1/14 a result forwarding unit for a synthesisable asynchronous processor luis tarazona and doug...
TRANSCRIPT

1/14
A Result Forwarding Unit for a Synthesisable Asynchronous
Processor
A Result Forwarding Unit for a Synthesisable Asynchronous
Processor
Luis Tarazona and Doug Edwards
Advanced Processor Technologies Group
School of Computer Science

2/14
Result ForwardingResult Forwarding
• Method to reduce inter-instruction data dependencies performance penalty
• Can even be used to allow out-of order execution.
• Hard to implement in asynchronous processors
• Earlier proposed solutions to resolve data dependencies in asynchronous processors:
– Register locking (AMULET1)
– Last-result register (AMULET2)
– Asynchronous ROB (AMULET3)
– Counterflow pipelines
Full-custom solutions!

3/14
Potential BenefitsPotential Benefits

4/14
Synthesisable Result Forwarding UnitSynthesisable Result Forwarding Unit
Synthesisable description advantages:
– Faster development
– Design-space exploration
– Technology mapping transparency
• The description serves to:
– Evaluate the capabilities of the Balsa language to describe performance-demanding systems
– Highlight performance-oriented description techniques

5/14
The Target Processor: nanoSpaThe Target Processor: nanoSpa
• Experimental new SPA specification
• Same 3-stage SPA pipeline architecture
• Main target: Performance
• No support yet for
– Thumb Instructions
– Interrupts
– Memory Aborts
– Coprocessors

6/14
Related Work: AMULET3 ROBRelated Work: AMULET3 ROB
• D.A. Gilbert & J.D. Garside 1997
• Asynchronous Reorder Buffer that provides forwarding and precise exceptions handling
• Implemented in single-rail
• Five-process reference model for the synthesisable FU
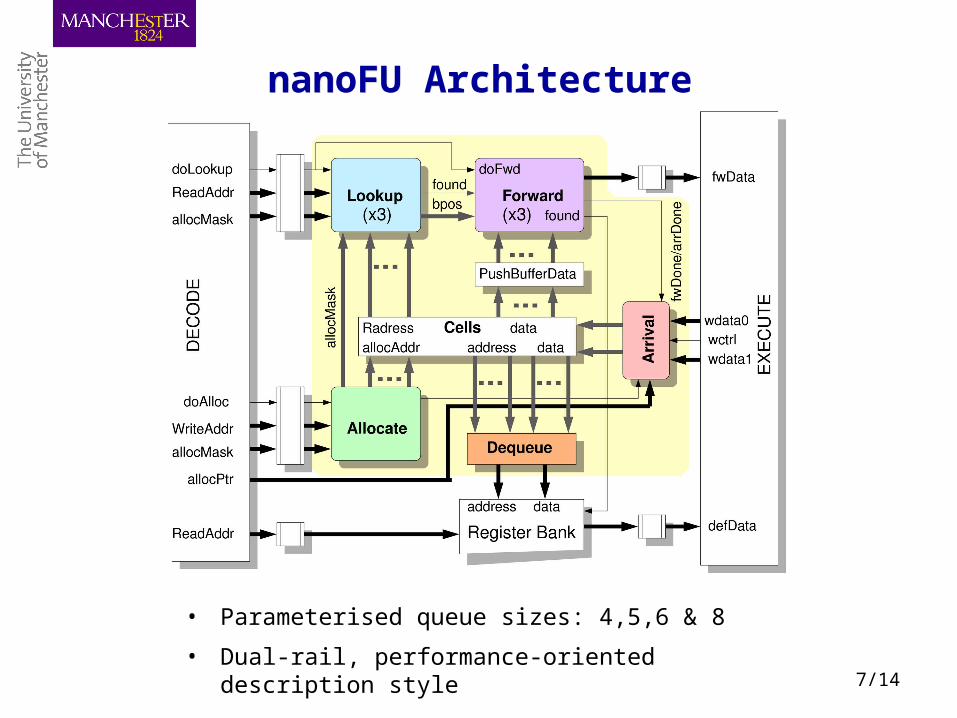
7/14
nanoFU ArchitecturenanoFU Architecture
• Parameterised queue sizes: 4,5,6 & 8
• Dual-rail, performance-oriented description style

8/14
Implementation Issues Implementation Issues
• Synchronisation between processes:
– Use data tokens instead of sync channels to increase performance
– Speculative buffer reads to decouple arrival and forwarding
– Buffer cell locking to decouple Forwarding and Allocation
– Drawbacks: power and area penalty

9/14
Implementation IssuesImplementation Issues
• CAM implementation based on comparators
– relatively simple but still slow
• Register bank operation:
– Potential hazards in dual-rail if speculatively reading while writing
• Register read must wait for Lookup to provide “default” forwarding value
– Number of tokens in pipeline guarantees that writeout never conflicts with reading

10/14
Simulation ResultsSimulation Results
Pre-layout, transistor-level simulations, 180nm technology

11/14
Balsa limitations highlightsBalsa limitations highlights
• Need for:
– Efficient ways of describing and synthesising associative arrays
– Deadlock-safe implementation that allows concurrent writes and reads in variables (for speculative reading)
– Signal-level manipulation to avoid excessive synchronisation
• Some peephole optimisations (next talk)

12/14
ConclusionsConclusions

13/14
Future workFuture work
• To extend the nanoSpa pipeline by including a memory stage and evaluate the performance of the forwarding unit within this architecture
• To implement and explore the effects of suggested optimisations and components

14/14
Thank you very much!
Questions?
Acknowledgement
• Thanks to Luis Plana, Andrew, Charlie and Will for their suggestions and comments.
• This work and PhD are supported by EPSCR and UoM School of Computer Science scholarships.