonsillar ectopia
• Mega-corpus callosum
• Polymicrogyria
Distal limb anomalies
• Postaxial polydactyly
• Familial recurrences rare

Megalencephaly-Polymicrogyria-Polydactyly-Hydrocephalus Syndrome
(MPPH)
• No recurrence in all reported families. • Exome sequencing of one trio:
• 5,980 heterozygous ‘functional’ variants identified in proband
• 5 candidate de novo variants • 4 true de novo variants validated by Sanger
sequencing
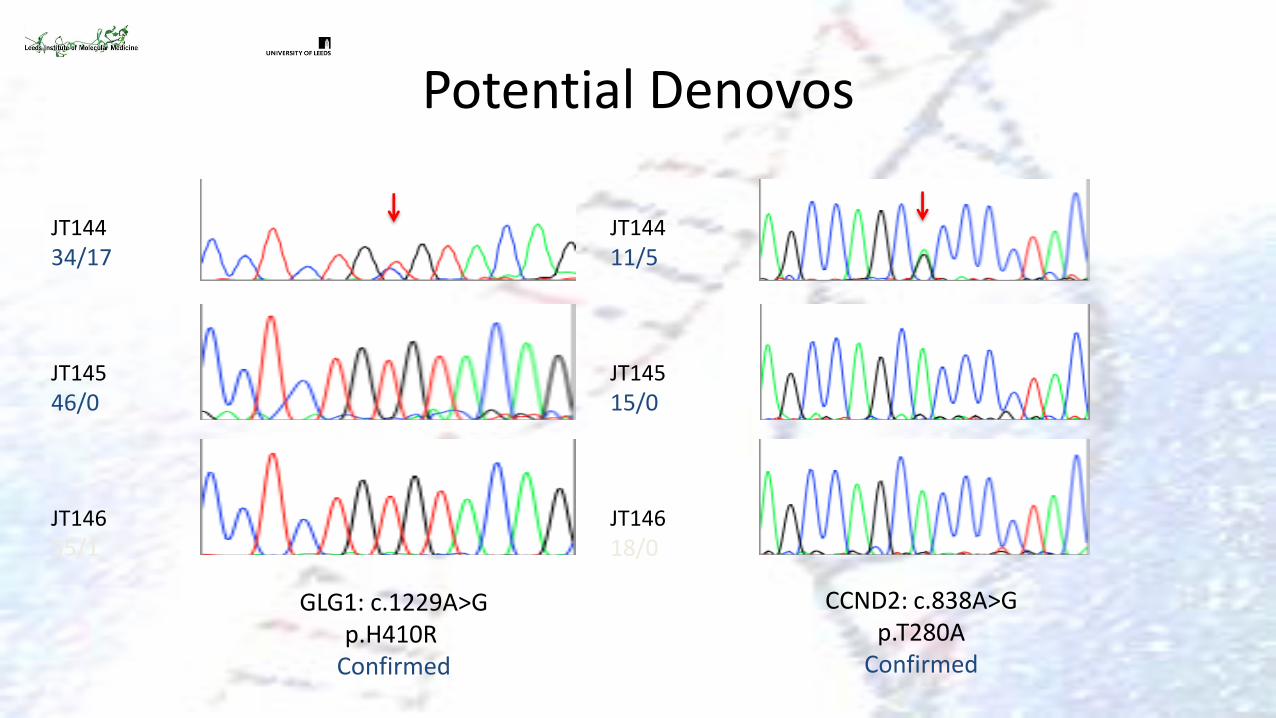
Potential Denovos
GLG1: c.1229A>G p.H410R
Confirmed
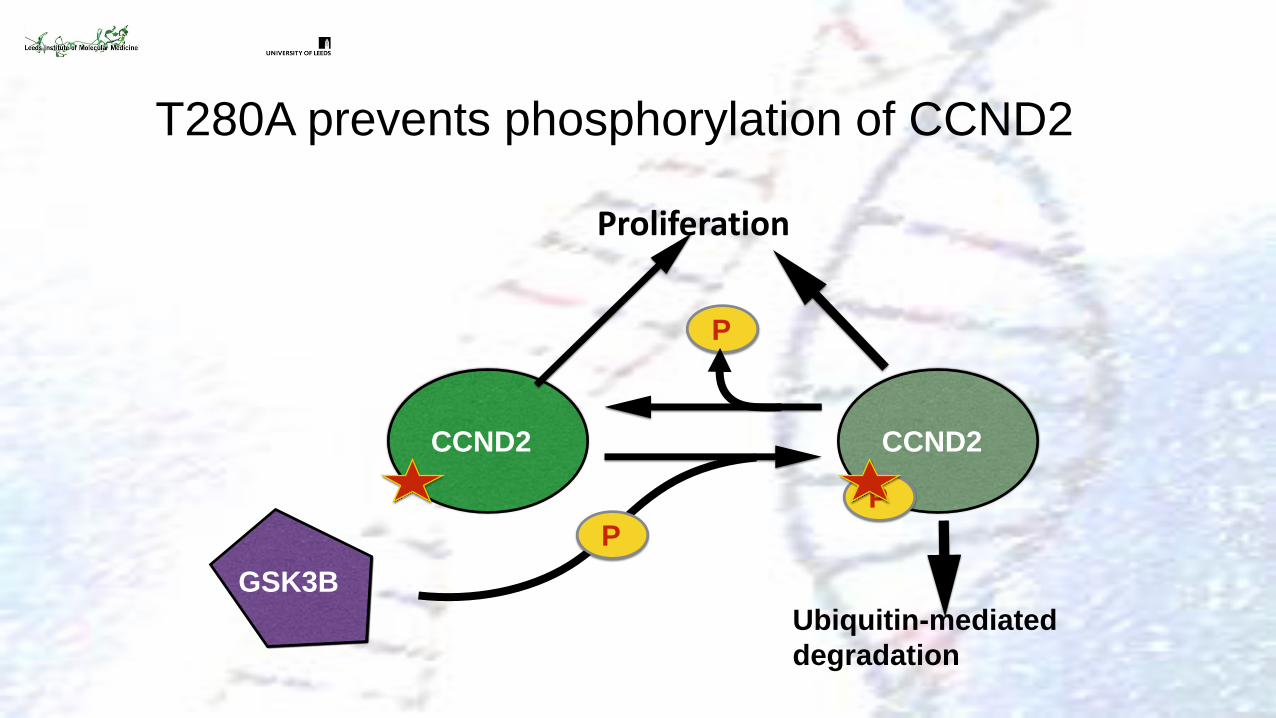
CCND2: c.838A>G p.T280A
Confirmed
JT144
11/5 JT145
15/0 JT146
18/0
JT144
34/17 JT145
46/0 JT146
55/1
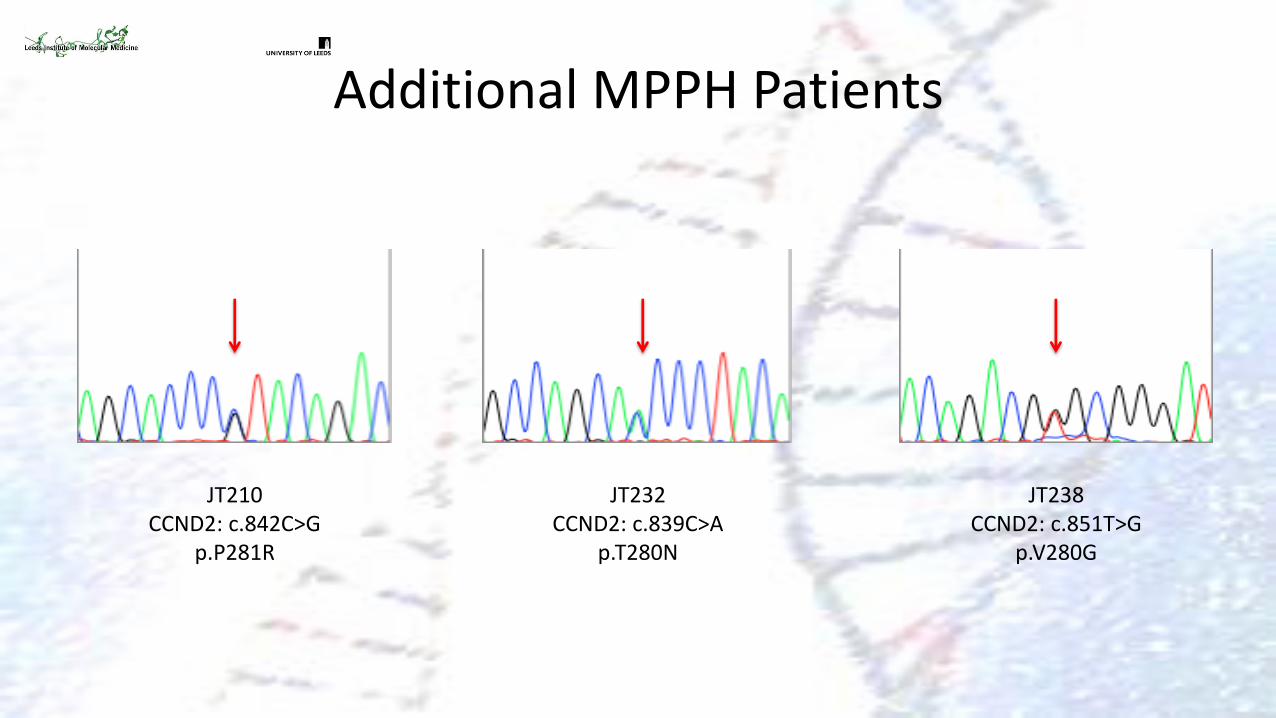
Additional MPPH Patients
JT210 CCND2: c.842C>G
p.P281R
JT232 CCND2: c.839C>A
p.T280N
JT238 CCND2: c.851T>G
p.V280G
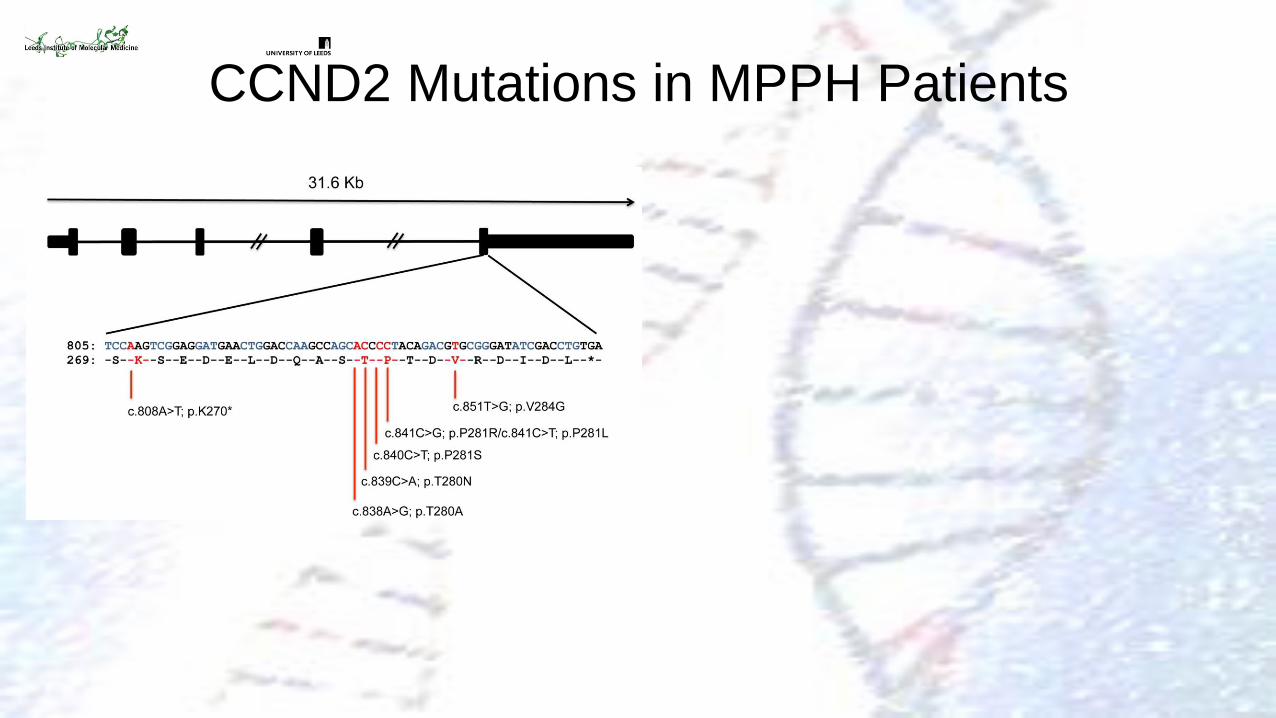
CCND2 Mutations in MPPH Patients
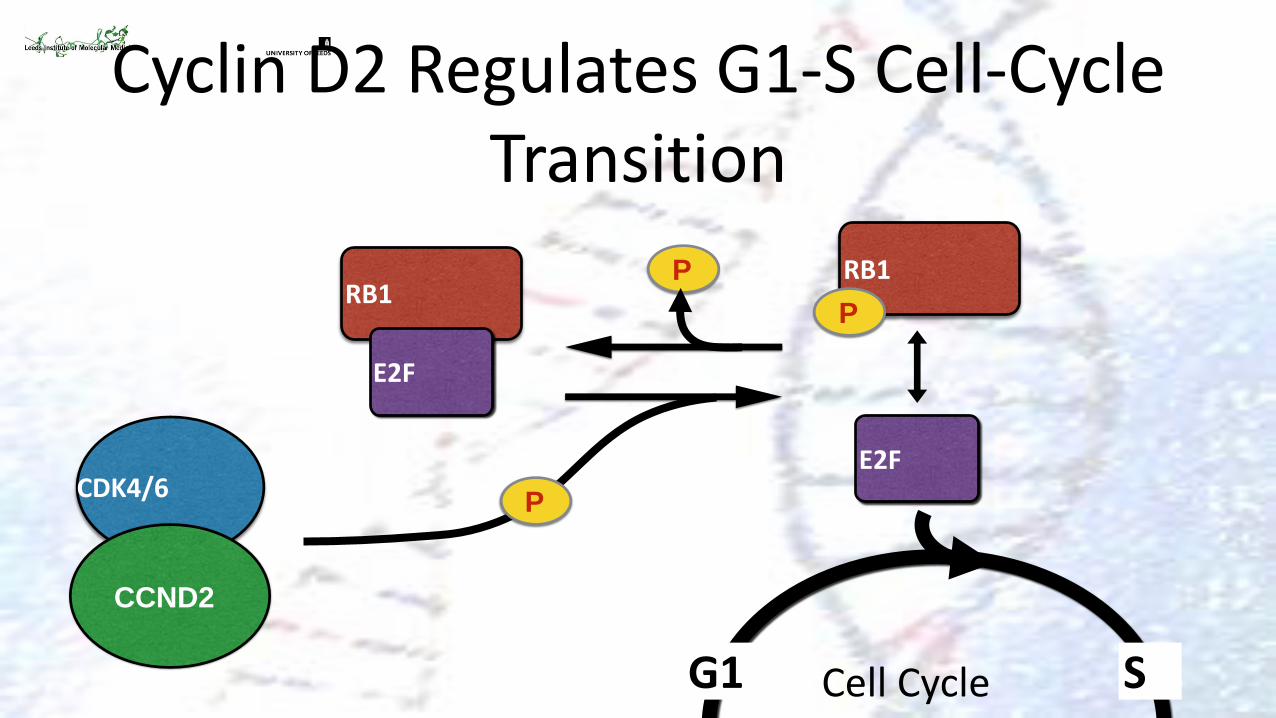
Cyclin D2 Regulates G1-S Cell-Cycle Transition
CDK4/6
P
P
RB1
E2F
E2F
RB1
P
G1 S
CCND2
Cell Cycle
P
CCND2 CCND2
P
P
GSK3B
Ubiquitin-mediated
degradation
Proliferation
T280A prevents phosphorylation of CCND2
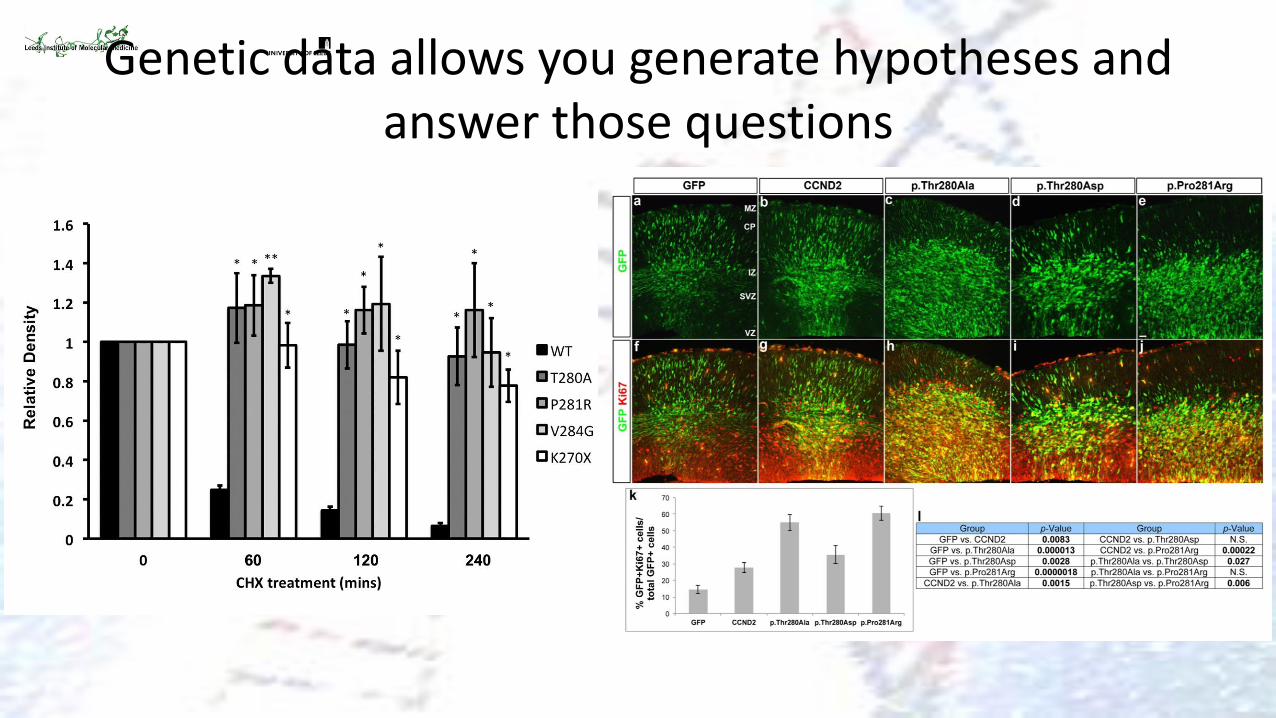
Genetic data allows you generate hypotheses and answer those questions
But you still have to get on with stuff
HyperActive
P CCND2 CCND2
P
GSK3B
Ubiquitin-mediated
degradation
P
GSK3B
P
AKT3
P
Proliferation
P
P P P P
Active
Inactive
Active
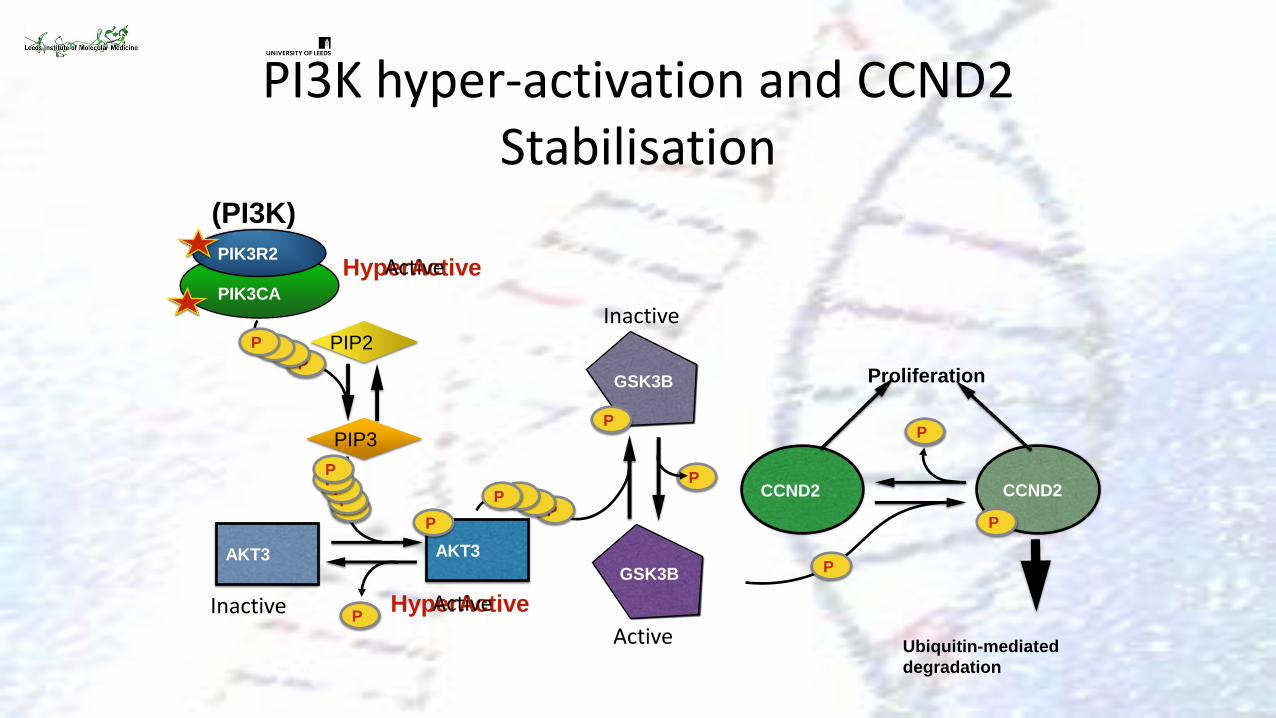
PI3K hyper-activation and CCND2 Stabilisation
PIK3CA
PIK3R2
P
AKT3
P
P
P
(PI3K)
Inactive
P P
P P
P P
HyperActive Active
PIP2
PIP3

Summary
• 100000 genomes will provide basic genetic data on large numbers of patients
• This will allow the generation of novel disease hypotheses
• It is up to us to further investigate those
• Provide new disease paradigms
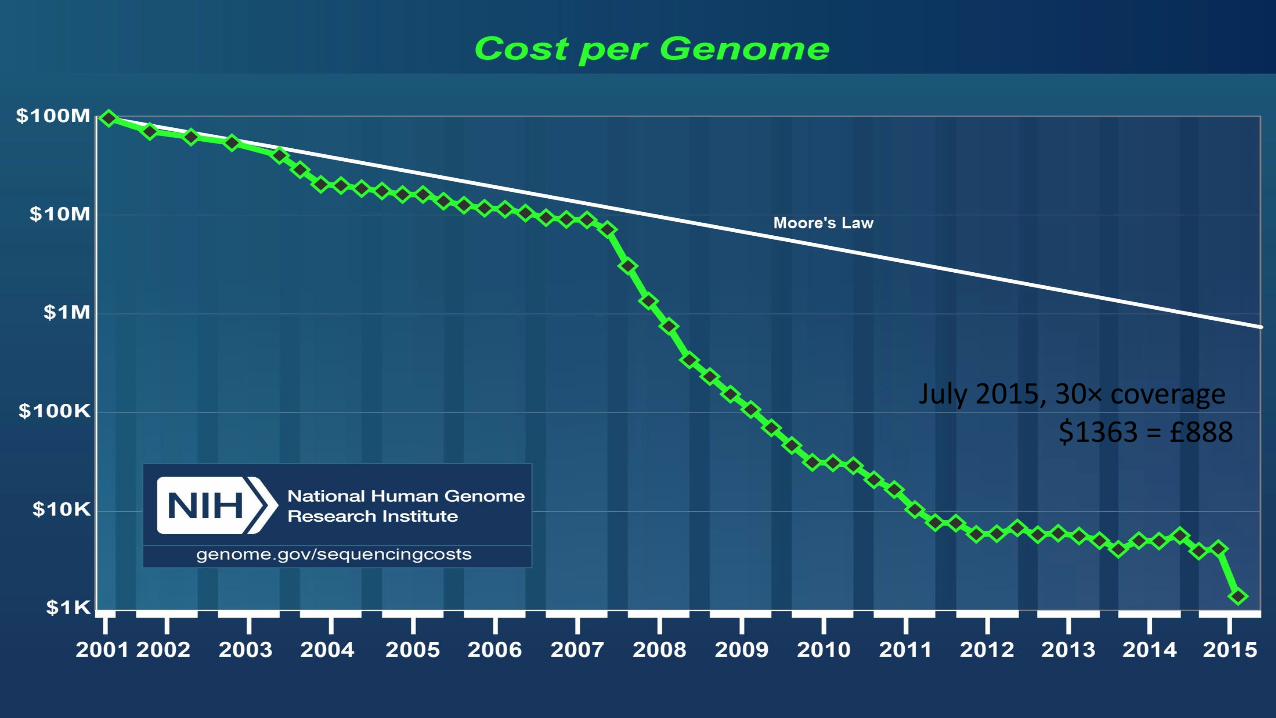
July 2015, 30× coverage $1363 = £888
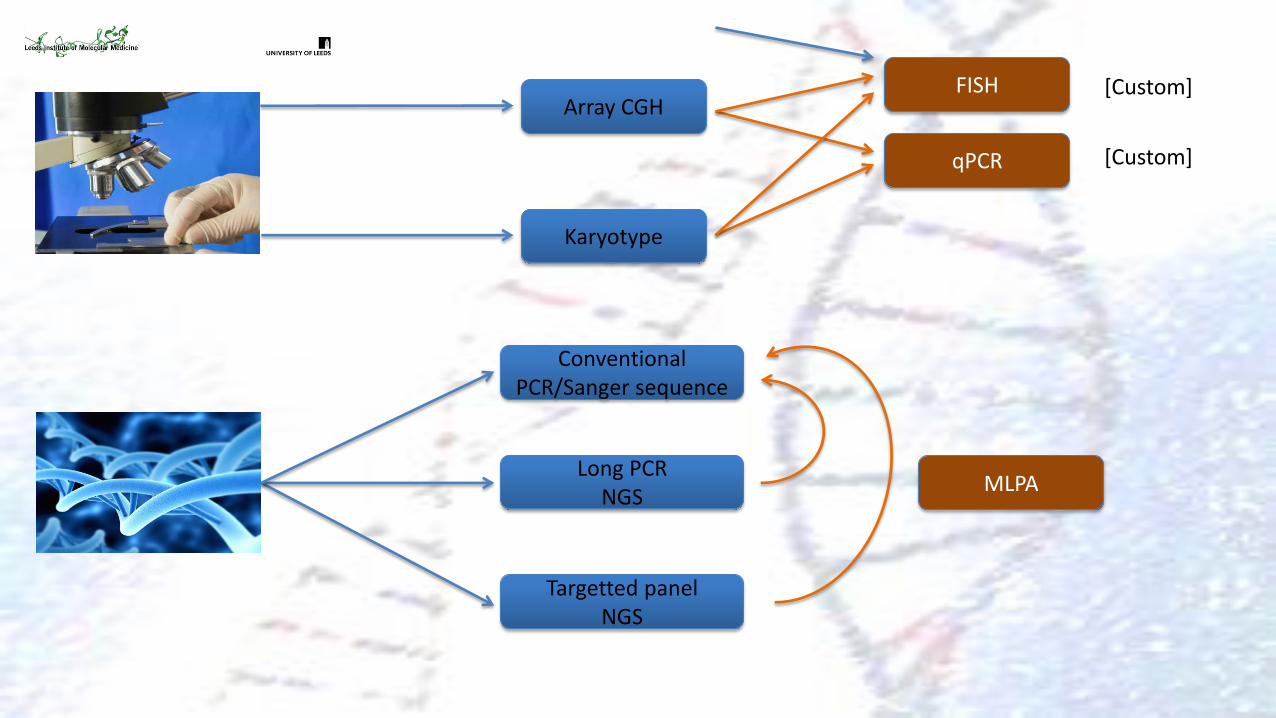
Array CGH
qPCR
FISH
Karyotype
Conventional PCR/Sanger sequence
[Custom]
[Custom]
Long PCR NGS
Targetted panel NGS
MLPA
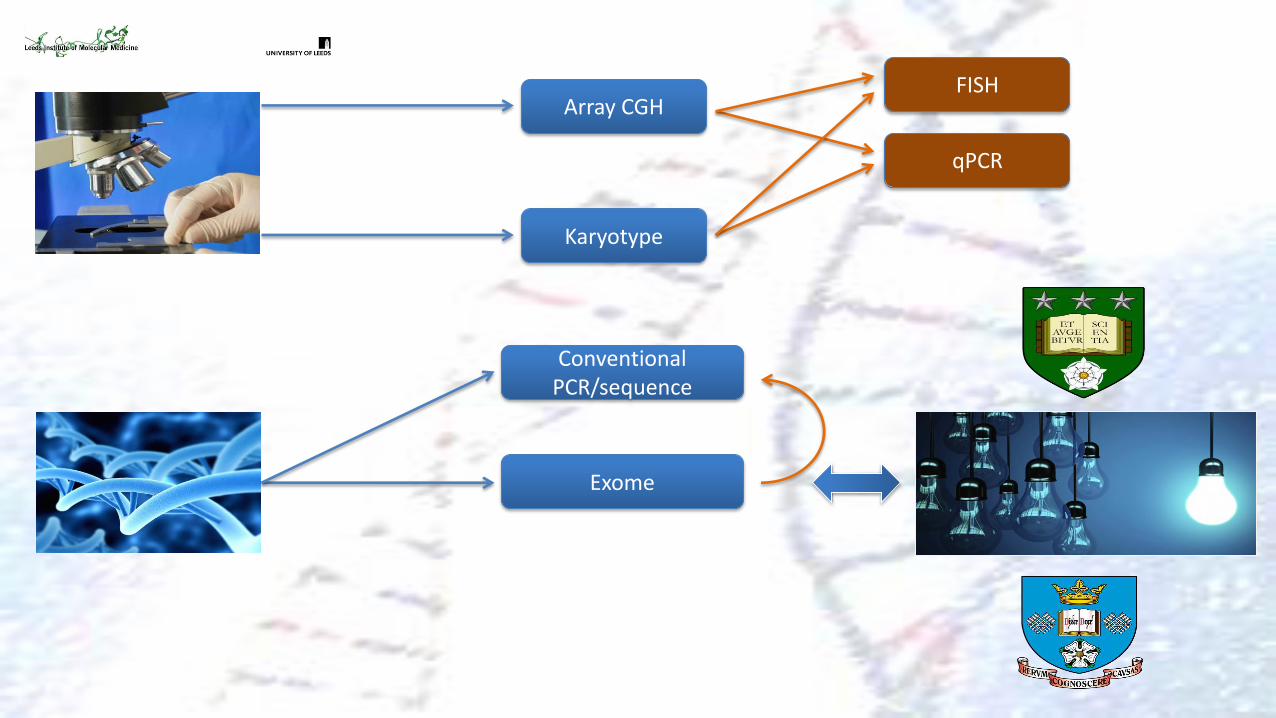
Array CGH
qPCR
FISH
Karyotype
Conventional PCR/sequence
Exome
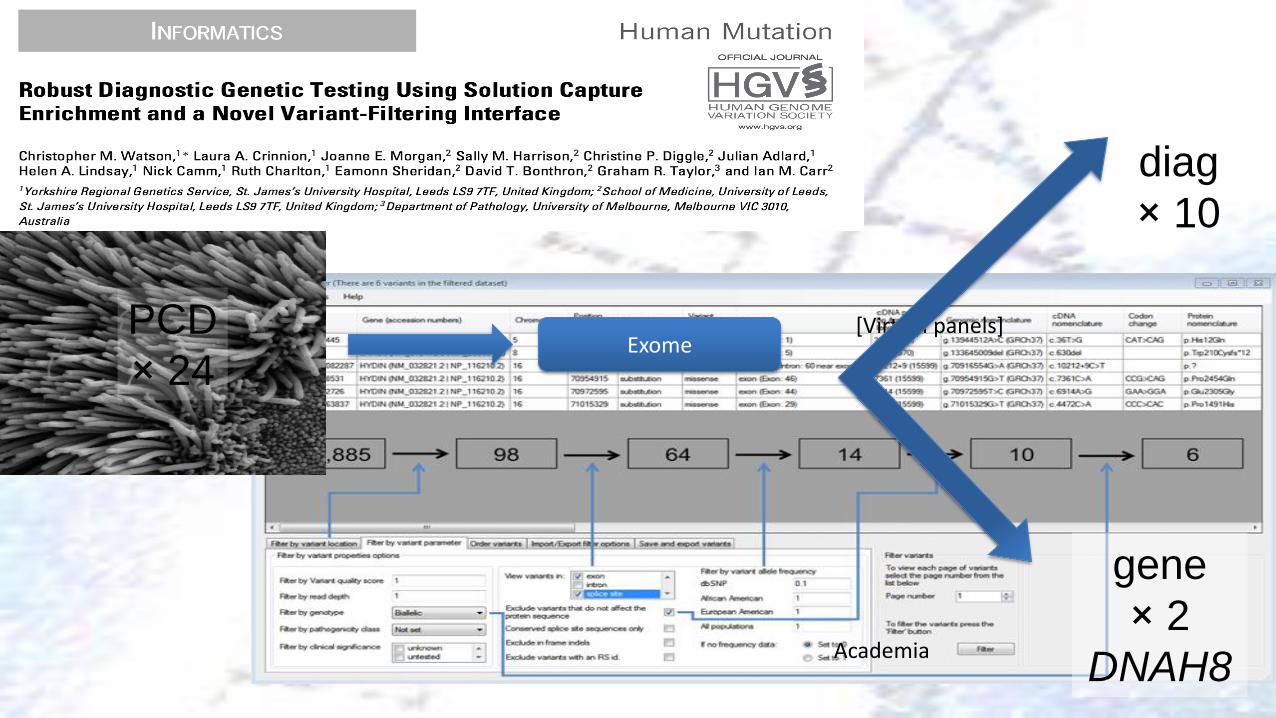
[Virtual panels] Exome
Academia
PCD
× 24
diag
× 10
gene
× 2
DNAH8
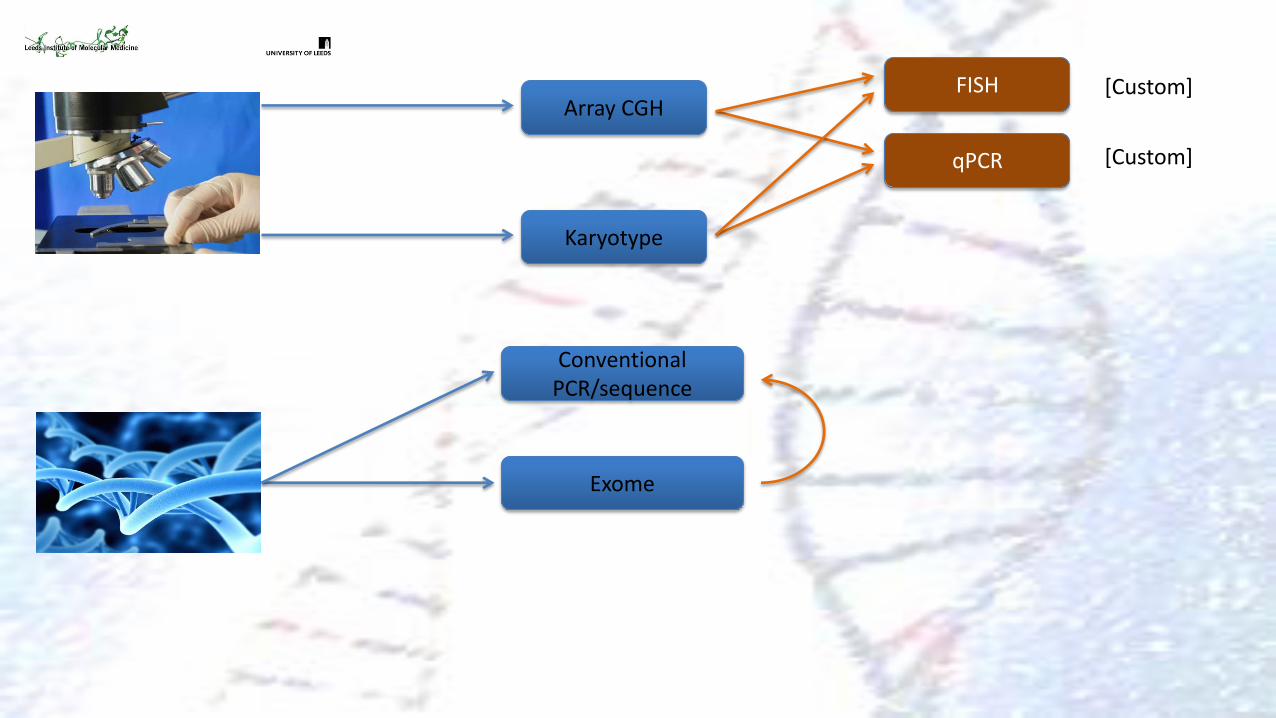
Array CGH
qPCR
FISH
Karyotype
[Custom]
[Custom]
Conventional PCR/sequence
Exome
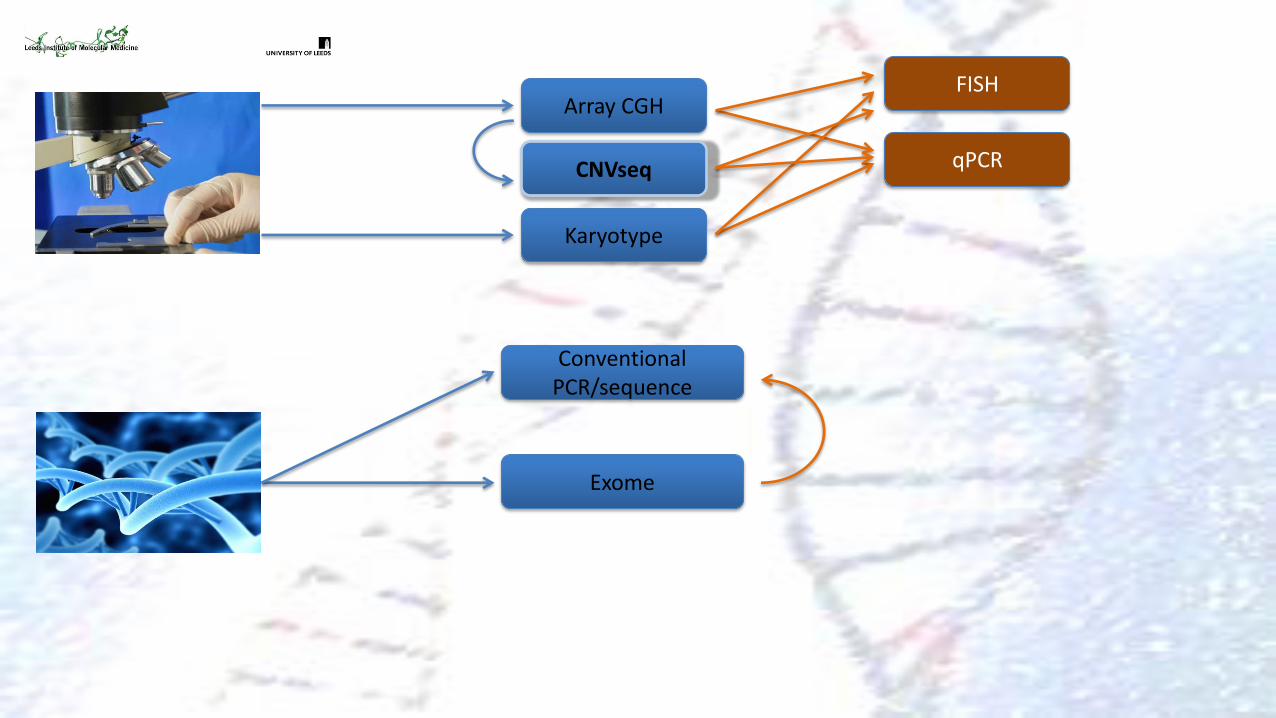
Conventional PCR/sequence
Exome
Array CGH
qPCR
FISH
Karyotype
CNVseq
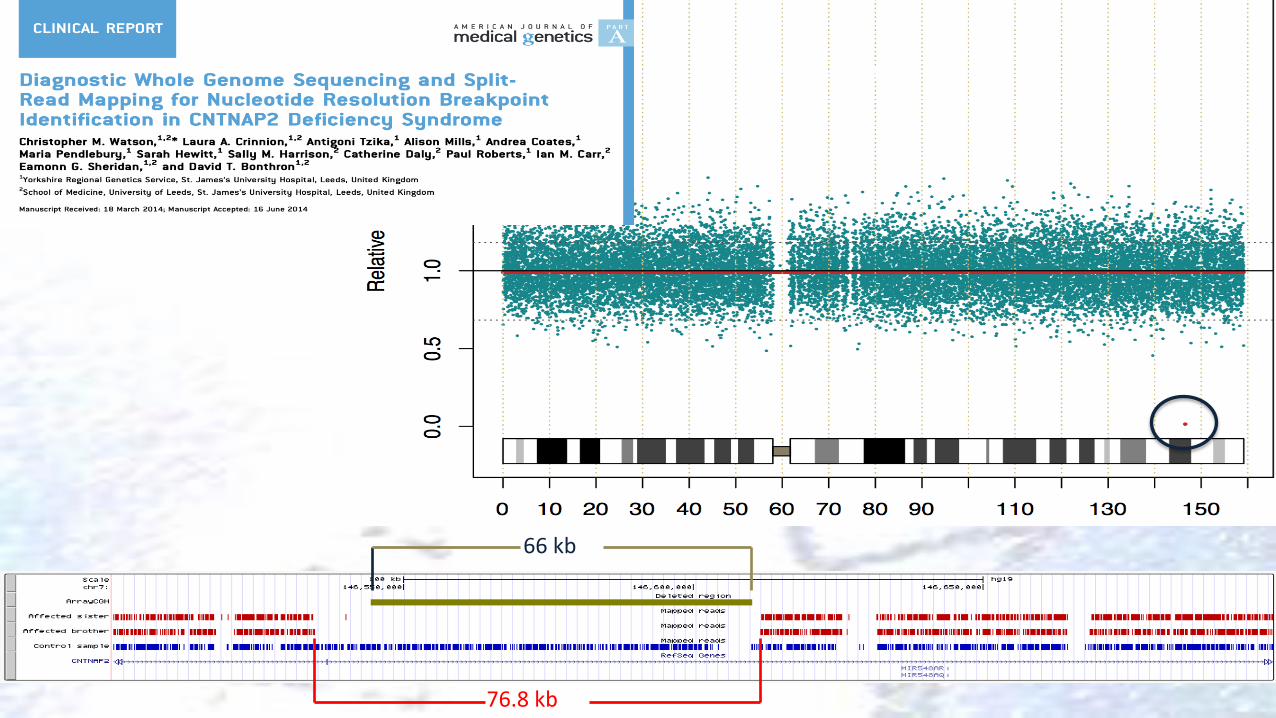
66 kb
76.8 kb
Chromosome 7
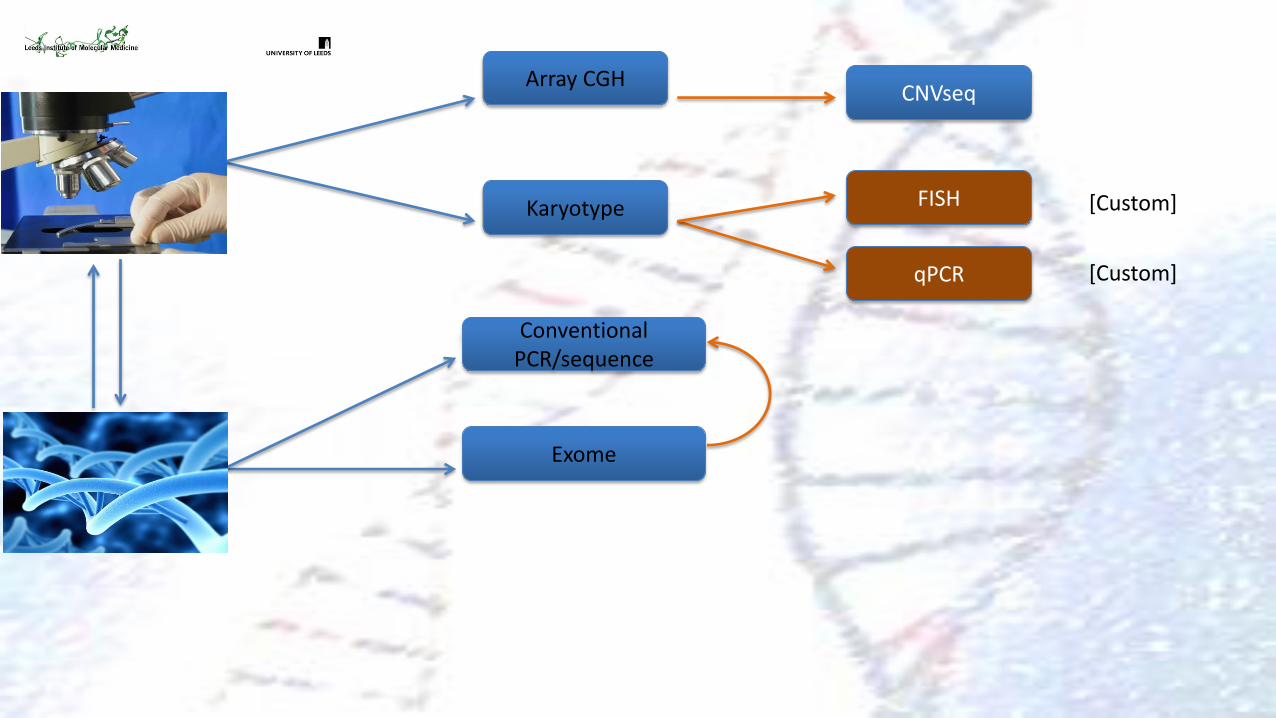
Array CGH
qPCR
FISH Karyotype
CNVseq
Conventional PCR/sequence
Exome
[Custom]
[Custom]
?
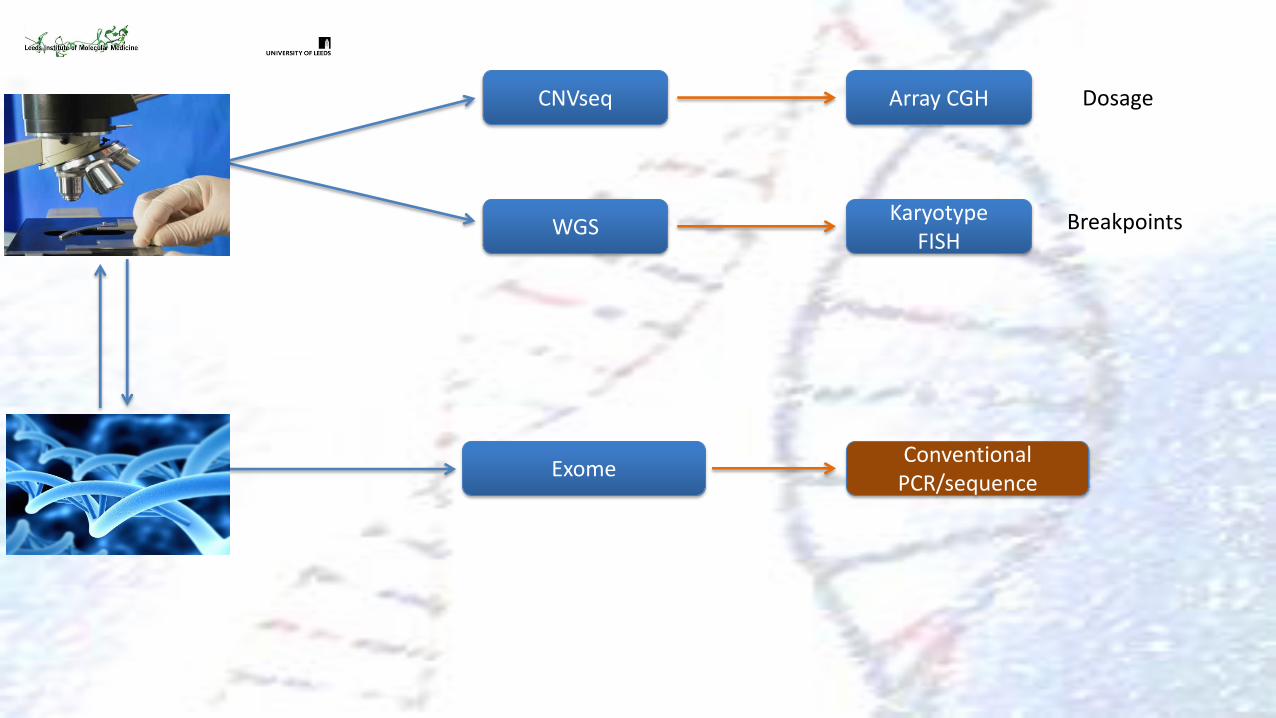
Array CGH
Karyotype FISH
CNVseq
WGS Breakpoints
Dosage
Conventional PCR/sequence
Exome
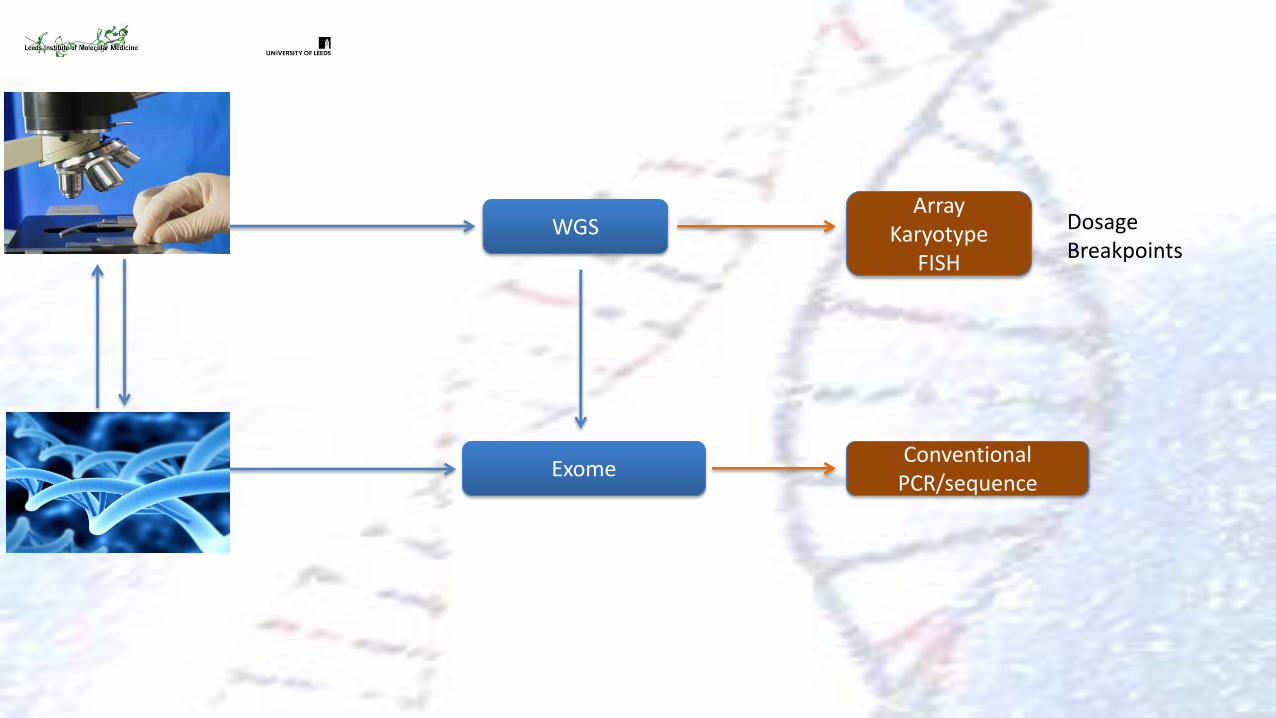
WGS Dosage Breakpoints
Array Karyotype
FISH
Conventional PCR/sequence
Exome

100,000 genomes
• Radically alter NHS provision of genomic services
• Single platform
• Common workflows
• Deep phenotyping
• Clinically relevant results
• Qucikly!