14 scaleabilty wics
TRANSCRIPT
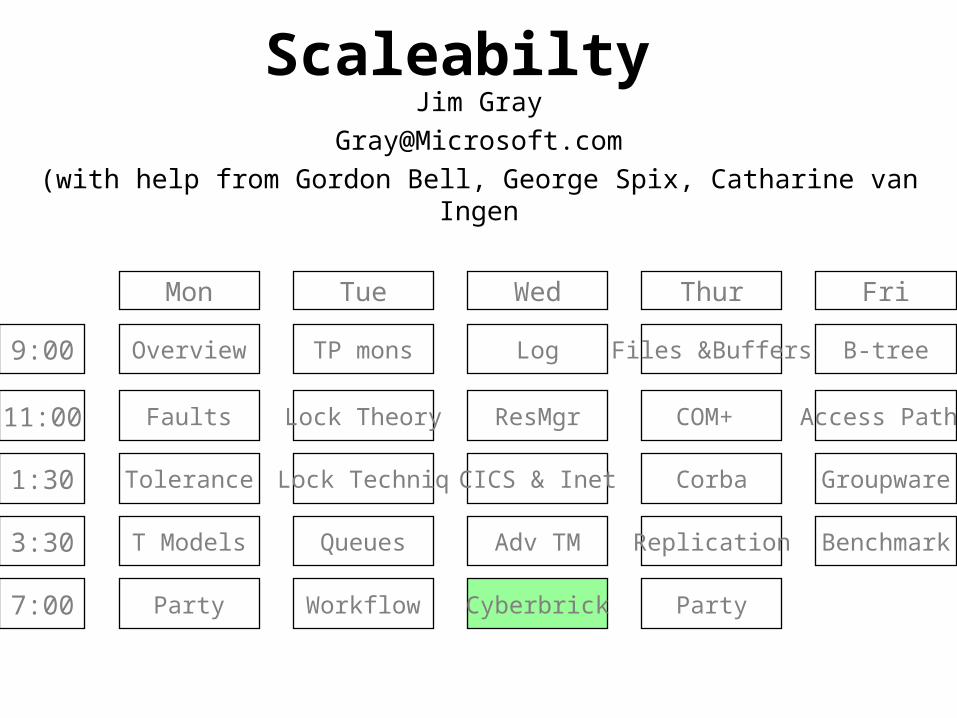
Scaleabilty Jim Gray
(with help from Gordon Bell, George Spix, Catharine van Ingen
9:00
11:00
1:30
3:30
7:00
Overview
Faults
Tolerance
T Models
Party
TP mons
Lock Theory
Lock Techniq
Queues
Workflow
Log
ResMgr
CICS & Inet
Adv TM
Cyberbrick
Files &Buffers
COM+
Corba
Replication
Party
B-tree
Access Paths
Groupware
Benchmark
Mon Tue Wed Thur Fri

A peta-op business app?
• P&G and friends pay for the web (like they paid for broadcast television) – no new money, but given Moore, traditional advertising revenues can pay for all of our connectivity - voice, video, data…… (presuming we figure out how to & allow them to brand the experience.)
• Advertisers pay for impressions and ability to analyze same.
• A terabyte sort a minute – to one a second.• Bisection bw of ~20gbytes/s – to ~200gbytes/s. • Really a tera-op business app (today’s portals)
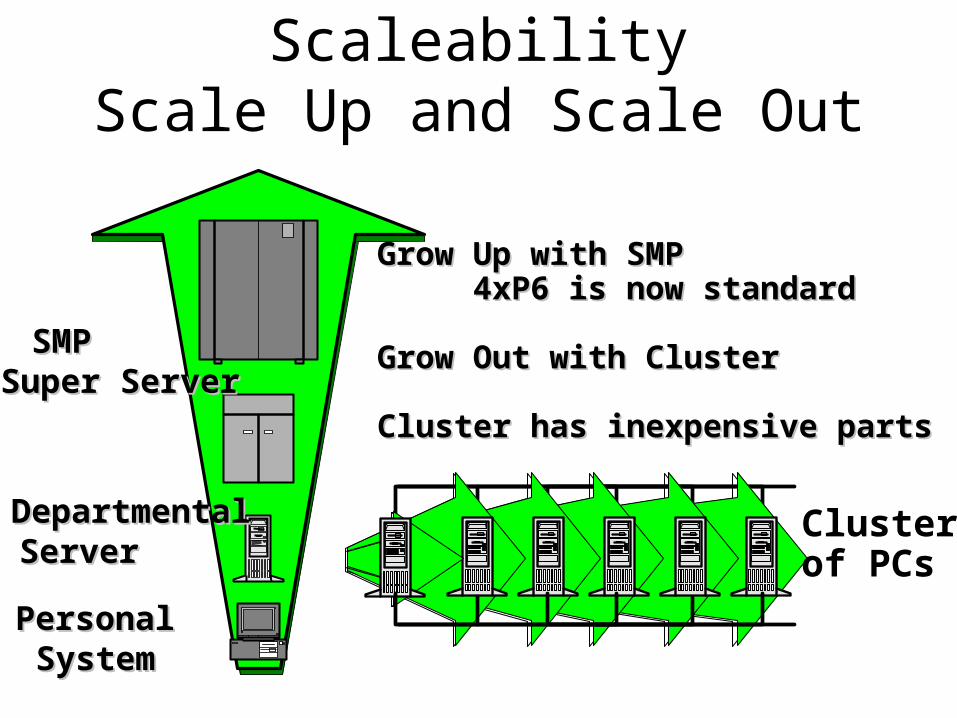
ScaleabilityScale Up and Scale Out
SMPSMPSuper ServerSuper Server
DepartmentalDepartmentalServerServer
PersonalPersonalSystemSystem
Grow Up with SMPGrow Up with SMP4xP6 is now standard4xP6 is now standard
Grow Out with ClusterGrow Out with Cluster
Cluster has inexpensive partsCluster has inexpensive parts
Clusterof PCs

There'll be Billions Trillions Of Clients
• Every device will be “intelligent”
• Doors, rooms, cars…
• Computing will be ubiquitous
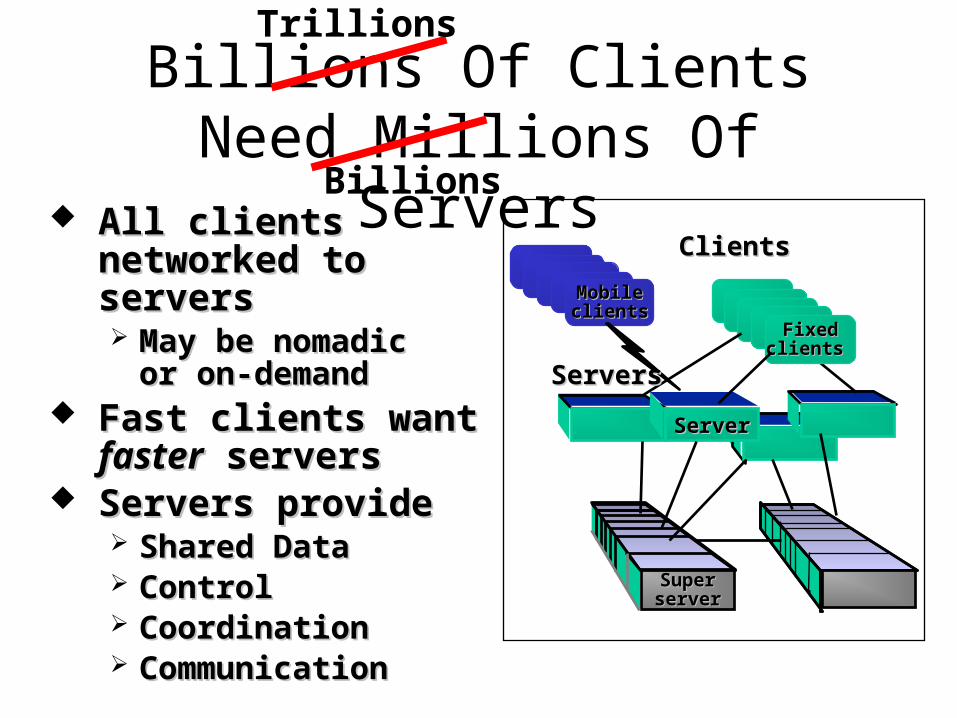
Billions Of ClientsNeed Millions Of Servers
MobileMobileclientsclients
FixedFixedclients clients
ServerServer
SuperSuperserverserver
ClientsClients
ServersServers
All clients networked All clients networked to serversto servers May be nomadicMay be nomadic
or on-demandor on-demand Fast clients wantFast clients want
fasterfaster servers servers Servers provide Servers provide
Shared DataShared Data ControlControl CoordinationCoordination CommunicationCommunication
Trillions
Billions

ThesisMany little beat few big
Smoking, hairy golf ballSmoking, hairy golf ball How to connect the many little parts?How to connect the many little parts? How to program the many little parts?How to program the many little parts? Fault tolerance & Management?Fault tolerance & Management?
$1 $1 millionmillion $100 K$100 K $10 K$10 K
MainframeMainframe MiniMiniMicroMicro NanoNano
14"14"9"9"
5.25"5.25" 3.5"3.5" 2.5"2.5" 1.8"1.8"1 M SPECmarks, 1TFLOP1 M SPECmarks, 1TFLOP
101066 clocks to bulk ram clocks to bulk ram
Event-horizon on chipEvent-horizon on chip
VM reincarnatedVM reincarnated
Multi-program cache,Multi-program cache,On-Chip SMPOn-Chip SMP
10 microsecond ram
10 millisecond disc
10 second tape archive
10 nano-second ram
Pico Processor
10 pico-second ram
1 MM 3
100 TB
1 TB
10 GB
1 MB
100 MB

4 B PC’s (1 Bips, .1GB dram, 10 GB disk 1 Gbps Net, B=G)
The Bricks of Cyberspace• Cost 1,000 $• Come with
– NT– DBMS– High speed Net– System management– GUI / OOUI – Tools
• Compatible with everyone else• CyberBricks

Computers shrink to a point• Disks 100x in 10 years
2 TB 3.5” drive
• Shrink to 1” is 200GB
• Disk is super computer!
• This is already true of printers and “terminals”
Kilo
Mega
Giga
Tera
Peta
Exa
Zetta
Yotta
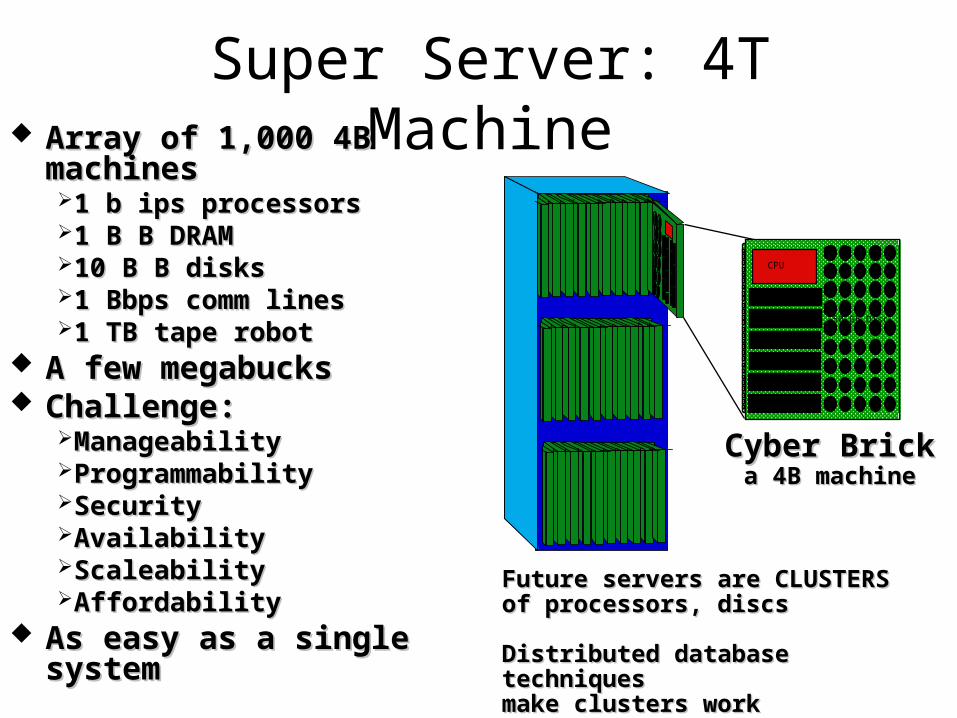
Super Server: 4T Machine Array of 1,000 4B machinesArray of 1,000 4B machines
1 b ips processors1 b ips processors1 B B DRAM 1 B B DRAM 10 B B disks 10 B B disks 1 Bbps comm lines1 Bbps comm lines1 TB tape robot1 TB tape robot
A few megabucksA few megabucks Challenge:Challenge:
ManageabilityManageabilityProgrammabilityProgrammabilitySecuritySecurityAvailabilityAvailabilityScaleabilityScaleabilityAffordabilityAffordability
As easy as a single systemAs easy as a single systemFuture servers are CLUSTERSFuture servers are CLUSTERSof processors, discsof processors, discs
Distributed database techniquesDistributed database techniquesmake clusters workmake clusters work
CPU
50 GB Disc
5 GB RAM
Cyber BrickCyber Bricka 4B machinea 4B machine

Cluster VisionBuying Computers by the Slice
• Rack & Stack– Mail-order components– Plug them into the cluster
• Modular growth without limits– Grow by adding small modules
• Fault tolerance: – Spare modules mask failures
• Parallel execution & data search– Use multiple processors and disks
• Clients and servers made from the same stuff– Inexpensive: built with
commodity CyberBricks

Systems 30 Years Ago• MegaBuck per Mega Instruction Per Second (mips)
• MegaBuck per MegaByte
• Sys Admin & Data Admin per MegaBuck

Disks of 30 Years Ago
• 10 MB
• Failed every few weeks

1988: IBM DB2 + CICS Mainframe65 tps
• IBM 4391 • Simulated network of 800 clients• 2m$ computer• Staff of 6 to do benchmark
2 x 3725 network controllers
16 GB disk farm
4 x 8 x .5GB
Refrigerator-sized CPU

1987: Tandem Mini @ 256 tps • 14 M$ computer (Tandem)• A dozen people (1.8M$/y)• False floor, 2 rooms of machines
Simulate 25,600 clients
32 node processor array
40 GB disk array (80 drives)
OS expert
Network expert
DB expert
Performance expert
Hardware experts
Admin expert
AuditorManager

1997: 9 years later1 Person and 1 box = 1250 tps
• 1 Breadbox ~ 5x 1987 machine room• 23 GB is hand-held• One person does all the work• Cost/tps is 100,000x less
5 micro dollars per transaction
4x200 Mhz cpu1/2 GB DRAM12 x 4GB disk
Hardware expertOS expertNet expertDB expertApp expert
3 x7 x 4GB disk arrays
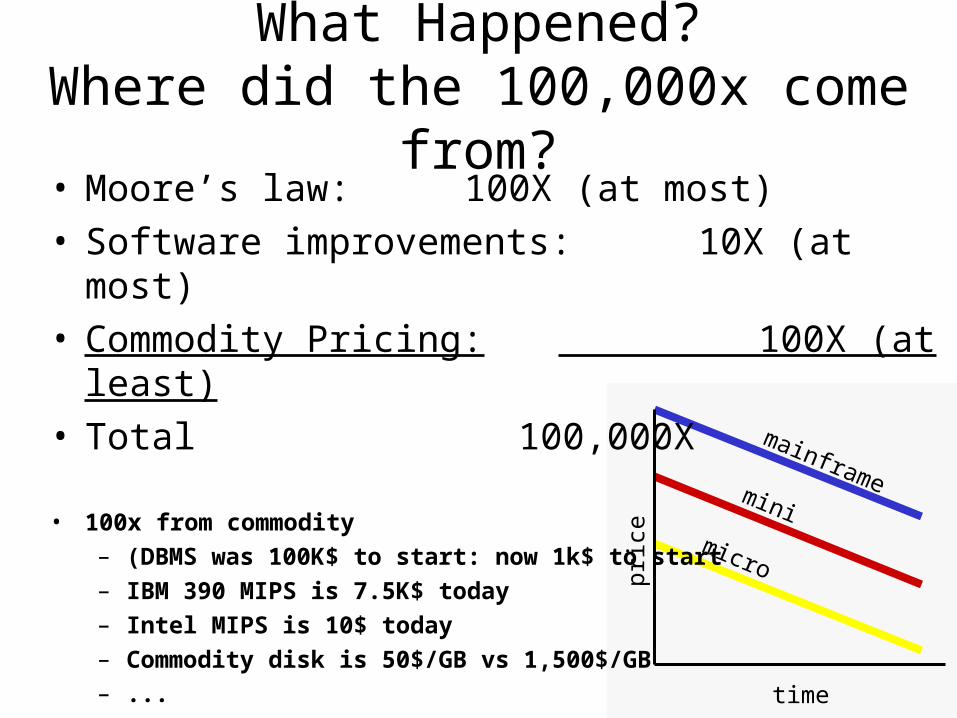
mainframemini
micro
time
pric
e
What Happened?Where did the 100,000x come from?• Moore’s law: 100X (at most)• Software improvements: 10X (at most)• Commodity Pricing: 100X (at least)• Total 100,000X
• 100x from commodity
– (DBMS was 100K$ to start: now 1k$ to start
– IBM 390 MIPS is 7.5K$ today
– Intel MIPS is 10$ today
– Commodity disk is 50$/GB vs 1,500$/GB
– ...

SGI O2K UE10K DELL 6350 Cray T3E IBM SP2 PoPC
per sqft
cpus 2.1 4.7 7.0 4.7 5.0 13.3
specint 29.0 60.5 132.7 79.3 72.3 253.3
ram 4.1 4.7 7.0 0.6 5.0 6.8 gb
disks 1.3 0.5 5.2 0.0 2.5 13.3
Standard package, full height, fully populated, 3.5” disks
HP, DELL, Compaq are trading places wrt rack mount lead
PoPC – Celeron NLX shoeboxes – 1000 nodes in 48 (24x2) sq ft. $650K from Arrow (3yr warrantee!) on chip at speed L2
Web & server farms, server consolidation / sqft
http://www.exodus.com (charges by mbps times sqft)
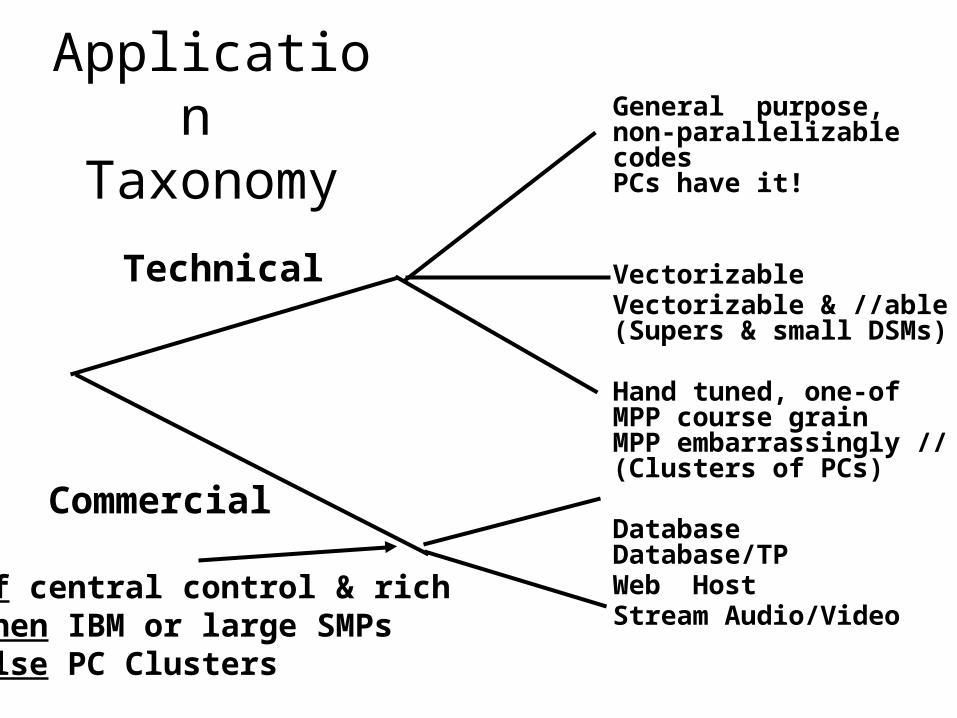
General purpose, non-parallelizable codesPCs have it!
VectorizableVectorizable & //able(Supers & small DSMs)
Hand tuned, one-ofMPP course grainMPP embarrassingly //(Clusters of PCs)
DatabaseDatabase/TPWeb HostStream Audio/Video
Technical
Commercial
Application Taxonomy
If central control & rich then IBM or large SMPselse PC Clusters
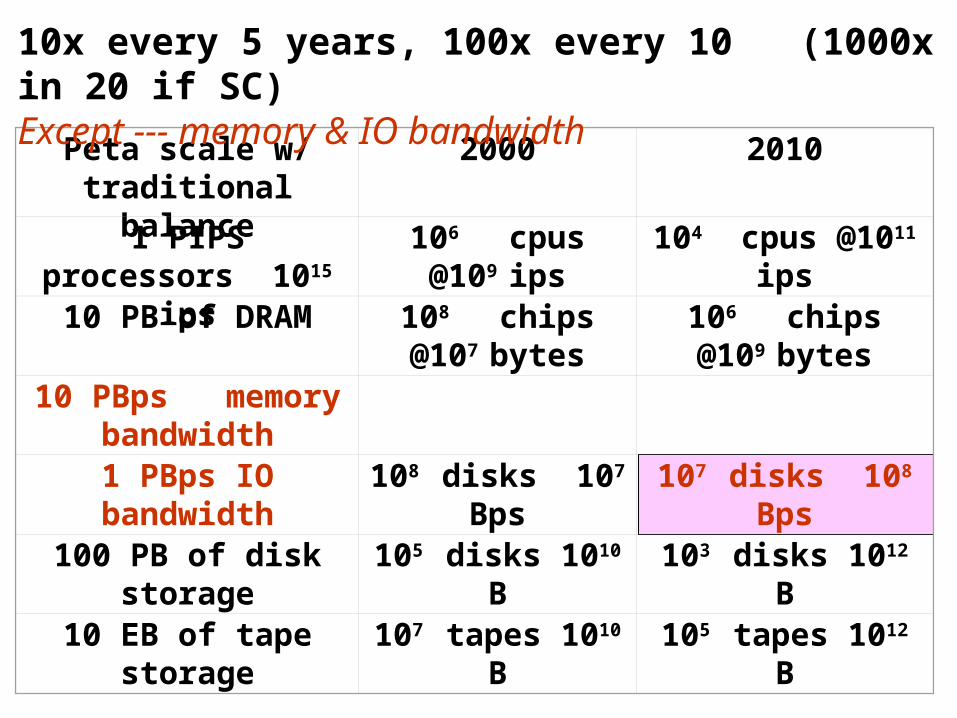
Peta scale w/ traditional balance
2000 2010
1 PIPS processors 1015 ips
106 cpus @109
ips104 cpus @1011
ips10 PB of DRAM 108 chips @107
bytes106 chips @109
bytes10 PBps memory
bandwidth
1 PBps IO bandwidth
108 disks 107
Bps107 disks 108 Bps
100 PB of disk storage
105 disks 1010 B 103 disks 1012 B
10 EB of tape storage
107 tapes 1010 B 105 tapes 1012 B
10x every 5 years, 100x every 10 (1000x in 20 if SC)Except --- memory & IO bandwidth

I think there is a world I think there is a world
market for maybe five market for maybe five
computers.computers.
““
”” Thomas Watson Senior, Chairman of IBM, 1943
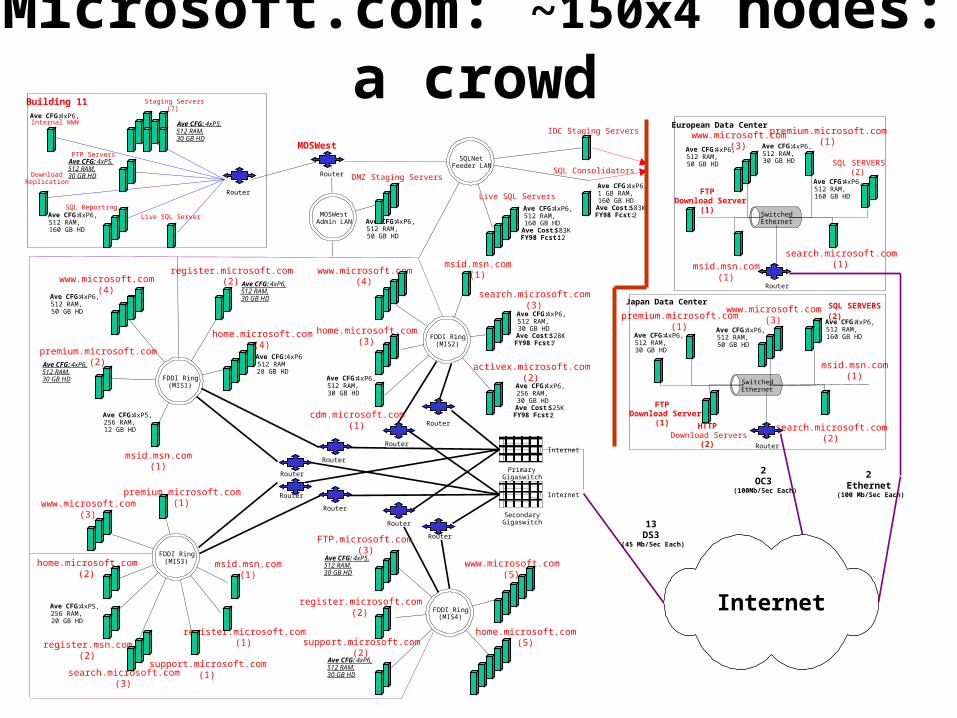
Microsoft.com: ~150x4 nodes: a crowd
(3)
SwitchedEthernet
SwitchedEthernet
www.microsoft.com(3)
search.microsoft.com(1)
premium.microsoft.com(1)
European Data Center
FTPDownload Server
(1)
SQL SERVERS(2)
Router
msid.msn.com(1)
MOSWestAdmin LAN
SQLNetFeeder LAN
FDDI Ring(MIS4)
Router
www.microsoft.com(5)
Building 11
Live SQL Server
Router
home.microsoft.com(5)
FDDI Ring(MIS2)
www.microsoft.com(4)
activex.microsoft.com(2)
search.microsoft.com(3)
register.microsoft.com(2)
msid.msn.com(1)
FDDI Ring(MIS3)
www.microsoft.com(3)
premium.microsoft.com(1)
msid.msn.com(1)
FDDI Ring(MIS1)
www.microsoft.com(4)
premium.microsoft.com(2)
register.microsoft.com(2)
msid.msn.com(1) Primary
Gigaswitch
SecondaryGigaswitch
Staging Servers(7)
search.microsoft.com
support.microsoft.com(2)
register.msn.com(2)
MOSWest
DMZ Staging Servers
premium.microsoft.com(1)
HTTPDownload Servers
(2) Router
search.microsoft.com(2)
SQL SERVERS(2)
msid.msn.com(1)
FTPDownload Server
(1)Router
Router
Router
Router
Router
Router
Router
Router
Internal WWW
SQL Reporting
home.microsoft.com(4)
home.microsoft.com(3)
home.microsoft.com(2)
register.microsoft.com(1)
support.microsoft.com(1)
Internet
13DS3
(45 Mb/Sec Each)
2OC3
(100Mb/Sec Each)
2Ethernet
(100 Mb/Sec Each)
cdm.microsoft.com(1)
FTP Servers
DownloadReplication
Ave CFG: 4xP6,512 RAM,160 GB HDAve Cost: $83KFY98 Fcst: 12
Ave CFG: 4xP5,256 RAM,12 GB HD
Ave CFG: 4xP6,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,50 GB HD
Ave CFG: 4xP6,512 RAM,30 GB HD
Ave CFG: 4xP6512 RAM28 GB HD
Ave CFG: 4xP6,256 RAM,30 GB HDAve Cost: $25KFY98 Fcst: 2
Ave CFG: 4xP6,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,50 GB HD
Ave CFG: 4xP5,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,160 GB HD
Ave CFG: 4xP6,
Ave CFG: 4xP5,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,30 GB HDAve Cost: $28KFY98 Fcst: 7
Ave CFG: 4xP5,256 RAM,20 GB HD
Ave CFG: 4xP6,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,50 GB HD
Ave CFG: 4xP6,512 RAM,160 GB HD
Ave CFG: 4xP6,512 RAM,160 GB HD
FTP.microsoft.com(3)
Ave CFG: 4xP5,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,30 GB HD
Ave CFG: 4xP6,512 RAM,30 GB HD
Ave CFG: 4xP6,1 GB RAM,160 GB HDAve Cost: $83KFY98 Fcst: 2
IDC Staging Servers
Live SQL Servers
SQL Consolidators
Japan Data Center
Internet
Internet
www.microsoft.com(3)
Ave CFG: 4xP6,512 RAM,50 GB HD

HotMail (a year ago): ~400 Computers Crowd (now 2x bigger)
LocalDirector
Front Door(P-200, 128MB)140 +10/mo
FreeBSD/Apache
200
MB
ps I
nter
net l
ink
Graphics15xP6
FreeBSD/Hotmail
Ad10xP6
FreeBSD/Apache
Incoming Mail25xP-200
FreeBSD/hm-SMTP
LocalDirector
LocalDirector
LocalDirector
Security2xP200-FreeBSD
Member Dir
U StoreE3k,xxMB, 384GB RAID5 +
DLT tape robotSolaris/HMNNFS
50 machines, many old13 + 1.5/mo 1 per million users
Ad Pacer3 P6
FreeBSD
Cisco Catalyst 5000Enet Switch
Loc
al 1
0 M
bps
Sw
itch
ed E
ther
net
M Serv(SPAC Ultra-1, ??MB)
4- replicasSolaris
TelnetMaintenance
Interface

DB Clusters (crowds)
• 16-node Cluster– 64 cpus
– 2 TB of disk
– Decision support
• 45-node Cluster– 140 cpus
– 14 GB DRAM
– 4 TB RAID disk
– OLTP (Debit Credit)• 1 B tpd (14 k tps)

The Microsoft TerraServer Hardware
• Compaq AlphaServer 8400Compaq AlphaServer 8400• 8x400Mhz Alpha cpus8x400Mhz Alpha cpus• 10 GB DRAM10 GB DRAM• 324 9.2 GB StorageWorks Disks324 9.2 GB StorageWorks Disks
– 3 TB raw, 2.4 TB of RAID53 TB raw, 2.4 TB of RAID5
• STK 9710 tape robot (4 TB)STK 9710 tape robot (4 TB)• WindowsNT 4 EE, SQL Server 7.0WindowsNT 4 EE, SQL Server 7.0
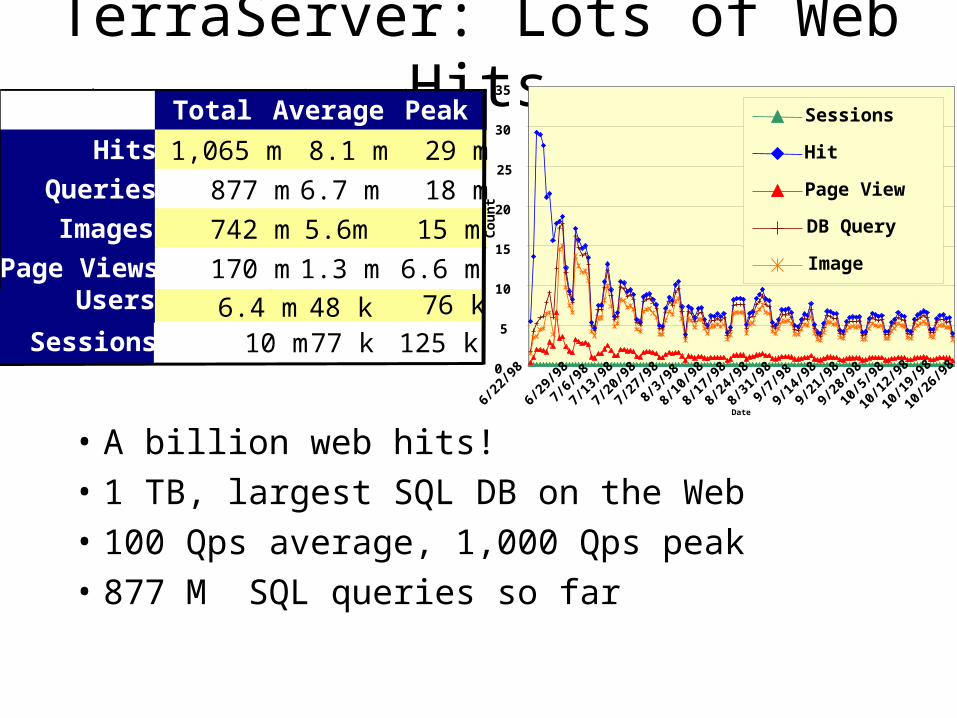
TerraServer: Lots of Web Hits
• A billion web hits!
• 1 TB, largest SQL DB on the Web
• 100 Qps average, 1,000 Qps peak
• 877 M SQL queries so far
Sessions 10 m 77 k 125 k
71 Total Average Peak
Hits 1,065 m 8.1 m 29 m
Queries 877 m 6.7 m 18 m
Images 742 m 5.6m 15 m
Page Views 170 m 1.3 m 6.6 mUsers 6.4 m 48 k 76 k
0
5
10
15
20
25
30
35
6/22
/98
6/29
/98
7/6/
98
7/13
/98
7/20
/98
7/27
/98
8/3/
98
8/10
/98
8/17
/98
8/24
/98
8/31
/98
9/7/
98
9/14
/98
9/21
/98
9/28
/98
10/5
/98
10/1
2/98
10/1
9/98
10/2
6/98
Date
Co
un
t
Sessions
Hit
Page View
DB Query
Image

TerraServer Availability• Operating for 13 months
• Unscheduled outage: 2.9 hrs • Scheduled outage: 2.0 hrs
Software upgrades• Availability:
99.93% overall up
• No NT failures (ever)• One SQL7 Beta2 bug• One major operator-assisted
outage
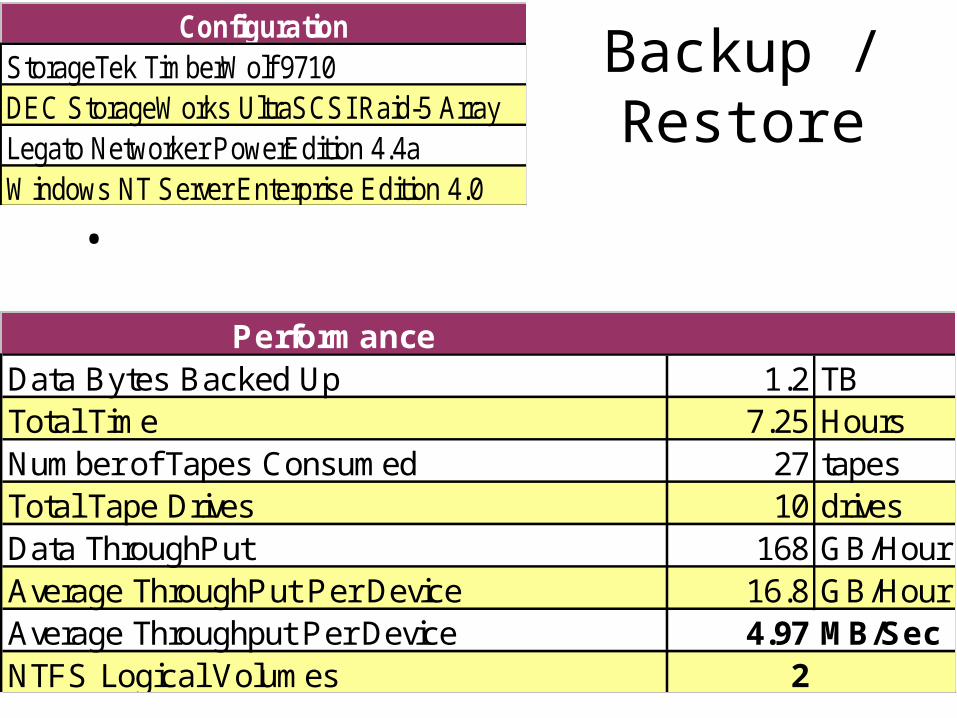
Backup / Restore
•
ConfigurationStorageTek TimberWolf 9710DEC StorageWorks UltraSCSI Raid-5 ArrayLegato Networker PowerEdition 4.4aWindows NT Server Enterprise Edition 4.0
PerformanceData Bytes Backed Up 1.2 TBTotal Time 7.25 HoursNumber of Tapes Consumed 27 tapesTotal Tape Drives 10 drivesData ThroughPut 168 GB/HourAverage ThroughPut Per Device 16.8 GB/HourAverage Throughput Per Device 4.97 MB/SecNTFS Logical Volumes 2
tpmC vs Time
010,00020,00030,00040,00050,00060,00070,00080,00090,000
Jan-95
Jan-96
Jan-97
Jan-98
Jan-99
Jan-00
tpm
C h
Unix
NT
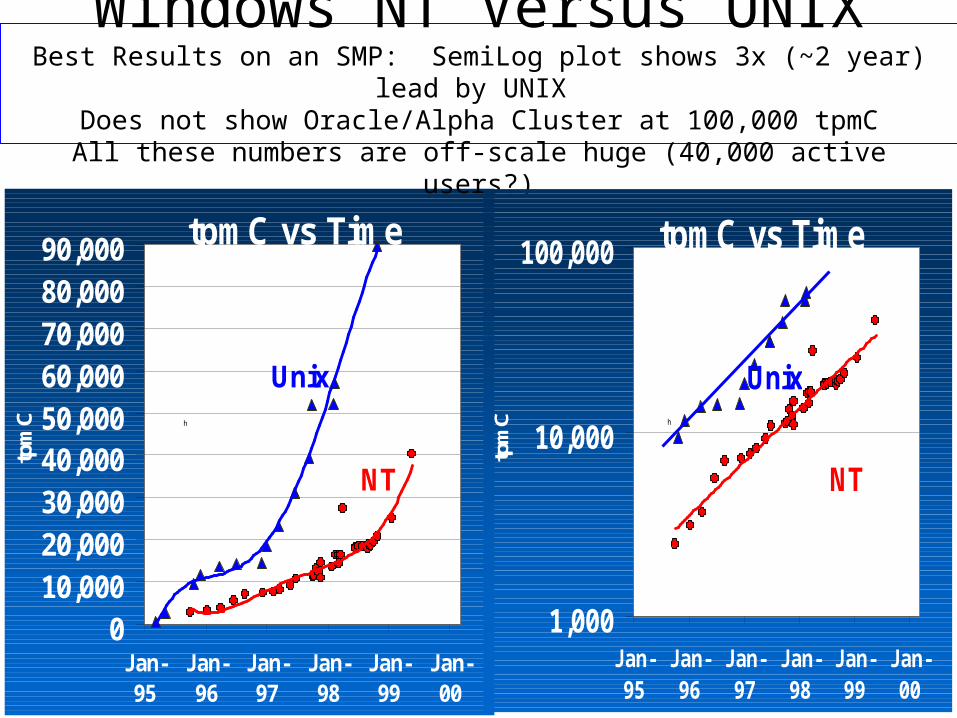
Windows NT Versus UNIXBest Results on an SMP: SemiLog plot shows 3x (~2 year) lead by UNIX
Does not show Oracle/Alpha Cluster at 100,000 tpmCAll these numbers are off-scale huge (40,000 active users?)
tpmC vs Time
1,000
10,000
100,000
Jan-95
Jan-96
Jan-97
Jan-98
Jan-99
Jan-00
tpm
C h
Unix
NT
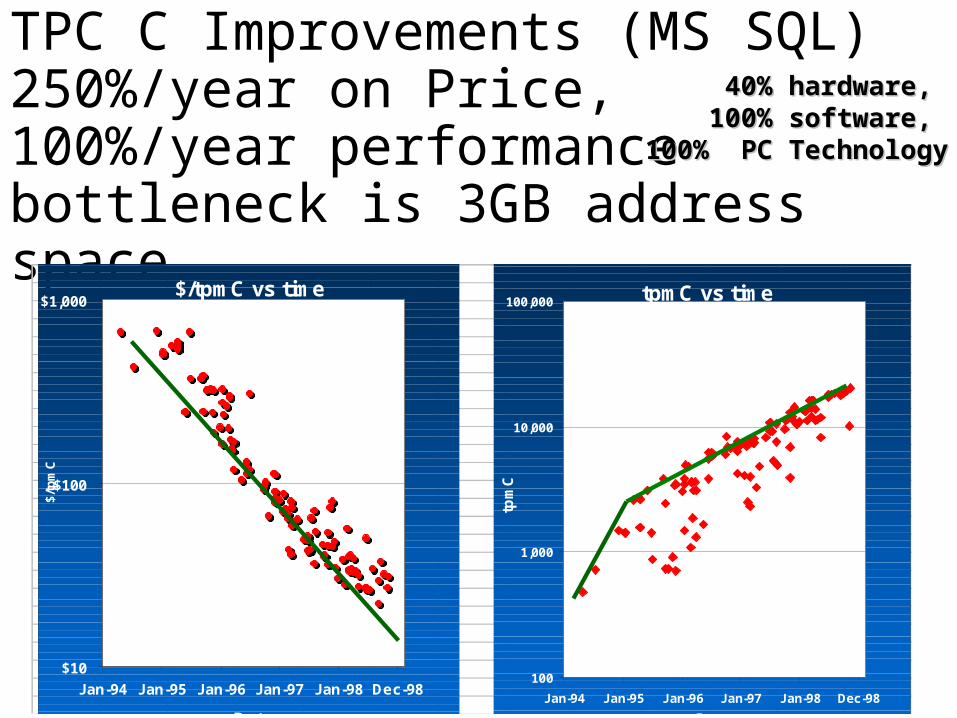
TPC C Improvements (MS SQL) 250%/year on Price, 100%/year performancebottleneck is 3GB address space
1.52.755676
$/tpmC vs time
$10
$100
$1,000
Jan-94 Jan-95 Jan-96 Jan-97 Jan-98 Dec-98
Date
$/t
pm
C
tpmC vs time
100
1,000
10,000
100,000
Jan-94 Jan-95 Jan-96 Jan-97 Jan-98 Dec-98
Date
tpm
C
40% hardware, 40% hardware, 100% software, 100% software,
100% PC Technology100% PC Technology
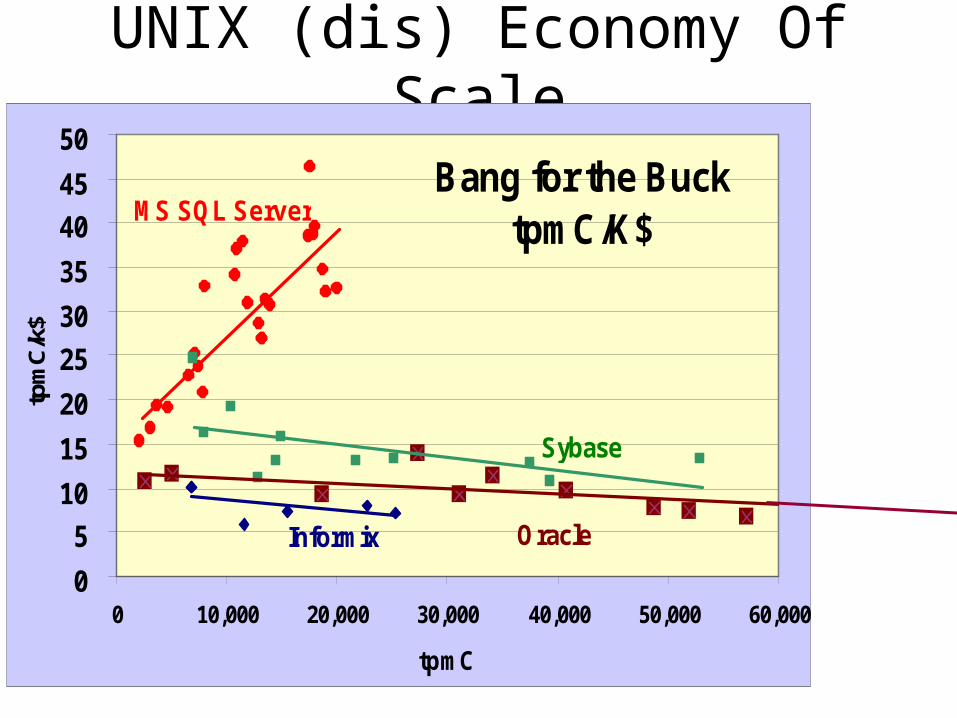
UNIX (dis) Economy Of Scale
Bang for the Buck tpmC/K$
0
5
10
15
20
25
30
35
40
45
50
0 10,000 20,000 30,000 40,000 50,000 60,000
tpmC
tpm
C/k
$
Informix
MS SQL Server
Oracle
Sybase
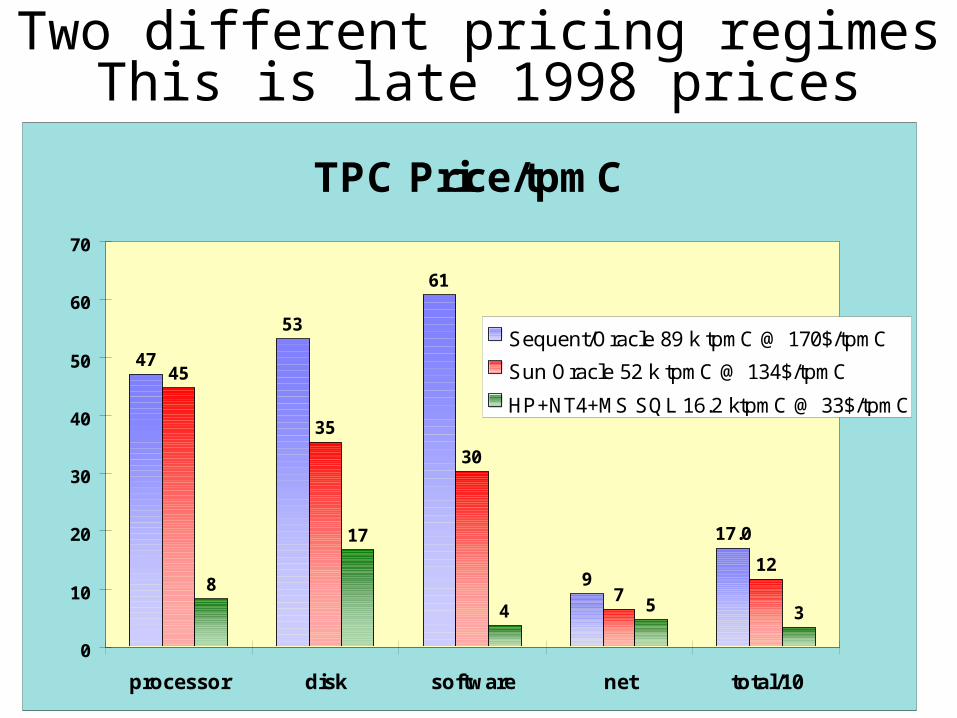
Two different pricing regimesThis is late 1998 prices
TPC Price/tpmC
47
53
61
9
17.0
45
35
30
7
128
17
4 5 3
0
10
20
30
40
50
60
70
processor disk software net total/10
Sequent/Oracle 89 k tpmC @ 170$/tpmC
Sun Oracle 52 k tpmC @ 134$/tpmC
HP+NT4+MS SQL 16.2 ktpmC @ 33$/tpmC
RegistersOn Chip CacheOn Board Cache
Memory
Disk
12
10
100
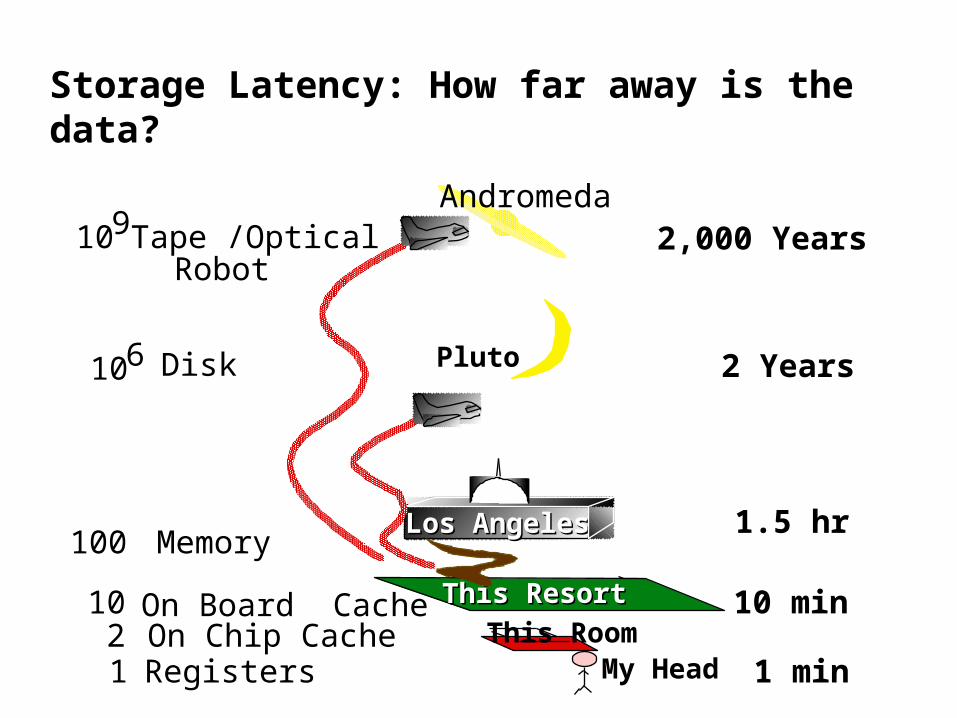
Tape /Optical Robot
109
106
This ResortThis Resort
This Room10 min
My Head 1 min
1.5 hrLos AngelesLos Angeles
2 YearsPluto
2,000 Years Andromeda
Storage Latency: How far away is the data?
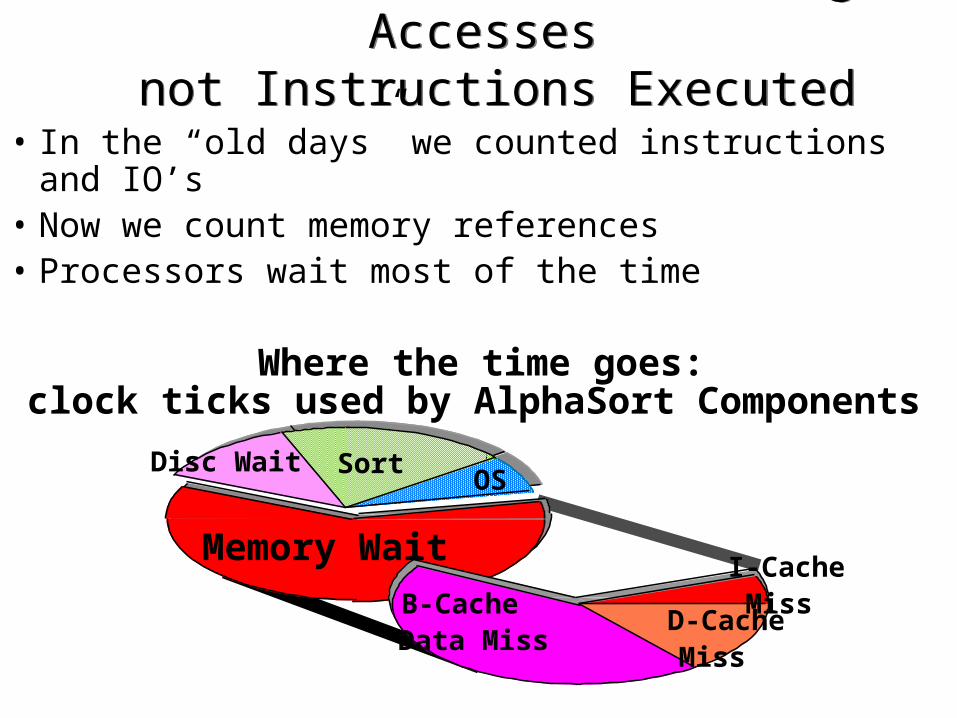
Thesis: Performance =Storage Accesses not Instructions Executed
Thesis: Performance =Storage Accesses not Instructions Executed
• In the “old days” we counted instructions and IO’s• Now we count memory references• Processors wait most of the time
SortDisc Wait
Where the time goes: clock ticks used by AlphaSort Components
SortDisc WaitOS
Memory Wait
D-Cache Miss
I-Cache MissB-Cache
Data Miss
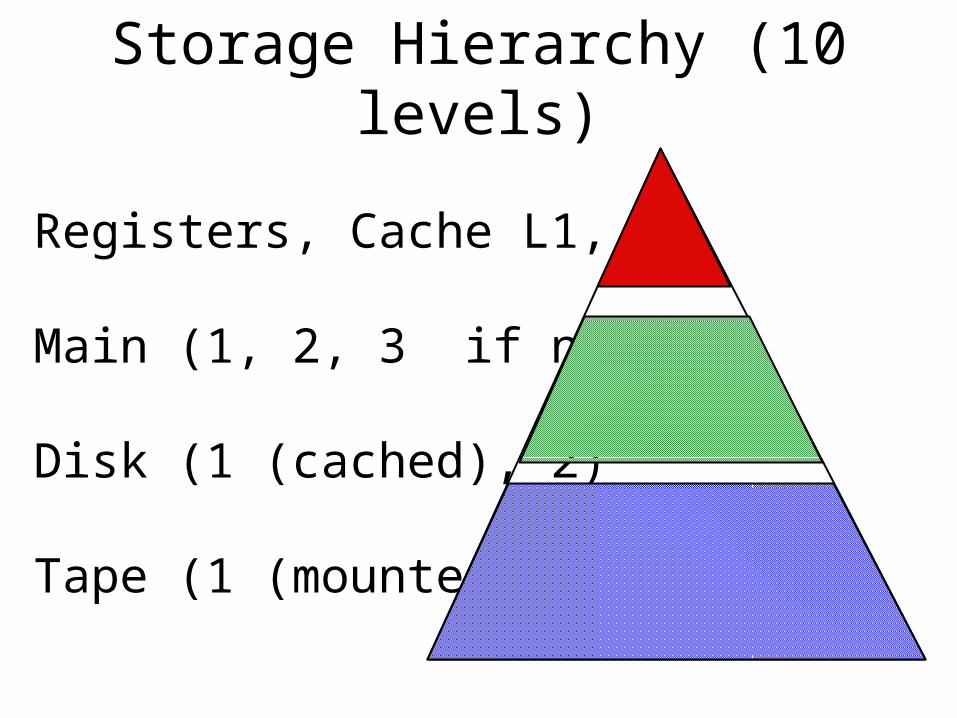
Storage Hierarchy (10 levels)
Registers, Cache L1, L2
Main (1, 2, 3 if nUMA).
Disk (1 (cached), 2)
Tape (1 (mounted), 2)

Today’s Storage Hierarchy : Speed & Capacity vs Cost Tradeoffs
Today’s Storage Hierarchy : Speed & Capacity vs Cost Tradeoffs
1015
1012
109
106
103
Typ
ical
Sys
tem
(by
tes)
Size vs Speed
Access Time (seconds)10-9 10-6 10-3 10 0 10 3
Cache
Main
Secondary
Disc
Nearline Tape Offline
Tape
Online Tape
104
102
100
10-2
10-4
$/M
B
Price vs Speed
Access Time (seconds)10-9 10-6 10-3 10 0 10 3
Cache
MainSecondary
DiscNearline
TapeOffline Tape
Online Tape

Meta-Message: Technology Ratios Are Important
Meta-Message: Technology Ratios Are Important
• If everything gets faster & cheaper at the same rate THEN nothing really changes.
• Things getting MUCH BETTER:– communication speed & cost 1,000x– processor speed & cost 100x– storage size & cost 100x
• Things staying about the same– speed of light (more or less constant)– people (10x more expensive)– storage speed (only 10x better)
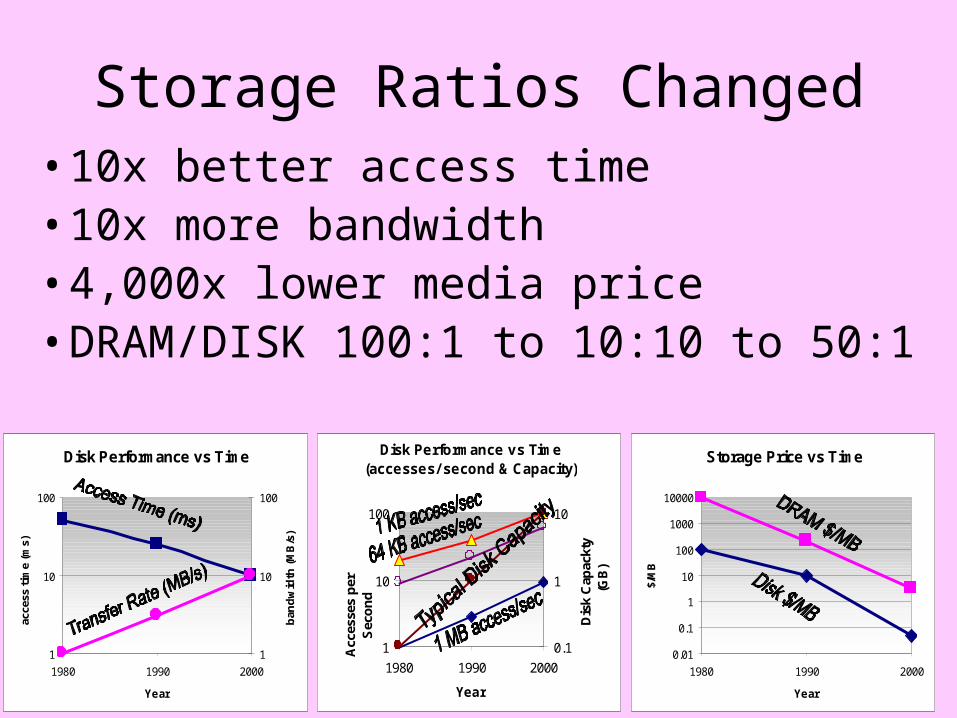
Storage Ratios Changed• 10x better access time• 10x more bandwidth• 4,000x lower media price• DRAM/DISK 100:1 to 10:10 to 50:1
Disk Performance vs Time
1
10
100
1980 1990 2000
Year
acce
ss t
ime
(ms)
1
10
100
ban
dw
idth
(M
B/s
)
Disk Performance vs Time(accesses/ second & Capacity)
1
10
100
1980 1990 2000
Year
Acc
esse
s p
er
Sec
on
d
0.1
1
10
Dis
k C
apac
kty
(GB
)
Storage Price vs Time
0.01
0.1
1
10
100
1000
10000
1980 1990 2000
Year
$/M
B

The Pico ProcessorThe Pico Processor
1 M SPECmarks
106 clocks/ fault to bulk ram
Event-horizon on chip.
VM reincarnated
Multi-program cache
Terror Bytes!
10 microsecond ram
10 millisecond disc
10 second tape archive 100 petabyte
100 terabyte
1 terabyte
Pico Processor
10 pico-second ram1 MM
3
megabyte
10 nano-second ram 10 gigabyte
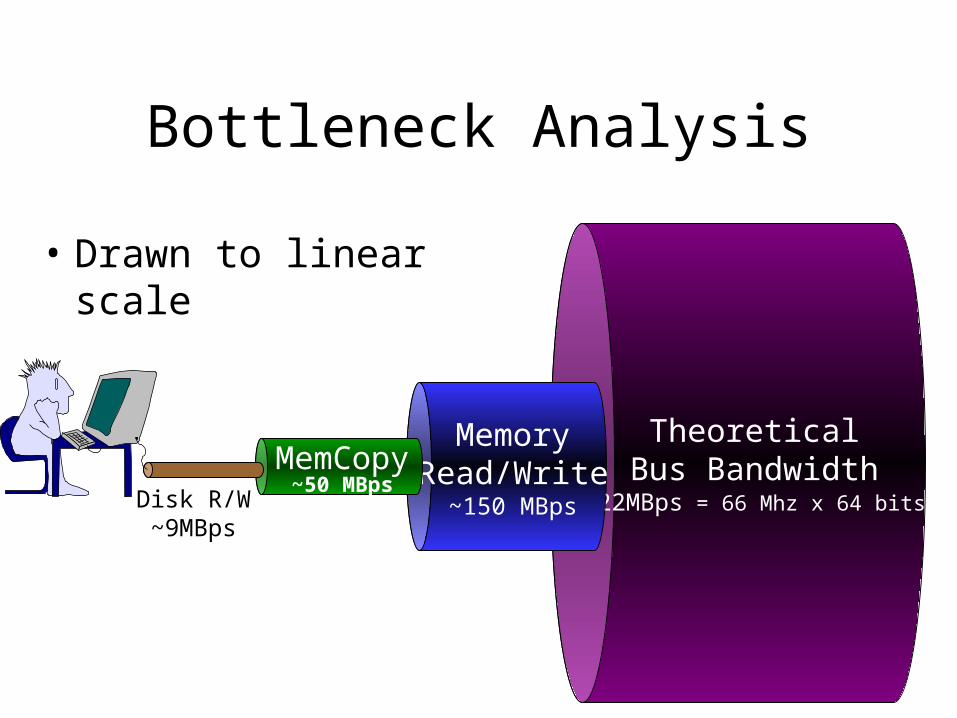
Bottleneck Analysis
• Drawn to linear scale
TheoreticalBus Bandwidth
422MBps = 66 Mhz x 64 bits
MemoryRead/Write
~150 MBps
MemCopy~50 MBps
Disk R/W~9MBps

Bottleneck Analysis• NTFS Read/Write • 18 Ultra 3 SCSI on 4 strings (2x4 and 2x5)
3 PCI 64 ~ 155 MBps Unbuffered read (175 raw)~ 95 MBps Unbuffered write
Good, but 10x down from our UNIX brethren (SGI, SUN)
Memory Read/Write ~250 MBps
PCI~110 MBps
Adapter~70 MBps
PCI
Adapter
Adapter
Adapter
155
MB
ps

PennySort• Hardware
– 266 Mhz Intel PPro– 64 MB SDRAM (10ns)– Dual Fujitsu DMA 3.2GB EIDE disks
• Software– NT workstation 4.3– NT 5 sort
• Performance– sort 15 M 100-byte records (~1.5 GB)
– Disk to disk– elapsed time 820 sec
• cpu time = 404 sec
PennySort Machine (1107$ )
board13%
Memory8%
Cabinet + Assembly
7%
Network, Video, floppy
9%
Software6%
Other22%
cpu 32%
Disk25%
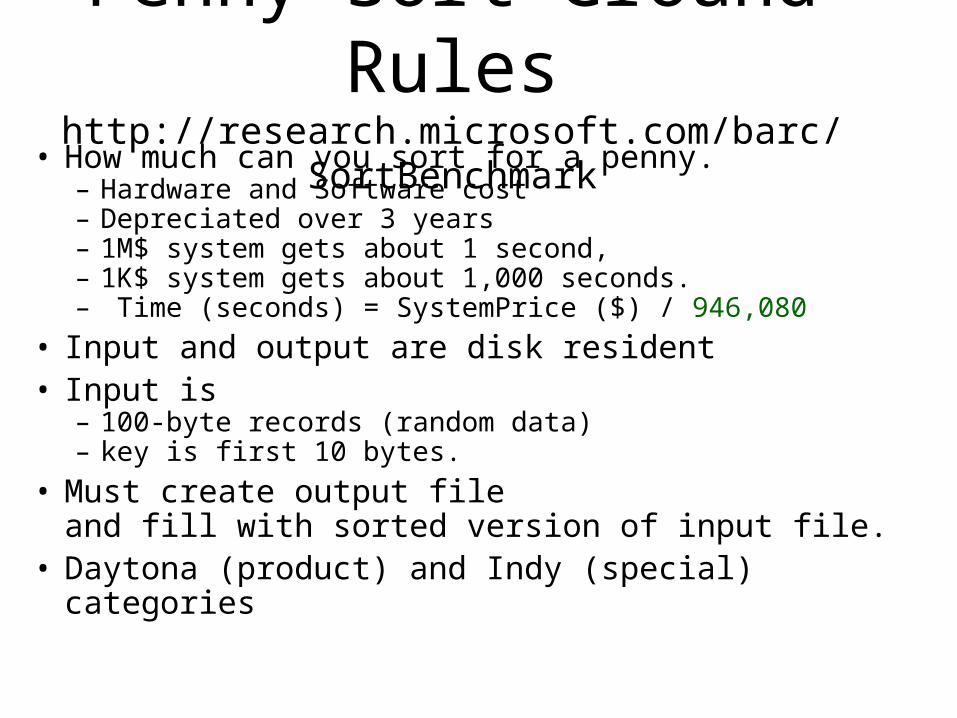
Penny Sort Ground Ruleshttp://research.microsoft.com/barc/SortBenchmark
• How much can you sort for a penny.– Hardware and Software cost– Depreciated over 3 years– 1M$ system gets about 1 second,– 1K$ system gets about 1,000 seconds.– Time (seconds) = SystemPrice ($) / 946,080
• Input and output are disk resident• Input is
– 100-byte records (random data)– key is first 10 bytes.
• Must create output file and fill with sorted version of input file.
• Daytona (product) and Indy (special) categories
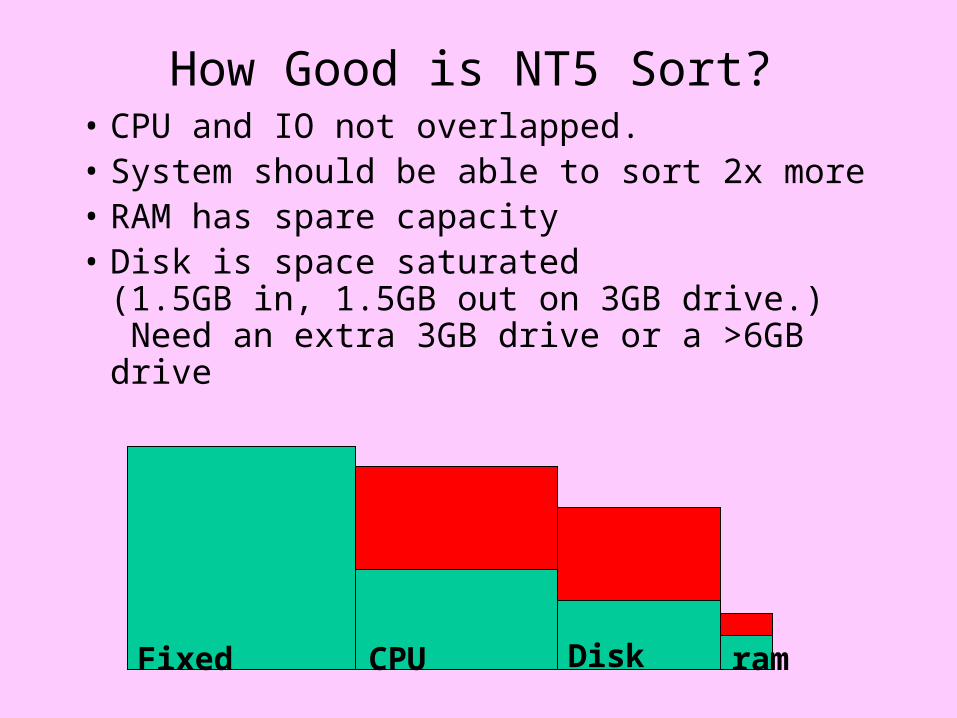
How Good is NT5 Sort?• CPU and IO not overlapped.• System should be able to sort 2x more• RAM has spare capacity• Disk is space saturated
(1.5GB in, 1.5GB out on 3GB drive.) Need an extra 3GB drive or a >6GB drive
CPU DiskFixed ram
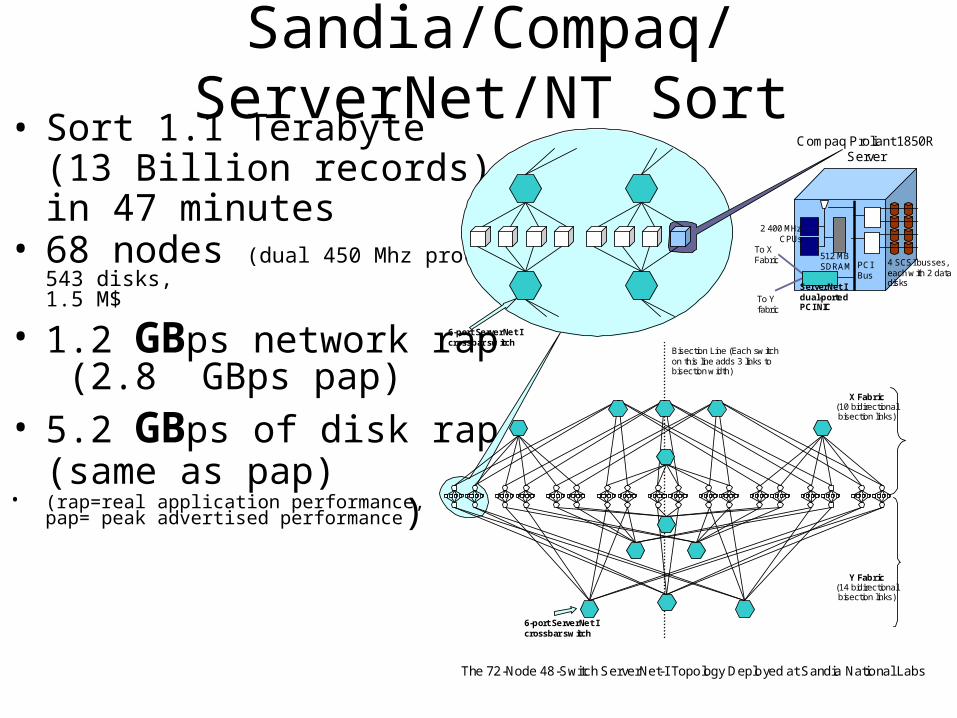
Sandia/Compaq/ServerNet/NT Sort• Sort 1.1 Terabyte
(13 Billion records) in 47 minutes
• 68 nodes (dual 450 Mhz processors)543 disks, 1.5 M$
• 1.2 GBps network rap (2.8 GBps pap)
• 5.2 GBps of disk rap (same as pap)
• (rap=real application performance,pap= peak advertised performance)
Bisection Line (Each switch on this line adds 3 links to bisection width)
Y Fabric (14 bidirectional bisection links)
X Fabric (10 bidirectional bisection links)
To Y fabric
To X Fabric 512 MB
SDRAM
2 400 MHz CPUs
6-port ServerNet I crossbar switch
6-port ServerNet I crossbar switch
Compaq Proliant 1850R Server
4 SCSI busses, each with 2 data disks
The 72-Node 48-Switch ServerNet-I Topology Deployed at Sandia National Labs
PCI Bus
ServerNet I dual-ported PCI NIC
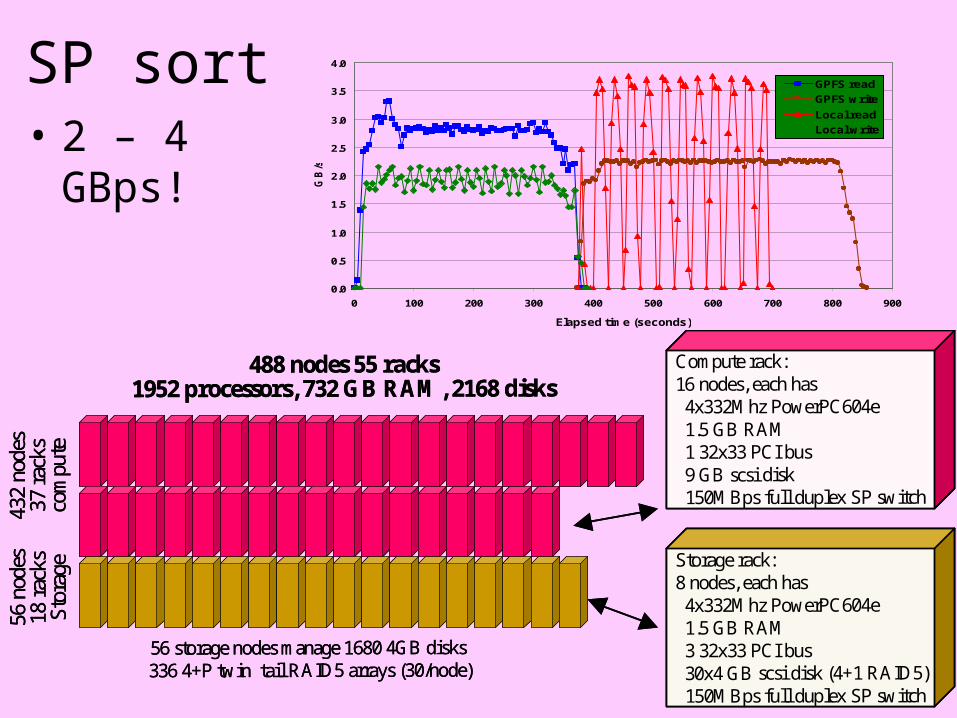
SP sort• 2 – 4 GBps!
432
node
s37
rac
ksco
mpu
te
488 nodes 55 racks1952 processors, 732 GB RAM, 2168 disks
56 n
odes
18 r
acks
Stor
age
Compute rack:16 nodes, each has4x332Mhz PowerPC604e1.5 GB RAM1 32x33 PCI bus9 GB scsi disk150MBps full duplex SP switch
Storage rack:8 nodes, each has4x332Mhz PowerPC604e1.5 GB RAM3 32x33 PCI bus30x4 GB scsi disk (4+1 RAID5)150MBps full duplex SP switch
56 storage nodes manage 1680 4GB disks 336 4+P twin tail RAID5 arrays (30/node)
432
node
s37
rac
ksco
mpu
te
488 nodes 55 racks1952 processors, 732 GB RAM, 2168 disks
56 n
odes
18 r
acks
Stor
age
Compute rack:16 nodes, each has4x332Mhz PowerPC604e1.5 GB RAM1 32x33 PCI bus9 GB scsi disk150MBps full duplex SP switch
Storage rack:8 nodes, each has4x332Mhz PowerPC604e1.5 GB RAM3 32x33 PCI bus30x4 GB scsi disk (4+1 RAID5)150MBps full duplex SP switch
56 storage nodes manage 1680 4GB disks 336 4+P twin tail RAID5 arrays (30/node)
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
0 100 200 300 400 500 600 700 800 900
Elapsed time (seconds)G
B/s
GPFS read
GPFS write
Local read
Local write
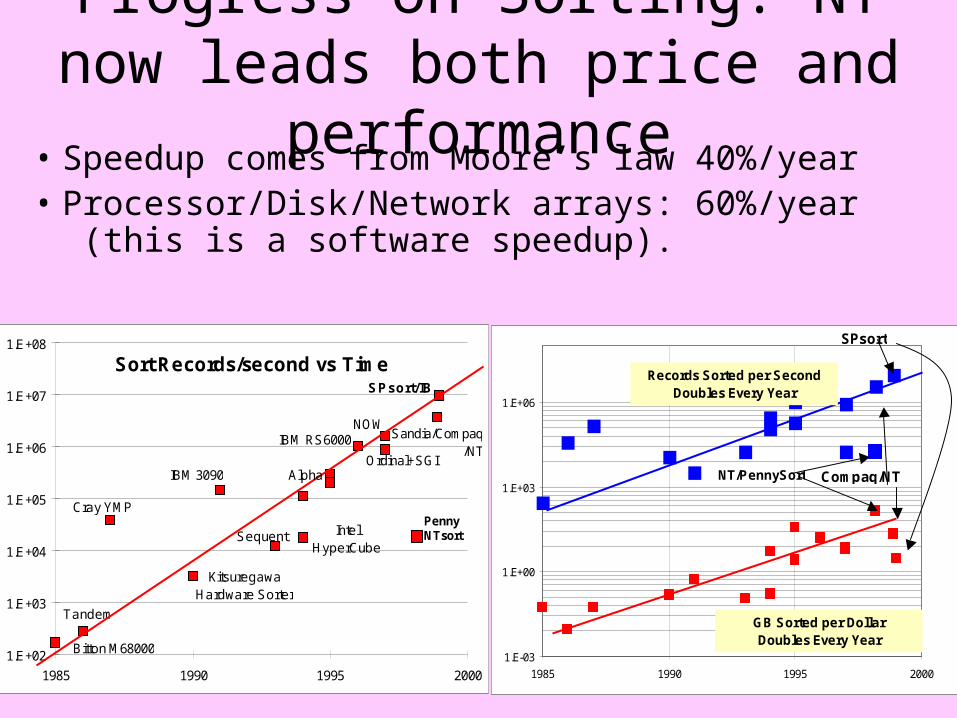
Progress on Sorting: NT now leads both price and performance
• Speedup comes from Moore’s law 40%/year• Processor/Disk/Network arrays: 60%/year
(this is a software speedup).
1.E+02
1.E+03
1.E+04
1.E+05
1.E+06
1.E+07
1.E+08
1985 1990 1995 2000
Ordinal+SGI
Sort Records/second vs Time
Bitton M68000
Cray YMP
IBM 3090
Tandem
Kitsuregawa Hardware Sorter
Sequent Intel HyperCube
IBM RS6000NOW
Alpha
PennyNTsort
Sandia/Compaq/NT
SPsort/IB
1.E-03
1.E+00
1.E+03
1.E+06
1985 1990 1995 2000
Records Sorted per SecondDoubles Every Year
GB Sorted per DollarDoubles Every Year
Compaq/NT NT/PennySort
SPsort

Recent Results• NOW Sort: 9 GB on a cluster of 100 UltraSparcs in 1 minute• MilleniumSort: 16x Dell NT cluster: 100 MB in 1.18 Sec
(Datamation)• Tandem/Sandia Sort: 68 CPU ServerNet
1 TB in 47 minutes
• IBM SPsort 408 nodes, 1952 cpu
2168 disks17.6 minutes = 1057sec(all for 1/3 of 94M$,
slice price is 64k$ for 4cpu, 2GB ram, 6 9GB disks + interconnect

Data Gravity Processing Moves to Transducers
• Move Processing to data sources
• Move to where the power (and sheet metal) is
• Processor in– Modem– Display– Microphones (speech recognition)
& cameras (vision)– Storage: Data storage and analysis
• System is “distributed” (a cluster/mob)

Gbps SAN: 110 MBps
SAN: Standard Interconnect
PCI: 70 MBps
UW Scsi: 40 MBps
FW scsi: 20 MBps
scsi: 5 MBps
• LAN faster than memory bus?
• 1 GBps links in lab.
• 100$ port cost soon
• Port is computer
• Winsock: 110 MBps(10% cpu utilization at each end)
RIPFDDI
RIPATM
RIPSCI
RIPSCSI
RIPFC
RIP?

Disk = Node• has magnetic storage (100 GB?)
• has processor & DRAM
• has SAN attachment
• has execution environment
OS KernelSAN driver Disk driver
File System RPC, ...Services DBMS
Applications

endend

Standard Storage MetricsStandard Storage Metrics• Capacity: – RAM: MB and $/MB: today at 10MB & 100$/MB– Disk:GB and $/GB: today at 10 GB and 200$/GB– Tape: TB and $/TB: today at .1TB and 25k$/TB
(nearline)• Access time (latency)
– RAM: 100 ns– Disk: 10 ms– Tape: 30 second pick, 30 second position
• Transfer rate– RAM: 1 GB/s– Disk: 5 MB/s - - - Arrays can go to 1GB/s– Tape: 5 MB/s - - - striping is problematic

New Storage Metrics:
Kaps, Maps, SCAN?
New Storage Metrics:
Kaps, Maps, SCAN?
• Kaps: How many KB objects served per second– The file server, transaction processing metric
– This is the OLD metric.
• Maps: How many MB objects served per sec– The Multi-Media metric
• SCAN: How long to scan all the data– The data mining and utility metric
• And
–Kaps/$, Maps/$, TBscan/$
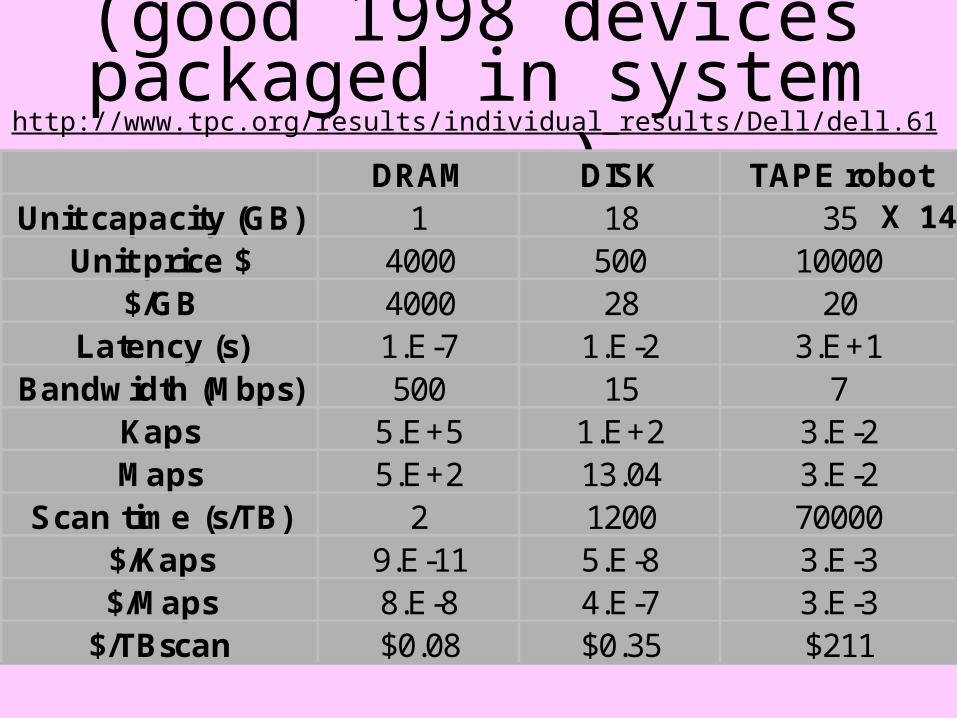
For the Record (good 1998 devices packaged in
systemhttp://www.tpc.org/results/individual_results/Dell/dell.6100.9801.es.pdf)DRAM DISK TAPE robot
Unit capacity (GB) 1 18 35Unit price $ 4000 500 10000
$/GB 4000 28 20Latency (s) 1.E-7 1.E-2 3.E+1
Bandwidth (Mbps) 500 15 7Kaps 5.E+5 1.E+2 3.E-2Maps 5.E+2 13.04 3.E-2
Scan time (s/TB) 2 1200 70000$/Kaps 9.E-11 5.E-8 3.E-3$/Maps 8.E-8 4.E-7 3.E-3
$/TBscan $0.08 $0.35 $211
X 14

For the Record (good 1998 devices packaged in
systemhttp://www.tpc.org/results/individual_results/Dell/dell.6100.9801.es.pdf)4.E+03
500
5.E+05
500
2
9.E-11
8.E-08
0.08
28 15 9913
1200
5.E-084.E-07
0.3520 7
0.03 0.03
7.E+04
3.E-03 3.E-03
211
1.E-12
1.E-09
1.E-06
1.E-03
1.E+00
1.E+03
1.E+06
$/GB
Bandw
idth (
Mbp
s)
Kaps
Map
s
Scan tim
e (s/
TB)
$/Kap
s
$/M
aps
$/TBsc
an
DRAM
DISK
TAPE robot X 14
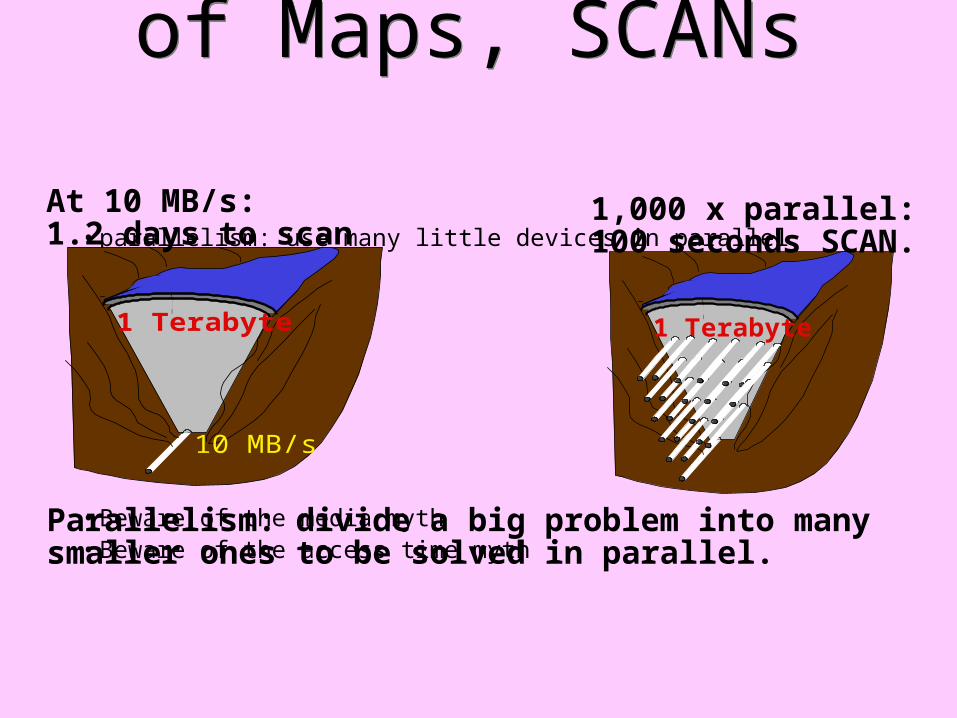
How To Get Lots of Maps, SCANs
How To Get Lots of Maps, SCANs
• parallelism: use many little devices in parallel
• Beware of the media myth• Beware of the access time myth
1 Terabyte
10 MB/s
At 10 MB/s: 1.2 days to scan
1 Terabyte
1,000 x parallel: 100 seconds SCAN.
Parallelism: divide a big problem into many smaller ones to be solved in parallel.

The Disk Farm On a Card
The Disk Farm On a Card
The 1 TB disc cardAn array of discsCan be used as 100 discs 1 striped disc 10 Fault Tolerant discs ....etcLOTS of accesses/second bandwidth
14"
Life is cheap, its the accessories that cost ya.
Processors are cheap, it’s the peripherals that cost ya (a 10k$ disc card).
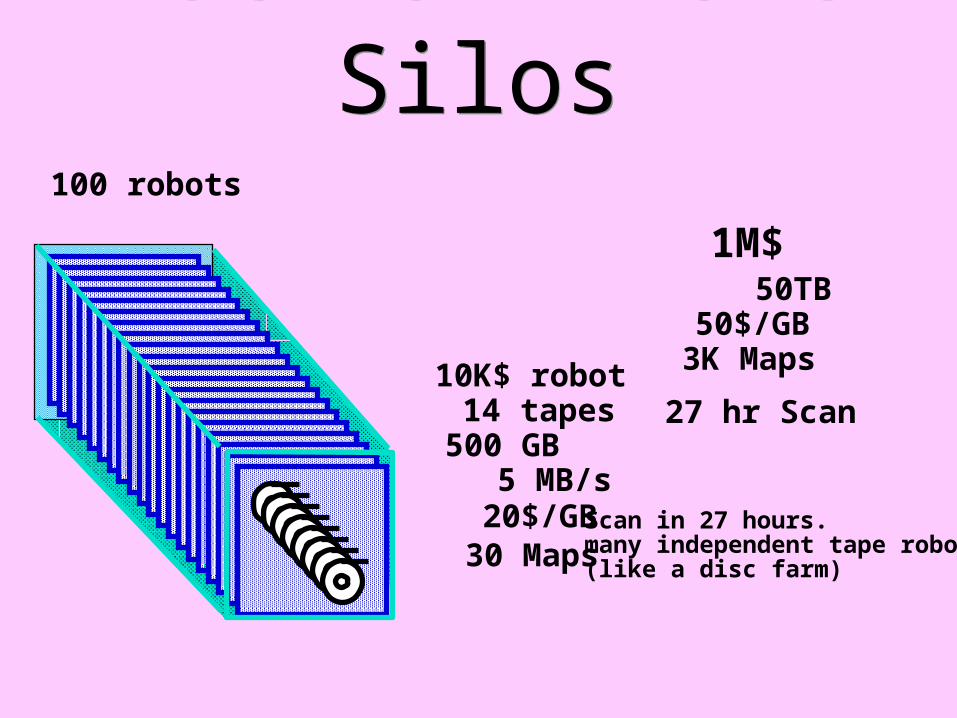
Tape Farms for Tertiary Storage
Not Mainframe Silos
Tape Farms for Tertiary Storage
Not Mainframe Silos
Scan in 27 hours.many independent tape robots(like a disc farm)
10K$ robot 14 tapes500 GB 5 MB/s 20$/GB 30 Maps
100 robots
50TB 50$/GB 3K Maps
27 hr Scan
1M$

Tape & Optical: Beware of the Media
Myth
Tape & Optical: Beware of the Media
Myth
Optical is cheap: 200 $/platter 2 GB/platter => 100$/GB (2x cheaper than disc)
Tape is cheap: 30 $/tape 20 GB/tape => 1.5 $/GB (100x cheaper than disc).

Tape & Optical Reality: Media is 10% of System
Cost
Tape & Optical Reality: Media is 10% of System
CostTape needs a robot (10 k$ ... 3 m$ ) 10 ... 1000 tapes (at 20GB each) => 20$/GB ... 200$/GB
(1x…10x cheaper than disc)
Optical needs a robot (100 k$ ) 100 platters = 200GB ( TODAY ) => 400 $/GB
( more expensive than mag disc ) Robots have poor access times Not good for Library of Congress (25TB) Data motel: data checks in but it never checks out!

The Access Time MythThe Access Time MythThe Myth: seek or pick time dominatesThe reality: (1) Queuing dominates (2) Transfer dominates BLOBs (3) Disk seeks often shortImplication: many cheap servers
better than one fast expensive server– shorter queues– parallel transfer– lower cost/access and cost/byte
This is now obvious for disk arraysThis will be obvious for tape arrays Seek
Rotate
Transfer
Seek
Rotate
Transfer
Wait
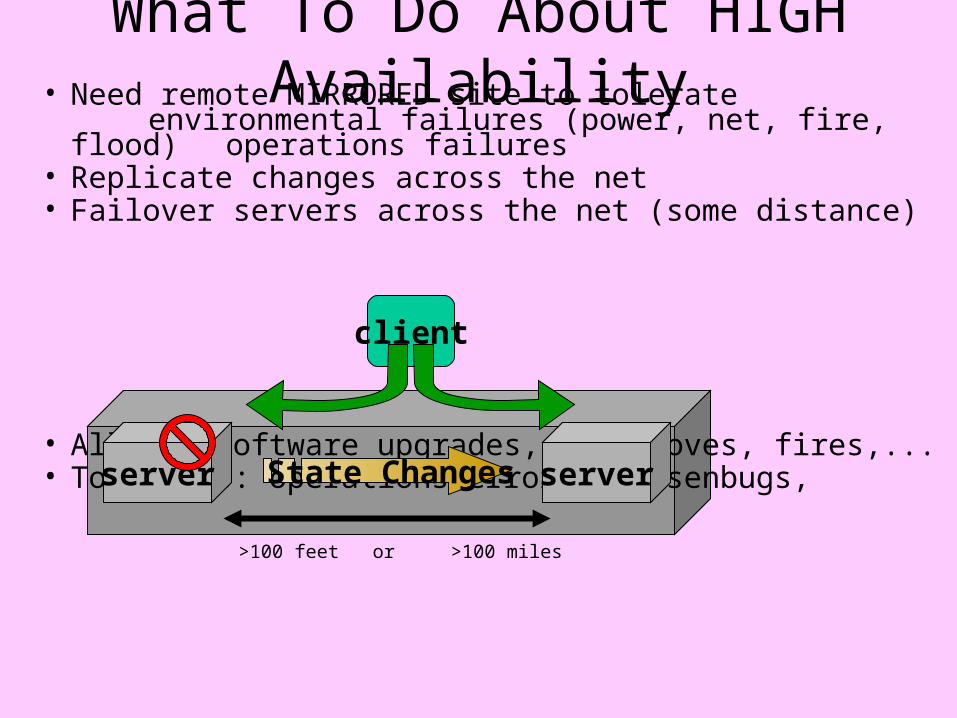
What To Do About HIGH Availability• Need remote MIRRORED site to tolerate
environmental failures (power, net, fire, flood) operations failures
• Replicate changes across the net• Failover servers across the net (some distance)
• Allows: software upgrades, site moves, fires,...• Tolerates: operations errors, hiesenbugs,
server
client
State Changes server
>100 feet or >100 miles

Mflop/s/$K vs Mflop/s
0.001
0.010
0.100
1.000
10.000
100.000
0.1 1 10 100 1000 10000 100000
Mflop/s
Mfl
op
/s/$
K
LANL Loki P6LinuxNAS ExpandedLinux ClusterCray T3E
IBM SP
SGI Origin 2000-195Sun UltraEnterprise 4000UCB NOW
Scaleup Has Limits(chart courtesy of Catharine Van Ingen)
• Vector Supers ~ 10x supers – ~3 Gflops/cpu
– bus/memory ~ 20 GBps
– IO ~ 1GBps
• Supers ~ 10x PCs – 300 Mflops/cpu
– bus/memory ~ 2 GBps
– IO ~ 1 GBps
• PCs are slow– ~ 30 Mflops/cpu
– and bus/memory ~ 200MBps
– and IO ~ 100 MBps
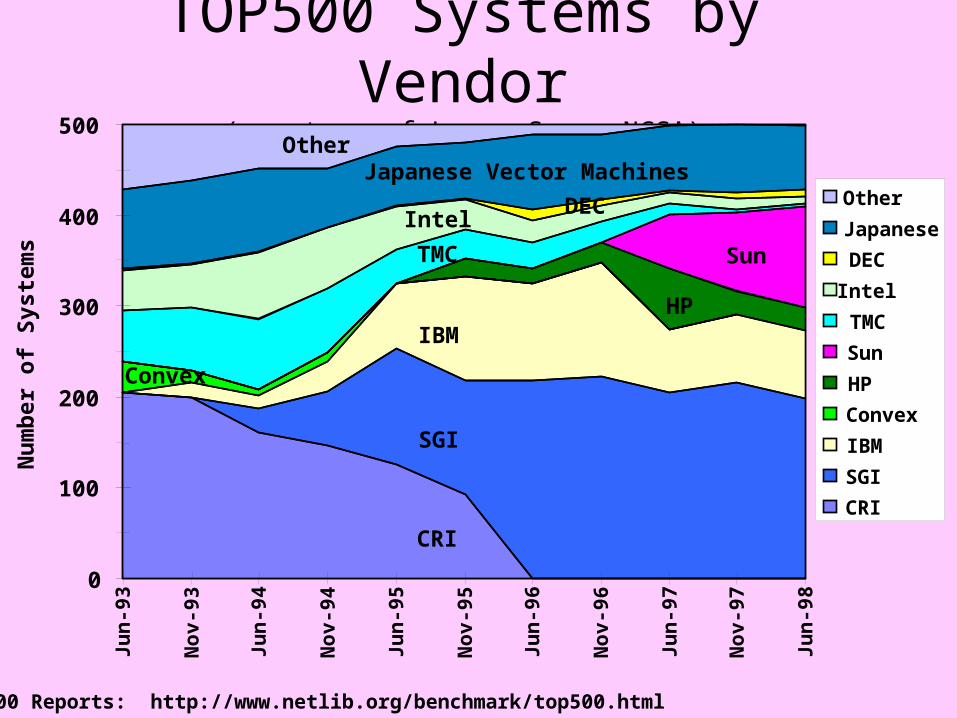
TOP500 Systems by Vendor(courtesy of Larry Smarr NCSA)
TOP500 Reports: http://www.netlib.org/benchmark/top500.html
CRI
SGI
IBM
Convex
HP
SunTMC
IntelDEC
Japanese Vector MachinesOther
0
100
200
300
400
500J
un
-93
No
v-9
3
Ju
n-9
4
No
v-9
4
Ju
n-9
5
No
v-9
5
Ju
n-9
6
No
v-9
6
Ju
n-9
7
No
v-9
7
Ju
n-9
8
Nu
mb
er o
f S
yste
ms
Other
Japanese
DEC
Intel
TMC
Sun
HP
Convex
IBM
SGI
CRI

NCSA Super ClusterNCSA Super Cluster
• National Center for Supercomputing ApplicationsUniversity of Illinois @ Urbana
• 512 Pentium II cpus, 2,096 disks, SAN• Compaq + HP +Myricom + WindowsNT• A Super Computer for 3M$• Classic Fortran/MPI programming• DCOM programming model
http://access.ncsa.uiuc.edu/CoverStories/SuperCluster/super.html

Avalon: Alpha Clusters for Science
http://cnls.lanl.gov/avalon/140 Alpha Processors(533 Mhz) x 256 MB + 3GB diskFast Ethernet switches= 45 Gbytes RAM 550 GB disk+ Linux…………………...
= 10 real Gflops for $313,000 => 34 real Mflops/k$
on 150 benchmark Mflops/k$
Beowulf project is Parenthttp://www.cacr.caltech.edu/beowulf/naegling.html 114 nodes, 2k$/node, Scientists want cheap mips.

• Intel/Sandia: 9000x1 node Ppro
• LLNL/IBM: 512x8 PowerPC (SP2)
• LANL/Cray: ?
• Maui Supercomputer Center– 512x1 SP2
Your Tax Dollars At WorkASCI for Stockpile Stewardship
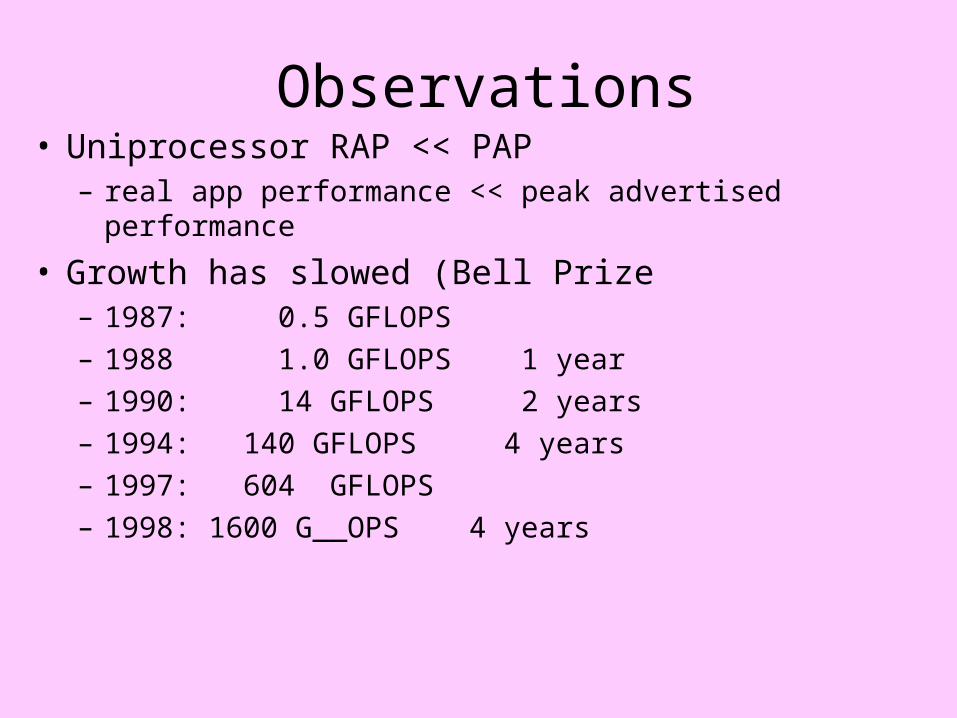
Observations• Uniprocessor RAP << PAP
– real app performance << peak advertised performance
• Growth has slowed (Bell Prize– 1987: 0.5 GFLOPS
– 1988 1.0 GFLOPS 1 year
– 1990: 14 GFLOPS 2 years
– 1994: 140 GFLOPS 4 years
– 1997: 604 GFLOPS
– 1998: 1600 G__OPS 4 years

Two Generic Kinds of computing• Many little
– embarrassingly parallel– Fit RPC model– Fit partitioned data and computation model– Random works OK– OLTP, File Server, Email, Web,…..
• Few big– sometimes not obviously parallel– Do not fit RPC model (BIG rpcs)– Scientific, simulation, data mining, ...

Many Little Programming Model
• many small requests• route requests to data• encapsulate data with procedures (objects)• three-tier computing• RPC is a convenient/appropriate model• Transactions are a big help in error handling• Auto partition (e.g. hash data and computation)• Works fine.• Software CyberBricks

Object Oriented ProgrammingParallelism From Many Little Jobs
• Gives location transparency
• ORB/web/tpmon multiplexes clients to servers
• Enables distribution
• Exploits embarrassingly parallel apps (transactions)
• HTTP and RPC (dcom, corba, rmi, iiop, …) are basis
Tp mon / orb/ web server

Few Big Programming Model
• Finding parallelism is hard– Pipelines are short (3x …6x speedup)
• Spreading objects/data is easy, but getting locality is HARD
• Mapping big job onto cluster is hard• Scheduling is hard
– coarse grained (job) and fine grain (co-schedule)
• Fault tolerance is hard

Kinds of Parallel Execution
Pipeline
Partition outputs split N ways inputs merge M ways
Any Sequential Program
Any Sequential Program
SequentialSequential
SequentialSequential Any Sequential Program
Any Sequential Program

Why Parallel Access To Data?
1 Terabyte
10 MB/s
At 10 MB/s1.2 days to scan
1 Terabyte
1,000 x parallel100 second SCAN.
Parallelism: divide a big problem into many smaller ones
to be solved in parallel.
BANDWID
TH

Why are Relational Operators
Successful for Parallelism?Relational data model uniform operatorson uniform data streamClosed under composition
Each operator consumes 1 or 2 input streamsEach stream is a uniform collection of dataSequential data in and out: Pure dataflow
partitioning some operators (e.g. aggregates, non-equi-join, sort,..)
requires innovation
AUTOMATIC PARALLELISM

Database Systems “Hide” Parallelism
• Automate system management via tools– data placement– data organization (indexing)– periodic tasks (dump / recover / reorganize)
• Automatic fault tolerance– duplex & failover– transactions
• Automatic parallelism– among transactions (locking)– within a transaction (parallel execution)
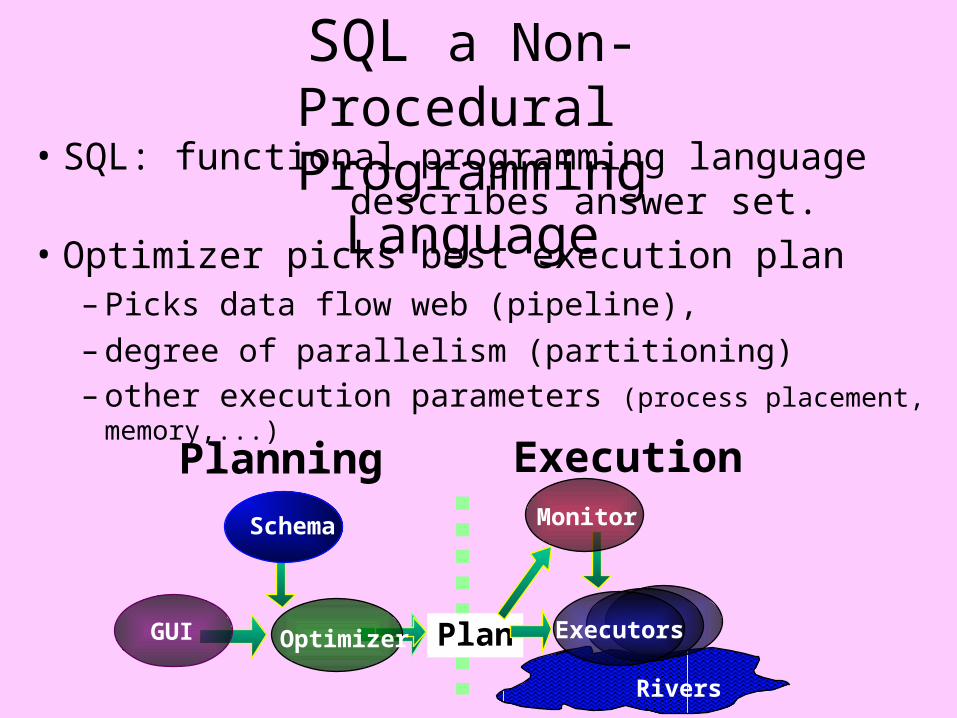
SQL a Non-Procedural Programming Language
• SQL: functional programming language describes answer set.
• Optimizer picks best execution plan– Picks data flow web (pipeline),
– degree of parallelism (partitioning)– other execution parameters (process placement, memory,...)
GUI
Schema
Plan
Monitor
Optimizer
ExecutionPlanning
Rivers
Executors

Partitioned Execution
A...E F...J K...N O...S T...Z
A Table
Count Count Count Count Count
Count
Spreads computation and IO among processors
Partitioned data gives NATURAL parallelism
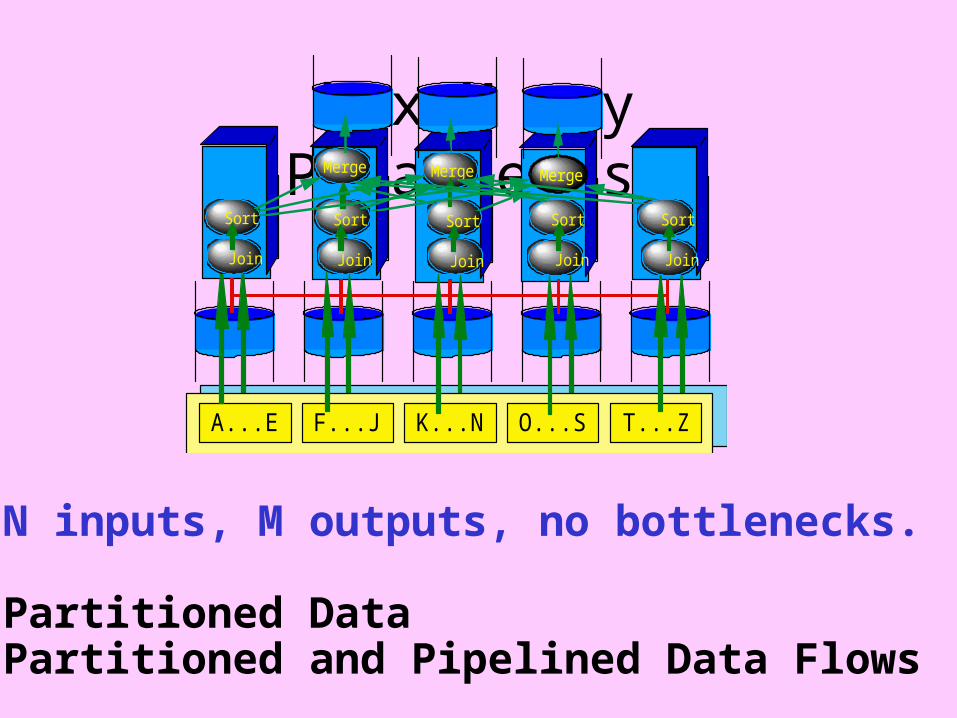
N x M way Parallelism
A...E F...J K...N O...S T...Z
Merge
Join
Sort
Join
Sort
Join
Sort
Join
Sort
Join
Sort
Merge Merge
N inputs, M outputs, no bottlenecks.
Partitioned DataPartitioned and Pipelined Data Flows
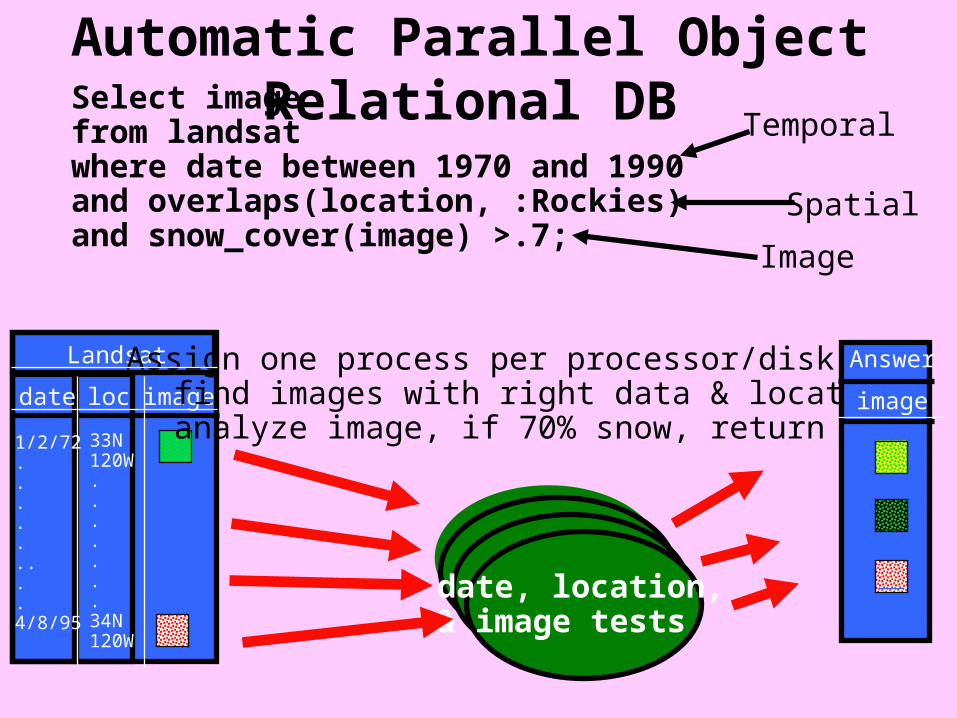
Automatic Parallel Object Relational DBSelect imagefrom landsatwhere date between 1970 and 1990and overlaps(location, :Rockies) and snow_cover(image) >.7;
Temporal
Spatial
Image
date loc image
Landsat
1/2/72.........4/8/95
33N120W.......34N120W
Assign one process per processor/disk:find images with right data & locationanalyze image, if 70% snow, return it
image
Answer
date, location, & image tests

Data Rivers: Split + Merge Streams
Producers add records to the river, Consumers consume records from the riverPurely sequential programming.River does flow control and buffering
does partition and merge of data records River = Split/Merge in Gamma =
Exchange operator in Volcano /SQL Server.
River
M ConsumersN producers
N X M Data Streams

Generalization: Object-oriented Rivers• Rivers transport sub-class of record-set (= stream of objects)
– record type and partitioning are part of subclass
• Node transformers are data pumps– an object with river inputs and outputs– do late-binding to record-type
• Programming becomes data flow programming– specify the pipelines
• Compiler/Scheduler does data partitioning and “transformer” placement

NT Cluster Sort as a Prototype
• Using – data generation and – sort
as a prototypical app
• “Hello world” of distributed processing
• goal: easy install & execute
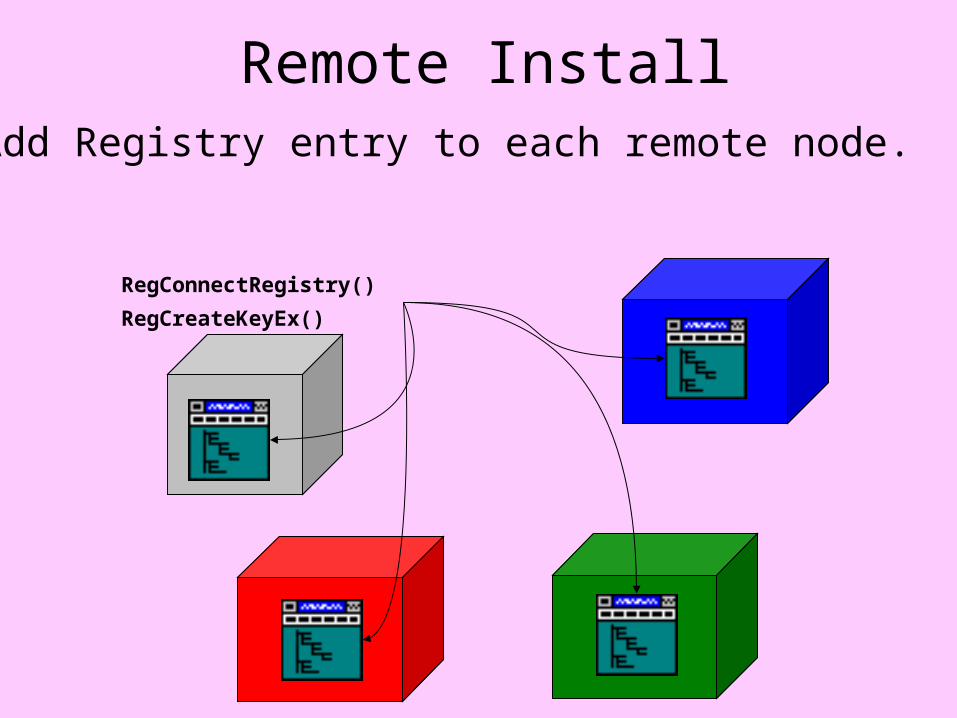
Remote Install
RegConnectRegistry()
RegCreateKeyEx()
•Add Registry entry to each remote node.

Cluster StartupExecution
MULT_QI COSERVERINFO•Setup :
MULTI_QI structCOSERVERINFO struct
•CoCreateInstanceEx()
•Retrieve remote object handle from MULTI_QI struct
•Invoke methods as usual
HANDLEHANDLE
HANDLE
Sort()
Sort()
Sort()
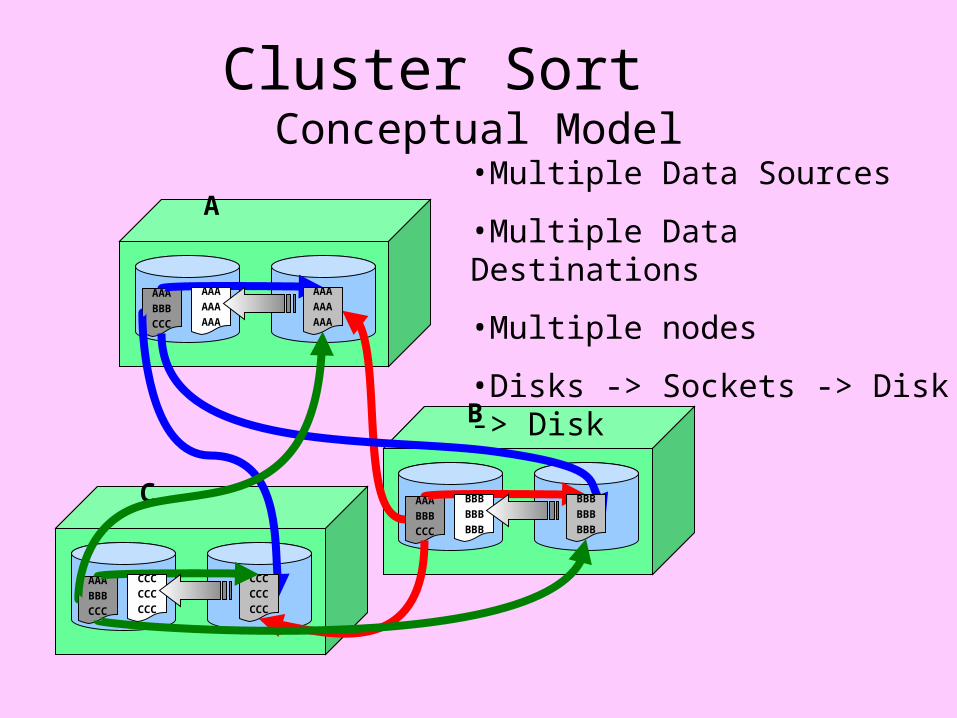
Cluster Sort Conceptual Model
•Multiple Data Sources
•Multiple Data Destinations
•Multiple nodes
•Disks -> Sockets -> Disk -> Disk
B
AAABBBCCC
A
AAABBBCCC
C
AAABBBCCC
BBBBBBBBB
AAAAAAAAA
CCCCCCCCC
BBBBBBBBB
AAAAAAAAA
CCCCCCCCC
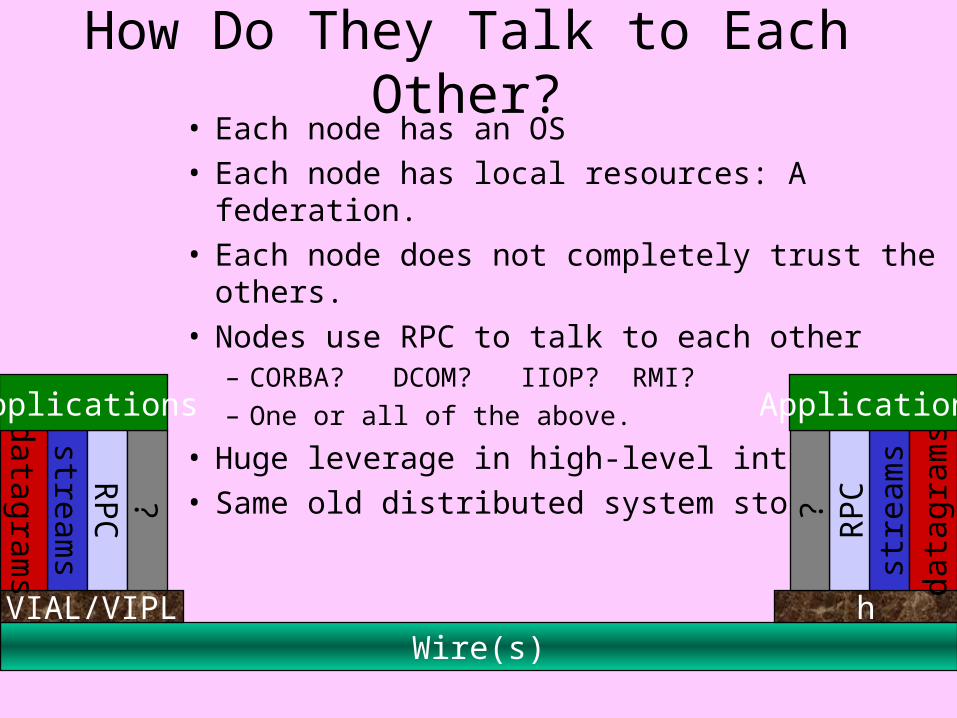
How Do They Talk to Each Other?• Each node has an OS• Each node has local resources: A federation.• Each node does not completely trust the others.• Nodes use RPC to talk to each other
– CORBA? DCOM? IIOP? RMI?
– One or all of the above.
• Huge leverage in high-level interfaces.• Same old distributed system story.
Wire(s)h
stre
ams
data
gram
s
RP
C?
Applications
VIAL/VIPL
streams
datagrams
RP
C ?
Applications